ibm toronto lab © 2006 ibm corporation cascon 20062006-10-16 avoiding live lock when patching code...
Post on 20-Dec-2015
218 views
TRANSCRIPT

IBM Toronto Lab
CASCON 2006 2006-10-16 © 2006 IBM Corporation
Avoiding Live Lock when Patching Codein Real-Time Execution Environments
Mark StoodleyReal-Time Java Compiler DevelopmentIBM Toronto Lab

IBM Toronto Lab
© 2006 IBM Corporation2 CASCON 2006 2006-10-16
Outline
Code patching background
The live lock problem
Two ways to avoid live lock
Two examples
1. Resolving a static field reference
2. Updating target of virtual invocation cache

IBM Toronto Lab
© 2006 IBM Corporation3 CASCON 2006 2006-10-16
Code patching
JIT compilers generate code designed to be modified during execution– Resolution for classes, fields, methods
– Fill in virtual/interface invocation caches
– Lazy call target update after (re)compilation
– Fixups for virtual guards
Typically performed by application threads via runtime helper– Another thread may execute during modification

IBM Toronto Lab
© 2006 IBM Corporation4 CASCON 2006 2006-10-16
Code patching is Hard
Multiple threads executing while patching
Processors not designed to support it well
– Undocumented coherence requirements/loopholes
– Not designed to be fast
Prevent execution of inconsistent instructions
Strongly influenced by instruction set
– Atomic writes: how much can you change at once

IBM Toronto Lab
© 2006 IBM Corporation5 CASCON 2006 2006-10-16
Code patching is Hard
Goal is quality code after patching
Interacts with lots of other complex things– Exception handling, stack walking
– Class loading and resolution rules
– Implementation induced complexities
Result is usually a complex dance– Careful design and layout of generated code
– Careful orchestration of steps

IBM Toronto Lab
© 2006 IBM Corporation6 CASCON 2006 2006-10-16
Example: Static field resolution (Intel x86)
inc dword ptr[0h]ff 05 00 00 00 00

IBM Toronto Lab
© 2006 IBM Corporation7 CASCON 2006 2006-10-16
Example: Static field resolution (Intel x86)
call Lsnippet
db 00h
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
db 0ff05h
Make sure first execution goes to snippet: generate 5B call instead of 6B inc
e8 d4 02 00 00 00
Generate 5B call, but make space for 6B inc

IBM Toronto Lab
© 2006 IBM Corporation8 CASCON 2006 2006-10-16
Example: Static field resolution (Intel x86)
call Lsnippet
db 00h
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
db 0ff05h
After resolving static address, glue prepares to patch 6B instruction
Resolves field to 088aa5ach
Need to patch 6 bytes atomically: Three step process
e8 d4 02 00 00 00

IBM Toronto Lab
© 2006 IBM Corporation9 CASCON 2006 2006-10-16
Example: Static field resolution (Intel x86)
jmp -2
db 00000002h
Lsnippet:
push 024h ; cpIndex
push 08564ach ; const pool
call unresolvedStaticGlue
db 0ff05h
Step 1: protect against multiple threads by patching self-loop
2-byte self loop (JMP -2)
2 bytes cannot cross patching boundary (8B on AMD64)
eb fe 02 00 00 00
After patching fence, these 4 bytes can now be patched with static address
Patching fence = mfence, clflush, mfence
Resolves field to 088aa5ach

IBM Toronto Lab
© 2006 IBM Corporation10 CASCON 2006 2006-10-16
Lsnippet:
push 024h ; cpIndex
push 08564ach ; const pool
call unresolvedStaticGlue
db 0ff05h
Example: Static field resolution (Intel x86)
jmp -2
db 088aa5ach
Step 2: write resolved static address in 4-byte field protected by self-loop
2-byte self loop (JMP -2)
eb fe ac a5 8a 08
Write resolved static address (nonatomic)
Then, patching fence to ensure all threads see address before self loop is removed
Resolves field to 088aa5ach

IBM Toronto Lab
© 2006 IBM Corporation11 CASCON 2006 2006-10-16
Lsnippet:
push 024h ; cpIndex
push 08564ach ; const pool
call unresolvedStaticGlue
db 0ff05h
Example: Static field resolution (Intel x86)
inc dword ptr[088aa5ah]
Step 3: remove the self-loop and restore the original instruction bytes
ff 05 ac a5 8a 08
Benefits:
thread-safe
final code quality good
BUT:
uses self-loop

IBM Toronto Lab
© 2006 IBM Corporation12 CASCON 2006 2006-10-16
Busy-wait loops can be BAD
Employed for safety in code patching
FIFO scheduling in Real-Time OS can result in live lock
T1 (priority 10) T2 (priority 20)Resolve field refPatch self-loop over instrPreempted by T2 T2 wakes up
Tries to execute same field ref
T2 stuck in self-loop
T1 can never remove self-loop: live lock

