reforms as experiments j - sfu.capalys/campbell-1969-reformsasexperiments.pdf · reforms as...
TRANSCRIPT

REFORMS AS EXPERIMENTS J
DONALD X. CAMPBELL 2
Northwestern University
THE United States and other modern nationsshould be ready for an experimental ap-proach to social reform, an approach in
which we try out new programs designed to curespecific social problems, in which we learn whetheror not these programs are effective, and in whichwe retain, imitate, modify, or discard them on thebasis of apparent effectiveness on the multipleimperfect criteria available. Our readiness for thisstage is indicated by the inclusion of specific pro-visions for program evaluation in the first wave ofthe "Great Society" legislation, and by the currentcongressional proposals for establishing "social in-dicators" and socially relevant "data banks." Solong have we had good intentions in this regardthat many may feel we are already at this stage,that we already are continuing or discontinuingprograms on the basis of assessed effectiveness. Itis a theme of this article that this is not at all so,that most ameliorative programs end up with nointerpretable evaluation (Etzioni, 1968; Hyman &Wright, 1967; Schwartz, 1961). We must lookhard at the sources of this condition, and designways of overcoming the difficulties. This article isa preliminary effort in this regard.
Many of the difficulties lie in the intransigenciesof the research setting and in the presence of re-current seductive pitfalls of interpretation. Thebulk of this article will be devoted to these prob-lems. But the few available solutions turn out todepend upon correct administrative decisions inthe initiation and execution of the program. These
1The preparation of this paper has been supported byNational Science Foundation Grant GS1309X. Versionsof this paper have been presented as the NorthwesternUniversity Alumni Fund Lecture, January 24, 1968;to the Social Psychology Section of the British Psy-chological Society at Oxford, September 20, 1968; tothe International Conference on Social Psychology atPrague, October 7, 1968 (under a different title); and toseveral other groups.
2 Requests for reprints should be sent to Donald T.Campbell, Department of Psychology, Northwestern Uni-versity, Evanston, Illinois 60201.
decisions are made in a political arena, and in-volve political jeopardies that are often sufficient toexplain the lack of hard-headed evaluation of ef-fects. Removing reform administrators from thepolitical spotlight seems both highly unlikely, andundesirable even if it were possible. What is in-stead essential is that the social scientist researchadvisor understand the political realities of thesituation, and that he aid by helping create apublic demand for hard-headed evaluation, by con-tributing to those political inventions that reducethe liability of honest evaluation, and by educatingfuture administrators to the problems and pos-sibilities.
For this reason, there is also an attempt in thisarticle to consider the political setting of programevaluation, and to offer suggestions as to politicalpostures that might further a truly experimentalapproach to social reform. Although such con-siderations will be distributed as a minor themethroughout this article, it seems convenient tobegin with some general points of this politicalnature.
Political Vulnerability from Knowing Outcomes
It is one of the most characteristic aspects of thepresent situation that specific reforms are ad-vocated as though they were certain to be suc-cessful. For this reason, knowing outcomes hasimmediate political implications. Given the in-herent difficulty of making significant improve-ments by the means usually provided and given thediscrepancy between promise and possibility, mostadministrators wisely prefer to limit the evaluationsto those the outcomes of which they can control,particularly insofar as published outcomes or pressreleases are concerned. Ambiguity, lack of trulycomparable comparison bases, and lack of con-crete evidence all work to increase the adminis-trator's control over what gets said, or at least toreduce the bite of criticism in the case of actualfailure. There is safety under the cloak of ignor-
409

410 AMERICAN PSYCHOLOGIST
ance. Over and above this tie-in of advocacy andadministration, there is another source of vulner-ability in that the facts relevant to experimentalprogram evaluation are also available to argue thegeneral efficiency and honesty of administrators.The public availability of such facts reduces theprivacy and security of at least some administra-tors.
Even where there are ideological commitments toa hard-headed evaluation of organizational effi-ciency, or to a scientific organization of society,these two jeopardies lead to the failure to evaluateorganizational experiments realistically. If thepolitical and administrative system has committeditself in advance to the correctness and efficacy ofits reforms, it cannot tolerate learning of failure.To be truly scientific we must be able to experi-ment. We must be able to advocate without thatexcess of commitment that blinds us to realitytesting.
This predicament, abetted by public apathy andby deliberate corruption, may prove in the longrun to permanently preclude a truly experimentalapproach to social amelioration. But our needsand our hopes for a better society demand we makethe effort. There are a few signs of hope. Inthe United States we have been able to achievecost-of-living and unemployment indices that, how-ever imperfect, have embarrassed the administra-tions that published them. We are able to conductcensuses that reduce the number of representativesa state has in Congress. These are grounds foroptimism, although the corrupt tardiness of stategovernments in following their own constitutionsin revising legislative districts illustrates theproblem.
One simple shift in political posture which wouldreduce the problem is the shift from the advocacyof a specific reform to the advocacy of the serious-ness of the problem, and hence to the advocacy ofpersistence in alternative reform efforts should thefirst one fail. The political stance would become:"This is a serious problem. We propose to initiatePolicy A on an experimental basis. If after fiveyears there has been no significant improvement, wewill shift to Policy B." By making explicit thata given problem solution was only one of severalthat the administrator or party could in good con-science advocate, and by having ready a plausiblealternative, the administrator could afford honestevaluation of outcomes. Negative results, a failure
of the first program, would not jeopardize his job,for his job would be to keep after the problemuntil something was found that worked.
Coupled with this should be a general morato-rium on ad hominum evaluative research, that is,on research designed to evaluate specific adminis-trators rather than alternative policies. If weworry about the invasion-of-privacy problem inthe data banks and social indicators of the future(e.g., Sawyer & Schechtcr, 1968), the touchiestpoint is the privacy of administrators. If wethreaten this, the measurement system will surelybe sabotaged in the innumerable ways possible.While this may sound unduly pessimistic, the re-current anecdotes of administrators attempting tosquelch unwanted research findings convince meof its accuracy. But we should be able to evaluatethose alternative policies that a given administratorhas the option of implementing.
Field Experiments and Quasi-Experimental Designs
In efforts to extend the logic of laboratory ex-perimentation into the "field," and into settings notfully experimental, an inventory of threats to ex-perimental validity has been assembled, in terms ofwhich some IS or 20 experimental and quasi-experimental designs have been evaluated (Camp-bell, 1957, 1963; Campbell & Stanley, 1963). Inthe present article only three or four designs willbe examined, and therefore not all of the validitythreats will be relevant, but it will provide usefulbackground to look briefly at them all. Followingare nine threats to internal validity.3
3 This list has been expanded from the major previouspresentations by the addition of Instability (but sec Camp-bell, 1968; Campbell & Ross, 1968). This has been donein reaction to the sociological discussion of the use oftests of significance in nonexperimental or quasi-experi-mental research (e.g., Selvin, 1957; and as reviewed byGaltung, 1967, pp. 358-389). On the one hand, I joinwith the critics in criticizing the exaggerated status of"statistically significant differences" in establishing con-victions of validity. Statistical tests arc relevant to atbest 1 out of 15 or so threats to validity. On the otherhand, I join with those who defend their use in situationswhere randomization has not been employed. Even inthose situations, it is relevant to say or to deny, "This isa trivial difference. It is of the order that would haveoccurred frequently had these measures been assigned tothese classes solely by chance." Tests of significance,making use of random reassignments of the actual scores,are particularly useful in communicating this point.

