sharon e. mitchell - cornell...
TRANSCRIPT

Genotyping By Sequencing (GBS) Method Overview
Sharon E. MitchellInstitute for Genomic Diversity
Cornell University
http://www.maizegenetics.net/

•Background/Goals
•GBS lab protocol
•Illumina sequencing review
•GBS adapter system
•How GBS differs from RAD
•Modifying GBS for different species
•GBS Workflow
Topics Presented

Background
Genotyping by sequencing (GBS) in any large genome species requires reduction of genome complexity.
II. Restriction Enzymes (REs)I. Target enrichment
•Long range PCR of specific genes or genomic subsets
•Molecular inversion probes
•Sequence capture approaches hybridization‐based (microarrays)
*Technically less challenging*
• Methylation sensitive REs filter out repetitive genomic fraction

QTL are often located in non‐coding regionsVgt1, Tb, B regulatory regions 60‐150kb from gene
Exon Exon Exon Exon
Exon captureMap large numbers ofgenome‐wide markers
QTL

Create inexpensive, robust multiplex
sequencing protocol
Low‐ or high‐coverageSequencing Illumina GA
Informatics Pipeline
Anchor markers acrosthe genome
Impute missing dataif needed
Combine genotypic & phenotypic data for QTL mapping, GS and
GWAS
We have created a public genotyping/informatics platform based on next‐generation sequencing

Open Source
• Method available for anyone to use / modify.• Analysis pipeline details and code are public.• Promote dataset compatibility.• Method published in PLoS ONE to promote accessibility.
• Genotype calls available for public projects.

< 450 bp
Restriction site( ) sequence tag
Loss of cut site
Sample1
Overview of Genotyping by Sequencing (GBS)
• Focuses NextGen sequencing power to ends of restriction fragments• Both SNPs and presence/absence markers can be scored• Small indels are identified but are not scored
Sample2

• Reduced sample handling• Few PCR & purification steps• No DNA size fractionation• Efficient barcoding system• Simultaneous marker discovery & genotyping
• Scales very well
GBS is a simple, highly multiplexed system for constructing libraries for next‐gen sequencing

GBS 96‐ to 384‐plex Protocol(http://www.maizegenetics.net/gbs‐overview)
1. Plate DNA & adapter pair
2. Digest DNA with RE3. Ligate adapters

GBS Adapters and Enzymes
BarcodeAdapter “Sticky Ends”
Barcode(4‐8 bp)
CommonAdapter
P1 P2
ApeKI G CWGCPstI CTGCA GEcoT22I ATGCA T
5’ 3’
Restriction Enzymes
Illumina Sequencing Primer 2
Illumina Sequencing Primer 1

GBS 96‐ or 384‐plex Protocol(http://www.maizegenetics.net/gbs‐overview)
............. ...
..... ..................... ........... ..
..
. .. ...
.
...
..... ......... .. .........
.....
...
. .. ....... ......
...
.. .......
...
. .
..
.... . .. . ....
1. Plate DNA & adapter pair
5. PCR
Primers
2. Digest DNA with RE3. Ligate adapters
Clean‐up4. Pool samples

. .
..
..
.
....
.. ...
...........
.
.
.. ........
.
.
. ... ...
..
.
.
..
.
.
.
.....
.
.
...... ..
..
.
.
.
.
...
.. ...
.. ...
......
.
..
.....
. ......
....
... ..
...
.. ... .
..
..
.
........
.
. .
.PCR
Pooled Digestion/Ligation Reactions
GBS“Library”
PRC primers:
P1 P2Insert O2O1

