tgn1412: ¿por qué la estructura es importante?
DESCRIPTION
TGN1412: ¿Por qué la estructura es importante?. Bergerat D, Delgado A, Fernandez M, Moreno M, Rico V, Ruiz S, Sió M, Subirana I, Tirado E, Villalobos X. índice. Planteamiento de las hipótesis Objetivo 1: Estructura inmnoglobulinas Plegamiento Ig-like Modelos cadenas ligera y pesada - PowerPoint PPT PresentationTRANSCRIPT

Bergerat D, Delgado A, Fernandez M, Moreno M, Rico V, Ruiz S, Sió M, Subirana I,
Tirado E, Villalobos X

1. Planteamiento de las hipótesis
2. Objetivo 1: Estructura inmnoglobulinas Plegamiento Ig-like Modelos cadenas ligera y pesada Interacciones
3. Objetivo 2: CD28 Macaca fascicularis CD28 Mus musculus
4. Objetivo 3: Unión de la Fc al receptor Fc Agregados
5. Objetivo 4: Siglecs
6. Suplemento
7. Bibliografía
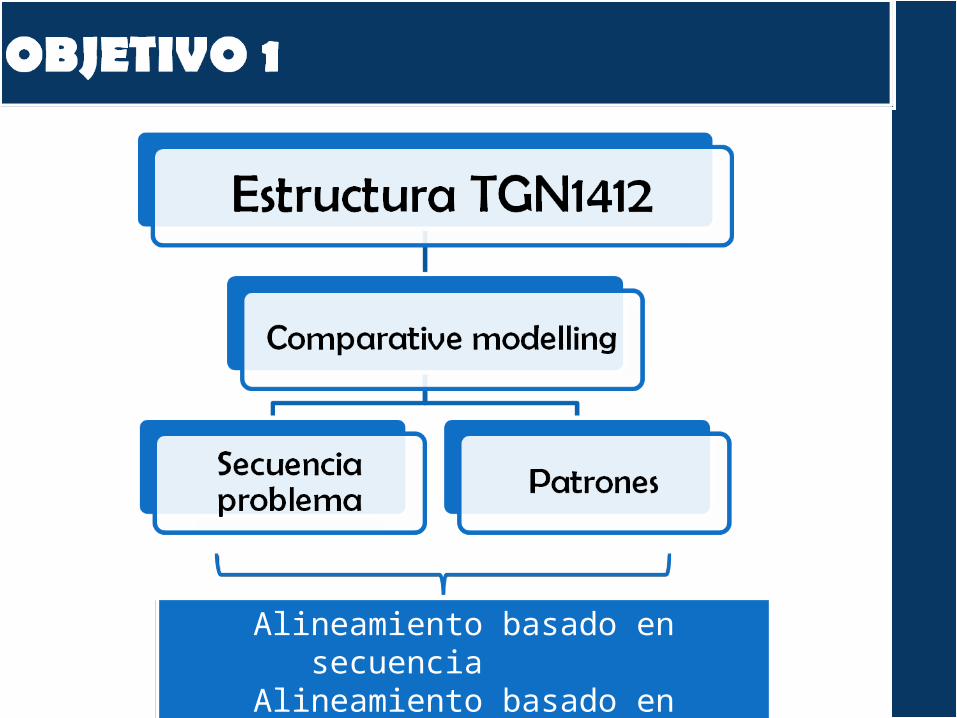
Alineamiento basado en secuencia
Alineamiento basado en estructura
Alineamiento basado en secuencia
Alineamiento basado en estructura
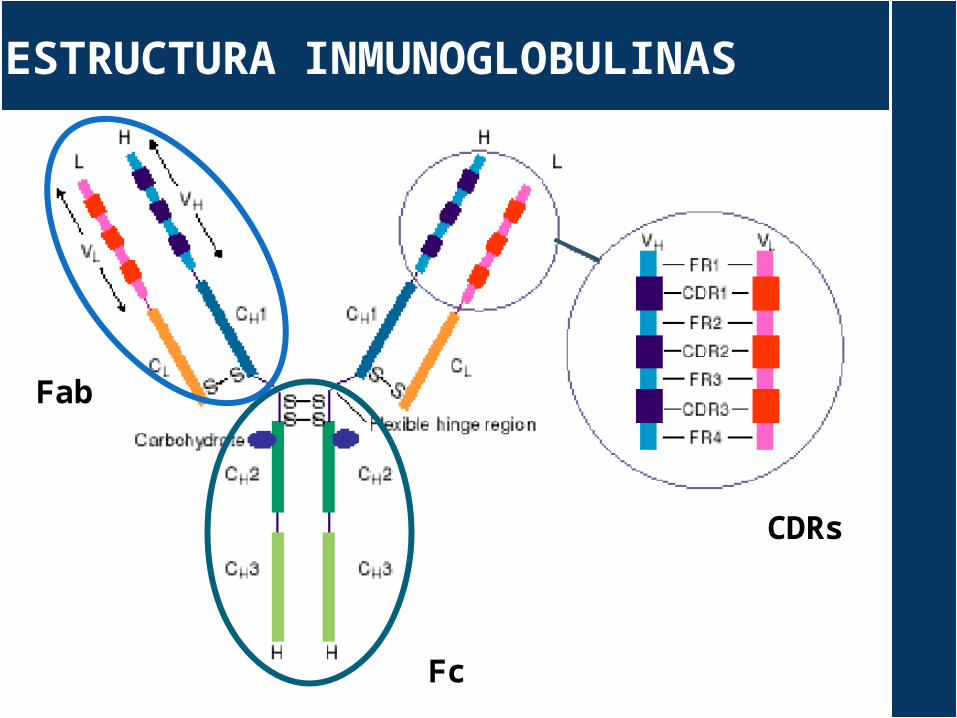
ESTRUCTURA INMUNOGLOBULINAS
Fc
Fab
CDRs

PLEGAMIENTO IG-LIKE
Dominio VH/VL
Dominio CH/CL
Sandwitch Greek Key
ClasificaciónClasificación

PLEGAMIENTO IG-LIKE
Dominio CL
Dominio VL
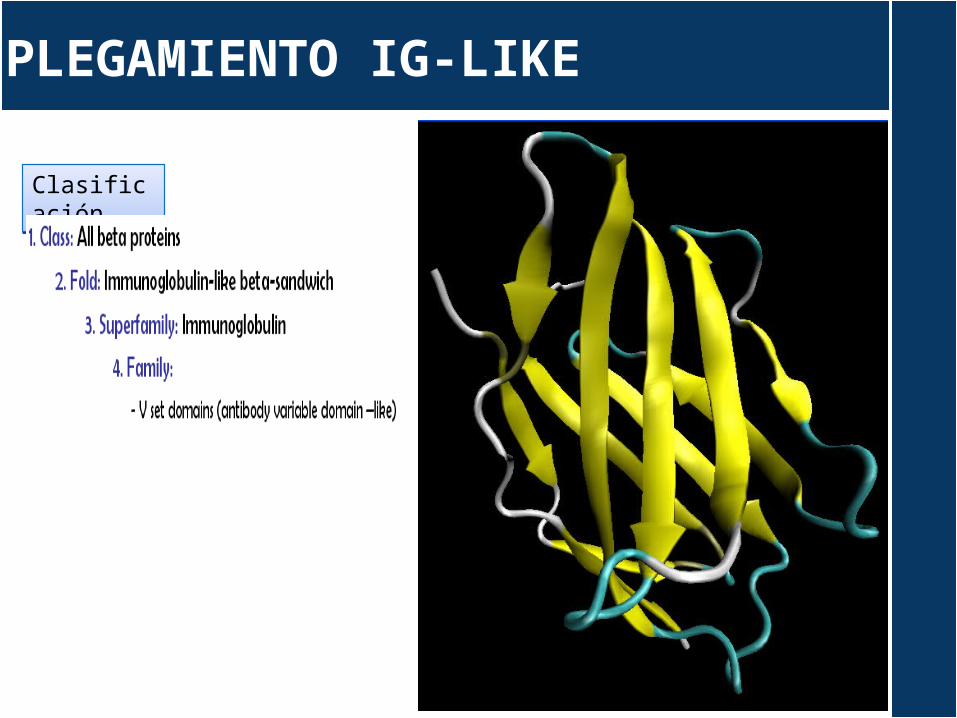
PLEGAMIENTO IG-LIKE
ClasificaciónClasificación


OBTENCIÓN DE LA SECUENCIA
Humanizar manualmente IgG humana IgG murina
A partir de la patente
Identificar CDRs
Sustituir en la IgG humana sus CDRs por los murinos
OBTENCIÓN DE LA SECUENCIA
Humanizar manualmente IgG humana IgG murina Identificar
CDRsSustituir en la IgG humana sus CDRs por los murinos
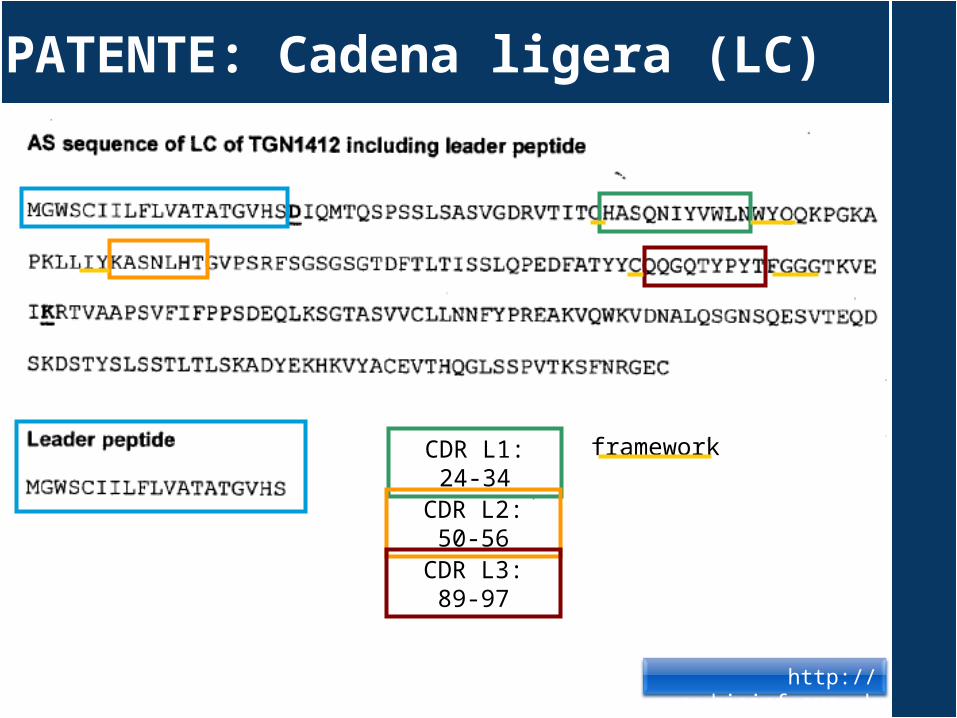
PATENTE: Cadena ligera (LC)
http://www.bioinf.org.uk/
frameworkCDR L1: 24-34
CDR L2: 50-56
CDR L3: 89-97

