apache spark meetup
TRANSCRIPT


Hands – On
• Instalación en su sistema • Introducción a Scala • Ejercicios con Scala • Break • Introducción a Apache Spark • Ejemplo de Scala con Apache Spark • Preguntas y Respuestas
Instalación hGps://spark.apache.org/downloads.html

Instalación en su sistema
• Descargar de ser posible en hGps://spark.apache.org/downloads.html • Descargar la versión 1.3.1 prebuilt para Hadoop 2.6
• Crear una carpeta en su sistema spark1.3 • Descomprimir la carpeta y renombrarla a spark1.3

Probando instalación
• Dirigirse a su carpeta de instalación de spark1.3 • Ejecutar bin/spark-‐shell • Se abrirá el shell de Apache Spark con Scala
scala > Nota: Scala es completamente descargable de hGp://www.scala-‐lang.org/download/all.html

Introducción a Scala
• Scala es un lenguaje orientado a objetos (OOP) y de programación funcional (FP)
• Compila a archivos class que empaquetamos como JAR (Java Archive) (Maven o SBT)
• Corre sobre la Java Virtual Machine • Creado por Mar^n Odersky • Cada variable es un objeto y cada operador es un método
• hGp://scala-‐lang.org

• Como corre sobre la JVM nos permite usar las librerías de Java
• SCALA CAMBIARÁ LA MANERA EN QUE PIENSAS COMO PROGRAMAR
• Permite escribir código de manera concisa • No te desesperes si no en^endes al principio
Introducción a Scala

Cadenas
• Abre tu prompt de Apache Spark (spark1.3) bin/spark-‐shell scala > “Hola Mundo” res0: String = Hola Mundo scala> "Hola scala".getClass.getName res2: String = java.lang.String

Cadenas scala> val s = "Hola Scala Meetup" s: String = Hola Scala Meetup scala> s.length res4: Int = 17 scala> s.foreach(println) H o l

Cadenas
• Podemos u^lizar métodos funcionales como filter ej:
scala> var result = s.filter(_ != 'l') result: String = Hoa Scaa Meetup
Ver (StringOps, StringLike, WrappedString)

Cadenas
scala> s1.drop(4).take(2).capitalize res6: String = Up scala> val s3 = "hola" s3: String = hola scala> s3 == "hola" res8: Boolean = true

Cadenas scala> val mensaje = "Apache Spark Meetup".map(c =>c.toUpper) mensaje: String = APACHE SPARK MEETUP Pero también podemos usar el carácter mágico _ para que nuestro código se vea mucho más limpio scala> val mensaje2 = "Apache Spark Meetup".map(_.toUpper) mensaje2: String = APACHE SPARK MEETUP A el método map se le pasan funciones (programación funcional)

Cadenas
• Ver como funcionan las expresiones regulares
scala> val address = "Dr Levante 1234 Edif 302 ".replaceAll("[0-‐9]","x")
address: String = "Dr Levante xxxx Edif xxx ”

Clases implicitas
• Las clases implícitas deben ser definidas en un ámbito donde las definiciones de método son permi^das (Scala 2.10)
• Permiten agregar nuestros propios métodos a objetos sin tener que extenderlos

Clases Implícitas package com.meetup.u^ls object U^lidades{ implicit class IncrementarCaracter(val s:String){
def incrementar = s.map(c => (c +1).toChar) } } package foo.bar import com.meetup.u^ls.U^lidades._ object Main extends App{ println(“ABC”.incrementar) }

Números
Char -‐16 bit unsigned Byte -‐ 8 Bit signed value Short – 16 bit signed value Int – 32 bit signed value Long -‐ 64 bit signed value Float – 32 bit IEEE 754 single precision float Double – 64 bit IEEE 754 single precision float

Números
“100”.toInt -‐ Usar métodos to para cas^ng “100”.toFloat …. Scala no ^ene operadores ++ ni – val es inmutable Scala > var a = 1

Números scala> val a = 1 a: Int = 1 scala> a += 1 <console>:22: error: value += is not a member of Int a += 1 ^ scala> var b = 1 b: Int = 1 scala> b+=1 scala> b res11: Int = 2

val r = scala.u^l.Random r.nextInt Podemos limitar la generación r.nextInt(100)
Números

val r = 1 to 100 val j = 1 to 100 by 2 val x = (1 to 10).toList val z = (1 to 100).toArray
Números

