page header
TRANSCRIPT

Architecture-ConsciousDatabase Systems
Anastassia Ailamaki
Ph.D. ExaminationNovember 30, 2000

© 2000 Anastassia Ailamaki Ph.D. Defense 2
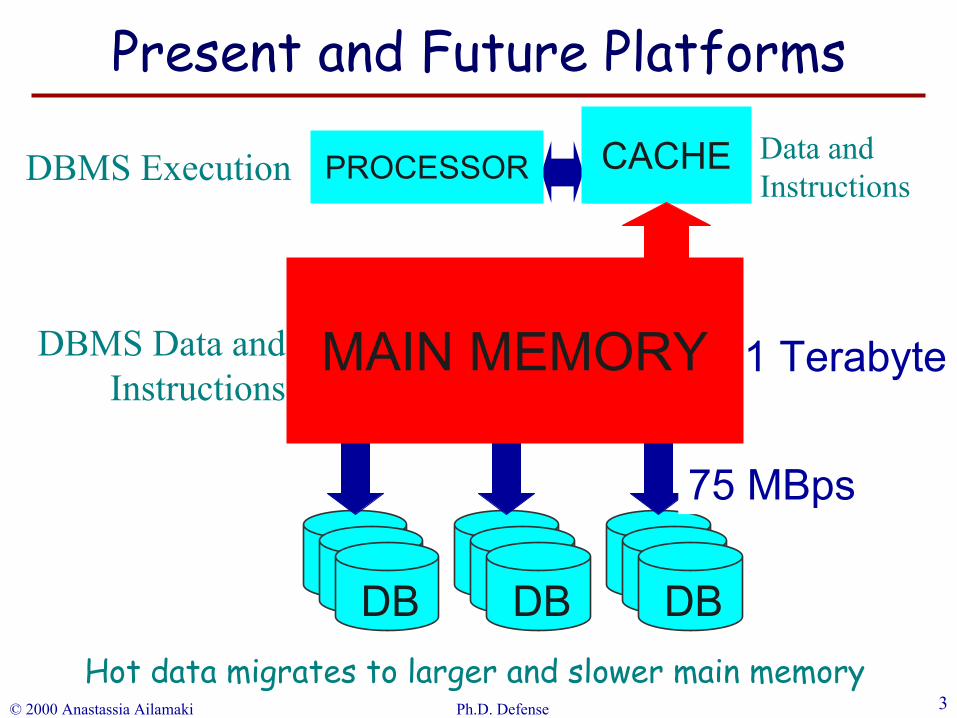
DATABASE
MAIN MEMORY
PROCESSORDBMS Execution
DBMS Data andInstructions
1 Megabyte(Buffer pool)
< 1 MBps
6 cycles
The main performance bottleneck was I/O latency
10 cycles/instruction
Hot data
A DBMS on a 1980 Computer
© 2000 Anastassia Ailamaki Ph.D. Defense 3
70 cycles
0.33 cycles/instruction
MAIN MEMORY
PROCESSORDBMS Execution
DBMS Data andInstructions
CACHE Data andInstructions
25 MBps
1 Gigabyte1 Terabyte
75 MBps
CACHE
MAIN MEMORY
DB DB DBHot data migrates to larger and slower main memory
Present and Future Platforms
© 2000 Anastassia Ailamaki Ph.D. Defense 4
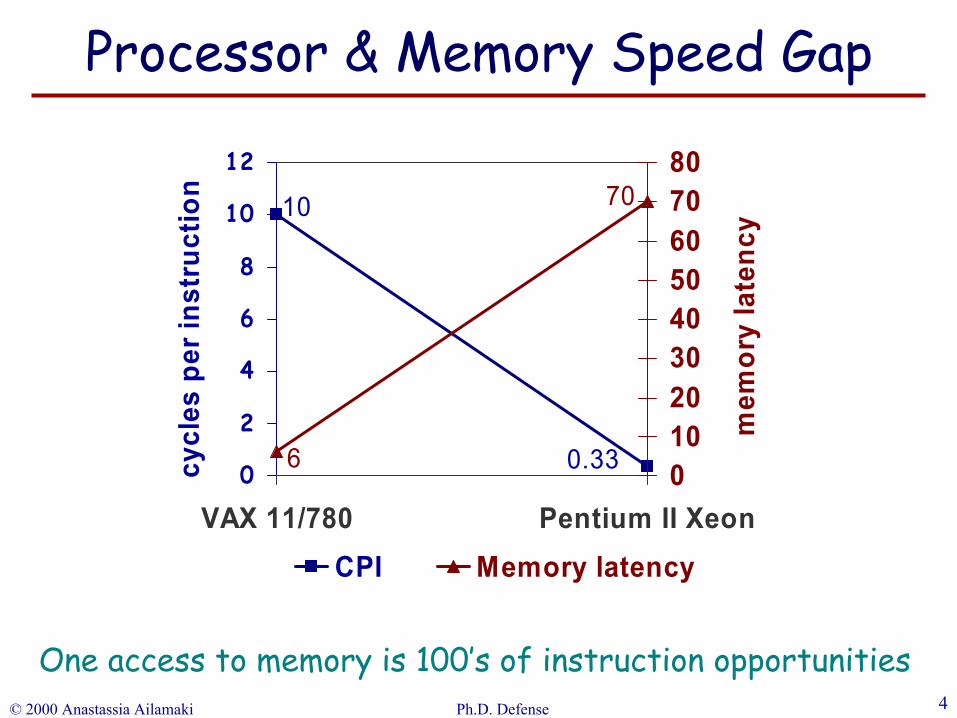
10
0.336
70
0
2
4
6
8
10
12
VAX 11/780 Pentium II Xeon
cycl
es p
er in
stru
ctio
n
01020304050607080
mem
ory
late
ncy
CPI Memory latency
One access to memory is 100’s of instruction opportunities
Processor & Memory Speed Gap

© 2000 Anastassia Ailamaki Ph.D. Defense 5
On Today’s Computers“When you think about what today’s machines do -
theylook at the instruction stream dynamically, find parallelism on the fly, execute instructions out of order, and speculate on branch outcomes -
it’s amazing that they work.”
John Hennessy, IEEE Computer, August 1999
New architectures are more sophisticated
© 2000 Anastassia Ailamaki Ph.D. Defense 6
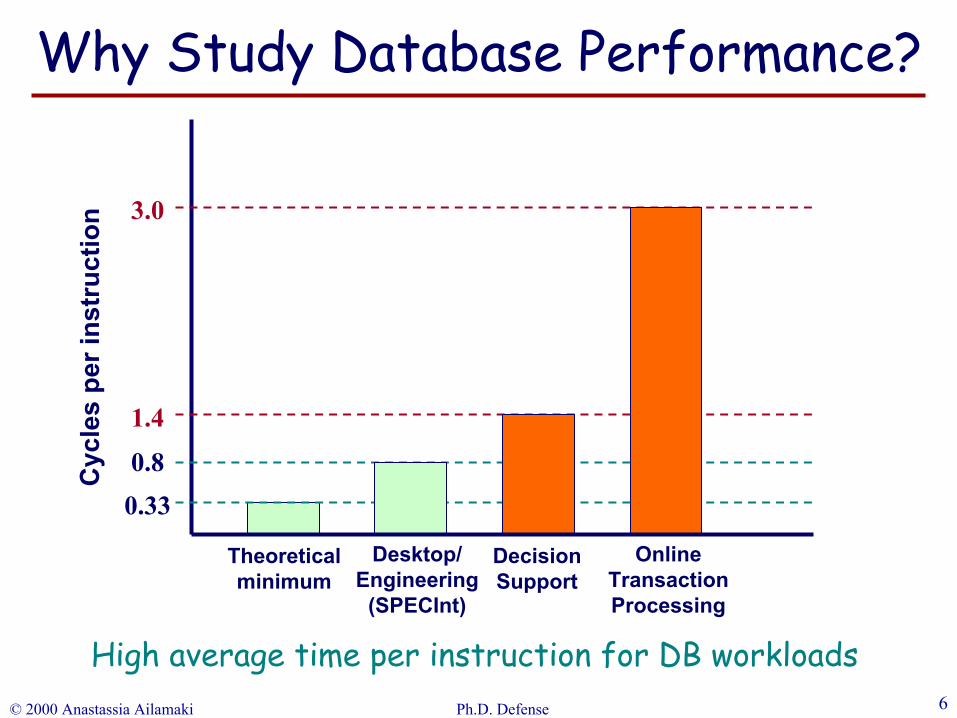
0.330.8
1.4
3.0
Theoreticalminimum
Desktop/Engineering
(SPECInt)
DecisionSupport
OnlineTransactionProcessing
Cyc
les
per i
nstr
uctio
n
High average time per instruction for DB workloads
Why Study Database Performance?

