leveraging the power of solr with spark: presented by johannes weigend, qaware
TRANSCRIPT

O C T O B E R 1 1 - 1 4 , 2 0 1 6 • B O S T O N , M A1

Leveraging the Power of Solr with Spark JOHANNES WEIGEND
CTO, QAware GmbH / Germany
2

3
01Agenda
Introduction to Solr Cloud and Spark
Importing
Searching and Aggregating
Scaling Up

It is Hard to Scale Horizontally!■ Functions- Trivial - Loadbalancing of stateless services (macro- / microservices) - More users -> more machines
- Nontrivial - More machines -> faster response times
■ Data- Trivial - Linear distribution of data on multiple machines - More machines -> more data
- Nontrivial - Constant response times with growing datasets
4

5
Cloud
-Document based NoSQL database with outstanding search capabilities A document is a collection of fields (string, number, date, …) Single und multiple fields (fields can be arrays) Nested documents Static und dynamic scheme Powerful query language (Lucene)
-Horizontally scalable with Solr Cloud Distributed data in separate shards Resilience by combination of zookeeper and replication
-Powerful aggregations (aka facets)

6
Shard2
Solr Server
Zookeeper
Solr ServerSolr Server
Shard1
Zookeeper Zookeeper Zookeeper Ensamble
Solr Cloud
Leader
Scale Out
Shard3
Replica8 Replica9
Shard5Shard4 Shard6 Shard8Shard7 Shard9
Replica2 Replica3 Replica5
Shards
Replicas
Collection
Replica4 Replica7 Replica1 Replica6
The Architecture of Solr Cloud
Two Levels of Distribution

Search Search Search
SearchIndexStore
Map Map Map
CalculateCacheJoin
Combine
Frontend
Reduce Business Layer
Combining Solr + Spark
7

READ THIS: https://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
■Distributed computing (100x faster than Hadoop M/R) ■Distributed Map/Reduce on distributed data can be done in-memory ■Supports online and batch workloads ■Scala with Java/Scala/Python APIs ■Processes data from distributed and local sources -Textfiles (accessible from all nodes) -Hadoop File System (HDFS) -Databases (JDBC) -Solr per Lucidworks API
8

Driver
9
Apache Sparkexecuting parallel tasks
executing parallel tasks
Executor
Executor

10
Cloud in a Box

The Cloud in a Box
6th generation Intel® Core™ i5-6260U processor with Intel® Iris™ graphics (1.9 GHz up to 2.8 GHz Turbo, Dual Core, 4 MB Cache, 15W TDP)
CPU
32 GB Dual-channel DDR4 SODIMMs 1.2V, 2133 MHz
RAM
256 GB Samsung M.2 internal SSDDISK
! Used for all benchmarks in this talk
10 Cores, 20 HT Units, 160 GB RAM, 1,25 TB DiskTotal
11

12

13
01
Introduction into Solr Cloud and Spark
Importing
Searching and Aggregating
Scaling Up
Agenda

