basics of solr and solr integration with aem6
TRANSCRIPT

Introduction to Solr and SolrIntegration with AEM
(Deepak Khetawat)
About me
❖ AEM6 Certified Expert Lead Consultant
❖ LinkedIn : https://www.linkedin.com/pub/deepak-khetawat/96/a44/99a
❖ Twitter : @dk452
❖ For any query mail at [email protected]

Agenda
❖ Search
❖ What is Solr ?
❖ Solr Architecture
❖ Working of Solr
❖ Solr Core
❖ Solr Queries
❖ Solr with AEM
❖ External Solr Integration with AEM
❖ Exercises

❖Search Stats :
➢ Google now processes over 40,000 search queries every second on
average , which translates to over 3.5 billion searches per day and 1.2 trillion
searches per year worldwide.
➢ 61% of global Internet users research products online .
➢ 44% of online shoppers begin by using a search engine .
➢ A study by Outbrain shows that Search is the #1 driver of traffic to content
sites , beating social medias .

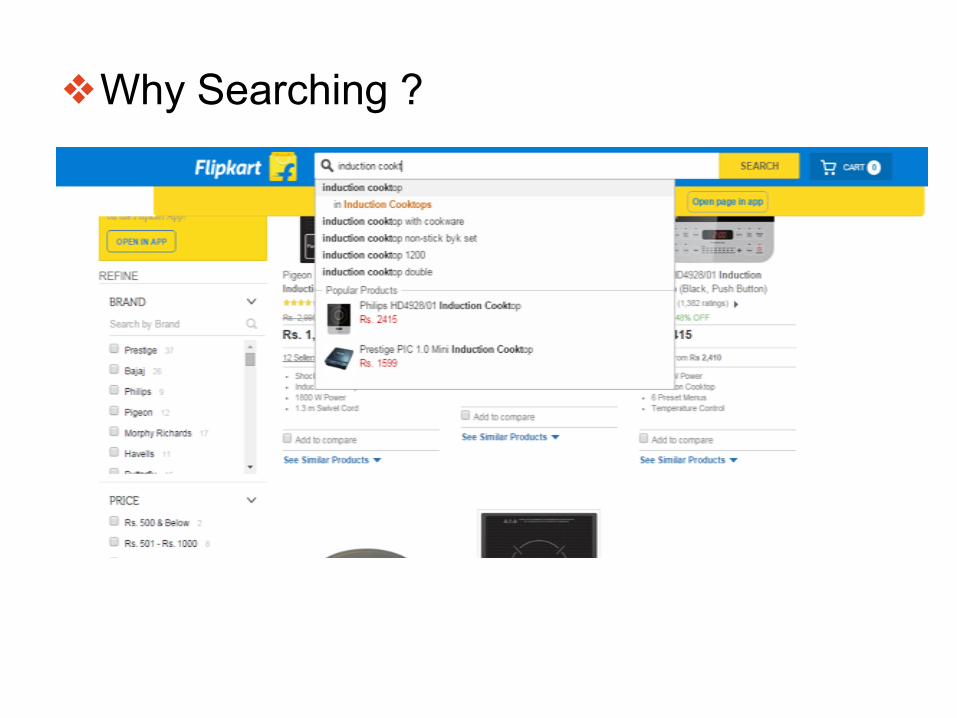
❖Why Searching ?
➢ Want to look up similar terms in database forming autocomplete , get
facet/categories results also in one-go?
➢ Instead of application(ex. e-commerce portals) storing all structured data in
database , it is recommended to find right products which is already built,
which can be adapted .
➢ This is where Search engines/servers comes into picture .
❖Why Searching ?