REFORMS AS EXPERIMENTS 411
1. History: events, other than the experimentaltreatment, occurring between pretest and posttestand thus providing alternate explanations of effects.
2. Maturation: processes within the respondentsor observed social units producing changes as afunction of the passage of time per se, such asgrowth, fatigue, secular trends, etc.
3. Instability: unreliability of measures, fluctua-tions in sampling persons or components, auton-omous instability of repeated or "equivalent" mea-sures. (This is the only threat to which statisticaltests of significance are relevant.)
4. Testing: the effect of taking a test upon thescores of a second testing. The effect of publica-tion of a social indicator upon subsequent readingsof that indicator.
5. Instrumentation: in which changes in thecalibration of a measuring instrument or changesin the observers or scores used may produce changesin the obtained measurements.
6. Regression artifacts: pseudo-shifts occurringwhen persons or treatment units have been selectedupon the basis of their extreme scores.
7. Selection: biases resulting from differentia]recruitment of comparison groups, producing dif-ferent mean levels on the measure of effects.
8. Experimental mortality: the differential lossof respondents from comparison groups.
9. Selection-maturation interaction: selectionbiases resulting in differential rates of "maturation"or autonomous change.
If a change or difference occurs, these are rivalexplanations that could be used to explain awayan effect and thus to deny that in this specificexperiment any genuine effect of the experimentaltreatment had been demonstrated. These are faultsthat true experiments avoid, primarily through theuse of randomization and control groups. In theapproach here advocated, this checklist is used toevaluate specific quasi-experimental designs. Thisis evaluation, not rejection, for it often turns outthat for a specific design in a specific setting thethreat is implausible, or that there are supplemen-tary data that can help rule it out even whererandomization is impossible. The general ethic,here advocated for public administrators as well associal scientists, is to use the very best methodpossible, aiming at "true experiments" with random•control groups. But where randomized treatmentsare not possible, a self-critical use of quasi-experi-
mental designs is advocated. We must do thebest we can with what is available to us.
Our posture vis-a-vis perfectionist critics fromlaboratory experimentation is more militant thanthis: the only threats to validity that we will allowto invalidate an experiment are those that admitof the status of empirical laws more dependableand more plausible than the law involving thetreatment. The mere possibility of some alterna-tive explanation is not enough—it is only theplausible rival hypotheses that are invalidating.Vis-a-vis correlational studies and common-sensedescriptive studies, on the other hand, our stanceis one of greater conservatism. For example, be-cause of the specific methodological trap of regres-sion artifacts, the sociological tradition of "ex postfacto" designs (Chapin, 1947; Greenwood, 1945)is totally rejected (Campbell & Stanley, 1963, pp.240-241; 1966, pp. 70-71).
Threats to external validity, which follow, coverthe validity problems involved in interpreting ex-perimental results, the threats to valid generaliza-tion of the results to other settings, to other ver-sions of the treatment, or to other measures ofthe effect:4
1. Interaction effects of testing: the effect of apretest in increasing or decreasing the respondent'ssensitivity or responsiveness to the experimentalvariable, thus making the results obtained for apretested population unrepresentative of the effectsof the experimental variable for the unpretesteduniverse from which the experimental respondentswere selected.
2. Interaction of selection and experimental treat-ment: unrepresentative responsiveness of thetreated population.
3. Reactive effects of experimental arrangements:"artificiality"; conditions making the experimentalsetting atypical of conditions of regular applica-tion of the treatment: "Hawthorne effects."
4. Multiple-treatment interference: where mul-tiple treatments are jointly applied, effects atypicalof the separate application of the treatments.
5. Irrelevant responsiveness of measures: all4 This list has been lengthened from previous presenta-
tions to make more salient Threats 5 and 6 which areparticularly relevant to social experimentation. Discus-sion in previous presentations (Campbell, 1957, pp. 309-310; Campbell & Stanley, 1963, pp. 203-204) had coveredthese points, but they had not been included in the check-list.
412 AMERICAN PSYCHOLOGIST
measures are complex, and all include irrelevantcomponents that may produce apparent effects.
6. Irrelevant replicability oj treatments: treat-ments are complex, and replications of them mayfail to include those components actually respon-sible for the effects.
These threats apply equally to true experiments andquasi-experiments. They are particularly relevantto applied experimentation. In the cumulative his-tory of our methodology, this class of threats wasfirst noted as a critique of true experiments in-volving pretests (Schanck & Goodman, 1939;Solomon, 1949). Such experiments provided asound basis for generalizing to other pretestedpopulations, but the reactions of unprctested popu-lations to the treatment might well be quite dif-ferent. As a result, there has been an advocacyof true experimental designs obviating the pretest(Campbell, 1957; Schanck & Goodman, 1939;Solomon, 1949) and a search for nonreactive mea-sures (Webb, Campbell, Schwartz, & Sechrest,1966).
These threats to validity will serve as a back-ground against which we will discuss several re-search designs particularly appropriate for evaluat-ing specific programs of social amelioration. Theseare the "interrupted time-series design," the "con-trol series design," "regression discontinuity de-sign," and various "true experiments." The orderis from a weak but generally available design tostronger ones that require more administrativeforesight and determination.
Interrupted Time-Series Design
By and large, when a political unit initiates areform it is put into effect across the board, withthe total unit being affected. Tn this setting theonly comparison base is the record of previousyears. The usual mode of utilization is a casualversion of a very weak quasi-experimental design,the one-group pretest-posttcst design.
A convenient illustration comes from the 1955Connecticut crackdown on speeding, which Sociolo-gist H. Laurence Ross and I have been analyzingas a methodological illustration (Campbell & Ross,1968; Glass, 1968; Ross & Campbell, 1968). Aftera record high of traffic fatalities in 1955, GovernorAbraham Ribicoff instituted an unprecedentedlysevere crackdown on speeding. At the end of ayear of such enforcement there had been but 284
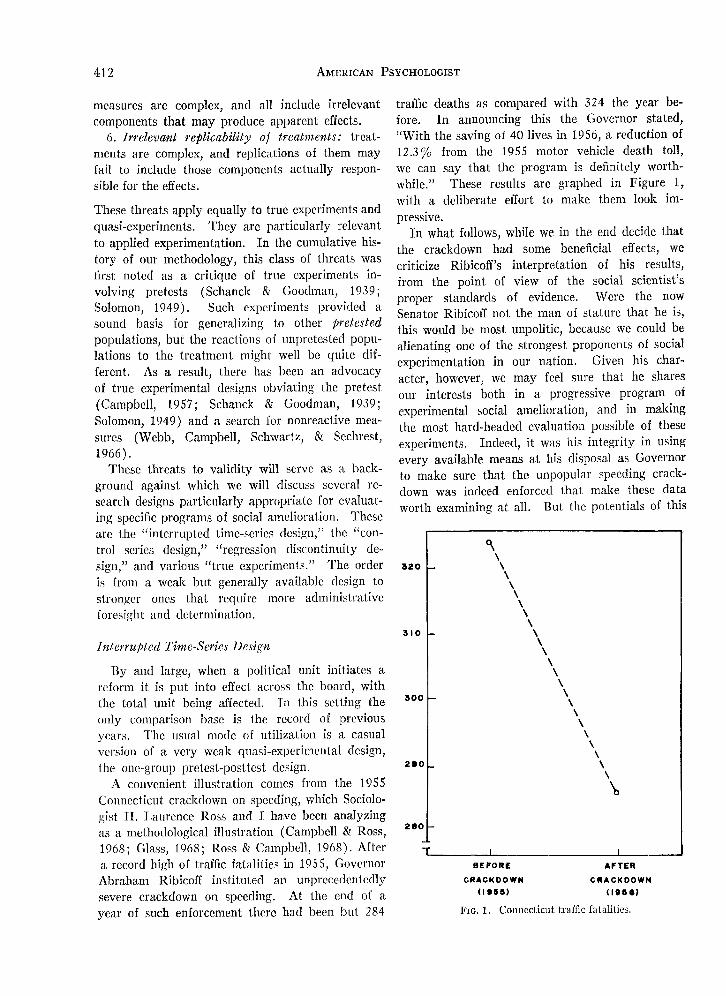
traffic deaths as compared with 324 the year be-fore. In announcing this the Governor stated,"With the saving of 40 lives in 1956, a reduction of12.3% from the 1955 motor vehicle death toll,we can say that the program is definitely worth-while." These results are graphed in Figure 1,with a deliberate effort to make them look im-pressive.
In what follows, while we in the end decide thatthe crackdown had some beneficial effects, wecriticize Ribicoff's interpretation of his results,from the point of view of the social scientist'sproper standards of evidence. Were the nowSenator Ribicoff not the man of stature that he is,this would be most unpolitic, because we could bealienating one of the strongest proponents of socialexperimentation in our nation. Given his char-acter, however, we may feel sure that he sharesour interests both in a progressive program ofexperimental social amelioration, and in makingthe most hard-headed evaluation possible of theseexperiments. Indeed, it was his integrity in usingevery available means at his disposal as Governorto make sure that the unpopular speeding crack-down was indeed enforced that make these dataworth examining at all. But the potentials of this
320
3 IO
300
2*0
2BO
_L I
BEFORE AFTER
CRACKDOWN CRACKDOWN(I»B8) ( I9B6)
FIG. 1. Connecticut traffic fatalities.

REFORMS AS EXPERIMENTS 413
one illustration and our political temptation tosubstitute for it a less touchy one, point to thepolitical problems that must be faced in experi-menting with social reform.
Keeping Figure 1 and Ribicoff's statement inmind, let us look at the same data presented as apart of an extended time series in Figure 2 andgo over the relevant threats to internal validity.First, History. Both presentations fail to controlfor the effects of other potential change agents.For instance, 1956 might have been a particularlydry year, with fewer accidents due to rain or snow.Or there might have been a dramatic increase inuse of seat belts, or other safety features. Theadvocated strategy in quasi-experimentation is notto throw up one's hands and refuse to use theevidence because of this lack of control, but ratherto generate by informed criticism appropriate tothis specific setting as many plausible rival hy-potheses as possible, and then to do the supplemen-tary research, as into weather records and safety-belt sales, for example, which would reflect onthese rival hypotheses.
Maturation. This is a term coming from criti-cisms of training studies of children. Applied hereto the simple pretest-posttest data of Figure 1, itcould be the plausible rival hypothesis that death
325
500
275
250
225
200-
I I'SI '52 *SS '64 '55 '56 '57 '58 '59
FIG. 2. Connecticut traffic fatalities. (Same data as inFigure 1 presented as part of an extended time series.)
rates were steadily going down year after year(as indeed they are, relative to miles driven orpopulation of automobiles). Here the extendedtime series has a strong methodological advantage,and rules out this threat to validity. The generaltrend is inconsistently up prior to the crackdown,and steadily down thereafter.
Instability. Seemingly implicit in the publicpronouncement was the assumption that all of thechange from 19SS to 19S6 was due to the crack-down. There was no recognition of the fact thatall time series are unstable even when no treat-ments are being applied. The degree of thisnormal instability is the crucial issue, and one ofthe main advantages of the extended time seriesis that it samples this instability. The great pre-treatment instability now makes the treatmenteffect look relatively trivial. The 1955-56 shift isless than the gains of both 1954-55 and 1952-53.It is the largest drop in the series, but it exceedsthe drops of 1951-52, 1953-54, and 1957-58 bytrivial amounts. Thus the unexplained instabilitiesof the series are such as to make the 1955-56 dropunderstandable as more of the same. On the otherhand, it is noteworthy that after the crackdownthere are no year-to-year gains, and in this re-spect the character of the time series seems defi-nitely to have changed.
The threat of instability is the only threat towhich tests of significance are relevant. Box andTiao (1965) have an elegant Bayesian model forthe interrupted time series. Applied by Glass(1968) to our monthly data, with seasonal trendsremoved, it shows a statistically significant down-ward shift in the series after the crackdown. Butas we shall see, an alternative explanation of atleast part of this significant effect exists.
Regression. In true experiments the treatmentis applied independently of the prior state of theunits. In natural experiments exposure to treat-ment is often a cosymptom of the treated group'scondition. The treatment is apt to be an effectrather than, or in addition to being, a cause. Psy-chotherapy is such a cosymptom treatment, as isany other in which the treated group is self-selectedor assigned on the basis of need. These all presentspecial problems of interpretation, of which thepresent illustration provides one type.
The selection-regression plausible rival hypothesisworks this way: Given that the fatality rate hassome degree of unreliability, then a subsample

