online training in oracle exadata in hyderabad
TRANSCRIPT

Offloading/Smart scan- Ramesh www.etraining.guru

Secret sauce of Exadata
The primary benefit of smartscan/offloading is the reduction in the volume of data that must be returned to the DB server.
Full table scan/Index scan invokes smart scans
Smartscan: Speeding up SQL query executionOffloading: Speeding up + returning the data to DB servers as well
3 big Smart Scan optimizations are:- Column Projection- Predicate Filtering (Must have WHERE clause)- Storage Indexes (Must have WHERE clause)
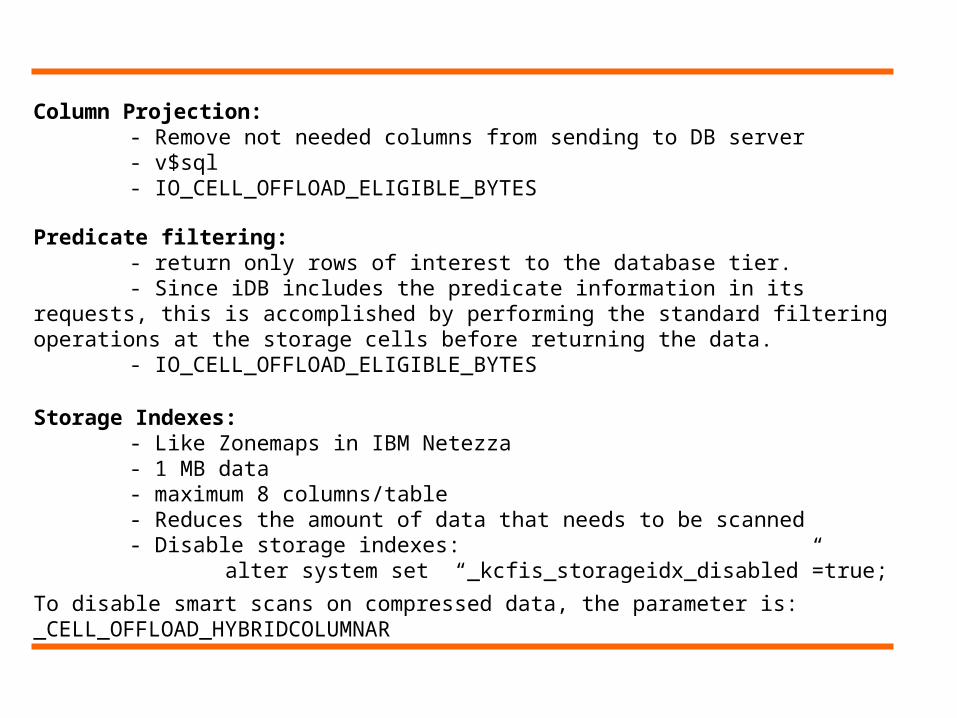
Column Projection:- Remove not needed columns from sending to DB server- v$sql- IO_CELL_OFFLOAD_ELIGIBLE_BYTES
Predicate filtering:- return only rows of interest to the database tier.- Since iDB includes the predicate information in its requests, this is
accomplished by performing the standard filtering operations at the storage cells before returning the data.
- IO_CELL_OFFLOAD_ELIGIBLE_BYTES
Storage Indexes:- Like Zonemaps in IBM Netezza- 1 MB data- maximum 8 columns/table- Reduces the amount of data that needs to be scanned- Disable storage indexes:
alter system set “_kcfis_storageidx_disabled”=true;
To disable smart scans on compressed data, the parameter is: _CELL_OFFLOAD_HYBRIDCOLUMNAR
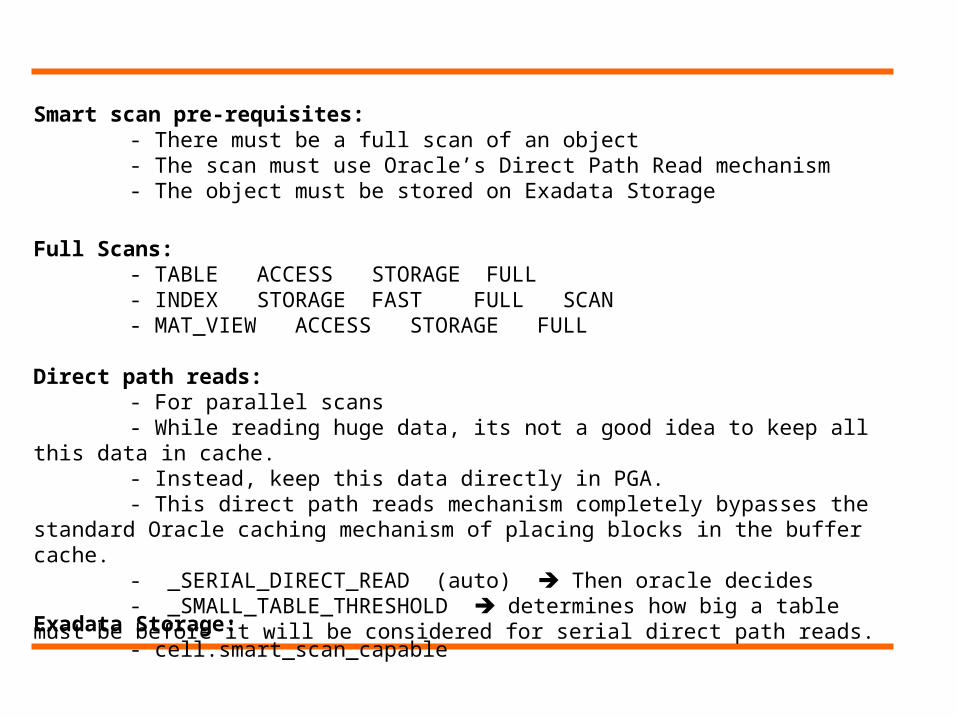
Smart scan pre-requisites:- There must be a full scan of an object- The scan must use Oracle’s Direct Path Read mechanism- The object must be stored on Exadata Storage
Full Scans:- TABLE ACCESS STORAGE FULL- INDEX STORAGE FAST FULL SCAN- MAT_VIEW ACCESS STORAGE FULL
Direct path reads:- For parallel scans- While reading huge data, its not a good idea to keep all this data in cache.- Instead, keep this data directly in PGA. - This direct path reads mechanism completely bypasses the standard Oracle
caching mechanism of placing blocks in the buffer cache. - _SERIAL_DIRECT_READ (auto) Then oracle decides - _SMALL_TABLE_THRESHOLD determines how big a table must be before
it will be considered for serial direct path reads.
