técnicas de aprendizaje automático en el análisis de...
TRANSCRIPT

Técnicas de aprendizaje automático en el análisis
de datos de DP Dr. Carlos Fernández Lozano
Juan de la Cierva-Formación

Índice
u Acerca de mí
u Big data?
u Medicina de precisión?
u Integración de datos?
u Aprendizaje automático?
u Todo eso con datos de DP?

Índice
u Acerca de mí
u Big data?
u Medicina de precisión?
u Integración de datos?
u Aprendizaje automático?
u Todo eso con datos de DP?

Acerca de mí
u Doctor en informática. Ciencias de la computación e inteligencia artificial
u Contrato Juan de la Cierva – Formación (FJCI-2015-26071). Ministerio de Economía, Industria y Competitividad
u Especialista en integración de datos, aprendizaje automático, selección de características, imagen médica
u Estancias de investigación:
Stefano Cagnoni, PhD Colin Campbell, PhD Christina Curtis, PhD

Big data

Big data
Enormes cantidades de datos Estructurados, semi y no estructurados

Big data
Enormes cantidades de datos Estructurados, semi y no estructurados
Datos heterogéneos Imágenes, coordenadas GPS, pasos,
genes…

Big data
Enormes cantidades de datos Estructurados, semi y no estructurados
Datos heterogéneos Imágenes, coordenadas GPS, pasos,
genes…
Imagen: Wisconsin Department of Natural Resources/Flickr

Big data
Enormes cantidades de datos Estructurados, semi y no estructurados
Datos heterogéneos Imágenes, coordenadas GPS, pasos,
genes…
Análisis de datos Velocidad de respuesta

Big data

Big data
u La ciencia cada vez genera más datos pero, tenemos un problema
u Si no son de calidad
u Si no se pueden utilizar todos
u Si no se pueden “juntar” datos de distintas fuentes
u Si para “juntarlos” necesitamos un grupo de 5 personas
u Si no tenemos modelos que extraigan conocimiento en tiempo asumible
u ….

Medicina de precisión
Historia familiar
Entorno
Estilo de vida Genética
Historia clínica

Medicina de precisión
Medicina para todos
Medicina estratificada
Medicina de precisión
Agrupados por: subtipo de enfermedad, demografía,
variables clínicas, biomarcadores
Prevención y tratamiento teniendo en cuenta:
variabilidad genética individual, entorno y estilo vida

Integración de datos
u En la prestación asistencial diaria, en general, se dispone de muchos datos:
u Historia clínica
u Antecedentes familiares
u Pruebas de imagen
u Pruebas complementarias
u …..

Integración de datos
u Estos datos son heterogéneos y en algunos casos, de gran volumen
u Desde el punto de vista informático, se hace esencial el desarrollo de técnicas de integración de datos para capturar la complejidad y heterogeneidad de los procesos biológicos y fenotipos implicados en el desarrollo de la enfermedad

Integración de datos
u Vale sí, integramos la información pero para qué? En general…
u disponemos de un número reducido de pacientes en relación al número de medidas que obtenemos de cada uno de ellos (pocos pacientes – muchos datos)
u los datos están en diferentes escalas, la recolección de datos puede estar sesgada y tantas variables pueden incluir mucho ruido
u la naturaleza de la información es complementaria
u se puede dar sentido a información no directamente extraída de las muestras

