similarity join wu yang 2009.4.9. main work ms--a primitive operator for similarity joins in data...
TRANSCRIPT

Similarity Join
Wu Yang2009.4.9

Main work
MS--A Primitive Operator for Similarity Joins in Data Cleaning ICDE 2006
Google--Scaling Up All Pairs Similarity Search www2007 University of New South Wales & NICTA Australia – Chuan Xiao , Wei Wang , Xuemin Lin
PPJoin : Efficient Similarity Joins for Near Duplicate Detection, WWW2008 ,
EdJoin:An Efficient Algorithm for Similarity Joins With Edit Distance Constraints , VLDB 2008
Approximate Entity Extraction with Edit Distance Constraints. SIGMOD 2009
Top-k Set Similarity Joins. ICDE 2009
23/4/21 2

23/4/21 3
Outline
Motivation Algorithms Experiments Thinking

23/4/21 4
Near Duplicate DataOn one end, a winded Pete Sampras tried to
summon enough energy to give the New York fans another memorable win to talk about it on the subway ride home. On the other side, Roger Federer wore a
sly grin like he knew age was about to catch up to the former world No. 1 - the man who owns the record of
14 Grand Slams he wants.
03/11/2008 | 11:28 AM By JAY COHEN, AP Sports Writer Mar 11, 4:23 am EDT
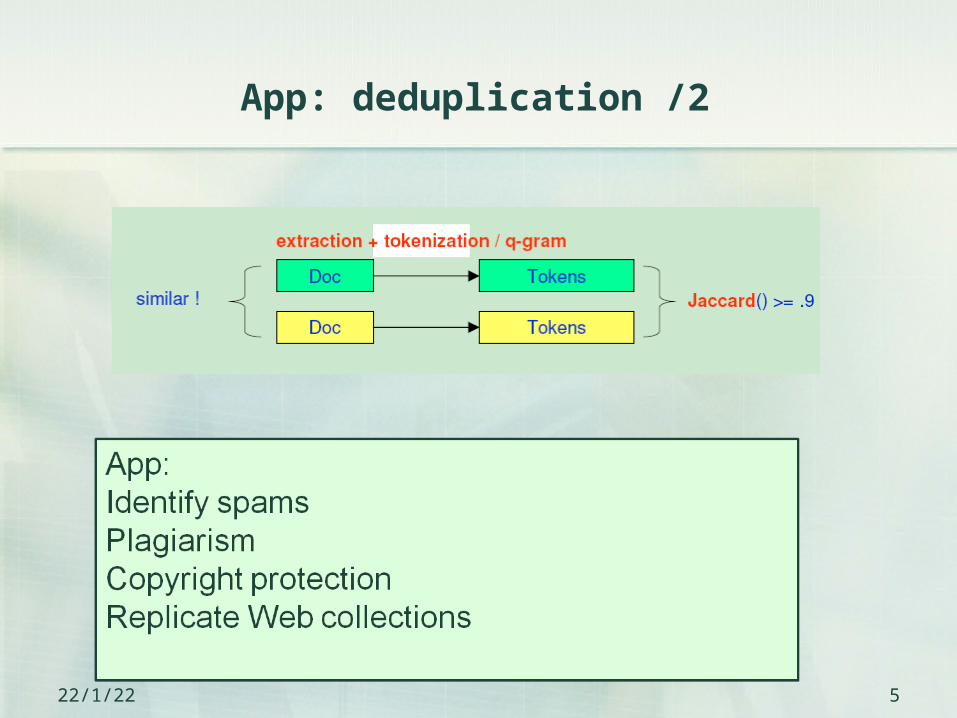
App: deduplication /2
23/4/21 5
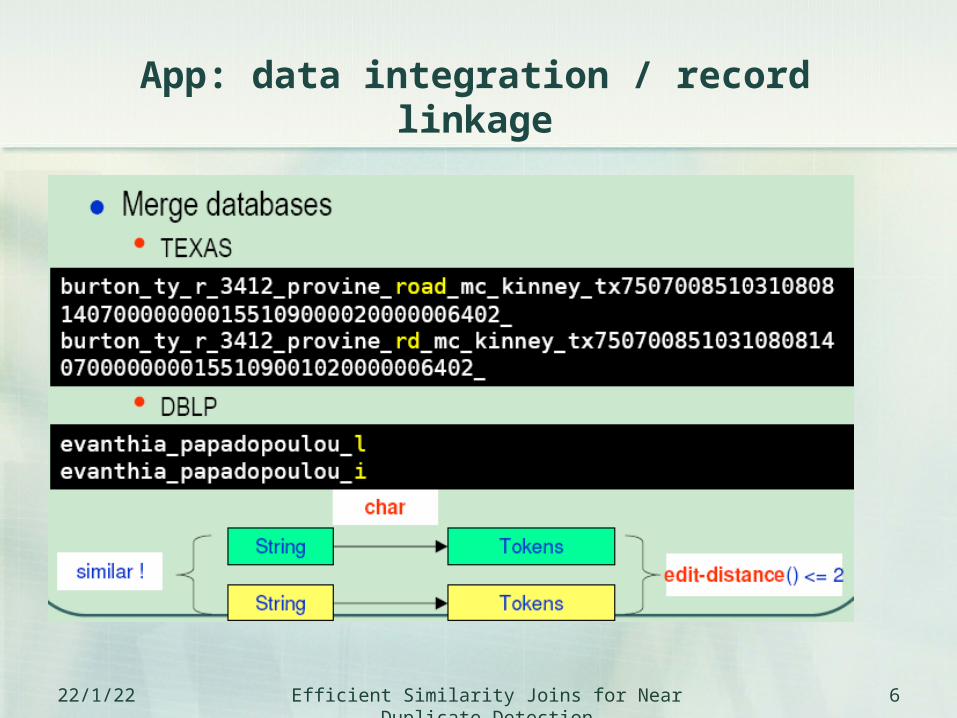
App: data integration / record linkage
Efficient Similarity Joins for Near Duplicate Detection23/4/21 6

