letizia tanca - exploring databases: the indiana project
TRANSCRIPT

Le#ziaTancaPolitecnicodiMilano
jointworkwithUniversitàdellaBasilicata(creditsinthelastslide)
Cogni#veSystemsIns#tuteSpeakerSeries

User Interaction
Visualize
AnnotationCollaboration
Efficiency
Explanations
Sampling
Personalization
Intensional view
Query Suggestion

• Richdata• Dialogue-basedinterac#on
• Basedonintensionalcharacteriza#onoftheinforma#on
• Meaningfulfeedback(relevance)• Userexperience
DatabaseExplora#onasaviewpointofExploratoryCompu5ng:
àonly,moreemphasisonefficiency

• Starting point: a large, “semantically-rich” db
• Goals • explore, to learn
interesting things • without a clear, a-priori
perception of what we are looking for


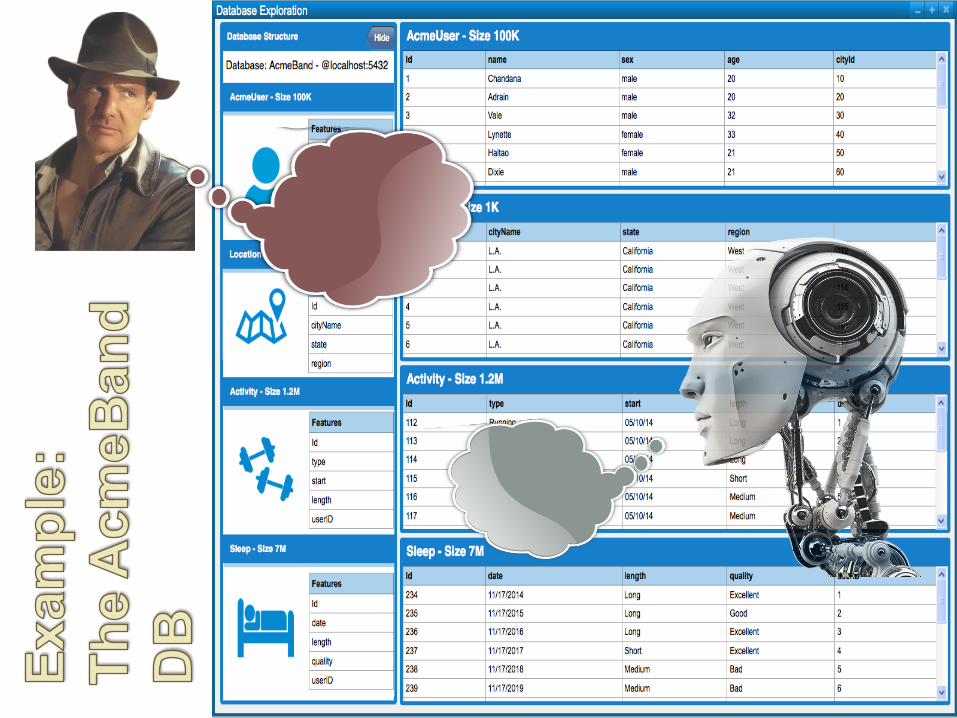








• A classical db is inherently transactional
• “Data Enthusiasts” are not willing to afford building a warehouse
• Interactive Data Cleaning
• Let’s do it on the database!

The UI Layer
The Engine Layer
The DB Layer
“interesting” attributes
Ac#vity
id
type
start
length
userId

AcmeUser Ac#vityLoca#on Sleep
The Engine Layer
The DB Layer
AcmeUser⨝Loca#on
Ac#vity⨝AcmeUser
Sleep⨝AcmeUser
typesex
quality
view X is a parent of view Y means Y contains X as a
subexpression