Integración de datos
u Un ejemplo con integración de datos ómicos
Juan R. González. BRGE. Bioinformatics Research Group in Epidemilogy (CREAL)
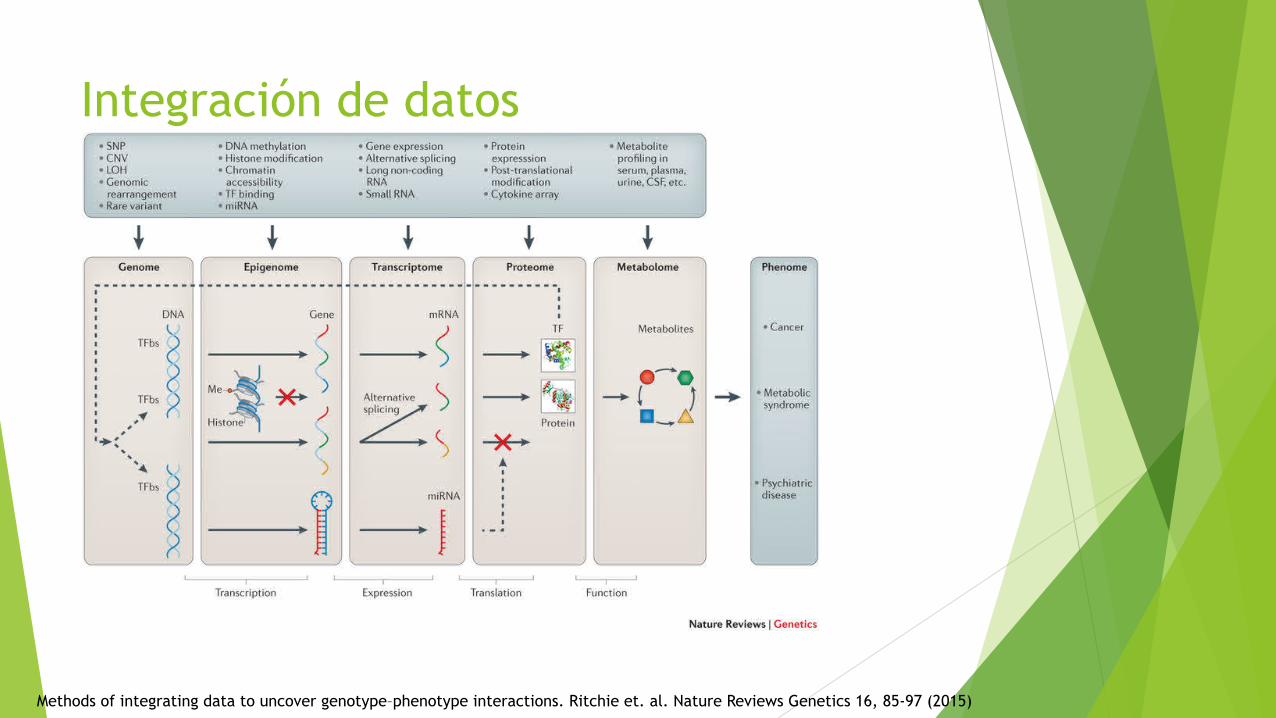
Integración de datos
Methods of integrating data to uncover genotype–phenotype interactions. Ritchie et. al. Nature Reviews Genetics 16, 85-97 (2015)
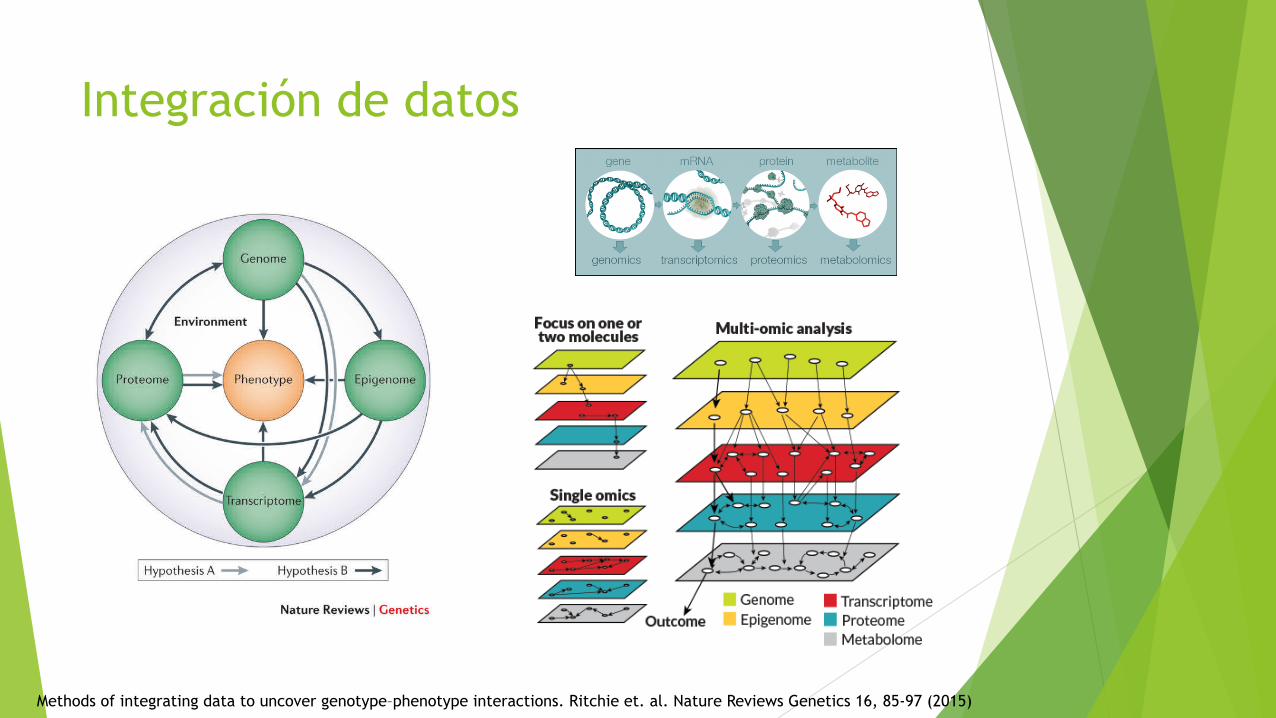
Integración de datos
