introduccion datawarehouse
TRANSCRIPT

AnálisisPredicitivo con Microsoft Azure Machine LearningDr. Eduardo Castro, MATI
IEEE Computer Society ViceChair
Microsoft SQL Server MVP
PASS Regional Mentor

Introducción para BI & Big Data
DAX
MDX
Minería de Datos
Excel BI
Recursos adicionales


Definiciones
Frase Objetivo
"La minería de datos" Toma de decisiones
"Machine Learning" Determinar el algoritmo de mejor desempeño

Introducción al Análisis predictivo
Predictive Analytics
Predictive ModelingData Mining

Análisis predictivo
• ¿Qué porcentaje de las aplicaciones analíticas utilizará las capacidades predictivas en 2014?

Análisis predictivo
• ¿Qué porcentaje de las aplicaciones analíticas utilizará las capacidades predictivas en 2014?

¿Por qué el resurgimiento en el análisis predictivo?

Científico de datos
Un científico de datos incorpora técnicas y teorías de muchos campos, incluyendo las matemáticas, la estadística, la ingeniería de datos, reconocimiento de patrones, aprendizaje avanzado , visualización, modelado de la incertidumbre, almacenamiento de datos y la computación de alto rendimiento con el objetivo de extraer el significado de datos.
Ciencia de datos: un términoutilizado indistintamente con inteligencia de negocio o análiticaempresarial

¿Qué es el análisis predictivo?
• El análisis de datos con técnicas matemáticas de estadística, minería de datos y aprendizaje automático. Se utiliza para descubrir patrones ocultos, que da una ventaja competitiva.

Qué es el análisis predictivo?
Predictive Analytics es el descubrimiento de información
predictiva, a veces oculta, de las bases de datos
utilizando atributos de datos relacionados y no
relacionados con la aplicación de algoritmos de análisis,
y la creación de modelos que generan resultados
predictivos.
Modelaje Predictivo es el proceso de creación de un modelo para predecir mejor la probabilidad de un resultado.

Minería de datos habilita Analítica Predictiva
Análisis predictivo
Presentación Exploración Descubrim
iento
Pasivo
Interactivo
Proactive
Insight
Negocios
Informes en
conserva
Ad hoc Reporting
Modelo de Datos
Data Mining
Papel de
Software

¿Qué es el análisis predictivo?

Escenarios comunes de clientes por análisis predictivo

Principales fuentes de datos
• Redes sociales y medios de comunicación• 700 millones de usuarios de Facebook, 250 millones de usuarios de Twitter y 156
millones de blogs públicos
• Dispositivos móviles• Más de 5 mil millones de teléfonos móviles en uso en todo el mundo
• Transacciones en Internet• miles de millones de compras en línea, operaciones de bolsa y otras
transacciones ocurren todos los días
• Dispositivos de red y sensores

Casos de uso
Sentiment Analysis
• Utilizado junto con Hadoop, herramientas avanzadas de análisis de texto analizan el texto no estructurado de las redes sociales y mensajes de redes sociales
• Incluyendo los Tweets y mensajes de Facebook, para determinar la confianza del usuario en relación con determinadas empresas, marcas o productos.
• El análisis puede centrarse en el sentimiento a nivel macro hasta el sentimiento usuario individual.

Casos de uso
Modelado de riesgo
• Las empresas financieras, bancos y otros utilizan Hadoop y NextGeneration Data Warehouse para analizar grandes volúmenes de datos transaccionales para determinar el riesgo y la exposición de los activos financieros
• Para preparar la posible "qué pasaría si" los escenarios basados en el comportamiento del mercado simulado, y para puntuación de clientes potenciales por el riesgo.

Casos de uso
Motor de recomendación
• Los minoristas en línea utilizan Hadoop para igualar y recomendar a los usuarios entre sí o con los productos y servicios basados en el análisis del perfil de usuario y los datos de comportamiento.
• LinkedIn utiliza este enfoque para potenciar su función de "la gente puede saber", mientras que Amazon utiliza para sugerir productos a la venta a los consumidores en línea.

Casos de uso
Detección de Fraude
• Utilizar técnicas de Big Data para combinar el comportamiento del cliente, históricos y datos de transacciones para detectar la actividad fraudulenta.
• Las compañías de tarjetas de crédito, por ejemplo, utilizan tecnologías de Big Data para identificar el comportamiento transaccional que indica una alta probabilidad de una tarjeta robada.

