restriccions manuals de desambiguació en el corpus clic ...lcots/recerca/restriccions.pdf · 1....
TRANSCRIPT

Restriccions manuals de
desambiguació en el corpus
CLiC-TALP-CAT
Lluís M. Cots Serra
Treball d’investigació per al DEA
6 crèdits
Direcció:
Mª Antònia Martí
Montserrat Civit
Universitat de Barcelona
Departament de Lingüística
2004


- 3 -
ÍNDEX
1. INTRODUCCIÓ.................................................................................................................................5
1.1. MARC GENERAL.............................................................................................................................5
1.2. ELS DESAMBIGUADORS MORFOSINTÀCTICS .................................................................................13
1.3. CARACTERÍSTIQUES DEL SISTEMA CLIC-TALP...........................................................................16
1.4. FORMALISME DE LES RESTRICCIONS ............................................................................................18
1.5. TREBALLS PRECEDENTS ...............................................................................................................21
2. DETECCIÓ DELS ERRORS DEL DESAMBIGUADOR AUTOMÀTIC .................................23
3. REGLES DE DESAMBIGUACIÓ BASADES EN EL CONEIXEMENT LINGÜÍSTIC .........31
3.1. RESTRICCIONS SOBRE LEMES .......................................................................................................32
3.1.1. Correcció d’etiquetes i lemes erronis .................................................................................33
3.1.2. Canvis de gènere a mots pertanyents a certs lemes segons el context ................................35
3.2. RESTRICCIONS SOBRE L’ETIQUETA LLARGA.................................................................................37
3.2.1. Canvi de la 1ª per la 3ª persona verbal...............................................................................38
3.2.2. Canvis en el mode verbal ....................................................................................................41
3.3. RESTRICCIONS SOBRE L’ETIQUETA CURTA...................................................................................42
3.3.1. Pronom relatiu o conjunció ................................................................................................43 3.3.1.1. “Que” pronom relatiu o conjunció .............................................................................................. 43
3.3.1.2. Altres canvis entre pronoms relatius i conjuncions..................................................................... 45
3.3.2. “Es” impersonal o pronominal...........................................................................................46
3.3.3. Altres restriccions sobre l’etiqueta curta............................................................................51

- 4 -
3.3.3.1.Canvi de Determinant Article per Pronom Personal.....................................................................51
3.3.3.2.Canvi de Determinant Indefinit per Pronom Indefinit ..................................................................52
3.3.3.3.Canvi d’Adjectiu Qualificatiu per Determinant Numeral.............................................................53
3.3.3.4.Canvi de qual Determinant Relatiu per Pronom Relatiu ..............................................................54
4. RESULTATS GLOBALS DE LA DESAMBIGUACIÓ AUTOMÀTICA.................................. 57
4.1. RESULTATS QUANTITATIUS ......................................................................................................... 57
4.2. ANÀLISI DELS PROBLEMES NO RESOLTS....................................................................................... 60
5. CONCLUSIONS .............................................................................................................................. 65
BIBLIOGRAFIA.................................................................................................................................. 69

- 5 -
1. Introducció
1.1. Marc general
El present treball es planteja com una aportació en la millora del
desambiguador morfològic del Centre de Llenguatge i Computació (CLiC) de la
Universitat de Barcelona, en concret el poliment del desambiguador morfològic del
corpus del català.
L’emmarcament dels objectius que cerquem i la tasca que pretenem
requereixen l’exposició d’uns fets i conceptes previs. El treball s’inscriu dins el que
s’anomena Lingüística de Corpus. Aquesta consisteix en l’estudi de la llengua a
partir d’exemples recopilats del seu ús. Són una mostra de la revalorització dels
estudis de la llengua a partir de dades externes al lingüista, és a dir, empíriques,
corrent que havia estat bandejat pel del domini dels corrents racionalistes en la
lingüística (McEnery i Wilson, 1996a i 1996b; Sampson, 1995 i 2001).

- 6 - 1. Introducció
Malgrat que hom pot definir un Corpus com una col·lecció de textos, d’un
temps ençà s’entén per Corpus un conjunt de textos en suport electrònic. Això ja ens
situa en la possibilitat de manegar de forma ràpida una gran quantitat de dades.
Segons el que es vol representar, el corpus haurà de ser més o menys ampli i variat:
un corpus que vol representar tota la llengua tindrà una variació major que un altre
que vol reflectir un domini específic (Civit, 2003; Leech, 1997; McEnery i Wilson,
1996a i 1996b; Ooi, 1998; Sampson, 1995 i 2001). En el cas que ens ocupa no estem
davant el que s’anomena un corpus de referència, és a dir, una selecció de textos
que sigui un subconjunt representatiu de tota la llengua, sinó d’un àmbit menor,
circumscrit a la premsa.
En un principi, els esforços de la Lingüística Computacional es dirigiren cap a
aplicacions de domini restringit que permeteren anar resolent els problemes actuant
seqüencialment sobre els diferents nivells de representació lingüística a partir del
propi coneixement del sistema en aquell nivell. Cada etapa corresponia a un cert
nivell de representació lingüística (segmentació, morfologia, sintaxi, semàntica, etc.),
processava el material d’entrada i la sortida servia d’entrada a la fase següent. El fet
de tractar-se de dominis molt restringits permetia que les fonts de coneixement
pròpies de cada nivell poguessin satisfer les necessitats del sistema.
Ara bé, les aplicacions es van obrint i s’estan adreçant cap a nous dominis en
què resulten insuficients les anàlisis convencionals del llenguatge. Concretament
això succeeix quan les aplicacions cerquen el Processament del Llenguatge Natural
(des d’ara PLN) en totes les seves manifestacions, i no només en llenguatges
restringits o sotmesos a entrades molt controlades. Aquest nou enfoc és el que genera
la necessitat del que hom anomena anàlisi robusta.
L’anàlisi robusta actua en contextos difícils (tan difícils com la pròpia realitat).
En aquests, els temes són oberts, el vocabulari no es troba limitat, apareixen
neologismes, manlleus o barbarismes, es poden trobar errors gramaticals, el material
lingüístic es barreja amb d’altres menes d’elements, algunes dades poden presentar-

1. Introducció - 7 -
se sobre múltiples representacions no estandarditzades... (Márquez, Padró,
Rodríguez, 2001).
Una de les característiques del llenguatge natural és la seva ambigüitat.
Aquesta pot ser desitjable en algunes ocasions que poden anar des dels acudits i jocs
de paraules fins als usos més retòrics com la poesia o la publicitat. En aquests casos,
els subjectes de la comunicació l’aprofiten de manera significativa. Però en la
majoria de casos, en el marc de processos de tractament computacional de la llengua,
representa una dificultat que el PLN ha de resoldre.
L’ambigüitat del llenguatge es presenta de múltiples maneres. En primer lloc,
pot ser de caire lèxic, com el cas de
(1) va dir que ho comprés tot i que després fes el que volgués
en front de
(2) tot i que feia tard, vaig decidir anar-hi.
En l’exemple (1) hem d’entendre que ha de comprar totes les coses i després
fer el que vulgui. Caldrà tractar aquesta seqüència de tres mots com a paraules
aïllades, és a dir, com a tres unitats lèxiques. En canvi, en l’exemple (2) la mateixa
seqüència pren el sentit de “malgrat que” i cal entendre-la com una sola unitat
multiparaula de tres elements.
L’ambigüitat morfològica es produeix quan un mateix mot pot interpretar-se
dintre de diferents categories gramaticals, com en l’exemple (3):
(3) pren el sol tot sol,
on s’utilitza la paraula sol com a substantiu i com a adjectiu.
L’ambigüitat semàntica es dóna quan hem d’escollir entre les diferents
accepcions d’una paraula. Per exemple,
(4) el noi va partir els pinyons
pot referir-se a dividir en dues o més parts de manera distributiva o trencar per la
meitat).

- 8 - 1. Introducció
L’ambigüitat sintàctica s’esdevé, per exemple, en l’anomenada homonímia
estructural, quan una mateixa oració es pot interpretar amb més d’una estructura.
Així, en l’exemple (5)
(5) els professors parlaven als alumnes de ciències
hom pot voler dir que “parlaven de ciències” o que els oients eren “alumnes de
ciències”.
O, també, l’ambigüitat pragmàtica, quan la desambiguació requereix un
coneixement del marc situacional o referencial de la comunicació.
L’ambigüitat del llenguatge comença ja al nivell morfològic. El processament
d’un text d’entrada sense tractar fins el text de sortida amb la seva anotació
morfològica, és a dir, l’etiquetat de cada mot amb la seva categoria gramatical i la
resta d’accidents gramaticals que el sistema precisa segons el seu afinament, presenta
el procés que es pot observar a la figura següent:
Text
desambiguat
Model de llenguatge
Algorisme de desambiguació
Analitzador
Segmentador
Text

1. Introducció - 9 -
La segmentació de les unitats lèxiques presenta un primer nivell d’ambigüitat.
Alguns conjunts de mots han de ser tractats com a unitats multiparaula (per exemple,
topònims complexos com Sant_Andreu_de_la_Barca, dates com
dilluns_10_maig_2004 o noms com Josep_Maria_García_Escudé); alguns d’aquests
elements, a més, poden tenir presentacions diverses (St per Sant, dl per dilluns, 05
per maig, J_M o Josep_M per Josep_Maria, entre d’altres molts casos només amb
els tres exemples esmentats més amunt). Els sistemes de PLN solen resoldre aquests
problemes a través de diferents mòduls.
Un segon nivell d’ambigüitat, i que és el que a nosaltres ens ocuparà
principalment, és el morfològic. L’analitzador ens donarà totes les possibles
interpretacions d’una paraula. El desambiguador haurà d’escollir la millor opció en
aquell context determinat.
CLiC compta amb un analitzador morfològic, MACO+, que dóna totes les
formes possibles d’una paraula a partir del seu lema o arrel. MACO+ identifica totes
les interpretacions possibles d’un mot, tant pel que fa al lema al qual pertany com a
les seves possibles interpretacions gramaticals. Per exemple, davant de la frase
L’home passejava per la muntanya, obtenim la resposta següent:
Aquesta tasca, que pot semblar aparentment senzilla, ha de tenir prèviament
resolts o anar resolent automàticament un seguit d’aspectes d’una certa complexitat.

- 10 - 1. Introducció
En primer lloc cal segmentar el text en unitats lèxiques. Normalment aquestes venen
marcades per espais en blanc o signes de puntuació, és a dir, coincideixen amb el que
habitualment entenem per paraules. Ara bé, podem trobar-nos amb unitats lèxiques
multiparaula, com per exemple les locucions, o també amb contraccions, o sigui,
paraules que contenen més d’una unitat lèxica com del, cal o pel.
Quan s’aborda l’anàlisi morfològica de textos irrestrictes i que precisen una
anàlisi robusta, a més d’associar una o més interpretacions a cada mot, cal resoldre
una sèrie de problemes associats a aquesta tasca. Alguns d’aquests problemes els
anotem a continuació, sense voluntat d’ésser exhaustius:
! En primer lloc, ens podem trobar amb unitats numèriques que poden presentar-se
sota formats diferents i remetre’ns a referents diversos, com poden ser xifres,
dates, hores, etc. Per exemple, les dates poden presentar-se en números, amb
lletres o amb diferents combinancions. El dia 7 de setembre de 2004 es pot
expressar així o com 7 / 09 / 04, 7 – setembre – 2004, set de setembre de 2004,
2004-09-07, etc. Algunes d’aquestes mateixes xifres, posem per cas 7:09, poden
referir-se a un determinat moment horari. El sistema ha de disposar de recursos
per identificar el tipus d’unitat de què es tracta i categoritzar-la correctament.
! Cal disposar també de recursos pels signes especials com %, €, $, &, @... i per
identificar correctament els acrònims o les abreviatures. Barcelona, per exemple,
pot aparèixer així o amb formes com Barna, Bcn o BCN.
! La identificació dels noms propis presenta peculiaritats singulars. D’una banda,
els noms de persones poden coindir amb d’altres unitats (noms comuns,
adjectius, topònims...). Al mateix temps, poden presentar-se sota diferents formes
(Josep_Maria_Esteve, J_M_E, Josep_M_Esteve, etc.), abreujant i / o ometent
elements. Les referències pronominals o anafòriques dificulten encara més la
tasca. I ens podem trobar fins i tot en la necessitat d’un coneixement suficient i
prou actualitzat del món extern, força difícil de mantenir fora d’àmbits molt
restringits (per exemple, Zapatero, ZP, president del govern espanyol indiquen la

1. Introducció - 11 -
mateixa persona, però algunes d’aquestes expressions poden tenir una vitalitat
relativament curta).
! Finalment, per tot això caldrà comptar amb un conjunt d’etiquetes que haurà
d’equilibrar criteris com la fonamentació lingüística, la claredat, la brevetat i la
facilitat d’aplicació en àmbits computacionals.
En el cas de MACO+, aquest consta de diferents mòduls per anar resolent els
problemes apuntats. El segmentador tracta els signes de puntuació i les abreviatures
conegudes; uns altres mòduls treballen amb els números, les quantitats monetàries i
percentuals i les dates; després es tracten les locucions i noms propis. El diccionari,
l’analitzador pròpiament dit, reconeix la resta de paraules reconeix la resta de
paraules. El mòdul de sufixos treballa amb els diminutius i augmentatius, els
adverbis en –ment i les formes verbals amb clítics. Finalment, un mòdul assigna un
pes probabilístic que serà utilitzar pel desambiguador. En el cas de l’etiquetat podem
dir que el sistema funciona amb la proposta de Eagles adaptada (EAGLESa i
EAGLESb).
Text Anotat
ProbabilitatsSufixsDiccionari
Noms Propis Locucions Dates
QuantitatsNúmerosSegmentador
Text Pla
Mòduls de MACO:

- 12 - 1. Introducció
RELAX és el desambiguador morfosintàctic que selecciona la interpretació
correcta en funció del context de cada paraula (Padró, 1997). Pren com a dades
d’entrada el resultat de l’anàlisi de MACO+ i ens donarà com a sortida una opció
d’anàlisi per a cada mot. En aquest cas donarà aquesta resposta:
Per entendre com s’arriba a aquest resultat exposarem els diferents tipus
de desambiguadors existents i com funciona el sistema utilitzat per CLiC. A
partir d’aquí podrem definir la nostra tasca, l’objectiu que ens proposem, i
començar-lo a desenvolupar.

