stratégie et veille : extraire et trier des données en ligne
TRANSCRIPT

Extraire et trier des données en ligne Erwan Tanguy
Stratégie et veille

Web scraping ?
Le web scraping est une technique d'extraction du contenu de sites Web, via un script ou un programme, dans le but de le transformer pour permettre son utilisation dans un autre contexte.
Attention, il peut y avoir une utilisation légale ou illégale du web scraping. Nous nous intéresserons qu’à la première.
Pour quoi faire ?
Transférer des données d’un site vers un autre site ou vers un document (type tableau Excel) ;
Transformer des données pour y ajouter une valeur avant de la partager sur des réseaux sociaux ;
Récupérer des informations provenant de la concurrence pour pouvoir les analyser ;
Illégal : récupérer des données et les publier à son compte ;
…

Pour faire de la veille ?
La veille est un élément stratégique important et souvent négligé. Elle aide à prendre des décisions, permet d’évoluer et de rester à l’écoute.
Ce n’est en aucun cas de l’espionnage !
La veille numérique travaille à partir des données disponible légalement sur internet :
Sur des sites publics ;
Via des requêtes sur les moteurs de recherche ;
…
La veille, associée à des techniques de web scraping, va pouvoir récupérer des données et les rendre lisibles, accessibles, pour un public large ou pour des personnes précises.
Ces données, provenant généralement de sites web, pourront être récupérées au sein d’un document dynamique (un spreadsheet sur Google Drive par exemple) ou compilées sur un flux RSS dans le but d’alimenter une newsletter…

Des outils de web scraping
Pour récupérer des données :
Google spreadsheet ;
Import.io ;
Kimono ;
Feed43 ;
Yahoo! Pipes…
Pour trier et transformer les données :
Yahoo! Pipes
Dlvr.it…
Pour pousser les données :
IFTTT ;
Dlvr.it ;
Zapier…
Pour partager les données :
Les suites d’outils Google (Drive, Group…) ;
Excel ;
Des intranets ou des sites privés…
Des sites ou des réseaux sociaux ouverts…

Partons d’un exemple
Sur une page de vente immobilière du site pap.fr, je voudrais suivre les nouvelles vente de maisons, d’appartements ou autres au fur et à mesure.
URL :
http://www.pap.fr/annonce/vente-immobiliere-rennes-35-g43618
Sur cette page, je ne souhaite récupérer que les informations de zones précises liées à ma recherche :

Import.io
Dans la liste des outils gratuits permettant de réaliser une récupération de données, vous pouvez utiliser Import.io qui propose un espace en ligne et une application.
Cet outil est relativement simple à utiliser puisqu’il nécessite juste de zoner les parties de la page avec laquelle nous souhaitons réaliser un flux.
Le flux obtenu pourra être récupérer en tableau soit dans Excel soit dans un spreadsheet sur Drive (avec la possibilité de le rendre dynamique).
Pour des approches simples, Import.io peut être redoutable mais dès que le flux souhaité nécessite des précisions, des filtres, il faudra passer sur un outil plus performant et plus complexe.

Import.io
Plusieurs méthodes d’extraction des données sont possibles via l’application gratuite :
Magic propose automatiquement de récupérer les données qui semblent être les plus évidentes
Extractor & Classic Extractor vous permet de cibler les éléments de la page et de les organiser dans un tableau
Authenticated Extrator vous permet d’extraire des données sur un site qui nécessite une authentification (attention, cela peut être illégale si vous transmettez ces données)
Import.io
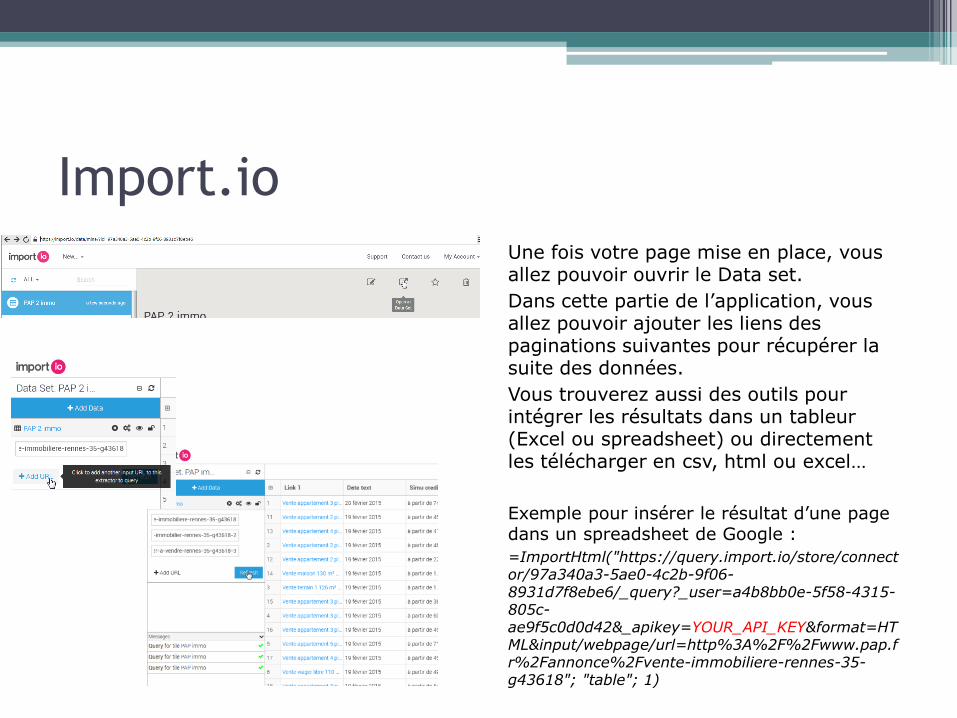
Une fois votre page mise en place, vous allez pouvoir ouvrir le Data set.
Dans cette partie de l’application, vous allez pouvoir ajouter les liens des paginations suivantes pour récupérer la suite des données.
Vous trouverez aussi des outils pour intégrer les résultats dans un tableur (Excel ou spreadsheet) ou directement les télécharger en csv, html ou excel…
Exemple pour insérer le résultat d’une page dans un spreadsheet de Google :
=ImportHtml("https://query.import.io/store/connector/97a340a3-5ae0-4c2b-9f06-8931d7f8ebe6/_query?_user=a4b8bb0e-5f58-4315-805c-ae9f5c0d0d42&_apikey=YOUR_API_KEY&format=HTML&input/webpage/url=http%3A%2F%2Fwww.pap.fr%2Fannonce%2Fvente-immobiliere-rennes-35-g43618"; "table"; 1)

