scaling recommendations, semantic search, & data analytics with solr
TRANSCRIPT

Scaling Recommendations, Semantic Search, & Data Analytics with Solr
Trey GraingerDirector of Engineering, Search & Analytics
@
Atla
Atlanta Solr Meetup 2014.10.21, Atlanta Tech Village
Sponsored by:

About Me
Trey Grainger Director of Engineering, Search & Analytics
• Joined CareerBuilder in 2007 as Software Engineer• MBA, Management of Technology – GA Tech• BA, Computer Science, Business, & Philosophy – Furman University• Mining Massive Datasets (in progress) - Stanford University
• Fun outside of CB: • Author (Solr in Action), plus several research papers• Frequent conference speaker• Founder of Celiaccess.com, the gluten-free search engine• Lucene/Solr contributor

Overview
• Intro• CareerBuilder’s Search Infrastructure• Solr as a Recommendation Engine• Semantic Search with Solr • Solr-powered Data Analytics• Q & A
Search Powers…

My Search Team
Joe StreekySearch Framework Development Manager
Search Infrastructure Team Core Search Team
Job Search Team Candidate Search Team Relevancy & Recommendations Team
Applied Search Teams:

Scaling Recommendations, Semantic Search, & Data Analytics with Solr

About Me
Joseph Streeky Manager, Search Framework Development
• Joined CareerBuilder in 2005 as Software Engineer• BS, Computer Science – GA Tech• Natural Language Processing – Columbia University• Software Engineering for SaaS – University of California, Berkeley

About Search @CareerBuilder
• 2 million active jobs each month
• 60 million actively searchable resumes
• 450 globally distributed search servers (in the U.S., Europe, & the cloud)
• Thousands of unique, dynamically generated search indexes
• 1.5 billion search documents
• 2-3 million searches an hour
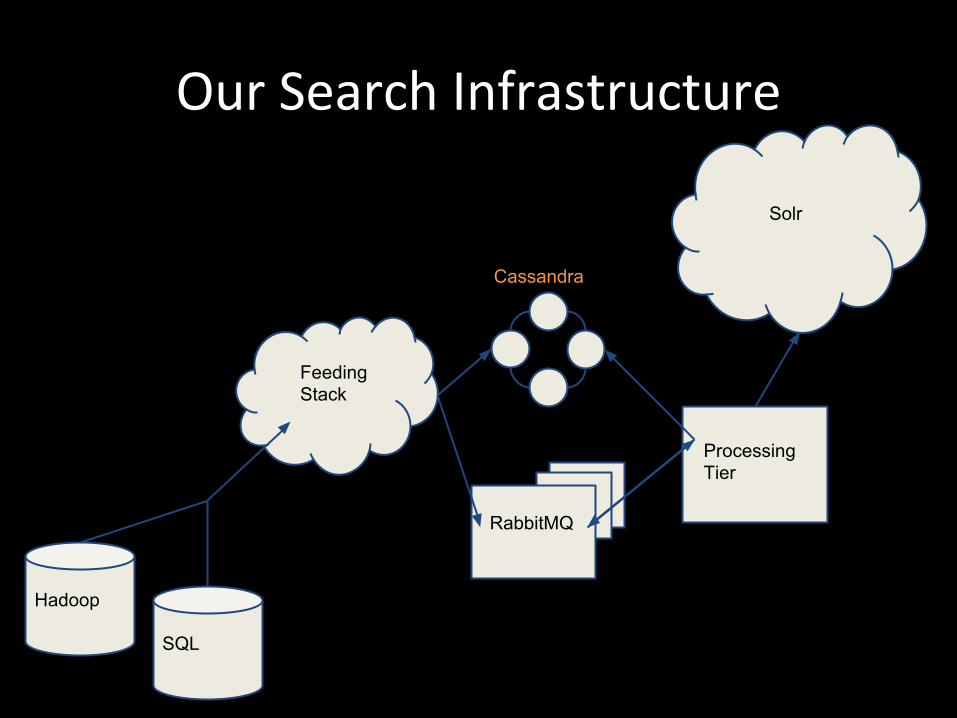
Our Search Infrastructure
Feeding Stack
Hadoop
SQL
RabbitMQ
Cassandra
Processing Tier
Solr

Solr Solr
Query Load Balancer
Solr
Feeding Platform
Our Search Infrastructure


Our Search Platform
• Generic Search API wrapping Solr + our domain stack
• Goal: Abstract away search into a simple API so that any engineer can build search-based products with no prior search background
• 3 Supported Methods (with rich syntax):– AddDocument– DeleteDocument– Search*users pass along their own dynamically-defined schemas on each call

Scaling Recommendations, Semantic Search, & Data Analytics with Solr

Business Case for Recommendations
• For companies like CareerBuilder, recommendations can provide as much or even greater business value (i.e. views, sales, job applications) than user-driven search capabilities.
• Recommendations create stickiness to pull users back to your company’s website, app, etc.

