metodi statistici per le ricerche di mercato · 30/05/2018 1 metodi statistici per le ricerche di...
TRANSCRIPT

30/05/2018
1
Metodi statistici per le ricerche di mercato
Prof.ssa Isabella MingoA.A. 2017-2018
Facoltà di Scienze Politiche, Sociologia, Comunicazione
Corso di laurea Magistrale in «Organizzazione e marketing per la comunicazione d'impresa»
Che cosa è l’Analisi Multidimensionale dei Dati?
Insieme di tecniche statistiche che consentono di interpretarefenomeni complessi mediante l’analisi di grandi quantità di dati
I dati sottoposti ad analisi sono caratterizzati dall'osservazionecongiunta di un insieme di p variabili su n unità statistiche
Il concetto di “dimensione” viene a volte ricondotto a quellogeometrico, altre volte a quello di costrutto concettuale. In tutti icasi si adotta un approccio “multi-variato”.
Le informazioni, espresse sia in forma codificata che inlinguaggio naturale, sono inserite in opportune tabelle e matricioggetto di trattamento matematico o grafico.
Lo sviluppo di queste tecniche e la loro applicazione è statapossibile grazie all’avvento degli elaboratori elettronici e si sonogeneralizzati con la diffusione odierna dei personal computer e diadeguati software.
I. Mingo 2017-2018

30/05/2018
2
Approccio esplorativo-descrittivo
• Nella sua impostazione originaria, l‘AMD analizza le relazioni tra levariabili sulla base degli strumenti della geometria euclidea edell'algebra, prescindendo da qualunque assunzione probabilistica.
• Il suo approccio è originariamente di tipo esplorativo:– si analizzano i dati per “cogliere indizi” utili alla formulazione di
ipotesi distributive delle variabili
– si tratta simultaneamente con variabili numerose e spesso eterogenee riguardo al loro livello di misurazione
• Le tecniche di AMD possono essere dunque considerate un sottoinsieme di quello più ampio dell’Analisi Multivariata che comprende anche altre tecniche di approccio non esplorativo.
I. Mingo 2017-2018
Un’approccio tipico di AMD:I principi della Scuola Francese dell’ Analyse des données
1. La statistica non è calcolo delle probabilità2. Il modello deve seguire i dati non l’inverso3. è opportuno trattare simultaneamente informazioni
concernenti il maggior numero possibile di dimensioni4. Per l’analisi dei fenomeni complessi è indispensabile il
computer5. L’uso del computer implica l’abbandono di ogni tecnica
concepita prima dell’avvento del calcolo automatico(Benzècri 1973)
I. Mingo 2017-2018

30/05/2018
3
AMD: classificazione delle tecniche Criterio: Metrica
Analisi metrica: adatta a variabili quantitative Analisi non metrica: applicabile a variabili di qualsiasi scala di misura
Criterio: Simmetria Metodi simmetrici: non evidenziano direzioni causali, le relazioni tra le
variabili sono considerate bidirezionali Metodi asimmetrici: evidenziare relazioni di dipendenza tra più sistemi
di variabili. Le variabili osservate sono divise in variabili dipendenti evariabili predittive (o esplicative o indipendenti).
Criterio: Linearità Relazioni lineari: si assume che la relazione che lega la variabile Y ad
un gruppo di variabili X1, X2, …,Xk è esprimibile attraverso una funzionelineare delle variabili esplicative più un termine residuale
Relazioni non lineari: si assume che la relazione sia di altro tipo(esponenziale, logaritmica, sinusoidale, polinomiale).
I. Mingo 2017-2018
Alcune finalità delle tecniche di AMD
Riduzione dei dati• Descrizione dei dati rilevati mediante forme semplici e compatte
analitiche e/o grafiche• Costruzione di indici sintetici
Evidenziazione strutture latenti
Raggruppamento e ricerca di tipologie• Definizione automatica di classi di unità più omogenee
Discriminazione • Identificazione delle caratteristiche che differenziano due o più
insiemi di unità.
I. Mingo 2017-2018

30/05/2018
4
Strategie di analisi
• Nella prassi della ricerca le tecniche di AMD vengonoconcatenate e possono costituire a loro volta il presuppostoper l’applicazione di altre tecniche.
• Una strategia è un processo di analisi dei dati che si avvale diun insieme di tecniche statistiche combinate tra loro in vistadi determinati fini conoscitivi.
I. Mingo 2017-2018
Sintesi delle variabili
Ricerca di tipologie
Esempio di strategia
Matrice dati
Tecniche multivariate di riduzione delle variabili:
L’analisi in componenti principali
I. Mingo 2017-2018

