how to organize digital music in a large social network norman casagrande ucl 21/01/2010
TRANSCRIPT

how to organize digital music in a large social network
Norman Casagrande
UCL21/01/2010

About Last.fm
• Music service– Enjoying music: free (supported by ads)– Community: sharing the experience
(35m users/month, 12 languages)– Radio, videos, events, charts, …– Recommendations
• Founded in 2002• East London• 2007: CBSi

What we doEspecially MIR!

Last.fm MIR (the Music Information Retrieval group)
• Recommendations (generic term)• Metadata• Search• Playlist generation• General data analysis• Evaluation• Scalability (especially real time!)• Play! :-)

Last.fm’s Recommendations• Many millions of items to many millions of users• Types of recommendations– Music (artists, events, radio, albums, tracks)– Neighbours– Human-to-human recommendations
• Modes of enjoying recommendations– Lean back/forwards
• Beyond PCs– Mobile devices (personalized radio, iPhone/Android)– Any devices connected to the internet
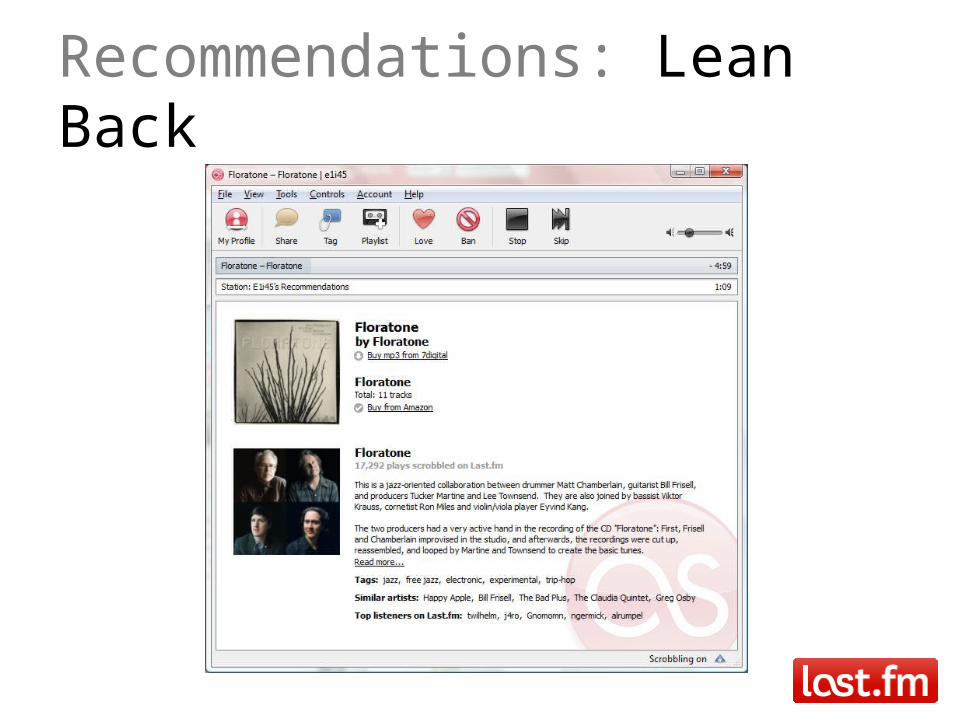
Recommendations: Lean Back

Recommendations: Lean Forward

The DataSource of all

Data & Recommendations
AudioScrobbler <user, track, time> Last.fm client (stand alone app., as plugin, API) ~30 million scrobbles a day (total 40,498,999,115) ~150 million songs (80M fingerprinted) ~15 million artists

Scrobbles & Charts
40 billion +30 million per day

Unwanted Scrobbles
http://playground.last.fm

Unwanted Scrobbles
http://playground.last.fm

Social Tags• 1.2m distinct tags (skewed)• 50m tags applied to:
– Tracks > 50%– Artists > 40%– Albums < 5%– Labels < 1%
Examples• Rock, instrumental, guitar, female vocalists, …• If you fall in love with me you should know these songs by heart• Wherein I compile a comprehensive list of songs about zombies
• 50m tags• 2.5m tags per month • 300k taggers per month

Social Tags
Radiohead

Social Tags
Ayla Nereo

Age vs Tagging Behaviour
Under 19 Average age of users (years)lame lame lame lame 18.2tokio hotel 18.5XD 18.7<3 18.7tr00 satanic black metal 18.8

Age vs Tagging Behaviour
Over 35 Average age of users (years)zydeco 37.3soukous 36.6cajun 35.9Zimbabwe 35.3jazz saxophone 35.1

Social Tags: Identity & Community
• Example groups on Last.fm:– The Special Interest Tag Radio Collective
(150 members)– Subscribers and their tag radio stations
(125 members)– Genre-free tags! (109 members)
• Special tags (social signalling)– “seen live” (76k taggers)– “albums I own” (6k taggers)

Tag AbuseExample: Paris Hilton

Tag AbuseExample: Paris Hilton

Tag Abuse Detection
• Do taggers like what they are tagging?• Correlations between taggers• Bot-like patterns• Tag Karma– How “useful” are contributions of a tagger?• E.g. if artist X is tagged metal, but everyone listening to
metal radio skips that artist...

