regresja liniowa oraz regresja wielokrotna w zastosowaniu...
TRANSCRIPT

Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania
predykcji danych.
Agnieszka Nowak – Brzezińska
Wykład III-VI

Analiza regresji
•Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące pomiędzy zmiennymi wejściowymi (objaśniającymi) a wyjściowymi (objaśnianymi). •Innymi słowy dokonujemy estymacji jednych danych korzystając z innych. •Istnieje wiele różnych technik regresji.

Linia regresji zapisana w postaci:
nazywana jest równaniem regresji lub oszacowanym równaniem regresji, gdzie:
– Szacowana wartość zmiennej objaśnianej
– Punkt przecięcia linii regresji z osią y
– Nachylenie linii regresji
– Współczynniki regresji
xbby 10
y
0b
1b
10 ,bb

Regresja liniowa •Metoda zakłada, że pomiędzy zmiennymi objaśniającymi i objaśnianymi istnieje mniej lub bardziej wyrazista zależność liniowa. •Mając zatem zbiór danych do analizy, informacje opisujące te dane możemy podzielić na objaśniane i objaśniające. Wtedy też wartości tych pierwszych będziemy mogli zgadywać znając wartości tych drugich. • Oczywiście tak się dzieje tylko w sytuacji, gdy faktycznie między tymi zmiennymi istnieje zależność liniowa. •Przewidywanie wartości zmiennych objaśnianych (y) na podstawie wartości zmiennych objaśniających (x) jest możliwe dzięki znalezieniu tzw. modelu regresji. •W praktyce polega to na podaniu równania prostej, zwanej prostą regresji o postaci:
y = b0 + b1 x gdzie: y - jest zmienną objaśnianą, zaś x - objaśniającą. W równaniu tym bardzo istotną rolę odgrywają współczynniki b0 i b1, gdzie b1 jest nachyleniem linii regresji, zaś b0 punktem przecięcia linii regresji z osią x (wyrazem wolnym) a więc przewidywaną wartością zmiennej objaśnianej gdy zmienna objaśniająca jest równa 0.
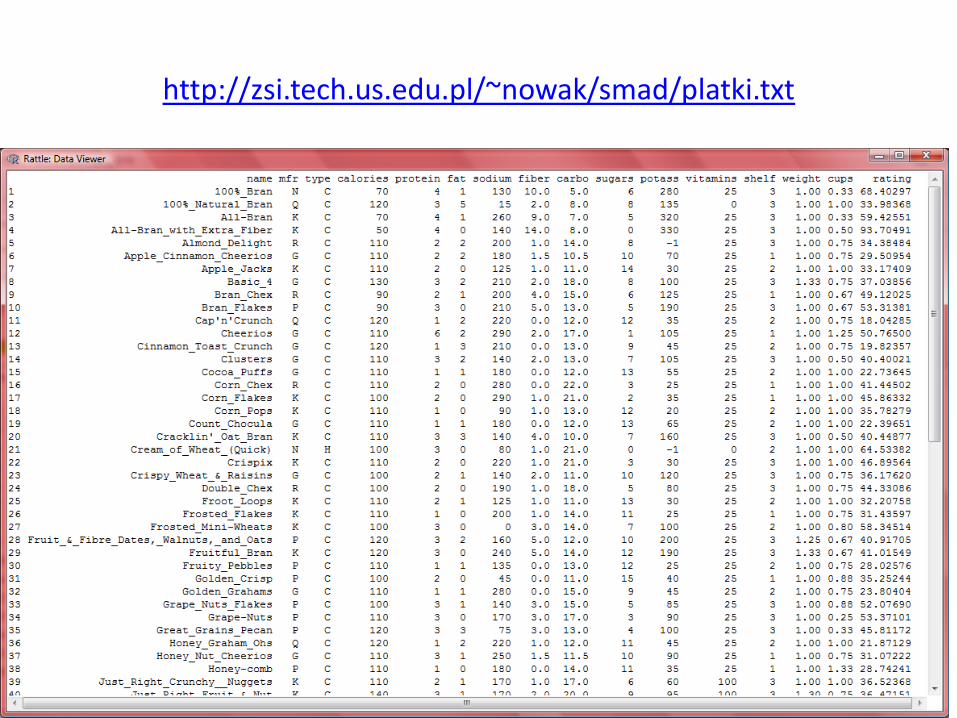
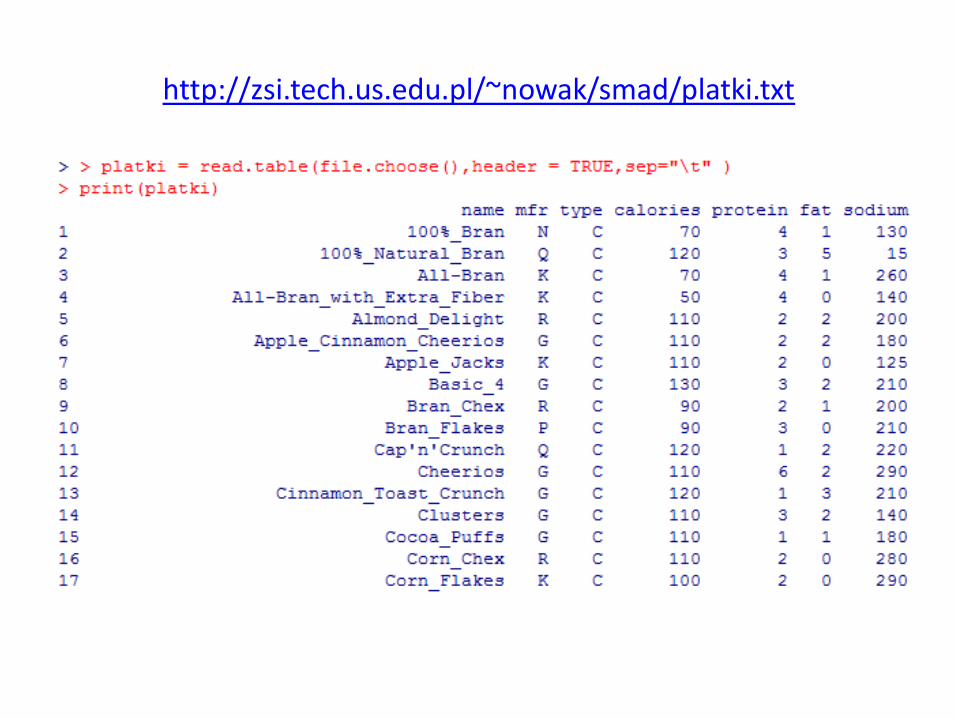