30/05/2018
5
Matrice di dati: rappresentazione geometrica
Ogni riga di una matrice di dati Xnpquantitativi può essere rappresentata come un vettore numerico a p dimensioni che indica le coordinate del punto-unità nello spazio Rp detto delle unità
Ogni colonna di una matrice di dati Xnp quantitativi può essere rappresentata come un vettore numerico a n dimensioni che indica le coordinate del punto-variabile nello spazio Rn detto delle variabili
I. Mingo 2017-2018
Glossario:Vettore e spazio vettoriale
• Il piano cartesiano è un esempio di spazio vettoriale
• Un vettore è un punto del piano cartesiano, determinato da una coppia di numeri reali (x, y).
• Disegnando una freccia che parte nell'origine (0, 0) e arriva in (x, y), si ottiene il significato fisico di vettore applicato nell'origine;
• I vettori possono essere sommati e moltiplicati per scalari e per altri vettori.
• Analogamente nello spazio n-dimensionale un vettore è una ennupla di numeri reali (x1, x2, …xn).
I. Mingo 2017-2018

30/05/2018
6
Esempio: nuvola di punti-unità nel piano e nello spazio p dimensionale
I. Mingo 2017-2018
All’aumentare degli n vettori diriga xi aumenta anche lanumerosità dei puntirappresentati nella nuvola deipunti-unità nello spazio Rp.
All’aumentare dei p vettoricolonna aumenta la numerositàdelle dimensioni dello spazio-unità e dunque la complessitàdei dati in analisi.
n punti in R2
n punti in R3
GlossarioBaricentro e Inerzia totale
• Il baricentro di una nuvola di punti-unità è il vettore delle mediedelle variabili
• La dispersione totale della nuvola dei punti unità intorno al lorobaricentro si definisce varianza totale o inerzia totale.
• Essa può essere calcolata sommando gli elementi della diagonaleprincipale (traccia) della matrice di varianza e covarianza.
I. Mingo 2017-2018

30/05/2018
7
L’analisi in componenti principali (ACP)
• E’ una tecnica di tipo fattoriale utile per ridurre la complessità, chesi propone di sintetizzare le variabili:– si basa sulle correlazioni esistenti tra di esse– individua una serie di p fattori comuni o componenti, di
importanza decrescente.– Le componenti sono:
• combinazioni lineari delle variabili originarie, pertanto nesintetizzano l’informazione
• non sono correlati tra di loro.
Esempi di applicazione:
•Quali sono le dimensioni del benessere dei comuni italiani?
• In quali componenti si possono sintetizzare le valutazioni attribuite dai cittadini alle funzioni amministrative degli enti locali ?
•In quali dimensioni possono essere sintetizzate i punteggi espressi dai clienti sulle caratteristiche di un prodotto?
I. Mingo 2017-2018
ACP : approccio geometrico
• Geometricamente, le componenti rappresentano un nuovo sistema di coordinate ottenuto ruotando il sistema originale con p assi coordinati
• L’obiettivo è di sceglierne un numero q ≤ p che spiegano la massima parte della varianza originaria.
Y2
I. Mingo 2017-2018
Nell’esempio la somma delle distanze al quadrato dai punti alla retta Y1 è minimizzata
• Y1 è una combinazione lineare delle variabili originarie

30/05/2018
8
Correlazione e riduzione
Tasso di disoccupazione
3020100
Tass
o di
dis
occu
pazio
ne g
iova
nile
70
60
50
40
30
20
10
0
r=0,976r=0,002
Le caratteristiche dei punti-unità espresse dalledue variabili (le due dimensioni del pianocartesiano) possono essere riassunte da unasola dimensione (la retta) che li sintetizza.
Non è possibile individuare una rettache riassuma le due dimensioni poichésono indipendenti.
I. Mingo 2017-2018
Uso del software : la correlazione
I. Mingo 2017-2018

30/05/2018
9
Analisi in Componenti Principali (ACP) : il modello
A partire da un insieme di variabili quantitative originarie:X1, X2 ,…, Xj,…, Xp
l’ACP conduce a un insieme di variabili non osservate
Y1,Y2,…,Yq (q≤p)
tale che ciascuna i-esima componente principale Yi sarà :Yi = wi1X1 + wi2X2 + ..... + wipXp i=1,2,…q
Dove wij sono i pesi associati ad ogni variabile per ogni componente
I. Mingo 2017-2018
ACP: calcolo della prima componente
• Si determineranno i pesi w1j della combinazione lineare in modo da :
• rendere massima la varianza della componente stessa: var (Y1) = max
• e sotto la condizione che la somma dei quadrati dei coefficienti wi1 della combinazione sia uguali a 1:
I. Mingo 2017-2018

