parallel processing - basavaraj talawarflynn's classification single instruction stream, single...
TRANSCRIPT

Parallel Processing

Outline
● Terminology● Flynn's Classification● Cache coherence.● Interconnection networks.● Parallel programming paradigms.
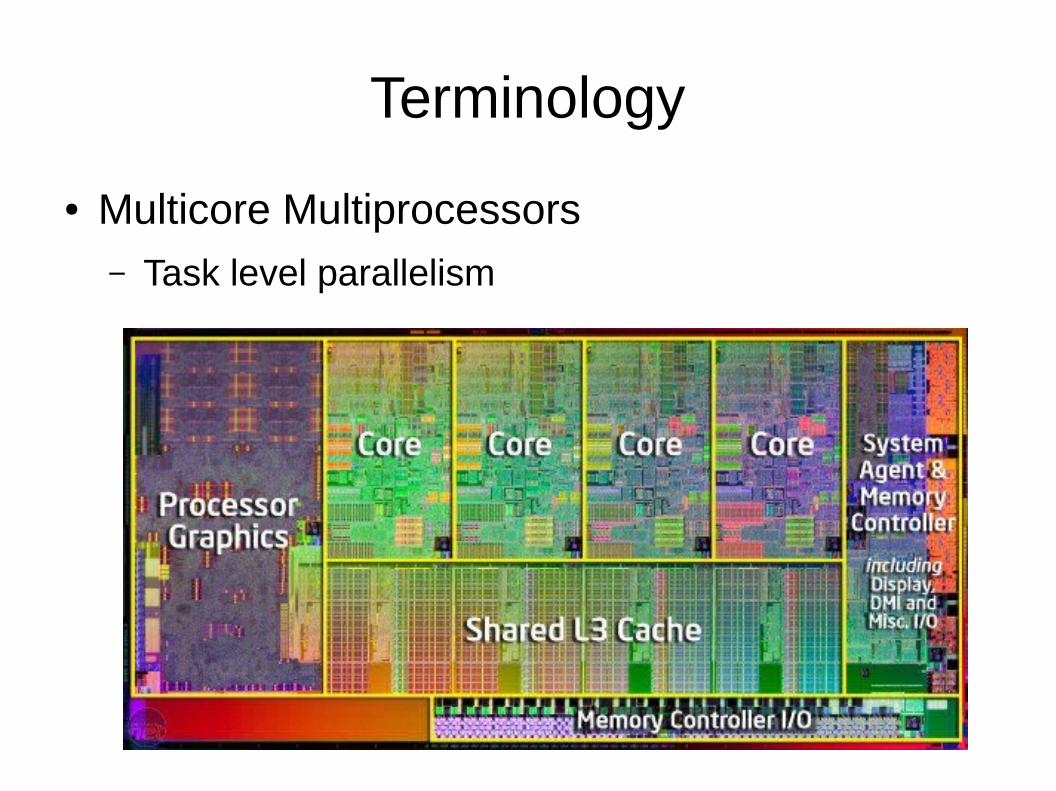
Terminology
● Multicore Multiprocessors– Task level parallelism

