podstawy informatyki dla inzynierÓwdzwinel/files/courses/podstinf-transp.pdf · reprezentacji...
TRANSCRIPT

PODSTAWY INFORMATYKI DLA INZYNIERÓW
Witolda Dzwinel

I WSTEP I PODSTAWOWE POJECIA 1.1 Metakomputer Matematyka to jezyk za pomoca, którego jestesmy w stanie „porozumiewac” sie z Natura i w tym dialogu, zwiekszac czynnik przystosowania naszej populacji i odpornosc na katastrofy zagrazajace jej istnieniu. Dzieki matematyce uwolnilismy sie od tyranii magii i mistycyzmu otwierajac droge do ekspansji ludzkosci we Wszechswiat. Moc matematyki jest tak wielka, ze powoli lamie ona podzial na niewielu, którzy ja rozumieja i uzywaja oraz wielu dla których jest ona tematem koszmarów nocnych.
W dobie rozwoju poteznego narzedzia, którego matka jest matematyka – informatyki – juz dzis wielu z nas, w bardziej lub mniej swiadomy sposób, uzywa matematyki na co dzien. Odbywa sie za sprawa komputera, a w zasadzie systemu komputerowego, obejmujacemu zarówno sprzet jak i oprogramowanie. Okazuje sie jednak, ze zanim zdazylismy sie przyzwyczaic do obecnosci popularnego peceta w naszym domu, juz niedlugo bedziemy musieli calkowicie zmienic swoje wyobrazenie o tym niezwyklym narzedziu, gdyz czasy peceta powoli przemijaja. Juz jutro jego miejsce zajmie tzw. metakomputer – skomplikowany organizm spajajacy w jednolita siec: Internet jutra bazujacy na superszybkich inteligentnych laczach, jego jutrzejsze zasoby obliczeniowe oraz nas - jutrzejszych wyspecjalizowanych klientów i bezposrednich twórców uslug komputerowych. Zatem juz calkiem niedlugo zamiast brzydkiej skrzynki i brzuchatego monitora bedziemy miec w domu ... ogromny plazmowy ekran na scianie lub „czarodziejskie okulary” oraz gniazdko w scianie (lub w przyszlosci np. w glowie). To gniazdko to dostep do zasobów wiedzy, informacji i rozrywki calej planety – oczywiscie w stopniu adekwatnym do zasobów naszych kieszeni (w zasadzie wirtualnych osobistych kont) i wysokosci placonego abonamentu. Zamiast kupowac nowy komputer, dysk, karte graficzna bedziemy placic zróznicowany abonament za tzw. zintegrowane uslugi multimedialne wyswiadczane nam przez dostawce mocy obliczeniowej. Uslugi te obejmowac beda rozmowy telefoniczne - pozwalajace równiez na wizualny kontakt z rozmówca - uslugi audiowizualne obejmujace wszystkie kanaly telewizyjne i radiowe swiata oraz uslugi obliczeniowe, od tych profesjonalnych do popularnych takich jak gry komputerowe i widowiska swiata wirtualnego. Postep technologiczny odczuwac bedziemy w ilosci nowych uslug i ich jakosci nabywanych za te same pieniadze.
Juz nastepne pokolenie prawdopodobnie nie bedzie kojarzylo slowa „komputer” z niczym konkretnym (podobnie jak wielu osobom trudno byloby zdefiniowac slowo Internet, choc podswiadomie kazdy z nich wie o co chodzi). Pokolenie to stanie sie uczestnikiem i fragmentem tzw. wszechogarniajacej informatyzacji (ang. pervasive computing) spajajacej nasza populacje w jeden organizm. Oprócz niewatpliwych zmian spolecznych, ekonomicznych, politycznych i charakterologicznych zwiazanych z nastaniem ery informatyzacji oraz z rozwojem spoleczenstwa informatycznego czekaja nas takze nowe rewolucje w nauce, inzynierii i ekonomii. W tym momencie trudno sobie nawet wyobrazic, jaki wplyw na rozwój struktury zatrudnienia bedzie mialo powszechne udostepnienie ogromnej mocy obliczeniowej calej planety. Pewne jest jedno. Ten, którego zabraknie w tworzeniu tzw. przestrzeni informatycznej lekkiego zycia miec nie bedzie. Ksiazka ta to zbiór materialów i zagadnien do przedmiotu Podstawy Informatyki opracowana przez wykladowce tego przedmiotu i asystentów Wyzszej Szkoly Ekonomii i Administracji w Kielcach. Podstawy informatyki zostaly potraktowane w tej ksiazce raczej z inzynierskiego punktu widzenia, niz z klasycznego, preferujacego teorie obliczen, automatów skonczonych i algorytmike jako rzeczywiste podstawy tej dziedziny wiedzy. Pierwszy rozdzial wstepny zawiera definicje podstawowych pojec, wyjasnia co nalezy rozumiec przez informacje i informatyke. Omówiono pewne problemy zwiazane z ograniczeniami konceptualnymi i fizycznymi rozwoju sprzetu komputerowego. W nastepnym rozdziale dokonano krótkiego

przedstawienia elementów architektur komputerowych, poczawszy od maszyny von Neumanna az do super-systemów obliczeniowych poczatku 21 wieku, czyli projektów ASCI, Earth Simulator oraz Blue Gene. W trzecim rozdziale zawarto podstawowe informacje dotyczace reprezentacji danych, przedstawiono podstawowe systemy kodowania, by w czwartym rozdziale ponownie wrócic do podstaw teorii obliczen. W rozdziale tym zaprezentowano maszyne Turinga, podstawy kodowania, zagadnienie stopu, elementy Lambda rachunku i twierdzenie Gödla. Nastepne rozdzialy dotycza problemów konstrukcji algorytmów i ich kodowania w jezyku C. Problematyka zlozonosci obliczeniowej poruszana jest w koncowych rozdzialach ksiazki. Omówiono w nich poszczególne klasy zlozonosci podajac przyklady reprezentatywnych algorytmów. Ostatni rozdzial to krótki opis funkcjonalnosci systemu operacyjnego LINUX. 1.2 Informacja
Przedmiotem badan informatyki jest informacja. Jednak istnienie precyzyjnej definicji informacji jest czesto kwestionowane. W wielu pracach podkresla sie jej subiektywny wymiar. Na przyklad waga informacji „Zona Hassana go zdradza” bedzie inna dla domniemanego Hassana i dla Autora. Dlatego jedyna definicja informacji, akceptowalna jako wystarczajaco precyzyjna by stac sie podstawowym elementem powaznej dyscypliny naukowej jest definicja Shannona oparta na pojeciu entropii. W termodynamice pojecie entropii wprowadzil w 1850 roku Rudolf Clausius i definiowana jest ona jako wielkosc termodynamiczna okreslajaca miare nieporzadku w ukladzie fizycznym. Ludwik Boltzmann identyfikowal maksymalna entropie S systemu jako logarytm z calkowitej ilosci wzajemnie rozróznialnych i mozliwych stanów x, w które dany system fizyczny moze przebywac.
Ta ostatnia definicja uzywana jest jako definicja informacji fizycznej lub po prostu informacji. Claude Shannon pokazal jak uogólnic definicje Boltzmanna w sytuacji, kiedy nasza wiedza o stanie x wyraza sie nie liczba stanów a prawdopodobienstwem p(x) z jakim dany uklad fizyczny moze sie w stanie x znalezc. Entropia dla danego systemu, w którym kazdy ze stanów x wystepuje z prawdopodobienstwem p(x) jest równa:
( ) ( )∑−=x
xpxpH ln
Tak zwana znana informacja wyraza sie wzorem (lnN) – H, gdzie N to calkowita ilosc stanów w ukladzie. Jezeli uzyjemy logarytmu o podstawie 2 w powyzszym wzorze, dla systemu, który z jednakowym prawdopodobienstwem przyjmuje jeden z dwóch stanów, otrzymamy ilosc informacji log22 = 1. Taka ilosc informacji nazywamy 1 bitem. 8 bitów to bajt (ang. byte). W przypadku, gdy podstawa logarytmu bedzie liczba e (a czesto jest to wygodne) to taka ilosc informacji dla której ln N=1 nazywamy nat. Mozna latwo policzyc, ze 1 nat to log2e = 1.44 bita. Nazwijmy znana informacja informacje fizyczna w tej czesci systemu, którego stan jest znany przez obserwatora, a entropia bedzie nazywana czesc, która jest nieznana (patrz Rysunek 1.1.1).

INFORMACJA ZNANA INFORMACJA NIEZNANA
Informacja fizyczna = Znana informacja + entropia =
Maksymalna entropia = maksymalna znana informacja
1 2 3 4 1 2 3 4
Przyklad System z 4 dwustanowymi
podsystemami N=24=16
Stan Charakter 1 Entropia 2 znany 3 Entropia 4 znany
Rysunek 1.1.1 Informacja znana i nieznana (entropia) dla systemu zlozonego z czterech spinów. Calkowita ilosc stanów N=24=16. Stany przekreslone sa nieznane. Wynika stad, ze znane sa jedynie dwa bity informacji (drugi i czwarty), pozostale sa nieznane (entropia). Jezeli nic nie wiemy o systemie, cala informacja fizyczna jest entropia. Jezeli poprzez interakcje z systemem odczytamy czesc informacji o stanie, w jakim sie uklad znajduje, pozostala nieodczytana czesc jest entropia. Jak pokazano na Rys.1.1.1 w momencie gdy znamy kierunki spinów w dwóch z czterech 2-stanowych podstanach ukladu, informacja nieznana – entropia - sa kierunki pozostalych dwóch spinów. Nastepujaca suma: Informacja znana + entropia = maksymalna entropia (maksymalna informacja) jest stala i niezmienna dla kazdego ukladu fizycznego pod warunkiem, ze wielkosc systemu nie ulega zmianie i do systemu nie jest dostarczana ani odbierana energia.
W rozszerzajacym sie Wszechswiecie liczba mozliwych jego stanów rosnie (trzecia zasada termodynamiki), lecz w jego malym kawalku o skonczonej objetosci i energii pozostaje stala. Zatem zamiana entropii przez obserwacje systemu w znana informacje pozornie przeczy trzeciej zasadzie termodynamiki, ze w zamknietym systemie entropia moze tylko rosnac. Jednak, jesli dokonujemy pomiaru na systemie to z tego wynika nie jest on calkowicie izolowany. Pomiar wymaga interakcji ukladu pomiarowego z systemem. Zatem ulega zmianie stan aparatu pomiarowego, w taki sposób, ze zalezy on od stanu mierzonego systemu. Zatem z punktu widzenia niezaleznego obserwatora, entropia, nawet jezeli zostala „usunieta” z mierzonego systemu, dalej istnieje i dalej jest entropia. Pokazuje to Rys.1.1.2. Wynika z tego, ze entropii nie da sie zniszczyc. Kazdy system obliczeniowy zmieniajacy stany zespolu przelaczników, który bedzie z entropii produkowal znana informacje musi ilosc entropii adekwatna do ilosci wytworzonej informacji przeniesc do ukladu obserwatora. Przenosi ja w postaci wydzielonego ciepla zgodnie ze wzorem:
TSE ⋅∂=∂ gdzie ∂E jest energia wydzielona w postaci ciepla na skutek zmiany entropii ∂S w temperaturze T. Najmniejsza ilosc ciepla która wydzieli idealny przelacznik dwustanowy to ∂Q=kTln2. Jezeli bedziemy zwiekszac upakowanie przelaczników na 1 cm2 i zwiekszac szybkosc ich przelaczania gwaltownie wzrosnie ilosc ciepla wydzielanego przez element obliczeniowy. Jak sie dalej

przekonamy, efekt ten stanowi trudna do pokonania bariere technologiczna zwiekszenia szybkosci przetwarzania w systemach komputerowych.
Rysunek 1.1.2 Zalózmy, ze mamy system B, który moze byc w stanie 1 lub 0. Zatem „zawiera” on 1 bit entropii. Pomiaru na systemie B dokonujemy przy pomocy narzedzia pomiarowego A, które dostosowuje (przez pomiar) swój stan do aktualnego stanu B. Czyli A tez moze byc w stanie 1 lub 0. Z punktu widzenia zewnetrznego obserwatora, który obserwuje oba systemy A i B, entropia calego ukladu A+B dalej pozostaje niezmieniona, bo uklad ten moze byc w stanie A=0 i B=0 lub A=1 i B=1. 1.3 Informatyka i problemy przetwarzania informacji Informatyka kojarzona jest z czteroma typami operacji wykonywanymi na informacji i zaczynajacymi sie na litere „P”:
1. przetwarzaniem informacji (np. systemy obliczeniowe), 2. przesylaniem informacji (sieci i magistrale), 3. przechowywaniem informacji (podsystemy pamieci, systemy przechowywania danych), 4. prezentacja informacji (systemy wizualizacji danych, grafika i animacja komputerowa).
Omówmy najpierw samo pojecie szybkosci obliczen zwiazane z procesem przetwarzania informacji, który stanowi podstawe informatyki jako dziedziny nauki. Pozostale trzy operacje, wykonywane na informacji omówione zostana pokrótce przy okazji wstepu do architektur komputerowych.
Przez przetwarzanie informacji nalezy rozumiec procesy obliczeniowe zachodzace bezposrednio w systemach informatycznych, niekoniecznie zwiazanych jednak z ukladem centralnego procesora (lub centralnych procesorów). Moze ono zachodzic na procesorach pomocniczych (karty graficzne, kontrolery, routery). Przetwarzanie informacji zwiazane jest z pojeciem algorytmu, czyli automatycznej metody transformacji jednego rodzaju informacji (dane) w drugi (rezultat). Sam algorytm tez jest informacja, która moze byc przetwarzana przez inny algorytm. Waznym elementem przetwarzania informacji jest czas. Czym szybciej przetwarzana informacja tym mamy do czynienia z bardziej efektywnym systemem informatycznym. Przetwarzanie informacji nie zwiazane jest z konkretnym miejscem w przestrzeni. Obliczenia rozproszone, które polegaja na przetworzeniu informacji czasem w bardzo odleglych od siebie geograficznie miejscach i zbieraniu wyników przetwarzania w jeszcze innym punkcie globu, to podstawa nowoczesnej informatyki.
Ponizej przedstawiamy pojecia zwiazane z szybkoscia przetwarzania.

Szybkosc maksymalna – to najwieksza szybkosc z jaka moze pracowac dana maszyna. Jest to górna granica szybkosci procesora okreslona przez fizyczna strukture sprzetu. 1 flop = jedna operacja zmennoprzecinkowa, 1 flops = 1 flop/s = jednostka szybkosci obliczen. Przez operacje zmiennoprzecinkowa nalezy rozumiec dowolna operacje arytmetyczna (dodawanie, odejmowanie, dzielenie, mnozenie), na liczbach z ulamkiem dziesietnym o niezdefiniowanej z góry precyzji. Dokladniejsza definicje poznamy w dalszych rozdzialach. Istnieja inne pomiary predkosci komputera (MIPS, SPEC (int, float), benchmarki, tpm/c, SAP R3), które eksponuja inne zalety systemu przetwarzajacego niz arytmetyka komputerowa np. jak szybko mozemy pobierac zadana informacje z systemu bazodanowego, jak szybko ja korygowac, ile osób równoczesnie moze korzystac z pewnego powszechnie uzywanego oprogramowania nie odczuwajac wyraznej degradacji efektywnosci systemu itp. Definiujemy takze tzw. Wydajnosc w piku = peak performance Jest to teoretycznie najwieksza predkosc, która dana maszyna moze osiagnac. Jednym z elementów decydujacych we wspólczesnych systemach informatycznych o predkosci obliczen jest tzw. zegar, czyli czestotliwosc taktujaca przelaczania ukladów elektronicznych. Mierzy sie ja w hertzach (Hz). Na przyklad, zakladajac, ze mamy do czynienia z procesorem sekwencyjnym majacym mozliwosc wykonania jednego dzialania w jednym takcie zegara: to dla procesora o szybkosci taktowania 1GHz, otrzymamy predkosc obliczen 109 flopsów, czyli 1 Gflops. Wydajnosc maksymalna Rpeak – to najwieksza szybkosc obliczen uzyskana dla problemu algebry liniowej pakietu benchmarków Linpack (Jack Dongarra). Przez termin benchmark nalezy rozumiec specjalnie skonstruowany program sluzacy do pomiaru predkosci obliczen. Pozostale terminy zwiazane z okresleniem szybkosci obliczen to: Nmax - wielkosc najwiekszego problemu dla którego uzyskano Rmax, N1/2 - wielkosc problemu dla którego uzyskano wydajnosc równa polowie Rmax (powinna byc jak najmniejsza). Pomiar tych wielkosci jest niezwykle wazny dla oceny wydajnosci systemów wieloprocesorowych. W przypadku, gdy N1/2 jest zbyt duze oznacza to, ze wydajnosc systemu gwaltownie maleje dla zmniejszajacego sie rozmiaru zadania co sugeruje, ze czas przeznaczony na komunikacje pomiedzy elementami obliczeniowymi (i pamiecia) jest zbyt duzy. Liste najwiekszych instalacji komputerowej na swiecie pokazuje tzw. lista TOP500 (www.top500.com). Szybkosc srednia (sustained performance) - najwieksza, stale osiagana szybkosc komputera. Oczywiscie wzrost predkosci maksymalnej przeklada sie na wzrost predkosci sredniej. Rosnie równoczesnie róznica pomiedzy predkoscia maksymalna i predkoscia srednia! Na przyklad podwojenie predkosci zegara zwieksza szybkosc maksymalna 2 razy. Szybkosc srednia rosnie mniej niz 2 razy ze wzgledu na wolniejszy niz szybkosc przetwarzania dostep do pamieci.

O ekonomicznych uwarunkowaniach zakupu mocy obliczeniowej decyduje tzw. price performance czyli stosunek koszt/szybkosc. Ponizej przyklad takiego oszacowania ekonomicznych kosztów systemu obliczeniowego. Maszyna Nr. 1 10 Tflopsów koszt 10 mln. USD 1 Gflops = 1000 USD Maszyna Nr 2 100 Gflopsów koszt 50 tys. USD 1 Gflops = 500 USD Oczywiscie z ekonomicznego punktu widzenia maszyna Nr.2 jest lepsza. Jednak czasami niektóre zadania czy aplikacje wymagaja tak duzych mocy obliczeniowych, których nie moze dostarczyc slabsza i tansza maszyna. Wtedy musimy za moc obliczeniowa zaplacic wiecej. 1.4. Ograniczenia informatyki 1.4.1 Ograniczenia formalne
Wielu uczonych od lat marzy o stworzeniu takiej maszyny, która bylaby w stanie zamodelowac dowolne zjawiska zachodzace we Wszechswiecie – niezaleznie od ich zlozonosci – wylacznie za pomoca elementów logiki matematycznej. Jezeli system ten ma w jakims stopniu reprezentowac Wszechswiat, bedzie posiadal on ogromna moc predykcyjna stajac sie powoli ogólnoswiatowa wyrocznia i filarem rozwoju nauki. Stanie sie takze filarem walki cywilizacji z zagrozeniami. Przewidywanie zagrozen dla rozwoju osobnika jak i calej populacji jest najlepszym sposobem ich unikniecia.
Jezeli taka maszyne mozna zbudowac, musi ona bazowac na modelu wspomnianego wczesniej metakomputera. Zatem tzw. wszechobecna informatyzacja (ang. pervasive computing) jako element spajajacy intelektualna moc calej ludzkosci przy pomocy narzedzi informatyki: systemów liczacych (komputerów), systemów polaczen (sieci komputerowych), systemów pamieci masowej oraz systemów wizualizacji, stanowic bedzie glówny motor rozwoju naszej cywilizacji i warunek naszego przetrwania.
Pozostaje jednak odpowiedziec na zasadnicze pytanie: Czy taka maszyne da sie rzeczywiscie zbudowac??
Od co najmniej kilkudziesieciu lat jestesmy swiadkami gwaltownego wzrostu mocy obliczeniowej komputerów, najczesciej definiowanej w ilosci przetwarzanych instrukcji zmiennoprzecinkowych na sekunde (ang. termin flops). Dla przykladu komputer laptop (technologii mobile) z procesorem taktowanym zegarem 1,6GHz, posiadajacy pamieci operacyjnej RAM 1GB i 100GB pamieci dyskowej kosztuje w granicy 0.01% ceny superkomputera lat 90tych o podobnej mocy obliczeniowej. O ile mniej kosztuje jego eksploatacja, oraz ile razy zmniejszono jego wymiar to dodatkowe atuty wspólczesnosci! Zakladajac aktualny wzrost predkosci przetwarzania informacji, która zgodnie z prawem Moora wzrasta od poczatku rozwoju komputerów w sposób wykladniczy (dokladnie ~t1.7) juz za 300 lat bedziemy w stanie modelowac wszystkie (?) 1080 bozonów z których sklada sie nasz Wszechswiat. Stad krótka droga do symulacji „wszystkiego” i stworzenia idealnej wyroczni. Czy jest jednak mozliwe utrzymanie tak szybkiego wzrostu mocy obliczeniowej? A moze istnieja bardziej fundamentalne przeszkody niz tylko technologiczne, nieskrepowanego rozwoju obliczen.
Pierwsza przeszkoda, a zarazem pierwsze powazniejsze pekniecie na fasadzie matematyki pojawilo sie w 1936 rok, gdy 24 letni Alan Turing (matematyk angielski) postawil pytanie, czy mozna w „czysto mechaniczny sposób” przeprowadzic wszystkie wywody matematyczne i logiczne. Odpowiedz negatywna oznaczalaby, ze istnieja zasadnicze ograniczenia naszej zdolnosci przedstawiania rzeczywistych procesów w postaci mechanicznych regul logicznych (czy ogólniej matematycznych) w tym równiez mozliwosci symulowania zachowania zlozonych ukladów przy pomocy maszyn. Zdecydowana odpowiedz „nie!”,

