network common data form netcdf an indroduction · network common data form netcdf ... a small...
TRANSCRIPT

Network Common Data Form NetCDF
An Indroduction NetCDF is a set of software libraries and self-describing, machine-independent data formats
that support the creation, access, and sharing of array-oriented scientific data.
1

The Purpose of NetCDF
2
● The purpose of the Network Common Data Form (netCDF) interface is to allow you to create, access, and share array-oriented data in a form that is self-describing and portable. ● Self-describing means that a dataset includes information defining
the data it contains. ● Portable means that the data in a dataset is represented in a form
that can be accessed by computers with different ways of storing integers, characters, and floating-point numbers.
● The netCDF software includes C, Fortran 77, Fortran 90, and C++ interfaces for accessing netCDF data.
● These libraries are available for many common computing platforms.

NETCDF Features
3
● Self-Describing: A netCDF file may include metadata as well as data: names of variables, data locations in time and space, units of measure, and other useful information.
● Portable: Data written on one platform can be read on other platforms.
● Direct-access: A small subset of a large dataset may be accessed efficiently, without first reading through all the preceding data.
● Appendable: Data may be efficiently appended to a netCDF file without copying the dataset or redefining its structure.
● Networkable: The netCDF library provides client access to structured data on remote servers through OPeNDAP protocols.
● Extensible: Adding new dimensions, variables, or attributes to netCDF files does not require changes to existing programs that read the files.
● Sharable: One writer and multiple readers may simultaneously access the same netCDF file. With Parallel netCDF, multiple writers may efficiently and concurrently write into the same netCDF file.
● Archivable: Access to all earlier forms of netCDF data will be supported by current and future versions of the software.

Format description
4
● The netCDF libraries support 3 different binary formats for netCDF files: ● The classic format was used in the first netCDF release, and is still the
default format for file creation. ● The 64-bit offset format was introduced in version 3.6.0, and it supports
larger variable and file sizes. ● The netCDF-4/HDF5 format was introduced in version 4.0; it is the HDF5
data format, with some restrictions.
● All formats are "self-describing"
● Starting with version 4.0, the netCDF API allows the use of the HDF5 data format. ● NetCDF users can create HDF5 files with benefits not available with the
netCDF format, such as much larger files and multiple unlimited dimensions.
● Full backward compatibility in accessing old netCDF files and using previous versions of the C and Fortran APIs is supported.

Classic dataset
5
● A netCDF classic or 64-bit offset dataset is stored as a single file comprising two parts: ● a header, containing all the information about dimensions, attributes,
and variables except for the variable data; ● a data part, comprising fixed-size data, containing the data for
variables that don't have an unlimited dimension; and variable-size data, containing the data for variables that have an unlimited dimension.
● Both the header and data parts are represented in a machine-independent form.

Classic netCDF data model
6

Limitations in the classic netCDF data model
7
● Its simplicity makes it is easy to understand, but limitations include: ● No real data structures, just multidimensional arrays and lists ● No nested structures, variable-length types, or ragged arrays ● Only one shared unlimited dimension for appending new data ● A flat name space for dimensions and variables ● Character arrays rather than strings ● A small set of numeric types
● In addition, the classic netCDF format has performance limitations for high performance computing with very large datasets: ● Large variables must be less than 4 GB (per record) ● No real compression supported, just scale/offset packing ● Changing a file schema (the logical structure of the file) may be very
inefficient ● Efficient access sometimes requires data to be read in the same order as
it was written ● Big-endian bias may hamper performance on little-endian platforms
● I/O is serial in Unidata netCDF-3 ● but see Argonne/Northwestern Parallel netCDF project

NetCDF HDF5 dataformat
8
● NetCDF-4 files are created with the HDF5 library, and are HDF5 files and can be read without the netCDF-4 interface. ● Note that modifying these files with HDF5 will almost certainly make them
unreadable to netCDF-4
● Groups in a netCDF-4 file correspond with HDF5 groups ”
● Variables in netCDF correspond with identically named datasets in HDF5. ● Attributes similarly.
● Since there is more metadata in a netCDF file than an HDF5 file, special datasets are used to hold netCDF metadata. ● The _netcdf_dim_info dataset (in group _netCDF) contains the ids of the shared
dimensions, and their length (0 for unlimited dimensions). ● The _netcdf_var_info dataset (in group _netCDF) holds an array of compound
types which contain the variable ID, and the associated dimension ids.
● backward compatibility to the classical format is preserved
● Support for parallel IO
● http://www.unidata.ucar.edu/netcdf/netcdf-4.

