master's thesis of turan yuksel - middle east technical...
TRANSCRIPT

PARTIAL ENCRYPTION OF VIDEO FOR COMMUNICATION AND STORAGE
A THESIS SUBMITTED TOTHE GRADUATE SCHOOL OF NATURAL AND APPLIED SCIENCES
OFTHE MIDDLE EAST TECHNICAL UNIVERSITY
BY
TURAN YUKSEL
IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF
MASTER OF SCIENCE
IN
THE DEPARTMENT OF COMPUTER ENGINEERING
SEPTEMBER 2003

Approval of the Graduate School of Natural and Applied Sciences.
Prof. Dr. Canan OzgenDirector
I certify that this thesis satisfies all the requirements as a thesis for the degreeof Master of Science.
Prof. Dr. Ayse KiperHead of Department
This is to certify that we have read this thesis and that in our opinion it is fullyadequate, in scope and quality, as a thesis for the degree of Master of Science.
Assoc. Prof. Dr. GozdeBozdagı AkarCo-Supervisor
Prof. Dr. Fatos T. Yarman VuralSupervisor
Examining Committee Members
Prof. Dr. A. Enis Cetin
Prof. Dr. Fatos T. Yarman Vural
Assoc. Prof. Dr. Gozde Bozdagı Akar
Dr. Cevat Sener
Dr. Meltem Turhan Yondem

ABSTRACT
PARTIAL ENCRYPTION OF VIDEO FOR COMMUNICATION AND STORAGE
Yuksel, Turan
M.S., Department of Computer Engineering
Supervisor: Prof. Dr. Fatos T. Yarman Vural
Co-Supervisor: Assoc. Prof. Dr. Gozde Bozdagı Akar
SEPTEMBER 2003, 66 pages
In this study, a new method is proposed to protect video data through partial en-
cryption. Unlike previous methods, the bit rate of the encrypted portion can be
controlled. In order to accomplish this task, a simple model for the time to break
the partial encryption by a chipertext-only attack is defined. Then, the encrypted
bit budget distribution strategy maximizing the time subject to the bitrate constraint
is found. An algorithm to estimate the model parameters is constructed and it is
then implemented over an MPEG-4 natural video codec together with the bit budget
distribution strategy. The encoder is tested with various image sequences and the
output is analyzed.
In addition to the developed video encryption method, a file format is defined to
store encryption related side information.
Keywords: Video Encryption, MPEG-4, IPMP.
iii

OZ
ILETISIM VE SAKLAMA ICIN KISMI VIDEO SIFRELEME
Yuksel, Turan
Yuksek Lisans, Bilgisayar Muhendisligi Bolumu
Tez Yoneticisi: Prof. Dr. Fatos T. Yarman Vural
Ortak Tez Yoneticisi: Doc. Dr. Gozde Bozdagı Akar
EYLUL 2003, 66 sayfa
Bu calısmada, video verisinin kısmi sifreleme yoluyla korunması icin yeni bir yontem
onerilmistir. Daha onceki yontemlerden farklı olarak, sifrelenmis kısmın boyutu-
nun kontrolu saglanmıstır. Bunu saglayabilmek icin kısmi sifrelemeyi kırmak icin
gereken zamanın basit bir modeli tanımlanmıstır. Sifrelenen kısmın buyuklugu kısıtı
altında modeli enbuyukleyen bit butcesi dagıtımı stratejisi bulunmustur. Calısma,
model parametrelerinin kestirimi icin de bir algoritma onermektedir. Algoritma ve
sifrelenmis bit butcesi dagıtımı stratejisi bir MPEG-4 dogal video kodlayıcı/cozucu
uzerinde gerceklenmis ve cesitli imge dizilerindeki bit dagılımı gozlenmistir.
Video sifreleme yonteminin yanı sıra, calısmada sifreleme yan bilgilerinin saklan-
ması icin bir dosya bicimi de tanımlanmıstır.
Anahtar Kelimeler: Video Sifreleme, MPEG-4, IPMP.
iv

ACKNOWLEDGMENTS
I am grateful to my advisors Dr. Fatos T. Yarman Vural and Dr. Gozde Bozdagı
Akar for their unique support. My family-at-large and friends (in alphabetical order)
Nafiz, Murat, Pınar, Faruk, Caglar, Emre, Oguz, Barıs, Ersan and Ulas get equiva-
lent credits for their academic and motivational support. My thesis implementation
is based on MPEG-4 reference software by MoMuSys and Microsoft teams, which
eliminated the need to write a from-scratch MPEG-4 natural video codec, although
making me feel regret at times.
v

TABLE OF CONTENTS
ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iii
OZ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iv
ACKNOWLEDGMENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
TABLE OF CONTENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi
LIST OF TABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ix
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . x
LIST OF ABBREVIATIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xii
1 INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Contributed Work . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 BACKGROUND ON VIDEO COMPRESSION AND ENCRYPTION . . 4
2.1 Video Compression . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 MPEG-4 Natural Video Coding Standard . . . . . . . . . . . . . 6
2.2.1 Natural Video Coding Tools Provided by MPEG-4 . . 6
2.2.1.1 Shape Coding . . . . . . . . . . . . . . . . 7
2.2.1.2 Motion Estimation and Compensation . . 8
2.2.1.3 Texture Coding . . . . . . . . . . . . . . . . 9
2.2.1.4 Sprites . . . . . . . . . . . . . . . . . . . . . 10
2.2.1.5 Scalable Video . . . . . . . . . . . . . . . . 11
2.2.1.6 Static Textures . . . . . . . . . . . . . . . . 12
2.2.2 Error Resillience and Concealment Tools . . . . . . . 13
2.2.3 MPEG-4 Visual Profiles and Levels . . . . . . . . . . . 14
2.3 MPEG-4 Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 Cryptography and Cryptanalysis . . . . . . . . . . . . . . . . . 16
vi

2.4.1 Cryptosystems . . . . . . . . . . . . . . . . . . . . . . 16
2.4.2 Cryptanalysis . . . . . . . . . . . . . . . . . . . . . . . 17
2.5 Image and Video Encryption . . . . . . . . . . . . . . . . . . . . 18
2.5.1 Application of encryption in the encoding process . . 18
2.5.2 Syntactical entities for encryption . . . . . . . . . . . . 19
2.5.3 Combined image encryption and compression frame-works . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.5.4 Data analysis and attacks to core chiper . . . . . . . . 21
2.5.5 Error concealment attacks . . . . . . . . . . . . . . . . 21
2.5.6 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 PROPOSED ENCRYPTION TECHNIQUE . . . . . . . . . . . . . . . . . 23
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2 Dependency Through Error Propogation . . . . . . . . . . . . . 23
3.3 The Bit Allocation Strategy . . . . . . . . . . . . . . . . . . . . . 24
3.4 Levels and Estimation of ci . . . . . . . . . . . . . . . . . . . . . 27
3.5 Encryption Strategy . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.6 Encryption Side-Information . . . . . . . . . . . . . . . . . . . . 30
3.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4 EXPERIMENTS AND RESULTS . . . . . . . . . . . . . . . . . . . . . . . 32
4.1 Implementation and Test Platform . . . . . . . . . . . . . . . . . 32
4.2 Implementation of SET-WEIGHTS and Budget Distribution . . 32
4.2.1 Core Chiper . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2.2 Restrictions of the Implementation . . . . . . . . . . . 33
4.3 Test Sequences . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.4 Encoding Parameters . . . . . . . . . . . . . . . . . . . . . . . . 34
4.5 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . 35
4.5.1 Bit Distribution Plots . . . . . . . . . . . . . . . . . . . 35
4.5.2 Encryption Ratios . . . . . . . . . . . . . . . . . . . . . 56
4.5.3 Bit Allocation with Changing GOV size and Bitrate . 57
4.5.4 Side Information Characteristics . . . . . . . . . . . . 58
4.5.5 Perceptual Quality . . . . . . . . . . . . . . . . . . . . 59
vii

5 CONCLUSION AND FUTURE WORK . . . . . . . . . . . . . . . . . . 61
5.1 Features of the Proposed Method . . . . . . . . . . . . . . . . . 61
5.2 Main Drawbacks . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.3 Suggested Future Work . . . . . . . . . . . . . . . . . . . . . . . 62
REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
viii

LIST OF TABLES
TABLE
3.1 Algorithm SET-WEIGHTS . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2 IPMP SelectiveDecryptionMessage stucture, specific to the proposed
system . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.1 Bit distribution for Carphone at 1700 bits/frame encryption, 12-VOPGOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.2 Bit distribution for Foreman at 1700 bits/frame encryption, 12-VOPGOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.3 Bit distribution for Foreman at 2500 bits/frame encryption, 12-VOPGOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.4 Bit distribution for Foreman at 3400 bits/frame encryption, 12-VOPGOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.5 Bit distribution for Foreman at 4200 bits/frame encryption, 12-VOPGOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.6 Bit distribution for Foreman at 5000 bits/frame encryption, 12-VOPGOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.7 Bit distribution for Miss America at 1700 bits/frame encryption, 12-VOP GOVs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.8 Length of side information for various sequences . . . . . . . . . . . . . 58
ix

LIST OF FIGURES
FIGURES
2.1 Block diagram for encoding process. . . . . . . . . . . . . . . . . . . . . 52.2 Some of the possible prediction configurations for temporally scalable
video . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.3 Decoder elements and IPMP control points . . . . . . . . . . . . . . . . 16
3.1 Macroblock interdependence . . . . . . . . . . . . . . . . . . . . . . . . 243.2 Error propogation from frame 268 to frame 271 of foreman . . . . . . . . 243.3 VOP dependence stacks . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.4 Referenced block areas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.1 Inter (above) and intra (below) bit distributions in Carphone with 1700bits/frame encryption and 12-VOP GOVs . . . . . . . . . . . . . . . . . 36
4.2 Inter (above) and intra (below) bit distributions in Carphone with 2500bits/frame encryption and 12-VOP GOVs . . . . . . . . . . . . . . . . . 37
4.3 Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 12-VOP GOVs . . . . . . . . . . . . . . . . . 38
4.4 Inter (above) and intra (below) bit distributions in Carphone with 4200bits/frame encryption and 12-VOP GOVs . . . . . . . . . . . . . . . . . 39
4.5 Inter (above) and intra (below) bit distributions in Carphone with 5000bits/frame encryption and 12-VOP GOVs . . . . . . . . . . . . . . . . . 40
4.6 Inter (above) and intra (below) bit distributions in Carphone encoded at384 kbps with 4200 bits/frame encryption . . . . . . . . . . . . . . . . . 41
4.7 Inter (above) and intra (below) bit distributions in Carphone encoded at576 kbps with 4200 bits/frame encryption . . . . . . . . . . . . . . . . . 42
4.8 Inter (above) and intra (below) bit distributions in Carphone encoded at768 kbps with 4200 bits/frame encryption . . . . . . . . . . . . . . . . . 43
4.9 Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 24-VOP GOVs . . . . . . . . . . . . . . . . . 44
4.10 Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 36-VOP GOVs . . . . . . . . . . . . . . . . . 45
4.11 Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 48-VOP GOVs . . . . . . . . . . . . . . . . . 46
4.12 Inter (above) and intra (below) bit distributions in Foreman with 3400bits/frame encryption and 24-VOP GOVs . . . . . . . . . . . . . . . . . 47
4.13 Inter (above) and intra (below) bit distributions in Miss America with3400 bits/frame encryption and 24-VOP GOVs . . . . . . . . . . . . . . 48
x

4.14 Distribution of the segment lengths for Carphone, Foreman and MissAmerica, encrypted at 1700 bits/frame, 24-VOP GOVs. y-axis is loga-rithmically scaled and samples with segment lengths greater than 2500are discarded. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.15 Foreman original (left) and encrypted at 2500 bits/frame (right), frame184 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.16 Miss America original (left) and encrypted at 1700 bits/frame (right),frame 89 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
xi

LIST OF ABBREVIATIONS
2-D Two-dimensional
3-D Three-dimensional
4:2:0 Color subsampling technique inwhich luminance component aresampled at full rate whereas chromi-nance components are sampledat half (horizontal and vertical)resolution.
AC Non-DC (coefficient of the trans-formation)
AES Advanced Encryption Standard
BIFS Binary Format for Scenes
CAE Context-based Arithmetic En-coding
CIF Common Image Format (352 by288)
DC The lowest frequency (coefficientof the transformation)
DCT Discrete Cosine Transform
DES Data Encryption Standard
DVB Digital Video Broadcast
fps Frames Per Second
GOP Group of Pictures
GOV Group of Video Object Planes
iDCT Inverse DCT
IEC International Electrotechnical Com-mission
IPMP Intellectual Property Manage-ment and Protection
ISO International Standards Orga-nization
ITU International TelecommunicationsUnion
JPEG Joint Photographic Experts Group
MB Macroblock
MPEG Moving Picture Experts Group
MV Motion Vector
MVD Motion Vector Difference
PSNR Peak Signal to Noise Ratio
QCIF Quarter CIF (176 by 144)
RGB Color space in which colors arerepresented as combinations ofred, green and blue light.
RSA Rivest, Shamir and Adleman (thenames of the inventors of thealgorithm)
RVLC Reversible Variable Length Cod-ing/Codeword
SAD Sum of Absolute Differences
SPIHT Set Partitioning in HierarchialTrees
VLC Variable Length Coding/Codeword
VO Video Object
VOL Video Object Layer
VOP Video Object Plane
VS Video Object Sequence
YUV Color space in which colors arerepresented in one luminance(Y) and two chrominance (U andV) components
xii

CHAPTER 1
INTRODUCTION
1.1 Motivation
Advances in compression, delivery and presentation technologies of digital video in
recent years have broadened the share of digital video in (audio)visual communica-
tion and entertainment, changing the ways that the end users create, access, store
and copy video. In contrast to analog technologies, the digital technology offers
• Computer-aided content creation and manipulation,
• Transmission over computer networks,
• Storage and in computer environment,
• Production of identical copies without any specialized hardware.
However, the listed benefits bring a problem on; access control. Video is transmitted
over insecure networks, where a malicious party can acquire any packet, including
those carrying private communication or commercially valued entertainment data.
The network, in particular the Internet, also allows peers to share their files, result-
ing exponentially increasing number of copies, a phenomenon, called superdistribu-
tion[1].
The path between the content creator and the viewer must be secured, so that
the only viewers that are authorized by the content creator (or presenter) can access
the video, which corresponds to preservation of privacy and prevention of piracy in
1

one-to-one communication and broadcasting cases, respectively. It is also desirable
that the viewer must be able to produce copies as long as a policy established by the
content creator permits.
Encryption of video, combined with access control logic implemented in the player
is essential to prevent unwanted content acquisition. There are a number of issues
to be considered while designing an access control mechanism, as pointed out by
previous works [2, 3]:
1. Encryption (and decryption) of a video stream entirely takes considerable amount
of time, which can be comparable to the decoding time. Therefore, only a care-
fully selected portion of video can be encrypted, to limit the cost of the opera-
tion.
2. The protection level for the content must be identified. Considering the bussi-
ness of copyrighted items trade, in particular entertainment, the increase in
piracy boosts the demand for legitimate items1. Therefore, paranoid protection
may offend the end user and reduce the demand, on the other hand a loose
protection mechanism may harm the bussiness setup, reducing the revenues.
3. The protected video may have a limited lifetime, in the sense that it is of no
value after some time on. For example, piracy makes sense if a protected live
soccer broadcast can be broken until excrepts from the match are broadcast
publicly in the succeeding sports programs. Therefore a protection scheme that
needs just more time than the lifetime of the content is robust.
4. Difficulty of breaking an encryption mechanism is usually estimated consid-
ering current computational resources. Upgrades or reconfigurations are re-
quired to keep them robust.
(1) is a well-studied problem, in the sense that different syntactical entities of
the video stream are tried for partial encryption, without considering any of (2,3).
Examples of such studies are discussed in Section 2.5. (4) is a problem of design at a
coarser level and solutions do exist; MPEG-4 IPMP is an example, which is discussed
in Section 2.3.
1 The curious reader may have a look at [4] and works referenced there.
2

