tesi francesco pascale
TRANSCRIPT

UNIVERSITA’ DEGLI STUDI DI SALERNO
FACOLTA’ DI INGEGNERIA
Tesi di laurea in
INGEGNERIA INFORMATICA
Riconoscimento di parole manoscritte:
Valutazione delle prestazioni di un algoritmo di labeling
Relatore:
Ch.mo Prof.
Angelo Marcelli
Candidato:
Francesco Pascale
Matr. 0610700088
Anno Accademico 2008/2009

Indice
Introduzione………………………………………………………………………………...4
Capitolo 1: L’algoritmo di labeling…………………………………………..…..7
1.1 Caratterizzazione statistica del numero di stroke per carattere................... 7
1.1.1 Metodo dei minimi quadrati .................................................................. 7
1.1.2 Calcolo delle distribuzioni ...................................................................... 8
1.2 Individuazione delle component ................................................................. 11
1.3 Analisi delle feature: individuazione degli anchor points ........................... 14
1.4 Algoritmo di matching ................................................................................. 17
Capitolo 2: Il Tool di labeling…………………………………………………… .21
2.1 Descrizione del tool utilizzato ..................................................................... 21
2.3 Riassegnazione delle Stroke ........................................................................ 27
2.3.1 Individuazione delle situazioni anomale .............................................. 27
2.3.2 Correzione dell’assegnazione ............................................................... 28
2.4 Raccolta delle informazioni ......................................................................... 32

pag. 3
Capitolo 3: Valutazione delle prestazioni …………………………………36
3.1 Calcolo degli indici prestazionali ................................................................. 36
3.2 Individuazione di classi di errore ................................................................. 41
3.3 Errori ricorrenti ............................................................................................ 53
Conclusioni…………………………………………………………………………………59
Bibliografia…………………………………………………………………………………62
Ringraziamenti………………………………………………………………………......63

pag. 4
Introduzione
Negli ultimi anni si è assistito ad un crescente interesse per i metodi per il
riconoscimento ottico della scrittura, in grado, cioe’, di associare
all’immagine di una parola la sua trascrizione in caratteri in un formato
utilizzabile da un calcolatore. La ricerca nel campo dei sistemi di
riconoscimento ottico dei caratteri isolati (Optical Character Recognition,
OCR) ha avuto uno sviluppo notevolissimo sia nel caso di caratteri stampati
che in quello di caratteri manoscritti, anche con riferimento ad alfabeti
diversi da quello latino, come il cinese, il giapponese, l’arabo, l’indiano e il
coreano. Per quanto riguarda il riconoscimento dalla scrittura corsiva
manoscritta, invece, si sono riscontrati diversi problemi derivanti dal fatto
che ogni persona scrive in maniera differente gli stessi caratteri o gruppi di
caratteri a seconda della parola che intende scrivere. Allo stato dell’arte [4]
esistono due principali metodi per il riconoscimento di parole manoscritte:
metodi analitici, che prevedono la scomposizione della parola nei suoi
caratteri componenti e il successivo riconoscimento dei singoli caratteri, e
metodi olistici, che prevedono il riconoscimento della parola nella sua
interezza. Indipendentemente dal tipo di metodo utilizzato, il maggiore
sforzo si è concentrato sull’individuazione da parte del progettista di un set
univoco di caratteristiche distintive (features) per descrivere la forma dei
caratteri o della parola da riconoscere e di un insieme di modelli di
riferimento (prototipi) per descrivere ognuna delle classi a cui il carattere o
la parola puo’ essere ascritta durante la classificazione.

pag. 5
L’approccio utilizzato dal Laboratorio di Computazione Naturale del
Dipartimento di Ingegneria dell’Informazione ed Ingegneria Elettrica
dell’Università degli studi di Salerno [5] è del tipo prototype-free ovvero
non fa uso di prototipi definiti a priori, validi per tutti gli scriventi. Il
metodo prevede di confrontare la scrittura da riconoscere con campioni di
riferimento, per ognuno dei quali si conosce l’interpretazione, e i tratti di
inchiostro simili (tra la scrittura da riconoscere e quelle dei campioni di
riferimento) costituiscono i prototipi da utilizzare per il riconoscimento.
Poiche’ ottenuti confrontando la scrittura da riconoscere con quelle di
riferimento, i prototipi dipendono dalla specifica scrittura. ovvero sono
writer-specific. Inoltre, variano al variare di quest’ultima e quindi rendono
il metodo, almeno in linea di principio in grado di modellare attraverso tali
prototipi qualsiasi stile di scrittura. Una volta individuati questi prototipi, il
riconoscimento della parola avviene concatenando, secondo l’ordine di
scrittura, e quindi da sinistra a destra nel caso dell’alfabeto latino, i prototipi
individuati durante il confronto.
Per l’implementazione del metodo, e in accordo con i modelli
computazionali relativi al funzionamento del sistema neuro-muscolo-
scheletrico durante la produzione della scrittura, e’ necessario individuare i
tratti elementari, chiamati stroke, usati dallo scrivente per comporre la
parola, e associare ad ogni stroke dei campioni di riferimento una label che
specifica a quale carattere della parola essa appartiene. In questo modo,
durante il confronto, le sequenze di stroke della parola da riconoscere che
risultano simili a sequenze presenti nei campioni verrano etichettate con le
stesse label associate a quest’ultime per costituire i prototipi di cui si ‘e
detto in precedenza. Il labeling dei campioni di riferimento e’ ottenuto
automaticamente mediante un algoritmo sviluppato nel laboratorio [1].
L’algoritmo consta di tre fasi: una fase di analisi delle component, una fase
di analisi delle feature e un’ultima fase di matching. A monte di queste tre

pag. 6
fasi vi è un’analisi preliminare per il calcolo delle distribuzioni per ogni
carattere.
Obiettivo della tesi è quello di verificare l’efficacia dell’algoritmo di
labeling, valutandone le prestazioni, e di proporre, li dove sia possibile,
miglioramenti per aumentarne le prestazioni.
Nel seguito, il Capitolo 1 descrive l’algoritmo di labeling di cui si vogliono
valutare le prestazioni, mentre il Capitolo 2 descrive i tool utilizzati nel
lavoro sperimentale. Il Capitolo 3, infine, riporta la valutazione delle
prestazioni, mentre le conclusioni riassumono il lavoro svolto e
suggeriscono possibili modifiche per aumentare le prestazioni
dell’algoritmo considerato.

pag. 7
L'algoritmo di labeling
Scopo di questo capitolo è illustrare l’algoritmo per il labeling delle stroke
costituenti la traccia d’inchiostro, dove le label indicano a quale dei
caratteri componenti la parola da analizzare appartiene ciascuna stroke. La
parte principale dell’algoritmo è rappresentata dall’algoritmo di matching
[2] il quale grazie alle distribuzioni statistiche del numero di stroke per
carattere riesce a dare un’assegnazione con maggiore probabilità.
1.1 Caratterizzazione statistica del numero di stroke per carattere
Il metodo utilizzato è basato sul metodo dei minimi quadrati per la
determinazione delle pdf (funzioni di distribuzione di probabilità di una
variabile aleatoria discreta) relative al numero di stroke per ogni singolo
carattere.
1.1.1 Metodo dei minimi quadrati
Consideriamo il seguente sistema lineare:
bxA =
dove:
• A rappresenta la matrice dei coefficienti del sistema;
• x rappresenta il vettore delle incognite del sistema;

pag. 8
• b rappresenta il vettore dei termini noti del sistema;
Nel caso in cui il sistema non sia risolvibile, è possibile cercare la migliore
approssimazione della soluzione, minimizzando, con il metodo dei minimi
quadrati, la norma dell’errore:
||||min bAxx
−
ed imponendo l’ulteriore vincolo di non negatività della soluzione [3].
1.1.2 Calcolo delle distribuzioni
Come detto in precedenza, una delle fasi più importanti è la generazione
delle distribuzioni per la caratterizzazione statistica del numero di stroke da
attribuire ad ogni carattere. Il problema puo’ essere riformulato in termini di
sistemi di equazioni lineari considerando, per ognuna delle parole del
training set, il numero (noto) di volte che ognuno dei ventisei caratteri
compare nella parola moltiplicato per il numero (incognito) di strokes di cui
e’ costituito ognuno dei ventisei caratteri, sommando tutti questi termini ed
imponendo che tale somma sia uguale al numero (noto) di strokes presenti
nella parola. In formule:
na�xa + nb�xb + … + nz�xz = Stot
Se ora consideriamo p parole e ad ognuna di esse applichiamo analogo
ragionamento otteniamo il sistema desiderato:
na1�xa + nb1�xb + … + nz1�xz = Stot1
na2�xa + nb2�xb + … + nz2�xz = Stot2
naP�xa + nbP�xb + … + nzP�xz = StotP

pag. 9
Date un insieme di T parole di cui si conosce la trascrizione, cioe’ i caratteri
che le costituiscono, detto (reference set), le distribuzioni del numero di
stroke per ognuno dei 26 caratteri minuscoli dell’alfabeto inglese sono state
generate considerando piu’ sistemi lineari, ognuno costituito da p equazioni
(p ≥ 26) in q incognite (m=26) e risolvendo ognuno di essi con il metodo
dei minimi quadrati.
Per ognuna delle soluzioni ottenute si calcola un indice di affidabilità Sc,j
cosi’ definito:
∑=
×−×
= sistnum
j
jcjcicic
icic
sistnum
nrnr
nS _
1
,,,,
,,
_
dove:
• icn , rappresenta il numero di occorrenze del carattere c-esimo
all’intero del sistema i-esimo;
• icr , rappresenta il numero di stroke per il c-esimo carattere
ottenuto risolvendo l’i-esimo sistema; • num_sist rappresenta il numero di sistemi considerati.
In questo modo, ad ogni soluzione sono associati 26 stimatori, uno per ogni
carattere. Per ottenere le pdf desiderate, che rappresentano la distribuzione
di probabilita’ del numero di stroke per ogni carattere, i parametri di
affidabilità relativi allo stesso carattere nelle H soluzioni vengono
normalizzati rispetto alla somma totale degli stessi. Vengo poi sommate
tutte le probabilità che corrispondono alle soluzioni che sono identiche tra
sistemi con diverso numero di equazioni e siccome le soluzioni risultano
essere reali queste vengono arrotondate all’intero più prossimo. La fig. 1
riporta le distribuzioni così ottenute.