30/05/2018
10
ACP: calcolo delle altre componenti
• La seconda componente sarà determinata con le medesime condizioni e con quella aggiuntiva che sia non-correlata con la prima, valga cioè la relazione:
r (Y1 Y2) = 0 -> w11 w12 + w21 w22 + …wq1 wq2 =0
• Le successive componenti principali si determinano in modo analogo; si avrà quindi:var (Y1) var (Y2) … var (Yq)
er(Ys Yk) =0 s,k tale che sk
I. Mingo 2017-2018
ACP : fasi
Fase 1 • La matrice iniziale: variabili e trasformazioni
Fase 2• La scelta del software: elaborazione
Fase 3• Lettura dell’output e interpretazione
I. Mingo 2017-2018

30/05/2018
11
Progettazione di una ACP
• Scelta delle variabili da analizzare:– Le variabili devono essere quantitative. – Si può optare per l’uso di variabili
standardizzate (scelta necessaria se si disponedi variabili espressi in differenti unità di misura) onon standardizzate.
Fase 1
I. Mingo 2017-2018
Esecuzione di una ACP
• Scelta del software:
• Si può fare ricorso a numerosi software statistici che dispongono di procedure adatte all’applicazione dell’ACP:
• SPSS, SAS, STATA, SPAD, NCSI……...
Fase 2
I. Mingo 2017-2018

30/05/2018
12
Uso del software Spss : esecuzione ACP
I. Mingo 2017-2018
Lettura dell’output e interpretazione
Analisi delle variabili in input Caratteristiche dei fattori estratti:Numero e quote di varianza spiegataComunalitàCorrelazioni fattori/variabili Punteggi delle variabiliPunteggi delle unità
Rappresentazioni grafiche
Fase 3
I. Mingo 2017-2018

30/05/2018
13
Analisi delle variabili in input
I. Mingo 2017-2018
L’analisi delle statistiche descrittivemonovariate precede l’applicazionedella tecnica multidimensionale econsente di controllare la eventualeesistenza di dati anomali o di casimancanti.
Test che ci consentono di stabilire se la struttura di correlazione delle variabili usate è adatta all’applicazione di una analisi di tipo fattoriale.KMO ( varia da 0-1) deve essere >0.7 e prossimo a 1. Test di Bartlett significativo (con sig < 0.05).
ACP: risultati
• La risoluzione del problema di massimo vincolato, applicatoalla matrice di correlazione R (o a quella di varianza ecovarianza S) tra le p variabili , conduce ad ogni passo atrovare : var (Yi) = λi (i=1,2,…q)
dove λi è l’iesimo autovalore della matrice R, pertanto per la condizione di varianza decrescente:
λ1 > λ2 > λ3 >… λq
i coefficienti w1i, w2i,…,wq1 sono l’autovettore associato ad ogni λi
I. Mingo 2017-2018

30/05/2018
14
Le caratteristiche dei fattori : numero e quote di varianza spiegata
I. Mingo 2017-2018
•Nell’ACP il numero deifattori estraibili è pari alnumero delle variabili (nelnostro esempio 10).
•A ciascun fattore èassociato un autovalore i(eigenvalue) e una quotadi varianza decrescente• i /) i (i=1,2,…q)
• Considerando soltantoalcuni fattori la varianzaspiegata è inferiore a 100.
Quanti fattori considerare?•Non esistono regole tassative, ma possono essere seguiti diversi criteri empirici:
fissare un livello minimo di percentuale cumulata di spiegazione dellavarianza e considerare fattori che cumulativamente consentono di raggiungerela soglia prefissata;- Si potrebbe richiedere che i fattori tengano conto mediamente di almeno il 95% della
varianza di ognuna delle p variabili originarie, cioè0,95p x 100 Al crescere del numero di variabili ci si può accontentare di una % minore
scegliere i fattori con autovalore >1 a prescindere dalla percentuale divarianza (Kaiser) se le variabili sono standardizzate, oppure almeno pari allavarianza media ( somma degli autovalori/ p);
rappresentare graficamente gli autovalori rispetto all’ordine di estrazione(scree test) e collegarli con una spezzata. Si considerano rilevanti quei fattori icui autovalori si collocano prima del punto di flesso della spezzata (Cattel).
I. Mingo 2017-2018