PATENTE: Cadena pesada (HC)
framework
CDR H1: 31-35
CDR H2: 50-66
CDR H3: 99-109
http://www.bioinf.org.uk/

LC: Patrones
Un único patrón pdb 1YJD (murino)Clustalw TGN1412 – 1YJDL Secuencia fasta LC TGN1412 (modificada)
Más de un patrón PSI-BLAST: búsqueda de homólogos remotos

LC: Patrones
Score: 75

LC: Patrones
Un único patrón pdb 1YJD (murino)Clustalw TGN1412 – 1YJDL Secuencia fasta LC TGN1412 (modificada)
Más de un patrón PSI-BLAST: búsqueda de homólogos remotos1º Contra SWISSPROT 2º Contra PDB

LC: Patrones

LC: Patrones
Un único patrón pdb 1YJD (murino)Clustalw TGN1412 – 1YJDL Secuencia fasta LC TGN1412 (modificada)
Más de un patrón PSI-BLAST: búsqueda de homólogos remotos1º Contra SWISSPROT 2º Contra PDB
2FGW Ig
1DEE IgM
1FVD IgG
1KB5 IgG
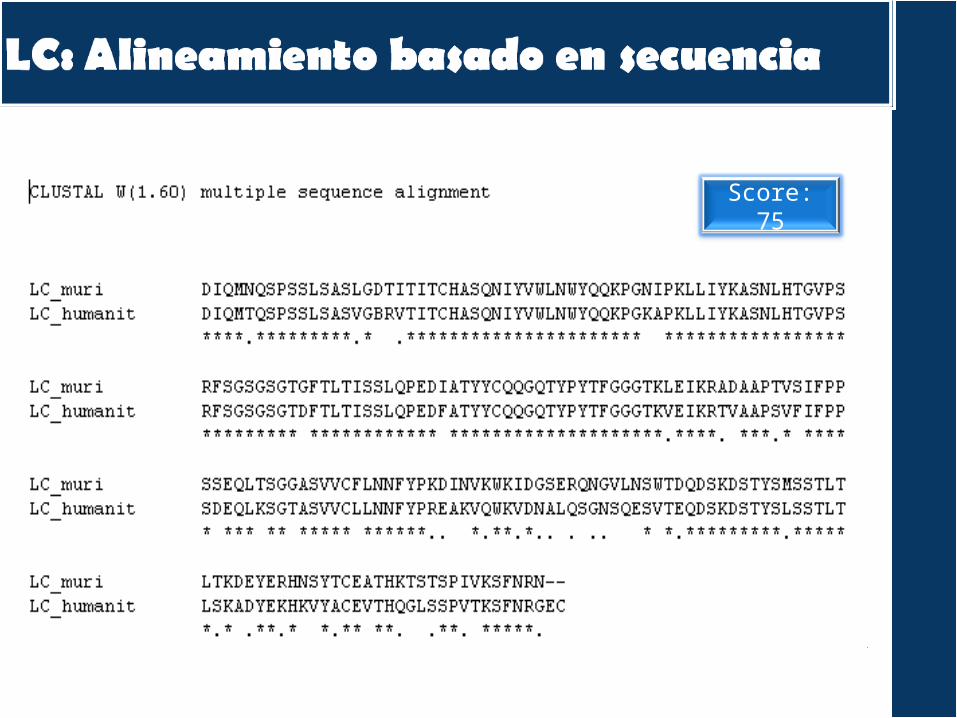
Score: 75

Únicamente alinea el dominio Ig-like una
vez!!!

XV
LC: Alineamiento basado en secuencia
V X

LC: Alineamiento basado en secuencia
Score: 59

Alineamiento estructural de los patrones: STAMPEstándar output
Obtención del alineamiento y del pdb
LC: Alineamiento basado en estructura
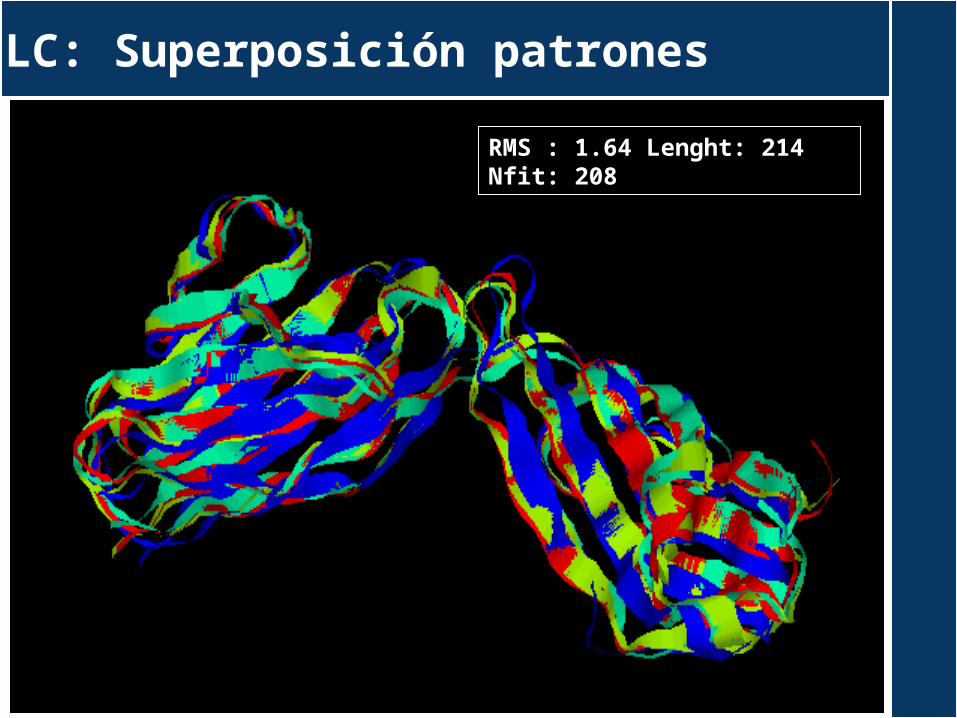
LC: Superposición patrones
RMS : 1.64 Lenght: 214 Nfit: 208
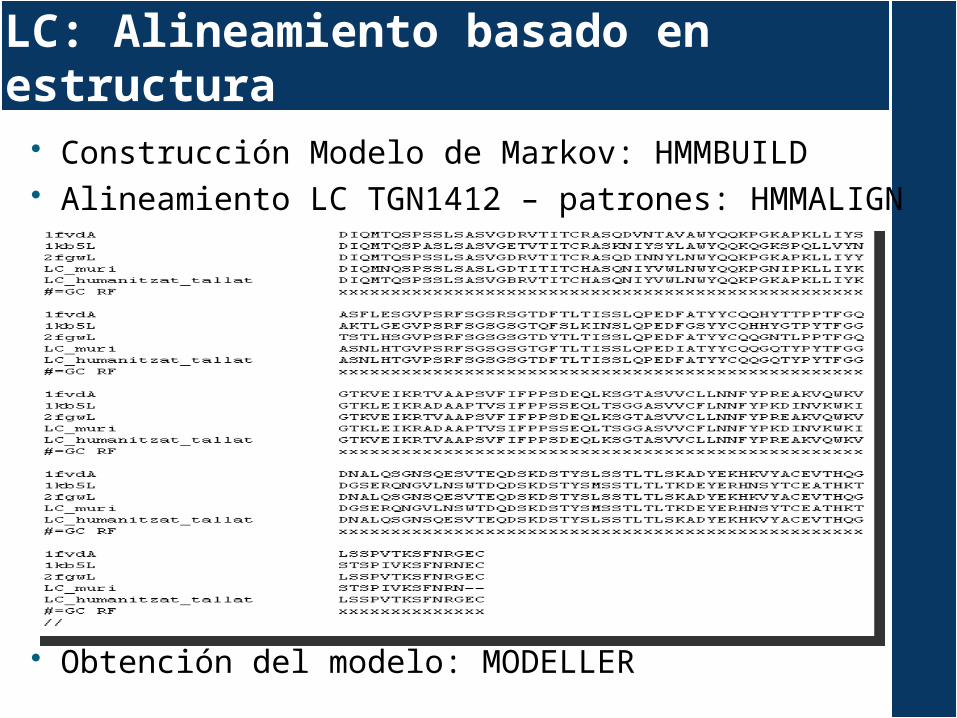
Construcción Modelo de Markov: HMMBUILD Alineamiento LC TGN1412 – patrones: HMMALIGN
Obtención del modelo: MODELLER
LC: Alineamiento basado en estructura

LC: Resultados
Hasta el momento hemos obtenido: 4 modelos basados en secuencia
2 con un patrón2 con más de un patrón
2 modelos basados en estructura
¿Cuál es el mejor?¿Cuál es el mejor?

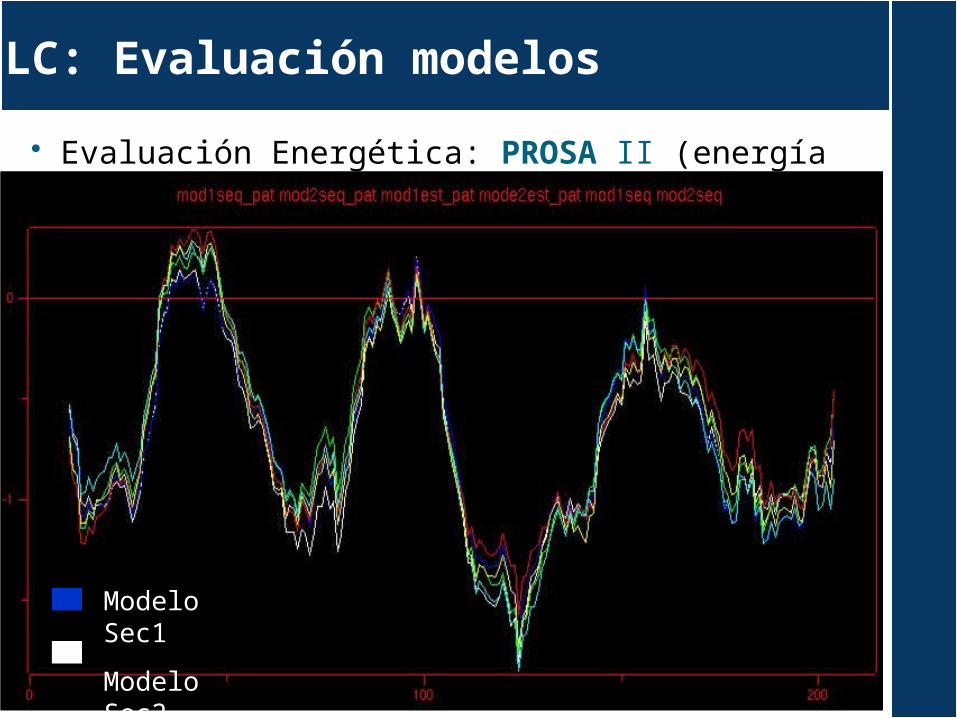
Evaluación Energética: PROSA II (energía pair modelos)
LC: Evaluación modelos