1.2 Contributed Work
This work proposes a method where the video stream is partially encrypted and the
distribution of encrypted bits over different syntactical entities of the video stream is
optimized constrained to the number of encrypted bits, based on a simple model to
assess the time to break the protection so that the average time to break the encryp-
tion over a temporal sample is maximized. Therefore, the developed method partial
encryption method can be configured in a straightforward way, regarding the value
of the data, providing solutions for (2) and (3).
A method to estimate the parameters of the model is also proposed. The estima-
tion method produces parameters depending on the video stream to be encrypted
and it can be used simultaneously with encoding.
Additionally, the layout of the encryption side information conforming to MPEG-
4 IPMP Final Proposed Draft Ammendment is described.
1.3 Organization
The succeeding chapters of this thesis are organized as follows: Chapter 2 gives back-
ground on how digital video is encoded compactly, focusing on MPEG-4 compres-
sion tools. Chapter 3 proposes a model for the cryptanalytic complexity of a MPEG-4
natural video stream and the bit budget distribution maximizing the time required
to break the encryption is found, constrained by the number of bits to be encrypted.
The side information format is also presented in that chapter. Chapter 4 contains ex-
perimental estimation the model parameters and quantitative information regarding
the encrypted video streams. The thesis is concluded in Chapter 5, with directions
for future studies in this area.
The CD includes the extended codec source files, scripts that make up the exper-
imental setup and raw video sequences used as test data.
3

CHAPTER 2
BACKGROUND ON VIDEO COMPRESSION AND
ENCRYPTION
This chapter describes state of the art video compression and encryption algorithms
to complement the succeeding chapters, concluding with a summary of previously
developed encryption methods for video.
2.1 Video Compression
Video data requires large amount of space for storage in its raw form. For exam-
ple, a one minute sequence of 352x288 RGB frames at 25fps is approximately 430
megabytes. Fortunately, a large amount of spatial and temporal redundancy resides
in such raw sequences, which can be reduced by compression. The succeeding para-
graphs of this section describes the source of redundancies and the basic approaches
used in current video compression techniques.
The human visual system is less sensitive to the chrominance information than
the luminance information, since there are more luminance sensing cells than chromi-
nance sensing cells in the retina. Therefore, one can downsample the chrominance
information in every individual frame to reduce the amount of data to represent a
perceptually equivalent frame [5].
A well-known approach for compression is to eliminate the spatial redundancy
by transform coding, which involves transforming the image.The image in the trans-
form domain can be approximated with all zero, but a few nonzero pixels. Dis-
4

Raw Video
Motion Estimation Transform Coding Quantization Entropy Coding
Encoded Video
Figure 2.1: Block diagram for encoding process.
crete cosine transform (DCT) and Wavelet transform are the most commonly used
transformations[6]. Although inferior in compression, DCT is more commonly used
than Wavelet transform since blockwise DCT of the image is more suitable for block-
based motion estimation and it is also more popular (and economic) than alternative
motion estimation methods.
Consecutive frames of a video sequence are usually similar (except for the loca-
tions where the scene changes), with slight differences due to motion. The redun-
dancies due to this similarity can be eliminated by modeling the motion.
Any source of symbols can be compressed by entropy coding. The symbols are
coded in a way that a symbol is mapped to a codeword with the length depending
on the frequency of the symbol. Most of the video coding schemes prefer using prefix
codes with predefined symbol to codeword mappings to eliminate the overhead due
to transmission of the tables. An alternate method is arithmetic coding [7], which
maps the string to be encoded to a number in the subinterval [0, 1] using the frequen-
cies of symbols to be encoded. The optimal codeword assignment is achieved with
arithmetic coding, but it requires more computational power, compared to prefix
coding with predefined tables.
The entire process of video encoding can be summarized as a block diagram, as
shown in Figure 2.1.
One can encode the video a scalable encoding so that a range of decoders with dif-
ferent capabilities can decode the video in different qualities and/or spatiotemporal
resolutions. Scalable encoding involves encoding a basic bitstream and enhancement
bitstreams, depending on the basic bitstream[5].
5

2.2 MPEG-4 Natural Video Coding Standard
MPEG-4 is a standard for coding audiovisual objects, enables re-use of audiovisual
content, mixtures of natural and synthetic content and spatiotemporal arrangements
of objects to form scenes. Thus, natural video coding tools were designed to be used
with such compositions as well as ordinary rectangular image sequences. Most of
these tools are specialized and practically applicable for a number of configurations.
For example, robust and fast segmentation algorithms are required to encode non-
rectangular video objects from a nature scene, on the other hand it’s much easier
with chroma keying in a studio environment. The remainder of this section is an
overview of natural video coding in MPEG-4 and a description of the bitstream syn-
tax, as a summary of [8] and [9].
2.2.1 Natural Video Coding Tools Provided by MPEG-4
The audiovisual object is the basic entity in an MPEG-4 scene, which is described in
the way specified in ISO/IEC 14496-1, as well as the transmission of the video object
to the decoder. Each video object is characterized by spatial and temporal informa-
tion in the form of texture, motion and shape. Texture is the spatial and motion is
the temporal relation between the video samples and the spatiotemporal boundary
of the samples is put by the shape information. An MPEG-4 scene may consist of one
or more video objects. The visual bitstream provides a hiearchial description of a vi-
sual scene from video objects down to temporal samples of the video objects and the
decoder can access any entity in the hierarchy by seeking certain codewords called
start codes, which are not generated elsewhere in the bitstream. The hierarchy levels
with their commonly used abbreviations are:
• Visual Object Sequence (VS): The sequence of 2D or 3D natural or synthetic ob-
jects.
• Video Object (VO): A video object corresponds to the atomic entity that has the
means of access (by seeking and browsing) and manipulation (by cuts, pastes
and relocations in the scene).
• Video Object Layer (VOL): Each VO can be encoded in non-scalable (single layer)
or scalable (multi layer) way, depending on the application. The VOL provides
6

support for scalability. There are two types of VOLs, the VOL with full MPEG-
4 functionality and the reduced functionality VOL, also called the VOL with
short headers. The latter provides bitstream compatibility with baseline H.263,
an ITU standard for video coding.
• Video Object Plane (VOP): A VOP is a temporal sample of a video object. VOPs
can be encoded independently from each other or dependent on other VOPs by
motion compensation. A conventional video frame can be represented with a
rectangle-shaped VOP.
• Group of Video Object Planes (GOV): GOVs group video object planes to provide
points in the bitstream where video object planes are encoded independently
from each other. Therefore GOVs provide random access points. GOVs are
optional.
A video object plane is divided into macroblocks which contain a section of the lu-
minance(Y) component and spatially subsampled chrominance components(Cr and
Cb). In the MPEG-4 visual standard, a macroblock is a 16x16 section of a VOP con-
taining four luminance and two chrominance blocks of size 8x8 pixels, which is also
referred as 4:2:0 subsampling, with associated motion and shape information. The
texture in each 8x8 block is encoded using DCT.
2.2.1.1 Shape Coding
MPEG-4 provides support shape representation in bitmaps for both binary and grayscale
shapes. In order to code the binary shape for a nonrectangular VOP, the VOP is
bounded by a rectangle which can be chosen so that it contains the minimum num-
ber of 16x16 nontransparent blocks. The shape compression algorithm provides sev-
eral modes to encode a shape block; the basic tool is Context-based Arithmetic En-
coding (CAE) algorithm, which involves estimation of a context number computed
from spatiotemporally neighboring pixels to initialize the arithmetic coder. Motion
compensation can be used to encode shape blocks depending on previously encoded
blocks. Coding with motion compensation and without motion compensation use
different variants of CAE; namely InterCAE and IntraCAE, respectively. The motion
vectors themselves are differentially coded. Every shape block can be coded in one
7

of these ways:
• Entire block is transparent or opaque. No shape coding is required. Texture is
coded for opaque blocks.
• The block is coded using IntraCAE without use of past information.
• Motion vector difference (MVD) for the shape is zero, but the block is not up-
taded.
• The block update is coded with InterCAE. MVD may be zero or nonzero.
• MVD is nonzero and the block is not coded.
Grayscale shapes correspond to the notion of alpha plane in computer graphics.
MPEG-4 provides syntax to code 8-bit grayscale shapes where a value of 0 corre-
sponds to a completely transparent pixel, a value of 255 corresponds to a completely
opaque pixel and intermediate values correspond to different values of transparency.
Grayscale shapes are encoded in a similar way to that of textures, with use of mo-
tion compensation and DCT; only lossy coding of grayscale shapes is allowed. The
grayscale shape coding also makes use of binary shape coding to code the regions
where grayscale shape is nonzero; the DCT coded grayscale shape belongs to this
coded region.
2.2.1.2 Motion Estimation and Compensation
The motion estimation and compensation tools in the MPEG-4 standard are similar to
those used in other video coding standards such as MPEG-2 and H.263 [5], adapting
the block-based techniques to the VOP structure. MPEG-4 provides three modes to
encode an input VOP:
• A VOP can be encoded independent from any other VOP and called to be an
intra VOP (I-VOP). The first coded VOP should be an I-VOP.
• A VOP may be predicted from another previously decoded VOP. Such VOPs
are called predicted VOPs (P-VOP).
• A VOP may be bidirectionally predicted from a past VOP and a future VOP.
(B-VOP) B-VOPs may only be predicted from I-VOPs or P-VOPs
8

When a VOL contains B-VOPs, VOPs are rearranged and then transmitted so that
the decoder needs to keep at most three VOPs at a time. If a B-VOP is received, it’s
decoded directly. If a P-VOP or I-VOP is received, the decoder outputs the frame
constructed from the previous I-VOP or P-VOP.
Encoding P-VOPs and B-VOPs require motion estimation. Motion estimation is
performed only for macroblocks in the bounding box of the VOP. If a macroblock is
entirely within a VOP, the motion vector is estimated minimizing the sum of absolute
difference (SAD) of the 16x16 macroblock as well as its 8x8 luminance blocks in ad-
vanced prediction mode, which results in a motion vector for the entire macroblock
and a vector per luminance block. The motion vectors represent the translations of
the blocks, i.e. the motion estimation model is f (x, y, t) = f (x + c, y + c, t′) + ε(x, y, t),
where f (x, y, t) is the pixel (x, y) at time t, ε is the estimation error and c is the trans-
lation parameter. c is constant within a macroblock, or within the 8x8 luminance
blocks of a macroblock in advanced prediction mode. Motion vectors are computed
to half-pixel precision. Motion vectors are estimated using a modified block match-
ing technique for the macroblocks that are partially in the VOP.
A motion vector is predictively coded based on three previously coded blocks.
Then VLC word, corresponding to this differential, is placed into the bitstream.
2.2.1.3 Texture Coding
Texture information of a video object plane is implicitly represented by the luminance
(Y) and two chrominance (Cb and Cr) channels of the video signal. In the case of an
I-VOP, texture is the luminance and chrominance components of the signal and it is
the residual error after motion compensation in B-VOPs and P-VOPs. In order to
encode the texture information, a 8x8 grid is superimposed on the VOP and blocks
of the grid are transformed using DCT. Blocks that entirely reside in the VOP are
directly transformed, on the other hand, boundary blocks are padded before DCT.
Blocks containing residual error after motion compensation are padded with zeros
and intra blocks are padded by the use of a low pass extrapolation filter.
Transformation of blocks are succeeded by quantization as a lossy compression
step, involving division of DCT coefficients by a quantization step size. The quanti-
zation step size can be held fixed within a block or changed in a way specified as a
9

quantization matrix.
Quantization step and quantized coefficients can be encoded by using prediction
from neighboring blocks. Prediction can be performed from either the block above
or the block left. The prediction direction is adaptive and selected in a direction,
depending the derivative of DC (the lowest frequency) coefficient on the horizontal
and vertical direction. Only the DC coefficient or first row/column of the AC (non-
DC) coefficients can be predicted.
Coefficients are ordered and coded based on the prediction direction, if there’s no
prediction a zigzag ordering is used. The zigzag ordering is then run-length encoded
using VLC. DC coefficient can be coded in the same way as AC coefficients, by using
a different VLC table or by using a fixed-length code. The last alternative is used in
encoding a bitstream with short headers.
2.2.1.4 Sprites
A sprite consists of the regions of a VO that are present in the scene throughout the
video segment, e.g. a panoramic background scene parts of which are visible in any
temporal sample of the VO. MPEG-4 allows sprite coding because it provides high
coding efficiency in cases like the example given. For any given time instant, the
background VOP can be extracted by warping and cropping the sprite appropriately.
The shape and texture of the background is encoded in the same way as that of an
I-VOP. MPEG-4 supports three modes of sprite encoding; basic, low-latency and scal-
able.
Basic encoding is encoding of the background sprite as an I-VOP and any other
VOPs as S-VOPs, which are VOPs coded dependent to the sprite and may be depen-
dent to another VOP. This I-VOP is not displayed, but it is stored in a sprite memory
and will be used by all the succeeding S-VOPs in the same VOL.
Since receiving a large I-VOP before starting the decoding process causes a delay,
a low latency sprite mode is also provided. In this case, an initial sprite sufficient to
reconstruct the first few VOPs is transmitted. Sprite “piece”s and “update”s can be
transmitted in succeeding S-VOPs. “piece”s are highly quantized replacements for
specified portions of the sprite and “update”s are residuals for specified portions of
the sprite. Sprite pieces in a VOP are terminated by either a “stop” signal, indicating
10

that all the sprite information for the VOL has been transmitted, or a “pause” sig-
nal, indicating that all the sprite information packed with the current VOP has been
transmitted.
Enhancements to sprites can also be encoded, as described in section 2.2.1.5.
2.2.1.5 Scalable Video
MPEG-4 offers both temporal and spatial scalability, which are meant to increase
temporal and spatial resolutions, respectively. Both methods are implemented using
more than one VOLs. A mid-processor connects the base layer decoder to the en-
hancement layer, which uses the base layer as a reference, performing any required
spatiotemporal conversions to be used to decode the enhancement layer. Finally,
the postprocessor combines the decoded layers prior to rendering. An enhancement
layer cannot provide both spatial and temporal enhancements at the same time; spa-
tial enhancements must be in the same temporal resolution as the base layer and
temporal enhancements must be in the same spatial resolution as the base layer.
Spatial scalability tools only support rectangular video objects. Base layer is en-
coded in the way described in preceeding subsections. The enhancement layer VOPs
in the enhancement layer can be encoded predictively depending on most recently
decoded enhancement VOP, most recent VOP of the reference layer, next VOP of the
reference layer and temporally coinciding VOP of the reference layer. In the last case,
no motion vectors are transmitted. Bidirectional prediction is also possible, allow-
ing prediction from four combinations of possible reference entities. Independently
coded VOPs are not allowed in enhancement layers, i.e. all VOPs in the enhancement
layer must be P-VOPs or B-VOPs.
Unlike spatial scalability tools, tools for temporal scalabilty suport nonrectangu-
lar layers and partial enhancements, e.g. a fast-moving car in an almost still scene
can be selected for enhancement. For P-VOPs, prediction from most recently de-
coded VOP of the same layer, most recent VOP of the reference layer or next VOP
of the reference layer is possible. B-VOPs can be predicted in three diffrerent refer-
ence configurations which are combinations of the possible references for P-VOPs. A
number of prediction configurations are illustrated in Figure 2.2. The arrows point
from the reference frames.
11