stanowila cios dla wszechmocnej wydawaloby sie matematyki i mozliwosci postrzegania Wszechswiata przez ludzkosc. Siedemnastego listopada 1930 roku dwudziestopiecioletni Kurt Gödel opublikowal artykul, który zawieral dowód, ze pewnych twierdzen matematycznych nie mozna ani wykazac ani obalic. Matematyka nie stanowi, zatem spójnego systemu i prowadzi do paradoksów typu „to zdanie jest falszywe” czy paradoksu Russela („R to zbiór wszystkich zbiorów nie bedacych swoimi elementami”). W obu przypadkach nie da sie udowodnic ani prawdziwosci ani falszywosci tych zdan logicznych.
Wyniki otrzymane przez Turinga i Gödla uswiadamiaja nam, ze abstrahujac od technicznych problemów budowy maszyny modelujacej Wszechswiat nie jest mozliwe ani stworzenie matematycznego modelu ani, tym bardziej, mechanicznej procedury odtwarzajacej jego wlasciwosci i przewidujacej z nieskonczona dokladnoscia jego rozwój. Wynika to takze z praw zwiazanych z podstawami mechaniki kwantowej czy z teorii chaosu deterministycznego, które mówia, ze nie jest mozliwe dokladne przewidywanie zachowan ukladów fizycznych w nieskonczonych interwalach czasowych ze wzgledu na obowiazujace w przyrodzie prawo nieoznaczonosci Heisenberga, narastajacy eksponencjalnie blad obliczen i wystepowanie tzw. efektów rezonansowych (rezonanse Poincare).
Pomimo tych pryncypialnych problemów obliczalnosci i przewidywalnosci zachowan Natury, istnieje mozliwosc predykcji lokalnych zjawisk w krótszych interwalach czasowych, czy wystepowania fundamentalnych zjawisk czy zdarzen z pewnym wyliczonym bledem. Przykladami niech beda prognozy pogody, czy przewidywanie trzesien ziemi. Odnosnie tych ostatnich, np. prognozuje sie olbrzymie trzesienie ziemi w okolicach Osaki w ciagu najblizszych 10 lat. To typowy przyklad predykcji zjawiska pewnego, jednak o bardzo nieprecyzyjnie zdefiniowanym czasie jego wystapienia. Wzrost mocy obliczeniowej pozwoli nam w najblizszej przyszlosci na wydluzenie czasu sprawdzania sie prognoz (pogoda) czy scislejszej lokalizacji w czasie i przestrzeni zjawisk pogodowych i katastrof (trzesienia ziemi, tornada, zderzenia z meteorem), a takze przewidywania, zatem minimalizacji skutków tych katastrof.
1.4.2 Fizyczne ograniczenia szybkosci obliczen Choc w mniej fundamentalny sposób niz przejawia sie to w pryncypialnych uwarunkowaniach ludzkosci do pojmowania swiata, istnieje szereg technicznych problemów osiagniecie duzych - acz skonczonych - mocy obliczeniowych. Wynikaja one z ograniczen narzucanych nam przez fizyke, a przede wszystkim:
• mozliwosci upakowania obwodów logicznych w zadanej objetosci, • dlugosci sciezek i predkosci zmiany stanów podstawowych elementów logicznych –
tranzystorów, • sposobów ograniczenia wydzielania ciepla podczas pracy ukladów przelaczajacych.
Szacuje sie, ze za okolo 100 lat w jednym atomie bedzie mozna przechowac 10 bitów informacji, co daje ok.1025 bitów informacji w 1cm3 – jest to 10-krotnie wiecej niz wynosi aktualna calkowita pamiec dyskowa i tasmowa na swiecie. Poniewaz i ta gestosc upakowania informacji znajduje sie jeszcze duzo ponizej limitów dopuszczalnych przez fizyke (np. oszacowanie Smitha i Lloyda dopuszcza upakowanie informacji do 1029 bitów w 1 cm3 – lecz „laptop” o takich mozliwosciach skladajacy sie z 1 tony fotonów o temperaturze miliarda stopni Celcjusza musialby byc zamkniety w obudowie wytrzymujacej dodatkowo cisnienie 1019 kg/m2) zatem w przypadku pamieci wystepuja jeszcze duze zapasy i osiagniecie limitu dozwolonego przez przyrode szybko nie nastapi. Nawet gdyby, to pozostaje nam trudna do oszacowania ilosc informacji, która moglaby byc skladowana w czarnych dziurach (oszacowanie Bekensteina mówi nawet o 1063 bitów na cm3).

Problemy pojawiaja sie juz jednak z iloscia energii, która ulega dyssypacji podczas obliczen. Przetworzenie jednego bita informacji powoduje wydzielenie sie skonczonej ilosci ciepla nie mniejszej niz kTln2 (gdzie k – stala Boltzmanna, T- temperatura), które narzucone jest przez fizyke – to znaczy nie mozna „zejsc nizej”. Aby cieplo nie wydzielalo sie, nalezaloby utrzymywac komputer w temperaturze zera bezwzglednego, co na pewno jest niezwykle drogie i uciazliwe. Granice minimalnej ilosci wydzielania ciepla (dla dowolnego materialu, z którego bedzie zrobiony komputer) osiagniemy juz za 35 lat. Przy szacowanych predkosciach obliczen 3.5×1022 bit/sek (milion razy wiekszych niz dzisiejszych) nasz laptop wydzielac bedzie cieplo w temperaturze pokojowej takie jak 100W zarówka. Milion razy szybciej to nie tak znów duzo. Wspólczesne superkomputery sa szybsze milion razy od legendarnego superkomputera wektorowego Cray-1 z konca lat siedemdziesiatych! Kazdy wzrost predkosci ponad te miare bedzie powodowal zwiekszanie wydzielania ciepla – niezaleznie od tego, jakich materialów uzyjemy do konstruowania elementów obliczeniowych i jaki paradygmat obliczen wykorzystamy (nie pomoga nam komputery kwantowe!). Zatem w przypadku problemów zwiazanych z wydzielaniem ciepla i energochlonnosci obliczen granice fizyczne sa bardzo blisko. Pewnym wyjsciem byloby budowanie tzw. procesorów adiabatycznych, wykorzystujacych do obliczen zuzyta juz informacje.
Jeszcze powazniej rysuje sie perspektywa ograniczen fizycznych zwiazanych z przesylaniem informacji. Tu na przeszkodzie stoi maksymalna predkosc rozchodzenia sie informacji w prózni zwiazana z propagacja fali elektro-magnetycznej oraz prawo promieniowania ciala doskonale czarnego Stefana-Boltzmanna. Ograniczaja one predkosc przesylania informacji do 68 kb/s na 1 nanometr (10-9) kwadratowy. Tymczasem potrzeby przesylania informacji po wewnetrznych magistralach 100GHz komputera to 1011 b/s. Wymagaloby to wytwarzania zródel fal elektromagnetycznych o gestosci energii 10MW/cm2 (daje to temperature zródla 14,000 K przekraczajaca dwukrotnie temperature powierzchni Slonca). I tu jednak mozna sobie poradzic, poszukujac innego nosnika informacji, np., poruszajacych sie atomów lub elektronów. Dla wyzej wspomnianego 100GHz komputera zakladajac, iz 1bit informacji mozna zakodowac w kostce materii o objetosci 1nm3, wystarczalby ich strumien o sredniej predkosci 100km/s.
Predkosc wykonywania obliczen zwiazana jest z mozliwosciami szybkiego przelaczania sie obwodów logicznych z jednego do drugiego stanu. O szybkosci przelaczania stanów decyduje bezwladnosc podstawowego „przelacznika” jakim jest (na razie) tranzystor polowy. O bezwladnosci decyduje technologia procesora, material z którego zostal wykonany, dlugosc sciezek pomiedzy elementami logicznymi. Zakladajac jednak, iz maksymalna predkosc zmiany dowolnego stanu kwantowego materii proporcjonalna jest do energii systemu (odwrotnie proporcjonalna do stalej Planck’a) otrzymamy górne ograniczenie dla „laptopa” Lloyda 5×1050Hz. Jednak dla bardziej realistycznego przelacznika zbudowanego z jednego elektronu o energii o 1eV wiekszej od stanu podstawowego otrzymamy predkosc zegara na poziomie 1PHz (1015 Hz) czyli 105 razy wiecej od wspólczesnych komputerów PC. Jak widac wspólczesna technologia i paradygmaty obliczen napotkaja juz niedlugo, dzis wydaje sie nieprzekraczalne, bariery formalne i fizyczne dalszego rozwoju. Interesujace jest jak nauka wybrnie (a ze jakos wybrnie to raczej nie ulega watpliwosci) z tego dolka. Jest to jednak pytanie o przyszlosc. Zobaczmy jednak, w jakim stanie wiedzy znajdujemy sie dzis. Omijajac wiele istotnych etapów rozwoju informatyki zatrzymajmy sie na problemach zwiazanych z rozwojem architektur komputerowych, które do dzis stanowia motor rozwoju tej dziedziny wiedzy.

II ELEMENTY ARCHITEKTUR KOMPUTEROWYCH
2.1 Klasyczna maszyna Von Neumanna
Tak zwana architektura von Neumanna jest modelem maszyny liczacej, która wykorzystuje pojedynczy podsystem skladowania danych – pamiec - do magazynowania zarówno zbioru instrukcji jak i danych oraz tymczasowych rezultatów obliczen. Tego typu maszyny nosza nazwe komputerów przechowujacych program (ang. stored-program computers). Podstawowa wlasnoscia tego typu maszyny jest to, iz podsystem pamieci oddzielony jest od elementu przetwarzajacego informacje – procesora lub jednostki centralnej (ang. central processing unit, CPU).
Rysunek 2.1.1 John von Neumann (w jasnym garniturze) wraz z Oppenheimerem oraz na drugim zdjeciu z Albertem Einstainem (von Neumann ledwie widoczny z tylu). Model maszyny uniwersalnego zastosowania (ang. general purpose machine) zostal nazwany nazwiskiem jego twórcy, którym byl znany matematyk pochodzenia wegierskiego John von Neumann. Maszyne ta opracowali razem z nim znani fizycy: John William Mauchly i J. Presper Eckert, którzy pracowali nad koncepcja maszyny przechowujacej w pamieci program oprogramowujac jeden z najwczesniejszych komputerów ENIAC. Traktujac instrukcje programu w ten sam sposób jak dane, maszyna „przechowujaca program” mogla wymieniac instrukcje. Innymi slowy komputer ten byl re-programowalny. Glówna motywacja tego udogodnienia byla potrzeba inkrementacji adresu instrukcji, lub w przeciwnym wypadku, jego modyfikacji. Jest to zdecydowanie mniej istotne, gdy rejestry indeksowe i posrednia adresacja staje sie powszechna cecha architektur komputerowych. Aktualne architektury procesorów nie wymagaja kodów samo-modyfikujacych sie wykorzystujacych posrednia adresacja, poniewaz przetwarzanie potokowe, systemy pamieci podrecznej powoduja, ze staja sie one nieefektywne. Traktujac instrukcje w jednakowy sposób jak dane, mozliwe jest stosowanie kompilatorów – programów tlumaczacych dowolny kod w ciag instrukcji wykonywanych bezposrednio przez system liczacy. Cecha ta jednak moze byc jednak wykorzystywana przez wirusy komputerowe, które moga kopiowac sie do istniejacych w systemie programów wykonywalnych. Problem ten moze byc kontrolowany wykorzystujac podsystemy ochrony pamieci (ang. memory protection), a w szczególnosci architektury bazujace na pamieciach wirtualnych (ang. virtual memory architectures). Podzial na jednostke obliczeniowa (CPU) i pamiec (ang. Memory) powoduje problemy znane jako „problemy dostepu do pamieci” (von Neumann bottleneck). Pasmo przenoszenia i

predkosc transmisji danych pomiedzy CPU jest bardzo mala w porównaniu z wielkoscia pamieci. W nowoczesnych maszynach jest ona równiez bardzo mala w porównaniu z czestotliwoscia pracy procesora. W pewnych sytuacjach, gdy wykorzystywana moc obliczeniowa procesora jest niewielka w porównaniu z iloscia operacji czytania i zapisu w pamieci, obserwuje sie gwaltowna degradacje obliczen, poniewaz jednostka obliczeniowa zamiast wykorzystywac swoja wydajnosc zmuszona jest oczekiwac na dane transferowane do i z pamieci. Pomimo gwaltownego rozwoju technologii komputerowej i odstepstw od sekwencyjnosci obliczen i rozwoju systemów równoleglych, do tej pory systemy komputerowe posiadaja glówne elementy i funkcjonalnosc architektury von Neumanna. Jak pokazuje Rys.2.1.1 model maszyny sklada sie z czterech jednostek:
• jednostki arytmetyczno-logicznej (ang. arithmetic-logical unit ALU), • jednostki kontrolnej (ang. control unit CU), • pamieci (ang. memory), • jednostki wejscia-wyjscia (input-output unit, I/O).
Elementy architektury spina magistrala (ang. bus).
Rysunek 2.1.1 Architektura von Neumanna.
Pamiec
W tym systemie, pamiec sklada sie z sekwencji numerowanych komórek (ang. cell), kazda zawierajaca “kawalek” informacji – slowo maszynowe. Tym „kawalkiem” informacji moze byc instrukcja (ang. instruction) mówiaca co maszyna ma dalej robic lub dana (ang. data), która komputer potrzebuje w celu wykonania instrukcji. Ta sama komórka pamieci moze raz zawierac dana drugi raz instrukcje. W ogólnosci, zmieniajaca sie zawartosc komórek pamieci upodabnia pamiec operacyjna do zmazywalnej tablicy. Wielkosc kazdej komórki oraz liczba komórek, zalezy od rodzaju komputera, jego mocy obliczeniowej i technologii uzytej do jego produkcji poczynajac od mechanicznych przekladni, elektromagnetycznych przekazników, ferromagnetycznych pierscieni, do tranzystorów i zintegrowanych obwodów elektronicznych z milionami elementów na pojedynczym chipie.
Obliczenia
Jednostka arytmetyczno-logiczna ALU jest urzadzeniem wykonujacym elementarne operacje takie jak operacje arytmetyczne: dodawanie, odejmowanie, mnozenie i dzielenie, operacje logiczne (suma i iloczyn logiczny, negacja itp.) oraz operacje porównania i przypisania. Jednostka ta jest centralnym elementem obliczen.

Jednostka kontrolna CU, jak sama nazwa wskazuje, kontroluje, które slowo w pamieci zawiera aktualna instrukcje wykonywana przez komputer, przydziela ALU rodzaj operacji do wykonywana i „mówi”, które dane sa niezbedne do jej wykonania, a takze transferuje wynik do odpowiedniej komórki pamieci. Decyduje ona takze o tym, która nastepna z kolei instrukcja ma byc wykonywana. Jest to najczesciej instrukcja o kolejnym adresie, jezeli wczesniej wykonywana instrukcja nie byla instrukcja skoku.
Instrukcje wejscia-wyjscia
Uklady wejscia-wyjscia I/O pozwalaja komputerowi na interakcje ze swiatem zewnetrznym, dostarczaniem programów do wykonania, danych do programu, umozliwiaja prezentacje wyników obliczen i komunikacje z czlowiekiem. Do urzadzen zewnetrznych nalezy zaliczyc: klawiature, monitor, myszke, streamer, drukarke, ploter, nagrywarke CD i DVD, dyski twarde, kamere internetowa itd. Wszystkie urzadzenia wejscia posiadaja jedna wspólna ceche: koduja informacje pewnego typu na dane maszynowe, które w dalszej kolejnosci sa przetwarzane przez system komputerowy. Z drugiej strony, urzadzenia wyjscia dekoduja dane w informacje, zrozumiala dla uzytkownika. System komputerowy jest zatem systemem przetwarzania danych.
Instrukcje
Instrukcje komputera, o których byla mowa, to nie jezyk równie bogaty jak mowa ludzka. Kazdy wspólczesny procesor posiada swój wlasny, silnie ograniczony, zbiór instrukcji podstawowych. Nie jest ich wiele, co najwyzej kilkadziesiat. Sa to instrukcje typu “skopiuj zawartosc komórki pamieci 123, i wstaw kopie do komórki 456” lub „jezeli zawartosc komórki 999 jest równa 0, wykonaj nastepna instrukcje z komórki 345”. Instrukcje sa kodowane jak liczby binarne, np. Instrukcja “kopiuj” moze byc liczba 001. Zbiór instrukcji podstawowych i regul ich uzycia nosi nazwe “maszynowego jezyka programowania”. Zazwyczaj czlowiekowi trudno uzywac zakodowanych instrukcji maszynowych, dlatego poslugujemy sie tak zwanymi jezykami wysokiego poziomu, tlumaczonymi do kodu maszyny przy pomocy kompilatorów (ang. compilers) lub interpreterów (ang. interpreters). Niektóre jezyki programowania sa bardzo bliskie jezykowi maszynowemu, tzn. ich skladnia pozwala na wykorzystanie wlasciwosci architektury procesora. Jezyki maszynowe i asemblery, w przeciwienstwie do jezyków wysokiego poziomu takich jak jezyk C czy Fortran 95, nie sa z reguly przenosne, tzn. sa specyficzne dla danej architektury procesora.
Architektury
We wspólczesnych procesorach juz od lat ALU i CU znajduja sie w jednym zintegrowanym elemencie procesora zwanym jednostka centralna (ang. central processing unit CPU). Typowa pamiec albo jest zintegrowana z chipem procesora (pamiec podreczna, ang. cache) albo umieszczona w jego poblizu i polaczona szybka magistrala. Pozostala „mase” komputera tworza systemy zasilania oraz podsystemy i urzadzenia zewnetrzne. Duze wspólczesne systemy obliczeniowe – omówione w dalszej czesci ksiazki – posiadaja wiele jednostek obliczeniowych, lub tzw. wezlów obliczeniowych (ang. computing nodes) skladajacych sie z kilku jednostek centralnych CPU, pamieci oraz przelacznika krzyzowego (ang. crossbar) lub magistrali, spietych szybka zewnetrzna siecia polaczen. Sa to tzw. komputery równolegle (ang. parallel computers).

PAMIEC
Jednostka arytmetyczno-
logiczna ALU
Jednostka kontrolna
CU
REJESTRY
JEDNOSTKA CENTRALNA CPU
Rysunek 2.1.2 Architektura von Neumanna wzbogacona o system rejestrów.
Funkcjonowanie komputera von Neumanna oparte jest na niezwykle prostej zasadzie. System pobiera instrukcje i dane z pamieci. Instrukcje sa wykonywane, a rezultaty ponownie zapisywane do pamieci. Za kazdym razem system wylicza adres nastepnego rozkazu, który znowu pobierany jest do wykonania. Powtarza sie to dopóki system nie trafi na instrukcje STOP, która konczy dzialanie programu, lub nie nastapi systemowe lub zewnetrzne przerwanie toku obliczen. Rys.2.1.2 przedstawia element komputera von Neumanna, w którym pamiec odseparowana jest od jednostki centralnej. Ta z kolei zawiera w sobie podsystem szybkiej pamieci zintegrowanej z ALU i CU zwanej systemem rejestrów (ang. registers). Zanim pobrane z pamieci glównej (ang. main memory) dane lub instrukcja zostana przetworzone, zostaja pobrane do szybkich rejestrów w momencie, gdy ALU i CU wykonuja wczesniejsza instrukcje (tzw. prefetching). Podobnie rezultaty wykonywanych w ALU obliczen zapisywane sa w rejestrach, by w momencie wykonywania nastepnych obliczen zostaly albo przeniesione do pamieci, albo wykorzystane jako dane dla nastepnej w kolejnosci instrukcji.
Programy
Programy komputerowe sa po prostu dluga lista instrukcji, opisujacych algorytm – model – realizowany automatycznie przez system komputerowy. Istnieja programy komputerowe zlozone z milionów i dziesiatków milionów instrukcji przetwarzajace giga i terabajty danych. Wiele z tych instrukcji wykonywanych jest w tzw. petlach. Jak wspominalismy w poprzednim rozdziale, czym bardziej zlozona instrukcja, tym trudniej “wycisnac” z komputera jego najwieksza wydajnosc. Jak dowiemy sie w nastepnym rozdziale, wlasnie pomysl przedstawienia kazdej instrukcji przy pomocy niewielkiej ilosci prostszych instrukcji, spowodowal rewolucyjny wzrost mocy obliczeniowej pojedynczego procesora. Dzisiejsze komputery, dzieki spadkowi ceny pojedynczego CPU, wykorzystuja kilka do kilku tysiecy pracujacych równolegle procesorów. Dzieki temu wzrosla proporcjonalnie do ilosci wykorzystywanych procesorów moc komputerów pracujacych w rezimie wielozadaniowym (ang. multitasking), na których wielu uzytkowników uruchamia równoczesnie wiele zadan. Oczywiscie równoczesnie wykonuja sie jedynie zadania wykorzystujace rózne procesory. Pojedynczy procesor pracujacy w rezimie wielozadaniowym, dzieli swój czas i moc obliczeniowa pomiedzy uruchomione procesy.

