p755 manabu
TRANSCRIPT

8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 1/7
W ord Se nse i ) ismnl}iguati<)n and T ex t Set menta tionBas(q on I ,c×ical (+ohcslOll
( ) K U M U I { A M a n a b u , I I O N I ) A Ta ke oSchool of [nforma,tion Science,
Japa n Adva nced Ins t i tu te o f Science a .nd Technol ogy( ' l 'a l . sunokuchi , l sh ikawa 923-12 Japan)
c-nmil: { oku,honda}¢~jai st .ac.j i~
A b s t r a c t
In this paper, we describe ihow word sense am=biguity can be resolw'.d with the aid of lexical eo-hesion. By checking ]exical coheshm between the
current word and lexical chains in the order ofthe salience, in tandem with getmration of lexica]chains~ we realize incretnental word sense disambiguation based on contextual infl)rmation thatlexical ch ains ,rev eah Next;, we <le~<:ribe how setmen< boundaries of a text can be determined withthe aid of lexical cohesion. Wc can measure theplausibili ty of each point in the te xt as a segmen tboundary by computing a degree of agreement ofthe star t and end p oints of lexical chaihs.
1 I n t r o d u c t i o n
A text is not a mere set of unrel ated sentences.Rather, sentences in a text are about the samething and connected to each other[l()]. C o h e s i o nand cohere neeare said to contribute to such con-nection of the sentences. While coherence is asemantic relationship and needs computationallyexpensive processing for identification, cohesionis a surface relationship among words iu a textand more accessible than coherence. Cohesionis roughly classitled into r e fe rence t , co r@tnc t ion ,and lez ica l coh,e s ion 2 .
Except conjmwtion that explicit ly indicates l ;he
relationship between sentences, l;he other two<:lasses are considered to t>e similar in that the re-lationship hetweer~ sentences is in<licated by twosemantically same(or related) words. But lexical
1Reference by pronouns and el lipsis in Halliday andHasan's classification[3] are included here.
2Reference by flf ll NPs, substitution mtd lcxical cohe-.sion in Ilalllday and Hasan's classillcation a.re includedhere.
cohesion is far easier to idenlAfy than reference b e -
c a u s e 1)oth words in lexical cohesion relation a p -
p e a r in a text while one word in reference relationis a pr<mom, or elided and has less information toinfer the other word in the relation automatically.
Based on this observation, we use lexical cohe-sion as a linguistic device for discourse analysis.We call a sequence of words which are in lexiealcohesion relation with each other a I cx i ca l cha inlike [10]. l,exical chains tend to indicate portionsof a text; th at form a sema nti c uttit. And so vari.-ous lexical chains tend to appear in a text corre.spou(ling to the change of the topic. Therefore ,
I. lexical chains provide a local context to aidin the resolution of word sense ambiguity;
2. lexical <'hains pro vide a <'lue for the dete rmi-nation of segnlent boundaries of the text[10].
]n this paper, we first describe how word senseambiguity can t)e resolved with the aid of lexicalcohesion. During t he process of generat ing lex-i<'al chains in crementall y, they are recorded in aregister in the order of the salience. T he sa l ie nccof lexical chains is based on their recency andlength. Since the more salient lexical chain re presents the nearby local context, by checking lexi:ca[ cohesion between the current word and lexiealchains in the order of tile salience, in tandem withgeneratiou of lexical chains, we realize incremen.tal word sense disambiguation based on contex-
tual in formati on that lexical chains reveal.Next;, we describe how segment boundaries o f
a text can be determi ned wit h the aid of lexicalcohesion. Since the sta rt and end point s of lexicalchains it, the text tend to indicate the start andend points of the segme nt, we can measure theplausibil ity o[' each point in the text as a segmentboundary by computing a degree of agreement ofthe sta.rt and end points of lexical chains.
755

8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 2/7
Morris and Itirst[10] pointed out the abovetwo importance of lexical cohesion for discourseanalysis and presented a way of computinglexical chains by using Roger's InternationalThesaurus[15]. IIowever, in spite of their me ntio nto the importance, they did not present the way
of word sense dis ambi guat ion based on lexical co-hesion and they only showed the correspondencesbetween lexical chains and segment boundaries bytheir intuitive analysis .
