labrosa research overview
TRANSCRIPT

LabROSA Overview - Dan Ellis 2010-09-10 /191
1. Real-World Sound2. Speech Separation3. Environmental Audio Classification4. Music Audio Analysis
LabROSA Research Overview
Dan EllisLaboratory for Recognition and Organization of Speech and Audio
Dept. Electrical Eng., Columbia Univ., NY USA
[email protected] http://labrosa.ee.columbia.edu/

LabROSA Overview - Dan Ellis 2010-09-10 /19
LabROSA Overview
2
InformationExtraction
MachineLearning
SignalProcessing
Speech
Music EnvironmentRecognition
Retrieval
Separation

LabROSA Overview - Dan Ellis 2010-09-10 /19
1. Real-World Sound
3
• Sounds rarely occur in isolation.. so analyzing mixtures (“scenes”) is a problem.. for humans and machines
02_m+s-15-evil-goodvoice-fade
0 2 4 6 8 10 12 time/s
frq/Hz
0
2000
1000
3000
4000
Voice (evil)Stab
Rumble StringsChoir
Voice (pleasant)
Analysis
level / dB-60
-40
-20
0

LabROSA Overview - Dan Ellis 2010-09-10 /19
Auditory Scene Analysis
“Imagine two narrow channels dug up from the edge of a lake, with handkerchiefs stretched across each one. Looking only at the motion of the handkerchiefs, you are to answer questions such as: How many boats are there on the lake and where are they?” (after Bregmanʼ90)
• Received waveform is a mixture2 sensors, N sources - underconstrained
• Use prior knowledge (models) to constrain
4

LabROSA Overview - Dan Ellis 2010-09-10 /19
2. Speech Separation
• Given models for sources, find “best” (most likely) states for spectra:
can include sequential constraints...
• E.g. stationary noise:
5
{i1(t), i2(t)} = argmaxi1,i2p(x(t)|i1, i2)p(x|i1, i2) = N (x;ci1+ ci2,Σ) combination
model
inference ofsource state
time / s
freq
/ mel
bin
Original speech
0 1 2
20
40
60
80
In speech-shaped noise (mel magsnr = 2.41 dB)
0 1 2
20
40
60
80
VQ inferred states (mel magsnr = 3.6 dB)
0 1 2
20
40
60
80
Roweis ’01, ’03Kristjannson ’04, ’06

LabROSA Overview - Dan Ellis 2010-09-10 /19
Eigenvoices• Idea: Find speaker model
parameter space
generalize without losing detail?
• Eigenvoice model:280 states x 320 bins= 89,600 dimensions10-30 dimensions
6
Weiss & Ellis ’09, ’10
Speaker modelsSpeaker subspace bases
µ = µ̄ + U w + B hadapted mean eigenvoice weights channel channelmodel voice bases bases weights
Freq
uenc
y (kH
z)
Mean Voice
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
Freq
uenc
y (kH
z)
Eigenvoice dimension 1
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
Freq
uenc
y (kH
z)Eigenvoice dimension 2
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
Freq
uenc
y (kH
z)
Eigenvoice dimension 3
b d g p t k jh ch s z f th v dh m n l r w y iy ih eh ey ae aaaw ay ah aoowuw ax
2
4
6
8
50
40
30
20
10
0
2
4
6
8
0
2
4
6
8
0
2
4
6
8

LabROSA Overview - Dan Ellis 2010-09-10 /19
Speaker-Adapted Separation
7

LabROSA Overview - Dan Ellis 2010-09-10 /19
Speaker-Adapted Separation
• Eigenvoices for Speech Separation taskspeaker adapted (SA) performs midway between speaker-dependent (SD) & speaker-indep (SI)
8
SI
SA

LabROSA Overview - Dan Ellis 2010-09-10 /19
3. Soundtrack Classification
• Short video clips as the evolution of snapshots10-100 sec, one location, no editingbrowsing?
• Need information for indexing...video + audioforeground + background
9