• John lives in Boston but wants to move to New York or possibly another big city. He is currently a sales manager but wants to move towards business development.
• Irene is a bartender in Dublin and is only interested in jobs within 10KM of her location in the food service industry.
• Irfan is a software engineer in Atlanta and is interested in software engineering jobs at a Big Data company. He is happy to move across the U.S. for the right job.
• Jane is a nurse educator in Boston seeking between $40K and $60K working in the state of Massachusetts
Consider the information you know about your users

http://localhost:8983/solr/jobs/select/? fl=jobtitle,city,state,salary& q=( jobtitle:"nurse educator"^25 OR jobtitle:(nurse educator)^10 ) AND ( (city:"Boston" AND state:"MA")^15 OR state:"MA”) AND _val_:"map(salary, 40000, 60000,10, 0)”
*Example from chapter 16 of Solr in Action
Query for Jane
Jane is a nurse educator in Boston seeking between $40K and $60K working in the state of Massachusetts

{ ... "response":{"numFound":22,"start":0,"docs":[ {"jobtitle":"Clinical Educator (New England/ Boston)", "city":"Boston", "state":"MA", "salary":41503},
…]}}
*Example documents available @ https://github.com/treygrainger/solr-in-action/blob/first-edition/example-docs/ch16/
Search Results for Jane
{"jobtitle":"Nurse Educator", "city":"Braintree", "state":"MA", "salary":56183},
{"jobtitle":"Nurse Educator", "city":"Brighton", "state":"MA", "salary":71359}

• We built a recommendation engine!
• What is a recommendation engine?
– A system that uses known information (or derived information from that known information) to automatically suggest relevant content
• Our example was just an attribute based recommendation… we’ll see that behavioral-based (i.e. collaborative filtering) is also possible.
What did we just do?

Redefining “Search Engine”
• “Lucene is a high-performance, full-featured text search engine library…”
Yes, but really…
• Lucene is a high-performance, fully-featured token matching and scoring library… which can perform full-text searching.

Redefining “Search Engine”
or, in machine learning speak:
• A Lucene index is multi-dimensional sparse matrix… with very fast and powerful lookup and vector multiplication capabilities.
• Think of each field as a matrix containing each term mapped to each document

The Lucene Inverted Index (traditional text example)
Term Documents
a doc1 [2x]
brown doc3 [1x]
, doc5 [1x]
cat doc4 [1x]
cow doc2 [1x]
, doc5 [1x]
…...
once doc1 [1x]
, doc5 [1x]
over doc2 [1x]
, doc3 [1x]
the doc2 [2x]
, doc3 [2x]
, doc4
[2x], doc5
[1x]
… …
Document Content Field
doc1 once upon a time, in a land far, far away
doc2 the cow jumped over the moon.
doc3 the quick brown fox jumped over the lazy dog.
doc4 the cat in the hat
doc5 The brown cow said “moo” once.
… …
What you SEND to Lucene/Solr:How the content is INDEXED into Lucene/Solr (conceptually):
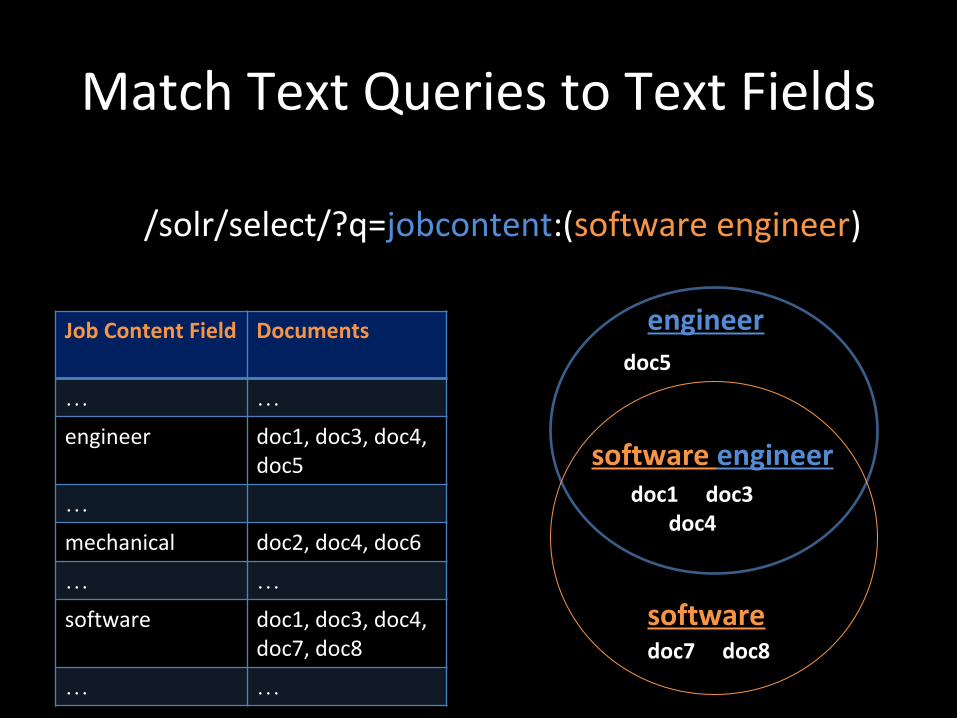
Match Text Queries to Text Fields
/solr/select/?q=jobcontent:(software engineer)
Job Content Field Documents
… …engineer doc1, doc3, doc4,
doc5
…mechanical doc2, doc4, doc6
… …software doc1, doc3, doc4,
doc7, doc8
… …
doc5
doc7 doc8
doc1 doc3 doc4
engineer
software
software engineer