Estructuras de Control
• If/then/else es similar a Java • Pueden regresar un resultado val x = if(a) y else b scala> val x = if("a"=="a") 9 else 7 x: Int = 9

• for y foreach • Nos sirven para hacer ciclos y sobre todo iterar en colecciones (List, Array, Range)
scala> val samp = List("isra","memo","paco") samp: List[String] = List(isra, memo, paco) scala> for(n <-‐ samp) yield n.capitalize res20: List[String] = List(Isra, Memo, Paco)
Estructuras de Control

scala> samp.foreach(println) isra memo Paco • Si se requiere más lineas samp.foreach{ e=> | val nuevo = e.toUpperCase | println(nuevo) | }
Estructuras de Control

Estructuras de Control
• Es muy importante saber como los ciclos son trasladados por el compilador
• for loop que itera sobre una colección se transforma en foreach
• for loop con un guard se traslada a una secuencia de withFilter seguida de un foreach
• for loop con un yield se traslada a un map e la colección

Estructuras de Control scala> val i = 5 i: Int = 5 scala> val month = i match{ | case 1 => "enero" | case 2 => "febrero" | case 3 => "marzo" | case 4 => "Abril" | case 5 => "Mayo” | case _ => “Mes inválido” | } month: String = Mayo

Métodos
• Los métodos los definimos como def scala> def square(x:Int): Int = x * x square: (x: Int)Int scala> square(5) res33: Int = 25

Colecciones
• Las colecciones en escala son amplias y debemos aprender a u^lizarlas dependiendo el contexto de nuestro requerimiento
• List, Array, Map y Set • Métodos como filter, foreach, map y reduceLe� aplican a las colecciones ^enen loops dentro de sus algoritmos
• El predicado es un método o función anónima que toma uno o más parámetros y regresa un valor booleano

Colecciones
Ej: (i:int) => i % 2 == 0 //función anónima _ % 2 == 0 val list = List.range(1,20) val events = list.filter(_ % 2 == 0)
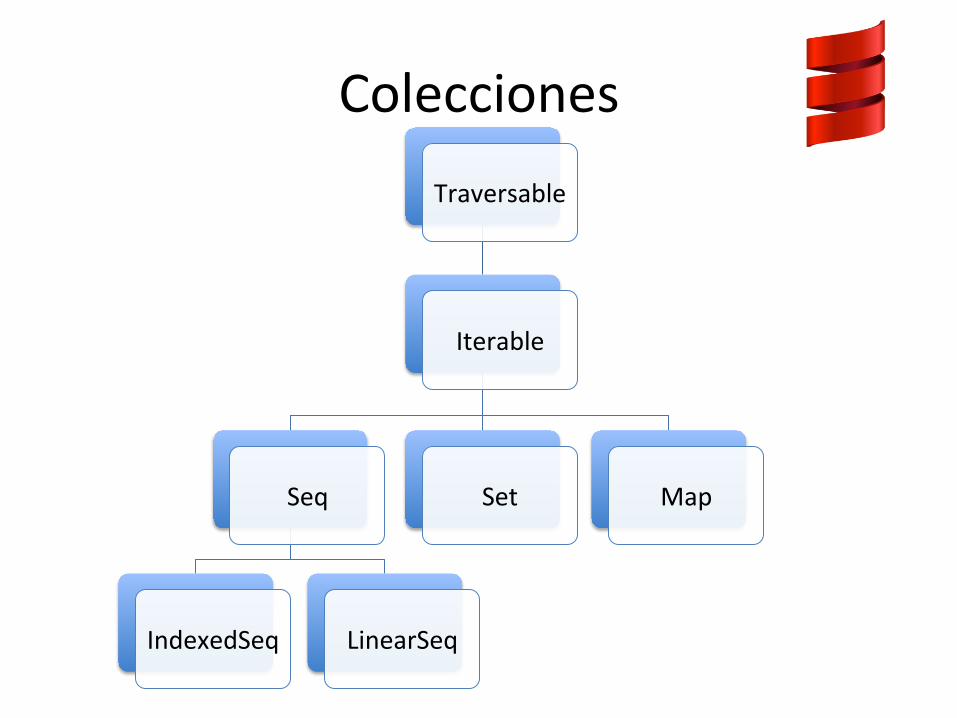
Colecciones Traversable
Iterable
Seq
IndexedSeq LinearSeq
Set Map