TemporalEnhancement
Base t=0 I
t=1 P
t=2 B
t=3 B
t=4 P
t=5 B
t=6 P
Figure 2.2: Some of the possible prediction configurations for temporally scalablevideo
2.2.1.6 Static Textures
MPEG-4 allows encoding of 2-D or 3-D meshes and static textures may be mapped on
the meshes. The way the textures are encoded provides a high degree of scalability
more than the DCT-based texture coding techniques mentioned previously. Static
texture coding technique is based on the wavelet transform. DC and AC bands of
the wavelet transform are coded separately and encoded using a zero-tree algorithm
and arithmetic coding.
Texture is separated into subbands by applying discrete wavelet transform to the
data. The number of decomposition levels can be adjusted on the encoder side. The
bitstream includes the information regarding whether the transform is an nteger or
floating-point transform and whether default filter banks or filter banks specified in
the bitstream is used. Wavelet transform allows a natural way of scalability; the more
bands the decoder processes, the more approximate the image is decoded. The low-
est resolution subband is called the DC subband and it’s coded using a predictive
scheme, depending on the horizontal and vertical derivatives of the coefficient. The
differential is then quantized and entropy coded using arithmetic coding. AC coeffi-
cients are encoded using the fact that most of the coefficients are zero and the zeroes
are correlated; a zero at a coarse scale means that zeroes are likely in the same spatial
position at finer scales, forming a tree. Special symbols are used to encode isolated
zeroes and zerotree roots; the latter indicates that the descendants in the tree are not
12

encoded. The formed symbol sequence is encoded using arithmetic coding. Pack-
etization of encoded data, which is the only error resilience tool provided for static
textures, is supported by MPEG-4 Version 2 only.
Static textures support only binary shapes in the same way as that of video en-
coding.
2.2.2 Error Resillience and Concealment Tools
Every undecrypted piece of bitstream is treated as a bitstream error by a standard
player. Therefore it is desired that the encryption scheme must be robust to any
concealment tool which is available due to the nature of the video stream.
Bit errors in VLC encoded data results loss of synchronization and the bitstream
till the next synchronization marker or start code cannot be decoded. In this way,
error is localized and precise localization results more correct decoding. MPEG-4
markers are placed into the bitstream so that the macroblocks between two resyn-
chronization markers are just above a predetermined threshold. In this way, data
is packetized so that each packet is equally important since they contain nearly the
same amount of compressed bitstream. A packet contains a variable number of mac-
roblocks, unlike the packetization schemes of H.263 or MPEG-2 where a number of
rows of macroblocks are packetized together. The resynchronization marker is fol-
lowed by the number of the first macroblock in the packet, its absolute quantization
scale, optionally redundant header information and the macroblocks in the packet.
The predictive coding used to code the macroblocks in a packet does not use predic-
tion information from other macroblocks.
In addition to the packet approach, MPEG-4 also adopts a second method called
fixed interval resynchronization. This method requires that VOP start codes and
resynchronization markers appear at only fixed locations in the bitstream, which
avoids most of the problems due to start code emulation. However, it has an over-
head of stuffing bits used to align the bitstream.
An error at the motion estimation residual encoded as texture can be concealed
assuming zero estimation error. In a similar way, errorneous motion vectors can
be concealed motion compensating with zero motion vectors. MPEG-4 provides an
encoding mode called data partitioning where motion and texture information in a
13

packet are separated by a marker, providing further error localization and a method
to conceal errors. MPEG-4 provides further error localization by use of reversible
VLC so that codewords can be decoded both in forward and reverse directions.
Another error resilience tool in MPEG-4 is inclusion of intra coded macroblocks
in non I-VOPs. The encoder can choose to encode a macroblock in intra mode if
motion prediction error exceeds a predetermined threshold. The technique is called
adaptive intra refresh.
2.2.3 MPEG-4 Visual Profiles and Levels
In order to classify the conformance of encoders, decoders and encoded bitstreams,
subsets of the standard which define conformance points, are defined by means of
profiles and levels. A profile is a subset of MPEG-4 coding tools and a level is the
restrictions on the parameters of the encoding tools, e.g. number of macroblocks per
second, bitrate etc. Profile and level information is signaled in the bitstream so that a
decoder can deduce whether it has the capability of processing the stream.
The Simple object is an error resilient rectangular natural video object of arbitrary
height/width ratio, developed for low bitrate applications. It uses I-VOPs and P-
VOPs with simple and inexpensive coding tools. Simple scalable object type is built
on top of simple, adding spatial and temporal scalability tools. Advanced simple object
type is also built on top of simple, by addition of B-VOP coding tools and interlaced
video support. Advanced simple profile is popular among video codecs for desktop
computers, such as DivX.
Core object type is also built on simple, by addition of tools to support binary
shapes and B-VOPs. N-Bit object type is built on core, by addition of support for pixel
depths in 4-12 bits range. Main object type supports sprites, interlacing and greylevel
shape, in addition to those supported by core.
Still textures are supported by scalable still texture profile and mapping of these
textures on 2D dynamic meshes is supported by animated 2D mesh profile. The inter-
ested readers in profiles and levels are directed to [9, 10].
14

2.3 MPEG-4 Systems
This section describes the systems layer of the standard, which defines the way that
audiovisual objects are delivered to the decoder in synchronization and the way that
a MPEG-4 scene is described. The systems layer also defines means of intellectual
property management and protection (IPMP) in MPEG-4. The standard only defines
control points for the IPMP tool and the structure of the container for IPMP data
including tool identification and the container for tool-specific data, permitting inte-
gration of proprieaty conditional acccess methods into the standard.
The final committee draft[11] does not specify a file format for MPEG-4, but a file
format based on that of QuickTime has been adopted later in an ammendment [12].
An interface for IPMP tools has also been added as an ammendment [13], in the same
way as in MPEG-2[14].
The components of the systems level is shown in Figure 2.3, which is adapted
from [11]. Demultiplexing framework acquires the elementary streams (ES), which
contain data of only one kind. Elementary streams are not required to reside in the
same medium, i.e. a number of them can be downloaded while others are read from
the file. Decoders are fed with elementary streams from demultiplex buffers (DB)
and their outputs are put into composition buffers (CB), which hold decoded content
prior to scene composition using the description from the scene description ES, which
is encoded in a format called BIFS (Binary Format for Scenes). The scene composer
gets descriptions of objects in the scene from the object descriptor (OD) stream. Then
required objects are acquired from audio and video composition buffers, using the
object description information. The composed scene is then rendered.
The IPMP control system can manipulate the decoding process at a number of
control points using the information from the IPMP-ES which, for example, can be
used to carry decryption keys. In Figure 2.3, control points are shown with gray
circles. The standard is flexible in the sense that it does not define any IPMP tools,
allowing proprieaty IPMP systems to be implemented. In this way, MPEG-4 is pro-
tected from becoming obsolete due to changes in technology (of cryptanalysis) and
bussiness models (affecting the way that users purchase/view content). IPMP tool
acquisition, authentication and operation (as a blackbox) are defined in ammend-
ments to the standard [13].
15

Audio DB
Video DB
OD DB
BIFS DB
IPMP DB
Audio Decode
Video Decode
OD Decode
BIFS Decode Decoded BIFS BIFS Tree
IPMP Systems, controling at s
Audio CB
Video CBC
omposition
Rendering
Dem
ultiplexer
IPMP ES
Figure 2.3: Decoder elements and IPMP control points
2.4 Cryptography and Cryptanalysis
Cryptography is the subset of science concerned in encoding data, also called encryp-
tion, so that it can only be decoded, also called as decryption, by specific individuals.
A system for encrypting and decrypting data is a cryptosystem. Encryption usu-
ally involves an algorithm for combining the original data (“plaintext”) with one or
more “keys” — numbers or strings of characters known only to the sender and/or
recipient. The resulting output of encryption is known as “ciphertext”.
There are two main classes of cryptosystems, with different practical application
areas in today’s technology. Public key methods use two different keys for encryption
and decryption. On the other hand, secret key encryption methods use the same key
for encryption and decryption.
2.4.1 Cryptosystems
Secret key methods can be classified in two groups, namely block and stream chipers.
Block chipers encrypt and decrypt in multiples of blocks and stream chipers encrypt
and decrypt at arbitrary data sizes. Block chipers are mostly based on the idea by
Shannon that sequential application of confusion and diffusion will obscure redun-
dancies in the plaintext, where confusion involves substitutions to conceal redun-
dancies and statistical patterns in the plaintext and diffusion involves transforma-
tions (or permutations) to dissipate the redundancy of the plaintext by spreading
it out over the chipertext. DES and Rijndael are examples of algorithms based on
16

this idea, which allows simple hardware implementations or fast computer imple-
mentations by use of simple arithmetic, however they are not fast enough to encrypt
large volumes of data in real time; an ANSI C implementation of Rijndael, which is
adopted as AES by US Government, requires 950 processor cycles per block on the
x86 architecture[15]1.
Most of the stream chipers rely on the fact that XORing the plaintext with a string
only known to the sender and receiver provides strong encryption. In order to gen-
erate the string one can use a block chiper to encrypt a sequence known to both, as
suggested in Rijndael specification. A stream can also be encrypted by block chipers
after being aligned to block boundaries, in chiper block chaining mode, where the
encryption process of a block depends on the previous block due to XORing of pre-
vious chipertext with the plaintext of the block.
The most popular public key method is RSA, which uses large prime numbers
and modular arithmetic to encrypt a given text. RSA is slower and more complicated
to be implemented in hardware since the primes are usually greater than 512-bits in
size and the algorithm requires computation of powers and remainders with those
large primes, the benchmark in Slagell’s thesis [16] concludes that RSA is at least
three times slower than secret-key methods and processing time increases cubically
with key size on x86 architecture whereas secret-key methods cause slight increases.
However, private key is not predictable given the public key and vice versa, therefore
a sender-receiver pair can establish a one-way secure channel with the transfer of the
encryption key from receiver to the sender. A common application of public key
methods is to transfer a secret key to encrypt a larger amount of data.
2.4.2 Cryptanalysis
Cryptanalysis is the science concerned in breaking cryptosystems. Cryptanalysis
generally involves the following main methods:
• A cryptanalyst can inspect a number of particular chipertexts for certain pat-
terns and correlations. This method of attempting to break a cryptosystem is
called a chipertext-only attack.
1 An MMX implementation for inverse DCT requires not less than a thousand processor cycles per8×8 block and iDCT counts one third of decoding effort
17

• The cryptanalyst may have the plaintexts besides the chipertexts. In this case, it
may be possible to investigate the relation between the plaintexts and the cor-
responding chipertexts. This type of attack is called a known-plaintext attack.
• In a chosen-plaintext attack, the cryptanalyst has access to the cryptosystem
and is able to get the chipertexts for the plaintexts he/she provides.
• As a last method, one can exhaustively try a set of keys until a decryption de-
cided to be valid is achieved, which is impractical for large amounts of data or
large key spaces.
In addition to these attacks, section 2.5.4 presents two more example attacks, specific
to video data.
2.5 Image and Video Encryption
Video encryption has two major fields of application. The first application is access
control to commercial multimedia content where the requirement is the minimiza-
tion of illegal accesses to the content while keeping the cost, in terms of increasing
player complexity and decreasing player usability, of encryption low. The second
application is the protection of video which is distributed from a source to one or a
few destinations, e.g. in videoconferencing, where privacy is essential.
This survey includes both image and video encryption schemes proposed prior
to this work. Image encryption schemes are also included since the presented ideas
may be helpful in texture encryption for video.
2.5.1 Application of encryption in the encoding process
As pointed by [17], data can be encrypted in any stage of the encoding process.
However, every point is not equally advantageous in terms of format compliance,
encryption overhead, compression efficiency, processability, syntax awareness and
transmission friendliness, which form a set of important criteria for many of the ex-
isting applications. Encryption prior to encoding is not suitable, because encrypting
a bitstream increases its entropy, therefore renders further compression impossible.
Encryption before variable length coding also causes an increase, less than the for-
mer, in the encoded bitstream size and it also results in a format compliant bitstream;
18

the bitstream does not contain any syntactical (e.g. invalid VLC codes) nor seman-
tical (e.g. more than 64 DCT coefficients in a 8x8 DCT) errors. The work by Wen et
al.[18, 2], encrypting the indexes of VLC and FLC entries is a good example. Their
work also proposes other methods such as shuffling of higher level structures like
macroblocks and runlevel codewords, the main drawback of which is that it causes
a delay in decoding since the entire area of shuffling must be retrieved before higher
level operations can be conducted, e.g. inverse DCT.
Compression prior to multiplexing and packetization can be conducted in a syntax-
aware manner, so that any fault-tolerant but undecrypting player can handle the bit-
stream; the video stream can still be browsable, the layers and the video objects on the
stream can still be separable, these abilities may be necessary to support transcoding
or traffic shaping. To do this, the video cryptosystem must not output bits emulating
the special codes that signal the structure of the video stream. Such methods reduce
compression efficiency less than that of the formerly stated methods. One advantage
of encrypting a high-entropy bitstream is that it permits using less encrypted bits still
providing high security, as presented in Qiao and Nahrstedt’s work [19].
Any encryption succeeding the packetization step at the systems layer is harder to
implement in a syntax-aware way efficiently. A syntax-unaware encryption, which
simply encrypts randomly or uniformly spaced fragments of the bitstream, on the
other hand, does not provide the facilities mentioned for pre-packetization encryp-
tion. Besides this, it may be insecure since it does not take error resilience tools nor
data interdependencies of the video coding scheme. An example is Griwodz’s work
[20]. Another example is the work of Wee and Apostolopoulos [21], which is a com-
bined scalable encoding and packetization framework optimized for transcoding.
2.5.2 Syntactical entities for encryption
There are a few basic ideas for selective encryption. Selecting a segment of a video
sequence on which some other part has been coded dependingly reduces the size of
the data to be encrypteed. For example, one can encrypt I-VOPs, on which encoding
P-VOPs and B-VOPs depend. However, encoders can be designed to encode a single
I-VOP at the begining and put intra MBs adaptively in P-VOPs [9].
In the same way, one can apply to encryption to the base layer of a scalalably
19