23/4/21 7
Applications
For Web search engines: Perform focused crawling Increase the quality and diversity of query results Identify spams.
For Web mining: Perform document clustering Find replicate Web collections Detect plagiarism
SPAM TEMPLATE
Sir/Madam,We happily announce to you the draw of the EURO MILLIONS SPANISH LOTTERY INTERNATIONALWINNINGS PROGRAM PROMOTIONS held on the 27TH MARCH 2008 in SPAIN. Your company or yourpersonal e-mail address attached to ticket number 653-908-321-675 with serial main number <NUMBER> drew lucky star winning numbers <NUMBER> which consequently won in the 2ND category, you have therefore been approved for a lump sum pay out of 960.000.00 Euros. (NINE HUNDRED AND SIXTY THOUSAND EUROS).CONGRATULATIONS!!!
Sincerely yours,<NAME><AFFILIATION>
Q. What are the advantages of RAID5 over RAID4?A. 1. Several write requests could be processed in parallel, since the bottleneck of a unique check disk has been eliminated. 2. Read requests have a higher level of parallelism. Since the data is distributed over all disks, read requests involve all disks, whereas in systems with a dedicated check disk the check disk never participates in read.
Q. What are the advantages of RAID5 over RAID4? A. 1. Several write requests could be processed in parallel, since the bottleneck of a single check disk has been eliminated. 2. Read requests have a higher level of parallelism on RAID5. Since the data is distributed over all disks, read requests involve all disks, whereas in systems with a check disk the check disk never participates in read.

