inria rhône-alpes - planète project 1 a host-based multicast (hbm) solution for group...
TRANSCRIPT

INRIA Rhône-Alpes - Planète project 1
A host-based multicast (HBM) solution for group
communications
[email protected] http://www.inrialpes.fr/planete/people/roca
Planète Project

Vincent Roca - INRIA Rhône-Alpes - planète project - 2
Part 1:
Motivations for overlay multicast...
An alternative group communication service

Vincent Roca - INRIA Rhône-Alpes - planète project - 3
Multicast routing not available everywhere!
[Diot00] “Deployment issues for the IP multicast service and architecture”
many deployment issues for ISPs:offering wide area multicast is technically complexrouting protocols still under development/researchmany functionalities are still not available (e.g.
security)brings router migration problemsrequires complex managementwhen is multicast more interesting than unicast?what billing model?
egg-and-chicken problem?
Vincent Roca - INRIA Rhône-Alpes - planète project - 4
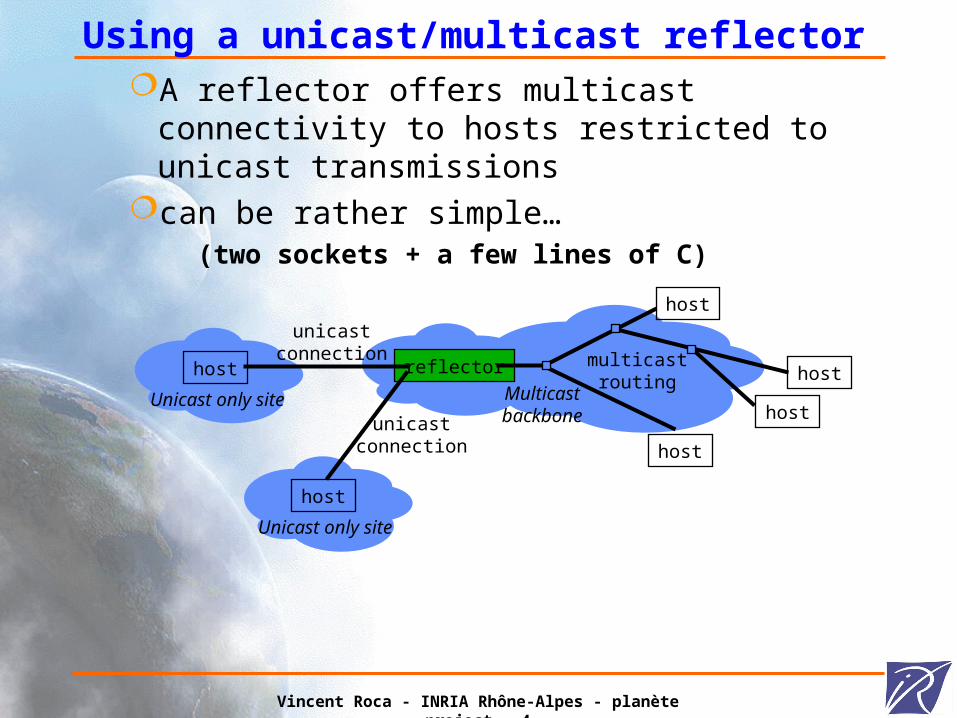
Using a unicast/multicast reflectorA reflector offers multicast connectivity to hosts
restricted to unicast transmissionscan be rather simple…
(two sockets + a few lines of C)
multicastrouting
reflectorhost
Unicast only site
unicastconnection
host
Unicast only site
unicastconnection
host
host
host
host
Multicastbackbone

Vincent Roca - INRIA Rhône-Alpes - planète project - 5
Using a unicast/multicast reflector... (cont’)Pros
simpleavailable
Consrequires a manual setuphow many reflectors are needed ?where to place them ?limited and uncontrolled efficiency
(depends on the placement of reflectors, on the number of unicast clients, etc.)
Overlay Multicast (OM) tries to solve these problems...

Vincent Roca - INRIA Rhône-Alpes - planète project - 6
Part 2:
Overlay Multicast (OM) specificities...

Vincent Roca - INRIA Rhône-Alpes - planète project - 7
The goals of Overlay Multicast (OM)Definition
Create automatically and easily a group Create automatically and easily a group communication service, using efficiently the communication service, using efficiently the underlying unicast/multicast routing servicesunderlying unicast/multicast routing services
Many different names… Overlay MulticastEnd Host MulticastApplication-level MulticastHost Based Multicastetc.
hosthost
hosthostpoint-to-point connection
Site 1Site 2
Site 3
point-to-point connection

Vincent Roca - INRIA Rhône-Alpes - planète project - 8
OM is not multicast
An OM node can bea host (general assumption)a (dedicated) server within the sitea (dedicated) server within the ISP
... but no assumption is made on routers (unlike multicast where the routers are supposed to implement a given routing protocol)