1. Introducció - 13 -
1.2. Els desambiguadors morfosintàctics
L’anàlisi morfològica assigna a cada paraula un conjunt d’etiquetes i lemes
possibles. La desambiguació morfològica consisteix a triar l’etiqueta correcta a cada
mot en funció del context on apareix. Per exemple, la paraula sopa pot ser un nom o
un verb; ara bé, si va precedida d’un determinant o seguida d’un adjectiu
probablement es tractarà d’un nom; si el context immediat és un pronom,
possiblement estiguem davant d’un verb. Això pot ser vàlid per expressions com La
sopa calenta o El Pere ho sopa on tenim l’adjectiu calenta o el pronom ho que
trenquen l’ambiguitat. Ara bé, ens podem trobar que la paraula ambigua vagi
acompanyada de d’altres que també ho són, com certes formes comunes de
determinants i pronoms, amb la qual cosa els sistemes de desambiguació es troben
amb què l’ambigüitat és múltiple. Així, la sopa, les sopes o fins i tot el sopa no
clarifiquen la categoria del segon mot, ja que el primer pot tractar-se d’un
determinant article o d’un pronom i caldrà recórrer, si el sistema ho permet, a d’altres
elements d’un context més ampli.
La desambiguació morfosintàctica és un dels processos primers en el
tractament del llenguatge natural. Succeeix després de la segmentació, l’aplicació de
diferents mòduls ja descrits i l’anàlisi morfològica i precedeix l’anàlisi sintàctica. En
aquesta fase del procés es decideix quina és l’etiqueta exacta que correspon a la
paraula.
Tal com hem vist en una figura anterior, alguns mots només obtenen una
resposta de l’analitzador; en aquest cas no caldrà cap procés desambiguador
posterior. És el cas de per o muntanya. D’altres admeten més d’una categoria
morfològica i caldrà un sistema per determinar quina d’aquestes és la correcta en la
situació actual (l’, home, la). Finalment, alguns mots tenen una sola categoria

- 14 - 1. Introducció
gramatical possible, però permeten diferents solucions en d’altres elements de la
informació gramatical (com és el cas de la 1ª o la 3ª persona de passejava) i aquí
també cal triar.
Hi ha diferents mètodes d’etiquetat morfosintàctic (Márquez, Padró,
Rodríguez, 2002). Aquests han de cercar una manera de trobar regularitats que
puguin ser capturades i explotades en el procés de tractament del llenguatge natural.
En principi aquests es classifiquen en dos grans grups segons el tipus de coneixement
que fan servir i la manera com han estat construïts: tenim els etiquetadors basats en el
coneixement lingüístic i els etiquetadors estadístics. A més d’aquests, cal esmentar
un subtipus dels estadístics: els etiquetadors basats en l’aprenentatge automàtic que
explicarem més endavant.
Els etiquetadors basats en coneixement lingüístic solen expressar aquest
coneixement en forma de regles. El metallenguatge sol ser senzill i facilita la
modificació de les regles. Presenten, però, l’inconvenient del seu alt cost, ja que
necessita un llarg procés d’elaboració, i les dificultats per ésser utilitzat, transportat, a
d’altres sistemes.
Els etiquetadors basats en l’estadística construeixen el seu model de llenguatge
a partir del processament de grans quantitats de dades. Amb elles deriven lleis
estadístiques que apliquen a la desambiguació. En concret, l’objectiu d’un
etiquetador estadístic és desambiguar assignant l’etiqueta més probable donada una
seqüència de paraules en una frase i inferir un model de llenguatge a partir de les
dades. El més habitual és que aquests etiquetadors treballin amb tres elements: el mot
en qüestió que cal etiquetar i dos mots veïns, ja sigui al seu davant, al darrera o a
ambdós costats.
Els avantatges i els inconvenients d’aquests etiquetadors són semblants als dels
basats en el coneixement lingüístic, però en sentit contrari. El seu llenguatge és ocult,
el que dificulta la posterior intervenció humana, la seva representació no és tan
acurada i els resultats resulten difícilment interpretables lingüísticament. Però, des

1. Introducció - 15 -
d’una òptica positiva, el seu cost humà i temporal és molt petit i esdevenen fàcilment
transportables.
Un dels problemes que solen presentar els etiquetadors estadístics és
l’estimació de casos poc freqüents per una freqüència objectivament baixa, perquè el
corpus d’aprenentatge és massa petit o poc representatiu o perquè volem estimar
paràmetres molt específics (per exemple, una seqüència determinada de quatre
elements és molt menys freqüent que una altra amb tres d’aquells quatre elements).
Per intentar fer front a aquest problema s’han realitzat treballs, també des d’una
perspectiva estadística, que cerquen el grau d’incertesa de casos determinats, però
sense considerar-ne cap d’improbabilitat absoluta, àdhuc aquells que no han succeït
mai en el corpus d’aprenentatge.
Finalment, comptem amb els etiquetadors basats en l’aprenentatge automàtic,
que acostumen a poder treballar amb restriccions més complexes i sofisticades que la
simple probabilitat. Una variant d’aquest mètode, que ens interessa particularment ja
que el sistema que ens ocupa forma part d’ella, és la construcció de sistemes híbrids
que combinen restriccions d’aprenentatge automàtic amb d’altres elaborades a mà.
RELAX és d’aquest darrer grup: el dels sistemes de desambiguació
d’aprenentatge automàtic que combinen coneixement inferit i coneixement lingüístic.
Com que el sistema d’aprenentatge automàtic dóna entrada a un percentatge
determinat d’errors, per millorar-lo RELAX admet la introducció de restriccions de
desambiguació manuals basades en el coneixement lingüístic.
L’inici del procés requereix un corpus prèviament etiquetat manualment a
partir del qual inferir les regles del model de llenguatge que s’aplicarà posteriorment.
Anomenem aquests corpus corpus d’entrenament. Al mateix temps, s’ha de reservar
una altra part del corpus anotat manualment per fer el test de comprovació dels
resultats. Se l’anomena corpus de test. El corpus d’entrenament serveix, primer,
perquè el sistema infereixi automàticament les restriccions que han d’etiquetar els
textos; segon, per construir un seguit de normes que millorin el sistema automàtic un
cop analitzats els resultats i errors que aquest genera. El corpus de test ens servirà per

- 16 - 1. Introducció
contrastar els resultats i les millores obtinguts amb les regles d’etiquetatge manuals
afegides a les elaborades automàticament.
En general, se sol reservar el 70 0 75% del corpus total per a l’entrenament
mentre que el 30 0 25% restant es fa servir per al test. En el nostre cas hem utilitzat
un corpus català amb les següents proporcions:
Corpus de test ≈ 30%
Corpus
d’entrenament
≈ 70%
CORPUS
ANOTAT
MANUALMENT
1.3. Característiques del sistema CLiC-TALP
El corpus CLiC-TALP-CAT consta de 103.205 paraules procedents de dues
fonts escrites: 25.169 de l’agència EFE i 78.036 de l’ACN (Agència Catalana de
Notícies), generades entre l’1 i el 2 de juny de 2000. El podem considerar, doncs,
representatiu del català periodístic escrit. L’etiquetatge morfosintàctic d’aquest
corpus del català s’ha realitzat amb l’objectiu d’utilitzar-lo tant a la recerca

1. Introducció - 17 -
lingüística o per a servir d’entrenament a desambiguadors automàtics a partir de
l’anotació manual dels trets morfosintàctics de cada mot. Aquest és el cas que ens
ocupa. RELAX és el desambiguador automàtic utilitzat. Un 70% del corpus validat
manualment es fa servir per l’entrenament del sistema. El 30% restant es reserva per
comprovar els resultats.
Amb aquest 70% de corpus anotat manualment, el sistema infereix un conjunt
de parelles d’etiquetes morfològiques i dóna un pes positiu o negatiu a cadascun dels
membres de la parella en funció de si apareixen o no en el corpus com a tal parella.
El pes d’aquestes restriccions pot ser positiu (el parell de categories és compatibles)
o negatiu (quan és incompatible). Aquest conjunt de restriccions responen a
l’anotació manual del corpus d’entrenament i han de poder etiquetar correctament
qualsevol corpus. S’apliquen les restriccions del model de llengua generat al mateix
corpus i ens dóna un determinat text anotat. Es compara aquesta darrera anotació
amb l’anotació manual del mateix text i es pot comprovar el nivell de funcionament
del sistema. El corpus de test servirà per validar aquests resultats, ja que no ha estat
utilitzat durant l’entrenament que ha generat el conjunt de restriccions.
Abans de l’anotació del corpus s’han de resoldre un seguit de problemes. Un
dels primers és l’establiment de les classes de paraules que prendrem en
consideració. Per això, el sistema compta amb un conjunt d’etiquetes basat en les
propostes del grup EAGLES (EAGLESa) per a l’anotació morfosintàctica de
lexicons i corpus per a totes les llengües europees. Tenim, en primer lloc, les classes
de paraules d’acord amb la tradició lingüística de les categories gramaticals: adjectiu,
adverbi, determinant, nom, verb, pronom, conjunció, interjecció i preposició. Però en
els textos reals que l’etiquetador ha d’analitzar apareixen d’altres elements no
contemplats en les categories gramaticals i als quals convé donar resposta. Per això
el sistema també considera aquestes altres categories: abreviatures, signes de
puntuació, xifres, i dates i hores.
Un altre aspecte a considerar és la quantitat d’atributs que poden especificar-se
a cada categoria. Com que el sistema està pensat per totes les llengües europees, mai

- 18 - 1. Introducció
s’utilitzen tots, sigui perquè no existeixen en aquell idioma o perquè no es consideren
rellevants. Per al català, el sistema utilitza més de tres-centes etiquetes.
El resultat d’un desambiguador no es pot prendre com quelcom de significació
absoluta, sense tenir en compte les característiques del sistema. Per exemple, com
més ampli és el conjunt d’etiquetes utilitzades, més fàcil serà que el percentatge
d’encert minvi. D’altra banda, hom pot considerar el que s’anomena etiqueta curta
(EC), que es correspon amb els dos o tres primers dígits (tres en el cas dels verbs,
dos en la resta de categories) i que en cas d’error reflectirà ambigüitat intercategorial,
o l’etiqueta llarga (EL), que fa referència a tots els dígits i que pot indicar
ambigüitats intracategorials. Per exemple, cantava pot rebre les etiquetes VMII1S0
(1ª persona del singular de l’imperfet d’indicatiu d’un verb principal) o VMII3S0 (3ª
persona del singular de l’imperfet d’indicatiu d’un verb principal). La confusió d’una
per l’altra serà un error intracategorial i afectarà l’etiqueta llarga, però no a la curta,
que en tots dos casos seria correcta. Vell pot ser etiquetat com AQ0MS0 (adjectiu
qualificatiu masculí singular) o com NCMS000 (nom comú masculí singular). En
aquest cas la confusió afectarà l’etiqueta curta, és a dir, els primers dígits, i serà
intercategorial.
1.4. Formalisme de les restriccions
El formalisme que fan servir les restriccions de RELAX en el cas de les regles
estadístiques dóna exemples com aquests, extrets de la desambiguació del corpus en
llengua catalana:

1. Introducció - 19 -
Exemple 1: -1.38292719358976 (<VAS*>) (-1 (<AQ*>));
Exemple 2: 2.9380228991622 (<Zm*>) (1 (<Fp*>));
La xifra superior esquerra indica el pes, positiu o negatiu, de la restricció. A
l’angle superior dret tenim la categoria (etiqueta curta) afectada. A la part inferior
observem successivament la posició del context, amb valor negatiu si és anterior al
mot afectat i positiu si és posterior, i la categoria de la paraula del context.
Fem notar, com ja hem esmentat, que les restriccions apreses estadísticament
només prenen en consideració els dos primers dígits de les etiquetes, llevat del cas
dels verbs en què se’n consideren tres, i que el context es limita a un sol element, és a
dir, el sistema treballa amb parells d’elements (bigrames): l’etiqueta afectada i una
altra de contextual (anterior o posterior).
En l’exemple 1 es presenta una restricció amb valor negatiu (–1.38) , cosa que
indica incompatibilitat entre dues etiquetes, <VAS*> i <AQ*> o verb auxiliar en
subjuntiu i adjectiu qualificatiu; el valor –1 de la segona línia indica la posició, en
aquest cas a l’esquerra. La restricció de l’exemple 1 s’ha de llegir com:
! hi ha una probabilitat negativa de trobar la seqüència AQ seguida de VAS
(o el que és el mateix, de trobar VAS precedit d’AQ)
En el cas de l’exemple 2 el valor de la restricció es positiu, cosa que indica una
alta compatibilitat, i el dígit que marca la posició també té valor positiu, el que vol
dir que Fp (punt) ha d’aparèixer a la dreta de Zm (moneda). Així, doncs, l’exemple 2
s’haurà de llegir com:
! hi ha una altra probabilitat de trobar la seqüència Zm seguida de Fp
RELAX ha generat automàticament 2250 restriccions. Com hom podrà
comprovar, el conjunt de restriccions manuals resulta comparativament molt menor.
La seva funció és la de polir o d’aconseguir una més alta precisió en els resultats allí