GBS 96‐ or 384‐plex Protocol(http://www.maizegenetics.net/gbs‐overview)
............. ...
..... ..................... ........... ..
..
. .. ...
.
...
..... ......... .. .........
.....
...
. .. ....... ......
...
.. .......
...
. .
..
.... . .. . ....
1. Plate DNA & adapter pair
5. PCR
Primers
2. Digest DNA with RE3. Ligate adapters4. Pool DNA aliquots
6. Evaluate fragment sizes
Clean‐upClean‐up
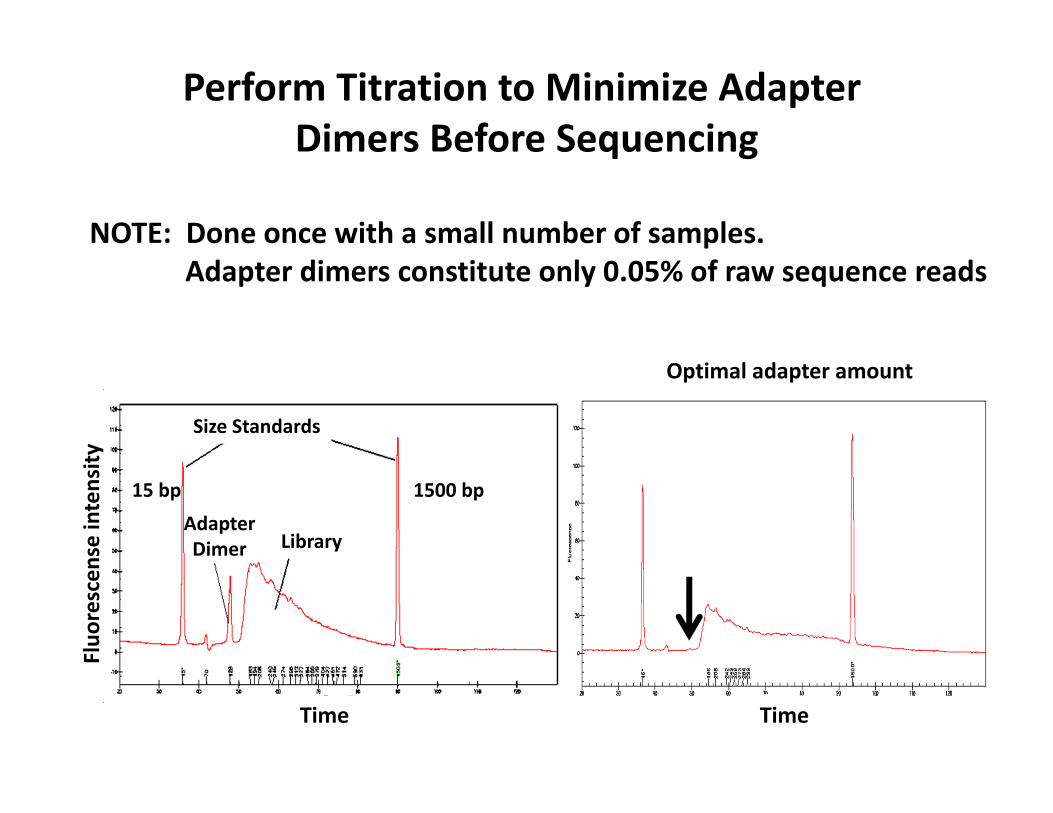
Perform Titration to Minimize Adapter Dimers Before Sequencing
Size Standards
LibraryAdapterDimer
1500 bp15 bp
NOTE: Done once with a small number of samples.Adapter dimers constitute only 0.05% of raw sequence reads
Fluo
rescen
seintensity
Time Time
Optimal adapter amount