LC: Evaluación modelos
Evaluación Energética: PROSA II (energía pair patrones)
Patrón murino 1YJD
CDR2 CDR3
Evaluación Energética: PROSA II (energía pair modelos)
LC: Evaluación modelos
Modelo Sec1
Modelo Sec2

LC: Evaluación modelos
Evaluación Estereoquímica: PROCHECK
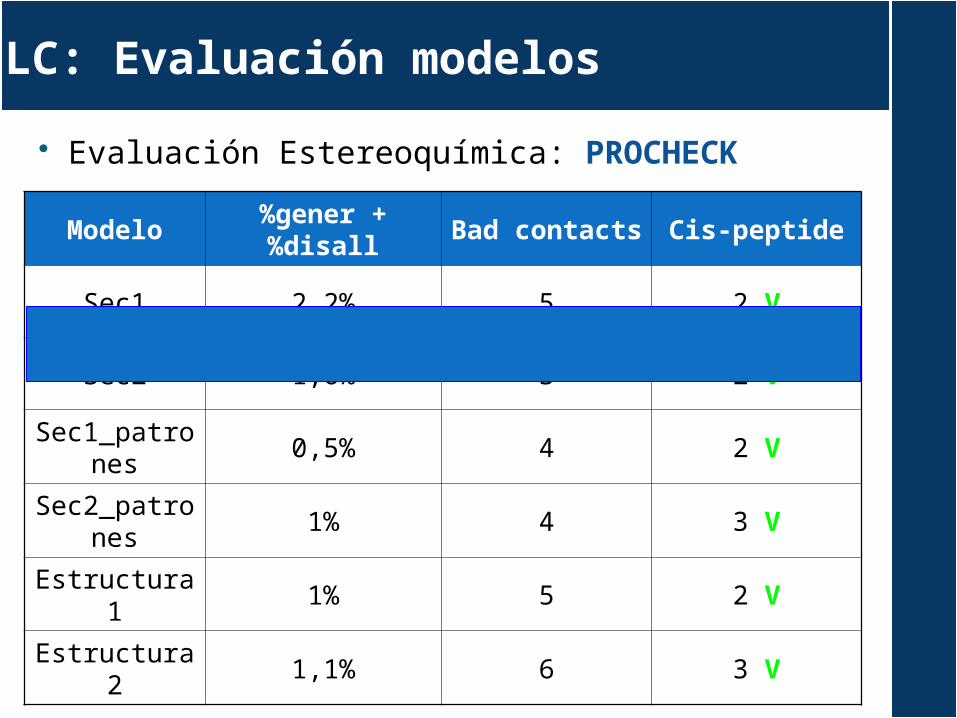
LC: Evaluación modelos
Evaluación Estereoquímica: PROCHECK
Modelo%gener +
%disallBad
contactsCis-peptide
Sec1 2,2% 5 2 V
Sec2 1,6% 3 2 V
Sec1_patrones
0,5% 4 2 V
Sec2_patrones
1% 4 3 V
Estructura1 1% 5 2 V
Estructura2 1,1% 6 3 V
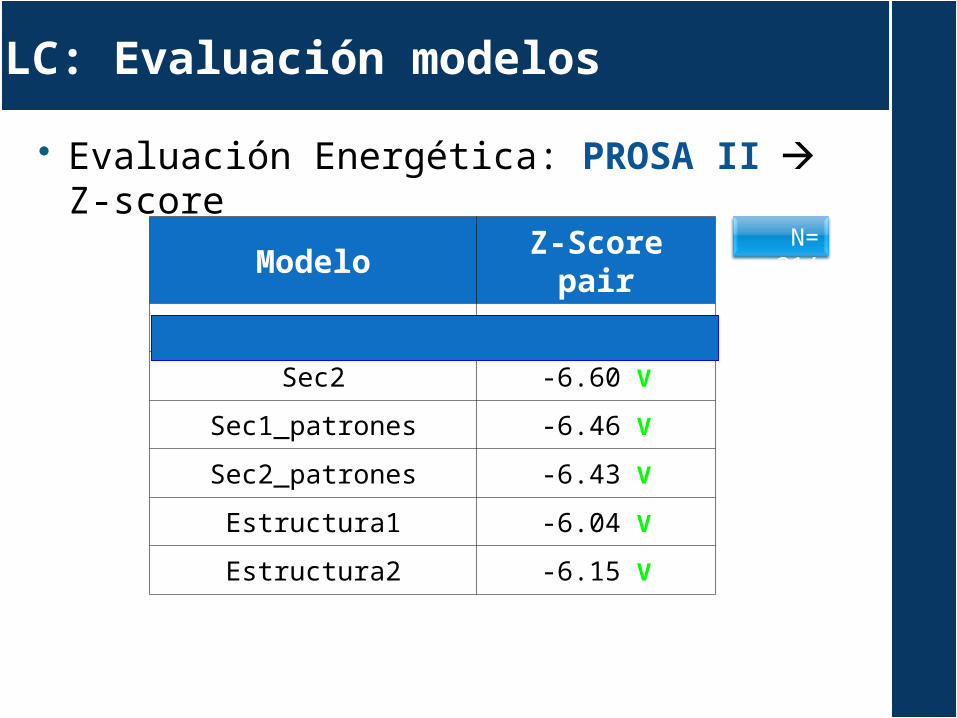
LC: Evaluación modelos
Evaluación Energética: PROSA II Z-score
ModeloZ-Score
pairSec1 -6.37 V
Sec2 -6.60 V
Sec1_patrones -6.46 V
Sec2_patrones -6.43 V
Estructura1 -6.04 V
Estructura2 -6.15 V
N= 214

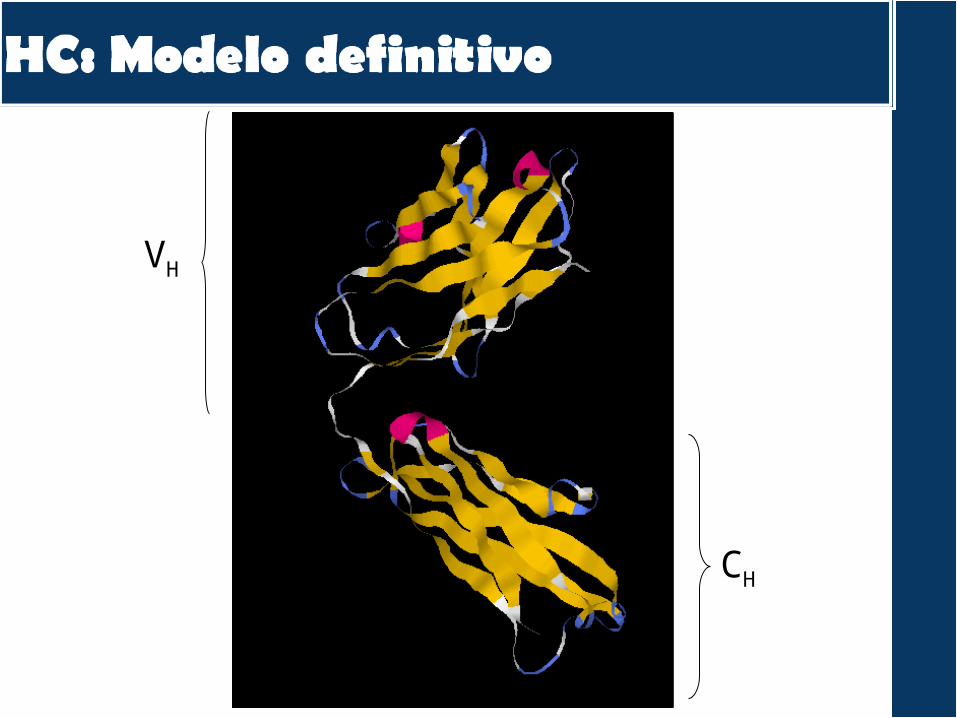
LC: Modelo definitivo
VL
CL

LC: Modelo definitivo
CDR-L1
CDR-L2
CDR-L3
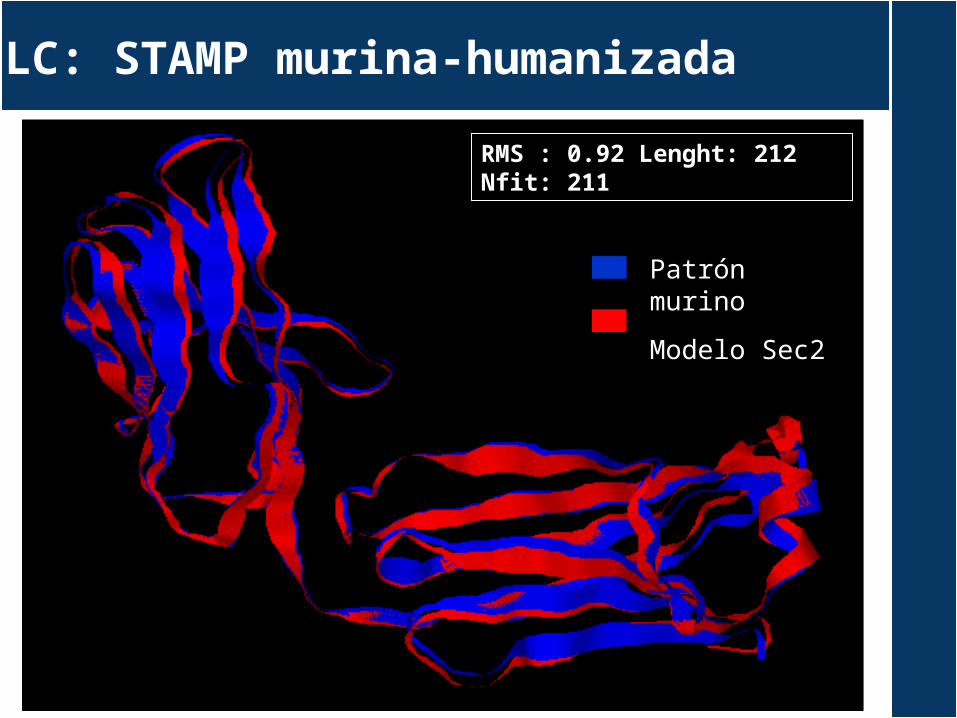
LC: STAMP murina-humanizada
Patrón murino
Modelo Sec2
RMS : 0.92 Lenght: 212 Nfit: 211