Methods of integrating data to uncover genotype–phenotype interactions. Ritchie et. al. Nature Reviews Genetics 16, 85-97 (2015)
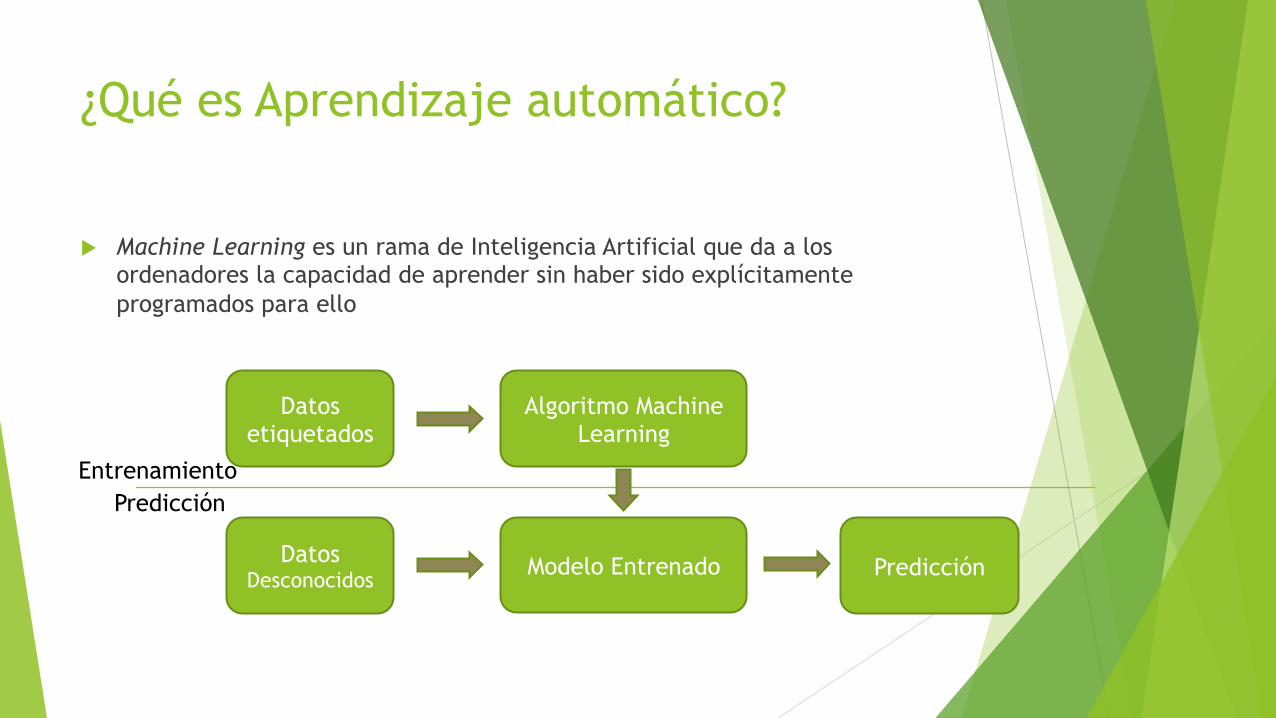
¿Qué es Aprendizaje automático?
u Machine Learning es un rama de Inteligencia Artificial que da a los ordenadores la capacidad de aprender sin haber sido explícitamente programados para ello
Datos etiquetados
Algoritmo Machine Learning
Datos Desconocidos
Modelo Entrenado Predicción
Entrenamiento Predicción

