kafka 0.10.0 アップデート、プロダクション100ノードでやってみた #yjdsnight
TRANSCRIPT

2016年8月31日
1
ヤフー株式会社 D&S データプラットフォーム本部 森谷 大輔
Kafka 0.10.0 アップデート
プロダクション100ノードでやってみた

自己紹介
• 氏名• 森谷 大輔
• 業務• 社内ストリーム処理PFの構築
• ストリームなアプリケーションの開発
• ストリーム周りで使う• Kafka, Storm,
Cassandra, Elasticsearch
2

本日の話
• Yahoo! のストリーム処理プラットフォームで稼働しているある1つのKafkaクラスタを 0.8.1.1 から0.10.0 にバージョンアップした話
• 0.10.0 の機能等にフォーカスした話はしません(この後のセッションにもあるし)
• 稼働中の0.8系や0.9系クラスタからアップデートする人や新規導入でリリースする人の検討の一助になればと思います
3

アジェンダ
• Y! のストリーム処理プラットフォームとKafka
• アップデート経緯
• 検証、リリース
• アップデートを通して戸惑ったこと
• まとめ
4

アジェンダ
• Y! のストリーム処理プラットフォームとKafka
• アップデート経緯
• 検証、リリース
• アップデートを通して戸惑ったこと
• まとめ
5

Yahoo! JAPAN のストリーム処理プラットフォーム
6
• 様々なデータソースをリアルタイムに各サービスに提供、サービスの価値に貢献
アプリログ
ソーシャルログ
Weblog
IoT
Photo by insidetwit https://www.flickr.com/photos/insidetwit/
・異常検知 ・ウィンドウ集計・オンライン機械学習 ・ETL

Kafka採用理由
• LinkedInで実績がある
• Stormと相性が良い
• 高可用性
• Hadoopとも連携できる
• とりあえずデータを投げればサービスをまたがって再利用可能• consumer group と offset という素晴らしい概念
7

アジェンダ
• Y! のストリーム処理プラットフォームとKafka
• アップデート経緯
• 検証、リリース
• アップデートを通して戸惑ったこと
• まとめ
8

Kafkaクラスタバージョンアップ• 今月頭、プラットフォームで稼働しているKafka(broker)クラスタの内1つを
Kafka 0.10.0 にバージョンアップデートした
• クラスタ概要
• 管轄している producer client もAPIバージョンアップ、Scala client ではなく Java client に
9
それまでのKafkaバージョン 0.8.1.1
クラスタ規模 100+ 物理ノード
(サーバあたり)ディスク SAS 4発
ネットワーク 1Gb Ethernet
メモリ 64GBMEM
CPU 12 core
<groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.8.1.1</version>
<groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.10.0.0</version>

Why 0.8.1.1 → 0.10.0 ?
• Kafkaクラスタへの書き込み性能向上見込み
• 普通にユーザが新しいOSSのclientを使えるようにしたい
• 新しいメッセージフォーマットに付与されたtimestampを使って audit がしたい• auditは過去もしていたのだがtimestampは独自producerライブラリをユーザに使ってもらう
ことで付与させていた
10

Kafkaクラスタへの書き込み性能向上見込み
• 投入ログの種類が増えることになったが、見積もったら現在のクラスタではbroker への書き込み性能限界にかかる• もうサーバは買わない、ソフト面で解決したい
• 対象クラスタのボトルネックは producer で圧縮したデータが broker で解凍再圧縮されることに端を発していた• 一定の保持期限を維持するためにgzip圧縮を採用していた
• 0.10では解消
• 大幅にクラスタの能力は向上するはずだという目論見があった• このクラスタは実は性能問題のためreplication factor=1にしていて、その状態でも冗長性を担保するため
にclientライブラリを自作し、ユーザに使うことを強制していた(やめたい)
11

