ibm spark technology center: real-time advanced analytics and machine learning with spark and...
TRANSCRIPT

Apache
Chris Fregly Solu3on Architect

Use Cases
• Relevant – Opera3ons that affect all data in data set – Batch Analy3cs
• Less-‐relevant – Fine-‐grained updates to shared state – Web apps

Performance
• 20x Hadoop for itera3ve ML and graph apps – Avoids IO and deserializa3on by storing data in memory as direct Java objects (versus binary data)
• 40x Hadoop for analy3cs • Query 1TB dataset interac3vely with 5-‐7s latency
• 25-‐100 m1.xlarge EC2 instances – 4 cores, 15GB RAM, HDFS w/ 256MB blocks
• 10 itera3ons on 100GB datasets

Benchmarks: Scan

Benchmarks: Aggrega3on

Benchmarks: Join
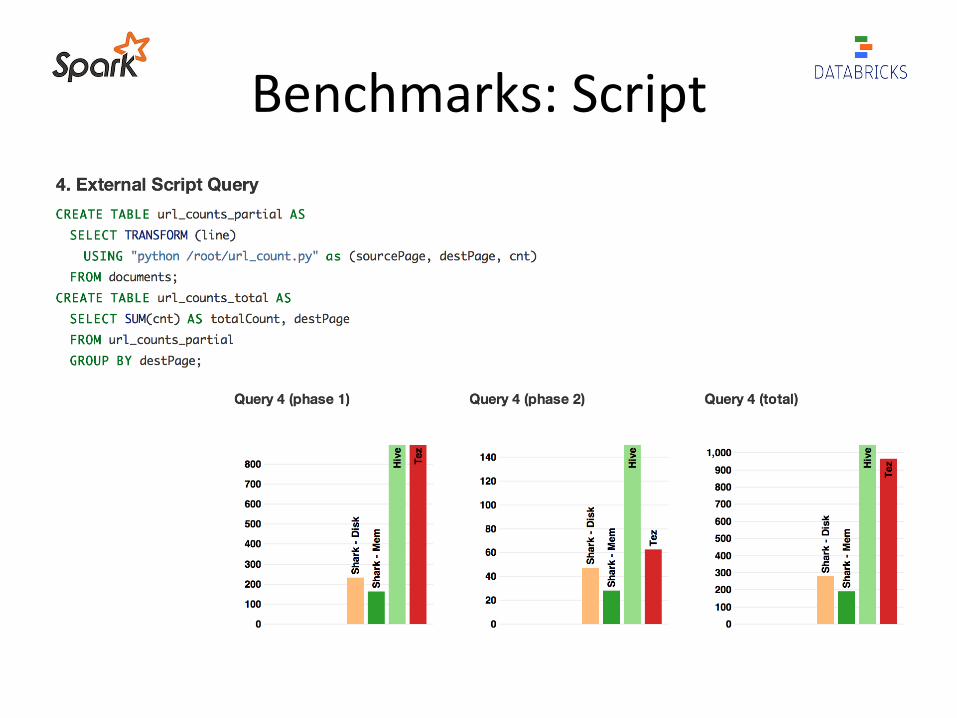
Benchmarks: Script

Interac3ve
• Scala REPL • Python interpreter

RDD • Resilient Distributed Dataset
– Immutable – Flexible storage strategies
• In-‐memory, spill-‐to-‐disk priority – Par33oned by key
• Op3mizes joins with data locality – Parallel – Fault-‐tolerant – Supports coarse-‐grained transforma3ons
• Versus Fine-‐grained updates to shared state – Enables in-‐memory data reuse between itera3ons
• Common in machine learning and graph algorithms • No disk IO serializa3on needed between itera3ons
– Rich set of opera3ons including map, flatMap, filter, join, groupByKey, reduceByKey, etc.