McRoy's work[8] can be considered as the onethat uses the information of lexical cohesion forword sense disambiguation, but her method doesnot; take into account the necessity to arrangelexical chains dynamically . Moreover, her wordsense disa mbig nat ion meth od based on lexical co-hesion is not evaluated fully.
In section two we outline what lexical cohe-sion is. In section three we explain the way ofincrementa l generation of lexical chains in tan-dem with word sense disambi guation and describethe result of the evaluation of our disambigu ationmethod . In section four we explain the measureof the plausibility of segment bounda ries and de-scribe the result of the evaluation of our measure.
2 L e x i c a l C o h e s i o n
Consider the following example, which is theEnglish translation of the fragment of one ofJapanese texts that we use for the experiment
later.In the universe that continues expancbing, a number of stars have appearedaml disappeared again and again. Andabo ut te n billion years after tile birthof the universe, in the same way asthe other stars, a primi tive galaxy wasformed with the primitive sun as thecenter.
Words {nniverse, star, universe, star, galaxy,sun} seem to be semant icall y same or related toeach other and they are included in the same cat-egory in Roget 's Interna tiona l Thesaurus. LikeMorris and tIirst, we compute such sequences ofrelated words(lexical chains) by using a thesaurusas the knowledge base to take into account notonly the repetition of the same word but the useof superordinates, subordinates, and synonyms.
We. use a Japanese thesaurus 'Bnnrui-goihyo'[1]. Bunru i-goihy o has a similar organi-zation to Roger's: it consists of 798 categories
and has a hierarchical structure above this level.For each word, a list of category numbers whichcorresponds to its multiple word senses is given.We count a sequence of words which are includ edin the same category as a lexical chain. It mightbe (:lear tha t this task is comp utat iona lly trivial.Note that we regard only a sequence of words inthe same category as a lexical chain, rather thanusing the complete Morris and Hirst's frameworkwith five types of thesaural relations.
The word sense of a word can be determinedin its context. For example, in the contex t{universe, star, universe, star, galaxy, sun}, theword 'earth' has a 'planet ' sense, not a 'ground'one. As clear from this exampl e, lexical chain s('an be used as a contextual aid to resolve wordsense ambiguity[10]. In the generatio n processof lexical chains, by choosing the lexical chainthat the current word is added to, its word senseis deter mined. Thus , we regard word sense dis-ambiguation as selecting the most likely categorynumber of the thesaurus, as similar to [16].
l';arlier we proposed incremental disambigua-tion method that uses intrasen tential informa-tion, such as selectional restrictions and caseframes[l 2]. In the next section, we describe incre-mental disamb iguation method that uses lexicalchains as intersentential( contextual) information.
3 G e n e r a t i o n o f L e x i c a l C h a i n s
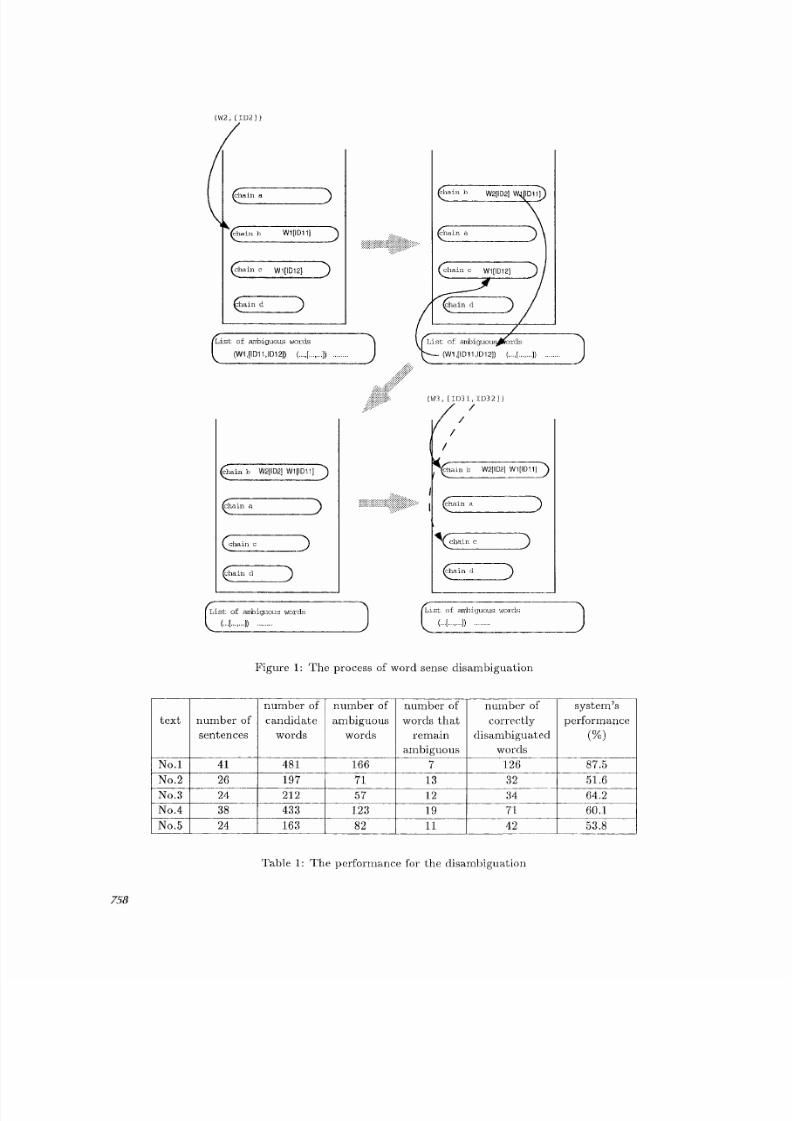