Beyond Text Searching
• Lucene/Solr is a search matching engine
• When Lucene/Solr search text, they are matching tokens in the query with tokens in the index
• Anything that can be searched upon can form the basis of matching and scoring:– text, attributes, locations, results of functions, user
behavior, classifications, etc.

Approaches to Recommendations
• Content-based– Attribute-based
• i.e. income level, hobbies, location, experience
– Classification-based• i.e. “medical//nursing//oncology”, “animal//dog//terrier”
– Textual Similarity-based• i.e. Solr’s MoreLikeThis Request Handler & Search Handler
– Concept-based• i.e. Solr => “software engineer”, “java”, “search”, “open source”
• Collaborative Filtering• “Users who liked that also liked this…”
• Hybrid Approaches

Collaborative Filtering
Term Documentsuser1 doc1, doc5user2 doc2user3 doc2user4 doc1, doc3,
doc4, doc5user5 doc1, doc4… …
Document “Users who bought this product” field
doc1 user1, user4, user5
doc2 user2, user3
doc3 user4doc4 user4, user5
doc5 user4, user1… …
What you SEND to Lucene/Solr: How the content is INDEXED into Lucene/Solr (conceptually):

Step 1: Find similar users who like the same documents
Document “Users who bought this product” field
doc1 user1, user4, user5
doc2 user2, user3
doc3 user4
doc4 user4, user5doc5 user4, user1… …
Top-scoring results (most similar users):1) user4 (2 shared likes)2) user5 (2 shared likes)3) user 1 (1 shared like)
doc1
user1 user4 user5
user4 user5
doc4
q=documentid: ("doc1" OR "doc4")
*Source: Solr in Action, chapter 16

Step 2: Search for docs “liked” by those similar users
Term Documents
user1 doc1, doc5
user2 doc2
user3 doc2
user4 doc1, doc3, doc4, doc5
user5 doc1, doc4
… …
Top recommended documents:1) doc1 (matches user4, user5, user1)2) doc4 (matches user4, user5)3) doc5 (matches user4, user1)4) doc3 (matches user4)
// doc2 does not match
Most similar users:1) user4 (2 shared likes)2) user5 (2 shared likes)3) user 1 (1 shared like)
/solr/select/?q=userlikes:("user4"^2 OR "user5"^2 OR "user1"^1)
*Source: Solr in Action, chapter 16

solrconfig.xml: <requestHandler name="/mlt" class="solr.MoreLikeThisHandler" />
Query:
/solr/jobs/mlt/?df=jobdescription& fl=id,jobtitle& rows=3& q=J2EE& // recommendations based on top scoring doc
mlt.fl=jobtitle,jobdescription& // inspect these fields for interesting terms
mlt.interestingTerms=details& // return the interesting terms
mlt.boost=true
Content-based Recommendations: More Like This (Query)
*Example from chapter 16 of Solr in Action

More Like This (Results)
{"match":{"numFound":122,"start":0,"docs":[ {"id":"fc57931d42a7ccce3552c04f3db40af8dabc99dc",
"jobtitle":"Senior Java / J2EE Developer"}] }, "response":{"numFound":2225,"start":0,"docs":[ {"id":"0e953179408d710679e5ddbd15ab0dfae52ffa6c",
"jobtitle":"Sr Core Java Developer"}, {"id":"5ce796c758ee30ed1b3da1fc52b0595c023de2db",
"jobtitle":"Applications Developer"}, {"id":"1e46dd6be1750fc50c18578b7791ad2378b90bdd",
"jobtitle":"Java Architect/ Lead Java Developer - WJAV Java - Java in Pittsburgh PA"},]},
"interestingTerms":[ "jobdescription:j2ee",1.0, "jobdescription:java",0.68131137, "jobdescription:senior",0.52161527, "jobtitle:developer",0.44706684, "jobdescription:source",0.2417754, "jobdescription:code",0.17976432, "jobdescription:is",0.17765637, "jobdescription:client",0.17331646, "jobdescription:our",0.11985878, "jobdescription:for",0.07928475, "jobdescription:a",0.07875194, "jobdescription:to",0.07741922, "jobdescription:and",0.07479082]}}
*Example from chapter 16 of Solr in Action

