lda tutorial
DESCRIPTION
Lda TutorialTRANSCRIPT

A Tutorial on Topic Models
Jia Zeng
Department of Computer ScienceHong Kong Baptist University
Tutorial
May 2010
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 1 / 63

Overview
1 Bayesian inference [Heinrich, 2008]
2 Latent Dirichlet allocation [Blei et al., 2003]Gibbs samplingVariational inference
3 ApplicationsNatural scene categorization [Fei-Fei and Perona, 2005]Network topic modeling [Zeng et al., 2009]
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 2 / 63

Inference problems
Machine learning is to learn patterns, rules or regularities from data.
Patterns or rules are represented by distributions.
Two inference problems:◮ Learning: estimate distribution parameters λ to explain observations O.◮ Prediction: calculate the probability of new observation o given
training observations, i.e., to find P(o|O) ≈ P(o|λ).
P(λ|O) =P(O|λ) · P(λ)
P(O), (1)
posterior =likelihood · prior
evidence. (2)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 3 / 63

Maximum likelihood (ML)
Given distribution parameters, the observations are assumed to beindependently and identically distributed (i.i.d.).Learning:
λML = arg maxλL(λ|O) ≈ arg max
λ
∑
o∈O
log P(o|λ). (3)
The common way to estimate the parameter is to solve the system:
∂L(λ|O)
∂λk
= 0,∀λk . (4)
Prediction:
P(o|O) =
∫
λ
P(o|λ)P(λ|O)dλ
≈
∫
λ
P(o|λML)P(λ|O)dλ
= P(o|λML). (5)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 4 / 63

Maximum a posterior (MAP)
Learning:
λMAP = arg maxλ
{
∑
o∈O
log P(o|λ) + log P(λ)
}
. (6)
We use parameterized priors P(λ|α) with hyperparameters α, inwhich the belief in the anticipated values of λ can be expressed withinthe framework of probability.
A hierarchy of parameters is created.
Prediction:
P(o|O) ≈
∫
λ
P(o|λMAP)P(λ|O)dλ = P(o|λMAP). (7)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 5 / 63

Bayesian inference
Learning:
P(λ|O) =P(O|λ)P(λ)
∫
λP(O|λ)P(λ)dλ
. (8)
Prediction:
P(o|O) =
∫
λ
P(o|λ)P(λ|O)dλ
=
∫
λ
P(o|λ)P(O|λ)P(λ)
P(O)dλ. (9)
The summations or integrals of the marginal likelihood are intractableor there are unknown variables.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 6 / 63

Conjugate priors
Bayesian inference often uses conjugate prior for convenientcomputation.
A conjugate prior P(λ) of a likelihood function P(o|λ) is adistribution that results in a posterior distribution P(λ|o) with thesame functional form as the prior with different parameters (e.g.,exponential family).
For example, the Dirichlet distribution is the conjugate prior for themultinomial distribution.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 7 / 63

Topic modeling
Large document and image networks require new statistical tools fordeep analysis.
Topic models have become a powerful unsupervised learning tool forlarge-scale document and image networks.
Topic modeling introduces latent topic variables in text and imagethat reveal the underlying structure with posterior inference.
Topic models can be used in text summarization, documentclassification, information retrieval, link prediction, and collaborativefiltering.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 8 / 63

What are topics?
Topics are a group of related words.
Topics1 learn kernel model reinforc algorithm machin classif2 model learn network neural bayesian time visual3 retriev inform base model text queri system4 model imag motion track recognit object estim5 imag base model recognit segment object detect
1 cell protein express gene activ mutat signal2 pcr assai detect dna method probe specif3 apo diseas allel alzheim associ onset gene4 cell express gene tumor apoptosi protein cancer5 mutat gene apc cancer famili protein diseas
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 9 / 63

Topic modeling = word clustering
A topic is a fuzzy set of words with different membership gradesbased on word co-occurrences in documents.
Fewer topics per document (homogeneous): Words co-occur withinthe same document tend to be clustered within the same topic(attractive force).
Fewer words per topic (heterogeneous): Words tend to be clusteredinto their dominant topics with the highest membership grade(repulsive force).
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 10 / 63

Examples
0 10 20 30 40 50
0.01
0.03
0.05topic 1
vocabulary0 10 20 30 40 50
topic 2
me
mb
ers
hip
0.01
0.03
0.05
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 11 / 63