In the last section, we showed that lexical chainscarl play a role of local context , t]owever, mult i-ple lexical chains might cooccur in portions of atext and they mi ght vary in their plausibil ity aslocal context. For this reason, for lexical chainsto function truly as local context, it is necessaryto arrange them in the order of the salience thatindicates the degree of tile plausibility. We basethe salie nce on the following two factors: the re-cency and the length. The more recently update dchains are considered to be the more activatedcontext in the neighborhood and are given moresalience. The longer chains are considered to bemore about the topic in the neighborhood andare given more salience.
By checking lexical cohesion between the cu>rent word and lexical chains in the order of thesalience, the lexical chain that is selected to addthe current word determines its word sense andplays a role of local context.
Based on this idea, incremental generation of
756

8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 3/7
8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 4/7

8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 5/7
trai ning on large corl)ora , but. our metho dcan at tai n such tolerab[e level of performancewithout any training.
However, our salience of lexical chains is, of
course, rather naive and muste
refined by us-ing other kinds of inibrmation, such as JapanesetopicM marker 'wa'.
c h a i n s
s t a r t ~ e n d
i - 2 4 )
4 - 13)
1 4 - i s )
8 - 9 )
1 4 - 1 8 )
t e x t
i
123456789012345678901234
4 T e x t S e g m e n t a t i o n b y L e x i -
c a l C h a i n s
The second importance of lexic~d chains is thatthey provide a clue for the deternfination of seg-ment boundaries. (Jertain spans of sentences ina text form selnantic units and are usuall y called
segments. It is crucial to identify the segmentboundaries as a first step to construct the struc-ture of a text[2].
4 . 1 T h e M e a s u r e f o r S e g n m n t t i o u n < l -a r i e s
When a portion of a text forms a semantic unit,there is a tendency for related words to be used.Therefore, if lexical chains can be found, theywill ten(t to indicate the segment boundaries ofthe text . Wh en a l.exical chain ends, there is a
ten den cy for a seg men t to end. [f a, llew cha inbegins, this might be an indication thai; a newsegment has begun[l 0]. Takin g into acc ount tiffscorresponde nce of [exieal chain bounda ries to seg-ment bounda ries, we measure the plausibilit;y eleach point; in the text; as ~ segment hotmdary: tbreach point betwee n sentences n an(l 'n k I (whereit ranges fl'om 1 to the m|nlt)er el' sentences in thetext minus 1), compute the stun of the numl)erof lexical chains that en l at the sentence ?z andthe number of lexical chains that begin at thesent ence n + 1. We call this naive me asur e of adegree of agreement of the start and end points of
lexicM chains w(n,n + l) boundary strength like[14]. The points ill the text are selected in theorder of boundary strength as candidates of seg-ment boundaries.
Consider for example the live lexieal chains inthe ima gina ry text tha t consists of 24 sentences inFigure 2. In this text, the bou ndar y strength canbe computed as follows: w ( a , 4 ) = 1 , , . , ( 7 , s )-1,w(9,10) ~- 1,w(13,14) -- 3, . . . .