30/05/2018
15
Scree test
I. Mingo 2017-2018
La bontà della riduzione: la comunalità
• Per valutare la ‘bontà’ dell’operazione, che riduce ilnumero di dimensioni da p a q (ossia da 10 a 2),possiamo fare riferimento alla comunalità diciascuna variabile originaria:
• Misura la percentuale di varianza di ciascuna variabile spiegata dallecomponenti estratte
I. Mingo 2017-2018

30/05/2018
16
Il significato di ogni fattore : le correlazioni con le variabili
I. Mingo 2017-2018
I coefficienti di correlazione tra ognifattore e le variabili originarieconsentono di attribuire alladimensione sintetica un “etichetta” :
• il segno del coefficiente indica il tipodi relazione lineare diretta (+) oinversa (-);•L’entità del coefficiente indica laforza della relazione.
Il grafico delle componenti
I. Mingo 2017-2018
•Se si disegna un cerchio diraggio=1, la prossimità dellevariabili alla circonferenza eall’asse evidenzia lacorrelazione prossima a |1| .•La lontananza indica unacorrelazione debole.

30/05/2018
17
Esercizio ACP
• Utilizzando il file qdv_esercizio.sav, considerare le variabili riguardanti il tenore di vita e il tempo libero.
• Applicare una ACP al fine di individuare dimensioni sintetiche.
• Interpretare l’output ottenuto, e in particolare:• motivare la scelta del numero di fattori• individuare le variabili meglio e peggio
rappresentate nel nuovo sistema di riferimento• attribuire un etichetta concettuale alle dimensioni
considerate, motivando la scelta.
I. Mingo 2017-2018
La rotazione delle componenti
• Per agevolare la interpretazione delle componenti si puòapplicare una rotazione ortogonale degli assi fattoriali in mododa minimizzare il numero di variabili che sono fortementecorrelate con ogni fattore.
• Il peso dei fattori è così distribuito più uniformemente el’interpretazione dei fattori è semplificata.
• Questo tipo di rotazione è denominata Varimax
I. Mingo 2017-2018

30/05/2018
18
La rotazione modifica:-l’autovalore e la % di varianza spiegata da ciascuna componente;- la matrice delle componenti
I. Mingo 2017-2018
I punteggi fattoriali
I. Mingo 2017-2018
Punteggi delle variabili sui fattori
Punteggi delle unità sui fattori
autovettori standardizzati:wij/√ij)

30/05/2018
19
ACP: i punteggi in SPSS
• Il punteggio (score) di ogni componente è definito da:• Yi = wi1X1 + wi2X2 + ..... + wipXp
dove w ij è il peso (autovettore) della prima componentee della iesima variabile
• Avendo imposto la condizione di normalizzazione i pesihanno media nulla e varianza pari all’autovalore di ognicomponente.
• Ciò riflette l’importanza di ogni componente ma presentalo svantaggio di non rendere direttamente comparabili lediverse componenti.
• A tal fine si possono ricavare pesi standardizzati, convarianza unitaria, dividendo per ogni fattore l’ autovettoreper la radice quadrata del rispettivo autovalore.
• SPSS adotta poi diverse procedure per calcolare ipunteggi delle unità statistiche sulle componenti.
• Per ogni unità statistica il punteggio sul fattore è la suacoordinata nel nuovo sistema di riferimento (cfr. graficoslide precedente) .
I. Mingo 2017-2018
Esercizio ACP
• Riprendendo l’applicazione ACP precedente:• Salvare i punteggi fattoriali delle unità di analisi• Ottenere delle graduatorie decrescenti delle unità
di analisi in base ai punteggi ottenuti.• Ottenere un grafico fattoriale delle prime due
componenti.• Commentare i risultati ottenuti.
I. Mingo 2017-2018

30/05/2018
20
Introduzione alla Cluster analysisTecniche e software
Individuare tipologie….
… è uno degli scopi della classificazione
Classificare vuol dire…
• individuare differenze e somiglianze tra elementi di un insieme,distinguere - come affermava Linneo – il simile dal dissimile perrendere più chiara la nostra interpretazione della realtà
• scegliere un punto vista su cui basare tale distinzione
• Nella ricerca empirica significa osservare e rilevare le modalitàassunte da una o più variabili sulla base delle quale raggruppare leunità di analisi in un numero finito di gruppi, in modo tale che le unitàdi un gruppo siano omogenee rispetto alle variabili considerate .•Nelle ricerche di mercato è utile per suddividere consumatori,prodotti, servizi o contesti territoriali in sottoinsieme omogenei.
I. Mingo 2017-2018

