lessons learned from deploying apache spark as a service on ibm power systems in the cloud
TRANSCRIPT

Lessons Learned from Deploying Apache Spark as a Service on IBM Power Systems in the Cloud Indrajit (I.P) Poddar, STSM, IBM Systems Technical Strategy Randy Swanberg, DE, IBM Power Systems Software and Solutions

Please Note:
1
• IBM’s statements regarding its plans, directions, and intent are subject to change or withdrawal without notice at IBM’s sole discretion.
• Information regarding potential future products is intended to outline our general product direction and it should not be relied on in
making a purchasing decision. • The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any
material, code or functionality. Information about potential future products may not be incorporated into any contract. • The development, release, and timing of any future features or functionality described for our products remains at our sole discretion. • Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual
throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user’s job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.

Agenda
• Infrastructure considerations for a differentiated cloud data service
• Apache Spark – a popular big data framework
• Lessons learned on an alternative infrastructure with OpenPOWER systems
1. Open source stack for cloud native agile development
2. Management stack for automation and continuous integration
3. Efficient resource allocation and scheduling for multi-tenancy
4. Cloud infrastructure economics
5. Potential of acceleration under the cloud service
• Putting it all together
• Summary / Questions
2

Infrastructure for a differentiated Cloud Data Service
1. Agile Open Source development
experience
• Dynamic and flexible provisioning and
management
• Automated deployment and continuous
integration
2. Cost effective high performance
server infrastructure
3. Economical cloud storage service
with encryption
3

Big Data in the Cloud Example use cases, architectures and components..

Big Data Journey
5
Operations Data
Warehouse
Insight Inspired
Decision Making
Insight Driven
Business
Transformation
Va
lue
Big-Data Maturity
• Cheaper Storage
• Data Lake
• ETL Offload
• Cold Data Offload
• Queryable Archive
• Full Data Analysis (not
just samples)
• Extract Value from
non-relational data
• View of all enterprise
data
• Exploratory Analysis
and Discovery
• New Business Models
• Real time risk aware
decision making
• Real time fraud and
threat detection
• Optimize operations
• Attract and Retain
Customers
Most are somewhere here

Demand for Business Value from ALL Data Sources
Transaction and application data
Machine, sensor data
Enterprise content
Image, geospatial, video
Social data
Third-party data
Deep
Analytics
data zone
EDW and
data mart
zone
New Customer
Insights
Discover
Relationship
Risk Aware
Decisions
Early Warnings
New Business
Opportunities
Fraud Detection

What is Apache Spark?
• Unified Analytics Platform
– Combine streaming, graph, machine learning
and sql analytics on a single platform
– Simplified, multi-language programming model
– Interactive and Batch
• In-Memory Design
– Pipelines multiple iterations on single copy of
data in memory
– Superior Performance
– Natural Successor to MapReduce
7
Fast and general engine for
large-scale data processing
Spark Core API
R Scala SQL Python Java
Spark SQL Streaming MLlib GraphX

Anatomy of Apache Spark as a Cloud Service Stack components, web services, continuous integration..

Interactive iPython notebook with Matplotlib GUI
9
Host interactive analytic apps on ipython server to ease code sharing and reuse

Architectural components of a Apache Spark Cloud Service
10
Object Store for data Platform as a Service
Multi-tenant Spark drivers
and executors
Multi-tenant interactive Jupyter
ipython notebook servers with
matplotlib GUI
Shared Compute Cluster
Infrastructure as a Service
Bare metals Virtual Machines
Continuous Integration
Build Deploy
Shared storage IBM Spectrum Scale (GPFS)
Test
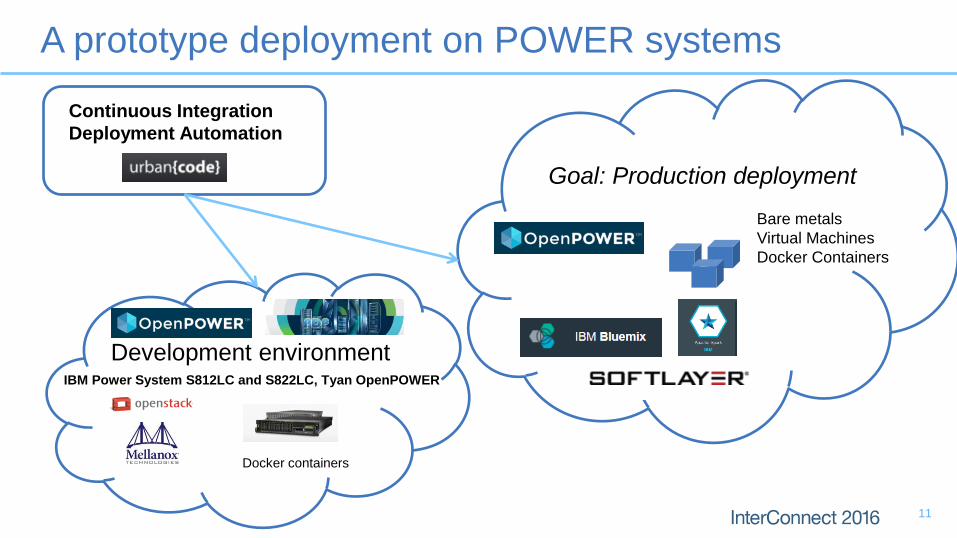
A prototype deployment on POWER systems
11
Goal: Production deployment
IBM Power System S812LC and S822LC, Tyan OpenPOWER
Development environment
Continuous Integration
Deployment Automation
Bare metals
Virtual Machines
Docker Containers
Docker containers