Lineage
• Logs coarse-‐grained RDD transforma3ons • Enables fault tolerance • Reconstruct by replaying log of parent/derived RDDs and their transforma3ons – Recomputed in parallel on separate nodes
• ~10KB versus 2x replica3on of complete dataset • Large lineages may benefit from checkpoin3ng* *more later

Dependencies • Two types of parent-‐child RDD dependencies • Narrow – Each par33on of the parent RDD is used by at most one par33on of the child RDD
– Allows pipelined execu3on on a single node – Node failure s3ll allows par33on-‐level recovery (parallelizable)
– ie. map(), union(), sample() • Wide
• Each par33on of the parent RDD is used by many par33ons of the child RDD
• Requires par33on of each parent RDD to be shuffled across nodes • Node failure may lead to complete re-‐execu3on if loss affects
par33ons of all parent RDDs (bad) • ie. join()* *unless parents are hash-‐par33oned

RDD Dependencies

Opera3ons • Two Types of RDD Opera3ons
– Transforma3ons • Define RDDs • Lazy ini3aliza3on
– Ac3ons • Compute • Store
• Some opera3ons are only available for key-‐value pairs – join(), groupByKey(), reduceByKey()
• map() – One-‐to-‐one transforma3on
• flatMap() – Zero-‐to-‐many transforma3on – Most similar to map() in MapReduce
• Par33oning – sort(), groupByKey(), reduceByKey() – Results in hash or range-‐par33oned RDD

RDD Opera3ons

Transforma3ons
• RDD -‐> RDD
lines=spark.textFile(“hdfs://…”) errors = lines.filter(_.startsWith(“ERROR”)) errors.persist()

Ac3ons
• RDD’s are lazily materialized when ac#on is invoked • count() – Counts the elements
• collect() – Returns the elements
• save() – Persists to storage
• persist() – Reuse in future itera3ons – Can spill to disk if memory is low

Par33oning
• Useful for grouping related data onto same node
• Improves join() performance • Par33ons – One par33on for each block
• PreferredLoca3ons – block-‐to-‐node mapping
• Iterator – Reads the blocks
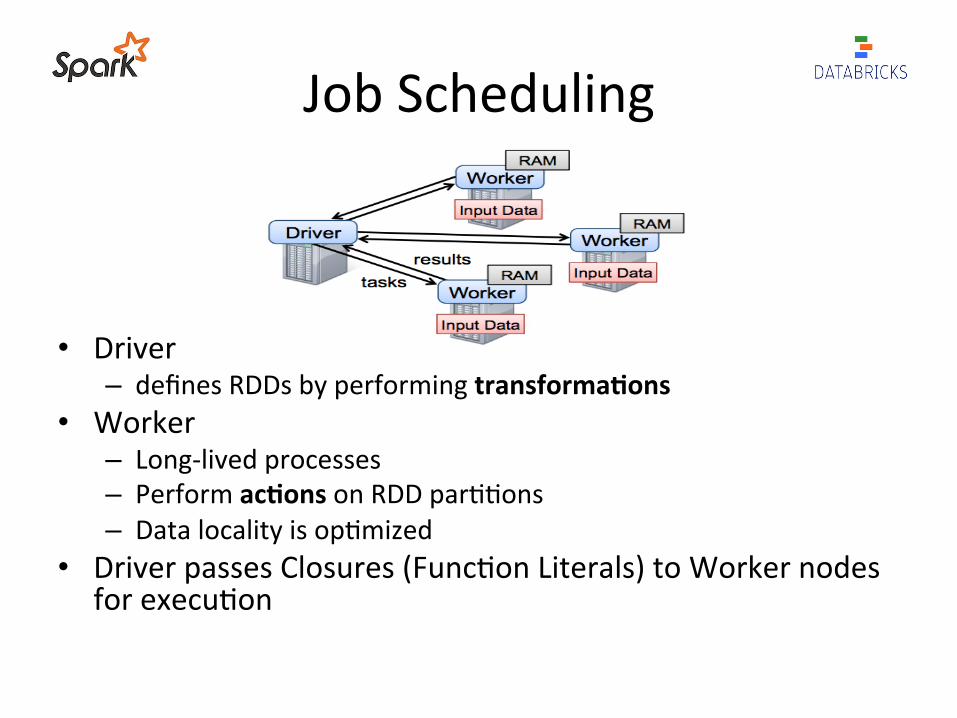
Job Scheduling
• Driver – defines RDDs by performing transforma#ons
• Worker – Long-‐lived processes – Perform ac#ons on RDD par33ons – Data locality is op3mized
• Driver passes Closures (Func3on Literals) to Worker nodes for execu3on

