ti teoria del muestreo 12052007
TRANSCRIPT

UNIVERSIDAD DE LA VIDA TRABAJO DE INVESTIGACIÓN
MARACAY-EDO. ARAGUA
T E O R Í A D E L M U E S T R E O
Elaborado por: Pascual Sardella
Maracay, Febrero de 2017

2
ÍNDICE pp.
Introducción ................................................................................................... 3
Teoría del Muestreo ....................................................................................... 4
Muestreo ....................................................................................................... 4
Población y Muestra ...................................................................................... 5
Parámetros y Estadísticos ............................................................................. 5
Tipos de Muestreos ....................................................................................... 6
Métodos de Muestreo Número de Muestras Tomadas de una Población ... 6
Muestreo Simple ..................................................................................... 6
Muestreo Doble ...................................................................................... 6
Muestreo Múltiple ................................................................................... 7
Métodos de Muestreo Selección de los Elementos de una Muestra. .......... 7
Muestreo de Juicio ................................................................................. 7
Muestreo Aleatorio o Probabilística ........................................................ 7
Otros Métodos de Muestreo ....................................................................... 9
Muestreo Discrecional ............................................................................ 9
Muestreo Opinático o Intencional............................................................ 9
Muestreo Casual o Incidental ............................................................... 10
Tamaño de la Muestra. Cálculos Estadísticos ............................................ 10
La Confianza o el Porcentaje de Confianza.............................................. 10
El Error o Porcentaje de Error .................................................................. 10
La Variabilidad ......................................................................................... 11
Muestreos Probabilísticos ............................................................................ 12
Muestreos Probabilísticos o Aleatorios con Reemplazo ........................... 13
Los Muestreos Probabilísticos o Aleatorios sin Reemplazo ...................... 13
Muestreo Aleatorio Simple .................................................................... 14
Aplicación de la Teoria de Muestreo en Enfermería ................................. 14
Toma de Decisiones en Base al Análisis de Muestreo en Enfermería ...... 16
Prueba de Hipótesis ............................................................................. 16
Pasos para Establecer un Ensayo de Hipotesis.................................... 18
Tipos de Ensayo ................................................................................... 19
Ensayos de Hipótesis y Significación .................................................... 21
Nivel de Significación ............................................................................ 21
Ensayo Referentes a la Distribución Normal ......................................... 22
Conclusión ................................................................................................... 26
Bibliografía................................................................................................... 27

3
INTRODUCCIÓN
El presente trabajo monográfico tiene el propósito de conocer y ampliar
nuestros conocimientos sobre la Teoría del Muestreo, la cual consiste en un
procedimiento por el cual mediante una muestra podemos generalizar las
características de una determinada población.
El punto de interés es la muestra, y mediante ciertos procedimientos de
selección se deben asegurar que las muestras tomadas de una población
reflejen las observaciones de la misma, ya que solo se pueden hacer
indagaciones probabilísticas sobre una población cuando se usan muestras
representativas de la misma.
Finalmente, se investigaran temas relacionados con la Teoría del
Muestreo, concepto de muestra, población, tipos de muestras,
características, cálculos estadísticos, tamaño de la muestra, aplicación a la
enfermería, toma de decisión en las muestras de enfermería, etc.

4
TEORÍA DEL MUESTREO
La Teoría del Muestreo consiste en un método que nos permite
establecer determinadas relaciones que pueden existir entre una población a
la cual se les realiza varias muestras, y poder observar si dichas muestras
son debidas al azar o si por el contrario son realmente significativos.
La Teoría del Muestreo consiste en realizar un estudio estadístico de
cualquier tipo con el fin de obtener unos resultados confiables y que puedan
ser aplicables. Como ya se comentó anteriormente, resulta casi imposible o
impráctico llevar a cabo algunos estudios sobre toda una población, por lo
que la solución es llevar a cabo el estudio basándose en un subconjunto de
ésta denominada muestra.
Sin embargo, para que los estudios tengan la validez y confiabilidad
buscada es necesario que tal subconjunto de datos, o muestra, posea
algunas características específicas que permitan, al final, generalizar los
resultados hacia la población en total. Esas características tienen que ver
principalmente con el tamaño de la muestra y con la manera de obtenerla.
MUESTREO
Es un procedimiento que consiste en seleccionar a los individuos que
formarán una muestra representativa de la calidad o condiciones medias de
un todo. Está Técnica es empleada para seleccionar una pequeña parte
estadísticamente determinada, la cual se utiliza para inferir el valor de una o
varias características del conjunto. Para que se puedan obtener conclusiones
fiables para la población a partir de la muestra, es importante tanto su
tamaño como el modo en que han sido seleccionados los individuos que la
componen. En tal sentido, el muestreo es una Herramienta de la
investigación científica cuya función básica es determinar qué parte de una
población en estudio debe examinarse con el fin de hacer inferencias sobre
dicha población.

