optimization methods in data mining - 2004
TRANSCRIPT

Fall 2004 1
Optimization Methods in Data Mining

Fall 2004 2
OverviewOptimization
MathematicalProgramming
CombinatorialOptimization
SupportVectorMachines
SteepestDescentSearch
Classification,Clustering,etc
Neural Nets,Bayesian Networks(optimize parameters)
GeneticAlgorithm
Feature selectionClassificationClustering

Fall 2004 3
What is Optimization? Formulation
Decision variables Objective function Constraints
Solution Iterative algorithm Improving search
Problem
Model
Solution
Formulation
Algorithm

Fall 2004 4
Combinatorial Optimization Finitely many solutions to choose from
Select the best rule from a finite set of rules Select the best subset of attributes
Too many solutions to consider all Solutions
Branch-and-bound (better than Weka exhaustive search)
Random search

Fall 2004 5
Random Search Select an initial solution x(0) and let k=0 Loop:
Consider the neighbors N(x(k)) of x(k)
Select a candidate x’ from N(x(0)) Check the acceptance criterion If accepted then let x(k+1) = x’ and
otherwise let x(k+1) = x(k)
Until stopping criterion is satisfied

Fall 2004 6
Common Algorithms Simulated Annealing (SA)
Idea: accept inferior solutions with a given probability that decreases as time goes on
Tabu Search (TS) Idea: restrict the neighborhood with a list of
solutions that are tabu (that is, cannot be visited) because they were visited recently
Genetic Algorithm (GA) Idea: neighborhoods based on ‘genetic
similarity’ Most used in data mining applications

Fall 2004 7
Genetic Algorithms Maintain a population of solutions
rather than a single solution Members of the population have
certain fitness (usually just the objective)
Survival of the fittest through selection crossover mutation

Fall 2004 8
GA Formulation Use binary strings (or bits) to
encode solutions:0 1 1 0 1 0 0 1 0
Terminology Chromosomes = solution Parent chromosome Children or offspring

Fall 2004 9
Problems Solved Data Mining Problems that have
been addressed using Genetic Algorithms: Classification Attribute selection Clustering

Fall 2004 10
Outlook
Sunny 100
Overcast 010
Rainy 001
Yes 10
No 01Windy
Classification Example

Fall 2004 11
Representing a RuleIf windy=yes then play=yes
playwindyoutlook
10 10 111If outlook=overcast and windy=yes then play=no
playwindyoutlook
01 10 010

Fall 2004 12
Single-Point Crossover
playwindyoutlook
10 10 111
playwindyoutlook
01 01 010
Crossover point
playwindyoutlook
01 01 111
playwindyoutlook
10 10 010
Parents Offspring

Fall 2004 13
Two-Point Crossover playwindyoutlook
10 10 111
playwindyoutlook
01 01 010
Crossover points
playwindyoutlook
10 01 111
playwindyoutlook
01 10 010
Parents Offspring

Fall 2004 14
Uniform Crossover
playwindyoutlook
01 10 1 11
playwindyoutlook
10 01 001
Parents Offspring
playwindyoutlook
00 10 110
playwindyoutlook
11 01 011Problem?

Fall 2004 15
Mutation
playwindyoutlook
01 01 010 playwindyoutlook
01 11 010
Parent Offspring
Mutated bit

Fall 2004 16
Selection Which strings in the population
should be operated on? Rank and select the n fittest ones Assign probabilities according to
fitness and select probabilistically, say
jj
ii x
xxP)(Fitness
)(Fitness]select [

Fall 2004 17
Creating a New Population Create a population Pnew with p individuals Survival
Allow individuals from old population to survived intact Rate: 1-r % of population How to select the individuals that survive: Deterministic/random
Crossover Select fit individuals and create new once Rate: r% of population. How to select?
Mutation Slightly modify any on the above individuals Mutation rate: m Fixed number of mutations versus probabilistic mutations

Fall 2004 18
GA Algorithm Randomly generate an initial population P Evaluate the fitness f(xi) of each individual in P Repeat:
Survival: Probabilistically select (1-r)p individuals from P and add to Pnew, according to
Crossover: Probabilistically select rp/2 pairs from P and apply the crossover operator. Add to Pnew
Mutation: Uniformly choose m percent of member and invert one randomly selected bit
Update: P Pnew Evaluate: Compute the fitness f(xi) of each individual in P
Return the fittest individual from P
jj
ii xf
xfxP)(
)(]select [