Algorithms
Data set Similarity function Algorithms
23/4/21 8
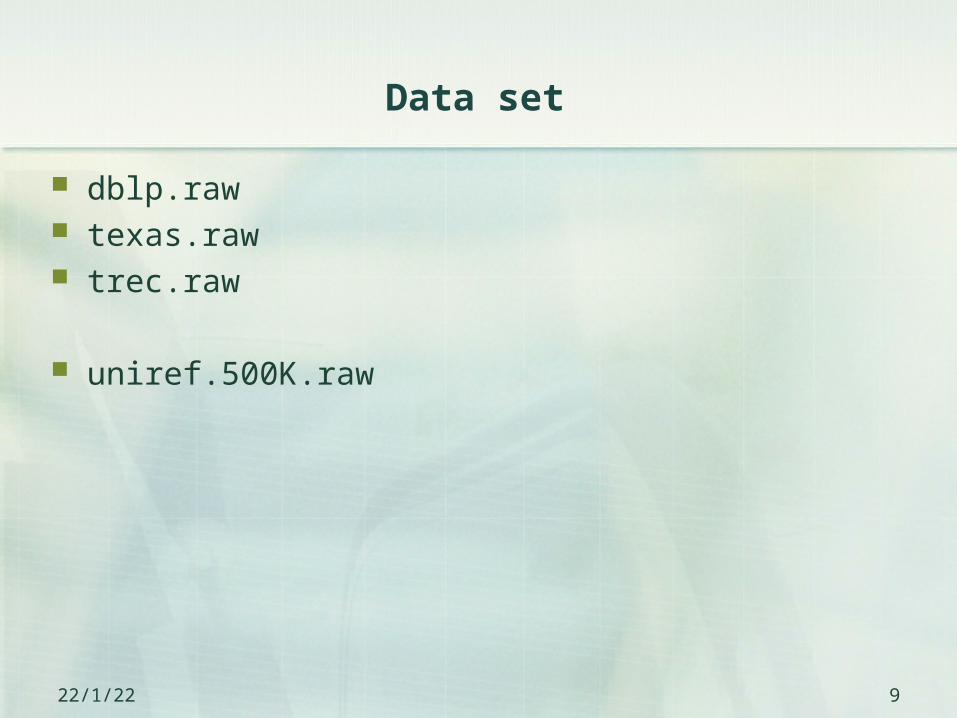
Data set
dblp.raw texas.raw trec.raw
uniref.500K.raw
23/4/21 9

23/4/21 10
Similarity Function
Common similarity functions:
Jaccard:
Cosine:
Overlap:
Jaccard can be equivalently converted to Overlap
tyx
yxyxJ
),(
tyx
yxyxC
),(
tyxyxO ),(
yxt
tyxO
1),(t
yx
yxyxJ
),(
x = {A,B,C,D,E}
y = {B,C,D,E,F}
4/6 = 0.67
4/5 = 0.8
4

Similarity Function
Hamming distance =|(x-y)U(y-x)| Edit distance
23/4/21 11
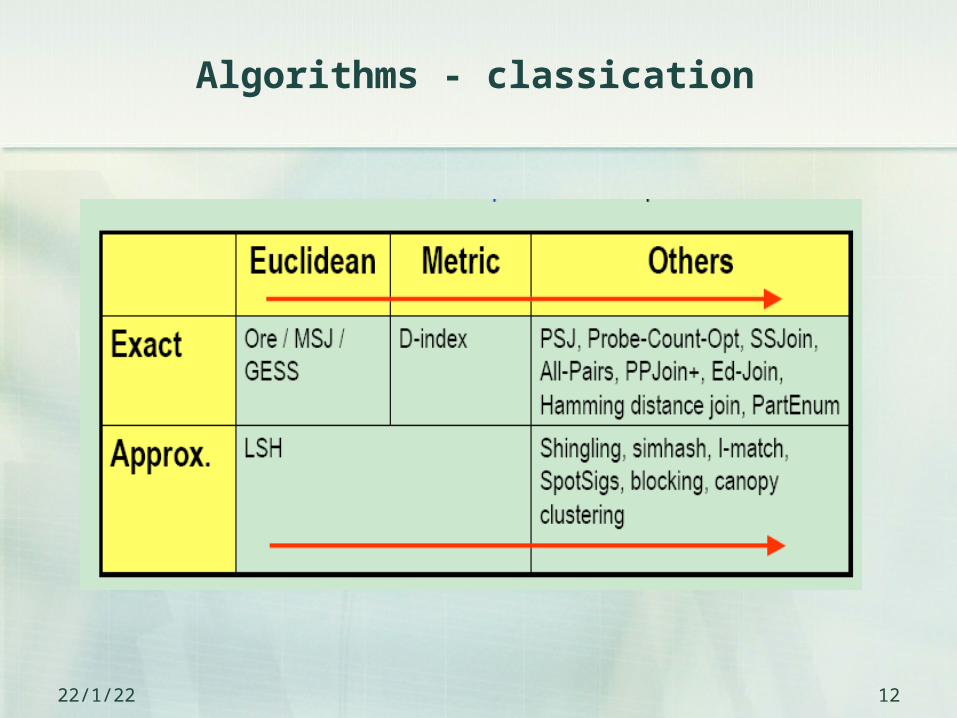
Algorithms - classication
23/4/21 12