リリースに踏み切る後押し理由
• 今回のアップデートは短期間で進めるのに好条件だった
• 背景にKafka 0.7 → 0.8バージョンアップ時の苦い経験• 互換性の無いAPI変更
• プラットフォーム側がコントロールできないほど多い利用者
• 原則ダウンタイム不可
• 何を検証すべきか、どんなオペレーションが発生するかノウハウが無い
• 想定外の高コストに・・・
• しかし今回クラスタのアップデート条件は• 0.8 client → 0.10 serverは互換性あり
• 利用者が少なく密な連携が可能
• リリース時ダウンタイム、損失が可能
• 前回の反省、ノウハウがある
12
いけるっ・・・

アジェンダ
• Y! のストリーム処理プラットフォームとKafka
• アップデート経緯
• 検証、リリース
• アップデートを通して戸惑ったこと
• まとめ
13

検証
• バージョンアップの検証は特に今動いているものがバージョンアップ後に同じ要件で動くかに注意する必要がある• 新しい機能が享受できるかに注意を奪われがちかも
14

• 何を検証すればいい?
• ドキュメントに書いてあるから検証しなくてもいいということはない、しかし細かくやったらキリがない
• 自信があればやらないし、自信がなければやる、細かいところは正直運用勘 時間とリスクを天秤
broker視点の検証
問い 答え
今使われている client は冗長性を担保しつつ問題無く動く? Yes
これから使うことが決まっている client は冗長性を担保しつつ問題無く動く? Yes
性能要件、サーバを増やさなくてもしばらく後まで耐えれる? Yes
今までの日常オペレーションと同じことができる? Yes
想定のリリースオペレーションはアップデート条件にかなう? Yes
15
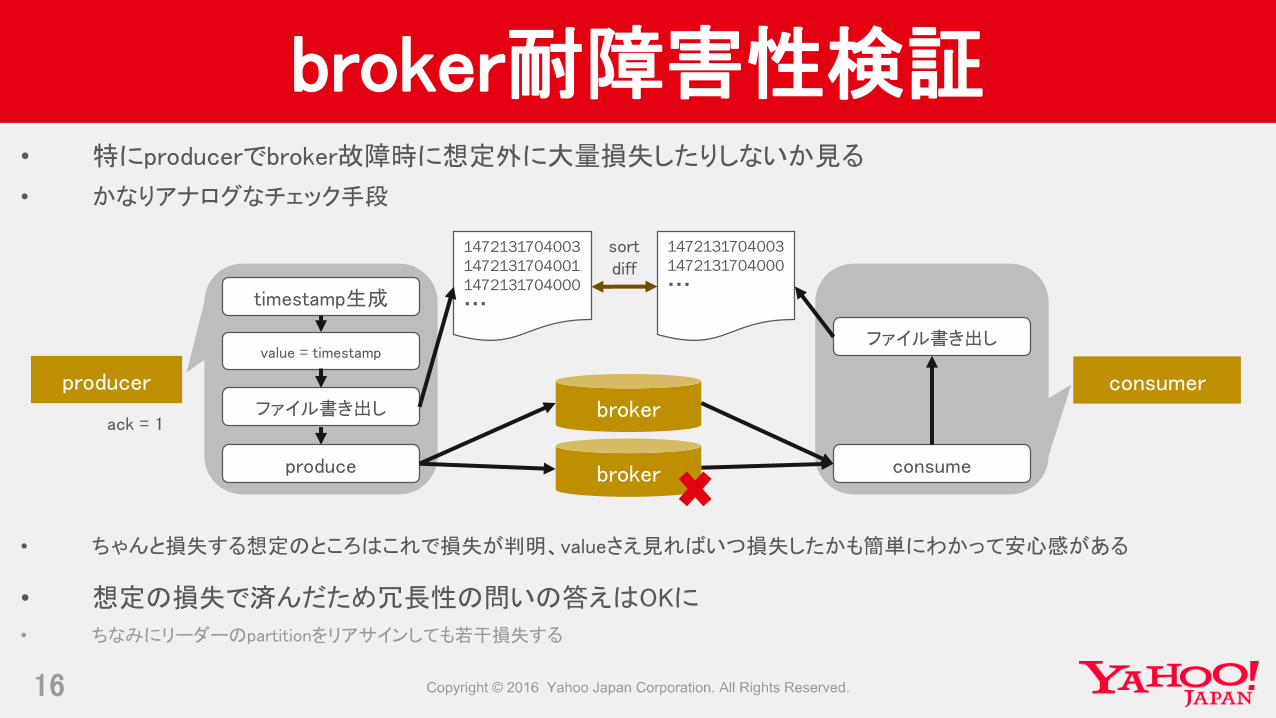
broker耐障害性検証• 特にproducerでbroker故障時に想定外に大量損失したりしないか見る
• かなりアナログなチェック手段
• ちゃんと損失する想定のところはこれで損失が判明、valueさえ見ればいつ損失したかも簡単にわかって安心感がある
• 想定の損失で済んだため冗長性の問いの答えはOKに
• ちなみにリーダーのpartitionをリアサインしても若干損失する
16
producer
value = timestamp
timestamp生成
ファイル書き出し
produce
broker
broker
consumer
ファイル書き出し
consume
1472131704003
1472131704001
1472131704000
・・・
1472131704003
1472131704000
・・・
sortdiff
ack = 1