414 AMERICAN PSYCHOLOGIST
selected for its extremity in 1955 would on theaverage, merely as a reflection of that unreliability,be less extreme in 1956. Has there been selectionfor extremity in applying this treatment? Probablyyes. Of all Connecticut fatality years, the mostlikely time for a crackdown would be after anexceptionally high year. If the time series showedinstability, the subsequent year would on the aver-age be less, purely as a junction of that instability.Regression artifacts are probably the most recur-rent form of self-deception in the experimentalsocial reform literature. It is hard to make themintuitively obvious. Let us try again. Take anytime series with variability, including one generatedof pure error. Move along it as in a time dimen-sion. Pick a point that is the "highest so far."Look then at the next point. On the average thisnext point will be lower, or nearer the generaltrend.
In our present setting the most striking shift inthe whole series is the upward shift just prior tothe crackdown. It is highly probable that thiscaused the crackdown, rather than, or in additionto, the crackdown causing the 1956 drop. At leastpart of the 1956 drop is an artifact of the 1955extremity. While in principle the degree of ex-pected regression can be computed from the auto-correlation of the series, we lack here an extended-enough body of data to do this with any confidence.
Advice to administrators who want to do genuinereality-testing must include attention to this prob-lem, and it will be a very hard problem to surmount.The most general advice would be to work onchronic problems of a persistent urgency or ex-tremity, rather than reacting to momentary ex-tremes. The administrator should look at thepretreatment time series to judge whether or notinstability plus momentary extremity will explainaway his program gains. If it will, he shouldschedule the treatment for a year or two later, sothat his decision is more independent of the oneyear's extremity. (The selection biases remainingunder such a procedure need further examination.)
In giving advice to the experimental adminis-trator, one is also inevitably giving advice to thosetrapped administrators whose political predicamentrequires a favorable outcome whether valid or not.To such trapped administrators the advice is pickthe very worst year, and the very worst socialunit. If there is inherent instability, there is nowhere to go but up, for the average case at least.
Two other threats to internal validity need dis-cussion in regard to this design. By testing wetypically have in mind the condition under whicha test of attitude, ability, or personality is itselfa change agent, persuading, informing, practicing,or otherwise setting processes of change in action.No artificially introduced testing procedures areinvolved here. However, for the simple before-and-after design of Figure 1, if the pretest were thefirst data collection of its kind ever publicized, thispublicity in itself might produce a reduction intraffic deaths which would have taken place evenwithout a speeding crackdown. Many traffic safetyprograms assume this. The longer time-series evi-dence reassures us on this only to the extent thatwe can assume that the figures had been publishedeach year with equivalent emphasis.5
Instrumentation changes are not a likely flawin this instance, but would be if recording prac-tices and institutional responsibility had shiftedsimultaneously with the crackdown. Probably ina case like this it is better to use raw frequenciesrather than indices whose correction parametersare subject to periodic revision. Thus per capitarates are subject to periodic jumps as new censusfigures become available correcting old extrap-olations. Analogously, a change in the miles pergallon assumed in estimating traffic mileage formileage-based mortality rates might explain ashift. Such biases can of course work to disguisea true effect. Almost certainly, Ribicoff's crack-down reduced traffic speed (Campbell & Ross,1968). Such a decrease in speed increases themiles per gallon actually obtained, producing aconcomitant drop in the estimate of miles driven,which would appear as an inflation of the estimate
5 No doubt the public and press shared the Governor'sspecial alarm over the 1955 death toll. This differentialreaction could be seen as a negative feedback servosysterain which the dampening effect was proportional to thedegree of upward deviation from the prior trend. Insofaras such alarm reduces traffic fatalities, it adds a negativecomponent to the autocorrelation, increasing the regressioneffect. This component should probably be regarded as arival cause or treatment rather than as artifact. (Theregression effect is less as the positive autocorrelation ishigher, and will be present to some degree insofar as thiscorrelation is less than positive unity. Negative cor-relation in a time series would represent regression beyondthe mean, in a way not quite analogous to negative correla-tion across persons. For an autocorrelation of Lag 1,high negative correlation would be represented by a seriesthat oscillated maximally from one extreme to the other.)

REFORMS AS EXPERIMENTS 415
of mileage-based traffic fatalities if the same fixedapproximation to actual miles per gallon wereused, as it undoubtedly would be.
The "new broom" that introduces abrupt changesof policy is apt to reform the record keeping too,and thus confound reform treatments with instru-mentation change. The ideal experimental ad-ministrator will, if possible, avoid doing this. Hewill prefer to keep comparable a partially imperfectmeasuring system rather than lose comparabilityaltogether. The politics of the situation do notalways make this possible, however. Consider, asan experimental reform, Orlando Wilson's reorgan-ization of the police system in Chicago. Figure 3shows his impact on petty larceny in Chicago—astriking increase! Wilson, of course, called thisshot in advance, one aspect of his reform being areform in the bookkeeping. (Note in the pre-Wilson records the suspicious absence of the ex-pected upward secular trend.) In this situationWilson had no choice. Had he left the record keep-ing as it was, for the purposes of better experi-mental design, his resentful patrolmen would haveclobbered him with a crime wave by deliberatelystarting to record the many complaints that hadnot been getting into the books.6
Those who advocate the use of archival mea-sures as social indicators (Bauer, 1966; Gross,1966, 1967; Kaysen, 1967; Webb et al, 1966)must face up not only to their high degree ofchaotic error and systematic bias, but also to thepolitically motivated changes in record keepingthat will follow upon their public use as social in-dicators (Etzioni & Lehman, 1967). Not allmeasures are equally susceptible. In Figure 4,Orlando Wilson's effect on homicides seems negli-gible one way or the other.
Of the threats to external validity, the one mostrelevant to social experimentation is Irrelevant Re-sponsiveness of Measures. This seems best dis-cussed in terms of the problem of generalizing fromindicator to indicator or in terms of the imperfectvalidity of all measures that is only to be overcomeby the use of multiple measures of independent
0 Wilson's inconsistency in utilization of records andthe political problem of relevant records arc ably docu-mented in Kamisar (1964). Etzioni (1968) reports thatin New York City in 1965 a crime wave was proclaimedthat turned out to be due to an unpublicized improvementin record keeping.
30.000
40.000
30.000
20.OOO
10,000
1
0U
15ZOV)-1
1— o
1I1
-V-^x^7^^^^
i i i i I i i i i i I I 1 i i i i i
fiiii
j - t i
'42 '4 4 '46 '48 '50 '52 *54 '56 '58 '60 '62
FIG. 3. Number of reported larcenies under $50 inChicago, Illinois, from 1942 to 1962 (data from UniformCrime Reports for the United States, 1942-62).
imperfection (Campbell & Fiske, 1959; Webb et al.,1966).
For treatments on any given problem within anygiven governmental or business subunit, there willusually be something of a governmental monopolyon reform. Even though different divisions mayoptimally be trying different reforms, within each
FIG. 4. Number of reported murders and nonnegligentmanslaughters in Chicago, Illinois, from 1942 to 1962 (datafrom Uniform Crime Reports for the United States, 1942-62).

416 AMERICAN PSYCHOLOGIST
division there will usually be only one reform ona given problem going on at a time. But formeasures of effect this need not and should not bethe case. The administrative machinery shoulditself make multiple measures of potential benefitsand of unwanted side effects. In addition, theloyal opposition should be allowed to add still otherindicators, with the political process and adversaryargument challenging both validity and relativeimportance, with social science methodologiststestifying for both parties, and with the basicrecords kept public and under bipartisan audit (asare voting records under optimal conditions). Thiscompetitive scrutiny is indeed the main source ofobjectivity in sciences (Polanyi, 1966, 1967;Popper, 1963) and epitomizes an ideal of demo-cratic practice in both judicial and legislativeprocedures.
The next few figures return again to the Con-necticut crackdown on speeding and look to someother measures of effect. They are relevant tothe confirming that there was indeed a crackdown,and to the issue of side effects. They also providethe methodological comfort of assuring us that insome cases the interrupted time-series design canprovide clear-cut evidence of effect. Figure 5shows (he jump in suspensions of licenses for speed-
33 -
30
27
24
2!
18
IB
12
9
6
3
'61 '62 '63 '64 '86 '5« '67 '&• '69
KIG. 5. Suspensions of licenses for speeding, as a percent-age o[ all suspensions.
ing—evidence that severe punishment was abruptlyinstituted. Again a note to experimental adminis-trators: with this weak design, it is only abruptand decisive changes that we have any chance ofevaluating. A gradually introduced reform will beindistinguishable from the background of secularchange, from the net effect of the innumerablechange agents continually impinging.
We would want intermediate evidence that trafficspeed was modified. A sampling each year of afew hundred five-minute highway movies (randomas to location and time) could have provided thisat a moderate cost, but they were not collected.Of the public records available, perhaps the dataof Figure 6, showing a reduction in speeding viola-tions, indicate a reduction in traffic speed. Butthe effects on the legal system were complex, andin part undesirable. Driving with a suspendedlicense markedly increased (Figure 7), at least inthe biased sample of those arrested. Presumablybecause of the harshness of the punishment ifguilty, judges may have become more lenient(Figure 8) although this effect is of marginalsignificance.
The relevance of indicators for the social prob-lems we wish to cure must be kept continually infocus. The social indicators approach will tend tomake the indicators themselves the goal of social
19
IB
17
16
16
14
IS
12
I I
10
'SI '62 'S3 '64 "66 "56 '67 '88 '89
FIG. 6. Speeding violations, as a percentage of alltraffic violations.