¿Qué es Aprendizaje automático?
Aprendizaje Supervisado El conjunto de datos está etiquetado Sanos vs.
Enfermos
Aprendizaje no Supervisado
Se buscan patrones desde datos no etiquetados
Clúster de genes relacionados con cáncer de colon
Aprendizaje por refuerzo
Aprendizaje basado en feedback o recompensa Jugar al ajedrez

¿Qué es Aprendizaje automático?
Clase A
Clase B
Clasificación Supervisado-Predictivo Regresión
Supervisado-Predictivo
Clustering No Supervisado-Descriptivo
Detección anomalías No Supervisado-Descriptivo
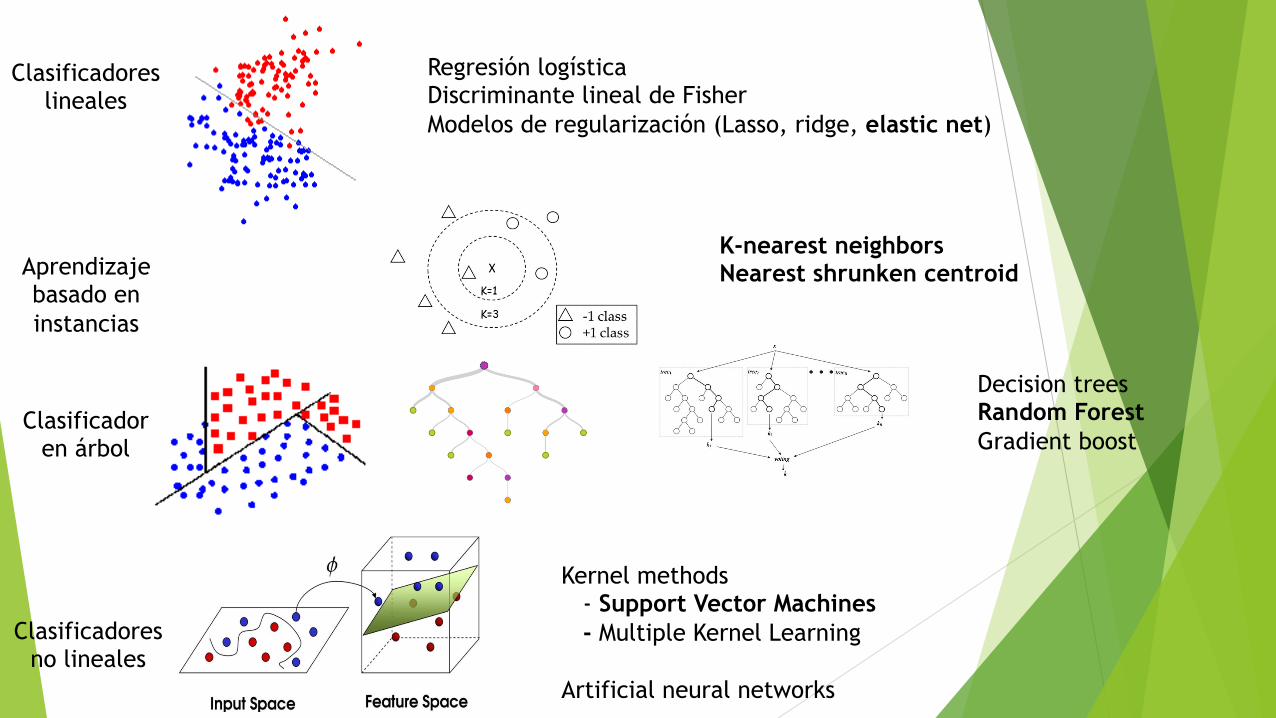
Regresión logística Discriminante lineal de Fisher Modelos de regularización (Lasso, ridge, elastic net)
Clasificadores lineales
Clasificador en árbol
Decision trees Random Forest Gradient boost
Clasificadores no lineales
Kernel methods - Support Vector Machines - Multiple Kernel Learning Artificial neural networks
K-nearest neighbors Nearest shrunken centroid Aprendizaje
basado en instancias