Figure 2: l,exieal chains in the text
4 . 2 T h e E v a h m t i o n
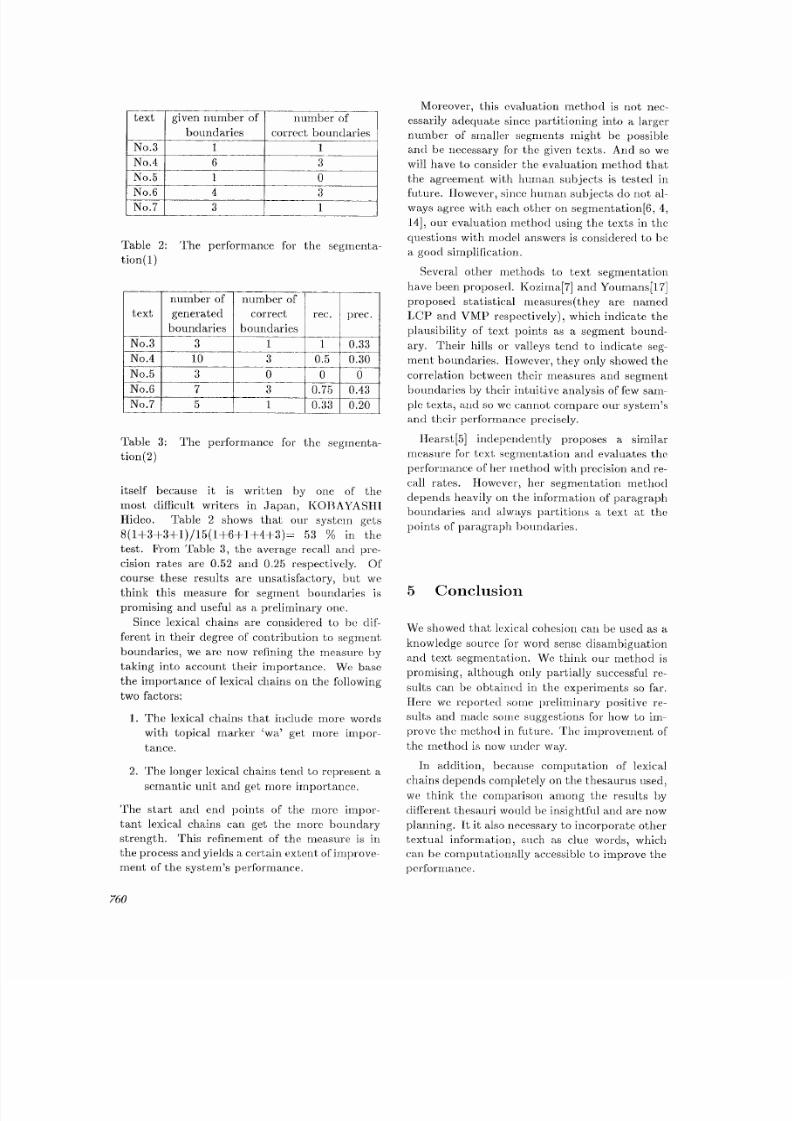
We, try to segnient the texts ill section 3.2and apply the above measure to the lexicalchains that were tbluned. We pick out threetexts(No.3,4,5), which are fi:om the e xam ques
tions of the J apane se language, tha t ask us to par-tiglon the texts into a given number of segments.The system's performmwe is judged by the com.p~rison with segment boundaries marked as anattaehe(l model answer. Two more texts(No.6,7)['rom the questio ns are also tried to be segtnented.
Here we do not t:M~e into ac cou nt the in tbr mation of paragraph lmundaries, such as the i nde nration, at all in the following rea,sons:
• ]{c eal l se Ol lF tex t s aFe h 'o i n the exam questions, n l a , n y ( )fthem have no I]Tta, ks of para-graph I)oundaries;
• ill? case of ,laps.nose, it is poin ted out tha tparagraph and segment boundaries do notalways coincide with each other[l 3].
Table 2 shows the t)crformanee in case wherethe system generates the given number of segmentbotm(laries 4 in the order el the stre ngth. FromTable 2, we can compute the system's marks asan e xanlinee in tim Lest that consists of these fivequesLiolm. Tal-)le 3 shows the pe rf or ma nc e in casewhere segment boundm:ies are gene rated down tohalf of the maxi mum strength. ' l 'he metrics thatwe. use for the ewduation are as follows: Recall is
the quotient of' the in|tuber of correctly identifiedboundaries by the total m mlber of correct boun daries. Precision is the quotient of the nmnber of(:orre(:t[y ident ifie( l I)ounda, ies by th e t nlln l)e r ofgenerated boundaries.