Job Scheduling • Ac3ons cause the scheduler to do the following:
– Examine the RDD’s lineage graph – Build a DAG of stages to execute – Computes missing par33ons at each stage un3l the target RDD is
reached • Stages
– Op3mized to pipeline transforma3ons of narrow dependencies – Shuffle opera3ons for wide dependencies
• Materializes intermediate records on the node holding the par33on of the parent RDD
– Short-‐circuits for already-‐computed par33ons of parent RDD • Delay scheduling (TODO: Understand this beper) • Data locality (in-‐memory or on-‐disk) is op3mized • Node failures
– Resubmits tasks to compute the missing par33ons in parallel • Scheduler failures are currently not handled

Memory
• LRU evic3on policy for RDDs • Cycles are prevented • Persistence priority can be set for each RDD • Spill to disk – Worst case performance is similar to exis3ng MapReduce performance due to IO
• Each Spark instance has its own memory space* *Future improvement may include unified memory manager to share RDDs across Spark instances

Checkpoin3ng • Snapshot of lineage graph • Asynchronously replicate RDDs to other nodes
– Immutability allows this to happen in the background without a stop-‐the-‐world event
• Speeds up recovery of lost RDD par33ons – Useful for large lineage graphs containing wide dependencies which
could require full re-‐computa3on • Lineage graphs containing narrow dependencies are less-‐likely to
require full re-‐computa3on • Lineage is forgopen aqer checkpoint occurs to avoid unbounded
lineage graphs • User can determine checkpoint strategy* *Future improvements may include an automa3c checkpoint policy based on data set characteris3cs (size, dependency types, and ini3al 3me to compute)

Run3me
• Runs standalone, YARN, Hadoop v1.x
• Mesos – Cluster-‐resource isola3on across distributed applica3ons
– Fine-‐grained sharing

Data Storage
• HDFS, HBase, S3, local files

Development Tools
• (TODO: Verify all of this) • Scala 2.10 • Java 1.6+ • Python 2.7 + NumP • Spark Debugger – Lineage graph inspector/replayer

Shark
• Hive on Spark • Run unmodified Hive queries on exis3ng data warehouse
• Supports UDF’s, Metastore, etc • Call MLLib directly on Hive tables
• Use the same Hive queries for real3me, near-‐real3me, and batch!

MLlib
• Machine learning algorithms – Naïve-‐Bayes Classifier – K-‐means clustering – Linear and logis3c regression – Alterna3ng least squares collabora3ve filtering
• Explicit ra3ngs • Implicit feedback
– Stochas3c gradient descent

Real-‐world Uses Dynamic stream-‐switching based on real-‐3me network condi3ons
Predict traffic-‐conges3on using expecta3on maximiza3on (EM) machine learning algorithm
Monarch Project: Twiper spam classifica3on using logis3c regression machine learning algorithm

GraphX
• Data-‐parallel and graph-‐parallel system • Ability to join graph data and table data • “Think like a vertex” • Vertex-‐locality is op3mized across the cluster

Streaming • Sources
– Kaya, Flume, Twiper Firehose, ZeroMQ, Kinesis • Custom connectors • Data must be stored reliably in case recompute is needed upon node
failure • Discre3zed streams of RDDs (D-‐Streams) • Series of determinis#c batch computa3ons over small 3me intervals
(versus record-‐at-‐a-‐3me like Storm and S4) • Determinism allows parallel re-‐computa#on on failure and specula#ve
execu#on on stragglers • Specula3ve execu3on happens if a task runs more than 1.4x longer than
the median task in its job stage • 0.5-‐2s latencies
– Good enough, but not meant for high-‐frequency trading – Allows beper fault-‐tolerance and efficiency
• Clear, exactly-‐once consistency seman3cs – Each record passed through the whole determinis3c process
• Distributed state is far easier to reason about • No long-‐lived, stateful opera3ons or cross-‐stream ordering

