statistiques univariées et bivariées : aspects descriptifs...
TRANSCRIPT

Statistiques univariées etbivariées : aspects descriptifs etinférentiels
Prof Bi I. Arsène ZORO (Agronome généticien)
Biostatistiques Appliquées en Protection des Végétaux
Formation thématique ProVeg (3-6 juillet 2015)
2Présentation du réseau
Huit laboratoires1. Génétique moléculaire2. Agrophysiologie3. Physiologie végétale4. Zoologie appliquée5. Virologie & Biotech. végétales6. Pathologie et Genét. moléculaire7. Technologie alimentaire8. Biosci. & Agron. pour le Devpt

3Programme du module 3
1. Conditions générales d’application des tests statistiques
2. Méthodes relatives aux variables qualitatives
3. Méthodes relatives à une ou deux moyennes
4. Analyse de la variance (ANOVA)

Chapitre 1Expérimentation et Conditions généralesd’Application des Tests statistiques
Modules 3 - Statistiques univariées et bivariéesProf ZORO

Plan du chapitre
1. Principe d’expérimentation2. Collecte de données3. Normalité de(s) distribution(s)4. Homogénéité des variances et covariances5. Sphéricité6. Taille des échantillons7. Multicolinéarité8. Données « aberrantes » (hors norme)9. Transformation de variables
5

6
Première phase de toute étude statistique (ou bio-statistique).
L’expérimentation est la provocation, dans des conditionsmaîtrisées au moins partiellement, d’un phénomène.
Toute expérience doit faire l’objet d’une préparation ou d’uneplanification minutieuse.
L’expérimentateur doit examiner impérativement certainesquestions clés au cours de la préparation d’un plan d’expérience(ou un protocole expérimental) :
o Définition du but et des conditions de l’expérienceo Définition des facteurs qu’on désir étudiero Définition es unités expérimentaleso Définition des observations à réalisero Définition du dispositif expérimentale
1 – Principes d’expérimentation
Principes généraux

7
Première phase de toute étude statistique (ou biométrique).
Se fait par enquête ou par expérimentation
Quelque soit l’approche, la collecte des données doit êtreorganisée dans des conditions telles que de nombreuxéléments soient parfaitement maîtrisés.
Les éléments à maîtriser sont par exemple :o Le choix des unités ou des individus à observero L’affectation des traitements aux unités expérimentaleso L’hétérogénéité du milieuo Etc.
1 – Principes d’expérimentation
Principes généraux

8
Le mode d’association des objets aux unités expérimentalesconstitue le dispositif expérimental.
Les principaux dispositifs expérimentaux sont :o le dispositif en blocs complètement aléatoireso le dispositif en blocs aléatoires completso le dispositif en carré latin
1 – Principes d’expérimentation
Principes généraux

91 – Principes d’expérimentation
Dispositif en blocs complètement aléatoires (BCA)
Ce dispositif permet de comparer k traitements comportant ou non unmême nombre de répétitions. Par exemple si on compare quatretraitements T1, T2, T3 et T4 en les répétant trois fois, l’essaicomportera 12 parcelles.
T3 T1 T4 T2
T4 T3 T4 T1
T2 T1 T2 T3
Dispositif blocs complètementaléatoires (BCA) pour 4 traitementset 3 répétitions
Ce dispositif n’est utilisable qu’en milieu très homogène et les interventionsdoivent être effectuées de façon simultanée et de manière uniforme.

101 – Principes d’expérimentation
Dispositif en blocs aléatoires complets (BAC)En expérimentation sur le terrain, on entend par bloc, un ensemble deparcelles voisines très semblables. Ces blocs sont dits complets lorsque tousles objets mis en expérience sont présents dans chacun d’eux.
T6 T1 T1
T5 T2 T4
T1 T6 T2
T3 T3 T3
T2 T4 T6
T4 T5 T5Bloc 1 Bloc 2 Bloc 3
gradient
Forme et orientation des parcelles etdes blocs en présence d’un gradient.NB : Les blocs sont contigües
T6 T5 T1 T3 T2 T4Bloc 2
T1 T2 T6 T3 T4 T5Bloc 3
T1 T4 T2 T3 T6 T5
Dispositif en blocs aléatoires complet(BAC) pour 3 blocs, 6 traitements et1 répétition.NB : Les blocs sont non contigües

111 – Principes d’expérimentation
Dispositif en carré latin
En matière d’expériences sur le terrain, on appelle carré latin (latinsquare) un dispositif constitué d’un nombre de parcelles qui est uncarré (9, 16, 25, etc.). Ce dispositif comporte autant de lignes deparcelles que de colonnes de parcelles et chaque objet est présentune et une seule fois dans chaque ligne et dans chaque colonne.
On appelle carré latin de base (standard latin square) un carré latindans lequel les objets sont rangés par ordre numérique (oualphabétique) dans la première ligne et dans la première colonne.
2 3 1 4
3 1 4 2
4 2 3 1
1 4 2 3
Dispositif en carré latin 4 x 4.NB : Chaque ligne et chaque colonneporte tous les traitements

12
Etant donné qu’il est rare d’étudier de manière exhaustive unepopulation statistique, on recherche à constituer un ou deséchantillons représentatifs pour que l’extrapolation oul’inférence soit possible.
On distingue deux types de méthodes d’échantillonnage :o les méthodes aléatoires ;o les méthodes par choix raisonné.
Dans les méthodes aléatoires, chaque unité d’échantillonnagea une probabilité connue et différente de zéro d’appartenir àl’échantillon.
Dans les méthodes par choix raisonné, l’échantillon estconstitué a priori à partir de certaines informations.
Méthodes d’échantillonnage
2 – Collecte de données

13
Les méthodes probabilistes doivent assurer un caractère aléatoireet simple à l’échantillonnage.
Un échantillonnage est dit aléatoire et simple quand est dit aléatoireet simple ou complètement aléatoire quand tous les individus de lapopulation ont une même probabilité de faire partie de l’échantillonet qu’en plus, les choix successifs des différents individus quidoivent constituer l’échantillon sont réalisés indépendamment lesuns des autres.
Méthodes d’échantillonnage
Dagnelie P. [2012]. Principes d'expérimentation: planification des expérienceset analyse de leurs résultats. Gembloux, Presses agronomiques, 413 p.ISBN 978-2-87016-117-3
2 – Collecte de données

