learning to grow structured visual summaries for document collections
TRANSCRIPT

Learning to Grow Structured Visual Summariesfor Document Collections
Daniil Mirylenka Andrea Passerini
University of Trento, Italy
Machine learning seminar, Waikato University, 2013

Problem: informative representation of documentsApplication: academic search
Input: document collection Output: topic map
⇒

Our approach:Building and summarizing the topic graph
⇒ ⇒

Building the topic graph:Overview
1. Map documents to Wikipedia articles
2. Retrieve the parent categories
3. Link categories to each other
4. Merge similar topics
5. Break cycles in the graph

Building the topic graph:Mapping the document to Wikipedia articles
“..we propose a method of summarizing collectionsof documents with concise topic hierarchies, andshow how it can be applied to visualization andbrowsing of academic search results.”
⇓
“..we propose a method summarizing collections ofdocuments with concise [[Topic (linguistics) |topic]][[Hierarchy |hierarchies]], and show how it can beapplied to [[Visualization (computer graphics)|visualization]] and [[Web browser |browsing]] of[[List of academic databases and search engines|academic search]] results.”
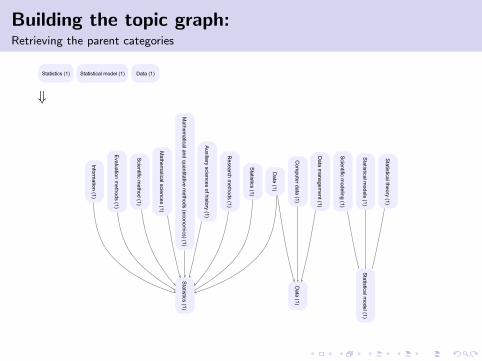
Building the topic graph:Retrieving the parent categories
⇓

Building the topic graph:Linking the categories
⇓

Building the topic graph:Merging similar topics
⇓

Building the topic graph:Breaking the cycles
⇓

Building the topic graph:Example of an actual topic graph built from 100 abstracts

Summarizing the topic graphReflection
⇒
What is a summary?
- a set of nodes (topics).
What is a good summary?
- ???
Let’s learn from examples!
- subjective

Summarizing the topic graphReflection
⇒
What is a summary?
- a set of nodes (topics).
What is a good summary?
- ???
Let’s learn from examples!
- subjective

Summarizing the topic graphReflection
⇒
What is a summary?
- a set of nodes (topics).
What is a good summary?
- ???
Let’s learn from examples!
- subjective

Summarizing the topic graphThe first attempt
Structured prediction
GT = arg maxGT
F (G ,GT )
Problem: evaluation on(|G |T
)subgraphs
- Example:
I 300-node topic graph
I 10-node summary
I 1 398 320 233 241 701 770 possible subgraphs(1 million graphs per second ⇒ 44 311 years)

Summarizing the topic graphThe first attempt
Structured prediction
GT = arg maxGT
F (G ,GT )
Problem: evaluation on(|G |T
)subgraphs
- Example:
I 300-node topic graph
I 10-node summary
I 1 398 320 233 241 701 770 possible subgraphs(1 million graphs per second ⇒ 44 311 years)

Summarizing the topic graphThe first attempt
Structured prediction
GT = arg maxGT
F (G ,GT )
Problem: evaluation on(|G |T
)subgraphs
- Example:
I 300-node topic graph
I 10-node summary
I 1 398 320 233 241 701 770 possible subgraphs(1 million graphs per second ⇒ 44 311 years)

Summarizing the topic graphKey idea
Restriction: summaries should be nested
∅ = G0 ⊂ G1 ⊂ · · · ⊂ GT
Now we can build summaries sequentially
Gt = Gt−1 ∪ {vt}
Still a supervised learning problem
- training data: summary sequences (G ,G1,G2, · · · ,GT )- or topic sequences: (G , v1, v2, · · · , vT )

Summarizing the topic graphKey idea
Restriction: summaries should be nested
∅ = G0 ⊂ G1 ⊂ · · · ⊂ GT
Now we can build summaries sequentially
Gt = Gt−1 ∪ {vt}
Still a supervised learning problem
- training data: summary sequences (G ,G1,G2, · · · ,GT )- or topic sequences: (G , v1, v2, · · · , vT )

