themen am 19.12.2006 - uni-goettingen.de · beispiele: guttman-skala, likert-skala. 3 datenanalyse...
TRANSCRIPT

1Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06
Empirie-Vorlesung im Wintersemester 2006/2007Teil A: Quantitative Methoden
Themen am 19.12.2006:• Datenanalyse
• Darstellung von Zusammenhängen in Tabellen• Kontrolle von Scheinkausalität durch Berücksichtigung von Drittvariablen• Reduzierung der statistischen Schlussvalidität durch Signifikanztests
• Ergebnispräsentation• Gliederung eines Forschungsberichts• Präsentation eines Zusammenhangs
Lernziele:1. Unterscheidung zwischen abhängiger Variable, erklärender Variable und Kontrollvariable2. Regeln für Prozentuierung und Interpretation in Tabellen3. Bedeutung von Drittvariablenkontrolle4. Logik des Signifikanztests5. Gesichtspunkte bei der Präsentation von Ergebnissen

2Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06
Wiederholung von letzter Woche
Auswahlverfahren II• Realisierung von Zufallsauswahlen:
bei persönlichen Befragungen: Karteiauswahl oder Random Walk; bei telefonischen Befragungen: Karteiauswahl, RD- oder RLD-Verfahren oder Auswahl aus Universum gültiger Blöcke;
• Ausfälle: Probleme durch systematische Ausfälle, Ausschöpfungsquote;• Gewichtung: Design-Gewichte und Redressment.
Datenaufbereitung• Datenkontrolle u. Datenenbereinigung (Dateneditierung);• Datenmodifikation: z.B. Rekodierung, Kategorisierung, Indexbildung, Skalierung;• Index: Bildung aus (mehreren) Ausgangsvariablen aufgrund theoretischer Vorgaben;
Beispiele: Arbeitslosenquote, Ingehart-Index;• Skalierungsverfahren: Zusammenfassung von mehreren Items zu einem Messintrument nach
statistischem Modell, daher Möglichkeit der empirischen Beurteilung der Skalenqualität bzw.Ausschluss von Items und/oder Fällen als nichtskalierbar in ein Skalenmodell;Beispiele: Guttman-Skala, Likert-Skala.

3
DatenanalyseDie aufbereiteten Daten müssen analysiert und interpretiert werden.In der quantitativen Sozialfoschung stehen hierzu eine Vielzahl von statistischen Modellen zur Verfügung.An dieser Stelle soll nur exemplarisch auf einige Möglichkeiten hingewiesen werden.
Untersuchung von Zusammenhängen in der Tabellenanalyse
In sehr vielen Untersuchungen der quantitativen Sozialforschung geht es darum, Zusammen-hänge zwischen Variablen aufzudecken oder zu überprüfen.
Beispiel:In der Politikwissenschaft gibt es eine Debatte darüber, ob es einen Unterschied gibt zwischen einem angesichts der deutschen Geschichte als problematisch angesehenen Nationalismus und einem positiver bewerteten (Verfassungs-)Patriotismus.In diesem theoretischen Zusammenhang mag der Zusammenhang zwischem dem Stolz,Deutscher zu sein, und der Links-Rechts-Selbsteinstufung interessieren. Ordnen sich Personen, die stolz darauf sind, Deutscher zu sein, auf der Links-Rechts-Skala weiter rechts ein, als Personen, die nicht darauf stolz sind?
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

4
Untersuchung von Zusammenhängen in der Tabellenanalyse
Als Datenbasis dienen die Antworten auf zwei Fragen aus dem Allbus 1996:
Variable: V68:(Falls Befragter die deutsche Staatsbürgerschaft besitzt)„Würden Sie sagen, dass Sie sehr stolz, ziemlich stolz, nicht sehr stolz oder überhaupt nicht stolz darauf sind, ein(e)Deutsche(r) zu sein?“Zusätzliche nicht vorgelesene Antwortkategorien: „keine Angabe“ und „keine deutsche Staatsangehörigkeit".
Variable V112:„Viele Leute verwenden die Begriffe 'links' und 'rechts',wenn es darum geht, unterschiedliche politische Einstellungen zu kennzeichnen. Wir haben hier einen Maßstab, der von links nach rechts verläuft. Wenn Sie an Ihre eigenen politischen Ansichten denken, wo würden Sie diese Ansichten auf dieser Skala einstufen? Machen Sie bitte ein Kreuz in eines der Kästchen“
links rechts1 2 3 4 5 6 7 8 9 10
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

5
Hypothese:Je mehr eine Person stolz darauf ist, Deutscher zu sein, desto höher ist die Wahrscheinlichkeit, sich selbst eher rechts zu positionieren.
Begründung für die Hypothese:• Die Frage nach dem Ausmaß des Stolzes Deutscher zu sein, misst Nationalbewusstsein• Die Frage nach der Links-Rechts-Einstufung misst die ideologische Selbstpositionierung.• Nationalbewusstsein korrespondiert mit einer rechten Position.
Abhängige Variable (Y): Links-Rechts-SelbsteinstufungErklärende oder unabhängige Variable (X): Ausmaß des Stolzes, Deutscher zu sein
Mit dem Programm SPSS produzierte Zusammenhansanalyse:
Verarbeitete Fälle
3212 91.3% 306 8.7% 3518 100.0%
V68 GENERELLERSTOLZ, DEUTSCHERZU SEIN * V112 LINKS-RECHTS-SELBSTEINSTUFUNG, BEFR.
N Prozent N Prozent N ProzentGültig Fehlend Gesamt
Fälle
Untersuchung von Zusammenhängen in der Tabellenanalyse
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