5
Población y Muestra
Algo importante que hay que mencionar es que no siempre se trabaja
con todos los datos. Esto por diversas razones, que pueden ser desde
prácticas hasta por economía. Por ejemplo, resultaría muy costoso obtener
los datos de todos los seres humanos, o impráctico (y a la vez destructivo)
obtener como datos el tiempo en el que se funden las bombillas producidas
por una cierta marca realizando la medición de toda la producción. El estudio
conduciría a la empresa a la ruina, pues la producción entera desaparecería.
Por esta razón se considera un subconjunto del total de los casos,
sujetos u objetos que se estudian y que se les obtienen los datos. La
población, entonces, es el total hipotético de los datos que se estudian o
recopilan. Ante la imposibilidad ocasional de conseguir a la población,
entonces se recurre a la muestra, que viene siendo un subconjunto de los
datos de la población, pero tal subconjunto tiene que contener datos que
pueden servir para posteriores generalizaciones de las conclusiones.
Parámetros y estadísticos
Existen medidas para realizar descripciones cuantitativas de los
conjuntos de datos, o poblaciones, y de sus muestras, diferenciándose entre
ellas las que se refieren a las mismas poblaciones y a las muestras.
Para el caso de las poblaciones, las medidas que las describen se
denominan parámetros, y suelen estar representadas con letras griegas (por
ejemplo y ) Por otro lado, para el caso de aquellas medidas que
describen a una muestra se les llama estadísticos o estimadores, y son
representados por letras de nuestro alfabeto (por ejemplo, x o s).

6
TIPOS DE MUESTREOS
Los métodos para seleccionar una muestra representativa son
numerosos, dependiendo del tiempo, dinero y habilidad disponibles para
tomar una muestra y la naturaleza de los elementos individuales de la
población. En tal sentido, una muestra debe ser representativa si va a ser
usada para estimar las características de la población. Luego, se requiere un
gran volumen para incluir todos los tipos de métodos de muestreo. Los
métodos de selección de muestras pueden ser clasificados de acuerdo a:
1. El número de muestras tomadas de una población dada para un
estudio y,
2. La manera en seleccionar los elementos incluidos en la muestra.
Métodos de Muestreo según el número de muestras tomadas de una población
En está clasificación, hay tres tipos de métodos de muestreo. Estos
son, muestreo simple, doble y múltiple.
Muestreo Simple
Este tipo de muestreo toma solamente una muestra de una población
dada para el propósito de inferencia estadística, y por lo tanto, el tamaño de
la muestra debe ser lo suficientemente grande para extraer una conclusión.
Una muestra grande muchas veces cuesta demasiado dinero y tiempo.
Muestreo Doble
Cuando el resultado del estudio de la primera muestra no es decisivo,
una segunda muestra es extraída de la misma población. Las dos muestras
son combinadas para analizar los resultados. Si la primera muestra arroja
una resultado definitivo, la segunda muestra puede no necesitarse.

7
Muestreo múltiple
El método es similar al expuesto en el muestreo doble, excepto que el
número de muestras sucesivas requerido para llegar a una decisión es más
de dos muestras.
Métodos de Muestreo según la selección de los elementos de una muestra.
Los elementos de una muestra pueden ser seleccionados de dos
maneras diferentes:
Basados en el juicio de una persona.
Por selección aleatoria (al azar)
Muestreo de juicio
Una muestra es llamada muestra de juicio cuando sus elementos son
seleccionados mediante juicio personal. La persona que selecciona los
elementos de la muestra, usualmente es un experto en la medida dada. Una
muestra de juicio es llamada una muestra probabilística, puesto que este
método está basado en los puntos de vista subjetivos de una persona y la
teoría de la probabilidad no puede ser empleada para medir el error de
muestreo, Las principales ventajas de una muestra de juicio son la facilidad
de obtenerla y que el costo usualmente es bajo.
Muestreo Aleatorio o Probabilística
Una muestra se dice que es extraída al azar cuando la manera de
selección es tal, que cada elemento de la población tiene igual oportunidad
de ser seleccionado. Son generalmente preferidas por los estadísticos
porque la selección de las muestras es objetiva y el error muestral puede ser
medido en términos de probabilidad bajo la curva normal. Los tipos comunes

8
de muestreo aleatorio son el muestreo aleatorio simple, muestreo
sistemático, muestreo estratificado y muestreo de conglomerados.
Muestreo Aleatorio Simple
Una muestra aleatoria simple es seleccionada de tal manera que cada
muestra posible del mismo tamaño tiene igual probabilidad de ser
seleccionada de la población. Para obtener una muestra aleatoria simple,
cada elemento de la población tiene la misma probabilidad de ser
seleccionado, el plan de muestreo puede no conducir a una muestra aleatoria
simple. Por conveniencia, este método pude ser reemplazado por una tabla
de números aleatorios.
Muestreo Sistemático
Una muestra sistemática es obtenida cuando los elementos son
seleccionados en una manera ordenada. La manera de la selección depende
del número de elementos incluidos en la población y el tamaño de la
muestra. El número de elementos en la población es, primero, dividido por el
número deseado en la muestra. El cociente indicará si cada décimo, cada
onceavo, o cada centésimo elemento en la población va a ser seleccionado.
El primer elemento de la muestra es seleccionado al azar. Por lo tanto,
una muestra sistemática puede dar la misma precisión de estimación acerca
de la población, que una muestra aleatoria simple cuando los elementos en
la población están ordenados al azar.
Muestreo Estratificado
Para obtener una muestra aleatoria estratificada, primero se divide la
población en grupos, llamados estratos, que son más homogéneos que la
población como un todo. Los elementos de la muestra son entonces
seleccionados al azar o por un método sistemático de cada estrato. Las