Streaming • Seemlessly interoperate with batch and interac3ve processing – all based
on RDDs – Real-‐3me, ad-‐hoc queries against live system – Helps avoid over-‐fi{ng in certain ML algorithms by combining real-‐3me
(sparse) data with historical data • Timing Issues
– Supports “slack 3me” to allow late-‐arriving records to be part of the correct batch • Adds fixed latency, of course
– Applica3on-‐level incremental reduce() to add the new records to a previous batch
• Sliding Window – Incremental Aggrega3on – Incremental reduceByWindow to aggregate within a given window – If aggrega3on func3on is inver3ble, you can subtract values to avoid duplicate
calcula3ons • State Tracking
– track() operator • Transforms streams of (key, event) into streams of (key, state) • ini3alize, update, 3meout func3ons

Streaming • Master
– D-‐Stream Lineage Graph – Task Scheduler – Block Tracker
• Workers – Receives input RDDs – Clock-‐sync’d with NTP – Executes tasks
• No3fies master of new input RDDs on regular intervals • Receives tasks from master • Computes new RDD par33ons
– Manages in-‐memory Block Store • Stores par33ons of immutable input RDDs and computed RDDs • Each block is given a unique ID • LRU Cache

Streaming
• Pipelines operators can be grouped into a single task – map().map()
• Task placement on workers – Data-‐locality aware
• Choose a worker that contains the data block – Par33on-‐aware
• Same keys on same node to avoid shuffling
• Block placement based on worker load • Master not fault-‐tolerant (yet)* *Future work to persist the D-‐Streams graph to allow a standby to take over

Streaming Performance
• 100 m1.xlarge EC2 instances – 4 cores, 15GB RAM
• 100 byte input records • 1 second latency target – 500 ms input intervals
• 6GB/s throughput! • Linear scalability

Other Streaming Solu3ons • Replica3on
– Requires synchroniza3on protocol (Flux, DPC) to preserve order • Upstream backup
– Upon failure, parent replays messages since last checkpoint to the standby
– Storm • At least once delivery • Requires applica3on code to recover state
– Storm + Triden • Keeps state in replicated DB • Commits updates in batches • Requires updates to be replicated across the network within a transac3on
• Costly, but recovers quickly • Doesn’t handle stragglers/slow nodes
– Will slow down the whole system given the required synchroniza3on

Streaming Comparison

Streaming Future Work • Dynamically adjust level of parallelism at each stage • Dynamically adjust interval size based on load – Lower interval size at low load for lower latencies
• Automa3c checkpoin3ng based on data set characteris3cs (size, dependency types, and ini3al 3me to compute)
• Limit ad-‐hoc query resources to avoid slowing the overall streaming system
• Return par3al results in case of failure – Launch a child task before its parents are done – Provide lineage data to know which parents are missing

Kinesis Connector Demo!

References • hpp://www.cs.berkeley.edu/~matei/papers/2012/
nsdi_spark.pdf
• hpp://www.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-‐2012-‐259.pdf
• hpp://spark.apache.org/

Available Training • Spark Streaming – AWS Kinesis-‐Spark Streaming integra3on
• Shark – Hive queries with Spark/HDFS
• MLlib – Anomaly detec3on with Spark
• GraphX – Distributed Graph Processing with Spark
• Installing Spark on Mesos • Installing Spark on YARN

Upcoming Talks
• AWS Meetup (SF, Oakland, and Berkeley) – hpp://www.meetup.com/AWS-‐Berkeley
• Spark Meetup (SF) – hpp://www.meetup.com/spark-‐users/
• Advanced AWS Meetup (SF and Peninsula) – hpp://www.meetup.com/AdvancedAWS/
• Ne}lix Internal CloudU (Los Gatos) • Scala Meetup (SF) – hpp://www.meetup.com/SF-‐Scala/