metodi di classificazione - sapienza · dati ed hanno avuto un notevole sviluppo a partire dalla...
TRANSCRIPT

Metodi di classificazione
Loredana Cerbara

Metodi di classificazione I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla
categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno avuto un notevole sviluppo a partire dalla disponibilità di elaborazioni elettroniche che hanno consentito di eliminare il problema della complessità computazionale.
Lo scopo della cluster analysis è quello di creare dei gruppi di unità statistiche presenti nel collettivo e su cui siano stati rilevati alcuni caratteri in modo che le unità appartenenti allo stesso gruppo siano più possibile simili tra loro e tra i gruppi ci sia la massima dissimilarità.
Questo obiettivo può essere raggiunto in vari modi, e dipende anche molto dal tipo di misura di similarità o dissimilarità che si adotta. Per questo si possono immaginare molti algoritmi di classificazione, ciascuno con un risultato diverso.

Metodi di classificazione L’obiettivo è individuare meglio
possibile la struttura dei dati. In un piano anche l’occhio umano può individuare tale struttura, anche se con qualche indecisione, ma già in tre dimensioni la cosa si complica. In n dimensioni le immagini non possono essere più riprodotte e dunque è necessario ricorrere ad un algoritmo matematico per identificare i gruppi.

Metodi di classificazione La situazione ottimale in cui le dimensioni sono solo due e i gruppi sono ben distinti è molto rara da ottenere. In genere, nei casi reali, abbiamo più dimensioni e più strutture nei dati. A volte i gruppi non sono affatto ben distinti, ma sono sovrapposti. In questo caso si parla di clumping, o ricopimenti, anziché di gruppi (overlapping clustering). Cioè ogni unità può appartenere a più di un gruppo. Infine, esistono metodi clustering che misurano quanto ogni unità è ‘attratta’ da tutti i gruppi. Questa classificazione si chiama fuzzy clustering.

Metodi di classificazione Oggetto di questo corso sono soprattutto i metodi di classificazione che restituiscono
una partizione dell’insieme delle unità statistiche. Secondo la teoria degli insiemi, una partizione di un insieme E non vuoto consiste nell’individuazione di n insiemi C (C1, C2, …, Cn) tali che
● ognuno degli insiemi C non è vuoto ● tutti gli insiemi C sono disgiunti tra loro, ossia non hanno elementi in comune ● l’unione degli insiemi C restituisce l’insieme E di partenza
Se per insieme E intendiamo il nostro collettivo, e per insiemi C i gruppi che individuiamo con la cluster analysis, la nostra partizione sarà costituita da gruppi di unità non vuoti e tali che ogni unità appartiene ad uno ed un solo gruppo.

Metodi di classificazione Come abbiamo già detto, esistono diversi tipi di algoritmi di classificazione. Solo la
conoscenza di come essi agiscono e su quali principi matematici si basano può aiutare il ricercatore a scegliere il migliore algoritmo per il proprio insieme di dati. Alcuni algoritmi sono più adatti quando si hanno molte unità, altri fanno cogliere meglio la forma geometrica, che non è detto debba essere sferica, dei dati, fornendo informazioni anche su questo dettaglio.
Gli algoritmi di classificazione si possono suddividere in grandi tipologie di metodi. Una distinzione può essere determinata rispetto al procedimento seguito: si chiamano algoritmi scissori, quegli algoritmi di cluster analysis che individuano i gruppi suddividendo il gruppo costituito da tutte le unità partenza; sono invece algoritmi aggregativi quelli che formano i gruppi aggregando le unità intorno a centri predeterminati.

Metodi di classificazione Un’altra importante distinzione riguarda il modo con cui si arriva ai gruppi finali: si
distinguono gli algoritmi gerarchici, quelli cioè che arrivano alla classificazione finale per passi successivi, passando da un raggruppamento più fine a uno meno fine (algoritmi gerarchici aggregativi) o passando dal totale delle unità a gruppi costituiti da una sola unità (algoritmi gerarchici scissori); oppure gli algoritmi non gerarchici che cercano il modo migliore di raggruppare le unità in k gruppi.
Generalmente gli algoritmi gerarchici vengono usati quando l’insieme delle unità da classificare non è troppo numeroso, perché l’algoritmo ha una forte complessità computazionale e il risultato stesso è interpretabile solo per un numero non elevato di unità. In aggiunta questo tipo di algoritmo riesce a dare informazioni dettagliate sulla dinamica della formazione dei gruppi.