性能検証
• ボトルネックになっていた broker への書き込み能力は 0.8.1.1 から
0.10.0 で約8倍の向上を計測した
• よって性能要件についての問いの答えはOKになった• producer でgzip圧縮しているユースケースならではの話
• 想定通りbrokerで解凍再圧縮が回避されているからだと思われる
• 注意• 圧縮に関わる性能テストは同じ内容のメッセージにすると圧縮率がものすごく良くなって意味
のないテストと化す
• 本番ログを一定量ファイルに書き出し、検証producerはそれを読んでproduceするようにした
17

リリース
• 割愛
• リリース作業時間が想定よりかかったけどうまくいった
18

アジェンダ
• Y! のストリーム処理プラットフォームとKafka
• アップデート経緯
• 検証、リリース
• アップデートを通して戸惑ったこと
• まとめ
19

戸惑ったこと①
• リリース時までパーティションの配置を正確に考えていなくてリリース時間がかかった• 例えば replication factor = 2 でも、オペレーションで一気に10台落としても大
丈夫なようにパーティション配置を考える必要がある
• 若干の損失が許容できるなら unclean leader election を有効にしていれば全レプリカが落ちても問題ないことは後で知った
• broker.idは自動採番でふったがその後ホスト名連番と合わせたくなった• log.dirsに配置されているmeta.propertiesファイルのbroker.idを書き換えて再起
動したら変更できた
20

戸惑ったこと②
• 特定のconsumer groupのオフセットリセットしたい要望があるんだけど0.10ではどうやるの?• 0.8系まではZooKeeperにオフセットが書かれる前提だったので今までは対象のznode
を削除するというオペレーションをしていた
• 0.9系からはKafkaにオフセットが書き込まれる前提、どうするのか?
• FAQに書いてあるが新しいJava consumerを使っていればseekメソッドで柔軟にオフセットが変更できる
• FAQは読んでおいた方がいい、ドキュメントの中でも重要度が高い
21

アジェンダ
• Y! のストリーム処理プラットフォームとKafka
• アップデート経緯
• 検証、リリース
• アップデートを通して戸惑ったこと
• まとめ
22

まとめ
• Y! のストリーム処理プラットフォームで稼働しているあるKafkaクラスタを0.8.1.1から0.10.0にバージョンアップした• 一番の目的は性能ボトルネックの改善• ユーザ要件は短期間で検証、アップデートする上で都合が
良かった• アップデートをする上で何を検証するべきか考えた• 性能検証ではこのユースケースにおいてはbrokerへの書き
込み能力が8倍に向上した
23