Algorithms object
Similarity between sets
• Binary similarity functions
• Contains, intersects
• Numerical similarity functions
• Overlap, Jaccard, dice, cosine
Similarity between strings
• Treat strings as sets
• Jaccard (on q-grams), edit distance
23/4/21 13

algorithms
SSJoin All-pairs PPJoin, PPJoin+ Top-k Set Similarity Joins
23/4/21 14

SSJoin
Based on sets Why string to set?
Cited from Efficient Exact Set-Similarity Joins --MS Generalizes to many string similarity funcs
Powerful primitive Sets ≈ Relations
Leverage relational data processing
23/4/21 15

SSjoin
find {(r, s) | r R, s S, overlap(r, s) ≥ t} ∈ ∈ A fundamental “operator”
can handle other similarity functions (Jaccard, cosine, Hamming, dice, edit distance, …) via transformation
Efficient Similarity Joins for Near Duplicate Detection23/4/21 16

Prefix Filtering-based similarity join
1. SSJoin[Chaudhuri et al, ICDE06]
• Formalize the prefix-filtering principle
2. All pairs [Bayardo et al, WWW07]
• Use prefix-filtering in an asymmetric way
3. PPJoin+[Xiao et al, WWW08]
• Employs prefix-filtering, position filtering and suffix Filtering-based Similarity Joins
23/4/21 17