Colecciones
Sequence : es una colección lineal de elementos que serán indexados Map: Con^ene una colección key/value como un Java Map, Ruby Hash o un diccionario en Python Set :es una colección que con^ene elementos sin duplicar

Colecciones
• Escoger un Sequence..¿La secuencia debe ser indexada o implementada como una linked list?
• ¿Queremos una colección mutable o inmutable? • Imutables:List, Queue, Range,Stack, Stream, String, Vector
• Mutables:Array, ArrayBuffer,ArrayStack, LinkedList,ListBuffer, MutableLIst, Queue, Stack, StringBuilder

Colecciones
• Escoger Map es más sencillo • Puedo escoger un SortedMap que almacenará elementos ordenados por llave
• LinkedHashMap para almacenar elementos en orden de inserción
• HashMap,LinkedHashMap,ListMap,Map,SortedMap,TreeMap,WeakHashMap

Colecciones
• Escoger un set es similar a un map • Existen clases mutables e inmutables • BitSet,HashSet,LinkedHashSet,ListSet,TreeSet,Set,SortedSet
• Algunas otras colecciones (Enumera^on,Iterator,Op^on,Tuple)

Colecciones
Un método de transformación es un método que construye una colección a par^r de una existente. Esta incluye métodos como map, filter, reverse etc. Existen colecciones strict y lazy. Strict aloja los elementos inmediatamente en memoria Lazy no aloja los elementos inmediatamente y las transformaciones no construyen nuevos elementos hasta que se ejecutan.

Colecciones • Métodos de filtrado:
collect,diff,dis^nct,drop,dropWhile,filter,filterNot,find,foldLe�,foldRight,head,headOp^on.
• Métodos de transformación: diff,dis^nct,collect,flatMap,map,reverse,sortWith,takeWhile,zip, zipWithIndex
• Métodos de agrupación: groupBy,par^^on,sliding,span,splitAt,unzip
• Métodos matemá^cos y de información: contains,containsSlice,count,endWith,exist,find,forAll,indexOf…max,min,product,size,sum.

Colecciones
scala> days.zipWithIndex.foreach{ | case(day,count) => println(s"$count es $day") | } 0 es Lunes 1 es Martes 2 es Miércoles 3 es Jueves 4 es Viernes

Colecciones
scala> val frutas = List("pera","manzana","plátano","mango","uva") frutas: List[String] = List(pera, manzana, plátano, mango, uva) scala> frutas.filter(_.length < 6).map(_.toUpperCase) res28: List[String] = List(PERA, MANGO, UVA)

scala> val listas=List(List(1,2),List(3,4)) listas: List[List[Int]] = List(List(1, 2), List(3, 4)) scala> val resultado = listas.flaGen resultado: List[Int] = List(1, 2, 3, 4)
Colecciones

scala> def toInt(in:String):Op^on[Int]={ | try{ | Some(Integer.parseInt(in.trim)) | } | catch{ | case e:Excep^on => None | } | } toInt: (in: String)Op^on[Int] scala> fms.flatMap(toInt) res32: List[Int] = List(1, 2, 5)
Colecciones

Colecciones
Ejercicios: -‐ Filtrar los mayores a 4 -‐ Filtrar los mayores a 5 -‐ Sumar los elementos de la colección
Mayor información : hGp://www.scala-‐lang.org/api/2.10.4/index.html#scala.collec^on.Seq

Programación Funcional
• Se construyen programas usando funciones puras • Las funciones no ^enen efectos colaterales • Modificar una variable, una estructura, establecer un campo en un objeto, arrojar una excepción, imprimir en la consola, leer o escribir un archivo, dibujar en pantalla
• Programación funcional es una restricción en COMO escribimos programas pero no en lo QUE nuestros programas pueden expresar.

Y ahora…



Spark 101 (Historia)
Ecosistema Big Data

Spark 101
• Map reduce es el modelo de programación y el corazón de Hadoop
• Toma datos de manera masiva y los divide a través de un número de nodos en un clúster
• Tiene dos fases la fase Map y la fase Reduce • Se programa en Java y se envía de manera distribuida al clúster (también se puede en Python, R, .NET a través de Hadoop Streaming)

Spark 101 (WordCount)
Mapper Reducer

Spark 101
Driver

Spark 101
• Es di�cil programar en Map Reduce • Cuellos de botellas de performance • Existen abstracciones como Hive y Pig • Aún así es complicado desarrollar