System operacyjny
Programy w systemach wielozadaniowych nadzorowane sa przez program uruchamiany zaraz po wlaczeniu systemu komputerowego do pracy. Program ten nosi nazwe systemu operacyjnego. Od jego funkcjonalnosci zalezy efektywnosc systemu komputerowego, jego mozliwosci, bezpieczenstwo i wygoda uzytkownika. System operacyjny przydziela zasoby obliczeniowe oraz uslugi (w tym uslugi wejscia/wyjscia) uzytkownikom, tak by ich praca byla przezroczysta (ang. transparent) dla innych. Wydziela i usprawnia proces wspóldzielenia zasobów obliczeniowych przez róznych uzytkowników i wspólzawodniczace o te zasoby procesy. System operacyjny ukrywa zlozone detale budowy komputera, reprezentujac jego elementy i manipulacje na nich w postaci latwo przyswajalnych przez uzytkownika obrazów i czynnosci (np. uruchomienie programu, przydzielenie mu odpowiedniego urzadzenia wejscia i wyjscia oraz zbioru danych i przygotowanie graficznej prezentacji danych, upraszcza sie np. do klikniecia mysza w ikone reprezentujaca dane i przeniesieniu jej w miejsce w której znajduje sie ikona programu (wykorzystanie mechanizmu drag-and-drop (przenies i upusc)).
2.2 Procesor – serce komputera Procesor, reprezentowany przez CPU (ang. Central Processing Unit), to najwazniejsza jednostka kazdego komputera, bedaca najczesciej pojedynczym mikroprocesorem, polaczonym z plyta glówna za pomoca specjalnego gniazda typu ZIF lub Slot. Ogól procesorów jest obecnie wytwarzany w postaci ukladów o niezwykle wysokim stopniu integracji dochodzacej do milionów tranzystorów na jednej plytce krzemu. Ponizszy rysunek (Rys2.2.1) przedstawia uproszczona budowe pojedynczego procesora bazujacego na architekturze von Neumanna. Wyrózniono w nim dodatkowo takie elementy zwiekszajace efektywnosc przetwarzania jak: kolejkowanie kolejnych instrukcji, jednostke buforujaca (przetrzymujaca w szybkiej pamieci rejestrowej lub podrecznej) adresy i dane (BU), jednostke dekodujaca pobierane instrukcje wspólpracujaca z pamiecia ROM zawierajaca definicje mikrorozkazów (IU), oraz jednostke wykonujaca skladajaca sie z jednostki arytmetyczno logicznej (ALU) oraz oddzielnie z jednostka realizujaca obliczenia zmiennoprzecinkowe (FPU).
Rysunek 2.2.1. Schemat blokowy mikroprocesora

Procesor przechodzil w ostatnim cwiercwieczu gwaltowne przeobrazenia, co odzwierciedlaja rózne typy przetwarzania i jego paradygmaty (modele) coraz bardziej oddalajace sie od typowego przetwarzania Von Neumanna. Ponizej przedstawiono najwazniejsze typy procesorów: przestarzala technologie CISC, wspólczesna RISC oraz wschodzaca technologie EPIC. CISC (ang. Complex Instruction Set Computers) Technologia ta byla najwczesniej rozwinieta technologia procesorów, z licznymi przykladami konkretnych realizacji architektur. Skrót CISC oznacza procesor o zlozonej, obszernej liscie rozkazów róznych dlugosci. Oba te fakty: zlozona lista rozkazów oraz rózna ich dlugosc, komplikuja w wysokim stopniu analize i optymalizacje kodu (kompilatory muszy byc bardzo rozbudowane) i utrudniaja uzyskanie równoleglosci na poziomie realizacji poszczególnych instrukcji. W wyniku tego niemozliwe jest uzyskanie wysokiej wydajnosci. Nielatwe jest równiez zwiekszenie czestotliwosci pracy, gdyz realizacja architektury wymaga duzej ilosci materialu, co wiaze sie z koniecznoscia odprowadzenia ciepla i podnosi koszty produkcji. Najczesciej technologia CISC realizowana jest w formie procesorów wieloukladowych. Ten typ technologii procesorowej charakterystyczny jest dla wczesniejszych rozwiazan.
RISC (ang. Reduced Instruction Set Computer) Pozwala na eliminacje mikroprogramów i przejecie sterowania komputerem na niskim poziomie przez oprogramowanie. Glównym celem architektury RISC jest zmniejszenie liczby taktów zegarowych skladajacych sie na cykl rozkazowy. Produkowane obecnie mikroprocesory z architektura RISC pozwalaja osiagnac rezultat jeden lub wiecej zakonczonych rozkazów w ciagu kazdego taktu zegarowego. Nie oznacza to jednak, ze cykl rozkazowy trwa jeden takt zegarowy. Wynik ten uzyskiwany jest droga przetwarzania strumieniowego (procesor MISD wg klasyfikacji Flynna) i oznacza srednia predkosc realizacji rozkazów. Predkosc dzialania procesora wyrazona liczba wykonanych rozkazów w ciagu jednostki czasu jest wtedy równa czestotliwosci generatora zegarowego.
Wlasnosci mikroprocesorów RISC Podstawowe wlasnosci mikroprocesora z architektura RISC mozna sformulowac w nastepujacy sposób :
• Wszystkie rozkazy maja ten sam format. Upraszcza to proces pobierania rozkazów z pamieci, ich przechowywanie w rejestrach posrednich (kolejkach rozkazów) oraz dekodowanie (ten sam typ informacji zajmuje zawsze te same bity).
• Wszystkie rozkazy maja ten sam (lub prawie ten sam) czas realizacji. Pelny cykl rozkazowy dzielony jest na fazy o takim samym czasie trwania. Kazda faza realizowana jest w czasie jednego taktu zegarowego. Ulatwia to organizacje przetwarzania strumieniowego i umozliwia synchroniczne sterowanie (zmiana faz odbywa sie na kazdym stopniu w tym samym czasie).
• Operacje wymiany informacji z pamiecia i operacje arytmetyczno-logiczne realizowane sa niezaleznie. Wszystkie operacje arytmetyczno-logiczne wykonywane sa na argumentach znajdujacych sie w rejestrach procesora i wynik operacji kierowany jest równiez do rejestru. Wiekszosc rozkazów wykonywanych w programach to rozkazy arytmetyczno-logiczne. W czasie wykonywania takich rozkazów nie jest wykonywany dostep do pamieci, pochlaniajacy najwiecej czasu. Architektura

procesorów, w których spelniona jest ta zasada, nazywana jest architektura "laduj/zapamietaj" (ang. Load/Store Architecture).
• Sterowanie przeplywem rozkazów i ich wykonaniem realizowane jest sprzetowo (jako przeciwienstwo sterowania mikroprogramowego).
• Wyposazenie mikroprocesora w duza liczbe rejestrów uniwersalnych. Stosowane sa nastepujace liczby rejestrów: 32, 64,128.
• Wyposazenie mikroprocesora w lokalna pamiec podreczna (ang. cache memory). Przy duzych czestotliwosciach generatorów czestotliwosci zegarowych (rzedu setek MHz), czas trwania taktu zegarowego jest rzedu kilku nanosekund (10-9 s). Produkowane obecnie uklady pamieci pólprzewodnikowej, które moga byc uzyte do konstrukcji pamieci operacyjnej (glównej), nie zapewniaja tak malych czasów dostepu. Oznacza to, ze rozkazy Load i Store nie moglyby byc wykonane w takim samym czasie, jak rozkazy arytmetyczno logiczne. Jest to szczególnie wazne przy pobieraniu rozkazów z pamieci (operacja ta zwiazana jest z kazdym cyklem rozkazowym). Prawie wszystkie produkowane mikroprocesory RISC posiadaja wbudowana pamiec podreczna o stosunkowo niewielkiej pojemnosci, lecz o czasie dostepu rzedu 5 ns lub nawet ponizej.
• Koniecznosc wykonywania operacji arytmetyczno - logicznych w jednym takcie zegarowym wyklucza praktycznie stosowanie klasycznej techniki sterowania mikroprogramowego. Wszystkie operacje arytmetyczno - logiczne musza byc wykonywane w ukladach kombinacyjnych. Powoduje to znaczna rozbudowe arytmometrów, zwlaszcza jesli chodzi o takie operacje jak mnozenie, dzielenie i operacje zmiennoprzecinkowe.
• W celu maksymalnego uproszczenia procesu dekodowania rozkazów, przyjmuje sie dla nich jednolity format. Oznacza to, ze rozkazy maja te sama dlugosc i poszczególne pola funkcjonalne zajmuja zawsze bity o tych samych numerach.
• W celu zmniejszenia liczby przeslan miedzyrejestrowych przyjmuje sie, ze wszystkie rozkazy arytmetyczno - logiczne odnosza sie do trzech operandów: dwa to argumenty, a trzeci to rezultat operacji. Oznacza to, ze w czasie wykonywania rozkazu zaden z argumentów nie jest niszczony.
• W celu zmniejszenia liczby rozkazów potrzebnych do wykonania zadania stosuje sie duza dlugosc slowa maszynowego: 32,64, a nawet 128 bitów.
Ostatnie trzy z tych wymagan pozwalaja utworzyc uniwersalny format rozkazu, który z niewielkimi zmianami stosowany jest we wszystkich mikroprocesorach RISC. Wiekszosc rozkazów sklada sie z pieciu pól, majacych nastepujace znaczenia:
KO - kod operacji, A,B,C - numery rejestrów zawierajacych argumenty i wynik operacji, M - modyfikatory funkcji rozkazu lub trybu adresowania.
KO A B C M
Rysunek 2.2.2. Typowy format rozkazu mikroprocesorów RISC
Przetwarzanie potokowe Powszechnie stosowana w mikroprocesorach RISC metoda, pozwalajaca zmniejszyc srednia liczbe taktów na rozkaz bez wydluzania taktu zegarowego, jest metoda strumieniowego –

potokowego - wykonywania rozkazów (ang. pipelining processing). Kluczowym zagadnieniem w organizacji strumieniowego wykonywania rozkazów jest podzial cyklu rozkazowego na fazy. W wiekszosci mikroprocesorów RISC, cykl rozkazowy dzielony jest na cztery fazy, wykonywane kolejno.
FETCH (IF) Faza pobierania rozkazu. W fazie tej rozkaz pobierany jest z pamieci i umieszczany w wewnetrznym rejestrze rozkazów lub w wewnetrznej, szybkiej pamieci buforowej, stanowiacej kolejke rozkazów. DECODE (ID) Faza dekodowania rozkazu. W fazie tej rozkaz jest dekodowany i ustalane jest polaczenie arytmometru z rejestrami zawierajacymi argumenty. W arytmometrze ustalany jest rodzaj wykonywanej operacji. Niekiedy do fazy tej zalicza sie takze pobranie argumentów z rejestrów uniwersalnych do rejestrów roboczych arytmometru.
EXECUTE (IE) Faza wykonania rozkazu. W przypadku rozkazów arytmetyczno - logicznych, w arytmometrze wykonywana jest operacja ustalona przez rozkaz. W przypadku rozkazów komunikacji z pamiecia w fazie tej obliczany jest adres fizyczny argumentu. Niekiedy faza ta moze trwac dluzej niz jeden takt zegarowy (np. w przypadku zlozonych operacji arytmetycznych takich, jak mnozenie i dzielenie).
WRITE (MEM) Faza zapisu wyniku. W przypadku rozkazu arytmetyczno-logicznego wynik operacji zapisywany jest w docelowym rejestrze uniwersalnym. W przypadku rozkazów komunikacji z pamiecia realizowany jest cykl zapisu lub odczytu z pamieci.
WRITE-BACK (WB)
Oznacza przeniesienie wyników czastkowych do rejestrów (np. akumulatora).
IF ID EX
MEM WB
Rysunek 2.2.3. Fazy cyklu rozkazowego

Rysunek 2.2.4 Fazy przetwarzania potokowego list rozkazów Przetwarzanie superskalarne
Rysunek 2.2.5. Architektura procesora superskalarnego Cecha charakterystyczna przetwarzania superskalarnego (patrz Rys.2.2.5-6) jest to, ze wszystkie rozkazy realizowane sa w kilku fazach, a kazda faza wykorzystuje swoje wlasne zasoby. Oznacza to, ze w jednym takcie zegarowym moze byc wykonywana tylko jedna faza kazdego rodzaju. Takie przetwarzanie rozkazów nazywa sie skalarnym. Dalsze zwiekszenie wydajnosci procesora mozna uzyskac przez zwielokrotnienie zasobów w taki sposób, by utworzyc dwa lub wiecej ciagów przetwarzania strumieniowego. Wtedy w jednym takcie zegarowym moze byc zakonczonych wiecej niz jeden rozkaz. Procesor, w którym w jednym takcie zegarowym
Pamiec
Uklad pobierania i rozdzielania
Element przetwarzajacy #1
Element przetwarzajacy #2
Element przetwarzajacy #n

wydawany jest wiecej niz jeden wynik dzialania rozkazu, nazywa sie procesorem super-skalarnym. Wspólczynnik T (liczba taktów na rozkaz) jest wtedy mniejszy od jednosci. Prawie wszystkie produkowane obecnie mikroprocesory RISC wyposazone sa co najmniej w dwa elementy przetwarzajace (wykonawcze, execution unit) z których jeden wykonuje operacje staloprzecinkowe (ang. integer unit) a drugi - operacje zmiennoprzecinkowe (ang. floating-point unit). W takich procesorach konflikty danych nie sa czestsze niz w procesorach skalarnych. Wyniki operacji staloprzecinkowych nie stanowia na ogól argumentów operacji zmiennoprzecinkowych i odwrotnie (z wyjatkiem byc moze konwersji liczb z postaci staloprzecinkowej na zmiennoprzecinkowa i odwrotnie; takie operacje wystepuja w programach bardzo rzadko). EPIC – (ang. explicitely parallel instruction Processing ) Podstawowymi zalozeniami EPIC sa : • dlugie slowo maszynowe, mieszczace trzy i wiecej niezaleznych instrukcji, • wykonywanie instrukcji nie w kolejnosci i ich „tasowanie”, lecz optymalizowane przez
kompilator, a nie przez podsystemy elektroniczne na chipie procesora (tak jak bylo w procesorach RISC)
• mozliwosc równoleglego wykonywania dowolnej liczby instrukcji (o liczbie instrukcji akceptowanej do równoleglego wykonania decyduje architektura procesora).
• brak ograniczenia dostepu do rejestrów przeznaczenia dla wykonywanych instrukcji (eliminacja sytuacji, kiedy wykonywanie instrukcji jest wstrzymane wskutek zajetosci rejestru przeznaczenia).
• mozliwosc równoleglego wykonywania, a potem uniewaznienia rezultatów wykonania rozgalezien programu, które po okresleniu warunków wczesniejszych instrukcji warunkowych if okazuja sie byc niewazne.
Rysunek 2.2.6 Typowa architektura procesora superskalarnego

Implementacja EPIC - procesor Merced (Itanium) Równolegle wykonywanie instrukcji w róznych strumieniach wykonawczych czy tez w róznych jednostkach wykonawczych nie jest novum - nowoscia w konstrukcji Itanium jest natomiast jedna z podstawowych zasad jego dzialania: „paczkowanie" instrukcji, podobne do skladania instrukcji VLIW.
VLIW (ang. Very Long Instruction Word) - bardzo dlugie slowo instrukcji - tak naprawde jest zlozeniem w jednym rejestrze kilku instrukcji, przeznaczonych do wykonania w jednym cyklu pracy jednostki wykonawczej. Technike ta zastosowano po raz pierwszy w CDC-6600 Seymoura Craya - 60 bitowe slowo jednostki wykonawczej moglo stanowic zlozenie 15- i 30-bitowych instrukcji. Nie rozpowszechnila sie ona glównie ze wzgledu na ograniczona skalowalnosc - procesor nowszej generacji, o np. dwukrotnie dluzszych rejestrach, nie bylby w stanie wykonywac poprawnie kodu skompilowanego dla wczesniejszej generacji maszyn. Jednak idea VLIW jest bardzo atrakcyjna dla projektantów procesorów, np. mozliwosc zlozenia w jednym 64-bitowym slowie kilku instrukcji x86, po raz pierwszy zastosowana w NexGenie, stala sie podstawa sukcesu procesorów AMD. Mutacja VLIW, która obecnie swieci triumfy w procesorach x86, jest tryb SIMD (ang. Single Instruction Multiple Data) czyli wykonywanie jedna instrukcja operacji na zestawie danych zaladowanych do jednego rejestru o duzej dlugosci. Zastosowanie VLIW w technice EPIC jest oczywiste, zreszta wielu analityków traktuje EPIC jako rozwiniecie VLIW. Spekulatywne wykonywanie instrukcji
Ten element technologii EPIC jest stosowany juz od dosc dawna w bardziej zaawansowanych mikroprocesorach RISC. Nawet niektóre bardziej skomplikowane technicznie procesory x86 potrafia wykonac "na zapas" instrukcje, wystepujaca w kodzie bezposrednio po instrukcji skoku warunkowego. Jednak w IA-64 spekulatywne wykonywanie dotyczy czegos wiecej niz jednej instrukcji - moze byc wykonaniem tak dlugiego ciagu programu, jaki zmiesci sie w jednym z potoków wykonawczych procesora. Aby zwiekszyc skutecznosc spekulacji, instrukcje Itanium sa wyposazone w grupe bitów predykatowych, pozwalajacych na przewidywanie dalszych rozgalezien programu. W celu uwzglednienia tych informacji procesor musial zostac wyposazony w grupe rejestrów predykatów, pozwalajacych na latwe szacowanie efektywnosci spekulacji, a takze na spekulatywne wykonywanie odleglych galezi kodu. Rozwiazanie to samo w sobie równiez nie jest nowoscia - juz przeszlo 20 lat temu w instrukcjach procesorów ARM zastosowano 4-bitowy kod predykatowy. W tym samym procesorze zastosowano równiez elementy jednego z przyszlych skladników intelowskiej rewolucji - technike VLIW.
Spekulatywne pobranie danych Wobec "powszechnej spekulacji", wynikajacej z architektury EPIC, spekulatywne pobranie danych nie stanowi specjalnego wyjatku - jesli z prefiksów ciagu instrukcji wynika, ze moga byc uzyte jakies dane z zewnatrz (tj. z pamieci RAM), zostana one pobrane do rejestru przeznaczenia, tak aby mogly stanowic argument kolejnej instrukcji bez potrzeby oczekiwania. Przy relatywnie dlugim potoku wykonawczym taki tryb pracy pozwala na zaoszczedzenie nawet kilkunastu cykli procesora w przypadku odwolan do danych z pamieci. Poniewaz jednak w wyniku spekulatywnych pobran, a takze spekulatywnego wykonania instrukcji znaczna czesc pobieranego (i wykonywanego!) kodu okazuje sie chwilowo bezuzyteczna, nalezy zwrócic uwage na fakt, ze architektura IA-64, której pierwszym reprezentantem jest Itanium, stawia zupelnie

nowe wymagania wobec otoczenia procesora. To, ze z pamieci pobierane jest "wszystko" - tj. kod zarówno wykonywanych, jak i pomijanych galezi programu, dane aktualnie potrzebne oraz dane chwilowo zbedne czy nawet calkowicie zbedne - sprawia, ze konieczne staje sie zapewnienie wyjatkowo sprawnej transmisji danych miedzy procesorem a jego otoczeniem. 2.3 Przechowywanie informacji – podsystemy pamieci i hierarchia pamieci Pamiec to jeden z podstawowych elementów (modulów) komputera mogaca przyjmowac, przechowywac (pamietac) i udostepniac w odpowiednim czasie dane w postaci nie zmienionej. W pamieci moga byc przechowywane zarówno wszelkiego rodzaju dane oraz programy sluzace do przetwarzania i obliczen lub sterowania praca komputera.
Pamieci komputerów zwykle nie sa utworzone z jednego ukladu scalonego, lecz sa skladane z pojedynczych kostek pamieciowych w struktury posiadajace wymagana organizacje i pojemnosc. Organizacja pamieci zwykle polega na umieszczaniu danych na oddzielnych stronach pamieci. Strona dzieli sie na wiersze i kolumny wybierane dwoma sygnalami elektrycznymi, a poniewaz stron moze byc wiele musza byc wybierane one trzecim sygnalem selekcji stron.
Pamiec fizyczna jest zorganizowana w postaci trójwymiarowej matrycy. Adres fizyczny komórki pamieci podany przez procesor jest przeksztalcany przez dekoder stron i komórek pamieci. Pamiec polaczona jest z procesorem szyna adresowa, szyna danych oraz pewna liczba sygnalów sterujacych (informujacych czy ma nastapic odczyt, zapis czy modyfikacja, czy pamiec jest gotowa do obslugi danych).
Adresowanie pamieci z punktu widzenia programisty nie odbywa sie na adresach fizycznych, lecz poprzez podawanie dwóch liczb - segmentu i offsetu. Pierwsza liczba jest zwiazana z numerem segmentu pamieci (segment) natomiast druga okresla odleglosc (przesuniecie) komórki pamieci od komórki stanowiacej poczatek danego segmentu (offset).
Adres zapisywany jest w postaci oddzielonych dwukropkiem dwóch liczb szesnastkowych segment:offset (np. 002E:0034 ). Adres ten jest zwany adresem logicznym. Adresy fizyczne wyliczane sa przez procesor w trakcie wykonywania dowolnego programu wedlug dosc skomplikowanego algorytmu z wykorzystaniem specjalnych wbudowanych w procesor rejestrów (rejestry segmentowe) i mechanizmów pomocniczych. Segmentacja i specjalne mechanizmy adresowania pozwalaja jednak procesorowi na obsluge znacznie wiekszej pamieci niz w trybie adresowania fizycznego (bezposredniego). Wielkosc przestrzeni adresów zwiazana jest z dlugoscia slowa nie zas z sama wielkoscia pamieci operacyjnej. Juz procesor 286 dzieki mechanizmowi segmentacji posiadal wirtualna przestrzen adresowa 1GB, 386 natomiast 4 GB.
Sposób segmentacji pamieci i obliczania adresów ulegal zmianie w kolejnych typach komputerów w wyniku czego wzrosla tez wirtualna przestrzen adresowa osiagajac wartosc 64 TB. Tryb wirtualny wiaze sie tez ze stworzeniem mechanizmów i srodowiska potrzebnego do pracy wielozadaniowej tzn. uruchamiania jednoczesnie kilku aplikacji (programów). Tryb chroniony zapewnia bezkonfliktowa prace i dostep do pamieci w systemach operacyjnych wielozadaniowych. Procesory Pentium posiadaja 32 bitowe rejestry adresowe co pozwala im fizycznie obslugiwac do 4 GB pamieci RAM. Wielkosc ta byla i jest jeszcze ograniczana do znacznie mniejszych wartosci ze wzgledu na:
? architekture procesora – budowe chipów i sposób komunikacji miedzy nimi, ? budowe fizyczna plyty glównej, ? pojemnosc dostepnych modulów pamieci.