Exadata Storage:- cell.smart_scan_capable
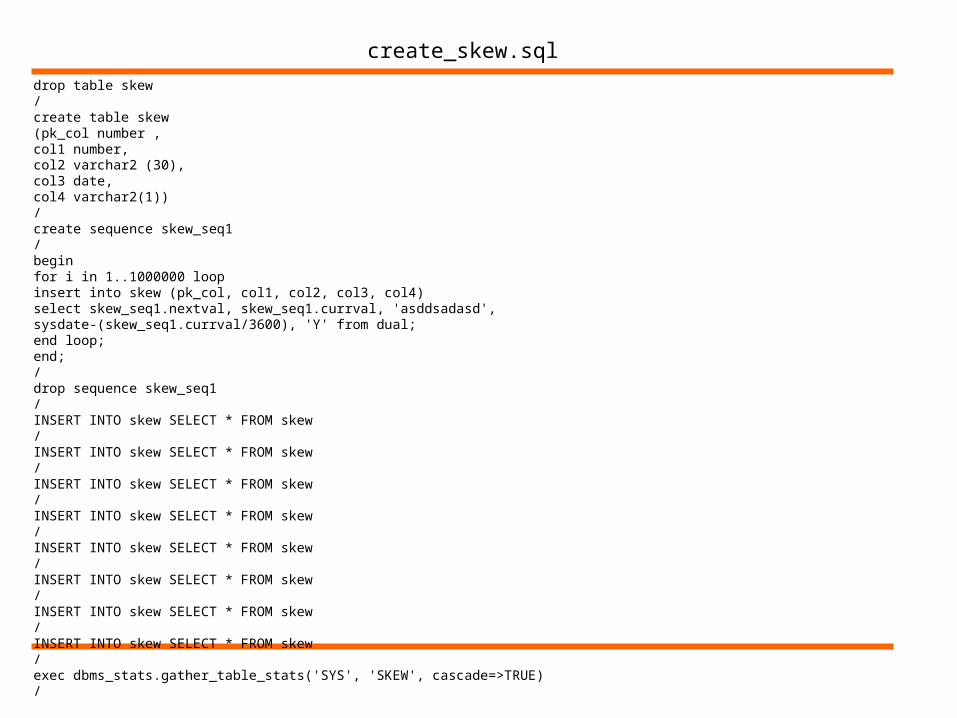
create_skew.sql
drop table skew/create table skew(pk_col number ,col1 number,col2 varchar2 (30),col3 date,col4 varchar2(1))/create sequence skew_seq1/beginfor i in 1..1000000 loopinsert into skew (pk_col, col1, col2, col3, col4)select skew_seq1.nextval, skew_seq1.currval, 'asddsadasd',sysdate-(skew_seq1.currval/3600), 'Y' from dual;end loop;end;/drop sequence skew_seq1/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/INSERT INTO skew SELECT * FROM skew/exec dbms_stats.gather_table_stats('SYS', 'SKEW', cascade=>TRUE)/
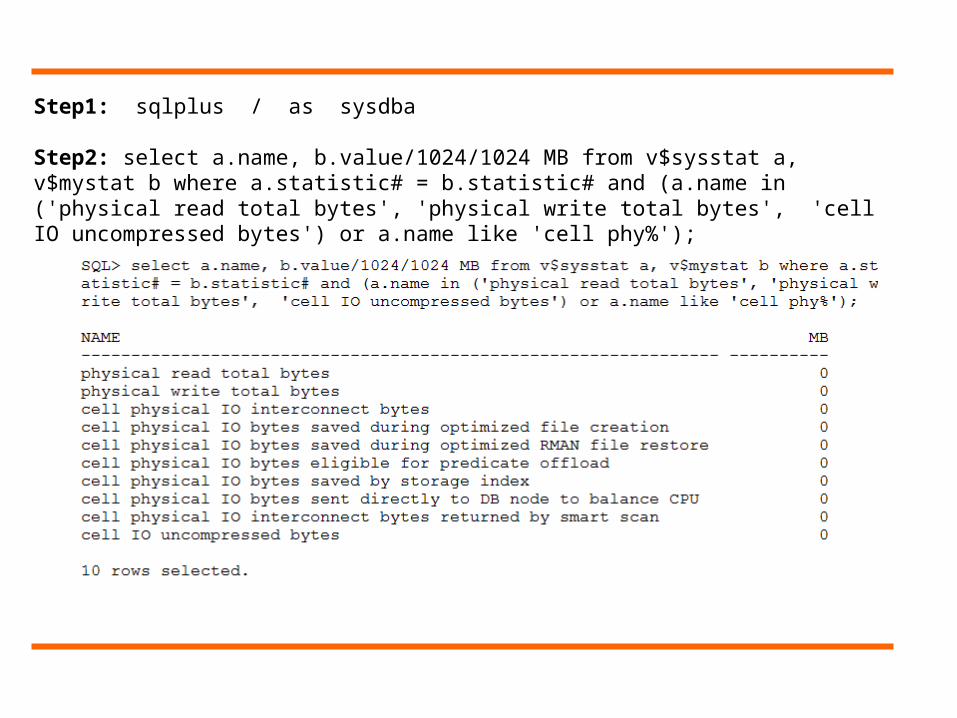