14
Procédés permettant d’assurer le caractère aléatoire et simple del’échantillonnage : méthodes probabilisteso les table de nombre aléatoireso nombre pseudo-aléatoires : xi+1 = kxi(modulo M).
k, M et xi sont des nombres entiers tandis que l’expression « modulo M »signifie qu’on retient comme valeur de xi+1 le reste de la division de kxi par M.
o échantillonnage systématiqueo échantillonnage stratifiéo Etc.
Procédés permettant d’assurer le caractère aléatoire et simple del’échantillonnage: méthodes par choix raisonnéo Méthode des quotas
Méthodes d’échantillonnage
2 – Collecte de données
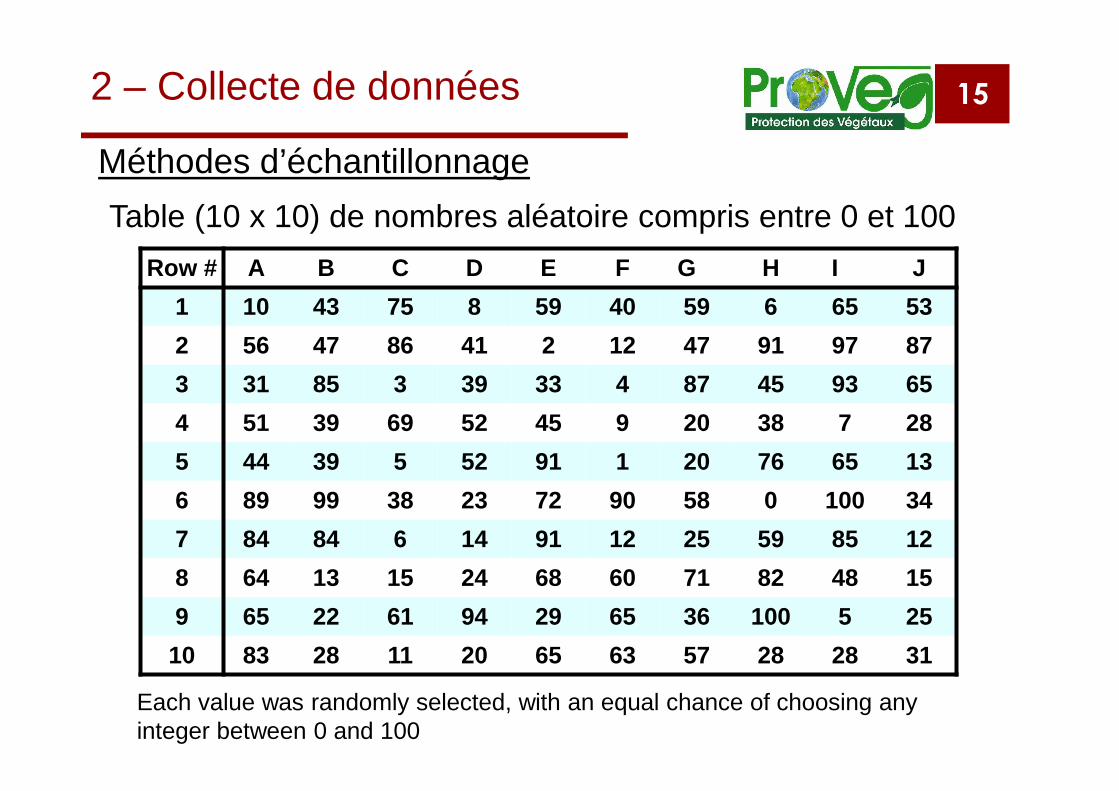
15
Row # A B C D E F G H I J1 10 43 75 8 59 40 59 6 65 532 56 47 86 41 2 12 47 91 97 873 31 85 3 39 33 4 87 45 93 654 51 39 69 52 45 9 20 38 7 285 44 39 5 52 91 1 20 76 65 136 89 99 38 23 72 90 58 0 100 347 84 84 6 14 91 12 25 59 85 128 64 13 15 24 68 60 71 82 48 159 65 22 61 94 29 65 36 100 5 25
10 83 28 11 20 65 63 57 28 28 31
Each value was randomly selected, with an equal chance of choosing anyinteger between 0 and 100
Table (10 x 10) de nombres aléatoire compris entre 0 et 100
Méthodes d’échantillonnage
2 – Collecte de données

16
Tests du caractère aléatoire et simple d’un série de données
Divers tests permettent de contrôler caractère aléatoire etsimple d’un série de données.
Certains de ces tests sont subordonnés à l’hypothèse denormalité de la distribution de la variable considérée tandisque d’autres sont non paramétriques :
o Tests paramétriques : Test du quotient de Von Neumann ou test de Durbin et Watson
o Tests non paramétriques Test des séquences homogènes
2 – Collecte de données
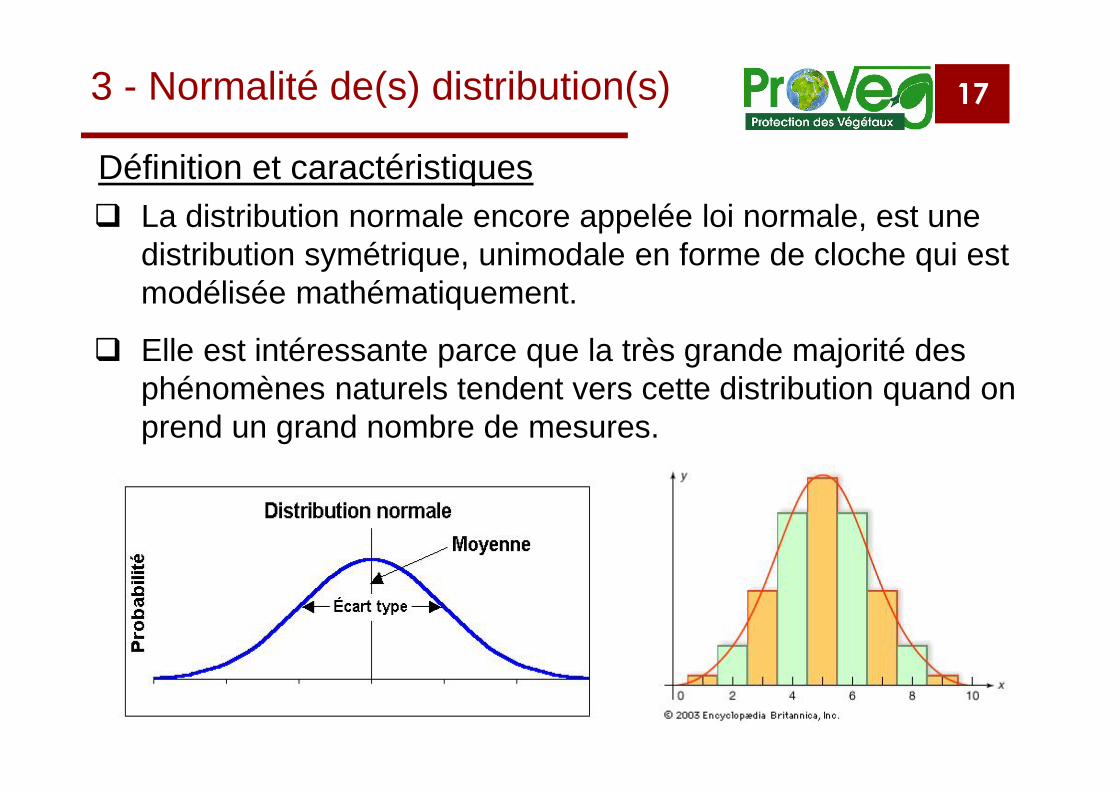
173 - Normalité de(s) distribution(s)
La distribution normale encore appelée loi normale, est unedistribution symétrique, unimodale en forme de cloche qui estmodélisée mathématiquement.
Elle est intéressante parce que la très grande majorité desphénomènes naturels tendent vers cette distribution quand onprend un grand nombre de mesures.
Définition et caractéristiques
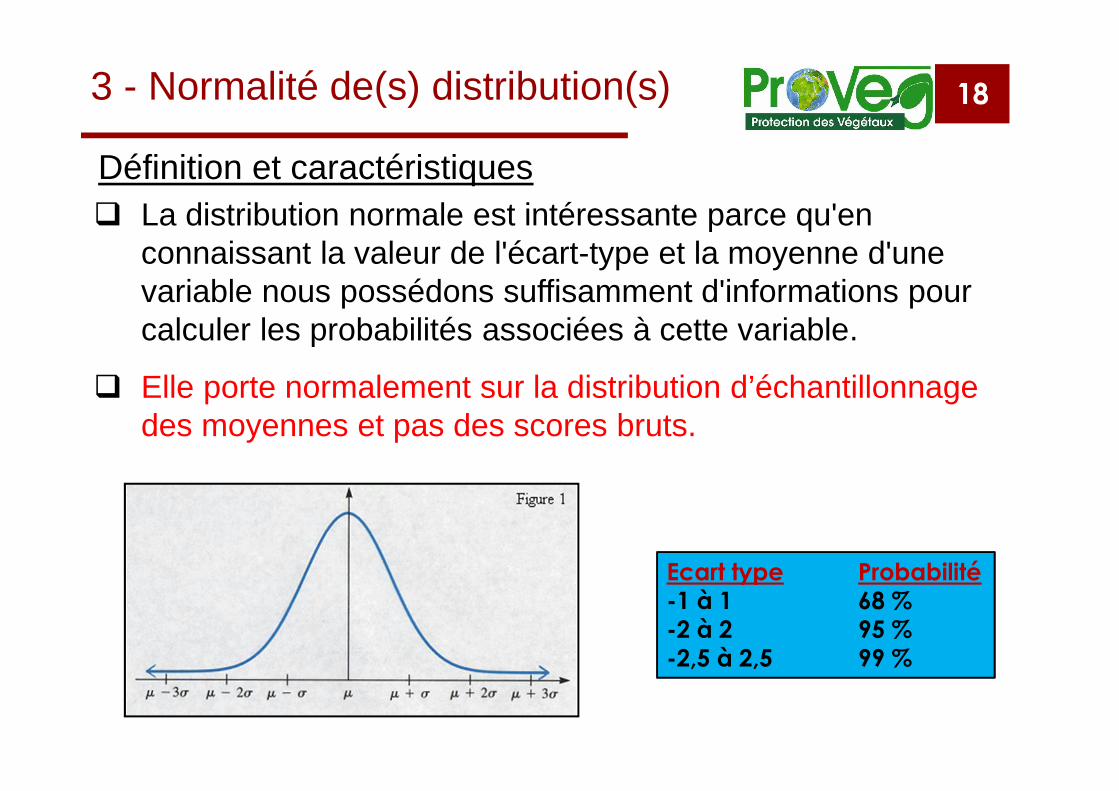
18
La distribution normale est intéressante parce qu'enconnaissant la valeur de l'écart-type et la moyenne d'unevariable nous possédons suffisamment d'informations pourcalculer les probabilités associées à cette variable.
Elle porte normalement sur la distribution d’échantillonnagedes moyennes et pas des scores bruts.
Ecart type Probabilité-1 à 1 68 %-2 à 2 95 %-2,5 à 2,5 99 %
Définition et caractéristiques
3 - Normalité de(s) distribution(s)