pag. 10
Fig. 1: distribuzioni calcolate a partire dal reference set

pag. 11
1.2 Individuazione delle component
La fase di matching è preceduta da una fase iniziale di scomposizione della
parola in pezzi. In questa fase vengono definite le component che
compongono la parola, cioe’ i tratti di inchiostro che risultano connessi. In
funzione dello stile di scrittura puo’ capitare che una parola sia fatta da una
o piu’ component e dunque, successivamente alla loro individuazione, le
component vengono analizzate per decidere se debbono essere mantenute
separate o unite. Nel primo caso ogni component e’ associata ad un
n-gramma1 diverso, nel secondo tutte le component sono associate allo
stesso n-gramma. Questa analisi e’ realizzata calcolando il feret box di ogni
component e analizzando le relazioni topologiche tra essi. Il feret box di
una component e’ il rettangolo di area minima che la include, come
illustrato in fig. 2.
Fig. 2: Individuazione della prima component e del suo feret box
A questo punto per stabilire se la successiva component (quella relativa al
primo carattere n) debba essere associata o meno a “colo”, si valuta la
distanza tra i due feret box e poiche’, in questo caso, essa e’ maggiore di
una soglia le due component non vengono associate. Diverso è invece il
caso illustrato in fig. 3, in cui abbiamo che la parola “partner” e’ composta
da 5 component: la prima è la “p”, la seconda è la successione“ar”, la terza
la parte verticale della “t”, la quarta il trattino della “t” e la quinta la
successione “ner” . In questo caso, i feret box della 3 e 4 component si
intersecano e dunque esse vanno associate entrambe allo stesso n-gramma,
1 Un n-gramma e’ una sequenza di n caratteri

pag. 12
in questo caso il carattere “t”. Di queste unioni si tiene conto nella fase di
matching.
Fig. 3: individuazione della terza component e del suo feret box
Definite quindi le varie component che devono essere processate bisogna
capire ora quali caratteri appartengono ad ogni pezzetto considerato.
Consideriamo nuovamente la parola “colonnare”: questa è stata suddivisa in
5 component:
Fig. 4: individuazione di tutte le component della parola “colonnade” e dei relativi feret box
Considerando ora le stroke che sono state individuate per ogni component
otteniamo: I component : 12 strokes; II component: 3 strokes; III
component : 3 strokes; IV component : 3 strokes; V component : 5 strokes;
Le distribuzioni del numero di stroke per le classi dei carateri presenti nella
parola sono le seguenti:

pag. 13
Fig. 5: distribuzioni relative ai caratteri della parola “colonnade”
Analizzando i valori di picco delle distribuzioni (in blu in fig. 5) si ottiene:
C è 2 stroke Oè 3 stroke Lè 2 stroke
Oè 3 stroke N è 5 stroke Nè 5 stroke
Aè 3 stroke Dè 3 stroke Eè 3 stroke
Andando a considerare la prima component notiamo che essa è costituita da
12 stroke. Adesso in base ai valori di massimo della distribuzione si
ottengono le lettere che con maggiore probabilità compongono il pezzo.
Consideriamo la lettera “C”: essa risulta essere costituita da 2 stroke.
Quindi andando a sottrarre le stroke della “c” alle stroke del primo
component otteniamo 10. Il procedimento continua anche con le successive
lettere. Abbiamo una “o” che risulta essere composta da 3 stroke e
determina una differenza di 7. Considerando la lettera “l” composta da 2
stroke si ottiene una differenza di 5 e infine considerando di nuovo la lettera
“o” si ottiene una differenza di 2. Considerando ora anche la lettera “n”
composta da 5 stroke la differenza risulta essere 3, maggiore di quella
minima. Si deduce quindi che la prima component sarà costituita dalla
lettere “colo”.

pag. 14
1.3 Analisi delle feature: individuazione degli anchor points
Immediatamente dopo la fase di divisione della parola in component questa
viene processata attraverso l’analisi delle feature e quindi dei cosiddetti
“punti vietati”. La traccia a questo punto viene divisa in particolari regioni
chiamate center zone, upper zone e lower zone
Fig. 6: individuazione delle zone riferite alla parola “chup”
Le feature che sono di maggiore interesse sono quelle che vengono
etichettate come ascender e descender: queste sono le stroke che
presentano una notevole estensione verticale, maggiore di quella orizzontale
e che impegnano più regioni della parola; in particolare sono definite:
• ascender up (indicate con “A”) le strokes che partono dalla center zone
e terminano nella upper zone;
• ascender down (indicate con “a”) le strokes che partono dalla upper
zone e terminano nella center zone;
• descender down (indicate con “d”) le strokes che partono dalla center
zone e terminano nella lower zone;
• descender up (indicate con “D”) le strokes che partono dalla lower
zone e terminano nella center zone.
La presenza di queste features consente di individuare all’interno della
traccia di inchiostro delle stroke che fungono da anchor points durante il

pag. 15
matching, nel senso che impongono che un certo carattere le contenga
all’inizio o alla fine e dunque determinano dove quel carattere comincia o
finisca, condizionando in tal modo l’attribuzione delle strokes rimanenti
agli altri caratteri. Cio’ e’ stato ottenuto mediante un’analisi statistica dei
casi che ha portato all’individuazione delle classe di caratteri che
presentano particolari sequenze di queste features. Si sono evidenziati
quattro sequenze:
• descender down – descender up a inizio carattere: il carattere “p”
• descender down – descender up a fine carattere: i caratteri “g” “j” “y”
“q”
• ascender up – ascender down a inizio carattere: i caratteri “b” “h” “k”
“l” “t”
• ascender up – ascender up a fine carattere: il carattere “d”
La presenza di queste sequenze consente di individuare anche dei punti
vietati, dei punti cioe’ che non possono rappresentare l’inizio o la fine di
uno dei caratteri che include le sequenze considerate.
Per comprendere come gli anchor points agiscono, si consideri la parola di
fig. 6, nella quale sono presenti la sequenza ascender up – ascender down e
la descender down – descender up. In questo caso l’algoritmo quando
analizza la traccia, sapendo che all’inizio e’ presente il carattere “c” seguito
dal carattere “h”, sa che il carattere “h” non puo’ iniziare nel punto vietato
(fig. 7).
Fig. 7: individuazione del punto vietato nel carattere “h” e possibili anchor points

pag. 16
Poiche’ la sequenza ascender up-ascender down deve trovarsi all’inizio
della “h”, conclude che la “h” comincia nel punto di segmentazione prima
del punto vietato, come illustrato in fig. 8.
Fig. 8: individuazione dell’anchor point nella successione “ch”
Individuato l’anchor point la component viene ulteriormente divisa in due
parti e tutto quello che si trovava prima viene passato come identificazione
del carattere “c”. Successivamente lo stesso procedimento viene fatto per il
carattere “p”: individuato il punto vietato caratterizzato dalla sequenza
descender down – descender up di inizio carattere, e sapendo che la traccia
contiene il carattere “p” l’algoritmo individua come anchor point il
segmento prima del punto vietato. Di conseguenza tutto ciò che si trova
dopo il punto trovato verrà etichettato come il carattere “p”. Si ottiene in tal
mdo un’ulteriore divisione della component, nella quale sono stati
individuati due caratteri isolati, la “c” e la “p” ed un tratto che rappresenta
l’n-gramma “hu”. Questo sara’ l’unico tratto sul quale lavorera’ l’algoritmo
di matching per attribuire la stroke che lo compongono le rispettive label.