LabROSA Overview - Dan Ellis 2010-09-10 /19
MFCC Covariance Representation
• Each clip/segment → fixed-size statisticssimilar to speaker ID and music genre classification
• Full Covariance matrix of MFCCs maps the kinds of spectral shapes present
• Clip-to-clip distances for SVM classifierby KL or 2nd Gaussian model
10
VTS_04_0001 - Spectrogram
freq
/ kH
z
1 2 3 4 5 6 7 8 9012345678
-20
-10
0
10
20
30
time / sec
time / sec
level / dB
value
MFC
C b
in
1 2 3 4 5 6 7 8 92468
101214161820
-20-15-10-505101520
MFCC dimension
MFC
C d
imen
sion
MFCC covariance
5 10 15 20
2
4
6
8
10
12
14
16
18
20
-50
0
50
Video Soundtrack
MFCCfeatures
MFCCCovariance
Matrix
LabROSA Overview - Dan Ellis 2010-09-10 /19
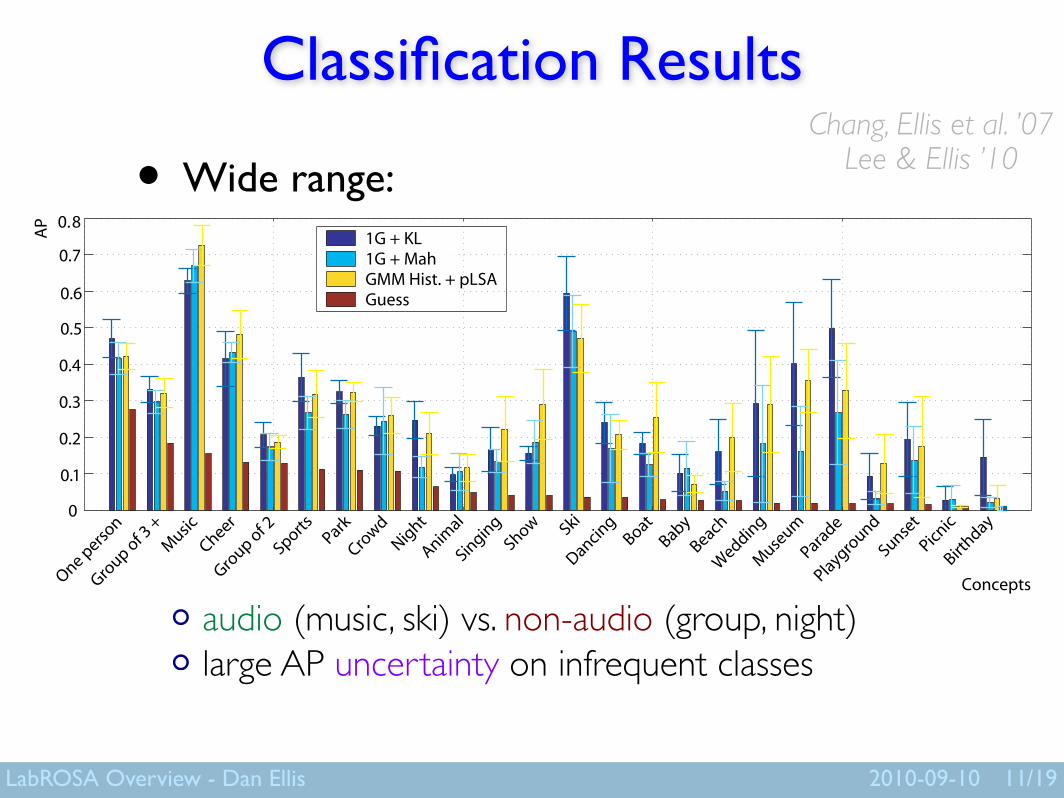
Classification Results
• Wide range:
audio (music, ski) vs. non-audio (group, night)large AP uncertainty on infrequent classes
11
Animal
BabyBeach
Birthday
Boat
Crowd
Group of 3
+
Group of 2
Museum
Night
One person
ParkPicn
ic
Playground
ShowSports
Sunset
Wedding
Dancing
Parade
SingingCheer
Music
Concepts
Ski0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
AP
1G + KL1G + MahGMM Hist. + pLSAGuess
Chang, Ellis et al. ’07Lee & Ellis ’10