Apache Big Data North America | Vancouver | 05.05.2016 | Johannes Weigend | © QAware GmbH
Monitoring Sample Data
■ Single CSV per process, host, metric type
wls1_lpapp18_jmx.csv
Datetime CPU % Usage Heap % Usage #GC Invocations
1/10/16 9:00,000 50 50 1000
1/10/16 10:00,000 60 60 1100
1/10/16 11:00,000 70 70 1300
1/10/16 12:00,000 80 80 1800
CSV Solr document per cell
14
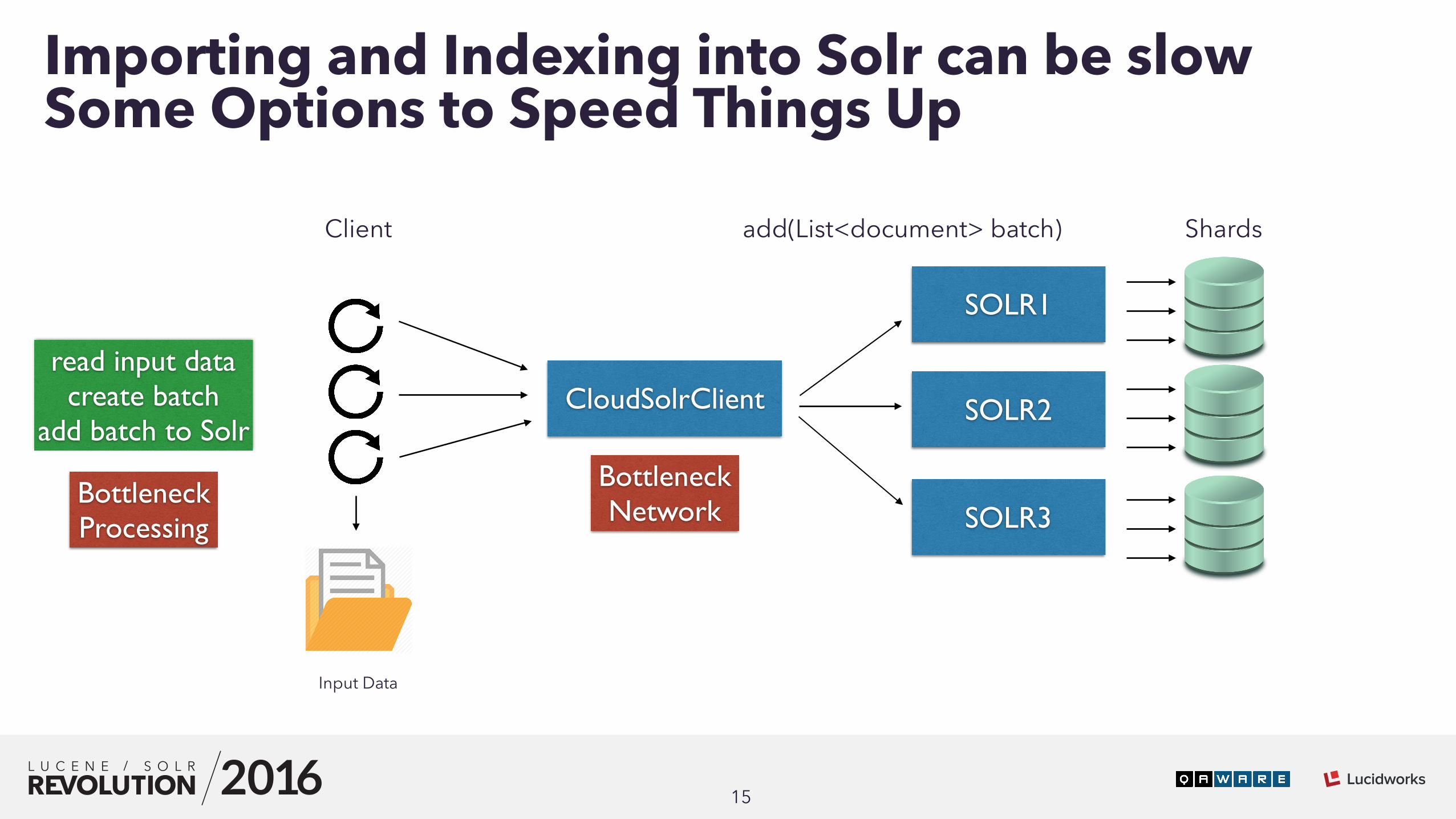
15
CloudSolrClient
SOLR1
SOLR2
SOLR3
add(List<document> batch) ShardsClient
Input Data
read input datacreate batch