More Like This (passing in external document)
/solr/jobs/mlt/?df=jobdescription& fl=id,jobtitle& mlt.fl=jobtitle,jobdescription& mlt.interestingTerms=details& mlt.boost=true
stream.body=Solr is an open source enterprise search platform from the Apache Lucene project. Its major features include full-text search, hit highlighting, faceted search, dynamic clustering, database integration, and rich document (e.g., Word, PDF) handling. Providing distributed search and index replication, Solr is highly scalable. Solr is the most popular enterprise search engine. Solr 4 adds NoSQL features.
*Example from chapter 16 of Solr in Action

More Like This (Results)
{"response":{"numFound":2221,"start":0,"docs":[ {"id":"eff5ac098d056a7ea6b1306986c3ae511f2d0d89 ",
"jobtitle":"Enterprise Search Architect…"}, {"id":"37abb52b6fe63d601e5457641d2cf5ae83fdc799 ",
"jobtitle":"Sr. Java Developer"}, {"id":"349091293478dfd3319472e920cf65657276bda4 ",
"jobtitle":"Java Lucene Software Engineer"},]},
"interestingTerms":[
"jobdescription:search",1.0,
"jobdescription:solr",0.9155779, "jobdescription:features",0.36472517, "jobdescription:enterprise",0.30173126, "jobdescription:is",0.17626463, "jobdescription:the",0.102924034, "jobdescription:and",0.098939896]} }
*Example from chapter 16 of Solr in Action

Understanding Our Users
• Machine learning algorithms can help us understand what matters most to different groups of users.
Example: Willingness to relocate for a job (miles per percentile)
Software Engineers
Restaurant Workers

Search & Recommendations are on a continuum...
• Why limit yourself to JUST explicit search or JUST automated recommendations?
• By augmenting your user’s explicit queries with information you know about them, you can personalize their search results.
• Examples:– A known software engineer runs a blank keyword search in New York…
• Why not show software engineering higher in the results?
– A new user runs a keyword-only search for nurse• Why not use the user’s IP address to boost documents geographically
closer?

Scaling Recommendations, Semantic Search, & Data Analytics with Solr
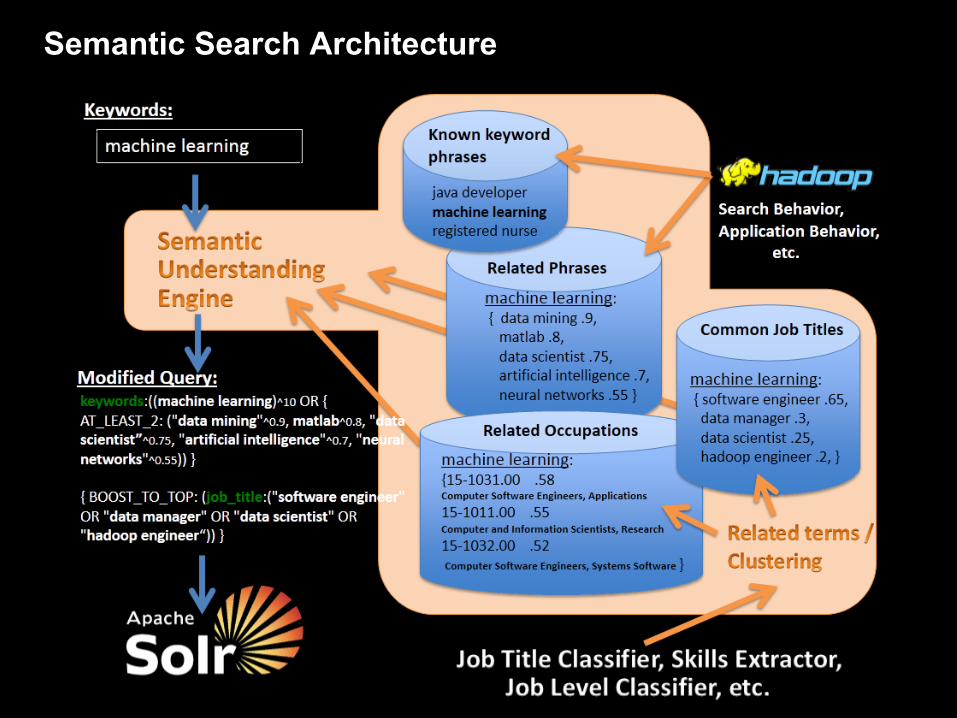
Semantic Search Architecture