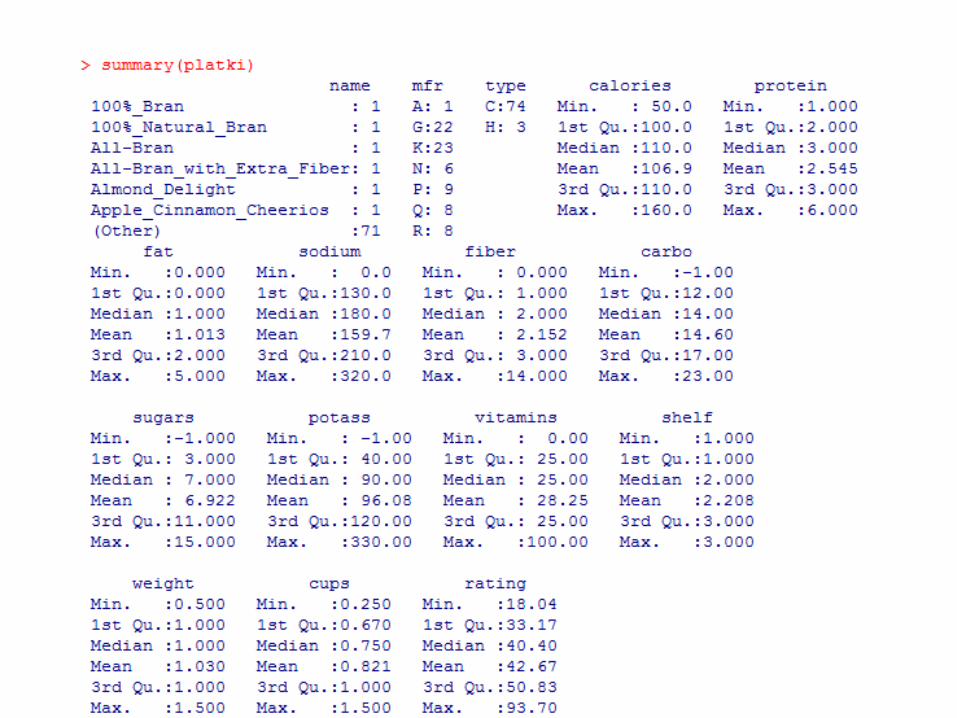
Cereals.data • Name – nazwa płatków
• Manuf – wytwórca płatków
• Type – typ płatków ( na ciepło (hot), na zimno (cold))
• Calories – kalorie w porcji
• Protein 0 białko (w gramach)
• Fat – tłuszcz (w gramach)
• Sodium – sód
• Fiber – błonnik
• Carbo – węglowodany
• Sugars – cukry
• Potass – potas ( w miligramach)
• Vitamins – procent zalecanego dziennego spożycia witamin (0%, 25 %, 100%)
• Shelf – położenie półki (1=dolna, 2=środkowa, 3 = górna)
• Weight – waga porcji
• Cups – liczba łyżek na porcję
• Rating – wartość odżywcza, obliczona przez Customer Reports
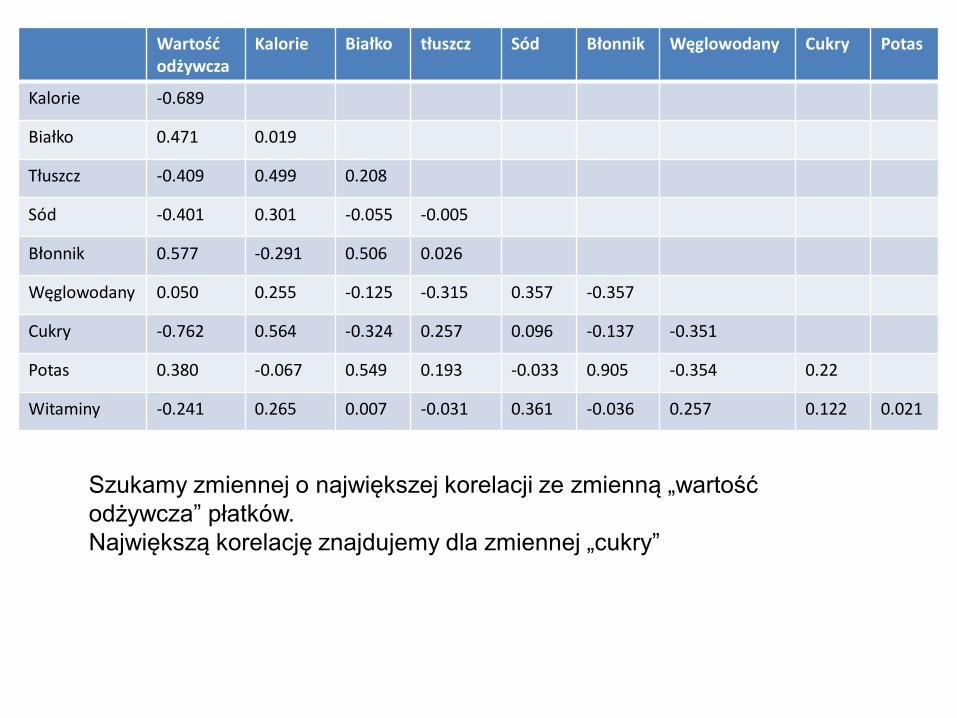
Wartość odżywcza
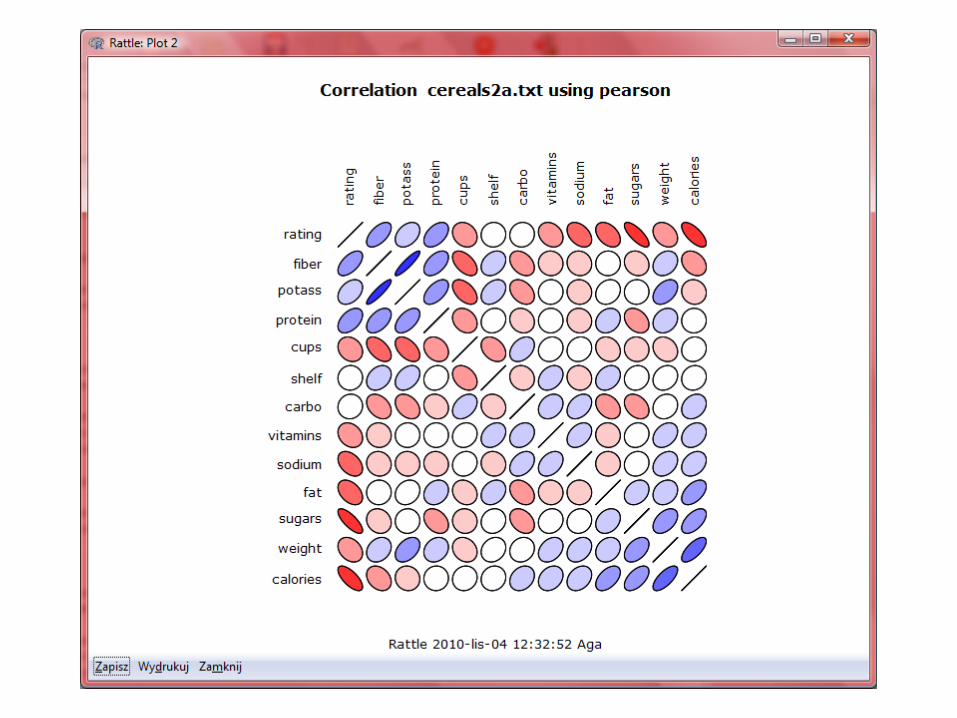
Kalorie Białko tłuszcz Sód Błonnik Węglowodany Cukry Potas
Kalorie -0.689
Białko 0.471 0.019
Tłuszcz -0.409 0.499 0.208
Sód -0.401 0.301 -0.055 -0.005
Błonnik 0.577 -0.291 0.506 0.026
Węglowodany 0.050 0.255 -0.125 -0.315 0.357 -0.357
Cukry -0.762 0.564 -0.324 0.257 0.096 -0.137 -0.351
Potas 0.380 -0.067 0.549 0.193 -0.033 0.905 -0.354 0.22
Witaminy -0.241 0.265 0.007 -0.031 0.361 -0.036 0.257 0.122 0.021
Szukamy zmiennej o największej korelacji ze zmienną „wartość
odżywcza” płatków.
Największą korelację znajdujemy dla zmiennej „cukry”
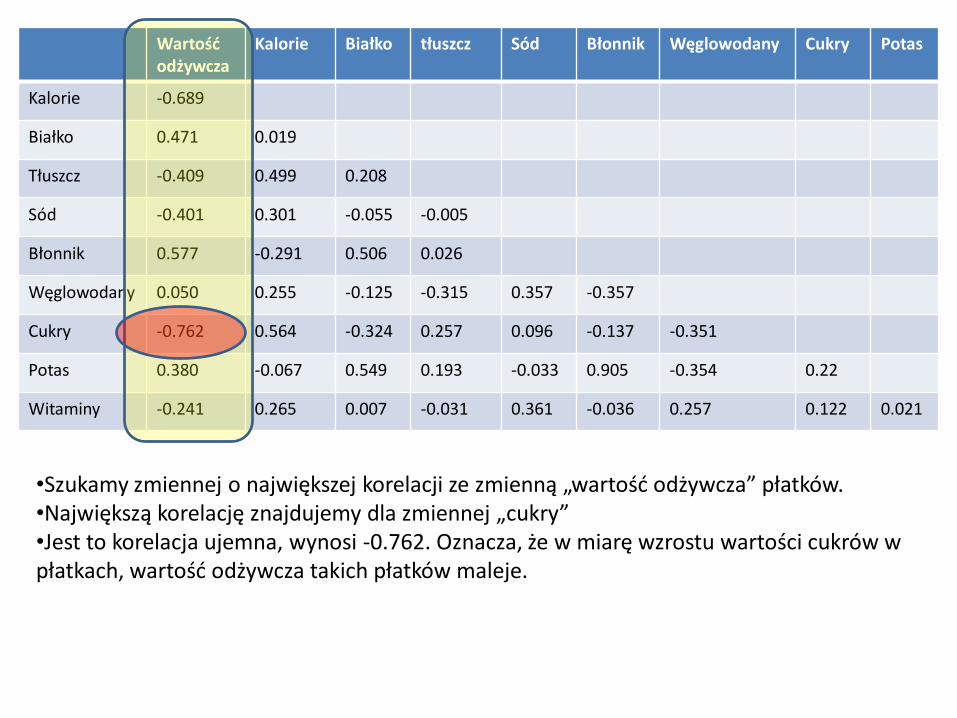
Wartość odżywcza
Kalorie Białko tłuszcz Sód Błonnik Węglowodany Cukry Potas
Kalorie -0.689
Białko 0.471 0.019
Tłuszcz -0.409 0.499 0.208
Sód -0.401 0.301 -0.055 -0.005
Błonnik 0.577 -0.291 0.506 0.026
Węglowodany 0.050 0.255 -0.125 -0.315 0.357 -0.357
Cukry -0.762 0.564 -0.324 0.257 0.096 -0.137 -0.351
Potas 0.380 -0.067 0.549 0.193 -0.033 0.905 -0.354 0.22
Witaminy -0.241 0.265 0.007 -0.031 0.361 -0.036 0.257 0.122 0.021
•Szukamy zmiennej o największej korelacji ze zmienną „wartość odżywcza” płatków. •Największą korelację znajdujemy dla zmiennej „cukry” •Jest to korelacja ujemna, wynosi -0.762. Oznacza, że w miarę wzrostu wartości cukrów w płatkach, wartość odżywcza takich płatków maleje.
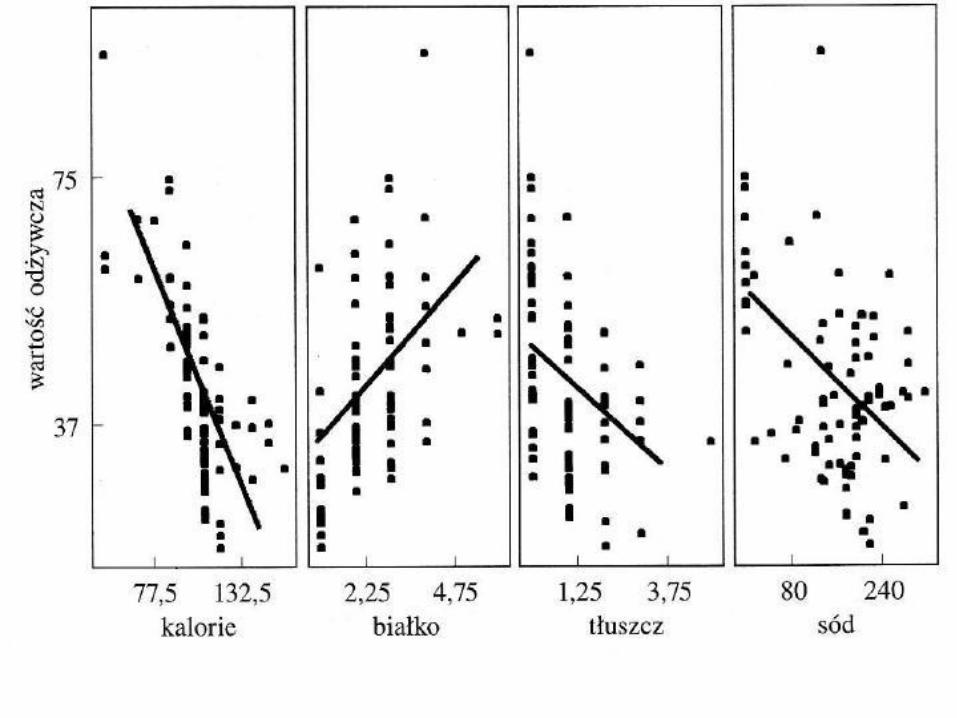
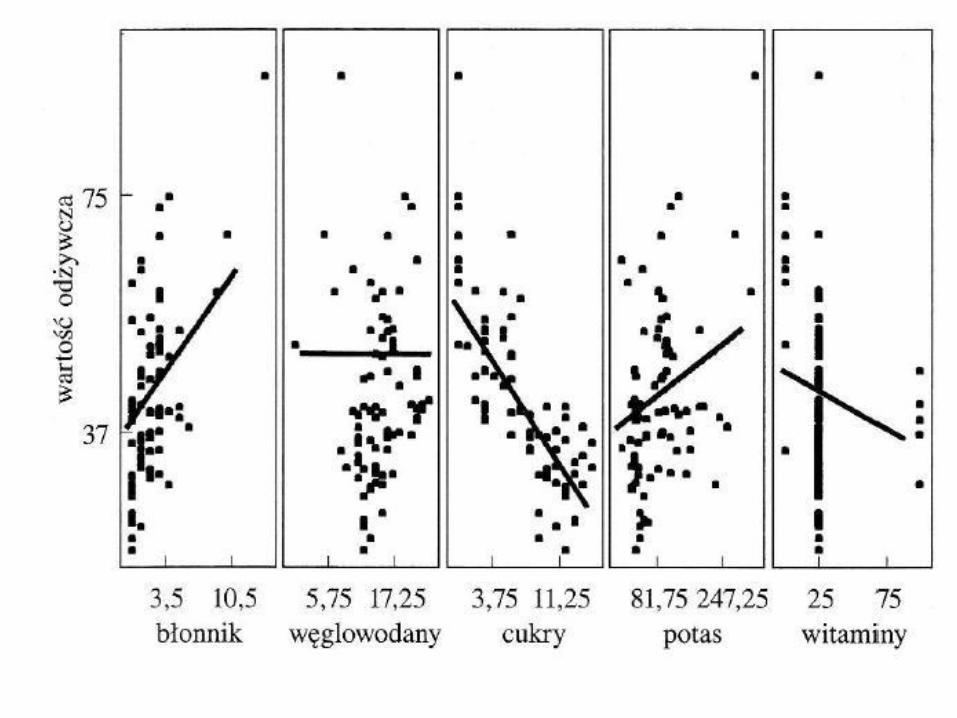
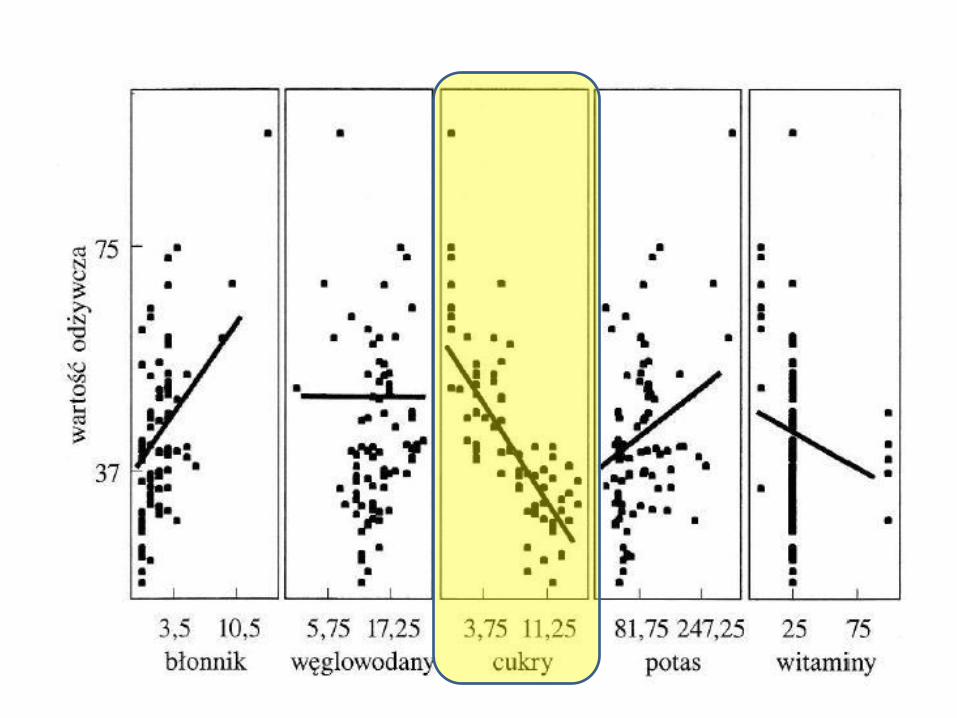

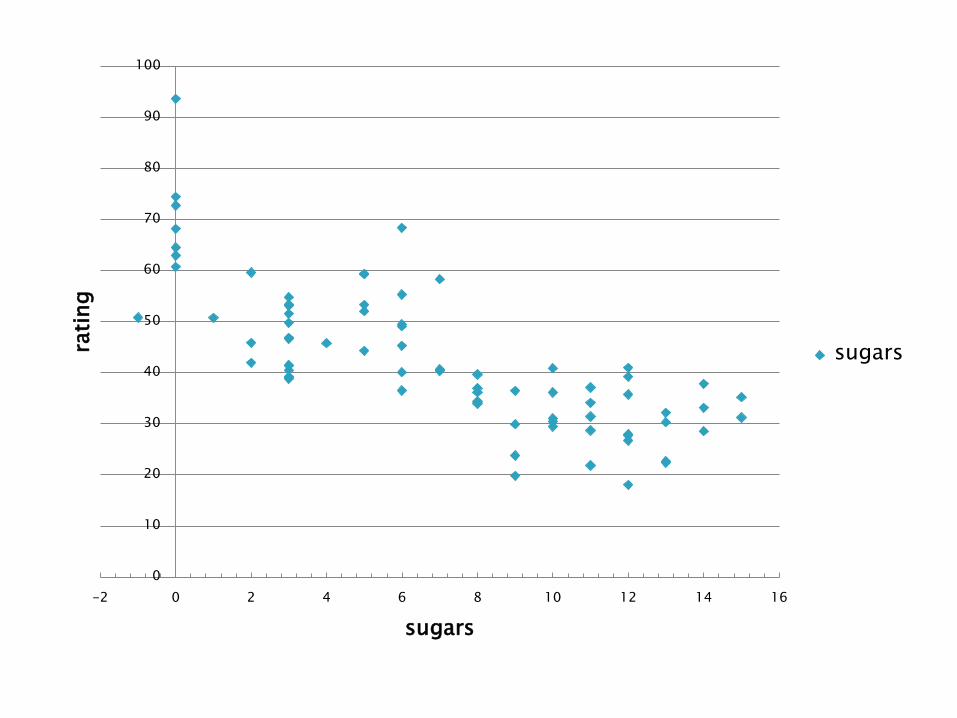
• A więc najpierw zajmiemy się zależnościami między dwiema zmiennymi: objaśnianą (wartość odżywcza płatków, rating) oraz objaśniającą (cukry, sugars).
• Analiza regresji pozwoli nam oszacować wartości odżywcze (rating) różnych typów płatków śniadaniowych, mając dane zawartości cukrów (sugars).
0
10
20
30
40
50
60
70
80
90
100
-2 0 2 4 6 8 10 12 14 16
rati
ng
sugars
sugars
0
10
20
30
40
50
60
70
80
90
100
-2 0 2 4 6 8 10 12 14 16
rati
ng
sugars
sugars
Liniowy (sugars)