Fall 2004 19
Analysis of GA: Schemas Does GA converge? Does GA move towards a good solution?
Local optima?
Holland (1975): Analysis based on schemas
Schema: string combination of 0s, 1s, *s Example: 0*10 represents {0010,0110}

Fall 2004 20
The Schema Theorem(all the theory on one slide)
)()1(1)(1),(
)(),(ˆ
)]1,([ somc p
lsdptsm
tftsutsmE
Number of instance ofschema s at time t
Average fitness ofindividuals in schema s at time t
Probabilityof crossover
Probabilityof mutation
Number ofdefined bitsin schema s
Distance betweendefined bits in s

Fall 2004 21
Interpretation Fit schemas grow in influence What is missing
Crossover? Mutation?
How about time t+1 ? Other approaches:
Markov chains Statistical mechanics

Fall 2004 22
GA for Feature Selection Feature selection:
Select a subset of attributes (features) Reason: to many, redundant, irrelevant
Set of all subsets of attributes very large
Little structure to search Random search methods

Fall 2004 23
Encoding Need a bit code representation Have some n attributes Each attribute is either in (1) or out
(0) of the selected set
windy
humidity
etemperatur
outlook
0101

Fall 2004 24
Fitness Wrapper approach
Apply learning algorithm, say a decision tree, to the individual x ={outlook, humidity}
Let fitness equal error rate (minimize) Filter approach
Let fitness equal the entropy (minimize) Other diversity measures can also be used
Simplicity measure?

Fall 2004 25
Crossover
windy
humidity
etemperatur
outlook
0101
windy
humidity
etemperatur
outlook
1100
windy
humidity
etemperatur
outlook
1101
windy
humidity
etemperatur
outlook
0100
Crossover point

Fall 2004 26
In Weka

Fall 2004 27
Clustering ExampleID Outlook Temperature Humidity Windy Play10 Sunny Hot High True No20 Overcast Hot High False Yes30 Rainy Mild High False Yes40 Rainy Cool Normal False Yes
OffspringParents
00101011
10100011
Crossover
{10,20}{30,40}
{20,40}{10,30}
{10,20,40}{30}
{20}{10,30,40}
Create two clusters for:

Fall 2004 28
Discussion GA is a flexible and powerful
random search methodology Efficiency depends on how well you
can encode the solutions in a way that will work with the crossover operator
In data mining, attribute selection is the most natural application

Fall 2004 29
Attribute Selection in Unsupervised Learning
Attribute selection typically uses a measure, such as accuracy, that is directly related to the class attribute
How do we apply attribute selection to unsupervised learning such as clustering?
Need a measure compactness of cluster separation among clusters
Multiple measures

Fall 2004 30
Quality Measures Compactness
K
k
n
ikjijik
withinwithin x
dZF
1 1
2111
Otherwise0
cluster tobelongs If1 kxiik
n
i ik
n
i ijikkj
x
1
1
Centroid
InstancesClusters
Number ofattributesNormalization
constant to make]1,0[withinF

Fall 2004 31
More Quality Measures Cluster Separation
K
k
n
i Jjkjijik
betbetween x
kdZF
1 1
211
111

Fall 2004 32
Final Quality Measures Adjustment for bias
Compexityminmax
min1KK
KKFclusters
111
DdFclusters

Fall 2004 33
Wrapper Framework Loop:
Obtain an attribute subset Apply k-means algorithm Evaluate cluster quality
Until stopping criterion satisfied

Fall 2004 34
Problem What is the optimal attribute
subset? What is the optimal number of
clusters?
Try to find simultaneously

Fall 2004 35
Example Find an attribute subset and optimal number of
clusters (Kmin = 2, Kmin = 3) forID Sepal Length Sepal Width Petal length Petal Width10 5.0 3.5 1.6 0.620 5.1 3.8 1.9 0.430 4.8 3.0 1.4 0.340 5.1 3.8 1.6 0.250 4.6 3.2 1.4 0.260 6.5 2.8 4.6 1.570 5.7 2.8 4.5 1.380 6.3 3.3 4.7 1.690 4.9 2.4 3.3 1.0
100 6.6 2.9 4.6 1.3

Fall 2004 36
Formulation Define an individual
Initial Population0 1 0 1 11 0 0 1 0
clusters
ofnumber
attributes Selected
*****

Fall 2004 37
Evaluate Fitness Start with 0 1 0 1 1 Three clusters and {Sepal Width, Petal Width}
Apply k-means with k=3
ID Sepal Width Petal Width10 3.5 0.620 3.8 0.430 3.0 0.340 3.8 0.250 3.2 0.260 2.8 1.570 2.8 1.380 3.3 1.690 2.4 1.0
100 2.9 1.3