6
Untersuchung von Zusammenhängen in der Tabellenanalyse
Kreuztabellierung des Zusammenhangs:
V68 GENERELLER STOLZ, DEUTSCHER ZU SEIN * V112 LINKS-RECHTS-SELBSTEINSTUFUNG, BEFR. Kreuztabelle
14 13 42 51 171 145 66 57 19 27 605
2.3% 2.1% 6.9% 8.4% 28.3% 24.0% 10.9% 9.4% 3.1% 4.5% 100.0%
25 46 135 163 431 343 151 97 26 26 1443
1.7% 3.2% 9.4% 11.3% 29.9% 23.8% 10.5% 6.7% 1.8% 1.8% 100.0%
20 37 109 107 216 152 66 26 8 6 747
2.7% 5.0% 14.6% 14.3% 28.9% 20.3% 8.8% 3.5% 1.1% .8% 100.0%
13 37 78 69 101 69 32 11 3 4 417
3.1% 8.9% 18.7% 16.5% 24.2% 16.5% 7.7% 2.6% .7% 1.0% 100.0%
72 133 364 390 919 709 315 191 56 63 3212
2.2% 4.1% 11.3% 12.1% 28.6% 22.1% 9.8% 5.9% 1.7% 2.0% 100.0%
Anzahl% von V68 GENERELLER DEUTSCHER ZAnzahl% von V68 GENERELLER DEUTSCHER ZAnzahl% von V68 GENERELLER DEUTSCHER ZAnzahl% von V68 GENERELLER DEUTSCHER ZAnzahl% von V68 GENERELLER DEUTSCHER Z
1 SEHR STOLZ
2 ZIEMLICH ST
3 NICHT SEHR
4 GAR NICHT S
V68 GENERELSTOLZ, DEUTSZU SEIN
Gesamt
1 LINKS 2 3 4 5 6 7 8 9 0 RECHTSV112 LINKS-RECHTS-SELBSTEINSTUFUNG, BEFR.
Gesamt
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

7
Untersuchung von Zusammenhängen in der Tabellenanalyse
Ausmaß des Stolzes, Deutscher zu seingar nicht nicht sehr ziemlich sehr stolz
rechts 10 1.0% 0.8% 1.8% 4.5%9 0.7% 1.1% 1.8% 3.1%8 2.6% 3.5% 6.7% 9.4%7 7.7% 8.8% 10.5% 10.9%6 16.5% 20.3% 23.8% 24.0%5 24.2% 28.9% 29.9% 28.3%4 16.5% 14.3% 11.3% 8.4%3 18.7% 14.6% 9.4% 6.9%2 8.9% 5.0% 3.2% 2.1%
links 1 3.1% 2.7% 1.7% 2.3%
(417) (747) (1443) (605)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Aus einer Tabelle sollte klar erkennbar sein, (a) was abhängige und was erklärende Variable ist,(b) welche Ausprägungen betrachtet werden,(c) bei Prozentangaben, auf welche Basis sich die Prozentangaben beziehen,(d) und schließlich, woher die Daten kommen (Datenquelle).
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

8
Untersuchung von Zusammenhängen in der Tabellenanalyse
Prozentuierung:Die Prozentwerte der abhängigen Variablen summieren sich innerhalb jeder Ausprägung der erklärenden Variablen zu 100%. Verglichen werden die Prozentwerte einer Ausprägung der abhängigen Variablen über die unterschiedlichen Ausprägungen der erklärenden Variablen.
Ausmaß des Stolzes, Deutscher zu seingar nicht nicht sehr ziemlich sehr stolz
rechts 10 1.0% 0.8% 1.8% 4.5%9 0.7% 1.1% 1.8% 3.1%8 2.6% 3.5% 6.7% 9.4%7 7.7% 8.8% 10.5% 10.9%6 16.5% 20.3% 23.8% 24.0%5 24.2% 28.9% 29.9% 28.3%4 16.5% 14.3% 11.3% 8.4%3 18.7% 14.6% 9.4% 6.9%2 8.9% 5.0% 3.2% 2.1%
links 1 3.1% 2.7% 1.7% 2.3%
(417) (747) (1443) (605)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

9
Untersuchung von Zusammenhängen in der Tabellenanalyse
Prozentuierung:Merkregel: Bei spaltenweiser Prozentuierung, zeilenweise vergleichen!
Ausmaß des Stolzes, Deutscher zu seingar nicht nicht sehr ziemlich sehr stolz
rechts 10 1.0% 0.8% 1.8% 4.5%9 0.7% 1.1% 1.8% 3.1%8 2.6% 3.5% 6.7% 9.4%7 7.7% 8.8% 10.5% 10.9%6 16.5% 20.3% 23.8% 24.0%5 24.2% 28.9% 29.9% 28.3%4 16.5% 14.3% 11.3% 8.4%3 18.7% 14.6% 9.4% 6.9%2 8.9% 5.0% 3.2% 2.1%
links 1 3.1% 2.7% 1.7% 2.3%
(417) (747) (1443) (605)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Befragte, die sich als gar nicht stolz bezeichnen, ordnen sich zu einem geringeren Anteil politisch rechts ein, als Befragte, die sich als sehr stolz bezeichnen.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