LC: STAMP murina-humanizada
Patrón murino
Modelo Sec2

HC: Patrones
• Un único patrón pdb 1YJD • Secuencia fasta 1yjdH• Clustalw

HC: Aliniamiento basado en secuencia
Un único patrón CLUSTALW
Score: 75

¿Cuál es el mejor modelo?
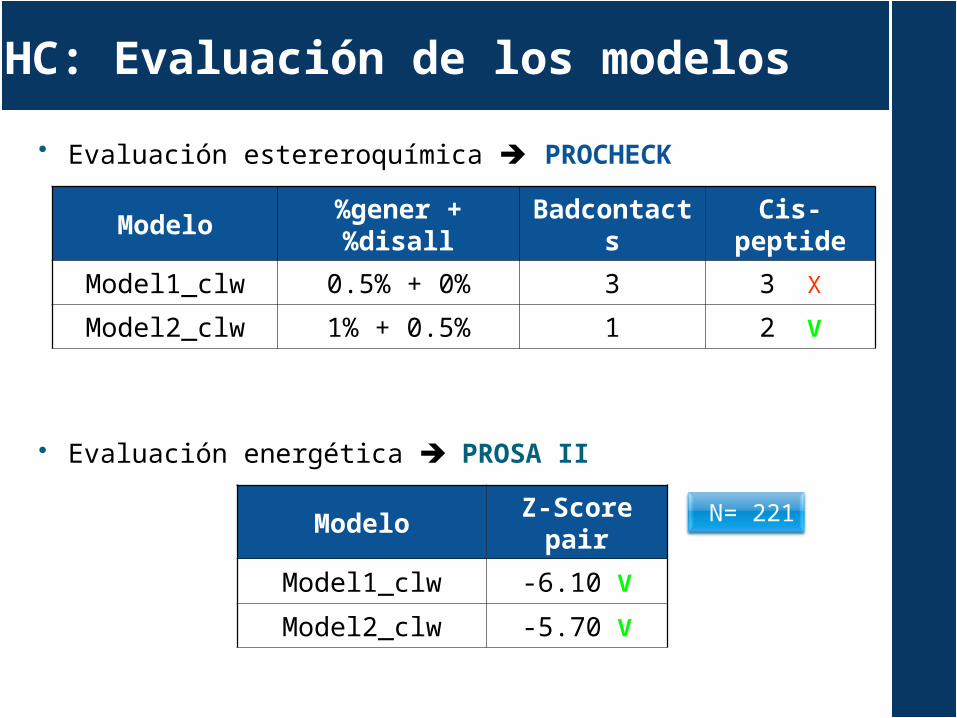
HC: Evaluación de los modelos
Modelo%gener +
%disallBadcontac
tsCis-
peptide
Model1_clw 0.5% + 0% 3 3 X
Model2_clw 1% + 0.5% 1 2 V
Evaluación estereroquímica PROCHECK
Evaluación energética PROSA II
ModeloZ-Score
pair
Model1_clw -6.10 V
Model2_clw -5.70 V
N= 221
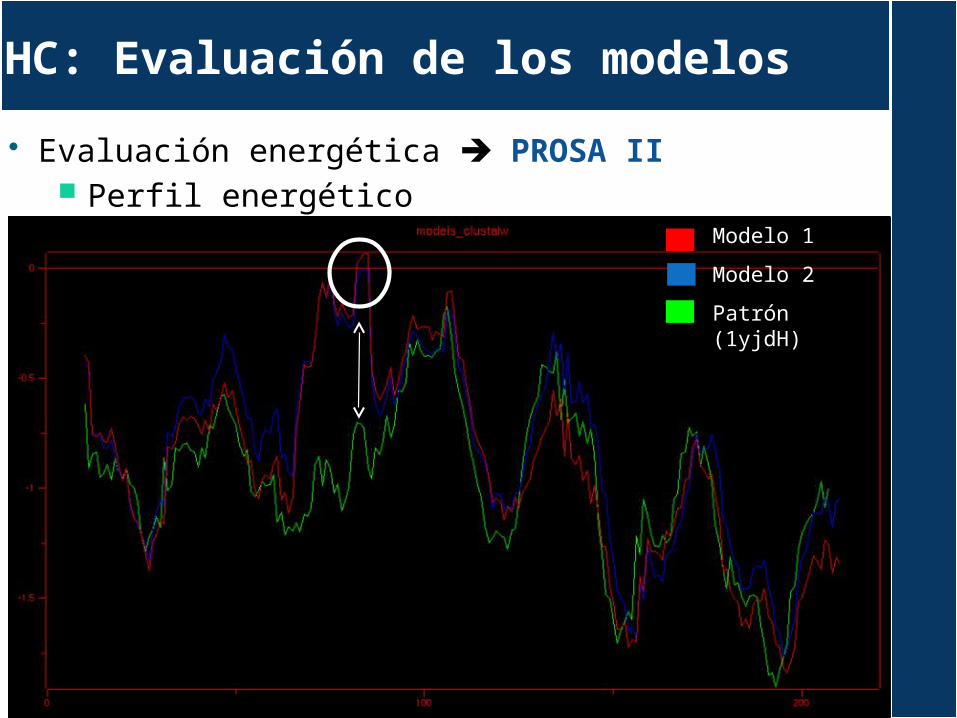
Evaluación energética PROSA II Perfil energético
HC: Evaluación de los modelos
Modelo 1
Modelo 2
Patrón (1yjdH)
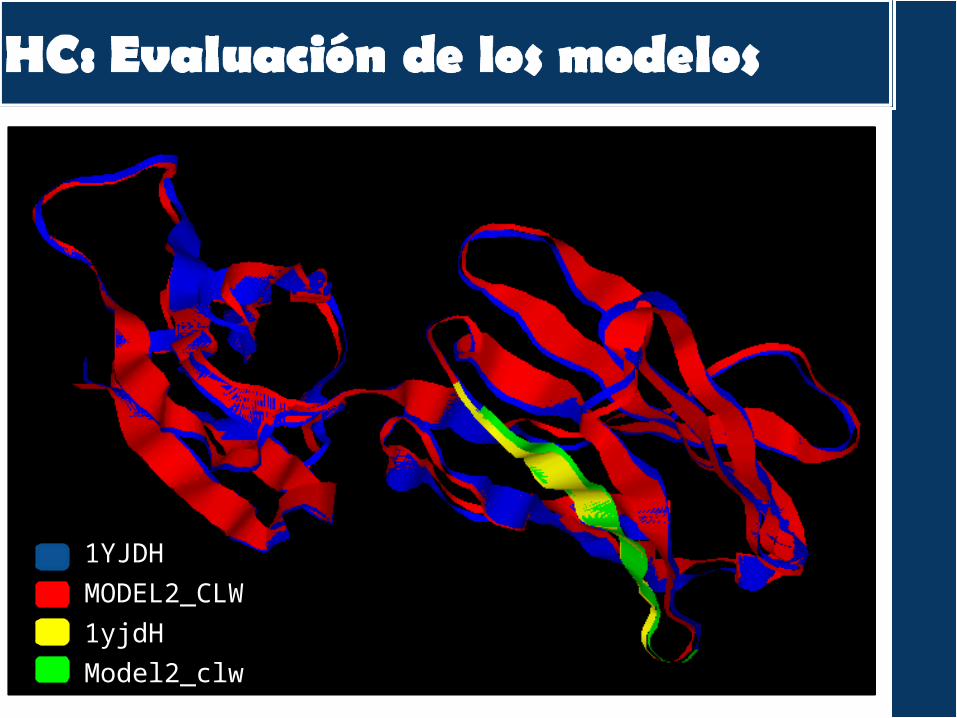
1YJDH
MODEL2_CLW
1yjdH
Model2_clw

Score: 75
VH
CH

CDR H1CDR H2CDR H3
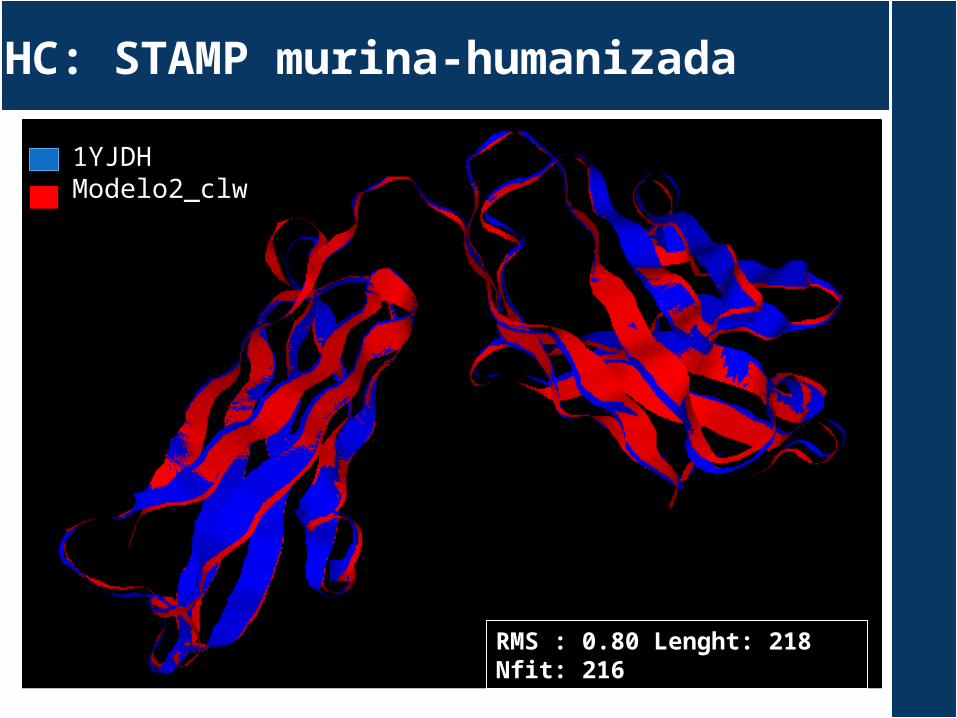
HC: STAMP murina-humanizada
RMS : 0.80 Lenght: 218 Nfit: 216
1YJDHModelo2_clw
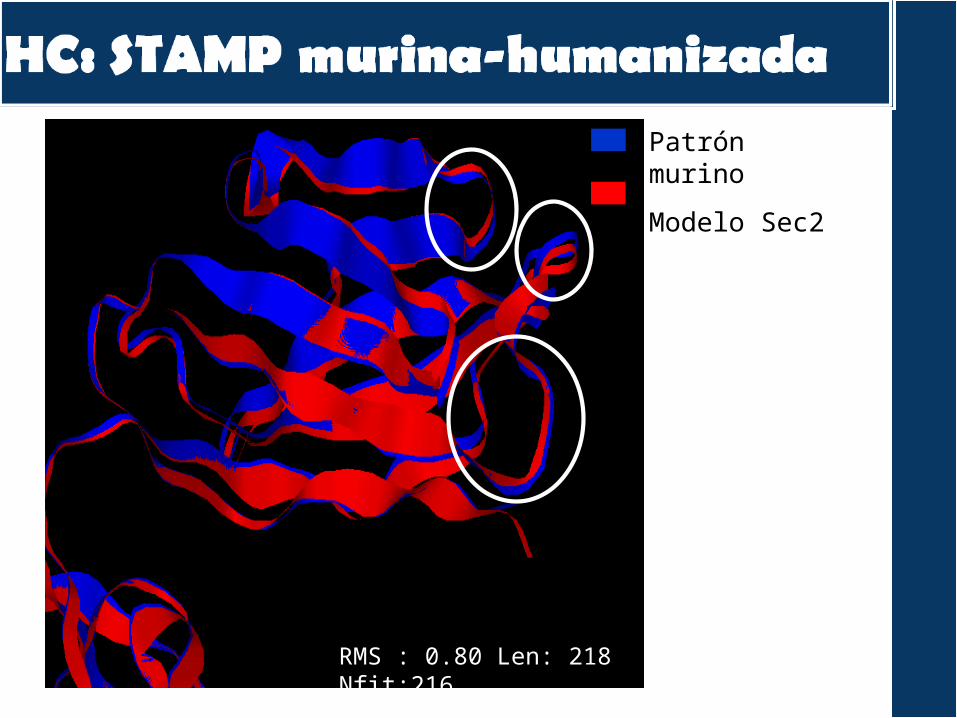
Patrón murino
Modelo Sec2
RMS : 0.80 Len: 218 Nfit:216
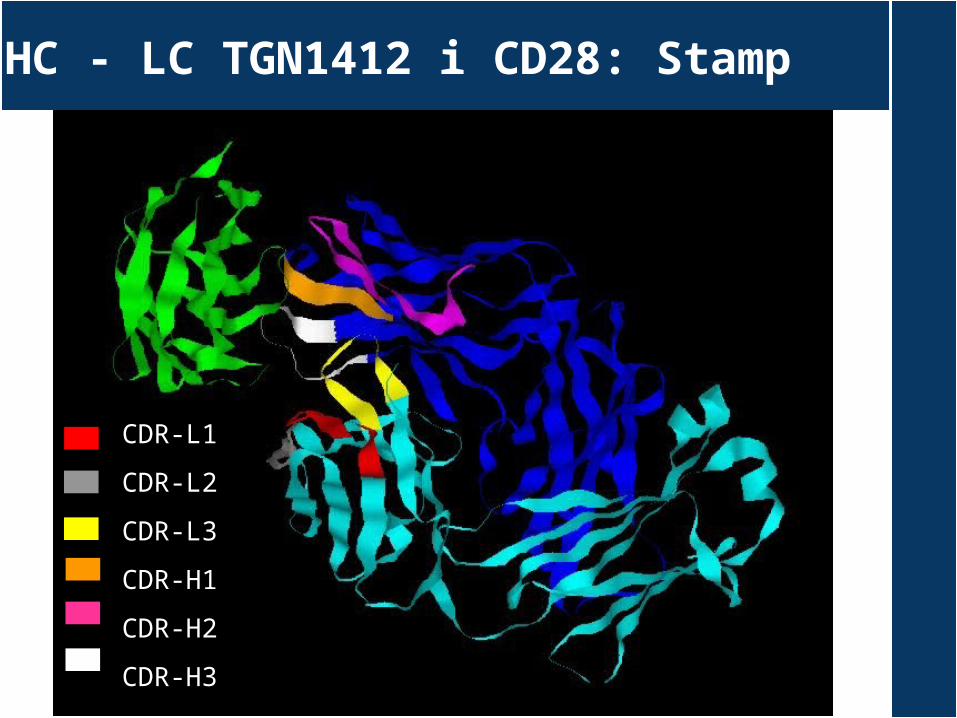
HC - LC TGN1412 i CD28: Stamp
CDR-L1
CDR-L2
CDR-L3
CDR-H1
CDR-H2
CDR-H3