Metodi di classificazione In generale, per gli algoritmi gerarchici valgono le condizioni: a) sono considerati tutti i livelli di distanze d non negative. b) i gruppi che si ottengono ad un certo livello di distanza sono contengono quelli ad
un livello di distanza inferiore. In pratica, un algoritmo gerarchico aggregativo, parte da una situazione in cui tutte le
n unità sono suddivise in n gruppi distinti formati da una sola unità. Nel passo successivo si aggregano i gruppi per i quali la distanza tra le unità è minima, formando così un raggruppamento con un numero minore di gruppi. Si ripete il procedimento aggregando via via tutti i gruppi fino ad arrivare ad un solo gruppo contenente tutte le unità.
Viceversa, per un algoritmo scissorio il procedimento è capovolto.

Metodi di classificazione Una rappresentazione grafica efficace degli algoritmi
gerarchici è costituita dal famoso DENDROGRAMMA.
Esso mostra come si possono considerare i gruppi che man mano si formano a seconda del livello di distanza tra le unità considerate. Ma mentre la distanza tra le unità dipende solo dal particolare indice di distanza scelto, quella tra gruppi va definita in maniera specifica e, a seconda del tipo di distanza tra gruppi che si sceglie, si ottiene un diverso metodo di classficazione.
Metodi di classificazione Altri dendrogrammi

Metodi di classificazione Alcuni metodi di classificazione gerarchica, distinti secondo il tipo di distanza tra
gruppi scelta, sono: Metodo del legame medio: i gruppi si formano man mano che varia la distanza media
tra le unità in essi comprese. Metodo del centroide: i gruppi si formano man mano che varia la distanza da un
centroide ottenuto come media delle unità del gruppo Metodo della mediana: i gruppi si formano man mano che varia la distanza dalla
mediana del gruppo Metodo del legame singolo: i gruppi si formano aggiungendo di volta in volta l’unità
più vicina ad una delle unità del gruppo già formato. Metodo del legame completo: i gruppi si formano aggiungendo di volta in volta l’unità
più vicina a tutte le unità già presenti nel gruppo

Metodi di classificazione Metodo del legame singolo o delle unità più vicine Quando si vuole catturare la struttura dei dati ma la forma
dei gruppi non è esattamente sferica, o almeno si presume che non lo sia, questo metodo è particolarmente adatto.
Nella sua formulazione aggregativa si impone inizialmente che ognuna delle n unità statistiche formi un gruppo e l’algoritmo termina quando tutte le unità sono raggruppate in un unico gruppo. Al passo 1 dell’algoritmo si cercano le due unità meno distanti e si uniscono in un solo gruppo, lasciando invariati gli altri. Se più di una coppia presenta la distanza minima si formano più gruppi di due unità.

Metodi di classificazione Metodo del legame singolo o delle unità più vicine A questo punto si ricalcola la matrice delle distanze sostituendo alle unità i gruppi
appena formati. Per calcolare la distanza tra un’unità e un gruppo formato da una coppia di unità i e j si assume che la distanza tra la coppia e un’altra unità k sia la minore tra le distanze tra i e k e tra j e k
d(i,j),k)=min(dik; djk) Analogamente, anche la distanza tra due coppie è definita come il minimo delle
distanze delle unità prese a due a due d(i,j),(r,s)=min(dir; dis; djr; djs)
Poi si continua fondendo insieme i cluster e ricalcolando di volta in volta le distanze, fino ad ottenere un unico cluster con tutte le unità iniziali.