• Query Engine • Frequency distributions
of attribute values • Sampling • Statistical hypothesis
tests: • Real-valued attributes:
• Kolmogorov-Smirnov • Categorical attributes
• Chi-Square • or Entropy Test for low
frequencies
Query Engine
Computing Distributions
Running Hypothesis Tests
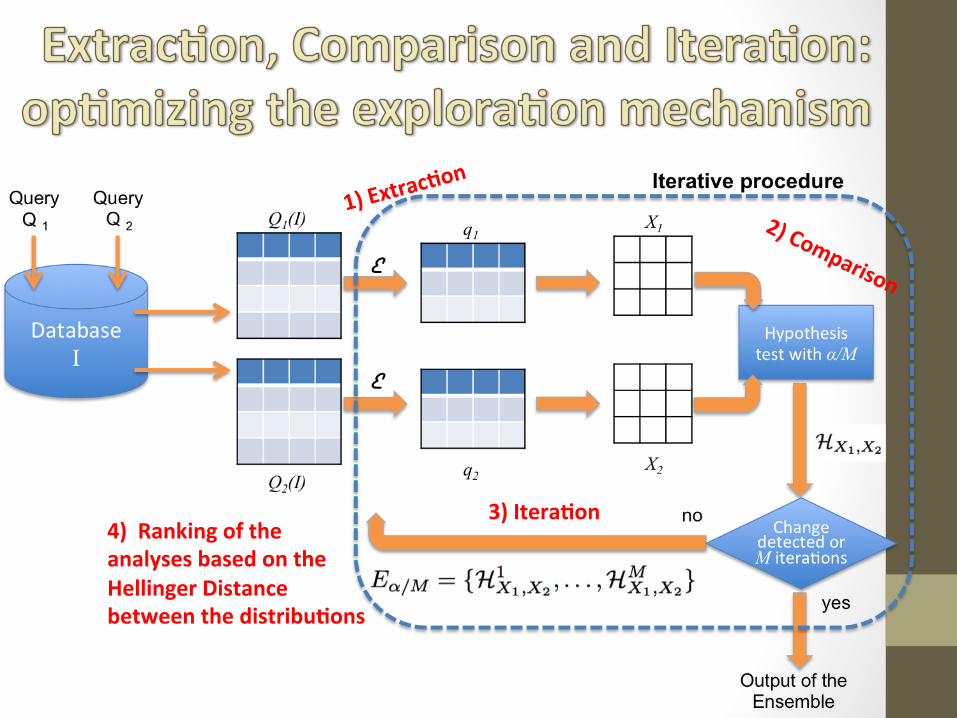
1)Extrac#on
3)Itera#on4)RankingoftheanalysesbasedontheHellingerDistancebetweenthedistribu#ons