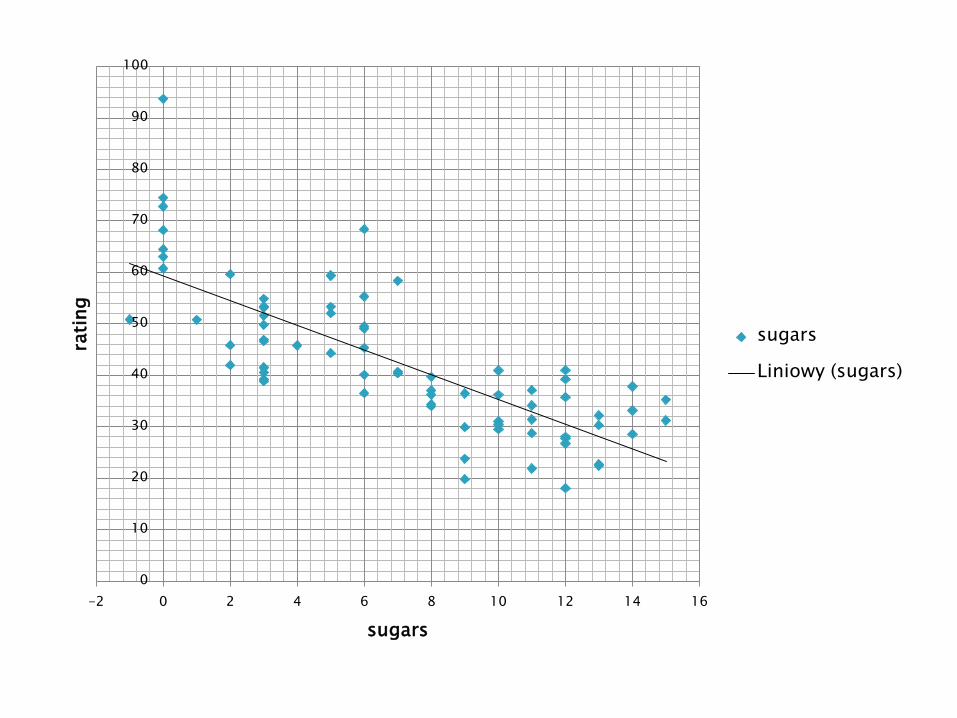
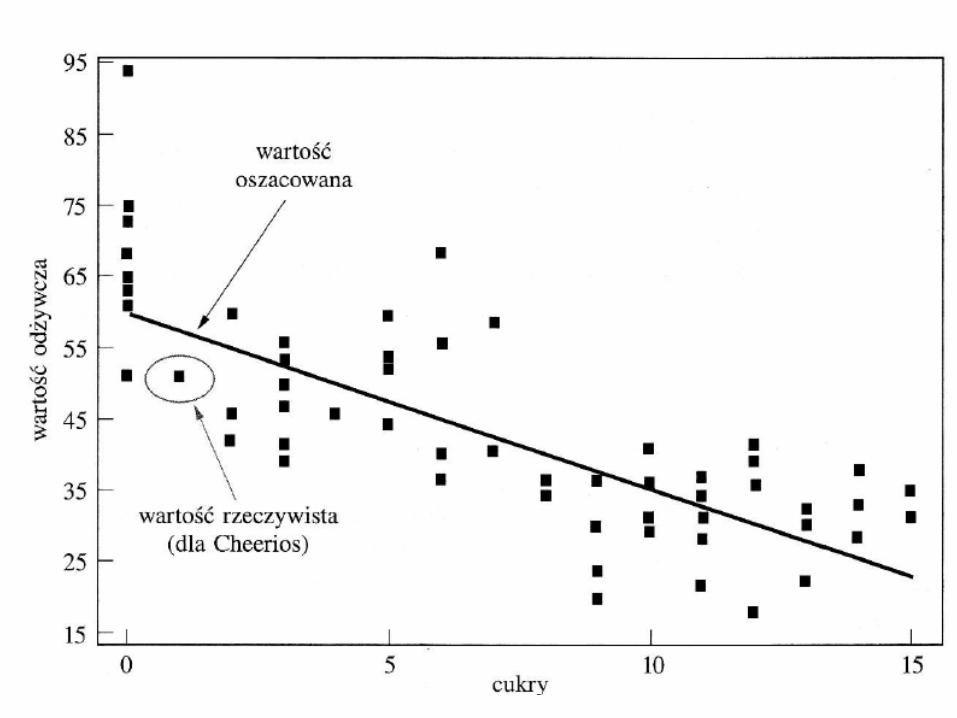
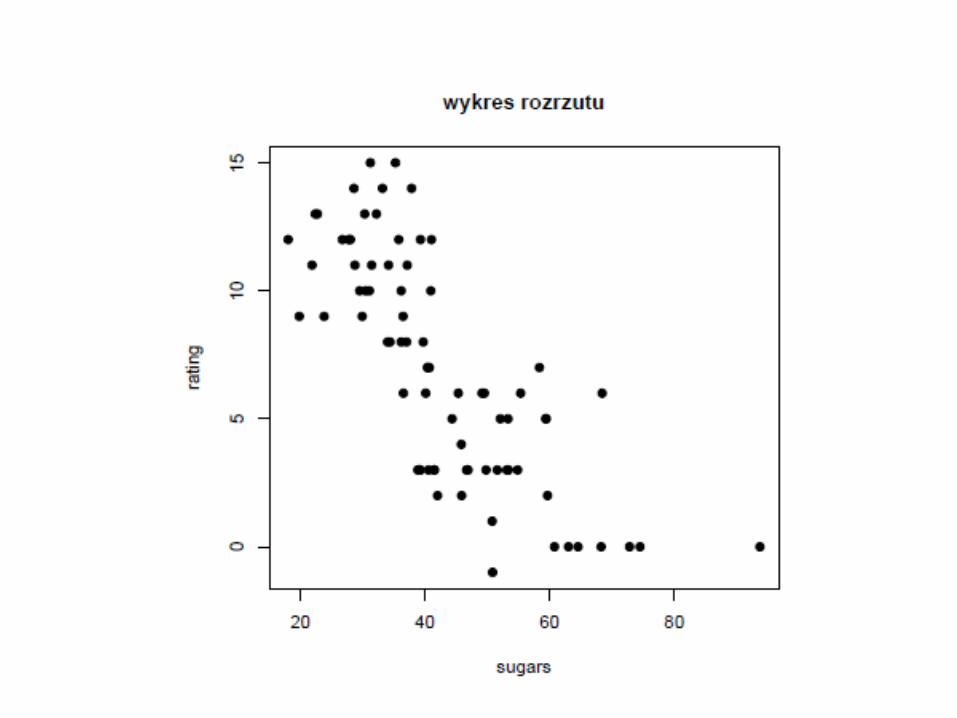
To wykres rozrzutu wartości odżywczych względem zawartości cukrów dla 77 rodzajów płatków śniadaniowych, razem z linią regresji najmniejszych kwadratów. Jest to linia regresji otrzymana za pomocą metody najmniejszych kwadratów. Linia regresji jest zapisana w postaci równania , które nazywa się równaniem regresji lub oszacowanym równaniem regresji, przy czym:
xbby 10
Szacowana wartość zmiennej objaśnianej Punkt przecięcia linii regresji z osią y Nachylenie linii regresji Współczynniki regresji
y
0b
1b
10 ,bb
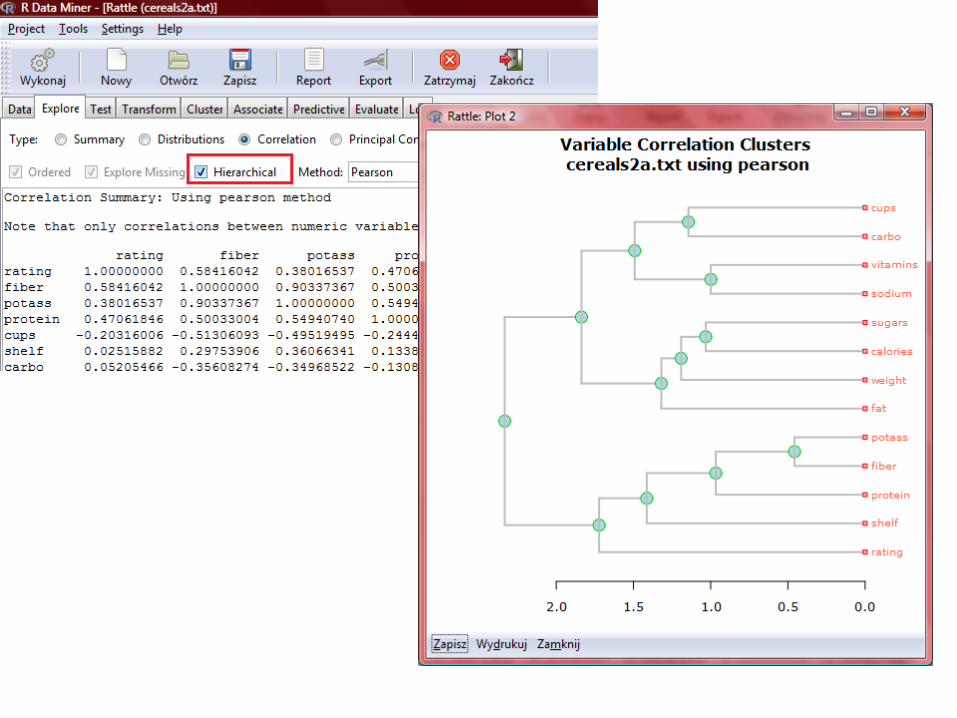
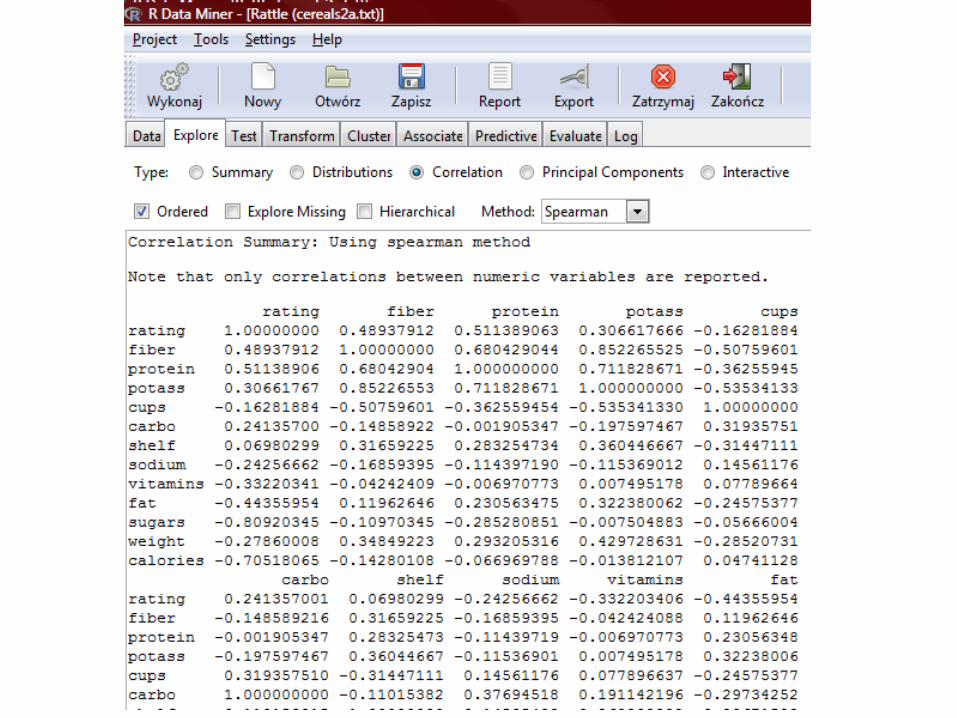
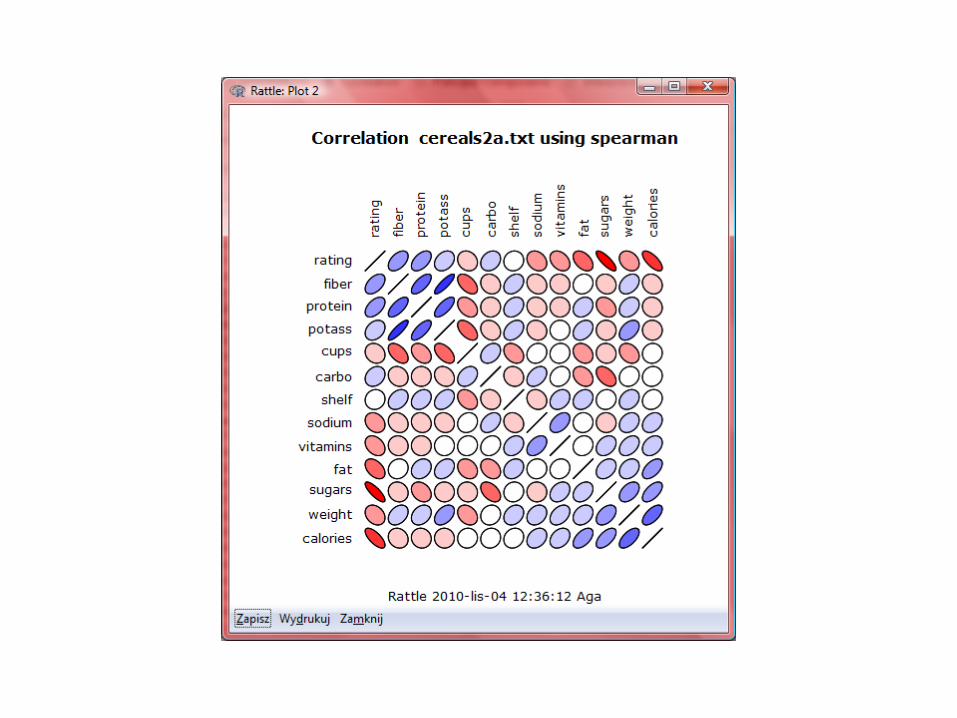
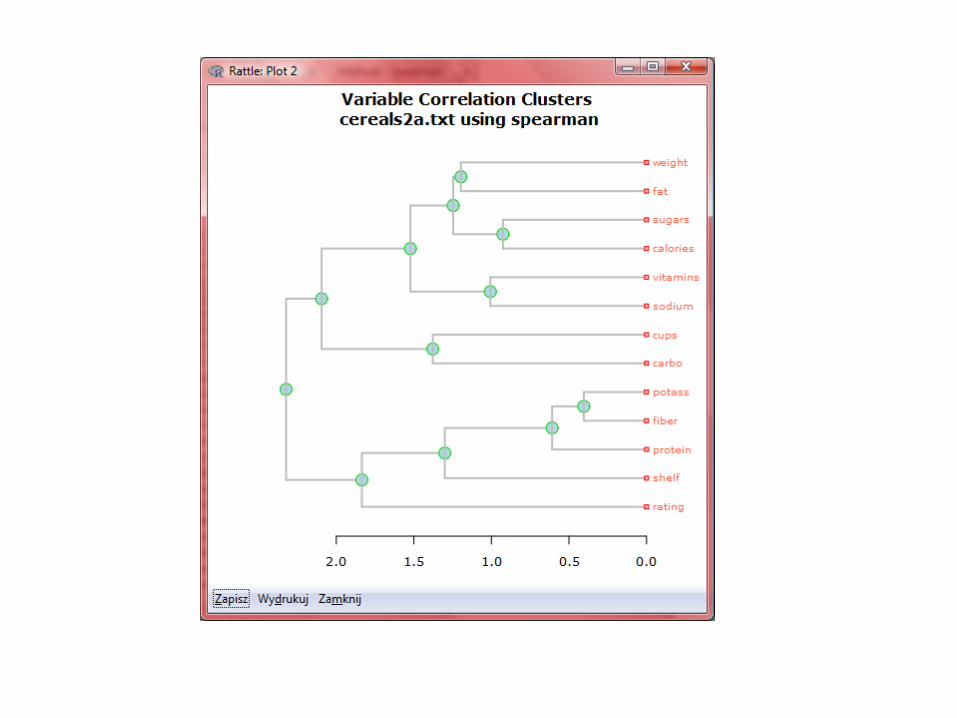
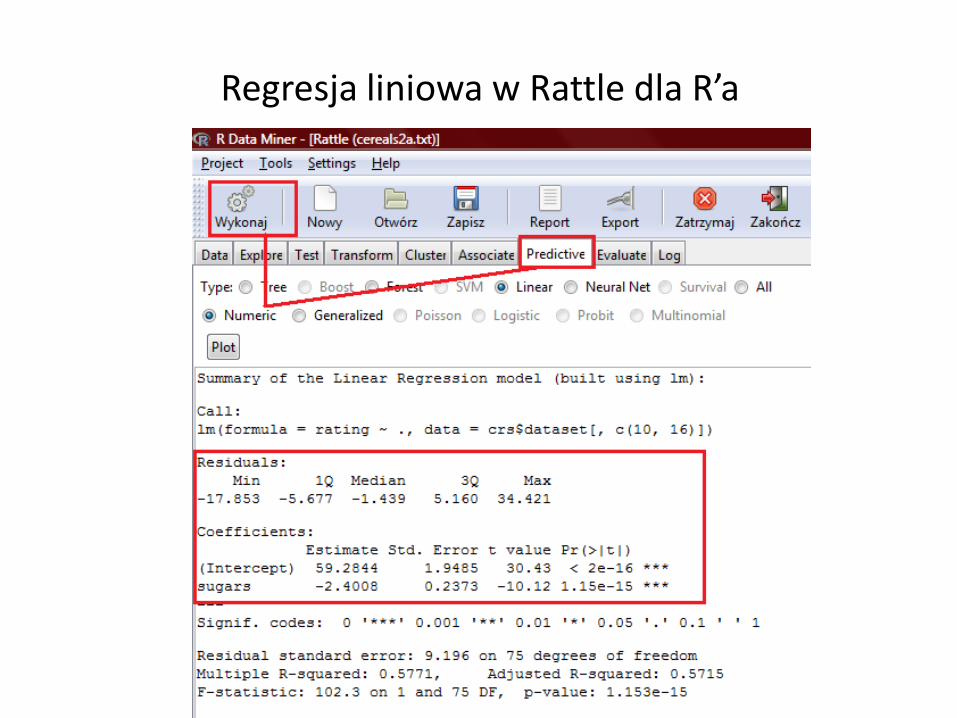
Regresja liniowa w Rattle dla R’a

Regresja liniowa w środowisku R…
W środowisku R procedura znajdowania równania regresji dla podanego zbioru danych możliwa jest dzięki wykorzystaniu funkcji lm. Komenda R postaci lm(y ~ x) mówi, że chcemy znaleźć model regresji liniowej dla zmiennej y w zależności od zmiennej x.