19
Cruciale pour la quasi totalité des tests univariés.
L’asymétrie (skewness) pose problème plus quel’applatissement (kurtosis).
Si cette condition est respectée, l’ANOVA est robuste dès lorsque les autres conditions sont remplies (données hors norme,effectifs égaux, etc.) et que les effectifs sont supérieurs à 20par condition.
Distribution univariée
3 - Normalité de(s) distribution(s)
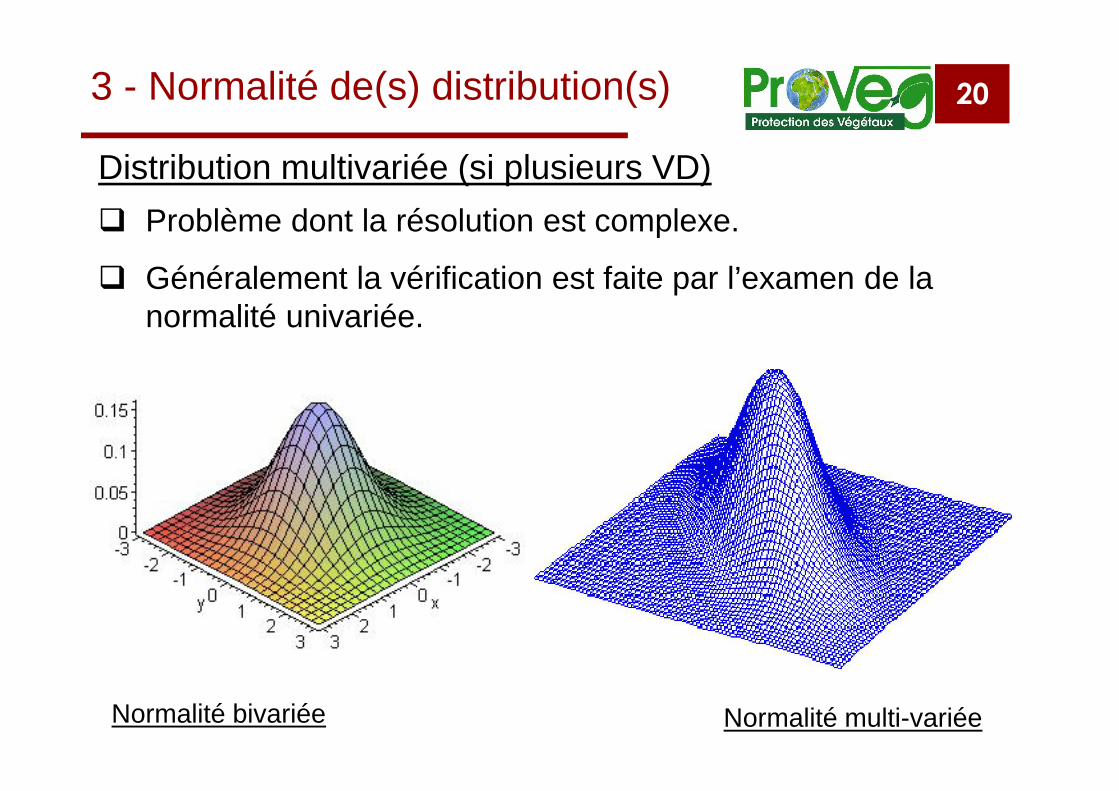
20
Problème dont la résolution est complexe.
Généralement la vérification est faite par l’examen de lanormalité univariée.
Distribution multivariée (si plusieurs VD)
Normalité bivariée Normalité multi-variée
3 - Normalité de(s) distribution(s)

21
Le contrôle de la normalité ou de la forme de toute autredistribution peut se faire par :
o Un test d’ajustement :
Tests 2 d’ajustement de PEARSON
Test de Kolmogorov-Smirnov
o Les diagrammes de probabilité (méthodes visuelles maispratiques)
Droite de Henri
Le test de Shapiro et Wilk (découlant d’une droite deprobabilité)
Vérification de la normalité d’une distribution
3 - Normalité de(s) distribution(s)

224 – Homogénéité des variances
Principes généraux
L’égalité des variances est une condition préalable aux méthodesrelatives à plusieurs paramètres, notamment la moyenne, lecoefficient de corrélation et le coefficient de régression.
Les méthodes relatives à la variance ne sont applicables que pourdes populations normales et des échantillons aléatoires et simples.
La condition de normalité est relativement stricte pour les méthodesrelatives à la variance, même dans le cas d’échantillons d’effectifsassez important, contrairement à ce qui se passe pour l’étude desmoyennes.
Si on dispose de plusieurs variables dépendantes, les matrices devariances/covariances doivent être les mêmes dans les différentesconditions.

234 – Homogénéité des variances
Tests d’homogénéité de variances
Test relatif à un échantillonTest 2 (N ≤ 30)
Les tests statistiques relatifs aux variances dépendent du nombre depopulations à comparer et du type d’échantillonnage
Distribution normale réduite (N > 30)
Tests relatifs à deux échantillonsEchantillons indépendants Test de FischerEchantillons non indépendants Test t de Student
Test s relatifs à plus deux échantillonsEchantillons indépendants Test de Bartlett / Test de HartleyEchantillons non indépendants Test de Levene
Test s relatifs à plusieurs variables dépendantesTest M de Box

245 – Sphéricité
Elle concerne les situations à mesures répétées (plus de deuxmesures), c’est à dire les ANOVA (VI intra).
Dans ce cas les corrélations entre les différentes mesures de la variabledépendante (VD) doivent être égales (i.e. rt1-t2 = rt1-t3 = rt2-t3).
C’est une condition difficile à remplir car les corrélations sont souvent plusimportantes lorsqu’elles concernent des moments proches.
La sphéricité est vérifiée par le test de Mauchly ou de Bartlett.

256 – Taille des échantillons
Elle concerne surtout les ANOVA (algorithme CM servant à laréalisation du test).
Lorsqu’il y a plusieurs VI et que les effectifs ne sont paségaux par condition :
o Les moyennes marginales sont calculées différemment
o Les effets des différentes variables ne sont plusindépendants (pas d’égalité entre SCEt, SCEa et SCEr)
o Il y a différentes manières de calculer les différentes SCE Moyennes pondérées par l’effectif
Moyennes non pondérées

267 – Multicolinéarité
Applicables dans le cas tests multivariés (MANOVA, ACP, etc.).
Les covariables ne doivent pas être trop fortement corrélées entreelles.
La vérification peut se faire par la valeur de la « tolérance » : 1 – R2
Faire attention si la tolérance < 0,30.
D’une façon générale, il est recommandé que les corrélationspositives ne soient pas supérieures à 0,90 ; elles ne doivent pasêtre supérieures à – 0,4 quand elles sont négatives.