Small Fragments are Enriched in GBS Libraries Total Fragm
ents
0%
5%
10%
15%
20%
25%
30%
35%
40%
0 50 100
150
200
250
300
350
400
450
500
550
600
650
700
750
800
850
900
950
1000
1000
0000
REFGENOME
IBM
ApeKI fragment size (bp) >10000
B73 RefGen v1IBM (B73 X Mo17) RILs
0
100000
200000
300000
400000
500000
600000
700000
800000
900000
1000000
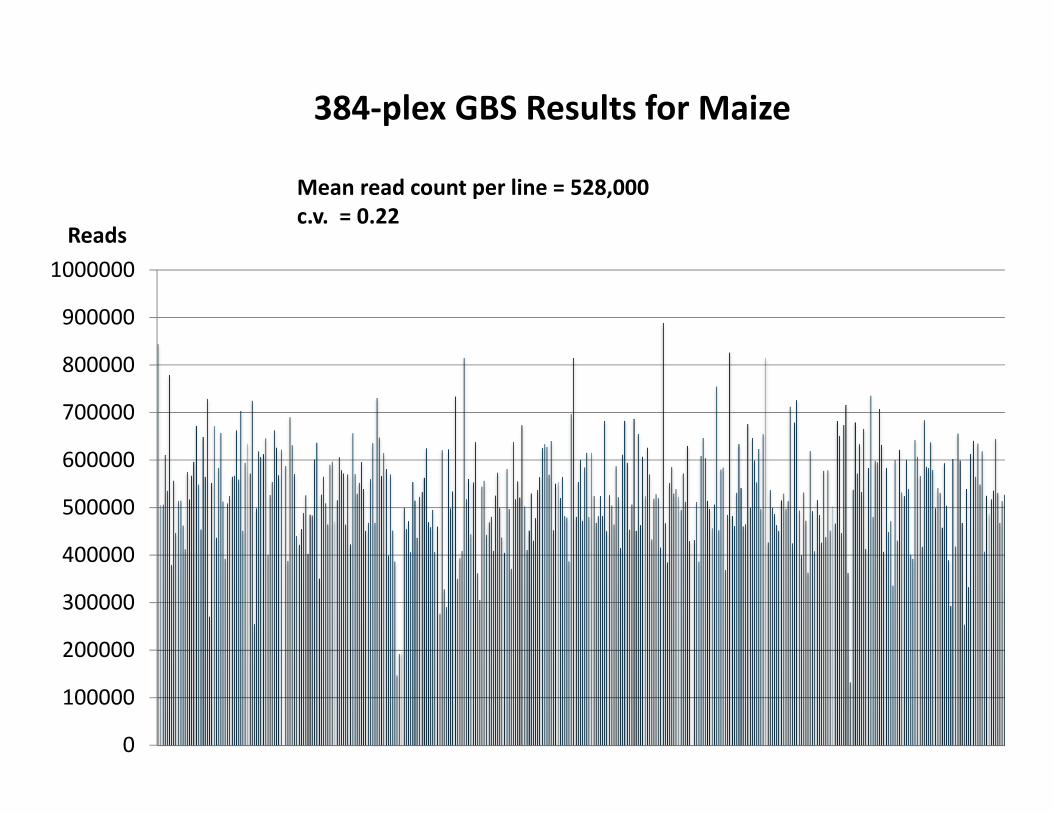
384‐plex GBS Results for Maize
Reads
Mean read count per line = 528,000c.v. = 0.22

Illumina Sequencing Overview


Flowcell8 channels
Solid Phase Oligos
Illumina Sequencing by Synthesis Review
Based on solid phase‐PCR

Illumina Sequencing Platform Based on:
PCR product attachedto surface
1 Solid‐Phase PCR

Flow cell with bound oligos
Denatured “Library”
Cluster Formation Amplifies Sequencing Signal
Linearization
CBot
Bridge Amplification
PCRCleavage

Illumina Sequencing Platform Based on:
2. “Sequencing by Synthesis”
ACGTGGC
T
Blocking group promotesconcurrent extension.