Wariant z 1 zmienną objaśniającą…
rating = -2.4 * sugars+ 59.3

więc
• Estymowane równanie regresji może być interpretowane jako „oszacowana wartość płatków jest równa 59,4 – 2,42 * masa cukru w gramach”
• Linia regresji i (oszacowane równanie regresji) są używane jako liniowe przybliżenie relacji pomiędzy zmiennymi x (wartością objaśniającą) a y (objaśnianą), tj. między zawartości cukru a wartością odżywczą.
sugarsrating *42.24.59
4.590 b 42.21 b
y

xbby 10
Jak to czytać ?
sugarsrating *42.24.59
A więc: 4.590 b 42.21 b
„Oszacowana wartość odżywcza płatków (rating) jest równa 59.4 i 2.42 razy
waga cukrów (sugars) w gramach”
Czyli linia regresji jest liniowym przybliżeniem relacji między zmiennymi x (objaśniającymi, niezależnymi) a y (objaśnianą, zależną) – w tym przypadku między zawartością cukrów a wartością odżywczą. Możemy zatem dzięki regresji: SZACOWAĆ, PRZEWIDYWAĆ…

• Gdy np. chcemy oszacować wartości odżywcze nowego rodzaju płatków (nieuwzględnionych dotąd w tej próbie 77 różnym badanych płatków śniadaniowych), które zawierają x=1 gram cukrów.
• Wówczas za pomocą oszacowanego równania regresji możemy wyestymować wartość odżywczą płatków śniadaniowych zawierającym 1 gram cukrów:
Po co przewidywać ?
98.561*42.24.59
y

• Gdy np. chcemy oszacować wartości odżywcze nowego rodzaju płatków (nieuwzględnionych dotąd w tej próbie 77 różnym badanych płatków śniadaniowych), które zawierają x=5 gram cukrów.
• Wówczas za pomocą oszacowanego równania regresji możemy wyestymować wartość odżywczą płatków śniadaniowych zawierającym 5 gram cukrów:
Po co przewidywać ?
3.475*42.24.59
y
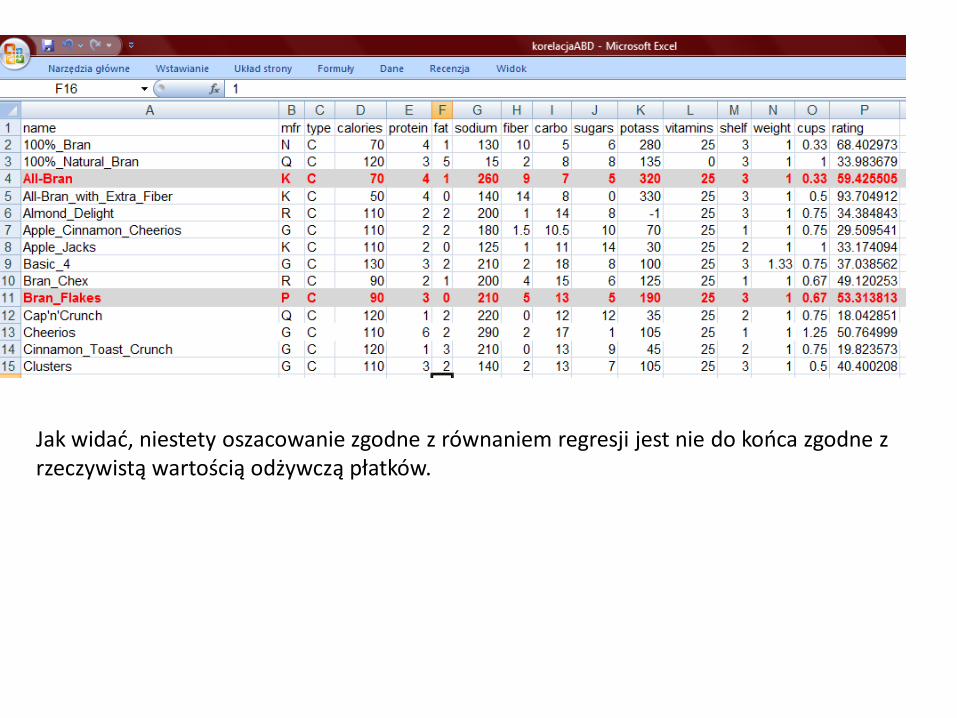
Jak widać, niestety oszacowanie zgodne z równaniem regresji jest nie do końca zgodne z rzeczywistą wartością odżywczą płatków.

• Wyraz wolny b0 jest miejscem na osi y gdzie linia regresji przecina tę oś, czyli jest to przewidywana wartość zmiennej objaśnianej, gdy zmienna objaśniająca jest równa 0. W wielu przypadkach zerowa wartość nie ma tu sensu. Przypuśćmy np. że chcielibyśmy przewidzieć wagę ucznia szkoły podstawowej (y) na podstawie jego wzrostu (x). Wartość zerowa wzrostu jest niejasna, a więcej interpretacji znaczenia wyrazu wolnego nie ma sensu w tym przypadku.
• Jednak dla naszego zbioru danych zerowa wartość cukrów w płatkach jak najbardziej ma sens, ponieważ istnieją płatki niezawierające cukrów. Zatem w naszym zbiorze danych wyraz wolny b0=59.4 reprezentuje przewidywaną wartość odżywczą płatków z zerową zawartością cukrów.
• Ale w naszym zbiorze nie mamy płatków o zerowej zawartości cukru które mają oszacowaną wartość odżywczą równą dokładnie 59.4. Właściwe wartości odżywcze razem z błędami oszacowania przedstawiono poniżej.

• Wszystkie przewidywane wartości są takie same. Bo wszystkie wymienione płatki mają identyczną wartość zmiennej objaśniającej (x=0).
• Współczynnik kierunkowy prostej regresji oznacza oszacowaną zmianę wartości y dla jednostkowego wzrostu x.
• Wartość b1 = 2.42 interpretujemy jako: „Jeżeli zawartość cukrów wzrośnie o 1 gram, to wartość odżywcza zmniejszy się o 2.42 punktu”.

Płatki o zerowej wartości SUGARS Proszę sprawdzić ile z tych płatków które faktycznie miały 0
wartość cukrów (sugars) miały wartość odżywczą (rating) równą 59.4?
Odp: żadne…
Co sugeruje, że nasz model regresji nie do końca dobrze przewiduje w tym przypadku wartość odżywczą płatków.

• Załóżmy np. że jesteśmy zainteresowani szacowaniem wartości odżywczych nowych płatków (nie zawartych w początkowych danych), które zawierają x=1 gram cukru.
• Za pomocą oszacowanego równania regresji możemy znaleźć oszacowaną wartość płatków zawierających 1 gram cukru jako 59.4 – 2.42 * 1 = 56.98
• Zauważmy, że ta oszacowana wartość dla wartości odżywczej leży bezpośrednio na linii regresji, w punkcie (x=1, y = 56.98). W rzeczywistości dla każdej danej wartości x (sugars) oszacowana wartość y (rating) będzie znajdować się dokładnie na linii regresji.
• W naszych zbiorze są płatki Cheerios, w których zawartość cukru jest równa 1 gram. Jednak ich wartość odżywcza to 50.765 a nie 56.98 jak oszacowaliśmy powyżej dla nowych płatków zawierających 1 gram cukru.
• Na wykresie rozrzutu punkt płatków Cheerios jest umiejscowiony w (x=1, y = 50.765) wewnątrz owalu. Górna strzałka wskazuje na położenie na linii regresji dokładnie powyżej punktu dla płatków Cheerios. Jest to punkt który przewidziała linia regresji dla wartości odżywczych, jeżeli zawartość cukru wynosi 1 gram.
• Wartość szacowana była zbyt duża o 56.98 – 50.765 = 6.215 – co jest odległością w pionie punktu reprezentującego płatki Cheerios od linii regresji. Ta pionowa odległość równa 6.215 w ogólności jest nazywana np. błędem predykcji, błędem szacowania lub resztą.
)( yy
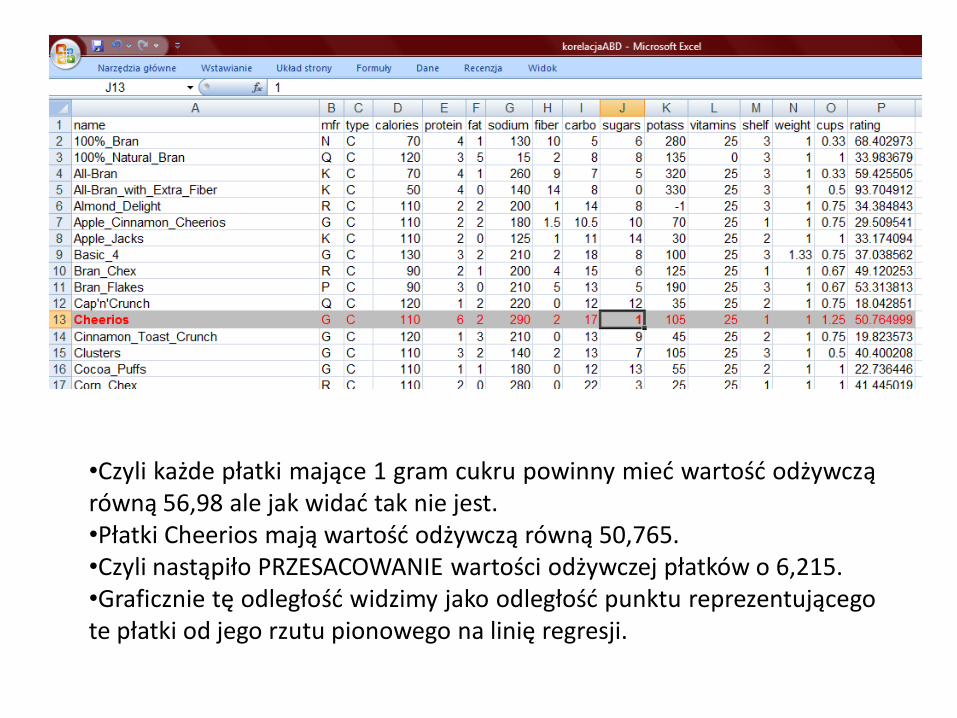
•Czyli każde płatki mające 1 gram cukru powinny mieć wartość odżywczą równą 56,98 ale jak widać tak nie jest. •Płatki Cheerios mają wartość odżywczą równą 50,765. •Czyli nastąpiło PRZESACOWANIE wartości odżywczej płatków o 6,215. •Graficznie tę odległość widzimy jako odległość punktu reprezentującego te płatki od jego rzutu pionowego na linię regresji.

Co wówczas ?
•Odległość tą mierzoną jako:
•Nazywać będziemy błędem predykcji (błędem oszacowania, wartością resztową, rezyduum). •Oczywiście powinno się dążyć do minimalizacji błędu oszacowania. •Służy do tego metoda zwana metodą najmniejszych kwadratów. Metoda polega na tym, że wybieramy linię regresji która będzie minimalizować sumę kwadratów reszt dla wszystkich punktów danych.
)( yy

Które residua (suma kwadratów) są najmniejsza?
Proste sumowanie: I -5+2+3=0; II -1+2-1=0; III -2+2+0
• MNK: I 25+4+9=38; II: 1+4+1=6; III 4+4=8

Metoda MNK
• Metoda MNK pozwala nam jednoznacznie wybrać linię regresji, która minimalizuje sumę kwadratów reszt dla wszystkich punktów danych.
• Jeśli mamy n obserwacji z modelu danego równaniem powyżej, wówczas
• Linia NK jest linią, która minimalizuje sumę kwadratów błędów dla populacji ()
xy 10
iii xy 10ni ,...,2,1
n
i
ii
n
i
ip xySSE1
2
10
1
)(

• Odpowiedź: pewnie NIE.
• Prawdziwą liniową zależność między wartością odżywczą a zawartością cukrów dla WSZYSTKICH rodzajów płatków reprezentuje równanie:
Czy to równanie będzie spełnione dla innych płatków niż te z badanego zbioru ?
xy 10
- Losowy błąd

• Linia najmniejszych kwadratów minimalizuje sumę kwadratów błędów SSE (population sum of squared errors):
Dla n obserwacji
iii xy 10i=1,…,n
n
i
n
i
iiiR
p xySSE1 1
2
10 )(

1. Różniczkujemy to równanie by oszacować
Co dalej ?
10 i
)(*2 10
10
i
n
i
i
pxy
SSE
)(*2 10
11
i
n
i
ii
pxyx
SSE
2. Przyrównujemy wynik do zera:
0)( 10
1
i
n
i
i xbby
0)( 10
1
i
n
i
ii xbbyx
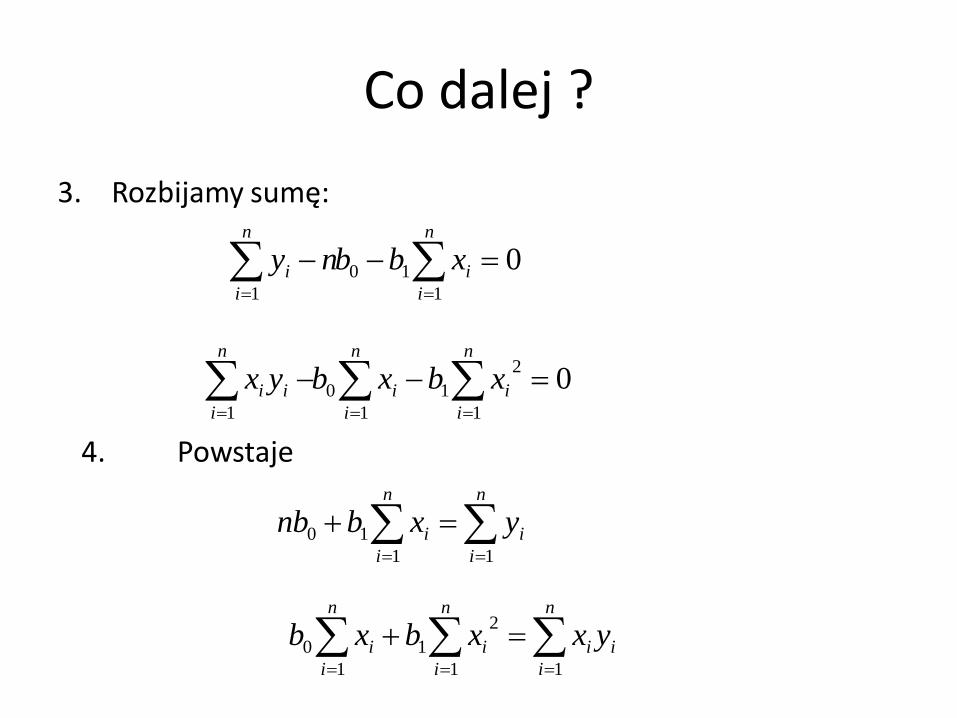
3. Rozbijamy sumę:
Co dalej ?
4. Powstaje
01
10
1
n
i
i
n
i
i xbbny
01
2
1
1
0
1
n
i
i
n
i
i
n
i
ii xbxbyx
n
i
i
n
i
i yxbnb11
10
n
i
ii
n
i
i
n
i
i yxxbxb11
2
1
1
0