Metodi di classificazione Metodo del legame singolo o delle unità più vicine Esempio. Supponiamo di classificare con il metodo del legame singolo 5 unità la
cui matrice delle distanze è esposta qui a fianco. Si individuano innanzi tutto le due unità meno distanti. Esse sono le unità a e b. Si forma pertanto la prima coppia. Si ricalcola la matrice delle distanze sostituendo alle unità a e b la coppia (a,b). La distanza di ciascuna altra unità da questa coppia è definita come la distanza minima tra a e l’altra unità o b e l’altra unità.
Ad esempio d(a, b),c=min(dac; dbc)=min(6, 5)=5 d(a, b),d=min(dad; dbd)=min(10, 9)=9 d(a, b),e=min(dae; dbe)=min(9, 8)=8 Questa nuova matrice delle distanze serve a ripetere il procedimento. Si
individua ancora la distanza minore, che è quella tra d ed e, si forma un’altra coppia e si ricalcola nuovamente la matrice delle distanze.
a b c d e
a 0 2 6 10 9
b 0 5 9 8
c 0 4 5
d 0 3
e 0
(a,b) c d e
(a,b) 0 5 9 8
c 0 4 5
d 0 3
e 0
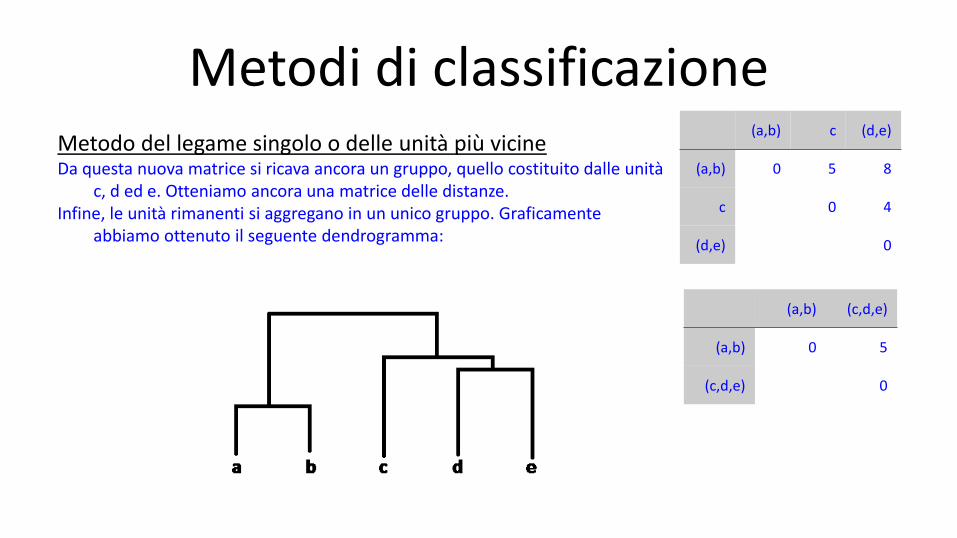
Metodi di classificazione Metodo del legame singolo o delle unità più vicine Da questa nuova matrice si ricava ancora un gruppo, quello costituito dalle unità
c, d ed e. Otteniamo ancora una matrice delle distanze. Infine, le unità rimanenti si aggregano in un unico gruppo. Graficamente
abbiamo ottenuto il seguente dendrogramma:
(a,b) c (d,e)
(a,b) 0 5 8
c 0 4
(d,e) 0
(a,b) (c,d,e)
(a,b) 0 5
(c,d,e) 0

Metodi di classificazione Metodo del legame singolo o delle unità più vicine Dal dendrogramma si vede come il gruppo (a,b) sia quello che si forma per primo, cioè ad una distanza
minore. Si tratta di un gruppo molto coeso, cioè composto di unità particolarmente simili tra loro. Poi si forma il gruppo (d,e) e infine si aggrega c a questo gruppo. Se tracciamo delle linee orizzontali, contando il numero di barre verticali che esse attraversano, possiamo contare il numero di gruppi che si sono formati a quel livello di distanza.