10
Untersuchung von Zusammenhängen in der Tabellenanalyse
Prozentuierung:Merkregel: Bei spaltenweiser Prozentuierung, zeilenweise vergleichen!
Ausmaß des Stolzes, Deutscher zu seingar nicht nicht sehr ziemlich sehr stolz
rechts 10 1.0% 0.8% 1.8% 4.5%9 0.7% 1.1% 1.8% 3.1%8 2.6% 3.5% 6.7% 9.4%7 7.7% 8.8% 10.5% 10.9%6 16.5% 20.3% 23.8% 24.0%5 24.2% 28.9% 29.9% 28.3%4 16.5% 14.3% 11.3% 8.4%3 18.7% 14.6% 9.4% 6.9%2 8.9% 5.0% 3.2% 2.1%
links 1 3.1% 2.7% 1.7% 2.3%
(417) (747) (1443) (605)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Befragte, die sich als gar nicht stolz bezeichnen, ordnen sich zu einem höheren Anteil politisch links ein, als Befragte, die sich als sehr stolz bezeichnen.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

11
Untersuchung von Zusammenhängen in der Tabellenanalyse
Prozentuierung:Merkregel: Bei zeilenweiser Prozentuierung, spaltenweise vergleichen!
Würde man entgegen dieser Regel vergleichen, gäbe es keinerlei Zusammenhangsinformation:Der empirische Befund, dass Personen, die sich als gar nicht stolz bezeichnen, sich zu 3.1% ganz links, zu 24.2% etwas links, zu 16.5% etwas rechts und zu 1.0%sehr rechts einstufen, sagt gar nicht darüber, wie sich Personen positionieren, die in einem höherem Ausmaß stolz sind.Sie könnten häufiger oder seltener links oder rechts sein.Erst der Vergleich über Gruppen mit unterschiedlichem Ausmaß an Stolz informiertdarüber, ob es einen Zusammenhang gibt.
Links-Rechts-Selbstorientierung (Angaben in Prozent)Ausmaß des Stolzes, links rechtsDeutscher zu sein 1 2 3 4 5 6 7 8 9 10 N
gar nicht stolz 3.1 8.9 18.7 16.5 24.2 16.5 7.7 2.6 0.7 1.0 (417)nicht sehr stolz 2.7 5.0 14.6 14.3 28.9 20.3 8.8 3.5 1.1 0.8 (747)ziemlich stolz 1.7 3.2 9.4 11.3 29.9 23.8 10.5 6.7 1.8 1.8 (1443)sehr stolz 2.3 2.1 6.9 8.4 28.3 24.0 10.9 9.4 3.1 4.5 (605)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

12
Links-Rechts-Selbstorientierung (Angaben in Prozent)Ausmaß des Stolzes, links rechtsDeutscher zu sein 1 2 3 4 5 6 7 8 9 10
sehr stolz 19.4 9.8 11.5 13.1 18.6 20.5 21.0 29.8 33.9 42.9ziemlich stolz 34.7 34.6 37.1 41.8 46.9 48.4 47.9 50.8 46.4 41.3nicht sehr stolz 27.8 27.8 29.9 27.4 23.5 21.4 21.0 13.6 14.3 9.5gar nicht stolz 18.1 27.8 21.4 17.7 11.0 9.7 10.2 5.8 5.4 6.3
(N) (72) (133) (364) (390) (919) (709) (315) (191) (56) (63)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Untersuchung von Zusammenhängen in der Tabellenanalyse
Von den Befragten, die sich ganz links einordnen, sind 19.8% sehr stolz, von denjenigen, die sich ganz rechts einordnen, sind es 42.9%.Umgekehrt sind 18.1% der Befragten, die sich ganz links einordnen, gar nicht stolz,während es 6.3% von denjenigen sind, die sich ganz rechts einordnen.
Prozentuierung:Merkregel: Bei spaltenweiser Prozentuierung, zeilenweise vergleichen!
→ → → → → → → → →→ → → → → → → → →→ → → → → → → → →→ → → → → → → → →
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

13
Links-Rechts-Selbstorientierung (Angaben in Prozent)Ausmaß des Stolzes, links rechtsDeutscher zu sein 1 2 3 4 5 6 7 8 9 10
sehr stolz 19.4 9.8 11.5 13.1 18.6 20.5 21.0 29.8 33.9 42.9ziemlich stolz 34.7 34.6 37.1 41.8 46.9 48.4 47.9 50.8 46.4 41.3nicht sehr stolz 27.8 27.8 29.9 27.4 23.5 21.4 21.0 13.6 14.3 9.5gar nicht stolz 18.1 27.8 21.4 17.7 11.0 9.7 10.2 5.8 5.4 6.3
(N) (72) (133) (364) (390) (919) (709) (315) (191) (56) (63)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Untersuchung von Zusammenhängen in der Tabellenanalyse
→ → → → → → → → →→ → → → → → → → →
→ → → → → → → → →→ → → → → → → → →
Spaltenweise Prozentuierung: die Werte der erklärenden Variable sind spaltenweise, die der abhängigen Variable zeilenweise eingetragen.
Zeilenweise Prozentuierung: die Werte der erklärenden Variable sind zeilenweise, die der abhängigen Variable spaltenweise eingetragen.
Links-Rechts-Selbstorientierung (Angaben in Prozent)Ausmaß des Stolzes, links rechtsDeutscher zu sein 1 2 3 4 5 6 7 8 9 10 N
gar nicht stolz 3.1 8.9 18.7 16.5 24.2 16.5 7.7 2.6 0.7 1.0 (417)nicht sehr stolz 2.7 5.0 14.6 14.3 28.9 20.3 8.8 3.5 1.1 0.8 (747)ziemlich stolz 1.7 3.2 9.4 11.3 29.9 23.8 10.5 6.7 1.8 1.8 (1443)sehr stolz 2.3 2.1 6.9 8.4 28.3 24.0 10.9 9.4 3.1 4.5 (605)(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
↓↓↓↓
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