HC - LC TGN1412 i CD28: STAMP
CDR-L1
CDR-L2
CDR-L3
CDR-H1
CDR-H2
CDR-H3
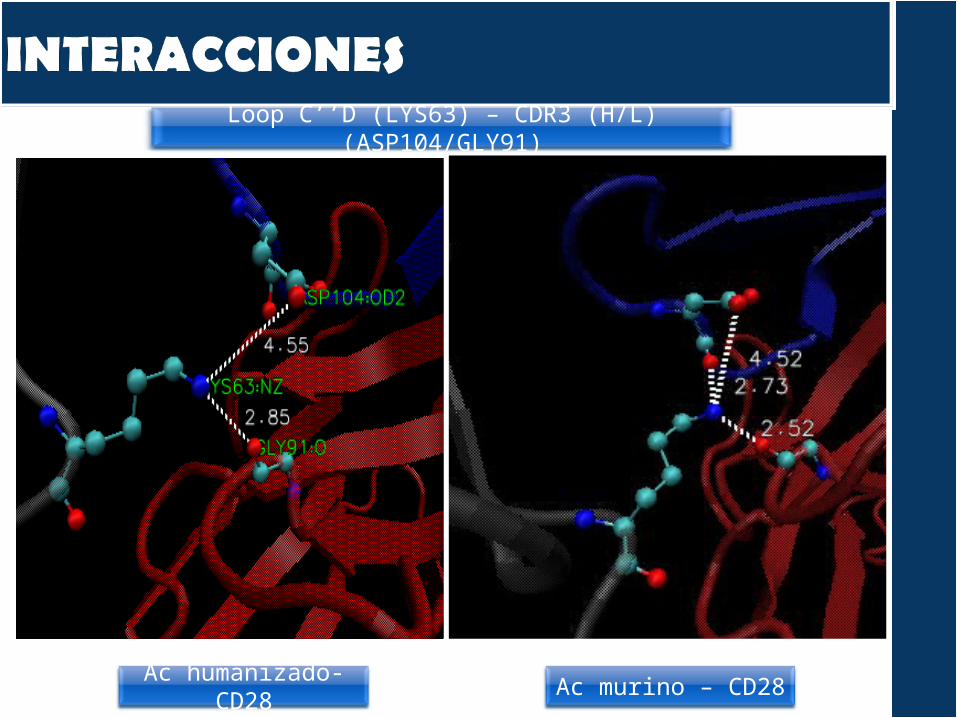
Loop C’’D

Comparamos las interacciones entre: el CD28 humano y el AC murino (cristal)el CD28 humano y el modelo TGN1412
¿Por qué? Podría ser que durante la humanización se hubieran provocado cambios estructurales que modificaran la interacción del TGN1412 con el CD28.

Las interacciones son del modelo NO OPTIMIZADO.
Regiones de interacción del CD28 con el Ac:Loop C’’DLámina C’’Lámina C’Lámina C
Principales interacciones encontradas:Puentes de hidrógeno Interacciones pi Electrostáticas

Ac humanizado- CD28
Ac murino – CD28
Loop C’’D (LYS63) – CDR3 (H/L) (ASP104/GLY91)

Ac humanizado- CD28
Ac murino – CD28
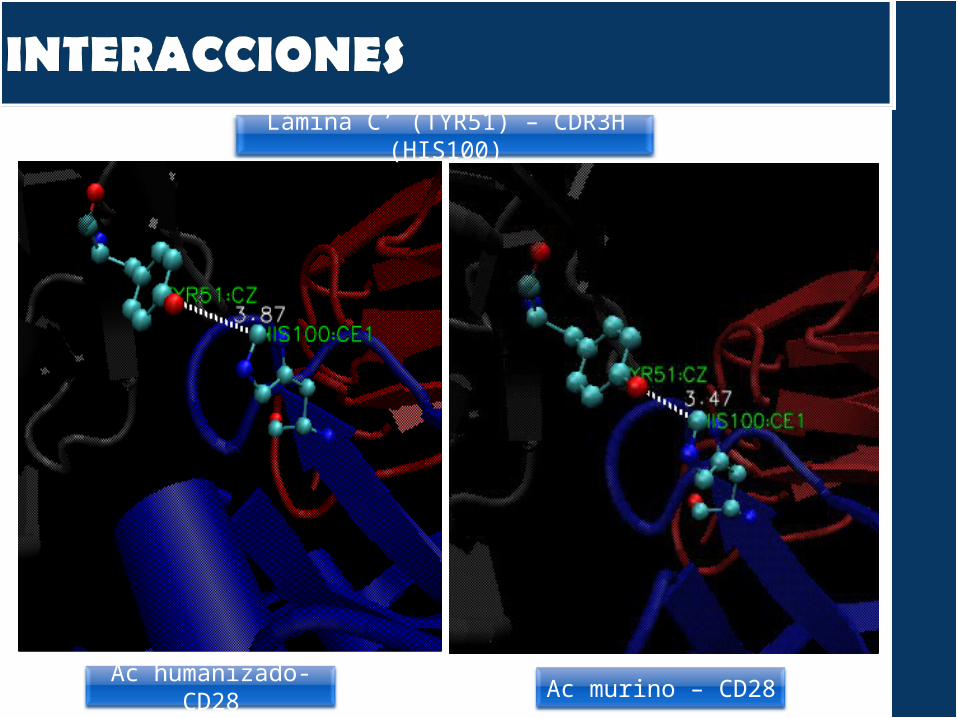
Lámina C’’ (TYR61) – CDR3H (TRP105) – CDR1L (TRP32)

Ac humanizado- CD28
Ac murino – CD28
Lámina C (GLU32) – CDR1H (SER31)
Ac humanizado- CD28 Ac murino – CD28
Lámina C’ (TYR51) – CDR3H (HIS100)

Hay interacciones que son distintas
Ha habido cambios en la activación del receptor
No podemos confirmarlo ya que el modelo no está optimizado
?

OBJETIVO 2
OBJETIVO: Establecer diferencias estructurales entre CD28 humano y los CD28 de las especies utilizadas en ensayos preclínicos:
Macaca fascicularis (Cynomolgus Monkey) Mus musculus (Ratón)
Metodología: Comparación de secuencia

CD28 Macaca fascicularis
Obtención secuencia GenBank: ABH06892 Clustalw CD28humano vs. CD28macaco
La estructura de la parte extrena de CD28 de Macaca Fascicularis será la
misma que la del patrón 1yjdC.
La estructura de la parte extrena de CD28 de Macaca Fascicularis será la
misma que la del patrón 1yjdC.
Externa Externa
Citosolica
Citosolica
TransmemTransmem
Mutación
Mutación
Schraven et al.2008

CD28 Mus musculus
Obtención secuencia GenBank: NP_031668
Clustalw CD28humano vs. CD28ratón

OBJETIVO 3
Objetivo: Analizar la Fc humana teniendo en cuenta la literatura conocida
¿La unión de la Fc con su receptor podría ser la causa de los efectos adversos?
¿Podría ser que se formaran agregados que amplificarán la señal?
Fc

NO cytokine storm
cytokine storm
NO cytokine storm
Fc: Receptor Fc
Unión especie-específico
¿?

Imatge aliniament i seleccionar residus diferents + imatge article
ALINEAMIENTO HC HUMANA-HC MURINA

Score: 93
Unión especie-específica ?