ACGTGGC
TG
P1 primer
CA
TTGTGC
Sequencing by Synthesis
FlowcellHiSeq 2000
TGCA


GACGT
GC
T
G
ACGTGGC
T
C
ACGT
GC
TG
G
T
ACGTGGC
T ACGTGGC
T ACGTGGC
T
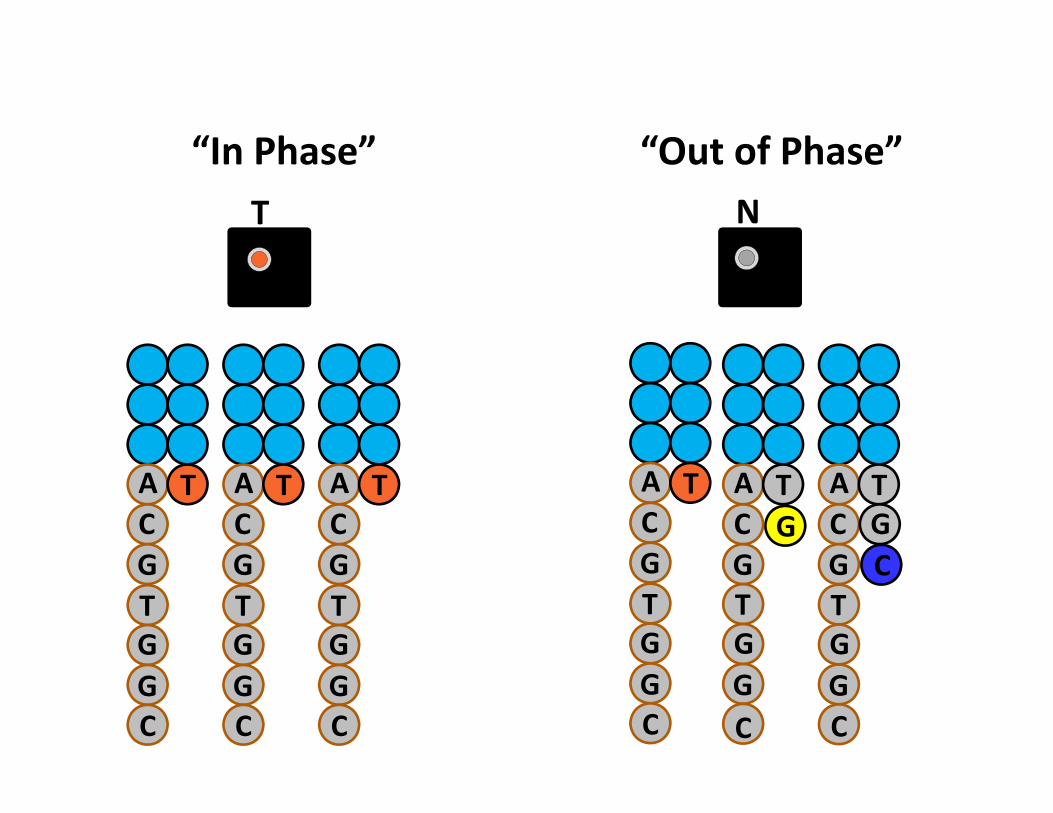
N
“In Phase” “Out of Phase”

Read 1
GBS captures barcode and insert DNA sequence in single read
Insert DNA
Barcode
Sequencing Primer 1
Sequencing Primer 2
Illumina
Read 1
Read 2
Sequencing Primer 1
BarcodeRE cut‐site
Insert DNA
GBS

Variable Length GBS Barcodes Solves Sequence Phasing Issues
•First 12 nt used to calculate phasing.•Algorithm assumes random nt distribution.•Incorrect phasing causes incorrect base calls.
Barcode
Illumina
Insert DNA
•Good design and modulating the RE cut site position with variable length barcodes produces even nt distribution.
Read 2
Read 1
BarcodeRE cut‐site
GBS
Insert DNA

Invariant GBS barcodes cause loss of signal intensity.

Successful GBS sequencing run.