kimonolabs
Kimonomabs propose une plateforme en ligne et un bookmarklet pour déclencher la récupération des données sur une page.
Les formats de sorties sont en json, csv ou rss. Assez simple donc ensuite de les importer en dynamique sur un spreadsheet par exemple.
Comme pour import.io, l’outil étant simple, il reste limité. Pour notre exemple, il est impossible de récupérer les images des annonces.

kimonolabs
À partir du bookmarklet, vous allez pouvoir définir, propriété par propriété, les différents éléments de votre tableaux.
Si vous souhaitez récupérer un flux RSS par la suite, je vous conseille de suivre les noms « title » et « description » pour définir les données principales, cela simplifiera sa création.
Une fois terminé, il ne vous reste plus qu’à enregistrer votre API et la consulter ou l’intégrer à une plateforme ou un logiciel.

Yahoo! Pipes
Yahoo! a mis en place un outil assez puissant qui permet de mettre en place des tuyaux (‘pipes’) qui vont pouvoir regrouper des informations provenant de flux RSS, de pages web, de CSV ou de json. Ces informations pourront ensuite être traitées pour filtrer ou modifier les données dans le but de les valoriser.
Plus technique que les deux précédents outils, il est aussi plus redoutable d’efficacité.

Yahoo! Pipes
Comme le permet aussi dans une certaine mesure import.io, le langage XPath nous donne la possibilité de cibler précisément des zones.
Dans notre exemple, toutes les annonces sont dans des éléments html « li » avec une classe « annonce », ce qui donne en XPath : //li[@class="annonce"]
//li indique que nous cherchons le ou les nœuds « li » dans la page
[@class="annonce"] pour ne prendre que ceux qui ont la classe « annonce ».

Yahoo! Pipes
Avant de définir les éléments du flux RSS final, nous allons correctement paramétrer la date de publication.
Dans les résultats obtenus avec le Xpath, nous pouvons dérouler un élément et y trouver la date en français :
div.0.span.content
Avec le module Regex, nous allons reformuler la date pour quelle se présente sous la forme
2015-02-23T07:00:00.00
Nous remplaçons donc la valeur intitial (ici 23 février 2015) appelé ainsi « (.*) (.*) (.*) » par « $3-$2-$1T07:00:00.00 ».
$1, $2 et $3 représentent les valeurs mémorisées par les 3 (.*) !

Yahoo! Pipes
Il faut ensuite remplacer le nom du mois par son chiffre :
janvier > 01
février > 02
…
Une fois les dates formatées, nous allons pouvoir mettre en place correctement notre flux.

Yahoo! Pipes Avec le module « Create RSS », nous allons indiquer pour chaque élément la valeur correspondante.
Titre : div.0.a.span.0.content
Lien : div.0.a.href
Date : div.0.span.content
URL de l’image : div.2.div.0.a.0.img.src
Enfin, nous allons mettre une première valeur dans la description, le prix du bien immobilier : div.0.a.span.1.content
En effet, nous avons plusieurs valeurs à saisir mais peu d’élément pour les contenir. Nous allons donc travailler la description pour qu’elle puisse contenir un maximum d’informations.
Enfin, pour finir avec ce module, nous allons ajouter l’URL de l’image dans l’espace « Author » qui n’est pas utilisé. Cela nous permettra, dans un spreadsheet, d’afficher l’image correctement (Google spreadsheet ne reconnait pas les medias associés).