REFORMS AS EXPERIMENTS 417
J I I I J L
'61 '52 '63 '54 "65 '86 '57 '5« '59
FIG. 1. Arrested while driving with a suspended license,as a percentage of suspensions.
action, rather than the social problems they butimperfectly indicate. There are apt to be tend-encies to legislate changes in the indicators per serather than changes in the social problems.
To illustrate the problem of the irrelevant re-sponsiveness of measures, Figure 9 shows a resultof the 1900 change in divorce law in Germany. Ina recent reanalysis of the data with the Box andTiao (1965) statistic, Glass (Glass, Tiao, &Maguire, 1969) has found the change highly sig-nificant, in contrast to earlier statistical analyses(Rheinstein, 19S9; Wolf, Luke, & Hax, 1959).But Rheinstein's emphasis would still be relevant:This indicator change indicates no likely improve-ment in marital harmony, or even in marital sta-bility. Rather than reducing them, the legalchange has made the divorce rate a less valid in-dicator of marital discord and separation than ithad been earlier (see also Etzioni & Lehman,1967).
Control Series Design
The interrupted time-series design as discussedso far is available for those settings in which nocontrol group is possible, in which the total govern-mental unit has received the experimental treat-
14
12
10
J L
'61 '52 '63 '54 '66 '86 '67 'SB 'S9
FTC. 8. Percentage of speeding violations judgednot guilty.
ment, the social reform measure. In the generalprogram of quasi-experimental design, we argue thegreat advantage of untreated comparison groupseven where these cannot be assigned at random.The most common of such designs is the non-equivalent control-group pretest-posttest design,in which for each of two natural groups, oneof which receives the treatment, a pretest andposttest measure is taken. Tf the traditional mis-taken practice is avoided of matching on pretestscores (with resultant regression artifacts), thisdesign provides a useful control over those aspectsof history, maturation, and test-retest effects sharedby both groups. But it does not control for the
93 95 97 99 01YEAR
FIG. 9. Divorce rate for German Empire, 1881-1914

418 AMERICAN PSYCHOLOGIST
plausible rival hypothesis of selection-maturationinteraction—that is, the hypothesis that the selec-tion differences in the natural aggregations involvenot only differences in mean level, but differencesin maturation rate.
This point can be illustrated in terms of thetraditional quasi-experimental design problem ofthe effects of Latin on English vocabulary (Camp-bell, 1963). In the hypothetical data of Figure10B, two alternative interpretations remain open.Latin may have had effect, for those taking Latingained more than those not. But, on the otherhand, those students taking Latin may have agreater annual rate of vocabulary growth thatwould manifest itself whether or not they tookLatin. Extending this common design into twotime series provides relevant evidence, as com-parison of the two alternative outcomes of FigureIOC and 10D shows. Thus approaching quasi-experimental design from either improving the non-equivalent control-group design or from improvingthe interrupted time-series design, we arrive at thecontrol series design. Figure 11 shows this forthe Connecticut speeding crackdown, adding evi-
dence from the fatality rates of neighboring states.Here the data are presented as population-basedfatality rates so as to make the two series ofcomparable magnitude.
The control series design of Figure 11 showsthat downward trends were available in the otherstates for 1955-56 as due to history and matura-tion, that is, due to shared secular trends, weather,automotive safety features, etc. But the data alsoshow a general trend for Connecticut to rise rela-tively closer to the other states prior to 1955, andto steadily drop more rapidly than other statesfrom 1956 on. Glass (1968) has used our monthlydata for Connecticut and the control states togenerate a monthly difference score, and this tooshows a significant shift in trend in the Box andTiao (1965) statistic. Impressed particularly bythe 1957, 1958, and 1959 trend, we are willing toconclude that the crackdown had some effect, overand above the undeniable pseudo-effects of re-gression (Campbell & Ross, 1968).
The advantages of the control series design pointto the advantages for social experimentation of asocial system allowing subunit diversity. Our
A
9th II th Grades
c
loth l l th Grades
B
D
lOttt llth Orudet
9th I Oth llth Grades
FIG. 10. Forms of quasi-experimental analysis for the effect of specific coursework, including control scries design.