5. Rozwiązując te równania otrzymujemy:
Co dalej ?
nxx
nyxyxb
ii
iiii
/)(
/))((221
xbyb 10
x
n – liczba obserwacji
- Średnia wartość zmiennej objaśniającej
y - Średnia wartość zmiennej objaśnianej
A sumy są od i=1 do n.
0b 1bi -estymatory najmniejszych kwadratów dla Czyli wartości które minimalizują sumę kwadratów błędów.
10 i
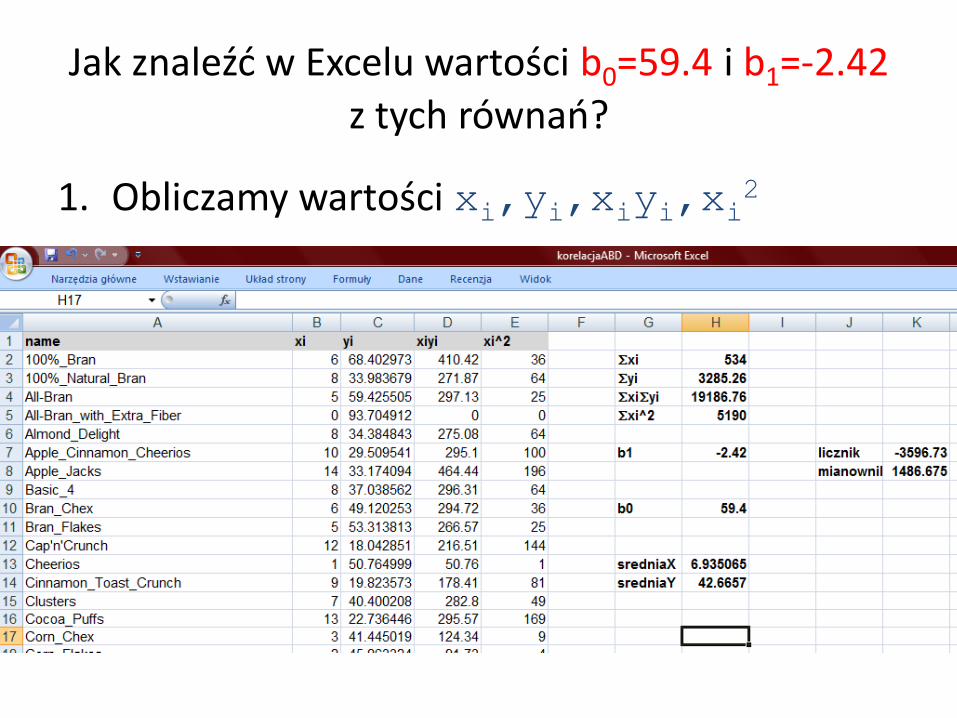
1. Obliczamy wartości xi,yi,xiyi,xi2
Jak znaleźć w Excelu wartości b0=59.4 i b1=-2.42 z tych równań?

xi=534 yi=3285.26 xiyi=19186.76 xi
2=5190
1. Obliczamy wartości:
2. Podstawiamy do wzorów:
42.267.1486
79.3596
77/5345190
77/26.3285*53476.1918621
b
4.59935.6*42.26657.4210 xbyb

Wnioski…
• Wyraz wolny b0 jest miejscem na osi y gdzie linia regresji przecina tę oś czyli jest
to przewidywana wartość zmiennej objaśnianej gdy objaśniająca równa się zeru.
• Współczynnik kierunkowy prostej regresji oznacza szacowaną zmianę wartość y
dla jednostkowego wzrostu x wartość b1=-2.42 mówi, że jeśli zawartość cukrów
wzrośnie o 1 gram to wartość odżywcza płatków zmniejszy się o 2.42 punktu.
• Czyli płatki A których zawartość cukrów jest o 5 większa niż w płatkach B powinny
mieć oszacowaną wartość odżywczą o 5 razy 2.42 = 12.1 punktów mniejszą niż
płatki typu B.
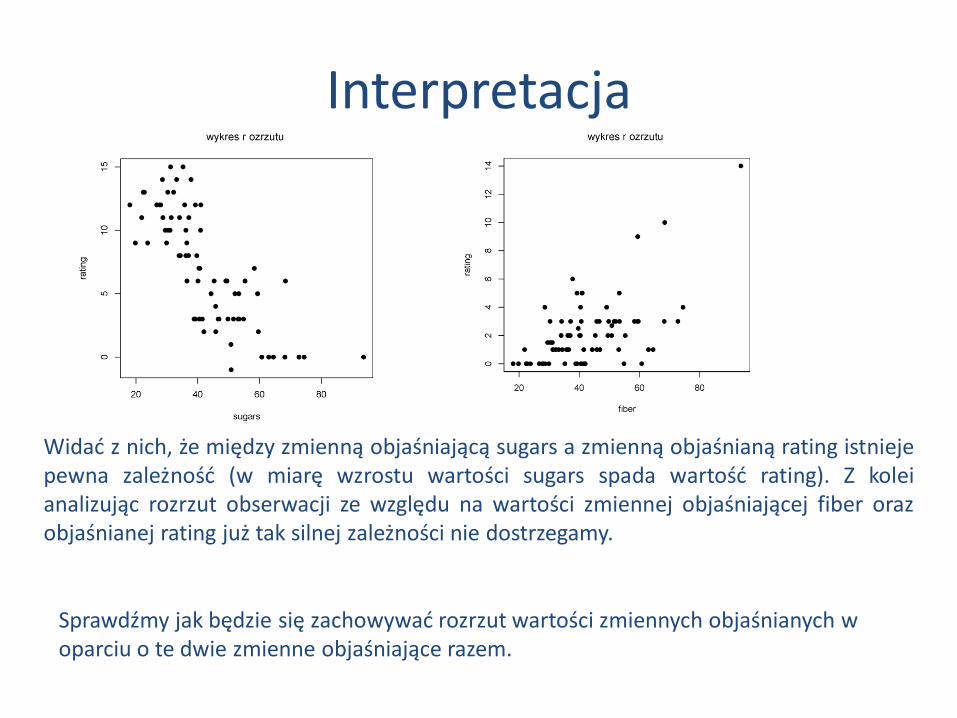
Interpretacja
Widać z nich, że między zmienną objaśniającą sugars a zmienną objaśnianą rating istnieje pewna zależność (w miarę wzrostu wartości sugars spada wartość rating). Z kolei analizując rozrzut obserwacji ze względu na wartości zmiennej objaśniającej fiber oraz objaśnianej rating już tak silnej zależności nie dostrzegamy.
Sprawdźmy jak będzie się zachowywać rozrzut wartości zmiennych objaśnianych w oparciu o te dwie zmienne objaśniające razem.

Regresja wielokrotna Omawiając regresję liniową (prostą) rozpatrywaliśmy dotąd jedynie takie przypadki zależności między zmiennymi objaśniającymi a objaśnianymi gdzie zmienna objaśniana była zależna tylko od jednej konkretnej zmiennej objaśniającej. Jednak w praktyce niezwykle często zmienna objaśniana zależna jest nie od jednej ale od kilku (wielu) zmiennych objaśniających. Będziemy zatem rozważać ogólne równanie regresji postaci:
mmxbxbxbby
...22110
gdzie m oznacza liczbę (najczęściej kilku) zmiennych objaśniających.
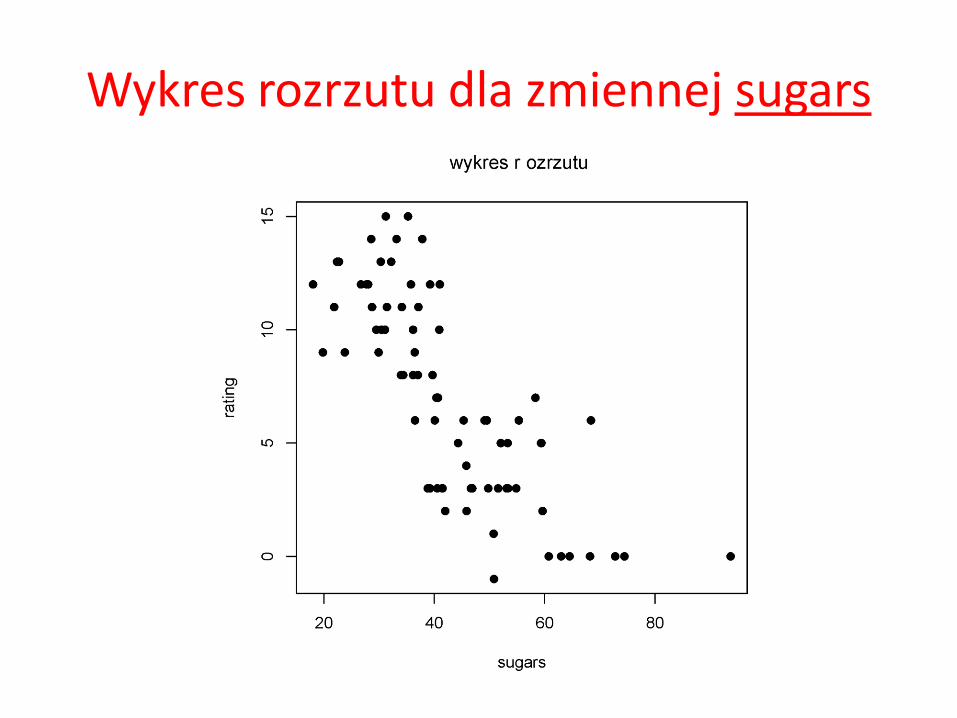
Wykres rozrzutu dla zmiennej sugars
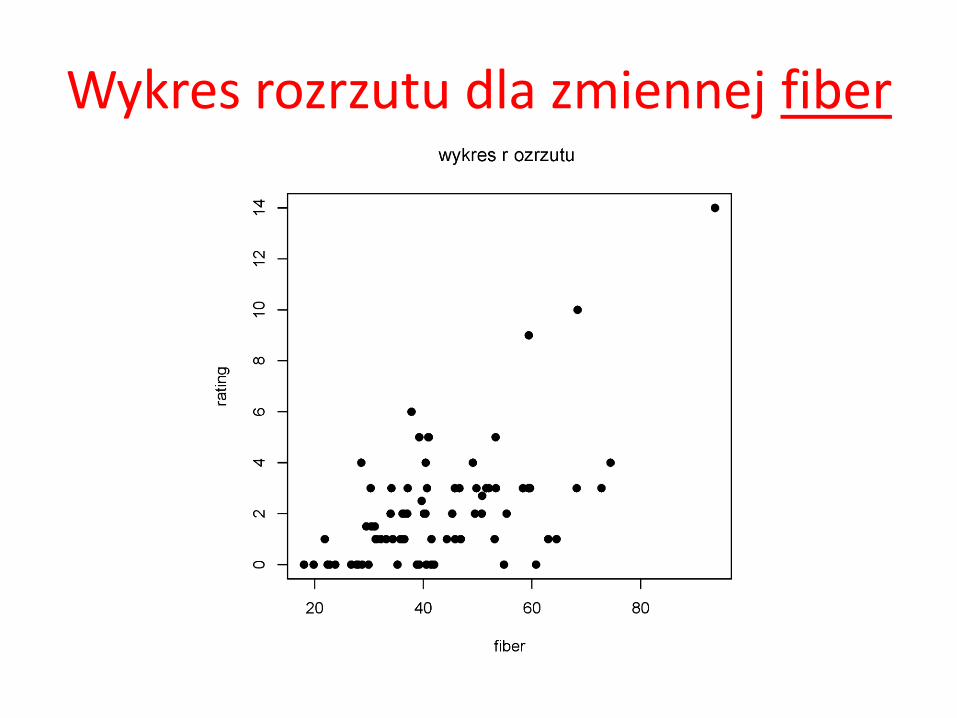
Wykres rozrzutu dla zmiennej fiber

Wariant z 2 zmiennymi objaśniającymi
rating = -2.18 * sugars+ 2.86 * fiber + 51.6
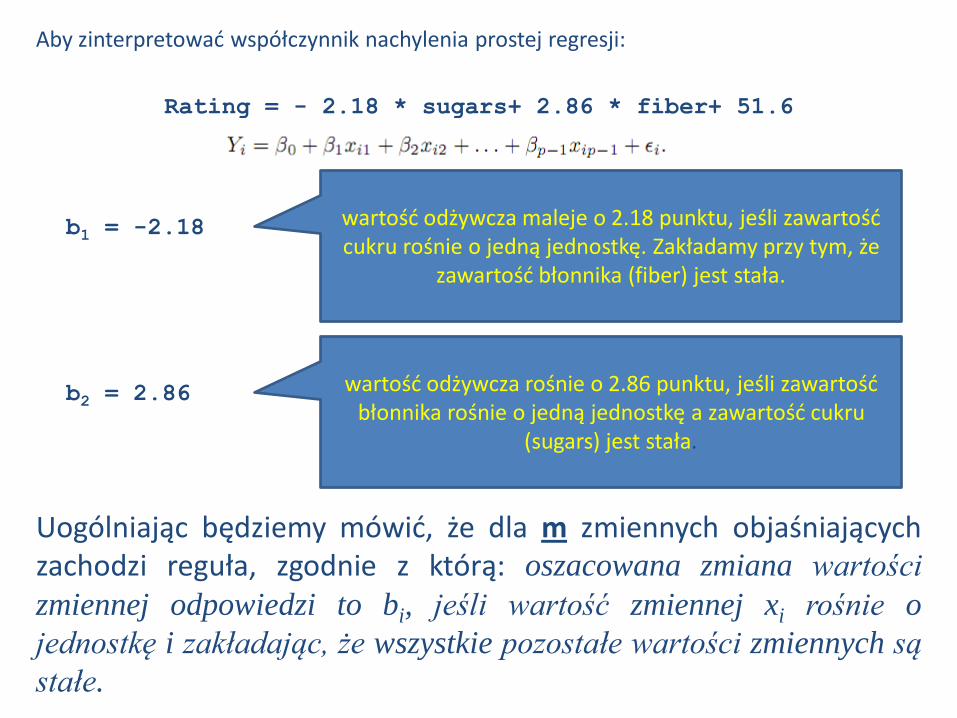
Uogólniając będziemy mówić, że dla m zmiennych objaśniających zachodzi reguła, zgodnie z którą: oszacowana zmiana wartości
zmiennej odpowiedzi to bi, jeśli wartość zmiennej xi rośnie o
jednostkę i zakładając, że wszystkie pozostałe wartości zmiennych są
stałe.
Rating = - 2.18 * sugars+ 2.86 * fiber+ 51.6
Aby zinterpretować współczynnik nachylenia prostej regresji:
b1 = -2.18 wartość odżywcza maleje o 2.18 punktu, jeśli zawartość cukru rośnie o jedną jednostkę. Zakładamy przy tym, że
zawartość błonnika (fiber) jest stała.
b2 = 2.86 wartość odżywcza rośnie o 2.86 punktu, jeśli zawartość
błonnika rośnie o jedną jednostkę a zawartość cukru (sugars) jest stała.