Spark
• Spark es un motor de cómputo DISTRIBUIDO • Op^mizado para velocidad, fácil uso e implementación de análisis
sofis^cado. • Es un proyecto open source de APACHE • APIS en Python, Java y Scala …R en Spark 1.4! • Lo u^lizamos para tareas de ciencia en datos • Lo u^lizamos para aplicaciones de procesamiento a gran escala
(terabytes o petabytes de datos = BIG DATA)
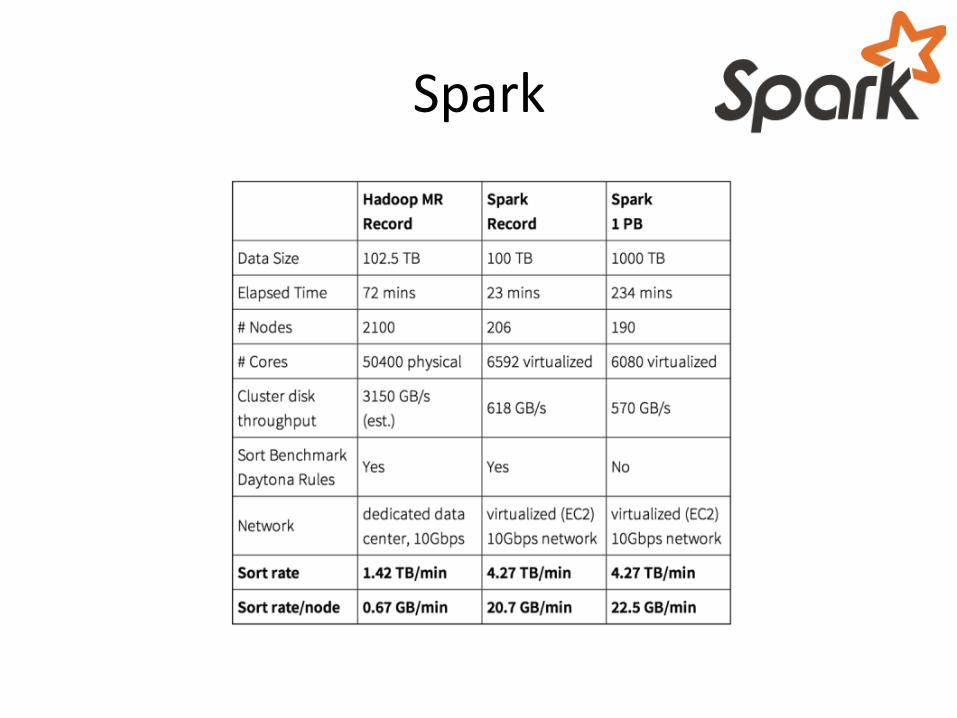
Spark

Resilient Distributed Datasets (RDDs) -‐Abstracción de programación de SPARK -‐Se desarrollan programas en términos de transformaciones y acciones (Dataflows) -‐Colección de objetos que pueden ser almacenados en memoria o en disco a través de un clúster -‐Estan desarrollados para transformaciones en paralelo (map, filter, etc) -‐ Los RDDs pueden ser almacenados en memoría, en disco u ambos. -‐Tolerancia a fallos
Spark