LabROSA Overview - Dan Ellis 2010-09-10 /19
Matching Videos via Fingerprints
• Landmark pairs are a noise-robust fingerprint
• Use to match distinct videos with same sound ambience
12
Cotton & Ellis ’10
VIdeo IMpLQaiHWbE at 195s
VIdeo Yi1hkNkqHBc at 218 s
195.5 196 196.5 197 197.5 198 198.5 199
218.5 219 219.5 220 220.5 221 221.5 2220
1
2
3
4fre
q / k
Hz
0
1
2
3
4
freq
/ kHz
time / sec
time / sec

LabROSA Overview - Dan Ellis 2010-09-10 /19
4. Music Audio Analysis
• ... at all levels from notes to genres
13
freq
/ kH
z
0
2
4
162 164 166 168 170 172 174 time / s
time / beats
level / dB
C4C5
C2
C2
C3
C4C5
Signal
Onsets& Beats
Per-framechroma
Per-beatnormalized
chroma
Melody
Piano
C3
-20
0
20
intensity0
0.50.25
0.751
Let it Be (final verse)
390 395 400 405 410 415
ACDEG
ACDEG

LabROSA Overview - Dan Ellis 2010-09-10 /19
High-Resolution Transcription
• Extract notes from audiodespite overlapping voiceswith precise tuning, timing
• Use musical scoretime alignment & approximate match
• Find most likely parametersfundamental, amplitudes of all harmonics
14
Smit & Ellis ’09
Freq
uenc
y (H
z)
Spectrogram of triplum track: YIN (red)
5 6 7 8 9 10200
300
400
500
600
700
dB
10
20
30
40
Time (s)
Freq
uenc
y (H
z)
Spectrogram of combined trackes: YIN (red), Prob (blue)
5 6 7 8 9 10200
300
400
500
600
700
dB
10
20
30
40

LabROSA Overview - Dan Ellis 2010-09-10 /19
Polyphonic Transcription
• Apply the Eigenvoice idea to musiceigeninstruments? • Subspace NMF
15
Grindlay & Ellis ’09

LabROSA Overview - Dan Ellis 2010-09-10 /19
Chord Recognition
• StructSVM vs. HMM: better results
16
Weller, Ellis, Jebara ’09