Teraz możemy przewidywać, że gdy poziom cukrów wynosi np 1 to wartość odżywcza płatków będzie wynosić 56.9 zaś gdy poziom cukrów będzie wynosił 10 wówczas wartość odżywcza zmaleje do wartości 35.3 (patrz poniżej).
> predict(model,data.frame(sugars=10), level = 0.9, interval = "confidence")
fit lwr upr
1 35.27617 33.14878 37.40356
> predict(model,data.frame(sugars=1), level = 0.9, interval = "confidence")
fit lwr upr
1 56.88355 53.96394 59.80316

Błędy predykcji są mierzone przy użyciu reszt Uwaga: w prostej regresji liniowej reszty reprezentują odległość (mierzoną wzdłuż osi pionowej) pomiędzy właściwym punktem danych a linią regresji, zaś w regresji wielokrotnej, reszta jest reprezentowana jako odległość między właściwym punktem danych a płaszczyzną lub hiperpłaszczyzną regresji. Przykładowo płatki Spoon Size Shredded Wheat zawierają x1=0 gramów cukru i x2 = 3 gramy błonnika, a ich wartość odżywcza jest równa 72.80 podczas gdy wartość oszacowana, podana za pomocą równania regresji:
Zatem dla tych konkretnych płatków reszta jest równa 60.21 - 72.80 = 12.59.
> predict(model, data.frame(sugars=0,fiber=3),level=0.95,
interval="confidence")
fit lwr upr
1 60.21342 57.5805 62.84635
Zwróćmy uwagę na to, że wyniki, które tutaj zwraca funkcja R: predict są bardzo istotne. Mianowicie, oprócz podanej (oszacowanej, przewidywanej) wartości zmiennej objaśniającej, otrzymujemy również przedział ufności na zadanym poziomie ufności równym 0.95, który to przedział mieści się między wartością 57.5805 (lwr) a 62.84635 (upr).
yy

Wariant z wieloma zmiennymi objaśniającymi…
Rating = - 0.22*calories
+2.9*protein+1.03*carbo-
0.84*sugars-2.00*fat-
0.05*vitamins+2.54*fiber-
0.05*sodium+ 56.19
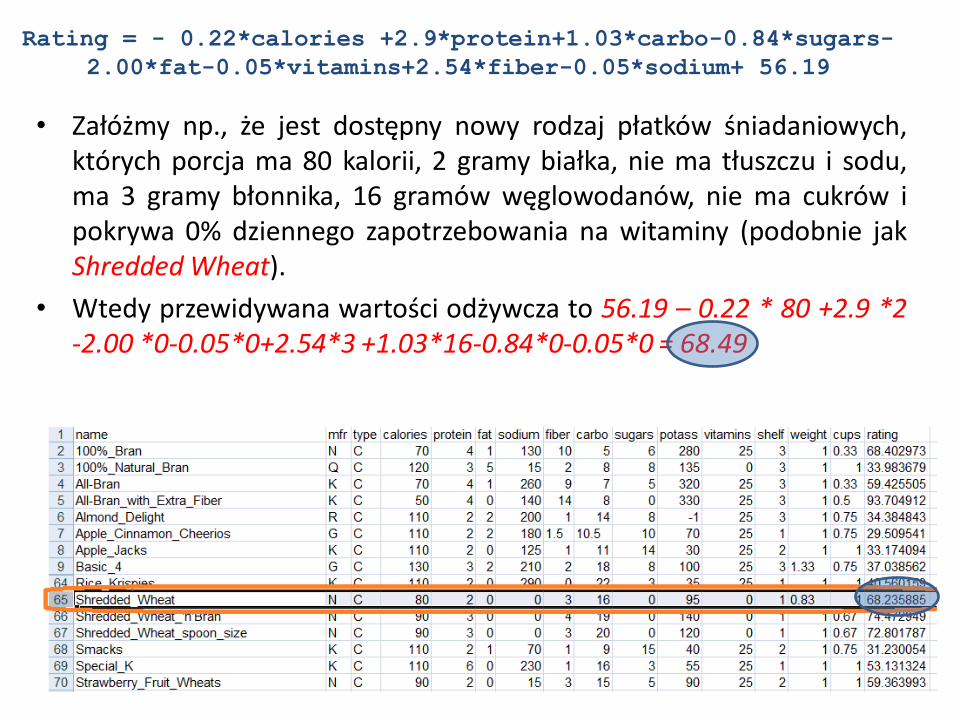
• Załóżmy np., że jest dostępny nowy rodzaj płatków śniadaniowych, których porcja ma 80 kalorii, 2 gramy białka, nie ma tłuszczu i sodu, ma 3 gramy błonnika, 16 gramów węglowodanów, nie ma cukrów i pokrywa 0% dziennego zapotrzebowania na witaminy (podobnie jak Shredded Wheat).
• Wtedy przewidywana wartości odżywcza to 56.19 – 0.22 * 80 +2.9 *2 -2.00 *0-0.05*0+2.54*3 +1.03*16-0.84*0-0.05*0 = 68.49
Rating = - 0.22*calories +2.9*protein+1.03*carbo-0.84*sugars-
2.00*fat-0.05*vitamins+2.54*fiber-0.05*sodium+ 56.19

• To przewidywanie jest niezwykle bliskie właściwej wartości odżywczej płatków Shredded Wheat równej 68.2358. zatem błąd szacowania = 68.2359-68.49 = -0.2541
• Oczywiście szacowanie punktu ma wady analogiczne do tych w przypadku prostej regresji liniowej, zatem również możemy znaleźć przedziały ufności dla średniej wartości odżywczej wszystkich takich płatków (o właściwościach podobnych do Shredded Wheat: 80 kalorii, 2 gramy białka) na poziomie ufności 95 % to (66.475,70.764). Jak poprzednio, przedział ufności dla losowo wybranego rodzaju płatków jest większy niż dla średniej wartości.
• Następnie omówimy dalsze wyniki regresji wielokrotnej. Wartość R2 równa 99.5 % jest niezwykle duża, prawie równa maksymalnej wartości równej 100%. To pokazuje, że nasz model regresji wielokrotnej przedstawia prawie całą zmienność wartości odżywczej. Błąd standardowy szacowania s jest równo około 1, co oznacza, ze typowy błąd przewidywania wynosi około jednego punktu w skali wartości odżywczej, a blisko 95% (na podstawie rozkładu normalnego błędów) przewidywań będzie w obrębie dwóch punktów od aktualnej wartości. Porównajmy to z wartością s równą około 9 dla modelu prostej regresji liniowej.
• Użycie większej liczby atrybutów w naszym modelu regresji pozwoliło nam na zredukowanie błędu przewidywania o czynnik równy 9.

Czy wybrana metoda regresji jest przydatna ?
• Można znaleźć taką linię regresji MNK, która modeluje zależność pomiędzy dwoma dowolnymi ciągłymi zmiennymi. Jednak nie ma nigdy gwarancji, że taka regresja będzie przydatna.
• W jaki sposób można stwierdzić, czy oszacowane równanie regresji jest przydatne do przewidywania?
• Jedną z miar jest współczynnik determinacji R2, będący miarą dopasowania regresji. Określa on stopień, w jakim linia regresji NK wyjaśnia zmienność obserwowanych danych.
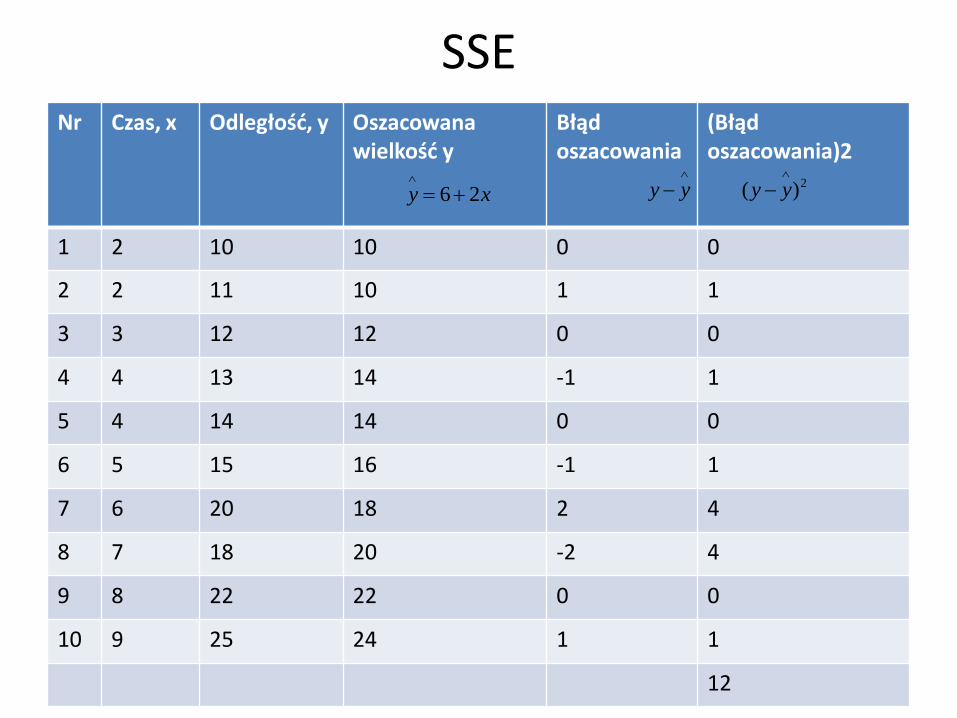
SSE Nr Czas, x Odległość, y Oszacowana
wielkość y
Błąd oszacowania
(Błąd oszacowania)2
1 2 10 10 0 0
2 2 11 10 1 1
3 3 12 12 0 0
4 4 13 14 -1 1
5 4 14 14 0 0
6 5 15 16 -1 1
7 6 20 18 2 4
8 7 18 20 -2 4
9 8 22 22 0 0
10 9 25 24 1 1
12
xy 26
yy 2)(
yy

• Pokazano odległość przebytą przez 10 zawodników biegu na orientację oraz czas trwania biegu każdego zawodnika. Pierwszy zawodnik przebył 10 km w 2 godziny.
• Na podstawie danych z tej tabeli oszacowane równanie regresji przyjmuje postać: .A więc estymowana odległość jest równa 6 km plus 2 razy liczba godzin.
• Oszacowane równanie regresji może być użyte do przewidywania przebytej odległości przez zawodnika, o ile znamy czas trwania biegu tego zawodnika.
• Estymowane wartości y znajdują się w kolumnie 3 tabeli można zatem obliczyć błąd oszacowania oraz jego kwadrat. Suma kwadratów błędu oszacowania lub suma kwadratów błędów reprezentuje całkowitą wartość błędu oszacowania w przypadku użycia równania regresji.
• Tutaj mamy wartość SSE = 12. Nie jesteśmy jeszcze teraz w stanie stwierdzić czy to wartość duża, bo w tym miejscu nie mamy żadnej innej miary.
xy 26

• Jeśli teraz chcemy oszacować przebytą odległość bez znajomości liczby godzin, a nie mamy dostępu do informacji o wartości zmiennej x, którą moglibyśmy wykorzystać do oszacowania wartości zmiennej y, nasze oszacowania przebytej odległości będą oczywiście mało wartościowe, gdyż mniejsza ilość dostępnym informacji zwykle skutkuje mniejszą dokładnością szacowań.
• Skoro nie mamy dostępu do informacji o zmiennych objaśniających, to najlepszym oszacowaniem dla y będzie po prostu średnia przebyta odległość. W takim przypadku, oszacowaniem przebytej odległości dla każdego zawodnika, niezależnie od jego czasu, byłaby wartość średnia = 16. Szacowania przebytej odległości, gdy ignorowana jest informacja o czasie, pokazuje pozioma linia średniej = 16.
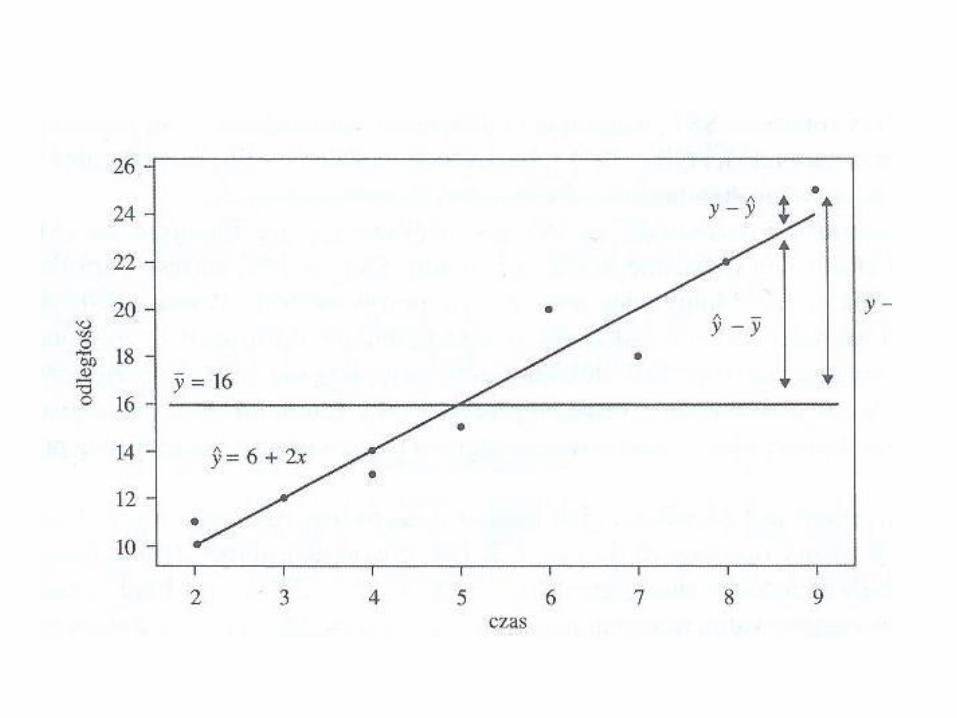
• Rysunek, strona 43.