Lessons Learned Open source stack, efficient resource allocation and continuous integration, better economics and potential for acceleration on OpenPOWER systems ..

Analytics open source stack for agile development
13
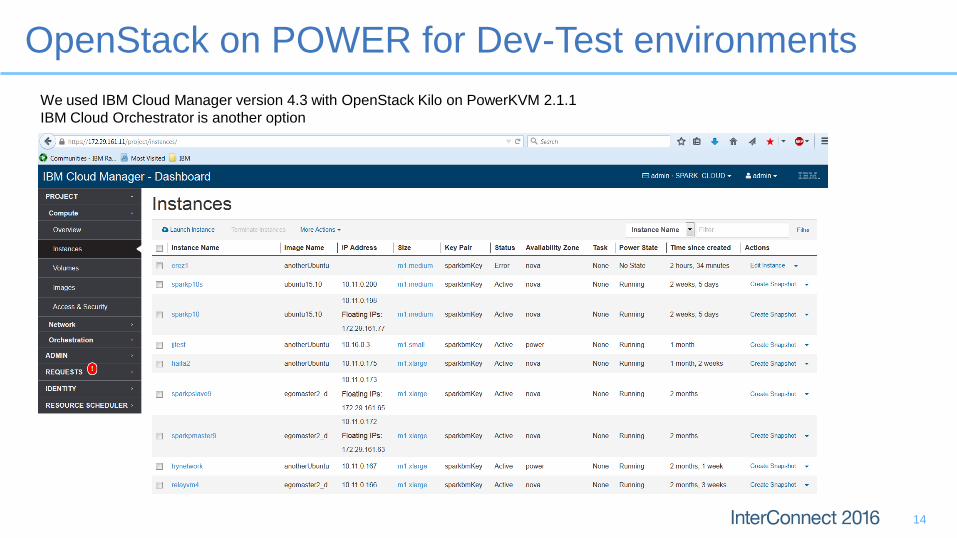
OpenStack on POWER for Dev-Test environments
14
We used IBM Cloud Manager version 4.3 with OpenStack Kilo on PowerKVM 2.1.1
IBM Cloud Orchestrator is another option

Continuous Integration with IBM Urban Code, OpenStack and Docker
targeting POWER systems
15
Create multiple deployment and development environments and visual deployment processes in IBM Urban Code Deployment
Run only UCD agents and relay on POWER VMs or bare metals

Continuous Integration Flows
16
Urban Code
Deploy
Server (x86)
Git Server
(x86)
Asset
Repository (x86)
Dev-Test Env
(OpenPOWER OpenStack VMs)
Build Env
(POWER Docker Containers)
Future Production Env
(OpenPOWER Bare metals)
1. Check in automation code
2. Build artifacts in Docker
3. Store built artifacts in a repository
4. Pull in artifacts into deployment automation
5. Deploy artifacts into dev-test env
6. Deploy artifacts into prod env

Efficient resource allocation using Platform Symphony
17
• Share system resources (CPU, memory)
with a distributed scheduler • Platform Symphony with Application
Service Controller (ASC) V7.1.1 and the
EGO scheduler for Ubuntu 14.04.2 on
POWER
• Platform Symphony + ASC features • Fine-grained scheduling
• Resource reclaim
• Standby service
• Data locality
• Shared storage through IBM Spectrum
Scale™

Economics of the Server Infrastructure
• Attributes directly influencing the economics
of hosting a Cloud Service:
• Number of servers needed to deliver a
competitive quality of service and response
time
• Cost of the individual servers or rental
• Number of users and jobs that can be
hosted concurrently (multi-tenancy)
• End user price charged for the service
• All of which are directly impacted by the
performance of the Server
18