GBS Adapter Design

Barcode Design Considerations• Barcode sets are enzyme specific
– Must not recreate the enzyme recognition site– Must have complementary overhangs
• Sets must be of variable length• Bases must be well balanced at each position• Must different enough from each other to avoid confusion if
there is a sequencing error.– At least 3 bp differences among barcodes.
• Must not nest within other barcodes• No mononucleotide runs of 3 or more bases
http://www.deenabio.com

Most significant GBS technical issues?
• DNA quality• DNA quantification

Different Ends 50%
Same Ends 50%
100%
Ligation
LigationPCR
GBSStandard
GBS does not use standard “Y” adapters

Denatured “library”
Flow Cell with Bound Oligos
Same‐ended Fragments Do Not Form Clusters
Bridge Amplification
Cluster Formation &“Linearization”
No P1 bindingsite
Cleaved from surface

< 450 bp
Restriction site( ) sequence tag
Loss of cut site
Sample1
GBS vs. RAD
• Focuses NextGen sequencing power to ends of restriction fragments• Scores both SNPs and presence/absence markers
Sample2

Digest
Ligate adapters
Pool
Random shear
Size select
Ligate Y adapters
PCR
RADGBS
ReferenceDavey et al. 2011

Modifying GBS
Considerations for using GBS with new species and / or different enzymes.

Why Modify the GBS Protocol?
• More markers• Fewer markers (deeper sequence coverage per locus)
• Increase multiplexing• More genome appropriate (avoid more repetitive DNA classes)
• Other novel applications (i.e., bisulfitesequencing).

Genome Sampling Strategies Vary by Species
Dependent on Factors that Affect Diversity:
•Mating System(Outcrosser, inbreeder, clonal?)
•Ploidy(Haploid, diploid, auto‐ or allopolyploid?)
•Geographical Distribution(Island population, cosmopolitan?)

Other Factors
• Genome size– The size of the genome has some bearing on the size of the fragment pool.
– Amount of repetitive DNA directly correlated with genome size.
• Genome composition– The base composition of the genome can affect the frequency and distribution of the cut sites.
– How repetitive DNA is organized in the genome affects library profiles

Sampling large genomes with methylation‐sensitive restriction enzymes.
5‐base cutter
6‐base cutter
MethylatedDNA
UnmethylatedDNA
GBS LibrarySequenced Fragments

Scrub jay
Vole Giantsquid
Deer Mouse
TunicateYeast
Solitary Bee
Grape Maize Cacao
Rice
Raspberry
Barley
Cassava
Goose
Sorghum
Cassava
Shrub willow
Optimizing GBS in New Species

MaizeSorghumRiceBarley
SwitchgrassBracypodiumPearl MilletTeosinte
AndropogonFonio
Finger MilletReed Canary Grass
TripsacumSugar caneRye grass
IrisBananaOil Palm
GrapeCassavaCacao
WatermelonAppleHop
EucalyptusCashewAuracariaGuinea YamHorseradishCottonChickpeaLentil
PineSpruce
Conifers
Flowering Plants
StrawberrySilene
SunflowerSafflowerSoybean
GoldenberryJatrophaWillow
Turnip rapeCanolaPlum
Monkey FlowerOnionPeanutCowpeaSquashTomatoClover
Corn SaladAlmondFlax
PepperCucumberSnap peaGourd
ArabidopsisWillowTea
PotatoCherry
RaspberryPeachKnautiaTomatilloCorn Salad
AlderApricotBean
Pigeon Pea

NeurosporaVerticilliumPhytophthora
Solitary BeeCorn Earworm
Cotton Bollworm
Mexican TetraKillifish
Top MinnowCatfish
Scrub JayGoose
ChickadeeFinches
WeaverbirdAntbirdAntwrenFairy‐wrenGnatwrenManakin
OropendolaSapsuckerWarbler
Woodcreeper
CowPigFox
DolphinSeal
Sea LionWalrus
Water BuffaloCamel
Deer MouseVoleHare
Snow LeopardLynx
NewtFrog
Giant SquidPearl Oyster

Choosing Appropriate Restriction Enzymes:Generalizations from the Bench

ApeKI works well for grasses.

EcoT22I I works well for fish, amphibians and invertebrates.

PstI works well for mammals and birds.

Most frequently asked question for new species:
“How many SNPs will I get”?

Answer: “It depends……”
• Genome size and expected heterozygosityaffects size of fragment pool for desiredamount of sequence coverage (enzyme choiceand multiplex level).
• Amount of extant diversity and how well your samples capture that diversity.
• Reference genome sequence? 3‐4X more SNPs attained by aligning to a reference sequence.