• Przewidywana przebyta odległość średnia y = 16, niezależnie od tego czy wędrowali tylko 2 czy 3 godziny, czy też nie było ich cały dzień. Czyli nie uwzględniając czasu. Jest to rzecz jasna rozwiązanie nieoptymalne.
• Punkty danych na rysunku jak widzimy skupiają się wokół oszacowanej linii regresji, a nie wokół tej linii y=16.To sugeruje, że błędy przewidywania są mniejsze, kiedy uwzględniamy informację o zmiennej x, aniżeli wtedy, gdy tej informacji nie wykorzystujemy.
• Weźmy przykład zawodnika nr 10. Przebył odległość y=25 km w ciągu x=9 godzin. Jeżeli zignorowalibyśmy informację o wartości zmiennej objaśniającej x, błąd szacowania byłby równy = 25 – 16 = 9 km. Ten błąd przewidywania jest reprezentowany przez pionową linię pomiędzy punktem danych dla tego zawodnika, a poziomą linią, co oznacza odległość pomiędzy obserwowaną wartością y i jej rzutem pionowych na prostą o równaniu na średnią y = 16, która przecież określa wartość estymowaną.
• Chcemy teraz znaleźć dla każdego rekordu w zbiorze danych, a następnie sumę kwadratów tych miar, tak jak zrobiliśmy to dla ,kiedy obliczaliśmy sumę kwadratów błędów.
• Otrzymujemy w ten sposób całkowitą sumę kwadratów SST.
yy
yy
yy

• Pozwala stwierdzić czy oszacowane równanie regresji jest przydatne do przewidywania.
• Określa stopień w jakim linia regresji najmniejszych kwadratów wyjaśnia zmienność obserwowanych danych.
Współczynnik determinacji r2
y yy 2)( yy x y

Na ile dobra jest regresja?
Współczynnik determinacji jest opisową
miarą siły liniowego związku
między zmiennymi, czyli miarą
dopasowania linii regresji do danych
współczynnik determinacji ---przyjmuje
wartości z przedziału [0,1] i wskazuje jaka
część zmienności zmiennej y jest
wyjaśniana przez znaleziony model.
Na przykład dla R2=0.619 znaleziony
model wyjaśnia około 62% zmienności y.

Współczynnik determinacji
• Oczywiście zawsze można znaleźć taką linię regresji metodą najmniejszych kwadratów, która modeluje zależność pomiędzy dwoma dowolnymi ciągłymi zmiennymi. Jednak nie ma gwarancji, że taka regresja będzie przydatna. Zatem powstaje pytanie, w jaki sposób możemy stwierdzić, czy oszacowane równanie regresji jest przydatne do przewidywania. Jedną z miar dopasowania regresji jest współczynnik determinacji R2.
• Określa on stopień, w jakim linia regresji najmniejszych kwadratów wyjaśnia zmienność obserwowanych danych. Przypomnijmy, że oznacza estymowaną wartość zmiennej objaśnianej, a jest błędem oszacowania lub resztą.
yy
y

• Suma kwadratów błędu oszacowania lub suma kwadratów błędów reprezentuje całkowitą wartość błędu oszacowania w przypadku użycia równania regresji.
• Jeśli nie znamy wartości zmiennej objaśniającej do oszacowania wartości zmiennej objaśnianej- nasze oszacowania będą oczywiście mało wartościowe.
• Lepszym oszacowaniem dla y będzie po prostu średnia(y). To zazwyczaj prezentuje pozioma linia na wykresie. Punkty danych jednak koncentrują się bardziej wokół oszacowanej linii regresji a nie wokół tej linii poziomej, co sugeruje, że błędy przewidywania są mniejsze, kiedy uwzględniamy informację o zmiennej x, aniżeli wtedy, gdy tej informacji nie wykorzystujemy.
• Jeśli liczymy różnice x – średnia(x) dla każdego rekordu, a następnie sumę kwadratów tych miar, tak jak przy oszacowanej wartości y ( ), kiedy obliczaliśmy sumę kwadratów błędów otrzymujemy całkowitą sumę kwadratów SST (sum of squares total):
• Stanowi ona miarę całkowitej zmienności wartości samej zmiennej objaśnianej bez odniesienia do zmiennej objaśniającej. Zauważmy, że SST jest funkcją wariancji zmiennej y, gdzie wariancja jest kwadratem odchylenia standardowego .
2
1
2 )1()()1()( y
n
i
i nyVarnyySST
n
i
i yySST1
2)(
yy

• Wszystkie trzy miary: SST, wariancja oraz odchylenie standardowe są jednowymiarowymi miarami zmienności tylko dla y. Czy powinniśmy oczekiwać, że SST jest większe czy też mniejsze od SSE ?
• Wykorzystując obliczenia mamy SST dużo większe niż SSE. Mamy więc teraz z czym porównać SSE. Wartość SSE jest dużo mniejsza od SST, co wskazuje, że uwzględnienie informacji ze zmiennej objaśniającej w regresji skutkuje dużo dokładniejszą estymacją niż gdybyśmy zignorowali tę informację. Sumy kwadratów są błędami przewidywań, zatem im ich wartość jest mniejsza tym lepiej. Innymi słowy, zastosowanie regresji poprawia nasze szacowania zmiennej objaśnianej.
• Jeśli chcemy określić, jak bardzo oszacowane równanie regresji poprawia estymację, obliczymy teraz sumę kwadratów Otrzymamy w ten sposób regresyjną sumę kwadratów (SSR, sum of squares regression) – miarę całkowitej poprawy dokładności przewidywań w przypadku stosowania regresji w porównaniu do przypadku, gdy informacja zmiennej objaśniającej jest ignorowana:
n
i
yySSR1
2)(
yy
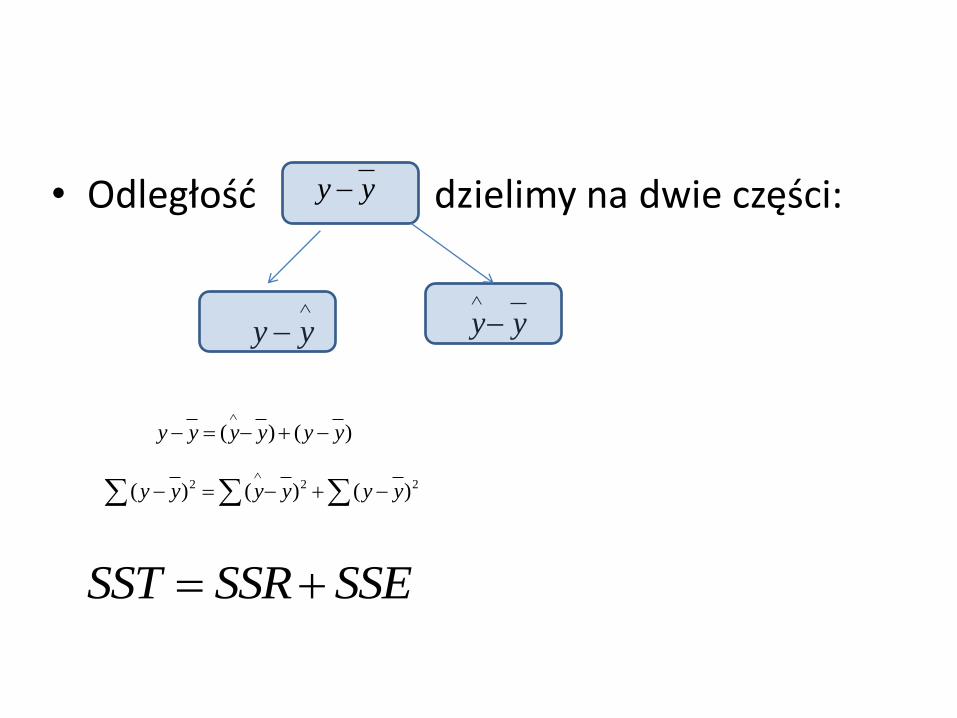
• Odległość dzielimy na dwie części:
yy
yy
yy
)()( yyyyyy
222 )()()( yyyyyy
SSESSRSST

• SST mierzy całkowitą zmienność zmiennej objaśnianej, zatem o SSR możemy myśleć jak o części zmienności zmiennej objaśniającej, która jest wyjaśniona przez regresję (SSR).
• Innymi słowy, SSR mierzy tę część zmienności zmiennej objaśniającej, która jest wyjaśniana przez liniową zależność między zmienną objaśniającą a objaśnianą.
• Ponieważ nie wszystkie punkty danych leżą dokładnie na linii regresji, więc pozostaje jeszcze pewna część zmienności zmiennej y, która nie została wyjaśniona przez regresję (tej części odpowiada wartość SSE).
• Możemy tu SSE traktować jako miarę całej zmienności y ze wszystkich źródeł, łącznie z błędem, po wyjaśnieniu liniowej zależności między x a y za pomocą regresji. Tutaj SSE jest nazywane zmiennością niewyjaśnioną.

• Ponieważ współczynnik determinacji przyjmuje postać ilorazu SSR i SST – możemy go interpretować jako tę część zmienności zmiennej y, która została wyjaśniona przez regresję, czyli przez liniowy związek pomiędzy zmienną celu a zmienną objaśniającą.

Jaka jest maksymalna wartość R2 ?
• Maksymalna wartość może być osiągnięta wtedy, gdy regresja idealnie pasuje do danych, co ma miejsce wówczas, gdy każdy z punktów danych leży dokładnie na oszacowanej linii regresji.
• W tej optymalnej sytuacji nie ma błędów oszacowania podczas stosowania regresji, a zatem każda wartość resztowa jest równa 0, co z kolei oznacza, że SSE jest =0.
• Jeżeli SSE = 0 to SST = SSR zatem współczynnik R2 jest równy SSR/SST = 1. Taka sytuacja ma miejsce gdy regresja idealnie modeluje dostępne dane.

Jaka jest minimalna wartość R2 ?
• Jeśli regresja nie wykazała żadnej poprawy, czyli nie wyjaśniła żadnej części zmienności zmiennej y.
• Wówczas wartość SSR jest równa zero, a więc również wartość R2 = 0. Zatem wartość współczynnika R2 jest z zakresu od 0 do 1.
• Im wyższa wartość R2, tym lepsze dopasowanie regresji do danych. Wartości R2 bliskie 1 oznaczają niezwykle dobre dopasowanie regresji do danych, wartości bliskie 0, oznaczają bardzo słabe dopasowanie.

SST
SSRr 2
Współczynnik determinacji r2:
Współczynnik determinacji r2
Mierzy stopień dopasowania regresji jako przybliżenia liniowej zależności pomiędzy zmienną celu a zmienną objaśniającą.
Jaka jest wartość maksymalna współczynnika determinacji r2 ?
Jest ona osiągana wtedy, gdy regresja idealnie pasuje do danych, co ma miejsce wtedy gdy każdy z punktów danych leży dokładnie na oszacowanej linii regresji. Wówczas nie ma błędów oszacowania, a więc wartości resztowe (rezydua) wynoszą 0, a więc SSE=0 a wtedy SST = SSR a r2=1.
Jaka jest wartość minimalna współczynnika determinacji r2 ?
Jest ona osiągana wtedy, gdy regresja nie wyjaśnia zmienności, wtedy SSR = 0, a więc r2=0.
Im większa wartość r2 tym lepsze dopasowanie regresji do zbioru
danych.
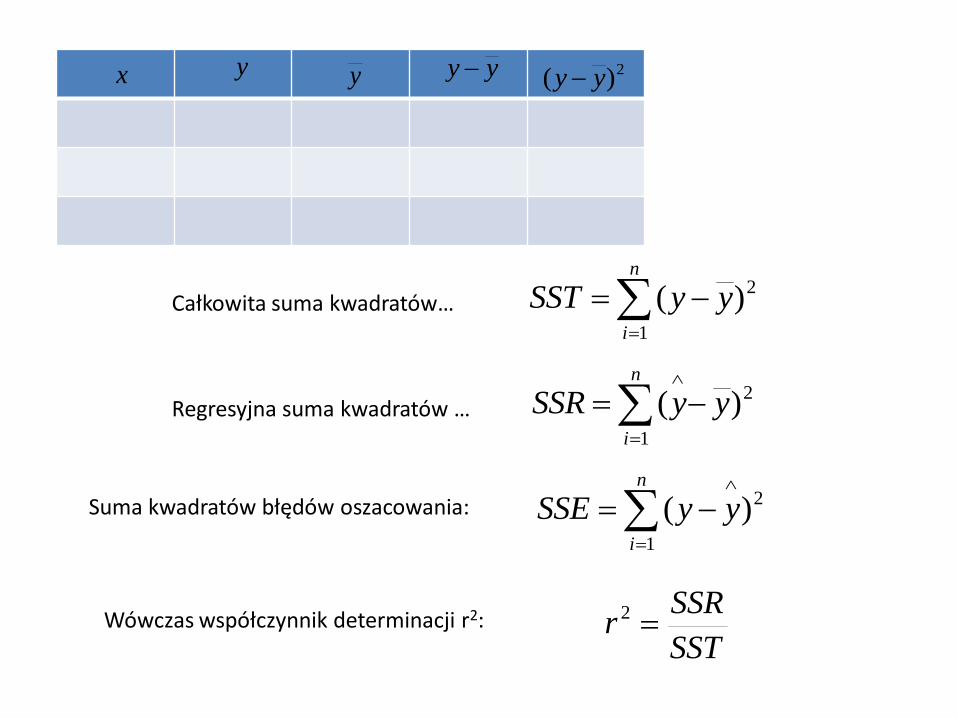
y yy 2)( yy x y
n
i
yySST1
2)(Całkowita suma kwadratów…
n
i
yySSR1
2)(Regresyjna suma kwadratów …
n
i
yySSE1
2)(Suma kwadratów błędów oszacowania:
SST
SSRr 2Wówczas współczynnik determinacji r2:

Przykład analizy współczynnika R2 dla wielu zmiennych objaśniających
Jak już wspomnieliśmy na początku, często w świecie rzeczywistym mamy do czynienia z zależnościami zmiennej objaśnianej nie od jednej ale raczej od wielu zmiennych objaśniających. Wykonanie tego typu analiz w pakiecie R nie jest rzeczą trudną. Wręcz przeciwnie. Nim przeprowadzimy analizę zależności zmiennej rating od wielu zmiennych objaśniających np. sugars oraz fiber przyjrzyjmy się wykresom rozrzutu dla tych zmiennych osobno. Wykres rozrzutu bowiem doskonale odzwierciedla zależności między pojedynczymi zmiennymi.