30/05/2018
21
Tecniche automatiche per individuare tipologie:Cluster Analysis (analisi dei gruppi – classification automatique)
La cluster analysis è un insieme di tecniche multivariateesplorative, basate sull'assunzione che le variabili e le unitàstatistiche possono essere considerate delle dimensioni delfenomeno studiato rappresentabili su spazi geometrici.
I gruppi omogenei vengono ottenuti in modo induttivo,automaticamente (unsupervised classification), mediantel’applicazione di algoritmi e non con criteri soggettivi.
La classificazione a cui consente di pervenire si fonda sulconcetto di prossimità (dissimilarità / similarità ) tra le diverseunità nello spazio, definito da un sistema di assi cartesianiciascuno dei quali riporta i valori assunti da una delle variabilirilevate.
I. Mingo 2017-2018
Individuazione di tipologieEsempio
% pop. usa posta elettronica
8070605040
% p
op. c
he u
sa In
tern
et
24
22
20
18
16
14
12
10
Sardegna
Sicilia
Calabria
B asilicata
Puglia
Campania
M o lise
Abruzzo
LazioM arche
Umbria
Toscana
Emilia Romagna
Liguria
Friuli
VenetoTrentino
Lombardia
Valle d'Aosta
P iemonte
Ogni regione vienerappresentata sul piano comeun punto che ha comecoordinate i valori assunti inognuna delle due variabili.
Tanto più le regioni sonovicine sul piano tanto piùsono simili rispetto alle duevariabili considerate (es.Lombardia ed EmiliaRomagna ; Valle d’Aosta-Toscana)
Tanto più le regioni sonodistanti sul piano tanto piùsono diverse rispetto alle duevariabili considerate (es.Basilicata ed EmiliaRomagna)
I gruppi omogenei si possonoindividuare in base alladistanza : deve essere minimaall’interno di un gruppo emassima tra gruppi diversi.
I. Mingo 2017-2018

30/05/2018
22
Tipi di dati
Matrice di dati Xnp
Matrice di dissimilarità Xnn
d(i, j) misura di dissimilarità tra dati
Matrice di similarità Xnn
d’(i, j)=sim= misura di similarità tra dati
I. Mingo 2017-2018
Dissimilarità e distanza
• La scelta della misura di dissimilarità è fondamentale nella strategia operativa della cluster analysis ed è condizionata dal tipo di variabili sulla base dei quali si vuole effettuare la classificazione.
• Le misure di dissimilarità soddisfano le seguenti proprietà:1. d (a,b)=0 se a=b (identità); 2. d(a,b) ≥ 0 se a≠ b (non negatività) 3. d(b,a)=d(a,b) (simmetria);
• se a queste tre proprietà si aggiunge anche la seguente:
d(a,c) <= d(ab)+d(bc) (diseguaglianza triangolare).
• si ottengono misure di distanza, utilizzabili per variabili quantitative .
I. Mingo 2017-2018

30/05/2018
23
Alcune distanze per variabili quantitative
– distanza euclidea (E)
– la distanza City Block (assoluta)o di Manhattan (AB+BC)
– la distanza di Mahalanobis che considera levarianze e covarianze tra i caratteri considerati econsente di ottenere distanze depurate dallainterdipendenza eventualmente presente tra levariabili.
I. Mingo 2017-2018
B
A
E
A B
C
Matrice di distanze: esempio
Matrice delle distanze
,000 4,140 7,628 3,471 2,617 5,314 9,849 5,131 12,402 12,126 15,7954,140 ,000 8,857 4,100 2,309 4,624 12,020 6,818 13,412 12,572 16,0107,628 8,857 ,000 10,913 6,815 4,554 3,624 2,500 4,789 4,623 8,2883,471 4,100 10,913 ,000 4,528 7,716 13,315 8,458 15,700 15,255 18,8812,617 2,309 6,815 4,528 ,000 3,189 9,800 4,604 11,517 10,878 14,4515,314 4,624 4,554 7,716 3,189 ,000 8,065 3,330 8,846 7,948 11,4139,849 12,020 3,624 13,315 9,800 8,065 ,000 5,204 4,123 5,308 8,2285,131 6,818 2,500 8,458 4,604 3,330 5,204 ,000 7,272 7,072 10,749
12,402 13,412 4,789 15,700 11,517 8,846 4,123 7,272 ,000 1,838 4,11112,126 12,572 4,623 15,255 10,878 7,948 5,308 7,072 1,838 ,000 3,67715,795 16,010 8,288 18,881 14,451 11,413 8,228 10,749 4,111 3,677 ,000
Caso5:Veneto6:Friuli0Venezia Giuli7:Liguria8:Emilia Romagna9:Toscana10:Umbria11:Marche12:Lazio13:Abruzzo14:Molise15:Campania
5:Veneto6:Friuli0Venezia Giuli 7:Liguria
8:EmiliaRomagna 9:Toscana 10:Umbria 11:Marche 12:Lazio 13:Abruzzo 14:Molise 15:Campania
Distanza euclidea
Questa è una matrice di dissimilarità
Caratteristiche:
•È quadrata: gli elementi in riga sono uguali a quelli in colonna•E’ simmetrica rispetto alla diagonale principale•Gli elementi della diagonale principale sono uguali a 0.
I. Mingo 2017-2018