14
Untersuchung von Zusammenhängen in der Tabellenanalyse
Festlegung von abhängiger und erklärender Variable entsprechend der postulierten Kausal-anordnung:• Erklärende Variable ist die Variable, die die abhängige Variable beeinflusst:
Ändert sich bei einer Untersuchungseinheit die Ausprägung der erklärenden Variable,dann ändert sich (wahrscheinlich) bei dieser Untersuchungseinheit auch die Ausprägungder abhängigen Variable.
• Abhängige Variable ist die Variable, die die erklärende Variable nicht beeinflusst:Ändert sich die Ausprägung bei der abhängigen Variablen, hat dies keine Konsequenzenbei der erklärenden Variable.Entweder hat sich der Wert der erklärenden Variable bereits vorher geändert, oder einedritte Variable hat die Veränderung bei der abhängigen Variable verursacht.
Probleme,(a) wenn keine zeitliche Erfassung der Veränderung möglich ist,(b) wenn keine Unabhängigkeit zwischen der erklärenden Variable und einer möglichen
Drittvariable besteht,(c) wenn wechselseitige Beeinflussung postuliert wird,(d) wenn keine a-priori Festlegung der Kausalanordnung sinvoll erscheint.→ Probleme gefährden die interne Validität von Untersuchungsergebnissen.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

15
Untersuchung von Zusammenhängen in der Tabellenanalyse
Festlegung von abhängiger und erklärender Variable entsprechend der erwünschten Vorhesage:• Erklärende Variable ist die Variable, bei deren Kenntnis die Ausprägungen der abhängigen
Variable vorausgesagt werden sollen.• Abhängige Variable ist die Variable, deren Ausprägungen bei Kenntnis der Ausprägungen
der erklärenden Variable (besser) vorausgesagt werden.
Alternative Begrifflichkeiten:• abhängige Variable = Zielvariable• erklärende Variable = unabhängige Variable = Prädiktor(variable) = Regressor (= Kovariate)• Drittvariable = Kontrollvariable = Kovariate
Mögliche Argumentationen im Beispiel:• Die Links-Rechts-Skalag ist eine generalisierte Position, deren Bedeutung
durch spezifische Wertvorstellungen festgelegt ist, wobei die Betonung des Nationalen ein Bedeutungselement ist.→ Links-Rechts-Selbsteinstufung ist abhängige Variable, die durch Stolz
beeinflusst wird.• Da die Links-Rechts-Skala eine generalisierte Position ist, ist sie hilfreich,
um das Nationalbewusstsein vorherzusagen.→ Links-Rechts-Selbsteinstufung ist Prädiktorvariable, mit deren Hilfe
das Ausmaß des Stolzes prognostiziert wird.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

16
KohortenanalysenBei einem Kohortendesign werden Kohorten, das sind z.B. Personen gleicher Geburtsjahr-gänge, über die Zeit betrachtet. Die Daten können aus Panel- oder Trendstudien kommen.
Im Beispiel sieht man, das die Werte in jeder Altersgruppe über die Zeit zunehmen, wobei sich der Anstieg von Kohort zu Kohorte verlangsamt. Bei den 1970 41-50jährigen steigen die Werte in den folgenden 10 Jahren um 15 an,bei den 1970 31-40jährigen um 10 und bei den 21-30jährigen um 5.
In jeder Spalte der Tabelle sind im Beispiel die Mittelwerte der Befragten eines Messzeit-punktes in Altersgruppen aufgeteilt.In einer Zeile sind Angaben von Personen, die zu den einzelnen Messzeitpunkten in der gleichen Altersgruppe sind.In den Diagonalelementen sieht man die Ent-wicklung einer Altersgruppe (Kohorte) über die Zeit.
Mit einem Kohortendesign wird versucht, Veränderungen zu unterscheiden, die durch Alterung (Alterseffekte), durch Kohortenzugehörigkeit (Kohorteneffekte) oder spezifische Ereignissen (Ereigniseffekte) ausgelöst werden.Die drei Effekte sind allerdings logisch voneinander abhängig!
MesszeitpunkteAltersgruppe 1970 1980 1990 2000
21 - 30 15 20 25 3031 - 40 25 20 22 2641 - 50 35 35 25 2451 - 60 45 50 45 30
(fiktive Daten)
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

17
DrittvariablenkontrolleIn Ex-post-facto-Designs ist die interne Validität besonders gefährdet.Hilfreich kann hier die explizite Kontrolle von alternativen Erklärungsmöglichkeiten sein, die sogenannte Drittvariablenkontrolle.
Beispiel: Zusammenhang zwischen der Zahl der bei der Brandbekämpfung eingesetzten Feuerwehrleute und der Größe des Schadens.
Die (fiktiven) Beispieldaten weisen darauf hin, dass ein großer Schaden eine um 25.3 (= 56.4% − 31.1%) Prozentpunkte höhere Auftretenschance hat, wenn statt einer niedrigen, eine hohe Zahl von Feuerwehrleuten eingesetzt wird.
Anzahl FeuerwehrleuteGröße des Schadens geringe Anzahl hohe Anzahl Total
kleiner Schaden 68.9% (310) 43.6% (240) 55.0% (550)großer Schaden 31.1% (140) 56.4% (310) 45.0% (450)
Total 100.0% (450) 100.0% (550) 100.0% (1000)(fiktive Daten)
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