Using Clustering to find semantic links
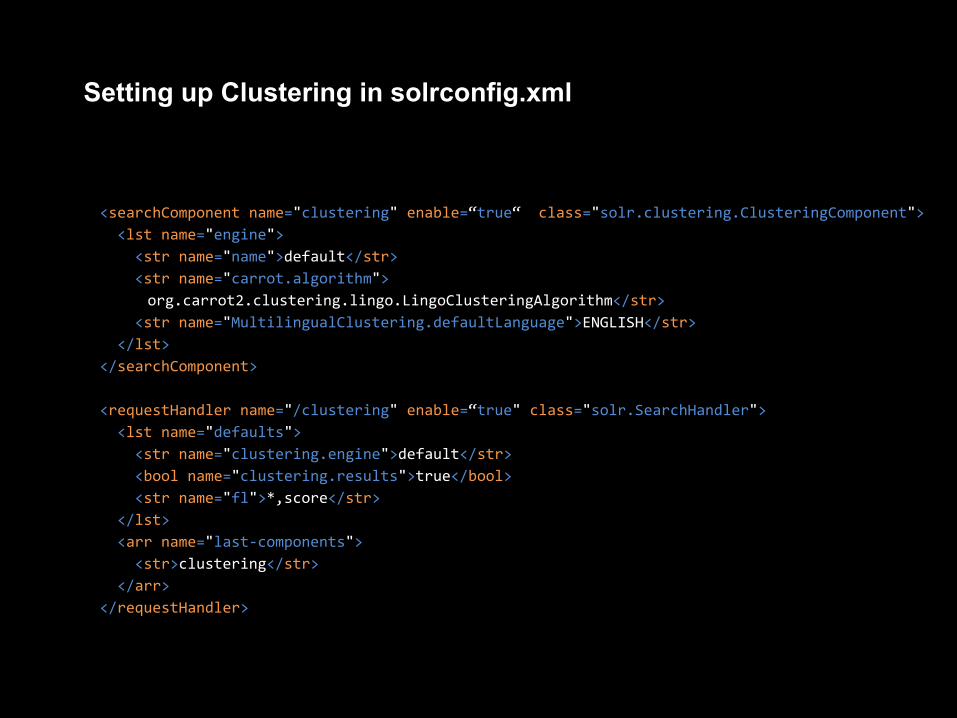
Setting up Clustering in solrconfig.xml

Clustering Query
/solr/clustering/?q=(solr or lucene) &rows=100 &carrot.title=titlefield &carrot.snippet=titlefield &LingoClusteringAlgorithm.desiredClusterCountBase=25//clustering & grouping don’t currently play nicely
Allows you to dynamically identify “concepts” and their prevalence within a user’s top search results

Original Query: q=(solr or lucene)
// can be a user’s search, their job title, a list of skills, // or any other keyword rich data source
Clustering Results
Clusters Identified:Developer (22) Java Developer (13) Software (10) Senior Java Developer (9) Architect (6) Software Engineer (6) Web Developer (5) Search (3) Software Developer (3) Systems (3) Administrator (2) Hadoop Engineer (2) Java J2EE (2) Search Development (2) Software Architect (2) Solutions Architect (2)
Stage 1: Identify Concepts

content:(“Developer”^22 or “Java Developer”^13 or “Software ”^10 or “Senior Java Developer”^9 or “Architect ”^6 or “Software Engineer”^6 or “Web Developer ”^5 or “Search”^3 or “Software Developer”^3 or “Systems”^3 or “Administrator”^2 or “Hadoop Engineer”^2 or “Java J2EE”^2 or “Search Development”^2 or “Software Architect”^2 or “Solutions Architect”^2)
// Your can also add the user’s location or the original keywords to the // recommendations search if it helps results quality for your use-case.
Stage 2: Use Semantic Links in your relevancy calculation

• Our primary approach: Search Co-occurrences[1] + Point-wise Mutual Information[1] + PGMHD[2]
• Strategy: Map/Reduce job which computes similar searches run for the same users
John searched for “java developer” and “j2ee”Jane searched for “registered nurse” and “r.n.” and “nurse”.Zeke searched for “java developer” and “scala” and “jvm”
• By mining the searches of tens millions of search terms per day, we get a list of top related searches, using multiple statistical measures.
• We also tie each search term to the top category of jobs (i.e java developer, truck driver, etc.), so that we know in what context people search for each term.
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data 2014.
[2] K. Aljadda, M.Korayem, C. Ortiz, T. Grainger, J. Miller, W. York. "PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems," in IEEE Big Data 2014
Synonym Discovery Techniques