Terminology
● Cluster
Wikipedia

Terminology – GPU

Terminology – GPU
Ref: Manuel Ujaldon, NVIDIA

Terminology – GPU
Ref: Manuel Ujaldon, NVIDIA
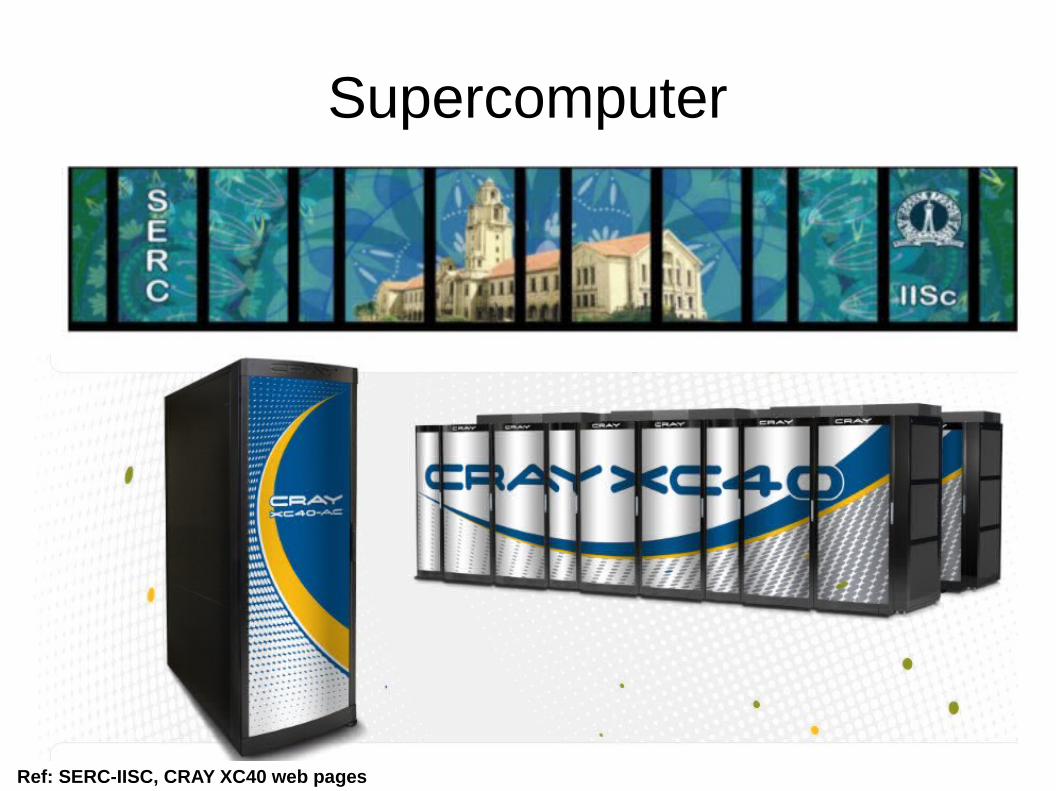
Supercomputer
Ref: SERC-IISC, CRAY XC40 web pages

Supercomputer

Supercomputer

Supercomputer● Cray XC40 = CPU Cluster (Intel Xeon Haswell processors) + Accelerator Cluster
(Nvidia K40 GPUs, Intel Xeon-Phi 5120D) + Aries interconnect (dragonfly topology) + DataDirectNetwork storage units.
● CPU cluster: Intel Haswell 2.5 Ghz; 1376 nodes; each node has 2 CPU sockets with 12 cores each, 128GB RAM and connected using Cray Aries interconnect.
● Accelerator based clusters: Two accelerator clusters; Nvidia Tesla K40 GPU cards (44 nodes) and the other with Intel Xeon-Phi 5120D cards (48 nodes).– Tesla K40 card has 2880 cores, 12GB device memory. Xeon-Phi Coprocessor has 60
cores; 8GB device memory.
● Each node - Intel IvyBridge 2.4 Ghz, 12 cores + one GPU or Phi card + 64GB RAM.
● Storage: 2 PB high speed DDN storage unit; Cray's parallel Lustre filesystem.● Software environment: Cray Linux Environment● Architecture specific compilers from Cray, Intel and open-source based Gnu
compilers.● Architecture specific parallel libraries - OpenMP, MPI, CUDA and Intel Cluster
software.
Ref: SERC-IISC, CRAY XC40 web pages

Scientific Computing
● Astronomy & Astrophysics
● Big Data Analytics● Computational
Physics● Computer Vision● Cloud Computing &
HPC● Energy Exploration● Finance
Ref: NVIDIA GPU Technology Conference
● Graphics Virtualization● Life Sciences● Machine Learning &
Deep Learning● Media & Entertainment● Real-Time Graphics● Supercomputing● Video & Image
Processing● ....