© 2000 Anastassia Ailamaki Ph.D. Defense 7
Problem: Where does query execution time go?
Proposed evaluation framework [VLDB’99]Identified bottlenecks in hardware
memory accesshardware implementation details
Discovered two memory-related bottleneckssecond-level cache data accessfirst-level instruction cache access
Methodological discovery: micro-benchmarks
A systematic evaluation framework
Contributions (I): Analysis

© 2000 Anastassia Ailamaki Ph.D. Defense 8
Problem: Current data placement hurts caches
Proposed novel data placement [subm. SIGMOD’01]rearranges data records on disk pageoptimizes data cache performance
Evaluated it against the popular scheme70% less data-related memory access delaysdoes not affect I/O behaviorespecially beneficial for decision support workloads
A cache-conscious data placement
Contributions (II): Software

© 2000 Anastassia Ailamaki Ph.D. Defense 9
Problem: Hardware design affects DB behavior
Compared Shore on four different systemsdifferent processor architectures/µ-architecturesdifferent memory subsystems
Found evidence that DBMSs would benefit from2-4 way associative, larger L2, no inclusionlarge blocks, no sub-blockinghigh-accuracy branch predictionmemory-aggressive execution engine
Step towards a DSS-centric machine
Contributions (III): Hardware

© 2000 Anastassia Ailamaki Ph.D. Defense 10
IntroductionPART I: Analysis
BackgroundQuery execution time breakdownExperimental resultsBottleneck assessment
PART II: Partition Attributes Across (PAX)PART III: Towards a DSS-centric h/w designConclusions
Outline

© 2000 Anastassia Ailamaki Ph.D. Defense 11
Workload characterization studies, e.g.,[Barroso 98], [Keeton 98]
Various platforms, mostly multiprocessorOne DBMS per platform
Results:Commercial different than scientific appsOLTP different than DSS workloadsMemory is major bottleneck
No coherent study across DBMSs and workloads
Previous Work
© 2000 Anastassia Ailamaki Ph.D. Defense 12
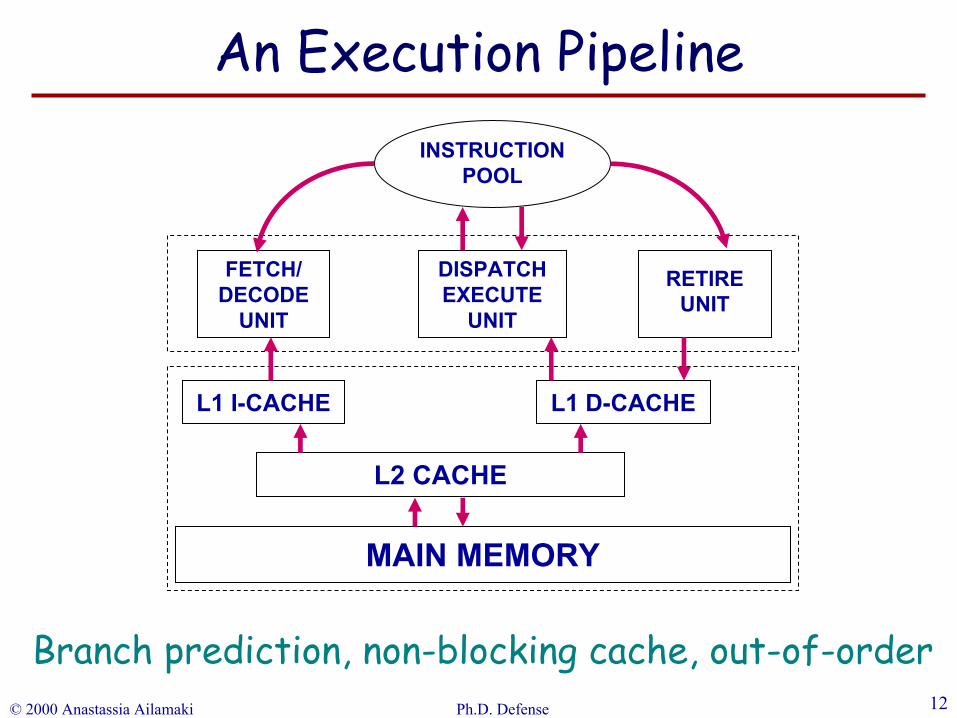
FETCH/DECODE
UNIT
DISPATCH EXECUTE
UNIT
RETIRE UNIT
INSTRUCTION POOL
L1 I-CACHE L1 D-CACHE
L2 CACHE
MAIN MEMORY
Branch prediction, non-blocking cache, out-of-order
An Execution Pipeline
© 2000 Anastassia Ailamaki Ph.D. Defense 13
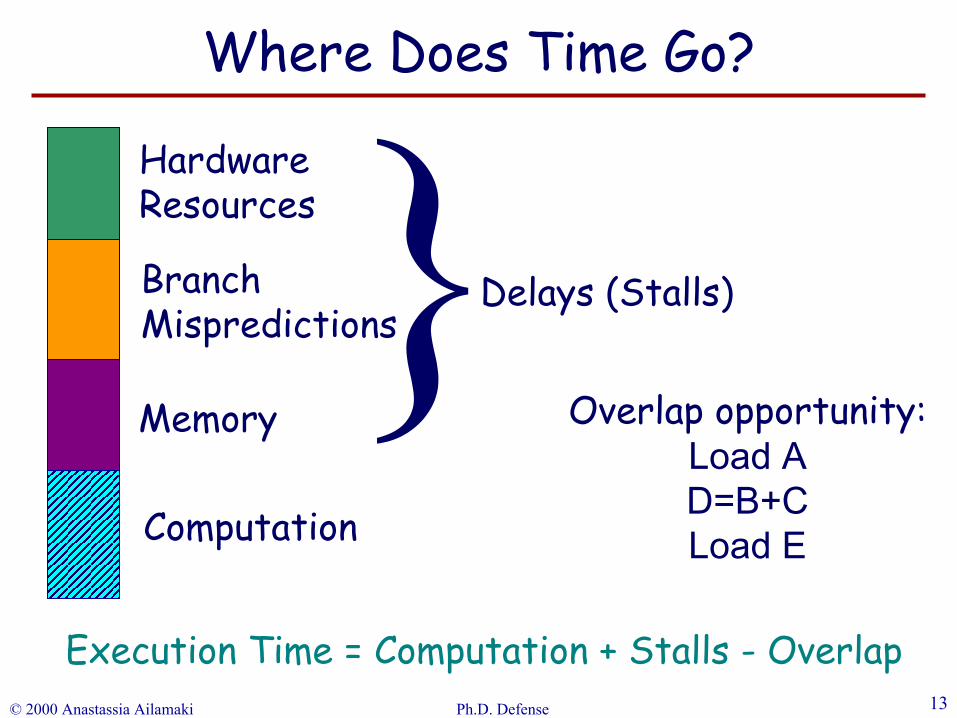
Computation
Memory
BranchMispredictions
HardwareResources
Delays (Stalls)
Overlap opportunity:Load AD=B+CLoad E
Execution Time = Computation + StallsExecution Time = Computation + Stalls - Overlap
Where Does Time Go?

© 2000 Anastassia Ailamaki Ph.D. Defense 14
Four commercial DBMSs: A, B, C, D6400 PII Xeon/MT running Windows NT 4Used processor counters to measure/estimate
Range Selection(sequential, indexed)
select avg (a3)from Rwhere a2 > Lo and a2 < Hi
Equijoin(sequential)
select avg (a3)from R, Swhere R.a2 = S.a1
Crafted microbenchmarks to isolate execution loops
Setup and Methodology