Fall 2004 38
K-Means Start with random centroids: 10, 70, 80
1007060
80
1020405030
90
0
0.5
1
1.5
2
2 2.5 3 3.5 4
Sepal Width
Peta
l Wid
th

Fall 2004 39
New Centroids
No change in assignment soterminate k-means algorithm
C1
C3
1007060
80
1020405030
90
0
0.5
1
1.5
2
2 2.5 3 3.5 4
Sepal Width
Peta
l Wid
th

Fall 2004 40
Quality of Clusters Centers
Center 1 at (3.46,0.34): {60,70,90,100} Center 2 at (3.30,1.60): {80} Center 3 at (2.73,1.28): {10,20,30,40,50}
Evaluation
67.000.060.655.0
complexity
clusters
between
within
FFFF

Fall 2004 41
Next Individual Now look at 1 0 0 1 0 Two clusters and {Sepal Length, Petal Width}
Apply k-means with k=3
ID Sepal Length Petal Width10 5.0 0.620 5.1 0.430 4.8 0.340 5.1 0.250 4.6 0.260 6.5 1.570 5.7 1.380 6.3 1.690 4.9 1.0
100 6.6 1.3

Fall 2004 42
K-Means Say we select 20 and 90 as initial
centroids:
90
3050 4020
10
8060
70 100
0
0.5
1
1.5
2
4 4.5 5 5.5 6 6.5 7
Sepal Width
Peta
l Wid
th

Fall 2004 43
Recalculate Centroids
90
3050 4020
10
8060
70 100
C1
C2
0
0.5
1
1.5
2
4 4.5 5 5.5 6 6.5 7
Sepal Width
Peta
l Wid
th

Fall 2004 44
Recalculate Again
90
3050 4020
10
8060
70 100
C1
C2
0
0.5
1
1.5
2
4 4.5 5 5.5 6 6.5 7
Sepal Width
Peta
l Wid
th
No change in assignment soterminate k-means algorithm

Fall 2004 45
Quality of Clusters Centers
Center 1 at (4.92,0.45): {10,20,30,40,50,90} Center 3 at (6.28,1.43): {60,70,90,100}
Evaluation
67.000.1
59.1439.0
complexity
clusters
between
within
FFFF

Fall 2004 46
Compare Individuals
67.000.1
59.1439.0
01001
complexity
clusters
between
within
FFFF
67.000.060.655.0
11010
complexity
clusters
between
within
FFFF
Which is fitter?

Fall 2004 47
Evaluating Fitness Can scale (if necessary) Then weight them together, e.g.,
Alternatively, we can use Pareto optimization
84.067.0059.1459.14
55.039.0)01001(
53.067.0059.1460.6
55.055.0)11010(
fitness
fitness

Fall 2004 48

Fall 2004 49
Mathematical Programming Continuous decision variables Constrained versus non-constrained Form of the objective function
Linear Programming (LP) Quadratic Programming (QP) General Mathematical Programming
(MP)

Fall 2004 50
Linear Program
xxf 5.02)(
10
15x
xx0
150s.t5.02max
x
x
Optimal solution

Fall 2004 51
Two Dimensional Problem
FeasibleRegion
2000
1500
1000
500
500 1000 1500 2000
15002 x
15001 x
175021 xx
480024 21 xx
01 x
02 x
2x
1x
0,480024175015001000s.t.
912max
21
21
21
2
1
21
xxxxxxxxxx
6000912 21 xx
Optimal Solution
12000912 21 xx
Optimum isalways at anextreme point

Fall 2004 52
Simplex Method2000
1500
1000
500
500 1000 1500 2000
15002 x
15001 x
175021 xx
480024 21 xx
01 x
02 x
2x
1x

Fall 2004 53
Quadratic Programming
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
f (x )=0.2+(x -1)2
10)1(2
)1(2)('
xx
xxf