278 – Données « aberrantes »
Données inhabituelles d’une variable ou une combinaison devariables (Exemple : très jeune avec très haut revenu).
La nature de ces peut être vérifiée par différents test :
o Pour les tests univariés : Analyse des boîtes à moustaches (qualitative) : une valeur
est considérée comme aberrante si la valeur absolue del'écart avec Q1 ou Q3 est supérieure à plus de 1,5 foisl'étendue interquartile.
Test de Dixon.
o Pour les analyses multivariées : calculer la distance deMahalanobis (distance entre un individu et le centroïde desautres individus). Vérifier les individus pour lesquels le chi²associé a une probabilité inférieure à 0,001.

289 – Transformation de variables
Dans la réalisation des méthodes d’inférence statistique,l’hypothèse d’égalité des variances, qui est la pluscontraignante que la normalité de la distribution, peut êtrerejetée. Dans ces conditions, on procède d’habitude à unetransformation de variable.
Le principe est de rechercher un Y tel que Y = Y(X) de tellesorte que la variance de Y est constante ouapproximativement constante, même si la variance de X estvariable.
Après la transformation, les calculs et les tests d’hypothèsespeuvent être réalisés tout à fait normalement et il est possiblede revenir aux variables initiales.
Principes généraux

299 – Transformation de variables
Transformation logarithmique :
Transformation racine carré :
Transformation angulaire (données en pourcentage) :
Transformations courantes
Y = logX ou Y = LnX ou Y = log(X + 1)
XY ou 8/3 XY
nXY /arcsin2 4/3/8/3arcsin2 nXYou
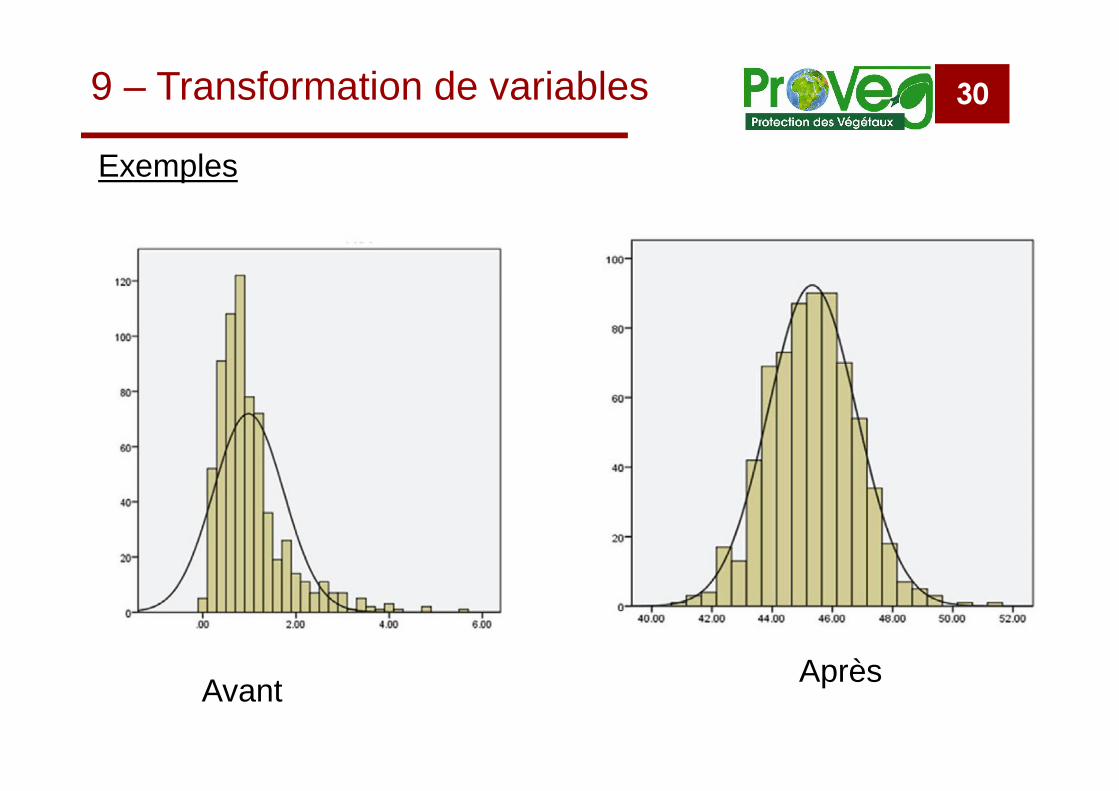
309 – Transformation de variables
Exemples
Avant Après

319 – Transformation de variables
ExemplesRace 1 20 17 16 15 15 14 14 14 13 13 13 12 12 12 11 11 10 09 09 08 07 06 05Race 2 13 12 12 10 10 10 10 09 08 08 07 07 07 07 07 06
Le test d’égalité de deux variances est relatif à l’hypothèsenulle : 2
221O :H
Il nécessite le calcul de la quantité :
2min
2max
S
SobsF
Le rejet de l’hypothèse nulle intervient, pour le test bilatéralde niveau de probabilité quand :
DL =k1 = nnum - 1
k2 = ndenum - 1
P(F ≥ Fobs) ≤ /2 ou Fobs ≥ F1-/2

329 – Transformation de variables
Exemples
SCE1 = 288,00
SCE2 = 68,94
S12 =13, 09
S22 = 4, 60
Fobs = 13,09 / 4,60 = 2,85
DL =k1 = 23 – 1 = 22
k2 = 16 – 1 = 15
F(0,95 ; 22 – 15) = 2,31
Race 1 1,30 1,23 1,20 1,18 1,18 … 1,04 1,04 1,00 0,95 0,95 0,90 0,85 0,78 0,70Race 2 1,11 1,08 1,08 1,00 1,00 … 0,85
SCE1 = 0,47
SCE2 = 0,17
S12 = 0, 02
S22 = 0, 01
Fobs = 0,02 / 0,01 = 2,05
DL =k1 = 23 – 1 = 22
k2 = 16 – 1 = 15
F(0,95 ; 22 – 15) = 2,31

Chapitre 2Méthodes relatives aux variables qualitatives
Prof ZORO Modules 3 - Statistiques univariées et bivariées

Plan du chapitre
Définition Méthodes relatives à une ou deux proportions Tableaux de contingence
34

35
Les variables qualitatives sont des variables dont on ne peutpas calculer le total des valeurs (ou attributs) pour uneensemble d’individus donné.
Concernant les variables qualitatives, on peut envisager lesproblèmes relatifs à une ou deux proportions (oupourcentages) et les problèmes relatifs à plus de deuxproportions (tableaux de contingence).
Nous supposerons toujours que les échantillons considéréssont aléatoires et simples et qu’ils proviennent de populationsinfinies ou pratiquement infinies (populations dont les effectifssont au moins dix fois plus importants que les effectifs deséchantillons).
1 – Définition

36
Test de conformité d’une proportion
Les tests de conformité d’une proportion sont basés sur l’hypothèsenulle :
€
uobs =
xn
− p0
p0 1− p0( )n
H0 : p = p0
Pour des échantillons d’effectifs suffisamment élevés, on peutemployer la méthode de l’erreur standard. A cet effet, on peut calculerla quantité suivante :
P(U uobs) ou uobs u1-/2
Pour un test bilatéral de niveau , rejeter l’hypothèse nulle quand :
2 – Une ou deux proportions