encoded video stream to protect the entire stream. In order to provide different qual-
ities of service with access control, one can also encrypt the enhancement layer with
a different key where only those possessing the two keys can decode the full-quality
video [22, 23, 24].
DCT is known to output coefficients with small correlation, so one can alter the
coefficients depending on the output of a chiper to encrypt the data. The work by Shi
and Bhargava is such an example [25]. DCT coefficients can also be permuted, as in
[26], however this is shown to be insecure [19] and it reduces compression efficiency.
The works by Tosun and Feng [27, 22] proposes a scheme where a portion of DCT
coefficients are encrypted. Qiao and Nahrstedt’s work, presenting a way to halve the
number of bits to encrypt, is also based on DCT encryption [19].
Encryption of motion vectors is infeasible in most cases since encryption of a
single motion vector will require markers as encryption side information. It’s only
feasible in a case like VLC index encryption by Wen et al.[18] or MPEG-4 data parti-
tioning mode. Moreover, Wen et al.have demonstrated that the errors due to a motion
vector only encryption is concealed to an acceptable degree.
On the other hand, encrypting headers does not provide security since header
information can be guessed most of the time.
2.5.3 Combined image encryption and compression frameworks
Bourbakis and Maniccam have proposed a image encryption/compression frame-
work based on traversal of the image plane in a way suitable for run length coding[28].
The traversal is encoded in a context-free grammar previously developed in Bour-
bakis’ works[29]. One can achieve both lossless compression and encryption by run-
length encoding the traversal of pixels and encrypted traversal description together.
The main disadvantage of their scheme is that it takes much greater effort to encode
than that of JPEG.
In [30], Chang et al.have proposed a method which involves building a quantiza-
tion table and encoding the table, which is encrypted afterwards. They argued that
their scheme is hard to break using known attacks. Their work does not include any
experimentation or application on some transform coding scheme.
Quadtree encoding with encryption have been firstly proposed by Chang et al.[30],
20

where a square image is divided into subimages until every subimage is homo-
geneous. Homogeneous subimages are leaves in the quadtree hierarchy, which is
formed according to image inclusion, where parent nodes include their children.
Then, the image is encoded as the tree traversal and leaf values. The image can
be encrypted by applying encryption on this tree structure. In later works by Cheng
[31, 32], encrypting certain traversals are presented as a method for image protec-
tion. Cheng, in his Master’s thesis [32], have also proposed a method to encrypt
SPIHT encoded images.
2.5.4 Data analysis and attacks to core chiper
The curious reader can find attacks to chipers such as DES in the literature, however
attacks to core chiper are considered to be impossible and infeasible in most of the
possible cases, legitimate access to the bitstream costs much less than the computa-
tional power required to break the core chipers in the case of encryption of video for
entertainment purposes. On the other hand, parts of data may still be guessed even
after encoding, as previously discussed in 2.4.2 and concluded in the next paragraph.
Video data is known to be spatiotemporally smooth, so one can speedup breaking
the the chipertext if a part of the plaintext is known; this technique is called nearest
neighbor attack in [30]. The same work also defines a jigsaw puzzle attack to be speeding
up the breaking process by division of the chipertext into small portions constrained
by smoothness and similarity to the neighbors in boundaries.
2.5.5 Error concealment attacks
Default values for undecodable fields can be set; motion vectors and difference of
quantizer step can be set to zero and Intra DC to a fixed value, when the decoder
is unable to retrieve them. Alternatively values from previous frames can be used
since these values tend to change in small steps, these methods are suggested as
simple means of error concealment in the literature [9, 18]. Besides these, the reader
can find various studies on other techniques that predict undecodable values from
the syntax or previously decoded values.
21

2.5.6 Discussion
There are two classes of cryptosystem breaks that can be considered for video encryp-
tion schemes described in this chapter. In the first class, the entire cryptosystem fails
so that the entire video sequence can be broken by a one-time effort, called simultane-
ous cryptanalysis. The second class is the one that the attacker can break an individual
video element at a time, called progressive cryptanalysis. Simultaneous cryptanalysis is
the case that one attacks the core chiper or the way that the decryption key is kept or
transmitted, which requires a systems-level attack or use of cryptanalytic techniques
to break the core chiper. Simultaneous cryptanalysis techniques require a study of
data security and general cryptanalysis, therefore they are left out of the scope of this
thesis. On the other hand, partially encrypted video is prone to the attacks of types
discussed in Chapter 2, e.g. run length encryption can be broken by bit togglings
until a valid VLC sequence is found, optionally constrained to give an output resem-
bling a given fragment of the video. In a similar way, index encryption can also be
broken, by trying a subset of possible codewords. Both techniques are not feasible to
apply on low-cost video, e.g. anyone to break the encryption in real time to watch a
live soccer broadcast needs much more expensive hardware than the cost of watch-
ing the broadcast in the proper way. Recent works like [18] mention this situation
and propose partial encryption of syntactic entities, e.g. partial encryption of MBs,
encryption of MVs with magnitude in a predefined interval. The current literature
does not propose any reasonable means to adjust the level of encryption depending
on the value of the video stream, although the encryption schemes in [27] or [18] can
be applied in multiple levels.
22

CHAPTER 3
PROPOSED ENCRYPTION TECHNIQUE
3.1 Introduction
Having attempted to encrypt every syntactical entity in the encoded video, the recent
concerns of the study of video encryption were syntax compliance and processability
of the unencrypted bitstream by third parties to manipulate transmission rates and to
allow searches. However, the limitation of the bit rate of the encrypted portion of the
video stream while keeping security maximized remains as an open problem, which
requires distribution of the budget of encrypted bits over the syntactical entities of
video. Another unattacked problem is encoding of the encryption side information
compactly and error resilient. An imprecise, yet efficiently computable solution to
the first problem is presented in this chapter. The storage format complying with
ammendments to the MPEG-4 standard is also given at the end of the chapter.
The reader can see that a solution to limit the bitrate of the encrypted stream while
keeping security maximized will have a great impact, if low-resource hardware that
can decrypt slower than some certain rate is considered, e.g. a wireless player with
constraints due to limited battery life, or a DVB box with constraints on production
costs.
3.2 Dependency Through Error Propogation
As briefly described in Chapter 2, VOPs in the video are encoded dependently on
one another by estimation of translational motion. A P macroblock is encoded as
23

texture and motion information depending on the reconstruction of at least one and
at most four macroblocks in the previously encoded I-VOP or P-VOP, as described
in Figure 3.1 and Figure 3.2. Because of the fact that natural video sequences contain
motion of more complex nature, more than one macroblock may depend on a certain
macroblock in the reference VOP, in particular the macroblocks that reside in a loca-
tion of the VOP, where the motion flux is large. Moreover, texture and motion in the
same video packet are encoded predictively, hence in-VOP dependency also exists,
which is also beneficial to consider while designing a video encryption scheme.
T = t T = t+1
Figure 3.1: Macroblock interdependence
Figure 3.2: Error propogation from frame 268 to frame 271 of foreman
3.3 The Bit Allocation Strategy
Achieving maximal security can be defined as the maximization of the computational
power required to break the encryption scheme. In the context of this work, the con-
straint for this maximization is the number of bits that can be encrypted. Break at-
24

tempts that result with the exact cleartext is considered to be a successful attempt
in order to make things simpler; it requires an exhaustive search of a subset of the
codeword space constrained by some criteria, e.g. the codeword space for the DC
component of a DCT transformed block can be constrained by the energy of a por-
tion of a known plaintext and the set of valid codewords. The process of searching
the reduced space has a complexity of f (x) = 2k′x, or f (x) = ekx with k = k′ ln 2
and k′ ∈ [0, 1], in terms of the number of encrypted bits x and a constant k. k is a
factor representing a reduction in the search space by syntax, heuristics or data anal-
ysis, hence it represents the “smartness” of the attacker and the “weakness” of the
underlying encryption method.
Because the encrypted portions are treated as errors by a no-decryption decoder,
the problem of breaking the encryption is equivalent to recovery of bitstream errors
and maximization of security in the sense described is equivalent to maximizing the
effort for recovery, constrained with the number of errorneous bits. Therefore, the
time required for cryptanalysis can be modeled, once the error propogation is mod-
eled.
A model for error propogation is established in the studies by Zhang et al.[33]. In
their study, MPEG-2 frames are classified into levels stacked on one another so that
error propogates from bottom to the top. The levels are numbered and propogation
of errors from level i to level j is found by exprerimentation and organized into a ma-
trix E, using the number of impaired macroblocks in level j due to the propogation
of an intrinsic (i.e. not propogated) error at level i as the error metric. Considering
rectangular VOPs, one can use this data to assign importances to macroblocks since
an average of m propogated errors in level j due to an intrinsic error in level i, i.e.
Eij = m can be interpereted as the requirement of m macroblocks in level i to decode
a macroblock in level i. Zhang et al.have worked with sequences encoded into peri-
odic I-frames and following P-B combinations, corresponding to Figure 3.3(a), which
is adapted from their work. However, other stack structures can be established for
different encoder configurations; Figure 3.3(b) is the stack for the encoder configura-
tion with single initial I-frame and 3.3(c) is the stack for bilayer video with periodic
intra refresh.
Once the encrypted and therefore undecodable portions are detected and local-
25

I, independently coded
P3, dependent on I
P6, dependent on P3
P9, dependent on P6
B-frames, dependenton I, P3, P6 and P9
B-VOPs, depending on P+ and P-
P+, coded depending on P-
P-, coded depending on P+
P2-, not dependingany VOP in the stack
I-VOP,independently coded
P-VOPs of base layer
B-VOPsof the baselayer
B-VOPs ofthe enh.layerP-VOPs ofthe enh.layer
(a) (b) (c)
Figure 3.3: VOP dependence stacks
ized, the average amount of time required to cryptanalyze a given VOP becomes
C(x1 . . . xN) =1N
N
∑i=1
ci fi(xi) (3.1)
where ci = ∑Nj=1 Eij, a weight representing the importance of layer i,N is the number
of layers and fi(xi) are assumed to be of the form ekxi . Equation (3.1) is constrained
by the number of encrypted bits:
N
∑i=1
xi = B (3.2)
where B > 0 is the number of encrypted bits. Although not taken into account, xi
is also bounded; 0 ≤ x ≤ Bi, where Bi is the number of bits in which the syntactical
entity i is encoded. Equation (3.1) constrained with (3.2) has only one extreme point
xi =BN− 1
Nk(
N
∑j=0,j 6=i
ln cj) (3.3)
which is a minimum. Hence, the maximizing solution is (which is in fact intuitive)
on the boundary:
xi = B i = arg maxi
ci (3.4)
xi = 0 i 6= arg maxi
ci (3.5)
26

However, the budget B is not entirely spent if Bi < B. Therefore, the maximizing
solution firstly requires sorting ci into c′i, c′i . . . c′i, where
ci = c′j ⇐⇒ ci < c′1 . . . ci < c′j−1
Then, the minimum of number of bits left in hand and Bi must be reserved for syn-
tactic entity i:
Bi = min(Bi,i
∑j=1
c′j) (3.6)
3.4 Levels and Estimation of ci
An enhancement for frame based leveling can be constructed by defining subse-
quences of DCT runs as the syntactical entities. Starting with [22], blocks of DCT
coefficients are separately considered as entities to be encrypted, hence frame-based
leveling can be refined to subdivide the DCT coefficients into sublevels to adapt the
models of Section 3.3 to encryption. In this study, DCT coefficients are divided into
three sublevels; in intra-coded blocks, the DC coefficient is the first sublevel1 and the
sequence of AC coefficients are divided into two, in scan order. Inter-coded blocks
are divided into three almost-equal sublevels. Consequently, all ci are replaced with
tuples, (ci1, ci2, ci3), cij are scalars.
Experimental estimation of ci for a sequence is found to be impractical as it re-
quires statistically sufficient number of error simulations in the decoder. Instead, ci
are estimated per GOV of the video stream. In order to estimate ci, intrinsic weights
ıi,x,y = (ıi1,x,y, ıi2,x,y, ıi3,x,y) are assigned to every block at level i. The intrinsic weight
for a block is proportional to the mean squared error between the block and the block
with coefficients affecting ıij,x,y set to zero. The weights are normalized in the sense
that sum of ıij,x,y for a block is one, if the block is intra and equal to the ratio of the
energy of the estimation error block to the energy of the reconstruction block for a
nonintra block. With every ıi,x,y, a reference count ri,x,y is associated, which is set
to zero initially. The motion vectors are used to alter the reference counts to reflect
propogation.
A predictively coded macroblock refers one or more macroblocks in the reference
VOP. Assuming the macroblock is uniform (which becomes more realistic as VOPs
1 Intra DC coefficients are not encoded differently from AC coefficients in all experiments.
27

get larger in spatial size), the referred macroblocks have effect on the error propor-
tional to both the size of the area overlapping with the reference area and the intrinsic
weight of the prediction for block (x, y).
After scaling ıi,x,y with ri,x,y, ci is estimated to be the average of all ıi,x,y Two ci
values are estimated, one from intra blocks ci and one from inter blocks ci. Inter and
intra ci values are sorted altogether and the available encrypted bits are distributed
in descending ci order.
Table 3.1 contains the algorithm updating the weights of the layers depending on
the reference area in a more complete format.
Table 3.1: Algorithm SET-WEIGHTS
SET-WEIGHTS()1 for each block b(x, y, t) in the estimation set2 do for each level i containing data in b(x, y, t)3 do r′j ← b(x, y, t) with coefficients of level i are zeroed , j = 1, 2, 34 ıij,x,y ← MSE(b′j, b(x, y, t))/ ∑k MSE(b′k, b(x, y, t))5 rij ← 06 if the block is nonintra, i.e. predicted7 then8 b′′ ← prediction, for which b(x, y, t) is the prediction error9 η(x, y, t) = MSE(b(x, y, t), 0)/(MSE(b(x, y, t), 0) + MSE(b′′, 0))
10 ıij,x,y = η(x, y, t)ıij,x,y1112 for each level i in descending order13 do for block b(x, y, t) in level i14 do Find a, b, c, d and the overlapping blocks ba, bb, bc, bd as in Figure 3.415 Normalize a, b, c, d so that a + b + c + d = 116 rk ← rk + k(1− η(x, y, t)) , k = a, b, c, d1718 for each level i in descending order19 do for block b(x, y, t) in level i20 do ıij ← ıijrij21 Findciandci22
3.5 Encryption Strategy
As Wen et al.pointed out in their studies [18], encryption of indexes is advantageous
over direct encryption of the bitstream, because it is more error resilient, preserves
syntax compliance and is compatible with other players that doesn’t have the decryp-
28

T = t T = t+1
a b
c d
MV(x,y)
Figure 3.4: Referenced block areas.
tion facility. However, a direct-encryption tool is implemented in this work, because
of the following reasons:
• Compatibility with other players is of little value if the content is provided as a
commercial service (e.g. pay tv broadcast). In this case, the service agreement
may include the use of a supported player not to void the service warranty.
• Direct encryption requires less number of bits to protect a syntactical entity of
the video and a level of error resilience can be achieved by the use of the side
information, if the side information is designed appropriately.
• Implementation of direct encryption over a codec that is implemented previ-
ously is found to be less complicated. In this study, the base codec was the
MPEG-4 reference implementation, which was not well documented.
The problems with direct encryption are resolved in the following ways:
• The start code emulations in the encrypted stream is cleaned by introduction of
stuffing bits (a value of ”1”) after 20 zeroes2
• Encryption side-information is synchronized with the bitstream, as described
in Section 3.6
2 MPEG-4 start codes begin with byte aligned “00000000 00000000 00000001”
29