9
estimaciones de la población, basadas en la muestra estratificada,
usualmente tienen mayor precisión (o menor error muestral) que si la
población entera muestreada mediante muestreo aleatorio simple. El número
de elementos seleccionado de cada estrato puede ser proporcional o
desproporcional al tamaño del estrato en relación con la población.
Muestreo de Conglomerados
Para obtener una muestra de conglomerados, primero se debe dividir la
población en grupos que son convenientes para el muestreo. En seguida,
seleccionar una porción de los grupos al azar o por un método sistemático.
Finalmente, tomar todos los elementos o parte de ellos al azar o por un
método sistemático de los grupos seleccionados para obtener una muestra.
Una muestra de conglomerados, usualmente produce un mayor error
muestral, da menor precisión de las estimaciones acerca de la población. La
variación entre los elementos obtenidos de las áreas seleccionadas es, por lo
tanto, frecuentemente mayor que la obtenida si la población entera es
muestreada mediante muestreo aleatorio simple.
Otros Métodos de Muestreo
Muestreo Discrecional
A criterio del investigador los elementos son elegidos sobre lo que él
cree que pueden aportar al estudio. Ejemplo: muestreo por juicios; cajeros de
un banco o un supermercado; etc.
Muestreo Opinático o Intencional
Este tipo de muestreo se caracteriza por un esfuerzo deliberado de
obtener muestras "representativas" mediante la inclusión en la muestra de
grupos supuestamente típicos.

10
Muestreo Casual o Incidental
Se trata de un proceso en el que el investigador selecciona directa e
intencionadamente los individuos de la población. El caso más frecuente de
este procedimiento es utilizar como muestra a los individuos a los que se
tiene fácil acceso (los profesores de universidad emplean con mucha
frecuencia a sus propios alumnos). Un caso particular es el de los
voluntarios.
TAMAÑO DE LA MUESTRA. CÁLCULOS ESTADÍSTICOS
Para calcular el tamaño de una muestra hay que tomar en cuenta tres
factores:
1. El porcentaje de confianza con el cual se quiere generalizar los datos
desde la muestra hacia la población total.
2. El porcentaje de error que se pretende aceptar al momento de hacer la
generalización.
3. El nivel de variabilidad que se calcula para comprobar la hipótesis.
La Confianza o el Porcentaje de Confianza
Es el porcentaje de seguridad que existe para generalizar los resultados
obtenidos. Para evitar un costo muy alto para el estudio o debido a que en
ocasiones llega a ser prácticamente imposible el estudio de todos los casos,
entonces se busca un porcentaje de confianza menor. Comúnmente en las
investigaciones sociales se busca un 95%.
El Error o Porcentaje de Error
Equivale a elegir una probabilidad de aceptar una hipótesis que sea
falsa como si fuera verdadera, o la inversa: rechazar la hipótesis verdadera
por considerarla falsa. Al igual que en el caso de la confianza, si se quiere

11
eliminar el riesgo del error y considerarlo como 0%, entonces la muestra es
del mismo tamaño que la población, por lo que conviene correr un cierto
riesgo de equivocarse. Comúnmente se aceptan entre el 4% y el 6% como
error, tomando en cuenta de que no son complementarios la confianza y el
error.
La Variabilidad
Es la probabilidad (o porcentaje) con el que se aceptó y se rechazó la
hipótesis que se quiere investigar en alguna investigación anterior o en un
ensayo previo a la investigación actual. El porcentaje con que se aceptó tal
hipótesis se denomina variabilidad positiva y se denota por p, y el
porcentaje con el que se rechazó se la hipótesis es la variabilidad negativa,
denotada por q. Hay que considerar que p y q son complementarios, es
decir, que su suma es igual a la unidad: p + q = 1. Además, cuando se habla
de la máxima variabilidad, en el caso de no existir antecedentes sobre la
investigación (no hay otras o no se pudo aplicar una prueba previa), entonces
los valores de variabilidad es: p = q = 0.5.
Una vez que se han determinado estos tres factores, entonces se
puede calcular el tamaño de la muestra. Hay que mencionar que estas
fórmulas se pueden aplicar de manera aceptable pensando en instrumentos
que no incluyan preguntas abiertas y que sean un total de alrededor de 30.
Vamos a presentar dos fórmulas, siendo la primera la que se aplica en el
caso de que no se conozca con precisión el tamaño de la población, y
es:
Donde:
n: es el tamaño de la muestra;
Z: es el nivel de confianza;
p: es la variabilidad positiva;
q: es la variabilidad negativa;
E: es la precisión o error.

12
Hay que tomar nota de que debido a que la variabilidad y el error se
pueden expresar por medio de porcentajes, hay que convertir todos esos
valores a proporciones en el caso necesario. También hay que tomar en
cuenta que el nivel de confianza no es ni un porcentaje, ni la proporción que
le correspondería, a pesar de que se expresa en términos de porcentajes. El
nivel de confianza se obtiene a partir de la distribución normal estándar, pues
la proporción correspondiente al porcentaje de confianza es el área simétrica
bajo la curva normal que se toma como la confianza, y la intención es buscar
el valor Z de la variable aleatoria que corresponda a tal área.
En el caso de que sí se conozca el tamaño de la población entonces
se aplica la siguiente fórmula:
Donde:
n: es el tamaño de la muestra;
Z: es el nivel de confianza;
p: es la variabilidad positiva;
q: es la variabilidad negativa;
N: es el tamaño de la población;
E: es la precisión o el error.
La ventaja sobre la primera fórmula es que al conocer exactamente el
tamaño de la población, el tamaño de la muestra resulta con mayor precisión
y se pueden incluso ahorrarse recursos y tiempo para la aplicación y
desarrollo de una investigación.
MUESTREOS PROBABILÍSTICOS
Las técnicas de muestreo probabilístico son aquellas en las que se
determina al azar los individuos que constituirán la muestra. Estas técnicas
nos sirven cuando se desean generalizar los resultados que se obtienen a
partir de la muestra hacia toda la población. Lo anterior se dice dado que se
supone que el proceso aleatorio permitirá la obtención de una muestra