Step1: sqlplus / as sysdba
Step2: select a.name, b.value/1024/1024 MB from v$sysstat a, v$mystat b where a.statistic# = b.statistic# and (a.name in ('physical read total bytes', 'physical write total bytes', 'cell IO uncompressed bytes') or a.name like 'cell phy%');
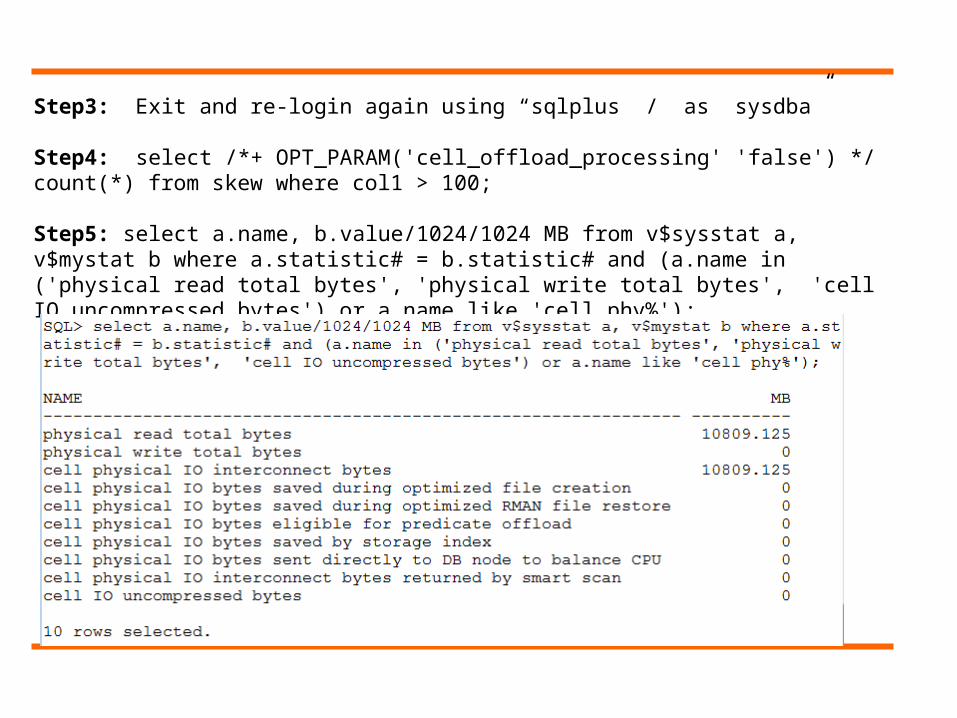
Step3: Exit and re-login again using “sqlplus / as sysdba”
Step4: select /*+ OPT_PARAM('cell_offload_processing' 'false') */ count(*) from skew where col1 > 100;
Step5: select a.name, b.value/1024/1024 MB from v$sysstat a, v$mystat b where a.statistic# = b.statistic# and (a.name in ('physical read total bytes', 'physical write total bytes', 'cell IO uncompressed bytes') or a.name like 'cell phy%');