18
Drittvariablenkontrolle
Drittvariablenkontrolle durch Bildung von Teiltabellen,Berechnung konditionaler Zusammenhänge bei gegebenen Werten einer Kontrollvariable:
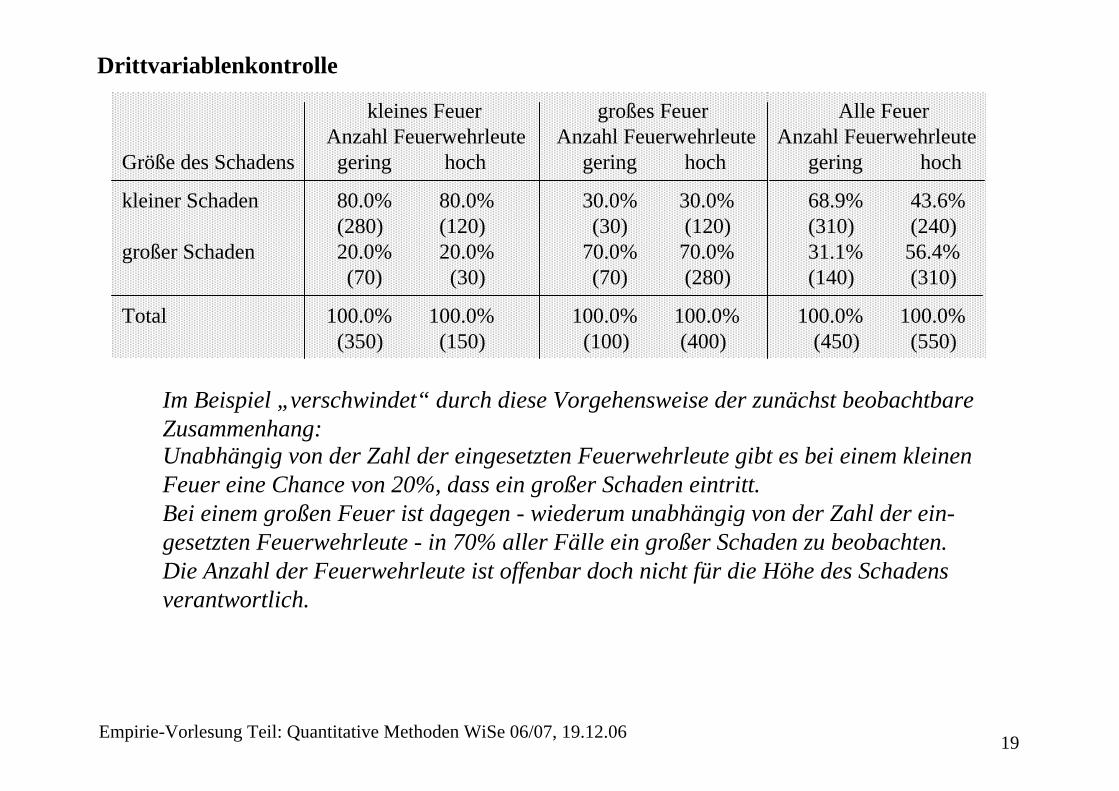
Dieses Ergebnis stellt sich jedoch nur dann ein, wenn die Größe des Feuers unberücksichtigt bleibt. In der Drittvariablenkontrolle werden für alle Werte von möglichen alternativen Erklärungs-größen (hier: Größe des Feuers) jeweils getrennt die konditionalen Zusammenhänge in Teil-tabellen oder Partialtabellen berechnet. Wird nicht zwischen der Größe des Feuers unterschieden, ergeben sich die Daten der bivariatenTabelle der vorigen Seite.
kleines Feuer großes FeuerAnzahl Feuerwehrleute Anzahl Feuerwehrleute
Größe des Schadens gering hoch gering hoch
kleiner Schaden 80.0% 80.0% 30.0% 30.0%(280) (120) (30) (120)
großer Schaden 20.0% 20.0% 70.0% 70.0%(70) (30) (70) (280)
Total 100.0% 100.0% 100.0% 100.0%(350) (150) (100) (400)
Alle FeuerAnzahl Feuerwehrleute
gering hoch
68.9% 43.6%(310) (240)31.1% 56.4% (140) (310)
100.0% 100.0%(450) (550)
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06
19
Drittvariablenkontrolle
kleines Feuer großes FeuerAnzahl Feuerwehrleute Anzahl Feuerwehrleute
Größe des Schadens gering hoch gering hoch
kleiner Schaden 80.0% 80.0% 30.0% 30.0%(280) (120) (30) (120)
großer Schaden 20.0% 20.0% 70.0% 70.0%(70) (30) (70) (280)
Total 100.0% 100.0% 100.0% 100.0%(350) (150) (100) (400)
Alle FeuerAnzahl Feuerwehrleute
gering hoch
68.9% 43.6%(310) (240)31.1% 56.4% (140) (310)
100.0% 100.0%(450) (550)
Im Beispiel „verschwindet“ durch diese Vorgehensweise der zunächst beobachtbare Zusammenhang: Unabhängig von der Zahl der eingesetzten Feuerwehrleute gibt es bei einem kleinen Feuer eine Chance von 20%, dass ein großer Schaden eintritt. Bei einem großen Feuer ist dagegen - wiederum unabhängig von der Zahl der ein-gesetzten Feuerwehrleute - in 70% aller Fälle ein großer Schaden zu beobachten. Die Anzahl der Feuerwehrleute ist offenbar doch nicht für die Höhe des Schadens verantwortlich.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