Summarizing the topic graphKey idea
Restriction: summaries should be nested
∅ = G0 ⊂ G1 ⊂ · · · ⊂ GT
Now we can build summaries sequentially
Gt = Gt−1 ∪ {vt}
Still a supervised learning problem
- training data: summary sequences (G ,G1,G2, · · · ,GT )- or topic sequences: (G , v1, v2, · · · , vT )

Learning to grow summariesas imitation learning
Imitation learning (racing analogy)
I destination: finish
I sequence of states
I driver’s actions (steering, etc.)
I goal: copy the behaviour
Supervised Training Procedure
Expert TrajectoriesDataset
Learned Policy: ))]s(,s,([Εminargˆ *
*)(D~ssup
5
(borrowed from the presentation of Stephane Ross)
Our problem
I destination: summary GT
I states: intermediate summaries G0,G1, · · · ,GT−1I actions: topics v1, v2, · · · , vT added to the summaries
I goal: copy the behaviour

Learning to grow summariesas imitation learning
Imitation learning (racing analogy)
I destination: finish
I sequence of states
I driver’s actions (steering, etc.)
I goal: copy the behaviour
Supervised Training Procedure
Expert TrajectoriesDataset
Learned Policy: ))]s(,s,([Εminargˆ *
*)(D~ssup
5
(borrowed from the presentation of Stephane Ross)
Our problem
I destination: summary GT
I states: intermediate summaries G0,G1, · · · ,GT−1I actions: topics v1, v2, · · · , vT added to the summaries
I goal: copy the behaviour

Learning to grow summariesHow can we do that?
Straightforward approach
I Choose a classifier π : (G ,Gt−1) 7→ vtI Train on the ‘ground truth’ examples ((G ,Gt−1), vt)
I Sequentially apply on the new graphs
∅ = G0π(G ,.)7→ G1
π(G ,.)7→ · · · π(G ,.)7→ GT
Will it work?
I No.(unable to recover from mistakes)

Learning to grow summariesHow can we do that?
Straightforward approach
I Choose a classifier π : (G ,Gt−1) 7→ vtI Train on the ‘ground truth’ examples ((G ,Gt−1), vt)
I Sequentially apply on the new graphs
∅ = G0π(G ,.)7→ G1
π(G ,.)7→ · · · π(G ,.)7→ GT
Will it work?
I No.(unable to recover from mistakes)

Learning to grow summariesHow can we do that?
Straightforward approach
I Choose a classifier π : (G ,Gt−1) 7→ vtI Train on the ‘ground truth’ examples ((G ,Gt−1), vt)
I Sequentially apply on the new graphs
∅ = G0π(G ,.)7→ G1
π(G ,.)7→ · · · π(G ,.)7→ GT
Will it work?
I No.(unable to recover from mistakes)

Learning to grow summariesDAgger (dataset aggregation)
S. Ross, G. J. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regretonline learning. Journal of Machine Learning Research - Proceedings Track, 15:627635, 2011.
Idea:
I train on the states we are going to encounter(our own-generated states)
How can we do that?
I We haven’t trained the classifier yet!
We will do it iteratively (for i = 0, 1,)
I train the classifier πi on the dataset Di
I generate the trajectories using πiI add new states to the dataset Di+1

Learning to grow summariesDAgger (dataset aggregation)
S. Ross, G. J. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regretonline learning. Journal of Machine Learning Research - Proceedings Track, 15:627635, 2011.
Idea:
I train on the states we are going to encounter(our own-generated states)
How can we do that?
I We haven’t trained the classifier yet!
We will do it iteratively (for i = 0, 1,)
I train the classifier πi on the dataset Di
I generate the trajectories using πiI add new states to the dataset Di+1

Learning to grow summariesDAgger (dataset aggregation)
S. Ross, G. J. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regretonline learning. Journal of Machine Learning Research - Proceedings Track, 15:627635, 2011.
Idea:
I train on the states we are going to encounter(our own-generated states)
How can we do that?
I We haven’t trained the classifier yet!
We will do it iteratively (for i = 0, 1,)
I train the classifier πi on the dataset Di
I generate the trajectories using πiI add new states to the dataset Di+1