OBJETIVO 3
Objetivo: Analizar la Fc humana teniendo en cuenta la literatura conocida
¿La unión de la Fc con su receptor podría ser la causa de los efectos adversos?
¿Podría ser que se formaran agregados que amplificarán la señal?
Fc

1. Alineamiento
C
C’
C’’
C’’-D
F-G
?

FC HUMANA
Dos patrones :
Región Fab HC : 1YJD (murino)Región Fc HC: pdb 1HZH (humano)
Alineamiento clustalw HC con patrones
Modelo basado en secuencia MODELLER
Evaluación modelos PROSAPROCHECK

Alineamento HC + patrons:
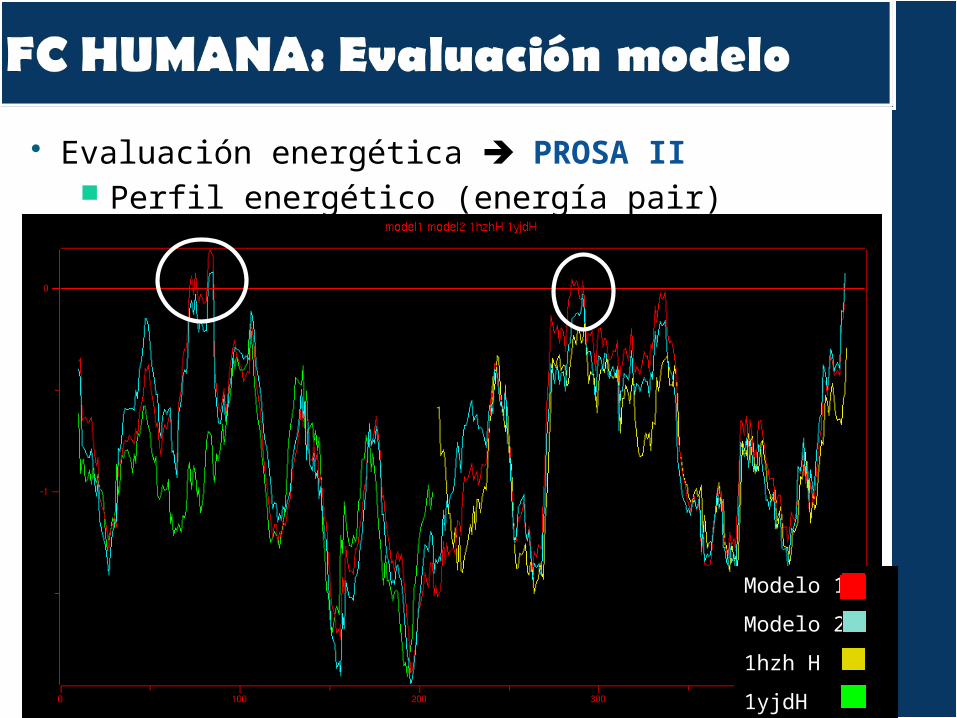
Evaluación energética PROSA II Perfil energético (energía pair)
Modelo 1
Modelo 2
1hzh H
1yjdH

Z-score: -7,78 (-6/-10)
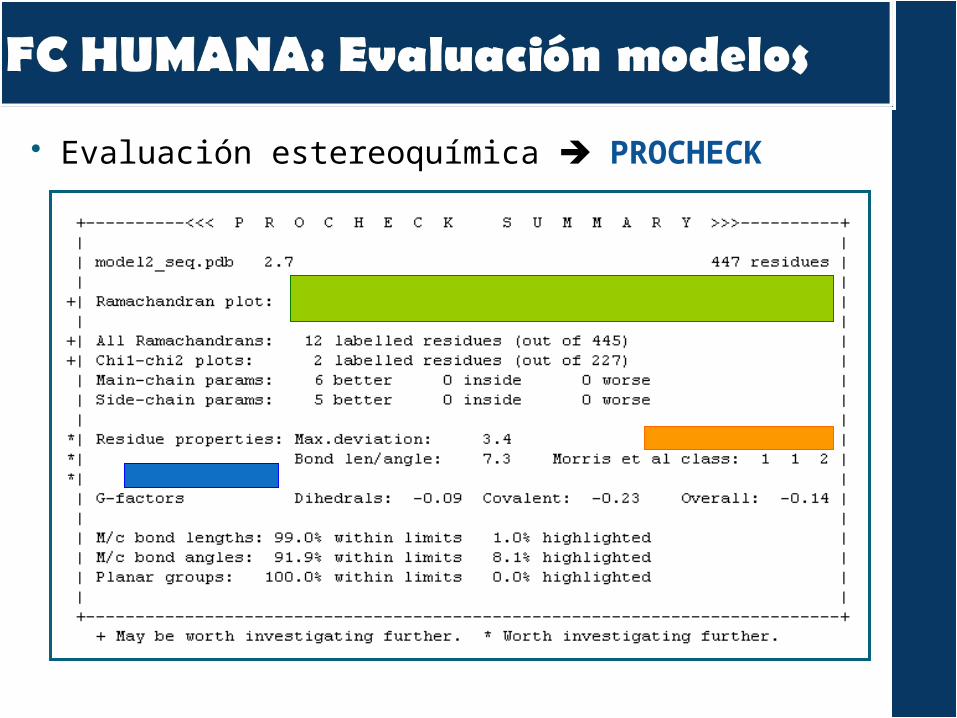
Evaluación estereoquímica PROCHECK

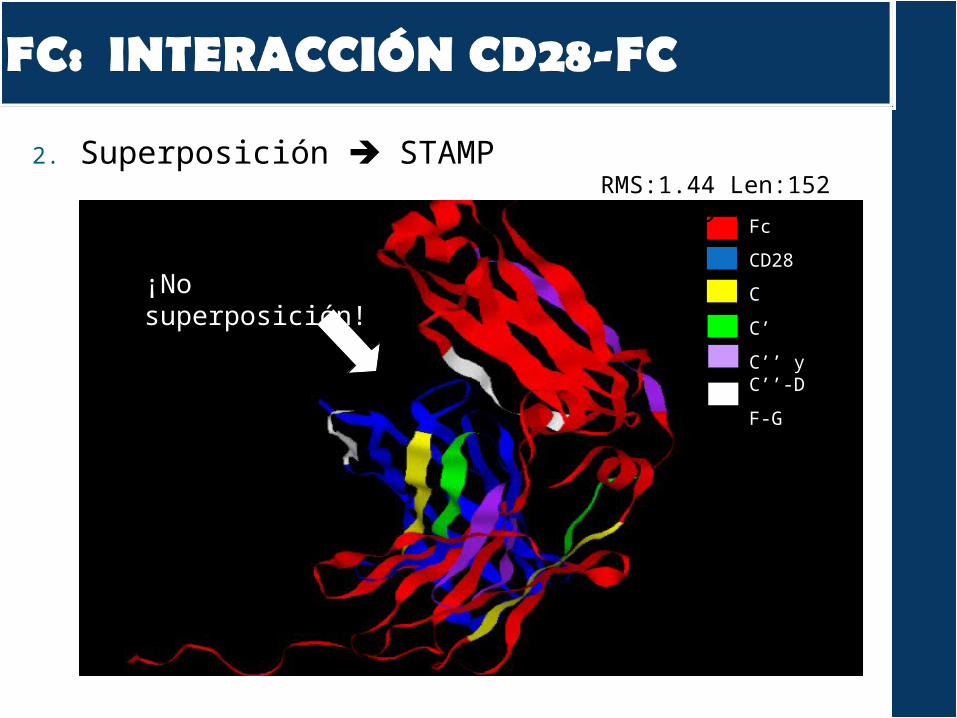
2. Superposición STAMP
Fc
CD28
C
C’
C’’ y C’’-D
F-G
¡No superposición!
RMS:1.44 Len:152 Nfit: 19
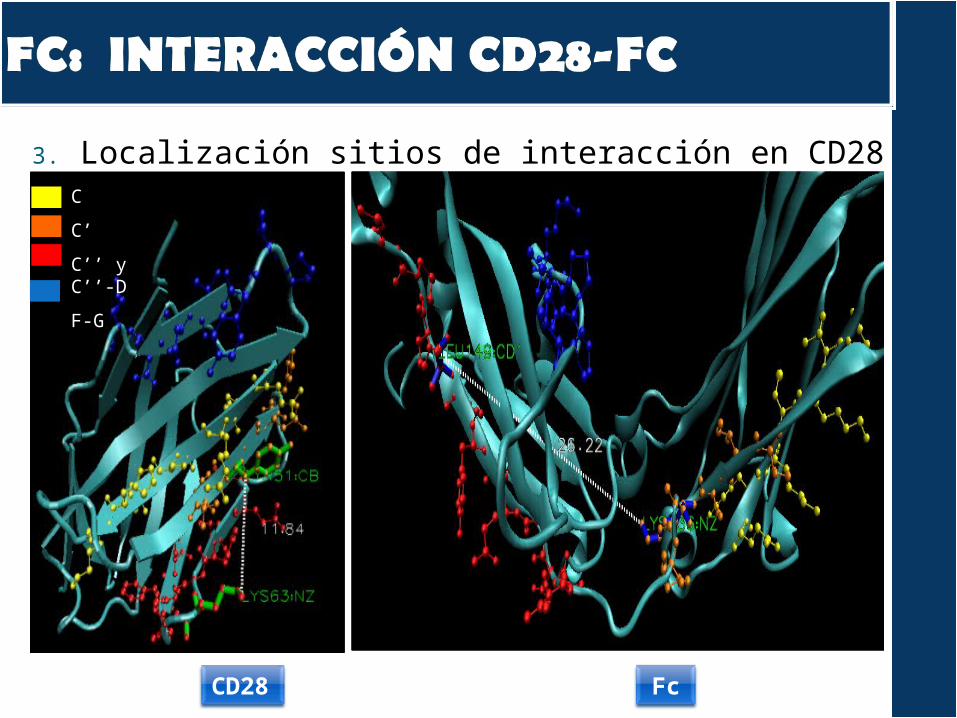
3. Localización sitios de interacción en CD28 y FcC
C’
C’’ y C’’-D
F-G
CD28
Fc
26,22

A nivel de secuencia, las zonas de interacción son diferentes
A nivel estructural, observamos que la disposición de los residuos de la interacción es diferente
Deducimos que el TGN1412 no se puede autorreconocer
Pero si...
Agregación humanos Agregación macaco
¿Qué pudo evitar la amplificación de la señal en los macacos?