13
representativa de la población. Los muestreos probabilísticos o aleatorios
pueden clasificarse de la siguiente manera:
Los muestreos probabilísticos o aleatorios con reemplazo
Los muestreos probabilísticos o aleatorios sin reemplazo
Muestreos Probabilísticos o Aleatorios con Reemplazo
Son aquellos en los que una vez que ha sido seleccionado un individuo
(y estudiado) se le toma en cuenta nuevamente al elegir el siguiente individuo
a ser estudiado. En este caso cada una de las observaciones permanece
independiente de las demás, pero con poblaciones pequeñas (un grupo de
escuela de 30 alumnos, por ejemplo) tal procedimiento debe ser considerado
ante la posibilidad de repetir observaciones. En el caso de poblaciones
grandes no importa tal proceder, pues no afecta sustancialmente una
repetición a las frecuencias relativas.
Los Muestreos Probabilísticos o Aleatorios sin Reemplazo
Son los que una vez que se ha tomado en cuenta un individuo para
formar parte de la muestra, no se le vuelve a tomar en cuenta nuevamente.
En este caso, y hablando específicamente para el caso de poblaciones
pequeñas, las observaciones son dependientes entre sí, pues al no tomar en
cuenta nuevamente el individuo se altera la probabilidad para la selección de
otro individuo de la población.
Para el caso de las poblaciones grandes (por ejemplo la población de
un país) dicha probabilidad para la selección de un individuo se mantiene
prácticamente igual, por lo que se puede decir que existe independencia en
las observaciones.
Las técnicas de muestreo probabilístico que mencionaremos serán
básicamente tres: el aleatorio simple, el aleatorio estratificado y el
sistemático.

14
Muestreo Aleatorio Simple
Podemos aquí mencionar que para el caso de que se estuviese
estudiando una proporción dentro de la población (una elección de candidato,
la aceptación o rechazo de una propuesta en una comunidad, la presencia o
ausencia de una característica hereditaria), y el en caso de un muestreo
aleatorio simple, la estimación que se puede hacer de la proporción buscada
a partir de la proporción hallada en la muestra se obtiene mediante la
construcción de un intervalo de confianza:
= P ± tolerancia de la muestra
Donde es la proporción buscada en la población y P es la proporción
presente en la muestra.
Por otro lado, la tolerancia de la muestra está relacionada
directamente con el nivel de confianza y se obtiene a partir de la distribución
normal al igual que como se obtuvo para el cálculo del tamaño de las
muestras. La representaremos con Z para obtener la fórmula:
APLICACIÓN DE LA TEORIA DE MUESTREO EN ENFERMERÍA
Ejemplo1. Supongamos que deseamos saber si existen diferencias entre
dos terapias diferentes A y B utilizadas habitualmente para tratar un
determinado tipo de cáncer. Para ello se planea realizar un estudio
prospectivo en el que se recogerá el estatus de los pacientes (vivos/muertos)
al cabo de un año de ser tratados ¿Cuántos pacientes deberán estudiarse
con cada tratamiento si se desea calcular el riesgo relativo con una precisión
del 50% de su valor real y una seguridad del 95%? De experiencias previas,
se estima que el valor real del riesgo relativo es aproximadamente igual a 3 y

15
la probabilidad de fallecer entre los pacientes tratados con el tratamiento A
de un 20%.
Solución:
En este caso se tiene que:
5.0
6.02.03
2.0
21
2
1
2
PRRPP
PRR
P
Aplicando la ecuación
2
22112
21
1ln
/1/1
PPPPzn
Se tiene:
31.37
5.01ln
2.0/2.016.0/6.0196.1
2
2
n
Es decir, se necesitaría en cada grupo una muestra de 38 pacientes.
Si el tamaño del efecto a detectar fuese menor, el tamaño muestral
necesario para llevar a cabo el estudio aumentará. Por ejemplo, si estimamos
que el RR correspondiente al nuevo tratamiento es aproximadamente igual a
2 (P1=0.4) el tamaño necesario sería:
98.43
5.01ln
2.0/2.014.0/4.0196.1
2
2
n
Es decir, un total de 44 pacientes tratados con cada una de las dos terapias.