❖What is Solr ?
Price High to Low : Endeca, FredHopper, Mercado, Google Mini,
Microsoft Search Server, Autonomy, Microsoft Search Server Express,
Lucene(Solr/Elastic Search)
Speed Fast to Slow : Google Mini/Endeca, FredHopper, Autonomy,
Lucene/MSS/MSSE
Features High to Low : Endeca, FredHopper, Mercado, Solr, Autonomy,
Lucene, MSS/MSSE, Google Mini
Extensibility High to Low : Lucene, Endeca, FredHopper, Mercado,
Autonomy, MSS/MSSE, Google Mini

❖What is Solr ?
➢ Apache Solr is a popular open source enterprise search server / web
application .
➢ Solr uses lucene search library and extends it . Solr exposes lucene Java
API’s as Restful services .
➢ Apache Solr is easy to use from virtually any programming language. It can
be used to increase the performance as it can search all the web content.
➢ We put documents in it (called indexing) via xml, json, csv, binary formats &
query it via GET request and receive search data in xml, json, csv, Python,
Ruby, PHP, binary etc. formats.

❖Key features of Solr :➢ Advanced Full-Text Search Capabilities .
➢ Optimized for High Volume Web Traffic .
➢ Standards Based Open Interfaces - XML , JSON and HTTP .
➢ Comprehensive HTML Administration Interfaces .
➢ Server Statistics exposed over JMX for Monitoring .
➢ Near Real Time Indexing .
➢ Extensible Plugin Architecture .

❖Other Key features of Solr : Faceting
Geospatial
Scaling
Query auto-complete
Rich Document(ex. PDF) Parsing

❖Solr Powered Sites :
Take a look at - PublicServers - Solr Wiki
Netflix
AT&T Interactive (http://YP.com)
Comcast
AOL
CitySearch
LA Times

❖Solr Architecture

❖Solr Search System

❖Indexing :
➢ Indexing is the processing of original data into a highly efficient cross-
reference lookup in order to facilitate rapid searching .
➢ This type of index is called an inverted index, because it inverts a page-
centric data structure (page->words) to a keyword-centric data structure (word-
>pages).
➢ Without an index, the search engine would scan every document which
requires considerable time and computing power .
➢ For example, while an index of 10,000 documents can be queried within
milliseconds, a sequential scan of every word in 10,000 large documents could
take hours .

❖Analysis: ➢ Analyze : Search engines does not index text directly . The text are broken
into a series of individual atomic elements called tokens .
➢ An Analyzer builds TokenStreams , which analyze texts and represents a
policy for extracting index terms from texts .
➢ Analyzers are used both when a document is indexed and at query time .
➢ Tokenizer break field data into lexical units or tokens .
➢ Filters examine a stream of tokens and keep them ,transform or discard
them, or create new ones .
https://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters
https://cwiki.apache.org/confluence/display/solr/Tokenizers
https://cwiki.apache.org/confluence/display/solr/About+Filters

❖Analysis :

❖Searching :
➢ Searching is the process of consulting the search index and retrieving the
documents matching the query , sorted in the requested sort order .
➢ Search Process works like following :

❖What is Core ?
➢ Solr server can handle multiple cores . Core is a index that is handled by
Solr server . To run Solr core need to have few configuration files to be
discussed later .
➢ Mostly cores run as isolated databases , not meant for interacting with
each other .
➢ A Solr index can accept data from many different sources including xml, csv
, data extracted from tables in a DB and common formats like a word or PDF .

❖Ways of loading data into Solr Index
➢ Upload files like XML , JSON by sending HTTP request to Solr .
➢ Index handlers to upload from database .
➢ Writing a custom java app to ingest data through Solr’s Java client .

❖Ways of loading data into Solr Index
➢ Upload files like XML , JSON by sending HTTP request to Solr .
➢ Index handlers to upload from database .
➢ Writing a custom java app to ingest data through Solr’s Java client .

❖Configuring Solr Linux
Installing and Starting Solr
# apt-get install openjdk-7-jre-headless -y
# java -version
# cd /opt/ && wget http://mirror.nexcess.net/apache/lucene/solr/5.4.1/solr-5.4.1.tgz
#
# cd solr-5.4.1
# bin/solr start
Access it using # http://<ip>:8983/solr/#/
Solr stores index in a directory called index in the data directory (/opt/solr-
5.4.1/server/solr/corename1/data/index/)
Create a core
To be able to Index and search, you need a core
# bin/solr create -c corename -d basic_configs