OBJETIVO 4
OBJETIVO: Estudiar y comparar las vías de señalización del Rc CD28 humano y de macaco con el fin de encontrar alguna diferencia entre ellas que expliquen la mayor activación de linfocitos T en humanos
Metodología: Literatura relacionada Bases de datos

Siglecs (sialic-acid-binding-ig-like lectins)
Literatura relacionada:Nguyen et al., 2006Crocker et al., 2007
SIGLECS
Crocker et al.2007
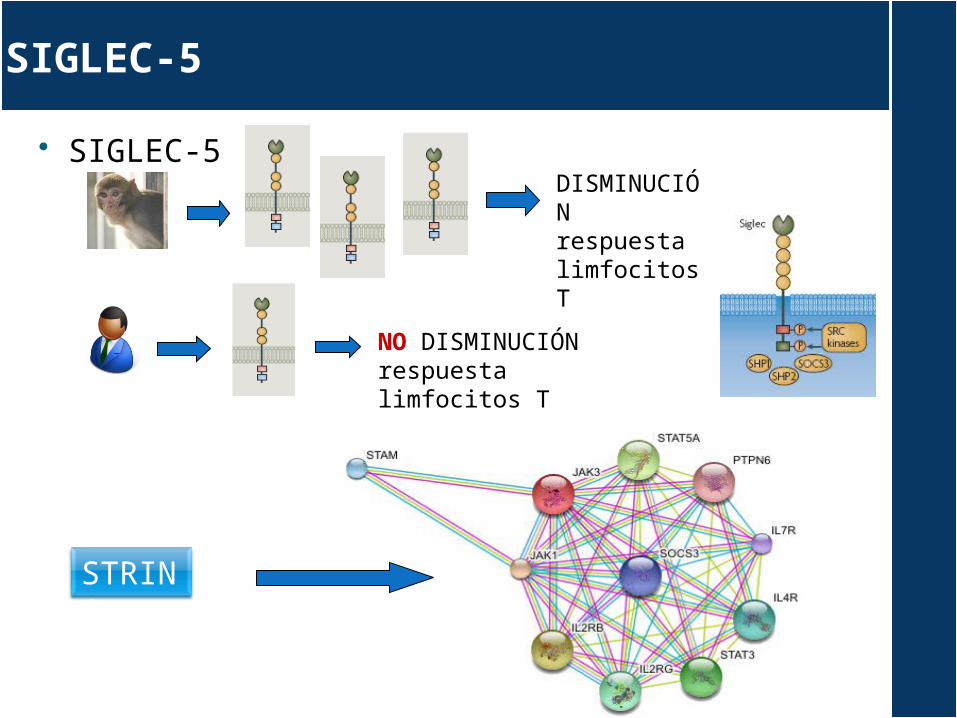
SIGLEC-5
SIGLEC-5DISMINUCIÓN respuesta limfocitos T
NO DISMINUCIÓN respuesta limfocitos T
STRING

CD28 Macaco: No existen diferencias a nivel externo. No obstante, pueden existir diferencias a nivel de la vía de
señalización.
CD28 murino: Existen diferencias a nivel externo que pueden implicar cambios en la interacción.
CD28 Macaco: No existen diferencias a nivel externo. No obstante, pueden existir diferencias a nivel de la vía de
señalización.
CD28 murino: Existen diferencias a nivel externo que pueden implicar cambios en la interacción.
CONCLUSIONES
HIPÓTESIS 1
HIPÓTESIS 2
No podemos aceptar/refutar la hipótesis ya que el modelo no está optimizado. Sin embargo, encontramos
diferencias en la interacción de CD28 con el modelo.
No podemos aceptar/refutar la hipótesis ya que el modelo no está optimizado. Sin embargo, encontramos
diferencias en la interacción de CD28 con el modelo.

CONCLUSIONS
HIPÓTESIS 3
Existen diferencias en las vías de señalización entre macaco y humano que podrían estar implicados en los
efectos adversos observados en humanos.
Existen diferencias en las vías de señalización entre macaco y humano que podrían estar implicados en los
efectos adversos observados en humanos.
HIPÓTESIS 4
Con los datos de los que disponemos no podemos confirmar que la unión de la Fc con su receptor sea
especie-específica.
No podemos confirmar la formación de agregados ya que no hemos observado un posible autoreconocimiento
por la región Fc.
Con los datos de los que disponemos no podemos confirmar que la unión de la Fc con su receptor sea
especie-específica.
No podemos confirmar la formación de agregados ya que no hemos observado un posible autoreconocimiento
por la región Fc.
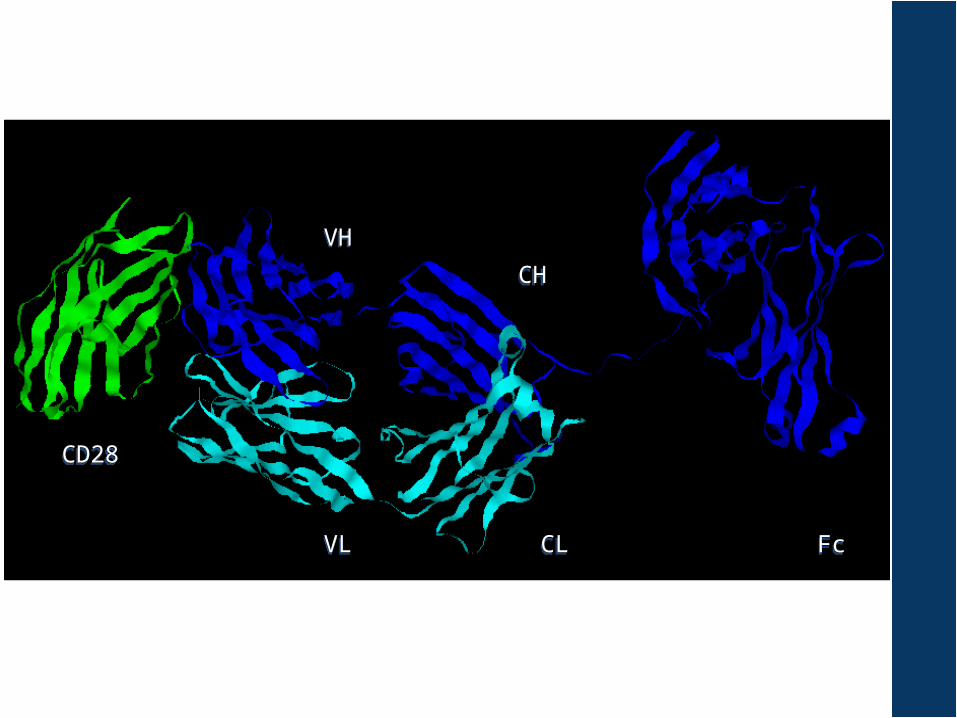
FcFcCLCL
CHCH
VHVH
VLVL
CD28CD28


Fab y Fc: comandas
Las comandas que aparecen en las siguientes diapositivas hacen referencia a las utilizadas con la cadena ligera. Sin embargo, hemos seguido el mismo procedimiento a la hora de trabajar con la cadena pesada y la porción Fc del TG1412.

ALINEAMIENTO BASADO EN SECUENCIA: ClustalW (1 patrón)
1. Obtener la secuencia en formato fasta y el pdb de la cadena ligera murina del 1YJD.pdb: /disc9/PERL/PDBtoSplitChain.pl -i 1YJD.pdb -o 1YJD
2. Concatenar el fichero de la secuencia fasta anterior con el de la cadena ligera humanizada: cat LC_muri.fa >> LC_muri_humanitzat.fa y cat LC_humanitzat.fa >> LC_muri_humanitzat.fa
3. Eliminar el péptido señal de la secuencia fasta de la cadena ligera humanizada: LC_muri_humanitzat_tallat.fa
4. Ejecutar ClustalW: LC_muri_humanitzat_tallat.aln

ALINEAMIENTO BASADO EN SECUENCIA: ClustalW (muchos patrones) (I)
1. Buscar homólogos de la proteína problema en la base de datos Swissprot: blastpgp -i LC_humanitzat_tallat.fa -d /disc9/DB/blast/sprot -j 20 -C LC_humanitzat_tallat_sprot_j20.pssm -o LC_humanitzat_tallat_sprot_j20.out
2. Utilizar la matriz de pesos creada con Swissprot para buscar homólogos de la proteína problema en la base de datos PDB: blastpgp -i LC_humanitzat_tallat.fa -d /disc9/DB/blast/pdb_seq -j 2 -R LC_humanitzat_tallat_sprot_j20.pssm -C LC_humanitzat_tallat_sprot_to_pdb_j20_2.pssm -o LC_humanitzat_tallat_sprot_to_pdb_j20_2.out
3. Copiar los pdbs de aquellos patrones con los valores de e-value más bajos: cp /disc9/DB/pdb/pdb2fgw.ent.Z .
4. Descomprimir los ficheros pdb de los patrones elegidos: gunzip *.Z

ALINEAMIENTO BASADO EN SECUENCIA: ClustalW (muchos patrones) (II)
5. Obtener las secuencias en formato fasta y los pdbs de cada una de las cadenas de los patrones: /disc9/PERL/PDBtoSplitChain.pl -i pdb1dee.ent -o 1dee
6. Crear un fichero con las secuencias fasta de los patrones (se incluye la murina) y con la de la cadena ligera humanizada cortada: emacs patrons_LC.fa &
7. Ejecutar ClustalW: patrons_LC.aln

ALINEAMIENTO BASADO EN SECUENCIA: HMMER (muchos patrones)
1. Buscar en una librería de modelos de Markov a partir de la secuencia problema: hmmpfam /disc9/DB/pfam/Pfam LC_humanitzat_tallat.fa > LC_humanitzat_tallat_patrons.hmm
2. Extraer el modelo de Markov que contenga el dominio de la secuencia problema: hmmfetch /disc9/DB/pfam/Pfam ig > LC_humanitzat_tallat_patrons_ig.hmm
3. Crear un alineamiento grande a partir de un alineamiento más pequeño que se encuentra en forma de modelo de Markov: hmmalign -o LC_ig_patrons.ali LC_humanitzat_tallat_patrons_ig.hmm patrons_LC.fa

ALINEAMIENTO BASADO EN ESTRUCTURA: muchos patrones
1. Crear el fichero .domains con los pdbs de los patrones: emacs LC_patrons.domains &
2. Superponer estructuralmente los patrones: stamp -l LC_patrons.domains -rough -n 2 -prefix LC_patrons_stamp > LC_patrons_stamp.out
3. Elegir el cluster óptimo y cambiar el alineamiento en vertical que produce STAMP por un formato que nos sea más útil: aconvert -in b -out c <LC_patrons_stamp.3> LC_patrons_stamp3.clw
4. Generar un fichero con los pdbs superpuestos para poder visualizar gráficamente esta superposición: transform -f LC_patrons_stamp.3 -g -o LC_patrons_stamp3.pdb y rasmol LC_patrons_stamp3.pdb
5. Construir un modelo de Markov a partir de este alineamiento estructural realizado con STAMP: hmmbuild LC_patrons_stamp3.hmm LC_patrons_stamp3.clw
6. Crear un alineamiento grande a partir de uno más pequeño que se encuentra en forma de modelo de Markov: hmmalign -o LC_humanitzat_stamp3.ali LC_patrons_stamp3.hmm patrons_LC.fa

CONSTRUCCIÓN DEL MODELO: a partir del alineamiento basado en secuencia (1 patrón)
1. Cambiar el formato del alineamiento original a formato pir: aconvert -in c -out p <LC_muri_humanitzat_tallat.aln> LC_muri_humanitzat_tallat.pir
2. Crear el fichero .top: emacs LC_muri_humanitzat_tallat.top &
3. Ejecutar el programa Modeller: mod LC_muri_humanitzat_tallat.top
4. Renombrar los ficheros .B99990001 y .B99990002: con la comanda mv
Para la construcción del modelo a partir del alineamiento basado en secuencia del ClustalW con muchos patrones, utilizamos las mismas comandas que aparecen en esta diapositiva.