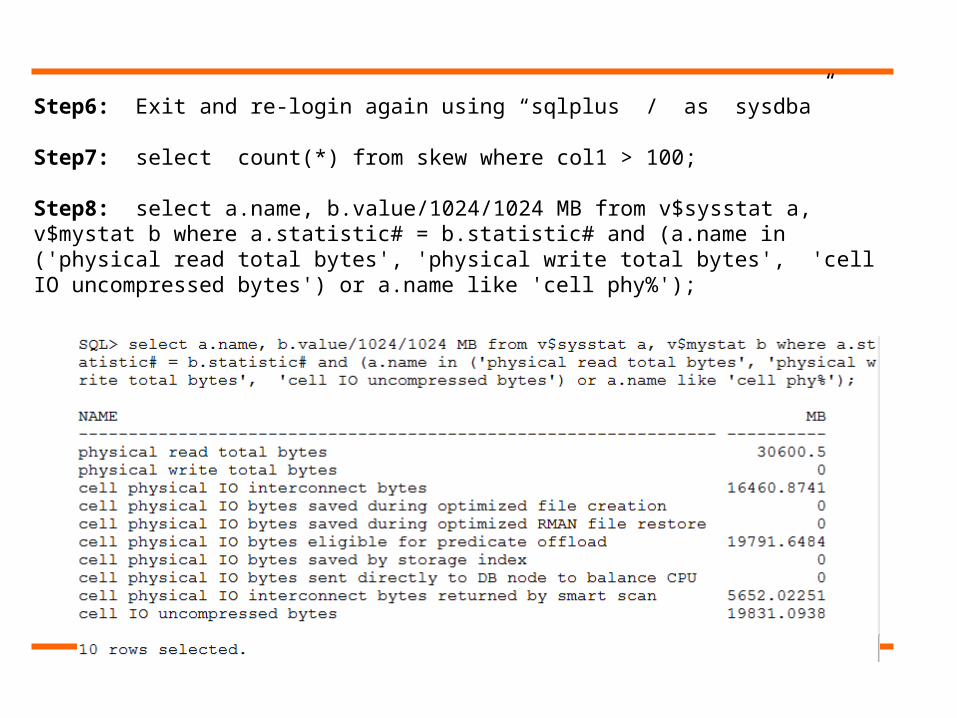
Step6: Exit and re-login again using “sqlplus / as sysdba”
Step7: select count(*) from skew where col1 > 100;
Step8: select a.name, b.value/1024/1024 MB from v$sysstat a, v$mystat b where a.statistic# = b.statistic# and (a.name in ('physical read total bytes', 'physical write total bytes', 'cell IO uncompressed bytes') or a.name like 'cell phy%');
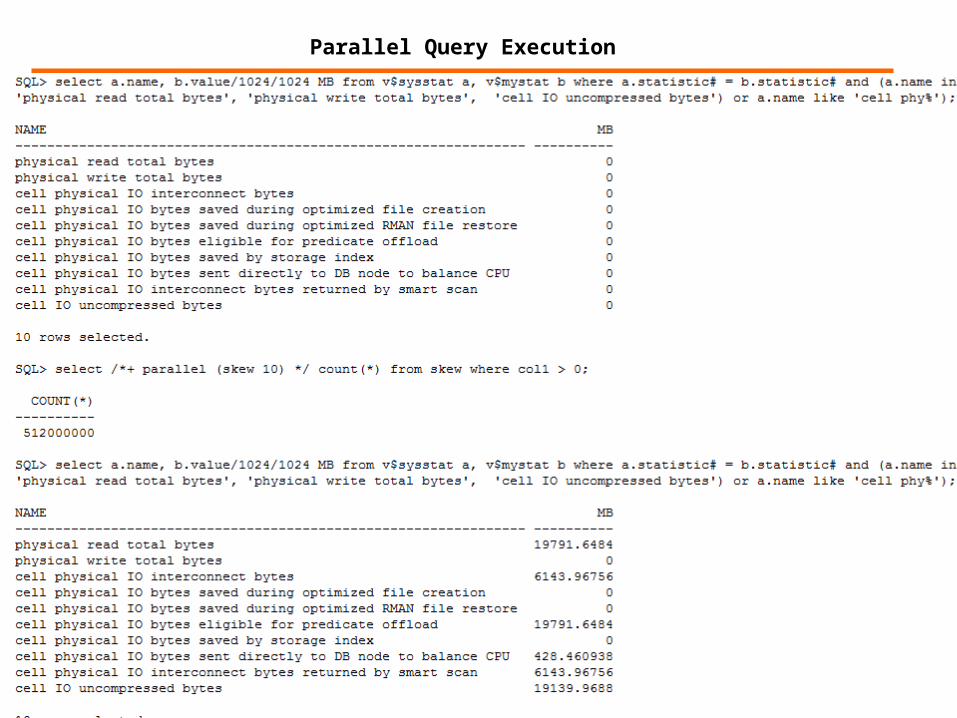
Parallel Query Execution
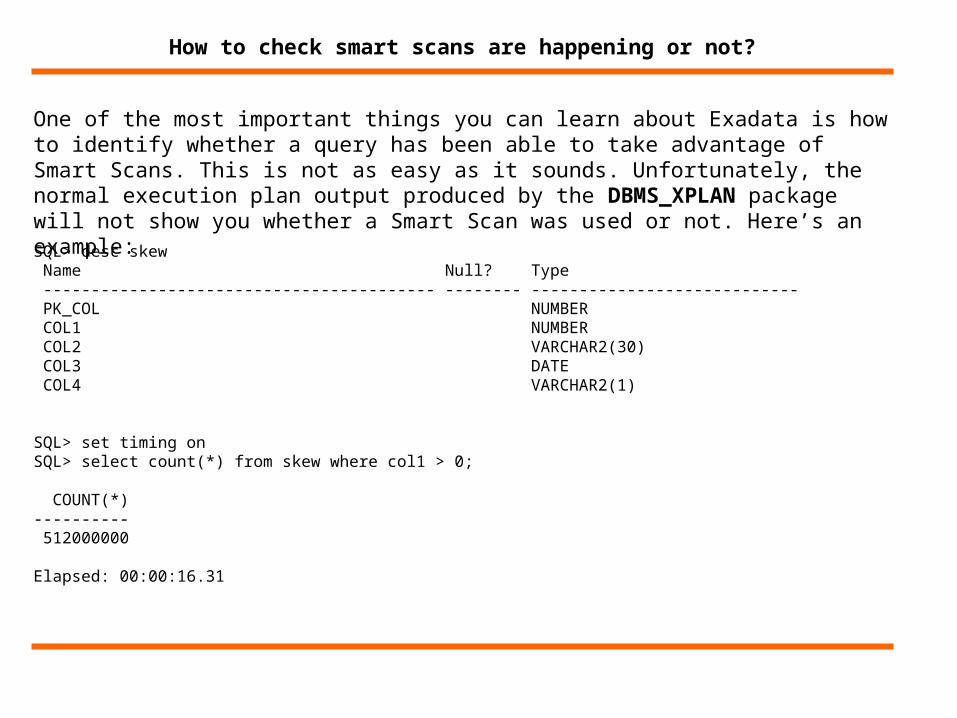
How to check smart scans are happening or not?