REFORMS AS EXPEKIMENTS 419
UI
1 7
I 6
1 6
< 14
V 1 3£-
i 12h-
£ 1 11 0
9
e
7
Connect icut
C o n t r o l S t o t i t -
• S I '52 'S3 'B4 '66 '66 '57 -H9 '89
YEAR
FIG. 11. Control series design comparing Connecticut fa-talities with those of four comparable states.
ability to estimate the effects of the speeding crack-down, Rose's (1952) and Stieber (1949) abilityto estimate the effects on strikes of compulsoryarbitration laws, and Simon's (1966) ability toestimate the price elasticity of liquor were madepossible because the changes were not being putinto effect in all states simultaneously, becausethey were matters of state legislation rather thannational. I do not want to appear to justify onthese grounds the wasteful and unjust diversity oflaws and enforcement practices from state to state.But I would strongly advocate that social engineersmake use of this diversity while it remains avail-able, and plan cooperatively their changes in ad-ministrative policy and in record keeping so asto provide optimal experimental inference. Moreimportant is the recommendation that, for thoseaspects of social reform handled by the centralgovernment, a purposeful diversity of implementa-tion be envisaged so that experimental and con-trol groups be available for analysis. Properlyplanned, these can approach true experiments,better than the casual and ad hoc comparisongroups now available. But without such funda-mental planning, uniform central control can re-duce the present possibilities of reality testing, thatis, of true social experimentation. In the samespirit, decentralization of decision making, both
within large government and within private monop-olies, can provide a useful competition for bothefficiency and innovation, reflected in a multiplicityof indicators.
Regression Discontinuity Design
We shift now to social ameliorations that are inshort supply, and that therefore cannot be givento all individuals. Such scarcity is inevitableunder many circumstances, and can make possiblean evaluation of effects that would otherwise beimpossible. Consider the heroic Salk poliomyelitisvaccine trials in which some children were giventhe vaccine while others were given an inert salineplacebo injection—and in which many more ofthese placebo controls would die than would haveif they had been given the vaccine. Creation ofthese placebo controls would have been morally,psychologically, and socially impossible had therebeen enough vaccine for all. As it was, due to thescarcity, most children that year had to go withoutthe vaccine anyway. The creation of experimentaland control groups was the highly moral allocationof that scarcity so as to enable us to learn the trueefficacy of the supposed good. The usual medicalpractice of introducing new cures on a so-calledtrial basis in general medical practice makes evalu-ation impossible by confounding prior status withtreatment, that is, giving the drug to the mostneedy or most hopeless. It has the further socialbias of giving the supposed benefit to those mostassiduous in keeping their medical needs in theattention of the medical profession, that is, theupper and upper-middle classes. The politicalstance furthering social experimentation here is therecognition of randomization as the most demo-cratic and moral means of allocating scarce resources(and scarce hazardous duties), plus the moral im-perative to further utilize the randomization sothat society may indeed learn true value of thesupposed boon. This is the ideology that makespossible "true experiments" in a large class ofsocial reforms.
But if randomization is not politically feasibleor morally justifiable in a given setting, there is apowerful quasi-experimental design available thatallows the scarce good to be given to the mostneedy or the most deserving. This is the regressiondiscontinuity design. All it requires is strict andorderly attention to the priority dimension. Thedesign originated through an advocacy of a tie-
420 AMERICAN PSYCIJOLOGIST
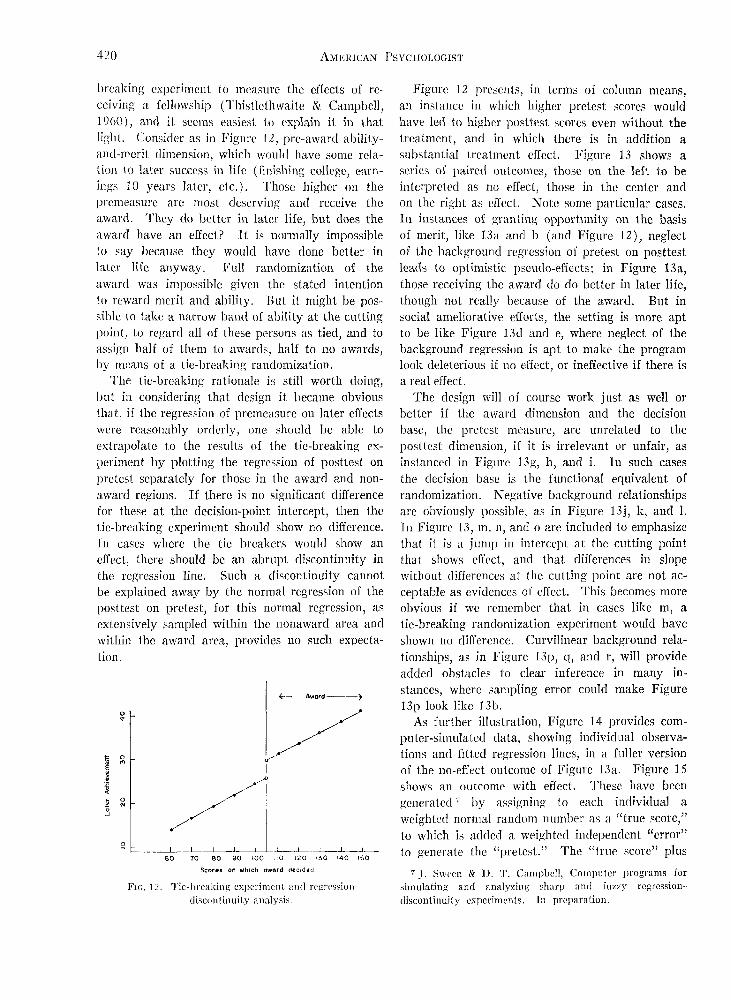
breaking experiment to measure the effects of re-ceiving a fellowship (Thistlelhwaite & Campbell,1960), and it seems easiest to explain it in thatlight. Consider as in Figure 12, pre-award ability -and-merit dimension, which would have some rela-tion to later success in life (finishing college, earn-ings 10 years later, etc.). Those higher on theprcmeasure are most deserving and receive theaward. They do better in later life, but does theaward have an effect? It is normally impossibleto say because they would have done better inlater life anyway. Full randomization of theaward was impossible given the stated intentionto reward merit and ability. But it might be pos-sible to take a narrow band of ability at the cuttingpoint, to regard all of these persons as tied, and toassign half of them to awards, half to no awards,by means of a tie-breaking randomization.
The tie-breaking rationale is still worth doing,but in considering that design it became obviousthat, if the regression of premeasure on later effectswere reasonably orderly, one should be able toextrapolate to the results of the tic-breaking ex-periment by plotting the regression of posttest onpretest separately for those in the award and non-award regions. If there is no significant differencefor these at the decision-point intercept, then thetie-breaking experiment should show no difference.Fn cases where the tie breakers would show aneffect, there should be an abrupt discontinuity inthe regression line. Such a discontinuity cannotbe explained away by the normal regression of theposttest on pretest, for this normal regression, asextensively sampled within the nonaward area andwithin the award area, provides no such expecta-tion.
70 80 90 100 HO 120 130 140 ISO
Scores on which award decided
FIG. 12. Tic-breaking experiment and regressiondiscontinuity analysis.
Figure 12 presents, in terms of column means,an instance in which higher pretest scores wouldhave led to higher posttest scores even without thetreatment, and in which there is in addition asubstantial treatment effect. Figure 13 shows aseries of paired outcomes, those on the left to beinterpreted as no effect, those in the center andon the right as effect. Note some particular cases.In instances of granting opportunity on the basisof merit, like 13a and b (and Figure 12), neglectof the background regression of pretest on posttestleads to optimistic pseudo-effects: in Figure 13a,those receiving the award do do better in later life,though not really because of the award. But insocial ameliorative efforts, the setting is more aptto be like Figure 13d and e, where neglect of thebackground regression is apt to make the programlook deleterious if no effect, or ineffective if there isa real effect.
The design will of course work just as well orbetter if the award dimension and the decisionbase, the pretest measure, are unrelated to theposttest dimension, if it is irrelevant or unfair, asinstanced in Figure 13g, h, and i. In such casesthe decision base is the functional equivalent ofrandomization. Negative background relationshipsare obviously possible, as in Figure 13j, k, and 1.In Figure 13, m, n, and o are included to emphasizethat it is a jump in intercept at the cutting pointthat shows effect, and that differences in slopewithout differences at the cutting point are not ac-ceptable as evidences of effect. This becomes moreobvious if we remember that in cases like m, atie-breaking randomization experiment would haveshown no difference. Curvilinear background rela-tionships, as in Figure 13p, q, and r, will provideadded obstacles to clear inference in many in-stances, where sampling error could make Figure13p look like 13b.
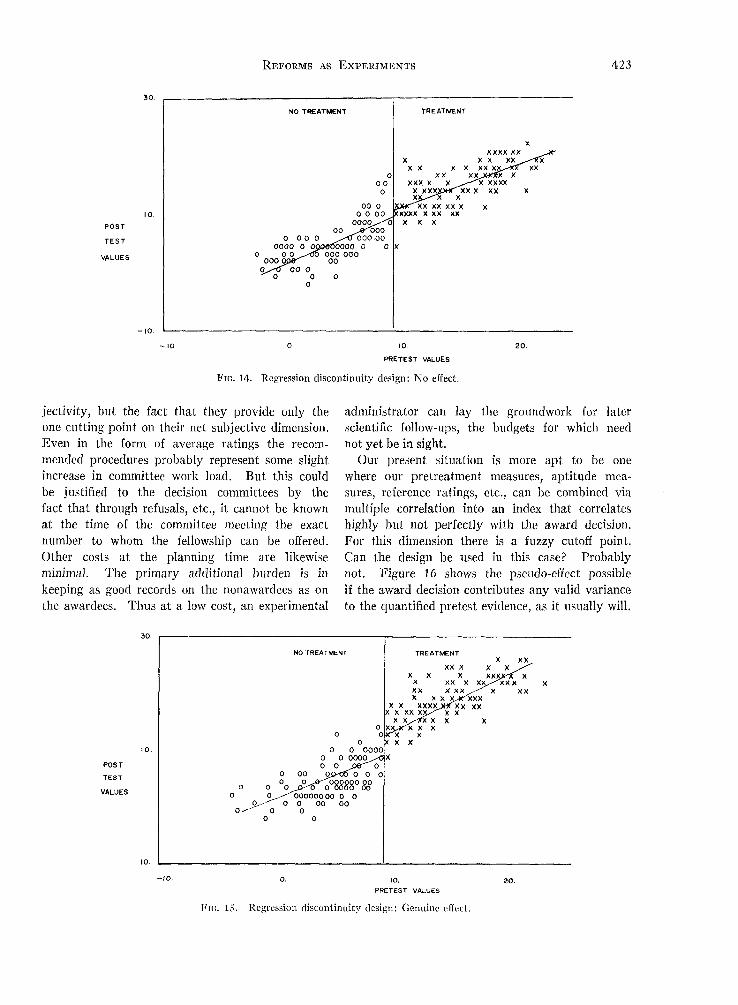
As further illustration, Figure 14 provides com-puter-simulated data, showing individual observa-tions and fitted regression lines, in a fuller versionof the no-effect outcome of Figure 13a. Figure ISshows an outcome with effect. These have beengenerated" by assigning to each individual aweighted normal random number as a "true score,"to which is added a weighted independent "error"to generate the "pretest." The "true score" plus
7 J . Swecn & D. T. Campbell, Computer programs forsimulating and analyzing sharp and fuzzy regression-discontinuity experiments. In preparation.

REFORMS AS EXPERIMENTS 421
another independent "error" produces the "post-test" in no-effect cases such as Figure 14. Intreatment-effect simulations, as in Figure IS, thereare added into the posttest "effects points" forall "treated" cases, that is, those above the cuttingpoint on the pretest score.8
This design could be used in a number of set-tings. Consider Job Training Corps applicants, in
8 While at least one workable test of significance isavailable, it may prove quite difficult to achieve a testthat preserves the imagery of extrapolating to a hypo-thetical tie-breaking randomization experiment. Initially,following Walker and Lev (1953, p. 400; Sween & Camp-bell, 1963, p. 7), we tested the significance of the differenceof the cutting-point intercepts of two regression lines (ofposttest on pretest), one fitted to the observations belowthe cutting point and one fitted to the observations above.In computer simulations of no-effect cases, "significant"pseudo-effects were repeatedly found. It turns out thatthis is one of those settings in which the least-squaressolution is biased. The nature of the bias can perhapsbe communicated by considering what would happen ifboth the regression lines of prctcst-on-posttest and ofposttest-on-pretest were to be plotted for the distributionas a whole. These two regression lines will cross at thecenter of the distribution (i.e., at the cutting point insymmetrical examples such as in Figures 14 and IS) andwill fan apart at the ends. When these two regressionsare fitted instead to the half distributions, they will crossin the center of each half and fan apart at the cuttingpoint. In an example such as Figure 14, the regression ofposttest on pretest will be the lower one at the cuttingpoint for the no-treatment half, and the higher one forthe treatment half. This pseudo-effect docs not appearfor plots of actual column means, as visually inspected,and Figures 14, IS, 16, and 17 should have been drawnwith actual column means plotted instead of the fittedstraight lines. The amount of this bias is a function of thepretest-posttest correlation and if this can be properly esti-mated, corrected cutting-point intercept estimates couldbe computed. However, the whole distribution cannotbe used to estimate this correlation, for a true effect willcause part of the correlation. An estimate might be basedupon the correlations computed separately above andbelow the cutting point, correcting for restricted range.Maximum likelihood estimation procedures may also befound.
At the moment, the best suggestion seems to be thatprovided by Robert P. Abelson. The posttest-on-pretestregression is fitted for a body of data extending aboveand below the cutting point in equal degrees. Columnmeans are expressed as departures from that regression.A t test is then used to compare the columns just belowand just above the cutting point. To increase the actuarialbase, wider column definitions can be explored. This lestunfortunately loses the analogy to the tie-breaking trueexperiment, an analogy that the present writer has beendependent upon for conceptual clarification.
larger number than the program can accommodate,with eligibility determined by need. The settingwould be as in Figure 13d and e. The base-linedecision dimension could be per capita family in-come, with those at below the cutoff getting train-ing. The outcome dimension could be the amountof withholding tax withheld two years later, or thepercentage drawing unemployment insurance, thesefollow-up figures being provided from the NationalData Bank in response to categorized social securitynumbers fed in, without individual anonymity beingbreached, without any real invasion of privacy—for it is the program that is being examined, viaregularities of aggregates of persons. While theplotted points could be named, there is no needthat they be named. In a classic field experimenton tax compliance, Richard Schwartz and theBureau of Internal Revenue have managed to puttogether sets of personally identified interviews andtax-return data so that satistical analyses such asthese can be done, without the separate custodiansof either interview or tax returns learning the cor-responding data for specific persons (Schwartz &Orleans, 1967; see also Schwartz & Skolnick,1963). Manniche and Hayes (1957) have spelledout how a broker can be used in a two-stagedmatching of doubly coded data. Kaysen (1967)and Sawyer and Schechter (1968) have wise dis-cussions of the more general problem.
What is required of the administrator of a scarceameliorative commodity to use this design? Mostessential is a sharp cutoff point on a decision-criterion dimension, on which several other qualita-tively similar analytic cutoffs can be made bothabove and below the award cut. Let me explainthis better by explaining why National Meritscholarships were unable to use the design for theiractual fellowship decision (although it has beenused for their Certificate of Merit). In theiroperation, diverse committees make small numbersof award decisions by considering a group of candi-dates and then picking from them the N best towhich to award the A? fellowships allocated them.This provides one cutting point on an unspecifiedpooled decision base, but fails to provide analogouspotential cutting points above and below. Whatcould be done is for each committee to collectivelyrank its group of 20 or so candidates. The topN would then receive the award. Pooling casesacross committees, cases could be classified accord-ing to number of ranks above and below the cutting