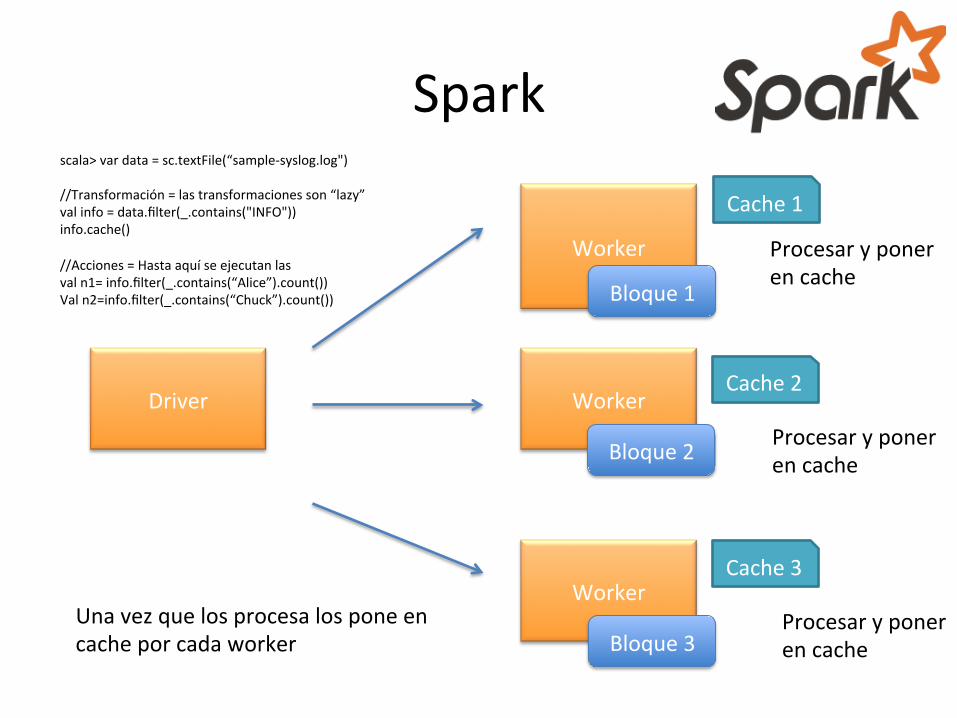
//Spark context sc variable especial de contexto //RDD Base scala> var data = sc.textFile(“sample-‐syslog.log") //Transformación = las transformaciones son “lazy” val info = data.filter(_.contains("INFO")) info.cache() //Acciones = Hasta aquí se ejecutan las val n1= info.filter(_.contains(“Alice”).count()) Val n2=info.filter(_.contains(“Chuck”).count())
Spark

Spark
• Formatos: Archivos de texto, JSON,CSV,TSV,SequenceFiles, ObjectFiles,Formatos de entrada/salida de Hadoop Amazon S3,HDFS,Avro,Parquet,Cassandra, Hbase,Mongo,Elas^cSearch etc.

• Spark traza una grafo lineal de transformaciones y acciones
• El driver se encarga de enviar nuestra aplicación a todos los nodos con este grafo
• Se enviaran instrucciones a los workers para ser ejecutadas (archivos de texto, hdfs etc)
• Cada worker leerá los datos y hará transformaciones y hará cache de los datos
Spark tras bambalinas