© 2000 Anastassia Ailamaki Ph.D. Defense 15
Measured: Resource stalls, L1I stallsEstimated:
L1 data stalls: # misses * penaltyL2 stalls: # misses * measured memory latencyBranch misprediction stalls: # mispr. * penalty
Overlap: measured CPI / expected CPI
Time Calculations
© 2000 Anastassia Ailamaki Ph.D. Defense 16
System B
0
0.5
1
1.5
2
2.5
3
3.5
mBench(seq)
TPC-D mBench(idx)
TPC-C
benchmark
Clo
ck c
ycle
s
Computation Memory Branch misprediction Resource
System D
0
0.5
1
1.5
2
2.5
3
3.5
mBench(seq)
TPC-D mBench(idx)
TPC-C
benchmark
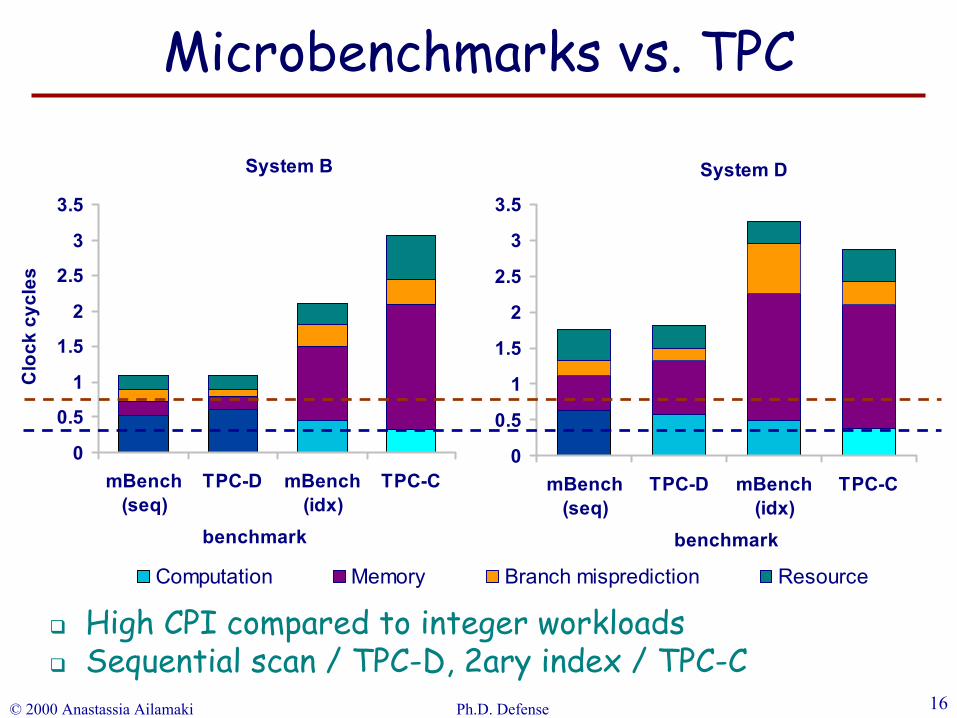
High CPI compared to integer workloadsSequential scan / TPC-D, 2ary index / TPC-C
Microbenchmarks vs. TPC
© 2000 Anastassia Ailamaki Ph.D. Defense 17
10% Sequential Scan
0%
20%
40%
60%
80%
100%
A B C DDBMS
% e
xecu
tion
time
10% 2ary index selection
0%
20%
40%
60%
80%
100%
B C DDBMS
Computation Memory Branch mispredictions Resource
Join (no index)
0%
20%
40%
60%
80%
100%
A B C DDBMS
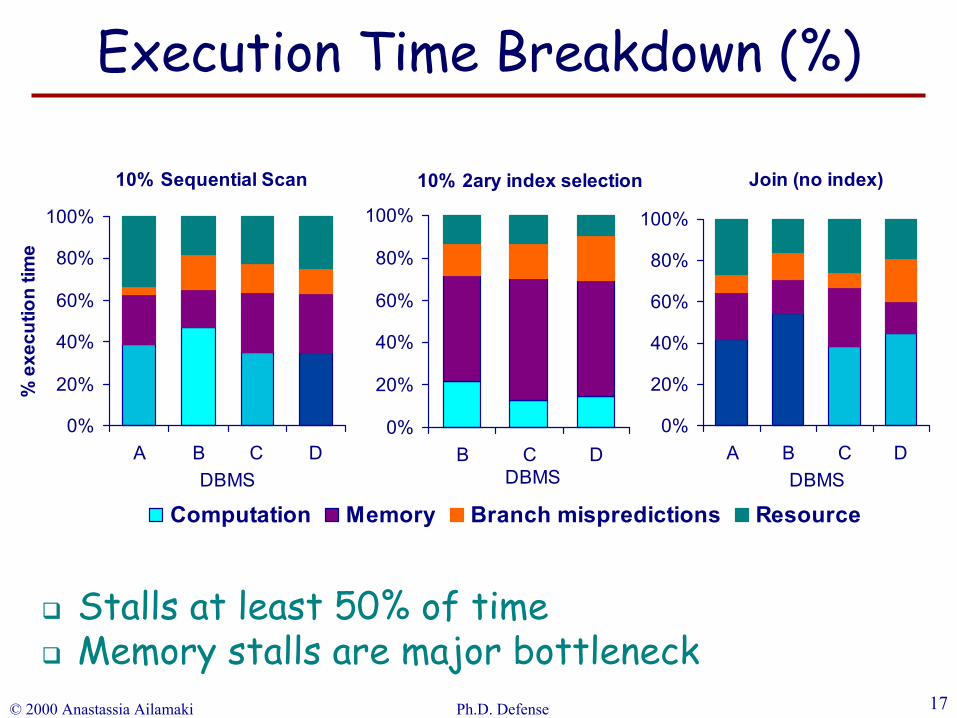
Stalls at least 50% of timeMemory stalls are major bottleneck
Execution Time Breakdown (%)
© 2000 Anastassia Ailamaki Ph.D. Defense 18
10% Sequential Scan
0%
20%
40%
60%
80%
100%
A B C DDBMS
Mem
ory
stal
l tim
e (%
)
10% 2ary index selection
0%
20%
40%
60%
80%
100%
B C DDBMS
L1 Data L2 Data L1 Instruction L2 Instruction
Join (no index)
0%
20%
40%
60%
80%
100%
A B C DDBMS
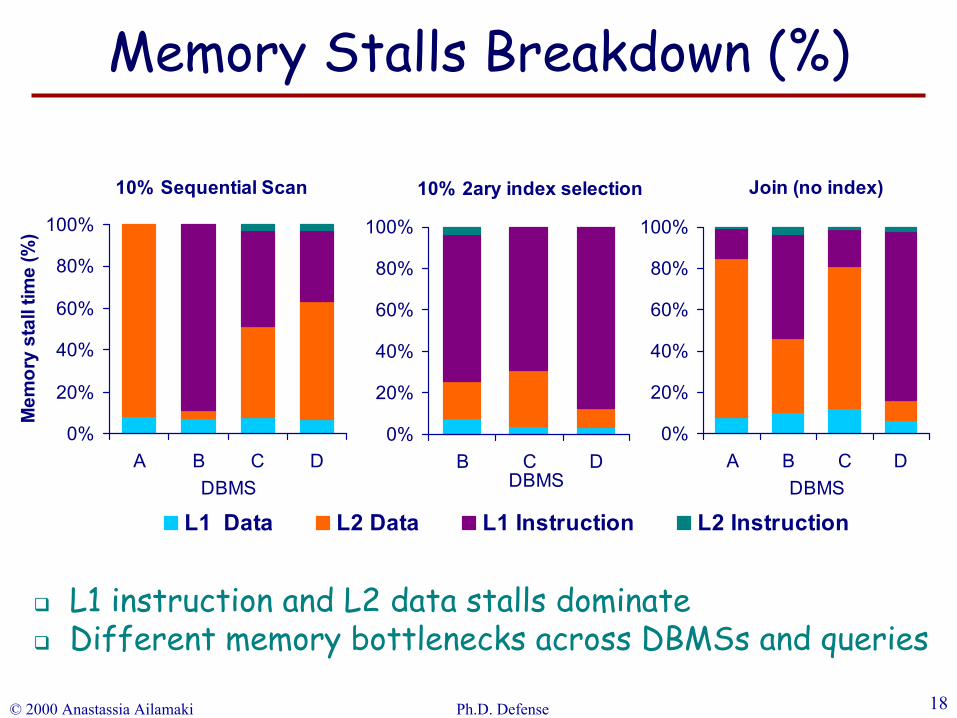
L1 instruction and L2 data stalls dominateDifferent memory bottlenecks across DBMSs and queries
Memory Stalls Breakdown (%)

© 2000 Anastassia Ailamaki Ph.D. Defense 19
We can use microbenchmarks instead of TPCExecution time breakdown shows trendsMemory access is a major bottleneck
Increasing memory-processor performance gapDeeper memory hierarchies expectedL2 cache data misses
L2 grows (8MB), but will be slowerStalls due to L1 I-cache misses
L1 I-cache not likely to grow as much as L2
We need to address every reason for stalls
Summary of Analysis

© 2000 Anastassia Ailamaki Ph.D. Defense 20
Memory
BBranchMispredictions
RHardwareResources
D-cache D
I-cache I
DBMS: improve locality
DBMS + Compiler
Compiler + Hardware
Hardware
Data cache: A clear responsibility of the DBMS
Addressing Bottlenecks

© 2000 Anastassia Ailamaki Ph.D. Defense 21
IntroductionPART I: Where Does Time Go?PART II: Partition Attributes Across
The current scheme: Slotted pagesPartition Attributes Across (PAX)Performance Results
PART III: Towards a DSS-centric h/w designConclusions
Outline