20
Drittvariablenkontrolle
Da nur bei Ignorierung der alternativen Erklärungsgröße (Dritt- oder Kontrollvariable) „Größe des Feuers“ ein bivariater Zusammenhang zwischen Anzahl der eingesetzten Feuerwehrleute und Größe des Schadens zu beobachten ist, spricht man auch von einer Scheinkausalität (oft auch als Scheinkorrelation bezeichnet) bei der Beziehung zwischen der Zahl der Feuerwehr-leute und der Schadenshöhe.
Das Beispiel weist auf den Unterschied zwischen Korrelation (= empirisch beobachtbarer Zusammenhang) und Kausalität (= Ursache-Wirkungs-Zusammenhang) hin.Drittvariablenkontrolle erleichtert die Unterscheidung von Korrelation und Kausalität, garan-tiert allerdings keine Aufdeckung von Kausalität, da es neben der kontrollierten Drittvariable (hier: Größe des Feuers) weitere Drittgrößen geben kann, die nicht kontrolliert worden sind. Auch wird durch Drittvariablenkontrolle allein die Zeitdimension noch nicht berücksichtigt. Trotz Drittvariablenkontrolle kann daher ein völlig falscher Eindruck über die tatsächlichen Kauslabeziehungen bestehen.Trotzdem ist die Drittvariablenkontrolle eine wichtige (und in Ex-post-facto-Designs die einzige) Methode, um die interne Validität von Untersuchungsergebnissen zu erhöhen.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

21
Signifikanztests
Bei deterministischen Zusammenhängen genügt ein Gegenbeispiel, um einen postulierten Zusammenhang zu falsifizieren.Bei statistischen Zusammenhängen werden dagegen viele Anwendungsbeispiele benötigt, die zusammen bei Anwendung des Gesetzes der großen Zahl für oder gegen einen Zusammenhang sprechen. Dabei besteht aufgrund des Induktionsproblems. d.h. des Schließens von den Anwendungs-beispielen auf die (theoretisch unbegrenzte) Gesamtheit aller möglichen Anwendungen, die Gefahr eines Fehlschlusses.Mit Hilfe von statistischen Tests wird versucht, diese Gefährdung der statistischen Schlussvali-dität zu minimieren.
Die Vorgehensweise kann anhand eines Signifikanztests über den Zusammenhang in einer Tabelle verdeutlicht werden.
Im Beispiel geht es um den Zusammenhang zwischen politischer Unzufriedenheitund der Wahl einer extremen Partei.Es wird vermutet, dass politisch unzufriedene Bürger eher eine extreme Parteiwählen als politisch zufriedene Bürger.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

22
Signifikanztests
Zur Überprüfung dieser Hypothese wird zunächst genau das Gegenteil dieser Forschungs-hypothese postuliert. Die sogenannte Nullhypothese behauptet daher, dass es keinen Zusam-menhang zwischen politischer Unzufiredenheit und Wahl einer extremen Partei gibt.
Für die Überprüfung wird zunächst angenommen, dass die Nullhypothese richtig ist, dass es also keinen Zusammenhang zwischen den beiden Variablen gibt.
Wenn es insgesamt 1 000 000 Wähler gibt und von diesen 50 000 unzufrieden sind und es insgesamt 27 000 Wähler einer extremen Partei gibt, dann müsste bei Unabhängigkeit der Anteil der Wähler einer extremen Partei unter den 50 000Unzufriedenen genau so hoch sein wie unter den 950 000 (=1 000 000 – 50 000) zufriedenen Wählern:
Wenn jeweils 500 Personen in der Gruppe der Unzufriedenen und der Zufriedenen zufällig ausgewählt werden, ist zu erwarten, dass in den beiden Stichprobengruppen jeweils etwa zwischen 2 und 3 % oder 10 bis 15 Personen eine extreme Partei wählen, wenn die Nullhypothese wahr wäre.
Wahl einer Wähler Politisch zufrieden?extremen Partei insgesamt in % ja nein
ja 27 000 2.7% 2.7% 25 650 2.7% 1 350nein 973 000 97.3% 97.3% 924 350 97.3% 48 650Total 1 000 000 100.0% (950 000) 950 000 (50 000) 50 000
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

23
Signifikanztests
Tatsächlich könnten aber z.B. auch folgende Stichprobenzusammensetzungen auftreten:
Stichprobe 1 Stichprobe 2Wahl einer Politisch unzufrieden Politisch unzufriedenextremen Partei ja nein ja neinja 20 (4%) 5 (1%) 10 (2%) 20 (4%)nein 480 (96%) 495 (99%) 490 (98%) 480 (96%)
In Stichprobe 1 wählen politisch unzufriedene Personen eher eine extreme Partei,in Stichprobe 2 wählen politisch unzufriedene Personen dagegen seltener eine extreme Partei als politisch zufriedene Personen.
Wahl einer Wähler Politisch zufrieden?extremen Partei insgesamt in % ja nein
ja 27 000 2.7% 2.7% 25 650 2.7% 1 350nein 973 000 97.3% 97.3% 924 350 97.3% 48 650Total 1 000 000 100.0% (950 000) 950 000 (50 000) 50 000
Wenn jeweils 500 Personen in der Gruppe der Unzufriedenen und der Zufriedenen zufällig ausgewählt werden, ist zu erwarten, dass in den beiden Stichprobengruppen jeweils etwa zwischen 2 und 3 % oder 10 bis 15 Personen eine extreme Partei wählen, wenn die Nullhypothese wahr wäre.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