pag. 17
Fig. 9: individuazione delle “zone” in cui sappiamo dove si trovano i caratteri
1.4 Algoritmo di matching
Ultima fase per l’individuazione dei caratteri all’interno di una traccia è la
fase di matching. A valle quindi della divisione della traccia originaria in
component e la successiva analisi delle feature, le parti di traccia che non
sono state ancora identificate vengono elaborate utilizzando le distribuzioni
sui caratteri a nostra disposizione. Come prima fase il metodo valuta il
numero di stroke che effettivamente compongono la parola, indicato con
ns_reale, e lo confronta con il numero di stroke stimato tramite i massimi
delle distribuzioni dei caratteri in gioco, indicato con ns_stimato. Si
possono quindi verificare 3 casi:
• ns_reale>ns_stimato, il numero di stroke stimato è minore del numero di stroke effettivo, di conseguenza vanno aggiunte delle stroke a quelle stimate;
• ns_reale<ns_stimato, il numero stimato di stroke stimato è maggiore del numero di stroke effettivo, di conseguenza vanno eliminate delle stroke da quelle stimate;

pag. 18
• ns_reale=ns_stimato, il numero stimato coincide con il numero di stroke effettivo; l’algoritmo termina.
I casi di interesse quindi risultano essere i primi due. Nel caso in cui
ns_reale>ns_stimato avviene che il numero di stroke che compongono il
tratto sono maggiori di quelle stimate quindi l’algoritmo deve provvedere
ad associare la stroke in eccesso ad uno o piu’ dei caratteri che compongono
il tratto. Prendendo come esempio la parola “bazaar” di fig. 10, in essa
ns_reale = 25, mentre in base ai massimi delle distribuzioni, riportati in fig.
11, si ha ns_stimato = 24.
Fig.10 parola considerata per l’algoritmo di matching
Si evince che bisognerà assegnare la stroke in eccesso ad uno dei carattere.
Considerando quindi i valori a destra dei valori di massimo delle
distribuzioni, vediamo che tra i caratteri considerati quello con maggiore
probabilità risulterà essere la “z” con un valore prossimo a 0,07. Pertanto
alla “z” verranno assegnate 5 stroke invece di 4 (valore piu’ probabile)
ottenendo ns_reale=ns_stimato, come illustrato in fig. 12.
Fig.11 distribuzioni relative alla parola “bazaar”

pag. 19
Fig.12 in rosso evidenziate le modifiche effettuate dall’algoritmo di matching
Il labeling definitivo per la parola di fig. 6 e’ mostrato in fig. 13.
Fig. 13: output finale dell’algoritmo di labeling
Caso analogo si ha quando ns_reale<ns_stimato: In questo caso invece che
andare a vedere le probabilità a destra dei massimi delle distribuzioni dei
carattere considerati, si vanno a vedere i valori a sinistra dei massimi fino
ad ottenere di nuovo la condizione ns_reale=ns_stimato.
Nonostante le prestazioni di tale algoritmo risultino essere efficaci, questo
non risulta essere sempre efficiente. Uno di questi vi è quando la distanza in
termini di stroke tra due massimi relativi è elevata. Ovvero quando ad
esempio abbiamo che la differenze tra ns_reale e ns_stimato è di una sola
stroke e andando a valutare le distribuzioni dei caratteri considerati
otteniamo che il valore con maggiore si trova ad una distanza, sempre in
termini di stroke, maggiore di uno. Ci troviamo quindi in una condizione in
cui sono state assegnate più strokes di quante ne servissero. Analogamente

pag. 20
l’algoritmo rivela questa incongruenza e ripete il controllo chiudendosi in
un loop infinito. In questi casi il sistema prevede quella che viene nominata
la fase “opzionale” o l’elaborazione di secondo livello. Questa riporterà il
tutto allo stato di partenza dell’elaborazione e andrà a ricercare di nuovo i
massimi assoluti delle distribuzioni. A partire da questi si muoverà
all’interno delle distribuzioni allo stesso modo di prima però ad ogni
iterazione lo spostamento sarà unitario. In questo modo si arriverà sempre
ad una soluzione.
Un altro caso anomalo è quello in cui dopo un cero numero di spostamenti
all’interno delle distribuzioni i valori tra i quali ricercare risultano essere
nulli. Per ovviare a questo problema l’algoritmo effettua una scelta in base
alla probabilità associate al numero di stroke che al momento sono
assegnate ai caratteri. Quindi tra questi valori considera quello più elevato e
ad esso aggiunge una stroke. Questo procedimento continua fino a
raggiungere la soluzione.

pag. 21
Il tool di labeling
In questo capitolo andremo ad analizzare il tool di labeling utilizzato per
effettuare la valutazione dell’algoritmo di labeling. Di notevole importanza
sarà capire come individuare le varie situazioni di errore e in che modo poi
queste verranno corrette. Si andrà poi a fare una raccolta di tutte le
informazioni le quali verranno puoi utilizzate per una valutazione statistica
delle prestazioni del sistema.
2.1 Descrizione del tool utilizzato
Il tool di labeling utilizzato è quello sviluppato dal Laboratorio di
Computazione Naturale del Dipartimento di Ingegneria dell’Informazione
ed Ingegneria Elettrica dell’Università degli studi di Salerno il quale mette a
disposizione diverse funzionalità, tra le quali il labeling delle parole del
reference set dando la possibilità di vedere a video i risultati (figg. 1 e 2).

pag. 22
Fig. 1: GUI del tool di labeling
Fig. 2: output video del tool di labeling
Nel nostro caso lo si è utilizzato per la valutazione del labeling automatico
su di un set definito di parole. A tal fine e’ stato eseguita prima
l’elaborazione descritta nel capitolo precedente per ottenere le distribuzioni

pag. 23
necessarie al labeling e successivamente le distribuzioni sono state
utilizzate per labellare l’insieme di parole che compongono il reference set.
La fig. 3 mostra il risultato del labeling su una delle parole del reference set.
Si nota che ad ogni carattere sono stati assegnati un certo numero di stroke
e che per ogni assegnazione abbiamo un diverso colore (vediamo ad
esempio che tutte le stroke assegnate alla lettera C sono di colore blu
mentre quelle assegnate alla lettera a sono di colore nero e così via)
Fig. 3: labeling automatico della parola “Carlo”
Notiamo che le distribuzioni relative ad ogni carattere appartenente alla
parola considerata risultano essere
Fig. 4: distribuzioni relative alla parola “Carlo”

pag. 24
La traccia considerata è stata processata dal sistema come un’unica
component. E’ stata successivamente passata all’analisi delle feature
durante la quale si è riscontrato un punto vietato in corrispondenza
dell’ascender up-ascender down di inizio carattere dovuto alla presenza
della lettera “l”. quindi si è successivamente provveduto all’individuazione
dell’anchor point il quale ha diviso la traccia in due pezzi.
A questo punto quindi si è applicato l’algoritmo di matching ai due tratti
d’inchiostro. Per il tratto “Car” abbiamo la situazione di fig. 5:
Fig. 5: matching sul trigramma “Car”
L’assegnazione delle stroke per carattere è risultata infine essere
C è 4 stroke A è 7 stroke R è 3 stroke
Per il tratto “lo” invece abbiamo la situazione di fig. 6:
Fig.6 matching sul bigramma “lo”
L’assegnazione delle stroke per carattere è risultata infine essere
L è 3 stroke O è 4 stroke

pag. 25
Questi due pezzi sono stati quindi processati dall’algoritmo di matching in
maniera separata e si è ottenuto quindi infine il label per la parola “Carlo”.
Il labeling della parola in questo caso è risultato corretto, e quindi non ha
bisogno di alcuna correzione.
Consideriamo ora un’altra volta la parola “Carlo” ma scritta da un’altra
persona. Notiamo subito che il labeling non è riuscito correttamente in
quanto l’assegnazione delle label ai caratteri risulta essere sbagliata.
Fig. 7: labeling automatico sulla parola “Carlo”
Così come per il caso precedente le assegnazioni risultano essere per il
tratto “Car” quelle che si ottengono dalle distribuzioni di fig. 8:
Fig. 8: matching sul trigramma “Car”
L’assegnazione delle stroke per carattere è risultata essere:

pag. 26
C è 4 stroke A è 6 stroke R è 2 stroke
Mentre per il tratto “lo” il matching si ottiene come in fig. 9:
Fig. 9: matching sul bigramma “lo”
L’assegnazione delle stroke per carattere è risultata essere:
L è 3 stroke O è 4 stroke
In questo caso però nonostante a livello concettuale non sono presenti errori
nell’assegnazione delle label (infatti il sistema non ha sbagliato nulla a
livello puramente concettuale), notiamo però un’incongruenza nel risultato
con quello che ci saremo aspettati di vedere. Infatti l’individuazione e
quindi la successiva correzione di questi casi anomali diviene di
fondamentale importanza per un corretto funzionamento del sistema nella
fase di labeling.
Per questo scopo il tool, grazie alla sua interfaccia grafica, mette a
disposizione diverse funzionalità, tra le quali:
• Accettazione della parola • Cancellazione delle modifiche effettuate • Proseguire alla parola successiva • Retrocedere alla parola precedente • Chiudere il tool di labeling
Grazie a questi strumenti è possibile effettuare le dovute interpretazioni del
labeling effettuato dal sistema e li dove sia necessario apporre le dovute

pag. 27
modifiche di assegnazione che verranno poi registrate per le dovute
considerazioni.
2.3 Riassegnazione delle Stroke
Come detto in precedenza l’individuazione dei casi di errore risulta
importantissimo ai fini del miglioramento delle prestazioni del sistema.
Quindi prima di darne una valutazione statistica bisogna innanzitutto capire
quali tipi di errori si stanno andando a valutare e successivamente stabilire
la maniera più corretta per correggere il labeling e quindi per raccogliere
tutti i dati.
2.3.1 Individuazione delle situazioni anomale
La prima fase dello studio è stata quella dell’individuazione delle situazioni
di errore. In riferimento al reference set utilizzato la prima cosa che si è
fatta è stata quella di andare ad individuare una prima macroclasse di errori
che sono quelli relativi ad una fase a monte del sistema ovvero gli errori di
sbrogliatura.
La sbrogliatura infatti è la fase in cui si analizza a partire dell’inizio del
tratto d’inchiostro fino alla sua fine il “movimento” che lo scrivente fa da
sinistra verso destra in modo tale da avere una traccia della parola.
Errori in questa fase ovviamente si ripercuotono a valle e quindi nel
momento in cui si presenta una parola “sbrogliata male” questa è stata di
conseguenza automaticamente scartata. L’esempio qui sotto riporta la
parola “Angelica” la quale risulta essere sbrogliata male.