© 2000 Anastassia Ailamaki Ph.D. Defense 22
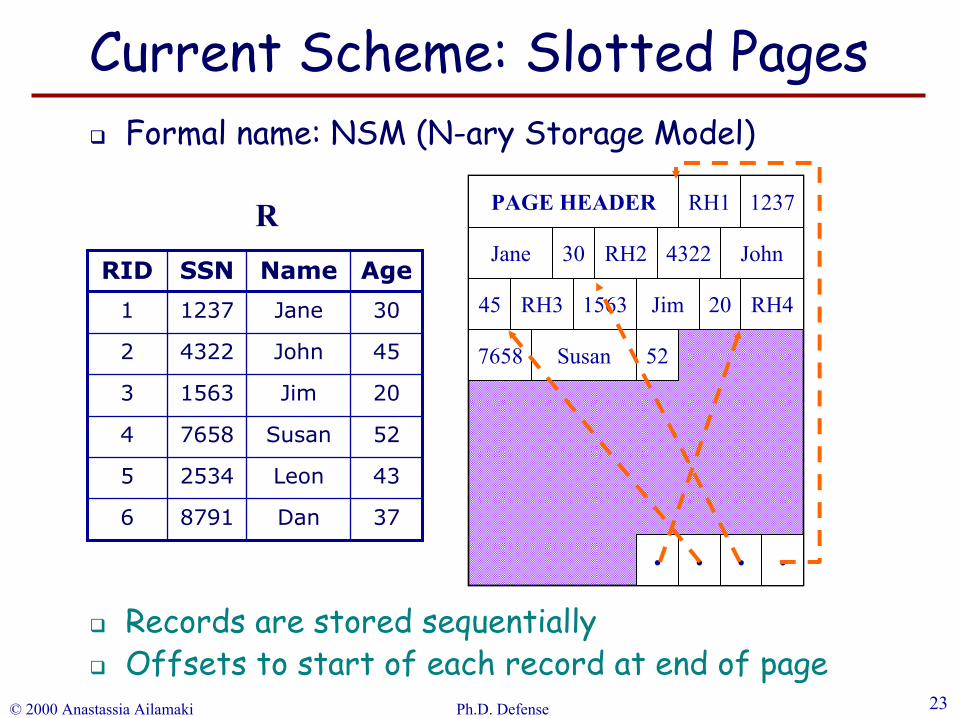
Slotted Pages: Used by all commercial DBMSsStore table records sequentiallyIntra-record locality (attributes of record r together)…but pollutes cache
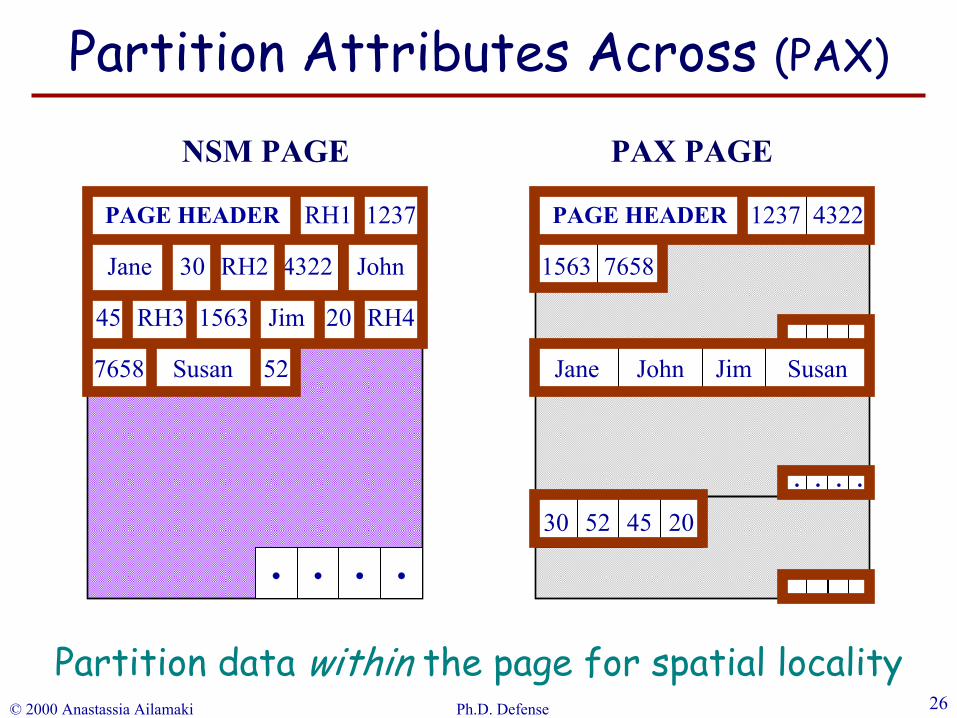
Inspiration: Vertical partitioning [Copeland’85]Store n-attribute table as n single-attribute tablesProblem: High record reconstruction cost
Partition Attributes Across (PAX)Have the cake and eat it, too!
PAX: Inter-record locality, low reconstruction cost
The Data Placement Tradeoff
© 2000 Anastassia Ailamaki Ph.D. Defense 23
1237RH1PAGE HEADER
30Jane RH2 4322 John
45 RH3 Jim 20
•••
RH4
7658 Susan 52
•
1563
37Dan87916
43Leon25345
52Susan76584
20Jim15633
45John43222
30Jane12371
AgeNameSSNRID
R
Records are stored sequentiallyOffsets to start of each record at end of page
Formal name: NSM (N-ary Storage Model)
Current Scheme: Slotted Pages
© 2000 Anastassia Ailamaki Ph.D. Defense 24
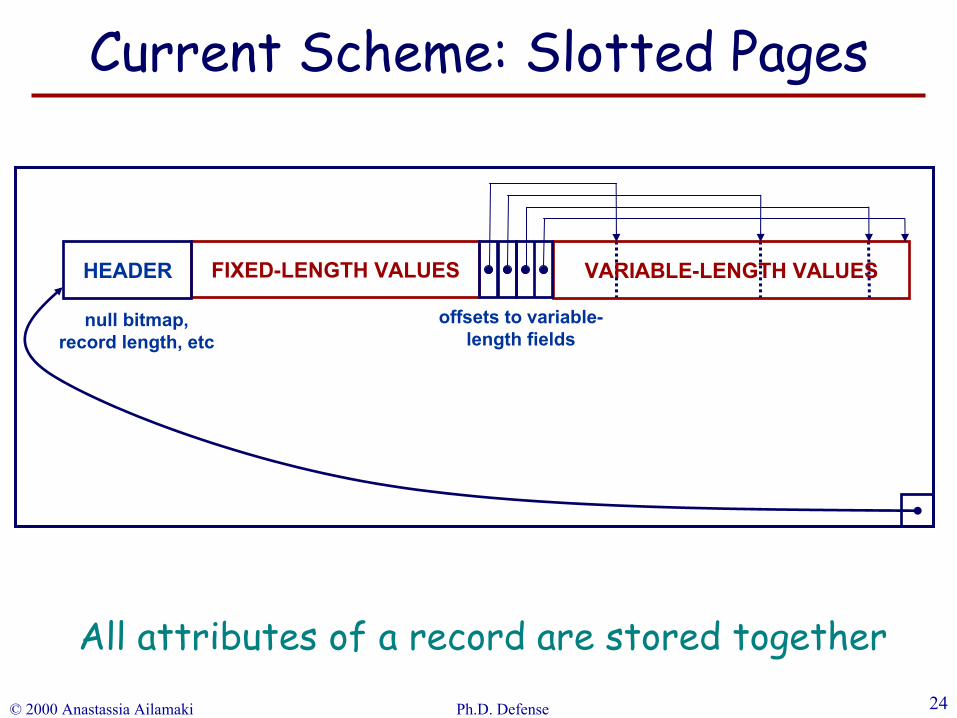
FIXED-LENGTH VALUES VARIABLE-LENGTH VALUESHEADER
offsets to variable-length fields
null bitmap,record length, etc
All attributes of a record are stored together
Current Scheme: Slotted Pages

© 2000 Anastassia Ailamaki Ph.D. Defense 25
CACHE
MAIN MEMORY
1237RH1PAGE HEADER
30Jane RH2 4322 John
45 RH3 Jim 20
•••
RH4
7658 52
•
1563
block 130Jane RH
52 2534 Leon block 4
Jim 20 RH4 block 3
45 RH3 1563 block 2
select namefrom Rwhere age > 40
NSM pollutes the cache and wastes bandwidth
2534 LeonSusan
NSM Cache Behavior
© 2000 Anastassia Ailamaki Ph.D. Defense 26
1237RH1PAGE HEADER
30Jane RH2 4322 John
45
1563
RH3 Jim 20
•••
RH4
7658 Susan 52
•
PAGE HEADER 1237 4322
1563
7658
Jane John Jim Susan
30 45 2052
• •••
NSM PAGE PAX PAGE
Partition data within the page for spatial locality
Partition Attributes Across (PAX)

© 2000 Anastassia Ailamaki Ph.D. Defense 27
CACHE
1563
PAGE HEADER 1237 4322
7658
Jane John Jim Suzan
30 45 2052• •••
block 130 45 2052
MAIN MEMORY
select namefrom Rwhere age > 40
Fewer cache misses, low reconstruction cost
PAX: Mapping to Cache
© 2000 Anastassia Ailamaki Ph.D. Defense 28
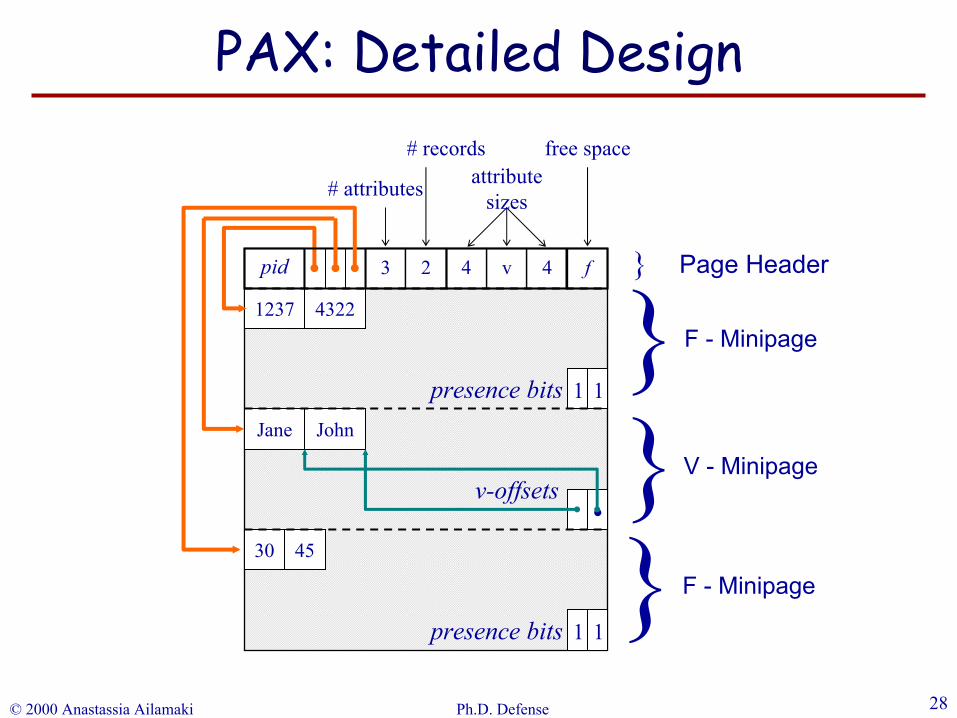
pid 3 2 4v4
43221237
Jane John
•
1 1
30 45
1 1
f }
}Page Header
attribute sizes
free space# records
# attributes
F - Minipage
presence bits
presence bits
v-offsets
}}
F - Minipage
V - Minipage
PAX: Detailed Design