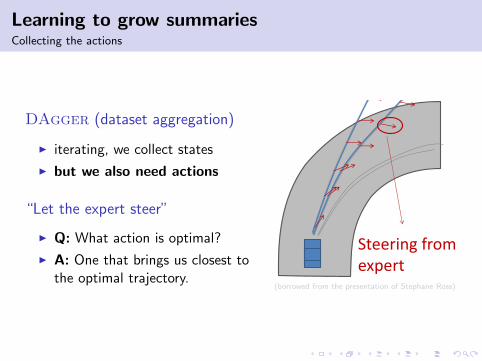
Learning to grow summariesCollecting the actions
DAgger (dataset aggregation)
I iterating, we collect states
I but we also need actions
“Let the expert steer”
I Q: What action is optimal?
I A: One that brings us closest tothe optimal trajectory.
DAgger: Dataset Aggregation
• Collect new trajectories with 11
14
Steering from expert
(borrowed from the presentation of Stephane Ross)
Learning to grow summariesCollecting the actions
DAgger (dataset aggregation)
I iterating, we collect states
I but we also need actions
“Let the expert steer”
I Q: What action is optimal?
I A: One that brings us closest tothe optimal trajectory.
DAgger: Dataset Aggregation
• Collect new trajectories with 11
14
Steering from expert
(borrowed from the presentation of Stephane Ross)
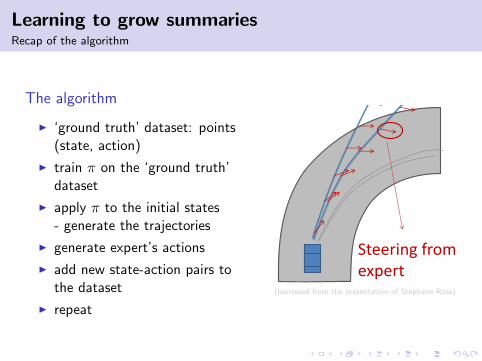
Learning to grow summariesRecap of the algorithm
The algorithm
I ‘ground truth’ dataset: points(state, action)
I train π on the ‘ground truth’dataset
I apply π to the initial states- generate the trajectories
I generate expert’s actions
I add new state-action pairs tothe dataset
I repeat
DAgger: Dataset Aggregation
• Collect new trajectories with 11
14
Steering from expert
(borrowed from the presentation of Stephane Ross)

Learning to grow summariesTraining the classifier
Classifierπ : (G ,Gt−1) 7→ vt
Scoring function
F (G ,Gt−1, vt) = 〈w ,Ψ (G ,Gt−1, vt)〉
Predictionvt = arg maxv F (G ,Gt−1, v)
Learning: SVM struct
- ensures that optimal topics score best

Learning to grow summariesProviding the expert’s actions
Expert’s action
I brings us closest to the optimal trajectory
Technically
I by minimizing the loss function
vt = arg minv
`G (Gt−1 ∪ {v},G optt )
Loss functions
I graphs as topic sets ⇒ redundancy
I key: consider similarity between the topics

Learning grow summariesGraph features
Some of the features:
I document coverage
I transitive document coverage
I average and max. overlap between topics
I average and max. parent-child overlap
I the height of the graph
I the number of connected components
I ...
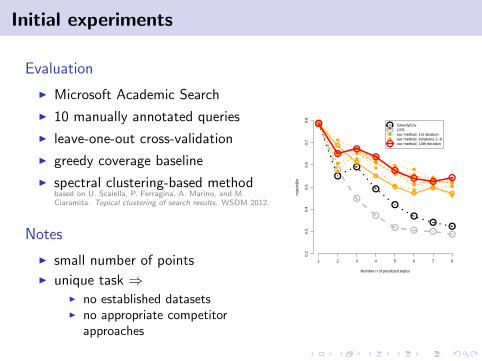
Initial experiments
Evaluation
I Microsoft Academic Search
I 10 manually annotated queries
I leave-one-out cross-validation
I greedy coverage baseline
I spectral clustering-based methodbased on U. Scaiella, P. Ferragina, A. Marino, and M.Ciaramita. Topical clustering of search results. WSDM 2012.
Notes
I small number of pointsI unique task ⇒
I no established datasetsI no appropriate competitor
approaches
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
● ●
●
● ●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
1 2 3 4 5 6 7 8
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Number n of predicted topics
mat
ch@
n
●
●
●
●
●
GreedyCovLSGour method: 1st iterationour method, iterations 2−9our method, 10th iteration