❖Configuring Solr Windows
http://mirror.nexcess.net/apache/lucene/solr/5.4.1/ to download solr .
Using cmd go upto bin and use solr start to start solr .
Access it using # http://<ip>:8983/solr/#/
Solr stores index in a directory called index in the data directory
(/solr-5.4.1/server/solr/corename1/data/index/)
Create a core
To be able to Index and search, you need a core. navigate the solr-5.4.1\bin folder in the command
window .
solr create -c corename -d basic_configs

❖Solr Configuration Files
● Solrconfig.xml :
➢ Manage request and data manipulation for users .
➢ Here we configure update handlers,update event listeners and
different search components .
➢ Can handle schemaless Solr feature by adding <schemaFactory
class="ManagedIndexSchemaFactory"> in Solrconfig.xml .
● Core.properties : For defining properties at the core level .
● Solr.xml : It is at entire Solr level for cores like how many cores we have ,
core details .
● Schema.xml :
➢ It is at core data-structure level having information like what field
type , fields .
➢ Analyzers are specified as a child of the <fieldType> element in the
schema.xml configuration file .

❖ Field Types
In Solr, every field has a type. Examples of basic field types available
in Solr include: float, long, double, date, text
New field types can be created/defined by combining filters and
tokenizers.
Field Definition
<field name="id" type="text" indexed="true"
stored="true"multiValued="true"/>
name: Name of the field
type: Field type
indexed: Should this field be added to the inverted index?
stored: Should the original value of this field be stored?
multiValued: Can this field have multiple values?

❖ Exercises
Create 2 cores test and solrpoc .
Configure your schema.xml .
https://lucidworks.com/blog/2014/03/31/introducing-solrs-restmanager-
and-managed-stop-words-and-synonyms/ (For POC)

❖Solr Queries
● Keyword Searching :
➢ Word Searching : title:aem doc
➢ Phrase Searching: title:"aem document"
➢ AND, OR, - operators
((title:"foo bar" AND body:"quick fox") OR title:fox)
● Wildcard Searching :
➢ title : ae*
➢ title : a*m

❖Solr Queries(Note in code snippet of queries we are using test core)
● Range Searching :
➢ modified_date:[20020101 TO 20030101]
Query Example :
➢ http://localhost:8983/solr/test/select?q=title:Design&wt=json&indent=true
➢ http://localhost:8983/solr/test/select?q=*:*&fl=author,title&facet=true&facet
.field=author&wt=json&indent=true

❖Solr Queries
● Fuzzy Search:
➢ Lucene supports fuzzy searches based on the Levenshtein Distance, or Edit Distance
algorithm. To do a fuzzy search use the tilde, "~", symbol at the end of a Single word
Term.
➢ For example to search for a term similar in spelling to "roam" use the fuzzy search:roam~
This search will find terms like foam and roams.
Starting with Lucene 1.9 an additional (optional) parameter can specify the required
similarity. The value is between 0 and 1, with a value closer to 1 only terms with a higher
similarity will be matched. For example:
roam~0.8
The default that is used if the parameter is not given is 0.5.
Query Example :
➢ http://localhost:8983/solr/test/select?q=DesignPatterns~.5&wt=json&inden
t=true&defType=edismax&qf=title

❖Common Query Parameters
● sort : title desc
(http://localhost:8983/solr/test/select?q=title:Desi*&sort=title+desc&wt=jso
n&indent=true)
● fq :This parameter can be used to specify a query that can be used to
restrict the super set of documents that can be returned, without
influencing score. It can be very useful for speeding up complex queries
since the queries specified with fq are cached independently from the
main query. Caching means the same filter is used again for a later query
(i.e. there's a cache hit).
fq=popularity:[10 TO *] & fq=section:0
● http://www.exadium.com/tools/online-url-encode-and-url-decode-tool/(to
encode and decode your Solr queries)

❖More Search Queries
● Highlighting :
http://localhost:8983/solr/test/select?q=title:Desi*&hl=true&hl.snippets=1&
hl.fl=*&hl.fragsize=0&wt=json&indent=true
● hl – Should be set to true as it enables highlighted snippets to be generated in the query response.
● hl.fl – Specifies a list of fields to highlight. Wild char * will highlight all the fields
● hl.fragsize – The size, in characters, of the snippets (aka fragments) created by the highlighter. In the
original Highlighter, “0” indicates that the whole field value should be used with no fragmenting. By default
fragment is of size 100 characters
● hl.snippets
The maximum number of highlighted snippets to generate per field. Note: it is possible for any
number of snippets from zero to this value to be generated. The default value is "1".