30/05/2018
24
Misure di dissimilarità e similarità per dati binari
Tabella di contingenza per coppie di dati binari:
•Coefficiente di matching semplice:
•Coefficiente di Jaccard: Le variabili categoriali possono essere trasformate in variabili binarie e si possono utilizzare queste stesse misure. • Distanza euclidea per dati binari:
I. Mingo 2017-2018
Cluster analysis : tipi di tecniche Cluster gerarchica aggregativa:
Utilizza algoritmi che partendo da un numero n di gruppi pari al numero deicasi, attraverso un procedimento iterativo di n-1 passaggi, conduce ad ungruppo unico in cui sono raggruppati tutti i casi originari. Genera un alberodi aggregazione o dendrogramma.
Cluster analysis non gerarchica: parte da una situazione di un numero di gruppi predeterminato a priori e
giunge ad una partizione che ottimizza (utilizzando una funzione obiettivo)la suddivisione in gruppi.
conduce a un'unica partizione dei dati da analizzare, comporta pertantoipotesi precise circa le modalità di strutturazione del collettivo statisticoconsiderato e,a volte, la scelta delle unità intorno alle quali aggregare lealtre unità del gruppo.
Si utilizza soprattutto quando le unità in analisi sono molto numerose. Tecniche miste:
che utilizzano sia algoritmi gerarchici che non gerarchici.
I. Mingo 2017-2018

30/05/2018
25
Cluster Analysis: fasi
Fase 1 • La matrice iniziale
Fase 2• La scelta del software e dell’algoritmo:
elaborazione
Fase 3• Lettura dell’output e interpretazione
Fase 4• Descrizione dei gruppi ottenuti
I. Mingo 2017-2018
Progettazione di una Cluster Analysis:la matrice iniziale
• Scelta delle variabili in base alle quali raggruppare le unitàstatistiche:– Le variabili possono essere quantitative o qualitative.– Se le variabili sono quantitative si può optare per l’uso di
variabili standardizzate o non standardizzate.– Il tipo di variabili incide sul tipo di misura di prossimità
(similarità o dissimilarità) da utilizzare– Il numero delle unità statistiche incide sul tipo di tecnica
(gerarchica o non gerarchica) di cluster adottabile.
Fase 1
I. Mingo 2017-2018