add batch to Solr
BottleneckProcessing
BottleneckNetwork
Importing and Indexing into Solr can be slow Some Options to Speed Things Up
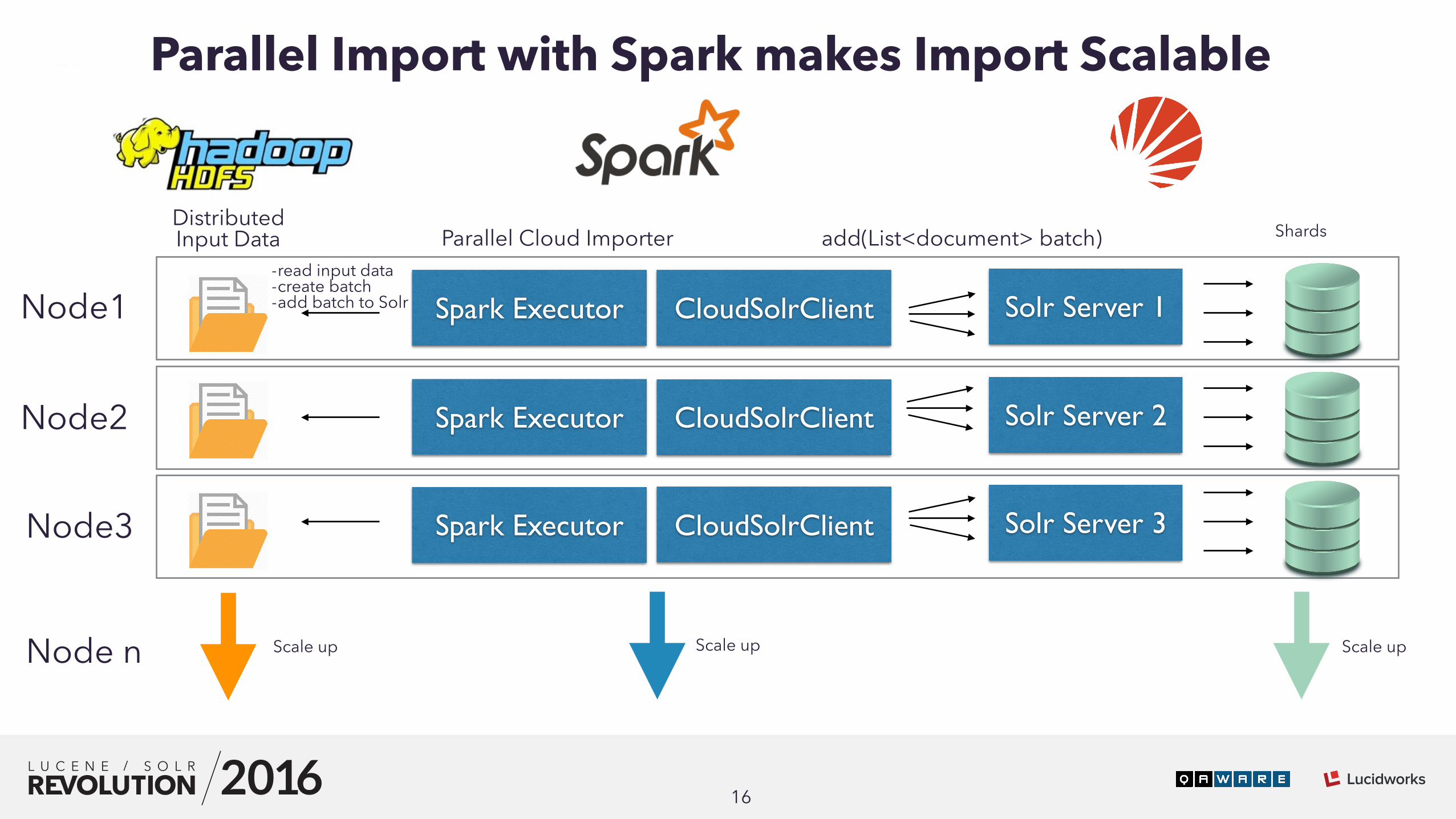
Spark Executor
16
CloudSolrClient Solr Server 1
add(List<document> batch) ShardsParallel Cloud ImporterDistributed Input Data
-read input data -create batch -add batch to Solr
Parallel Import with Spark makes Import Scalable
Node1
CloudSolrClient Solr Server 2Spark ExecutorNode2
Scale upScale up Scale upNode n
Solr Server 3CloudSolrClientSpark ExecutorNode3