Współczynnik determinacji
gdzie SSR to regresyjna suma kwadratów zaś SST to całkowita suma kwadratów Będziemy go interpretować jako część zmienności zmiennej objaśnianej, która jest wyjaśniana przez liniową zależność ze zbiorem zmiennych objaśniających. Im większa będzie liczba zmiennych objaśniających tym nie mniejsza będzie wartość
współczynnika determinacji R2.
Możemy wnioskować, że gdy dodajemy nową zmienną objaśniającą do modelu, wartość R2 będzie nie mniejsza niż przy modelu o mniejszej liczbie zmiennych. Oczywiście skala (wielkość) tej różnicy jest bardzo istotna w zależności od tego czy dodamy tę zmienną do modelu czy też nie. Jeśli wzrost jest duży to uznamy tę zmienną za znaczącą (przydatną).
Niezwykle istotna jest miara nazwana już wcześniej współczynnikiem determinacji R2 określana za pomocą wzoru:
SST
SSRR 2 2
^
1
)( yySSTn
i
2̂^
1
)( yySSRn
i

Jeśli takie reszty obliczymy dla każdej obserwacji to możliwe będzie wyznaczenie wartości współczynnika determinacji R2. W naszym przypadku jest on równy 0.8092 czyli 80.92 %. Oznacza to w naszej analizie, że 80.92 % zmienności wartości odżywczej jest wyjaśniane przez liniową zależność pomiędzy zmienną wartość odżywcza a zbiorem zmiennych objaśniających - zawartością cukrów i zawartością błonnika. Jeśli popatrzymy jaka była wartość tego współczynnika, gdy badaliśmy na początku zależność zmiennej objaśnianej tylko od jednej zmiennej objaśniającej (cukry) to wartość ta wynosiła R2 = 57.71% . Dla dwóch zmiennych objaśniających ta wartości wyniosła 80.92 %. Czyli powiemy, że dodając nową zmienną objaśniającą (w tym przypadku błonnik) możemy wyjaśnić dodatkowe 80.92 - 57.71 = 22.19% zmienności wartości odżywczej (rating) płatków. Typowy błąd oszacowania jest tu obliczany jako standardowy błąd oszacowania s i wynosi 6.22 punktu. Oznacza to, że estymacja wartości odżywczej płatków na podstawie zawartości cukrów i błonnika zwykle różni się od właściwej wartości o 6.22 punktu. Jeśli nowa zmienna jest przydatna, to błąd ten powinien się zmniejszać po dodaniu nowej zmiennej.

Ile zmiennych objaśniających w modelu regresji ?
gdzie p oznacza liczbę parametrów modelu (i jest to zazwyczaj liczba zmiennych objaśniających + 1) zaś n oznacza wielkość próby. Zwykle wartość R2
adj będzie po prostu nieco mniejsza niż wartość R2. W środowisku R współczynnik determinacji R2 wyznaczymy stosując bezpośrednio komendę: summary(model.liniowy)\$r.square
Z kolei współczynnik determinacji ale ten tzw. skorygowany (ang. Adjusted) za pomocą komendy: summary(model.liniowy)\$adj.r.squared
Najprostszym sposobem na wybór optymalnej liczby zmiennych objaśniających jest współczynnik R2
adj zwany skorygowanym. Wiedząc, że R2 = 1 – SSE/SST wartość R2adj
obliczymy jako:
1
12
n
SST
pn
SSE
R adj

> dane<- read.table("C:\\Cereals.data", header = TRUE, row.names = 1)
> model<-lm(rating~sugars+fiber, data=dane)
> summary(model)$r.square
[1] 0.8091568
> summary(model)$adj.r.squared
[1] 0.8039988
Chcąc wyznaczyć wartości tych współczynników dla naszego testowego modelu z dwiema zmiennymi objaśniającymi sugars oraz fiber w środowisku R użyjemy odpowiednich komend, jak to pokazuje poniższy kod R wraz z wynikami:
Jak widzimy współczynnik R2 wynosi 0.809 zaś R2
adj odpowiednio 0.804.


Funkcja r.square

Funkcja r.square.adjusted

Funkcja coeff

Przykład analizy współczynnika R2 dla jednej zmiennej objaśniającej
• Procedura analizy współczynnika determinacji R2 dla jednej zmiennej objaśniającej może wyglądać następująco. Jeśli założymy, że zmienną objaśnianą ma być wartość odżywcza płatków (rating) zaś zmienną objaśniającą poziom cukrów (sugars) to komenda R wywołującą badanie zależności między tymi zmiennymi będzie nastepująca:
• lm(rating~sugars, data=dane)
• Wówczas pełny zapis okna dialogu z R-em będzie następujący:
• > dane<- read.table("C:\\Cereals.data", header = TRUE, row.names = 1)
• > model<-lm(rating~sugars, data=dane)
• > summary(model)

Call:
lm(formula = rating ~ sugars, data = dane)
Residuals:
Min 1Q Median 3Q Max
-17.853 -5.677 -1.439 5.160 34.421
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 59.2844 1.9485 30.43 < 2e-16 ***
sugars -2.4008 0.2373 -10.12 1.15e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 9.196 on 75 degrees of freedom
Multiple R-squared: 0.5771, Adjusted R-squared: 0.5715
F-statistic: 102.3 on 1 and 75 DF, p-value: 1.153e-15
>
Widzimy zatem, że równanie regresji, gdy zmienną objaśnianą będzie zmienna rating (wartość odżywcza płatków) zaś objaśniającą sugars (poziom cukrów), będzie następującej postaci: rating = -2.4 * sugars+ 59.3

• Teraz możemy przewidywać, że gdy poziom cukrów wynosi np. 1 to wartość odżywcza płatków będzie wynosić 56.9 zaś gdy poziom cukrów będzie wynosił np. 10 wówczas wartość odżywcza zmaleje do wartości 35.3 (patrz poniżej).
> predict(model,data.frame(sugars=10), level = 0.9, interval
= "confidence")
fit lwr upr
1 35.27617 33.14878 37.40356
> predict(model,data.frame(sugars=1), level = 0.9, interval =
"confidence")
fit lwr upr
1 56.88355 53.96394 59.80316

Przykład analizy współczynnika R2 dla wielu zmiennych objaśniających
Często w świecie rzeczywistym mamy do czynienia z zależnościami zmiennej objaśniającą nie od jednej zmiennej objaśnianej ale raczej od wielu zmiennych objaśniających.
Wykonanie tego typu analiz w pakiecie R nie jest rzeczą trudną. Wręcz przeciwnie.
Nim przeprowadzimy analizę zależności zmiennej rating od wielu zmiennych objaśniających np. sugars oraz fiber przyjrzyjmy się wykresom rozrzutu dla tych zmiennych osobno. Wykres rozrzutu bowiem doskonale odzwierciedla zależności między pojedynczymi zmiennymi.

> model<-lm(rating~sugars+fiber, data=dane)
> summary(model)
Call:
lm(formula = rating ~ sugars + fiber, data = dane)
Residuals:
Min 1Q Median 3Q Max
-12.133 -4.247 -1.031 2.620 16.398
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 51.6097 1.5463 33.376 < 2e-16 ***
sugars -2.1837 0.1621 -13.470 < 2e-16 ***
fiber 2.8679 0.3023 9.486 2.02e-14 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6.219 on 74 degrees of freedom
Multiple R-squared: 0.8092, Adjusted R-squared: 0.804
F-statistic: 156.9 on 2 and 74 DF, p-value: < 2.2e-16
Przykład analizy zmiennej objaśnianej (a więc wartości odżywczej płatków ze zbioru Cereals od kilku zmiennych, np. sugars oraz fiber (a więc odpowiednio: poziom cukrów oraz błonnik) przedstawiamy poniżej.

• wtedy powiemy, że równanie regresji będzie wyglądać następująco:
• rating = - 2.1837 * sugars+2.8679 * fiber+ 51.6097
• Czyli, aby zinterpretować współczynnik nachylenia prostej regresji b1 = -2.1837 powiemy, że wartość odżywcza maleje o 2.1837 punktu, jeśli zawartość cukru rośnie o jedną jednostkę. Zakładamy przy tym, że zawartość błonnika (fiber) jest stała.
• Z kolei interpretacja współczynnika b2 = 2.8679 jest taka, że wartość odżywcza rośnie o 2.8679 punktu, jeśli zawartość błonnika rośnie o jedną jednostkę a zawartość cukru (sugars) jest stała.

• Uogólniając będziemy mówić, że dla m zmiennych objaśniających zachodzi reguła, zgodnie z którą oszacowana zmiana wartości zmiennej odpowiedzi to bi, jeśli wartość zmiennej xi rośnie o jednostkę i zakładając, że wszystkie pozostałe wartości zmiennych są stałe.
• Błędy predykcji są mierzone przy użyciu reszt • Co ważne: • w prostej regresji liniowej reszty reprezentują odległość (mierzoną wzdłuż osi pionowej) pomiędzy
właściwym punktem danych a linią regresji. Zaś w regresji wielokrotnej, reszta jest reprezentowana jako odległość między właściwym punktem danych a płaszczyzną lub hiperpłaszczyzną regresji.
• Przykładowo płatki Spoon Size Shredded Wheat zawierają x1=0 gramów cukru i x2 = 3 gramy błonnika, a ich wartość odżywcza jest równa 72.80
• podczas gdy wartość oszacowana, podana za pomocą równania regresji:
> predict(model, data.frame(sugars=0,fiber=3),level=0.95, interval="confidence")
fit lwr upr
1 60.21342 57.5805 62.84635
>
yy

• Zatem dla tych konkretnych płatków reszta jest równa 60.21 - 72.80 = 12.59 • Zwróćmy uwagę na to, że wyniki które tutaj zwraca funkcja R: predict są bardzo
istotne. Mianowicie, oprócz podanej (oszacowanej, przewidywanej) wartości zmiennej objaśniającej, otrzymujemy również przedział ufności na zadanym poziomie ufności równym 0.95, który to przedział mieści się między wartością 57.5805 (lwr) a 62.84635 (upr).
• Pamiętamy, że z pojęciem regresji wiąże się pojęcie współczynnika determinacji:
• gdzie SSR to regresyjna suma kwadratów:
• zaś SST to całkowita suma kwadratów:
• Będziemy R2 interpretować jako część zmienności zmiennej objaśnianej, która jest
wyjaśniana przez liniową zależność ze zbiorem zmiennych objaśniających.
SST
SSRR 2
n
i
yySSR1
2)(
n
i
yySST1
2)(

• Co ważne: • Im większa będzie liczba zmiennych objaśniających tym nie mniejsza będzie wartość współczynnika
determinacji R2 • Możemy wnioskować, że gdy dodajemy nową zmienną objaśniającą do modelu, wartość R2 będzie
nie mniejsza niż przy modelu o mniejszej liczbie zmiennych. Oczywiście skala (wielkość) tej różnicy jest bardzo istotna w zależności od tego czy dodamy tę zmienną do modelu czy też nie. Jeśli wzrost jest duży to uznamy tę zmienną za znaczącą (przydatną).
• Jeśli takie reszty obliczymy dla każdej obserwacji to możliwe będzie wyznaczenie wartości współczynnika determinacji R2
. W naszym przypadku jest on równy 0.8092 czyli 80.92%. Oznacza to w naszej analizie, że 80.92% zmienności wartości odżywczej jest wyjaśniana przez liniową zależność (płaszczyznę) pomiędzy zmienną wartość odżywcza a zbiorem zmiennych objaśniających - zawartością cukrów i zawartością błonnika.
• Jeśli popatrzymy jaka była wartość tego współczynnika, gdy badaliśmy na początku zależność zmiennej objaśnianej tylko od jednej zmiennej objaśniającej (cukry) to wartość ta wynosiła R2 = 57.71%. Dla dwóch zmiennych objaśniających ta wartości wyniosła 80.92 %. Czyli powiemy, że dodając nową zmienną objaśniającą (w tym przypadku błonnik) możemy wyjaśnić dodatkowe 80.92 - 57.71 = 22.19% zmienności wartości odżywczej (rating) płatków.
• Typowy błąd oszacowania jest tu obliczany jako standardowy błąd oszacowania s i wynosi 6.22 punktu. Oznacza to, że estymacja wartości odżywczej płatków na podstawie zawartości cukrów i błonnika zwykle różni się od właściwej wartości o 6.22 punktu. Jeśli nowa zmienna jest przydatna, to błąd ten powinien się zmniejszać po dodaniu nowej zmiennej.

Najprostszym sposobem na wybór optymalnej liczby zmiennych objaśniających jest współczynnik R2
adj zwany skorygowanym (ang. adjusted). Wiedząc, że wartość R2
adj obliczymy jako i zwykle ta wartość będzie po prostu nieco mniejsza niż wartość R2 . W środowisku R współczynnik determinacji R2
wyznaczymy stosując bezpośrednio komendę: summary(model.liniowy)$r.square
Z kolei współczynnik determinacji ale ten tzw. skorygowany (ang. adjusted) za pomocą komendy: summary(model.liniowy)$adj.r.squared.
Chcąc wyznaczyć wartości tych współczynników dla naszego testowego modelu w dwiema zmiennymi objaśniającymi sugars oraz fiber w środowisku R użyjemy odpowiednich komend, jak to pokazuje poniższy kod R wraz z wynikami:
> dane<- read.table("C:\\Cereals.data", header = TRUE, row.names = 1)
> model<-lm(rating~sugars+fiber, data=dane)
> summary(model)$r.square
[1] 0.8091568
> summary(model)$adj.r.squared
[1] 0.8039988
Jak widzimy współczynnik R2 wynosi 0.809 zaś R2adj odpowiednio 0.804.
)1(
)(12
nSST
pnSSERadj
SST
SSER 12

• Użyjemy równania regresji aby oszacować wartość odżywczą Chocolade Frosted Sugar Bombs:
y = 59.4 – 2.42 * sugars = 59.4 – 2.42 * 30 = -3.2
• Innymi słowy, ulubione płatki mogą mieć tak dużo cukru, że wartość odżywcza jest liczbą ujemną, w przeciwieństwie do innych płatków w zbiorze danych (minimalna wartość odżywcza = 18) i analogicznie do ujemnej oceny studenta z egzaminu.
• Co tu się dzieje ?
• Ujemna przewidywana wartość odżywcza dla tych płatków jest przykładem nieuzasadnionej ekstrapolacji.

Po dzisiejszym wykładzie powinieneś znać odpowiedź na następujące pytania:
• Jaką postać przyjmuje równanie regresji liniowej?
• Jak z równania regresji dokonywać predykcji?
• Co to znaczy, że regresja jest wielokrotna ?
• Czym jest współczynnik determinacji ? Jak się go mierzy ?
Jaka jest jego max i min wartość ?
• Jak sprawdzić czy regresja jest przydatna ?
• Do czego służy metoda MNK ?

Na następnym wykładzie poznasz odpowiedź na następujące pytania:
• Jak graficznie sprawdzać założenia regresji liniowej ?
• Co to jest wykres kwantylowy ?
• Co to jest wykres studentyzowanych i standaryzowanych reszt ?
• Jak znaleźć w modelu obserwacje wpływowe, obserwacje odstąjące czy
obserwacje wysokiej dźwigni ?
• Jak weryfikować poprawność modelu regresji ?
• Jak wybrać lepszy model regresji ?
• Jak badać regresję nieliniową ?
• …