Fall 2004 54
General MP
0)(' xf
Derivative beingzero is a necessarybut not sufficientcondition
0)(' xf
0)(' xf
0)(' xf
0)(' xf
Fall 2004 55
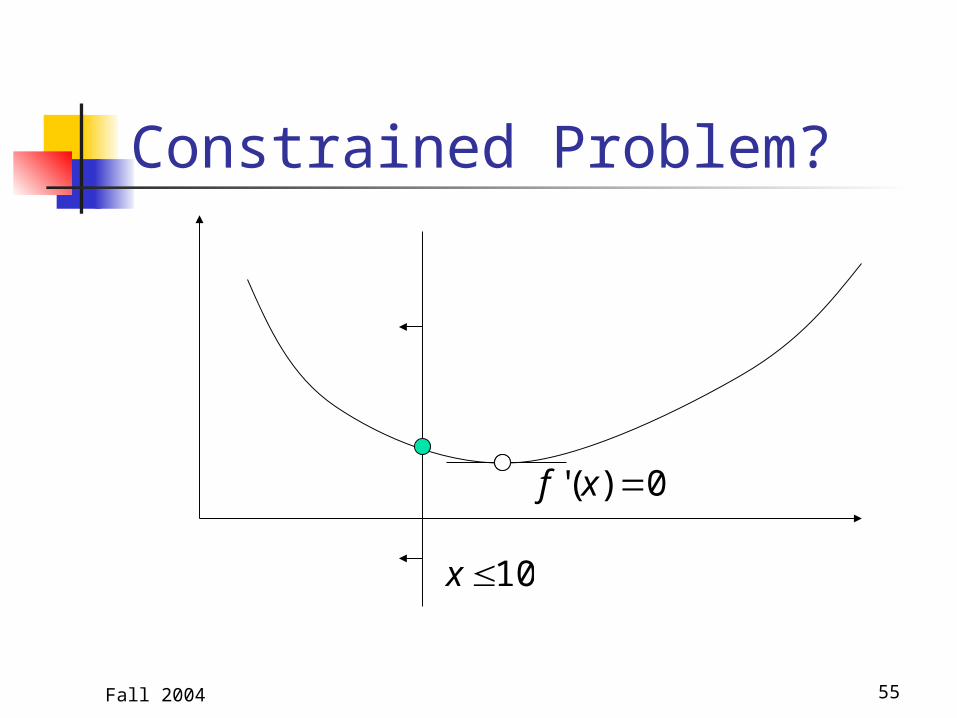
Constrained Problem?
0)(' xf
10x

Fall 2004 56
General MP
)g,...,g,(g)h,...,h,(h
ariablesdecision v ofVector
)(s.t.)(min
m21
m21
(x)(x)(x)g(x)(x)(x)(x)h(x)
x0g(x)0xh
x
f
We write a general mathematical program in matrix notation as:

Fall 2004 57
Karush-Kuhn-Tucker (KKT) Conditions
0g(x)0xh
x
)(s.t.)(min
for minimum relative a is If *
fx
0*
***
xgμ0xgμxhλx
T
TTf
such that ,,exist There 0μλ

Fall 2004 58
Convex Sets
Convex Not Convex
A set C is convex if any line connecting two points in theset lies completely within the set, that is,
CC 2121 )1(:)1,0(,, xxxx

Fall 2004 59
Convex Hull The convex hull co(S) of a set S is
the intersection of all convex sets containing S
A set V Rn is a linear variety ifRxxxx ,)1(:, 2121 VV

Fall 2004 60
HyperplaneA hyperplane in Rn is a (n-1)-dimensional
variety
Hyperplane in R3Hyperplane in R2

Fall 2004 61
Convex Hull ExamplePlay
No Play
Temperature
Humidity
Separating hyperplanebisects closest points
Closets points inconvex hulls
c
d

Fall 2004 62
Finding the Closest Points
0
1
1
s.t.21min
YesPlay
YesPlay
NoPlay
YesPlay
2
i
i:i
i:i
i:ii
i:ii
xd
xc
dc
Formulate as QP:

Fall 2004 63
Support Vector MachinesPlay
No Play
Temperature
Humidity
SeparatingHyperplane
Support Vectors

Fall 2004 64
ExampleID Sepal Width Petal Width10 3.5 0.620 3.8 0.430 3.0 0.340 3.8 0.250 3.2 0.260 2.8 1.570 2.8 1.380 3.3 1.690 2.4 1.0100 2.9 1.3

Fall 2004 65
Separating Hyperplane
0
0.2
0.40.6
0.8
1
1.21.4
1.6
1.8
2 2.5 3 3.5 4

Fall 2004 66
Assume Separating Planes
.1:,11:,1
iii
iii
yibyib
wxwx
Constraints:
Distance to each plane:
w1

Fall 2004 67
Optimization Problem
.1:,11:,1subject to
max 2
b,
iii
iii
yibyib
wxwx
ww

Fall 2004 68
How Do We Solve MPs?
-5 -4 -3 -2 -1 0 1 2 3 4 5-5
-4
-3
-2
-1
0
1
2
3
4
5