Spark
• RDDS ^enen dos ^pos de operaciones • TRANSFORMACIONES: Las transformaciones siempre me regresarán un nuevo RDD y no son procesadas inmediatamente
• ACCIONES:Las acciones siempre me devolverán un resultado (se regresan al driver)
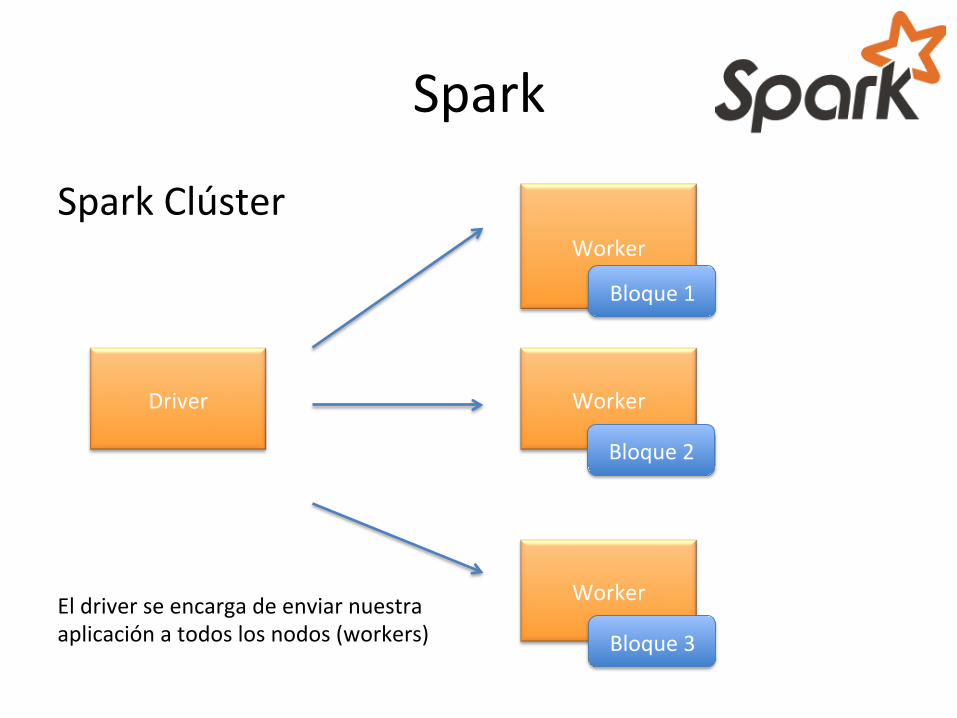
Spark Clúster
Spark
Driver
Worker
Worker
Worker
Bloque 1
Bloque 2
Bloque 3 El driver se encarga de enviar nuestra aplicación a todos los nodos (workers)
Driver
Worker
Worker
Worker
Bloque 2
Bloque 3
Spark
Bloque 1
Cache 1
Cache 2
Cache 3
Una vez que los procesa los pone en cache por cada worker
scala> var data = sc.textFile(“sample-‐syslog.log") //Transformación = las transformaciones son “lazy” val info = data.filter(_.contains("INFO")) info.cache() //Acciones = Hasta aquí se ejecutan las val n1= info.filter(_.contains(“Alice”).count()) Val n2=info.filter(_.contains(“Chuck”).count())
Procesar y poner en cache
Procesar y poner en cache
Procesar y poner en cache
Spark
Driver
Worker
Worker
Worker
Bloque 2
Bloque 3
Bloque 1
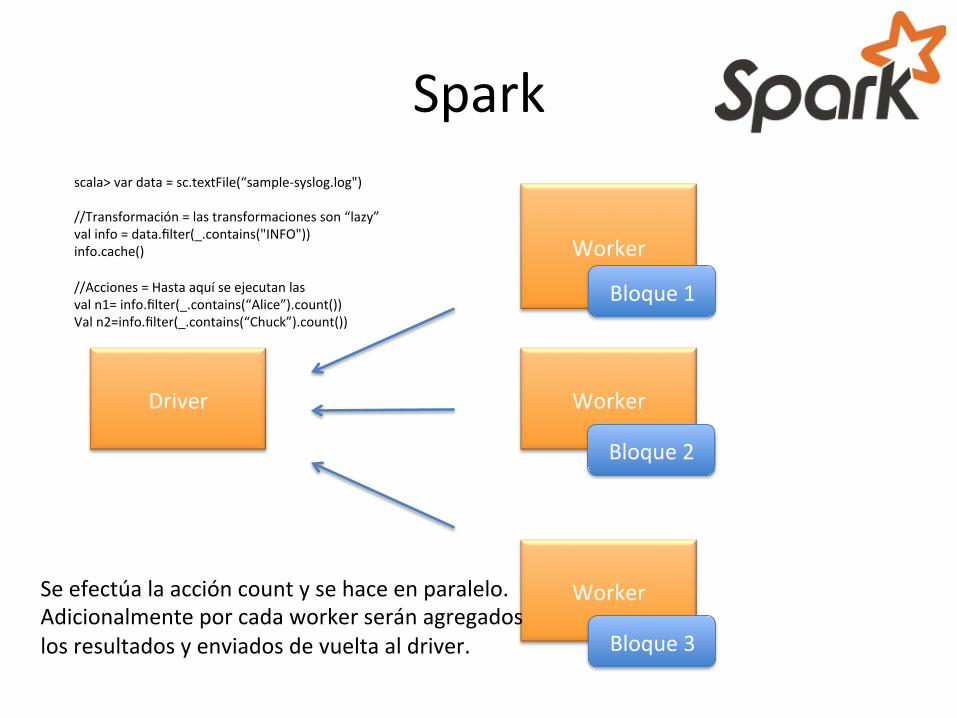
scala> var data = sc.textFile(“sample-‐syslog.log") //Transformación = las transformaciones son “lazy” val info = data.filter(_.contains("INFO")) info.cache() //Acciones = Hasta aquí se ejecutan las val n1= info.filter(_.contains(“Alice”).count()) Val n2=info.filter(_.contains(“Chuck”).count())
Se efectúa la acción count y se hace en paralelo. Adicionalmente por cada worker serán agregados los resultados y enviados de vuelta al driver.