Na pamiec skladaja sie: ? uklady umozliwiajace wprowadzenie (zapisanie) danych lub ich wyprowadzanie (czytanie), ? elementy lub materialy majace zdolnosc dlugotrwalego pamietania. Z funkcjonalnego punktu widzenia ogólnie rozróznia sie: ? pamiec wewnetrzna, ? pamiec zewnetrzna. Mozliwosci pamieci charakteryzuje sie za pomoca takich wielkosci jak: ? pojemnosc, ? cykl lub szybkosc przesylania danych, ? czas dostepu. Czym szybszy dostep do pamieci, tym pamiec jest drozsza, a jej pojemnosc mniejsza. Na Rysunku 4 przedstawiono hierarchie pamieci. Najszybsze elementy procesora: rejestry oraz pamiec podreczna umieszczona jest na chipie procesora. Pamieci pierwszego poziomu (pamiec operacyjna) oraz pamieci zewnetrzne, wymagaja polaczenia do procesora poprzez magistrale. W zaleznosci od typu polaczenia i szybkosci pamieci wyzszego poziomu magistrale taktowane sa z rózna czestotliwoscia.
Rejestry
Podstawowa cache
Druga cache
Pamiec pierwszego poziomu
Pamiec dodatkowa
Pamiec dyskowa
High Performance storage devices(pamiec CD. optyczna, roboty tasmowe)
Pamiec wirtualna
Procesor
Rysunek 2.3.1 Hierarchia pamieci w systemach komputerowych. Pamiec podreczna (CACHE) We wspólczesnych procesorach stosuje sie rozwiazanie kompromisowe, polegajace na zastosowaniu pamieci wewnetrznej dwupoziomowej. Mikroprocesor wyposaza sie we wzglednie duza i wolniejsza pamiec glówna, oraz w mniejsza, ale szybsza pamiec podreczna - cache. Takie

rozwiazanie pozwala na korzystanie z pamieci o duzej pojemnosci, jednoczesnie mozliwe jest umieszczenie najpotrzebniejszych danych, w szybkiej pamieci podrecznej. Pamiec podreczna zawiera kopie czesci zawartosci pamieci glównej. Gdy procesor zamierza odczytac slowo z pamieci, najpierw nastepuje sprawdzenie, czy slowo to nie znajduje sie w pamieci podrecznej. Jesli tak, to slowo to jest szybko dostarczane do procesora. Jesli nie, to blok pamieci glównej RAM zawierajacy okreslona liczbe kolejnych slów jest wczytywany do pamieci podrecznej, a nastepnie potrzebne slowo (zawarte w tym bloku) jest dostarczane do procesora. Nastepne odwolania do tego samego slowa i sasiednich zawartych w przepisanym bloku beda realizowane juz znacznie szybciej. Organizacja wspólpracy procesora z takimi pamieciami wymaga zastosowania dodatkowego ukladu - kontrolera cache, który steruje tym procesem. Efektywnosc stosowania cache zalezy w znacznej mierze od sposobu ulozenia kodu programów i danych pobieranych z pamieci przez mikroprocesory. Zwykle kod i dane nie sa "porozrzucane" przypadkowo po calej dostepnej przestrzeni adresowej w pamieci RAM.
Wiekszosc odwolan do pamieci w trakcie wykonywania programu odbywa sie przez pewien czas pracy mikroprocesora w waskim obszarze. Zjawisko to jest okreslane mianem lokalnosci odniesien. Lokalnosc odniesien mozna uzasadnic intuicyjnie w nastepujacy sposób: • Z wyjatkiem rozkazów skoku i wywolania procedury, realizacja programów ma charakter
sekwencyjny. Tak wiec, w wiekszosci przypadków nastepny rozkaz przewidziany do pobrania z pamieci nastepuje bezposrednio po ostatnio pobranym rozkazie.
• Rzadkoscia jest wystepowanie w programach dlugich, nieprzerwanych sekwencji wywolan procedury (procedura wywoluje procedure itd.), a potem dlugiej sekwencji powrotów z procedur. Wymagaloby to ciaglego odwolywania sie do oddalonych od siebie obszarów pamieci glównej, zawierajacych kody poszczególnych procedur.
• Wiekszosc petli (konstrukcji bardzo czesto wystepujacych w programach) sklada sie z malej liczby wielokrotnie powtarzanych rozkazów. Podczas iteracji nastepuje kolejne powtarzanie zwartej czesci programu.
• W wielu programach znaczna czesc obliczen obejmuje przetwarzanie struktur danych, takich jak tablice lub szeregi rekordów ulozone kolejno w pamieci operacyjnej. Tak wiec procesor pobiera dane zapisane w sposób uporzadkowany w malym jej fragmencie.
Rysunek 2.3.2 Podlaczenie pamieci podrecznej do procesora Oczywiscie w dlugim czasie wykonywania programu procesor potrzebuje dane rozmieszczone w róznych odleglych miejscach pamieci. Zwykle jednak, po wykonaniu skoku nastepne odniesienia odbywaja sie juz lokalnie. Przepisanie bloku kolejnych komórek pamieci do szybkiego ukladu cache moze wiec skutecznie przyspieszyc dostep do pamieci. Na drodze rozwazan teoretycznych i róznych symulacji wyznaczono rozmiar tego waskiego obszaru, do którego odwoluje sie

procesor. Stwierdzono, iz mozna przyjac z prawdopodobienstwem 0,9 ze wiekszosc odwolan do pamieci miescic sie bedzie w bloku o rozmiarze nie przekraczajacym 16 kB. Potwierdzaja to praktyczne testy. Wystarczy naprawde maly uklad pamieci podrecznej cache, aby skutecznie przyspieszyc dzialanie mikroprocesora. Rozmiary calej pamieci RAM wspólczesnych komputerów sa rzedu 64 - 128 MB, podczas gdy rozmiary cache w popularnych procesorach to 8 - 512 kB.
Pamieci ROM i RAM Ze wzgledu na zastosowanie wyróznia sie nastepne dwa rodzaje pamieci pólprzewodnikowej
• ROM (Read Only Memory) - przeznaczonej tylko do odczytu • RAM (Random Access Memory) - pamieci z mozliwoscia odczytu i zapisu danych
W pamieciach nieulotnych typu ROM umieszczone sa informacje stale. ROM jest najbardziej niezawodnym nosnikiem informacji o duzej gestosci zapisu. Zapis informacji dokonuje sie w procesie produkcji lub podczas ich programowania. Pamieci typu ROM przeznaczone sa glównie do umieszczania w nich startowej sekwencji instrukcji, kompletnych programów obslugi sterowników i urzadzen mikroprocesorowych, takze ustalonych i rzadko zmienianych danych stalych.
Uklady pamieci RAM zbudowane sa z elektronicznych elementów, które moga zapamietac swój stan. Dla kazdego bitu informacji potrzebny jest jeden taki uklad. W zaleznosci od tego czy pamiec RAM jest tak zwana statyczna pamiecia (SRAM-Static RAM), czy dynamiczna (DRAM-Dynamic RAM) zbudowana jest z innych komponentów i swoje dzialanie opiera na innych zasadach.
• Pamiec SRAM jako element pamietajacy wykorzystuje przerzutnik • DRAM bazuje najczesciej na tzw. pojemnosciach pasozytniczych (kondensator).
DRAM charakteryzuje sie niskim poborem mocy, jednak zwiazana z tym sklonnosc do samorzutnego rozladowania sie komórek sprawia, ze konieczne staje sie odswiezanie zawartosci impulsami pojawiajacymi sie w okreslonych odstepach czasu. W przypadku SRAM, nie wystepuje koniecznosc odswiezania komórek, lecz okupione jest to ogólnym zwiekszeniem poboru mocy. Pamieci SRAM, ze wzgledu na krótki czas dostepu sa czesto stosowane jako pamiec podreczna. Wykonane w technologii CMOS pamieci SRAM maja mniejszy pobór mocy, sa jednak stosunkowo drogie w produkcji. Pamiec SRAM Pamiec ta przechowuje bity informacji w postaci stanów przerzutników bistabilnych tworzacych matryce pamieciowa. Informacja raz wpisana do takiej pamieci pozostaje w niej, az do momentu gdy zostanie wpisana nowa informacja badz wylaczymy zasilanie. Podstawowa zaleta takich pamieci jest prostota stosowania oraz uzyskiwanie bardzo krótkich cykli i czasów dostepu. Pamieci tego typu znajduja zastosowanie w systemach wymagajacych malej pojemnosci i krótkiego czasu dostepu. Wspólczesne pamieci SRAM sa wykonane w technologii CMOS, charakteryzujacej sie bardzo malym poborem pradu zasilania, co predysponuje je do stosowania w urzadzeniach zasilanych bateryjnie. Istnieje wiele odmian pamieci SRAM o róznej szybkosci dzialania. Obecnie sa dostepne pamieci SRAM o standardowej pojemnosci od 1 kB do 2 MB, o organizacji jedno-, cztero- lub osmiobitowej i czasach dostepu w zakresie od 100 ns do 10 ns, a nawet mniejszym. Pamieci o niewielkiej pojemnosci i bardzo krótkich czasach dostepu sa uzywane jako buforowe pamieci podreczne cache.

Pamiec dynamiczna DRAM (Dynamic RAM) W pamieciach DRAM informacja jest przechowywana w postaci ladunków zgromadzonych na wewnetrznych pojemnosciach ukladu scalonego. Informacja umieszczona w pamieci dynamicznej znika samoistnie przecietnie w czasie krótszym od 1 sek. (rozladowanie kondensatorów), chyba ze zostanie "odswiezona". Poniewaz pamiec DRAM traci informacje w miare uplywu czasu, jedynym sposobem utrzymania jej jest okresowe odnawianie stanu wszystkich wierszy w dwuwymiarowej matrycy bitów tworzacej pamiec. Przykladowo utrzymanie informacji w pamieci DRAM o pojemnosci 256 kb wymaga adresowania kazdego z 256 wierszy co 4 ms. Istotna zaleta pamieci dynamicznych jest kilkakrotnie nizsza cena od pamieci statycznej SRAM, przy takiej samej pojemnosci informacji jak w pamieci statycznej. Istnieje wiele wersji pamieci dynamicznych DRAM rózniacych sie pojemnoscia (256 kb-64 Mb w jednym ukladzie), czasem dostepu (15 - 150 ns), organizacja pamieci (1-, 4-, 8-, 16-, i 64-bitowa), konstrukcja (jednorzedowe SIL i dwurzedowe DIL) oraz sposobem dostepu od strony systemu operacyjnego i urzadzen zewnetrznych (dostep jedno- lub wielokanalowy). Najbardziej popularne sa pamieci jednokanalowe o duzej pojemnosci i jednobitowej szerokosci slowa. Minimalizacja koncówek zewnetrznych przestaje miec znaczenie, gdyz stosuje sie nowoczesne obudowy typu DIMM lub SIMM. Wiele rozwiazan specjalistycznych uwzglednia zaspokojenie nietypowych potrzeb, takich jak: praca nakladkowa, wspóldzialanie z szybkimi pamieciami typu cache, niezalezny wielodostep do kilku kanalów czy efektywna wspólpraca z graficznymi sterownikami obrazu o podwyzszonej rozdzielczosci.
Istnieje wiele rodzajów pamieci RAM jak np.: Fast Page Mode (FPM RAM), Bedo RAM, Synchroniczna DRAM, FCRAM, VRAM, DDR, RDRAM itp. Pamieci zewnetrzne Pamiec zewnetrzna jest pamiecia, w której mozna zapisywac i odczytywac dane, a po wylaczeniu zasilania dane te nie sa tracone. Pamieci te sa znakomitym miejscem na przechowywanie danych w czasie, gdy nasz komputer jest wylaczony. Najpopularniejsza pamiecia zewnetrzna sa dyskietki, dyski optyczne (CD-R, CD-RW), ZIPy, pamieci typu FLASH, DVD, a przede wszystkim dyski twarde oraz w wielkich hurtowniach danych – tasmy magnetyczne i roboty tasmowe. Ponizsza tabela zawiera niektóre typy pamieci zewnetrznej wraz z jej niektórymi waznymi wlasciwosciami jak: pojemnosc, cena przechowywania 1MB czas dostepu.
Medium Pojemnosc Czas dostepu
Koszt 1MB (USD)
Pamiec statyczna RAM — 5 –15 ns 5 - 10 Pamiec dynamiczna RAM — 30–100 ns 0.5 - 1 Dysk sztywny 100 GB 3–5 ms 0.003 – 0.01 Macierze dyskowe RAID 0.5 – 4 TB 3–5 ms 0.01–0.05 Dysk magneto-optyczny 2.6–5.2 GB 15–40 ms 0.003–0.005 Dysk optyczny CD-ROM 0.8 GB 50 –100 ms 0.002 Tasmy magnetyczne liniowe 10–70 GB 40–60 s 0.001 Biblioteki optyczne 0.1–10 TB 6–10 s 0.002 Biblioteki tasmowe DLT 1–80 TB 0.5–2 min 0.001 Biblioteki tasmowe VHS Petabajty minuty 0.003

Wspólczesne systemy komputerowe stawiaja duze wymagania odnosnie przechowywania i przetwarzania danych. Jest to konsekwencja postepu cywilizacyjnego i wzrostu ilosci przechowywanych informacji stanowiacych ogromna wartosc zarówno poznawcza jak i ekonomiczna. Przechowywac, wiedziec i umiec wykorzystac dane skladowane stanowi o byc albo nie byc wielu instytucji, firm i organizacji. Pojedynczy dysk twardy, szpula z tasma magnetyczna, dysk optyczny czy tez niewielka ilosc pamieci pólprzewodnikowej nie oferuja wystarczajacych pojemnosci, a przede wszystkim nie gwarantuja bezpieczenstwa danych w razie awarii któregos z elementów systemu. Stad tez zrodzila sie idea laczenia mniejszych urzadzen w wieksze calosci, dyski magnetyczne w macierze, poszczególne szpule z tasma w biblioteki obslugiwane przez roboty, a ostatnio takze idea rozproszonego przechowywania danych w sieci komputerowej tzw. klastry. Jednym z najtanszych i najbardziej dostepnych rozwiazan jest RAID - technika laczenia grupy dysków magnetycznych w jedna calosc. W 1988 roku David Patterson, Randy Katz i Gerth Gibson z Uniwersytetu w Berkeley w Kalifornii (USA) opublikowali prace pt. "A Case for Redundant Arrays of Inexpensive Disks", w której zaprezentowali koncepcje macierzy dyskowych oraz wprowadzili pojecie RAID. Redundant Arrays of Inexpensive Disks (RAID) umozliwia polaczenie grupy dysków twardych w jeden duzy naped wirtualny. Umozliwia to znaczaca poprawe wydajnosci systemu pamieci masowych, a takze zwiekszenie bezpieczenstwa przechowywanych danych. Sredni zakladany czas miedzy awariami MTBF (Mean Time Between Failure) liczony dla calej macierzy jest równy czasowi MTBF dla kazdego dysku podzielonemu przez ich ilosc w macierzy (zakladamy, ze macierz sklada sie z jednakowych dysków). A wiec awaryjnosc macierzy jest mniejsza od awaryjnosci pojedynczego dysku. Aby, w razie usterki, mozna bylo odtworzyc zniszczone dane, stosuje sie mechanizmy nadmiarowosci w przechowywaniu informacji. Istnieje wiele poziomów macierzy dyskowych typu RAID. Oto dwa z nich:
RAID 0 (Non-Redundant Striped Array) jest zwykle definiowany jako grupa dysków polaczonych ze soba tak, ze w kazdym z nich przechowuje sie czesc danych (ang. striping). Stosuje sie tutaj mechanizm przeplotu (ang. interleaving) polegajacy na równomiernym zapelnianiu danymi wszystkich dysków. Zapewnia to wieksza wydajnosc w dostepie do informacji (równoleglosc wykonywania operacji odczytu lub zapisu na kilku dyskach) i równomiernie obciaza system pamieci masowej nie dopuszczajac do sytuacji, w której czesc dysków zawierajacych czesciej uzywane dane bylaby nadmiernie obciazona, podczas gdy reszta pozostawalaby zwykle nie do konca wykorzystana lub nawet bezczynna. RAID 0 nie zapewnia mechanizmów sprawdzajacych parzystosci bitów ani redundancji danych.
Poszczególne bloki zapisywane na dyskach moga miec rózne wielkosci (od 512 bitów do kilku MB). Poziom ten zapewnia najlepsza efektywnosc wykorzystania miejsca do przechowywania danych oraz najszybszy do nich dostep. Jednak powaznym mankamentem jest brak mechanizmów ochrony danych. Gdy jeden dysk macierzy RAID 0 ulegnie uszkodzeniu - cala macierz staje sie bezuzyteczna a dane gina bezpowrotnie. Najlepsze zastosowania to przetwarzanie obrazu VIDEO, grafika i inne aplikacje wymagajace szybkiej transmisji danych,
ale nie w zastosowaniach krytycznych ze wzgledu na zachowanie bezpieczenstwa przechowywanych danych.
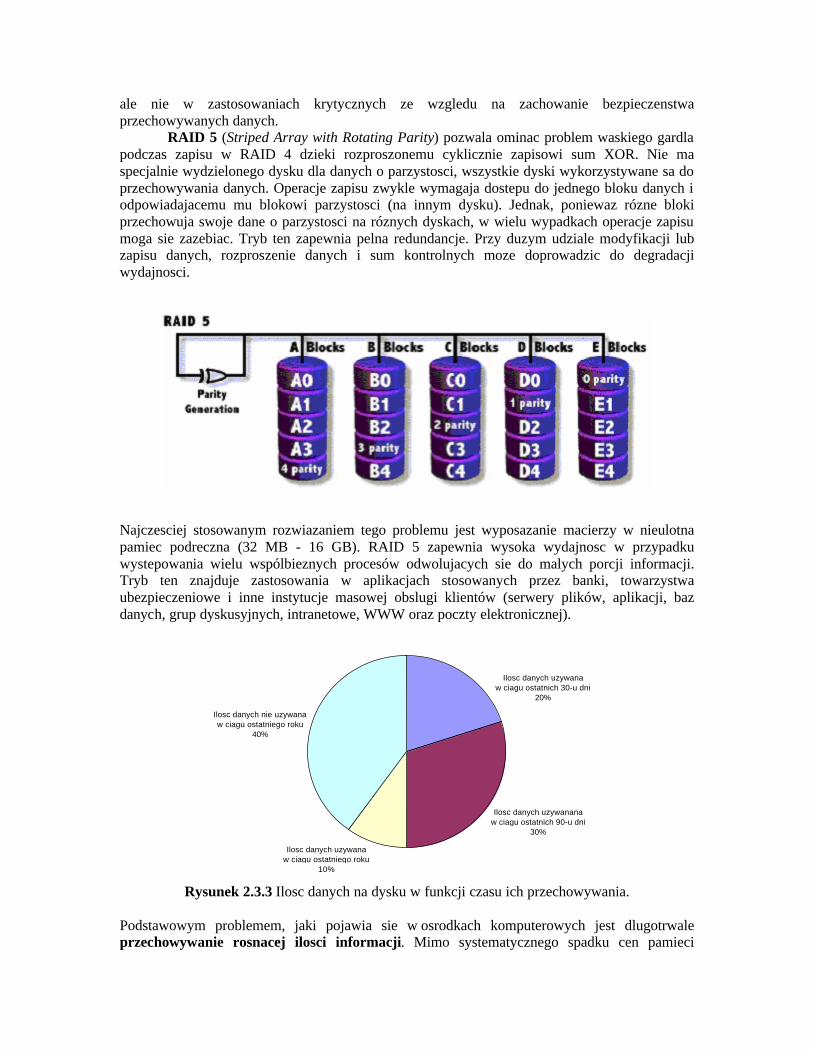
RAID 5 (Striped Array with Rotating Parity) pozwala ominac problem waskiego gardla podczas zapisu w RAID 4 dzieki rozproszonemu cyklicznie zapisowi sum XOR. Nie ma specjalnie wydzielonego dysku dla danych o parzystosci, wszystkie dyski wykorzystywane sa do przechowywania danych. Operacje zapisu zwykle wymagaja dostepu do jednego bloku danych i odpowiadajacemu mu blokowi parzystosci (na innym dysku). Jednak, poniewaz rózne bloki przechowuja swoje dane o parzystosci na róznych dyskach, w wielu wypadkach operacje zapisu moga sie zazebiac. Tryb ten zapewnia pelna redundancje. Przy duzym udziale modyfikacji lub zapisu danych, rozproszenie danych i sum kontrolnych moze doprowadzic do degradacji wydajnosci.
Najczesciej stosowanym rozwiazaniem tego problemu jest wyposazanie macierzy w nieulotna pamiec podreczna (32 MB - 16 GB). RAID 5 zapewnia wysoka wydajnosc w przypadku wystepowania wielu wspólbieznych procesów odwolujacych sie do malych porcji informacji. Tryb ten znajduje zastosowania w aplikacjach stosowanych przez banki, towarzystwa ubezpieczeniowe i inne instytucje masowej obslugi klientów (serwery plików, aplikacji, baz danych, grup dyskusyjnych, intranetowe, WWW oraz poczty elektronicznej).
Ilosc danych uzywanana w ciagu ostatnich 90-u dni
30%
Ilosc danych uzywana w ciagu ostatniego roku
10%
Ilosc danych uzywana w ciagu ostatnich 30-u dni
20%
Ilosc danych nie uzywana w ciagu ostatniego roku
40%
Rysunek 2.3.3 Ilosc danych na dysku w funkcji czasu ich przechowywania.
Podstawowym problemem, jaki pojawia sie w osrodkach komputerowych jest dlugotrwale przechowywanie rosnacej ilosci informacji. Mimo systematycznego spadku cen pamieci