422 AMERICAN PSYCHOLOGIST
NO EFFECT
award
AUGMENTINGEFFECT
DECREMENTALEFFECT
award
Fir,. 13. Illustrative outcomes of regression discontinuity analyses.
point, these other ranks being analogous to theaward-nonaward cutting point as far as regres-sion onto posttreatment measures was concerned.Such group ranking would be costly of committeetime. An equally good procedure, if committeesagreed, would be to have each member, after fulldiscussion and freedom to revise, give each candi-date a grade, A+, A, A—, R + , B, etc., and toaward the fellowships to the N candidates averag-ing best on these ratings, with no revisions allowedafter the averaging process. These ranking orrating units, even if not comparable from com-mittee to committee in range of talent, in number
of persons ranked, or in cutting point, could bepooled without bias as far as a regression discon-tinuity is concerned, for that range of units aboveand below the cutting point in which all committeeswere represented.
It is the dimensionality and sharpness of thedecision criterion that is at issue, not its com-ponents or validity. The ratings could be basedupon nepotism, whimsey, and superstition and stillserve. As has been stated, if the decision criterionis utterly invalid we approach the pure random-ness of a true experiment. Thus the weakness ofsubjective committee decisions is not their sub-
REFORMS AS EXPERIMENTS 423
POST
TEST
VALUES
NO TREATMENT
X X
000
X X X X XXX X
X X XX XX^XX XXxx xxjwnfx x
XXX X X -^ — * XXXXx XXXJOHT xx x xx x
X:x xx x x
<XXXX X XX XXX X X
0. 10,
PRETEST VALUES
FIG. 14. Regression discontinuity design: No effect.
jectivity, but the fact that they provide only theone cutting point on their net subjective dimension.Even in the form of average ratings the recom-mended procedures probably represent some slightincrease in committee work load. But this couldbe justified to the decision committees by thefact that through refusals, etc., it cannot be knownat the time of the committee meeting the exactnumber to whom the fellowship can be offered.Other costs at the planning time are likewiseminimal. The primary additional burden is inkeeping as good records on the nonawardees as onthe awardees. Thus at a low cost, an experimental
administrator can lay the groundwork for laterscientific follow-ups, the budgets for which neednot yet be in sight.
Our present situation is more apt to be onewhere our pretreatment measures, aptitude mea-sures, reference ratings, etc., can be combined viamultiple correlation into an index that correlateshighly but not perfectly with the award decision.For this dimension there is a fuzzy cutoff point.Can the design be used in this case? Probablynot. Figure 16 shows the pseudo-effect possibleif the award decision contributes any valid varianceto the quantified pretest evidence, as it usually will.
POST
TEST
VALUES
NO TREATMENT
XX Xx
X XXXX X XX / - XX X X X^tO<XX
X X X X X X X X XX XXX X XX XX-^X X
. X X X Xx x
10.
PRETEST VALUES
FIG. 15. Regression discontinuity design: Genuine effect.

424 AMERICAN PSYCHOLOGIST
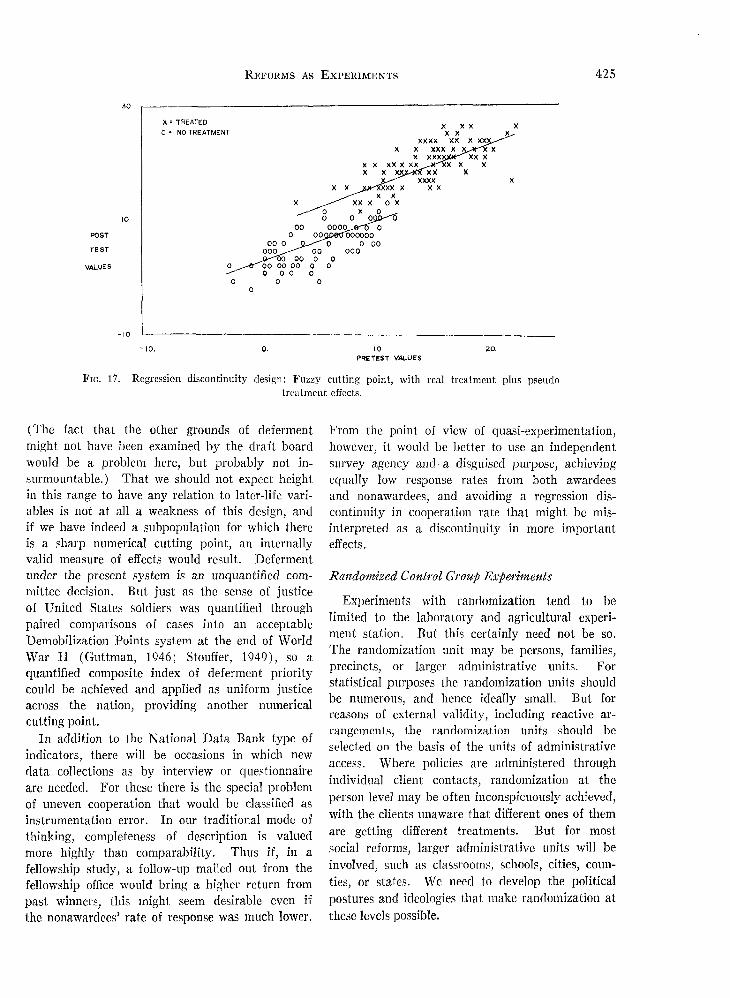
The award regression rides above the nonawardregression just because of that valid variance inthis simulated case, there being no true awardeffect at all. (hi simulating this case, the awarddecision has been based upon a composite oftrue score plus an independent award error.)Figure 17 shows a fuzzy cutting point plus agenuine award effect.0 The recommendation to theadministrator is clear: aim for a sharp cuttingpoint on a quantified decision criterion. If thereare complex rules for eligibility, only one of whichis quantified, seek out for follow-up that subset ofpersons for whom the quantitative dimension wasdeterminate. If political patronage necessitatessome decisions inconsistent with a sharp cutoff,record these cases under the heading "qualitativedecision rule" and keep them out of your experi-mental analysis.
Almost all of our ameliorative programs de-signed for the disadvantaged could be studied viathis design, and so too some major governmental
9 There are some subtle statistical clues that might dis-tinguish these two instances if one had enough cases.There should be increased pooled column variance in themixed columns for a true effects case. H the data arcarbitrarily treated as though there had been a sharpcutting point located in the middle of the overlap area,then there should be no discontinuity in the no-effect case,and some discontinuity in the case of a real effect, albeitan underestimated discontinuity, since there are untreatedcases above the cutting point and treated ones below,dampening the apparent effect. The degree of suchdampening should be estimable, and correctable, perhaps byilerativc procedures. But these arc hopes for the future.
actions affecting the lives of citizens in ways we donot think of as experimental. For example, for aconsiderable period, quantitative test scores havebeen used to call up for military service or rejectas unfit at the lower ability range. .If these cuttingpoints, test scores, names, and social security num-bers have been recorded for a number of steps bothabove and below the cutting point, we could makeelegant studies of the effect of military service onlater withholding taxes, mortality, number of de-pendents, etc. Unfortunately for this purpose,the nobly experimental "Operation 100,000" (Officeof the Secretary of Defense, 1967) is fuzzing upthis cutting point, but there are several years ofearlier Vietnam experience all ready for analysis.
This illustration points to one of the threatsto external validity of this design, or of the tie-breaking experiment. The effect of the treatmenthas only been studied for that narrow range oftalent near the cutting point, and generalizationof the effects of military service, for example, fromthis low ability level to the careers of the most ablewould be hazardous in the extreme. But in thedraft laws and the requirements of the militaryservices there may be other sharp cutting points ona quantitative criterion that could also be used.For example, those over 6 feet 6 inches are ex-cluded from service. Imagine a five-year-laterfollow-up of draftees grouped by inch in the 6 feet1 inch to 6 feet 5 inches range, and a group of theircounterparts who would have been drafted exceptfor their heights, 6 feet 6 inches to 6 feet 10 inches,
POST
TEST
X = TREATED
0 = NO TREATMENT
10.PRETEST
FIG. 16. Regression discontinuity design: Fuzzy cutting point, pseudo treatment effect only.
REFORMS AS EXPERIMENTS 425
POST
TEST
VALUES
X = TREATED
0 * NO TREATMENTx x xX X
XXXX XX X XXX.
00 0ooo^,—" oo
00 0 000 00 00 0 00 0 0 0
0 0
PRETEST VALUES
FIG. 17. Regression discontinuity design: Fuzzy cutting point, with real treatment plus pseudotreatment effects.
(The fact that the other grounds of defermentmight not have been examined by the draft boardwould be a problem here, but probably not in-surmountable.) That we should not expect heightin this range to have any relation to later-life vari-ables is not at all a weakness of this design, andif we have indeed a subpopulation for which thereis a sharp numerical cutting point, an internallyvalid measure of effects would result. Defermentunder the present system is an unquantified com-mittee decision. But just as the sense of justiceof United States soldiers was quantified throughpaired comparisons of cases into an acceptableDemobilization Points system at the end of WorldWar II (Guttman, 1946; Stouffer, 1949), so aquantified composite index of deferment prioritycould be achieved and applied as uniform justiceacross the nation, providing another numericalcutting point.
In addition to the National Data Bank type ofindicators, there will be occasions in which newdata collections as by interview or questionnaireare needed. For these there is the special problemof uneven cooperation that would be classified asinstrumentation error. In our traditional mode ofthinking, completeness of description is valuedmore highly than comparability. Thus if, in afellowship study, a follow-up mailed out from thefellowship office would bring a higher return frompast winners, this might seem desirable even ifthe nonawardees' rate of response was much lower.
From the point of view of quasi-experimentation,however, it would be better to use an independentsurvey agency and-a disguised purpose, achievingequally low response rates from both awardeesand nonawardees, and avoiding a regression dis-continuity in cooperation rate that might be mis-interpreted as a discontinuity in more importanteffects.
Randomized Control Group Experiments
Experiments with randomization tend to belimited to the laboratory and agricultural experi-ment station. But this certainly need not be so.The randomization unit may be persons, families,precincts, or larger administrative units. Forstatistical purposes the randomization units shouldbe numerous, and hence ideally small. But forreasons of external validity, including reactive ar-rangements, the randomization units should beselected on the basis of the units of administrativeaccess. Where policies are administered throughindividual client contacts, randomization at theperson level may be often inconspicuously achieved,with the clients unaware that different ones of themare getting different treatments. But for mostsocial reforms, larger administrative units will beinvolved, such as classrooms, schools, cities, coun-ties, or states. We need to develop the politicalpostures and ideologies that make randomization atthese levels possible.