Casos de uso
Análisis de la campaña de marketing
• Los departamentos de marketing a través de industrias han utilizado durante mucho tiempo la tecnología para monitorear y determinar la efectividad de las campañas de marketing.
• Big Data permite a los equipos de marketing para incorporar mayores volúmenes de datos cada vez más granulares, como los datos de click-stream y registros detallados de llamadas, para aumentar la precisión de los análisis.

Casos de uso
Análisis Social Graph
• Junto con Hadoop los datos de redes sociales se extraen para determinar qué clientes representan la mayor influencia sobre los demás dentro de las redes sociales.
• Esto ayuda a determinar las empresas que son sus clientes "más importantes", que no siempre son los que compran la mayoría de los productos o de los que más gastan, pero los que tienden a influir en el comportamiento de compra de la mayoría de los demás.

Casos de uso
Customer Experience Analytics
• Empresas orientadas al consumidor utilizan Hadoop y tecnologías relacionadas con Big Data para integrar los datos de antes silos canales de interacción con clientes
• Tales como centros de llamadas, chat en línea, Twitter, etc, para obtener una visión completa de la experiencia del cliente.

El análisis predictivo ejemplo de flujo de trabajo: tarjetas de crédito
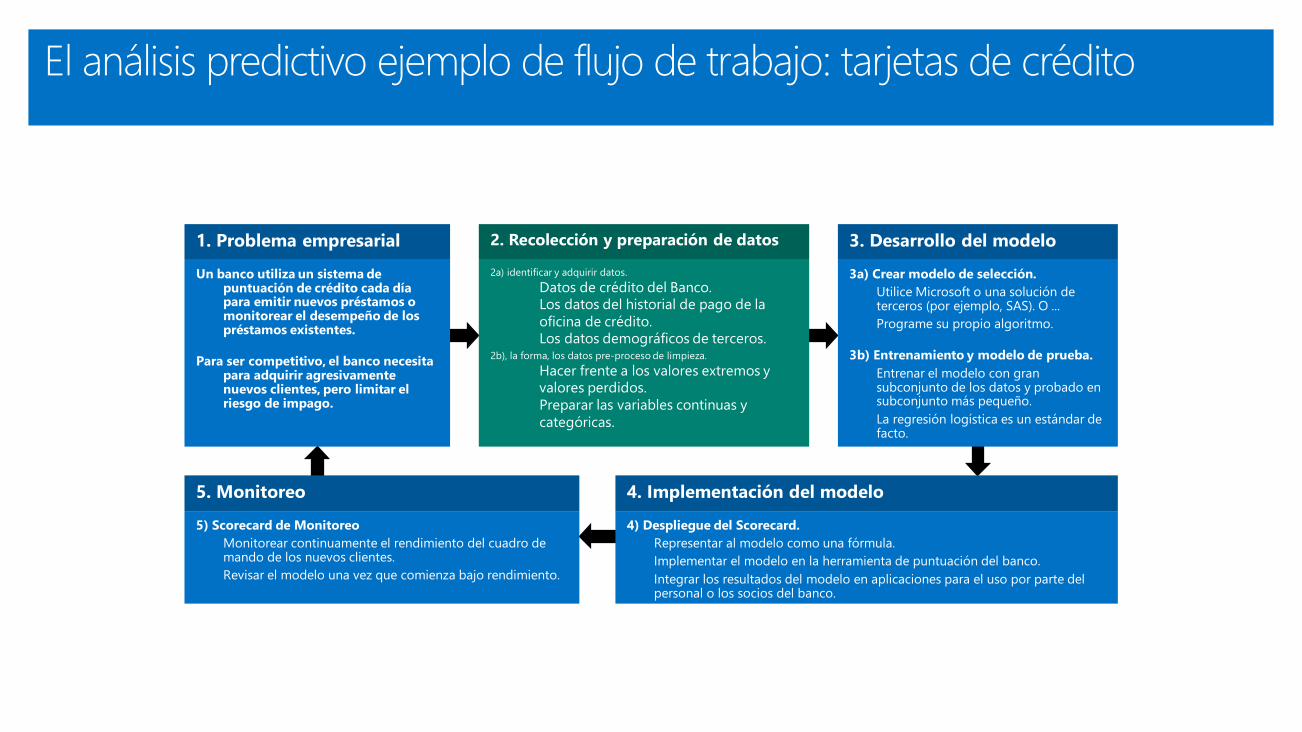
El análisis predictivo ejemplo de flujo de trabajo: tarjetas de crédito
Datos de crédito del Banco.
Los datos del historial de pago de la
oficina de crédito.
Los datos demográficos de terceros.
Hacer frente a los valores extremos y
valores perdidos.
Preparar las variables continuas y
categóricas.