Yahoo! Pipes
Pour finaliser notre flux, il nous reste à intégrer 4 valeurs dans la description :
1. Le bloc textuel ;
2. Le nombre de pièces ;
3. Le nombre de chambres ;
4. La surface.
Nous allons pour cela utiliser un module Regex pour ajouter du contenu avant (« ^ ») ou après (« $ ») le contenu déjà en place dans description.
Pour commencer nous allons ajouter le terme prix devant la valeur en place.
Nous plaçons donc devant (replace : ^) les éléments « Prix : ». Pour que le : ne soit pas collé à la valeur existante, il est utile de rajouter un espace.

Yahoo! Pipes
Pour le reste, ligne par ligne, nous allons soit placer des sauts de ligne, soit du contenu, à la suite des données déjà présentes avec le symbole $.
Le contenu se trouve là : ${div.2.div.1.p}.
Et les 3 autres valeurs respectivement là ${div.2.div.1.ul.li.0.p}, là ${div.2.div.1.ul.li.1.p} et là ${div.2.div.1.ul.li.2.p}.
Vous nommez et enregistrez votre flux et c’est prêt.
Vous pouvez ensuite l’intégrer à un spreadsheet comme pour les précédents, le connecter à votre boite mail ou à d’autres services via des applications comme IFTTT.
Yahoo! Pipes
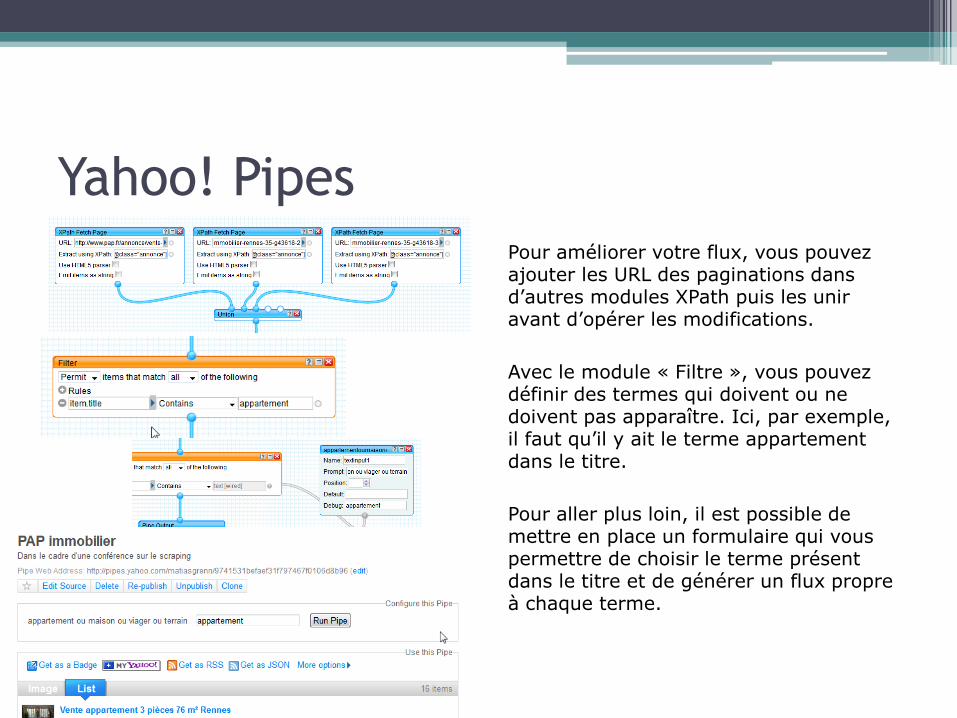
Pour améliorer votre flux, vous pouvez ajouter les URL des paginations dans d’autres modules XPath puis les unir avant d’opérer les modifications.
Avec le module « Filtre », vous pouvez définir des termes qui doivent ou ne doivent pas apparaître. Ici, par exemple, il faut qu’il y ait le terme appartement dans le titre.
Pour aller plus loin, il est possible de mettre en place un formulaire qui vous permettre de choisir le terme présent dans le titre et de générer un flux propre à chaque terme.

Voir en ligne
La page sur pap.fr : http://goo.gl/62sOtz
La présentation sur slideshare (téléchargeable en PDF) :
http://goo.gl/HxmWim
Le pipe sur Yahoo! Pipes : http://goo.gl/1EZ7TC
Tableau des données sur import.io : http://goo.gl/WsRo7u
Flux RSS du kimonolabs : http://goo.gl/hRdqcX

Erw
an T
anguy
www.erwantanguy.fr
www.digital-strategy.fr
www.ouestlab.fr
Consultant et formateur
Web, veille numérique, réseaux
sociaux, référencement
Spécialiste CMS Wordpress, SPIP
HTML, CSS3, jQuery, PHP
06 62 15 11 02