© 2000 Anastassia Ailamaki Ph.D. Defense 29
Main-memory resident RQuery:
select avg (ai)from Rwhere aj >= Lo and aj <= Hi
PII Xeon running Windows NT 416KB L1-I, 16KB L1-D, 512 KB L2, 512 MB RAMUsed processor countersImplemented schemes on Shore Storage Manager
Similar behavior to commercial Database Systems
Basic Evaluation: Methodology
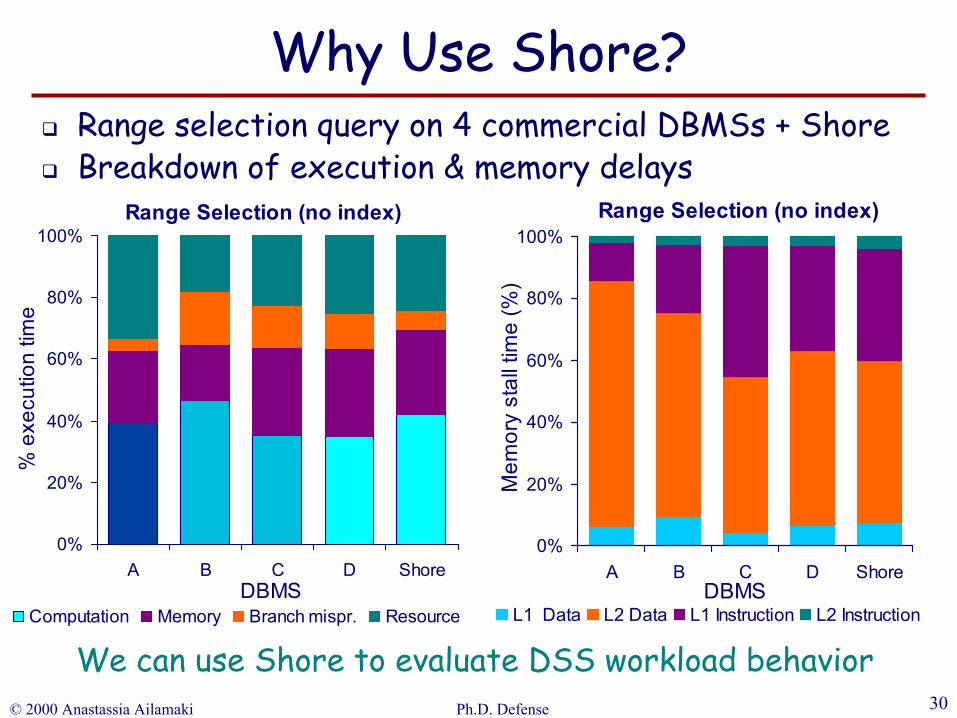
© 2000 Anastassia Ailamaki Ph.D. Defense 30
Range Selection (no index)
0%
20%
40%
60%
80%
100%
A B C D ShoreDBMS
% e
xecu
tion
time
Computation Memory Branch mispr. Resource
Range Selection (no index)
0%
20%
40%
60%
80%
100%
A B C D ShoreDBMS
Mem
ory
stal
l tim
e (%
)
L1 Data L2 Data L1 Instruction L2 Instruction
We can use Shore to evaluate DSS workload behavior
Range selection query on 4 commercial DBMSs + ShoreBreakdown of execution & memory delays
Why Use Shore?
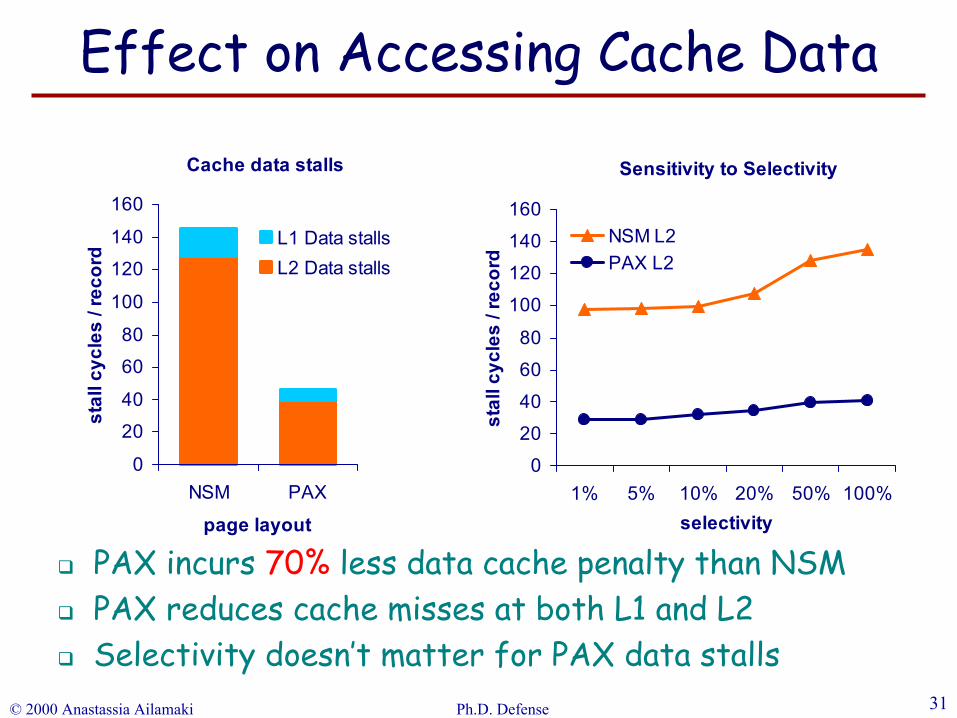
© 2000 Anastassia Ailamaki Ph.D. Defense 31
Sensitivity to Selectivity
0
20
40
60
80
100
120
140
160
1% 5% 10% 20% 50% 100%selectivity
stal
l cyc
les
/ rec
ord
NSM L2PAX L2
PAX incurs 70% less data cache penalty than NSM PAX reduces cache misses at both L1 and L2Selectivity doesn’t matter for PAX data stalls
Effect on Accessing Cache Data
Cache data stalls
0
20
40
60
80
100
120
140
160
NSM PAX
page layout
stal
l cyc
les
/ rec
ord
L1 Data stallsL2 Data stalls

© 2000 Anastassia Ailamaki Ph.D. Defense 32
PAX: 75% less memory penalty than NSM (10% of time)Execution times converge as number of attrs increases
Execution time breakdown
0
300
600
900
1200
1500
1800
NSM PAXpage layout
cloc
k cy
cles
per
reco
rd
Resource
BranchMispred.Memory
Comp.
Sensitivity to # of attributes
0
1
2
3
4
5
6
2 4 8 16 32 64
# of attributes in recordel
apse
d tim
e (s
ec)
NSMPAX
Time and Sensitivity Analysis
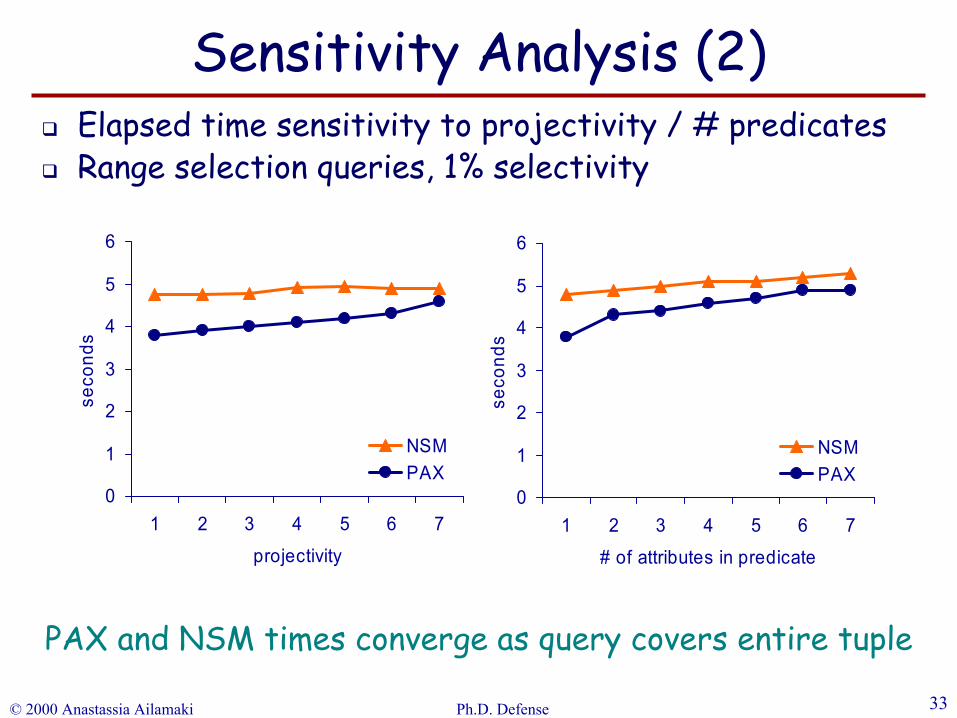
© 2000 Anastassia Ailamaki Ph.D. Defense 33
PAX and NSM times converge as query covers entire tuple
0
1
2
3
4
5
6
1 2 3 4 5 6 7
projectivity
seco
nds
NSMPAX
0
1
2
3
4
5
6
1 2 3 4 5 6 7
# of attributes in predicate
seco
nds
NSMPAX
Sensitivity Analysis (2)Elapsed time sensitivity to projectivity / # predicatesRange selection queries, 1% selectivity

© 2000 Anastassia Ailamaki Ph.D. Defense 34
Loaded 100M, 200M, and 500M TPC-H DBsRan Queries:
Range Selections w/ variable parameters (RS)TPC-H Q1 and Q6
sequential scanslots of aggregates (sum, avg, count)grouping/ordering of results
TPC-H Q12 and Q14(Adaptive Hybrid) Hash Join complex ‘where’ clause, conditional aggregates
PII Xeon running Windows NT 4Used processor counters
Evaluation Using a DSS Benchmark