One of the most important things you can learn about Exadata is how to identify whether a query has been able to take advantage of Smart Scans. This is not as easy as it sounds. Unfortunately, the normal execution plan output produced by the DBMS_XPLAN package will not show you whether a Smart Scan was used or not. Here’s an example:
SQL> desc skew Name Null? Type ----------------------------------------- -------- ---------------------------- PK_COL NUMBER COL1 NUMBER COL2 VARCHAR2(30) COL3 DATE COL4 VARCHAR2(1)
SQL> set timing onSQL> select count(*) from skew where col1 > 0;
COUNT(*)---------- 512000000
Elapsed: 00:00:16.31
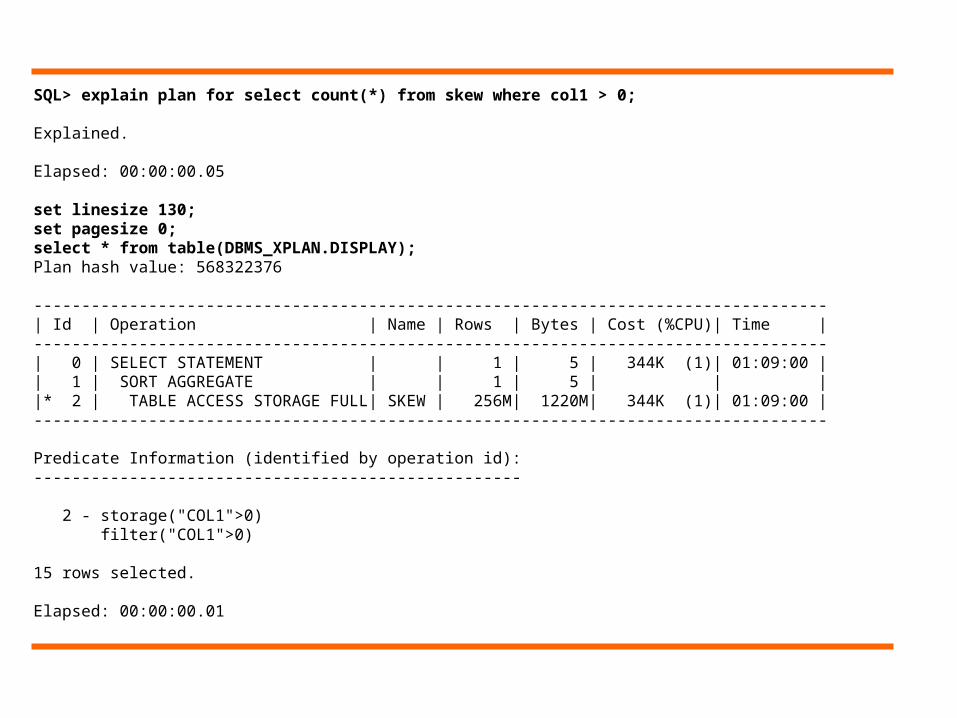
SQL> explain plan for select count(*) from skew where col1 > 0;
Explained.
Elapsed: 00:00:00.05
set linesize 130;set pagesize 0;select * from table(DBMS_XPLAN.DISPLAY);Plan hash value: 568322376
-----------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 5 | 344K (1)| 01:09:00 || 1 | SORT AGGREGATE | | 1 | 5 | | ||* 2 | TABLE ACCESS STORAGE FULL| SKEW | 256M| 1220M| 344K (1)| 01:09:00 |-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):---------------------------------------------------
2 - storage("COL1">0) filter("COL1">0)
15 rows selected.
Elapsed: 00:00:00.01
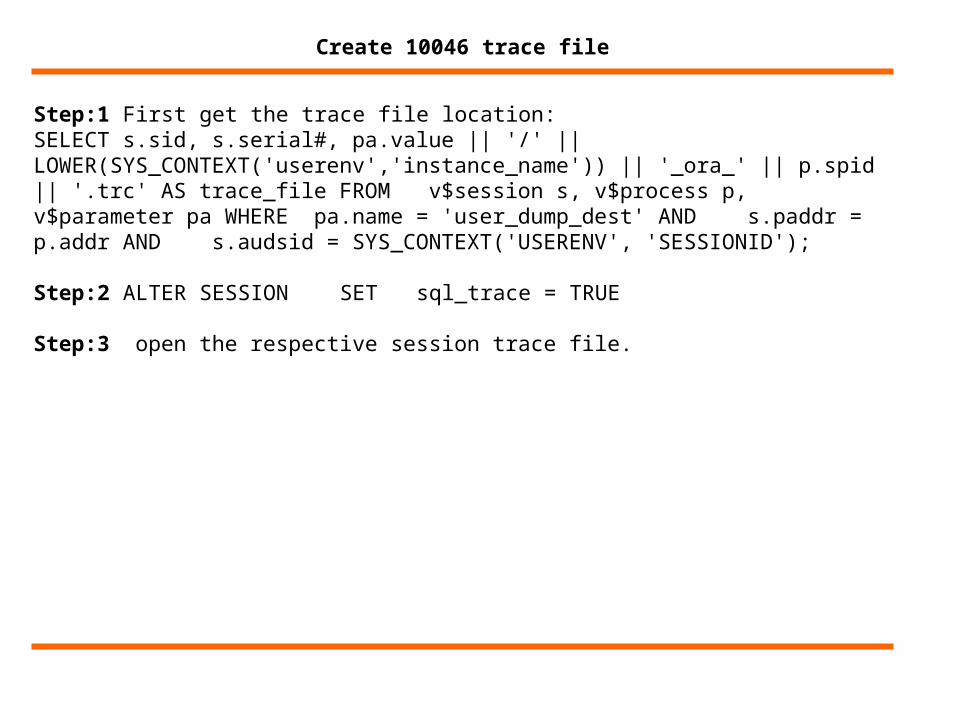
Step:1 First get the trace file location:SELECT s.sid, s.serial#, pa.value || '/' || LOWER(SYS_CONTEXT('userenv','instance_name')) || '_ora_' || p.spid || '.trc' AS trace_file FROM v$session s, v$process p, v$parameter pa WHERE pa.name = 'user_dump_dest' AND s.paddr = p.addr AND s.audsid = SYS_CONTEXT('USERENV', 'SESSIONID');
Step:2 ALTER SESSION SET sql_trace = TRUE
Step:3 open the respective session trace file.