SpeciesGenome Size (Mb) Enzyme Sample Size No. SNPs
Maize 2,600 ApeKI 33,000 2,200K
Rice 400 ApeKI 850 60K
Grape 500 ApeKI 8,000 1,200K
Willow* 460 ApeKI 459 23K
Pine* 16,000 ApeKI 12 63K
Vole* 3,400 PstI 283 53K
Fox* 2,400 EcoT22I 48 16K
Cow 3,000 PstI 48 64K
Neurospora(fungus isolates)
40 ApeKI 384 100K
How many SNPs will I get?
*No reference genome. UNEAK analysis pipeline used for analysis. To avoid homology/paralogyissues this pipeline calls SNPs very conservatively.

GBS SNP calls in Sorghum bicolor ‐ Lots of Missing Datars# alleles chrom pos strand RIL_1 RIL_10 RIL_100 RIL_101 RIL_102 RIL_103 RIL_104 RIL_105
S10_13181 T/G 10 13181 + T T T T N T N T
S10_13355 T/C 10 13355 + T T T N T N T T
S10_15605 A/G 10 15605 + N A N A A A A N
S10_15607 A/G 10 15607 + N A N A A A A N
S10_15619 A/G 10 15619 + N A N A A A A N
S10_15629 G/A 10 15629 + G G G G G G G G
S10_15685 C/G 10 15685 + C N C C C N C C
S10_15687 G/A 10 15687 + G N G G G N G G
S10_15699 G/C 10 15699 + G G G G G N G G
S10_15720 A/G 10 15720 + N N N N N N N A
S10_15721 G/C 10 15721 + N N N N N N N G
S10_15722 A/T 10 15722 + N N N N N N N N
S10_15723 T/C 10 15723 + N N N N N N N T
S10_16315 G/T 10 16315 + N G G G G N N G
S10_16419 A/G 10 16419 + A A A A N N A A
S10_16432 C/G 10 16432 + C C C C N N C C
S10_16439 A/G 10 16439 + N N N N N N N N
S10_16497 C/A 10 16497 + C C C N C C N N
S10_16498 A/G 10 16498 + A A A N A A N N
S10_16499 C/A 10 16499 + C C C N C C N N
S10_16573 T/A 10 16573 + T T N N T T T T
S10_17505 G/A 10 17505 + G G N G G G G G
S10_17518 G/T 10 17518 + G N G G G G G G
S10_17528 G/C 10 17528 + G G N G G G G G
S10_17533 C/G 10 17533 + C N C C C C C C
S10_17550 G/C 10 17550 + G N G G G G G G
S10_17551 A/C 10 17551 + A N A A A A A A
S10_17591 G/C 10 17591 + G G G G G G N G
S10_17593 T/C 10 17593 + T T T T T T N T
S10_17613 A/G 10 17613 + A A A A A A N A

Filtering SNPs to remove most of the missing data.
Will be covered later in discussion of TASSEL (http://www.maizegenetics.net/)

Missing Data Strategies
• Impute Missing SNPs. ‐Many algorithms for doing this.
• Technical Options– Reduce the multiplexing level– Sequence the same library multiple times
• Molecular Options– Choose less frequently cutting enzymes

DNA sample info entered to webform
HTS databaseProject approved?Samples shipped
GBS libraries made
Reference genome
Non‐reference genome
HapMap FileSNPs/SampleCoordinates
Lab Analysis Pipelines
DNA sequence data HapMap File
SNPs/Sample
GBS workflow in the IGD

BioinformaticsKatie HymaJeff Glaubitz
Qi Sun
Method DevelopmentRob ElshireEd Buckler
Sharon Mitchell
GBS Team
Laboratory/ProductionCharlotte Acharya
Wenyan ZhuLisa Blanchard
Jennifer Hagadone
Workshop CoordinatorTheresa Fulton