pag. 28
Fig.10: errore di sbrogliatura sulla parola “Angelica”
Quindi dopo una prima scrematura delle parole considerate si è passati ad
analizzare le restanti. Come criterio di scelta per stabilire se una parola era
stata labellata bene o meno ci si è fatto riferimento alla migliore
verosimiglianza con i caratteri considerati ovvero si è stabilito che si era in
presenza di un labeling errato quando l’assegnazione delle stroke ad ogni
singolo carattere fatta in maniera automatica comportava un interpretazione
errata delle lettera considerata e una successiva rassegnazione delle stroke
avrebbe portato ad un miglioramento nell’interpretazione.
Ovviamente le parole che sono state labellate bene dal sistema rimanevano
invariate in quanto non c’era bisogno di alcuna correzione.
2.3.2 Correzione dell’assegnazione
Al fine di illustrare come avviene la correzione degli errori di labeling,
riprendiamo il caso di fig. 7 che, per comodita’, riportiamo in fig. 11.

pag. 29
Fig. 11: labeling automatico sulla parola “Carlo”
Come detto in precedenza dal punto di vista puramente concettuale il
sistema ha svolto le sue operazioni senza alcun errore, però notiamo che il
labeling è risultato sbagliato. Vediamo che l’assegnazione delle stroke fatta
in maniera automatica risulta essere:
C è 4 stroke A è 6 stroke R è 2 stroke
L è 3 stroke O è 4 stroke
A questo punto quindi operiamo con la riassegnazione delle stroke per
carattere in maniera manuale così da portarci nel caso di riconoscimento
ottimale.
Grazie alle funzionalità messeci a disposizione dal tool di labeling andiamo
ad intervenire direttamente sulla traccia visualizzata a video in maniera
manuale. Prendendo ad esempio il caso precedente risulta evidente che alla
lettera “a” non siano state etichettate bene le stroke. Notiamo che le ultime
2 stroke assegnate alla lettera “C” in realtà, per il criterio di verosimiglianza
dei caratteri, devono essere assegnate alla lettera “a”. Stesso discorso vale
per l’ultima stroke della lettera “a” che risulta debba essere assegnata alla

pag. 30
lettera “r” e l’ultima stroke della lettera “r” che risulta debba essere
assegnata alla lettera “l”.
A questo punto si va ad intervenire per la rassegnazione. Iniziamo con il
selezionare con un click del mouse il punto di segmentazione iniziale da cui
partono le stroke da riassegnare ad un dato carattere:
Fig.11 individuazione del punto di segmentazione iniziale per la rassegnazione delle stroke
Individuato ora il punto di segmentazione di finale, dove terminano le
stroke da riassegnare al carattere considerato e cliccandoci sopra con il
mouse effettuiamo la rassegnazione:
Fig.12 Individuazione del punto finale per la rassegnazione delle stroke

pag. 31
A questo punto reiterando lo stesso procedimento anche per gli altri due
casi di errore riscontrati nella traccia considerata il labeling risulta essere:
Fig.13 labeling manuale sulla parola “Carlo”
L’assegnazione manuale delle stroke quindi risulta essere:
C è 2 stroke A è 7 stroke R è 2stroke
L è 4 stroke O è 4 stroke
Notiamo da subito che questa seconda configurazione rispetto alla prima
risulta essere quella più verosimile. Infatti mentre che per la prima
configurazione avevamo una quasi irriconoscibilità delle lettere “a” ed “r”,
con questa seconda configurazione tutti i caratteri della parola “Carlo” sono
ben riconoscibili.
Queste modifiche apportate nonostante siano giustificate dal fatto che ora la
parola risulta ben labelata, vanno in contrasto con la metodologia proposta
dal sistema. Bisogna quindi capire (vedi capitolo 3) come poter intervenire
sul sistema affinchè possa migliorare le sue prestazioni.

pag. 32
A questo punto non ci resta che raccogliere in maniera ordinata tutti i dati a
nostra disposizione così da poter poi effettuare tutte le dovute conclusioni.
2.4 Raccolta delle informazioni
Parte finale è quella della raccolta delle informazioni a nostra disposizione.
Infatti grazie alla grossa mole di dati ottenuti come feedback da questo
esperimento abbiamo la possibilità di non solo valutare le prestazioni del
labeling, ma proporre li dove sia possibile delle soluzioni per migliorare il
sistema e per aumentarne l’efficienza.
A questo punto, processate tutte le 1600 parola del reference set
(ovviamente tolte quelle con errata sbrogliatura) abbiamo estratto una serie
di informazioni che sono state processate dal sistema.
Come prima informazione utile che è stata raccolta abbiamo calcolato il
numero effettivo di parole “ben labellate” e parole “labellate male”. Questa
informazione risulta essere la più importante in quanto è indice
dell’efficienza del sistema. Infatti le parole “ben labellate” sono quelle che
non sono state modificate e che sono risultate verosimili.
Altra informazione raccolta è quella riferita al numero di stroke riassegnate
per parola, i bigrammi coinvolti e soprattutto il criterio con cui sono state
apportate le modifiche (ad esempio specificando in che modo le stroke sono
state riassegnate, da chi sono state tolte e a chi sono state date). Questa
informazione risulta essere essenziale per poter individuare all’interno del
nostro sistema, li dove ci può essere, errori che si verificano più o meno in
maniera ripetitiva.
pag. 33
Ultima informazione raccolta sono i commenti lasciati alle azioni svolte.
Questi non solo tengono traccia di tutto il lavoro svolto ma fungono anche
da base per le considerazioni affrontate nel prossimo capitolo.
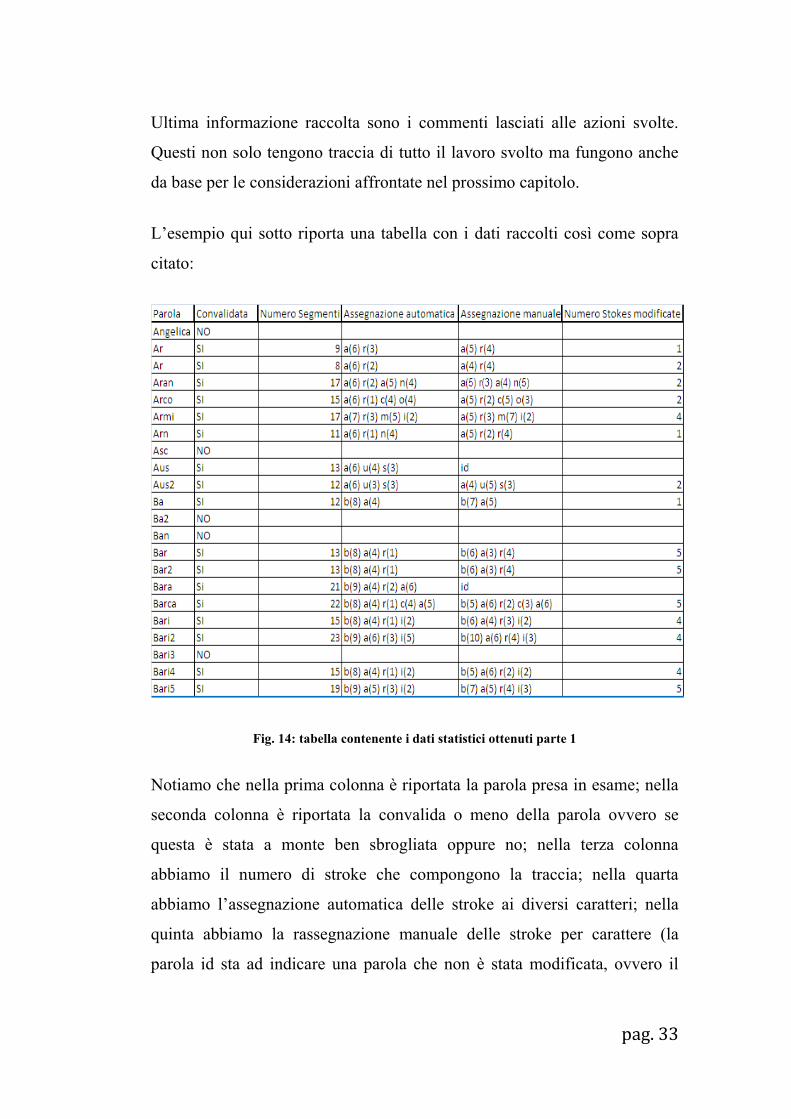
L’esempio qui sotto riporta una tabella con i dati raccolti così come sopra
citato:
Fig. 14: tabella contenente i dati statistici ottenuti parte 1
Notiamo che nella prima colonna è riportata la parola presa in esame; nella
seconda colonna è riportata la convalida o meno della parola ovvero se
questa è stata a monte ben sbrogliata oppure no; nella terza colonna
abbiamo il numero di stroke che compongono la traccia; nella quarta
abbiamo l’assegnazione automatica delle stroke ai diversi caratteri; nella
quinta abbiamo la rassegnazione manuale delle stroke per carattere (la
parola id sta ad indicare una parola che non è stata modificata, ovvero il

pag. 34
labeling su di essa è stato effettuato in maniera corretta dal sistema); nella
quinta colonna abbiamo invece il numero effettivo di stroke modificate;
Fig. 15: tabella contenente i dati statistici ottenuti parte 2
Continuando, cosi’ come illustrato in fig. 13, nella sesta colonna abbiamo
l’elenco del criterio di modifica delle stroke per ogni parola, mentre nella
settimana colonna (fig. 14) abbiamo i commenti ad ogni parola modificata.
Come detto in precedenza questa risulterà molto utile per la valutazione
finale delle prestazioni del sistema.

pag. 35
Fig. 16: tabella contenente i dati statistici ottenuti parte 3
Le informazioni raccolte sono utilizzate come illustrato nel prossimo
capitolo per valutare statisticamente le prestazioni dell’algoritmo di labeling
e capire, li dove ce ne fosse la possibilità, come migliorarlo.