Create 10046 trace file

SQL> select name, value from v$mystat s, v$statname n where n.statistic# = s.statistic# and name like nvl('%cell scans%',name) order by 1;
NAME VALUE---------------------------------------------------------------- ----------cell scans 0
SQL> select count(*) from skew where col1 > 0;
COUNT(*)---------- 120900001
SQL> select name, value from v$mystat s, v$statname n where n.statistic# = s.statistic# and name like nvl('%cell scans%',name) order by 1;
NAME VALUE---------------------------------------------------------------- ----------cell scans 1
From v$mystat

SQL> alter session set cell_offload_processing=false;
Session altered.
SQL> select count(*) from skew where col1 > 0;
COUNT(*)---------- 120900001
SQL> select name, value from v$mystat s, v$statname n where n.statistic# = s.statistic# and name like nvl('%cell scans%',name) order by 1;
NAME VALUE---------------------------------------------------------------- ----------cell scans 1
SQL> alter session set cell_offload_processing=true;
Session altered.
SQL> select count(*) from skew where col1 > 0;
COUNT(*)---------- 120900001
SQL> select name, value from v$mystat s, v$statname n where n.statistic# = s.statistic# and name like nvl('%cell scans%',name) order by 1;
NAME VALUE---------------------------------------------------------------- ----------cell scans 2
contd …

HCC

The main flavors of compression used by Oracle are:
BASIC OLTP
HCC
BASIC: Compresses data only on direct path loads Modifications force data to be stored in uncompressed format Compression unit is single block Symbol table to replace repeating values CREATE TABLE .. COMPRESS; PCTFREE = 0
OLTP: Data compressed for all operations, not just direct path loads Modifications force data to be stored in uncompressed format Compression unit is single block CREATE TABLE .. COMPRESS FOR OLTP; Symbol table to replace repeating values PCTFREE = 10 Size(OLTP compressed table) > Size(BASIC Compressed)

HCC: Only available for tables stores on Exadata storage Only for direct path loads Conventional inserts/updates cause records to be stored in OLTP compressed format HCC provides 4 levels of compression
Query Low:
HCC Level 1 LZO Compression Algorithm Lowest compression ratios Least CPU for compression and decompression operations For maximizing speed rather than compression Decompression is very fast (=) WAREHOUSE LOW COMPRESS FOR QUERY LOW Expected compression ratio:4x
Query High:
HCC Level 2 ZLIB(gzip) Compression Algorithm Expected compression ratio: 6x

Archive Low:
HCC Level 3 ZLIP (gzip) compression algorithm Compression higher than QUERY HIGH COMPRESS FOR ARCHIVE LOW Expected compression ratio: 7x
Archive High:
HCC Level 4 Bzip2 compression Highest compression but most CPU intensive Use this when space is in critically short supply COMPRESS FOR ARCHIVE HIGH Expected compression ratio: 12x

SQL> select count(*) from skew;
COUNT(*)---------- 512000000
SQL> select segment_name, sum(bytes)/1024/1024 MB from dba_segments where segment_name = 'SKEW' group by segment_name;
SEGMENT_NAME MB------------------------------ ----------SKEW 19804
SQL> select table_name, compression, compress_for from dba_tables where table_name = 'SKEW';
TABLE_NAME COMPRESS COMPRESS_FOR------------------------------ -------- ------------SKEW DISABLED
No HCC!