ALL Pairs
23/4/21 18

23/4/21 19
Prefix + Positional Information
We use prefix filter (All-Pairs [www07]) as basic framework Intuition
tokens sorted -> rank, or position of tokens within a record estimate tighter upper bounds of overlap between x and y with
positional information
Contributions index construction
index not only tokens, but their positions in the record
ppjoin algorithm candidate generation
probe tokens in suffix, compare the positions in the record
ppjoin+ algorithm
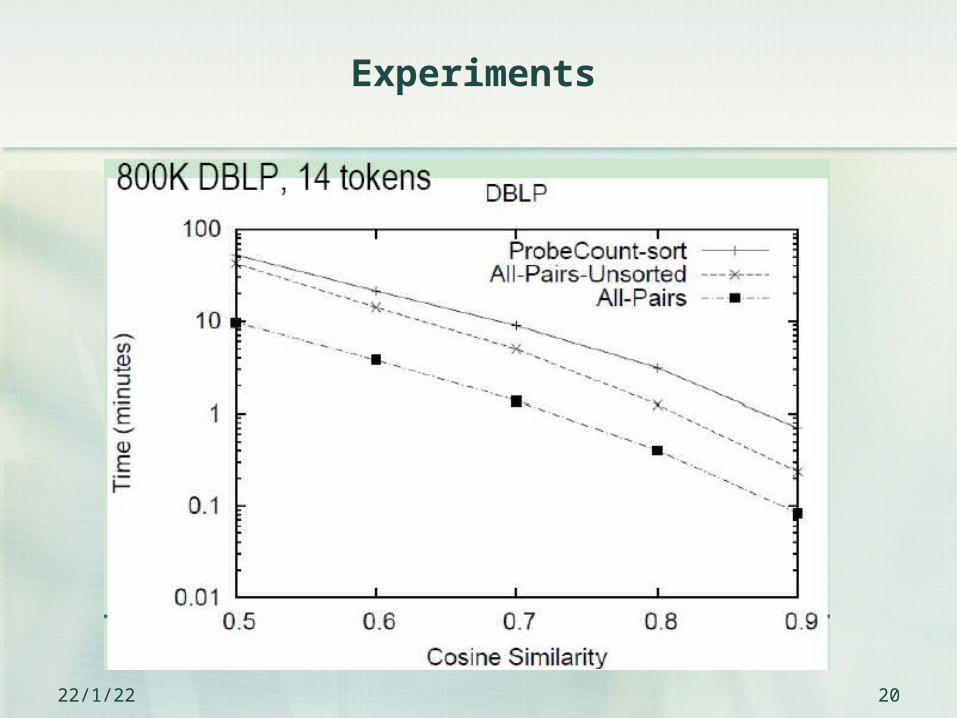
Experiments
23/4/21 20
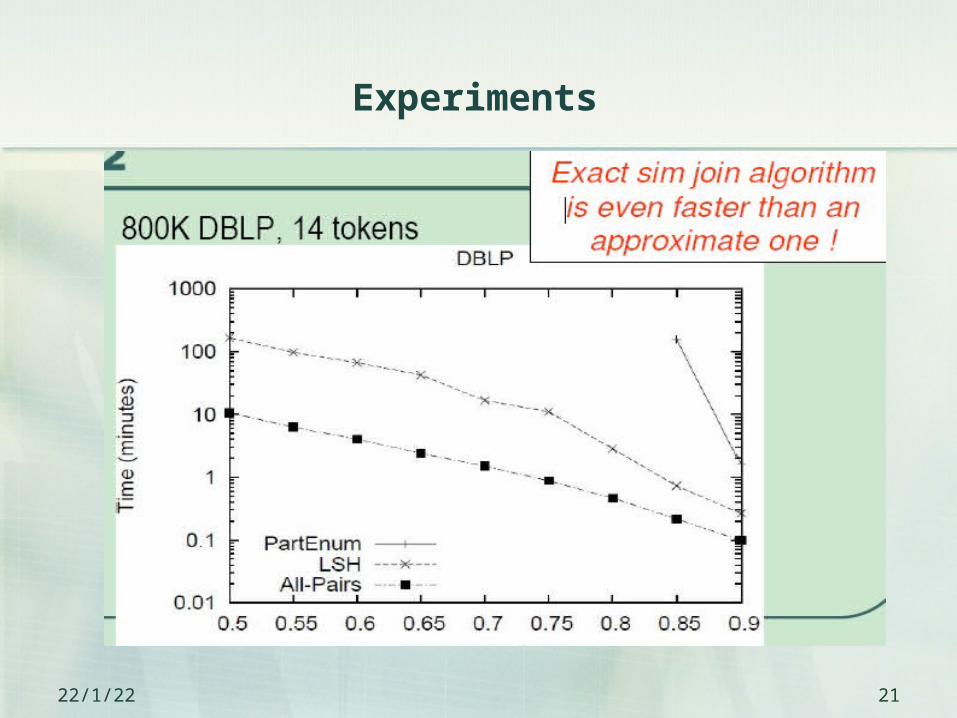
Experiments
23/4/21 21
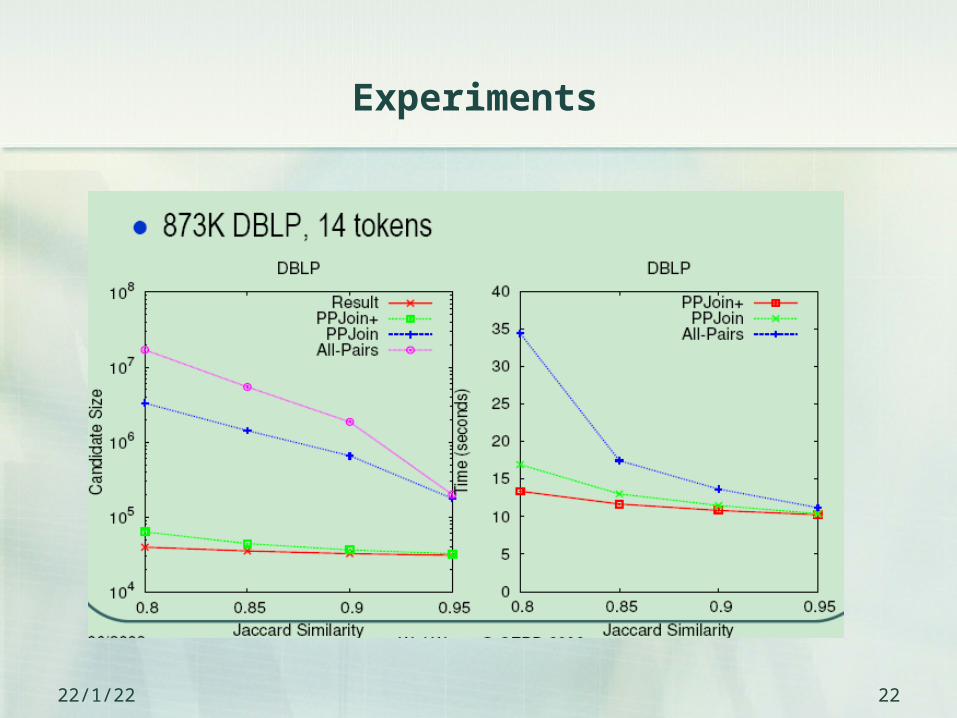
Experiments
23/4/21 22