- 20 - 1. Introducció
on es poden millorar els assolits per la informació estadística. El formalisme bàsic de
les seves regles és el mateix, però el sistema permet explotar possibilitats no
aprofitades per les regles automàtiques i fer restriccions més específiques: sobre
paraules, sobre lemes, en contextos més amplis, amb condicions negatives o
disjuntives. Les restriccions manual són més àmplies perquè tenen en compte més
paràmetres. Les restriccions automàtiques només actuen sobre bigrames d’etiquetes
curtes, mentre que les manuals treballen sobre EL, lemes i paraules. Un exemple
podria ser el següent:
6.0 (<PP3*>) (0(<DA0*>))
(1(<VA*>) OR (<VM*>));
Aquí s’expressa, en primer lloc, la classe d’ambigüitat. Aquesta restricció
afecta aquelles paraules que poden ser pronom personal de 3ª persona (PP3) i
determinant article (DA0). L’etiqueta que s’està primant és la que apareix en primer
lloc (PP3). El pes de la restricció en aquest cas és 6. L’última línia de la restricció
indica el context en què s’ha aplicar. Igual que en les restriccions automàtiques, el
valor numèric amb valor positiu indica la posició a la dreta (si fos negatiu indicaria la
posició a l’esquerra). La lectura d’aquesta restricció és:
! etiquetar com a PP3 una paraula que tingui les etiquetes PP3 i DA0 si la
paraula següent té l’etiqueta VA* (verb auxiliar) o VM* (verb principal).
Podem entendre, doncs, que en el nostre cas la restricció ens indica que
l’etiqueta pronom personal de 3ª persona és més compatible que determinant article
quan va seguida d’un verb principal o auxiliar.
D’altres signes del formalisme són els parèntesis angular (<>) per delimitar el
començament i el final de l’etiqueta, l’asterisc (*) com a comodí per indicar
qualsevol valor en els dígits especificats a partir d’allí, el punt i coma (;) per senyalar
el final de la restricció, l’expressió NOT quan la condició és negativa, les cometes

1. Introducció - 21 -
(“”) per indicar lema i els guions entre comentes (“--”) per assenyalar una paraula en
la seva forma literal.
1.5. Treballs precedents
D’aquest treball que aquí apliquem al català, en tenim un precedent en llengua
castellana (Civit, 2003). Es tracta de la millora dels resultats del desambiguador
automàtic RELAX sobre el corpus CLiC-TALP en espanyol. Les 2906 restriccions
apreses automàticament en el corpus d’entrenament van donar els resultats exitosos
següents sobre el corpus que s’utilitzà com a test:
Àmbit Percentatge d’encert
EC 97.29% EC+L 96.53%
EL 94.48% EL+L 94.36%
Ja hem comentat que EC, etiqueta curta, fa referència als primers dígits de
l’etiqueta. EL, etiqueta llarga, correspon a l’etiqueta amb tots els seus dígits. L
indica els encerts en el lema. Els errors a l’EC seran intercategorials; a l’EL,
intracategorials.
Els resultats finals i la millora després de l’aplicació de les restriccions manuals
van ser els següents:

- 22 - 1. Introducció
Àmbit Percentatge d’encert
Percentatge de millora
EC 97.40% 0.11% EC+L 96.66% 0.13%
EL 96.28% 1.80% EL+L 96.18% 1.82%
Observem, doncs, que unes quantes restriccions introduïdes manualment i
basades en el coneixement lingüístic milloren significativament el resultat fins
arribar gairebé al 2% en l’àmbit de l’etiqueta llarga, que és on es pot incidir més en
les regles manuals. Una millora d’un 2% sobre l’etiquetatge automàtic seria, per tant,
un resultat acceptable en el nostre cas.

- 23 -
2. Detecció dels errors del desambiguador
automàtic
En aquesta secció s’explica el grau d’encert del desambiguador RELAX amb les
regles que ha generat automàticament i es comprova quins són els errors més freqüents.
A continuació es tipifiquen i classifiquen aquests errors amb l’objectiu de facilitar la
recerca de regles de desambiguació en la secció següent. Finalment, es comparen els
resultats de les restriccions automàtiques en català i en castellà.
De les aproximadament cent mil paraules del corpus CLiC-TALP-CAT, RELAX
ha après automàticament unes regles de desambiguació utilitzant el corpus
d’entrenament, d’unes 70000 paraules. Els altres 30.000 mots s’han reservat per a un test
final de verificació. Després de generades les regles, les apliquem sobre aquest mateix
corpus, comparem els etiquetats de RELAX amb les del corpus anotat manualment i
obtenim una primera valoració del rendiment del sistema sobre el corpus d’entrenament.
L’encert del sistema presenta aquests resultats:

- 24 - 2. Detecció dels errors del desambiguador automàtic
Àmbit Percentatge d’encert
EC: Etiqueta curta 96.85% EC+L: Etiqueta curta i lema 95.41% EL: Etiqueta llarga 94.76% EC+L: Etiqueta llarga i lema 94.55%
La primera constatació és l’alt grau d’encert del funcionament automàtic del
sistema. Un 5.45% d’error en el pitjor dels casos i un 3.15% si només considerem l’EC
és un bon resultat, tot i que per determinades aplicacions pot ser excessiu. Després,
podem observar que l’error és menor en l’etiqueta curta (3.15%) que en la llarga
(5.24%), fet obvi si tenim en compte que els errors en l’EC també ho són de l’EL i no
necessàriament a l’inrevés. El fet que el sistema automàtic treballi amb l’EC ha
d’incrementar encara més aquesta diferència en els resultats.
Finalment, si considerem l’error en el lema a més del de l’etiqueta, el percentatge de
desencerts augmentarà una mica: 4.59% d’errors considerant l’EC i el lema, 5.45% d’EL
i lema. Això implica que existeix un conjunt de mots que encerten l’etiqueta malgrat
equivocar-se en el lema: un 1.44% dels mots tenen l’EC correcta però el lema equivocat,
percentatge gens petit; un 0.3% tenen l’EL correcta i el lema erroni.
A continuació presentem els errors que es donen en 10 o més casos després de la
desambiguació automàtica. Cada línia consta de 7 elements. En primer lloc tenim el
nombre de casos que es presenta aquest error en el corpus d’entrenament desambiguat
amb les regles automàtiques. Després tenim el mot, el lema i l’etiqueta erronis (com ja
s’ha comentat, l’error pot ser de lema, etiqueta o d’ambdós elements). Finalment, figuren
el mot, el lema i l’etiqueta correctes, és a dir, els realitzats manualment:
392 es ell P0300000 es es P0000000 356 que que PR0CN000 que que CS 261 s' ell P0300000 s' es P0000000 74 Generalitat generalitat NCFS000 Generalitat Generalitat NP00000 72 una un DI0FS0 una un DN0FS0 70 un un DI0MS0 un un DN0MS0 45 havia haver VAII1S0 havia haver VAII3S0 36 que que CS que que PR0CN000 36 se ell P0300000 se se P0000000

2. Detecció dels errors del desambiguador automàtic - 25 -
31 cas ca NCFP000 cas cas NCMS000 31 s' ell P0300000 s' ell PP3CN000 30 Govern govern NCMS000 Govern Govern NP00000 29 era ser VSII1S0 era ser VSII3S0 29 joves jova NCFP000 joves jove NCCP000 28 Ajuntament ajuntament NCMS000 Ajuntament Ajuntament NP00000 22 van anar VAIP3P0 van anar VMIP3P0 21 fons fon NCMP000 fons fons NCMN000 21 Parlament parlament NCMS000 Parlament Parlament NP00000 20 estava estar VMII1S0 estava estar VMII3S0 20 sigui ser VSSP1S0 sigui ser VSSP3S0 19 hagi haver VASP1S0 hagi haver VASP3S0 18 estat ser VSP00SM estat estar VMP00SM 17 diumenge diumenge NCMS000 diumenge [diumenge:??/??/??:??.??] W 16 actes acta NCFP000 actes acte NCMP000 16 el el DA0MS0 el ell PP3MSA00 15 Es ell P0300000 Es es P0000000 15 nou nou DN0CP0 nou nou AQ0MS0 15 quan quan PR000000 quan quan CS 15 tenia tenir VMII1S0 tenia tenir VMII3S0 14 Congrés congrés NCMS000 Congrés Congrés NP00000 14 dilluns dilluns NCMN000 dilluns [dilluns:??/??/??:??.??] W 14 la el DA0FS0 la ell PP3FSA00 13 podria poder VMIC1S0 podria poder VMIC3S0 13 qual qual DR0CS0 qual qual PR0CS000 12 Estat estat NCMS000 Estat Estat NP00000 12 Estat ser VSP00SM Estat Estat NP00000 11 altres altre DI0CP0 altres altre PI0CP000 11 maig maig NCMS000 maig [??:??/5/??:??.??] W 11 pugui poder VMSP1S0 pugui poder VMSP3S0 11 tingui tenir VMSP1S0 tingui tenir VMSP3S0 10 alumnes alumna NCFP000 alumnes alumne NCMP000 10 l' el DA0CS0 l' ell PP3CSA00 10 pessetes pesseta Zm pessetes pesseta NCFP000
Una primera aproximació ha de consistir en una sistematització d’aquests errors.
Estem treballant sobre 1866 casos incorrectes si considerem els que com a mínim es
produeixen deu vegades. Encara que no siguin tots, sí que es tracta d’una mostra prou
significativa. Els agrupem en un seguit de grups amb un criteri simplificador,
homogeneitzador i clarificador.
a) Errors deguts als mòduls del sistema:
Tenim un primer grup d’etiquetes incorrectes que es deuen als propis mòduls del
sistema i sobre les que no podrem actuar. Es tracta de les etiquetes de noms propis, de les

- 26 - 2. Detecció dels errors del desambiguador automàtic
de dates i de les monedes. Sumen un conjunt de 243 errors (191 en els noms propis com
Govern, Generalitat, Parlament, Ajuntament, Congrés..., 42 en els dies de la setmana i 10
en les pessetes). Representen un 13.02% dels etiquetats erronis indicats a la llista com a
més freqüents.
b) Errors en la forma “es”:
És l’error més freqüent. En la llista anterior apareix en 735 ocasions. Això
representa un 39.39%. Aquest pronom pot aparèixer sota diferents formes: es, se, s’, Es...
i pot correspondre a tres etiquetes (d’on prové la seva ambigüitat):
! P0000000 per a usos com a marca d’oració impersonal o de passiva reflexa.
! P0300000 en els verbs pronominals
! PP3CN000 com a pronom personal
c) Errors de “que” conjunció o pronom:
Afecta 410 casos, especialment per un etiquetat excessiu com a pronom.
Representa un 21.97 % dels errors que es donen en deu o més casos.
d) Errors en l’etiquetat com a “numeral” o “indefinit”:
Es detecten 142 (7.61%) casos de determinants, en una proporció gairebé igual de
numerals i indefinits intercanviats erròniament. Encara que la situació també es dóna
entre pronoms, aquests no apareixen degut a l’escassa quantitat d’errors en aquesta
categoria gramatical. Aquests casos exemplificaran la problemàtica de la desambiguació,
fins i tot manual.
e) Errors en la persona verbal:
El desambiguador ha optat per la primera persona en moltes de les situacions en
què podia triar entre 1ª i 3ª (cantava, cantaria, canti, cantés). Aquest error es dóna
aparentment menys del que succeeix en realitat (183 casos en la llista d’errors principals,
un 9.81%). Ara bé, aquest llistat només recull aquestes persones en els temps i verbs més

2. Detecció dels errors del desambiguador automàtic - 27 -
freqüents (havia, era, estava, sigui, hagi, tenia, podria, pugui, tingui), però es dóna en
moltes situacions en molts lemes diferents i menys utilitzats. La correcció d’aquestes
errades suposarà una millora molt més notable de la que hom podria suposar aquí.
f) Errors en el lema:
107 (5.73%) etiquetes presenten errors en el lema, cosa que provoca errors també
en els atributs de l’etiqueta. Remarquem un altre cop que aquí només es poden
identificar aquells casos més freqüents i que un sistema de desambiguació potser hauria
de tenir sistemes d’actualització que permetessin corregir successives deteccions
d’aquest fenomen.
h) Errors entre determinant i pronom:
Aquest és un error que observem entre determinant i pronom indefinits (11
exemples) i, més habitual, entre determinant article i pronom personal (formes el, la, l’,
40 casos). En total, 2.73% del llistat d’errors més freqüents.
i) Errors en la tipologia verbal:
El sistema d’etiquetació utilitzat distingeix entre verb principal (VM), semiauxiliar
(VS) i auxiliar (VA). Alguns errors provenen d’una assignació errònia del segon atribut
categorial. És el cas de van, que rep l’etiqueta VA* en lloc de VM* en 22 casos, i
d’estat, que en 18 casos és etiquetat com a VS* en lloc de VM* després d’un error en
l’assignació de lema (ser per estar). Hem optar per incloure aquest darrer error en aquest
apartat, ja que f) Errors en el lema inclou només noms.
j) Errors entre determinant numeral i adjectiu qualificatiu:
Mots com nou presenten una ambigüitat entre determinant numeral (nou amics) i
adjectiu qualificatiu (un amic nou).