17
How to Import Multiple (HDFS) Files
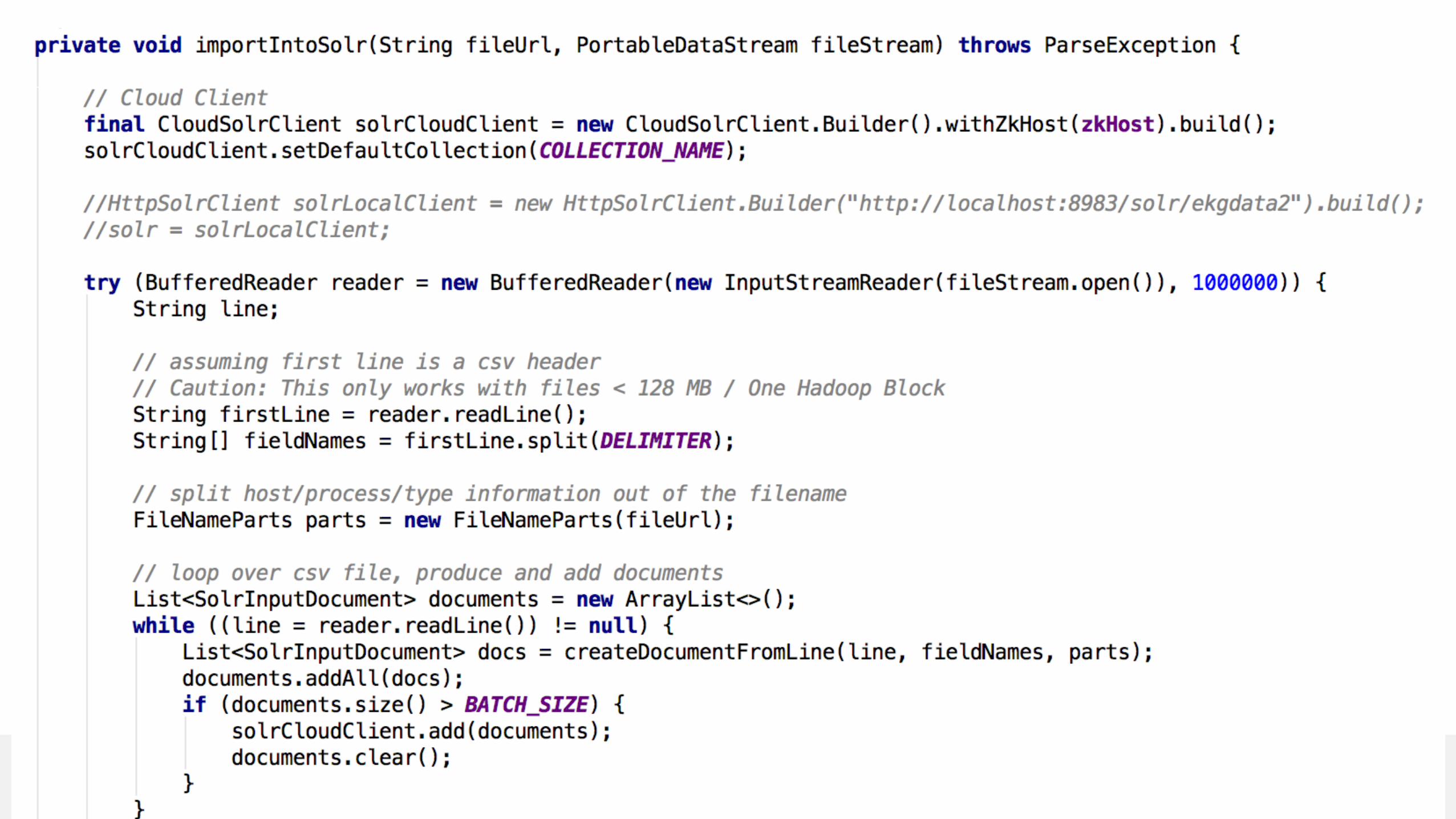
18

19
Solr UUID-Field

20
Import takes - 78411 ms
—> 180.000 Docs per Second
Indexing 14 Mio Docs in 1:20 Min

SolrJ and Spark have Different Transitive Dependencies Depending on the Software Version
■ Adding both libraries to your classpath leads by transitivity to serious problems at runtime (Serialization errors / ClassNotFoundExceptions…)
■ Pinning / Exclusion helps - but can produce strange errors. There is currently no satisfying solution for the BigData class path hell.
21

22
01
Introduction into Solr Cloud and Spark
Importing
Searching and Aggregating
Scaling Up
Agenda