Table 3.2: IPMP SelectiveDecryptionMessage stucture, specific to the proposed sys-tem
class IPMP_SelectiveDecryptionMessage extends IPMP_ToolMessageBase:bit(8) tag = IPMP_SelectiveDecryptionMessage_tag;
{bit(8) mediaTypeExtension;bit(8) mediaTypeIndication;bit(8) profileLevelIndication;const bit(8) compliance = 0x01;const bit(8) numBufs = 1;Struct bufInfoStruct {
bit(128) cipher_Id;bit(8) syncBoundary;bit(1) isBlock;const bit(7) reserved = 0b0000.000;bit(8) mode;bit(16) blockSize;bit(16) keySize;
}const bit(1) isContentSpecific = 0;const bit(7) reserved = 0b0000.000;bit(16) nSegments;bit(16) RLE_Data[nSegments];
}
3.6 Encryption Side-Information
Although a more compact side-information format is possible, the suggested side
information storage format is an IPMP SelectiveDecryptionMessage data structure,
as described in [13]. The structure specific to this work is given in Table 3.2.
The sequence of encrypted and unencrypted segments are encoded into the array
RLE Data , as lengths of the segments, starting with the length of an unencrypted
segment. The array RLE Data contains nSegments RLE encoded segment lengths.
The video cryptosystem requires a single buffer to decrypt the data and the chiper
is synchronized at the start of the syntactic entity (e.g. VOP) specified at
syncBoundary field for error resilience.
The file can be incorporated into the MPEG-4 file as an ipsm track, multiplexed
with other streams after the file creation and multiplexing utilities are modified; the
mp4creator utility that comes in the mpeg4ip package [34] is a suitable platform
to apply this idea.
30

3.7 Summary
A model for the cryptanalytic complexity of video streams is presented. The equa-
tions to find the encrypted bit distribition maximizing cryptanalytic complexity are
derived and an algorithm is defined using the outcomes of the equation, depend-
ing on a set of parameters. The parameters ci can be estimated experimentally, from
video sequences of similar nature, however it’s considered to be costly. A method to
estimate these parameters is proposed in Section 3.4.
31

CHAPTER 4
EXPERIMENTS AND RESULTS
4.1 Implementation and Test Platform
The proposed method is implemented over MoMuSys video codec which is devel-
oped as MPEG-4 Verification Model. The implementation also uses previously im-
plemented AES functionality, in the separated encryption module. Red Hat Linux 9
with GNU C compiler and GNU make is used as the development platform.
4.2 Implementation of SET-WEIGHTS and Budget Distribution
Set-Weights is implemented for the VOP hierarchies, Figure 3.3(a) and Figure 3.3(c),
however only results regarding hierarchy (a) are discussed in this chapter. The algo-
rithm is able to find the weights for a set of VOPs after the VOPs are encoded, this
does not matter for the configurations where pre-encoded content is served. On the
other hand, encryption of data by a delay of a few VOPs can be a problem in live
broadcasts or videoconferencing.
The functions that make up SET-WEIGHTS is found to consume around 0.8% of
the CPU time, but the share of CPU time is expected to increase in more optimized
codecs.
4.2.1 Core Chiper
Although many stream chipers are available, a new one is constructed at the expense
of efficiency. The main reason is that the author was unable to find a stream chiper
32

implementation that encrypts in bits. The AES implementation in ANSI C by Brian
Gladman, which is publicly available, is used for the stream chiper.
The stream chiper is implemented by XORing input bits with a random sequence.
The random sequence is obtained by encryption of an increasing sequence with AES.
The sequence is initiated by using the encryption key for AES and new blocks filled
with the increasing sequence are encrypted whenever needed. An application of
Berlekamp-Massey algorithm over the stream shows that the sequence is not linear,
so one cannot break the sequence by finding the linear recurrence that generates it.
Once the encoder generates the sequence of segments for the visual stream, the
encryption program is run to encrypt the given segments of the bitstream with the
specified key.
4.2.2 Restrictions of the Implementation
The video encryption implementation does not support suitable encryption schemes
for all the natural video coding tools, nor does it support any particular profile. A
few of the tools are considered not to be suitable for encryption. A few other cannot
be rate controlled by the developed model, due to restrictions on the implemented
codec. The remaining tools can be supported by slight and straightforward modifi-
cations and they are considered as future work.
B-VOP encryption is not implemented because B-VOPs are assumed to have lower
reference counts than P-VOPs.
RVLC coded video is not supported since it’s believed by the author that it is difficult
to output a compact chipertext that can be divided into reversible codewords.
Interlaced video encryption is not implemented as the underlying codec does not
provide full support.
Still textures are not supported since they don’t have temporal extent.
Sprite encryption is not implemented. A specification or draft of GMC was not
available to the author, either.
Grayscale shapes are not supported. Because graysacale shapes are encoded in the
same way as texture, reference maps can also be kept for grayscale shapes,
33

however combined rate control for shape/texture encryption is left as an open
problem.
Binary shape maps are not supported. A binary shape has no effect on macroblock
addressing, hence a coarser shape is always available for an attacker.
4.3 Test Sequences
Video sequences that were commonly used in the literature are selected for the ex-
periments. The sequences are obtained in (or later converted to) uncompressed 4:2:0
YUV. Only QCIF (176×144) sequences are used for tests, due to implementation prob-
lems. The first 300 frames of each sequence are used.
Carphone Single object QCIF sequence with high motion foreground and background.
Foreman Talking head QCIF sequence with high motion foreground and a camera
pan at the end.
Miss America QCIF sequence containing almost still foreground and background
with motion.
The sequences are included in the compact disc as AVI files with uncompressed YV12
video tracks.
4.4 Encoding Parameters
The files are encoded with periodic I-VOP refreshes followed by sequences of B and
P-VOPs, so that every third VOP is a P-VOP. Every sequence is coded at 30 fps. In
order to simplify the implementation, every nonintra macroblock is coded with one
motion vector and regular motion compensation. Motion vectors are computed to
half sample precision. Qp is initially set to 4 for all texture coding schemes. Video
is packetized so that every packet includes macroblock-aligned data just exceeding
20 bits, hence avoiding spatially predictive coding. The rate controlled sequences
are coded using Q2 rate control algorithm with default parameters of the MoMuSys
implementation. The first 300 frames of Foreman and news are used in the experimen-
tation. The first 150 frames of Miss America are used in the experimentation, as its
length is less than others.
34

4.5 Experimental Results
The test sequences are encoded and encrypted by the implemented encoder and the
effects of encryption are measured in the relative size of encryption side informa-
tion and the distribution of encrypted bits over various syntactical structures of the
video. The time consumed by index extraction and encryption/decryption functions
in terms of CPU time is not measured since the implementation is not optimal; the
reader must be informed that three additional iDCT per block are performed to find
the bit distribution.
Tests are conducted to investigate the nature of bit selection strategy when
1. A constant Qp is used with fixed GOV size.
2. GOV sizes are changed, holding Qp constant.
3. Bit rate of the encoded video is restricted by a rate control algorithm, while Qp
is changed by the algorithm and GOV sizes change due to skipped VOPs.
4.5.1 Bit Distribution Plots
The plots are taken here in order to relax the alignment of the actual text, as the
graphs are large in size. A grid is put onto the plot to identify GOVs.
Each plot have three different entities. In intra plots, “DC”, “AC1” and “AC2”
are the bitrates of the DC coefficient, 30 coefficients succeeding (in zig zag order) the
DC coefficient and the remaining coefficients of intra coded blocks, respectively. In
inter plots, “AC1”, “AC2” and “AC3” are the bitrates of the first 20 (in zig zag order),
succeeding 20 and remaining coefficients of inter coded blocks.
Plots for which GOV size is specified are obtained without rate control and plots
for which bitrate is specified are obtained with 12-VOP GOV setting, however a num-
ber of frames are skipped to meet the bitrate constraint.
Encoding parameters for the plots are specified in Section 4.4.
35

500
1000
1500
2000
2500
3000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.1: Inter (above) and intra (below) bit distributions in Carphone with 1700bits/frame encryption and 12-VOP GOVs
36
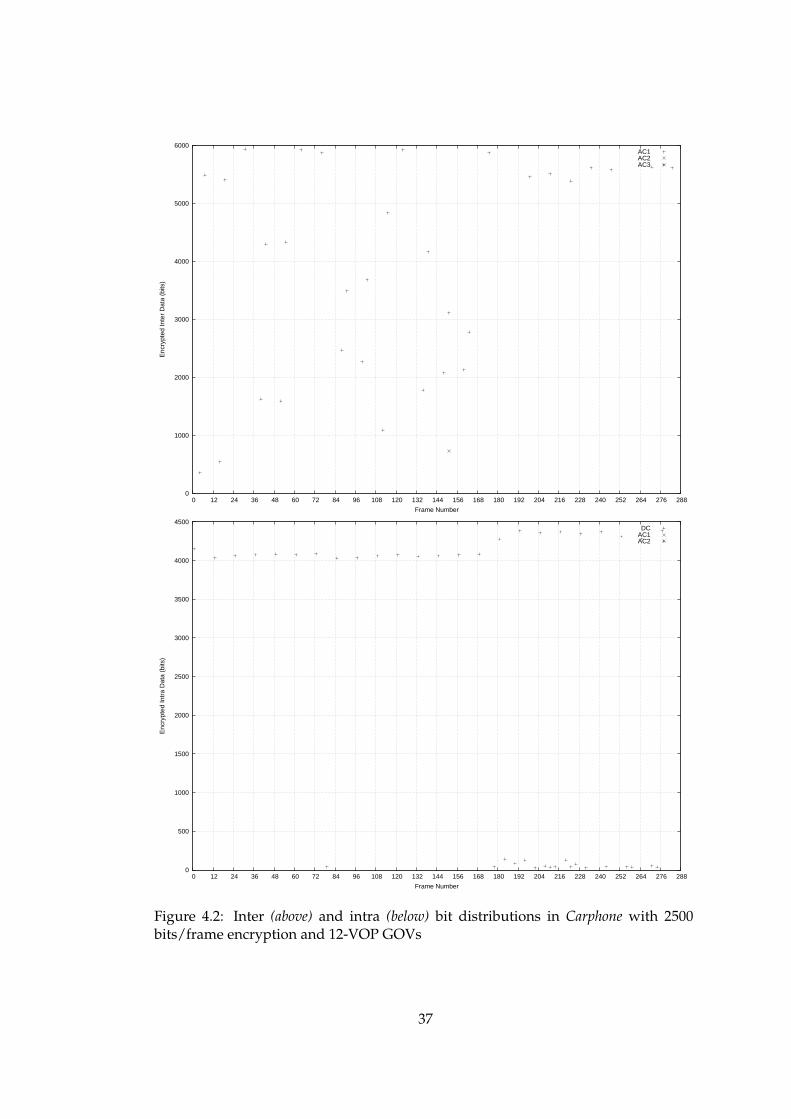
0
1000
2000
3000
4000
5000
6000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.2: Inter (above) and intra (below) bit distributions in Carphone with 2500bits/frame encryption and 12-VOP GOVs
37
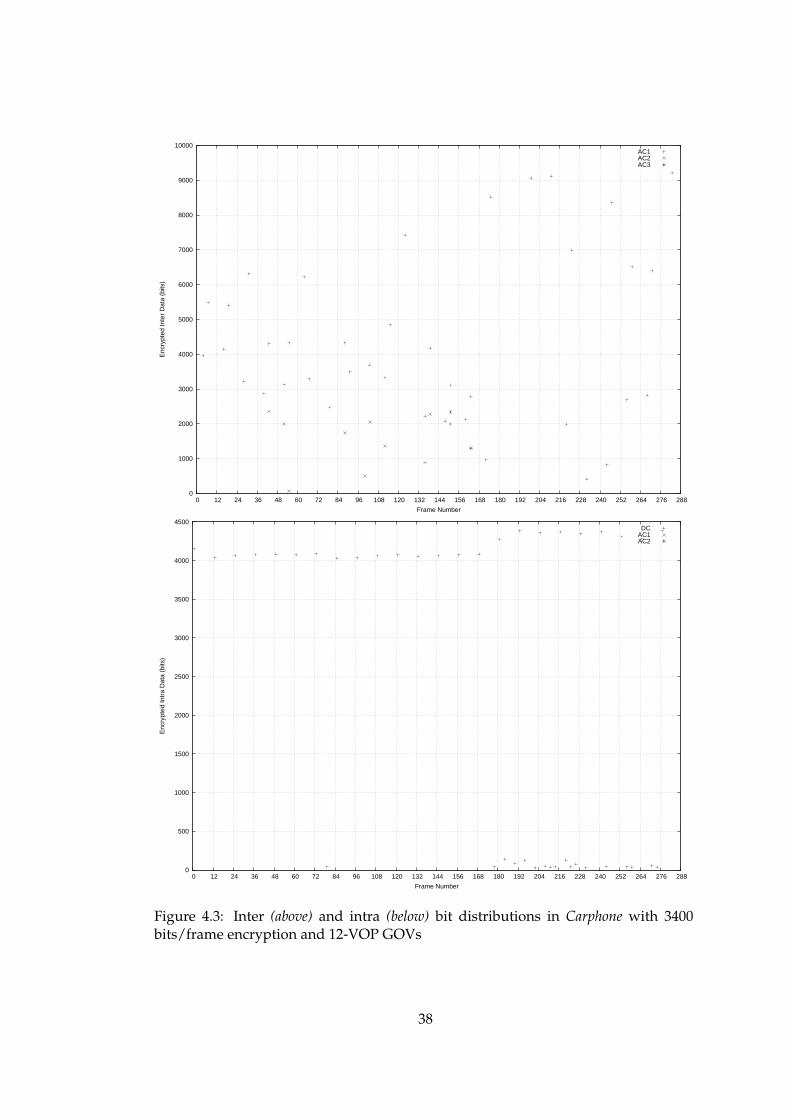
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.3: Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 12-VOP GOVs
38

0
2000
4000
6000
8000
10000
12000
14000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.4: Inter (above) and intra (below) bit distributions in Carphone with 4200bits/frame encryption and 12-VOP GOVs
39

0
2000
4000
6000
8000
10000
12000
14000
16000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
1000
2000
3000
4000
5000
6000
7000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.5: Inter (above) and intra (below) bit distributions in Carphone with 5000bits/frame encryption and 12-VOP GOVs
40