Examples of “related search terms”
Example: “accounting”accountant 8880,accounts payable 5235,finance 3675,accounting clerk 3651,bookkeeper 3225,controller 2898,staff accountant 2866,accounts receivable 2842
Example: “RN”:registered nurse 6588,rn registered nurse 4300,nurse 2492,nursing 912,lpn 707,healthcare 453,rn case manager 446,registered nurse rn 404,director of nursing 321,case manager 292

Related Keywords / Automatic Boolean Query Expansion

Categories of related terms...
Synonyms: cpa => Certified Public Accountant rn => Registered Nurse r.n. => Registered Nurse
Ambiguous Terms*: driver => driver (trucking) ~80% driver => driver (software) ~20%
Related Terms: r.n. => nursing, bsn hadoop => mapreduce, hive, pig
*disambiguation occurs based upon context and popularity

Semantic Search “under the hood”

Scaling Recommendations, Semantic Search, & Data Analytics with Solr

Workforce Supply & Demand

Why Solr for Analytics?
• Allows “ad-hoc” querying of data by keywords
• Is good at on-the-fly aggregate calculations (facets + stats + functions + grouping)
• Solr is horizontally scalable, and thus able to handle billions of documents
• Insanely Fast queries, encouraging user exploration

//Range Faceting&facet.range=years_experience&facet.range.start=0&facet.range.end=10&facet.range.gap=1&facet.range.other=after
Faceting Overview/solr/select/?q=…&facet=true
//Field Faceting&facet.field=city
"facet_ranges":{ "years_experience":{ "counts":[ "0",1010035, "1",343831, … "9",121090 ], … "after":59462}}
"facet_fields":{ "city":[ "new york, ny",2337, "los angeles, ca",1693, "chicago, il",1535, … ]}
"facet_queries":{ "0 to 10 km":1187, "10 to 25 km":462, "25 to 50 km":794, "50+":105296 },
//Query Faceting:&facet.query={!frange key="0 to 10 km" l=0 u=10 incll=false}geodist()
&facet.query={!frange key="10 to 25 km" l=10 u=25 incll=false}geodist()
&facet.query={!frange key="25 to 50 km" l=25 u=50 incll=false}geodist()
&facet.query={!frange key="50+" l=50 incll=false}geodist()
&sfield=location&pt=37.7770,-122.4200

Supply of Candidates

Supply of Candidates

Demand for Jobs

Supply over Demand (Labor Pressure)

Wait, how’d you do that?
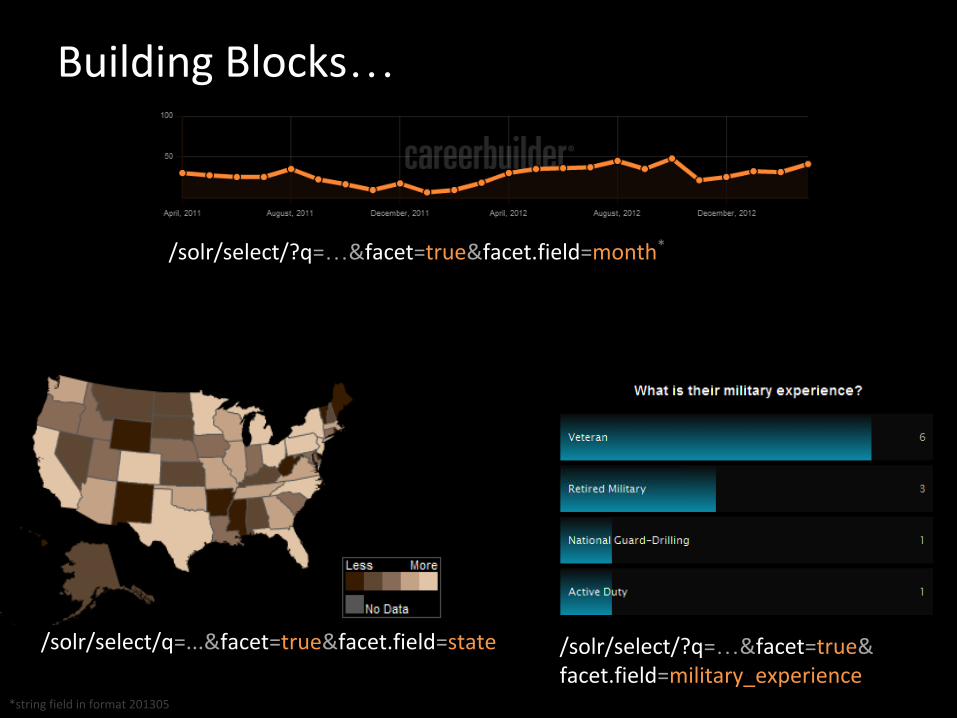
/solr/select/q=...&facet=true&facet.field=state
/solr/select/?q=…&facet=true&facet.field=month*
/solr/select/?q=…&facet=true&facet.field=military_experience
Building Blocks…
*string field in format 201305