37
Test de conformité d’une proportion
2 – Une ou deux proportions
ApplicationVérifier si un échantillon complètement aléatoire de 50 graines présentantun pouvoir germinatif de 72% (36 graines ayant germé) peut être considérécomme provenant d’une population dont le pouvoir germinatif serait de80% au moins.
Nous devons donc vérifier l’hypothèse nulle :
H0 : p = 0,80
En calculant la quantité :
€
uobs =
3650
− 0,80
0,80 1− 0,80( )50
=1,41
avec u0,975 = 1,960
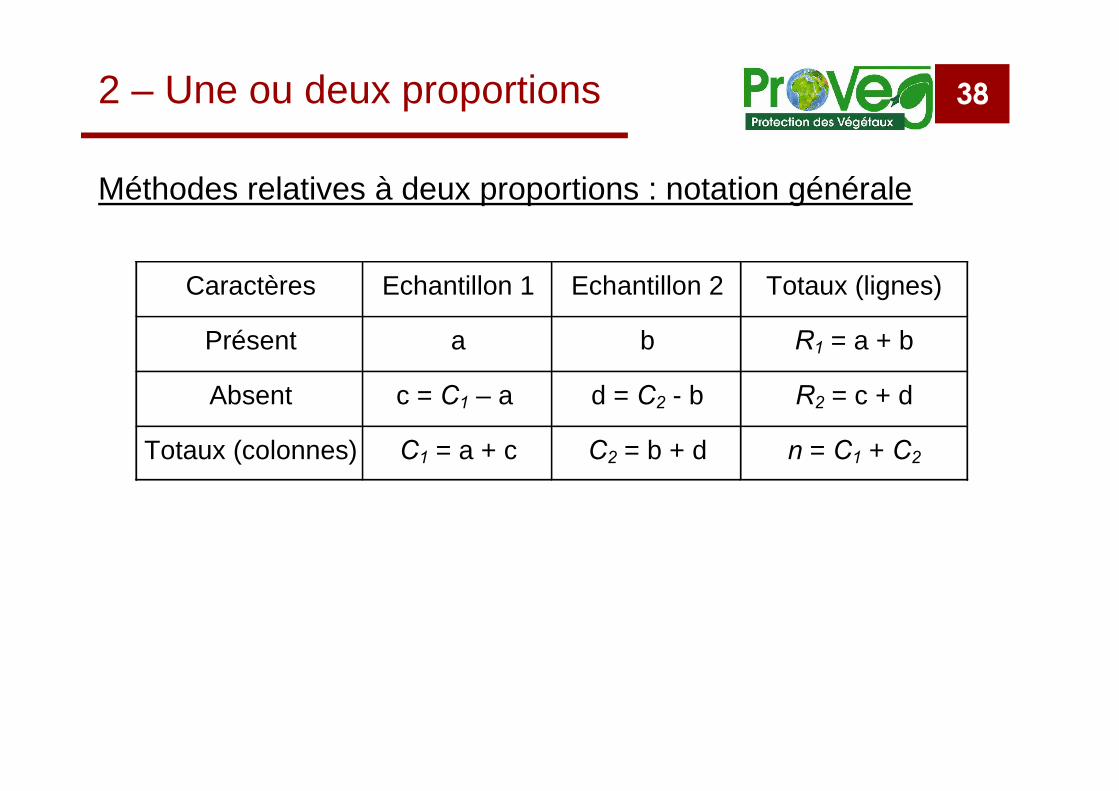
38
Méthodes relatives à deux proportions : notation générale
2 – Une ou deux proportions
Caractères Echantillon 1 Echantillon 2 Totaux (lignes)
Présent a b R1 = a + b
Absent c = C1 – a d = C2 - b R2 = c + d
Totaux (colonnes) C1 = a + c C2 = b + d n = C1 + C2

39
Deux proportions, échantillons indépendants : test de Fischer
2 – Une ou deux proportions
Le test de Fischer, aussi appelé test exact de Fischer est basé surles distributions hypergéométriques qui peuvent être présentées dela manière suivante :
€
P(a) =
R1!R2!C1!C2!n!
a!b!c!d!
Cette relation permet de déterminer la probabilité de rencontrer,quand l’hypothèse nulle est vraie, une répartition aussi anormale ouplus anormale que celle qui a été réellement observée.
On présente toujours les données de telle sorte que :C1 ≤ C2 et R1 ≤ R2

40
Deux proportions, échantillons indépendants : test basé sur U
2 – Une ou deux proportions
Le test de l’hypothèse d’égalité des deux proportions est basé sur l’hypothèsenulle :
Il nécessite le calcul de la quantité :
H0 : p1 = p2
€
uobs =p̂1 − p̂2
p̂ 1− p̂( ) 1/C1 +1/C2( )
P(U uobs) ou uobs u1-/2
Dans le cas d’un test bilatéral de niveau , rejeter l’hypothèse nulle quand :
L’approximation normale peut être considérée ici comme satisfaisante quandle produit des deux effectifs marginaux les plus petits (C1 ou C2 d’une part etR1 ou R2 d’autre part) est plus grand qu’au moins cinq fois l’effectif total n.
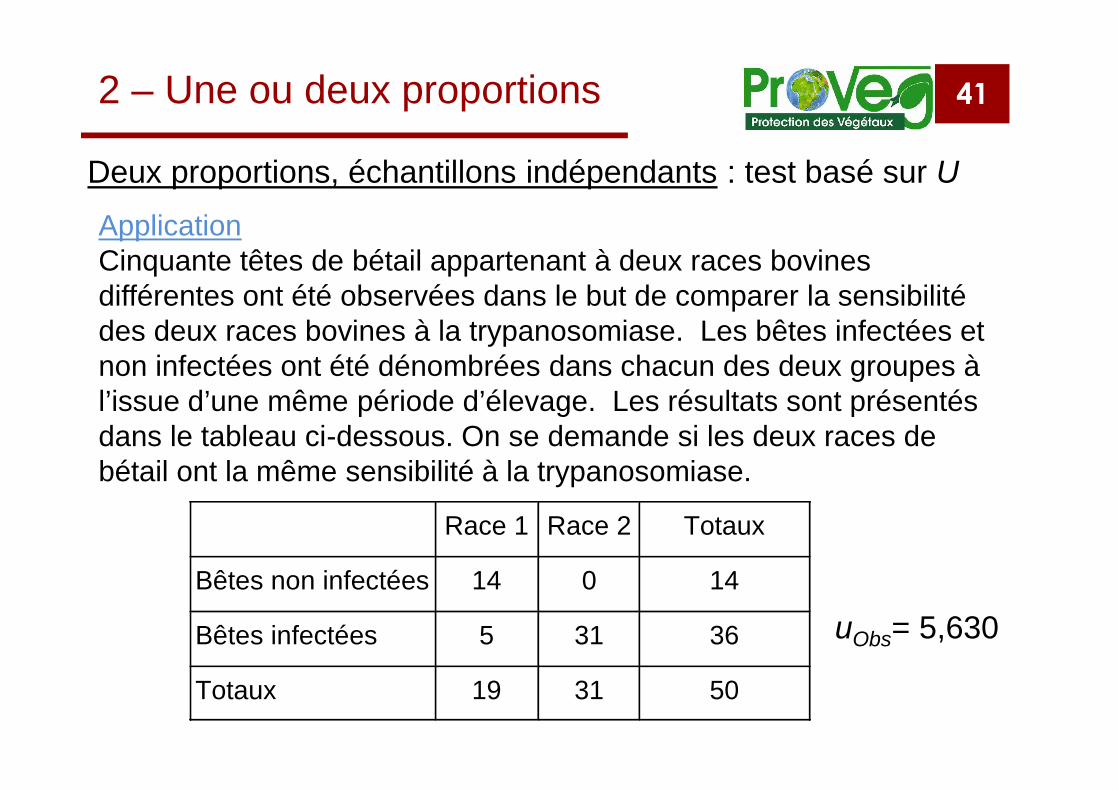
41
Deux proportions, échantillons indépendants : test basé sur U
2 – Une ou deux proportions
ApplicationCinquante têtes de bétail appartenant à deux races bovinesdifférentes ont été observées dans le but de comparer la sensibilitédes deux races bovines à la trypanosomiase. Les bêtes infectées etnon infectées ont été dénombrées dans chacun des deux groupes àl’issue d’une même période d’élevage. Les résultats sont présentésdans le tableau ci-dessous. On se demande si les deux races debétail ont la même sensibilité à la trypanosomiase.
Race 1 Race 2 Totaux
Bêtes non infectées 14 0 14
Bêtes infectées 5 31 36
Totaux 19 31 50
uObs= 5,630

42
Deux proportions, échantillons non indépendants : notations
2 – Une ou deux proportions
Caractère 1
Caractère 2 présent absent Totaux
présent a b a + b
absent c d c + d
Totaux a + c b + d n
Tester l’égalité de deux proportions pour des échantillons nonindépendants (associées par paires) correspond notamment au casoù deux caractères différents sont observés simultanément sur lesmêmes individus. Une solution peut être apportée à ce problème parle test de McNemar.