dyskowej rosnace zapotrzebowanie powoduje, ze wydatki na masowa pamiec dyskowa przybieraja coraz wieksze rozmiary. Drugim problemem zwiazanym z dostepem do danych jest ich ochrona przed utrata lub zniszczeniem. Zagadnienie to jest zwlaszcza istotne w przypadku informacji o duzej wartosci np. komercyjnej, która wymaga trwalej i pewnej archiwizacji.
Powszechnie stosowana metoda zagwarantowania dostepnosci danych w przypadku, gdy dane pamietane na dyskach ulegna zniszczeniu lub zostana utracone, jest tworzenie kopii bezpieczenstwa (ang. backup). W malych systemach komputerowych czesto spotykane jest reczne tworzenie kopii bezpieczenstwa na pojedynczych tasmach. Jednakze kazda profesjonalna i dbajaca o bezpieczenstwo swoich danych instytucja powinna posiadac mozliwosc trwalego gromadzenia i zabezpieczenia danych. Mozliwosc taka oferuja nowoczesne, zautomatyzowane systemy pamieci masowych pracujace z wykorzystaniem napedów tasmowych, dysków magneto-optycznych (wielokrotnego zapisu) lub dysków typu WORM. Biblioteki takie nie tylko gwarantuja pewnosc i bezpieczenstwo danych w systemie komputerowym, ale jednoczesnie stwarzaja mozliwosc praktycznie nieograniczonej przestrzeni dyskowej za posrednictwem hierarchicznego systemu zarzadzania zasobami (ang. Hierarchical Storage Management – HSM). Tego rodzaju urzadzenia stanowia zaplecze danych w hurtowniach danych, a pojemnosci pamieci nalezy liczyc w petabajtach (1015 bajtów).
2.4 Serwery i komputery
Procesor wraz z ukladami hierarchii pamieci oraz urzadzeniami wejscia i wyjscia, o których (poza pamieciami zewnetrznymi) nie mówilismy w tej ksiazce, tworza pojedynczy system komputerowy. W tym podrozdziale podamy jedynie definicje glówne typy systemów komputerowych.
W historycznej kolejnosci pojawiania sie na rynku sa to architektury: ? host/terminal bazujace glównie na mainframach ? klient/serwer - aktualnie bazujace w zdecydowanym stopniu na komputerach o procesorach RISC ? sieciowe zwane takze chudy-klient/tlusty-serwer Systemy Mainframe W przezywajacych swój rozkwit w latach 70-tych architekturach typu host/terminal, zarówno wszystkie dane jak i aplikacje rezyduja na komputerze mainframe (najczesciej pod kontrola systemu operacyjnego MVS lub OS/390- obecnie). Uzytkownik posiada do nich dostep poprzez proste (funkcje zdeterminowane) terminale o malej mocy obliczeniowej (nie posiadajace swojej pamieci dyskowej) zazwyczaj malej pamieci operacyjnej i niskiej efektywnosci przetwarzania obrazu. Aplikacje uruchamia sie zwykle w systemie batch jobs.

ZBIORCZYSKLAD DANYCH
System/390
MAGAZYNINFORMACJI
WIELKIEAPLIKACJE
GLOBALNECENTRUMDANYCH
ZARZADZANIE ZASOBAMI ROZPROSZONYMI
SERWERPRZEDSIEBIORSTWA
EKONOMIA KOSZTÓW IWYDAJNOSC OPERACJI
Rysunek.2.4.1 Schematyczne przedstawienie roli architektur mainframe w Centrach Obliczeniowych. W okresie najwiekszego spadku zamówien na sprzet produkowany przez IBM (1993-94), firma ta wprowadzila na rynek serie serwerów typu mainframe nowej generacji (klasy 9672) opartej na technologii CMOS. Nosza one nazwe Parallel Enterprise Servers, ostatnie z nich to serwery S/390, a najnowsze produkty firmy ukrywaja sie pod nazwa System/390 (9672-RY5). OS/390 jest najnowsza wersja MVS posiadajaca funkcjonalnosc K/S Unix'a. Rys.2.4.1 pokazuje mozliwosc zastosowania tego typu przetwarzania w duzych centrach obliczeniowych.
Systemy klient-serwer Architektury Klient-Serwer, które szczególnie mocno weszly na rynek w latach 90-tych bazuja na nowej generacji - niezwykle mocnych, wyposazonych w procesory RISC, wyspecjalizowanych serwerach UNIX-owych. W zasadzie wszystkie nowoczesne systemy komputerowe pracuja w tym paradygmacie obliczen.
Serwer jest to komputer, który swiadczy w sieci jakies uslugi. Moze to byc zwykly PC, ale jesli zostaly na nim uruchomione jakies serwery uslug, to formalnie zostaje serwerem. Najczesciej funkcje serwerów spelniaja maszyny nastawione na szybka i bezawaryjna prace, dlatego posiadaja plyty wieloprocesorowe, zdublowane dyski twarde gdzie w razie awarii jednego praca serwera nie zostaje wstrzymana.
Kontaktujacy sie z nimi "klienci" to komputery poczynajac od klasy PC do wyspecjalizowanych stacji roboczych, posiadajace (choc w zróznicowanym stopniu w zaleznosci od klasy sprzetu) swoje lokalne zasoby pamieci operacyjnej, dyskowej, mozliwosci graficzne, podstawowe aplikacje i bazy danych.
Jedna z najwazniejszych cech jest mozliwosc fizycznego i logicznego rozdzialu zlozonych aplikacji w taki sposób, ze przetwarzania dokonuje sie w optymalnym miejscu. Z tego tez powodu nowoczesne instalacje realizuja tzw. trójwarstwowe podejscie:

? serwery dla baz danych, ? serwery aplikacyjne, ? serwery do prezentacji,
Istniejacy podzial serwerów K-S bazuje na nastepujacych elementach:
• mechanizmu przetwarzania informacji (instruction flow, data flow), • wzajemnej zaleznosci strumieni instrukcji i danych zdeterminowanej sposobem sterowania
procesem przetwarzania informacji (SISD, SIMD, MIMD, MISD), • dostepu do pamieci i sposobu komunikacji pomiedzy wezlami (ang. shared memory - threads,
distributed memory - message passing), • hierarchizacji dostepu do pamieci (UMA - uniform memory access, NUMA - non- uniform
memory access), • rodzaju sieci polaczen pomiedzy wezlami obliczeniowymi oraz procesorami i blokami
pamieci. Fundamentalnymi jej elementami sa: 1. Uniform Memory Access Architectures (UMA) - architektury jednorodnego dostepu do
pamieci, gdzie z punktu widzenia pojedynczego wezla obliczeniowego dostep do kazdego bloku pamieci zabiera srednio taka sama ilosc czasu.
2. Non-Uniform Memory Access Architectures (NUMA) - architektury o zhierarchizowanym dostepie do pamieci, gdzie predkosc dostepu do poszczególnych poziomów pamieci, dla kazdego z wezlów obliczeniowych, jest inna (pamiec bliska i daleka).
Tak zwane, symetryczne systemy wieloprocesorowe (ang. Symmetric MultiProcessing System) sa to najprostsze i najbardziej dzis popularne architektury systemów komercyjnych. Ten podstawowy schemat systemu o pamieci dzielonej zyskal najwieksza popularnosc poniewaz idealnie odpowiada celom aplikacji ogólnego zastosowania typu • OLTP (ang. on-line transaction processing) dotyczacych np. operacji transakcji na duzych
bazach danych, • DSS (ang. decision support system) czyli systemów wspomagania decyzji i systemów
eksperckich.
CPU
CPU
CPU
Pamiec I/O
SMP
Rysunek 2.4.2 Schemat architektury SMP (I/O - urzadzenia wejscia-wyjscia, CPU - procesor).

Systemy sieciowe
Architektury sieciowe (ang. Network or Java Computing) to calkiem nowy paradygmat architektury bedacy rezultatem obserwowanej w ostatnim czasie eksplozji pomyslów wykorzystania sieci lokalnych i globalnych oraz sukcesu Internetu, systemów typu GRID oraz systemów lacznosci bezprzewodowej i telefonii komórkowej. Idee architektury sieciowej charakteryzuje ogromna liczba tzw. chudych-klientów, komputerów sieciowych wyposazonych jedynie w OS Java oraz maszyne wirtualna Java w celu uruchamiania apletów i aplikacji. Komputery sieciowe (telefony komórkowe) polaczone sa z wydajnym superserwerem (gruby-serwer) i poprzez szybkie lacza pobieraja z jego dysku aplikacje (aplety) wykonujac je lokalnie, lecz korzystajac z baz danych umieszczonych na dyskach serwera. Wymagania takiej architektury w stosunku do komputerów sieciowych odnosnie szybkosci przetwarzania, wielkosci pamieci operacyjnej i dyskowej sa znacznie skromniejsze niz dla klientów/serwerów UNIX-owych. Niski koszt komputera sieciowego czy telefonu komórkowego (ok. 80 - 300 USD) oraz niskie koszty jego utrzymania sa glównym elementem preferujacym ta architekture w najblizszej przyszlosci.
2.5 Przesylanie informacji, sieci i magistrale 2.5.1 Pojecia podstawowe Kolejnym elementem operacji wykonywanych na informacji jest jej przesylanie. Bedzie ono odgrywalo szczególna role w czasie zwiazanym z gwaltownym rozwojem systemów sieciowych (takze tych bezprzewodowych – ang. wireless), integracja wielkich systemów obliczeniowych, przechowywania danych oraz systemów wizualizacyjnych tworzac szkielet metakomputera. Przesylanie informacji pomiedzy najdrobniejszymi elementami systemu informatycznego, a takze wezlami obliczeniowymi (ang. nodes) odbywa sie przy pomocy magistral (ang. bus) oraz lokalnych LAN (ang. local area network) czy rozleglych WAN sieci komputerowych (ang. wide area network). Posrednim rodzajem sieci komputerowych sa sieci metropolitalne MAN (ang. metropolitan area network).
Magistrala jest inteligentna czescia komputera sluzaca do przesylania informacji pomiedzy poszczególnymi komponentami oraz urzadzeniami zewnetrznymi. W komputerze istnieje kilka rodzajów magistrali, np.: ? magistrala adresowa, ? magistrala danych. Pierwsza z nich realizuje polaczenie pomiedzy procesorem i pamiecia operacyjna w komputerze. Polaczeniem tym jest przekazywany adres komórki, z której w danej chwili korzysta mikroprocesor. Druga realizuje polaczenie w celu przekazywania danych pomiedzy mikroprocesorem a ukladami (urzadzeniami) w komputerze, np. pamiecia operacyjna, karta grafiki, itd. Obecnie na plytach glównych najpopularniejszym typem magistrali danych jest, PCI, AGP,USB, a takze inne bardzo szybkie polaczenia SCSI Fibre Channel. Szybkosc przesylania danych za pomoca magistrali podaje sie jednostkach zwanych bps (ang. bit-per-second).

Rysunek 2.5.1. Funkcjonalnosc magistrali danych USB.
bps – jest to jednostka okreslajaca liczbe bitów przesylanych w kanalach cyfrowym w czasie jednej sekundy.
Jest to podstawowa jednostka miary szybkosci transmisji danych. Korzystanie z magistrali danych przez okreslone urzadzenie w postaci tzw. karty rozszerzen jest mozliwe przez umieszczenie jego karty w gniezdzie rozszerzajacym. 2.5.2 Struktura warstwowa sieci. Ogólnie przyjetym modelem sieci jest model warstwowy. Najwyzsza warstwa jest odpowiedzialna za konwersje protokolów uzytkownika lub funkcje zarzadzania urzadzeniami, najnizsza warstwa za sterowanie fizycznym medium transmisji danych.
Komunikacja pomiedzy komputerami odbywa sie na poziomie odpowiadajacych sobie warstw i dla kazdej z nich powinien zostac stworzony wlasny protokól komunikacyjny. W rzeczywistej sieci komputerowej komunikacja odbywa wylacznie sie na poziomie warstwy fizycznej (linia ciagla na rysunku). W tym celu informacja kazdorazowo przekazywana jest do sasiedniej nizszej warstwy az do dotarcia do warstwy fizycznej. Tak wiec, pomiedzy wszystkimi warstwami z wyjatkiem fizycznej istnieje komunikacja wirtualna (linie przerywane na Rys.2.5.2), mozliwa dzieki istnieniu polaczenia fizycznego.
W modelu warstwowym pelny zbiór funkcji komunikacyjnych zostaje podzielony na podzbiory w taki sposób, by bylo mozliwe traktowanie kazdego podzbioru jako pewnej calosci wykonujacej autonomiczne zadanie. Wyodrebnione podzbiory funkcji sa powiazane ze soba tak, ze tworza strukture hierarchiczna w postaci uporzadkowanych warstw.
Kazda warstwa sklada sie z obiektów rozproszonych w róznych urzadzeniach sieci komputerowej. Podstawowa zasada jest to, ze komunikuja sie ze soba tylko równorzedne pary obiektów jednej warstwy korzystajac jedynie z uslug transmisji danych oferowanych przez warstwy nizsze. Kazda warstwa modelu jest opisana przez protokól wymiany informacji pomiedzy równorzednymi obiektami warstwy oraz przez zbiór uslug komunikacyjnych spelnianych dla warstwy znajdujacej sie bezposrednio nad nia.
Komunikujace sie komputery, terminale, drukarki, wezly sieciowe i inne urzadzenia wykorzystuja skomplikowane procedury dostepu do sieci, adresowania, przesylania danych, konwersji formatów itp. Dodatkowo w wiekszosci przypadków jest to sprzet produkowany przez

róznych producentów, którzy niejednokrotnie nie slyszeli nic o sobie. Jest jednak oczywiste, ze skomplikowana komunikacja musi funkcjonowac dobrze, a to wymaga wysokiego stopnia wspólpracy, a jednoczesnie dobrej standaryzacji wszelkich protokolów.
Jednym z podstawowych pojec zwiazanych z budowa i funkcjonowaniem sieci komputerowych jest termin - protokól sieciowy. Protokolem w sieci komputerowej nazywamy zbiór zasad syntaktycznych i semantycznych sposobu komunikowania sie jej elementów funkcjonalnych. Tylko dzieki nim urzadzenia tworzace siec moga sie porozumiewac. Podstawowym zadaniem protokolu jest identyfikacja procesu, z którym chce sie komunikowac proces bazowy. Aby bylo to mozliwe konieczne jest podanie sposobu okreslania wlasciwego adresata, sposobu rozpoczynania i konczenia transmisji, a takze sposobu przesylania danych. Przesylana informacja moze byc porcjowana - protokól musi umiec odtworzyc informacje w postaci pierwotnej. Ponadto informacja moze z róznych powodów byc przeslana niepoprawnie - protokól musi wykrywac i usuwac powstale w ten sposób bledy, proszac nadawce o ponowna transmisje danej informacji.
Model warstwowy, w którym kazda warstwa posluguje sie wlasnym protokolem znacznie upraszcza projektowanie niezwykle skomplikowanego procesu komunikacji sieciowej. Musza jednak jasno zostac zdefiniowane zasady wspólpracy tych protokolów. Warstwowy model OSI stanowi przyklad takiego opisu, bedac w istocie "protokolem komunikacji miedzy protokolami".
Jednym z najbardziej podstawowych protokolów (rózniace sie troche od modelu OSI) sa protokoly TCP i IP, które ustalaja zasady komunikacji w sieci Internet - opisuja szczególy formatu komunikatów, sposób odpowiadania na otrzymany komunikat, okreslaja jak komputer ma obslugiwac pojawiajace sie bledy lub inne nienormalne sytuacje. Umozliwiaja one rozpatrywanie zagadnien dotyczacych komunikacji niezaleznie od sprzetu sieciowego. Zapewniaja szereg popularnych uslug dostepnych dla uzytkowników, takich jak:
• poczta elektroniczna. • przesylanie plików, • praca zdalna.
Rozwiazaniem problemu komunikacji w zlozonej heterogenicznej sieci stal sie jednak Model Odniesienia ISO/OSI, który jest obecnie standardem wszystkich urzadzen chcacych wymieniac dane, na którym musi wzorowac sie kazdy producent. ISO/OSI jest polaczeniem dwóch skrótów ISO to Miedzynarodowa Organizacja Standaryzacyjna (ang. International Standards Organization), która tworzyla model. OSI to okreslenie Laczenie Systemów otwartych (ang. Open Systems Interconnection).
Proces transmisji danych przez siec zostal podzielony na 7 etapów zwanych warstwami, a struktura tworzona przez warstwy OSI nazwana jest stosem protokolów wymiany danych. W calym procesie komunikacji wyodrebnia sie pewne niezalezne zadania, które wykonywane przez uklady sprzetowe lub pakiety oprogramowania, zwane obiektami. Klase obiektów rozwiazujacych dane zagadnienie nazywa sie warstwa. Pojecie warstwy nie jest jednoznaczne z pojeciem protokolu - funkcje danej warstwy moga byc realizowane przez kilka róznych protokolów. Kazdy protokól komunikuje sie ze swoim odpowiednikiem, bedacym implementacja tego samego protokolu w równorzednej warstwie komunikacyjnej systemu odleglego. Dane przekazywane sa od wierzcholka stosu poprzez kolejne warstwy az do warstwy fizycznej, która wysyla je poprzez siec do odleglego hosta. Na szczycie stosu znajduja sie uslugi swiadczone bezposrednio uzytkownikowi przez aplikacje sieciowe, na spodzie - sprzet realizujacy transmisje

sygnalów niosacych informacje. Czyli przykladowo, dane wysylane przez warstwe sieciowa w stacji nadawczej odbierane sa przez stacje odbiorcza, dostarczane do jej warstwy sieciowej i przetwarzane przez nia, tak aby mogly byc przekazane kolejnym warstwom do dalszej obróbki. Kazda kolejna warstwa musi znac jedynie format danych wymagany do komunikacji poprzez warstwe nizsza, zwany protokolem wymiany danych. Przy przechodzeniu do warstwy nizszej, warstwa dokleja do otrzymanych przez siebie danych naglówek z informacjami dla swojego odpowiednika na odleglym komputerze. Dzieki temu kolejne warstwy nie ingeruja w zawartosc otrzymana z warstwy poprzedniej. Po odebraniu danych z warstwy nizszej warstwa wyzsza interptertuje naglówek "doklejony" przez swojego odpowiednika z komputera odleglego i jesli zachodzi potrzeba przekazania danych do warstwy wyzszej, usuwa swój naglówek i przekazuje dane dalej.
Rysunek 2.5.2 Struktura sieci wielowarstwowej. Model ISO/OSI koncentruje sie na wymianie informacji miedzy dwoma systemami otwartymi i nie wnika w wewnetrzne funkcjonowanie kazdego z nich. Naklada na system wymagania dotyczace jego zdolnosci do wymiany informacji z innym systemem i realizowania pewnych zadan. Celem modelu jest zdefiniowanie standardów, które pozwola wspólpracowac systemom otwartym znajdujacym sie w dowolnych miejscach na kuli ziemskiej, polaczonych standardowym kanalem komunikacyjnym dzieki realizowaniu modelu odniesienia ISO/OSI.
2.5.3 Charakterystyka warstw modelu OSI Warstwa fizyczna zapewnia przesylanie strumienia bitów w fizycznym medium transmisji. Jednostka danych jest tutaj bit. Okresla m.in. sposób polaczenia mechanicznego (np. standard wtyczki, kabla lub innego medium transmisyjnego), elektrycznego (np. poziomy napiec sygnalów i czasy ich trwania) lub optycznego (dla swiatlowodów) i standard kodu stosowanego w transmisji danych. w sklad jej obiektów wchodza m.in. przewody, karty sieciowe, modemy, regeneratory, koncentratory.