Building Blocks…
/solr/select/?q="construction worker"&fq=city:"las vegas, nv"&facet=true&facet.field=company
/solr/select/?q="construction worker"&fq=city:"las vegas, nv"&facet=true&facet.field=lastjobtitle

Building Blocks…
/solr/select/? q=...&facet=true&facet.field=experience_ranges
/solr/select/?q=...&facet=true&facet.field=management_experience
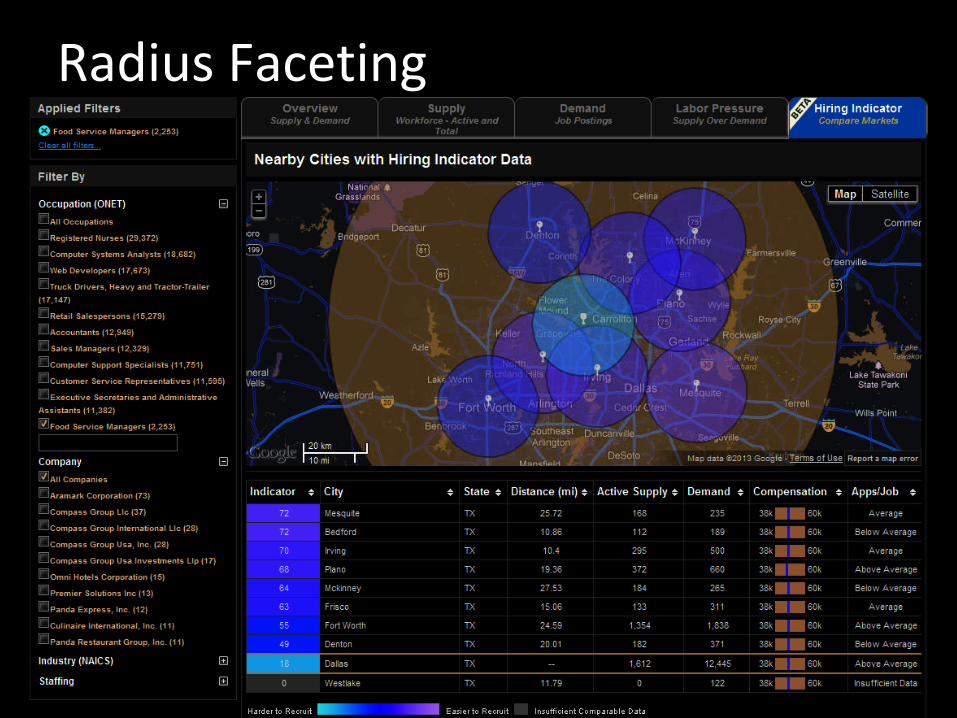
Radius Faceting

Hiring Comparison per Market

Query 1:/solr/select/?...fq={!geofilt sfield=latlong pt=37.777,-122.420 d=80}&facet=true&facet.field=city&
"facet_fields":{ "city":[ "san francisco, ca",11713, "san jose, ca",3071, "oakland, ca",1482, "palo alto, ca",1318, "santa clara, ca",1212, "mountain view, ca",1045, "sunnyvale, ca",1004, "fremont, ca",726, "redwood city, ca",633, "berkeley, ca",599]}Query 2:
/solr/select/?...&facet=true&facet.field=city&fq=( _query_:"{!geofilt sfield=latlong pt=37.7770,-122.4200 d=20} " //san francisco OR _query_:"{!geofilt sfield=latlong pt=37.338,-121.886 d=20} " //san jose … OR _query_:"{!geofilt sfield=latlong pt=37.870,-122.271 d=20} " //berkeley
)
Geo-spatial Analytics

SOLR-2894: “Distributed Pivot Faceting”
Status: This feature was developed primarily by the CareerBuilder search team and committed by Chris Hostetter to the latest released version of Solr (4.10).
#1 Most requested Solr feature
56

SOLR-3583: “Stats within (pivot) facets”
Status: We have submitted a patch (built on top of distributed pivot facets), but this will likely be replaced with SOLR-6350 + SOLR 6351 in the future.