24
Signifikanztests
Wahl einer Wähler Politisch zufrieden?extremen Partei insgesamt in % ja nein
ja 27 000 2.7% 2.7% 25 650 2.7% 1 350nein 973 000 97.3% 97.3% 924 350 97.3% 48 650Total 1 000 000 100.0% (950 000) 950 000 (50 000) 50 000
Es kann nun für jede Stichprobe ausgerechnet werden, wie wahrscheinlich es ist, dass es die in der Stichprobe beobachtete oder aber eine noch größere Abweichung von dem Ergebnis gibt, dass nach der Nullhypothese eigentlich zu erwarteten wäre.
Wenn die Nullhypothese, dass es keinen Zusammenhang gibt, richtig wäre, müssten in Stichprobe 1 jeweils 2.5% (=25/1000) und in Stichprobe 2 jeweils 3.0% (=30/1000) der politisch zufriedenen wie unzufriedenen Personen eine extreme Partei wählen.
Mit Hilfe der sogenannten Chiquadratstatistik und der zugehörigen Chiquadrat-Verteilungkann diese Wahrscheinlichkeit berechnet werden.
Stichprobe 1 Stichprobe 2Wahl einer Politisch unzufrieden Politisch unzufriedenextremen Partei ja nein ja neinja 20 (4%) 5 (1%) 10 (2%) 20 (4%)nein 480 (96%) 495 (99%) 490 (98%) 480 (96%)Chiquadrat 9.231 (p: 0.002) 3.436 (p: 0.064)
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

25
Signifikanztests
Im Beispiel beträgt in Stichprobe 1 die Wahrscheinlichkeit 0.2% (0.002), dass die beobachteten oder noch größere Unterschiede im Wahlverhalten zwischen den unzu-friedenen und den zufriedenen Personen zu beobachten sind, falls es in der Popula-ion tatsächlich keinen Zusammenhang gibt.In Stichprobe 2 beträgt diese Wahrscheinlichkeit dagegen 6.4% (0.064).
Stichprobe 1 Stichprobe 2Wahl einer Politisch unzufrieden Politisch unzufriedenextremen Partei ja nein ja neinja 20 (4%) 5 (1%) 10 (2%) 20 (4%)nein 480 (96%) 495 (99%) 490 (98%) 480 (96%)Chiquadrat 9.231 (p: 0.002) 3.436 (p: 0.064)
Beim Signifikanztest wird nun folgendermaßen argumentiert:• Wenn die Wahrscheinlichkeit des Chiquadrattests klein ist, dann ist es unwahrscheinlich,
dass das beobachtete Ergebnis auftritt, falls die Nullhypothese richtig wäre. Daher ist die Nullhypothese vermutlich falsch und wird verworfen. Da die Nullhypothese das Gegenteil der ursprünglichen theoretischen Vermutung beinhaltet, wird dann umgekehrt geschlossen, dass die ursprüngliche Vermutung richtig ist, nach der es einen Zusammenhang gibt. Die Forschungshypothese ist dann bestätigt.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

26
Signifikanztests
Stichprobe 1 Stichprobe 2Wahl einer Politisch unzufrieden Politisch unzufriedenextremen Partei ja nein ja neinja 20 (4%) 5 (1%) 10 (2%) 20 (4%)nein 480 (96%) 495 (99%) 490 (98%) 480 (96%)Chiquadrat 9.231 (p: 0.002) 3.436 (p: 0.064)
In den Sozialwissenschaften wird oft eine Irrtumswahrscheinlichkeit (auch Signifikanzniveaugenannt) von 5% verwendet. Wenn ein Signifikanztest zu einer Wahrscheinlichkeit führt, die kleiner/gleich dieser Irrtums-wahrscheinlichkeit ist, dann wird die Nullhypothese verworfen und das Ergebnis als signifikant bezeichnet.
Bei einer Irrtumswahrscheinlichkeit von 5% wird also in Stichprobe 1 die Null-hypothese verworfen, in Stichprobe 2 dagegen beibehalten.Während in Stichprobe 1 mit hinreichender Sicherheit ausgeschlossen werden kann,dass es keinen Zusammenhang zwischen politischer Zufriedenheit und Wahlabsichtgibt, ist dies in Stichprobe 2 nicht der Fall.
Im Beispiel beträgt in Stichprobe 1 die Wahrscheinlichkeit 0.2% (0.002), dass die beobachteten oder noch größere Unterschiede im Wahlverhalten zwischen den unzu-friedenen und den zufriedenen Personen zu beobachten sind, falls es in der Popula-ion tatsächlich keinen Zusammenhang gibt.In Stichprobe 2 beträgt diese Wahrscheinlichkeit dagegen 6.4% (0.064).
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

27
Signifikanztests
Stichprobe 1 Stichprobe 2Wahl einer Politisch unzufrieden Politisch unzufriedenextremen Partei ja nein ja neinja 20 (4%) 5 (1%) 10 (2%) 20 (4%)nein 480 (96%) 495 (99%) 490 (98%) 480 (96%)Chiquadrat 9.231 (p: 0.002) 3.436 (p: 0.064)
Formal folgt die Logik des statistischen Signifikanztests folgender aussagenlogisch korrekter Argumentation:
(1) Wenn die Nullhypothese richtig wäre, wäre mit Ergebnis A zu rechnen. (2) Ergebnis A wird aber nicht beobachtet.(3) Also ist die Nullhypothese falsch.Formal: ( ( H ⇒ A) & ¬A ) ⇒¬H.
Zu berücksichtigen ist dabei allerdings, dass das Ergebnis A ein Ereignis ist, dass nur mit einer bestimmten Wahrscheinlichkeit auftritt. Je geringer die noch akzeptierte Irrtunswahrscheinlich-keit ist, desto eher folgt der Test dem logischen Schluss.
Ein Problem dieses auf den Statistiker Fischer zurückgehenden Testprinzips ist, dass es neben der akzeptierten Irrtumswahrscheinlichkeit auch die Fehlerwahrscheinlichkeit gibt, die Null-hypothese nicht zu verwerfen, obwohl sie richtig ist. Soll auch dieser Fehler 2. Art berücksichtigt werden, ist eine komplexere Testlogik not-wendig.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