pag. 36
Valutazione delle prestazioni
In questo capitolo verranno esposti i risultati dell’esperimento effettuato
sulle 1600 parole del reference set in modo che si possa pervenire ad una
valutazione prestazionale del labeling e all’individuazione di classi
ricorrenti di errore e li dove sia possibile proporre delle nuove soluzione per
poter migliorare l’algoritmo di labeling e quindi il sistema.
3.1 Calcolo degli indici prestazionali
Nella prima fase di valutazione delle prestazione dell’algoritmo di labeling
ci si appresta a presentare i risultati dell’esperimento effettuato. Innanzitutto
identifichiamo quelli che sono i parametri di maggiore importanza dai quali
poi dipenderanno tutte le considerazioni.
Come primo parametro individuiamo il valore di riferimento dal quale
effettuare la nostra analisi. In prima battuta andiamo a considerare tutte le
1600 parole del reference set. La fig. 1 riporta dati globali sull’intero
reference set:

pag. 37
Fig. 1: tabella contenente gli indici riferita al totale delle parole
Del totale delle parole del referene set abbiamo che 568 risultano quelle
sbrogliate male e quindi scartate mentre le parole effettivamente considerate
risultano essere 1032. Se limitiamo a queste ultime la valutazione del
labelling, i dati diventano quelli di fig. 2, dai quali si evidenzia che tra le
parole ben sbrogliate, 493 (47,77%) risultano essere quelle labellate in
modo corretto mentre 539 (52,23%) sono quelle che hanno riportato un
errore di assegnazione delle stroke. Tra queste ultime, pero’, in 266 casi
(25,77%) l’algoritmo ha erroneamente attribuito una sola stroke, in 124
(12,02%) due stroke. Errori derivanti dal’assegnazione errata di tre o piu’
strokes sono riscontrati nelle rimanenti 149 parole.

pag. 38
Fig. 2: tabella contenente gli indici riferita alle parole ben sbrogliate
Notiamo da subito che le percentuali così ottenute sono molto incoraggianti
in quanto quasi la metà delle parole considerate non sono state modificate
in quante sono state labellate bene dal sistema. Notiamo poi che al crescere
delle stroke modificate abbiamo che l’errore diminuisce in maniera
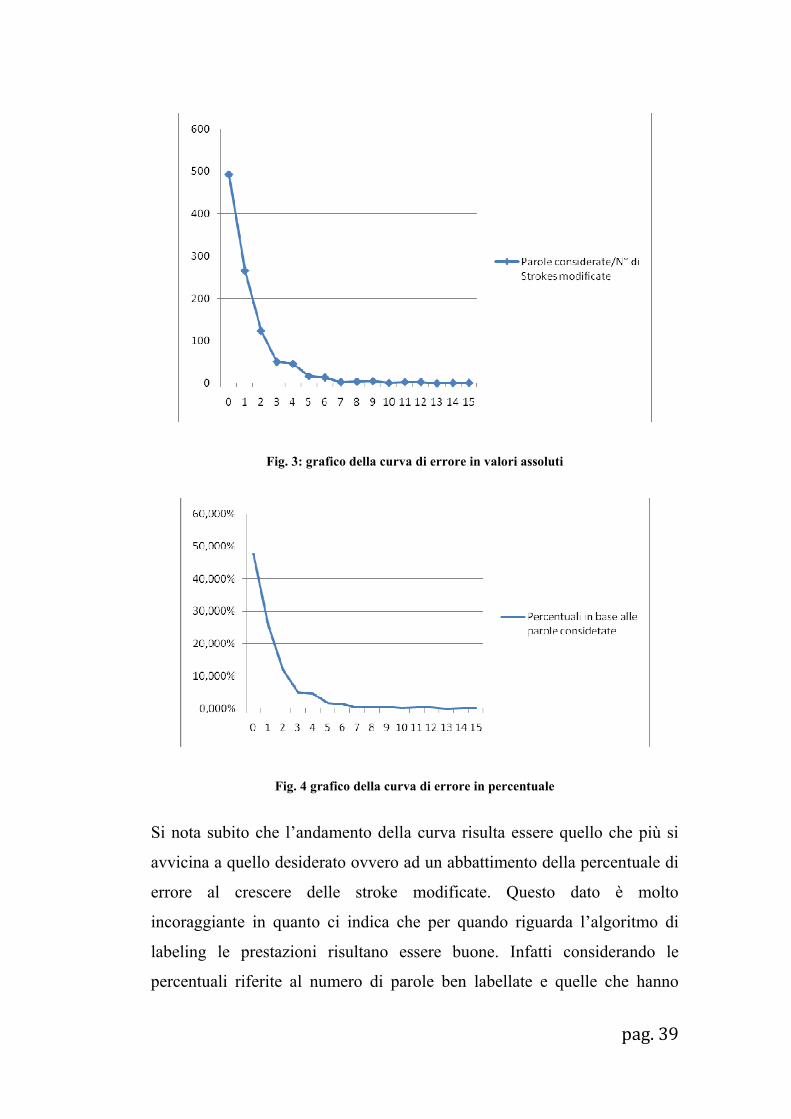
considerevole fino ad annullarsi del tutto per grosse modifiche. I grafici qui
sotto riportano questi stessi valori in termini assoluti (fig. 3) e percentuali
(fig. 4).
pag. 39
Fig. 3: grafico della curva di errore in valori assoluti
Fig. 4 grafico della curva di errore in percentuale
Si nota subito che l’andamento della curva risulta essere quello che più si
avvicina a quello desiderato ovvero ad un abbattimento della percentuale di
errore al crescere delle stroke modificate. Questo dato è molto
incoraggiante in quanto ci indica che per quando riguarda l’algoritmo di
labeling le prestazioni risultano essere buone. Infatti considerando le
percentuali riferite al numero di parole ben labellate e quelle che hanno
pag. 40
subito un errore di assegnazione di solo una stroke si raggiunge un livello di
circa il 74% delle parole considerate.
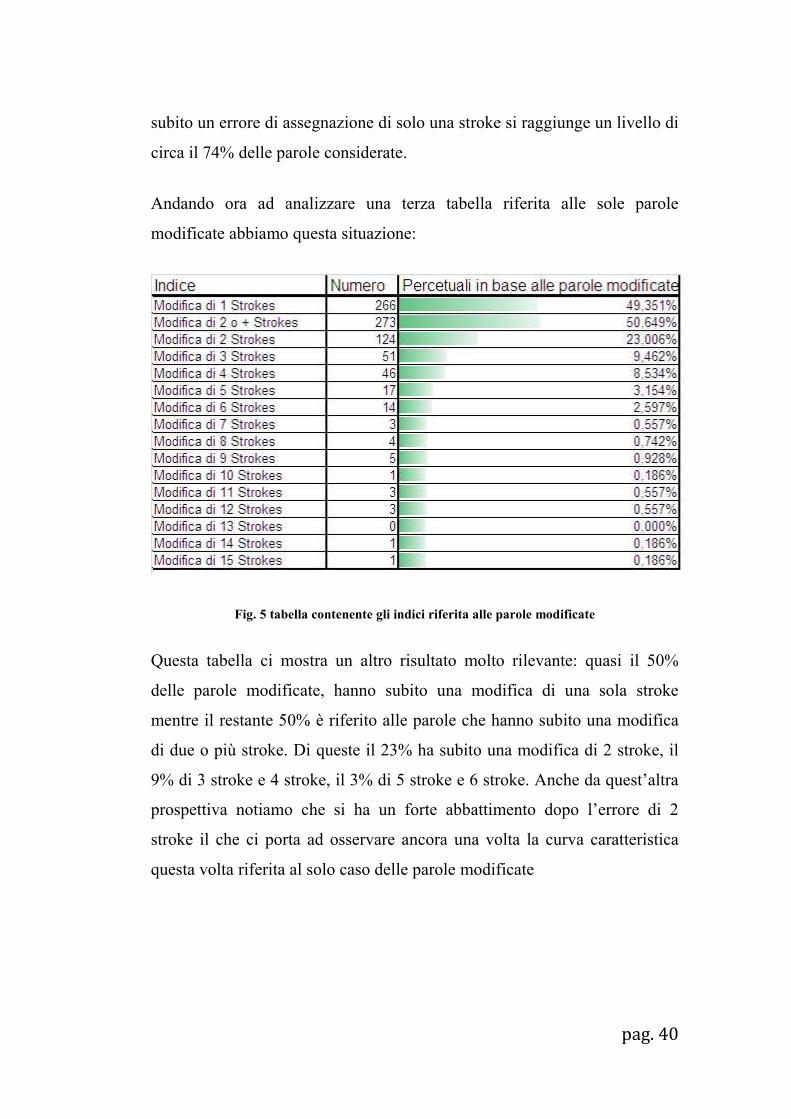
Andando ora ad analizzare una terza tabella riferita alle sole parole
modificate abbiamo questa situazione:
Fig. 5 tabella contenente gli indici riferita alle parole modificate
Questa tabella ci mostra un altro risultato molto rilevante: quasi il 50%
delle parole modificate, hanno subito una modifica di una sola stroke
mentre il restante 50% è riferito alle parole che hanno subito una modifica
di due o più stroke. Di queste il 23% ha subito una modifica di 2 stroke, il
9% di 3 stroke e 4 stroke, il 3% di 5 stroke e 6 stroke. Anche da quest’altra
prospettiva notiamo che si ha un forte abbattimento dopo l’errore di 2
stroke il che ci porta ad osservare ancora una volta la curva caratteristica
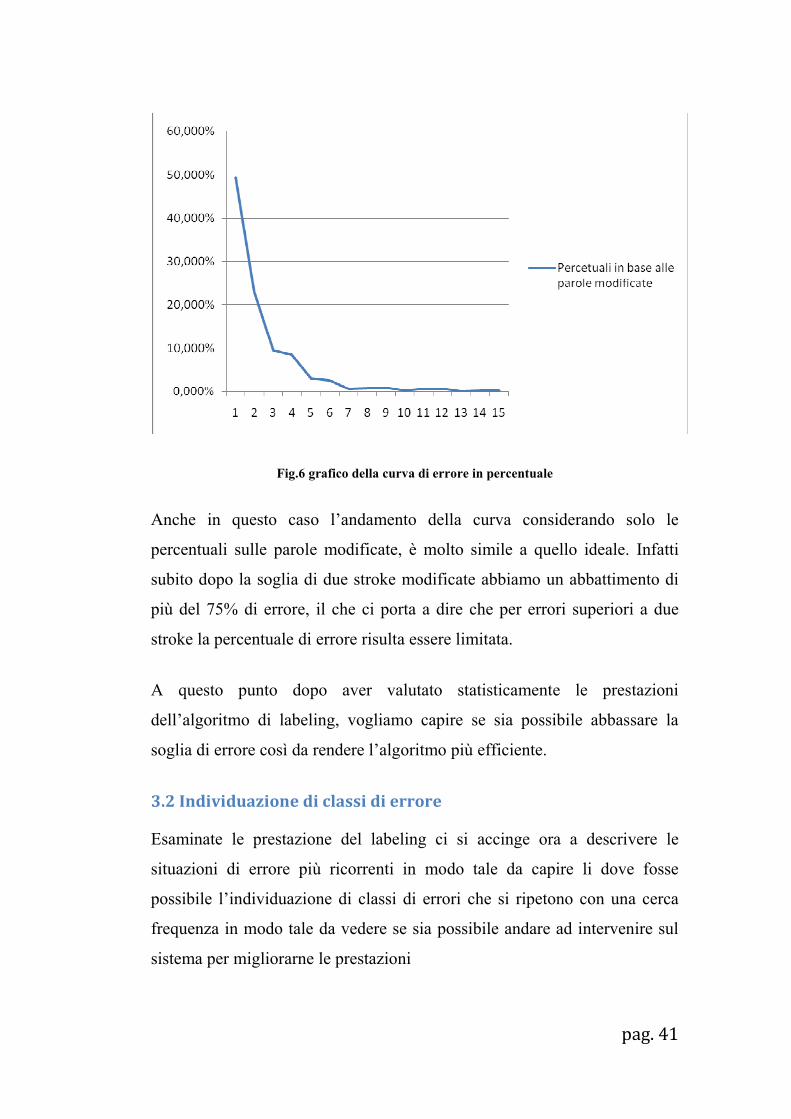
questa volta riferita al solo caso delle parole modificate
pag. 41
Fig.6 grafico della curva di errore in percentuale
Anche in questo caso l’andamento della curva considerando solo le
percentuali sulle parole modificate, è molto simile a quello ideale. Infatti
subito dopo la soglia di due stroke modificate abbiamo un abbattimento di
più del 75% di errore, il che ci porta a dire che per errori superiori a due
stroke la percentuale di errore risulta essere limitata.
A questo punto dopo aver valutato statisticamente le prestazioni
dell’algoritmo di labeling, vogliamo capire se sia possibile abbassare la
soglia di errore così da rendere l’algoritmo più efficiente.
3.2 Individuazione di classi di errore
Esaminate le prestazione del labeling ci si accinge ora a descrivere le
situazioni di errore più ricorrenti in modo tale da capire li dove fosse
possibile l’individuazione di classi di errori che si ripetono con una cerca
frequenza in modo tale da vedere se sia possibile andare ad intervenire sul
sistema per migliorarne le prestazioni