We think the poor result for the text No.5might be caused by the difficulty of tile text
~The number of boundaries to be given is the mtmberof segments given in the question minus 1.
7 5 9
8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 6/7
text
No.3No.4No.5No.6No.7
given number ofboundaries
number ofcorrect boundaries
1 16 31 043 1
Table 2: The perfor mance for the segmenta-t ion(l )
text
_ _
No.3No.4
No.5No.6No.7
number ofgenerated
boundaries
number ofcorrect
boundaries3 1
10 3
7 35 1
rec. prec.I
1 0.3H0.--T-~0~
- % o 1o .7 ~ o . 4 ~ ]
_ 0 . a K 0 .2 0 A
Table 3: The performa nce for the segmenta-tion(2)
itself because it is written by one of themost difficult writers in Japan, KOBAYASH[Hideo. Table 2 shows tha t our system gets8 (1+ 3+ 3+ 1) /1 5 (1+ 6+ 1+ 4F3) = 53 % in thetest. From Table 3, the average recall and pre-
cision rates are 0.52 and 0.25 respectively. Ofcourse these results are unsatisfactory, but wethink this measure for segment boundaries ispromising and useful as a preliminary one.
Since lexical chains are considered to be dif-ferent in their degree of contribu tion to segmentboundaries, we arc now refining the measure bytaking into account their importance. We basethe importance of lexical chains on the followingtwo factors:
1. The lexical chains that include more wordswith topical marker 'wa' get more impor-tance.
2. T he longer lexical chains tend to repres ent asemantic unit and get more importance.
The start and end points of the more impor-tant lexical chains can get the more boundarystrength. This refinement of the measure is inthe process an d yields a certain ext ent of improve-ment of the system's performance.
Moreover, this ewduation method is not nec-essarily adequ ate since partiti onin g into a largernumber of smaller segments might be possibleand be nec essary for the given texts. And so wewill have to consider the evalua tion method th atthe agreement with hmnan subjects is tested infuture. Ilowever, since hum an subjec ts do not al-ways agree with each other on segmentation[6, 4,14], our eval uati on meth od using the texts in thequestions with model answers is considered to bea good simplification.
Several other methods to text segmentationhave been proposed. Kozima[7] and Youmans[17]proposed statistical measures(they are namedLCP and VMP respectively), which indicate theplausibility of text points as a segment bound -ary. Their hills or valleys tend to indica te seg-ment boundaries. However, they only showed the
correlation between their measures and segmentbound arie s by their intuil, ve analysis of few sam-ple texts, and so we cannot compare our system'sand their performance precisely.
ltearst[5] indep end ent ly proposes a similarmeasure for text segmentation and evaluates theperformance o[ her method with precision and re-call rates. However, her segme ntat ion meth oddepends heavily on the informatio n of paragraphboundaries and always partitions a text at thepoints of paragraph boundaries.
5 C o n c l u s i o n
We showed that lexical cohesion can be used as aknowledge source for word sense disambiguationand text segrnentatinn. We think our method ispromising, although only partially successful re-sults can be obtained in the experiments so far.Here we reported some preliminary positive re-sults and made some suggestions for how to im-prove the method in future. The impro vement ofthe method is now under way.
In addition, because computation of lexicalchains depends completely on the thesaurus used,we think the comparison among the results bydifferent thesauri would be insightful and are nowplanning. [t it also necessary to incorporate othertextual information, such as clue words, whichcan be comput ationall y accessible to improve theperformance.
760

8/13/2019 p755 Manabu
http://slidepdf.com/reader/full/p755-manabu 7/7
R e f e r e n c e s
[1] B u n r u i - G o i h y o . Shue i Shup pan . , :1964 . inJ a p a n e s e .
[2 ] B . J . G r o s z a n d C . L . S id n e r. A t t e n t i o n ,
in ten t ions , and the s t ruc tu re o f d i scou rse .Coraputat ionol Li~iguis t ics ,12(3 ) :175 204 ,1986 .
[ 3 ] I t . A . K . f t a l l i d a y a n d R . H a s s a n .C o h e s i o nin Eng l i sh .L o n g ma n , 1 9 7 6 .