Warstwa lacza danych zajmuje sie sterowaniem dostepu do medium i sprawna transmisja ciagów bajtów za pomoca warstwy fizycznej. Podstawowa jednostka w tej warstwie jest ramka. Warstwa ta zajmuje sie transmitowaniem ramek do okreslonego sasiada stacji nadajacej. Przy wysylaniu ramek warstwa lacza danych posluguje sie potwierdzeniami. W przypadku braku potwierdzenia lub potwierdzenia negatywnego odbieranej ramki przez stacje docelowa ramka jest retransmitowana. W ten sposób na poziomie warstwy drugiej transmisja jest juz wyposazona w podstawowe mechanizmy kontroli i korygowania bledów (CRC), dostarczajac warstwie wyzszej (sieci) uslugi praktycznie bezblednej transmisji. Warstwa ta czesto zajmuje sie równiez kompresja danych. W sklad jej obiektów wchodza sterowniki urzadzen sieciowych oraz mosty i switch’e. Warstwa sieci zapewnia metody ustanawiania, utrzymania i rozlaczania polaczenia sieciowego, obsluge bledów komunikacji oraz transmisje bloków danych (pakietów) przez siec komunikacyjna po odpowiednio dobranych trasach. tlumaczy ona adresy logiczne (np. IP) na fizyczne ( MAC). Glównym zadaniem warstwy sieciowej jest znalezienie drogi dla pakietów w obrebie podsieci i miedzy podsieciami (routing). Nalezy pamietac, ze wszystkie warstwy wyzsze od tej warstwy (sieciowej) pracuja wylacznie w koncowych systemach komunikujacych sie ze soba, tzn. ze jezeli komputery A i B wymieniaja dane miedzy soba, ale pomiedzy nimi znajduje sie komputer C (jako wezel sieci), to w takiej komunikacji siedem warstw Modelu Odniesienia bedzie aktywnych tylko w komputerach A i B, natomiast w komputerze C beda pracowaly tylko trzy warstwy. Warstwa transportowa zapewnia calosciowe polaczenie pomiedzy nadawca a odbiorca, sklada dane w strumien. Warstwa ta realizuje transport danych miedzy systemami koncowymi. Zapewnia ona podzial wiadomosci na pakiety, bezbledne ich przekazywanie miedzy punktami koncowymi, bez ich utraty, zmiany kolejnosci, kontrolujac jednoczesnie priorytety, opóznienia oraz tajnosc przesylania informacji. Pakiety moga byc przesylane w trybie polaczeniowym (ang. connection-oriented) lub bezpolaczeniowym (ang. connectionless). W pierwszym przypadku najpierw jest ustanawiane polaczenie sieciowe tzw. kanal wirtualny, którym nastepnie sa przesylane pakiety. W drugim przypadku kazdy pakiet posiada wszystkie informacje niezbedne dla prawidlowego dotarcia do adresata i jest przesylany przez siec niezaleznie, co powoduje, ze pakiety moga przybywac do wezla docelowego w innej kolejnosci niz zostaly nadane. Warstwa sesji zapewnia aplikacjom na odleglych komputerach realizacje wymiany danych pomiedzy nimi. Wymiana dokonywana jest w czasie trwania polaczenia nazywanego sesja. Kontroluje nawiazywanie i zrywanie polaczenia przez aplikacje. Okresla tez tryb sesji (przekazywanie danych: dwukierunkowe jednoczesne, naprzemienne, jednokierunkowe). Warstwa ta równiez realizuje funkcje zwiazane z synchronizacja dostepu do wspólnych zasobów, porzadkuje proces wymiany danych oraz odpowiada za bezpieczenstwo (uwierzytelnianie). Warstwa prezentacji zajmuje sie konwersja typów danych pomiedzy komunikujacymi sie stacjami, szyfrowaniem i deszyfrowaniem danych oraz kompresja i dekompresja danych. Jezeli dwa systemy otwarte wymieniaja dane, to konwersja typów jest konieczna ze wzgledu na niekompatybilnosc systemów komputerowych. Kazdy komputer, terminal, drukarka moze interpretowac dane w rózny sposób, miec slowa o innej dlugosci, poslugiwac sie róznymi zestawami znaków itp. i w takiej sytuacji w warstwie prezentacji nalezy ujednolicic format zapisu danych. Warstwa ta dokonuje wiec transformacji kodów i formatów danych stosowanych przez uzytkownika na kody i formaty uzywane w sieci ( w tym kompresji lub szyfrowania danych), i odwrotnie.

Warstwa aplikacji umozliwia programom aplikacyjnym dostep do srodowiska ISO/OSI. Swiadczy ona uslugi koncowe dla aplikacji, m.in. udostepnianie zasobów (plików, drukarek). Na tym poziomie rezyduja procesy sieciowe dostepne bezposrednio dla uzytkownika. Warstwa aplikacji przeslania aplikacjom (uzytkownikowi) cale srodowisko komunikacyjne tak, aby aplikacja (uzytkownik) nie musiala odwolywac sie do sprzetu. Przykladami uslug wysokiego poziomu sa: transfer plików, poczta elektroniczna. Ostatecznym efektem realizacji protokolu warstwy aplikacji jest pomyslne przeslanie danych. W przypadku protokolu TCP/IP wymienione warstwy wykorzystuja nastepujace protokoly sieciowe:
Protokoly wystepujace w modelu TCP/IP
Warstwa aplikacji HTTP FTP
POP3 SMTP
Warstwa transportowa TCP UDP
Warstwa Internetu IP
Warstwa dostepu do sieci Ethernet
PPP 2.5.4 Polaczenia w sieci wielowarstwowej. Punkt - punkt Polaczenie bezposrednie.
Repeater Repeater jest to urzadzenie aktywne do wzmacniania sygnalów w sieci. Dziala w warstwie fizycznej. Potrzeba wzmacniania sygnalu wynika z wlasnosci medium - sygnal w kablu ulega tlumieniu, które jest proporcjonalne do dlugosci kabla.
Bridge Bridge (most) jest urzadzeniem wykorzystywanym w polaczeniach miedzysieciowych. Dziala w warstwie fizycznej i lacza danych. Moze laczyc dwa lub wiecej segmentów sieci lub podsieci pod warunkiem, ze sieci te maja kompatybilna strukture adresów w warstwie lacza(np. ISO 8802-2 z

ISO 8802-2 lub ISO 8802-2 z ISO 8802-5). Bridge operuja tylko na adresach sprzetowych, okreslajac tylko, do którego segmentu sieci nalezy przeslac pakiet. Nie majac informacji z warstwy sieciowej nie moga dobierac optymalnej trasy przesylania pakietów.
Router Router podobnie jak bridge jest urzadzeniem sprzegajacym sieci. Funkcjonuje w warstwach fizycznej, lacza danych i sieciowej. W przeciwienstwie do bridga ma informacje o adresach miejsc przeznaczenia pakietów, moze zatem podjac decyzje o wyborze optymalnej trasy przeslania pod warunkiem, ze jest wybór wielu róznych tras. Routery moga obslugiwac jeden protokól warstwy sieciowej np. IP albo wiele protokolów np. IP, IPX, DECnet.
Gateway Gateway jest urzadzeniem sprzegajacym dwie sieci, których systemy komputerowe w celach wzajemnego komunikowania sie wymagaja konwersji stosowanych protokolów. Gateway dziala na wszystkich siedmiu warstwach modelu ISO/OSI. Laczy z reguly dwa systemy rózniace sie nie tylko akceptowanymi protokolami, ale tez systemami operacyjnymi.
2.5.5 Topologie sieci komputerowych Jedna z waznych wlasnosci sieci jest jej topologia. Najwazniejszymi typami polaczen sa: Magistrala Stacje sa przylaczone do centralnej magistrali, która musi byc z oby stron zakonczona terminatorami.
Drzewo Kazda stacja jest polaczona jednokierunkowymi laczami z dwoma sasiednimi stacjami.
Magistrala-Drzewo Stacje sa przylaczone do centralnej magistrali, która musi byc z oby stron zakonczona terminatorami. Do magistrali moze byc tez przylaczone drzewo zlozone z koncentratorów i stacji. Pierscien Kazda stacja jest polaczona jednokierunkowymi laczami z dwoma sasiednimi stacjami.

Podwójny pierscien Polaczenia miedzy stacjami w sieci sa podwójne. Pierscienie przesylaja dane w przeciwnych kierunkach co pozwala na poprawna prace nawet w przypadku bledu przerwania polaczenia. Pierscien drzew Kazda stacja pierscienia jest polaczona jednokierunkowymi laczami z dwoma sasiednimi stacjami. W pierscieniu moga sie znajdowac koncentratory stacji. Gwiazda W centrum znajduje sie koncentrator, do którego podwójnymi polaczeniami sa podlaczone stacje i koncentratory.
2.5.6 Standardy polaczen sieci komputerowych Istnieje kilka waznych standardów polaczen sieciowych rózniacych sie rodzajem polaczen, warstwa sprzetowa oraz protokolami przesylan w najnizszych warstwach komunikacyjnych. Do najwazniejszych zaliczamy Ethernet, FDDI, ATM, Fibre Channel, HIPPI. Ethernet Najpowszechniejszy standard polaczen. Historia Ethernetu zaczela sie w 1970 roku, kiedy to firma XEROX stworzyla prototyp sieci komputerowej. Pierwsza siec bedaca podstawa Ethernetu zostala zaprojektowana w 1976 r przez dr. Robert M. Metcalfe. Zostala ona zaprezentowana na konferencji National Computer Conference w czerwcu tegoz roku. W 1980 Digital Equipment Corp. (DEC), Intel i Xerox zaczely promocje jednopasmowej sieci komputerowej na kablu koncentrycznym przy uzyciu metody dostepu CSMA/CD i opublikowaly "Blue Book Standard" dla wersji 1. Ethernetu. Ten standard zostal rozszerzony w 1985 r do wersji ETHERNET II. IEEE's (Institute of Electrical and Electronics Engineers') bazujac na Ethernecie w wersji 2, opracowala standard sieci opartych na CSMA/CD - 802.3.
W sieci Ethernet zastosowano dostep rywalizacyjny, polegajacy na zaprzestaniu transmisji w momencie kolizji wiadomosci na kablu. W razie wykrycia kolizji nalezy powtórzyc nadawanie, do momentu uzyskania polaczenia. Ponizej przedstawiono glówne wlasciwosci protokolu dla sieci Ethernet. W Ethernecie zastosowano wariant metody CSMA/CD - protokól 802.3, który obejmuje nastepujace zalozenia:
1. Kazda stacja prowadzi ciagly nasluch lacza, sprawdzajac czy lacze jest wolne, zajete lub czy
trwa strefa buforowa. Strefa buforowa jest odcinkiem czasu po ustaniu zajetosci lacza. Lacze jest uwazane za zajete, jezeli odbiornik wykryje sygnal pochodzacy od co najmniej jednego nadajnika.
2. Nadawanie jest dozwolone tylko, gdy lacze jest wolne. Jezeli lacze jest zajete a nadajnik ma dane do wyslania, nalezy poczekac do konca strefy buforowej.
3. Gdy podczas nadawania zostaje wykryta kolizja, stacja nadaje jeszcze przez pewien czas zwany czasem wymuszenia i zawiesza dzialalnosc na czas Ti.

4. Oprócz pierwszej próby stacja podejmuje jeszcze, co najwyzej, 15 ewentualnych nastepnych prób. Jezeli wystapilo 16 kolejnych kolizji nadajnik przerywa dzialanie i sygnalizuje ten fakt warstwie wyzszej, która zglosila zadanie nadawania.
5. Po nieudanej i-tej próbie dostepu stacja zawiesza dzialanie na czas Ti = Ri S, gdzie S jest szerokoscia szczeliny czasowej (ang. slot), a Ri jest liczba losowa z przedzialu <0, 2n-1>, n=min{i,10}. Czas Ti jest wiec zalezny od liczby juz podjetych prób, przy czym preferowane sa stacje, które zrealizowaly mniejsza liczbe powtórzen prób dostepu. Czas Ti jest liczba losowa, bo, gdyby wszyscy uczestnicy kolizji czekali tak samo dlugo, to natychmiast wystapilaby ponowna kolizja. Scislej mówiac, czas Ti nie jest zupelnie losowy, gdyz jest wyznaczany przez pewien algorytm na podstawie 6 bajtowego adresu ethernetowego karty. W zwiazku z tym pewne serie kart moga byc uprzywilejowane.
6. Szczelina czasowa S jest zdefiniowana jako podwojony maksymalny czas propagacji sygnalu powiekszony o czas wykrycia kolizji i czas wymuszania. Jednoczenie S wyznacza minimalna dlugosc ramki (bez preambuly). Jezeli danych do przeslania jest mnie, wprowadzane jest dodatkowe pole uzupelnienia PAD (ang. padding). W ten sposób uzyskuje sie pewnosc, ze w przypadku wystapienia kolizji bedzie ona wykryta przed zakonczeniem nadawania.
FDDI Siec FDDI (ang. Fiber Distributed Data Interface) jest siecia lokalna o przepustowosci do 1 Gb/s zdefiniowana przez standardy ANSI i ISO. Zostala ona zaprojektowana z mysla o zastosowaniu swiatlowodów, ale obecnie istnieja standardy równiez dla innych mediów. Siec FDDI uzywa dostepu do medium z przekazywaniem uprawnienia. Wiekszosc standardów FDDI zostala opracowana przez Acredited Standards Committee X3T9.5. W 1995 roku, X3T9.5 zostal przemianowany na X3T12. Standardy FDDI zostaly zatwierdzone zarówno przez ANSI (American National Standards Institute), jak i przez ISO (International Standards Organization).
Rysunek 2.5.1 Polaczenie FDDI – podwójny pierscien.
Jak pokazano na Rys.2.5.1 polaczenia miedzy stacjami w sieci sa podwójne. Pierscienie przesylaja dane w przeciwnych kierunkach, co pozwala na poprawna prace nawet w przypadku bledu przerwania polaczenia. Jezeli jedno z polaczen podwójnego pierscienia nie dziala lub jest niepolaczone, dwie najblizsze stacje przechodza w stan „zawiniecia”. Powoduje to, ze z dwóch pierscieni o przeciwnych kierunkach transmisji powstaje jeden. Przesylanie informacji w sieci odbywa sie na zasadzie przesylania znacznika (ang. token). Stacja, która otrzymala znacznik przejmuje role stacji nadawczej.

Zdefiniowane sa 3 zegary:
THT - Token Holding Time - czas przez jaki moze nadawac stacja po odebraniu znacznika (ang. token).
THT = TTRT -TRT
TRT- Token Rotation Time - czas pomiedzy kolejnymi odbiorami tokenu przez stacje jest równy. Zalezy on od liczby aktywnych stacji i wartosci THT. TRT = Liczba aktywnych stacji * THT + czas przejscia sygnaly przez caly pierscien TTRT- Target Token Rotation Time - oznacza maksymalna dopuszczalna wartosc TRT. Wartosc TTRT jest ustalana przez stacje w drodze glosowania. Wybierana jest najmniejsza wartosc ze wszystkich stacji. W celu zwiekszenia efektywnosci nalezaloby maksymalnie zwiekszyc wartosc THT, jednakze wtedy rosnie równiez wartosc TRT, czego skutkiem jest dlugi czas oczekiwania na token. Tymczasem pewne programy moga miec scisle okreslone ograniczenia na czas dostepu do medium (np. przesylanie strumienia wideo czy glosu). FDDI definiuje dwa typy ruchu w sieci: synchroniczny i asynchroniczny. Ramki synchroniczne zapewniaja ciaglosc przesylania danych, z pewna okreslona przepustowoscia. Sa nadawane po otrzymaniu tokenu, niezaleznie od stanu zegarów THT i TRT. Ramki asynchroniczne moga byc nadawane, kiedy stacja odebrala znacznik, wytransmitowala ramki synchroniczne i jeszcze ma prawo do nadawania. Ruch synchroniczny z reguly ma znaczna przepustowosc, ale nie ma gwarancji utrzymania jej na pewnym minimalnym poziomie.
Podczas inicjalizacji sieci FDDI, po zagubieniu znacznika i wlaczeniu lub wylaczeniu stacji, do sieci nalezy wystawic nowy znacznik. Proces odtwarzania tokenu (ang. claim token proces) powoduje wybranie stacji, która odtworzy znacznik i okresla wartosc TTRT (target token rotation time). Proces odtwarzania znacznika wygrywa stacja, która zada najmniejszej wartosci TTRT. Jezeli takich stacji jest kilka, to decyduje wyzszy adres stacji. Caly proces wyglada jak nastepuje:
1. Stacja, która przez dluzszy czas nie odbiera ramki ani znacznika rozpoczyna proces
odtwarzania znacznika: nadaje ramki typu claim, których zawartoscia jest zadana wartosc TTRT. Ramki sa nadawane jedna po drugiej az do zakonczenia procesu.
2. Stacja, która odbierze ramke claim porównuje swoje zadanie TTRT z zawartoscia ramki. Jezeli zadanie stacji jest mniejsze od odebranego stacja kasuje nadchodzace ramki i nadaje wlasne. Jezeli zadanie stacji jest wieksze stacja przechodzi w stan CLAIMREPEAT i przestaje brac aktywny udzial w procesie. W stanie CLAIMREPEAT stacja tylko retransmituje ramki czekajac na zakonczenie procesu odtwarzania tokenu..
3. Jezeli wartosci TTRT odebrana i zadana przez stacje sa sobie równe, decyduje adres stacji. Wygrywa stacja z wyzszym adresem.
4. Jesli stacja odebrala wlasna ramke typu claim, to oznacza, ze wygrala proces odtwarzania znacznika. Stacja wystawia token.
5. W pierwszym okrazeniu znacznik nie jest uzywany przez zadna stacje. Sluzy on do zakonczenia procesu odtwarzania znacznika i informuje stacje o nowej wartosci TTRT.

ATM Siec ATM, w odróznieniu od popularnej sieci Ethernet, ma charakter polaczeniowy. Oznacza to, ze przed rozpoczeciem transmisji danych wystepuje faza nawiazania polaczenia wirtualnego. Przymiotnik „wirtualne" podkresla fakt, iz polaczenia w sieci ATM nie sa polaczeniami fizycznymi, tak jak w przypadku tradycyjnej telefonii, a jedynie ich logicznymi odpowiednikami.
Polaczeniowa natura sieci ATM jest istotna w zastosowaniach multimedialnych, gdyz decyzje dotyczace trasy przejscia pewnej porcji danych podejmowane sa jedynie raz - podczas fazy nawiazywania polaczenia. Gdy polaczenie jest juz ustalone, kazdy element danych podaza ta sama trasa. Urzadzenie przelaczajace celki ATM nie musi okreslac trasy przejscia dla kazdego pakietu z osobna, jak to ma miejsce w tradycyjnych protokolach IP, zwiekszajac w ten sposób szybkosc transmisji oraz zmniejszajac opóznienia.
Oczywiscie istnieje równiez negatywna strona transmisji w trybie polaczeniowym. Awaria pojedynczej przelacznicy w sieci ATM wymusza koniecznosc zmiany wszystkich polaczen przechodzacych przez te przelacznice. Jest to zagadnienie zdecydowanie trudniejsze od zmiany trasy pakietów IP, z których kazdy posiada adres docelowy. Celki ATM nie zawieraja informacji adresowej, a cala wiedza dotyczaca trasy pakietów zlokalizowana jest w przelacznicach. Polaczenia w sieci ATM identyfikowane sa za pomoca pary liczb:
• VPI (Virtual Path Identifier) • VCI (Virtual Channel Identifier).
Przydzielanie aplikacjom identyfikatorów VPI oraz VCI moze odbywac sie poprzez reczna konfiguracje dokonana przez administratora sieci, lub dynamicznie, za posrednictwem procedur sygnalizacyjnych. Podstawowa jednostka transmisji w sieci ATM jest celka (ang. cell), która w odróznieniu od ramki posiada stala dlugosc równa 53 bajtom.
Wybór stalej dlugosci jednostki transmisji znacznie uproscil konstrukcje przelacznic ATM, zwiekszajac jednoczesnie ich szybkosc. Rozmiar celki ATM zostal zatwierdzony na drodze kompromisu. Decydujac sie na taki rozmiar celki ATM, brano pod uwage takie czynniki jak:
• opóznienie zwiazane z przetwarzaniem celki, • mozliwosc transportu przekazów czasu rzeczywistego w komórkach ATM, • mozliwosc wykorzystania istniejacej infrastruktury telekomunikacyjnej do transportu
celek ATM, • minimalizacje czasu retransmisji w przypadku utraty fragmentu przekazu.
Wybór tak malego rozmiaru celki ATM posiada równiez cechy negatywne, z których bardzo istotna jest duzy udzial wielkosci naglówka w wielkosci calej jednostki transmisji. Naglówek celki ATM ma dlugosc 5 bajtów, co stanowi prawie 10% dlugosci calej celki. Dwa podstawowe typy polaczen wystepujacych w sieciach ATM to:
• punkt-punkt, laczace dwie stacje koncowe. Polaczenia tego typu moga byc jedno lub dwukierunkowe,
• punkt-wiele punktów. W polaczeniach tego typu wyrózniamy jedna stacje zwana korzeniem i wiele stacji zwanych liscmi. Polaczenia te sa jednokierunkowe.
Rozgalezianie strumienia komórek ATM realizowane jest sprzetowo przez przelacznice. Odbywa sie to poprzez dodanie do tablicy przelacznicy wpisu zawierajacego dwa lub wiecej kanalów