28
ErgebnispräsentationNur wenn die Ergebnisse einer Untersuchung der Wissenschaft für eine kritische Diskussion zur Verfügung stehen, kann die Forschung zum allgemeinen Erkenntnisgewinn beitragen. Die Wissenschaft finanzierenden Stiftungen verlangen daher bei der Bereitstellung von For-schungsgeldern nicht nur, dass Forschungsberichte angefertigt werden, sondern drängen auch auf eine Publikation der Ergebnisse in der „scientific community“ durch Vorträge auf Fachta-gungen, Aufsätze in Fachzeitschriften oder Publikation von Monographien.Neuerdings wird auch verstärkt auf die praktische Nutzbarkeit der Ergebnisse z.B. für die Bildung oder Politik geachtet.
ForschungsberichtDer Forschungsbericht soll über die Fragestellung, die Vorgehensweise der Forschung und die Ergebnisse Auskunft geben. Dabei hat sich eine Dreiteilung der Darstellung bewährt1 Theorie:1.1. Fragestellung1.2. Stand der Forschung und Forschungsdefizite1.3. Hypothesenbildung2. Methoden2.1. Untersuchungsdesign2.2. Auswahlplan und realisierte Stichprobe2.3. Erhebungsinstrumente2.4. Analysemethode
3. Ergebnisse3.1. Deskription3.2. Statistische Analysen3.3. Interpretation und Schlussfolgerungen
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

29
Präsentation des Zusammenhangs zwischen Stolz und Links-Rechts-Selbsteinstufung
Ausmaß des Stolzes, Deutscher zu seingar nicht nicht sehr ziemlich sehr stolz
rechts 10 1.0% 0.8% 1.8% 4.5%9 0.7% 1.1% 1.8% 3.1%8 2.6% 3.5% 6.7% 9.4%7 7.7% 8.8% 10.5% 10.9%6 16.5% 20.3% 23.8% 24.0%5 24.2% 28.9% 29.9% 28.3%4 16.5% 14.3% 11.3% 8.4%3 18.7% 14.6% 9.4% 6.9%2 8.9% 5.0% 3.2% 2.1%
links 1 3.1% 2.7% 1.7% 2.3%
(417) (747) (1443) (605)
(Quelle: Allbus 1996: gültige Angaben von 3212 der insgesamt 3518 Befragten)
Hypothese: Je stolzer eine Person ist, desto eher nimmt sie auf der Links-Rechts-Skala eine rechte Position ein.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

30
Präsentation des Zusammenhangs zwischen Stolz und Links-Rechts-Selbsteinstufung
Links-Rechts-Selbsteinstufung nach Stolz, Deutscher zu sein
0.05.0
10.015.020.025.030.035.0
1 2 3 4 5 6 7 8 9 10
Links-Rechts-Einstufung
Proz
ent
sehr stolz ziemlich stolznicht sehr stolz gar nicht stolz
(Quelle: ALLBUS 1996, n=3212)
Hypothese: Je stolzer eine Person ist, desto eher nimmt sie auf der Links-Rechts-Skala eine rechte Position ein.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

31
Präsentation des Zusammenhangs zwischen Stolz und Links-Rechts-Selbsteinstufung
Hypothese: Je stolzer eine Person ist, desto eher nimmt sie auf der Links-Rechts-Skala eine rechte Position ein.
0.05.0
10.015.020.025.030.035.0
1 2 3 4 5 6 7 8 9 10
Links-Rechts-Selbsteinstufung
Proz
ent
sehr stolz ziemlich stolznicht sehr stolz gar nicht stolz
Links-Rechts-Selbsteinstufung nach Stolz, Deutscher zu sein
(Quelle: ALLBUS 1996, n=3212)
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

32
Präsentation des Zusammenhangs zwischen Stolz und Links-Rechts-Selbsteinstufung
Hypothese: Je stolzer eine Person ist, desto eher nimmt sie auf der Links-Rechts-Skala eine rechte Position ein.
(Quelle: ALLBUS 1996, n=3212)
4.544.885.355.71
1.0
5.5
10.0
sehr st
olz
ziemlich
stolz
nicht se
hr stolz
gar nich
t stolz
links
rechts
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06

33
Präsentation des Zusammenhangs zwischen Stolz und Links-Rechts-Selbsteinstufung
Bei der grafischen Darstellung von Problemen ist sehr viel Sorgfalt notwendig, da ansonsten leicht falsche Schlussfolgerungen gezogen werden.
4.544.885.355.71
1
5.5
10
sehr st
olz
ziemlich
stolz
nicht se
hr stolz
gar nich
t stolz
4.54
4.88
5.35
5.71
4.50
4.75
5.00
5.25
5.50
5.75
sehr st
olz
ziemlich
stolz
nicht se
hr stolz
gar nich
t stolz
Obwohl beide Grafiken das gleiche Ergebnis zeigen, wird in der rechten Abbildung der Ein-druck suggeriert, dass es einen sehr starken Zusammenhang zwischen dem Stolz, Deutscher zu sein, und der Links-Rechts-Selbsteinstufung gibt. Tatsächlich beträgt der maximale Unterschied nur etwas mehr als 1 Einheit auf der zehnstufigen Skala.Ursache des Eindrucks eines sehr starken Zusammenhangs in der rechten Abbildung ist zum einen die Begrenzung des Wertebereichs auf der (vertikalen) Links-Rechts-Skala und sind zum anderen die wagerechten Linien, die nicht den Abstand 1, sondern nur 0.25 aufweisen.
Empirie-Vorlesung Teil: Quantitative Methoden WiSe 06/07, 19.12.06