43
Deux proportions, échantillons non indépendants : test de McNemar
2 – Une ou deux proportions
H0 : p1 = p2
Dans ces conditions et pour un échantillon aléatoire et simple, laréalisation du test de McNemar est basée sur le calcul de la quantité :
€
uobs =b− cb+ c
P(U uobs) ou uobs u1-/2
Dans le cas d’un test bilatéral de niveau , rejeter l’hypothèse nullequand :

44
Principes généraux
3 – Tableaux de contingence
D’une manière générale, les tableaux de contingence sontdes distributions de fréquences qui ont trait à deux ouplusieurs caractères qualitatifs considérés simultanément.
Les caractères envisagés peuvent être binaires, nominaux ouordinaux.
Le problème qui est abordé le plus souvent en ce quiconcerne les tableaux de contingence à deux dimensions estle contrôle de l’indépendance des deux caractères.
Cette question est envisagée en utilisant le test2
d’indépendance au sens de Pearson dans le cas d’un tableaude contingence 2 x 2.

45
Test2 d’indépendance de deux variables
3 – Tableaux de contingence
Dans le cas particulier 2 x 2, la définition de la valeur observée deKhi-2 conduit à la formule suivante :
€
cObs2 =
n n11n22 − n12n21( )2
n1•n2•n•1n•2( )
En adoptant les notations du tableau relatif au test de McNemar :
€
cObs2 =
n ad −bc( )2
a+b( ) c + d( ) a+ c( ) b+ d( )[ ] DL = 1
46
Test2 d’indépendance de deux variables
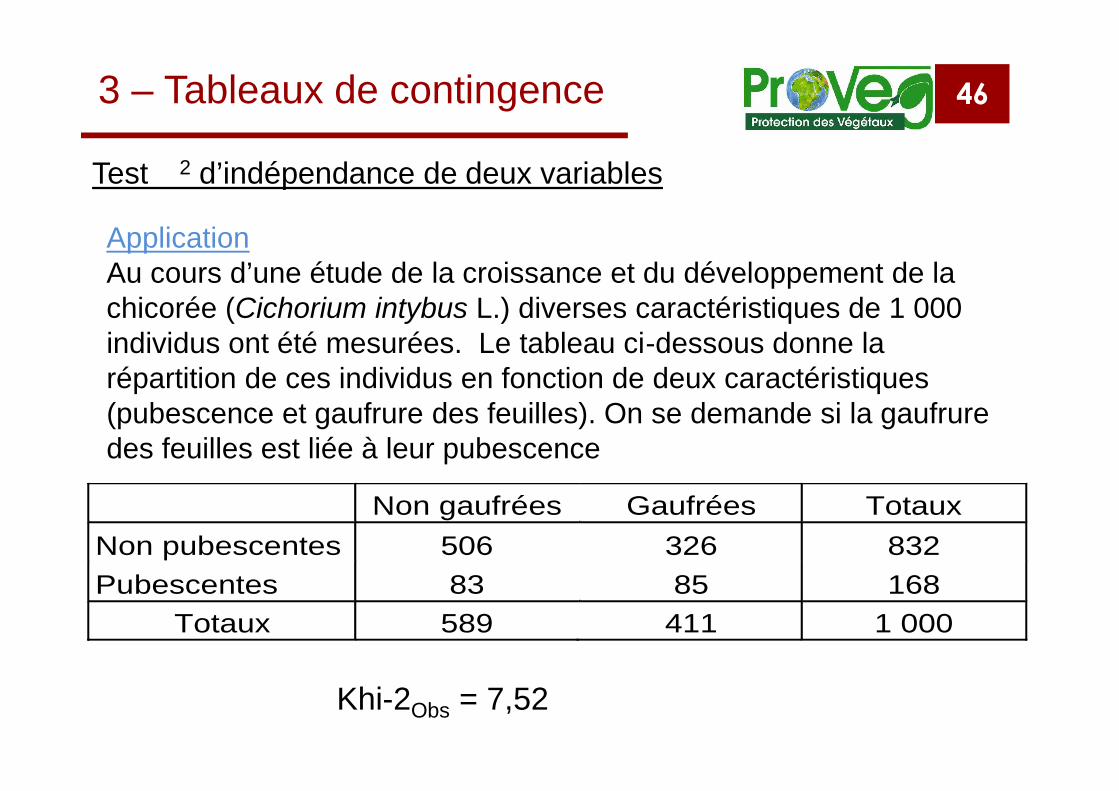
3 – Tableaux de contingence
ApplicationAu cours d’une étude de la croissance et du développement de lachicorée (Cichorium intybus L.) diverses caractéristiques de 1 000individus ont été mesurées. Le tableau ci-dessous donne larépartition de ces individus en fonction de deux caractéristiques(pubescence et gaufrure des feuilles). On se demande si la gaufruredes feuilles est liée à leur pubescence
Non gaufrées Gaufrées TotauxNon pubescentes 506 326 832Pubescentes 83 85 168
Totaux 589 411 1 000
Khi-2Obs = 7,52

47
Test2 d’indépendance de plus de deux variables
3 – Tableaux de contingence
Pour deux caractères possédant respectivement p et qmodalités, on dispose de :o pq fréquences observées nij
o p fréquences marginales ni.
o q fréquences marginales n.j.
Dans l’hypothèse d’indépendance des deux caractères, onpeut calculer les fréquences attendues (théoriques) :
nP̂ij = ni•n• j / n

48
Test2 d’indépendance de plus de deux variables
3 – Tableaux de contingence
Le test d’indépendance nécessite alors le calcul de la quantité:
DL = (p – 1)(q – 1)
L’approximation est généralement considérée commesatisfaisante quand les fréquences attendues sont toutes aumoins égales à 5.
Si cette condition n’est pas remplie, des regroupements delignes et / ou colonnes doivent être envisagées.
cobs2 =
nij −nP̂ij( )2
nP̂ijj=1
q
∑i=1
p
∑

Chapitre 3Méthodes relatives à une ou deux moyennes
Prof ZORO Modules 3 - Statistiques univariées et bivariées

Plan du chapitre
Méthode relative à une moyenne (test de conformité) Méthodes relatives à deux moyennes
50

511 – Test de conformité
Le test de conformité d’une moyenne le plus courant relatif àl’hypothèse nulle :
omm :HO
Pour réaliser ce test, on doit calculer la quantité :
1-SCE
0
nn
mxtobs
Pour le test bilatéral de niveau , l’hypothèse nulle doit être rejetéequand :
P(t ≥ tobs) ≤ ou tobs ≥ t1-/2
DL = n - 1

522 – Comparaison de deux populations
Echantillons indépendants : test paramétrique
Pour des populations normales, des échantillons aléatoires etsimples et de mêmes variances, ce test suppose le calcul de laquantité :
Il s’agit d’un test t d’égalité de deux moyennes, encore appelé test tde Student. Il est basé sur l’hypothèse nulle suivante :
21O :H mm
Pour le test bilatéral de niveau , l’hypothèse nulle doit être rejetéequand :
P(t ≥ tobs) ≤ ou tobs ≥ t1-/2
2121
21
21
11
2
SCESCE
nnnn
xxtobs
DL = n1 + n2 - 2

532 – Comparaison de deux populations
ApplicationCi-dessous, les hauteurs des arbres de deux types de forêts mesurésen vue d’estimer la productivité. On peut utiliser le test t pour voir s’il ya différence de productivité.
Type 1 23,4 24,4 24,6 24,9 25,0 26,2 26,3 26,8 26,8 26,9 27,0 27,6 27,7
Type 2 22,5 22,9 23,7 24,0 24,4 24,5 25,3 26,0 26,2 26,4 26,7 26,9 27,4 28,5
SCE1 = 22,15
SCE2 = 40,88
97,25x1
39,25x2
141
131
2141340,8822,15
39,2597,25obst P(t ≥ 0,95) =0,35= 0,95

542 – Comparaison de deux populations
Echantillons indépendants : test non paramétriqueLa méthode non paramétrique qui est utilisée le plus souvent pourcomparer deux populations à partir d’échantillons indépendants estle test des rangs, aussi appelé test de MANN et WHITNEY ou testde WILCOXON.
Pour les effectifs suffisamment élevés (n1 + n2 30), on calcule laquantité :
12
1
2
1
2121
2111
nnnn
nnnX
uobs
P(U uobs) ≤ ou uobs u1-/2
Pour un test bilatéral de niveau de probabilité , on doit rejeterl ’ hypothèse d ’ identité des distributions des deux populations-parents quand :
21O :H mm