wyjsciowych. Nalezy jednoczesnie zwrócic uwage na fakt, iz siec ATM zapewnia odpowiednia kolejnosc celek. Moze miec miejsce sytuacja, kiedy przelacznica gubi celki wskutek przeciazenia, nigdy jednak nie zmieni ona kolejnosci celek. Polaczenia grupowe w sieci ATM sa jednokierunkowe - transmisja odbywa sie od stacji bedacej korzeniem do wszystkich lisci. W ramach jednego polaczenia nie istnieje mozliwosc transmisji pomiedzy liscmi ani od liscia do korzenia.
Oprócz wymienionych trzech standardów sieci, istnieja jeszcze lokalne sieci – przelaczniki takie jak Fibre-Channel oraz HIPPI, uzywane glównie do szybkich polaczen w obrebie Centrum obliczeniowego i superkomputera. Nie sa one jednak, ze wzgledu na ograniczone zastosowanie, omawiane w tej ksiazce. 2.5.7 Architektura sprzetowa sieci komputerowych Sprzet, który buduje siec sklada sie z: - mediów transmisyjneych - karty sieciowe - modem - most (bridge) - koncentrator (hub) - regenerator (repeater) - przelacznik (switch) - router - komputer - serwer Media transmisyjne (najczesciej stosowane) Przewód koncentryczny czesto nazywany "koncentrykiem", sklada sie z dwóch koncentrycznych (czyli wspólosiowych) przewodów. Kabel ten jest doslownie wspólosiowy, gdyz przewody dziela wspólna os. Najczesciej spotykany rodzaj kabla koncentrycznego sklada sie z pojedynczego przewodu miedzianego biegnacego w materiale izolacyjnym. Izolator (lub inaczej dielektryk) jest okolony innym cylindrycznie biegnacym przewodnikiem, którym moze byc przewód lity lub pleciony, otoczony z kolei nastepna warstwa izolacyjna. Calosc oslonieta jest koszulka ochronna z polichlorku winylu (PCW) lub teflonu. Mimo, ze kable koncentryczne wygladaja podobnie, moga charakteryzowac sie róznymi stopniami impedancji. Grubosc kabla ma wplyw na max. dlugosc segmentu sieci. Siec budowana jest na zasadzie lini tzn. pierwszy komputer polaczony jest drugim, drugi z trzecim itd. przy zastosowaniu trójników do przylaczania kart sieciowych oraz terminatorów, którymi zakonczone sa koncówki kabla. Zaleta kabli koncentrycznych jest to, ze potrafia obslugiwac komunikacje w pasmach o duzej szerokosci. Kabel koncentryczny byl pierwotnym nosnikiem sieci Ethernet. Od tego czasu zostal on zupelnie wyparty przez specyfikacje warstwy fizycznej Ethernetu oparte na skretce dwuzylowej. Przyczyny tej dezaktualizacji sa proste. Wystepuje ograniczenie szybkosci do 10 Mb/s oraz ma slaba skalowalnosc. Dodatkowymi czynnikami zniechecenia do stosowania kabli koncentrycznych sa ich koszt i rozmiar. Okablowanie koncentryczne jest drozsze anizeli skretka dwuzylowa za wzgledu na jego bardziej skomplikowana budowe. Kazdy koncentryk ma tez co najmniej 1 cm srednicy. W zwiazku z tym zuzywa on olbrzymia ilosc miejsca w kanalach i torowiskach kablowych, którymi powadzone sa przewody. Chociaz sieci z zastosowaniem kabla koncentrycznego wychodzaca z uzytku, nadal moze sie okazac przydatna w niektórych zastosowaniach. Przykladowo przy instalacji malej sieci domowej - do 5 komputerów - koszt

takiej instalacji jest o wiele nizszy od instalacji z wykorzystaniem skretki. Ciekawym zastosowaniem tej technologii, staja sie ostatnio sieci osiedlowe. W przypadku odleglosci pomiedzy blokami powyzej 100 m, czesto wykorzystuje sie przewód koncentryczny. Skretka dwuzylowa Okablowanie skretka dwuzylowa, od dawna uzywane do obslugi polaczen glosowych, stalo sie standardowa technologia uzywana w sieciach LAN. Skretka dwuzylowa sklada sie z dwóch dosc cienkich przewodów o srednicy od 4 do 9 mm kazdy. Przewody pokryte sa cienka warstwa polichlorku winylu (PCW) i splecione razem. Skretka przewodów razem równowazy promieniowanie, na jakie wystawiony jest kazdy z dwóch przewodów znoszac w ten sposób zaklócenia elektromagnetyczne, które inaczej przedostawalyby sie do przewodnika miedzianego. Skretka dwuzylowa jest skrecana nie bez przyczyny; a jest nia fakt, ze skrecanie likwiduje duza czesc zaklócen sygnalu. W sieciach LAN najczesciej stosowane sa cztery pary przewodów polaczone razem w wiazki, które osloniete sa wspólna koszulka PCW lub teflonu. Dwoma najczesciej stosowanymi rodzajami skretek osmiozylowych sa ekranowana i nieekranowana. Swiatlowód (Fiber Optic Cable) jest obecnie najnowoczesniejszym i zapewniajacym najwieksze szybkosci transmisji medium. Jego dzialanie opiera sie na transmisji impulsów miedzy nadajnikiem przeksztalcajacym sygnaly elektryczne na swietlne, a odbiornikiem przeksztalcajacym sygnaly swietlne odebrane ze swiatlowodu w sygnaly elektryczne.
Swiatlowód wypelniony jest w srodku wlóknem optycznym, które przenosi impulsy swietlne. Wlókno to sklada sie z dwóch rodzajów szkla o róznych wspólczynnikach zalamania. Czesc srodkowa nazywana jest rdzeniem, w którym wedruje promien swiatla - najczesciej spotykany w sieciach LAN ma srednice 62,5 mikrometra. Czesc zewnetrzna o srednicy 125 mikrometra nazywamy plaszczem zewnetrznym. Pozostale elementy to: warstwa akrylowa, tuba- izolacja o srednicy 900 mikrometrów, oplot kewlarowy, izolacja wewnetrzna.
Zasada dzialania swiatlowodu opiera sie na zalamywaniu wedrujacej w przewodzie wiazki swiatla. Gdy promien pada od strony rdzenia na plaszcz pod pewnym katem, to czesc swiatla odbija sie od plaszcza i wraca z powrotem do rdzenia. W zaleznosci od kata padania i wspólczynników zalamania materialow rdzenia i plaszcza zmienia sie ilosc odbitego swiatla. Dla katów ponizej pewnej wartosci zachodzi znane z fizyki zjawisko calkowitego odbicia wewnetrznego i swiatlo zostaje odbite bez strat. Umozliwia to transmisje strumienia swietlnego przez wlókno. Karta sieciowa - to plytka drukowana instalowana w wolnym gniezdzie magistrali komputera. Sklada sie z kontrolera LAN, transformatora zlacza sieciowego RJ-45 i\lub BNC, pamieci EEPROM oraz opcjonalnie pamieci FLASH. Urzadzenie to laczy komputer z siecia komputetrowa, zawiera dwa interfejsy: jeden do polaczenia z siecia (skretka UTP (RJ-45), koncentryk (BNC)) (zdj 3) i drugi do polaczenia z komputerem (ISA, PCI, USB). Najwazniejszym z elementów jest modul kontrolera LAN. Obecnie produkowane karty maja wbudowany wlasny procesor, co umozliwia przetwarzanie niektórych danych bez angazowania procesora glównego, oraz wlasna pamiec RAM, która pelni role buforu w przypadku, gdy karta nie jest w stanie przetworzyc naplywajacych z duza szybkoscia danych.
Glównym zadaniem karty sieciowej jest transmisja i rozszyfrowywanie informacji przychodzacych z sieci. Przesylanie danych rozpoczyna sie od uzgodnienia parametrów transmisji pomiedzy stacjami (np. predkosc, rozmiar pakietów). Nastepnie dane sa przeksztalcane na sygnaly elektryczne, kodowane, kompresowane i wysylane do odbiorcy. Jego karta dokonuje ich deszyfracji i dekompresji. Tak wiec karta odbiera i zamienia pakiety na bajty zrozumiale dla procesora stacji roboczej.

Modem jest to urzadzenie sluzace do polaczenia komputerów najczesciej poprzez siec telefoniczna. Glównym zadaniem modemów jest zamiana sygnalów cyfrowych na analogowe i odwrotnie. Modem lokalny odbiera dane cyfrowe przesylane z komputera, zamienia je w modulatorze na postac analogowa i transmituje poprzez linie telefoniczna do modemu oddalonego. Ten z kolei dokonuje za pomoca demodulatora zamiany postaci analogowej danych na postac cyfrowa i wysyla je do komputera. Kazdy modem musi byc wiec wyposazony w modulator i demodulator, których zadaniem jest konwersja danych z postaci cyfrowej na analogowa i odwrotnie. W pamieci NVRAM (EPROM) przechowywane sa pewne standardowe parametry modemu ustawiane przez producenta, takie jak: szybkosc transmisji (bit/s). Pamiec RAM wykorzystywana jest jako bufor danych w przypadku polaczenia modemów z korekcja bledów i kompresja danych. Modemy dzielimy na zewnetrzne podlaczane do portu szeregowego i wewnetrzne podlaczane do zlacz komputera. Regenerator (repeater) jest urzadzeniem stosowanym do laczenia segmentów kabla sieciowego. Regenerator odbierajac sygnaly z jednego segmentu sieci wzmacnia je, koryguje znieksztalcenia, poprawia ich parametry czasowe i przesyla do innego segmentu. Moze laczyc segmenty sieci o róznych mediach transmisyjnych. Pracuje w warstwie fizycznej modelu OSI, a co za tym idzie jego mozliwosci sa niewielkie: nie izoluje segmentów, uszkodzen ani pakietów, laczy ze soba sieci o tej samej architekturze, uzywajace tych samych protokolów i technik transmisji. Aktualnie rzadko spotykany w popularnych zastosowaniach. Koncentrator (hub) jest urzadzeniem majacym wiele portów do laczenia wielu stacji roboczych, umozliwiajac tworzenie sieci o topologii gwiazdy. Zaleta takiego rozwiazania jest to, ze przerwanie polaczenia miedzy hubem a kompem nie powoduje zatrzymania ruchu w calej sieci. Jednak awaria huba unieruchamia cala siec. Wyrózniamy huby aktywne i pasywne. Huby aktywne poza rola laczeniowa, wzmacniaja i regeneruja ksztalt sygnalów ze stacji roboczych, co pozwala na wydluzenie polaczenia. Hub jest jak wieloportowy regenerator. W zaleznosci od liczby przylaczonych do sieci komputerów mozna uzyc wielu hubów. Przelacznik (switch) sa urzadzeniami warstwy lacza danych (warstwy 2) i lacza wiele fizycznych segmentów LAN w jedna wieksza siec . Zwykle maja kilka portów wykorzystywanych do podlaczenia stacji roboczych innych przelaczników lub koncentratorów. Przelaczniki dzialaja podobnie do koncentratorów z ta róznica, ze transmisja pakietów nie odbywa sie z jednego wejscia na wszystkie wyjscia przelacznika, ale na podstawie adresów MAC kart sieciowych przelacznik tworzy sobie tablice przyporzadkowujaca do adresu sprzetowego stacji numer portu, do którego podlaczony jest dany komputer i w przypadku pojawienia sie transmisji do danej stacji caly ruch kierowany jest na odpowiedni port i nie przedostaje sie na inne porty czyli kieruje pakiety tylko do konkretnego odbiorcy co powoduje wydatne zmniejszenie ruchu w sieci. W przeciwienstwie do koncentratorów, przelaczniki dzialaja w trybie full-duplex (jednoczesna transmisja w obu kierunkach). Router - jest to urzadzenie wyposazone najczesciej w kilka interfejsów sieciowych LAN, porty obslugujace siec WAN, pracujacy wydajnie procesor i oprogramowanie zawiadujace ruchem pakietów przeplywajacych przez router. Potrafi kierowac dane do wielu róznych sieci. Router jest zaawansowanym urzadzeniem do laczenia ze soba poszczególnych sieci IP. Jest konfigurowalny , najczesciej pozwala na sterowanie przepustowoscia sieci jak równiez przekazywac dane pomiedzy sieciami opartymi na róznych technologiach. Jego glównym zadaniem jest odczytywanie adresów z poszczególnych pakietów, tak aby wiedziec gdzie je kierowac. W sieciach rozleglych dane przechodza przez wiele wezlów posrednich i moga podrózowac róznymi trasami. Router jest jednym z takich wezlów i ma za zadanie przeslac dane jak najlepsza i jak najszybsza droga. Taki proces ich dostarczania nazywa sie trasowaniem. Do kierowania

przesylek uzywana jest tzw. tablica routingu czyli informacje zakodowane w pamieci routera o wszystkich mozliwych polaczeniach w swoim zasiegu i ich stanie. Tablica routingu moze byc statyczna - aktualizowana recznie lub dynamiczna - aktualizowana automatycznie przez oprogramowanie sieciowe, które monitoruje ruch w sieci i np. w przypadku awarii kieuje dane inna droga tak by omijaly powstaly zator. Funkcjonuje w 1,2 i 3 warstwie modelu ISO/OSI. W sieciach lokalnych stosowany, gdy chcemy podzielic siec na wiecej podsieci. Segmentacja sieci powoduje, ze poszczególne podsieci sa od siebie odseparowane i pakiety nie przenikaja z jednej podsieci do drugiej. W ten sposób zwiekszamy przepustowosc kazdej podsieci. Most (bridge) sluzy do przesylania i filtrowania ramek miedzy dwoma sieciami. Sledzi adresy MAC umieszczane w przesylanych do nich pakietach. Mosty nie maja dostepu do adresów warstwy sieciowej, dlatego nie mozna ich uzyc do dzielenia sieci opartej na protokole TCP/IP na dwie podsieci IP. To zadanie moga wykonywac wylacznie routery. Analizujac adresy MAC, urzadzenie wie, czy dany pakiet nalezy wyekspediowac na druga strone mostu, czy pozostawic bez odpowiedzi. Mosty podobnie jak przelaczniki przyczyniaja sie w znacznym stopniu do zmniejszenia ruchu w sieci. Mosty posiadaja technike uczenia sie. Zaraz po dolaczeniu do sieci wysylaja sygnal do wszystkich wezlów z zadaniem odpowiedzi. Na tej podstawie oraz na analizie przeplywu pakietów, tworza tablice adresów fizycznych komputerów w sieci. Przy przesylaniu danych bridge odczytuje z tablicy polozenie komputera odbiorcy i zapobiega rozsylaniu pakietów po wszystkich segmentach sieci.
W nastepnym rozdziale przedstawiono jeszcze inne metody zwiekszenia szybkosci obliczen oparte na systemach polaczen procesorów w wielkie tzw. systemy wieloprocesorowe – wspólczesne superkomputery.
2.6 Nowoczesne instalacje komputerowe, komputery równolegle 2.6.1 Taksonomia systemów równoleglych Obliczenia o wielkiej skali zlozonosci cechuja sie wysokim stopniem synergizmu zachodzacego pomiedzy problemem obliczeniowym, algorytmem obliczeniowym i jego komputerowa realizacja oraz architektura komputerowa.
Pierwsza maszyna cyfrowa, istotnie rózna od sekwencyjnej architektury zaproponowanej przez Johna von Neumanna, byl wektorowy superkomputer Cray-1 (opracowany przez Seymura Craya), który pojawil sie w 1976r. Zapoczatkowal on rozwój komputerów o wielu procesorach, nowych modeli programowania, algorytmów odpowiednich dla realizacji na wielu procesorach jednoczesnie, oraz udostepnil moc obliczeniowa pozwalajaca na symulacyjne badanie problemów naukowych pozostajacych poza zasiegiem mozliwosci ówczesnych maszyn.
W konsekwencji, sformulowana zostala przez Larrego Smarra idea metaprzetwarzania, w którym zapewnia sie uzytkownikowi przezroczysty dostep do róznorodnych uslug komputerowych, w szczególnosci do duzej mocy obliczeniowej, uslug graficznych, multimedialnych i wizualizacji naukowej oraz do uslug archiwizacji i udostepniania duzych zbiorów danych. Wymienione problemy doprowadzily do wielu osiagniec naukowych i implementacyjnych oraz nadal sa rozwijane z pozytkiem dla mozliwosci realizacji coraz bardziej zaawansowanych zastosowan srodków i narzedzi informatyki w zakresie badan naukowych.
Modele programowania maszyn o wielu procesorach wynikaja ze szczególów architektury implementowanej w poszczególnych rozwiazaniach. W celu systematyki, wprowadza sie szereg klasyfikacji, z których najbardziej wszechstronne to klasyfikacje pod wzgledem:

• Mechanizmu sterowania, • Organizacji przestrzeni adresowej, • Organizacji warstwy komunikacyjnej.
Klasyfikacja maszyn pod wzgledem mechanizmu sterowania dokonywana jest w oparciu o taksonomie Flynna, wedlug której wyróznia sie cztery typy, do których naleza: SISD (ang. Single Instruction Stream/Single Data Stream), SIMD (ang. Single Instruction Stream/Multiple Data Stream), MIMD (ang. Multiple Instruction Stream/Multiple Data Stream), MISD (ang. Multiple Instruction Stream/Single Instruction Stream).
Klasyczna architektura sekwencyjna zaliczana jest do klasy SISD. Komputery klasy SIMD reprezentowane sa przez maszyny wektorowe i macierzowe, w oparciu o specjalizowane procesory, z zapewnieniem mozliwosci czestej synchronizacji miedzy procesami realizowanymi w poszczególnych jednostkach przetwarzajacych. Klasa ta ostatnio stracila na znaczeniu na rzecz klasy MIMD, w której zapewnia sie mozliwosc równoleglej realizacji na procesorach róznych instrukcji (dla róznych danych). Stosuje sie procesory ogólnego przeznaczenia, co ulatwia proces programowania i obniza koszty eksploatacji. Do klasy tej nalezy wiekszosc obecnie wytwarzanych komputerów o wielu procesorach, a takze klastry komputerów oraz systemy sieciowe. Ostatnia klasa – MISD – nie wystepuje w praktyce.
Rysunek 2.6.1 Podzial maszyn równoleglych na maszyny z a) rozproszona pamiecia, b) wirtualnie wspóldzielona pamiecia i c) wspóldzielona pamiecia,
Organizacja przestrzeni adresowej jest kolejnym elementem róznicujacym wspólczesne komputery. Organizacja ta stanowi odzwierciedlenie technicznej realizacji pamieci operacyjnej, wsród której wystepuja trzy zasadnicze jej typy:
• pamiec wspóldzielona, • pamiec rozproszona, • pamiec wirtualnie wspóldzielona, fizycznie rozproszona.
W pierwszym z typów, mozliwa jest liniowa adresacja komórek pamieci oraz uzyskanie dla kazdego z procesorów jednakowego kosztu dostepu do niej. W maszynach z tego typu organizacja pamieci operacyjnej stosuje sie zazwyczaj takze wspóldzielenie pozostalych

zasobów, takich, jak urzadzenia wejscia/wyjscia. W rezultacie, wykorzystanie takiej organizacji jest stosunkowo latwe w praktyce – wiekszosc komputerów o niewielkiej liczbie procesorów stosuje ten typ organizacji. W przypadku rozproszonej pamieci operacyjnej kazdy wezel obliczeniowy (procesor) posiada przypisana lokalna pamiec operacyjna, która nie jest bezposrednio dostepna przez procesy obliczeniowe alokowane na pozostalych procesorach. Organizacja ta jest charakterystyczna dla wczesnych rozwiazan komputerów o wielu procesorach, a takze dla architektur klastrowych i systemów sieciowych; jej wykorzystanie jest stosunkowo trudne w obliczeniach naukowych.
Najpopularniejsza obecnie organizacja jest architektura o pamieci wirtualnie wspóldzielonej, fizycznie rozproszonej. Jest ona charakterystyczna dla komputerów o duzej liczbie procesorów. Oferuje aplikacjom pamiec liniowo adresowana, co ulatwia proces tworzenia oprogramowania, lecz z róznym kosztem dostepu do komórek pamieci.
W komputerach o wielu procesorach wystepuje duza róznorodnosc realizacji warstwy komunikacyjnej; warstwa ta moze byc zaprojektowana dla realizacji polaczen statycznych lub dynamicznych. W pierwszym przypadku, do najpopularniejszych topologii naleza polaczenia w topologii kraty, drzewa lub hiper-szescianu, w drugim – architektura magistralowa, przelacznica krzyzowa i sieci wielostopniowe.
W praktycznych realizacjach duzych instalacji stosowane sa rozwiazania mieszane. Na przyklad kilkuprocesorowe wezly obliczeniowe z pamiecia wspóldzielona wykorzystujace architekture magistralowa laczone sa siecia innego standardu – z uzyciem przelacznicy krzyzowej lub sieci przelaczajacej.
Na tle przedstawionej powyzej systematyki komputerów o wielu procesorach okreslic mozna dwa modele obliczen równoleglych:
• Model z wymiana wiadomosci, • Model z wykorzystaniem pamieci wspóldzielonej.
Model z wymiana wiadomosci wykorzystuje w aplikacji odwolania do bibliotek komunikacyjnych, realizujacych wyslanie komunikatu do okreslonego wezla (procesu) komputera, badz odbiór komunikatu od okreslonego nadawcy. Mozliwe sa operacje synchroniczne, asynchroniczne badz grupowe. Rola twórcy aplikacji jest odpowiedni podzial zadania obliczeniowego na czesci oraz organizacja koordynacji obliczen miedzy nimi. W tym celu czesto wykorzystuje sie model PCAM (ang. partitioning, communication, agglomeration, mapping), wprowadzony przez Iana Fostera. Typowymi srodowiskami programistycznymi dla potrzeb obliczen naukowo-technicznych sa PVM i MPI, udostepniajace stosowne biblioteki komunikacyjne.
Model z wykorzystaniem pamieci wspólnej jest latwiejszy w zastosowaniach praktycznych i polega na wykorzystaniu wlasnosci oferowanych przez kompilatory przeznaczone na te architektury. Kompilator mozna wspomóc w analizie mozliwosci równoleglej realizacji aplikacji poprzez uzycie dyrektyw informujacych o braku zaleznosci miedzy fragmentami obliczen lub miedzy danymi, co stanowi warunek konieczny realizacji równoleglej. Bardziej zaawansowanym podejsciem jest wykorzystanie srodowiska OpenMP.
W praktyce obliczen naukowo-technicznych stosuje sie niekiedy oba podejscia jednoczesnie, dla potrzeb wykorzystania pelnych mozliwosci oferowanych przez algorytm obliczeniowy i architekture komputera. 2.6.2 Najwieksze systemy komputerowe Od poczatku lat 70-tych, gdy zastosowanie komputerów w modelowaniu zjawisk fizycznych zaczelo dawac wymierne rezultaty, brak odpowiedniej mocy obliczeniowej zaczal byc podstawowy czynnikiem krepujacym rozwój badan w takich dziedzinach jak np. fizyka jadrowa,