Measuring Performance of Spark on POWER
19
The following charts show Performance
results of comparing multiple Spark Workloads
from SparkBench using data sizes from
100GB to 10TB (https://github.com/SparkTC/spark-bench)
7-node cluster of Intel Haswell servers • E5-2620 V3
• 12-core
• 256GB
vs
7-node cluster of POWER servers • POWER8 S812LC
• 10-core
• 256GB
• Machine Learning (Spark MLlib)
• Matrix Factorization
• Logistic Regression
• Support Vector Machine
• SQL (Spark SQL)
sqlContext.sql("SELECT COUNT(*) FROM orderTab").count()
sqlContext.sql("SELECT COUNT(*) FROM orderTab where bid>5000").count()
sqlContext.sql("SELECT * FROM oitemTab WHERE price>250").count()
sqlContext.sql("SELECT * FROM oitemTab WHERE price>500").count()
sqlContext.sql("SELECT * FROM orderTab r JOIN oitemTab s ON r.oid =
s.oid").count()
• Graph (Spark GraphX)
• Page Rank
• Triangle Count
• Singular Value Decomp++

System Performance of Spark on POWER
20
Machine Learning SQL Graph
1.7X
Raw System Performance Options for the Service Provider:
• Deliver higher qualities of service
• 70% faster job completion
times on average
• Faster time-to-insight
• Charge higher premium for the service
• Competitive advantage for the service

21
Per Core Performance of Spark on POWER
Per-core Performance View • 70 POWER8 Cores vs. 84 Intel Cores
• Enables headroom for better system
resource utilization
Machine Learning SQL Graph
2X

22
Price Performance of Spark on POWER
Machine Learning SQL Graph
1.5X
Price Performance View* Options for the Service Provider:
• Spend 33% less on infrastructure
supporting the same amount of workload
• Spend the same on infrastructure but
host 50% more workload
• Lower the price for the service for
competitive advantage
* - based on preliminary SoftLayer pricing targets – subject to change

But wait….there’s more to the story
23
0
0.5
1
1.5
2
2.5
3
E5-2620v3
100GBMat.Fact.
100GB(inmem)LR
1TB(inmem)LR
1TB(50/50)LR
1TBSVM
10TBLR
1TB5query
2TB5query
130GBPageRank
1TBTriangleCnt
1TBSVD++
AVERAGE
Re
lative
Syste
m
Perf
orm
an
ce
SparkWorkloads• A Deeper Look at the System
Performance profile for one of the
workloads close to our overall
average relative performance
• Machine Learning Logistic
Regression on a 1TB data set that
had a relative performance of 1.74X
Machine Learning SQL Graph
1.7X

More efficient use of resources (Spark 1TB Logistic Regression Example)
24
0
20
40
60
80
100
22:4
4
22:4
4
22:4
5
22:4
5
22:4
6
22:4
6
22:4
7
22:4
7
22:4
8
22:4
8
22:4
9
22:4
9
22:5
0
22:5
0
22:5
1
22:5
1
22:5
2
22:5
2
22:5
3
22:5
3
22:5
4
22:5
4
22:5
5
CPU POWER
User% Sys% Wait%
0
20
40
60
80
100
10:1
4
10:1
4
10:1
5
10:1
6
10:1
6
10:1
7
10:1
8
10:1
8
10:1
9
10:2
0
10:2
0
10:2
1
10:2
2
10:2
2
10:2
3
10:2
4
10:2
4
10:2
5
10:2
6
10:2
6
10:2
7
10:2
8
10:2
8
CPU Haswell
User% Sys% Wait%
-1500
-1000
-500
0
500
1000
22:4
4
22:4
4
22:4
5
22:4
5
22:4
6
22:4
6
22:4
7
22:4
7
22:4
8
22:4
8
22:4
9
22:4
9
22:5
0
22:5
0
22:5
1
22:5
1
22:5
2
22:5
2
22:5
3
22:5
3
22:5
4
22:5
4
22:5
5
MB
/se
c
Network I/O POWER
Total-Read Total-Write (-ve)
-600
-500
-400
-300
-200
-100
0
100
200
300
400
10:1
410:1
410:1
510:1
510:1
610:1
710:1
710:1
810:1
810:1
910:1
910:2
010:2
110:2
110:2
210:2
210:2
310:2
410:2
410:2
510:2
510:2
610:2
610:2
710:2
810:2
8
MB
/sec
Network I/O Haswell Total-Read Total-Write (-ve)
POWER
• CPU headroom to
host higher density
• More data pushed
over network due to
higher thread density
Haswell
• CPU fully pegged on
just this workload
• Underutilizing the
Network Resource

0
50000
100000
150000
200000
250000
300000
350000
400000
Ru
nti
me (
ms)
Total Heap Memory
x Degrees of Separation on Spark
Disk
CAPI/Flash
25
CAPI Flash for RDD Cache = 4X memory reduction at equal performance
Next Steps - Acceleration in the Cloud
RDMA for Spark Shuffle = 30% Better Response Time, Lower CPU Utilization
• CAPI Flash and RDMA can be Leveraged Transparently to Spark Applications under the Cloud Service
• Coming…. HDFS CAPI FPGA Erasure Code Acceleration, CAPI FPGA Compression Acceleration, ….