LabROSA Overview - Dan Ellis 2010-09-10 /19
Melodic-Harmonic Mining
• 100,000 tracks from morecowbell.djas Echo Nest Analyze
• Frequent clusters of 12 x 8 binarized event-chroma
17
#1 (3491) #2 (2775) #3 (2255) #4 (1241) #5 (1224) #6 (1218) #7 (1092) #8 (1084) #9 (1080) #10 (1035)
#11 (1021)
#1 (3491)
#12 (1005)
)#2 (2775)
#13 (974)
#3 (2255)
#14 (942)
)#4 (1241)
#15 (936)
)#5 (1224)
#16 (924)
)#6 (1218)
#17 (920)
)#7 (1092)
#18 (913)
)#8 (1084)
#19 (901)
)) #10 (1035)#9 (1080)
#20 (897)#
#21 (887)
#11 (1021) #
#21 (887)#21 (887) #22 (882)
)#12 (1005)
))#22 (882)#22 (882) #23 (881)
#13 (974)
#23 (881)#23 (881) #24 (881)
)#14 (942)
))#24 (881)#24 (881) #25 (879)
)#15 (936)
))#25 (879)#25 (879) #26 (875)
)#16 (924)
))#26 (875)#26 (875) #27 (875)
)#17 (920)
))#27 (875)#27 (875) #28 (874)
)#18 (913)
))#28 (874)#28 (874) #29 (868)
) #20 (897)#19 (901)
))#29 (868)#29 (868) #30 (844)
#31 (839) #32 (839) #33 (794) #34 (786) #35 (785) #36 (747) #37 (731) #38 (714) #39 (706) #40 (698)
#41 (682)
#31 (839)#31 (839)
#42 (678)
))#32 (839)#32 (839)
#43 (675)
#33 (794)#33 (794)
#44 (657)
))#34 (786)#34 (786)
#45 (656)
))#35 (785)#35 (785)
#46 (651)
))#36 (747)#36 (747)
#47 (647)
))#37 (731)#37 (731)
#48 (638)
))#38 (714)#38 (714)
#49 (610)
)) #40 (698)#40 (698)#39 (706)#39 (706)
#50 (593)
#51 (592)
#41 (682)#41 (682)
#52 (591)
))#42 (678)#42 (678)
#53 (589)
#43 (675)#43 (675)
#54 (572)
))#44 (657)#44 (657)
#55 (571)
))#45 (656)#45 (656)
#56 (550)
))#46 (651)#46 (651)
#57 (549)
))#47 (647)#47 (647)
#58 (534)
))#48 (638)#48 (638)
#59 (534)
)) #50 (593)#50 (593)#49 (610)#49 (610)
#60 (531)
#61 (528)
#51 (592)
#62 (525)
)#52 (591)
#63 (522)
#53 (589)
#64 (514)
)#54 (572)
#65 (510)
)#55 (571)
#66 (507)
)#56 (550)
#67 (500)
)#57 (549)
#68 (497)
)#58 (534)
#69 (486)
) #60 (531)#59 (534)
#70 (479)
#71 (476)
#61 (528)#61 (528)
#72 (468)
))#62 (525)#62 (525)
#73 (468)
#63 (522)#63 (522)
#74 (466)
))#64 (514)#64 (514)
#75 (463)
))#65 (510)#65 (510)
#76 (454)
))#66 (507)#66 (507)
#77 (453)
))#67 (500)#67 (500)
#78 (448)
))#68 (497)#68 (497)
#79 (441)
)) #70 (479)#70 (479)#69 (486)#69 (486)
#80 (440)
#81 (435)
#71 (476)#71 (476)
#82 (430)
))#72 (468)#72 (468)
#83 (430)
#73 (468)#73 (468)
#84 (425)
))#74 (466)#74 (466)
#85 (425)
))#75 (463)#75 (463)
#86 (419)
))#76 (454)#76 (454)
#87 (419)
))#77 (453)#77 (453)
#88 (417)
))#78 (448)#78 (448)
#89 (416)
)) #80 (440)#80 (440)#79 (441)#79 (441)
#90 (414)
#91 (411)
#81 (435)#81 (435)
#91 (411)#91 (411) #92 (410)
))#82 (430)#82 (430)
))#92 (410)#92 (410) #93 (408)
#83 (430)#83 (430)
#93 (408)#93 (408) #94 (406)
))#84 (425)#84 (425)
))#94 (406)#94 (406) #95 (401)
))#85 (425)#85 (425)
))#95 (401)#95 (401) #96 (398)
))#86 (419)#86 (419)
))#96 (398)#96 (398) #97 (397)
))#87 (419)#87 (419)
))#97 (397)#97 (397) #98 (396)
))#88 (417)#88 (417)
))#98 (396)#98 (396) #99 (396)
)) #90 (414)#90 (414)#89 (416)#89 (416)
))#99 (396)#99 (396) #100 (395)
Musicaudio
LocalitySensitive
Hash Table
Beattracking
Chromafeatures
Keynormalization
Landmarkidentification
Bertin-Mahieux et al. ’10

LabROSA Overview - Dan Ellis 2010-09-10 /19
Results - Beatles• Over 86 Beatles tracks
• All beat offsets = 41,705 patchesLSH takes 300 sec - approx NlogN in patches?
• High-pass along time to avoid sustainednotes
• Song filterremove hitsin same track
18
chro
ma bi
n
02-I Should Have Known Better 92.4-97.7s
2
4
6
8
10
12
chro
ma bi
n
05-Here There And Everywhere 12.1-20.5s
2
4
6
8
10
12
chro
ma bi
n
beat
09-Martha My Dear 90.9-98.6s
5 10 15 20
2
4
6
8
10
12
chro
ma bi
nbeat
12-Piggies 22.0-29.6s
5 10 15 20
2
4
6
8
10
12

LabROSA Overview - Dan Ellis 2010-09-10 /19
Summary
• LabROSA : getting information from sound
• Speechmonaural separation using eigenvoices
binaural + reverb using MESSL
• Environmentalclassification of consumer video
landmark-based events and matching
• Musictranscription of notes, chords, ...
large corpus mining19