Vincent Roca - INRIA Rhône-Alpes - planète project - 9
OM is not multicast... (cont’)OM is an overlay
the physical topology is hidden at the OM levelcreate a complete virtual graph with all
nodes/distances between themseveral possible metrics (unidirectional delay, RTT,
number of hops)
N1
N3
N2
N4
N5
N2: 17N3: 2N4: 28N5: 27
N1: 17N3: 17N4: 33N5: 32
N1: 2N2: 17N4: 28N5: 27
N1: 27N2: 32N3: 27N4: 3
N1: 28N2: 33N3: 28N5: 3
...to complete virtual graphFrom physical topology...
N1
N3
N2
N4
N5
1
2
1
1
10
20
1
5 Site 3
Site 2
Site 1

Vincent Roca - INRIA Rhône-Alpes - planète project - 10
OM is not multicast... (cont’)Membership knowledge
In traditional multicast, knowledge is distributed/uncompleterouters only know that an interface leads to receiver
In OM, group members are known...either by a Rendez-vous Point (e.g. HBM)or by the sourceor by everybody (distributed scheme)
receiver N2 receiver N3
N2 and N3 for group G,neighbor is N2
source N1
N1 and N3 for group G,neighbors are N1 and N3
N1 and N2 for group G,neighbor is N2
Membership knowledge with HBM.
receiver N3receiver N2
join
join
rx on if1 for group G
rx on if0 for group G
source N1
Membership knowledge with a per-source tree.
local router knows existance ofat least one local rx for group G

Vincent Roca - INRIA Rhône-Alpes - planète project - 11
OM is not multicast... (cont’)reliability is more limited
a node is less reliable than routers/linksif OM is implemented in a library, the application may
be stopped/crash…
redundancy, adaptation and fast failure discovery/tree update are required
tree setup is entirely under controlOM topology can be tailored
e.g. several OM topologies are possible depending on requirements
e.g. a specific tunnel can be setup on a lossy, congested path

Vincent Roca - INRIA Rhône-Alpes - planète project - 12
Using OM for unicast/multicast integration...
Pros: automatic setupmore efficient than reflectorsdynamic adaptation to network conditionsmore security
Cons:can turn out to be rather complexhosts may be unstable (much more than
routers/links!)OM is neither as efficient nor as scalable as native
multicast routing
two key points: robustness and efficiency

Vincent Roca - INRIA Rhône-Alpes - planète project - 13
PART 3:
Our HBM (Host Based Multicast) proposal

Vincent Roca - INRIA Rhône-Alpes - planète project - 14
Sketch of the protocolHBM in a nutshell:
creates a self-organizing overlay that periodically self-improves
this is a RP-based protocolthe RP calculates the shared virtual topologythe RP has a complete knowledge of group
membership/communication costsmembers periodically evaluate distances between
them and inform their RPdata flows on the virtual topology (no RP
implication)distinguish:
core-members (CM) can be transit nodenon-core members (nonCM) are always leaves

Vincent Roca - INRIA Rhône-Alpes - planète project - 15
Sketch of the protocol... (cont’)OK, that’s not scalable...
other OM solutions are not scalable eitherthe only solution is native multicast routing...
...except if you use DM protocols, or MSDP, or any other non scalable piece of protocol
anyway a single HBM node can serve many local participants using native local multicast !
OK, reliability greatly depends on the RP reliability...
not an issue if RP is collocated with primary sourceyou can also setup secondary RPs
(like secondary DNS/NIS/... servers)

Vincent Roca - INRIA Rhône-Alpes - planète project - 16
Sketch of the protocol... (cont’)...but this is simple
limited coherency problems
(everything is centralized)limited burden on the hosts
(an asset in case of PDAs)
...and it creates a “not too bad” distribution topology
optimal with respect to known distances at that timetopology regularly updated
(periodic update, depending on the group size/stability/etc., or triggered by some event)

Vincent Roca - INRIA Rhône-Alpes - planète project - 17
A robust group communication service...adding redundancy
see paper for an algorithm that adds some redundant virtual links (RVL)
proba_partitioned_topology_after_a_failure < threshold
fast failure discoverydepends on virtual topology
• with a tree, use ACK Aggregation• with a ring topology 1 or 2 nodes should receive each
packet twice
• with RVL, after a failure a node will receive traffic on a redundant link only
sourcepacket tx
packet tx 1 or 2 opposite hosts should receive 2 copies

Vincent Roca - INRIA Rhône-Alpes - planète project - 18
A robust group comm. service... (cont’)adding adaptation
unstable nodes should be leaves rather than transit nodes...
each node has a capability
Cap(node) = f(user_desires, node_stability, group_req)
[0; alpha[ disconnected
[alpha, beta] leaf_only
]beta;1] transit_possibleenables adaptation...
reliable host
unreliable hosts

Vincent Roca - INRIA Rhône-Alpes - planète project - 19
A robust group comm. service... (cont)
Several topologies are possible:
tree:tree: medium fault-tolerance
optimal perf. requires per-source tree
minimum global cost tree possible
ring:ring: 1-fault tolerance if bi-directional
perf. does not depend on source position
balanced load on all links
star:star: good fault-tolerance except for the core
source must be core for optimal perf.
very high traffic load close to core