© 2000 Anastassia Ailamaki Ph.D. Defense 35
Estimate average field sizesStart inserting recordsIf a record doesn’t fit,
Reorganize page(move minipage boundaries)
Adjust average field sizes
50% of reorganizations accommodate a single record
Elapsed Bulk Load Times
0
500
1000
1500
2000
2500
3000
3500
100 MB 200 MB 500 MBDatabase Size
time
(sec
onds
)
NSMPAXDSM
PAX loads a TPC-H database in 2-26% longer than NSM
Insertions with PAX
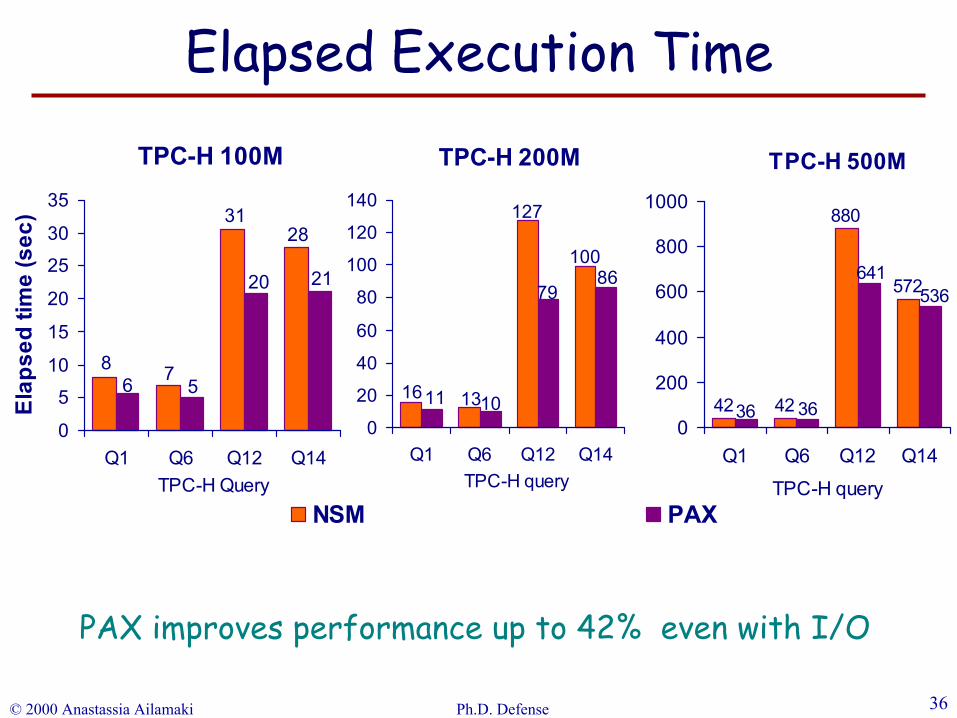
© 2000 Anastassia Ailamaki Ph.D. Defense 36
TPC-H 100M
2831
8 76 5
20 21
0
5
10
15
20
25
30
35
Q1 Q6 Q12 Q14TPC-H Query
Elap
sed
time
(sec
)
TPC-H 200M
100
127
16 13
79
11 10
86
0
20
40
60
80
100
120
140
Q1 Q6 Q12 Q14TPC-H query
NSM PAX
TPC-H 500M
572
42
880
42
641
36 36
536
0
200
400
600
800
1000
Q1 Q6 Q12 Q14
TPC-H query
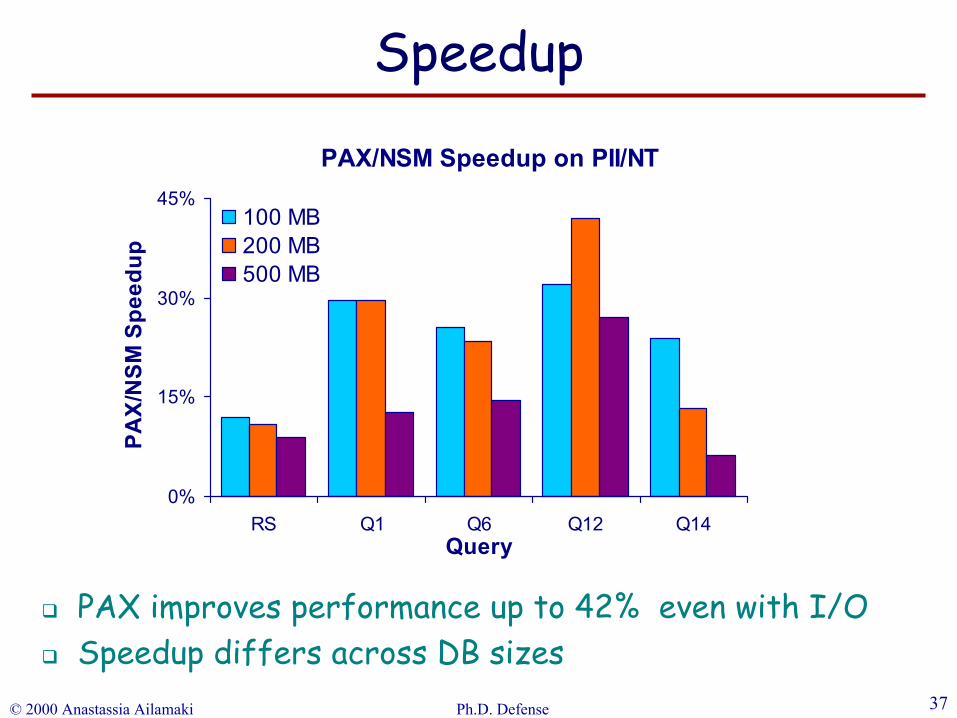
PAX improves performance up to 42% even with I/O
Elapsed Execution Time
© 2000 Anastassia Ailamaki Ph.D. Defense 37
PAX/NSM Speedup on PII/NT
0%
15%
30%
45%
RS Q1 Q6 Q12 Q14Query
PAX/
NSM
Spe
edup
100 MB200 MB500 MB
PAX improves performance up to 42% even with I/OSpeedup differs across DB sizes
Speedup

© 2000 Anastassia Ailamaki Ph.D. Defense 38
AdvantagesHigh data cache performanceFaster than NSM for DSS queriesOrthogonal to other storage decisionsDoes not affect I/O performance
Current DisadvantagesComplex free space mgmt with variable length attributes ⇒ Complicates update algorithm
PAX beneficial for read-mostly workloads (e.g., DSS)(update-intensive workloads in future work)
PAX: Summary

© 2000 Anastassia Ailamaki Ph.D. Defense 39
IntroductionPART I: Where Does Time Go?PART II: Partition Attributes AcrossPART III: Towards DSS-Centric H/W
Memory subsystemBranch prediction mechanismProcessor pipeline
Conclusions
Outline
© 2000 Anastassia Ailamaki Ph.D. Defense 40
ArchitectureRISC or CISC Instruction set
MicroarchitecturePipeline
Speculation (out-of-order, multiple issue)Branch prediction
Memory subsystemCache size, associativityBlock size, subblockingInclusion
Which design looks beneficial for DSS workloads?
Platform Differences
© 2000 Anastassia Ailamaki Ph.D. Defense 41
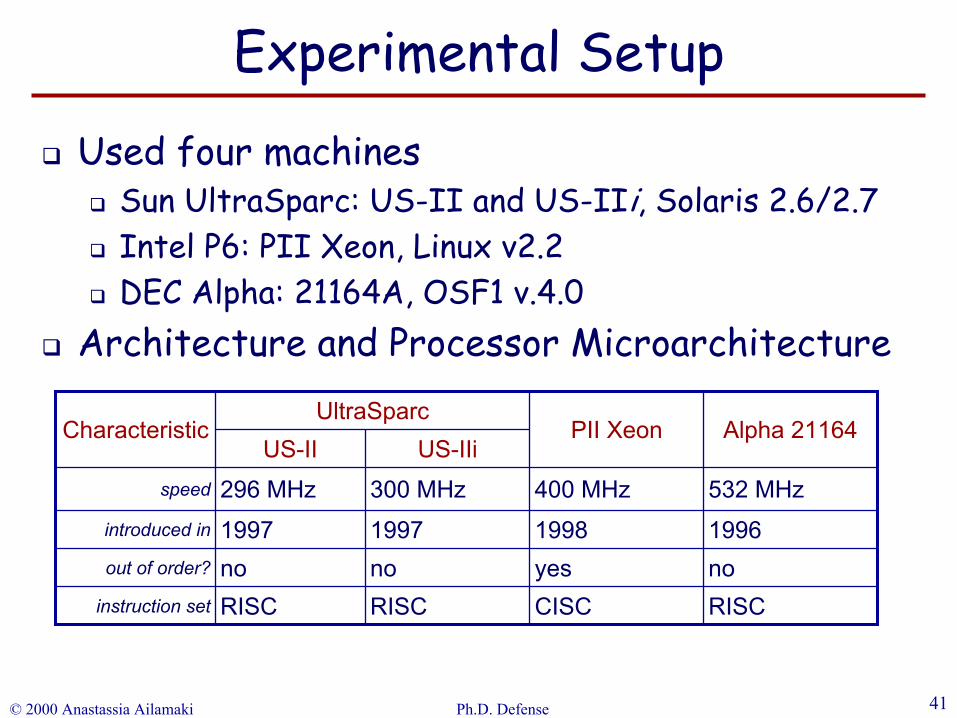
Used four machinesSun UltraSparc: US-II and US-IIi, Solaris 2.6/2.7Intel P6: PII Xeon, Linux v2.2DEC Alpha: 21164A, OSF1 v.4.0
Architecture and Processor Microarchitecture
noyesnonoout of order?
RISCCISCRISCRISCinstruction set
1996199819971997introduced in
532 MHz400 MHz300 MHz296 MHzspeed
US-IIiUS-IIAlpha 21164PII Xeon
UltraSparcCharacteristic
Experimental Setup
© 2000 Anastassia Ailamaki Ph.D. Defense 42
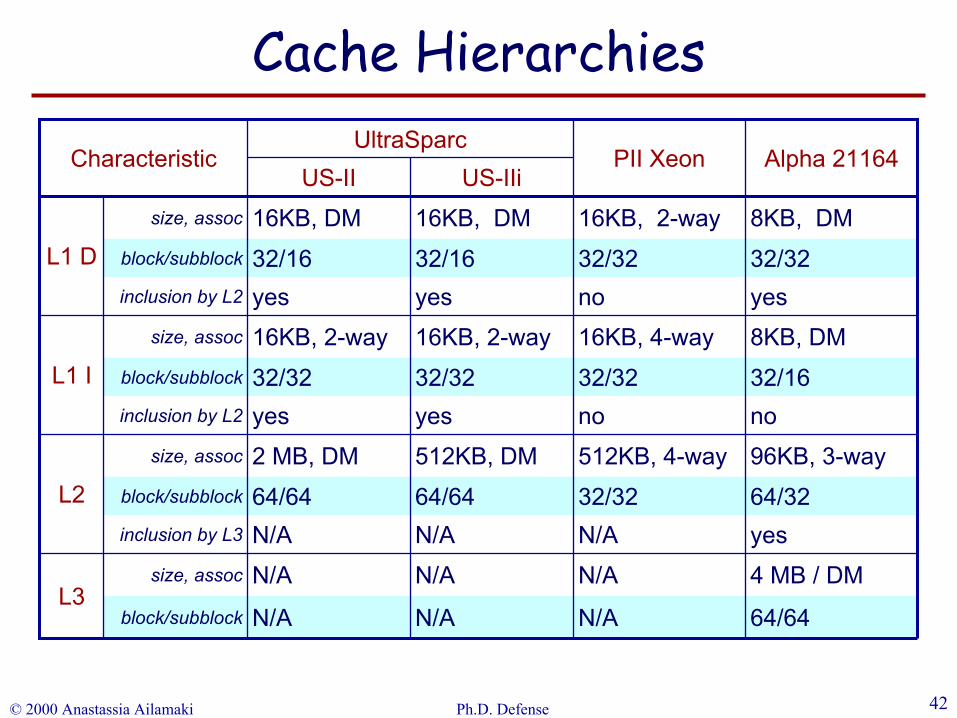
yesN/AN/AN/Ainclusion by L3
nonoyesyesinclusion by L2
yesnoyesyesinclusion by L2
block/subblock
size, assoc 4 MB / DMN/AN/AN/AL3
64/64N/AN/AN/A
block/subblock
size, assoc 96KB, 3-way512KB, 4-way512KB, DM2 MB, DML2 64/3232/3264/6464/64
block/subblock
size, assoc 8KB, DM16KB, 4-way16KB, 2-way16KB, 2-wayL1 I 32/1632/3232/3232/32
block/subblock
size, assoc
Alpha 21164PII XeonUltraSparc
32/3232/3232/1632/16
8KB, DM16KB, 2-way16KB, DM16KB, DML1 D
US-IIiUS-IICharacteristic
Cache Hierarchies