Probabilistic topic modeling
Treat data as observations that arise from a generative modelcomposed of latent variables.
◮ The latent variables reflect the semantic structure of the document.
Infer the latent structure using posterior inference (MAP):◮ What are the topics that summarize the document network?
Predict new data by the estimated topic model◮ How the new data fit into the estimated topic structures?
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 12 / 63

Latent Dirichlet allocation (LDA) [Blei et al., 2003]
Simple intuition: a document exhibits multiple topics.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 13 / 63

Generative models
Topics
promoter 0.04
dna 0.02
genetic 0.01
evolve 0.04
life 0.02
organism 0.01
gene 0.04
neuron 0.02
recognition 0.01... ...
... ...
... ...
Topic proportions
Latent topic variablesDocuments
Each document is a mixture of corpus-wide topics.
Each word is drawn from one of those topics.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 14 / 63

The posterior distribution (inference)
Topics
Topic proportions
Latent topic variablesDocuments
?
?
?
?
?
?
?
Observations include documents and their words.
Our goal is to infer the underlying topic structures marked by “?”from observations.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 15 / 63

LDA
α θd Zd,n Wd,n
N
D K
βk η
Dirichletparameter
Per-documenttopic proportions
Topic
TopicPer-wordtopic assignment
Observedword
distribution
hyperparameter
A fuller hierarchical Bayesian model composed of random variables.Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 16 / 63

LDA: generative process
α θd Zd,n Wd,n
N
D K
βk η
Draw each topic βk ∼ Dir(η), for k ∈ {1, . . . ,K}.
For each document:◮ Draw topic proportions θd ∼ Dir(α).◮ For each word:
⋆ Draw Zd,n ∼ Mult(θd).⋆ Draw Wd,n ∼ Mult(βZd,n
).
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 17 / 63

LDA: inference
α θd Zd,n Wd,n
N
D K
βk η
From a collection of documents, infer◮ Per-document topic assignment Zd,n.◮ Per-document topic proportions θd .◮ Per-corpus topic distribution βk .
Use posterior expectations Zd,n, θd , and βk to perform documentclassification and information retrieval.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 18 / 63

LDA: intractable exact inference
α θd Zd,n Wd,n
N
D K
βk η
P(Z , θ, β|W , α, η) = P(W ,Z , θ, β|α, η)/P(W |α, η).
P(W |α, η) = P(β|η)∫
θP(W |θ, β)P(θ|α).
Because θ and β are coupling, the integration is intractable.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 19 / 63

LDA: approximate inference
α θd Zd,n Wd,n
N
D K
βk η
Collapsed Gibbs sampling [Griffiths and Steyvers, 2004].
Mean field variational inference [Blei et al., 2003].
Expectation propagation [Minka and Lafferty, 2002].
Collapsed variational inference [Teh et al., 2007].
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 20 / 63

Collapsed Gibbs sampling (GS)
“Collapse” means marginalizing out parameters θ and β.
P(W ,Z , θ, β|α, η) =
∫
θ
∫
β
P(W ,Z , θ, β|α, η)dθdβ (10)
∫
θ
D∏
d=1
P(θd |α)N∏
n=1
P(Zd,n|θd)dθ (11)
∫
β
K∏
k=1
P(βk |η)
D∏
d=1
N∏
n=1
P(Wd,n|βZd,n)dβ (12)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 21 / 63

Marginalizing θd for the dth document
∫
θd
P(θd |α)N∏
n=1
P(Zd,n|θd)dθd (13)
∫
θd
Γ(∑K
k=1 αk)∏K
k=1 Γ(αk)
K∏
k=1
θαk−1d,k P(Zd,n|θd)dθd (14)
P(Zd,n|θd) =
K∏
k=1
θnk
d,·
d,k (15)
nkd,· is the number of words in the dth document with the kth topic
nkd,· =
∑
w nkd,w
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 22 / 63

Marginalizing θd for the dth document
∫
θd
Γ(∑K
k=1 αk)∏K
k=1 Γ(αk)
K∏
k=1
θnk
d,·+αk−1
d,k (16)
∫
θd
Γ(∑K
k=1 nkd,· + αk)
∏Kk=1 Γ(nk
d,· + αk)
K∏
k=1
θnk
d,·+αk−1
d,k = 1 (17)
Eq. (11) becomes
Γ(∑K
k=1 αk)∏K
k=1 Γ(αk)
∏Kk=1 Γ(nk
d,· + αk)
Γ(∑K
k=1 nkd,· + αk)
(18)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 23 / 63