16
TOMA DE DECISIONES EN BASE AL ANÁLISIS DE MUESTREO EN ENFERMERÍA
Prueba de Hipótesis
Puede encontrarse ya sea un sólo número (estimador puntual) o un
intervalo de valores posibles (intervalo de confianza). Sin embargo, muchos
problemas de ingeniería, ciencia, y administración, requieren que se tome
una decisión entre aceptar o rechazar una proposición sobre algún
parámetro. Esta proposición recibe el nombre de hipótesis. Este es uno de
los aspectos más útiles de la inferencia estadística, puesto que muchos tipos
de problemas de toma de decisiones, pruebas o experimentos en el mundo
de la ingeniería, pueden formularse como problemas de prueba de hipótesis.
Una hipótesis estadística es una proposición o supuesto sobre los
parámetros de una o más poblaciones. Es importante recordar que las
hipótesis siempre son proposiciones sobre la población o distribución bajo
estudio, no proposiciones sobre la muestra. Por lo general, el valor del
parámetro de la población especificado en la hipótesis nula se determina en
una de tres maneras diferentes:
Puede ser resultado de la experiencia pasada o del conocimiento del
proceso, entonces el objetivo de la prueba de hipótesis usualmente es
determinar si ha cambiado el valor del parámetro.
Puede obtenerse a partir de alguna teoría o modelo que se relaciona con
el proceso bajo estudio. En este caso, el objetivo de la prueba de
hipótesis es verificar la teoría o modelo.
Cuando el valor del parámetro proviene de consideraciones externas,
tales como las especificaciones de diseño o ingeniería, o de obligaciones
contractuales. En esta situación, el objetivo usual de la prueba de
hipótesis es probar el cumplimiento de las especificaciones.
Un procedimiento que conduce a una decisión sobre una hipótesis en
particular recibe el nombre de prueba de hipótesis. Los procedimientos de

17
prueba de hipótesis dependen del empleo de la información contenida en la
muestra aleatoria de la población de interés. Si esta información es
consistente con la hipótesis, se concluye que ésta es verdadera; sin embargo
si esta información es inconsistente con la hipótesis, se concluye que esta es
falsa. Debe hacerse hincapié en que la verdad o falsedad de una hipótesis en
particular nunca puede conocerse con certidumbre, a menos que pueda
examinarse a toda la población. Usualmente esto es imposible en muchas
situaciones prácticas. Por tanto, es necesario desarrollar un procedimiento de
prueba de hipótesis teniendo en cuenta la probabilidad de llegar a una
conclusión equivocada.
La hipótesis nula, representada por Ho, es la afirmación sobre una o
más características de poblaciones que al inicio se supone cierta (es decir, la
"creencia a priori").
La hipótesis alternativa, representada por H1, es la afirmación
contradictoria a Ho, y ésta es la hipótesis del investigador.
La hipótesis nula se rechaza en favor de la hipótesis alternativa, sólo si
la evidencia muestral sugiere que Ho es falsa. Si la muestra no contradice
decididamente a Ho, se continúa creyendo en la validez de la hipótesis nula.
Entonces, las dos conclusiones posibles de un análisis por prueba de
hipótesis son rechazar Ho o no rechazar Ho.
El error tipo I se define como el rechazo de la hipótesis nula Ho cuando
ésta es verdadera. También es conocido como ó nivel de significancia.
En este caso, la hipótesis nula Ho será rechazada en favor de la alternativa
H1 cuando, de hecho, Ho en realidad es verdadero. Este tipo de conclusión
equivocada se conoce como error tipo I ó error .
El error tipo II ó error se define como la aceptación de la hipótesis
nula cuando ésta es falsa. En este caso se acepta Ho cuando ésta es falsa.
Este tipo de conclusión recibe el nombre de error tipo II ó error . Por tanto,
al probar cualquier hipótesis estadística, existen cuatro situaciones diferentes
que determinan si la decisión final es correcta o errónea.

18
Decisión Ho es verdadera Ho es falsa
Aceptar Ho No hay error Error tipo II ó
Rechazar Ho Error tipo I ó No hay error
Los errores tipo I y tipo II están relacionados. Una disminución en la
probabilidad de uno por lo general tiene como resultado un aumento en la
probabilidad del otro.
El tamaño de la región crítica, y por tanto la probabilidad de cometer un
error tipo I, siempre se puede reducir al ajustar el o los valores críticos.
Un aumento en el tamaño muestral n reducirá y de forma simultánea.
Si la hipótesis nula es falsa, es un máximo cuando el valor real del
parámetro se aproxima al hipotético. Entre más grande sea la distancia
entre el valor real y el valor hipotético, será menor
PASOS PARA ESTABLECER UN ENSAYO DE HIPOTESIS
Para establecer un ensayo de hipótesis Independientemente de la
distribución que se este tratando, se deben seguir los siguientes pasos:
1. Interpretar correctamente hacia que distribución muestral se ajustan los
datos del enunciado.
2. Interpretar correctamente los datos del enunciado diferenciando los
parámetros de los estadísticos. Así mismo se debe determinar en este
punto información implícita como el tipo de muestreo y si la población es
finita o infinita.
3. Establecer simultáneamente el ensayo de hipótesis y el planteamiento
gráfico del problema. El ensayo de hipótesis está en función de
parámetros ya que se quiere evaluar el universo de donde proviene la
muestra. En este punto se determina el tipo de ensayo (unilateral o
bilateral).