© 2000 Anastassia Ailamaki Ph.D. Defense 43
Compiled Shore with gcc 2.95.2Alpha version not optimized
Ran DSS workloadRange Selections w/ variable parameters (RS)TPC-H 1, 6, 12, 14
Used processors’ countersSun: run-pic (by Glenn Ammons, modified)PII: PAPI (public-domain counter library)Alpha: DCPI (sampling software by Compaq)
Methodology
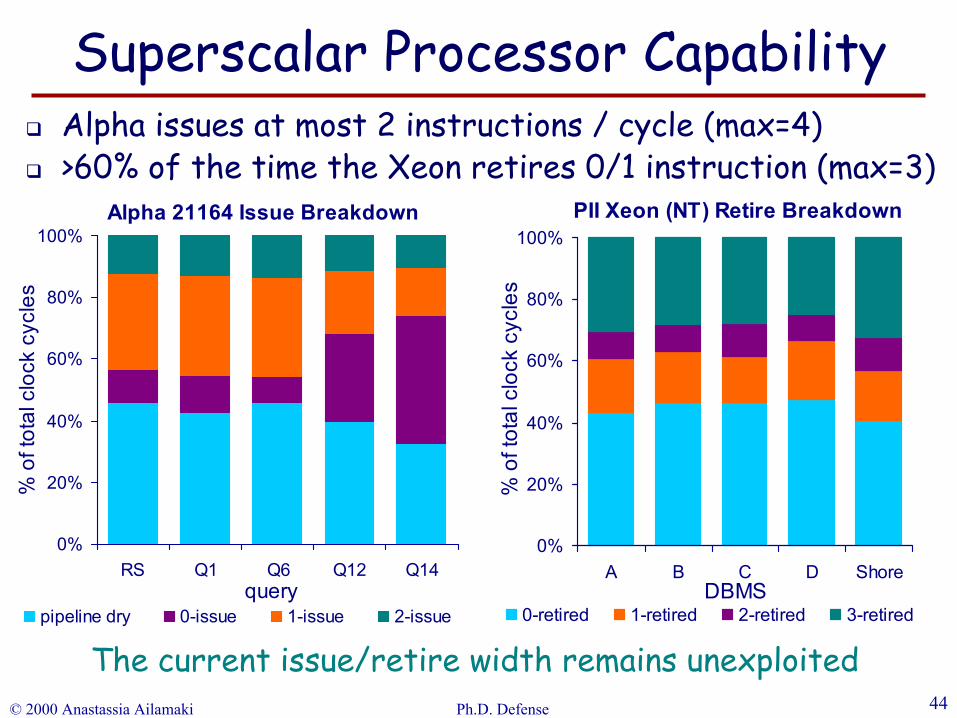
© 2000 Anastassia Ailamaki Ph.D. Defense 44
The current issue/retire width remains unexploited
Alpha issues at most 2 instructions / cycle (max=4)>60% of the time the Xeon retires 0/1 instruction (max=3)
Superscalar Processor Capability
Alpha 21164 Issue Breakdown
0%
20%
40%
60%
80%
100%
RS Q1 Q6 Q12 Q14query
% o
f tot
al c
lock
cyc
les
pipeline dry 0-issue 1-issue 2-issue
PII Xeon (NT) Retire Breakdown
0%
20%
40%
60%
80%
100%
A B C D ShoreDBMS
% o
f tot
al c
lock
cyc
les
0-retired 1-retired 2-retired 3-retired
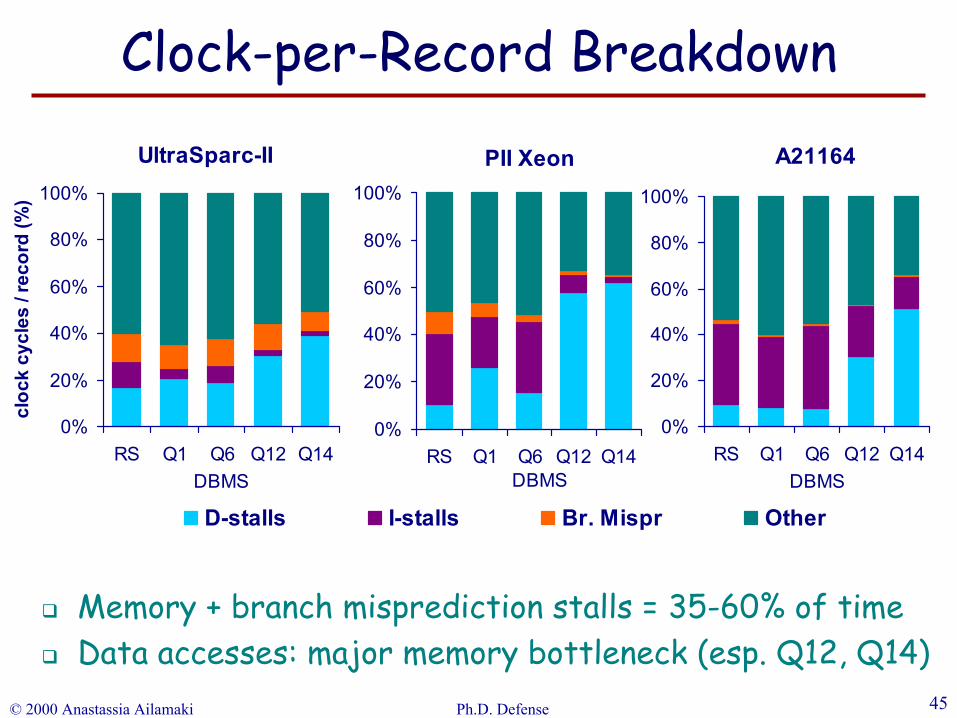
© 2000 Anastassia Ailamaki Ph.D. Defense 45
UltraSparc-II
0%
20%
40%
60%
80%
100%
RS Q1 Q6 Q12 Q14DBMS
cloc
k cy
cles
/ re
cord
(%)
PII Xeon
0%
20%
40%
60%
80%
100%
RS Q1 Q6 Q12 Q14DBMS
D-stalls I-stalls Br. Mispr Other
A21164
0%
20%
40%
60%
80%
100%
RS Q1 Q6 Q12 Q14DBMS
Memory + branch misprediction stalls = 35-60% of timeData accesses: major memory bottleneck (esp. Q12, Q14)
Clock-per-Record Breakdown

© 2000 Anastassia Ailamaki Ph.D. Defense 46
Q12, Q14
RS, Q1, Q6
Q12, Q14
RS, Q1, Q6
9%22%15%3.5%Branch
misprediction rate 6%1%
515Branch penalty (cycles)
7%18%Branch frequency
Alpha 21164PII XeonCharacteristic
Branch penalty = frequency*misprediction rate*penaltyFrequency is typically 20-25%In-order processors => lower penaltyLow misprediction accuracy may break it (e.g., UltraSparc)
High-accuracy predictors
Branch Prediction