- 28 - 2. Detecció dels errors del desambiguador automàtic
k) D’altres casos:
Amb aquests apartats hem conclòs la classificació d’errors que apareixen com a
mínim deu vegades després d’aplicar les restriccions de desambiguació d’aprenentatge
automàtic. Ara bé, hem detectat algunes situacions en què els errors individualment són
molt poc nombrosos, però si els agrupem segons determinats criteris, el seu volum és
considerable. Un primer cas es presenta en alguns errors en el mode verbal quan formes
d’imperatiu dominen sobre l’indicatiu o el subjuntiu (canta, canti, cantin). La situació és
prou poc habitual perquè no aparegui a la llista deu o més cops en cap cas, però prou
freqüent a través de diferents verbs perquè el conjunt sigui significatiu. Una altra situació
és la dels errors en el lema dels noms: una major exhaustivitat en l’anàlisi dels errors
podria augmentar el poliment a través de les restriccions manuals.
Recordem, finalment, que les dades es basen sobre la llista d’errors que es
presenten 10 o més cops. El nombre d’alguns d’ells es podria incrementar amb
variacions de menor quantia (per exemple, els de que). D’altres que apareixen en un
percentatge molt reduït responen a tipologies més àmplies que s’escapen de la llista sota
múltiples casos amb lema diferent, cada un d’ells de poca quantia, però importants
presos en conjunt. Per exemple, els nombrosos verbs que presenten confusions entre
primera i tercera persona del singular són detectats pel sistema com un cas diferent per
cada lema verbal i en figuren a la llista una part molt reduïda. Els errors entre certes
formes d’imperatiu per d’altres d’indicatiu o subjuntiu ni figuren a la llista perquè no es
donen mai en deu o més casos, malgrat que tots junts resulten numèricament força
rellevants.
Ja hem indicat les dades estadístiques que ens proporciona el sistema sobre el grau
d’encert quan aplica les restriccions automàtiques sobre el corpus d’entrenament. Com
podem comprovar si contrastem aquestes dades amb el desambiguador en llengua
castellana del sistema CliC-TALP, els resultats han estat lleugerament millors en aquest
idioma en l’etiqueta curta, especialment en l’encert del lema, i més encertats en català en
l’etiqueta llarga:
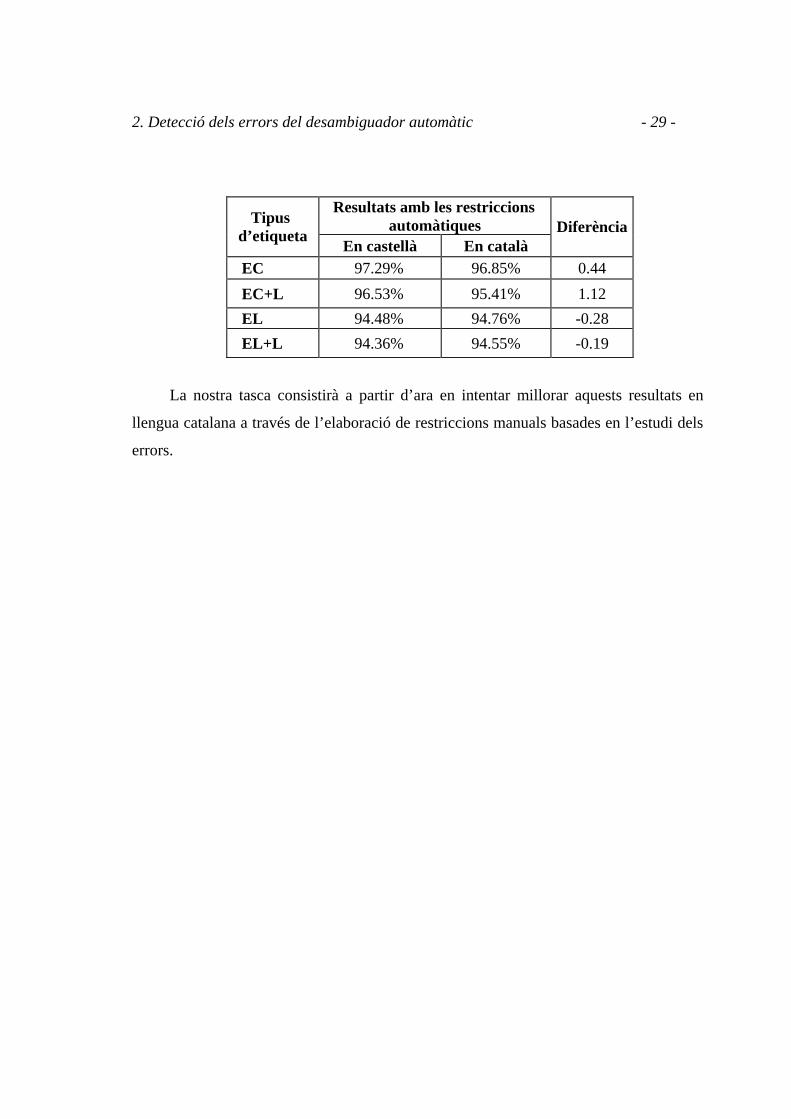
2. Detecció dels errors del desambiguador automàtic - 29 -
Resultats amb les restriccions automàtiques Tipus
d’etiqueta En castellà En català Diferència
EC 97.29% 96.85% 0.44 EC+L 96.53% 95.41% 1.12 EL 94.48% 94.76% -0.28 EL+L 94.36% 94.55% -0.19
La nostra tasca consistirà a partir d’ara en intentar millorar aquests resultats en
llengua catalana a través de l’elaboració de restriccions manuals basades en l’estudi dels
errors.


- 31 -
3. Regles de desambiguació basades en
el coneixement lingüístic
En aquest capítol del treball exposarem les diferents restriccions elaborades
manualment, la seva justificació i les millores que aporten al sistema. Encara que el
funcionament i el formalisme de les regles automàtiques i de les manuals sigui
essencialment el mateix, observem certes diferències.
Les regles manuals presenten una major complexitat que les automàtiques en
els seus elements. Primer, com ja sabem, es poden formular des de l’etiqueta amb un
sol o més dígits i asterisc fins a l’etiqueta completa. Després, es treballa amb una
diversitat en el nombre d’elements contextuals, fins a tres en el nostre cas a més de la
pròpia etiqueta objecte de modificació. A més, s’hi introdueixen elements nous, com
la presa en consideració dels lemes o les disjuncions en els elements contextuals.
Finalment, aquestes restriccions actuen sobre l’etiquetat ja realitzat automàticament i
que intenten modificar en els errors detectats.

- 32 - 3. Regles de desambiguació basades en el coneixement lingüístic
Com ja s’ha comentat, les restriccions automàtiques afecten l’etiqueta curta
(EC). Les manuals, en canvi, poden afectar l’EC, l’etiqueta llarga (EL) i també al
lema de la paraula (L).
3.1. Restriccions sobre lemes
Entenem per restriccions sobre lemes aquelles que defineixen la posició 0, és a
dir, l’element al qual afecta la restricció, a través d’un lema i no d’una etiqueta. Dins
aquest grups hem hagut d’efectuar dues restriccions. En primer lloc, una per aquells
mots que tenen assignat un lema equivocat i cal corregir-lo per evitar errors de
gènere i nombre. És el cas de l’exemple següent extret de l’apartat 3.1.1.:
! Són els escenaris dels diferents actes.
En segon lloc, una altra per aquells elements que, sense tenir el lema equivocat,
presenten problemes de gènere que es poden corregir en determinats contextos, com
és el cas d’aquest exemple de l’apartat 3.1.2.:
! amb un capital social.
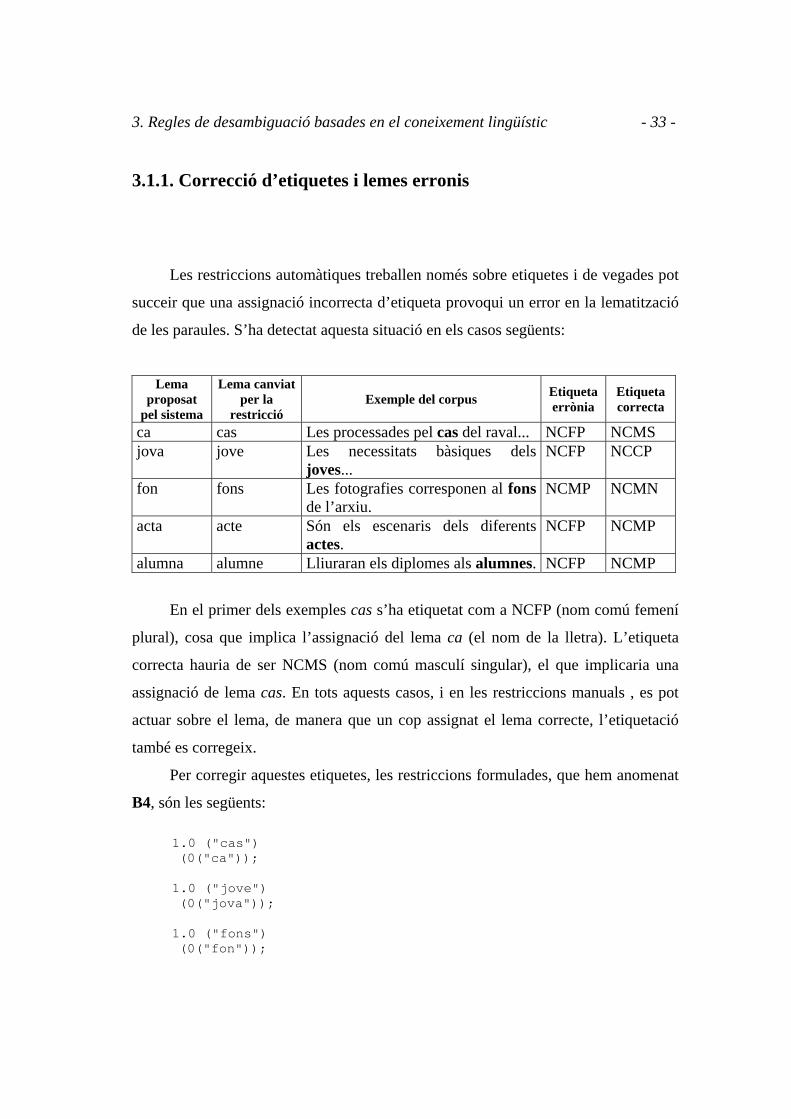
3. Regles de desambiguació basades en el coneixement lingüístic - 33 -
3.1.1. Correcció d’etiquetes i lemes erronis
Les restriccions automàtiques treballen només sobre etiquetes i de vegades pot
succeir que una assignació incorrecta d’etiqueta provoqui un error en la lematització
de les paraules. S’ha detectat aquesta situació en els casos següents:
Lema
proposat pel sistema
Lema canviat per la
restricció Exemple del corpus Etiqueta
errònia Etiqueta correcta
ca cas Les processades pel cas del raval... NCFP NCMS jova jove Les necessitats bàsiques dels
joves... NCFP NCCP
fon fons Les fotografies corresponen al fons de l’arxiu.
NCMP NCMN
acta acte Són els escenaris dels diferents actes.
NCFP NCMP
alumna alumne Lliuraran els diplomes als alumnes. NCFP NCMP
En el primer dels exemples cas s’ha etiquetat com a NCFP (nom comú femení
plural), cosa que implica l’assignació del lema ca (el nom de la lletra). L’etiqueta
correcta hauria de ser NCMS (nom comú masculí singular), el que implicaria una
assignació de lema cas. En tots aquests casos, i en les restriccions manuals , es pot
actuar sobre el lema, de manera que un cop assignat el lema correcte, l’etiquetació
també es corregeix.
Per corregir aquestes etiquetes, les restriccions formulades, que hem anomenat
B4, són les següents:
1.0 ("cas") (0("ca")); 1.0 ("jove") (0("jova")); 1.0 ("fons") (0("fon"));

- 34 - 3. Regles de desambiguació basades en el coneixement lingüístic
1.0 ("acte") (0("acta")); 1.0 ("alumne") (0("alumna"));
El primer dels lemes afectats, per exemple, indica al sistema de restriccions
automàtiques que quan pugui triar entre els lemes ca i cas, es quedi amb cas.
Després, i en conseqüència, ja no s’etiquetarà erròniament, sinó correcta.
Observem, doncs, que aquí només es produeix un canvi de lema. L’assignació
del correcte genera per si sol el canvi d’etiqueta. Remarquem que aquesta opció té
l’avantatge que permet amb una gran facilitat successives ampliacions a mesura que
s’observen noves situacions semblants. El sistema restaria obert a un manteniment
constant senzill pel que fa referència a aquesta restricció.
La solució aportada no representa, de fet, un canvi basat en el coneixement
lingüístic, sinó en l’observació estadística de quin dels dos lemes és més habitual i en
l’error del sistema a l’hora de triar. És evident que ara poden aparèixer errors quan
un text contingui cas com a forma plural del nom d’una determinada lletra de
l’abecedari o joves com a plural de “jova”, muller del fill. Ara bé, d’acord amb el
corpus, aquests errors seran menys nombrosos que els que hem corregit. Aquest és
un cas de restricció que té en compte la pròpia estadística dels lemes i això les
restriccions automàtiques no podrien fer-ho mai perquè no actuen sobre ells.
Els resultats en la millora del sistema han estat els següents:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B4 96.85 95.56 94.90 94.69 Millora 0.00 0.15 0.14 0.14
Podem observar com millora el lema (de fet, és l’element que hem corregit
directament) i l’etiqueta llarga (es poden veure afectats els dígits tercer i quart).