Data Model in NetCDF-4/HDF5 Files
9

Fortran Code example
10
● http://www.unidata.ucar.edu/software/netcdf/examples/programs/ ● Download simple_xy_rd.f90 and simple_xy_wr.f90 Extract from simple_xy_wr.f90 ! This is a very simple example which writes a 2D array of ! sample data. To handle this in netCDF we create two shared ! dimensions, "x" and "y", and a netCDF variable, called "data". ! Open the file call check( nf90_create(FILE_NAME, NF90_CLOBBER, ncid) ) ! Define the dimensions. NetCDF will hand back an ID for each. call check( nf90_def_dim(ncid, "x", NX, x_dimid) ) call check( nf90_def_dim(ncid, "y", NY, y_dimid) ) dimids = (/ y_dimid, x_dimid /) ! Define the variable. call check( nf90_def_var(ncid, "data", NF90_INT, dimids, varid) ) ! End define mode. This tells we are done defining metadata. call check( nf90_enddef(ncid) ) call check( nf90_put_var(ncid, varid, data_out) ) call check( nf90_close(ncid) )
Define Mode

Code example (Using a Cray XC or XE), page 2
11
● How to compile > module load cray-‐netcdf > ftn simple_xy_rd.f90 –o simple_xy_rd > ftn simple_xy_wr.f90 –o simple_xy_wr
● Executing (in interactive mode) : > srun ./simple_xy_wr *** SUCCESS writing example file simple_xy.nc! > srun ./simple_xy_rd *** SUCCESS reading example file simple_xy.nc!

Code example (Using a Cray XC or XE), page 3
12
> ncdump simple_xy.nc netcdf simple_xy { dimensions: x = 6 ; y = 12 ; variables: int data(x, y) ; data:
data = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71 ; }

Self-Describing Data
13
● The mere use of netCDF is not sufficient to make data "self-describing" and meaningful to both humans and machines. ● The names of variables and dimensions should be meaningful and
conform to any relevant conventions. Dimensions should have corresponding coordinate variables where sensible.
● Attributes play a vital role in providing ancillary information. It is important to use all the relevant standard attributes using the relevant conventions.
● A number of groups have defined their own additional conventions and styles for netCDF data. Descriptions of these conventions, as well as examples incorporating them can be accessed from the netCDF Conventions site, http://www.unidata.ucar.edu/netcdf/conventions.html.
● These conventions should be used where suitable. Additional conventions are often needed for local use.

Second example : Adding attributes
14
● Using sfc_pres_temp_wr.f90 from the same webpage as before Note : Each netCDF call has a ‘call check(statement) around it. Removed here for easy of reading (see example 1) ! We will write surface temperature and pressure fields. character (len = *), parameter :: PRES_NAME="pressure" character (len = *), parameter :: UNITS = "units" character (len = *), parameter :: PRES_UNITS = "hPa" nf90_def_var(ncid, PRES_NAME, NF90_REAL, dimids, pres_varid) !Assign units attributes to the pressure and temperature netCDF variables.
nf90_put_att(ncid, pres_varid, UNITS, PRES_UNITS) nf90_enddef(ncid) nf90_put_var(ncid, pres_varid, pres_out)

Second example (output)
15
netcdf sfc_pres_temp { dimensions: latitude = 6 ; longitude = 12 ; variables: float latitude(latitude) ; latitude:units = "degrees_north" ; float longitude(longitude) ; longitude:units = "degrees_east" ; float pressure(latitude, longitude) ; pressure:units = "hPa" ; float temperature(latitude, longitude) ; temperature:units = "celsius" ; data: latitude = 25, 30, 35, 40, 45, 50 ; longitude = -‐125, -‐120, -‐115, …, -‐90, -‐85, -‐80, -‐75, -‐70 ; pressure = 900, 906, …, 971 ; temperature = 9, 10.5, …, 26.75 ; }

NetCDF-4 Performance Improvements
16
● Per-variable compression Compresses a variable with zlib. Transparent to the user
● Per-variable chunking (multidimensional tiling) A chunk is a hyper-rectangle of any shape. When a dataset is chunked, each chunk is read or written as a single I/O operation, and individually passed from stage to stage of the pipeline and filters
● Parallel-I/O for platforms with parallel file systems HDF5's, not Argonne's Parallel
● "Reader makes right" rules ● Writer always uses native representations, so no conversion is necessary on writing ● Reader is responsible for detecting what representation is used and applying a
conversion, if necessary, to reader's native representation ● No conversion is necessary if reader and writer use same representation
● Efficient dynamic schema changes Can add new metadata without copying data
● Performance benefits for writers creating "classic model" files
● Performance benefits for netCDF-3 reader programs reading "classic model" netCDF-4 (HDF5) files by relinking with the netCDF-4 library