Amdahl's Law
● What is the overall speedup?
Speedup parl=ExecutionTimeseqExecutionTime parl
Parallelizable Parallelizable
Program Execution (Sequential)
Parallel
Program Execution (Parallel)
Parallel
ExecutionTime parl=T parallelizable
N+T seq

Amdahl's Law
Sequential part of the parallel program limits overall speedup
ExecutionTime new=ExecutionTime old∗((1−Fractionenhanced )+ FractionenhancedSpeedupenhanced )
A program contains 50% FP arithmetic instructions. This program is run on a system that contains 4 FP ALUs. What is the speedup?
Objective: Make the program 10 times faster. Say, 25% of the program is waiting in I/O and cannot be enhanced. How much should the speedup of the enhanced computer be?

Flynn's Classification
● Single instruction stream, single data stream (SISD)
– Uniprocessor.● Single instruction stream, multiple data streams (SIMD)
– Data-level parallelism– Applying same operations to multiple items of data in parallel– Eg. Multimedia extensions, Vector architectures– Applications: Gaming, 3-dimensional, real-time virtual
environments.● Multiple instruction streams, single data stream (MISD)● Multiple instruction streams, multiple data streams (MIMD)
– Thread-level parallelism

Symmetric Multiprocessor (SMP)
ProcessorProcessor ProcessorProcessor ProcessorProcessor ProcessorProcessor
One or more levels
of Cache
One or more levels
of Cache
One or more levels
of Cache
One or more levels
of Cache
One or more levels
of Cache
One or more levels
of Cache
One or more levels
of Cache
One or more levels
of Cache
Shared CacheShared Cache
Main MemoryMain Memory I/O SystemI/O SystemSymmetric Shared MemoryCentralized Shared Memory
Uniform Memory Access
Symmetric Shared MemoryCentralized Shared Memory
Uniform Memory Access
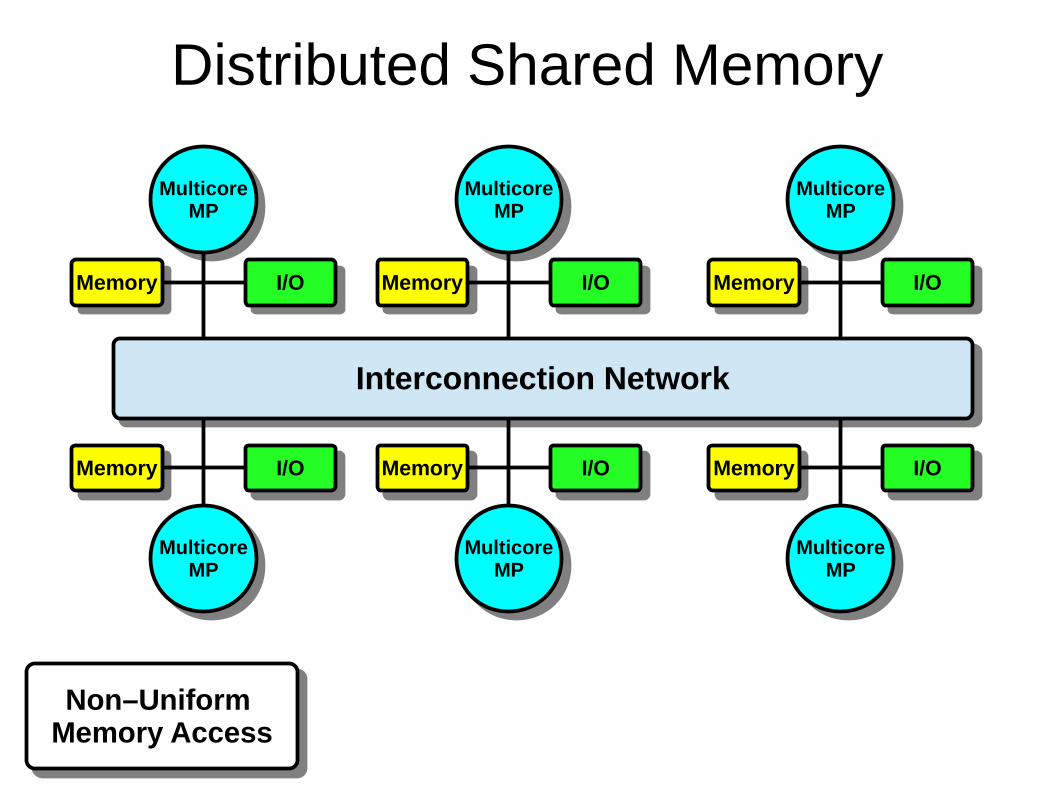
Distributed Shared Memory
MulticoreMP
MulticoreMP
Interconnection NetworkInterconnection Network
Non–Uniform Memory AccessNon–Uniform
Memory Access
MemoryMemory I/OI/O
MulticoreMP
MulticoreMP
MemoryMemory I/OI/O
MulticoreMP
MulticoreMP
MemoryMemory I/OI/O
MulticoreMP
MulticoreMP
MemoryMemory I/OI/O
MulticoreMP
MulticoreMP
MemoryMemory I/OI/O
MulticoreMP
MulticoreMP
MemoryMemory I/OI/O