Joint probability
Marginalizing βk for the kth topic, Eq. (12) becomes
Γ(∑W
w=1 ηw )∏W
w=1 Γ(ηw )
∏Ww=1 Γ(nk
·,w + ηw )
Γ(∑W
w=1 nk·,w + ηw )
(19)
P(W ,Z |α, η) =
D∏
d=1
Γ(∑K
k=1 αk)∏K
k=1 Γ(αk)
∏Kk=1 Γ(nk
d,· + αk)
Γ(∑K
k=1 nkd,· + αk)
×
K∏
k=1
Γ(∑W
w=1 ηw )∏W
w=1 Γ(ηw )
∏Ww=1 Γ(nk
·,w + ηw )
Γ(∑W
w=1 nk·,w + ηw )
(20)
The collapsed form bridges the observed words W and latent topicassignment Z with hyperparameters α and η directly.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 24 / 63

Posterior probability
P(Zd,n = k|Z−(d,n),W , α, η) ∝
P(Zd,n = k,Wd,n = w ,Z−(d,n),W−(d,n), α, η) (21)
∝
(
Γ(∑K
k=1 αk)∏K
k=1 Γ(αk)
)M∏
−d
∏Kk=1 Γ(nk
d,· + αk)
Γ(∑K
k=1 nkd,· + αk)
×
(
Γ(∑W
w=1 ηw )∏W
w=1 Γ(ηw )
)K K∏
k=1
∏
−w
Γ(nk·,w + ηw )×
∏Kk=1 Γ(nk
d,· + αk)
Γ(∑K
k=1 nkd,· + αk)
K∏
k=1
Γ(nk·,w + ηw )
Γ(∑W
w=1 nk·,w + ηw )
(22)
Dependent on the jth document and w th word.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 25 / 63

Posterior probability
If we separate the kth topic, Eq. (22) can be decomposed to
∝
∏
−k Γ(nk,−(d,n)d,· + αk)
Γ(∑K
k=1 nk,−(d,n)d,· + αk + 1)
∏
−k
Γ(nk,−(d,n)·,w + ηw )
Γ(∑W
w=1 nk,−(d,n)·,w + ηw )
×
Γ(nk,−(d,n)d,· + αk + 1)
Γ(nk,−(d,n)·,w + ηw + 1)
Γ(∑W
w=1 nk,−(d,n)·,w + ηw + 1)
. (23)
Note that Γ(x + 1) = xΓ(x).
P(Zd,n = k|W , α, η) ∝ (nk,−(d,n)d,· + αk)
nk,−(d,n)·,w + ηw
∑Ww=1 n
k,−(d,n)·,w + ηw
. (24)
nk,−(d,n)d,· and n
k,−(d,n)·,w are the number of topic assignments excluding
Zd,n = k.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 26 / 63

Gibbs sampling [Griffiths and Steyvers, 2004]
Sampling from target distribution using Markov chain Monte Carlo(MCMC) method.
In MCMC, a Markov chain is constructed to converge to the targetdistribution, and samples are then taken from that Markov chain.
Each state of the chain is an assignment of values to the variablesbeing sampled, in this case Zd,n, and transitions between states followa simple rule.
Gibbs sampling is an stochastic approximate inference, where the nextstate is reached by sequentially sampling all variables from theirdistribution when conditioned on the current values of all othervariables and the data.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 27 / 63

Parameter estimation
For simplicity, we use the symmetric Dirichlet hyperparametersαk = α and ηw = η.
Eq. (24) can be simplified to
P(Zd,n = k|W , α, η) ∝ (θβ)−(d,n). (25)
P(θd |Z ,W , α) = Dir(θd |nd,· + α)⇒ θd,k =nkd,· + α
∑
k nkd,· + Kα
, (26)
P(φk |Z ,W , η) = Dir(φk |nk + η)⇒ βw ,k =
nk·,w + η
∑
w nk·,w + W η
. (27)
Note that E[Dir(α)] = αi/∑
i αi .
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 28 / 63