Todo eso con datos de DP?
u Tenemos dos cohortes diferentes sobre DP
u USC. Dr. Rafael Alonso Valente
u 114 pacientes
u Factores de riesgo cardiovascular en diálisis peritoneal
u Se han reportado un gran número de ellos en la literatura
u Análisis de variables asociadas con el perfil de riesgo cardiovascular
u Factores tradicionales
u Factores relacionados con la enfermedad renal crónica avanzada
u Factores propios de la DP

Todo esto con datos de DP?
u Algo de información más técnica
u Cuatro algoritmos de aprendizaje automático: Support Vector Machines, Elastic NET, Random Forest, K-nearest neighbors
u Se busca la combinación de los mejores hiperparámetros de cada técnica
u Se repiten los experimentos 10 veces
u Se utilizan técnicas de validación cruzada para evitar sobre ajuste a los datos y obtener una medida de la capacidad de generalización del sistema
u Se utiliza una aproximación de selección de características para reducir la dimensionalidad del problema (T-test)
u Medidas de rendimiento: AUROC, Sensibilidad, Especificidad
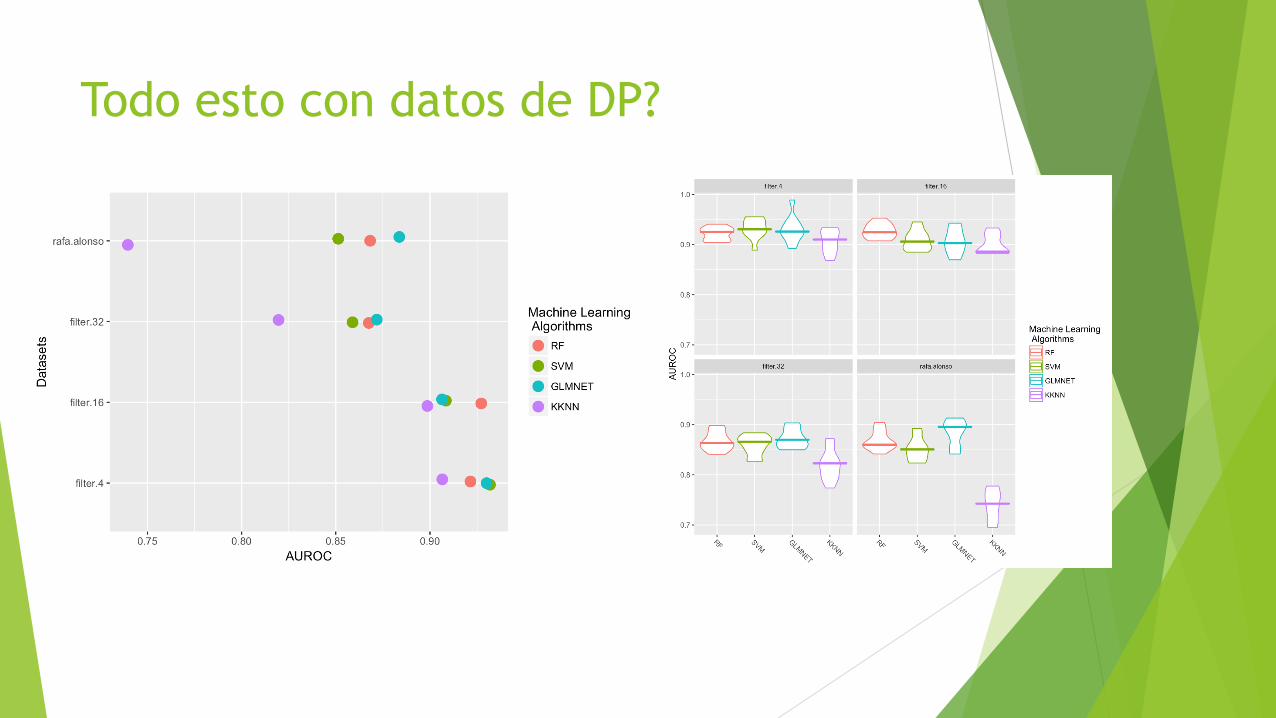
Todo esto con datos de DP?
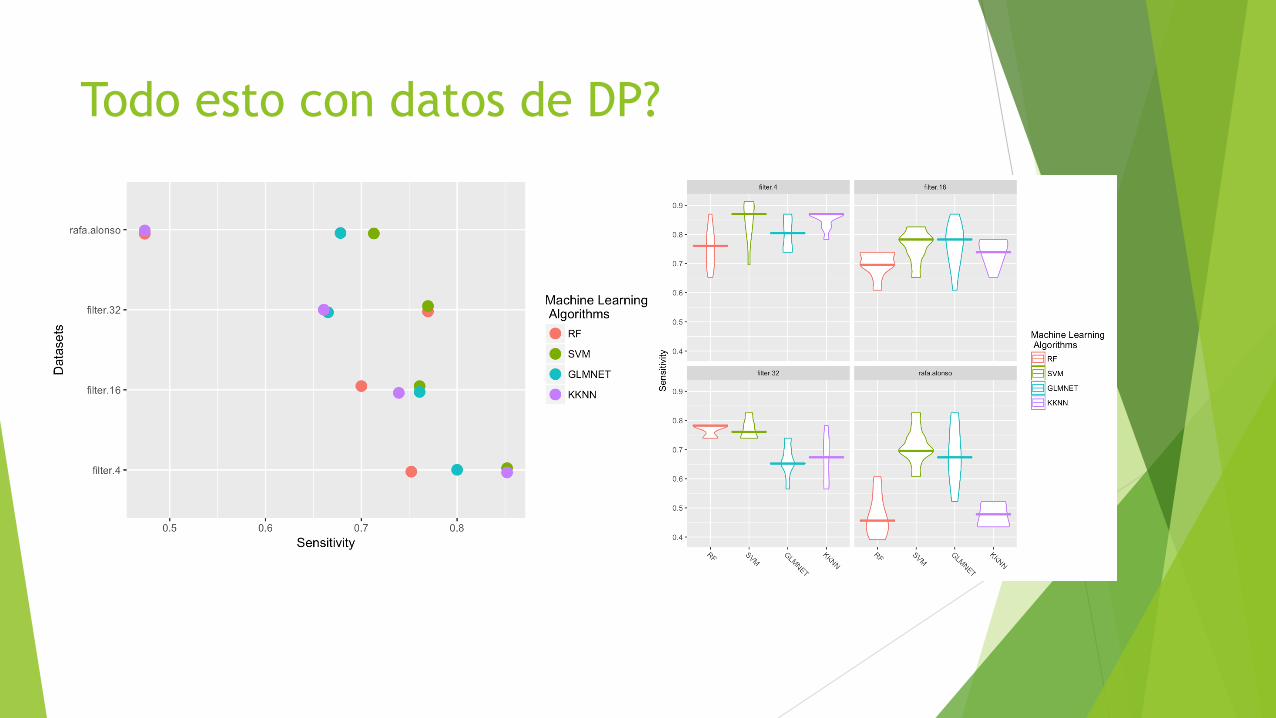
Todo esto con datos de DP?