3. Regles de desambiguació basades en el coneixement lingüístic - 35 -
L’etiqueta curta no presenta cap millora perquè els dos primers dígits ja eren
correctes i no s’han vist afectats. Remarquem que la recerca d’errors menys freqüents
o l’ampliació del corpus podria permetre la millora i el manteniment del sistema de
desambiguació en aquest punt.
3.1.2. Canvis de gènere a mots pertanyents a certs lemes segons el
context
Aquestes restriccions, que hem anomenat B7, tenen unes característiques
comuns amb el grup B4: es tracta de noms que presenten problemes en l’assignació
correcta de l’atribut de gènere. En aquest cas gènere femení en lloc de masculí i
gènere comú en lloc de femení. Ara bé, no presenten una dualitat de lemes possibles
i, per tant, la restricció no consisteix en un canvi de lema. Aquest bloc de restriccions
assigna una etiqueta de nom amb un gènere determinat quan es troba amb un cert
lema en un context concret.
Indiquem en un quadre l’etiqueta nova, el lema afectat, el context, un exemple
de text erròniament etiquetat i l’etiqueta errònia. Les cometes emmarquen una
expressió literal i amb # senyalem la posició del mot objecte de canvis en el seu
context, si s’escau:

- 36 - 3. Regles de desambiguació basades en el coneixement lingüístic
Etiqueta correcta
Lema afectat Context Etiqueta errònia Etiqueta
errònia NCF droga perquè no intervingueren en un focus de
droga NCC
NCMP finals SPS#SP Es van iniciar les tasques de neteja a finals del mes
NCFP
NCFS policia DA0F# La policia catalana busca per la comarca NCCS NCF vista “de”# des del punt de vista econòmic NCCS NCM capital SP# transaccions especulatives de capital NCFS NCM capital DI0M# amb un capital social NCFS
El darrer dels exemples del quadre anterior indica al sistema de desambiguació
que quan trobi el lema “capital” precedit d’un determinant indefinit masculí assigni a
aquest mot els atributs de nom comú masculí; es corregirà aleshores el gènere erroni
proporcionat pel sistema automàtic. Veiem també en el quadre que el context el
definim de manera diversa: lemes i etiquetes de diferents categories situades abans i
després del mot.
Les restriccions són les següents: 1.0 (<NCF*>) (0("droga")); 1.0 (<NCMP*>) (0("finals")) (-1(<SPS*>)) (1(<SP*>)); 1.0 (<NCFS*>) (0("policia")) (-1(<DA0F*>)); 1.0 (<NCF*>) (0("vista")) (-1("de")); 1.0 (<NCM*>) (0("capital")) (-1(<SP*>));

3. Regles de desambiguació basades en el coneixement lingüístic - 37 -
1.0 (<NCM*>) (0("capital")) (-1(<DI0M*>));
Els resultats obtinguts han estat els següents:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B7 96.85 95.41 94.81 94.60 Millora 0.00 0.00 0.05 0.05
En aquest cas el lema ja era correcte i els dos primers dígits (EC) no s’han vist
afectats. Es modifica, doncs, l’etiqueta llarga en l’atribut de gènere (tercer dígit).
Comentem, finalment, que aquest conjunt de restriccions també resta obert a
successives ampliacions, ja que el seu formalisme és enumeratiu de diferents casos.
3.2. Restriccions sobre l’etiqueta llarga
Entenem per restriccions sobre l’etiqueta llarga (EL) aquelles que afecten els
atributs, però no la categoria. Quan es produeix un canvi en els primers dígits, el
sistema avaluador del desambiguador entén que han canviat les etiquetes curta i
llarga. Quan el canvi no es produeix fins el tercer dígit, o el quart en el cas dels
verbs, es considera que ha canviat només l’EL, tot i que, lògicament, en la definició
hi hagin aparegut aquests primers atributs categorials.

- 38 - 3. Regles de desambiguació basades en el coneixement lingüístic
3.2.1. Canvi de la 1ª per la 3ª persona verbal
La conjugació verbal del català presenta ambigüitats en les formes de la
primera i la tercera persona del singular del temps simples següents: present de
subjuntiu, pretèrit imperfet d’indicatiu i de subjuntiu i condicional simple. En el cas
dels temps compostos, podem atribuir les ambigüitats a les formes simples dels verbs
auxiliars corresponents.
Ja s’ha comentat que el sistema d’aprenentatge automàtic de les restriccions
treballa només amb l’etiqueta curta. No pot, per tant, establir restriccions sobre la
persona verbal que es troba en el quart dígit. El sistema ha decidit en múltiples
ocasions atribuir la primera persona en lloc de la tercera. D’acord amb el corpus, la
tercera persona té moltes més aparicions que la primera i ha de ser rendible invertir
les prioritats, que és el que fa el conjunt de restriccions anomenades B1. Tampoc es
tracta, per tant, d’una regla de base lingüística ni té en compte criteris contextuals,
sinó d’una prioritat estadística.
Afecta dotze etiquetes que corresponen a les coincidències morfològiques
següents:
a) 1ª i 3ª persones del singular del pretèrit imperfet d’indicatiu dels verbs
considerats en l’etiquetatge com a principals, semiauxiliars i auxiliars.
b) 1ª i 3ª persones del singular del condicional dels verbs amb els mateixos tres
valors.
c) 1ª i 3ª persones del singular del present de subjuntiu dels mateixos tres tipus
de verbs.
d) 1ª i 3ª persones del singular del pretèrit imperfet de subjuntiu dels tres valors
de verbs.

3. Regles de desambiguació basades en el coneixement lingüístic - 39 -
Alguns exemples d’etiquetatge erroni del sistema són els següents:
! VMII1S0 en lloc de VMII3S0: Josep Suñé reconeixia ahir que hi va
haver cert optimisme.
! VMIC1S0 en lloc de VMIC3S0: L’ús del vehicle privat baixaria un 43%
! VMSP1S0 en lloc de VMSP3S0: Demanarà que s’adeqüi la platja de
Tarragona.
! VMSI1S0 en lloc de VMSI3S0: Va demanar que li comprés una beguda.
! VSII1S0 en lloc de VSII3S0: El pressupost total de les obres era de
18.420.000 pessetes.
! VSIC1S0 en lloc de VSIC3S0: L’any Dalí seria una ocasió per estimular
una nova lectura.
! VAII1S0 en lloc de VAII3S0: Hi havia l’advocat defensor present.
! VASP1S0 en lloc de VASP3S0: L’ACA no té coneixement que hagi
entrat en les seves dependències el projecte.
El conjunt de restriccions, molt llarg ja que contempla dotze possibilitats, pren
la forma següent:
1.0 (<VMII3S0>) (0(<VMII1S0>)); 1.0 (<VMIC3S0>) (0(<VMIC1S0>)); 1.0 (<VMSP3S0>) (0(<VMSP1S0>)); 1.0 (<VMSI3S0>) (0(<VMSI1S0>)); 1.0 (<VSII3S0>) (0(<VSII1S0>)); 1.0 (<VSIC3S0>) (0(<VSIC1S0>)); 1.0 (<VSSP3S0>)

- 40 - 3. Regles de desambiguació basades en el coneixement lingüístic
(0(<VSSP1S0>)); 1.0 (<VSSI3S0>) (0(<VSSI1S0>)); 1.0 (<VAII3S0>) (0(<VAII1S0>)); 1.0 (<VAIC3S0>) (0(<VAIC1S0>)); 1.0 (<VASP3S0>) (0(<VASP1S0>)); 1.0 (<VASI3S0>) (0(<VASI1S0>));
Els resultats d’afegir només aquesta regla a les automàtiques dóna aquesta
millora en el sistema:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B1 96.85 95.41 95.43 95.22 Millora 0.00 0.00 0.67 0.67
Observem que la millora és sensiblement importat en les etiquetes llargues del
corpus, les úniques afectades. El llistat d’errors inicials de deu o més ocurrències
només inclou les formes havia, era, estava, sigui, hagi, tenia, podria, pugui i tingui,
que no permetrien aquest alt percentatge de millora (0.67%). Ara bé, aquest error
s’ha de presentar en moltes ocasions en un nombre petit de casos per tractar-se de
verbs d’aparició menys freqüent, però importants en conjunt.

3. Regles de desambiguació basades en el coneixement lingüístic - 41 -
3.2.2. Canvis en el mode verbal
Un error semblant a l’anterior és la confusió per part del sistema entre certes
formes d’imperatiu que coincideixen amb d’altres formes verbals d’indicatiu i de
subjuntiu. El sistema ha optat per la forma de l’imperatiu i la restricció manual, que
hem anomenat B3, corregirà aquesta tria. Veiem que és una altra regla que no es
fonamenta en el context, sinó en la freqüència d’aparició en el corpus.
Afecta tres situacions, de les quals exposem un exemple de cada una amb
etiquetatge erroni extret del corpus d’entrenament:
! VMM02S0 en lloc de VMIP3S0: La xarxa suposa una amenaça.
! VMM03S0 en lloc de VMSP3S0: Ha servit perquè l’alpinisme manresà
superi l’assignatura pendent de fer el cim.
! VMM03P0 en lloc de VMSP3P0: Ha recomanat els dirigents del PSC que
dormin tranquils.
Les tres restriccions que s’empren per triar el mode verbal són:
1.0 (<VMIP3S0>) (0(<VMM02S0>)); 1.0 (<VMSP3S0>) (0(<VMM03S0>)); 1.0 (<VMSP3P0>) (0(<VMM03P0>));
Els resultats han estat els següents:

- 42 - 3. Regles de desambiguació basades en el coneixement lingüístic
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B3 96.86 95.43 94.93 94.72 Millora 0.01 0.02 0.17 0.17
Observem aquí que la millora fonamental s’ha produït en l’etiqueta llarga, tal
com era d’esperar. Des d’un punt de vista lògic, aquest és l’únic canvi explicable.
Malgrat això, es presenten petites millores en l’etiqueta curta que no eren de
preveure. Sovint observarem petit canvis en els percentatges d’èxits en l’etiquetat de
difícil justificació, només explicables per la complexa interacció de les restriccions
manuals amb els milers de restriccions automàtiques.
3.3. Restriccions sobre l’etiqueta curta
Aquestes restriccions són les que donen un millor rendiment sobre el resultat
global, ja que una millora en l’etiqueta curta suposa, com a mínim, una millora igual
en l’etiqueta llarga. Els dos tipus d’errors més importants afecten aquesta etiqueta.
Ens referim a la forma que com a pronom o conjunció i a es en les seves diferents
formes com a pronominal o com a marca d’impersonalitat. Tanmateix, aquests errors
són dels més difícils de corregir i els que han quedat amb més elements pendents de
solució.

3. Regles de desambiguació basades en el coneixement lingüístic - 43 -
3.3.1. Pronom relatiu o conjunció
S’han inclòs dos conjunts de restriccions que corregeixen assignacions errònies
entre pronom relatiu i conjunció subordinant, les anomenades B5 i B11.
3.3.1.1. “Que” pronom relatiu o conjunció
B5 rectifica certs etiquetats erronis entre el pronom relatiu “que” i la mateixa
conjunció subordinant. El procediment de recerca ha consistit en l’anàlisi exhaustiva
d’aquestes situacions i en la detecció de certes constants contextuals. S’ha hagut
d’anar jugant amb els pesos de cada una de les restriccions, que deurien interactuar
amb d’altres d’automàtiques, fins a obtenir els millors resultats.
És importat assenyalar que la nostra tasca aquí ha consistit en adaptar
l’etiquetador per acostar-lo el màxim possible als resultats del corpus manual i no ens
plantegem l’adscripció de qualsevol que a alguna d’aquestes categories. Identifiquem
els errors i cerquem la manera de què el desambiguador automàtic s’acosti el màxim
possible a la desambiguació manual.
Aquest grup de restriccions afecten les situacions següents, que les modifiquen
en el sentit descrit aquí:
a) La restricció manual etiqueta com a conjunció quan la paraula que va
precedida de verb. Per exemple:
! l’alt tribunal sosté que és evident...