Summary of Gibbs sampling
If we use X for data and Z for labeling configuration, we obtain thefollowing optimal marginal distribution [Bishop, 2006]
lnQj(Zj) ∝ Ei 6=j [lnP(X ,Z )]. (28)
From the “variational inference” view, we aim to maximize the lowerbound of the model evidence P(W |α, η) in terms of Qj(Zj).
From the “passing messages” (belief propagation) perspective, weaim to update the belief Qj(Zj) ∼ θd over Zd,n through all otherdocuments belief θ as well as clique potentials based on β, whichimplies that LDA is similar to a Potts model (Markov random fields).
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 29 / 63

Mean field variational inference [Blei et al., 2003]
Use the fully factorized variational distributions Q to approximate thetrue posterior distribution P by maximizing the lower bound Lbecause the KL (Kullback-Leibler) divergence is always non-negative:
lnP(W |α, η) = L(Q) + KL(Q‖P). (29)
Mean field assumption: Q can be factorized.
Generally,
L(Q) =
∫
Q(Z ) ln
{
P(X ,Z )
Q(Z )
}
. (30)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 30 / 63

Lower bound
In LDA,
L(Q) = EQ [lnP(X ,Z , θ, β|α, η)] − EQ [lnQ(Z , θ, β|λ, φ, γ)]. (31)
Q(Z , θ, β|λ, φ, γ) =K∏
k=1
Q(βk |λk)D∏
d=1
Qd(θd |γd)N∏
n=1
Q(Zd,n|φd,n).
(32)
λ ∼ η, φ ∼ θ, and γ ∼ α are variational parameters.
Coupling between θ and β does not exist.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 31 / 63

Factorization
L = EQ [lnP(θ|α)]
+ EQ[ln P(Z |θ)]
+ EQ[ln P(W |Z , β)]
+ EQ[ln P(β|η)]
− EQ[ln Q(θ)]
− EQ[ln Q(Z )]
− EQ[ln Q(β)]. (33)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 32 / 63

Expansion
L = ln Γ(K∑
k=1
αk) −K∑
k=1
ln Γ(αk ) +K∑
k=1
(αk − 1)[Ψ(γi ) − Ψ(K∑
k=1
γk )]
+N∑
n=1
K∑
k=1
φn,k [Ψ(γk) − Ψ(K∑
k=1
γk)]
+N∑
n=1
K∑
k=1
W∑
w=1
φn,kwn ln βk,w
+ ln Γ(K∑
k=1
ηk) −K∑
k=1
ln Γ(ηk ) +K∑
k=1
(ηk − 1)[Ψ(λi ) − Ψ(K∑
k=1
λk )]
− ln Γ(K∑
k=1
γk) +K∑
k=1
ln Γ(γk ) −K∑
k=1
(γk − 1)(Ψ(γk ) − Ψ(K∑
k=1
γk))
−N∑
n=1
K∑
k=1
φn,k ln φn,k
− ln Γ(K∑
k=1
λk) +K∑
k=1
ln Γ(λk ) −K∑
k=1
(λk − 1)(Ψ(λk ) − Ψ(K∑
k=1
λk)). (34)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 33 / 63

Lagrangian multipliers
φn,k ← βk,w exp(Ψ(γti ))
normalize∑
k
φn,k = 1
γk ← αk +
N∑
n=1
φn,k
λk,w ← ηk +
N∑
n=1
φn,kwn
βk,w ←
N∑
n=1
φn,kwn
Newton-Raphson iteration
α ∼ γ
η ∼ λJia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 34 / 63

Summary of variational inference
Variational inference is a deterministic alternative to MCMC.
At each iterative step, we use deterministic optimization instead ofonline sampling.
Variational inference is fast but has a bias to the true posterior.
Gibbs sampling has no bias but does not know when to converge.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 35 / 63

Natural scene categorization [Fei-Fei and Perona, 2005]
ObjectObjectObjectObject Bag of Bag of ‘‘wordswords’’Bag of Bag of ‘‘wordswords’’
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 36 / 63

Bag of words (BOW)
Independent features
Histogram representation
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 37 / 63

Categorization system
categorycategory
decisiondecisioncategorycategory
decisiondecision
learninglearninglearninglearning
feature detection
& representation
feature detection
& representation
codewords dictionarycodewords dictionarycodewords dictionarycodewords dictionary
image representationimage representation
category modelscategory models
(and/or) classifiers(and/or) classifierscategory modelscategory models
(and/or) classifiers(and/or) classifiers
recognitionrecognitionrecognitionrecognition
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 38 / 63