El análisis predictivo ejemplo de flujo de trabajo: tarjetas de crédito
Utilice Microsoft o una solución de
terceros (por ejemplo, SAS). O ...
Programe su propio algoritmo.
Entrenar el modelo con gran subconjunto
de los datos y probado en subconjunto
más pequeño.
La regresión logística es un estándar de
facto.

El análisis predictivo ejemplo de flujo de trabajo: tarjetas de crédito
Utilice Microsoft o una solución de
terceros (por ejemplo, SAS). O ...
Programe su propio algoritmo.
Entrenar el modelo con gran subconjunto
de los datos y probado en subconjunto
más pequeño.
La regresión logística es un estándar de
facto.
Representar al modelo como una fórmula.
Implementar el modelo en la herramienta de puntuación del banco.
Integrar los resultados del modelo en aplicaciones para el uso por parte del personal o
los socios del banco.

El análisis predictivo ejemplo de flujo de trabajo: tarjetas de crédito
Utilice Microsoft o una solución de
terceros (por ejemplo, SAS). O ...
Programe su propio algoritmo.
Entrenar el modelo con gran subconjunto
de los datos y probado en subconjunto
más pequeño.
La regresión logística es un estándar de
facto.
Monitorear continuamente el rendimiento del cuadro de mando
de los nuevos clientes.
Revisar el modelo una vez que comienza bajo rendimiento.
Representar al modelo como una fórmula.
Implementar el modelo en la herramienta de puntuación del banco.
Integrar los resultados del modelo en aplicaciones para el uso por parte del personal o
los socios del banco.

• La automatización de la automatización
• Utilizar computadoras para programarcomputadoras
• Escribir software es el cuello de botella
• Deje que los datos hagan el trabajo!
Qué es el aprendizaje autómático o Machine Learning

2
¿Por qué "Aprender"?• El aprendizaje automático es la programación de
computadoras para optimizar un criterio de desempeño usando datos como ejemplo o experiencia previa.
• El aprendizaje se utiliza cuando:• Experiencia humana no existe (la navegación en Marte),
• Los seres humanos son incapaces de explicar su experiencia (reconocimiento de voz)
• Solución cambios en el tiempo (el enrutamiento en una red informática)
• Solución necesita ser adaptada a los casos particulares (biométrica de usuario)

Cumpliendo con uno de los viejos sueños
del co-fundador de Microsoft, Bill Gates:
Computadoras que podemos ver, oír
y entender.
John PlattCientífico distinguido en
Microsoft Research
¿Qué es Aprendizaje Automático?
Sistemas informáticos de predicción se vuelven más inteligentes, con experiencia
"
"

3
De qué hablamos cuando hablamos de "Aprendizaje"
• Aprender modelos generales a partir de ejemplos de datos particulares
• Los datos son baratos y abundantes (data warehouses, data marts); el conocimiento es caro y escaso.
• Ejemplo para comercio minorista: las transacciones de los clientes y la conducta del consumidor:
Las personas que compraron "Código Da Vinci" también compraron "Las cinco personas que conoces en el cielo" (www.amazon.com)
• Construir un modelo que es una aproximación buena y útil de los datos.

ComputadoraDatos
ProgramaSalida
ComputadoraDatos
SalidaPrograma
Programación tradicional vs machine learning

Analytics Vision
Utilizando los datos del pasado para predecir el futuro
Motores
recomenda-ción
Análisis
Publicidad
El pronóstico del
tiempo para la
planificación de
negocios
Análisis de redes
sociales
Legal
descubrimiento y
archivo de
documentos
Análisis de
precios
Fraude
detección
Mantequera
análisis
Supervisión de
equipos
Seguimiento y
servicios
basados en
localización
Seguros
personalizada
El aprendizaje automático y el análisis predictivo son capacidades básicas que se necesitan en toda la empresa

• Búsqueda Web
• Biología computacional
• Finanzas
• E-commerce
• La exploración espacial
• Robótica
• Extracción de información
• Redes sociales
• Depuración
Aplicaciones de ejemplo

• Muchos algoritmos de aprendizaje automático
• Cientos nuevas cada año
• Cada algoritmo de aprendizaje automático tienetres componentes:
• Representación
• Evaluación
• Optimización
ML en resumen

• Los árboles de decisión
• Conjuntos de reglas / Programas de Logica
• Instancias
• Modelos gráficos (Bayes / redes de Markov)
• Las redes neuronales
• Máquinas de vectores
Representación de Algoritmos de ML