IBM Toronto Lab
© 2006 IBM Corporation13 CASCON 2006 2006-10-16
Busy-wait-free code patching: no live lock
Two basic approaches
1. All threads do idempotent patch: let them all do it• Cache line ping-pong effect may be slow(er) but correct
2. Only one thread must patch: construct backup path• Direct threads that arrive while patching to backup path• Slower but correct execution
Sometimes lowers resulting code quality

IBM Toronto Lab
© 2006 IBM Corporation14 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[0h]
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 00 00 00 00

IBM Toronto Lab
© 2006 IBM Corporation15 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[0h]
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 00 00 00 00
e8 d4 02 00 00 call Lsnippet
5B call generated explicitly ahead of the instruction to be resolved
IBM Toronto Lab
© 2006 IBM Corporation16 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[088aa5ach]
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 ac a5 8a 08
e8 d4 02 00 00 call Lsnippet
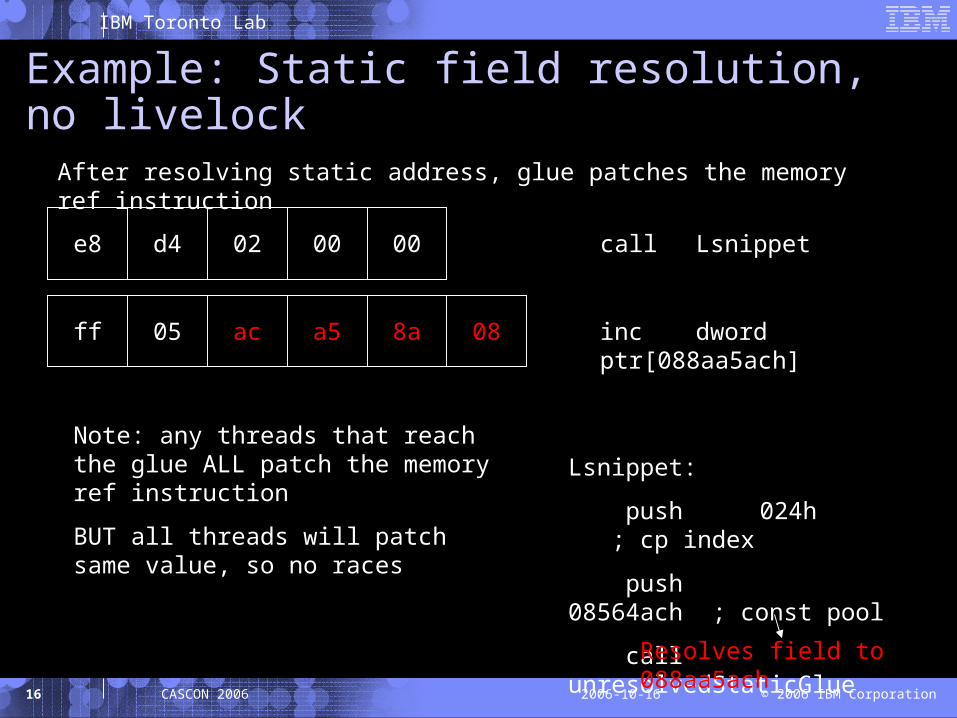
After resolving static address, glue patches the memory ref instruction
Resolves field to 088aa5ach
Note: any threads that reach the glue ALL patch the memory ref instruction
BUT all threads will patch same value, so no races

IBM Toronto Lab
© 2006 IBM Corporation17 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[088aa5ach]
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 ac a5 8a 08
e8 d4 02 00 00 call Lsnippet
Now need to get rid of call to snippet, since ref has been resolved
Patch a 5-byte NOP over the call:
lea eax, ds:[eax]
BUT: can’t do it atomically in one shot, need 3 steps again
NOTE that any thread can now safely execute the memory reference instruction because it’s been patched Resolves field to 088aa5ach

IBM Toronto Lab
© 2006 IBM Corporation18 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[088aa5ach]
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 ac a5 8a 08
eb 03 02 00 00 jmp +3
db 000002h
Step 1: patch short jump JMP +3 to memory ref instruction (lock cmpxchg)
Resolves field to 088aa5ach

IBM Toronto Lab
© 2006 IBM Corporation19 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[088aa5ach]
Lsnippet:
push 024h ; cp index
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 ac a5 8a 08
eb 03 44 20 00 jmp +3
db 002044h
Step 2: patch last three bytes of 5-byte NOP instruction
Resolves field to 088aa5ach

IBM Toronto Lab
© 2006 IBM Corporation20 CASCON 2006 2006-10-16
Example: Static field resolution, no livelock
inc dword ptr[088aa5ach]
Lsnippet:
push 024h ; cpIndex
push 08564ach ; const pool
call unresolvedStaticGlue
ff 05 ac a5 8a 08
3e 8d 44 20 00 lea eax, ds:[eax]
Step 3: patch first 2 bytes of 5 byte NOP over the JMP +3
Benefits:
thread-safe
no live lock because no busy-waits
BUT:
5-byte NOP residue
hot code size increase Resolves field to 088aa5ach