Codewords
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 39 / 63

Image representation
…..…..
freq
ue
ncy
codewords
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 40 / 63

LDA
Latent Dirichlet Allocation (LDA)
Fei-Fei et al. ICCV 2005
“beach“beach”
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 41 / 63

Spatial information
Image patches have strong spatial structural information.
BOW assumptions are still weak to handle real-world problems.
Incorporating discriminative methods into generative methods.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 42 / 63

Weaknesses
No rigorous geometric information of the object components.
Intuitive to most of us that objects are made of parts õno suchinformation.
Not extensively tested yet for◮ View point invariance.◮ Scale invariance.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 43 / 63

Network topic modeling [Zeng et al., 2009]
Network data:◮ Document and image network.◮ Social network.◮ Biological network.
Basic components:◮ A set of entities (e.g., documents, images, individuals, genes).◮ A set of relations (e.g., citation, coauthor, co-tag, friends, pathways).
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 44 / 63

Examples
Citation network Coauthor network
Social network
Gene regularoty network
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 45 / 63

Research issues
Static network analyses assume that the network has invariantstructure.
◮ Static structural pattern modeling.
Dynamic network analyses assume that the network structure changeswith time.
◮ Dynamic structural pattern modeling.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 46 / 63

Structural patterns
Loose definition: known relations + unknown relations.
More stricter definition: a cluster of entities with homogeneousrelation compared with other entities.
Properties: structural patterns can be propagated through networks.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 47 / 63

Tasks
Learn arbitrary topic structure from network data.
Propagate and regularize topic structures in order to extractmeaningful topics.
Predict network structure including entities and relations.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 48 / 63

Examples
Citation network Coauthor network
?
?
?
?
?
?
?
?
?
?
?
?
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 49 / 63

Problems
Multiple relation types:◮ Citation.◮ Coauthor.◮ Co-proceedings and journals.◮ Year.◮ · · ·
Higher-order relations:◮ A, B, and C collaborate to write a paper. So A, B, C form the
higher-order relation rather than the pairwise relation alone.◮ A cites B and C, while B cites C, which forms a higher-order relation.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 50 / 63

Examples
Multiple relation Higher-order relation
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 51 / 63

Factor graph [Kschischang et al., 2001]
network data factor graph
document
author
Factor graph is a hypergraph, which is used in higher-order relationmodeling.
Factor graph is equivalent to higher-order Markov random fields,which is used in image processing and computer vision.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 52 / 63

Computational problems
Multiple relation modeling meets the problem of how to fuse differentrelation information.
Higher-order structural topic modeling is significantly hampered bythe intractable complexity of optimizing the long-range topicdependence.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 53 / 63
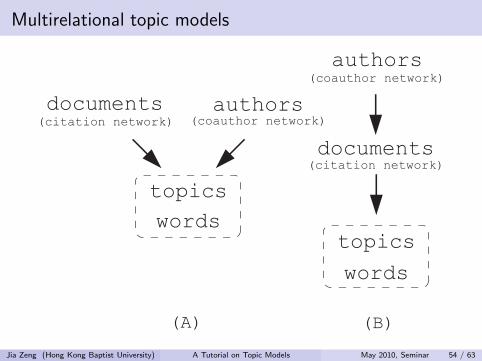
Multirelational topic models
authors
documents
topics
words
words
topics
documents(citation network)
authors(coauthor network)
(coauthor network)
(citation network)
(A) (B)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 54 / 63

Multirelational topic models
(A) (B)
αα
α β
fa
fa
fa′
fa′
z
hd
hd
hd′
hd′
zi zi′
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 55 / 63

Summary
Cascade information fusion.
Parallel information fusion (weights).
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 56 / 63
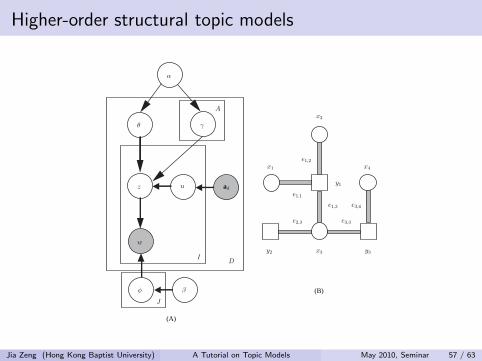
Higher-order structural topic models
α
θ γ
z
w
adu
ID
φ β
(A)
(B)
J
A
e1,1
e1,2
e2,3
e1,3 e3,4
e3,3
x1
x2
x3
x4
y1
y2 y3
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 57 / 63