© 2000 Anastassia Ailamaki Ph.D. Defense 47
UltraSparc II/IIi cache comparison (RS)
0
0.15
0.3
0.45
0.6
0.75
0.9
1.05
Elapsedtime
L1Dmisses
L1I misses
L2Dmisses
L2I misses
norm
aliz
ed u
nit
UltraSparc-IIi UltraSparc-II
Small caches should not maintain inclusion
Cache Inclusion
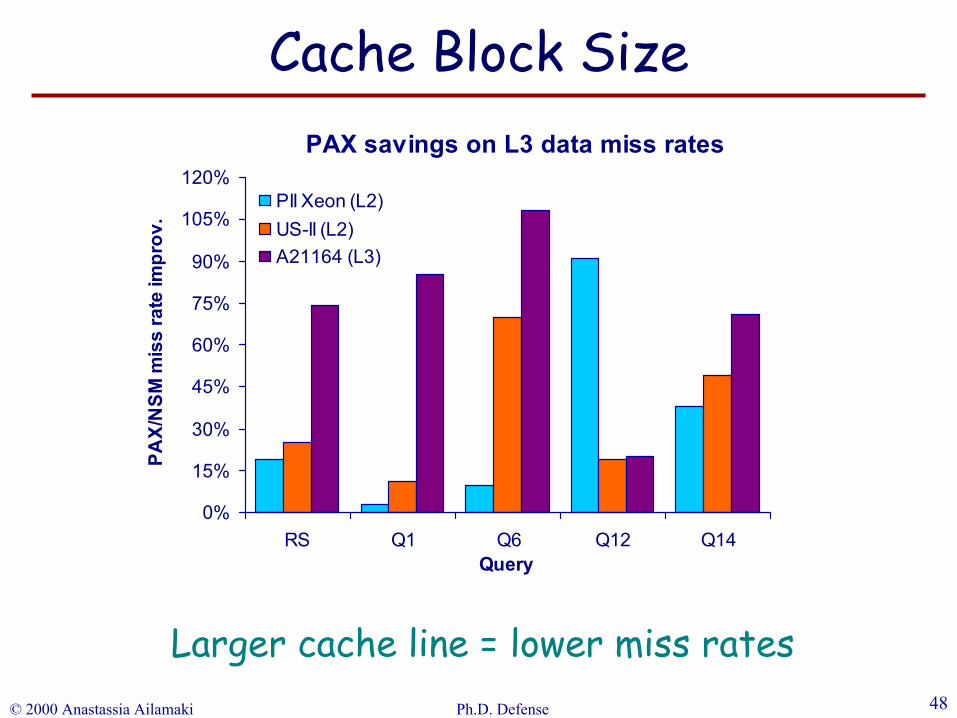
© 2000 Anastassia Ailamaki Ph.D. Defense 48
PAX savings on L3 data miss rates
0%
15%
30%
45%
60%
75%
90%
105%
120%
RS Q1 Q6 Q12 Q14Query
PAX/
NSM
mis
s ra
te im
prov
.
PII Xeon (L2)US-II (L2)A21164 (L3)
Larger cache line = lower miss rates
Cache Block Size
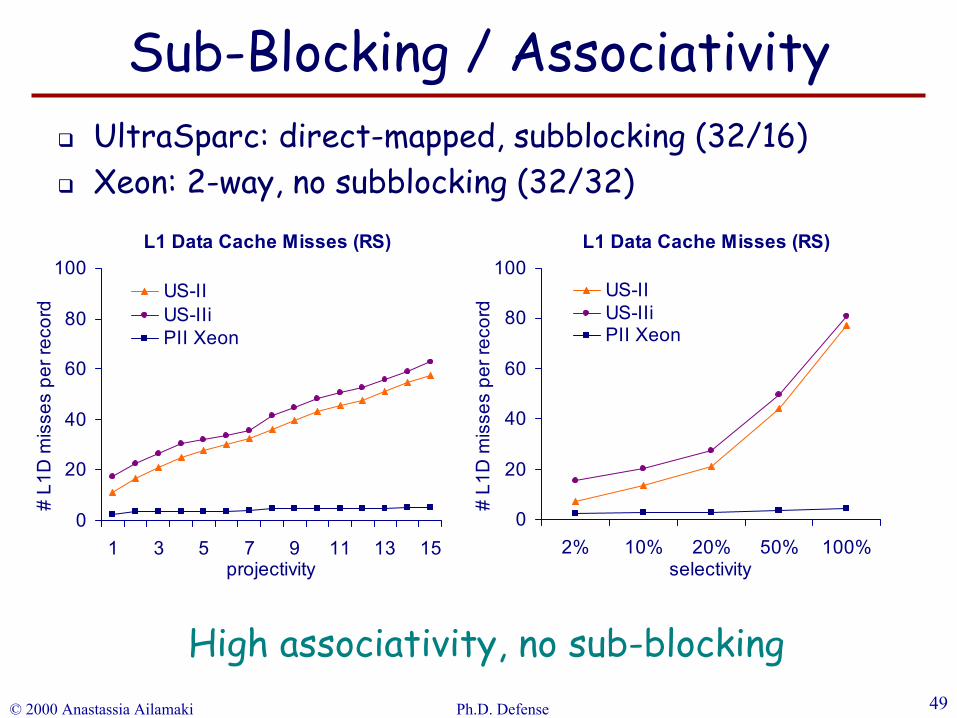
© 2000 Anastassia Ailamaki Ph.D. Defense 49
L1 Data Cache Misses (RS)
0
20
40
60
80
100
1 3 5 7 9 11 13 15projectivity
# L1
D m
isse
s pe
r rec
ord
US-IIUS-IIiPII Xeon
L1 Data Cache Misses (RS)
0
20
40
60
80
100
2% 10% 20% 50% 100%selectivity
# L1
D m
isse
s pe
r rec
ord
US-IIUS-IIiPII Xeon
High associativity, no sub-blocking
UltraSparc: direct-mapped, subblocking (32/16)Xeon: 2-way, no subblocking (32/32)
Sub-Blocking / Associativity
© 2000 Anastassia Ailamaki Ph.D. Defense 50
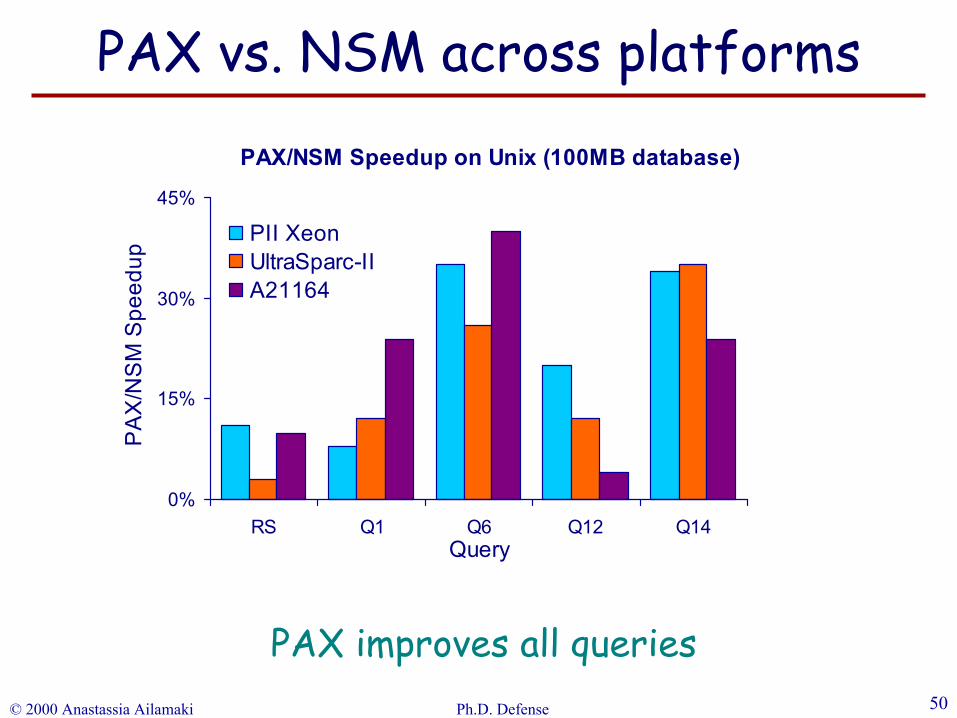
PAX/NSM Speedup on Unix (100MB database)
0%
15%
30%
45%
RS Q1 Q6 Q12 Q14Query
PA
X/N
SM
Spe
edup
PII XeonUltraSparc-IIA21164
PAX improves all queries
PAX vs. NSM across platforms

© 2000 Anastassia Ailamaki Ph.D. Defense 51
Memory HierarchyNon-blocking caches>64-byte block, no sub-blockingGenerous-sized L1-I (128K) and L2 (> 2MB)
A tiny, fast L1/2 with a large, slow L3 won’t add muchHigh associativity (2-4) No inclusion (at least for instructions)
Processor pipelineIssue width is fine, out-of-order overlaps stall timeExecution engine to sustain >1 load/store instr.High-accuracy branch prediction
Summary
…provided that implementation cost remains stable.

© 2000 Anastassia Ailamaki Ph.D. Defense 52
Found trends in behavior of commercial DBMSsusing an analytic framework to model execution time
Identified bottlenecks among HW componentsMain memory access is the new DB bottleneckMajor showstoppers: L1 Instruction + L2 Data
Proposed new design for cache performanceIncrease spatial locality using novel data placement70% less data-related memory access delaysSignificant improvement on sequential scans
Evaluated several hardware parametersSuggested DSS-centric processor and memory design
Conclusions