0
1000
2000
3000
4000
5000
6000
7000
8000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.6: Inter (above) and intra (below) bit distributions in Carphone encoded at 384kbps with 4200 bits/frame encryption
41
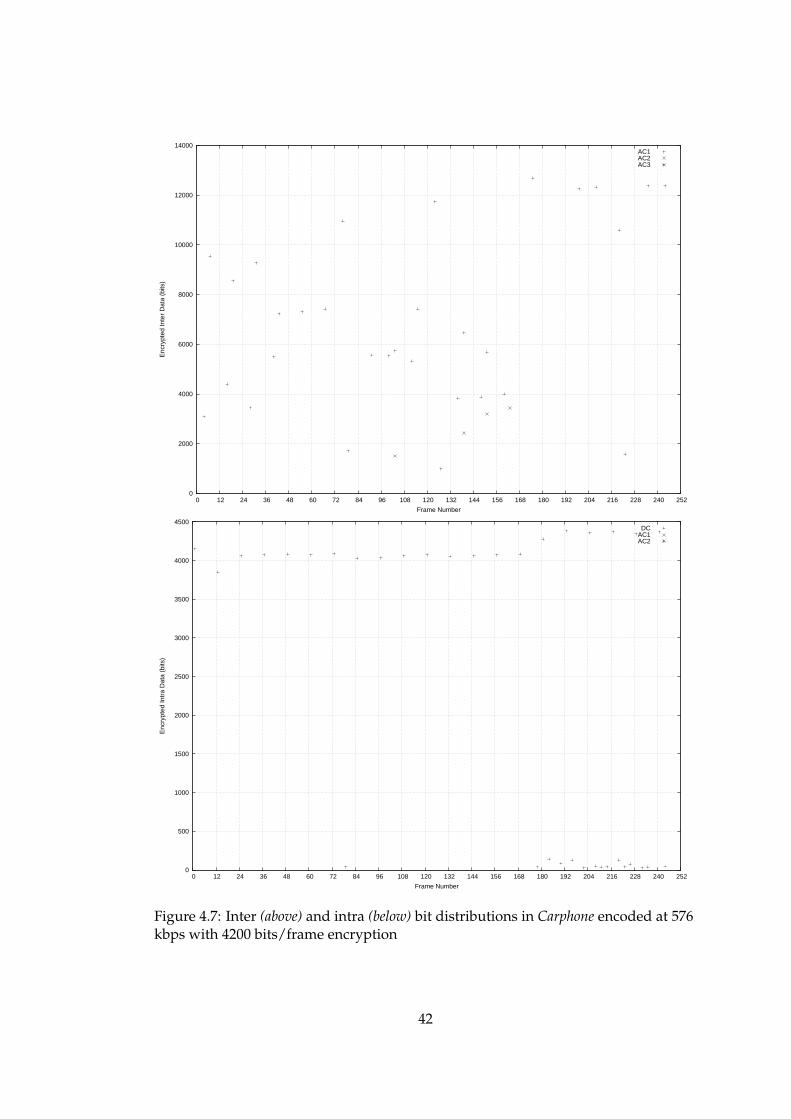
0
2000
4000
6000
8000
10000
12000
14000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.7: Inter (above) and intra (below) bit distributions in Carphone encoded at 576kbps with 4200 bits/frame encryption
42

0
2000
4000
6000
8000
10000
12000
14000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.8: Inter (above) and intra (below) bit distributions in Carphone encoded at 768kbps with 4200 bits/frame encryption
43
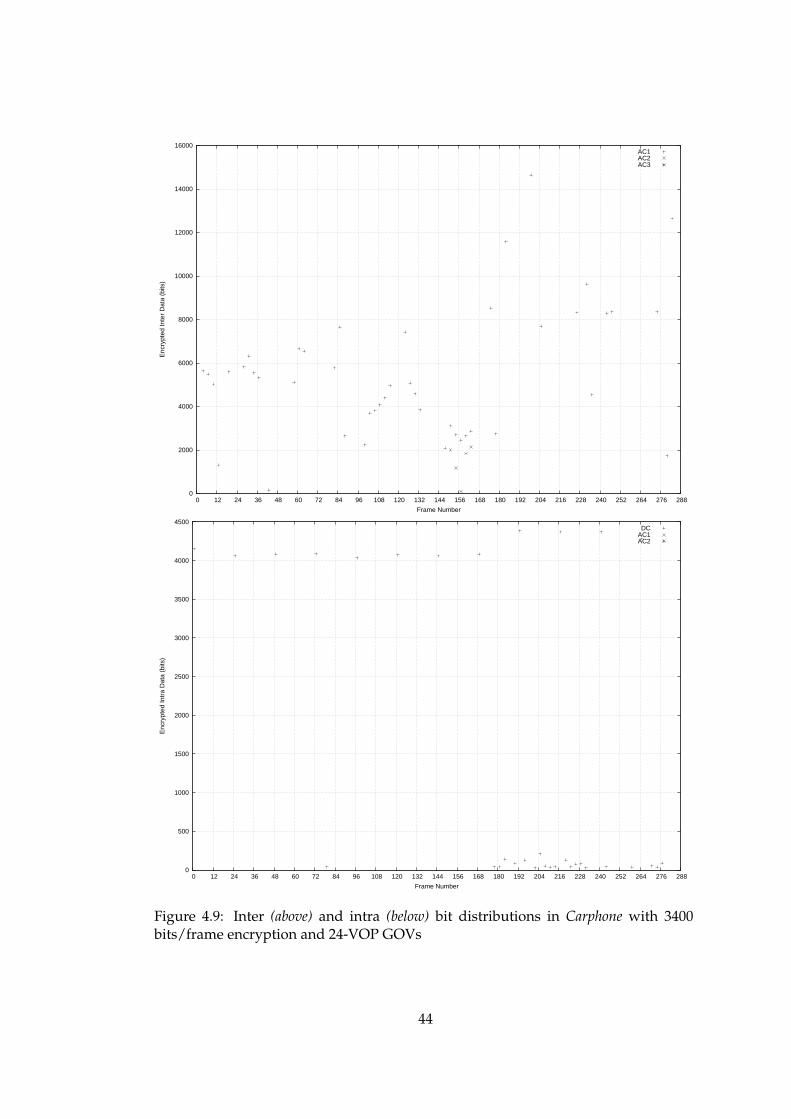
0
2000
4000
6000
8000
10000
12000
14000
16000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.9: Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 24-VOP GOVs
44

0
2000
4000
6000
8000
10000
12000
14000
16000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.10: Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 36-VOP GOVs
45

0
2000
4000
6000
8000
10000
12000
14000
16000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.11: Inter (above) and intra (below) bit distributions in Carphone with 3400bits/frame encryption and 48-VOP GOVs
46

0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.12: Inter (above) and intra (below) bit distributions in Foreman with 3400bits/frame encryption and 24-VOP GOVs
47
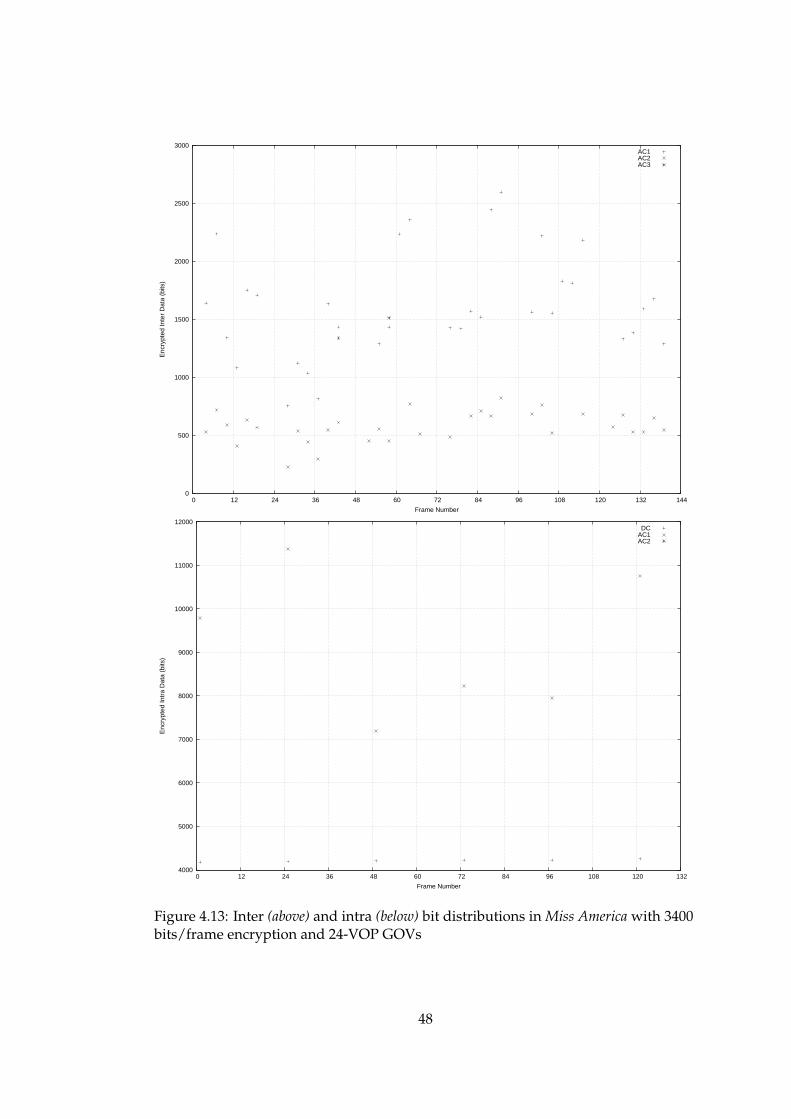
0
500
1000
1500
2000
2500
3000
0 12 24 36 48 60 72 84 96 108 120 132 144
Enc
rypt
ed In
ter
Dat
a (b
its)
Frame Number
AC1AC2AC3
4000
5000
6000
7000
8000
9000
10000
11000
12000
0 12 24 36 48 60 72 84 96 108 120 132
Enc
rypt
ed In
tra
Dat
a (b
its)
Frame Number
DCAC1AC2
Figure 4.13: Inter (above) and intra (below) bit distributions in Miss America with 3400bits/frame encryption and 24-VOP GOVs
48

Table 4.1: Bit distribution for Carphone at 1700 bits/frame encryption, 12-VOP GOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.889 0.921 0.0290 1 1 0 0.094 0.293 0.0180 1 2 0 0.008 0.293 0.0021 0 0 0.100 0.391 0.390 0.0971 0 1 0 0.148 0.293 0.0311 0 2 0 0.070 0.293 0.0191 1 0 1 1.919 0.862 0.3741 1 1 0 0.020 0.460 0.0241 1 2 0 0.004 0.460 0.0042 0 0 0.381 0.420 0.487 0.0912 0 1 0 0.158 0.341 0.0282 0 2 0 0.074 0.341 0.0192 1 0 1 1.878 0.729 0.4532 1 1 0 0.027 0.623 0.0242 1 2 0 0.004 0.623 0.0033 0 0 0 0.003 0.341 0.0043 0 1 0 0.001 0.341 0.0013 0 2 0 0 0.341 03 1 0 1 0.989 0.872 0.0113 1 1 0 0.011 0.462 0.0103 1 2 0 0.002 0.462 0.002
49
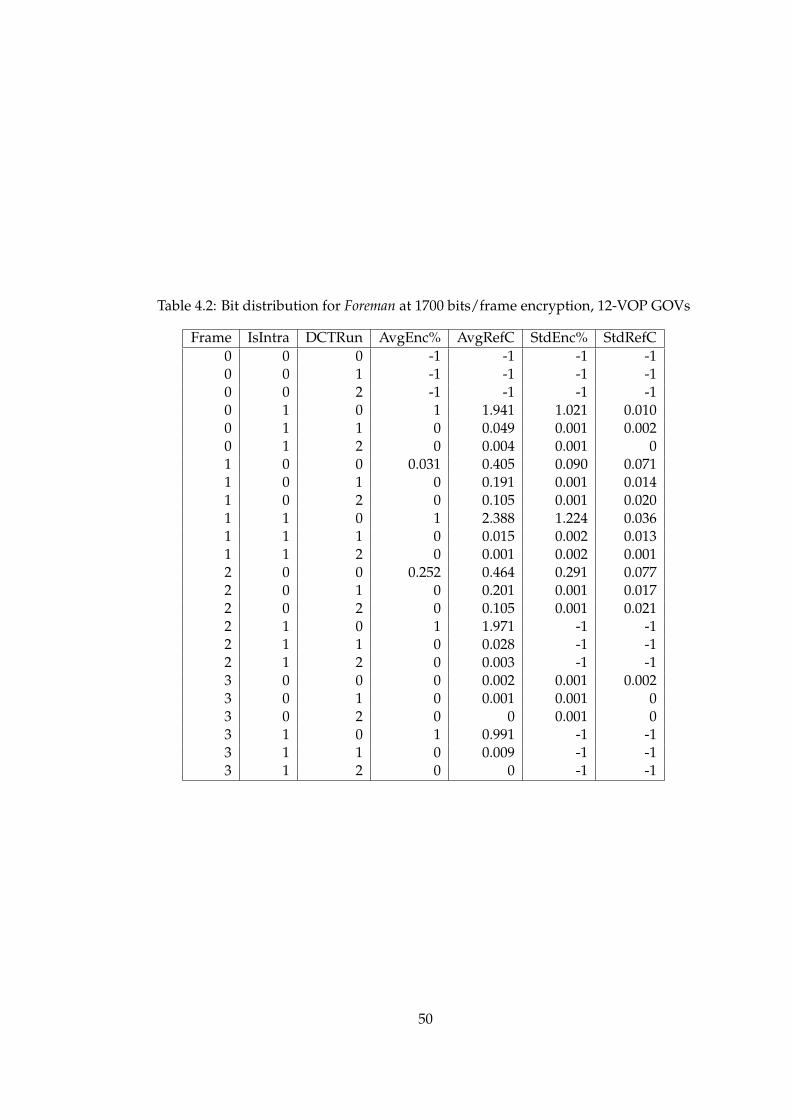
Table 4.2: Bit distribution for Foreman at 1700 bits/frame encryption, 12-VOP GOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.941 1.021 0.0100 1 1 0 0.049 0.001 0.0020 1 2 0 0.004 0.001 01 0 0 0.031 0.405 0.090 0.0711 0 1 0 0.191 0.001 0.0141 0 2 0 0.105 0.001 0.0201 1 0 1 2.388 1.224 0.0361 1 1 0 0.015 0.002 0.0131 1 2 0 0.001 0.002 0.0012 0 0 0.252 0.464 0.291 0.0772 0 1 0 0.201 0.001 0.0172 0 2 0 0.105 0.001 0.0212 1 0 1 1.971 -1 -12 1 1 0 0.028 -1 -12 1 2 0 0.003 -1 -13 0 0 0 0.002 0.001 0.0023 0 1 0 0.001 0.001 03 0 2 0 0 0.001 03 1 0 1 0.991 -1 -13 1 1 0 0.009 -1 -13 1 2 0 0 -1 -1
50

Table 4.3: Bit distribution for Foreman at 2500 bits/frame encryption, 12-VOP GOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.941 1.021 0.0100 1 1 0 0.049 0.001 0.0020 1 2 0 0.004 0.001 01 0 0 0.094 0.405 0.238 0.0711 0 1 0 0.191 0.001 0.0141 0 2 0 0.105 0.001 0.0201 1 0 1 2.388 1.224 0.0361 1 1 0 0.015 0.002 0.0131 1 2 0 0.001 0.002 0.0012 0 0 0.608 0.464 0.693 0.0772 0 1 0 0.201 0.001 0.0172 0 2 0 0.105 0.001 0.0212 1 0 1 1.971 -1 -12 1 1 0 0.028 -1 -12 1 2 0 0.003 -1 -13 0 0 0 0.002 0.001 0.0023 0 1 0 0.001 0.001 03 0 2 0 0 0.001 03 1 0 1 0.991 -1 -13 1 1 0 0.009 -1 -13 1 2 0 0 -1 -1
51