CONSTRUCCIÓN DEL MODELO: a partir del alineamiento basado en estructura
1. Cambiar el formato del alineamiento original a formato pir: aconvert -in h -out p <LC_humanitzat_stamp3.ali> model_estructura_patrons.pir
2. Crear el fichero .top: emacs model_estructura_patrons.top &
3. Ejecutar el programa Modeller: mod model_estructura_patrons.top
4. Renombrar los ficheros .B99990001 y .B99990002: con la comanda mv

EVALUACIÓN INTERNA DEL MODELO: Procheck
1. Ejecutar el programa Procheck: procheck model1_estructura_patrons.pdb 3
2. Abrir el fichero de extensión .sum para visualizar los parámetros principales: emacs model1_estructura_patrons.sum &
3. Abrir el fichero de extensión _01.ps con el programa gimp para ver el mapa de Ramachandran: gimp model1_estructura_patrons_01.ps
Estas comandas están hechas con uno de los dos modelos obtenidos a partir del alineamiento basado en estructura. Pero sirven de igual modo para el resto de los modelos.

EVALUACIÓN EXTERNA DE LOS MODELOS: Prosa II
1. Escribir las comandas necesarias en un fichero de extensión .cmd: emacs prosa_pair.cmd &
2. Ejecutar el programa Prosa II: prosa prosa_pair.cmd

SUPERPOSICIÓN DEL MODELO CON EL PDB 1YJD
1. Crear el fichero .domains de modo que contenga el pdb del modelo y el del 1YJD: emacs stamp_mod1seq_patrons.domains &
2. Superponer estructuralmente el pdb 1YJD y el del modelo con STAMP: stamp -l stamp_mod1seq_patrons.domains -rough -n 2 -prefix stamp_mod1seq_patrons > stamp_mod1seq_patrons.out
3. Generar un fichero con los pdbs superpuestos para poder visualizar gráficamente esta superposición: transform -f stamp_mod1seq_patrons.1 -g -o stamp_mod1seq_patrons.pdb
Estas comandas están hechas con uno de los cuatro modelos obtenidos a partir del alineamiento basado en secuencia. Pero sirven de igual modo para el resto de los modelos.

COMPARACIÓN DE ESTRUCTURAS SECUNDARIAS
1. Ejecutar el programa Psi-pred para que haga una predicción de la estructura secundaria de la secuencia problema: psipred LC_humanitzat_tallat.fa
1. Cambiar el formato del fichero .ss2 a formato pir: psipred.pl LC_humanitzat_tallat.ss2 > LC_humanitzat_tallat_ss2.pir
1. Obtener la estructura secundaria del modelo: dssp model2_estructura_patrons.pdb model2_estructura_patrons.dssp
1. Pasar la estructura secundaria del modelo a formato fasta: aliss.pl model2_estructura_patrons.dssp > model2_estructura_patrons_dssp.pir
1. Concatenar los dos ficheros de salida anteriores en un solo fichero: cat LC_humanitzat_tallat_ss2.pir model2_estructura_patrons.dssp >> compare_mod2_estruct_pat_ss2_dssp.pir
1. Convertir el fichero anterior a formato ClustalW: aconvert -in p -out c <compare_mod2_estruct_pat_ss2_dssp.pir> compare_mod2_estruct_pat_ss2_dssp.clw

BIBLIOGRAFÍA Armour KL, van de Winkel JG, Williamson LM, Clark MR. Differential binding to
human fcgammariia and fcgammariib receptors by human igg wildtype and mutant antibodies. Mol Immunol. 2003 Dec;40(9):585-93
Angata T, Varki A. Siglecs. The major subfamily of type-I lectins. Glycobiology. 2006 Jan; 16(1):1-27.
Blasius AL, Cella M, Maldonado J, Takai T, Colonna M. Siglec-H is an IPC-specific receptor that modulates type I IFN secretion through DAP12. Blood. 2006 Mar 15; 107(6): 2474-6.
Can super-antibody drugs be tamed? Can super-antibody drugs be tamed? Nature. 2006 Apr 13;440(7086):855-6.
Crocker PR., Paulson JC, Varki A. Siglecs and their roles in the immune system. Nature Reviews. 2007; 7: 255-266.
Evans EJ, Esnouf RM, Manso-Sancho R, Gilbert RJ, James JR, Yu C, Fennelly JA, Vowles C, Hanke T, Walse B, Hünig T, Sørensen P, Stuart DI, Davis SJ. Crystal structure of a soluble CD28-Fab complex. Nat Immunol. 2005 Mar;6(3):271-9. Epub 2005 Feb 6.
Farzaneh L, Kasahara N, Farzaneh F. The strange case of TGN1412. Cancer Immunol Immunother. 2007 Feb;56(2):129-34. Epub 2006 Jun 17.

BIBLIOGRAFIA Fiser A, Sali A. Comparative protein structure modeling. Pels Family
Center for Biochemistry and Structural Biology. The Rockefeller University.
Hansen S, Leslie RG. TGN1412: scrutinizing preclinical trials of antibody-based medicines. Nature. 2006 May 18;441(7091):282.
Hünig T. Manipulation of regulatory T-cell number and function with CD28-specific monoclonal antibodies. Adv Immunol. 2007;95:111-48.
Kalinke U, Schraven B. CD28 superagonists: what makes the difference in humans? Immunity. 2008 May; 28(5):591-5.
Lühder F, Huang Y, Dennehy KM, Guntermann C, Müller I, Winkler E, Kerkau T, Ikemizu S, Davis SJ, Hanke T, Hünig T. Topological requirements and signaling properties of T cell-activating, anti-CD28 antibody superagonists. J Exp Med. 2003 Apr 21;197(8):955-66.
Mathews, Van Holde, Ahern. Bioquímica 3ªed. Addison Wesley, 2002.

BIBLIOGRAFÍA
Orozco M. La determinación de la estructura de proteínas en la era genómica. Departamento de Bioquímica y Biología Molecular, de la Facultad de Química de la Universidad de Barcelona; 5 de julio de 2000.
Schneider CK, Kalinke U, Löwer J. TGN1412--a regulator's perspective. Nat Biotechnol. 2006 May;24(5):493-6.
Tema 7: Plegamiento de proteínas [acceso 19 de mayo de 2008] [fecha de la última actualización 23 de septiembre de 2003] URL disponible en: http://mmb.pcb.ub.es/em/PDF/TEMA7.pdf

PREGUNTAS
Respecto a las Siglec, elige la respuesta correcta.
a) Se trata de proteínas transmembrana de la familia de las lectinas.
b) Se expresan de forma diferente en humanos y simios.
c) Las dos anteriores.
d) Podrían explicar el hecho de que en macacos no se produjera la citokine storm.
e) Todas las anteriores.
Respecto a las Siglec, elige la respuesta correcta.
a) En general, en el dominio citoplasmático tienen motivos ITIM.
b) Se expresan en gran cantidad en linfocitos T humanos.
c) Regulan la producción de neurotransmisores.
d) Todas las anteriores son correctas.
e) Todas las anteriores son falsas.

¿Cuál de los siguientes epitopos se corresponden con un anticuerpo antiCD28 convencial y cual con un superagonista, respectivamente?
a) Loop FG y motivo MYPPPYb) Loop FG y loop C’’-Dc) Motivo MYPPPY y loop C’’-Dd) Las dos anteriorese) Loop C’’-D y motivo MYPPPY
El anticuerpo TGN1412 es un superagonista porque:a) Contiene la región Fc correspondiente a un anticuerpo.b) Es capaz de actuar sinérgicamente con el receptor TCR para
activar los linfocitos T.c) Debido a que es capaz de producir una activación del linfocito T
cien veces mayor que el anticuerpo monoclonal convencial.d) Activa al linfocito T sin la necesidad de la activación del
TCR.e) Ninguna de las anteriores.

Quina de les següents afirmacions és certa?a) Farem l’avaluació del model construït mitjançant procheck i
escollirem sempre la resolució que sigui més elevada de tots els patrons.
b) Per avaluar el model de la Fab de l’anticòs és recomanable analitzar el perfil energètic de l’energia combinada.
c) Les dues anteriors.d) El millor alineament basat en seqüència per a la construcció dels
models de les cadenes de la Ig és l’obtingut amb HMMER utilitzant el domini Ig extret de Pfam.
e) Totes les anteriors. De las siguientes afirmaciones, señale la verdadera:
a) Las técnicas bioinformáticas de predicción de estructuras de las proteínas se basan en dos aproximaciones diferentes, pero complementarias: los métodos físicos y los métodos estadísticos.
b) Hay métodos teóricos y experimentales para predecir la estructura de una proteína como comparative modelling y cristalografía, respectivamente.
c) Las dos anteriores son ciertas.d) La calidad de un patrón aumenta cuando más similar sea su
secuencia a la de la secuencia diana y disminuye con el número y la longitud de los gaps en el alineamiento.
e) Todas las anteriores son ciertas.

Dentro de las interacciones no enlazantes, señale el orden que seguirían de más a menos intensas:
a) Puentes de hidrógeno > puentes disulfuro > interacciones hidrofóbicas > interacciones electrostáticas.
b) Puentes disulfuro > puentes salinos > puentes de hidrógeno > interacciones de van der Waals.
c) Interacciones iónicas > puentes de hidrógeno > interacciones de van der Waals.
d) Interacciones electrostáticas > puentes disulfuro > interacciones hidrofóbicas > puentes de hidrógeno.
e) Puentes disulfuro > puentes de hidrógeno > interacciones de van der Waals > interacciones iónicas.
Señala la respuesta correcta:a) Proteínas con la misma secuencia, la misma estructura y la misma función se
denominan homólogos ortólogos.b) Proteínas con secuencias y funciones distintas y que se pliegan de la misma
manera se denominan análogos.c) Las dos anteriores.d) Proteínas con la misma secuencia, la misma estructura y función diferente se
denominan parálogos.e) Todas las anteriores.

Respecte les immunoglobulines, quina de les següents opcions és la falsa:
a) El domini constant està format per 7 fulles β repartides en dos grups de 3 i 4 cadenes.
b) La fulla de 5 cadenes β del domini variable és estructuralment homologa a la fulla de 3 cadenes β del domini constant però amb dues cadenes extres C’ i C’’.
c) El plegament s’estabilitza per la formació de ponts d’hidrogen entre les cadenes β de cada fulla, d’enllaços hidrofòbics entre els residus de l’interior de les fulles i per un pont de sofre entre les cadenes B i F.
d) Els CDRs són loops que connecten les cadenes β 1-2, 3-3 i 4-5.
e) La unió de carbohidrats a l’Asn306 del segon domini constant de cada cadena pesada (CH2) produeix un augment de la protuberància del peu de la Y.
Respecte al modelat de proteïnes, quina de les següents afirmacions és veritat:a) En la optimització, la conformació biologicament activa es correspon sempre a la
mínima energia.b) Les zones corresponents als centres catalítics de les proteïnes poden presentar
pics energètics més positius degut a la seva menor estabilitat.c) Les dues anteriors són certes. d) Un bon modelat no implica sempre un perfil energètic negatiu. e) La b i la d són certes.