552 – Comparaison de deux populations
Echantillons non indépendants : test paramétrique
Il s’agit d’un test t par paires ou par couples est basé sur le calculdes différences entre les couples d’observations. Il concerne lamême hypothèse nulle que le test t classique :Il peut être réalisé en calculant les différences : d1 = x11 – x21, …., dn =x1n – x2n
Et la quantité :
1
SCE21
nn
xxt
d
obs
SCEd représentant la SCE des différences di.
P(U tobs) ≤ ou tobs t1-/2
Pour un test bilatéral de niveau de probabilité , on doit rejeterl ’ hypothèse d ’ identité des distributions des deux populations-parents quand :

562 – Comparaison de deux populations
Echantillons non indépendants : test paramétriqueApplicationReprenons l’exemple des deux méthodes de mesure de la hauteurdes arbres pour réaliser une comparaison de moyennes.
Les deux populations de mesures étant supposées normales, les échantillonnagesdes arbres étant aléatoires et simples et lhypothèse d’égalité des variances ayantété vérifiée, on peut procéder à un test paramétrique : le test t de Student par paire.
Débout 20,4 25,4 25,6 26,6 28,6 28,7 29,0 29,8 30,5 30,9 31,1
Abattus 21,7 26,3 26,8 28,1 26,2 27,3 29,5 32,0 30,9 32,3 31,7
SCEd = 17,98
1111117,98
44,2887,27
obst = 1,39 DL= 11 – 2 = 9
pour DL = 9 t1-/2 = t0,975 = 2,262

572 – Comparaison de deux populations
Echantillons non indépendants : test non paramétrique
Le test non paramétrique le plus courant en ce qui concerne lacomparaison de deux échantillons non indépendants est égalementle test des rangs de WILCOXON et parfois appelé test des rangs parpaires ou test des rangs et des signes.
24
121
4
1
nnn
nnX
uobs
P(U uobs) ≤ ou uobs u1-/2
Pour un test bilatéral de niveau de probabilité , on doit rejeterl ’ hypothèse d ’ identité des distributions des deux populations-parents quand :

Chapitre 4Analyse de la Variance (ANOVA)
Prof ZORO Modules 3 - Statistiques univariées et bivariées

Plan du chapitre
Analyse de la variance à un facteur (ANOVA1) Analyse de la variance à deux facteurs Analyse de la variance à mesures répétées répétées
59

601 – Analyse de la variance à un facteur
Principes généraux D’une manière générale, l’analyse de la variance (Analysis of
variance, ANOVA) a pour objectif de comparer plus de deuxmoyennes en identifiant les sources de variation qui peuventexpliquer les différences existant entre elles.
En particulier, l’analyse de la variance à un critère de classificationou à un facteur ou à une voie (One-way analysis of variance)s’applique quand les moyennes ne sont classées que sur la based’un seul critère.
L’ANOVA s’applique à des populations normales et de mêmevariance et des échantillons aléatoires simples et indépendants.
611 – Analyse de la variance à un facteur
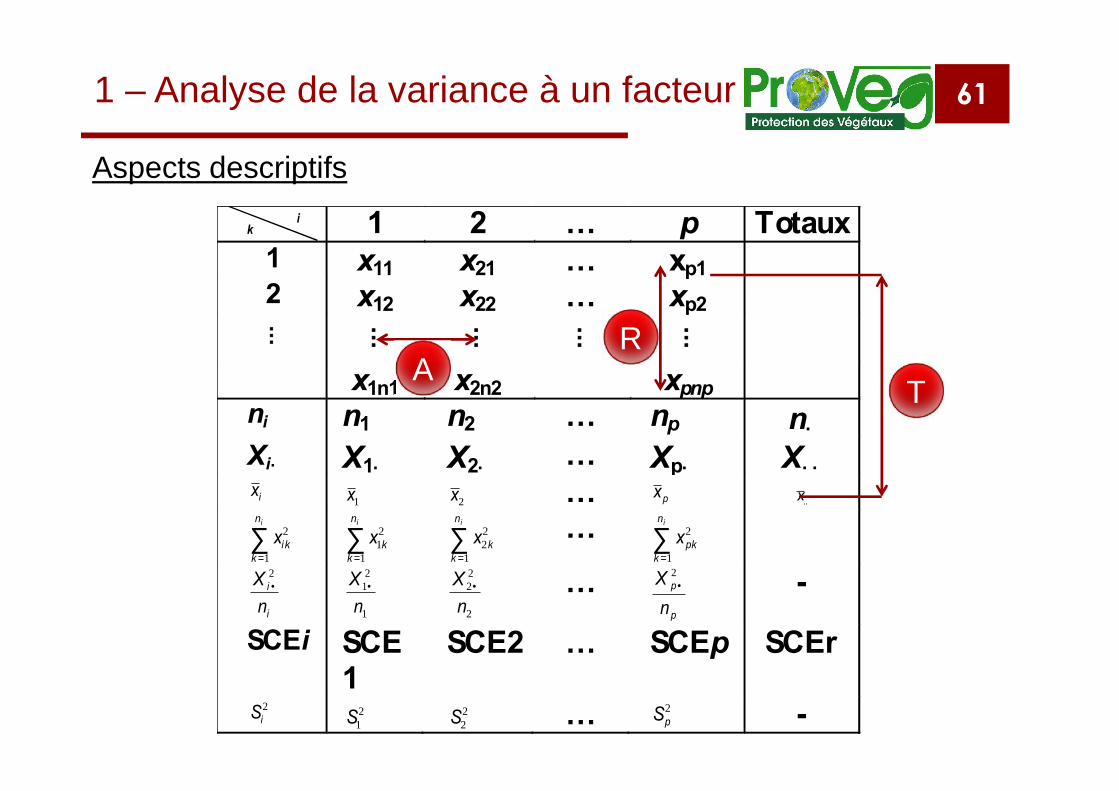
Aspects descriptifsi
k 1 2 … p Totaux1 x11 x21 … xp12 x12 x22 … xp2∶ ∶ ∶ ∶ ∶
x1n1 x2n2 xpnpni n1 n2 … np n·
Xi· X1· X2· … Xp· X··ix 1x 2x … px x..
∑=
in
kikx
1
2 ∑=
in
kkx
1
21 ∑
=
in
kkx
1
22
… ∑=
in
kpkx
1
2
i
i
nX 2
•
1
21
nX •
2
22
nX • …
p
p
nX 2
• -
SCEi SCE1
SCE2 … SCEp SCEr
2iS 2
1S22S … 2
pS -
TA
R

621 – Analyse de la variance à un facteur
Aspects descriptifs
iikiik xxxxxx
La composante globale est appelée variation totale et les deuxcomposantes partielles sont appelées, d’une part, variation factorielleou variation liée au facteur contrôlé ou encore variation entreéchantillons et d’autre part, variation résiduelle ou variation dans leséchantillons.

631 – Analyse de la variance à un facteur
Aspects descriptifs
SCEt = SCEa + SCEr
n - 1 = (p – 1) + (n - p)
CMt = SCEt / (n -1) CMa = SCEa / (p – 1) CMr = SCEr / (n - p)
Ces carrés moyens sont aussi appelés variances. Comme les SCE,les carrés moyens constituent des mesures globales des variationsexistant aux trois niveaux considérés.

641 – Analyse de la variance à un facteur
Aspects inférenciels
L’ANOVA1 se présente sous la forme de deux modèles distincts : lemodèle fixe ou modèle I et le modèle aléatoire ou modèle II.
Le modèle fixe qui est le plus classique a pour objet la comparaisond’un nombre limité p de populations pour toutes lesquelles peut êtreprélevé chaque fois un échantillon.
Le modèle aléatoire concerne au contraire, à la comparaison d’uneinfinité ou d’un très grand nombre (quasi infinité) de populationspour toutes lesquelles il n’est pas possible, en pratique, de préleverchaque fois un échantillon.
Dans l’interprétation des résultats fournis par le modèle aléatoire,on doit être particulièrement attentif au fait qu’on ne s’intéresse passpécifiquement aux p populations pour lesquelles on disposed’observations.