19
4. Establecer la regla de decisión. Esta se puede establecer en función del
valor crítico, el cual se obtiene dependiendo del valor de (Error tipo I o
nivel de significancia) o en función del estadístico límite de la distribución
muestral. Cada una de las hipótesis deberá ser argumentada
correctamente para tomar la decisión, la cual estará en función de la
hipótesis nula o Ho.
5. Calcular el estadístico real, y situarlo para tomar la decisión.
6. Justificar la toma de decisión y concluir.
Tipos de Ensayo
Se pueden presentar tres tipos de ensayo de hipótesis que son:
Unilateral Derecho
Unilateral Izquierdo
Bilateral
Dependiendo de la evaluación que se quiera hacer se seleccionará el
tipo de ensayo.
Unilateral Derecho.
El investigador desea comprobar la hipótesis de un aumento en el
parámetro, en este caso el nivel de significancia se carga todo hacia el lado
derecho, para definir las regiones de aceptación y de rechazo.
Ensayo de hipótesis:
Ho; Parámetro x
H1; Parámetro x

20
Unilateral Izquierdo
El investigador desea comprobar la hipótesis de una disminución en el
parámetro, en este caso el nivel de significancia se carga todo hacia el lado
izquierdo, para definir las regiones de aceptación y de rechazo.
Ensayo de hipótesis:
Ho; Parámetro x
H1; Parámetro x
Bilateral
El investigador desea comprobar la hipótesis de un cambio en el
parámetro. El nivel de significancia se divide en dos y existen dos regiones
de rechazo.
Ensayo de hipótesis:
Ho; Parámetro = x
H1; Parámetro x

21
Ensayos de Hipótesis y Significación
Si en el supuesto de que una hipótesis determinada es cierta, se
encuentra que los resultados observados en una muestra al azar difieren
marcadamente de aquellos que cabía esperar con la hipótesis y con la
variación propia del muestreo, se diría que las diferencias observadas son
significativas y se estaría en condiciones de rechazar la hipótesis (o al menos
no aceptarla de acuerdo con la evidencia obtenida). Los procedimientos que
facilitan el decidir si una hipótesis se acepta o se rechaza o el determinar si
las muestras observadas difieren significativamente de los resultados
esperados se llaman ensayos de hipótesis, ensayos de significación o reglas
de decisión.
Nivel de Significación
La probabilidad máxima con la que en el ensayo de una hipótesis se
puede cometer un error del Tipo I se llama nivel de significación del
ensayo. Esta probabilidad se denota frecuentemente por , generalmente se
fija antes de la extracción de las muestras, de modo que los resultados
obtenidos no influyen en la elección. En la práctica se acostumbra a utilizar
niveles de significación del 0,05 ó 0,01, aunque igualmente pueden
emplearse otros valores. Si por ejemplo, se elige un nivel de significación del
0,05 ó 5%, al diseñar un ensayo de hipótesis, entonces hay
aproximadamente 5 ocasiones en 100 en que se rechazaría la hipótesis
cuando debería ser aceptada, es decir, se está con un 95% de confianza de
que se toma la decisión adecuada. En tal caso se dice que la hipótesis ha
sido rechazada al nivel de significación del 0,05, lo que significa que se
puede cometer error con una probabilidad de 0,05.