• Precisión
• Precisión y recuperación
• Error cuadrado
• Probabilidad
• Posterior probabilidad
• Costo / Utilidad
• Margen
• Entropía
• K-L divergencia
• Etcétera
Evaluación de algoritmos de ML

• Optimización combinatoria• Por ejemplo .: búsqueda Greedy
• Optimización convexa• Por ejemplo .: descenso de gradiente
• Optimización con restricciones• Por ejemplo .: programación lineal
Optimización de algoritmos de ML

• Aprendizaje por análisis de asociación
• Aprendizaje Supervisado (inductivo)• Los datos de entrenamiento incluye salidas deseadas
• Clasificación
• Regresión/ Predicción
• Aprendizaje no supervisado• Los datos de entrenamiento no incluye salidas deseadas
• Aprendizaje semisupervisado• Los datos de entrenamiento incluye un par de productos deseados
• Aprendizaje por refuerzo• Recompensas con base en secuencia de acciones
Tipos de aprendizaje

• Dado ejemplos de una función (X, F (X))
• Predecir función F (X) para nuevos ejemplos X• Discreto F (X): Clasificación
• Continuo F (X): Regresión
• F (X) = Probabilidad (X): Estimación de Probabilidad
Apredizaje inductivo

• El aprendizaje supervisado• Inducción por Árbol de decisiones
• Inducción por reglas
• Aprendizaje basado en Instancias
• Aprendizaje bayesiano
• Las redes neuronales
• Máquinas de vectores
• Aprendizaje no supervisado• Clustering
• Reducción de dimensionalidad
Clasificación de aprendizajes

Aprendizaje por asociación• Análisis de la carrito de compras:
P(Y|X) La probabilidad de que alguien que compra X También compra Y donde X y Yson productos / servicios.
Ejemplo: P(Frijoles molidos | Tortillitas) = 0,7
Transacciones de carrito de compras
ID Producto
1 Arroz, Coca Cola
2 Arroz, Coca Cola, Frijoles
3 Arroz, Frijoles
4 Tortillitas, Frijoles
Molidos
5 Arroz, Coca Cola, Frijoles
Molidos, Tortillitas

Aprendizaje por clasificación
9
• Ejemplo: El puntaje de crédito
• Diferenciar entre bajo riesgo y de riesgo alto con base en los ingresos y ahorros de los clientes
Discriminante: IF ingresos > Θ1 Y ahorros > Θ2
ENTONCES bajo riesgo ELSE riesgo alto
Modelo

Regresión lineal
• La regresión lineal es una de las técnicas de predicción más antiguos de estadística. El objetivo de la regresión lineal es ajustar un modelo lineal entre las variables de respuesta e independientes, y lo utilizan para predecir el resultado dado un conjunto de variables independientes observados . Un modelo de regresión lineal simple es una fórmula con la estructura:

Regresión lineal• Y es la variable de respuesta (es decir, el resultado que usted está tratando
de predecir), como las millas por galón.
• X1,X2, X3, etc., son las variables independientes que se utilizan para predecir el resultado.
• b0 es una constante que es la intersección de la línea de regresión.
• b1, b2, b3, etc., son los coeficientes de las variables independientes.Estos se refieren a las pistas parciales de cada variable.
• e es el error o ruido asociado con la variable de respuesta queno se puede explicar por la variables independientes X1, X2, X3 y.

Un modelo de regresión lineal simple que predice millas de un carro porgalón de supotencia de motor

Redes Neuronales• Las redes neuronales artificiales son un conjunto de algoritmos
que imitan el funcionamiento del cerebro.
• Hay muchos algoritmos de redes neuronales diferentes, incluidas las redes de retropropagación, redes de Hopfield, Redes de Kohonen (también conocidos como mapas auto-organizados) y Redes ART (o ART) redes.
• Sin embargo, el más común es el algoritmo de back-propagation, también conocido como multilayered perceptron.