Thinking
Further optimization on performances 1. Index for similarity functions (e.g., cosine)
2. Better pruning techniques
3. Optimize for the specific similarity/distance function
23/4/21 23
Thinking
已有方法对于 token的处理 基于 inverted-list方法 TF , IDF IR中常见加权的方式 wi,j=tf*idf
直觉:既然 token的权重对于算法的效率有影响,那么有没有更好的方式处理 token的排序呢?是否对结果有影响呢?思考:对于 token排序的过程中,对于某些词,是否可以屏蔽掉,对于某些词,是否定义其权重。
23/4/21 24

continue
报告中所介绍的算法,都是基于 SET的。如图

23/4/21 26
Related Work
Approximate: LSH: A. Gionis, P. Indyk, and R. Motwani. Similarity search in high
dimensions via hashing. In VLDB, 1999. Shingling: A. Z. Broder. On the resemblence and containment of
documents. In SEQS, 1997. Exact:
Index-based: S. Sarawagi and A. Kirpal. Efficient set joins on similarity predicates. In
SIGMOD, 2004. Prefix-based:
S. Chaudhuri, V. Ganti, and R. Kaushik. A primitive operator for similarity joins in data cleaning. In ICDE, 2006.
All-Pairs: R. J. Bayardo, Y. Ma, and R. Srikant. Scaling up all pairs similarity search. In WWW, 2007.
PPjoin,PPjoin+ Chuan Xiao, Wei Wang, Xuemin Lin, Jeffrey Xu Yu. Efficient Similarity Joins for Near Duplicate Detection . WWW 2008
Pigeon-hole principle based: PartEnum: A. Arasu, V. Ganti, and R. Kaushik. Efficient exact set-similarity
joins. In VLDB, 2006.

23/4/21 27
References
[SEQS97] A. Z. Broder. On the resemblance and containment of documents. In SEQS 1997. [MIR] R. Baeza-Yates and B. Ribeiro-Neto. Modern Information Retrival. Addison Wesley, 1st
edition, May 1999. [VLDB99] LSH: A. Gionis, P. Indyk, and R. Motwani. Similarity search in high dimensions via
hashing. In VLDB, 1999. [SIGMOD04] S. Sarawagi and A. Kirpal. Efficient set joins on similarity predicates. In SIGMOD,
2004. [ICDE06] S. Chaudhuri, V. Ganti, and R. Kaushik. A primitive operator for similarity joins in data
cleaning. In ICDE, 2006. [VLDB06] PartEnum: A. Arasu, V. Ganti, and R. Kaushik. Efficient exact set-similarity joins. In
VLDB, 2006. [WWW07] All-Pairs: R. J. Bayardo, Y. Ma, and R. Srikant. Scaling up all pairs similarity search. In
WWW, 2007. [WWW 2008] Efficient Similarity Joins for Near Duplicate Detection Chuan Xiao, Wei Wang,
Xuemin Lin, Jeffrey Xu Yu.. WWW 2008 [VLDB 2008]. Ed-Join: An Efficient Algorithm for Similarity Joins with Edit Distance
Constraints. VLDB 2008. [ICDE 2009] . Top-k Set Similarity Joins Chuan Xiao, Wei Wang, Xuemin Lin, Haichuan Shang