- 44 - 3. Regles de desambiguació basades en el coneixement lingüístic
! amb la protesta reclamen que l’empresa variï la seva actitud.
b) S’etiqueta com a conjunció quan va precedida dels verbs ser o estar més una
etiqueta d’adjectiu qualificatiu. Aquesta doble restricció corregeix les freqüents
aparicions de “és cert que”, “és evident que”, “està clar que”... com en l’exemple
següent:
! és clar que els acusats van actuar...
c) S’etiqueta com a conjunció subordinant quan que va precedit de conjunció
coordinant, com és el cas de:
! l’informe és que es preveuen inversions i que no hi ha cap pla d’ampliar
! es demana una dotació i que es busquin les solucions.
Les regles s’expressen de la manera següent:
15.0 (<CS>) (0(<PR0CN000>)) (-1(<V*>)); 8.0 (<CS>) (0(<PR0CN000>)) (-1(<AQ0*>)) (-2("ser")); 8.0 (<CS>) (0(<PR0CN000>)) (-1(<AQ0*>)) (-2("estar")); 5.0 (<CS>) (0(<PR0CN000>)) (-1(<CC>));
I les millores obtingudes són aquestes:

3. Regles de desambiguació basades en el coneixement lingüístic - 45 -
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B5 97.14 95.70 95.05 94.84 Millora 0.29 0.29 0.29 0.29
Es pot apreciar, primer, com els resultats són força considerables. En segon
lloc, afecta l’etiqueta curta, la més difícil de modificar i la més rendible, ja que també
es veu modificada la llarga, cosa que no succeeix a l’inrevés. Finalment, observem,
aquí i en altres restriccions, que les modificacions basades en l’etiqueta i no en el
lema tenen una rendibilitat major, encara que un comportament més difícil de
controlar.
3.3.1.2. Altres canvis entre pronoms relatius i conjuncions
Aquest petit bloc de restriccions intenta resoldre alguns casos d’errors en el
mot quan com a conjunció i com a pronom relatiu. Hem forçat l’etiqueta de
conjunció quan el mot anava precedit de nom comú i seguit de pronom i verb o
directament de verb. Seria el cas d’aquests exemples que les restriccions
automàtiques havien desambiguat erròniament com a pronom relatiu:
! va conèixer el jove quan esperava el tren;
! va atacar amb una barra de ferro quan es trobava a les dutxes.
En canvi, hem forçat l’etiqueta pronom relatiu quan els elements precedents
eren un determinant i un nom.
Les restriccions s’expressen així:
5.0 (<CS>)

- 46 - 3. Regles de desambiguació basades en el coneixement lingüístic
(0(<PR000000>)) (-1(NC*)) (1(<V*>)); 5.0 (<CS>) (0(<PR000000>)) (-1(NC*)) (1(<P*>)) (2(<V*>)); 5.0 (<PR000000>) (0(<CS>)) (1(<D*>)) (2(<NC*>));
Aquesta situació també es dóna en els mots on i com, a més de quan. De fet,
però, com que la seva freqüència d’aparició en el corpus és molt baixa, les millores
obtingudes són força reduïdes:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B11 96.85 95.42 94.72 94.52 Millora 0.00 0.01 0.01 0.01
3.3.2. “Es” impersonal o pronominal
Es i totes les seves formes (se, -se, s’, ‘s) poden rebre tres etiquetes:
! P0000000 amb lema es quan intervé en construccions passives
(“aquesta actitud s’agraeix molt”) o impersonals (“es diu que vindrà”).
! P0300000 amb lema ell quan actua en un verb pronominal (“es cansa
ràpidament”).

3. Regles de desambiguació basades en el coneixement lingüístic - 47 -
! PP3CN000 amb lema ell quan apareix com a pronom personal (“es
posa la camisa nova”).
Aquest mot és el que genera més errors després d’aplicar les restriccions
automàtiques. Entre els errors de més de cinc aparicions podem observar aquestes
dades:
P03 en lloc de P00 P03 en lloc de PP3 PP3 en lloc de P03
711 40 7
Amb aquestes dades ja podem observar que l’error de desambiguació més
rellevant és l’assignació de l’etiqueta P0300000 en lloc de P0000000. Aquest error
només es presenta en aquest sentit i mai en l’invers. No passa el mateix entre les
etiquetes P0300000 i PP3CN000 que presenten algunes confusions en ambdós
sentits.
De fet, si analitzem el corpus veurem que el desambiguador automàtic no
utilitza mai l’etiqueta P0000000. Davant l’opció entre P0300000 i P0000000 sempre
s’utilitza la primera. Caldrà veure, doncs, si invertir la preferència del sistema
millorarà el resultat. El corpus d’entrenament ens dóna les aparicions següents:
! P0000000: 715 casos.
! P0300000: 238 casos.
Per tant, si invertim la preferència reduirem en 477 els errors.
Aquesta restricció, que hem anomenat B8, pren aquesta forma:
1.0 (<P0000000>)
(0(<P0300000>));
S’ha produït aquesta millora en els resultats:

- 48 - 3. Regles de desambiguació basades en el coneixement lingüístic
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B8 96.85 96.09 95.43 95.22 Millora 0.00 0.68 0.67 0.67
Veiem que el rendiment d’aquesta petita restricció és considerable i que des
d’un punt de vista estadístic aquesta solució resulta molt millor ja que provoca menys
errors que l’altra. Ara, a més, s’ha invertit la direcció dels errors. Si abans teníem
més de set-cents casos que prenien l’etiqueta P0300000 per P0000000, ara en podem
comptar més de dos-cents en sentit invers. Es tracta de verbs pronominals que no són
identificats així.
Hem buscat procediments per depurar aquesta restricció i millorar-ne els
resultats. Una possibilitat és la d’ampliar la restricció tornant a canviar l’etiqueta
d’aquells verbs que només s’utilitzen pronominalment. Al Diccionari General de la
Llengua Catalana hem trobat 2327 verbs que tenen el pronom se en la forma
d’entrada del diccionari. Ara bé, caldrà extreure només aquells que tenen un ús
exclusivament pronominal. En una exploració parcial, d’entre 781 verbs n’hem
localitzat 156 (un 20%). L’observació d’aquest llistat ens mostra que es tracta de
verbs molt poc utilitzats amb un corpus com el que treballem i de poca rendibilitat
pel cost que suposa la seva confecció. L’elaboració d’aquesta restricció a través de
sistemes automàtics d’extracció d’informació seria el procediment més idoni.
Hem optat, doncs, per un altre sistema que pretén completar la restricció B8
amb la B12. S’ha fet una cerca en el corpus d’entrenament fins a identificar tots els
verbs pronominals que hi apareixen acompanyant el pronom es, el seu nombre
d’aparicions i els contextos més immediats. Es localitzen 131 lemes verbals, des de
17 aparicions (trobar) fins a una. Les restriccions B12 amb tots aquests verbs que en
el corpus d’entrenament apareixen amb un ús pronominal tornaran a etiquetar com a
P0300000 l’esmentada forma. Ara bé, alguns d’aquests canvis generaran nous errors,

3. Regles de desambiguació basades en el coneixement lingüístic - 49 -
ja que alguns d’aquests verbs poden anar acompanyats de es P00* a més d’es P03*.
La restricció es podrà depurar comprovant cas per cas quina és l’etiqueta correcta del
pronom es en cada una de les aparicions de cada un dels verbs. Si és més freqüent
P0000000, aquest verb és suprimit de la restricció.
Finalment, el conjunt de restriccions B12 queden així:
2.0 (<P0300000>) (0(<P0000000>)) (1("trobar") OR ("situar") OR ("dirigir") OR ("convertir") OR ("comprometre") OR ("reunir") OR ("referir") OR ("veure") OR ("quedar") OR ("posar") OR ("pronunciar") OR ("negar") OR ("mostrar") OR ("manifestar") OR ("entrevistar") OR ("sumar") OR ("plantejar") OR ("oposar") OR ("mantenir") OR ("limitar") OR ("incorporar") OR ("fer-se_càrrec") OR ("emmarcar") OR ("desplaçar") OR ("consolidar") OR ("basar") OR ("anar") OR ("acostar") OR ("abstenir") OR ("reduir") OR ("incloure") OR ("dedicar") OR ("centrar") OR ("afegir") OR ("recuperar") OR ("queixar-se") OR ("posicionar") OR ("personar") OR ("ocupar") OR ("interessar") OR ("integrar") OR ("identificar") OR ("gastar") OR ("expressar") OR ("estendre") OR ("encarregar") OR ("emportar") OR ("elevar") OR ("dividir") OR ("correspondre") OR ("compondre") OR ("caracteritzar") OR ("beneficiar") OR ("baixar") OR ("apoderar") OR ("anomenar") OR ("allargar") OR ("ajustar") OR ("unir") OR ("treballar") OR ("traslladar") OR ("tornar") OR ("titular") OR ("tancar") OR ("sorprendre") OR ("solidaritzar") OR ("retirar") OR ("ressentir") OR ("renovar") OR ("remuntar") OR ("rellevar") OR ("reincorporar") OR ("refugiar") OR ("proposar") OR ("pretendre") OR ("precipitar") OR ("posar_en_marxa") OR ("perdre") OR ("optar") OR ("molestar") OR ("mobilitzar") OR ("llicenciar") OR ("llegir") OR ("jugar") OR ("introduir") OR ("inscriure") OR ("guanyar") OR ("girar") OR ("evaporar") OR ("evadir") OR ("estar") OR ("especialitzar") OR ("esmerçar") OR ("escaure") OR ("entregar") OR ("entendre") OR ("enfadar") OR ("endur") OR ("duplicar") OR ("distingir") OR ("desviar") OR ("desenvolupar") OR ("decidir") OR ("contemplar") OR ("connectar") OR ("col·locar") OR ("classificar") OR ("autoinculpar") OR ("aturar") OR ("asseure") OR ("assegurar") OR ("assecar") OR ("aproximar") OR ("apropiar") OR ("apropar") OR ("aplegar") OR ("apartar") OR ("allunyar") OR ("alegrar") OR ("agrupar") OR ("agreujar") OR ("adequar") OR ("adaptar") OR ("acumular") OR ("accidentar") OR ("accelerar") OR ("acabar")); 2.0 (<P0300000>) (0(<P0000000>)) (1("haver")) (2{LLISTA DE VERBS PRONOMINALS}); 2.0 (<P0300000>)

- 50 - 3. Regles de desambiguació basades en el coneixement lingüístic
(0(<P0000000>)) (-1{LLISTA DE VERBS PRONOMINALS}); 2.0 (<P0300000>) (0(<P0000000>)) (1(<PP3*>)) (2{LLISTA DE VERBS PRONOMINALS}); 2.0 (<P0300000>) (0(<P0000000>)) (1(<PP3*>)) (2("haver")) (3{LLISTA DE VERBS PRONOMINALS}); 2.0 (<P0300000>) (0(<P0000000>)) (-1("haver")) (1{LLISTA DE VERBS PRONOMINALS}); 2.0 (<P0300000>) (0(<P0000000>)) (1("haver")) (2("anar")) (3{LLISTA DE VERBS PRONOMINALS}); 2.0 (<P0300000>) (0(<P0000000>)) (-1{LLISTA DE VERBS PRONOMINALS}) (-2("anar")) (-3("anar"));
Sobre aquestes restriccions B12 cal comentar que han d’actuar un cop
introduïda la restricció B8, sense la qual el seu resultat és nul. Esmentem, també, que
no han funcionat amb contextos d’etiqueta verbal (<VM*> i <VA*>) i ha calgut
recórrer als lemes. Per tant, observem de nou que els contextos amb lema són molt
més segurs i controlables que amb etiqueta, però més treballosos d’identificar, ja que
s’ha de ser exhaustiu, i amb un menor rendiment.
El rendiment de les dues restriccions actuant conjuntament és força alt i puja
un dècim el resultat de B8 sola:

3. Regles de desambiguació basades en el coneixement lingüístic - 51 -
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B8 i B12 96.85 96.88 95.52 95.32 Millora 0.00 0.77 0.76 0.77
3.3.3. Altres restriccions sobre l’etiqueta curta
Exposarem, finalment, les darreres quatre restriccions, amb un resultat discret,
però rellevant en el conjunt.
3.3.3.1. Canvi de Determinant Article per Pronom Personal
Existeixen uns quants casos en l’etiquetat de les restriccions d’aprenentatge
automàtic que marquen com a DA* (Determinant Article) algunes formes que
haurien de ser PP3* (Pronoms Personals de 3ª persona) i que s’han resolt amb la
restricció B2: se substitueix l’etiqueta de determinant article per la de pronom
personal de 3ª persona quan la forma es troba davant d’un verb. Aquesta classe
d’ambigüitat afecta les formes el, la o l’, totes tres coincidents amb formes de
pronom personal. S’ha hagut d’anar incrementant el pes per anar obtenint millores,
però fins a un cert punt en què ja es començaven a produir desviacions negatives.
S’ha deixat en el valor que s’ha cregut de rendiment més òptim, tot i que en alguna
forma, especialment l’, encara restaven força correccions per fer.
Alguns exemples d’errors d’etiquetació trets del corpus d’entrenament són:

- 52 - 3. Regles de desambiguació basades en el coneixement lingüístic
! El rècord de 42 el va fer l’embarcació francesa.
! Aquesta escola taller la finança el Departament de Treball.
! Ha estat enviat a la comissió legislativa perquè l’estudiï.
La restricció s’expressa així:
6.0 (<PP3*>) (0(<DA0*>)) (1(<VA*>) OR (<VM*>));
I la millora és la següent:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B2 96.87 95.44 94.78 94.57 Millora 0.02 0.03 0.02 0.02
Si mirem el resultat final amb els errors després d’aplicar les restriccions
manuals ens adonarem que alguns casos no s’arrangen. Es tracta, en la majoria dels
casos, d’errors en l’etiquetat manual, és a dir, el sistema ja ho feia bé automàticament
i està detectant com a errors quelcom que no ho és.
3.3.3.2. Canvi de Determinant Indefinit per Pronom Indefinit
Amb aquesta restricció, la B6, hem pogut corregir casos d’etiquetatge erroni
com a determinant indefinit de certs pronoms indefinits. La solució ha estat canviar
l’etiqueta quan anava seguida de punt, el que és evidentment contextual. Per
exemple:

3. Regles de desambiguació basades en el coneixement lingüístic - 53 -
! ... Jaume Abat entre d’altres.
El formalisme és:
6.0 (<PI0CP000>) (0(<DI0CP0>)) (1(<F*>));
S’obté aquesta petita millora:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B6 96.86 95.42 94.77 94.56 Millora 0.01 0.01 0.01 0.01
3.3.3.3. Canvi d’Adjectiu Qualificatiu per Determinant Numeral
Observem uns quants errors en l’etiquetatge del mot nou com a adjectiu qualificatiu i
com a determinant numeral en el cas que aquest element precedeixi el nom que
determina o qualifica. Per exemple:
! “el nou equipament” apareix amb DN0CP0, i
! “ha estat gairebé nou anys cap de l’oficina” amb AQ0MS0.
El tema es resol pel seu entorn immediat. En el cas de l’adjectiu, el nom que
segueix tindrà nombre singular; en el cas del determinant numeral, nombre plural.
Són les restriccions B9:
8.0 (<AQ0MS0>) (0(<DN0CP0>)) (1(<NCMS*>));