Todo esto con datos de DP?

Todo esto con datos de DP?
u Resultados preliminares, es necesario profundizar más: u Se puede priorizar un modelo más sensible sobre uno más específico y viceversa
u Tanto a la hora de obtenerlo como de utilizarlo
u Para seleccionar a qué clase pertenece un determinado paciente (sano o enfermo) se utiliza un valor arbitrario de threshold de 0.5, se puede buscar el más adecuado al problema
u Los mejores resultados en AUROC se obtienen sólo con 4 variables: u 3 Factores tradicionales: tabaco si, tabaco no, HVI si
u 1 Factor de evolución: tx actual
u Se obtienen muy buenos resultados en AUROC con 16 variables:
u 12 Factores tradicionales: edad, talla, DM (Diabetes Mellitus) si, DM no, IMC 25 no, IMC 25 si, tabaco no, tabaco si, HVI no, HVI si, ENF base DM, ENF base vascular
u 1 Factor de riesgo ERCA: ProBNP
u 3 Factores de evolución: Icodextina si, Icodextina no, tx actual

Todo esto con datos de DP?

Todo esto con datos de DP?
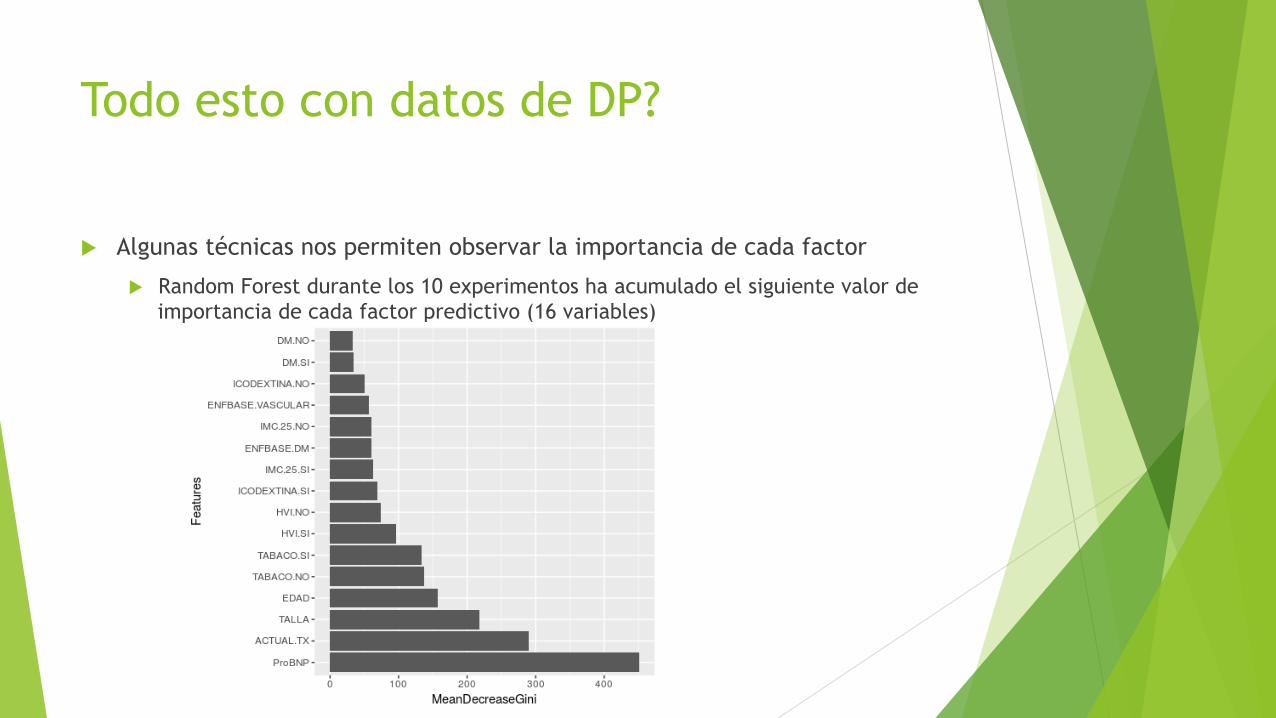
u Algunas técnicas nos permiten observar la importancia de cada factor
u Elastic NET durante los 10 experimentos ha acumulado el siguiente valor de importancia de cada factor predictivo (4 variables)
Todo esto con datos de DP?
u Algunas técnicas nos permiten observar la importancia de cada factor
u Random Forest durante los 10 experimentos ha acumulado el siguiente valor de importancia de cada factor predictivo (16 variables)