[4 ] M . A . l t e a r s t . Te x t t i l i n g : A q u a n t i t a t i v e a p -p r o a c h to d i s c ou r s e s e g me n t a t i o n . Te c h n i -c a l R e p o r t 9 3 / 2 4 , U n i v e r s i t y o f C a l i f o r n i a ,Berke ley, 1993 .
[5] M . A . H e a r s t . M u l t i - p a r a g r a p h s e g m e n t w
t i o n o f e x p o s i t o r y t e x t s . Te c h n i c a l R e p o r t9 4 / 7 9 0 , U n i w ~ r s i ty o f C a l i f o r ni a , B e r k e le y,1994:.
[6 ] J . t t i r s chberg and B . C ,ro sz . ln t :ona t iona l fea -tu res o f loca l and g loba l d i scou rse s t ruc tu re .In Proc. o f the Darpa Worksh op on Speechand Natu~vd Language,pages ,141 - 446 , 199 2 .
[7 ] H . K o z i m a . Te x t s e g me n t a t i o n b a s e d o n s i m-i l a ri t y b e t w e e n w o r d s . I nProc . o f t he 31s tA nn .lLa l Mee t ing o f the A ssoc ia t ion fo r Co m-p u t a t i o n a l L i n g u i s ti c s ,pages 286 288 , 1993 .
[8] S .W . M cll~oy. Us ing mu l t ip le know ledgesou rces fo r word sense d i sc r imina t ion .C o m -p u t a t i o n a l L i n g u i s t ic s ,18(1):1 30 , 1992.
[9] C.S. Mell ish . C o m p u t e r I n t e r p r e t a t i o n o fNatu ra l Language Descr ip t ions .Ellis Hor--w o o d , 1 9 8 5 .
[10 ] J . M orr i s and G. t l i r s t . Lex ica l cohes ionc o mp u t e d b y t h e s a u r a l r e l a t i o n s a s a n in d i-c a t o r o f th e s t r u c t u r e o f t e x t .C o m p u t a t i o n a lLingu i s t i cs ,17(1 . ) :21 -48 , 1991 .
[ 11 ] N a g a o L a b . , K y o t o U n i v e r s it y.,]apancscM o r p h o l o gi c a l A n a l y s i s S y s t e m , ] U M A NM a n u a l Ve r s i o n l . O ,1993 . in , l apanese .
[ 12 ] M . O k u mu r a a n d H . Ta n a k a . To w a r d s i n-c r e me n t a l d i s a mb i g u a t i o n w i t h a g e n e r a l -i z e d d i s c r i mi n a t io n n e t w o r k . I nProc. of the8 th Nat io na l C onference on Ar t i ] ic i a l In t e l -ligence,pages 990 995 , 1990 .
[ 1 3] T. O o k u ma . G e n g o t a n ' i t o sh i t e n o b u n ~shou . Nihongo gaku ,11 ( 4 ) : 2 0 - 2 5 , 1 9 9 2 . i nJ a p a n e s e .
[ 1 4 ] R . J . P a s s o n n e a u . I n t e n t i o n - b a s e d s e g me n t a . -t i o n : H u ma n r e l i a b i l i t y a n d c o r r e l a t i o n w i t h
l ingu i s t ic cues . InProc. o f t he 31s t An -n u a l M e e t i n g o f th e A s s o c i a t i o n f o r C o m p u -ta t iona l Lingu i s t i cs ,p a g e s 1 4 8 - 1 5 5 , 1 9 9 3 .
[15] P. I{oget . R o g e t s I n t e r n a t i o n a l Th e s a u r u s ,Four th Ed i t ion .H a r p e r a n d R o w P u b l i s h e r sInc . , 1977 .
[ 1 6] D . Ya r o w s k y . Wo r d - s e n s e d i s a mb i g u a t i o nus ing s t a t i s t i ca l mod e l s o f roge t ' s ca tego r iest r a i n e d o n l a rg e c o r p o r a . I nProc. o f the ld th .[ n t c rna t iona l Co~@re~nce on C omp uta t ion a lLingu i s t i cs ,pages 454 --460 , 1992 .
[ 1 7] G . Yo u m a n s . A n e w t o o l f o r d i s co u r s e a n a l -y s is : T h e v o c a b u l a r y - m a n a g e m e n t p ro f il e.Language ,67 :763 --789 , 1991 .
7(/1