- 54 - 3. Regles de desambiguació basades en el coneixement lingüístic
8.0 (<DN0CP0>) (0(<AQOMS0>)) (1(<NCMP*>) OR (<NCFP*>));
Proporcionen aquesta millora:
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B9 96.86 95.43 94.78 94.57 Millora 0.01 0.02 0.02 0.02
3.3.3.4. Canvi de qual Determinant Relatiu per Pronom Relatiu
Finalment, s’observen alguns errors de qual amb l’etiqueta DR0CS0 en lloc de
pronom relatiu. Es tracta de seqüències del corpus com per exemple:
! un conveni de col·laboració mitjançant el qual;
! l’empresa de la qual en forma part;
! ha condemnat a un any de presó N..., el qual, juntament amb...
Aquest nombre reduït d’errors s’ha pogut resoldre introduint l’etiqueta
<PR0CS000> quan va precedida d’article i, abans d’aquest, de preposició o coma.
Curiosament, aquesta regla obté millors resultats sense especificar l’etiqueta errònia.
Aquesta restricció, la B10, ha quedat finalment formulada així:
8.0 (<PR0CS000>) (-1(<DA*>)) (-2(<SP*>) OR (<Fc>));
La millora aportada ha estat aquesta:
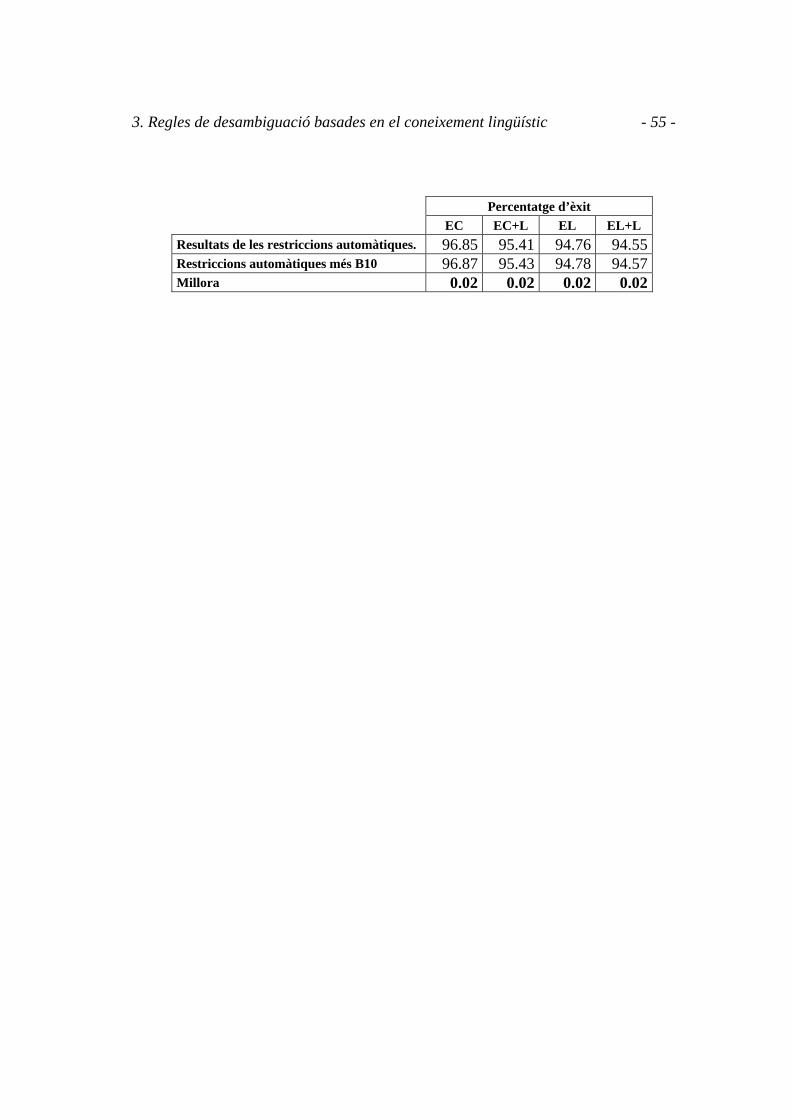
3. Regles de desambiguació basades en el coneixement lingüístic - 55 -
Percentatge d’èxit EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques més B10 96.87 95.43 94.78 94.57 Millora 0.02 0.02 0.02 0.02


- 57 -
4. Resultats globals de la desambiguació
automàtica
4.1. Resultats quantitatius
Hem presentat dotze restriccions manuals que milloren el resultat de les
restriccions estadístiques elaborades automàticament pel sistema. Arribats al moment
de fer balanç, presentem un resum recopilatori de les millores que proporciona cada
una de les restriccions:
Percentatge d’èxit
Restriccions manuals EC EC+L EL EL+L
B1 Canvi de la 1ª per la 3ª persona verbal 0.00 0.00 0.67 0.67
B2 Canvi de Determinant Article per Pronom Personal 0.02 0.03 0.02 0.02
B3 Canvis en el mode verbal 0.01 0.02 0.17 0.17
B4 Correcció d’etiquetes i lemes erronis 0.00 0.15 0.14 0.14
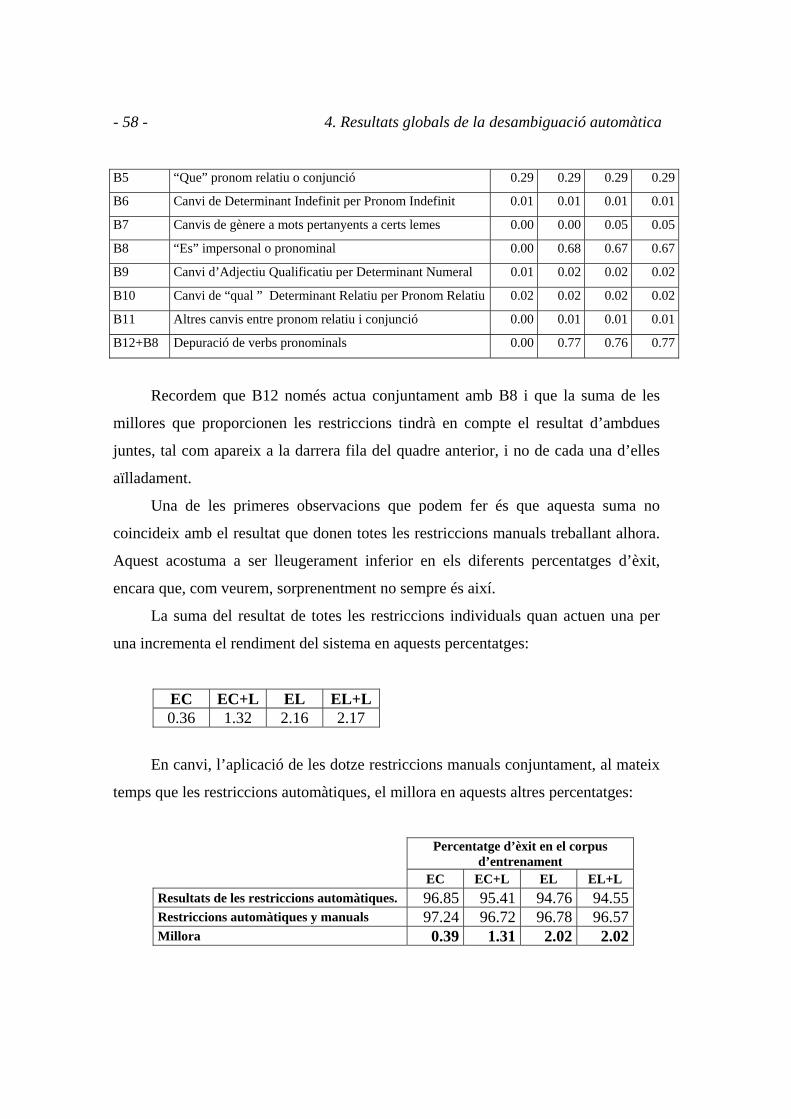
- 58 - 4. Resultats globals de la desambiguació automàtica
B5 “Que” pronom relatiu o conjunció 0.29 0.29 0.29 0.29
B6 Canvi de Determinant Indefinit per Pronom Indefinit 0.01 0.01 0.01 0.01
B7 Canvis de gènere a mots pertanyents a certs lemes 0.00 0.00 0.05 0.05
B8 “Es” impersonal o pronominal 0.00 0.68 0.67 0.67
B9 Canvi d’Adjectiu Qualificatiu per Determinant Numeral 0.01 0.02 0.02 0.02
B10 Canvi de “qual ” Determinant Relatiu per Pronom Relatiu 0.02 0.02 0.02 0.02
B11 Altres canvis entre pronom relatiu i conjunció 0.00 0.01 0.01 0.01
B12+B8 Depuració de verbs pronominals 0.00 0.77 0.76 0.77
Recordem que B12 només actua conjuntament amb B8 i que la suma de les
millores que proporcionen les restriccions tindrà en compte el resultat d’ambdues
juntes, tal com apareix a la darrera fila del quadre anterior, i no de cada una d’elles
aïlladament.
Una de les primeres observacions que podem fer és que aquesta suma no
coincideix amb el resultat que donen totes les restriccions manuals treballant alhora.
Aquest acostuma a ser lleugerament inferior en els diferents percentatges d’èxit,
encara que, com veurem, sorprenentment no sempre és així.
La suma del resultat de totes les restriccions individuals quan actuen una per
una incrementa el rendiment del sistema en aquests percentatges:
EC EC+L EL EL+L0.36 1.32 2.16 2.17
En canvi, l’aplicació de les dotze restriccions manuals conjuntament, al mateix
temps que les restriccions automàtiques, el millora en aquests altres percentatges:
Percentatge d’èxit en el corpus d’entrenament
EC EC+L EL EL+L Resultats de les restriccions automàtiques. 96.85 95.41 94.76 94.55 Restriccions automàtiques y manuals 97.24 96.72 96.78 96.57 Millora 0.39 1.31 2.02 2.02
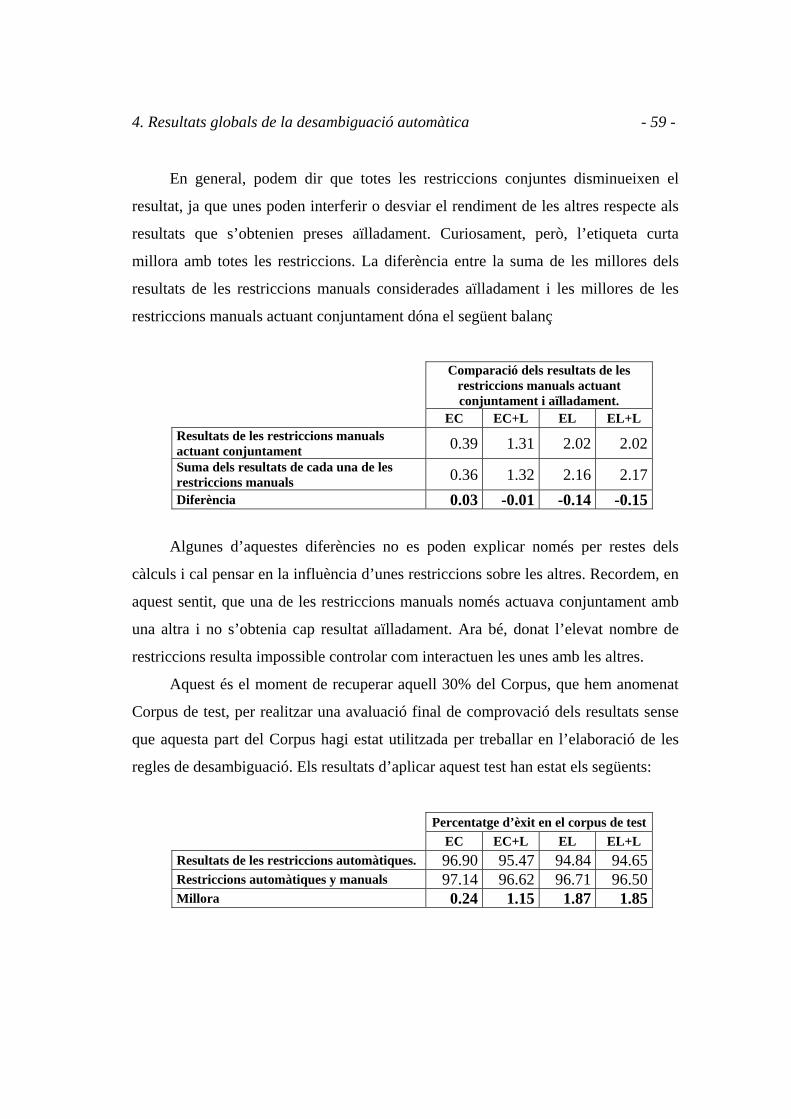
4. Resultats globals de la desambiguació automàtica - 59 -
En general, podem dir que totes les restriccions conjuntes disminueixen el
resultat, ja que unes poden interferir o desviar el rendiment de les altres respecte als
resultats que s’obtenien preses aïlladament. Curiosament, però, l’etiqueta curta
millora amb totes les restriccions. La diferència entre la suma de les millores dels
resultats de les restriccions manuals considerades aïlladament i les millores de les
restriccions manuals actuant conjuntament dóna el següent balanç
Comparació dels resultats de les
restriccions manuals actuant conjuntament i aïlladament.
EC EC+L EL EL+L Resultats de les restriccions manuals actuant conjuntament 0.39 1.31 2.02 2.02 Suma dels resultats de cada una de les restriccions manuals 0.36 1.32 2.16 2.17 Diferència 0.03 -0.01 -0.14 -0.15
Algunes d’aquestes diferències no es poden explicar només per restes dels
càlculs i cal pensar en la influència d’unes restriccions sobre les altres. Recordem, en
aquest sentit, que una de les restriccions manuals només actuava conjuntament amb
una altra i no s’obtenia cap resultat aïlladament. Ara bé, donat l’elevat nombre de
restriccions resulta impossible controlar com interactuen les unes amb les altres.
Aquest és el moment de recuperar aquell 30% del Corpus, que hem anomenat
Corpus de test, per realitzar una avaluació final de comprovació dels resultats sense
que aquesta part del Corpus hagi estat utilitzada per treballar en l’elaboració de les
regles de desambiguació. Els resultats d’aplicar aquest test han estat els següents:
Percentatge d’èxit en el corpus de test EC EC+L EL EL+L
Resultats de les restriccions automàtiques. 96.90 95.47 94.84 94.65 Restriccions automàtiques y manuals 97.14 96.62 96.71 96.50 Millora 0.24 1.15 1.87 1.85