22
S
SSz
Z = -1,96 Z = 1,96
Región Crítica
Región Crítica
0.025 0.025
0.95
Ensayo Referentes a la Distribución Normal
Para aclarar las ideas anteriores, supóngase que con una hipótesis
dada, la distribución muestral de un estadístico S es una distribución normal
con media S y desviación típica S. Entonces la distribución de la variable
tipificada (representada por z) dada por:
Es una normal tipificada (media 0, varianza 1) y se muestra en la figura
siguiente:
Como se indica en la figura anterior, se puede estar con el 95%, de
confianza de que, si la hipótesis es cierta, el valor de z obtenido de una
muestra real para el estadístico S se encontraría entre -1,96 y 1,96 (puesto
que el área bajo la curva normal entre estos valores es 0,95). Sin embargo, si
al elegir una muestra al azar se encuentra que z para ese estadístico se halla
fuera del rango -1,96 a 1,96, lo que quiere decir que es un suceso con
probabilidad de solamente 0,05 (área sombreada de la figura anterior) si la
hipótesis fuese verdadera. Entonces puede decirse que está z difiere
significativamente de la que cabía esperar bajo esta hipótesis y se estaría
inclinado a rechazar la hipótesis.
El área total sombreada 0,05 es el nivel de significación del ensayo.
Representa la probabilidad de cometer error al rechazar la hipótesis es decir,
la probabilidad de cometer error del Tipo I. Así, pues, se dice que la hipótesis
se rechaza al nivel de significación del 0,05 o que la z obtenida del
estadístico muestral dado es significativa al nivel de significación del 0,05.
23
El conjunto de las z que se encuentran fuera del rango -1,96 a 1,96
constituyen lo que se llama región crítica o región de rechace de la hipótesis
o región de significación. El conjunto de las z que se encuentran dentro del
rango -1,96 a 1,96 podía entonces llamarse región de aceptación de la
hipótesis o región de no significación.
De acuerdo con lo dicho hasta ahora, se puede formular la siguiente
regla de decisión o ensayo de hipótesis o significación:
1. Se rechaza la hipótesis al nivel de significación del 0,05 si la z obtenida
para el estadístico S se encuentra fuera del rango -1,96 a 1,96 (es decir,
z1,96 ó z-1,96). Esto equivale a decir que el estadístico muestral
observado es significativo al nivel del 0,05.
2. Se acepta la hipótesis (o si se desea no se toma decisión alguna) en caso
contrario.
Debe ponerse de manifiesto que pueden igualmente emplearse otros
niveles de significación. Por ejemplo, si se utilizase el nivel del 0,01 se
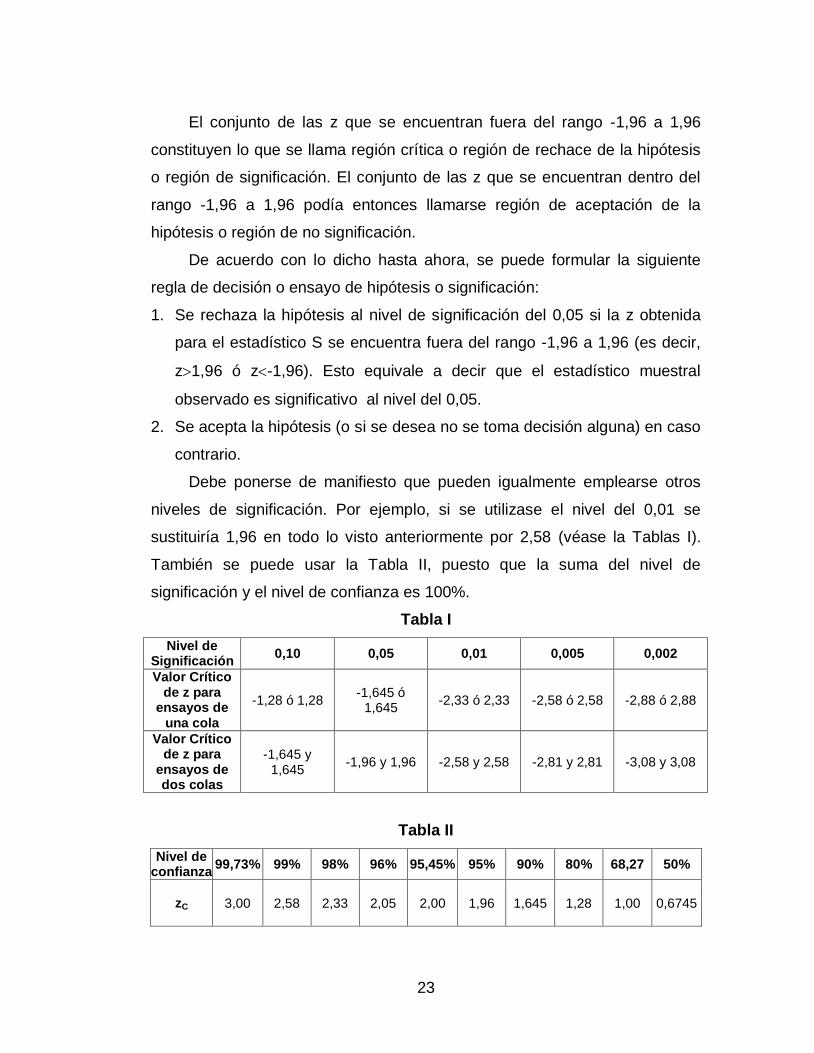
sustituiría 1,96 en todo lo visto anteriormente por 2,58 (véase la Tablas I).
También se puede usar la Tabla II, puesto que la suma del nivel de
significación y el nivel de confianza es 100%.
Tabla I
Nivel de Significación
0,10 0,05 0,01 0,005 0,002
Valor Crítico de z para
ensayos de una cola
-1,28 ó 1,28 -1,645 ó
1,645 -2,33 ó 2,33 -2,58 ó 2,58 -2,88 ó 2,88
Valor Crítico de z para
ensayos de dos colas
-1,645 y 1,645
-1,96 y 1,96 -2,58 y 2,58 -2,81 y 2,81 -3,08 y 3,08
Tabla II
Nivel de confianza
99,73% 99% 98% 96% 95,45% 95% 90% 80% 68,27 50%
zC
3,00 2,58 2,33 2,05 2,00 1,96 1,645 1,28 1,00 0,6745

24
Ejemplo 1.- En una industria farmacéutica se cambió un dosificador líquido
por uno nuevo. El anterior tenía un promedio histórico de 5,01 ml con un
desvío de 0,08 ml en 100 pruebas de calidad. Al actual se le realizaron 50
pruebas arrojando una media de 5,048 ml y un desvío de 0,05 ml. Con esta
información se debe decidir si ambos dosificadores son equivalentes.
H0 : μN = μV Son equivalentes.
H1 : μN ≠ μV Hay diferencia entre ambos.
Usando la fórmula general donde el supuesto principal es que las varianzas
son diferentes, pero los valores esperados son equivalentes entonces
resulta: σ1 ≈ DS1 = 0,08 y σ2 ≈ DS2 = 0,05 con sus tamaños muestrales de
100 y 50 respectivamente:
Z = 3,56*** ∉ CI 99,9% (-3,29 ; +3,29)
μN -μV = 0,038 ∉ CI 99,9% (-0,035; +0,035)
Hay fuerte evidencia de que no son equivalentes.
Notar que se ha probado que hay una diferencia del 1,2% entre ambos. Lo
que significa que cada medicamento fabricado tendrá, en promedio, una
cantidad mayor que la histórica lo que implicará un aumento de los costos de
producción. Esta evidencia aconseja no usar el nuevo dosificador.
Ejemplo 2.- Dos grupos A y B formados por 100 pacientes sufren un cierto
tipo de infección. Se administra un nuevo remedio a los del grupo A y un
placebo a los del grupo B que es el grupo testigo o control. En todo lo demás,
se trata a los 200 pacientes de la misma forma. Transcurrido el tiempo de
prueba se verifica que se han curado 75 individuos del grupo A y 65 del B.
Decidir si el nuevo remedio ayuda a curar la enfermedad.
Solución:

25
Ho : πA ≤ πB Las diferencias detectadas se deben al azar, el remedio no es
efectivo.
H1 : πA > πB Hay diferencia entre ambas y el remedio es efectivo.
Acá conviene hacer un ensayo de una sola cola porque lo que interesa
es ver si el remedio sirve, esto es, si el número de curados es mayor en al
grupo A que en el grupo B. Los valores muestrales de proporciones se usan
para estimar los poblacionales. Entonces:
Con estos valores se puede calcular:
Z = 0,10 / 0,0644 = 1,55 (no significativo) μ1-2 = 0,10 cae dentro de CI 95%
(- ∞ ; + 0,13) Esto significa que no se tiene prueba científica como para poder
afirmar que el suero es efectivo. Si se le realiza la corrección por continuidad
el valor de Z es todavía menor ( Z = 1,48 ).
Otra forma de resolver este problema es haciendo los supuestos
siguientes:
a) Ambas muestras provienen de la misma población, esto es π=πA= πB
b) La mejor estimación del valor desconocido π es con la media
ponderada de las proporciones observadas.
Esto es: π ≈ [100 (0,75) + 100 (0,65)] / (100 + 100) = 0,7
Y la varianza se calcula ahora con este valor estimado de 0,7. Esto es:
σ2 = π (1 – π) [(1/n1) + (1/n2)] =0,7 . 0,3 [(1/100) + (1/100)] = 0,0042 o sea,
σ = 0,06481
c) Se formula la Ho lo que significa que el valor observado de la diferencia se
debe al azar. Z = (p1 – p2) / σ = 0,10 / 0,06481 = 1,543 (no significativo) Notar
que los dos procedimientos son muy similares y puede adoptarse cualquiera
de ambos en casi todos los casos. La excepción es cuando las diferencias
entre los tamaños muestrales es muy grande y cuando las proporciones
difieren substancialmente. En todo otro caso, los valores del desvío estándar
son muy parecidos como en el ejemplo anterior σ1-2 = 0,0644 y σ = 0,06481.

26
CONCLUSIÓN
Una parte fundamental para realizar un estudio estadístico de cualquier
tipo es obtener unos resultados confiables y que puedan ser aplicables.
Como ya se comentó anteriormente, resulta casi imposible o impráctico llevar
a cabo algunos estudios sobre toda una población, por lo que la solución es
llevar a cabo el estudio basándose en un subconjunto de ésta denominada
muestra.
Sin embargo, para que los estudios tengan la validez y confiabilidad
buscada es necesario que tal subconjunto de datos, o muestra, posea
algunas características específicas que permitan, al final, generalizar los
resultados hacia la población en total. Esas características tienen que ver
principalmente con el tamaño de la muestra y con la manera de obtenerla.
Las técnicas de muestreo probabilístico son aquellas en las que se
determina al azar los individuos que constituirán la muestra. Estas técnicas
nos sirven cuando se desean generalizar los resultados que se obtienen a
partir de la muestra hacia toda la población. Lo anterior se dice dado que se
supone que el proceso aleatorio permitirá la obtención de una muestra
representativa de la población. Los muestreos probabilísticos pueden ser con
o sin reemplazo.
Finalmente, podemos concluir que la teoría de muestreo es importante
debido que muestra a los profesionales de enfermería que medicamento
puede ser más eficaz en para el combate de una determinada enfermedad,
podría escoger que marca cumple los estándares de calidad y eficacia.

27
BIBLIOGRAFÍA
Alatorre F., S., et.al. (s/f) Introducción a los Métodos Estadísticos. Universidad Pedagógica Nacional. México. (3 volúmenes. Sistema de Educación a Distancia.)
Benson, ES Connelly, DP y Burke, DM; (1981) Estrategias de selección de
pruebas de laboratorio; Ed. Médica Panamericana. Enciclopedia Electrónica Encarta 2007 (2006). Microsoft Company. USA Kohan, NC y Carro, JM; (1972) Estadística aplicada; 5ª Edición, EUDEBA.
Lee ET. (1980) Statistical Methods for Survival Data Analysis. Belmont, California: Lifetime Learning Publications.
Lewis, AE; (2004) Bioestadística, C:E:C:S:
Lison, L; (1990) Estadística aplicada a la biología experimental, EUDEBA.
Lwanga SK, Lemeshow S. (1991) Determinación del tamaño muestral en los estudios sanitarios. Manual Práctico. Ginebra: O.M.S.
Pértega Díaz S, Pita Fernández S. (2001) La distribución normal. Cad Aten Primaria.
Pita Fernández S. (1996) Determinación del tamaño muestral.
Remington, R y Schork, M; (2003) Estadística Biométrica y Sanitaria, Prentice Hall. México.
Spiegel, M.R. (2002) Estadística. McGraw-Hill. México. (Serie Schaum.)
Teoría de Muestreo (2010) [Documento en línea] Disponible en: http://aula-clip.com/estadistica/teoriade muestreo/index.html [Consultado:1/02/17]
Ciro Martínez. Estadística y muestreo (2017) [Documento en Línea] Disponible en: https://es.slideshare.net/caarias/estadstica-y-muestreo-13va-E [Consultado: 15/02/2017]