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
Read XRead X
Cache Miss
Cache Miss
Cache Miss
CPU CCPU C CPU DCPU D
P1P1 P2P2

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
Read XRead X
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 0

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 0
Read XRead X
X: 0

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 0 X: 0
Write XWrite X

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 1
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 1 X: 0
Write XWrite X
X: 1

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemory
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 1 X: 0
Read XRead X
P2 reads X as 0 thoughIts new value is 1 !
P2 reads X as 0 thoughIts new value is 1 !
X: 1

Cache Coherence Problem
● If each processor in a shared memory multiple processor machine has a data cache– Potential data consistency problem: the cache coherence
problem
– Shared variable modification, private cache
● Objective: processes shouldn’t read `stale’ data● Solutions
– Hardware: cache coherence mechanisms
– Software: compiler assisted cache coherence

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
Read XRead X
CPU CCPU C CPU DCPU D
P1P1 P2P2

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
Read XRead X
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 0

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 0
Read XRead X
X: 0

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 0
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 0 X: 0
Write XWrite X

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemory
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 1 X: 0
Write XWrite X
X: 1
Cache Controller in CPU Cinvalidates its copy of X
Cache Controller in CPU Cinvalidates its copy of X
X: 0

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 1
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 1
Write XWrite X
X: 1
Cache Controller in CPU Cinvalidates its copy of X
Cache Controller in CPU Cinvalidates its copy of X

Shared Memory Architecture
CPU ACPU A CPU BCPU B
MemoryMemoryX: 1
CPU CCPU C CPU DCPU D
P1P1 P2P2
X: 1
Read XRead X
Cache MissCache Miss

Write Once Protocol
● Assumption: shared bus interconnect where all cache controllers monitor all bus activity– Snooping
● There is only one operation through bus at a time; cache controllers can be built to take corrective action and enforce coherence in caches– Corrective action could involve updating or
invalidating a cache block

Interconnection Networks
● Uses of interconnection networks– Connect processors to shared memory
– Connect processors to each other
● Interconnection media types– Shared medium
– Switched medium