- 60 - 4. Resultats globals de la desambiguació automàtica
D’entrada, les restriccions automàtiques donen millor resultat sobre el corpus
de test que sobre el d’entrenament. Tanmateix, el que resulta més significatiu és la
lleugera disminució de les millores a través de les regles manuals (aproximadament
quinze centèsims en cada un dels apartats, que compensen amb escreix la situació de
partida més favorable al corpus de test). Aquest és un fet inevitable, ja que el
poliment de les restriccions a través del corpus d’entrenament lògicament haurà de
donar els millors resultats en aquest mateix corpus. Una raó bàsica és que per tot allò
que fa referència a lemes o a paraules concretes només s’han tingut en compte els
casos del corpus d’entrenament.
4.2. Anàlisi dels problemes no resolts
El percentatge d’errors pendents en el corpus d’entrenament és el següent:
EC EC+L EL EL+L2.76 3.28 3.22 3.43
Un dels aspectes més interessants és veure quins errors de l’etiquetatge
automàtic s’han pogut resoldre, quins no i quins s’escapaven completament de les
possibilitats de correcció a través de restriccions manuals.
En un altre apartat d’aquest treball s’han recollit els errors que apareixien en
deu o més ocasions després d’aplicar les restriccions automàtiques de desambiguació

4. Resultats globals de la desambiguació automàtica - 61 -
morfològica. Si apliquem aquestes mateixes restriccions i les dotze que hem elaborat
manualment, els errors que apareixen en deu o més ocasions són aquests:
145 que que PR0CN000 que que CS 99 es ell P0300000 es es P0000000 74 Generalitat generalitat NCFS000 Generalitat Generalitat NP00000 72 una un DI0FS0 una un DN0FS0 70 un un DI0MS0 un un DN0MS0 46 que que CS que que PR0CN000 36 s' ell P0300000 s' es P0000000 30 Govern govern NCMS000 Govern Govern NP00000 28 Ajuntament ajuntament NCMS000 Ajuntament Ajuntament NP00000 22 s' ell P0300000 s' ell PP3CN000 22 van anar VAIP3P0 van anar VMIP3P0 21 Parlament parlament NCMS000 Parlament Parlament NP00000 18 estat ser VSP00SM estat estar VMP00SM 17 diumenge diumenge NCMS000 diumenge [diumenge:??/??/??:??.??] W 14 Congrés congrés NCMS000 Congrés Congrés NP00000 14 dilluns dilluns NCMN000 dilluns [dilluns:??/??/??:??.??] W 14 el el DA0MS0 el ell PP3MSA00 14 es es P0000000 es ell P0300000 13 Estat ser VSP00SM Estat Estat NP00000 12 Estat estat NCMS000 Estat Estat NP00000 12 la el DA0FS0 la ell PP3FSA00 11 maig maig NCMS000 maig [??:??/5/??:??.??] W 10 pessetes pesseta Zm pessetes pesseta NCFP000 10 quan quan PR000000 quan quan CS
El total d’errors és de 824, mentre que en la primera llista n’hi havia 1866.
S’han pogut resoldre, doncs, un 56% de les errades més freqüents. Si comparem
aquestes dades amb la millora global del sistema, que en el cas més òptim, l’Etiqueta
Llarga, resol un 42.5% dels errors inicials, podrem concloure que la nostra tasca ha
actuat comparativament més sobre els errors més freqüents, fet d’altra banda lògic ja
que hom treballava principalment sobre aquestes dades.
Tampoc apareixen en aquesta llista alguns errors de baixa ocurrència, però
d’una tipologia amb una freqüència d’aparició numèricament important (primera /
tercera persona verbal, casos de temps i mode verbal...)
Pensem que podem agrupar els errors no resolts en quatre categories:

- 62 - 4. Resultats globals de la desambiguació automàtica
a) Errors atacats per les restriccions i no resolts:
! 201 casos alternen equivocadament una etiqueta de pronom (PR*) amb
la de conjunció subordinant (CS) en el mot que. Malgrat el nombre
d’etiquetes no resoltes s’han millorat un 50.6% dels casos de la llista
inicial (407).
! Persisteixen 171 errors entre vàries etiquetes pronominals en les
diferents formes de se dels 735 de la llista inicial amb deu o més
ocurrències. La millora ha estat d’un 76.7%
Tot plegat representa un 46.1% dels casos no resolts.
b) Errors no desambiguats contextualment:
Existeixen dues situacions en què no s’ha sabut trobar una manera de
desambiguar contextualment les etiquetes equivocades. De fet, la primera d’elles, la
numèricament més important, ja costa de determinar durant l’anotació manual del
corpus. Es tracta de les següents:
! 142 casos de confusió entre numerals i indefinits, siguin pronoms o
determinants.
! 18 formes estat amb confusió de lema entre ser o estar.
Representen un 19.4% dels casos no resolts.
c) Errors en l’etiquetat manual:
En un etiquetat manual de més de cent mil paraules és inevitable un petit marge
d’error. Es pot donar el cas, i de fet així se’ns ha presentat, que les restriccions
automàtiques etiquetin bé mots incorrectament etiquetats en el corpus de referència
(ja que en aquella situació l’error és accidental i l’encert, la norma, el que generarà
unes restriccions correctes). En aquestes situacions, un mot correctament marcat pel
sistema es comptabilitzarà com error, ja que el corpus de referència ho induirà així.
Hem identificat dues situacions d’aquesta mena amb deu o més ocurrències:

4. Resultats globals de la desambiguació automàtica - 63 -
! 22 casos de la forma van com a verb principal o auxiliar.
! Alguns dels 26 casos de confusió entre formes de determinant article i pronom
personal.
Amb aquestes xifres, el percentatge d’aquest tipus d’error no arriba al 5%
de casos no resolts (o falsos errors).
d) Errors que depenen d’altres mòduls del sistema:
Un 29.6% dels errors no poden ser resolts, ja que depenen de d’altres mòduls
del sistema sobre els que no actuen les normes de desambiguació. Es tracta de les
categories de mots següents:
! Noms propis (192).
! Dates (42).
! Xifres (10).
A més d’aquestes situacions, però, tenim un conjunt de casos que es resolen
completament, almenys en els de deu o més ocurrències, i que permeten la millora
del sistema en més d'un 2%. Es tracta dels canvis de primera a tercera persona, dels
problemes en alguns atributs de la flexió nominal resolts a través de canvis de lema i
d’alguns casos particulars com la confusió entre cert determinant numeral amb cert
adjectiu qualificatiu o la de determinant i pronom relatius.


- 65 -
5. Conclusions
Aquest treball d’investigació s’emmarca dins l’àrea del processament
automàtic del corpus i s’ha plantejat com una aportació en la millora del
desambiguador morfològic del Centre de Llenguatge i Computació (CLiC) de la
Universitat de Barcelona. En concret, el treball ha consistit en el poliment de
RELAX, el desambiguador morfològic dels corpus del català, a través de la recerca
de restriccions de desambiguació elaborades manualment que incrementin els
percentatges d’encert de les restriccions creades automàticament pel propi sistema.
En primer lloc, s’ha constatat l’alt rendiment del sistema automàtic a l’hora de
generar les seves pròpies restriccions de desambiguació a partir d’un corpus
d’entrenament etiquetat manualment. Els encerts superen sempre, en el cas del
català, el 94.5% i s’arriba a només un 3.15% d’errors en l’etiqueta curta.
En els 12 blocs de restriccions que hem elaborat, s’ha actuat, segons els casos,
sobre lemes o sobre etiquetes de categories gramaticals en la posició 0, la que calia
corregir. L’observació dels resultats d’implementar aquestes restriccions en el
sistema ha conduït a certes observacions sobre les conseqüències d’incidir sobre uns
o altres. Les actuacions sobre lemes tenen un rendiment inferior, però més seguretat
en el resultat, ja que es produeixen menys interferències amb el conjunt de

- 66 - Conclusions
restriccions i menys correccions no desitjades. A més, el manteniment o actualització
de les restriccions a partir del coneixement posterior de noves dades resulta més
senzill. A l’altra banda tenim les actuacions sobre etiquetes de categories
gramaticals. En aquest cas, el rendiment acostuma a ésser molt superior, però també
les interferències amb d’altres restriccions amb les consegüents correccions no
desitjades d’etiquetes prèviament correctes. Al mateix temps, l’actualització de la
restricció resulta molt més problemàtica, ja que no es pot limitar a una addició de
nous elements, sinó que cal una reflexió sobre tot el seu funcionament global i les
conseqüències de qualsevol canvi sobre el conjunt.
Malgrat que hom defineix les restriccions manuals de desambiguació com
aquelles que milloren el rendiment del sistema a través de l’aplicació del
coneixement lingüístic, es poden obtenir millores considerables a través d’actuacions
correctores sobre una base estadística d’aquells casos en què les restriccions manuals
no actuen i després d’analitzar el conjunt d’errors (vegeu, per exemple, les nostres
restriccions sobre persones o modes verbals).
El procés de desambiguació no analitza la correcció del corpus manual que
serveix d’entrenament, ja que això és una decisió i una tasca prèvies, sinó que es
limita a treballar perquè el desambiguador automàtic doni els mateixos resultats que
l’etiquetat manual.
Les restriccions manuals poden aconseguir una millora considerable, que en
aquesta investigació arriba al 2.02% en el cas de l’etiqueta llarga. Resten per resoldre
al voltant d’un 3% d’etiquetes, algunes no resolubles per qüestions relatives als
propis mòduls del sistema (aproximadament una tercera part) i d’altres pendents de
solució.
El treball manual es realitza sobre les errades més freqüents (en aquest treball
sobre tots els errors que es donen 10 o més vegades amb algunes actuacions sobre
casos relacionats amb aquells i que es produeixen menys). S’han pogut resoldre més
de la meitat d’errors d’aquest conjunt dels més freqüents (56%). Evidentment, l’èxit
és menor sobre el total.

Conclusions - 67 -
Finalment, s’observa que les restriccions manuals sempre funcionen millor
sobre el corpus d’entrenament amb què s’ha treballat que sobre el corpus de test o
sobre el text obert, sobretot en les referides a lemes o paraules.


- 69 -
Bibliografia
Castellón, I., M. Civit i M. A. Martí. 2001. Joven periodista triste busca casa frente al mar
o, la ambigüedad en la anotación del corpus. Disponible a
http://www.clic.fil.ub.es/personal/civit/publicacions.html
Civit, M. 2003. Criterios de etiquetación y desambiguación morfosintáctica de corpus en
español. Tesis Doctoral. Universitat de Barcelona.
EAGLESa. Introducció a les etiquetes EAGLES (v. 2.0). Disponible a
http://www.lsi.upc.es/~nlp/freeling/parole-ca.pdf
EAGLESb. Introducción a las etiquetas EAGLES. Disponible a
http://www.lsi.upc.es/~nlp/freeling/parole-es.pdf
Leech, G. 1997a. Grammatical Tagging. En R. Garside G. Leech i T. McEnery, editors,
Corpus Annotation. Linguistic Information from Computer Text Corpora. Longman,
capítol 2, pàgines 19-33.
Leech, G. 1997b. Introducing Corpus Annotation. En R. Garside G. Leech i T. McEnery,
editors, Corpus Annotation. Linguistic Information from Computer Text Corpora.
Longman, capítol 1, pàgines 1-18.
Márquez, Ll., Ll. Padró i H. Rodríguez. 2002.Mètodes robustos en l’anàlisi del llenguatge
(El processament de text no restringit). Universitat Oberta de Catalunya. Barcelona.
Martí, M. A. 2001. Les tecnologies del llenguatge. UOC. Barcelona.
McEnery, T. i A. Wilson. 1996a. Corpus Linguistics. Edimburg University Press.
Introductory course on corpus linguistic, based on the book, disponible:
http://www.ling.lanc.ac.uk/monkey/ihe/linguistics/contents/htm

- 70 - Bibliografia
McEnery, T. i A. Wilson. 1996b. Corpus Linguistics. Edimburg University Press, 2d, 2001.
Ooi, Vincent B. Y. 1998. Computer Corpus Lexicography. Edimburg University Press.
Padró, Ll. 1997. A Hybrid Environment for Syntax-Semantic Tagging. Tesi Doctoral.
Universitat Politècnica de Catalunya. Barcelona.
PAROLE. PAROLE part-of-speech tags for Spanish. Disponible a
http://www.lsi.upc.es/~nlp/tools/parole-eng.html
Sampson, G. 1995. English for the Computer. The SUSANNE corpus and Analytic Scheme.
Clarendon Press. Oxford.
Sampson, G. 2001. Empirical Linguistics. Continuum, London and New York.