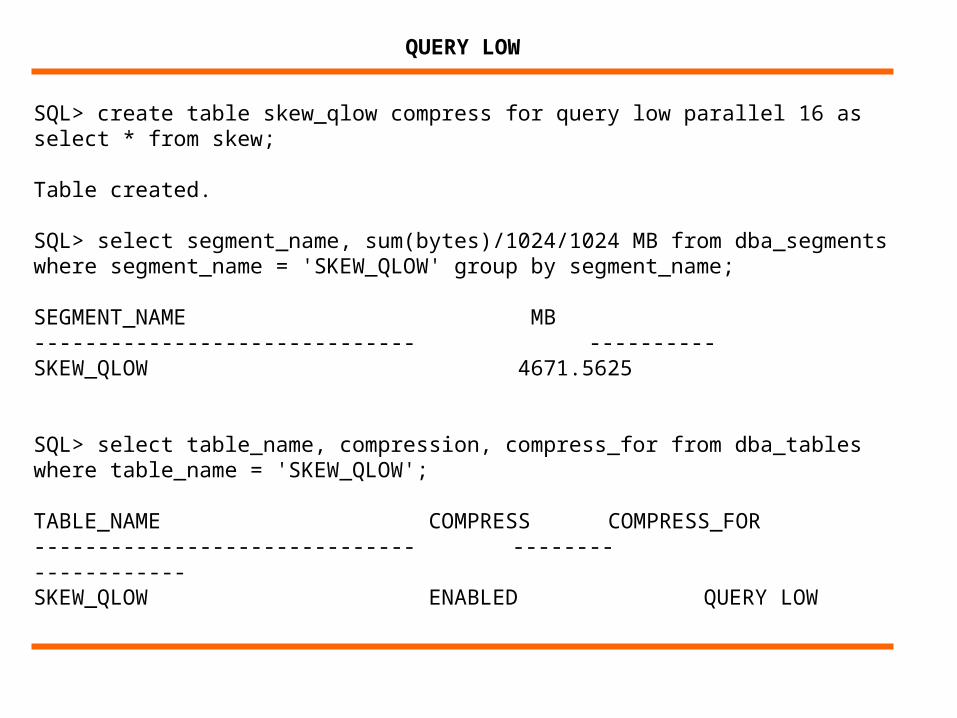
SQL> create table skew_qlow compress for query low parallel 16 as select * from skew;
Table created.
SQL> select segment_name, sum(bytes)/1024/1024 MB from dba_segments where segment_name = 'SKEW_QLOW' group by segment_name;
SEGMENT_NAME MB------------------------------ ----------SKEW_QLOW 4671.5625
SQL> select table_name, compression, compress_for from dba_tables where table_name = 'SKEW_QLOW';
TABLE_NAME COMPRESS COMPRESS_FOR------------------------------ -------- ------------SKEW_QLOW ENABLED QUERY LOW
QUERY LOW
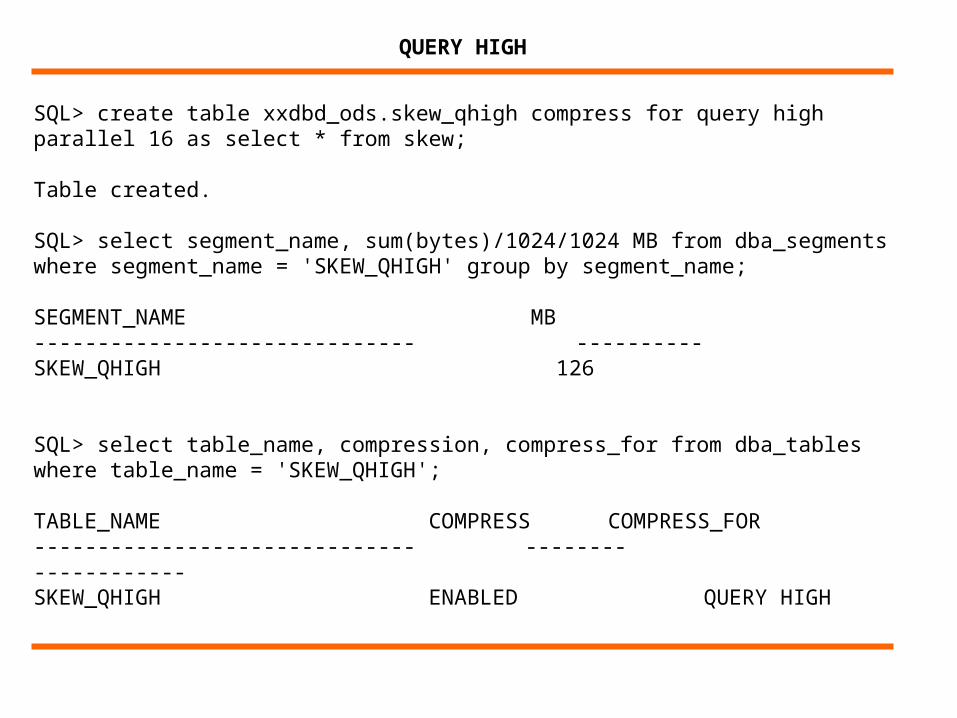
SQL> create table xxdbd_ods.skew_qhigh compress for query high parallel 16 as select * from skew;
Table created.