26
Acceleration of Spark with GPUs:
• Adverse Drug Reaction Prediction built on Spark
• 25X Speed up for Building Model stage (using Spark Mllib Logistic Regression)
• Again, Transparent to the Spark Application
• Game changer for Personalized Medicine

More efficient, cost effective, balanced cloud resources
• Better quality of service through workload acceleration and real time insights
• Efficient scale out architecture avoiding imbalanced resources
• New controls to balance resource utilization
27
GPUs and FPGAs for Compute
offload, consolidation, specialized
acceleration
CAPI Flash for Memory
consolidation/expansion, and Storage
acceleration
RDMA for better latency, better
network utilization and lower CPU
utilization
Fostering Acceleration in the Cloud : SuperVessel for OpenPOWER
ptopenlab.com
28

Putting it All Together….
29
Object Store for data Platform as a Service
Multi-tenant Spark drivers
and executors
Multi-tenant interactive Jupyter
ipython notebook servers with
matplotlib GUI
Shared Compute Cluster
Infrastructure as a Service
Bare metals Virtual Machines
Continuous Integration
Build Deploy
Shared storage IBM Spectrum Scale (GPFS)
Test
Docker

Summary
30
• Big Data solutions in the Cloud demand elasticity and scale
• Real time insights from all sources of data will become the norm
• Try open source Apache Spark with IBM Platform Symphony
• OpenPOWER systems can differentiate your cloud data service through:
• Improved cloud infrastructure economics and cost performance advantage
• An agile open source development experience
• Advanced forms of acceleration in cloud infrastructures will further differentiate
services

Notices and Disclaimers
31
Copyright © 2016 by International Business Machines Corporation (IBM). No part of this document may be reproduced or transmitted in any form without written permission
from IBM.
U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM.
Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of
initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. THIS DOCUMENT IS
DISTRIBUTED "AS IS" WITHOUT ANY WARRANTY, EITHER EXPRESS OR IMPLIED. IN NO EVENT SHALL IBM BE LIABLE FOR ANY DAMAGE ARISING FROM THE
USE OF THIS INFORMATION, INCLUDING BUT NOT LIMITED TO, LOSS OF DATA, BUSINESS INTERRUPTION, LOSS OF PROFIT OR LOSS OF OPPORTUNITY.
IBM products and services are warranted according to the terms and conditions of the agreements under which they are provided.
Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice.
Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers
have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary.
References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in
which IBM operates or does business.
Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials
and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or
their specific situation.
It is the customer’s responsibility to insure its own compliance with legal requirements and to obtain advice of competent legal counsel as to the identification and
interpretation of any relevant laws and regulatory requirements that may affect the customer’s business and any actions the customer may need to take to comply with such
laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer is in compliance with any law

Notices and Disclaimers Con’t.
32
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not
tested those products in connection with this publication and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products.
Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM does not warrant the quality of any third-party products, or the
ability of any such third-party products to interoperate with IBM’s products. IBM EXPRESSLY DISCLAIMS ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING BUT
NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
The provision of the information contained h erein is not intended to, and does not, grant any right or license under any IBM patents, copyrights, trademarks or other intellectual
property right.
IBM, the IBM logo, ibm.com, Aspera®, Bluemix, Blueworks Live, CICS, Clearcase, Cognos®, DOORS®, Emptoris®, Enterprise Document Management System™, FASP®,
FileNet®, Global Business Services ®, Global Technology Services ®, IBM ExperienceOne™, IBM SmartCloud®, IBM Social Business®, Information on Demand, ILOG,
Maximo®, MQIntegrator®, MQSeries®, Netcool®, OMEGAMON, OpenPower, PureAnalytics™, PureApplication®, pureCluster™, PureCoverage®, PureData®,
PureExperience®, PureFlex®, pureQuery®, pureScale®, PureSystems®, QRadar®, Rational®, Rhapsody®, Smarter Commerce®, SoDA, SPSS, Sterling Commerce®,
StoredIQ, Tealeaf®, Tivoli®, Trusteer®, Unica®, urban{code}®, Watson, WebSphere®, Worklight®, X-Force® and System z® Z/OS, are trademarks of International Business
Machines Corporation, registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM
trademarks is available on the Web at "Copyright and trademark information" at: www.ibm.com/legal/copytrade.shtml.

Thank You Your Feedback is Important!
Access the InterConnect 2016 Conference Attendee
Portal to complete your session surveys from your
smartphone,
laptop or conference kiosk.