pag. 42
Partiamo con una prima considerazione. Abbiamo nel precedente capitolo
parlato di errori di sbrogliatura. In effetti pur non essendo questo un errore
della fase di labeling della traccia è comunque, per come è progettato il
sistema, un errore che, riperquotendosi a valle, produce un output errato.
Infatti come visto prima le parole sbrogliate male costituiscono circa il 36%
del totale del reference set. Essendo comunque una parte considerevole del
totale sono errori che devono per forza di cose essere tenuti in
considerazione.
Altri due tipi di errori che non appartengono alla fase di labeling ma che
costituiscono un’altra parte molto rilevante sono quelli dovuti ad una
sbagliata segmentazione della parola. Infatti la parola generalmente viene
divisa in segmenti a seconda del movimento dello scrivente. Quindi
successivamente trattata dalla fase di labeling per effettuare l’assegnazione
delle stroke ad ogni carattere. Ora questi errori di segmentazione della
parola (la parola viene o sovra segmentata oppure sotto segmentata) portano
ad un errata assegnazione delle stroke per carattere e quindi ad un errato
riconoscimento della parola. Questo purtroppo dipende molto dalla grafia
dello scrivente e diventa quindi più una cosa soggettiva che oggettiva.
Un esempio di sovra segmentazione e quindi di errore di assegnazione
delle stroke per carattere è il seguente

pag. 43
Fig. 7: errore di labeling dovuto ad errore di segmentazione
Si nota subito che a causa della presenza eccessiva di segmenti
l’assegnazione delle stroke nel tratto considerato è risultata sbagliata. Infatti
le prime tre strokes assegnate al carattere “e” dovevano essere attribuite alla
lettera “l” per avere una corretta interpretazione.
Concentrandoci ora su quelli che invece sono i gli errori riscontrati nella
fase di labeling. Si sono individuate 5 classi di errori che sono ricorrenti:
• Errata assegnazione delle stroke alle tracce che iniziano con lettere maiuscole
• Shift di assegnazione verso destra nel caso di parole con più di 3 caratteri causato dall’errata assegnazione delle stroke ad inizio parola
• Assegnazione di una sola stroke per un dato carattere • Assegnazione di più stroke di quante ne servirebbero in presenza
delle vocali “a” ed “o” • Problema di assegnazione delle stroke in presenza dei caratteri “r”
“n” “m” “s” “t” “z”

pag. 44
Per quanto riguarda gli errori della prima classe si è notato che in presenza
di parole che iniziano con lettera maiuscola l’algoritmo tende quasi sempre
a sbagliare l’assegnazione dando troppo peso alla maiuscola rispetto al resto
dei caratteri caratterizzanti la parola.
In questo esempio abbiamo la parola “Gar” labellata dal sistema:
Fig. 8: errori di labeling dovuti alla presenza di maiuscole
Notiamo subito che l’assegnazione delle stroke risulta essere errata, infatti il
grosso “peso” attribuito alla lettera “G” ha portato ad un errata
interpretazione sia della lettera “a” che della lettera “r”. In questo caso
l’assegnazione automatica delle stroke per carattere è:
G è 13 stroke A è 7 stroke R è 3 stroke
Riordinando le stroke in maniera adeguata otteniamo in seguente risultato

pag. 45
Fig. 9: labeling manuale della parola “Gar”
L’assegnazione delle stroke in maniera manuale risulta quindi essere:
G è 7 stroke A è 7 stroke Rè 9 stroke
Tale problema e’ essenzialmente dovuto alla piccola quantita’ di caratteri
maiuscoli presenti nel reference set e si può pensare di superarlo
aumentando la dimensione del reference set in modo da includere piu’
esempi di lettera maiuscole e ricalcolare le distribuzioni. L’esempio di fig. 8
ci consente anche di affrontare gli eroori della seconda classe. E’ ovvio che,
per effetto della errata attribuzione delle stroke al carattere “G” risultano
errate anche quelle successive per trascinamento dell’errore da sinistra a
destra. Infatti nel caso in cui siano presenti (questo effetto è maggiormente
presente con le parole che iniziano con lettere maiuscole) errori dei
assegnazione delle stroke al primo bigramma, questo errore di assegnazione
si ripercuote a tutte le lettere a valle della parola.
Analizziamo ora la parola “Bari” di fig. 9:

pag. 46
Fig. 10: trascinamento verso destra di errori di labeling
Siamo in presenza di un’evidente errore di assegnazione causato da
un’errata labellazione dei primi due caratteri che sembra coinvolgere anche
le lettere successive.
Le stroke assegnate dal sistema risultano essere:
B è 9 stroke Aè 6 stroke Rè 3 stroke Iè 2 stroke
Andando ad operare la riassegnazione manuale otteniamo
Fig. 11: labeling manuale della parola “Bari”

pag. 47
le stroke a questo punto risultano essere:
B è 7 stroke Aè 6 stroke Rè 4 stroke Iè 3 stroke
Questo problema si verifica quindi in presenza di parole che sono composte
da tre o più caratteri e soprattutto quando queste iniziano con una lettera
maiuscola. Si nota che, come nel caso precedentemente analizzato, se si
ricalcolassero le distribuzioni, così da evitare un numero elevato di stroke
attribuite ai caratteri maiuscoli, si potrebbero migliorare le prestazioni
dell’algoritmo.
La terza classe, che sembra essere quella più banale e scontata ma che
purtroppo in alcuni casi è stata riscontrata, è quella di attribuzione di una
sola stroke per un carattere. Di fatti pensare di attribuire una sola stroke ad
una carattere, sia anche una “i”, è evidentemente sbagliato in quanto sempre
considerando il criterio di verosimiglianza dei caratteri e considerando le
modalità di scrittura, nessuna lettera dell’alfabeto latino può essere
composta da una sola stroke.
In fig. 12 è riportata il risultato del labeling sulla la parola “ecc”.
Fig. 12 errori di labeling che comportano l’assegnazione di una sola label ad un carattere.