/solr/select?q=...&facet=true&facet.pivot=state,city&
facet.stats.percentiles=true&facet.stats.percentiles.averages=true&
facet.stats.percentiles.field=compensation&
f.compensation.stats.percentiles.requested=10,25,50,75,90&f.compensation.stats.percentiles.lower.fence=1000&f.compensation.stats.percentiles.upper.fence=200000&f.compensation.stats.percentiles.gap=1000
"facet_pivot":{ "state,city":[{ "field":"state", "value":"california", "count":1872280, "statistics":[ "compensation",[ "percentiles",[ "10.0","26000.0", "25.0","31000.0", "50.0","43000.0", "75.0","66000.0", "90.0","94000.0"], "percentiles_average",52613.72, "percentiles_count",1514592]], "pivot":[{ "field":"city", "value":"los angeles, ca", "count":134851, "statistics":{ "compensation":[ "percentiles",[ "10.0","26000.0", "25.0","31000.0", "50.0","45000.0", "75.0","70000.0", "90.0","95000.0"], "percentiles_average",54122.45, "percentiles_count",213481]}} … ]}]}
SOLR-3583: “Stats within (pivot) facets”
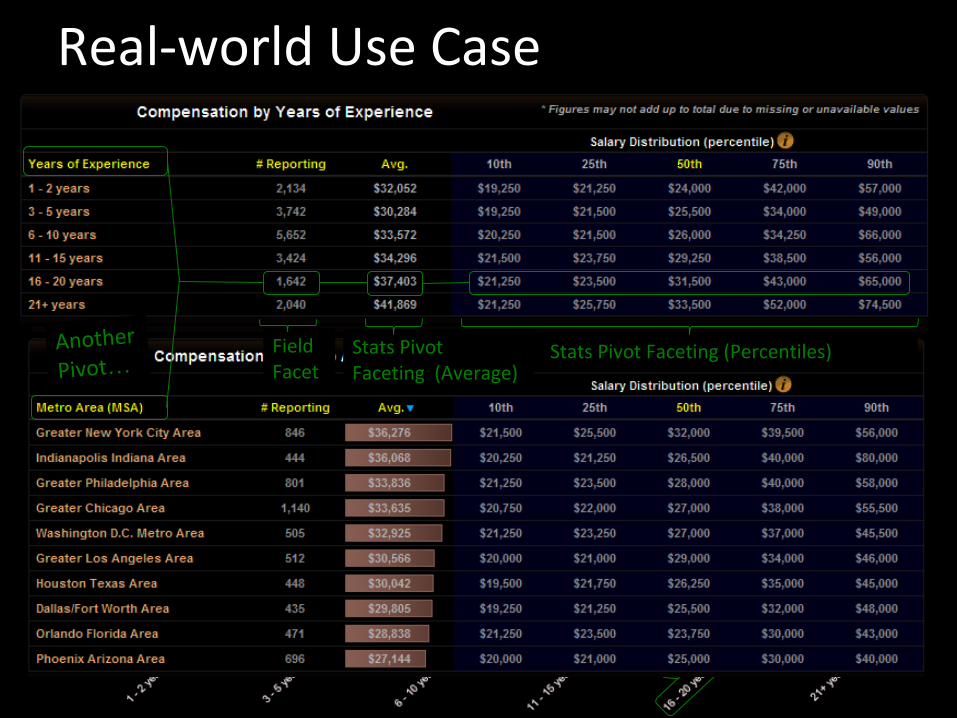
Real-world Use Case
Stats Pivot Faceting (Percentiles)Stats Pivot Faceting (Average)
Another
Pivot…Field Facet

Key Takeaways
• Traditional search & recommendations are at two ends of a continuum between user-driven and automatic matching, and Solr is really good at giving you access to that full continuum.
• Searching on text is one of many forms of matching. If you can migrate to searching on behaviors, entities, and concepts, you will see much better, more personalized results.
Solr is a highly-scalable platform for rapid matching across large amounts of unstructured and structured data. Performing real-time analytics at scale is not only possible, but incredibly fast and flexible.

2014 Publications & PresentationsBooks:Solr in Action - A comprehensive guide to implementing scalable
search using Apache Solr
Research papers:● Towards a Job title Classification System● Augmenting Recommendation Systems Using a Model of Semantically-related Terms Extracted from
User Behavior● sCooL: A system for academic institution name normalization● Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific jargon● PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems● SKILL: A System for Skill Identification and Normalization (pending publication)
Speaking Engagements:● WSDM 2014 Workshop: “Web-Scale Classification: Classifying Big Data from the Web”● Atlanta Solr Meetup● Atlanta Big Data Meetup● The Second International Symposium on Big Data and Data Analytics● Lucene/Solr Revolution 2014● RecSys 2014● IEEE Big Data Conference 2014
Contact Info
Yes, WE ARE HIRING @CareerBuilder. Come talk with me if you are interested…
▪ Trey [email protected]@treygrainger
Other presentations: http://www.treygrainger.com http://solrinaction.com
Meetup discount (42% off): solrmuau

Other Presentations: