il data mining - dataskills.it · crisp-dm, he sta per “cross industry standard process for data...
TRANSCRIPT

www.dataskills.it E-mail [email protected]
Il data mining
di Alessandro Rezzani
Cos’è il data mining. ................................................................................................................................. 2
Knowledge Discovery in Databases (KDD) ............................................................................................. 3
Lo standard CRISP-DM ............................................................................................................................. 4
La preparazione dei dati ........................................................................................................................... 7
Costruzione del modello .......................................................................................................................... 7
Attività tipiche ......................................................................................................................................... 8
Valutazione del modello........................................................................................................................... 9
La matrice di confusione ...................................................................................................................... 9
La curva ROC (Receiver Operating Characteristic) ............................................................................... 11
Lift chart ............................................................................................................................................ 13
Bibliografia............................................................................................................................................. 14

www.dataskills.it E-mail [email protected]
Cos’è il data mining. Se esaminiamo come le modalità di analisi dei dati si sono evolute negli anni, notiamo come da indagini
effettuate direttamente sulle fonti operazionali, si è passati, a partire dagli anni ’90, all’utilizzo di una base
dati creata appositamente: il data warehouse. Con il data warehouse e i database multidimensionali è
possibile analizzare i dati non solo al massino livello di dettaglio, ma anche a diversi livelli di aggregazione, e,
inoltre, eseguendo operazione di drill-down o slicing e dicing si ottengono dinamicamente prospettive
diverse del dato. Tuttavia si tratta sempre di una visione storica, che consente soltanto una valutazione a
consuntivo di ciò che è accaduto nel passato, oppure di ciò che sta accadendo ora. Più di recente, a partire
dai primi anni 2000, ha cominciato ad affermarsi la necessità di effettuare analisi previsionali, per anticipare
gli eventi e ottenere un vantaggio di business. La grande quantità di dati disponibili ha reso inoltre necessaria
l’adozione di tecniche di analisi efficienti e in grado di lavorare su valori numerici, testuali o binari (per es. le
immagini).
Le tecniche di analisi, a cui ci riferiamo, prendono il nome di data mining, poiché consentono di “scavare”
nei dati ed estrarre informazioni, pattern1 e relazioni non immediatamente identificabili e non note a priori.
Il data mining può essere utilizzato in qualsiasi settore economico, per risolvere molteplici problemi di
business:
- Ricerca di anomalie. Il data mining può essere impiegato per l’identificazione di comportamenti
fraudolenti nell’utilizzo di carte di credito.
- Churn Analysis. La churn analysis consiste nell’analisi della clientela per determinare i clienti che
presentano un’alta probabilità di passare alla concorrenza, al fine di intervenire in anticipo ed
evitarne la migrazione.
- Segmentazione della clientela. Le tecniche di segmentazione possono essere utili, per esempio, a
determinare il profilo comportamentale dei clienti. Una volta identificati i segmenti di clienti simili,
è possibile studiare strategie di marketing differenziate per ciascun gruppo.
- Previsioni. Le analisi predittive dell’andamento delle vendite, o, genericamente dell’andamento di
serie temporali, sono un altro degli ambiti di impiego del data mining.
- Campagne pubblicitarie mirate. L’utilizzo del data mining nell’ambito delle campagne di marketing
mirate, consente di stabilire a priori quali siano, tra i prospect, quelli con maggior probabilità di
acquistare i prodotti dell’azienda, in modo da impiegare su di essi le risorse del marketing.
- Market basket analysis. Le tecniche di market basket analysis sono utili a suggerire, a un certo
cliente, ulteriori prodotti da acquistare in base ai suoi comportamenti d’acquisto abituali, oppure a
definire il layout dei prodotti sugli scaffali.
Il data mining comporta l’utilizzo integrato di diverse discipline, come il data warehousing, la statistica,
l’intelligenza artificiale, le tecniche di visualizzazione, l’analisi delle serie temporali e l’analisi di dati geo-
spaziali. La componente tecnologica riveste una grande importanza, poiché gli algoritmi di data mining
richiedono una certa potenza di calcolo e tecniche di ottimizzazione delle performance sono essenziali,
soprattutto in presenza di una mole di dati elevata. Nel processo di data mining è però la figura dell’utente
ad assumere un ruolo centrale: si tratta, infatti, di un processo che richiede l’interazione di un esperto del
business, che deve sfruttare la propria conoscenza per la preparazione dei dati, per costruzione dei modelli
e per la valutazione dei risultati.
La tabella seguente contiene un sunto delle caratteristiche del data mining.
1 Per pattern intendiamo una struttura, un modello, o, più in generale una rappresentazione sintetica dei dati.

www.dataskills.it E-mail [email protected]
Tabella 1 Caratteristiche del data mining.
Caratteristica Descrizione
Scopo Il data mining utilizza tecniche analitiche per identificare pattern nascosti nei dati.
Ambito dei dati Il data mining può trattare dati qualitativi, qualitativi, testuali, immagini e suoni.
Ipotesi di partenza Non richiede ipotesi a priori da parte del ricercatore, nemmeno sulla forma distributiva2 delle variabili.
Requisiti E’ necessaria una buona conoscenza de business nel cui ambito si vogliono applicare le tecniche di data mining. Ciò consente la corretta valutazione e selezione dei dati di partenza rilevanti. Inoltre occorre aver pienamente compreso i requisiti e gli obiettivi che si vogliono raggiungere, al fine di poter interpretare nel modo corretto i risultati dei modelli.
Interazione L’analista e il sistema di data mining devono interagire al fine di produrre un modello valido. L’analista sceglie i dati da analizzare, configura il sistema di data mining e valuta i risultati. Il processo può essere ripetuto per affinare il modello.
Capacità di elaborazione Gli algoritmi sono ottimizzati per minimizzare i tempi di elaborazione anche in presenza di un numero elevato di osservazione e un numero elevato di variabili.
Interpretazione dei risultati I software i data mining offrono propongono i risultati in forma semplice, anche attraverso l’uso di strumenti visuali che ne facilitano l’interpretazione.
Knowledge Discovery in Databases (KDD)
Il data mining fa parte di un più ampio processo chiamato Knowledge Discovery in Databases (KDD) e ne
rappresenta la fase più importante. Il KDD, come si evince dal nome, ha lo scopo di estrarre la conoscenza
dai dati. Sappiamo che il dato è il risultato di una misurazione di un certo evento e di per sé non ha grande
utilità. Tuttavia valutando i dati in un preciso contesto e applicandovi opportune elaborazioni è possibile
ricavare informazioni: in questo modo il dato diventa utile e in grado di rispondere a una richiesta specifica.
Tuttavia l’informazione va utilizzata in modo produttivo al fine di ottenere conoscenza. La conoscenza è
dunque il risultato di un percorso che parte dai dati grezzi e termina con l’interpretazione e lo sfruttamento
produttivo dei risultati.
Il processo di KDD contiene diversi passi:
1) Selezione dei dati. E’ evidente come un database possa contenere nati di varia natura, che per il
problema in esame possono risultare inutili. E’ dunque importante comprendere il dominio
applicativo determinato dagli obiettivi dell’utente finale.
2) Preelaborazione. Dopo aver ridotto l’ambito dei dati da considerare, è comunque poco opportuno
analizzarli per intero, poiché la quantità di dati potrebbe essere ancora molto elevata. Può essere
conveniente estrarre un campione e analizzare soltanto quello. Inoltre nella fase di preelaborazione
rientrano le attività di pulizia dei dati e di definizione del trattamento dei dati mancanti. Teniamo in
2 Le tecniche statistiche richiedono quasi sempre di formulare ipotesi sulla distribuzione delle variabili esaminate.

www.dataskills.it E-mail [email protected]
considerazione, però, che, se i dati provengono dal data warehouse, molte le operazioni di pulizia
dovrebbero essere già state messe in opera nella fase di ETL.
3) Trasformazione. Le trasformazioni possono riguardare cambiamenti nei tipi di dato (da numero a
stringa, per esempio), la discretizzazione di valori continui, oppure la normalizzazione dei valori.
4) Data Mining. La fase di data mining vede la determinazione dell’algoritmo da utilizzare, la
costruzione e il testing di un modello.
5) Interpretazione dei risultati.I risultati del modello di data mining evidenzia dei pattern nascosti nei
dati: occorre però valutare se essi sono utili e possono apportare un beneficio per il business.
Figura 1 Il processo di KDD.
Lo standard CRISP-DM CRISP-DM, che sta per “Cross Industry Standard Process for Data Mining” è un metodo di comprovata
efficacia per l’implementazione di un processo di data mining. I lavori di definizione dello standard
prendono avvio nel 1996 come iniziativa finanziata dall’Unione Europea e portata avanti da un consorzio di
quattro società: SPSS, NCR Corporation, Daimler-Benz e OHRA. La prima versione della metodologia vede la
luce nel 1999, mentre nel 2006 iniziano i lavori per definire lo standard CRISP-DM 2.0. Tuttavia, la seconda
versione non ha mai visto la luce e nessun tipo di attività o comunicazione è più pervenuta dal gruppo di
lavoro dal 2007, tant’è che anche il sito web non è più attivo da parecchio tempo. Nonostante questo la
metodologia CRISP-DM è valida ed è stata largamente adottata dalle aziende che hanno affrontato progetti
di data mining.

www.dataskills.it E-mail [email protected]
Il presupposto della metodologia risiede nella volontà di rendere il processo di data mining affidabile e
utilizzabile da persone con pochi skill in materia, ma con elevata conoscenza del business. La metodologia
fornisce un framework che prevede sei fasi, che possono essere ripetute ciclicamente con l’obiettivo di
revisionare e rifinire il modello previsionale:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
La figura che segue mostra l’intero processo.
Figura 2 Metodologia CRISP-DM.
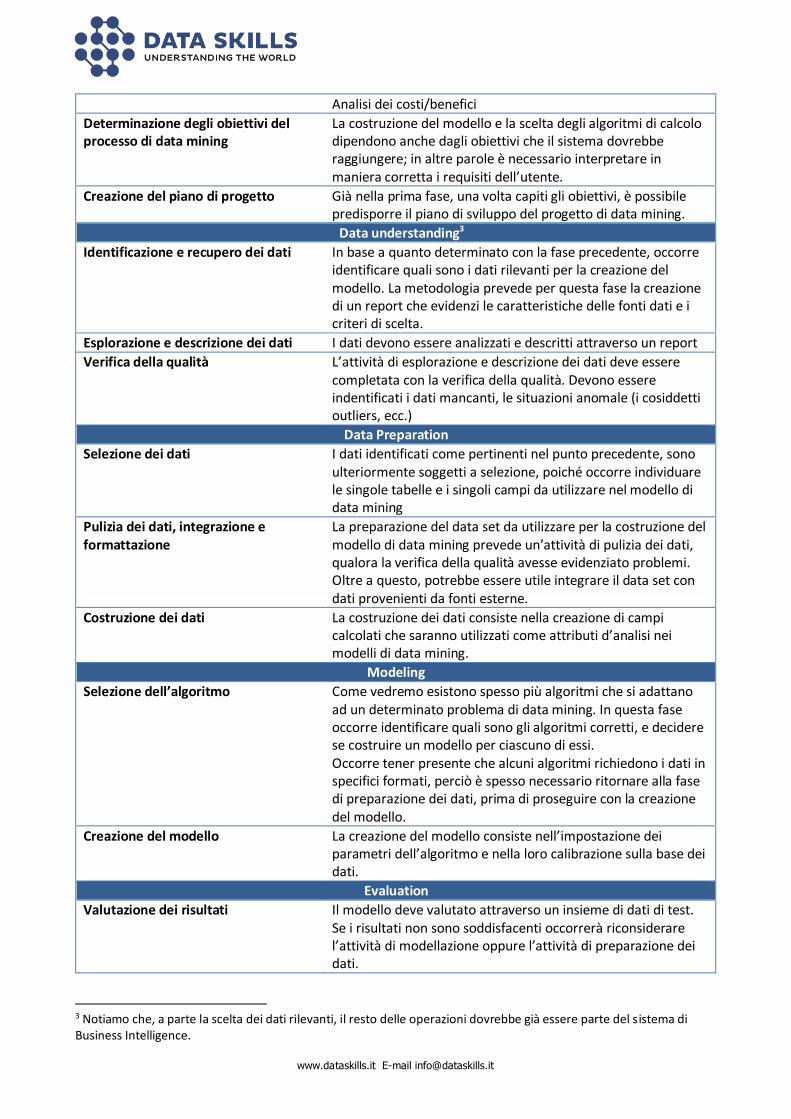
Ciascuna delle fasi si articola in più punti, illustrati nella tabella seguente.
Tabella 2 Punti della metodologia CRISP-DM
Business Understanding
Determinazione degli obiettivi di business Assessment della situazione attuale
La comprensione delle problematiche del business e degli obiettivi aziendali è necessaria al fine di poter creare un modello di data mining adeguato. Le attività di assessment riguardano tipicamente: Inventario delle risorse Requisiti, presupposti e vincoli Rischi e imprevisti
www.dataskills.it E-mail [email protected]
Analisi dei costi/benefici
Determinazione degli obiettivi del processo di data mining
La costruzione del modello e la scelta degli algoritmi di calcolo dipendono anche dagli obiettivi che il sistema dovrebbe raggiungere; in altre parole è necessario interpretare in maniera corretta i requisiti dell’utente.
Creazione del piano di progetto Già nella prima fase, una volta capiti gli obiettivi, è possibile predisporre il piano di sviluppo del progetto di data mining.
Data understanding3
Identificazione e recupero dei dati In base a quanto determinato con la fase precedente, occorre identificare quali sono i dati rilevanti per la creazione del modello. La metodologia prevede per questa fase la creazione di un report che evidenzi le caratteristiche delle fonti dati e i criteri di scelta.
Esplorazione e descrizione dei dati I dati devono essere analizzati e descritti attraverso un report
Verifica della qualità L’attività di esplorazione e descrizione dei dati deve essere completata con la verifica della qualità. Devono essere indentificati i dati mancanti, le situazioni anomale (i cosiddetti outliers, ecc.)
Data Preparation
Selezione dei dati I dati identificati come pertinenti nel punto precedente, sono ulteriormente soggetti a selezione, poiché occorre individuare le singole tabelle e i singoli campi da utilizzare nel modello di data mining
Pulizia dei dati, integrazione e formattazione
La preparazione del data set da utilizzare per la costruzione del modello di data mining prevede un’attività di pulizia dei dati, qualora la verifica della qualità avesse evidenziato problemi. Oltre a questo, potrebbe essere utile integrare il data set con dati provenienti da fonti esterne.
Costruzione dei dati La costruzione dei dati consiste nella creazione di campi calcolati che saranno utilizzati come attributi d’analisi nei modelli di data mining.
Modeling
Selezione dell’algoritmo Come vedremo esistono spesso più algoritmi che si adattano ad un determinato problema di data mining. In questa fase occorre identificare quali sono gli algoritmi corretti, e decidere se costruire un modello per ciascuno di essi. Occorre tener presente che alcuni algoritmi richiedono i dati in specifici formati, perciò è spesso necessario ritornare alla fase di preparazione dei dati, prima di proseguire con la creazione del modello.
Creazione del modello La creazione del modello consiste nell’impostazione dei parametri dell’algoritmo e nella loro calibrazione sulla base dei dati.
Evaluation
Valutazione dei risultati Il modello deve valutato attraverso un insieme di dati di test. Se i risultati non sono soddisfacenti occorrerà riconsiderare l’attività di modellazione oppure l’attività di preparazione dei dati.
3 Notiamo che, a parte la scelta dei dati rilevanti, il resto delle operazioni dovrebbe già essere parte del sistema di Business Intelligence.

www.dataskills.it E-mail [email protected]
Revisione del processo Una volta eseguita la valutazione del modello, è bene, anche in caso di risultati positivi, ricontrollare tutte le fasi del processo, soprattutto per indentificare eventuali omissioni di regole di business e per verificare la congruità dei risultati con gli obiettivi stabiliti.
Decisione sull’utilizzo del modello A questo punto è possibile decidere se utilizzare i risultati del modello nel processo di KDD, procedendo quindi con il deployment agli utenti.
Deployment
Pianificazione del deployment La fase di deployment include anche l’integrazione del modello con i sistemi esistenti. Inoltre la raccolta dati, la loro preparazione e l’elaborazione attraverso il modello devono essere automatizzati.
Manutenzione e verifiche Nel definire le attività di deployment occorre programmare anche l’attività di manutenzione.
Revisione finale La fase di deployment si conclude con la documentazione dell’intero processo e con una revisione finale con il coinvolgimento degli utenti.
La metodologia CRISP-DM ha il vantaggio di essere applicabile a qualsiasi ramo di attività e di essere
indipendente dallo strumento software utilizzato. Inoltre è strettamente collegata al modello d’azione della
KDD.
Nei paragrafi che seguono approfondiremo i punti principali relativi alla costruzione e alla valutazione di un
modello di data mining. In particolare vedremo gli aspetti di preparazione dei dati, di scelta dell’algoritmo e
di valutazione dei risultati.
La preparazione dei dati La preparazione dei dati assume un ruolo cruciale nel processo di data mining, poiché essa può influenzare
in maniera sostanziale la bontà dei modelli. Il primo aspetto da considerare riguarda la qualità dei dati. Se
supponiamo che i dati da utilizzare per il data mining arrivino dal data warehouse, allora possiamo dare per
scontato che il processo di pulizia, integrazione e uniformazione dei dati sia già stato compiuto. Se così non
fosse, occorre valutare il grado di affidabilità e completezza dei dati e porre rimedio ai problemi di qualità,
pena la costruzione di modelli destinati ad essere completamente inefficaci.
Esiste poi un problema legato ai valori mancanti degli attributi, che, in parte può essere sanato nel data
warehouse attraverso l’integrazione diverse fonti, anche esterne all’azienda (si pensi all’acquisto di dati
demografici o relativi al territorio da banche dati specializzate). Accade però che per alcuni attributi non sia
sempre possibile ottenere un valore. In questo caso, nel data warehouse, invece di presentare un valore
NULL, si utilizzerà un valore di default che indica la mancanza del dato, ma questa soluzione non è ottimale
per il data mining ed è da gestire al momento della preparazione dei dati.
Alcuni algoritmi richiedono che i dati siano trasformati, di solito attraverso operazioni di vario genere:
normalizzazioni, riduzione del numero di attributi, riclassificazione dei valori di un attributo.
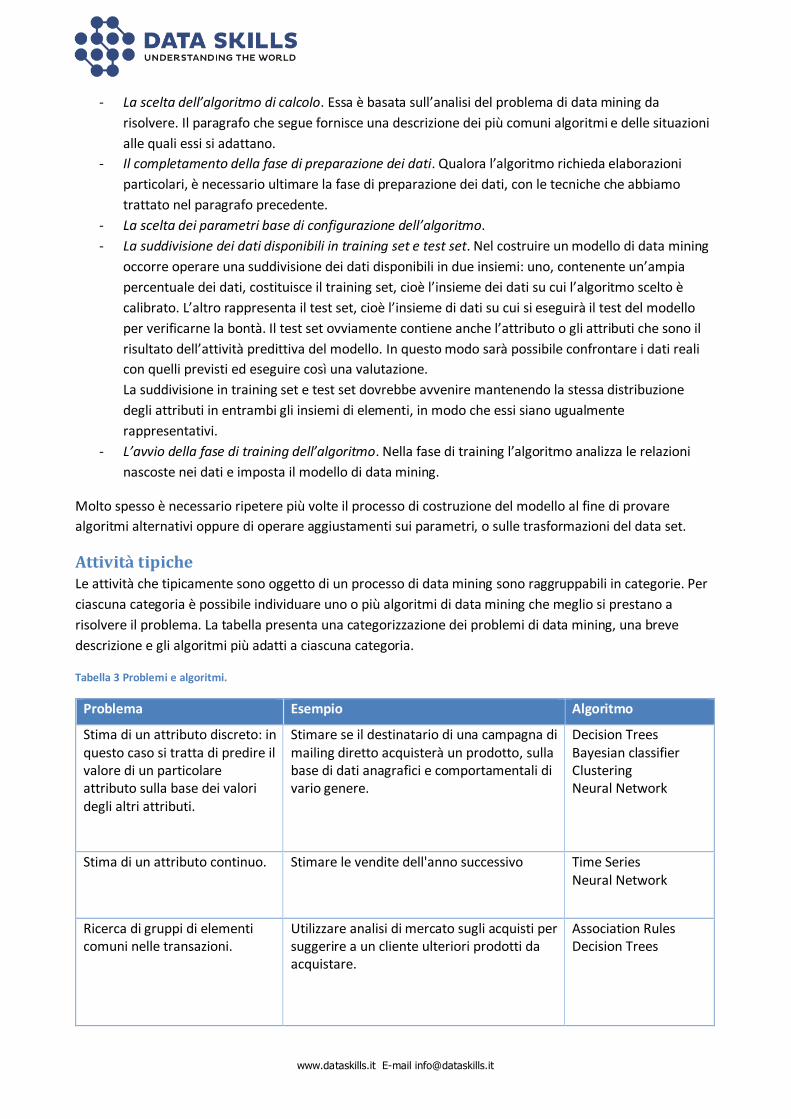
Costruzione del modello La costruzione del modello di data mining si articola su più fasi:
www.dataskills.it E-mail [email protected]
- La scelta dell’algoritmo di calcolo. Essa è basata sull’analisi del problema di data mining da
risolvere. Il paragrafo che segue fornisce una descrizione dei più comuni algoritmi e delle situazioni
alle quali essi si adattano.
- Il completamento della fase di preparazione dei dati. Qualora l’algoritmo richieda elaborazioni
particolari, è necessario ultimare la fase di preparazione dei dati, con le tecniche che abbiamo
trattato nel paragrafo precedente.
- La scelta dei parametri base di configurazione dell’algoritmo.
- La suddivisione dei dati disponibili in training set e test set. Nel costruire un modello di data mining
occorre operare una suddivisione dei dati disponibili in due insiemi: uno, contenente un’ampia
percentuale dei dati, costituisce il training set, cioè l’insieme dei dati su cui l’algoritmo scelto è
calibrato. L’altro rappresenta il test set, cioè l’insieme di dati su cui si eseguirà il test del modello
per verificarne la bontà. Il test set ovviamente contiene anche l’attributo o gli attributi che sono il
risultato dell’attività predittiva del modello. In questo modo sarà possibile confrontare i dati reali
con quelli previsti ed eseguire così una valutazione.
La suddivisione in training set e test set dovrebbe avvenire mantenendo la stessa distribuzione
degli attributi in entrambi gli insiemi di elementi, in modo che essi siano ugualmente
rappresentativi.
- L’avvio della fase di training dell’algoritmo. Nella fase di training l’algoritmo analizza le relazioni
nascoste nei dati e imposta il modello di data mining.
Molto spesso è necessario ripetere più volte il processo di costruzione del modello al fine di provare
algoritmi alternativi oppure di operare aggiustamenti sui parametri, o sulle trasformazioni del data set.
Attività tipiche Le attività che tipicamente sono oggetto di un processo di data mining sono raggruppabili in categorie. Per
ciascuna categoria è possibile individuare uno o più algoritmi di data mining che meglio si prestano a
risolvere il problema. La tabella presenta una categorizzazione dei problemi di data mining, una breve
descrizione e gli algoritmi più adatti a ciascuna categoria.
Tabella 3 Problemi e algoritmi.
Problema Esempio Algoritmo
Stima di un attributo discreto: in questo caso si tratta di predire il valore di un particolare attributo sulla base dei valori degli altri attributi.
Stimare se il destinatario di una campagna di mailing diretto acquisterà un prodotto, sulla base di dati anagrafici e comportamentali di vario genere.
Decision Trees Bayesian classifier Clustering Neural Network
Stima di un attributo continuo. Stimare le vendite dell'anno successivo Time Series Neural Network
Ricerca di gruppi di elementi comuni nelle transazioni.
Utilizzare analisi di mercato sugli acquisti per suggerire a un cliente ulteriori prodotti da acquistare.
Association Rules Decision Trees

www.dataskills.it E-mail [email protected]
Ricerca di gruppi di elementi simili.
Segmentare i dati demografici in gruppi, con comportamenti d’acquisto simili
Clustering
Ricerca di anomalie nei dati Per esempio la ricerca di utilizzi fraudolenti di strumenti di pagamento, come le carte di credito.
Clustering
Valutazione del modello Con qualsiasi algoritmo la si realizzi, una delle operazioni più frequenti nel data mining è la classificazione:
dato un certo numero di elementi che appartengono a classi diverse, ciò che vogliamo ottenere è un
modello che assegni ciascun elemento alla classe corretta. Per esempio, può essere utile, prima di iniziare
una campagna di vendita, classificare i prospect in due classi: quella dei probabili acquirenti e quella dei
non acquirenti, in modo da concentrare gli sforzi soltanto sulla prima classe.
Nell’implementare un qualsiasi modello, abbiamo visto come sia necessario suddividere i dati in due
insiemi: il training set e il test set. Entrambi gli insiemi devono contenere gli elementi con la corretta
classificazione; il training set sarà utilizzato per la calibrazione dei parametri del modello, mentre il test set
per valutare i risultati del classificatore. Teniamo sempre presente che è praticamente impossibile costruire
un modello di classificazione perfetto, e che dovremo accontentarci di un modello sub ottimale. La scelta
del modello da utilizzare avviene selezionando il migliore da un insieme di modelli calibrati e testati,
costruiti con algoritmi e con parametri differenti. E’ chiara dunque la necessità di uno strumento che ci
permetta di valutare la bontà di un modello e che ci permetta di confrontarlo con altri, al fine di poter
scegliere tra essi il più efficace.
Molti problemi di classificazione possono essere ricondotti a una classificazione binaria, cioè con sole due
opzioni, dove una classe è detta classe positiva e l’altra è chiamata classe negativa. Nel nostro esempio
della campagna di marketing, la classe positiva è quella dei possibili acquirenti, mentre la classe negativa è
rappresentata dai non acquirenti.
Descriviamo i metodi per la valutazione dei modelli.
La matrice di confusione
La performance di un modello è determinata dal numero di predizioni corrette o, per contro, dal numero di
errori di predizione. Una prima metrica per la valutazione del modello è rappresentata dalla cosiddetta
matrice di confusione il cui generico elemento Eij rappresenta il numero di elementi della classe i-esima che
il modello assegna, erroneamente, alla classe j-esima.
Come esempio, poniamo di dover rappresentare attraverso la matrice di confusione le previsioni di un
modello di classificazione dei possibili acquirenti. I dati del modello, eseguito sul test set sono inclusi nella
tabella che segue.
Tabella 4 Esempio di risultati di un test.
Codice cliente Dato reale Previsione

www.dataskills.it E-mail [email protected]
1 Acquirente_SI Acquirente_SI
2 Acquirente_NO Acquirente_NO
3 Acquirente_NO Acquirente_NO
4 Acquirente_SI Acquirente_SI
5 Acquirente_SI Acquirente_SI
6 Acquirente_NO Acquirente_SI
7 Acquirente_NO Acquirente_NO
8 Acquirente_SI Acquirente_SI
9 Acquirente_NO Acquirente_SI
10 Acquirente_SI Acquirente_NO
In questo caso la matrice di confusione è data da:
Predizione
Acquirente_SI Acquirente_NO
Dat
i Re
ali Acquirente_SI 4
(VERI POSITIVI) 1 (FALSI NEGATIVI)
Acquirente_NO 2 (FALSI POSITIVI)
3 (VERI NEGATIVI)
Nella matrice di confusione abbiamo quattro quadranti che esprimono:
- I veri positivi (VP), cioè i veri acquirenti, classificati come tali.
- I falsi positivi (FP), cioè i non acquirenti, classificati come acquirenti dal modello.
- I veri negativi (VN), cioè i non acquirenti correttamente classificati.
- I falsi negativi (FN), cioè gli acquirenti, classificati come non acquirenti dal modello.
Inoltre abbiamo che il numero totale di positivi è dato da P=VP+FN e che il numero totale di negativi è dato
da N=FP+VN
Dalla matrice possiamo ricavare alcune misure di performance:
% falsi positivi = FP/N
% veri positivi = VP/P
Accuratezza = (VP+VN)/(P+N)
Precisione = VP/(VP+FP)
Bisogna fare attenzione in particolare all’interpretazione della misura di accuratezza, soprattutto nel caso di
classi molto sbilanciate (solitamente questi casi sono quelli più interessanti!). Se avessimo nella realtà 999
non acquirenti reali e 1 solo acquirente reale e il modello classificasse tutti come non acquirenti, avremmo
l’accuratezza pari a (999+0)/(999+1) = 99.9%. In realtà a noi interesserebbe soltanto la previsione dei veri
acquirenti, che non si realizzerebbe mai (almeno secondo il nostro modello).
Se associamo ai quadranti della matrice di confusione un ricavo derivante dalla corretta previsione o un
costo che si origina dalla mancata previsione, otteniamo una matrice di costo per ciascuno dei modelli che
sviluppiamo. I modelli possono così essere confrontati non solo in base alle misure proposte poco sopra,
ma anche attraverso il risultato economico derivante dalla previsione. Come esempio, associamo i seguenti

www.dataskills.it E-mail [email protected]
costi e ricavi ai quadranti della matrice, ipotizzando che, in base alle previsioni, contatteremo soltanto i
potenziali clienti:
- Al quadrante VP associamo un margine netto di 50€ per cliente
- Al quadrante FP associamo un costo di 10€ per ciascun cliente contattato che non si rivela essere
acquirente.
- Ai quadranti FN e VN associamo un risultato economico pari a 0.
Il risultato dell’operazione sarebbe 4*50 -2*10 = 180, mostrando quindi un risultato economico positivo a
fronte dell’applicazione del modello. Tuttavia il risultato è molto più significativo se utilizzato per
paragonare vari modelli oppure parametrizzazioni diverse dello stesso modello, al fine di determinare
quello più performante.
La curva ROC (Receiver Operating Characteristic)
La curva ROC è uno strumento messo a punto durante la seconda guerra mondiale dagli ingegneri che si
occupavano dei radar per cercare di distinguere i segnali relativi a oggetti nemici dai segnali causati da
stormi di uccelli. La curva è stata impiegata in diversi campi, tra cui vi è anche il data mining. La curva ROC è
ampiamente utilizzata per valutare i risultati di un modello previsionali.
Per il calcolo delle curve ROC occorre che il modello produca come output oltre alla previsione anche la
probabilità di realizzazione. Ciò accade in modo nativo per modelli che utilizzano algoritmi come Naïve
Bayes o reti neurali, mentre per altri algoritmi è comunque possibile calcolare la probabilità con tecniche
specifiche. Solitamente se la probabilità è superiore a 0.5 allora l’appartenenza ad una certa classe è vera,
altrimenti è falsa. La curva, mostrata in Figura 3, è disegnata ricalcolando la percentuale di falsi positivi e la
percentuale di falsi negativi spostando via via la soglia di probabilità di appartenenza da 0 a 1 a piccoli
intervalli.
Figura 3 Esempi di tre curve ROC che descrivono modelli con performance differenti.
Nel grafico ROC, il punto (0,0) rappresenta una classificazione in cui non vi sono falsi positivi, ma nemmeno
veri positivi. Il punto (0,100) indica una classificazione perfetta: 0 falsi positivi e 100% veri positivi. Il punto
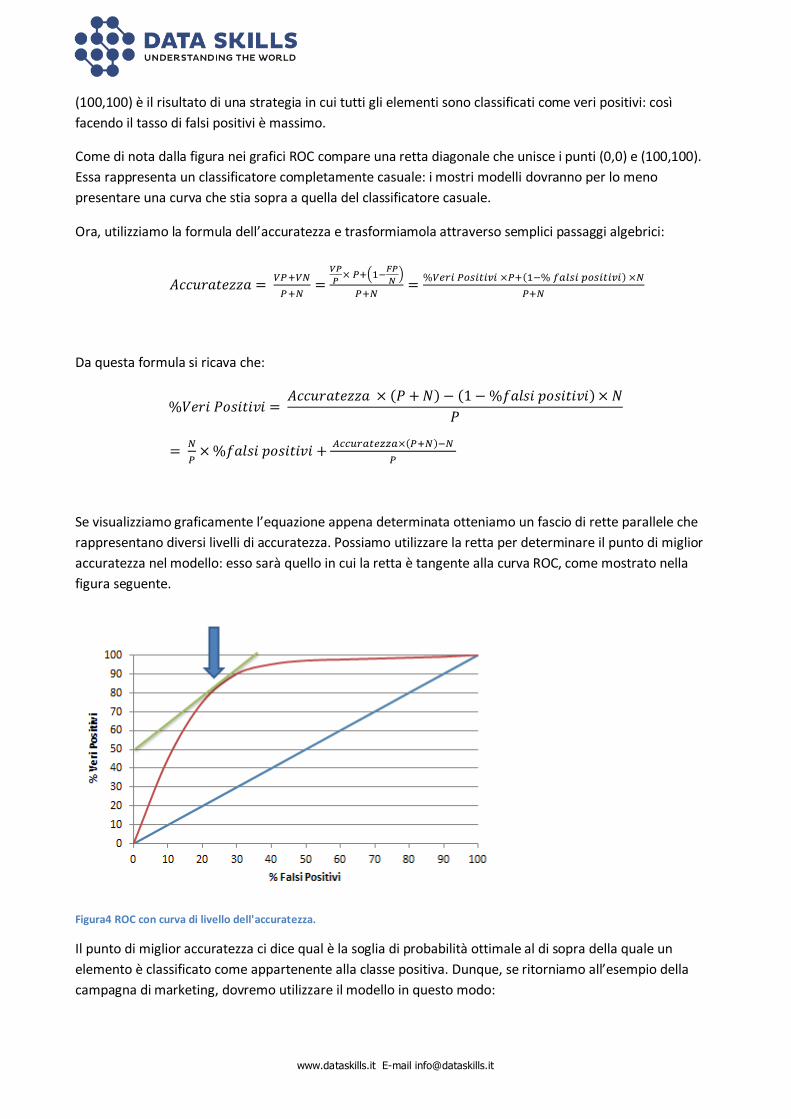
www.dataskills.it E-mail [email protected]
(100,100) è il risultato di una strategia in cui tutti gli elementi sono classificati come veri positivi: così
facendo il tasso di falsi positivi è massimo.
Come di nota dalla figura nei grafici ROC compare una retta diagonale che unisce i punti (0,0) e (100,100).
Essa rappresenta un classificatore completamente casuale: i mostri modelli dovranno per lo meno
presentare una curva che stia sopra a quella del classificatore casuale.
Ora, utilizziamo la formula dell’accuratezza e trasformiamola attraverso semplici passaggi algebrici:
𝐴𝑐𝑐𝑢𝑟𝑎𝑡𝑒𝑧𝑧𝑎 = 𝑉𝑃+𝑉𝑁
𝑃+𝑁=
𝑉𝑃
𝑃× 𝑃+(1−
𝐹𝑃
𝑁)
𝑃+𝑁=
%𝑉𝑒𝑟𝑖 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑖 ×𝑃+(1−% 𝑓𝑎𝑙𝑠𝑖 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑖) ×𝑁
𝑃+𝑁
Da questa formula si ricava che:
%𝑉𝑒𝑟𝑖 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑖 = 𝐴𝑐𝑐𝑢𝑟𝑎𝑡𝑒𝑧𝑧𝑎 × (𝑃 + 𝑁) − (1 − %𝑓𝑎𝑙𝑠𝑖 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑖) × 𝑁
𝑃
= 𝑁
𝑃× %𝑓𝑎𝑙𝑠𝑖 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑖 +
𝐴𝑐𝑐𝑢𝑟𝑎𝑡𝑒𝑧𝑧𝑎×(𝑃+𝑁)−𝑁
𝑃
Se visualizziamo graficamente l’equazione appena determinata otteniamo un fascio di rette parallele che
rappresentano diversi livelli di accuratezza. Possiamo utilizzare la retta per determinare il punto di miglior
accuratezza nel modello: esso sarà quello in cui la retta è tangente alla curva ROC, come mostrato nella
figura seguente.
Figura4 ROC con curva di livello dell'accuratezza.
Il punto di miglior accuratezza ci dice qual è la soglia di probabilità ottimale al di sopra della quale un
elemento è classificato come appartenente alla classe positiva. Dunque, se ritorniamo all’esempio della
campagna di marketing, dovremo utilizzare il modello in questo modo:
www.dataskills.it E-mail [email protected]
- Come prima azione, eseguiamo la classificazione dei prospect in modo da determinare gli
appartenenti alla classe dei probabili acquirenti (classe positiva)
- Come output del modello otteniamo anche la probabilità di assegnazione alla classe.
- Determiniamo il livello della soglia di probabilità ottimale attraverso la curva ROC e l’equazione
delle rette di accuratezza.
- Selezioniamo gli elementi che appartengono alla classe dei probabili acquirenti e la cui probabilità
di appartenenza è maggiore della soglia di probabilità ottimane
Lift chart
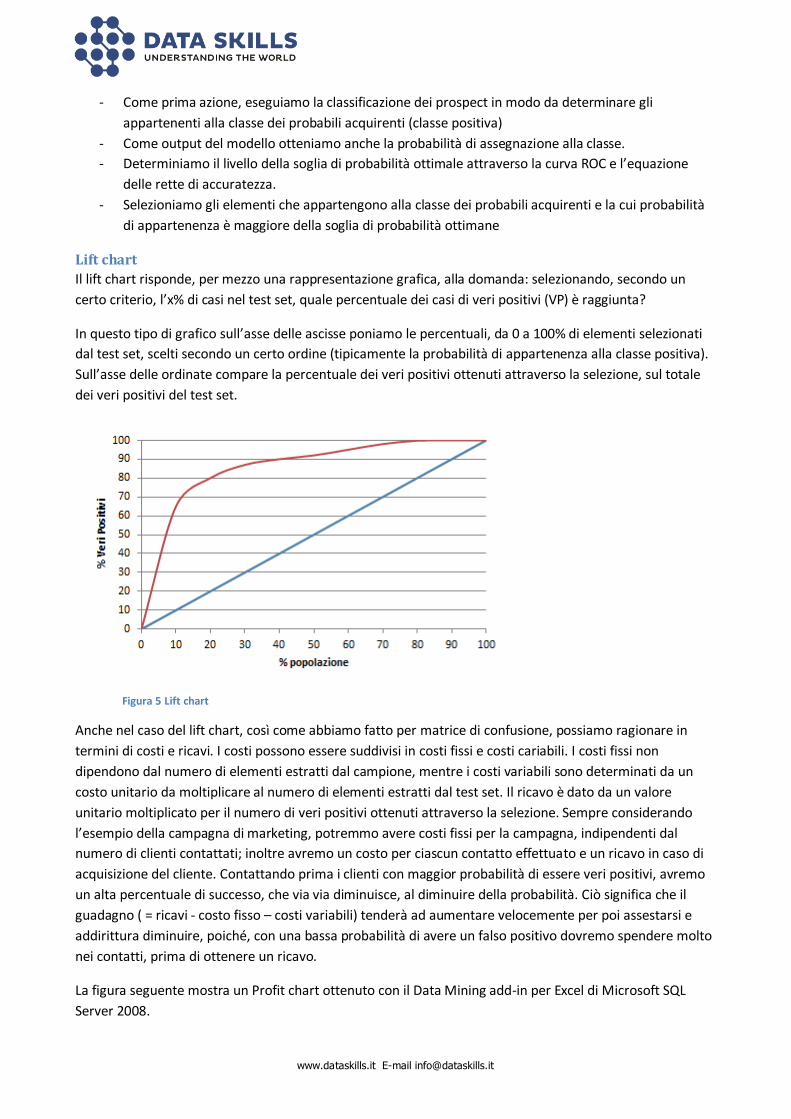
Il lift chart risponde, per mezzo una rappresentazione grafica, alla domanda: selezionando, secondo un
certo criterio, l’x% di casi nel test set, quale percentuale dei casi di veri positivi (VP) è raggiunta?
In questo tipo di grafico sull’asse delle ascisse poniamo le percentuali, da 0 a 100% di elementi selezionati
dal test set, scelti secondo un certo ordine (tipicamente la probabilità di appartenenza alla classe positiva).