Fall 2004 69
Improving Search Direction-step approach
kkk xxx 1
Step size
Search directionCurrent Solution
New Solution

Fall 2004 70
Steepest Descent Search direction equal to negative
gradient
Finding is a one-dimensional optimization problem of minimizing
)( kf xx
)()( kkf xx

Fall 2004 71
Newton’s Method Taylor series expansion
The right hand side is minimized at
)()( 11 kkkk fF xxxx
)()()(21
))(()()(
kkT
k
kkk
F
fff
xxxxx
xxxxx

Fall 2004 72
Discussion Computing the inverse Hessian is
difficult Quasi-Newton
Conjugate gradient methods Does not account for constraints
Penalty methods Lagrangian methods, etc.
)(1 kkkkk f xSxx

Fall 2004 73
Non-separable
.,01:,11:,1
iyibyib
i
iiii
iiii
wxwx
Add an error term to the constraints:

Fall 2004 74
Wolfe Dual
.0
0subject to
21max
,
2
iii
i
jijijiji
ii
y
C
yy
xxwα
Simpleconstraints
Only placedata appears

Fall 2004 75
Extension to Non-Linear
)()()( yxyx, K Kernel functions
Mapping Hn R: Takes place ofdot product inWolfe dual
High dimensionalHilbert space

Fall 2004 76
Some Possible Kernels
)tanh()()(
)1()(22 2/
yxyx,yx,
yxyx,yx
KeK
K p

Fall 2004 77
In Weka Weka.classifiers.smo Support vector machine for nominal
data only Does both linear and non-linear models

Fall 2004 78
Optimization in DMOptimization
MathematicalProgramming
SupportVectorMachines
Classification,Clustering,etc
SteepestDescentSearch
Neural Nets,Bayesian Networks(optimize parameters)
CombinatorialOptimization
GeneticAlgorithm
Feature selectionClassificationClustering

Fall 2004 79
Bayesian Classification Naïve Bayes assumes independence
between attributes Simple computations Best classifier if assumption is true
Bayesian Belief Networks Joint probability distributions Directed acyclic graphs
Nodes are random variables (attributes) Arcs represent the dependencies

Fall 2004 80
Example: Bayesian NetworkFamily History Smoker
Lung Cancer Emphysema
Positive X-Ray Dyspnea
Lung Cancer is conditionally independent of emphysema. given Family History and Smoker
FH,S FH,~S ~FH,S ~FH,~S
LC 0.8 0.5 0.7 0.1
~LC 0.2 0.5 0.3 0.9
Lung Cancer depends on Family History and Smoker

Fall 2004 81
Conditional Probabilities
n
iiin Zzzz
11 )(Parents|Pr),...,Pr(
9.0)no""Smoker,no""oryFamilyHist|no""LungCancerPr(8.0)yes""Smoker,yes""oryFamilyHist|yes""LungCancerPr(
Randomvariable
Outcome of therandom variable The node representing
the class attribute iscalled the output node

Fall 2004 82
How Do we Learn? Network structure
Given/known Inferred or learned from the data
Variables Observable Hidden (missing values / incomplete
data)

Fall 2004 83
Case 1: Known Structure and Observable Variables Straightforward Similar to Naïve Bayes Compute the entries of the
conditional probability table (CPT) of each variable

Fall 2004 84
Case 2: Known Structure and Some Hidden Variables Still need to learn the CPT entries Let S be a set of s training instances
Let wijk be the CPT entry for variable Yi=yij having parents Ui=uik.
.,...,, 21 sXXX

Fall 2004 85
CPT Example
}"","{"},{
""
yesyesuSmokeroryFamilyHistU
yesyLungCancerY
ik
i
ij
i
FH,S FH,~S ~FH,S ~FH,~S
LC 0.8 0.5 0.7 0.1
~LC 0.2 0.5 0.3 0.9
ijkw
kjiijkw
,,w

Fall 2004 86
Objective Must find the value of
The objective is to maximize the likelihood of the data, that is,
How do we do this?
kjiijkw
,,w
s
ddXS
1
Pr)(Pr ww

Fall 2004 87
Non-Linear MP Compute gradients:
Move in the direction of the gradient
s
d ijk
dikiiji
ijk wXuUyY
wS
1
|,Pr)(Prw
From training data
ijkijkijk w
Slww
)(Prw
Learning rate

Fall 2004 88
Case 3: Unknown Network Structure Need to find/learn the optimal network structure for the data
What type of optimization problem is this?
Combinatorial optimization (GA etc.)