Generative process
1 θd |α, γ|α ∼ Dirichlet(α), u|ad ∼ Uniform(ad),
2 zd,i |θd , γu ∼ Multi(θd)Multi(γu),
3 wd,i |zd,i , φ ∼ Multi(φzd,i), φzd,i
|β ∼ Dirichlet(β),
xd = arg maxj
θd,j , (35)
ya = arg maxj
γa,j . (36)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 58 / 63
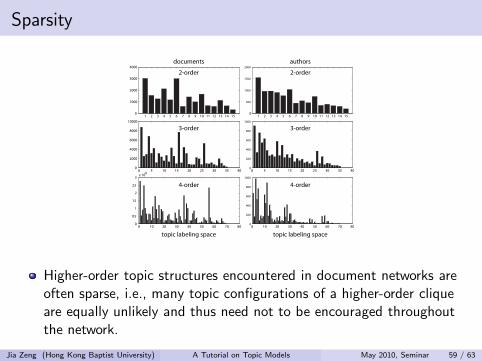
Sparsity
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
1000
2000
3000
4000
0 5 10 15 20 25 30 35 400
2000
4000
6000
8000
10000
0 10 20 30 40 50 60 70 800
0.5
1
1.5
2
2.5
3x 10
4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
500
1000
1500
2000
0 5 10 15 20 25 30 35 400
200
400
600
800
1000
0 10 20 30 40 50 60 70 800
200
400
600
800
1000
4-order
3-order
2-order
4-order
3-order
2-order
documents authors
topic labeling space topic labeling space
Higher-order topic structures encountered in document networks areoften sparse, i.e., many topic configurations of a higher-order cliqueare equally unlikely and thus need not to be encouraged throughoutthe network.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 59 / 63

Learning clique potentials
Generalized linear model:
f (xa) = σ(ηTθxa + b), xa ∈ X. (37)
The feature is defined as
θxa =∏
d
θd,xd, xd ∈ xa. (38)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 60 / 63

Belief propagation and Gibbs sampling for inference
Belief propagation:
θd,xd=
∏
ya∈ne(xd )
[
∑
xa\xd
f (xa)∏
xd′∈ne(ya)\xd
θd ′,xd′
]
. (39)
Gibbs sampling:
P(zi , ui |z−i ,u−i ,w, a, e;α, β) ∝ (φθγ)−i θγ. (40)
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 61 / 63

Summary
Sparsity relieves the computational complexity significantly.
Hybrid belief propagation and Gibbs sampling algorithm works well.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 62 / 63

Thank you!
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 63 / 63

Bishop, C. M. (2006).Pattern recognition and machine learning.Springer.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003).Latent dirichlet allocation.J. Mach. Learn. Res., 3(4-5):993–1022.
Fei-Fei, L. and Perona, P. (2005).A Bayesian hierarchical model for learning natural scene categories.In CVPR.
Griffiths, T. L. and Steyvers, M. (2004).Finding scientific topics.Proc. Natl. Acad. Sci., 101:5228–5235.
Heinrich, G. (2008).Parameter estimation for text analysis.Technical Note, University of Leipzig, Germany.
Kschischang, F. R., Frey, B. J., and Loeliger, H.-A. (2001).
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 63 / 63

Factor graphs and the sum-product algorithm.IEEE Transactions on Information Theory, 47(2):498–519.
Minka, T. P. and Lafferty, J. (2002).Expectation propagation for the generative aspect model.In UAI, pages 352–359.
Teh, Y. W., Newman, D., and Welling, M. (2007).A collapsed variational bayesian inference algorithm for latent dirichletallocation.In NIPS.
Zeng, J., Cheung, W. K.-W., hung Li, C., and Liu., J. (2009).Multirelational topic models.In ICDM, pages 1070–1075.
Jia Zeng (Hong Kong Baptist University) A Tutorial on Topic Models May 2010, Seminar 63 / 63