651 – Analyse de la variance à un facteur
Aspects inférentiels
Dans le cas du modèle fixe (modèle I), l’hypothèse nulle à laquelleon s’intéresse est l’hypothèse d’égalité des moyennes :
H0 : m1 = m2 = … = mp
Le test de l’hypothèse nulle nécessite le calcul de la quantité :
CMr
CMaFobs
Le rejet de l’hypothèse nulle, au niveau de probabilité intervientquand cette quantité est trop élevée, c’est à dire quand :
P(F Fobs) ≤ ou Fobs F1-
DL =k1 = p – 1
k2 = n• – p

661 – Analyse de la variance à un facteur
Aspects inférentiels
Dans le cas du modèle aléatoire (modèle II), l’hypothèse concernel’infinité ou la quasi-infinité de populations considérées. Elle s’écritpar rapport à la variance :
Le test de l’hypothèse nulle nécessite le calcul de la quantité :
CMr
CMaFobs
Le rejet de l’hypothèse nulle, au niveau de probabilité intervientquand cette quantité est trop élevée, c’est à dire quand :
P(F Fobs) ≤ ou Fobs F1-
DL =k1 = p – 1
k2 = n• – p
0σ:Ho 2M

671 – Analyse de la variance à un facteur
Aspects inférentiels
Sources de variation DL SCE CM F P
Différences entre échantillons p – 1 SCEa CMa Fa
Différences entre observations n - p SCEr CMr
Totaux n -1 SCEt
Tableau de l’analyse de la variance à un critère de classification

681 – Analyse de la variance à un facteur
Test non paramétrique
Le test non paramétrique utilisé couramment pour comparer ppopulations est le test de Kruskal et Wallis (basé sur les rangs) etconstitue une généralisation du test de Mann et Whitney.
131
12χ1
22obs
n
n
X
nn
p
i i
i DL = p - 1
αχχP 2obs
2 2α-1
2obs χχ ou

692 – Analyse de la variance à deux facteurs
Principes généraux
L’analyse de la variance à deux critères de classification (Two-wayanalysis of variance, ANOVA2) est une analyse de la variance quitient compte de deux facteurs.
Les deux facteurs considérés peuvent être soit placés sur le mêmepied d’égalité soit au contraire subordonnés l’un à l’autre. Dans lepremier cas, les modèles de l’analyse de la variance sont ditscroisés alors que dans le deuxième cas, ils sont dits hiérarchisés.
Dans un cas comme dans l’autre, on doit également faire ladistinction entre les modèles fixes (Modèle I), les modèlesaléatoires (Modèle II) et les modèles mixtes (Modèle III).
Aussi, dans un cas comme dans l’autre, les échantillons peuventêtre d’effectifs égaux (modèles équilibrés) ou inégaux (modèlesdéséquilibrés)

702 – Analyse de la variance à deux facteurs
Aspects descriptifs du modèle croisé à effectifs égaux
SCEt = SCEa + SCEb + SCEab + SCEr
En associant les lettres a et b respectivement à chacun des deuxcritères de classification et en désignant les différents termes parSCEt, SCEa, SCEb, SCEab et SCEr on peut simplifier comme suit,l’équation de l’ANOVA2 :
Aux différentes SCE peuvent être associés des nombres de degrésde liberté qui sont liés par la relation :
npq - 1 = (p – 1) + (q – 1) + (p – 1) (q – 1) + pq(n – 1)
Enfin, en divisant les différentes SCE par leurs DL, on obtient lescarrés moyens CMt, CMa, CMb, CMab et CMr.

712 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle croisé à effectifs égaux
La formulation de l’hypothèse nulle dépend du modèle

722 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle croisé à effectifs égaux
La formule de calcul du Fobs dépend du modèle
FacteurFormule de FObs
Modèle fixe (I) Modèle aléatoire (II) Modèle mixte (III)
Facteur a Fa = CMa / CMr Fa = CMa / CMab Fa = CMa / CMab
Facteur b Fb = CMb / CMr Fb = CMb / CMab Fb = CMb / CMr
Interaction (ab) Fab = CMab / CMr Fab = CMab / CMr Fab = CMab / CMr
NB : Dans le modèle mixte, a est le facteur fixe tandis que b est lefacteur aléatoire.

732 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle croisé à effectifs égaux Le terme d’interaction apparaît dans le modèle observé d’analyse
de la variance à deux critères de classification lorsqu’on veutéquilibrer ce modèle après y avoir fait figurer les écarts factoriels etrésiduel.
Elle est nulle quand les différences liées à l’action d’un des deuxfacteurs ne dépendent pas de l’autre facteur, c’est à dire quand parexemple les écarts relatifs au premier facteur sont indépendantsdes modalités du deuxième facteur.
Quand il n’y a pas d’interaction, alors l’effet conjoint des deuxfacteurs est égal à la somme de leurs effets individuels. Le modèled’analyse de la variance est alors dit additif.
Quand l’interaction n’est pas nulle surtout dans le cas particulier 2 x2 (p = q = 2), on parle de synergie ou d’antagonisme selon quel’interaction est positive ou négative.

742 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle croisé à effectifs égaux
Sources de variation DL SCE CM F P
Facteur a p – 1 SCEa CMa Fa
Facteur b q – 1 SCEb CMb Fb
Interaction (p – 1) (q – 1) SCEab CMab Fab
Variation résiduelle pq(n – 1) SCEr CMr
TOTAUX pqn - 1 SCEt

752 – Analyse de la variance à deux facteurs
Aspects descriptifs du modèle hiérarchisé à effectifs égaux Les modèles hiérarchisés d’analyse de la variance à deux critères
de classification correspondent à des situations où un des deuxcritères est subordonné à l’autre.
Exemple – Comparaison des rendements laitiers d’une race bovinedans plusieurs régions, en choisissant au hasard etindépendamment, plusieurs élevages dans chaque région et enmesurant dans chacune d’elles les rendements de plusieurs bêtes.Le facteur élevage est alors subordonné au facteur région.
Le facteur subordonné est généralement aléatoire et le facteurprincipal peut être fixe ou aléatoire. Les modèles d’analyse de lavariance à prendre en considération sont donc modèle mixte oumodèle aléatoire.

762 – Analyse de la variance à deux facteurs
Aspects descriptifs du modèle hiérarchisé à effectifs égaux
SCEt = SCEa + SCEb\a + SCEr
SCEb\a = SCEb + SCEab
pqn – 1 = (p – 1) + p(q – 1) + pq(n-1)
CMb\a = SCEb\a / p(q – 1)

772 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle hiérarchisé à effectifs égaux
La formulation de l’hypothèse nulle dépend du modèle

782 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle hiérarchisé à effectifs égaux
La formule de calcul du Fobs dépend du modèle
FacteurFormule de FObs
Modèle aléatoire (II) Modèle mixte (III)
Facteur a Fa = CMa / CMb\a Fa = CMa / CMb\a
Facteur b\a Fb\a = CMb\a / CMr Fb = CMb\a / CMr

792 – Analyse de la variance à deux facteurs
Aspects inférentiels du modèle hiérarchisé à effectifs égaux
Sources de variation DL SCE CM F PFacteur a p – 1 SCEa CMa FaFacteur b (dans a) p(q – 1) SCEb\a CMb\a Fb\aVariation résiduelle pq(n – 1) SCEr CMr
TOTAUX pqn – 1 SCEt

803 – Comparaisons post-ANOVA
Globalement, trois situations peuvent se présenter :
Quand il s’agit de la comparaison de p moyennes deux à deux,on peut utiliser : La méthode de la plus petite différence significative La méthode de TUKEY La méthode de SCHEFFÉ (flexible et conservatif) La méthode de NEWMAN et KEULS (même effectifs) La méthode de DUNCAN
Quand il s’agit de la comparaison de p – 1 moyennes à untémoin, on peut utiliser la méthode de DUNNETT ;
Pour la recherche des moyennes les plus élevées la méthodede GUPTA peut être utilisée.