23
Using Solr Facet Queries for Aggregation# # Grouping per sub query # curl $SOLR/$COLLECTION/select -d ' q=process:wls1 AND metric:*.HeapMemoryUsage.used& rows=0& json.facet={ Hosts: { type: terms, field: host, facet:{ Off : { query : "value: [* TO 0]" }, Idle : { query : "value: [0 TO 1000000000]" }, Busy : { query : "value: [1000000001 TO 10000000000]" }, Overload : { query : "value: [10000000001 TO *]" } } } }

Why Do we Need Even More?
■Data centerer applications need a scalable way of - Post processing search results or facets (business logik, ML,
data analytics) - Post filtering search results - Processing denormalized data (if you store a one-to-many
relation in a single Solr document)
24

Accessing Solr from Spark with SolrRDD
■ https://github.com/lucidworks/spark-solr
■ You have to build the library locally. There is no released version at Maven Central.
■ Make sure to adjust the versions depending on your environment
25

Streaming from Solr into Spark
Not Bad! 14 Mio in 1:27 Minutes26

27
You Can Speed up Spark / Solr by Factor 10 Using the Export Handler

Using SolrRDD with Java
28

29
Reading 14 Mio Docs in 10 Seconds
Streaming 14 Mio Solr documents into Spark takes 10 Seconds
—> 1.400 000 Docs per Second

RDDs using /export Handler Rocks!
30

Scaling up
31

Apache Big Data North America | Vancouver | 05.05.2016 | Johannes Weigend | © QAware GmbH
Recap: Monitoring Sample Data
■ Single CSV per process, host, metric type
wls1_lpapp18_jmx.csv
Date CPU % Usage Heap % Usage #GC Invocations
1/10/16 9:00,000 50 50 1000
1/10/16 10:00,000 60 60 1100
1/10/16 11:00,000 70 70 1300
1/10/16 12:00,000 80 80 1800
CSV SOLR
32
1000 lines with 10.000 columuns = 3MB gzipped 1000 x 10.000 docs = 1 Mio Solr docs

A Naive Solr Datamodel
A single Solr document per CSV cell ‣ Advantage
You can use Solr for aggregation, sorting and searching for values or time intervals
‣ Disadvantage Data explosion (single compressed CSV file with 3MB in size produces 1 Mil Solr documents)
33

Column Based Denormalization
wls1_lpapp18_jmx.csv
Date CPU % Usage Heap % Usage #GC Invocations
1/10/16 9:00,000 50 50 1000
1/10/16 10:00,000 60 60 1100
1/10/16 11:00,000 70 70 1300
1/10/16 12:00,000 80 80 1800
CSVSolrDocument {
process: wls1 host: lpapp18 type: jmx maxdate: 1/10/16 9:00 mindate: 1/10/16 12:00 metric: CPU % Usage values: [BINARY (Date, Long)] max: 80 min: 50 avg: 65
}
n 1
Store 1000-10000 events in a single document
Document per column
34

Storing 1-to-1400 Relation in a Single Document
Base64 encoded and gzipped
values: [{date: …, value:}, … ]35
32k Limit for DocValues

Benefits of Denomalization‣ Benefits - You can scale from a xxx million documents in a Solr Cloud up to
trillions of searchable events - Import is vastly faster
‣ Drawbacks - Searching on single values requires additional logic - Counting and faceting requires additional logic
‣ Spark can solve these problems by parallel post processing - Decompressing, aggregating, joining, grouping
36

Accessing Compressed Data within Spark
37

38
Indexing 19 Million of CSV Values in 13500 Solr documents
takes now 24 Seconds (before 1:20)
—> 800,000 Values per Second

39
Streaming One Billion of Solr Values into Spark Takes now 34 Seconds (Before 700 s)
—> 29,000,000 Values per Second

Summary■ The combination of Solr Cloud and Spark gives you the power to
deal with BigData workloads in realtime ■Denormalization can make your Solr application vastly faster ■Make use of the /export handler when using the SolrRDD ■ Parallel post processing is mandatory for nontrivial applications ■ If you want to learn more: come to the Chronix talk on Friday
40

Learn More
■ https://github.com/lucidworks/spark-solr ■ https://github.com/jweigend/solr-spark ■ http://chronix.io ■ https://github.com/ChronixDB/chronix.spark/ ■ http://qaware.blogspot.de
41

42

43