pag. 48
L’assegnazione delle stroke risulta essere:
E è 1 stroke Cè 4 stroke Cè 4 stroke
Andando a riassegnare le stroke in maniera manuale otteniamo:
Fig. 13: labeling manuale della parola “ecc”
Quindi l’assegnazione delle stroke in maniera manuale risulta essere
E è 3 stroke Cè 3 stroke Cè 3 stroke
Si nota subito che la configurazione ottenuta manualmente è sicuramente
migliore di quella automatica. Si può pensare quindi di imporre un vincolo
al sistema il quale non può assegnare una sola stroke ad un carattere.
La quarta classe di errore risulta essere quella riferita alle vocali “a” ed “o”.
In molte occorrenze si è visto che il forte peso, a livello di assegnazione,
che la lettera “a” e la lettera “o” hanno ha portato a errori di assegnazione
delle stroke in quanto a questi caratteri vengono assegnate più stroke di
quante ne servirebbero.
In fig. 14 si è riportata la parola “anara” labellata automaticamente:

pag. 49
Fig. 14: errori di labeling dovuta d una sovrastima delle stroke appartenenti al carattere “a”
L’assegnazione automatica delle stroke risulta essere
A è 5 stroke N è 4 stroke A è 5 stroke
R è 2 stroke A è 6 stroke
Andando ora a riassegnare le stroke in maniera manuale otteniamo:
Fig. 15: labeling manuale della parola “anara”
L’assegnazione manuale delle stroke risulta quindi essere:
A è 4 stroke N è 5 stroke A è 4 stroke
R è 4 stroke A è 5 stroke
Una considerazione che a questo punto si deve fare è quella di andare ad
analizzare il numero di occorrenze dei caratteri “a” ed “o” all’interno del
reference set. Di fatto il carattere “a” è presente circa 850 volte mentre
quello della “o” è presente circa 500 volte mentre tutti gli altri caratteri

pag. 50
hanno un’occorrenza minore. A questo punto viene logico pensare che se
comunque le distribuzioni, le quali si basano sul criterio a minima distanza,
sono frutto di un calcolo iterato basato anche sul numero di occorrenze di
un carattere, l’aver una presenza forte di questi due caratteri rispetto agli
altri ha potuto portare ad avere dei valori di assegnazione delle stroke più
alti di quanto previsto. Bilanciare quindi le occorrenze dei caratteri in
maniera adeguata potrebbe portare ad avere delle distribuzioni migliori in
termini di assegnazione delle stroke, e evitare casi come quello mostrato in
precedenza.
La quinta ed ultima classe di errore risulta essere quella relativa ai caratteri
“r” “n” “m” “s” “t” “z”. Infatti per questi particolari tipi di caratteri il modo
in cui lo scrivente traccia il carattere diventa fondamentale al fine
dell’individuazione delle stroke da assegnare. Gli esempi di figg. 16 e 17
mostrano nel primo caso una lettera “r” tracciata bene e nel secondo caso
una lettera “r” troncata e quindi tracciata non in maniera ottimale.
Notiamo che l’assegnazione nel primo caso risulta essere errata mentre nel
secondo caso risulta essere buona:
Fig. 16: labeling automatico della parola “ro” con il carattere “r” scritto in maniera corretta

pag. 51
Fig. 17: labeling automatico della parola “ro” con il carattere “r” scritto in maniera troncata
In quest’altro esempio invece abbiamo riporta il caso del carattere “m”:
Fig. 18: labeling automatico della parola “ma” con il carattere “m” scritto in maniera corretta
Fig. 19: labeling automatico della parola “ma” con il carattere “m” scritto al “contrario”

pag. 52
A valle di queste considerazione si può pensare di andare a rielaborare le
occorrenze dei caratteri in questione così da avere un numero pari di
caratteri scritti in modo diverso. In questo modo avendo ad esempio 10 “r”
scritte bene e 10 “r” scritte troncate si potrebbe ottenere una distribuzione
sulla r più verosimile a quella ideale.
Un ultimo caso esaminato, ma che non costituisce una classe di errore per
l’algoritmo di labeling è quello della successone della doppia “ll”. infatti si
nota che spesso vi è un problema di segmentazione tra le due “l” e il
sistema tende a non individuare il punto di segmentazione tra di essere
portando ad un problema di riconoscimento. Nell’esempio riportato qui
sotto abbiamo la parola “ellu” nella quale è presente questo tipo di errore.
Fig. 20: labeling automatico della parola “ellu”
Nonostante questo errore non faccia parte degli errori in fase di labeling è
comunque da tener presente in quanto comporta in questa fase degli errori a
valle e quindi delle errate assegnazioni dei caratteri successivi alla doppia
“l”.

pag. 53
3.3 Errori ricorrenti
A questo punto ci poniamo come obiettivo quello di individuare, se
esistono, delle particolari successioni che riportano degli errori ricorrenti e
di capire come sia possibile correggere tali errori. Nel corso degli
esperimenti su reference set si sono riscontrate molte situazioni anomale
molte delle quali sono state ricondotte al caso di successioni notevoli di
errori ripetitivi. All’interno di queste poi si sono individuate tre classi di
errori:
• Errori ripetitivi costanti • Errori ripetitivi non costanti • Errori ripetitivi variabili
Questi errori vengono definiti ripetitivi in quanto sono stati riscontrati
sempre nella stessa successione. Ovviamente per essere considerati tali
devono avere un occorrenza che superi almeno il 50% del totale delle
parole considerate.
Andando ora ad esaminare la prima classe, gli errori ripetitivi costanti,
appartengono a questa classe gli n-grammi “Be” “Mi” “ani” “ro” “to”.
Questi vengono definiti costanti in quanto l’errore di assegnazione del
numero di stroke riscontrato all’interno delle successioni rimane invariato.
Prendendo ad esempio il bigramma “ro” si è riscontrato che su 17 parole
totali contenute nel reference set 3 sono risultate quelle labellate bene e 14
sono risultate quelle labellate male. Nelle 14 parole poi è stato riscontrato
sempre lo stesso errore di assegnazione di una stroke. Nella figura è
mostrato un esempio dell’errore nella successione “ro”.

pag. 54
Fig. 21: labeling automatico della parola “ro”
Notiamo che l’assegnazione delle stroke in maniera automatica è
R è 3 stroke O è 6 stroke
Mentre quella manuale risulta essere
R è 4 stroke O è 5 stroke
In figura vi è riportato l’assegnazione delle stroke in maniera manuale:
Fig. 22: labeling manuale della parola “ro”
Quindi vi è sempre, nei 14 casi considerati, un errore di assegnazione il
quale assegna una stroke in più alla lettera “o”. In questa particolare classe

pag. 55
di errore si può pensare di andare ad intervenire in questo modo:
Considerando il fatto che su 17 parole considerate 3 solo labellate bene e 14
sono labellate male e presentano tutte un errore della stesso tipo, andando
ad operare sul sistema imponendo una riassegnazione automatica delle
stroke in presenza di questo bigramma si può pensare che le prestazioni
migliorino e come in questo caso che la situazione si possa ribaltare ovvero
passare dall’avere 3 parole labellate bene e 14 labellate male alla situazione
di 14 parole labellate bene e 3 parole labellate male. In questo modo, non si
sarà risolto sicuramente il problema, però l’efficienza del labeling sarà
sicuramente maggiore rispetto al caso precedente.
Alla seconda classe invece appartengono quegli n-grammi nelle quali
l’errore di assegnazione del numero di stroke non è costante ovvero cambia
a seconda della particolare traccia considerata. Fanno parte di questa classe
gli n-grammi “ar” “ari” “ce” “er” “mo” “om”.
Prendiamo ad esempio il bigramma “ar”. Su 15 parole considerate, 2 sono
risultate ben labellate mentre 13 sono risultate labellate male. Andando poi
ad analizzare le 13 parole labellate male si è riscontrato che l’errore di
labellazione avveniva sempre sistematicamente dal carattere “r” al carattere
“a” (ovvero vengono sempre assegnate più stroke alla lettera “a” di quante
ne servirebbero). La particolarità rispetto al caso precedente è che il numero
effettivo di stroke assegnate male purtroppo è variabile e cambia molto a
seconda della traccia.
Nell’esempio sotto sono riportate due tracce con numero diverso di stroke
assegnate male:

pag. 56
Fig. 23: errore di labeling su due strokes
Fig. 24: errore di labeling su una stroke
Si nota subito che la prima successione è composta da 8 stroke mentre la
seconda da 7 stroke. Nel primo caso abbiamo l’assegnazione di 6 stroke alla
lettera “a” e 2 stroke alla lettera “r” mentre nel secondo caso abbiamo
l’assegnazione di 5 stroke alla lettera “a” e 3 stroke alla lettera “r”. Se nel
primo caso l’errore di assegnazione risulta essere di 2 stroke, nel secondo
caso risulta essere di 1 stroke.