Vincent Roca - INRIA Rhône-Alpes - planète project - 20
A robust group comm. service... (cont)sun:sun: balance between ring and star topologies
good fault tolerance if unreliable hosts are moved at the end of sun beams
unreliable hostsreliable host

Vincent Roca - INRIA Rhône-Alpes - planète project - 21
Some simulation resultsimpacts of a single node failure…
Vincent Roca - INRIA Rhône-Alpes - planète project - 22
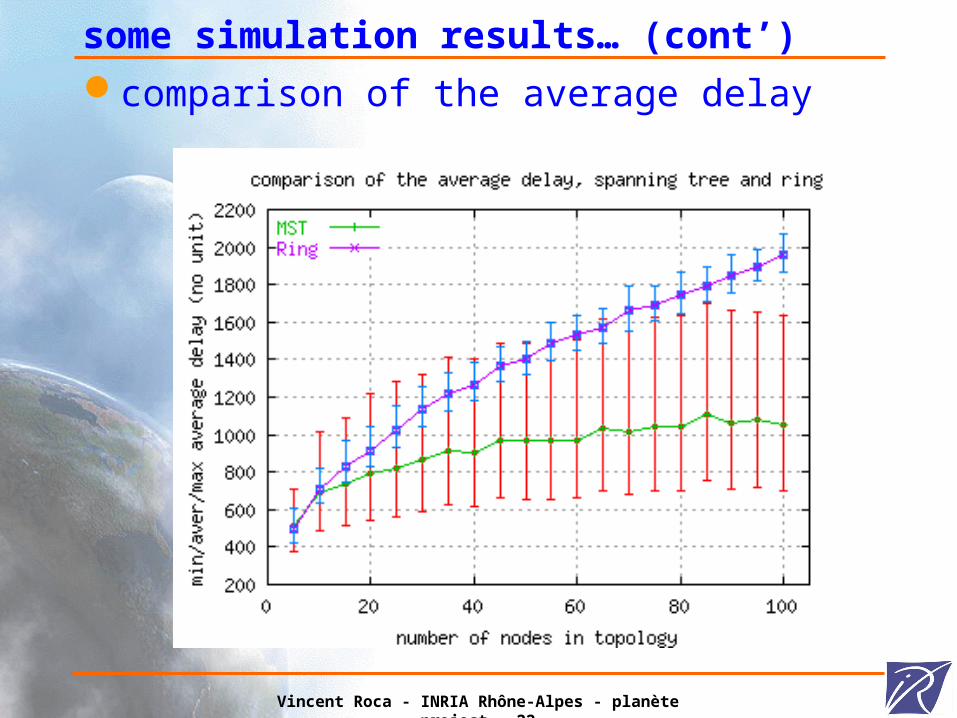
some simulation results… (cont’)comparison of the average delay

Vincent Roca - INRIA Rhône-Alpes - planète project - 23
Part 4:
Conclusions

Vincent Roca - INRIA Rhône-Alpes - planète project - 24
Conclusionsdiscussion on issues raised by creation and
management of an OM topology
a centralized solution where group membership is known by a RP has many advantagessimpleefficienttakes advantage of known node features
adding redundancy is important as OM is intrinsically fragile

Vincent Roca - INRIA Rhône-Alpes - planète project - 25
Additional hidden slides

Vincent Roca - INRIA Rhône-Alpes - planète project - 26
Using OM for unicast/multicast integration
build a group interconnection topology between participants
use unicast or multicast where available/efficient
OM can include multicast areas for improved:• scalability (all the nodes are collapsed)• efficiency (avoids several point-to-point connections)
hosthost
hosthostpoint-to-point connection
Site 1Site 2
Site 3
point-to-point connection

Vincent Roca - INRIA Rhône-Alpes - planète project - 27
OM is not multicast... (cont’)
OM can only rely on end-hosts...easy deployment, flexiblebut not very efficient with bandwidth limited sites
OM can include dedicated servers at each site...
a server is certainly more stable than hostsno processing power problems
or even dedicated servers within ISPscertainly the most efficient solution from a
networking point of viewend-hosts are in “leaf-only” mode, so packets cross
the ISP/site link only once

Vincent Roca - INRIA Rhône-Alpes - planète project - 28
Sketch of the protocol
everything is under the control of central RPknows CM and nonCMknows distances between them (several metrics)is responsible of the distribution topology
calculation and dissemination
CM periodically evaluate distances between them and inform the RP
likewise nonCM evaluate their distances with (a subset of) CM and inform the RP

Vincent Roca - INRIA Rhône-Alpes - planète project - 29
Sketch of the protocol... (cont’)an example:
CM1
CM3
nonCM5CM2
nonCM4
RP
(1) evaluates inter-node distances
(3) calculate newdistribution topology
(2) send this info to the RP
(4) distribute newtopology information(either in pt-to-ptor along the new tree)
CM2: distCM3: distneighbors in topo: XXX
CM1: distCM2: distneighbors in topo: XXX
CM1: distCM3: distneighbors in topo: XXX
CM1: distCM2: distCM3: distneighbor: XXX
CM1: distCM2: distCM3: distneighbor: XXX
core treenonCM graft on the core tree(e.g. closest CM)
CM1
CM3
CM2