Using Parallel IO in NetCDF4
17
● Special nc_create_par and nc_open_par functions are used to create/open a netCDF file. The files they open are normal NetCDF-4/HDF5 files, but these functions also take MPI paramters.
● The parallel access associated with these functions is not a characteristic of the data file, but the way it was opened. The data file is the same, but using the parallel open/create function allows parallel I/O to take place.
EXTERNAL int nc_create_par(const char *path, int cmode, MPI_Comm comm, MPI_Info info, int *ncidp); EXTERNAL int nc_open_par(const char *path, int mode, MPI_Comm comm, MPI_Info info, int *ncidp);

Example of parallel IO
18
/* Create a parallel netcdf-‐4 file. */ if ((res = nc_create_par(FILE, NC_NETCDF4|NC_MPIIO, MPI_COMM_WORLD, info, &ncid))) ERR; /* Create two dimensions. */ if ((res = nc_def_dim(ncid, "d1", DIMSIZE, dimids))) ERR; if ((res = nc_def_dim(ncid, "d2", DIMSIZE, &dimids[1]))) ERR; /* Create one var. */ if ((res = nc_def_var(ncid, "v1", NC_INT, NDIMS, dimids, &v1id))) ERR; if ((res = nc_enddef(ncid))) ERR; /* Set up slab for this process. */ start[0] = mpi_rank * DIMSIZE/mpi_size; start[1] = 0; count[0] = DIMSIZE/mpi_size; count[1] = DIMSIZE; /* Create phoney data. for (i=mpi_rank*QTR_DATA; i < (mpi_rank+1)*QTR_DATA; i++) data[i] = mpi_rank; if ((res = nc_var_par_access(ncid, v1id, NC_INDEPENDENT))) ERR; if ((res = nc_put_vara_int(ncid, v1id, start, count, &data[mpi_rank*QTR_DATA]))) ERR; if ((res = nc_var_par_access(ncid, v1id, NC_COLLECTIVE))) ERR; if ((res = nc_put_vara_int(ncid, v1id, start, count, &data[mpi_rank*QTR_DATA]))) ERR; if ((res = nc_close(ncid))) ERR;

Parallel NetCDF (PnetCDF)
PnetCDF is a library providing high-performance I/O while still maintaining file-format compatibility
with Unidata’s NetCDF. http://trac.mcs.anl.gov/projects/parallel-netcdf
19

What is parallel-netcdf
20
● An extension of netCDF for parallel computing called Parallel-NetCDF (or PnetCDF) has been developed by Argonne National Laboratory and Northwestern University. This is built upon MPI-IO, the I/O extension to MPI communications.
● Using the high-level netCDF data structures, the Parallel-NetCDF libraries can make use of optimizations to efficiently distribute the file read and write applications between multiple processors.
● The Parallel-NetCDF package can read/write only classic and 64-bit offset formats.
● Parallel-NetCDF cannot read or write the HDF5-based format available with netCDF-4.0.
● The Parallel-NetCDF package uses different, but similar APIs in Fortran and C.

The pNetCDF Package
21
● For classic and 64-bit offset formats parallel I/O can be obtained with parallel-netcdf, the parallel netCDF package from Argonne and Northwestern.
● Parallel netCDF uses MPI I/O to perform parallel I/O. It is a complete rewrite of the core C library using MPI I/O instead of POSIX.
● Unfortunately the parallel netCDF package implements a different API from the netCDF API, making portability with other netCDF code a problem.
● Fortunately, netCDF-4 can now use the parallel netCDF library to access classic and 64-bit offset files using parallel I/O, just as if they were HDF5/NetCDF-4 files. ● Use the NC_PNETCDF flag to achieve this.
if (nc_create_par(file_name, NC_PNETCDF, comm, info, &ncid)) ERR;
● For an example check : https://github.com/erdc-cm/netCDF/blob/master/nc_test4/tst_parallel2.c

Features
22
● PnetCDF contains a set of new APIs for accessing netCDF files in parallel
● The new APIs incorporate the parallel semantics following the Message Passing Interfaces (MPI) and provide backward compatibility with the netCDF file formats
● Minimize the changes to the netCDF API syntax (see next slide)