Todo esto con datos de DP?
u Tenemos dos cohortes diferentes sobre DP
u 178 pacientes
u Factores de riesgo cardiovascular en
u Pacientes con DP y Hemodialisis
u Pacientes con enfermedad renal crónica avanzada
u DP como alternativa a HD
u Múltiples análisis distintos
u Complicaciones con diálisis
u Enfermedad cardiovascular
u ….

Todo esto con datos de DP?
u Algo de información más técnica
u Cuatro algoritmos de aprendizaje automático: Support Vector Machines, Elastic NET, Random Forest, K-nearest neighbors
u Se busca la combinación de los mejores hiperparámetros de cada técnica
u Se repiten los experimentos 10 veces
u Se utilizan técnicas de validación cruzada para evitar sobre ajuste a los datos y obtener una medida de la capacidad de generalización del sistema
u Se utiliza una aproximación de selección de características para reducir la dimensionalidad del problema (T-test)
u Medidas de rendimiento: AUROC, Sensibilidad, Especificidad

Todo esto con datos de DP?
u Pocos pacientes con enfermedad cardiovascular o con complicaciones de cualquier tipo
u Muy desbalanceado
u No tienen los mismos factores
u No se pueden juntar cohortes
u Los datos están anotados para supervivencia
u Futuros análisis

Todo esto con datos de DP? Complicaciones con diálisis

Todo esto con datos de DP? Complicaciones con diálisis

Todo esto con datos de DP? Complicaciones con diálisis

u Random Forest durante los 10 experimentos ha acumulado el siguiente valor de importancia de cada factor predictivo (24 variables)
Todo esto con datos de DP? Complicaciones con diálisis

Todo esto con datos de DP? Enfermedad Cardiovascular

Todo esto con datos de DP? Enfermedad Cardiovascular

Todo esto con datos de DP? Enfermedad Cardiovascular

Todo esto con datos de DP? Enfermedad Cardiovascular

Conclusiones
u Existen múltiples opciones para explotar datos de DP mediante técnicas de aprendizaje automático
u Los trabajos que se han presentado no son finales, es una muestra de capacidades
u Aprendizaje automático no es estadística. Nuestras técnicas tienen un tremendo componente matemático detrás (no para hoy)
u He utilizado la presentación para mostrar lo que ya estamos haciendo en otros campos (biología de sistemas en cáncer, genómica, imagen médica…) pero que en DP todavía no se ha aplicado
u Oportunidades!!!
u Colaboraciones!!!

Técnicas de aprendizaje automático en el análisis
de datos de DP Dr. Carlos Fernández Lozano
Juan de la Cierva-Formación