30/05/2018
26
Uso del software : Cluster analysis
I. Mingo 2017-2018
Fase 2
Cluster gerarchica:si possono calcolare le distanze
-Tra due unità statistiche
% pop. usa posta elettronica
8070605040
% p
op. c
he u
sa In
tern
et
24
22
20
18
16
14
12
10
Sardegna
Sicilia
Calabria
Basilicata
P uglia
Campania
M o lise
Abruzzo
LazioM arche
Umbria
Toscana
Emilia Ro magna
Liguria
Friuli
Veneto
Trentino
Lo mbardia
Valle d'A osta
P iemonte
Tra una unità ed un gruppo di unità
Tra due gruppi di unità
Si possono adottare diverse soluzioniper misurare le distanze tra gruppi diunità, considerando:
•le distanze fra le medie dei gruppi(group means)
•le distanze fra le loro unità più vicine(nearest neighbour)
•le distanze fra le loro unità più lontane(furthest neighbour)
•La media delle distanze fra tutte leunità di un gruppo e tutte quelledell’altro (group average)
I. Mingo 2017-2018
30/05/2018
27
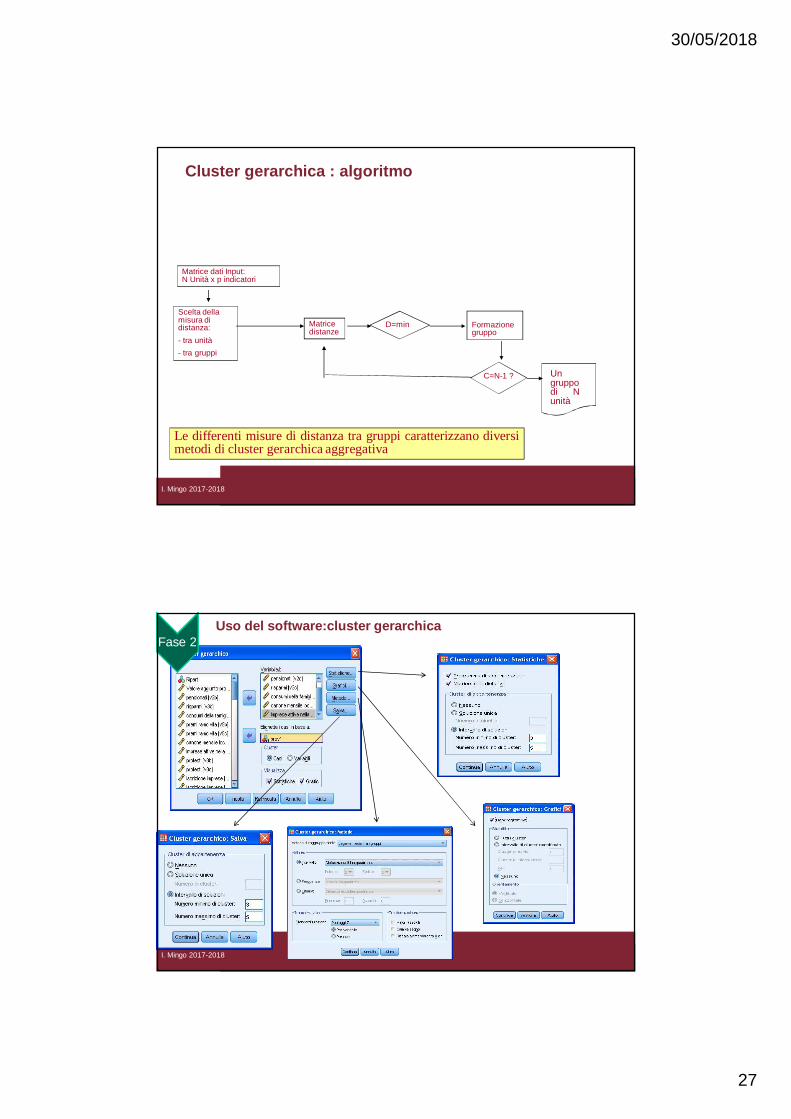
Cluster gerarchica : algoritmo
Matrice dati Input: N Unità x p indicatori
Matricedistanze
D=min Formazionegruppo
C=N-1 ?
si
no Ungruppodi Nunità
Scelta della misura di distanza: - tra unità- tra gruppi
Le differenti misure di distanza tra gruppi caratterizzano diversimetodi di cluster gerarchica aggregativa
I. Mingo 2017-2018
Uso del software:cluster gerarchica
I. Mingo 2017-2018
Fase 2

30/05/2018
28
Cluster gerarchica aggregativaAlcuni metodi di raggruppamento
I. Mingo 2017-2018
Metodo del legame singolo (nearestneighbour ) :
la distanza tra il gruppo A e il gruppo B è la distanza minore tra le unità del gruppo A e quelle del gruppo B.I gruppi che si ottengono hanno forma allungata a losanga.
Metodo del legame completo (furthestneighbour ):
la distanza tra il gruppo A e il gruppo B è la distanza maggiore le unità del gruppo A e quelle del gruppo B.I gruppi che si ottengono hanno forma circolare.
Cluster gerarchica aggregativaAlcuni metodi di raggruppamento
Metodo legame medio fra i gruppi: considera lamedia di tutte le distanze possibili tra i casi all'internodi un cluster nuovo singolo determinato dallacombinazione di un cluster A e di un cluster B.
Metodo della media entro i gruppi: la distanza tra il gruppo A e il gruppo B è data dalla media aritmetica delle distanze tra ogni unità del gruppo A e ogni unità del gruppo B.
Metodo di Ward: Per ogni gruppo viene calcolata la media di tutte le variabili Viene poi calcolata la distanza euclidea di ogniunità dalla media del gruppoVengono sommati i quadrati delle distanze pertutte le unitàAd ogni step di aggregazione vengono fusi igruppi per i quali risulta minimo l'incremento dellasomma dei quadrati delle distanze all'interno delgruppo.
I. Mingo 2017-2018