Sull’asse delle ordinate compare la percentuale dei veri positivi ottenuti attraverso la selezione, sul totale
dei veri positivi del test set.
Figura 5 Lift chart
Anche nel caso del lift chart, così come abbiamo fatto per matrice di confusione, possiamo ragionare in
termini di costi e ricavi. I costi possono essere suddivisi in costi fissi e costi cariabili. I costi fissi non
dipendono dal numero di elementi estratti dal campione, mentre i costi variabili sono determinati da un
costo unitario da moltiplicare al numero di elementi estratti dal test set. Il ricavo è dato da un valore
unitario moltiplicato per il numero di veri positivi ottenuti attraverso la selezione. Sempre considerando
l’esempio della campagna di marketing, potremmo avere costi fissi per la campagna, indipendenti dal
numero di clienti contattati; inoltre avremo un costo per ciascun contatto effettuato e un ricavo in caso di
acquisizione del cliente. Contattando prima i clienti con maggior probabilità di essere veri positivi, avremo
un alta percentuale di successo, che via via diminuisce, al diminuire della probabilità. Ciò significa che il
guadagno ( = ricavi - costo fisso – costi variabili) tenderà ad aumentare velocemente per poi assestarsi e
addirittura diminuire, poiché, con una bassa probabilità di avere un falso positivo dovremo spendere molto
nei contatti, prima di ottenere un ricavo.
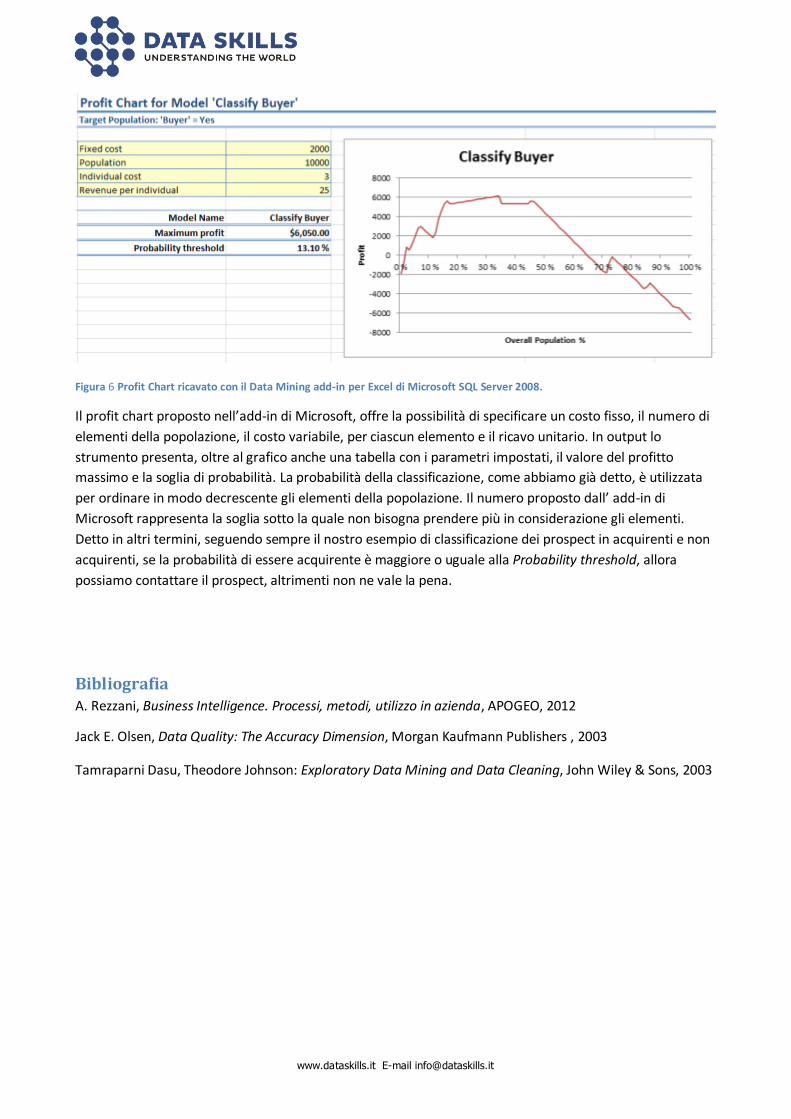
La figura seguente mostra un Profit chart ottenuto con il Data Mining add-in per Excel di Microsoft SQL
Server 2008.
www.dataskills.it E-mail [email protected]
Figura 6 Profit Chart ricavato con il Data Mining add-in per Excel di Microsoft SQL Server 2008.
Il profit chart proposto nell’add-in di Microsoft, offre la possibilità di specificare un costo fisso, il numero di
elementi della popolazione, il costo variabile, per ciascun elemento e il ricavo unitario. In output lo
strumento presenta, oltre al grafico anche una tabella con i parametri impostati, il valore del profitto
massimo e la soglia di probabilità. La probabilità della classificazione, come abbiamo già detto, è utilizzata
per ordinare in modo decrescente gli elementi della popolazione. Il numero proposto dall’ add-in di
Microsoft rappresenta la soglia sotto la quale non bisogna prendere più in considerazione gli elementi.
Detto in altri termini, seguendo sempre il nostro esempio di classificazione dei prospect in acquirenti e non
acquirenti, se la probabilità di essere acquirente è maggiore o uguale alla Probability threshold, allora
possiamo contattare il prospect, altrimenti non ne vale la pena.
Bibliografia A. Rezzani, Business Intelligence. Processi, metodi, utilizzo in azienda, APOGEO, 2012
Jack E. Olsen, Data Quality: The Accuracy Dimension, Morgan Kaufmann Publishers , 2003
Tamraparni Dasu, Theodore Johnson: Exploratory Data Mining and Data Cleaning, John Wiley & Sons, 2003