Table 4.4: Bit distribution for Foreman at 3400 bits/frame encryption, 12-VOP GOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.941 1.021 0.0100 1 1 0 0.049 0.001 0.0020 1 2 0 0.004 0.001 01 0 0 0.370 0.405 0.549 0.0711 0 1 0.028 0.191 0.139 0.0141 0 2 0 0.105 0.001 0.0201 1 0 1 2.388 1.224 0.0361 1 1 0 0.015 0.002 0.0131 1 2 0 0.001 0.002 0.0012 0 0 0.823 0.464 0.893 0.0772 0 1 0 0.201 0.001 0.0172 0 2 0 0.105 0.001 0.0212 1 0 1 1.971 -1 -12 1 1 0 0.028 -1 -12 1 2 0 0.003 -1 -13 0 0 0 0.002 0.001 0.0023 0 1 0 0.001 0.001 03 0 2 0 0 0.001 03 1 0 1 0.991 -1 -13 1 1 0 0.009 -1 -13 1 2 0 0 -1 -1
52
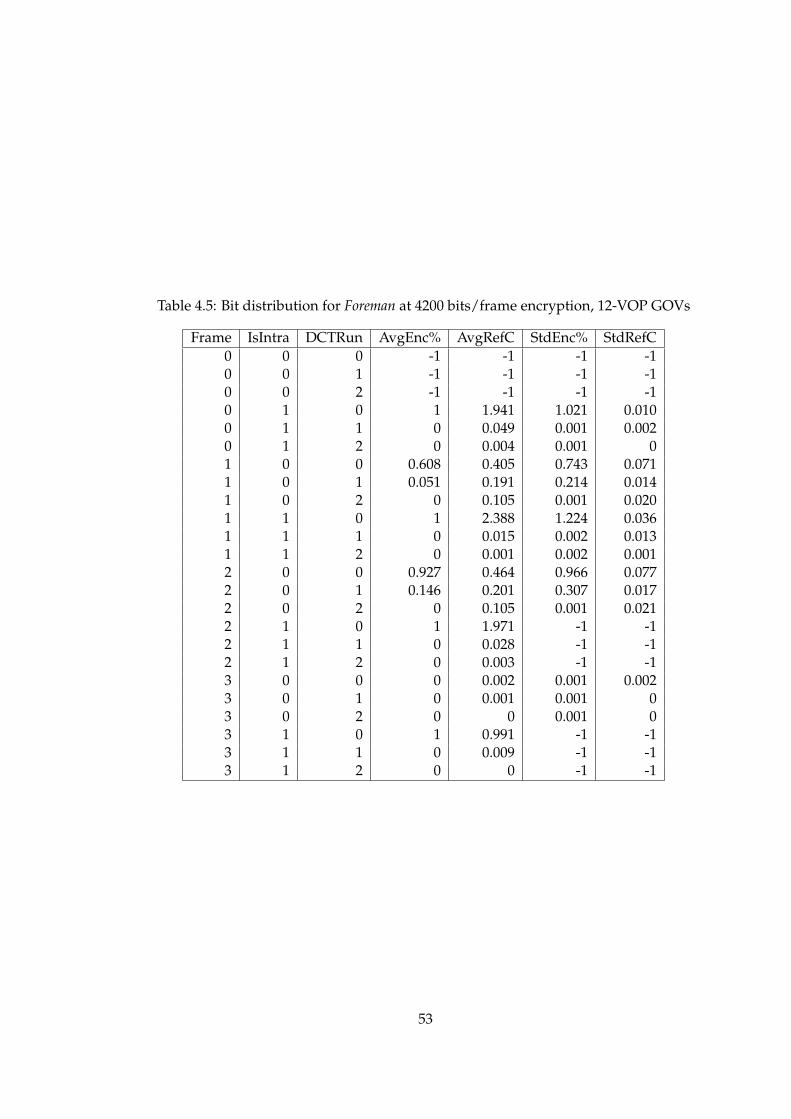
Table 4.5: Bit distribution for Foreman at 4200 bits/frame encryption, 12-VOP GOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.941 1.021 0.0100 1 1 0 0.049 0.001 0.0020 1 2 0 0.004 0.001 01 0 0 0.608 0.405 0.743 0.0711 0 1 0.051 0.191 0.214 0.0141 0 2 0 0.105 0.001 0.0201 1 0 1 2.388 1.224 0.0361 1 1 0 0.015 0.002 0.0131 1 2 0 0.001 0.002 0.0012 0 0 0.927 0.464 0.966 0.0772 0 1 0.146 0.201 0.307 0.0172 0 2 0 0.105 0.001 0.0212 1 0 1 1.971 -1 -12 1 1 0 0.028 -1 -12 1 2 0 0.003 -1 -13 0 0 0 0.002 0.001 0.0023 0 1 0 0.001 0.001 03 0 2 0 0 0.001 03 1 0 1 0.991 -1 -13 1 1 0 0.009 -1 -13 1 2 0 0 -1 -1
53

Table 4.6: Bit distribution for Foreman at 5000 bits/frame encryption, 12-VOP GOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.941 1.021 0.0100 1 1 0 0.049 0.001 0.0020 1 2 0 0.004 0.001 01 0 0 0.786 0.405 0.857 0.0711 0 1 0.197 0.191 0.375 0.0141 0 2 0 0.105 0.001 0.0201 1 0 1 2.388 1.224 0.0361 1 1 0 0.015 0.002 0.0131 1 2 0 0.001 0.002 0.0012 0 0 0.984 0.464 1.007 0.0772 0 1 0.328 0.201 0.558 0.0172 0 2 0.028 0.105 0.140 0.0212 1 0 1 1.971 -1 -12 1 1 0 0.028 -1 -12 1 2 0 0.003 -1 -13 0 0 0 0.002 0.001 0.0023 0 1 0 0.001 0.001 03 0 2 0 0 0.001 03 1 0 1 0.991 -1 -13 1 1 0 0.009 -1 -13 1 2 0 0 -1 -1
54
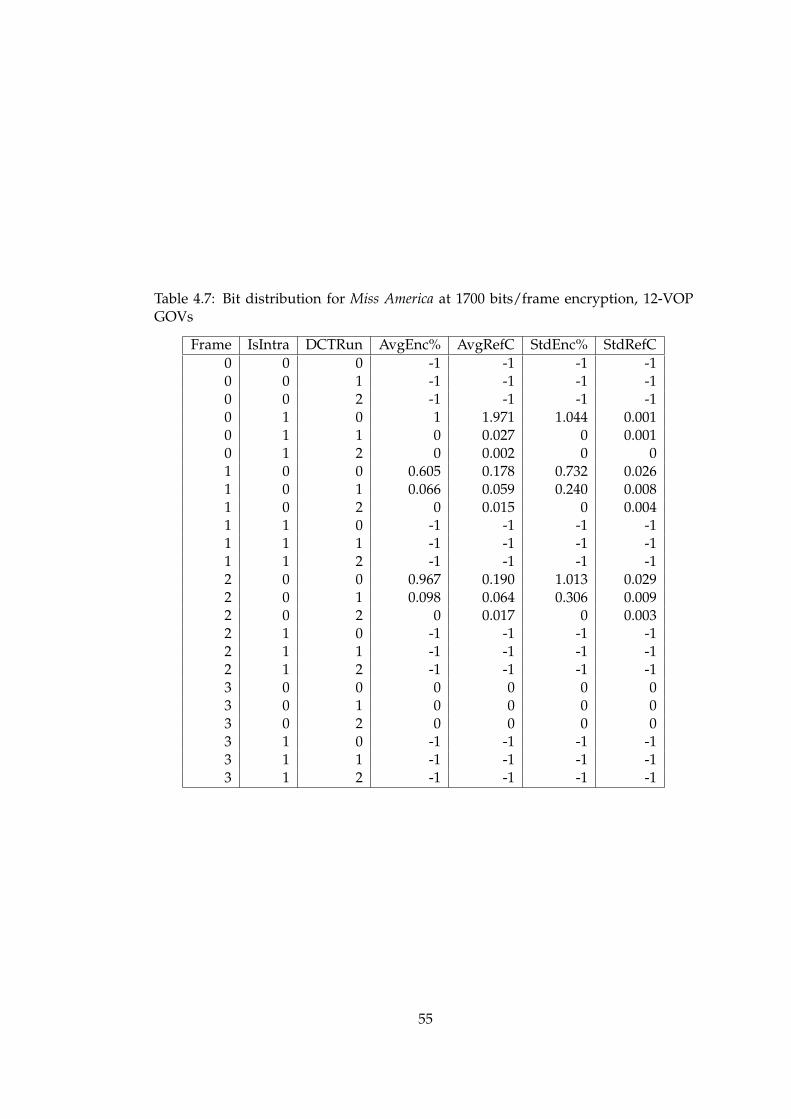
Table 4.7: Bit distribution for Miss America at 1700 bits/frame encryption, 12-VOPGOVs
Frame IsIntra DCTRun AvgEnc% AvgRefC StdEnc% StdRefC0 0 0 -1 -1 -1 -10 0 1 -1 -1 -1 -10 0 2 -1 -1 -1 -10 1 0 1 1.971 1.044 0.0010 1 1 0 0.027 0 0.0010 1 2 0 0.002 0 01 0 0 0.605 0.178 0.732 0.0261 0 1 0.066 0.059 0.240 0.0081 0 2 0 0.015 0 0.0041 1 0 -1 -1 -1 -11 1 1 -1 -1 -1 -11 1 2 -1 -1 -1 -12 0 0 0.967 0.190 1.013 0.0292 0 1 0.098 0.064 0.306 0.0092 0 2 0 0.017 0 0.0032 1 0 -1 -1 -1 -12 1 1 -1 -1 -1 -12 1 2 -1 -1 -1 -13 0 0 0 0 0 03 0 1 0 0 0 03 0 2 0 0 0 03 1 0 -1 -1 -1 -13 1 1 -1 -1 -1 -13 1 2 -1 -1 -1 -1
55

4.5.2 Encryption Ratios
The bit distribution tables are obtained without rate control and by averaging over
all GOVs. Encoding configurations specified in Section 4.4 are used to obtain the
values. The field names are abbreviated whenever necessary and contain quantities
specified below:
Frame denotes the place of the VOP in the GOV. 0 denotes the I-VOP and increasing
values represent following P-VOPs.
IsIntra specifies if the entry belongs to intra coded entities. A value of 1 denotes that
the entry contains values belonging to intra coded entities.
DCTRun specifies the the DCT coefficient sequence of the entry. In intra entries 0,
1 and 2 correspond to DC, AC1 and AC2 coefficients, respectively. In nonintra
entries 0, 1 and 2 correspond to AC1, AC2 and AC3 coefficients, respectively.
AvgEnc% denotes the average encryption ratio. A value of 1 means that all data of
that type is encrypted and zero means none of the data of that type is encrypted.
A value of -1 means that no data of that type exists in the encoded bitstream.
AvgRefC% denotes the average reference count. -1 has the same meaning as for
AvgEnc%
StdEnc% denotes the standard deviation of encryption ratios. -1 has the same mean-
ing as for AvgEnc%.
StdRefC% denotes the standard deviation of reference counts. -1 has the same
meaning as for AvgRefC%.
As it can be seen from Figure 4.9, 4.12 and 4.13, the distribution of encrypted
bits changes depending on the nature of the video sequence. Note that the sequence
Miss America requires fewer bits to encode, thus relatively larger portion of the video
is encrypted. The common point between the three graphs is that Intra DCs are
always encrypted and require almost constant amount of bits, as expected. Only one
field per VOP is encrypted, as 1700bits/frame (which is approximately 10% of the
bitstream, considering the Carphone sequence) is not enough to encrypt other fields.
Corresponding average reference counts ri and the average ratio of encrypted parts
over all VOPs can be found in Tables 4.1, 4.2 and 4.7. As expected, reference counts
for I-VOP level are larger and reference counts decrease as the level increases. The
56
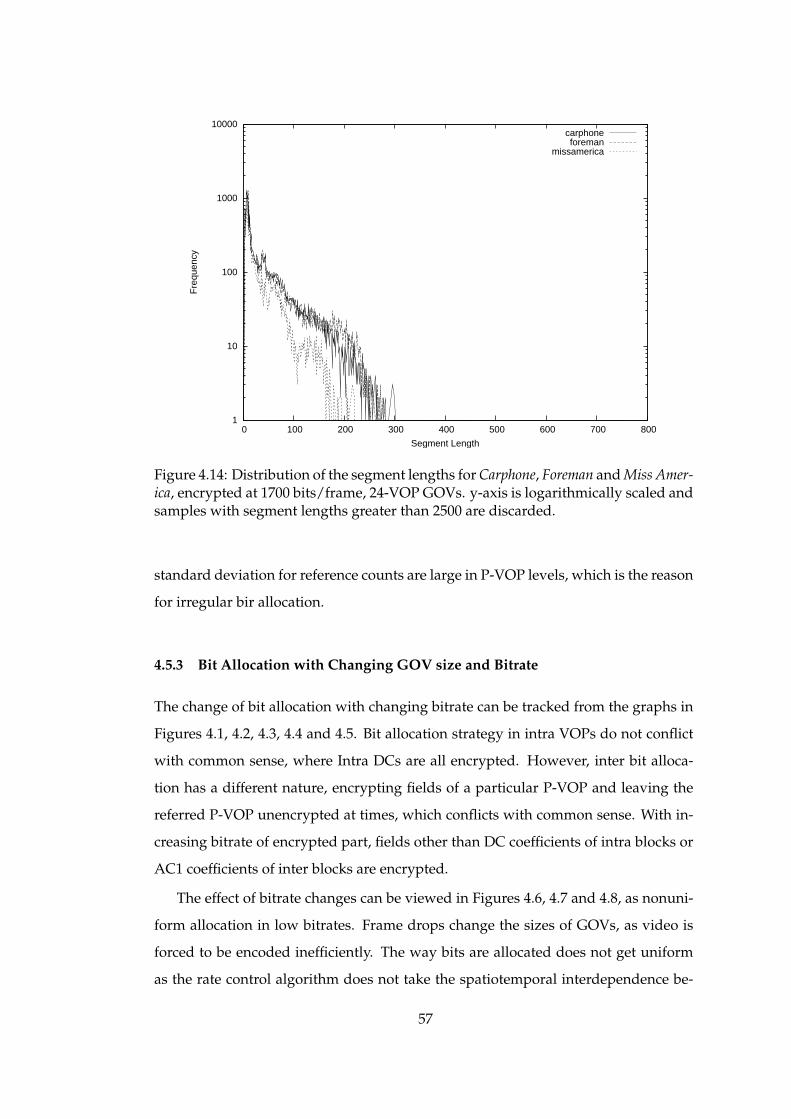
1
10
100
1000
10000
0 100 200 300 400 500 600 700 800
Fre
quen
cy
Segment Length
carphoneforeman
missamerica
Figure 4.14: Distribution of the segment lengths for Carphone, Foreman and Miss Amer-ica, encrypted at 1700 bits/frame, 24-VOP GOVs. y-axis is logarithmically scaled andsamples with segment lengths greater than 2500 are discarded.
standard deviation for reference counts are large in P-VOP levels, which is the reason
for irregular bir allocation.
4.5.3 Bit Allocation with Changing GOV size and Bitrate
The change of bit allocation with changing bitrate can be tracked from the graphs in
Figures 4.1, 4.2, 4.3, 4.4 and 4.5. Bit allocation strategy in intra VOPs do not conflict
with common sense, where Intra DCs are all encrypted. However, inter bit alloca-
tion has a different nature, encrypting fields of a particular P-VOP and leaving the
referred P-VOP unencrypted at times, which conflicts with common sense. With in-
creasing bitrate of encrypted part, fields other than DC coefficients of intra blocks or
AC1 coefficients of inter blocks are encrypted.
The effect of bitrate changes can be viewed in Figures 4.6, 4.7 and 4.8, as nonuni-
form allocation in low bitrates. Frame drops change the sizes of GOVs, as video is
forced to be encoded inefficiently. The way bits are allocated does not get uniform
as the rate control algorithm does not take the spatiotemporal interdependence be-
57
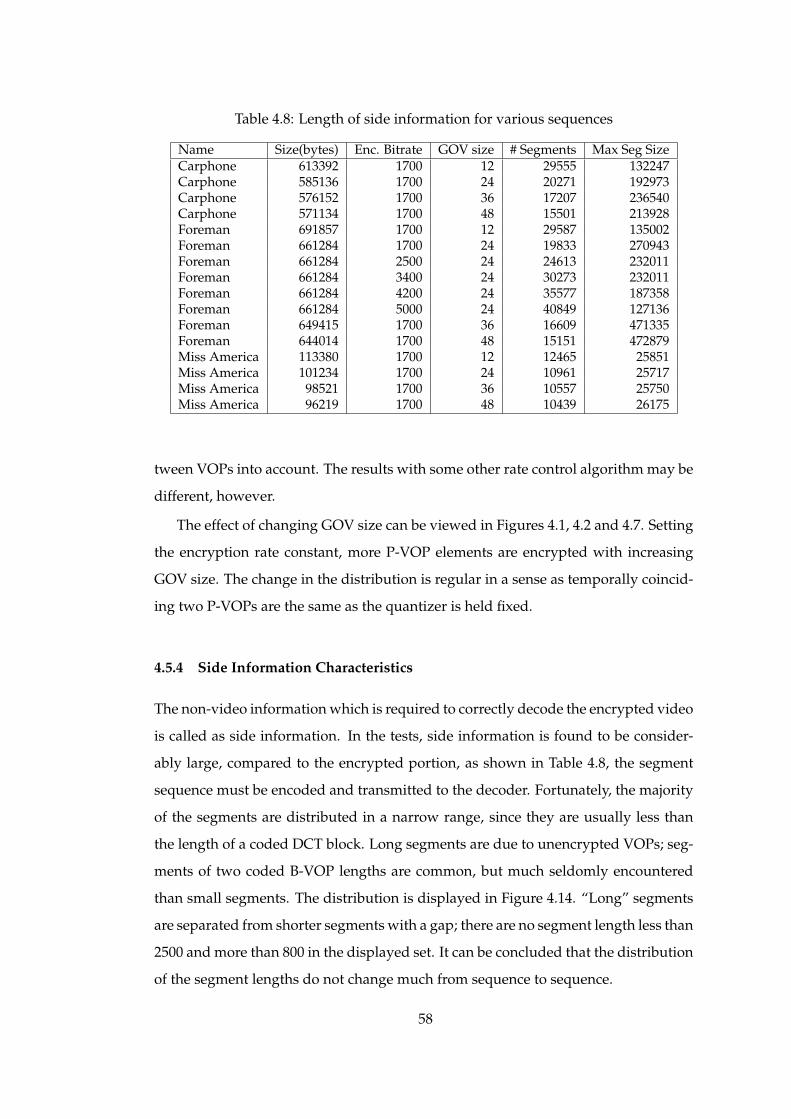
Table 4.8: Length of side information for various sequences
Name Size(bytes) Enc. Bitrate GOV size # Segments Max Seg SizeCarphone 613392 1700 12 29555 132247Carphone 585136 1700 24 20271 192973Carphone 576152 1700 36 17207 236540Carphone 571134 1700 48 15501 213928Foreman 691857 1700 12 29587 135002Foreman 661284 1700 24 19833 270943Foreman 661284 2500 24 24613 232011Foreman 661284 3400 24 30273 232011Foreman 661284 4200 24 35577 187358Foreman 661284 5000 24 40849 127136Foreman 649415 1700 36 16609 471335Foreman 644014 1700 48 15151 472879Miss America 113380 1700 12 12465 25851Miss America 101234 1700 24 10961 25717Miss America 98521 1700 36 10557 25750Miss America 96219 1700 48 10439 26175
tween VOPs into account. The results with some other rate control algorithm may be
different, however.
The effect of changing GOV size can be viewed in Figures 4.1, 4.2 and 4.7. Setting
the encryption rate constant, more P-VOP elements are encrypted with increasing
GOV size. The change in the distribution is regular in a sense as temporally coincid-
ing two P-VOPs are the same as the quantizer is held fixed.
4.5.4 Side Information Characteristics
The non-video information which is required to correctly decode the encrypted video
is called as side information. In the tests, side information is found to be consider-
ably large, compared to the encrypted portion, as shown in Table 4.8, the segment
sequence must be encoded and transmitted to the decoder. Fortunately, the majority
of the segments are distributed in a narrow range, since they are usually less than
the length of a coded DCT block. Long segments are due to unencrypted VOPs; seg-
ments of two coded B-VOP lengths are common, but much seldomly encountered
than small segments. The distribution is displayed in Figure 4.14. “Long” segments
are separated from shorter segments with a gap; there are no segment length less than
2500 and more than 800 in the displayed set. It can be concluded that the distribution
of the segment lengths do not change much from sequence to sequence.
58