30/05/2018
29
Lettura dell’outputProgramma di agglomerazione e dendrogramma
• Il processo di agglomerazione delle unità indica i vari step con cui le unità vengono aggregate in corrispondenza a un indice di distanza che aumenta al crescere dei passi di agglomerazione.
• Il dendrogramma rappresenta graficamente tale processo.
I. Mingo 2017-2018
Programma di agglomerazione
Stadio Cluster accorpati
Coefficienti
Stadio di formazione del cluster Stadio
successivo Cluster 1 Cluster 2 Cluster 1 Cluster 2
d
i
m
e
n
s
i
o
n
0
1 31 42 4591,350 0 0 37
2 11 23 5464,530 0 0 30
3 29 93 7445,270 0 0 22
4 6 49 7623,230 0 0 26
5 12 16 7660,920 0 0 23
6 20 71 8499,170 0 0 38
7 77 103 8979,810 0 0 32
8 22 52 9129,370 0 0 40
9 53 81 9208,590 0 0 40
10 64 65 9628,290 0 0 20
11 1 30 9776,430 0 0 27
12 21 44 9848,570 0 0 34
13 7 69 10383,720 0 0 25
14 19 91 10597,110 0 0 33
15 48 68 11512,560 0 0 47
…. …. …. …. …. …. ….
86 14 36 94970,380 78 63 92
87 9 18 99761,677 81 62 94
88 2 3 102031,156 82 85 90
89 1 6 102913,471 77 80 91
90 2 31 114558,490 88 74 95
91 1 19 139465,534 89 84 94
92 14 55 143272,756 86 79 95
93 79 94 146681,990 0 0 97
94 1 9 183965,139 91 87 98
95 2 14 207466,536 90 92 96
96 2 15 229907,319 95 0 99
97 72 79 239277,085 0 93 101
98 1 37 266105,127 94 0 100
99 2 4 374810,001 96 0 100
100 1 2 427052,823 98 99 102
101 54 72 559967,397 0 97 102
102 1 54 1122564,349 100 101 0
Fase 3
I. Mingo 2017-2018
Tagliare un dendrogramma(albero di aggregazione)
3 gruppi
4 gruppi
5 gruppi

30/05/2018
30
Quali criteri adottare per tagliare un dendrogramma?
• Sezionare l’albero all’altezza del massimo salto tra i livelli di distanza a cui sono avvenute le aggregazioni
– g+1 d-gd=max
• Sezionare l’albero dove si trovano i gruppi coesi, applicando test statistici ad hoc (es: test di Beale, lambda di Wilks, ecc.)
La valutazione di un gruppo è effettuata sia riguardo alleproprietà statistiche sia in termini sostanziali, analizzandocioè le caratteristiche dei gruppi ottenuti.
I. Mingo 2017-2018
Descrizione dei gruppi
• L’intervallo di soluzioni salvato genera nella matrice nuove variabili categoriali che indicano per ciascuna unità statistica l’appartenenza ai gruppi ottenuti nelle diverse soluzioni.
• Queste nuove variabili possono essere utilizzate per descrivere mediante ulteriori analisi le caratteristiche dei gruppi ottenuti.
I. Mingo 2017-2018
Fase 4

30/05/2018
31
Esercizio: Applicazione di una cluster gerarchica
• Utilizzando il file regioni.sav, applicare una tecnicadi Cluster gerarchica aggregativa su variabilistandardizzate.
• Ispezionare il dendrogramma• Reiterare l’analisi salvando l’appartenenza ai gruppi
in corrispondenza della partizione ritenuta ottimale.• Descrivere i gruppi ottenuti.
I. Mingo 2017-2018
Strategia di analisi per l’individuazione di tipologie
Scelta di una o più variabili, indicatoridi un fenomeno
Individuazione di unità aventicaratteristiche simili rispetto agliindicatori considerati: tipi o gruppiomogenei[ Scelte da effettuare: tipo di clusteranalysis, misure di prossimità tra unitàe tra gruppi, numero di gruppi,….]
Descrizione dei gruppi sulla base degliindicatori iniziali e di altre variabili cheagevolano l’interpretazione
I. Mingo 2017-2018