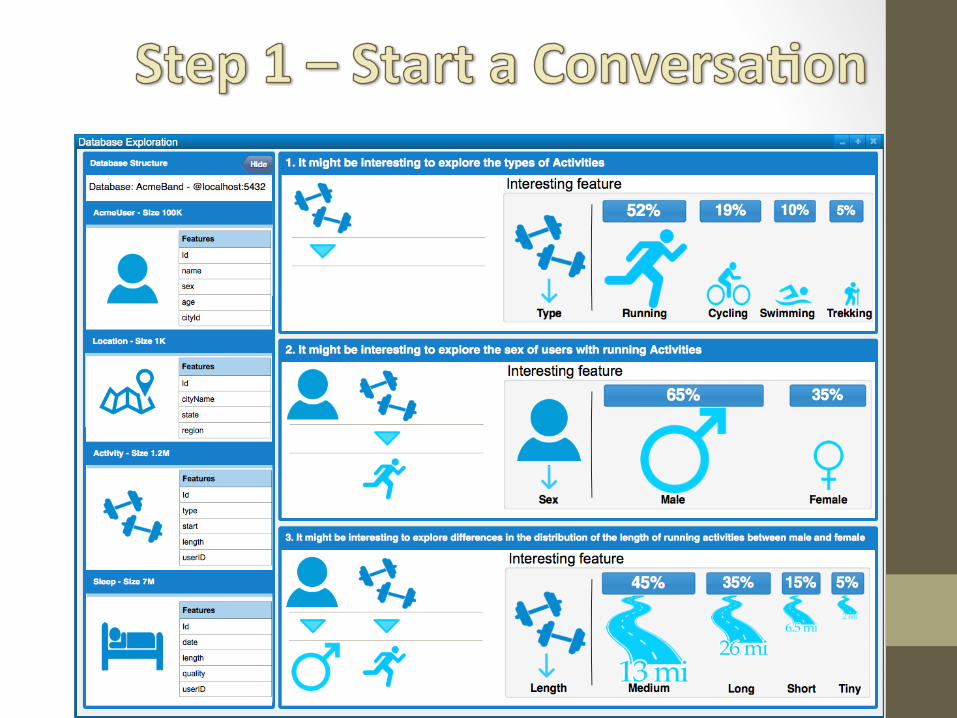
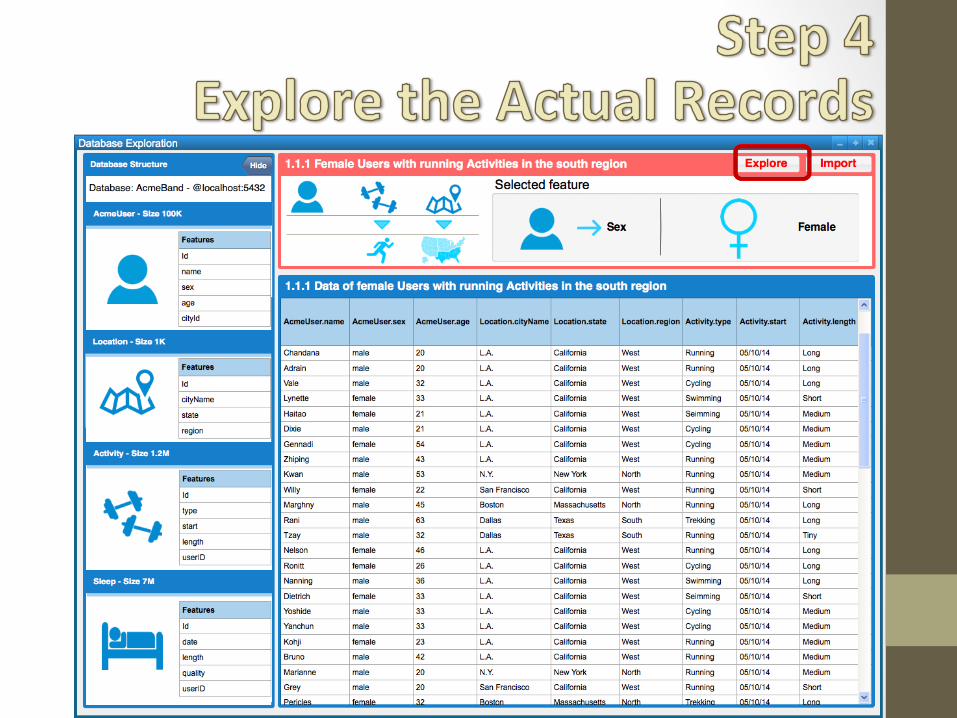
An interactive dialogue: • Users may change their
minds • Feedback: emphasis on
dataset properties, not on extensions
• Summarization
What is interesting is discovered: • Discontinuities • Niche knowledge detection
is serendipitous: surprise vs. previous subsets or vs. user’s expectations
• At each iteration the user should understand • the “current” subset of
items (its properties) • the main differences vs.
one or more of the previous subsets
• where to focus her attention (what is interesting?)
• Statistical approach to finding discrepancies
• A way to highlight relevant properties

• PolitecnicodiMilano:PaoloPaolini,NicoleQaDiBlas,ElisaQuintarelli,ManuelRoveri,MirjanaMazuran
• UniversitàdellaBasilicata:GiansalvatoreMecca,DonatelloSantoro,MarcelloBuoncris#ano,AntonioGiuzio
• M.Buoncris#ano,G.Mecca,E.Quintarelli,M.Roveri,D.Santoro,L.Tanca:DatabaseChallengesforExploratory
Compu5ng.SIGMODRecord,2015• N.DiBlas,M.Mazuran,P.Paolini,E.Quintarelli,L.Tanca:
Exploratorycompu5ng:adra=Manifesto.DSAA2014• S.Idreos,O.Papaemmanouil,S.Chaudhuri:
OverviewofDataExplora5onTechniques.SIGMOD2015.• MypostontheSIGMODBlog