Interconnection Networks
● Shared medium vs. Switched medium

Indirect Network Topologies
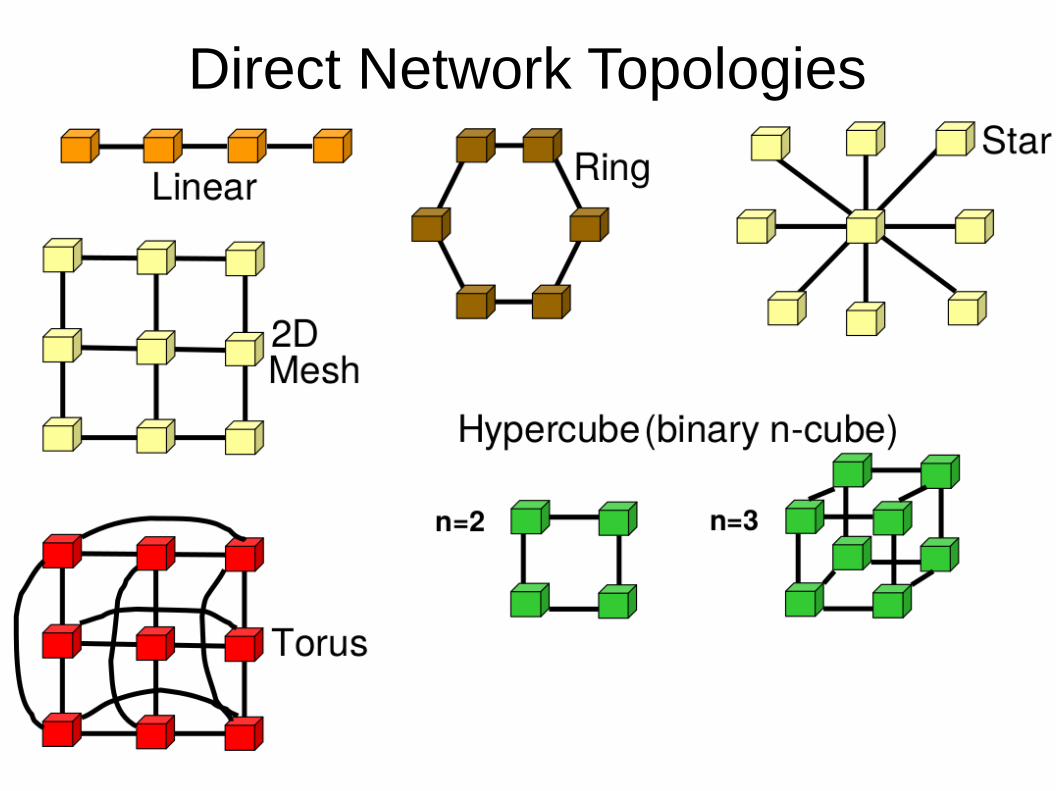
Direct Network Topologies

Crossbar
2x2

Crossbar
2x2i0
i1 o1
o0
o1o0
i0
i1
s0 s1

Shared Memory vs. Message Passing
A
PP
MM
InterconnectInterconnect
PP
MM
PP
MM
PP
MMA A
Read A
Read A

Shared Memory vs. Message Passing● Shared Memory Machine: processors share
the same physical address space– Implicit Communication, Hardware controlled
cache coherence
● Message Passing Machine– Explicit communication – programmed
– No cache coherence (simpler hardware)
– Message passing libraries: MPI
PP
CC
Main MemoryMain Memory
PP
CC
PP
CC
PP
CC
PP
MM
InterconnectInterconnect
PP
MM
PP
MM
PP
MM

Shared Memory Programming
● OpenMP – Open MultiProcessing● Specification for a set of compiler directives,
library routines, and environment variables that can be used to specify shared memory parallelism in Fortran and C/C++ programs.

OpenMP HelloWorld Example#include <stdio.h>#include <omp.h>main() { int ThreadID, NoofThreads;
omp_set_num_threads(6);
#pragma omp parallel private(ThreadID) {
ThreadID = omp_get_thread_num(); printf("\nHello World is being printed by the thread id %d\n", ThreadID);
if (ThreadID == 0) { printf("\n Master prints Numof threads \n"); NoofThreads = omp_get_num_threads(); printf(" Total number of threads are %d\n", NoofThreads); } }}
#include <stdio.h>#include <omp.h>main() { int ThreadID, NoofThreads;
omp_set_num_threads(6);
#pragma omp parallel private(ThreadID) {
ThreadID = omp_get_thread_num(); printf("\nHello World is being printed by the thread id %d\n", ThreadID);
if (ThreadID == 0) { printf("\n Master prints Numof threads \n"); NoofThreads = omp_get_num_threads(); printf(" Total number of threads are %d\n", NoofThreads); } }}

OpenMP HelloWorld Example

Summary
● Multiprocessors, Cluster, GPU, Supercomputer● Flynn's Classification● Cache coherence.● Interconnection networks.● Parallel programming paradigms.
– Shared Memory – OpenMP
– Message Passing – MPI
– Heterogeneous Parallel Programming – CUDA, OpenCL
– fork-join, pthreads, ...