Metodi di classificazione Metodo del centroide o del legame medio Anche in questo caso si procede per passi successivi a partire dalla matrice delle distanze per arrivare ad una classificazione finale. Ad ogni passo, però, cambia il modo di definire la distanza tra un gruppo ed una unità; in questo caso si definisce la distanza tra un gruppo ed una unità come la distanza tra quell’unità ed una opportuna media. Se parliamo del metodo del centroide la distanza da calcolare è quella con il centro delle unità appartenenti al gruppo; viceversa, nel metodo del legame medio si calcola la media delle distanze delle unità del gruppo Esempio. Supponiamo di classificare con il metodo del legame medio le unità a, b, c, d, e dell’esempio precedente. Riprendiamo la matrice delle distanze già vista. anche in questo caso le unità più vicine sono a e b. Uniamole in un gruppo e ricalcoliamo la matrice delle distanze.
a b c d e
a 0 2 6 10 9
b 0 5 9 8
c 0 4 5
d 0 3
e 0

Metodi di classificazione Metodo del legame medio Stavolta la distanza si trova facendo una media. d(a, b),c=media(dac; dbc)=(6+5)/2=5,5 d(a, b),d=media(dad; dbd)=(10+9)/2=9,5 d(a, b),e=media(dae; dbe)=(9+8)/2=8,5 Al passo successivo si uniscono le unità d ed e, e si calcolano di nuovo le
distanze. d(a, b),(d,e)=media(d(a,b),d; d(a,b),e)=(9,5+8,5)/2=9 d(d, e),c=media(ddc; dec)=(4+5)/2=4,5 Infine l’unità c si aggrega al gruppo (d,e), prima dell’aggregazione di tutte le
unità nello stesso gruppo. Il dendrogramma in questo caso non è diverso da quello già visto prima.
(a,b) c d e
(a,b) 0 5,5 9,5 8,5
c 0 4 5
d 0 3
e 0
(a,b) c (d,e)
(a,b) 0 5,5 9
c 0 4,5
(d,e) 0

Metodi di classificazione I metodi che abbiamo visto fino ad ora sono di tipo gerarchico aggregativo e il loro risultato può essere rappresentato con un dendrogramma. Questa rappresentazione grafica però non fornisce una sola partizione dei dati, ma ne da una serie in successione. A noi rimane il problema di selezionare, attraverso l’utilizzo di linee che attraversano il dendrogramma, il numero di gruppi che si desiderano ottenere. Questo è un problema aperto perché fino ad ora non sono stati ideati metodi univoci per posizionare tali linee. A volte si sceglie di tagliare in modo che i gruppi abbiano un numero di unità né eccessivamente grande né eccessivamente piccolo, ma questo dipende dal particolare caso in esame. Inoltre a volte si ricorre ad una standardizzazione dei dati originali in modo da ottenere cluster che non dipendono dalle medie dei fenomeni analizzati.

Metodi di classificazione Metodi non gerarchici
Sono metodi di classificazione che forniscono una partizione dei dati in un numero di
gruppi che dobbiamo decidere prima di classificare i dati. DI solito anche in
questo caso si tratta di algoritmi aggregativi che nei passi successivi cercano di
migliorare la partizione ottenuta, ma il numero di gruppi è definito una sola volta
e non cambia.
L’inizializzazione dell’algoritmo avviene indicando g centri di partenza intorno a cui aggregare le unità. A differenza dei metodi gerarchici, l’assegnazione
di un oggetto ad un cluster non e’ irrevocabile. Ovvero le unità vengono riassegnate
ad un diverso cluster se l’allocazione iniziale risulta inappropriata.
Anche in questo caso esistono diversi algoritmi.

Metodi di classificazione Metodi non gerarchici
Il metodo non gerarchico più noto è quello delle k-medie (K-MEANS). Esso considera
all’inizio come centri intorno a cui aggregare i gruppi, le prime k unità della matrice
dei dati. Ad esse associa, formando k gruppi, le unità che si trovano più vicine a
ciascuna. Poi ricalcola le medie dei gruppi e le utilizza nel secondo passo come centri
intorno a cui aggregare i gruppi. In questo momento alcune unità che all’inizio erano
state assegnate ad un gruppo possono cambiare gruppo. L’algoritmo continua fino a
che nessuna unità cambia più gruppo, quindi fino a che non si raggiunge l’ottimo.
E’ da notare che talvolta questo ottimo non è l’ottimo globale, cioè l’algoritmo può
fallire il suo obiettivo. Per questo talvolta si ripete più volte cambiando le prime k
unità in modo da confrontare i risultati e prendere quelli che si verificano più volte.