Features 2
23
● PnetCDF APIs mimic the syntax of the netCDF APIs with only a few changes to add parallel I/O concept. ● All parallel APIs are named after originals with prefix of
● "ncmpi_" for C/C++, ● "nfmpi_" for Fortran 77 ● "nf90mpi_" for Fortran 90
● An MPI communicator and an MPI_Info object are added to the argument list of the open/create APIs. The communicator defines the set of processes accessing the netCDF file. The info object allows users to specify I/O hints for PnetCDF and MPI-IO to further improve performance
● PnetCDF allows two I/O modes, collective and independent, which correspond to MPI collective and independent I/O operations. Similar to MPI naming convention, all collective APIs carry an extra suffix "_all".
● PnetCDF changes the integer data types for all the API arguments that are defined as size_t in netCDF to MPI_Offset.
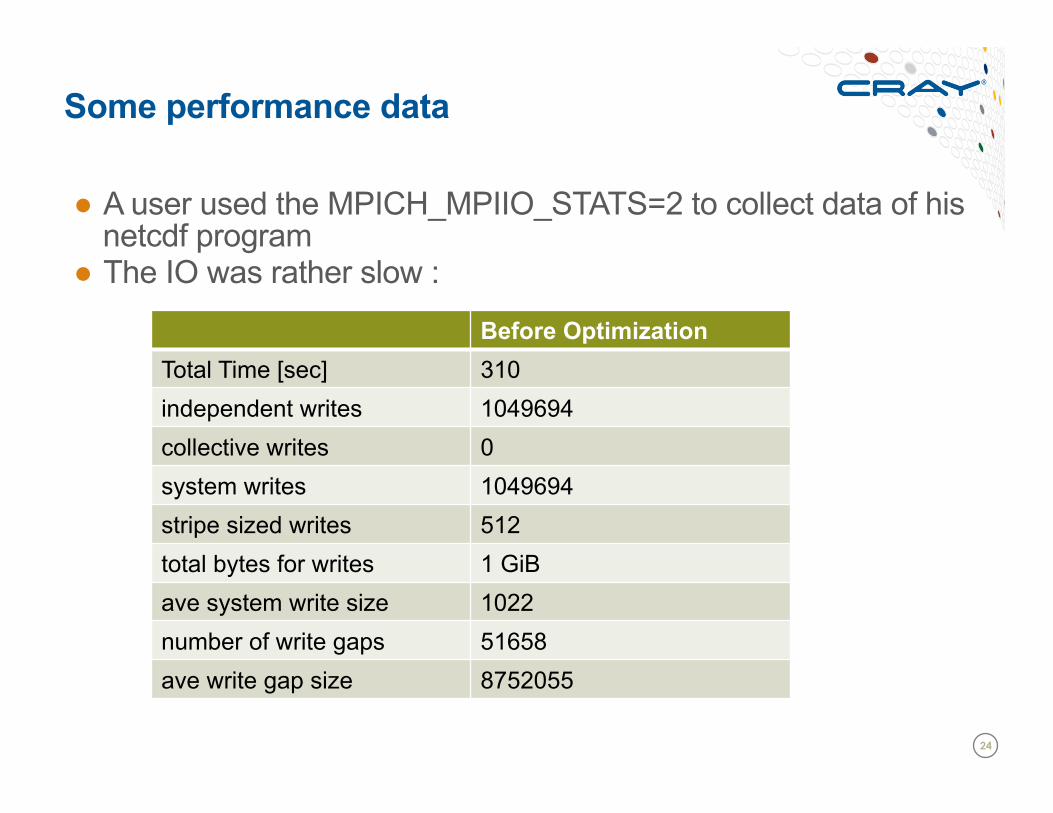
Some performance data
24
● A user used the MPICH_MPIIO_STATS=2 to collect data of his netcdf program
● The IO was rather slow :
Before Optimization Total Time [sec] 310 independent writes 1049694 collective writes 0 system writes 1049694 stripe sized writes 512 total bytes for writes 1 GiB ave system write size 1022 number of write gaps 51658 ave write gap size 8752055

Some performance data, part 2
25
Optimizations done : ● Added nf90_def_var_fill(ncid, field_id, 1, 1)
This stops the initial writes to fill the fields with fill values and reduced the writes from 640 MB to 320 MB per dump file
● Added nf90_var_par_access(ncid, field_id, NF90_COLLECTIVE) This defines parallel collective writes for each particular field

Some performance data, part 2
26
Before Optimization After Optimization
Total Time [sec] 310 90 independent writes 1049694 619
collective writes 0 2048 system writes 1049694 1135 stripe sized writes 512 508 total bytes for writes 1 GiB 512 MiB
ave system write size 1022 473051
number of write gaps 51658 75
ave write gap size 8752055 135173719

More information
● http://www.unidata.ucar.edu/software/netcdf/workshops/2010/index.html
● http://trac.mcs.anl.gov/projects/parallel-netcdf ● http://cucis.ece.northwestern.edu/projects/PnetCDF/
27