426 AMERICAN PSYCHOLOGIST
"Pilot project" is a useful term already in ourpolitical vocabulary. It designates a trial pro-gram that, if it works, will be spread to other areas.By modifying actual practice in this regard, with-out going outside of the popular understanding ofthe term, a valuable experimental ideology couldbe developed. How are areas selected for pilotprojects? If the public worries about this, itprobably assumes a lobbying process in which thegreater needs of some areas are only one con-sideration, political power and expediency beingothers. Without violating the public tolerance orintent, one could probably devise a system in whichthe usual lobbying decided upon the areas eligiblefor a formal public lottery that would make finalchoices between matched pairs. Such decisionprocedures as the drawing of lots have had a justlyesteemed position since time immemorial (e.g.,Aubert, 19S9). At the present time, record keep-ing for pilot projects tends to be limited to theexperimental group only. In the experimentalideology, comparable data would be collected ondesignated controls. (There are of course ex-ceptions, as in the heroic Public Health Servicefluoridation experiments, in which the teeth of OakPark children were examined year after year ascontrols for the Evanston experimentals [Blayney&Hill, 1967].)
Another general political stance making possibleexperimental social amelioration is that of stagedinnovation. Even though by intent a new reformis to be put into effect in all units, the logistics ofthe situation usually dictate that simultaneous in-troduction is not possible. What results is a hap-hazard sequence of convenience. Under the pro-gram of staged innovation, the introduction of theprogram would be deliberately spread out, andthose units selected to be first and last would berandomly assigned (perhaps randomization frommatched pairs), so that during the transition periodthe first recipients could be analyzed as experi-mental units, the last recipients as controls. Athird ideology making possible true experimentshas already been discussed: randomization as thedemocratic means of allocating scarce resources.
This article will not give true experimentationequal space with quasi-experimentation only be-cause excellent discussions of, and statistical con-sultation on, true experimentation are readily avail-able. True experiments should almost always bepreferred to quasi-experiments where both are
available. Only occasionally are the threats to ex-ternal validity so much greater for the true ex-periment that one would prefer a quasi-experiment.The uneven allocation of space here should not beread as indicating otherwise.
More Advice jor Trapped Administrators
But the competition is not really between thefairly interpretable quasi-experiments here reviewedand "true" experiments. Both stand together asrare excellencies in contrast with a morass ofobfuscation and self-deception. Both to empha-size this contrast, and again as guidelines for thebenefit of those trapped administrators whosepolitical predicament will not allow the risk offailure, some of these alternatives should be men-tioned.
Grateful testimonials. Human courtesy andgratitude being what it is, the most dependablemeans of assuring a favorable evaluation is to usevoluntary testimonials from those who have hadIhe treatment. If the spontaneously producedtestimonials are in short supply, these should besolicited from the recipients with whom the pro-gram is still in contact. The rosy glow resultingis analogous to the professor's impression of histeaching success when it is based solely upon thecomments of those students who come up andtalk with him after class. In many programs, asin psychotherapy, the recipient, as well as theagency, has devoted much time and effort to theprogram and it is dissonance reducing for himself,as well as common courtesy to his therapist, to re-port improvement. These grateful testimonialscan come in the language of letters and conversa-tion, or be framed as answers to multiple-item"tests" in which a recurrent theme of "I am sick,""I am well," "I am happy," "I am sad" recurs.Probably the testimonials will be more favorableas: (a) the more the evaluative meaning of theresponse measure is clear to the recipient—it iscompletely clear in most personality, adjustment,morale, and attitude tests; (b) the more directlythe recipient is identified by name with his answer;(c) the more the recipient gives the answer directlyto the therapist or agent of reform; (d) the morethe agent will continue to be influential in therecipient's life in the future; (e) the more theanswers deal with feelings and evaluations ratherthan with verifiable facts; and (/) the more therecipients participating in the evaluation are a

REFORMS AS EXPERIMENTS 427
small and self-selected or agent-selected subset ofall recipients. Properly designed, the grateful testi-monial method can involve pretests as well asposttests, and randomized control groups as wellas experimentals, for there are usually no placebotreatments, and the recipients know when theyhave had the boon.
Confounding selection and treatment. Anotherdependable tactic bound to give favorable out-comes is to confound selection and treatment, sothat in the published comparison those receivingthe treatment are also the more able and wellplaced. The often-cited evidence of the dollarvalue of a college education is of this nature—allcareful studies show that most of the effect, andof the superior effect of superior colleges, is ex-plainable in terms of superior talents and familyconnections, rather than in terms of what is learnedor even the prestige of the degree. Matchingtechniques and statistical partialings generallyundermatch and do not fully control for the selec-tion differences—they introduce regression artifactsconfusable as treatment effects.
There are two types of situations that must bedistinguished. First, there are those treatmentsthat are given to the most promising, treatmentslike a college education which are regularly givento those who need it least. For these, the laterconcomitants of the grounds of selection operatein the same direction as the treatment: those mostlikely to achieve anyway get into the college mostlikely to produce later achievement. For thesesettings, the trapped administrator should use thepooled mean of all those treated, comparing it withthe mean of all untreated, although in this settingalmost any comparison an administrator might hitupon would be biased in his favor.
At the other end of the talent continuum arethose remedial treatments given to those who needit most. Here the later concomitants of thegrounds of selection are poorer success. In theJob Training Corps example, casual comparisonsof the later unemployment rate of those who re-ceived the training with those who did not are ingeneral biased against showing an advantage tothe training. Here the trapped administrator mustbe careful to seek out those few special compari-sons biasing selection in his favor. For trainingprograms such as Operation Head Start and tutor-ing programs, a useful solution is to compare thelater success of those who completed the training
program with those who were invited but nevershowed plus those who came a few times anddropped out. By regarding only those who com-plete the program as "trained" and using the othersas controls, one is selecting for conscientiousness,stable and supporting family backgrounds, enjoyment of the training activity, ability, determinationto get ahead in the world—all factors promisingwell for future achievement even if the remedialprogram is valueless. To apply this tactic effec-tively in the Job Training Corps, one might haveto eliminate from the so-called control group allthose who quit the training program because theyhad found a job—but this would seem a reasonablepractice and would not blemish the reception of aglowing progress report.
These are but two more samples of well-triedmodes of analysis for the trapped administratorwho cannot afford an honest evaluation of the socialreform he directs. They remind us again that wemust help create a political climate that demandsmore rigorous and less self-deceptive reality testing.We must provide political stances that permit trueexperiments, or good quasi-experiments. Of theseveral suggestions toward this end that are con-tained in this article, the most important is prob-ably the initial theme: Administrators and partiesmust advocate the importance of the problemrather than the importance of the answer. Theymust advocate experimental sequences of reforms,rather than one certain cure-all, advocating Re-form A with Alternative B available to try nextshould an honest evaluation of A prove it worthlessor harmful.
Multiple Replication in Enactment
Too many social scientists expect single experi-ments to settle issues once and for all. This maybe a mistaken generalization from the history ofgreat crucial experiments in physics and chemistry.In actuality the significant experiments in thephysical sciences are replicated thousands of times,not only in deliberate replication efforts, but alsoas inevitable incidentals in successive experimenta-tion and in utilizations of those many measurementdevices (such as the galvanometer) that in theirown operation embody the principles of classicexperiments. Because we social scientists haveless ability to achieve "experimental isolation,"because we have good reason to expect our treat-