IBM Toronto Lab
© 2006 IBM Corporation21 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
Virtual invocation o.foo()
– Target method depends on class of receiver object o
– Full virtual dispatch uses lookup in o’s class virtual function table
• Expensive: indirection from object’s class
For performance, use virtual invocation cache
– if (receiver class is C) call C.foo(); else call o.foo();

IBM Toronto Lab
© 2006 IBM Corporation22 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, <CLASS C>
jne FullDispatchSnip
call <C.foo() entry>
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 TT TT TT TT
0f 85 FD FD FD FD
81 f9 CC CC CC CC
0xCCCCCCCC, 0x0f85, and 0xFDFDFDFD must be patched atomically to initialize cache

IBM Toronto Lab
© 2006 IBM Corporation23 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, <CLASS C>
jne FullDispatchSnip
call <c.foo() entry>
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Ti Ti Ti Ti
0f 85 FD FD FD FD
81 f9 CC CC CC CC
If target Ti not compiled when cache initialized, then patch new target Tc over Ti after C.foo() is compiled (actually next time called)

IBM Toronto Lab
© 2006 IBM Corporation24 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, <CLASS C>
jne FullDispatchSnip
call <c.foo() entry>
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Ti Ti Ti Ti
0f 85 FD FD FD FD
81 f9 CC CC CC CC
This cache cannot be placed so that none of these fields cross 8B patching boundary

IBM Toronto Lab
© 2006 IBM Corporation25 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
If target not compiled yet, target written into cache is address of glue function
Glue function looks at target: compiled yet?– If not compiled, transition to interpreter
– If compiled, patch compiled target into cache
Problem: can’t write entire target atomically– Can atomically write first 2 bytes of call instruction
– Fancy footwork to avoid writing full target atomically

IBM Toronto Lab
© 2006 IBM Corporation26 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, <CLASS C>
jne FullDispatchSnip
call <c.foo() entry>
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Tg Tg Tg Tg
0f 85 FD FD FD FD
81 f9 CC CC CC CC
Patching boundary can fall before 0f or after 85: same as if call didn’t need patching

IBM Toronto Lab
© 2006 IBM Corporation27 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, <CLASS C>
jne FullDispatchSnip
call <c.foo() entry>
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Tg Tg Tg Tg
0f 85 FD FD FD FD
81 f9 CC CC CC CC
Patching has several steps so cannot allow multiple threads to proceed: establish backup path to full dispatch

IBM Toronto Lab
© 2006 IBM Corporation28 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, 0ffffffffh
jne FullDispatchSnip
call <c.foo() entry>
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Tg Tg Tg Tg
0f 85 FD FD FD FD
81 f9 ff ff ff ff
First, clear out class pointer: effectively converts ‘jne’ into ‘jmp’
(atomic compare and exchange)
Patching Fence

IBM Toronto Lab
© 2006 IBM Corporation29 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, 0ffffffffh
jne FullDispatchSnip
jmp -14
db TgTgTg
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
eb f2 Tg Tg Tg
0f 85 FD FD FD FD
81 f9 ff ff ff ff
Next, protect last 3 bytes of call instruction with JMP -14 (back to compare instruction)
Patching Fence

IBM Toronto Lab
© 2006 IBM Corporation30 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, 0ffffffffh
jne FullDispatchSnip
jmp -14
db TcTcTc
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
eb f2 Tc Tc Tc
0f 85 FD FD FD FD
81 f9 ff ff ff ff
Now we can patch the last three bytes of the call with the new target Tc
Patching Fence

IBM Toronto Lab
© 2006 IBM Corporation31 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, 0ffffffffh
jne FullDispatchSnip
call TcTcTcTc
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Tc Tc Tc Tc
0f 85 FD FD FD FD
81 f9 ff ff ff ff
Remove the JMP -14 by putting the call instruction back

IBM Toronto Lab
© 2006 IBM Corporation32 CASCON 2006 2006-10-16
Example 2: Virtual invocation cache
cmp ebx, <CLASS C>
jne FullDispatchSnip
call TcTcTcTc
Continue:
FullDispatchSnip:
mov ecx, [ebx-<VFT slot>]
call ecx
jmp Continue
e8 Tc Tc Tc Tc
0f 85 FD FD FD FD
81 f9 CC CC CC CC
Finally, put the true class pointer back into the compare instruction

IBM Toronto Lab
© 2006 IBM Corporation33 CASCON 2006 2006-10-16
Summary
Modern JITs generate code that can patch itself via runtime helpers
–Helpers are complex,hand-written assembler
– Interactions with class loading, stack walking
–Busy-wait loops employed to prevent thread races
Real-Time operating systems use FIFO scheduling
–Busy-wait loops can result in live lock

IBM Toronto Lab
© 2006 IBM Corporation34 CASCON 2006 2006-10-16
Summary
Avoid live lock with two techniques:
1. If same value to be written, let all threads write it
2. If only one thread can write, establish backup path first for all threads but one to use
Two examples
– Unresolved static field reference
– Updating virtual invocation cache target when it has been (re)compiled

IBM Toronto Lab
© 2006 IBM Corporation35 CASCON 2006 2006-10-16
Questions?
Mark Stoodley
IBM Toronto Lab