pag. 57
In questa particolare classe una possibile soluzione al problema potrebbe
essere quella di fare una stima sulla media delle stroke assegnate male così
da poter andare ad intervenire sul labeling in modo da modificarne
l’assegnazione in presenza di queste particolari n-grammi sulla base di una
media statistica dei casi. Per fare ciò occorrerebbe sicuramente andare a
fare il test su molte più parole così da avere un stima molto più precisa.
Terza ed ultima classe è quella a cui appartengono gli n-grammi con errori
di tipo variabile. A questa classe di solito appartengono le parole composte
da più di due caratteri. La caratteristica principale è che gli errori di
attribuzione delle stroke alle successioni considerate non avvengono sempre
allo stesso modo (ovvero l’errore di assegnazione non avviene sempre in
una direzione come nel caso precedente), ma dipendono dalla traccia
considerata. Appartengono a questa classe gli n-grammi “ano” “lano” “za”
“se”.
Consideriamo ad esempio il trigramma “ano”. Su 12 occorrenze, 4 risultano
essere ben labellate mentre 8 risultano essere labellate male. Delle 8
occorrenze labellate male si sono riscontrati degli errori di assegnazione
delle stroke per carattere che sono risultati essere differenti sia per il
numero sia per il carattere. Osserviamo questi due esempi:
Fig. 25 errore di labeling con sovrastima delle stroke da assegnare al carattere “o”

pag. 58
Fig.26 errore di labeling con sovrastima delle stroke da assegnare ai caratteri “a” e “o”
Nel primo abbiamo un errore di assegnazione di una stroke tra il carattere
“o” e il carattere “n”, nel secondo esempio invece abbiamo anche un errore
di assegnazione di una stroke tra il carattere “a” e il carattere “n”. In questa
particolare classe di errore purtroppo non è possibile fare delle
considerazioni ragionevoli che possano portare a degli spunti per il
miglioramento del labeling.

pag. 59
Conclusioni
In questa tesi si sono esaminate le prestazioni dell’algoritmo di
labeling utilizzato per l’assegnazione delle strokes costituenti la traccia di
una parola manoscritta. Il lavoro svolto si è quindi concentrato sulla
valutazione dei risultati del labeling automatico effettuato sulle 1600 parole
presenti nel reference set.
I risultati sperimentali hanno mostrato che nel 30% dei casi, le stroke delle
parole costituenti il reference set è stato etichettato correttamente, mentre
nel 34% dei casi le label assegnate alle stroke differiscono da quelle
desiderate. Nel rimanente 36% dei casi la sequenza delle stroke prodotta
dall’algoritmo di sbrogliatura non corrispondeva alla sequenza effettiva.
Quindi considerando le sole parole con un livello di sbrogliatura accettabile,
si è ottenuto che il 48% delle parole considerate sono state labellate in
maniera corretta. mentre nel rimanente 52% delle parole sono stati
riscontrati degli errori. L’analisi di questi errori ha mostrato che nel 50% di
essi e’ stata etichettata in maniera errata 1 stroke, nel 25% sono state
etichettate in maniera errata 2 stroke, nel 9% sono state etichettate in
maniera errata 3 stroke e nell’8% sono state etichettate in maniera errata 4
stroke. Il restante 8% ha riportato un errore di etichettatura superiore.
Considerate quindi le percentuali di errore rispetto al numero di stroke
assegnate male, si nota che si ha un abbattimento degli errori al crescere del
numero di stroke. Questo risulta molto rimarcato per errori di stroke

pag. 60
superiori a tre. Per quanto riguarda invece errori di poche stroke osserviamo
che sommando le percentuali degli errori per una stroke e per due stroke
otteniamo il 75% del totale degli errori.
A questo punto, al fine di ottimizzare il labeling e ottenere un abbattimento
della soglia di errore ci si è andati a concentrare sulle possibili cause di
errore.
A tal proposito si sono individuate cinque classi di errore più o meno
ricorrenti, citate nel capitolo III, le quali hanno facilitato tale ricerca.
Gli errori piu’ frequenti sono quelli dovuti all’attribuzione del numero di
stroke per un dato carattere. Il criterio di assegnazione delle stroke, a causa
delle molti sorgenti di variabilita’ che abbiamo piu’ volte menzionato, ha
prestazioni non adeguate per specifiche classi di carattere e dunque e’
necessaria una rivisitazione.
Un’ulteriore indagine sui risultati sperimentali ha evidenziato che esistono
particolari successioni che presentano errori sistematici di assegnazione. Si
è quindi arrivati a distinguere altre tre classi di errori sistematici, descritte
nel capitolo III.
A valle di questa fase ci si presta ad elencare tutta una serie di spunti per
possibili miglioramenti futuri al sistema. Il criterio di correzione
dell’assegnazione delle stroke per carattere del tool automatico è stato
implementato utilizzando un criterio di verosimiglianza con i caratteri. In
generale questa correzione dovrebbe essere fatta sulla base di esperimenti
condotti da un gruppo composto di tre esperti. In questo caso ci si è affidati
alla sperimentazione condotta da un singolo elemento e quindi converrebbe
in futuro, al fine di evitare “bias” dovuti all’esperto, ricorrere a di più di un
esperto nella fase di verifica.

pag. 61
Prendendo in esame i dati statistici a nostra disposizione si è arrivati alla
conclusione che sicuramente le distribuzioni calcolate sulle lettere
maiuscole necessitano di una rivisitazione in quanto risultano essere nella
maggior parte dei casi errate, e di fatto portano anche ad avere altri
problemi quali quello dello shift verso destra di assegnazione delle stroke
per carattere .
Un’altra considerazione che bisogna fare è sicuramente quella sulle
occorrenze dei caratteri all’interno del reference set. Si è notato che avere
una grossa discrepanza di occorrenze tra i caratteri porta ad avere delle
distribuzioni che tendono a dare più importanza a lettere più occorrenti e
meno importanza a lettere che occorrono di meno. Una possibile soluzione
a tale problema potrebbe essere quella di bilanciare in modo adeguato tutte
le occorrenze così da avere delle distribuzioni migliori.
Ultima considerazione da fare è quella relativa alle varie grafie presenti
all’interno del reference set. Siccome molti scriventi tendono a fare i
caratteri in maniera del tutto diversa si potrebbe pensare, sempre al fine di
migliorare le distribuzioni per ogni carattere, di analizzare le tracce più
ricorrenti di ogni carattere e cercare di uguagliare le ricorrenze di ognuno di
essi così da avere un numero uguale di varie tracce di ogni carattere.
A questo punto si richiederebbe una nuova valutazione statistica delle
prestazioni dell’algoritmo di labeling a valle di queste migliorie proposte
così da misurare gli eventuali miglioramenti.

pag. 62
Bibliografia
[1] R. Senatore, “Dove sono i caratteri? Un approccio bayesiano al labeling
di parole manoscritte”, Tesi di laurea specialistica, Università di
Salerno, Ottobre 2007
[2] Y.Xu and G.Nagy, “Prototype Extraction and Adaptative OCR”, IEEE
Transaction on Pattern Analysis and Machine Intelligence, vol. 21, n.
12, pages 1282-1284,Dec.99.
[3] C.L. Lawson and R.J.Hanson, Solving Least Square Problems, Prentice
Hall,1974.
[4] A. Marcelli, “Stato dell’arte nell’ambito dei sistemi di riconoscimento
automatico off-line della scrittura corsiva”, Technical Report NCLab,
Aprile 2005.
[5] A.Marcelli, “Reverse handwriting: from ink to word”, Invited Paper,
Proc. PRIP ’09, Minsk, BIELORUSSIA, May 16-21, 2009.

pag. 63
Ringraziamenti
I miei più vivi ringraziamenti vanno al Chiarissimo professore Angelo
Marcelli il quale si è dimostrato sempre molto disponibile e professionale
durante tutto il periodo della tesi.
Ringrazio tutto lo staff del Laboratorio di Computazione Naturale del
Dipartimento di Ingegneria dell’Informazione ed Ingegneria Elettrica
dell’Università degli studi di Salerno che mi ha ospitato durante il periodo
del mio lavoro. In particolare mi sento in dovere di ringraziare due presone:
Rosa Senatore e Adolfo Santoro i quali mi hanno sempre aiutato tantissimo
e senza di loro sicuramente non avrei potuto rispettare le scadenze
burocratiche di consegna.
Ringrazio poi la mia famiglia che mi è sempre stata vicina nelle gioie e nei
dolori che questi anni trascorsi all’università mi hanno dato. A mia madre
che mi ha sempre spinto a dare il meglio di me. A mio padre che mi ha dato
la possibilità di continuare gli studi. Alle mie due sorelle che mi hanno
sempre dato i consigli giusti in ogni occasione. A mia Nonna la quale ha
avuto sempre una parola di conforto quando le situazioni sembravano
essere insostenibili. A mia Zia Pia e a mio Zio Cosimo che sono stati
sempre pronti a darmi una mano.
Venendo a noi, Ringrazio tutti gli amici che mi sono stati vicino in questi
anni di università ed in particolare ringrazio Luigi, Gennaro, Marco
Antonio, Vincenzo, Cosimo, Emanuele e tutti gli amici della 5D. Ringrazio
tutti i ragazzi di UNISA e dell’A.G.A. in modo speciale Luca con il quale
posso realmente dire di averci condiviso tutto in questi 4 anni. Ringrazio
tutti i ragazzi di R0X e L’associazione Prima…Vera A.S.I. per gli splendidi

pag. 64
anni passati insieme. Ringrazio tutti gli amici di Eboli e tutti quelli del resto
d’Italia.
Un ultimo ringraziamento, se me lo concedete, va a me. Si perché
nonostante i miei numerosissimi tentativi di mandare all’aria tutto, in più di
un occasione, sono riuscito a conseguire questo mio primo risultato. Non
avrei mai sperato di arrivare qui il giorno in cui mi diplomai, però, come
nella più banale delle eccezioni che confermano la regola, ce l’ho fatta.
A tutte le persone che mi vogliono bene e anche a tutti quelli che oggi non
sono potuti essere qui. Grazie di cuore.