Árboles de decisión
• Algoritmos de árboles de decisión son técnicas jerárquicas que funcionan mediante la división del conjunto de datos de forma iterativa en base a ciertos criterios estadísticos.
• El objetivo de los árboles de decisión es maximizar la varianza entre los diferentes nodos en el árbol, y minimizar la varianza dentro de cada nodo

Ejemplo de árbol de decisión

• La comprensión de dominio, conocimiento previo, y las metasdeseadas
• La integración de datos, selección, limpieza, pre-procesamiento, etc.
• Modelos de aprendizaje
• Interpretación de los resultados
• La consolidación y el despliegue de conocimiento descubierto
Machine Learning en la práctica

¿Cómo utilizo Azure Machine Learning?
Importar datosConstuir un
modelo
Combinar el
Modelo con el
API

Una solución de Aprendizaje Automático – obtener resultados a partir de los datos
Azure Portal
Operaciones Azure Equipo
ML Studio
Científico de Datos
HDInsight
Almacenamiento
En Azure
Datos de
escritorio
Azure Portal y
Servicio API ML
Equipo de operaciones de Azure
PowerBI/ DashboardsAplicaciones MóvilesAplicaciones Web
Servicio API ML Desarrollador

Una solución de Aprendizaje Automático - obtener resultados a partir de los datos
Azure Portal
Operaciones Azure Equipo
ML Estudio
Datos Científico
HDInsight
Almacenamiento
Azure
Datos de
escritorio
Azure Portal y
Servicio API ML
Operaciones Azure Equipo
PowerBI/ DashboardsAplicaciones MóvilesAplicaciones Web
Servicio API ML Revelador
ML Studioy el científico de datos
• Acceso y preparación de
datos
• Crear, modelos de prueba
• Con un solo clic pasar a la
etapa de producción a través
de la API de Servicios
Servicio API Azure Portal y
ML
• Crear ML Studio Workplace
• Asignar cuenta de almacenamiento
(s)
• Monitor Consumo ML
• Ver alertas cuando el modelo es listo
• Publicar WebServices
API ML servicio y el desarrollador
• Modelos disponibles como una url que se puede invocar
Los usuarios pueden acceder
fácilmente a los resultados: desde
cualquier lugar,en cualquier dispositivo

Hola, Machine Learning Studio!


Machine Learning StudioExperimentos: Los experimentos que se han creado, ejecutado, yguardado como borradores. Estos incluyen un conjunto de experimentos de ejemplo que se incluyen con el servicio que le ayudará en sus proyectos.
Servicios Web Servicios: Una lista de los experimentos que se han publicadocomo servicios web. Esta lista estará vacía hasta que publique su primerexperimento.
Settings: Una colección de parámetros que puede utilizar para configurarsu cuenta y recursos. Puede utilizar esta opción para invitar otros usuarios compartir su espacio de trabajo en Azure Machine Learning.

Componentes de un experimento• Un experimento consta de los componentes clave necesarios para
construir, probar y evaluar un modelo predictivo. En Azure Machine Learning, un experimento contiene dos componentes principales: los conjuntos de datos y módulos.
• Un conjunto de datos contiene datos que se han subido a Machine Learning Studio. El conjunto de datos se utiliza al crear un modelo predictivo. Machine Learning Studio también ofrece varios conjuntos de datos de demostración para ayudarle a reactivar la creación de sus primeros experimentos.
• Un módulo es un algoritmo que va a utilizar en la construcción de su modelo predictivo.

Módulos• Reader: Este módulo se utiliza para leer los datos de varias fuentes,
incluyendo la Web, base de datos SQL Azure, almacenamiento Blob Azure, o mesas Hive.
• Split: Este módulo se divide un conjunto de datos en dos partes. Normalmente se utiliza para dividir un conjunto de datos de aprendizaje y prueba de datos separadas.
• Elementary Statistics: Calcula estadísticas elementales como la media, la desviación estándar, etc., de un determinado conjunto de datos.
• Regresión lineal: se puede utilizar para crear un modelo predictivo con un algoritmo de regresión lineal.

Módulos
• Train Model: Este módulo entrena un algoritmo de clasificación o regresiónseleccionado con un conjunto de datos de entrenamiento dado.
• Evaluate Model: Este módulo se utiliza para evaluar el desempeño de un modelo de clasificación o regresión entrenado.
• Cross Validate Model: Este módulo se utiliza para llevar a cabo validacióncruzada para evitar el exceso de ajuste. Por defecto, este módulo usa 10 veces la validación cruzada.
• Score Model: Puntúa un modelo de clasificación o regresión entrenado.

Pasos para la creación de un experimento
• Crear un modelo• Paso 1: Obtener datos
• Paso 2: Preproceso de datos
• Paso 3: Definir las características
• Entrenar el modelo• Paso 4: Seleccionar y aplicar un algoritmo de aprendizaje
• Pruebe el Modelo
• Paso 5: Predecir sobre nuevos datos

Flujo en Azure Machine Learning

Flujo en Azure Machine Learning

Flujo en Azure Machine Learning

Flujo en Azure Machine Learning


Errores comunes en el análisis predictivo