Spark
WORD COUNT scala> val f = sc.textFile("Readme.md") scala> val wc=f.flatMap(l => l.split(“ ”)).map(word=>(word,1)).reduceByKey(_ + _) scala> wc.saveAsTextFile("salida1")

Spark
• En procesos ETL es muy común juntar dos conjuntos de registros
• Los RDDs pueden juntarse o hacer union. • Tener en cuenta los Pairs RDDS que son RDDs especiales

scala> val format = new java.text.SimpleDateFormat("yyyy-‐MM-‐dd") format: java.text.SimpleDateFormat = java.text.SimpleDateFormat@f67a0200 scala> case class Register(d: java.u^l.Date,uuid:String,cust_id:String,lat:Float,lng:Float) defined class Register scala> case class Click(d:java.u^l.Date,uuid:String,landing_page:Int) defined class Click scala> val reg = sc.textFile("reg.tsv").map(_.split("\t")).map( | r => (r(1), Register(format.parse(r(0)), r(1), r(2), r(3).toFloat, r(4).toFloat)) | ) scala> val clk = sc.textFile("clk.tsv").map(_.split("\t")).map( | c => (c(1), Click(format.parse(c(0)), c(1), c(2).trim.toInt)) | ) scala>reg.join(clk).collect()
Spark

Spark
• Enviar aplicaciones • Para pruebas el shell es bueno y se puede reu^lizar mucho código
• En ambientes de producción las aplicaciones se envían a través de bin/spark–submit
• Se debe tener instalado SBT para aplicaciones en Scala y poder compilar y empaquetar
• Maven en el caso de Java

Spark package com.vitatronix!!!import org.apache.spark.SparkContext!
import org.apache.spark.SparkContext._!import org.apache.spark.SparkConf!
!object SimpleApp {!!
!def main(args: Array[String]) {! !
! !val logfile="/Users/israelgaytan/Documents/Lambda/spark1.3/README.md"!! !val conf= new SparkConf().setAppName("Spark Stand Alone")!! !val sc= new SparkContext(conf)!
! !!! !val input = sc.textFile(logfile)!
!
! !val words = input.flatMap(line => line.split(" "))!!
! !var counter= words.count()!!!
! !val counts = words.map(word=>(word,1)).reduceByKey{case (x,y) => x+y}!! !//counts.saveAsTextFile("finish.txt")!
!! !println(s"Finished and counting word $counter")!
!
!!}!
}!

Spark
1.-‐ Crear build.sbt 2.-‐ Crear lib,project,src y target 3.-‐ Dentro de src crear main 4-‐ Dentro de main crear java, resources y scala mkdir –p src/{main,test}/{java,resources,scala}!mkdir lib project target!

name := "Spark Meetup Wordcount”!!version := "1.0”!!scalaVersion := "2.10.4”!!libraryDependencies ++= Seq(!"org.apache.spark" %% "spark-core" % "1.3.0" % "provided",!"org.apache.spark" %% "spark-streaming" % "1.3.0" % "provided"!)!
Spark
Crear en la raíz build.sbt

Spark
Ejecutamos sbt para que cree el proyecto MacBook-‐Pro-‐de-‐Israel:scala-‐wsh israelgaytan$ sbt [info] Loading project defini^on from /Users/israelgaytan/Documents/Lambda/scala-‐wsh/project/project [info] Loading project defini^on from /Users/israelgaytan/Documents/Lambda/scala-‐wsh/project [info] Set current project to Spark Meetup Wordcount (in build file:/Users/israelgaytan/Documents/Lambda/scala-‐wsh/) EMPAQUETAMOS >package
Spark

Y POR ÚLTIMO ENVIAMOS !!
!bin/spark-submit --class "com.vitatronix.SimpleApp" --master local[*] /Users/israelgaytan/Documents/Lambda/scala-wsh/target/scala-2.10/spark-meetup-wordcount_2.10-1.0.jar!!Le pasamos en los parámetros en nombre de la clase, el cluster en este caso –master local[*] tomará todos los cores de la máquina y finalmente el Jar que empaquetamos con SBT!
Spark

SPARK
SERVIDOS CHATOS

Recursos hGps://databricks.com/spark/developer-‐resources Func^onal Programming in Scala – Paul Chiusano Rúnar Bjarnason (Manning) Learning Spark – Holden Karau (O`Reilly) Advanced Analy^cs With Spark – Sandy Reza , Uri Laserson (O`Reilly) Scala for the Impa^ent – Cay S Horstmann Scala Cookbook – Alvin Alexander (O`Reilly) Scala for the intrigued -‐ hGps://www.youtube.com/watch?v=grvvKURwGNg&list=PLrPC0_h8PkNOtAr4BRTFf46Gwctb6kE9f

GRACIAS Apache Spark Meetup Introducción a Scala #ApacheSparkMX
• @isragaytan • [email protected] • [email protected]