428 AMERICAN PSYCHOLOGIST
ment effects to interact significantly with a widevariety of social factors many of which we havenot yet mapped, we have much greater needs forreplication experiments than do the physicalsciences.
The implications are clear. We should not onlydo hard-headed reality testing in the initial pilottesting and choosing of which reform to make generallaw; but once it has been decided that the reform isto be adopted as standard practice in all admini-strative units, we should experimentally evaluateit in each of its implementations (Campbell, 1967).
CONCLUSIONS
Trapped administrators have so committed them-selves in advance to the efficacy of the reform thatthey cannot afford honest evaluation. For them,favorably biased analyses are recommended, in-cluding capitalizing on regression, grateful testi-monials, and confounding selection and treatment.Experimental administrators have justified the re-form on the basis of the importance of the problem,not the certainty of their answer, and are com-mitted to going on to other potential solutions ifthe one first tried fails. They are therefore notthreatened by a hard-headed analysis of the re-form. For such, proper administrative decisionscan lay the base for useful experimental or quasi-experimental analyses. Through the ideology ofallocating scarce resources by lottery, through theuse of staged innovation, and through the pilotproject, true experiments with randomly assignedcontrol groups can be achieved. If the reformmust be introduced across the board, the inter-rupted time-series design is available. If there aresimilar units under independent administration, acontrol series design adds strength. H a scarceboon must be given to the most needy or to themost deserving, quantifying this need or meritmakes possible the regression discontinuity analysis.
REFERENCES
AUUEUT, V. Chance in social affairs. Inquiry, 19S9, 2,1-24.
BAUER, R. M. Social indicators. Cambridge, Mass.: M.I.T.Press, 1966.
BLAYNEY, J. R., & HILL, t. N. Fluorine and dental caries.The Journal of the American Dental Association (SpecialIssue), 1967, 74, 233-302.
Box, G. E. P., & Two, G. C. A change in level of a non-stationary time series. Biomelrika, 1965, 52, 181-192.
CAMPBELL, D. T. Factors relevant to the validity ofexperiments in social settings. Psychological Bulletin,1957, 54, 297-312.
CAMPBELL, D. T. From description lo experimentation:Interpreting trends as quasi-experimcnts. In C. W.Harris (Ed.), Problems in measuring change. Madison:University of Wisconsin Press, 1963.
CAMPBELL, D. T. Administrative experimentation, in-stitutional records, and nonreacl.ivc measures. In J. C.Stanley (Ed.), Improving experimental design and statis-tical analysis. Chicago: Rand McNally, 1967.
CAMPBELL, D. T. Quasi-experimental design. In D. L.Sills (Ed.), International Encyclopedia of the SocialSciences. New York: Macmillan and Free Press, 1968,Vol. 5, 259-263.
CAMPHKLL, D. T., & FISKE, D. W. Convergent and dis-criminant validation by the multitrait-multimcthodmatrix. Psychological Bulletin, 1959, 56, 81-105.
CAMPBELL, D. T., & Ross, H. L. The Connecticut crack-down on speeding: Time-scries data in quasi-experimentalanalysis. Law and Society Review, 1968, 3(1), 33-53.
CAMPBELL, D. T., & STANLEY, J. C. Experimental andquasi-experimental designs for research on teaching. InN. L. Gage (Ed.), Handbook of research on teaching.Chicago: Rand McNally, 1963. (Reprinted as Experi-mental and quasi-experimental design for research.Chicago: Rand McNally, 1966.)
CHAPIN, F. S. Experimental design in sociological research.New York: Harper, 1947.
ET/IONI, A. "Shortcuts" to social change? The PublicInterest, 1968, 12, 40-51.
ETXEONL, A., & LEHMAN, E. W. Some dangers in "valid"social measurement. Annals of the American Academyof Political and Social Science, 1967, 373, 1-15.
GALTUNG, J. Theory and methods of social research.Oslo: Universitetsf orlogct; London: Allen & Unwin;New York: Columbia University Press, 1967.
GLASS, G. V. Analysis of data on the Connecticut speedingcrackdown as a time-series quasi-experiment. Law andSociety Review, 1968, 3(1), 55-76.
GLASS, G. V., TJAO, G. C., & MAGUIRE, T. O. Analysis ofdata on the 1900 revision of the German divorce lawsas a quasi-experimcnt. Law and Society Review, 1969,in press.
GREENWOOD, E. Experimental sociology: A study inmethod. New York: King's Crown Press, 1945.
GROSS, B. M. The slate of the nation: Social system ac-counting. London: Tavistock Publications, 1966. (Alsoin R. M. Bauer, Social indicators. Cambridge, Mass.:M.I.T. Press, 1966.)
GROSS, B. M. (Ed.) Social goals and indicators. Annalsof the American Academy of Political and Social Science,1967, 371, Part 1, May, Pp. i-iii and 1-177; Part 2,September, Pp. i-iii and 1-218.
GUTTMAN, L. An approach for quantifying paired com-parisons and rank order. Annals of MathematicalStatistics, 1946, 17, 144-163.
HYMAN, H. H., & WRIGHT, C. R. Evaluating social actionprograms. In P. F. Lazarsfeld, \V. H. Sewcll, & H. L.Wilensky (Eds.), The uses of sociology. New York:Basic Books, 1967.

REFORMS AS EXPERIMENTS 429
KAMISAR, Y. The tactics of police-persecution orientedcritics of the courts. Cornell Law Quarterly, 1964, 49,458-471.
KAYSEN, C. Data banks and dossiers. The Public Interest,1967, 7, 52-60.
MANNICHE, E., & HAYES, D. P. Respondent anonymityand data matching. Public Opinion Quarterly, 1957,21(3), 384-388.
OFFICE OF THE SECRETARY OF DEFENSE, Assistant Secretaryof Defense (Manpower), Guidance paper: Project OneHundred Thousand. Washington, D. C., March 31,1967. (Multilith)
POLANYI, M. A society of explorers. In, The tacit dimen-sion. (Ch. 3) New York: Doubleday, 1966.
POLANYI, M. The growth of science in society. Minerva,1967, 5, 533-545.
POPPER, K. R. Conjectures and refutations. London:Routlcdge and Kegan Paul; New York: Basic Books,1963.
RHEINSTEIN, M. Divorce and the law in Germany: A re-view. American Journal of Sociology, 1959, 65, 489-498.
ROSE, A. M. Needed research on the mediation of labordisputes. Personnel Psychology, 1952, 5, 187-200.
Ross, H. L., & CAMPBELL, D. T. The Connecticut speedcrackdown: A study of the effects of legal change. InH. L. Ross (Ed.), Perspectives on the social order:Readings in sociology. New York: McGraw-Hill, 1968.
SAWYER, J., & SCHECIITER, H. Computers, privacy, and theNational Data Center: The responsibility of social sci-entists. American Psychologist, 1968, 23, 810-818.
SCIIANCK, R. L., & GOODMAN, C. Reactions to propa-ganda on both sides of a controversial issue. PublicOpinion Quarterly, 1939, 3, 107-112.
SCHWARTZ, R. D. Field experimentation in sociologicalresearch. Journal of Legal Education, 1961, 13, 401-410.
SCHWARTZ, R. D., & ORLEANS, S. On legal sanctions. Uni-versity of Chicago Law Review, 1967, 34, 274-300.
SCHWARTZ, R. D., & SKOLNICK, J. II. Televised com-munication and income tax compliance. In L. Arons &M, May (Eds.), Television and human behavior. NewYork: Applcton-Century-Crofts, 1963.
SKLVJN, H. A critique of tests of significance in surveyresearch. American Sociological Review, 1957, 22, 519-527.
SIMON, J. L. The price elasticity of liquor in the U. S. anda simple method of determination. Econometrica, 1966,34, 193-205.
SOLOMON, R. W. An extension of control group design.Psychological Bulletin, 1949, 46, 137-150.
STIEBER, J. W. Ten years of the Minnesota Labor Rela-tions Act. Minneapolis: Industrial Relations Center,University of Minnesota, 1949.
STOTJFFER, S. A. The point system for redeployment anddischarge. In S. A. Stouffer et al., The American soldier.Vol. 2, Combat, mid its aftermath. Princeton: PrincetonUniversity Press, 1949.
SUCIIMAN, E. A. Evaluative research: Principles andpractice in public service and social action programs.New York: Russell Sage, 1967.
SWEEN, J., & CAMPBELL, D. T. A study of the effect ofproximally auto-correlated error on tests of significancefor the interrupted time-series quasi-experimental design.Available from author, 1965. (Multilith)
TIIISTLETIDWAITE, D. L., & CAMPBELL, D. T. Regression-discontinuity analysis: An alternative to the ex postfacto experiment. Journal of Educational Psychology,1960, 51, 309-317.
WALKER, H. M., & LEV, J. Statistical inference. New York:Holt, 1953.
WEBB, E. J., CAMPBELL, D. T., SCHWARTZ, R. D., &SECUREST, L, B. Unobtrusive measures: Non-reactive re-search in the social sciences. Chicago: Rand McNally,1966.
WOLF, E., LUKE, G., & HAX, H. Scheidung und Scheid-ungsrecht: Grundfriigen de,r Ehescheidung in Deutschland.Tiibigen: J. C. B. Mohr, 1959.