❖Exercises
1. Under test core achieve all the following with one query :
a) Get only fields author and title in query results .
b) Fuzziness Index of .5 in title field .
c) Title should be start with design
d)Change title field to text_general instead of string .
e)Faceting for title field .
f) Highlighting title field
g)author name should only Range between Arvind to Jasvinder .

❖Exercises
1.Under test core with your schema.xml created, achieve all the following :
Full Text Search
Fuzzy Search
Faceting
Spatial Search
Highlighting
Wild Card Search
Range Search

❖Solr with AEM 6
● The integration in AEM 6.0 happens at the repository level so that Solr is
one of the possible indexes that can be used in Oak, the new repository
implementation shipped with AEM 6.0.
It can be configured to work as an embedded server with the AEM
instance, or as a remote server.
Configuring AEM with an embedded SOLR server
The embedded SOLR server is recommended for developing and testing the
Solr index for an Oak repository. Make sure you use a remote SOLR for
production instances.

❖Configure the embedded Solr server
by:
● Search for "Oak Solr server provider".
● Press the edit button and in the following window set the server type to
Embedded Solr in the drop-down list.
● Next, edit "Oak Solr embedded server configuration" and create a
configuration
Add a node called solrlndex of type oak:QueryIndexDefinition under
oak:index with the following properties:
type:solr (of type String)
async:async (of type String)
reindex:true (of type Boolean)
Testing Solr Index(Recommended Configuration) :
https://docs.adobe.com/docs/en/aem/6-0/deploy/upgrade/queries-and-
indexing.html

❖External Solr with AEM
1. Creation of Custom Replication Agent .
http://localhost:7502/miscadmin
Select “Agents on Author” New > Page
Select Replication Agent > Add Title and Name (e.g Solr-Replication-Agent)
Now go to the agent (double click) properties , Edit Settings
Serialization Type = POC Solr XML Content Serializer
Retry Delay = 60000 , Enable the Log Level to Debug
Transport Tab put the URl http://localhost:8983/solr/solrpoc?update=true

❖2. Get the Page to be indexed(Push to
Solr)
Suppose you want to Index:
http://localhost:7502/editor.html/content/geometrixx-outdoors/en/activities.html
Now open CRXDE page (http://localhost:7502/crx/de/index.jsp) for the
respective page:
Check jcr:content of the the above page and get the value of
“sliing:resourceType”
(value = geometrixx-outdoors/components/page_sidebar)

❖2. Get the Page to be indexed(Push to
Solr)
In Felix go to Content extractor service for Solr indexing (codebase in
https://github.com/deepakkhetawat/SolrPOCWithAEM)
Edit the “Component Indexed values” for the page you want to index in
apache solr.
Then add/put above value into the “Component Indexed values”
geometrixx-outdoors/components/page_sidebar@articletext=jcr:title
Note: @articletext -> Field which is mentioned/added into schema.xml
earlier.
jcr:title -> “Name” field mentioned in jcr:content properties of above page

❖2. Get the Page to be indexed(Push to
Solr)
You need to decide where you want to map the page property to what
field of Solr and it should be present in the schema.xml
Once you publish the content , apache solr indexes data as we
configured the separate replication agent SOLR in agents on Author.

❖Exploratory Exercises
Create your own fieldtype in Solr like textgeneral .
Explore AEM 6.1 Solr Indexing by Default
Implement Highlighting for title field
Try geospatial search with AEM

❖References
Code of “Tag Based Faceting using External Apache Solr with AEM” available at https://github.com/deepakkhetawat/SolrPOCWithAEM.git
Needful References are mentioned in between Slides .