SQL> select segment_name, sum(bytes)/1024/1024 MB from dba_segments where segment_name = 'SKEW_QHIGH' group by segment_name;
SEGMENT_NAME MB------------------------------ ----------SKEW_QHIGH 126
SQL> select table_name, compression, compress_for from dba_tables where table_name = 'SKEW_QHIGH';
TABLE_NAME COMPRESS COMPRESS_FOR------------------------------ -------- ------------SKEW_QHIGH ENABLED QUERY HIGH
QUERY HIGH
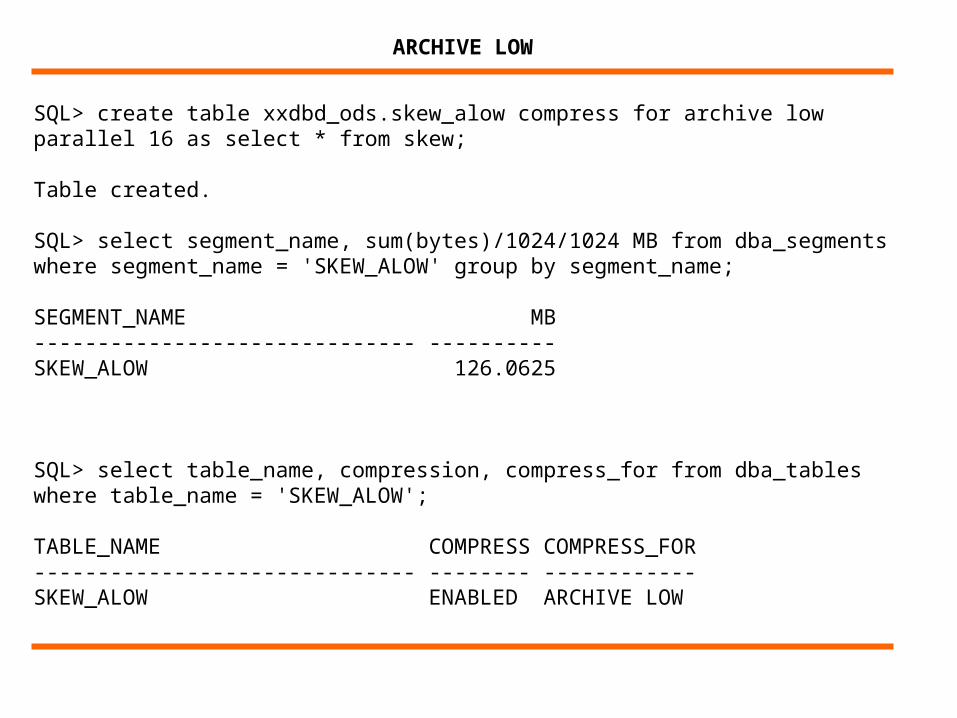
SQL> create table xxdbd_ods.skew_alow compress for archive low parallel 16 as select * from skew;
Table created.
SQL> select segment_name, sum(bytes)/1024/1024 MB from dba_segments where segment_name = 'SKEW_ALOW' group by segment_name;
SEGMENT_NAME MB------------------------------ ----------SKEW_ALOW 126.0625
SQL> select table_name, compression, compress_for from dba_tables where table_name = 'SKEW_ALOW';
TABLE_NAME COMPRESS COMPRESS_FOR------------------------------ -------- ------------SKEW_ALOW ENABLED ARCHIVE LOW
ARCHIVE LOW
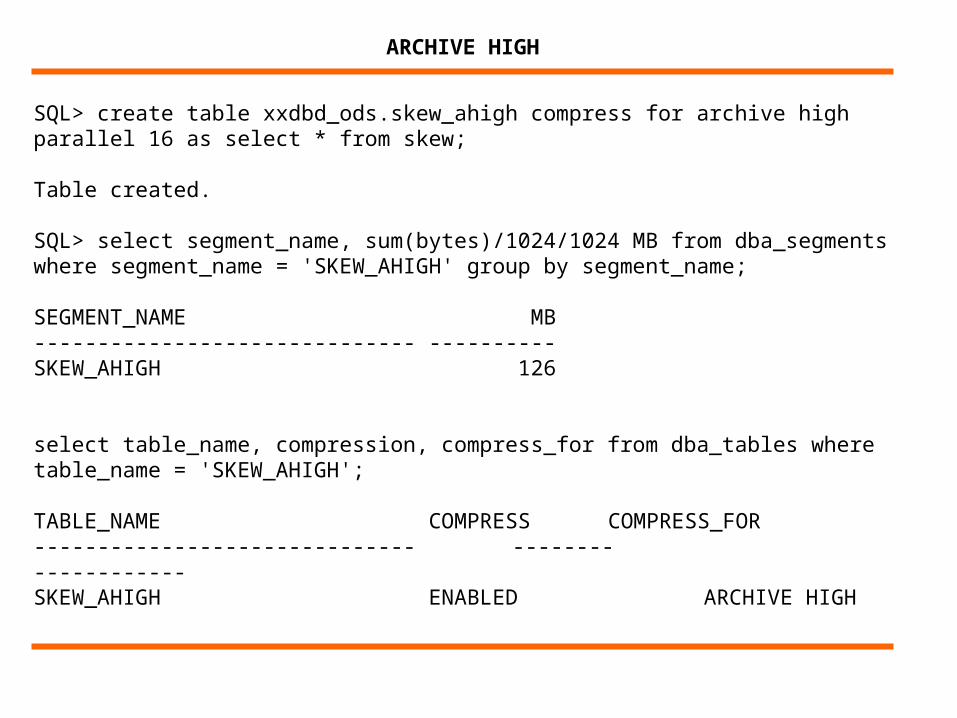
SQL> create table xxdbd_ods.skew_ahigh compress for archive high parallel 16 as select * from skew;
Table created.
SQL> select segment_name, sum(bytes)/1024/1024 MB from dba_segments where segment_name = 'SKEW_AHIGH' group by segment_name;
SEGMENT_NAME MB------------------------------ ----------SKEW_AHIGH 126
select table_name, compression, compress_for from dba_tables where table_name = 'SKEW_AHIGH';
TABLE_NAME COMPRESS COMPRESS_FOR------------------------------ -------- ------------SKEW_AHIGH ENABLED ARCHIVE HIGH
ARCHIVE HIGH