Figure 4.15: Foreman original (left) and encrypted at 2500 bits/frame (right), frame184
Figure 4.16: Miss America original (left) and encrypted at 1700 bits/frame (right),frame 89
4.5.5 Perceptual Quality
When played by a no-decryption player, the encrypted bitstream is viewed as a heav-
ily damaged video file. On some occasions, the player can crash. As it can be seen
from Figure 4.15, the image is degraded beyond acceptability for entertainment pur-
poses. Since intra refreshes in P-VOPs are also encrypted, no blockwise revealations
occur. It can be concluded that high motion sequences, where bits corresponding to
prediction errors coded as texture are unencrypted, may reveal the nature of the mo-
tion and the video sequence when Figure 4.15 is compared with Figure 4.16, which is
a lower motion sequence. This revealation is not of acceptable quality for entertain-
ment, but it may be informative if the encrypted video is just a peer-to-peer commu-
nication. The output changes from player to player; the given results are obtained
59

with QuickTime 6.3 for Windows [35], it is found to be more robust and reveal more
of the encrypted stream than other tested players.
The results are as expected, given the perceptual results published in previous
studies on video encryption.
60

CHAPTER 5
CONCLUSION AND FUTURE WORK
Access control on the media is essential in both commercial broadcasting and peer-
to-peer communication. An access control mechanism must be supported by encryp-
tion in order to ensure that only authorized accesses are possible.Partial encryption
takes relatively small amount of time, compared to the decoding process; the time
is not negligible, however. A configurable yet maximally secure encryption method
is required, as not all video streams are of equal value. In order to accomplish this
task, a solution to encrypt video is proposed, which consists of a simple model of the
average time required to break a portion of the encrypted video and an algorithm to
estimate the model parameters.
5.1 Features of the Proposed Method
Unlike previously developed video encryption methods, the proposed method is ca-
pable of controlling the rate of the encrypted stream at a level that can be specified
by the content creator/provider while keeping the stream as robust as possible. The
advantage of this control can be used in two ways:
• The content provider can assess the level of encryption to protect a video stream
with known value
• The player designer/implementer can estimate the computational power re-
quired to play a video with certain security requirements, which will lead to a
more efficient design
61

The model is generalizable to other video coding schemes, including codecs with
temporal scalability; the procedure involves identification of levels with dependency
relations between one another. As a next step, the error propogation between those
levels must be estimated.
By experimentation, it’s shown that the bit allocation is irregular in the proposed
encryption method even when the bitrate is controlled. However a rate control tak-
ing spatiotemporal relations into account may result in uniform encryption, i.e. en-
cryption of a specific field all the time.
5.2 Main Drawbacks
It is difficult to evaluate the robustness of the system quantitively nor compare en-
cryption results with those of previously published algorithms, since there’s no com-
monly used test setup in the previous works.
The implementation does not take any spatial prediction into account, which is
commonly used in practical encoding configurations. A better adaptation can be
made to assign per-MB bit budgets, depending on the implemented rate control
mechanism at the encoder. This approach is beneficial when spatial prediction is
used to improve coding efficiency.
It can also be seen that the system introduces a delay, which may be undesirable.
On the other hand, using the parameters estimated from previous GOVs are not op-
timal in case of scene changes.
5.3 Suggested Future Work
The following subjects are suggested for further study, which can make use of the
findings of this thesis:
• First of all, the performance of the proposed system can be tested once the
parts mentioned in Section 4.2.2 are implemented; encryption over sprites and
shapes are unstudied, to the best of the author’s knowledge.
• Integration of the encryption framework as an MPEG-4 IPMP element is left
as a software development task, since it requires modifications on a large code
62

base. mpeg4ip is a good candidate for such an extension, it uses a modified ver-
sion of microsoft’s MPEG-4 implementation as a natural video decoder. This
requires implementation of facilities to multiplex the IPMP stream (carrying
information generated by an implementation of this thesis) with the audiovi-
sual content and the IPMP system interpereting the stream.
• The parameters ci depend on the characteristics of the video stream. The care-
ful reader should have seen that the attacker can extract these parameters from
the lengths of the encrypted segments or by perfect localization of errors, if
the lengths of the encrypted segments are secured. It is worth investigating
whether implicit transmission of ci reveals valuable information for cryptanal-
ysis. The question that whether encryption side information should be secured
is also left unanswered in this study.
• In order to avoid the problem stated above, one can set up a series of exper-
iments to establish a number of encrytion profiles. Selection between preset
profiles might be helpful with a lightweight encoder. Experiments show that
the encryption in low motion video is more uniform, thus this method can be
implemented for video communication applications.
• The method can be extended to video access control implementations that en-
crypt the indexes of codewords instead of codewords themselves, instead of
the direct encryption method implemented here.
63

REFERENCES
[1] A. M. Eskicioglu, J. Town, and E. J. Delp, “Security of digital entertainmentcontent from creation to consumption,” Signal Processing: Image Communication,vol. 18, pp. 237–262, 2003.
[2] J. Wen, M. Severa, W. Zeng, M. Luttrell, and W. Jin, “A format compliant con-figurable encryption framework for access control of multimedia,” in Proc. IEEEWorkshop on Multimedia Signal Processing, pp. 435–440, 2001.
[3] A. M. Eskicioglu and E. J. Delp, “An overview of multimedia content protec-tion in consumer electronics devices,” Signal Processing: Image Communication,vol. 16, pp. 681–699, 2001.
[4] A. Gayer and O. Shy, “Copyright protection and hardware taxation,” InformationEconomics and Policy, vol. 0 (in print), pp. 0–0, 2003.
[5] A. M. Tekalp, Digital Video Processing, pp. 432–500. Prentice Hall, 1995.
[6] S. Mallat, A Wavelet Tour of Signal Processing. Academic Press, 1998.
[7] W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, NumericalRecipes in C: The Art of Scientific Computing, pp. 903–926. Cambridge UniversityPress, 2 ed., 1992.
[8] T. Ebrahimi and C. Horne, “MPEG-4 natural video coding – an overview,” SignalProcessing: Image Communication, vol. 15, pp. 365–385, 2000.
[9] ISO/IEC JTC1/SC29 WG11, ISO/IEC 14496-2 FCD N2202, March 1998.
[10] R. Koenen, “Profiles and levels in MPEG-4: approach and overview,” SignalProcessing: Image Communication, vol. 15, pp. 463–478, 2000.
[11] ISO/IEC JTC1/SC29 WG11, ISO/IEC 14496-1 N2201, May 1998.
[12] ISO/IEC JTC1/SC29 WG11, ISO Media File format specification N4270-1, June2003.
[13] ISO/IEC JTC1/SC29 WG11, FPDAM ISO/IEC 14496-1:2001 / AMD3 N4701,March 2002.
[14] ISO/IEC JTC1/SC29 WG11, ISO/IEC 13818-1:2000/FPDAM2 N4986 (MPEG-2IPMP), July 2002.
64

[15] J. Daemen and V. Rijmen, Rijndael, http://csrc.nist.gov/CryptoToolkit/aes/rijndael/ .
[16] A. J. Slagell, “A simple, portable and expandable cryptographic application pro-gram interface,” Master’s thesis, University of Illinois at Urbana-Champaign,2003.
[17] M. Wu and Y. Mao, “Communication-friendly encryption of multimedia,” inProc. of IEEE Multimedia System Processing Workshop, 2002.
[18] J. Wen, M. Severa, W. Zeng, M. Luttrell, and W. Jin, “A format compliant config-urable encryption framework for access control of multimedia,” IEEE Trans. onCircuits and Systems for Video Technology, vol. 12, no. 6, pp. 545–557, 2002.
[19] L. Qiao and K. Nahrstedt, “Comparison of MPEG encryption algorithms,” Com-puters and Graphics, vol. 22, no. 4, pp. 437–448, 1998.
[20] C. Griwodz, “Video protection by partial content corruption,” in Multimedia andSecurity Workshop at ACM Multimedia ’98, Bristol, UK,, 1998.
[21] S. Wee and J. Apostolopoulos, “Secure scalable video streaming for wireless net-works,” in Proc. of the IEEE International Conference on Acoustics, Speech and SignalProcessing, 2001.
[22] A. S. Tosun and W.-C. Feng, “Efficient multi-layer coding and encryption ofMPEG video streams,” in IEEE International Conference on Multimedia and Expo,2000.
[23] T. Kunkelmann, “Applying encryption to video communication,” in Multimediaand Security Workshop at ACM Multimedia ’98, Bristol, UK,, 1998.
[24] T. Kunkelmann and U. Horn, “Partial video encryption based on scalable cod-ing,” in 5th International Workshop on Systems, Signals and Image Processing (IWS-SIP’98), 1998.
[25] C. Shi, S. Wang, and B. Bhargava, “Mpeg video encryption in real-time usingsecret key cryptography,” in Proc. of PDPTA ’99, (Las Vegas, Nevada), 1999.
[26] L. Tang, “Methods for encrypting and decrypting MPEG video data efficiently,”in ACM Multimedia, pp. 219–229, 1996.
[27] A. S. Tosun and W.-C. Feng, “Lightweight security mechanisms for wirelessvideo transmission,” in International Conference on Information Technology: Cod-ing and Computing, 2001.
[28] S. S. Maniccam and N. G. Bourbakis, “Lossless image compression and encryp-tion using scan,” Pattern Recognition, vol. 34, pp. 1229–1245, 2001.
[29] N. Bourbakis and C. Alexopoulos, “A fractal based image processing language– formal modeling,” Pattern Recognition, vol. 32, pp. 317–338, 1999.
[30] C.-C. Chang, M.-S. Hwang, and T.-S. Chen, “A new encryption algorithm forimage cryptosystems,” The Journal of Systems and Software, vol. 58, pp. 83–91,2001.
65

[31] X. Li, J. Knipe, and H. Cheng, “Image compression and encryption using treestructures,” Pattern Recognition Letters, vol. 18, pp. 1253–1259, 1997.
[32] H. Cheng, “Partial encryption for image and video communication,” Master’sthesis, University of Alberta, 1998.
[33] T. Zhang, U. Jennehag, and Y. Xu, “Numerical modeling of transmission errorsand video quality of MPEG-2,” Signal Processing: Image Communication, vol. 16,pp. 817–825, 2001.
[34] D. Mackie, B. Eisenberg, and W. May, mpeg4ip, http://mpeg4ip.sourceforge.net/ .
[35] Apple Corporation, QuickTime, http://quicktime.apple.com/ .
66