fizyka pólprzewodników, chemia fizyczna, biologia molekularna, przewidywanie i prognozy pogody, oraz modelowanie zjawisk ekonomicznych. W celu kumulacji drogiej mocy obliczeniowej jak grzyby po deszczu zaczely powstawac silne centra komputerowe, ogniskujace badania zwiazane z modelowaniem komputerowym.
Centra te powstawaly zazwyczaj „wokól” pojedynczej maszyny duzej mocy tzw. superkomputera. Zjawisko centralizacji mocy obliczeniowej nasililo sie po wejsciu a rynek niezwykle drogich komputerów z jednostka potokowa, a z czasem tzw. komputerów wektorowych jak „Cray 1” czy „Cyber 205”. Zmiana sposobu przetwarzania z sekwencyjnego na wektorowy wymusilo poszukiwanie nowatorskich algorytmów optymalnie wykorzystujacych wlasciwosci nowych maszyn. Prawdziwa rewolucja dla obliczen wielkiej skali bylo jednak powstanie zupelnie nowej technologii opartej o systemy wieloprocesorowe. W systemach tych podstawowa jednostka obliczeniowa nie byl drogi, wyspecjalizowany procesor wektorowy, ale popularny i tani procesor wchodzacych na rynek stacji roboczych, a nawet popularnych komputerów osobistych. Dawalo to mozliwosc – przynajmniej teoretyczna – dokonywania obliczen równolegle na N procesorach, które komunikujac sie poprzez wykorzystanie warstwy polaczen lub przez wspólna pamiec rozwiazywaly w tym samym czasie zadanie N razy wieksze. Oczywiscie okazalo sie zaraz, ze chociazby ze wzgledu na skonczony czas komunikacji, a takze inherentna sekwencyjnosc niektórych zagadnien, uzyskanie liniowego (w zaleznosci od rosnacej liczby procesorów) przyspieszenia obliczen okazalo sie iluzoryczne. Co wiecej, klopoty wystepujace przy wektoryzacji kodu na maszynach wektorowych, okazaly sie niczym w porównaniu z jego zrównolegleniem, czyli znalezieniem optymalnego algorytmu umozliwiajacego efektywne obliczenia (minimalizujace komunikacje pomiedzy wezlami obliczeniowymi) w systemie wielu wspólpracujacych ze soba jednostek obliczeniowych.
Próby calkowitego zautomatyzowania tego procesu zakonczyly sie w zasadzie fiaskiem, pomimo wytworzenia niezliczonych srodowisk ulatwiajacych programowanie równolegle i wysilków wlozonych w budowe jezyków do programowania równoleglego. Sprawy nie ulatwiala niepewnosc co do ostatecznej definicji komputera równoleglego, a ciagle zmieniajaca sie architektura pojedynczego procesora, nowe podsystemy dostepu do pamieci, realizacji sieci polaczen, a takze nowatorskie rozwiazania dt. metod kompilacji, systemów operacyjnych, nie pozwalaly sprecyzowac priorytetów potrzebnych do zaprojektowania stabilnego i przenosnego srodowiska programistcznego. Trudnosci z wytworzeniem w krótkim czasie efektywnego oprogramowania równoleglego efektywnie wykorzystujacego setki i tysiace wspóldzialajacych procesorów wraz z równoczesnym wzrostem mocy obliczeniowej i spadku ceny pojedynczego procesora, a takze pojawienia sie technologii RISC (reduced instruction set computer), a niedawno EPIC (explicitly parallel instruction computer) oraz ukladów kumulujacych kilka jednostek obliczeniowych na jednym chip’ie, spowodowalo spadek zainteresowania Obliczeniami Wielkiej Skali. W rzeczywistosci oznaczalo to jednak tylko tyle, iz wzrost rozwoju technologii informatycznej przewyzszyl oczekiwania srodowisk naukowych. Do tej pory nie zostal jeszcze skonsumowany. Obliczenia wielkiej skali (a w zasadzie te, które do niedawna na takie miano zaslugiwaly) mozna przeprowadzic juz na pojedynczym wezle obliczeniowym zlozonym z kilku lub kilkunastu procesorów. Na realizacje rzeczywiscie duzych zadan w wiekszosci przypadków brakuje zapotrzebowania, pomyslu na nowe modele i algorytmy oraz pieniedzy. Czas potrzebny na zaprojektowanie i zrealizowanie unikatowego systemu o ogromnej mocy obliczeniowej, zaplecza softwarowego i wytrenowania ludzi, a potem uruchomieniu oprogramowania dla danego zagadnienia (pod warunkiem, ze to oprogramowanie juz istnieje) jest dluzszy niz czas wprowadzenia nowych technologii budowy podstawowych elementów infrastruktury informatycznej. Zatem skonstruowany ogromnym kosztem nowoczesny system informatyczny jest juz wewnetrznie przestarzaly w momencie jego uruchomienia.

Rysunek 2.6.2. Systemy komputerowe do obliczen wielkiej skali programu ASCI (USA) oraz „Earth Simulator”.
Mimo tej niesprzyjajacej dla rozwoju obliczen wielkiej skali sytuacji, istnieja takie organizacje i takie problemy, dzieki którym istnienie monstrualnych systemów obliczeniowych jest wciaz uzasadnione. Tymi organizacjami sa najwieksze mocarstwa ekonomiczne, a projekty ogromnych systemów komputerowych dedykowane sa problemom, z którymi panstwa te aktualnie sie borykaja. Budzet projektu ASCI (Accelerated Strategic Computational Initiative), nadzorowanego przez DOE (Department of Energy), w wysokosci 1 mld USD zatwierdzila administracja prezydenta Clintona w 1995 roku. W ramach tego projektu powstaja kolejne systemy komputerowe o rosnacej wydajnosci. W tym wyscigu o wydajnosc rywalizuja trzy najwieksze rzadowe centra obliczeniowe USA: Lawrence Livermore, Los Alamos i Sandia oraz najwieksi producenci procesorów IBM, SGI i Intel. Bardzo ogólnym celem postawiony twórcom projektu jest kontrola potencjalu jadrowego Stanów Zjednoczonych, modelowanie wybuchów jadrowych, prace nad zaawansowanymi systemami obronnymi, badania nad skutkami zanieczyszczen bedacych wynikiem wczesniejszego wyscigu zbrojen. Na przyklad w „zwierciadlanym” do Los Alamos osrodku badan jadrowych zajmujacym sie produkcja broni jadrowej w Hadford-Richland-Pasco i zamknietym w poczatku lat 90tych, ziemia skazona jest na glebokosci 1km. Przeplywajaca w poblizu rzeka Columbia zaopatrujaca w wode miliony gospodarstw domowych jest zagrozona przeniknieciem do niej zanieczyszczen. Dlatego problem transportu wody i zanieczyszczen w glebie, ich neutralizacja jest przedmiotem modelowania i symulacji. W zwiazku z zagrozeniem terrorystycznym komputery projektu ASCI wykorzystywane sa do przeszukiwania i do analizy ogromnych zbiorów danych. Problemy tzw. data mining zwiazane z ekstrakcja wiedzy z olbrzymich zbiorów danych, wystepuja takze w takich dziedzinach jak „bialy wywiad”, analiza rynków ekonomicznych i in. W ramach Projektu ASCI powstawaly do niedawna najwieksze systemy komputerowe na swiecie okupujace pierwsze miejsca listy TOP 500 takie jak ASCI White Pacific (rok 2001 i 2000, 7424 procesory, 7 Teraflopsów - 7×1015 operacji zmiennoprzecinkowych na sekunde - mocy obliczeniowej potwierdzonej tzn. uzyskanej na uruchomionej aplikacji), ASCI Red Intel Pentium (rok 1999, 9632 procesory, 2,3 Teraflopsa) ASCI Blue Pacific (rok 1998, 5808 procesorów, 2,1 Teraflopsa) (patrz Rys.2.6.2a, 2.6.3a).

Rysunek 2.6.3 a) Modelowanie klimatu, b) Badanie struktury i ekspresji genów w lancuchach DNA. Dla innego typu problemów przeznaczony jest wieloprocesorowy system zrealizowany ze srodków przeznaczonych przez rzad Japonii do badan zwiazanych z naukami o ziemi i nad systemami przewidywania kataklizmów i modelowania klimatu. Tak zwany „Earth Simulator” (Rys. 2.2.2b) jest wprawdzie systemem wieloprocesorowym, lecz o wyraznej specyfice odrózniajacej go od komputerów amerykanskich. Zbudowany jest on na bazie ogromnej przelacznicy krzyzowej 640x640 umozliwiajacej bezposredni dostep kazdego z wezlów obliczeniowych do zasobów pamieciowych innego wezla. Kazdy z wezlów zbudowany jest z 8 procesorów wektorowych kazdy o mocy obliczeniowej 8Gigaflopsów, ze wspólna pamiecia 16 GB. Zatem caly system umozliwia obliczenia z predkoscia 40 Teraflopów i pamieci calkowitej 10TB. Jest to aktualnie najmocniejsza instalacja na swiecie o potwierdzonej mocy obliczeniowej 36 Teraflopsów (przy maksymalnej mocy 41 TFlopsów!), prawie 5 razy wiecej niz najwiekszy komputer ASCI. Ciekawostka jest fakt, iz w przeciwienstwie do komputerów projektu ASCI dostepnych dla kazdego zatwierdzonego projektu niezaleznie od przynaleznosci narodowosciowej projektodawcy, projekty realizowane na systemie „Earth Simulator” musza byc nadzorowane przez instytucje japonskie. Do innych celów ma sluzyc komputer IBM „Blue Gene”, którego instalacja jest odpowiedzia na japonskie wyzwanie. „Blue Gene” jest pierwszym komputerem, który realizuje wizjonerskie wizje von Neumanna, w których komputer stanowilby odwzorowanie ludzkiego mózgu tzn. elementy obliczeniowe bylyby fizycznie blisko elementów pamieci, nie jak w klasycznym schemacie komputera, w którym pamiec i elementy obliczeniowe stanowily dwie oddzielne komunikujace sie ze soba czesci. Odzwierciedleniem tego zlozenia jest przedstawiona na Rys.2.6.4 jego budowa. Podstawowym elementem komputera jest chip Power 4, który sklada sie z dwóch procesorów 64bitowych (cores) (o zagregowanej mocy obliczeniowej 5,6Gflopsów) i wspólnej szybkiej pamieci podrecznej 4MB. Elementy te laczy sie w ramki te z kolei w wezly obliczeniowe (16 ramek), szafy i systemy szaf. Spodziewana moc maksymalna to 360 Tflopsów i 16 TB pamieci. System ma sluzyc do obliczen struktur lancuchów DNA (Rys 2.6.3b), ekspresji genów, problemów zwijania sie bialek oraz do innych zagadnien biotechnologicznych w tym

takich jak symulacje mechanizmów procesów zachodzacych w komórkach, a takze ukladu nerwowego i przeplywu krwi w naczyniach (patrz Rys.2.6.5)
Rysunek 2.6.4 Nowatorskie upakowanie elementów obliczeniowych w systemie „Blue Gene”.
Rysunek 2.6.5. Trzywymiarowa symulacja przeplywu krwi wizualizowana na „Power Wall” w University of Minnesota.
Gdyby moc obliczeniowa wspólczesnych komputerów rosla zgodnie z tzw. prawem Moora, za 300 lat mozliwa by byla symulacja 1080 czastek – czyli wszystkich bozonów we Wszechswiecie. Musza, zatem istniec ograniczenia zwiazane z wlasciwosciami Wszechswiata w którym zyjemy, które nie pozwola na dalszy rozwój wydajnosci obliczen obserwowany od kilkudziesieciu lat. W przypadku granic zwiazanych z pojemnoscia pamieci, granice te jeszcze nie sa istotne. Zgodnie z podanymi wczesniej oszacowaniami Smitha i Lloyda w 1Å3 (1Å = 10-10 m) mozna pomiescic kilkadziesiat kilobajtów informacji, a wychodzac z bardziej ostroznych oszacowan, w jednym atomie juz w najblizszej przyszlosci pomiescic bedzie mozna 10 bajtów, czyli kostka materii o objetosci 1cm3 bedzie przechowywac 1024 bajtów informacji.

Znacznie blizej barier fizycznych znajdujemy sie, jezeli chodzi o osiagniecie granicy minimalnej dyssypacji energii dla ukladu nieodwracalnego, która osiagniemy za 35 lat (niezaleznie od materialu, z którego wykonywac bedziemy elementy obliczeniowe). Cieplo produkowane jest w wyniku dyssypacji, wyciekania zuzytej informacji i zwiazanym z tym procesem wzrostem entropii. Aby wstrzymac ten proces mozliwe jest w przyszlosci konstruowanie procesorów adiabatycznych wykorzystujacych zuzyta informacje.
Powaznym problemem staje sie osiagniecie w najblizszej przyszlosci granic przesylania informacji przy zalozeniu, ze nosnikiem informacji jest fala elektromagnetyczna. Podobnie zakladajac, ze elementem przelaczajacym bedzie pojedynczy elektron, maksymalna predkosc przelaczania jest jedynie 106 razy wieksza niz aktualnie uzyskiwana. Zakladajac jednak, ze przyszloscia obliczen wielkiej skali jest komputer kwantowy, a takze – w niektórych przypadkach komputery biologiczne (Rys.2.6.6) – mozna przypuszczac, ze granice te zepchniete zostana znacznie dalej. Tym bardziej, ze istnieje duzy „zapas”, zwiazany z rozwojem nowych modeli, algorytmów i technik obliczeniowych pozwalajacych o rzedy wielkosci zmniejszyc zapotrzebowanie na moc obliczeniowa.
Rysunek 2.6.6 a) Bramka dwukubitowa komputera kwantowego i jej macierzowa reprezentacja. b) Bramka logiczna komputera biologicznego na lancuchach DNA.
2.6.3 Modelowanie rzeczywistosci Modelowanie rzeczywistych, zlozonych procesów zachodzacych w naszym swiecie, wykorzystujace architektury wspólczesnych systemów liczacych, wymaga wypracowania nowych paradygmatów i algorytmów czesto oderwanych od klasycznych modeli bazujacych na numerycznym calkowaniu równan fizyki i chemii. Wielorozdzielczosc swiata, który wyglada inaczej w zaleznosci od skali przestrzenno-czasowej w której sie go obserwuje, determinuje istnienie obok siebie czesto heterogenicznych modeli, których hierarchiczna zaleznosc wymusza usrednianie zachowan zachodzacych w mikroswiecie do obliczen w mezoskali, makroskali i wreszcie do skal astronomicznych. Granice miedzy tymi swiatami sa plynnne, co wiecej wystepuje dodatkowe zróznicowanie modeli opisujacych podobne zjawiska dla tych samych skal czasowych. Na przyklad, inny model zastosujemy do symulacji paniki, czy zachowan stadnych, a inny do symulacji ruchu samochodowego.
Z punktu widzenia obliczen, bardziej istotne niz specyficzny sposób przesylania informacji i komunikacji pomiedzy elementami symulowanego systemu jest wspólna baza

metodologiczna i podobne srodki implementacyjne uzyte do realizacji modelu oraz zdefiniowanie sposobu przesylania informacji z poziomów o wyzszej (ruch atomów i czastek) do poziomów o nizszej (ruch samochodów) rozdzielczosci. Problem ten do dzis nie jest rozwiazany, a modele osrodka ciaglego sa inne od tych rzadzacych fizyka swiata zlozonego z atomów i czastek oraz od zjawisk zachodzacych na dlugosciach zwiazanych ze stala Planca. Wypracowanie wspólnej bazy algorytmicznej dla tak róznorodnych zjawisk stanowi najwazniejsze wyzwanie dla metod symulacji rzeczywistosci. Metody te mozna podzielic na dwie klasy. Pierwsza, klasyczna (chociaz postep w tej dziedzinie jest niewiarygodny) bazuje na calkowaniu numerycznym równan rózniczkowych czastkowych, glównie metodami elementów skonczonych czy metodami róznic skonczonych. Zastosowanie nowoczesnych metod generacji siatek, siatek z ruchomymi wezlami, zaawansowanych metod interpolacyjnych i aproksymacyjnych, a takze nowoczesnych narzedzi analizy sygnalów: analizy Fourierowskiej, a ostatnio falek, sprawilo, iz metodologia ta uzywana jest powszechnie w modelowaniu i projektowaniu CAD/CAM.
Metody dyskretne takie jak metody oddzialujacych czastek, dyssypatywna i wygladzona metoda czastek, bezposrednia symulacja Monte-Carlo, umozliwia modelowanie swiata, który zbudowany jest z elementów dyskretnych (oddzialujace molekuly, drobiny, osrodek granularny – proszki, koloidy, zele), stanowi mieszanine osrodka ciaglego i dyskretnego (woda z piaskiem) posiada niezwykle skomplikowane warunki brzegowe (przeplywy w cialach porowatych, kapilarach Rys.2.6.5, zlewanie sie cieczy po chropowatej powierzchni Rys.2.6.7a) i który nie moze byc przyblizany modelami sluzacymi do opisu osrodka ciaglego. Modele tego typu nie opisuja jednak wszystkich zjawisk zachodzacych w swiecie rzeczywistym np. takich jak osypywanie sie piasku ze sterty (Rys.2.6.7b), odrywanie sie kropli (Rys.2.6.7c) ucieczka tlumu z palacego sie wiezowca, ruch samochodów czy wzrost roslin (Rys.2.6.7d).
Rysunek 2.6.7. Przyklady zastosowania nowych algorytmów do modelowania komputerowego a) metoda czastek w symulacji splywania cieczy po pionowe scianie, b) automat komórkowy w symulacji kaskad osypywania sie piasku, c) odrywanie sie kropli modelowane przy pomocy metody gazu siatkowego Boltzmanna d) generacja zlozonych ksztaltów przy pomocy L-systemów. Najbardziej interesujacym meta-modelem umozliwiajacym symulacje rzeczywistosci, wykorzystujacym w sposób optymalny mozliwosci wspólczesnych paradygmatów obliczen równoleglych, sa Automaty Komórkowe. Wedlug jednego z twórców S.Wolframa, Automaty Komórkowe stanowia metodologiczna baze do symulacji KAZDEGO zjawiska (patrz np.Rys.2.6.7) wystepujacego w przyrodzie (New Kind of Science). System automatów komórkowych definiuje srodowisko, w którym one ewoluuja – jest to najczesciej plansza lub

siatka 3D - oraz reguly zmieniajace stan automatu w zaleznosci od jego sasiedztwa. Dywersyfikujac automat komórkowy, wyposazajac go we fragmenty kodu, otrzymujemy zlozony system ewoluujacych agentów – obiektów o zindywidualizowanych zachowaniach. Takze wedlug Tomasso Tiffoli pierwszego naukowca, który skonstruowal wyspecjalizowany komputer CAM 6 (potem CAM 8) integrujacy model wirtualny ze specjalnie skonstruowanym wieloprocesorowym systemem optymalizujacym funkcje najczesciej wywolywane w realizacji automatu komórkowego, swiat mozna traktowac jako wielorozdzielczy automat komórkowy. Róznorodnosc form otrzymywanych w wyniku realizacji regul automatu zwiazana jest takze z róznymi mozliwosciami definicji tych regul dopasowujacych automat do rzeczywistego zjawiska. Zjawiska zwiazane z dynamika osrodka zlozonego z ogromnej ilosci komponentów (np. cieczy zbudowanej z kropelek) modelowane sa przy pomocy „dynamicznej” odmiany automatu, tzw. gazu siatkowego i jego modyfikacji, w którym elementy systemu poruszaja sie po wezlach siatki. Natomiast statyczne, zlozone formy biologiczne jak np. kwiaty, drzewa (patrz Rys.2.6.7d), opisuja tzw. L-systemy, w których zadane reguly przeksztalcaja ciagi symboli zdefiniowanego wczesniej jezyka. Reasumujac, postep w dziedzinie obliczen duzej skali nie zalezy tylko od wielkosci mocy obliczeniowej systemu komputerowego. Zalezy on od przyjetego modelu obliczen, srodowisk programistycznych, kompilatorów, i od postepu w dziedzinie algorytmiki i modelowania. Rozwinieciem idei obliczen równoleglych i rozproszonych realizowanych na sieciach rozleglych sa tzw. obliczenia gridowe, stanowiace bezposrednio realizacje metaprzetwarzania. Srodowiska gridowe dostarczaja infrastruktury obliczeniowej (w postaci uslug róznego typu), która koordynuje zasoby bedace przedmiotem administracji przez lokalnych administratorów, udostepnia zasoby uzytkownikom poprzez standardowe, typowe protokoly i interfejsy sieciowe oraz gwarantuje odpowiedni poziom uslug. Na obecnym etapie istotny nacisk polozony jest na rozwój tej infrastruktury (to jest warstwy posredniej) oraz metodologie dostosowania istniejacych aplikacji do obliczen na gridzie. Do najbardziej rozwinietych srodowisk nalezy GlobusToolkit, rozwiniety w Argonne National Laboratory. Oprócz uslug o charakterze obliczeniowym, rozwijane sa takze i inne, np. uslugi wizualizacji naukowej lub archiwizacji i replikacji danych. Unia Europejska finansuje szereg projektów badawczych z tego zakresu. Do ciekawszych nalezy European Data Grid (koordynowany przez CERN) oraz projekty realizowane przy wspólpracy z naukowymi osrodkami Polski, np. Crossgrid.