Additional Sources of Data
• Love/ban/skip• Events (~1M)• Playlists (user generated)• Audio files (xM)• Wikis (~1M)• Groups• ...• (magic)

RecommendingAn approach

Model of the user
(att. prof.)
Data & Recommendations
Model of how things are related
Recs
Scrobbles, tags, …

Data & Recommendations
n
ij
jijuiu ),Sim(),Rating(),Rating(

Data & Recommendations
n
ij
jijuiu ),Sim(),Rating(),Rating(
i

Data & Recommendations
n
ij
jijuiu ),Sim(),Rating(),Rating(
Model of the user
Relationshipbtw items

Data & Recommendations
n
ij
jijuiu ),Sim(),Rating(),Rating(
Model of the user
Relationshipbtw items
Selection ofthe candidates!

Data & Recommendations
n
ij
jijuiu ),Sim(),Rating(),Rating(
Relationshipbtw items

Similarity (Collaborative Filtering)
Items
Use
rs

Wait! Before even beginning… Pre-processing, pre-processing, pre-
processing, developers, pre-processing, ..― Removing bad/old/useless stuff (noise)― Finding relationships (who like what and how
much)― Make sure everyone has its fair share (spammers)― Take into account time― … etc
Data & Recommendations

Similarity (Collaborative Filtering)
Items
Use
rs

Similarity (Collaborative Filtering)
Items
Use
rs

Similarity (Collaborative Filtering)
Items
Use
rs

Similarity (Collaborative Filtering)
Items
Use
rs
Candidate Similar Items

Similarity (Collaborative Filtering)
Huge sparse user/item matrices Last.fm data:
Total pairs: several trillions (last time I checked 543,475,707,228 + 49,705,598,540)

Similarity (Collaborative Filtering)
Huge sparse user/item matrices Last.fm data:
Total pairs: several trillions
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(

Similarity (Collaborative Filtering)
Huge sparse user/item matrices Last.fm data:
Total pairs: several trillions• Don’t forget the pitfalls of CF!– Dot product issues– Understand the data

Pitfalls Dot Product
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(
2 5 15 2 2 1 3
2 4 7 12 1 5 1y
x
First case

Pitfalls Dot Product
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(
2 5 15 2 2 1 3
2 15 2 2 6 1 2y
x
Second case

Pitfalls Dot Product
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(
2 5 15 2 2 1 3
2 4 7 12 1 5 1y
x
First case

Pitfalls Dot Product
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(
2 5 15 2 2 1 3
2 4 7 12 1 5 1y
x
≈ 0.18First case

Pitfalls Dot Product
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(
2 5 15 2 2 1 3
2 15 2 2 6 1 2y
x
Second case

Pitfalls Dot Product
m
i i
m
i i
m
i ii
yx
yx
yx
yxyx
22)cos(),sim(
2 5 15 2 2 1 3
2 15 2 2 6 1 2y
x
≈ 0.81Second case

Pitfalls Dot Product: Densities
2 5 3 15 2 5 2 1 2 2 2 8 1 3
15 7y
x
≈ 0.86

Pitfalls Type of data!
― Artist similarity != User similarity(even if it’s the same matrix)
User x User y
+ =

Pitfalls Type of data!
― Artist similarity != User similarity(even if it’s the same matrix)
Item x Item y
+ = Spammer?

Pitfalls Type of data!
― Artist similarity != User similarity(even if it’s the same matrix)
Need consensus― Normalization functions― Weighting users― Etc..

Evaluation of Recommendations
• Measuring improvements– Interaction with recommended items
e.g. skipping on radio stations
• User response = ground truth• A/B testing– Split users into 2 or more groups– Subjects one or more groups to new algorithm– Measure statistical significance of differences

A/B TestingG
oodn
ess
Time
Test 1
Test 2

FingerprintFinally some ML

Audio Fingerprint● Several tens of millions tracks, but..
– Huge misspelling rate– Only a fraction has more than 5 listeners
● Bad track names = Bad recommendations● Get rid of duplicates!● Copyright!

Audio Fingerprint● Other implementations
– Philips– OpenIP (MusicBrainz)– Gracenote– ...

Audio Fingerprint● Other implementations
– Philips ($$$$$)– OpenIP (MusicBrainz) (slow!)– Gracenote ($$$$$)– ... (sucks..)

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Use Viola&Jones haar-like filters (2001)

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Use Viola&Jones haar-like filters (2001)
• Black Area – White Area = Value

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Use Viola&Jones haar-like filters (2001)
• Black Area – White Area = Value

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Use Viola&Jones haar-like filters (2001)
• Black Area – White Area = Value
• AdaBoost: Binary classifier
h(x)

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Use Viola&Jones haar-like filters (2001)

Audio Fingerprint
~300ms
33freq
● Vision-inspired algorithm (Ke, Hoiem, Sukthankar, 2005)
● Use Viola&Jones haar-like filters (2001)

Audio Fingerprint● Binary classifier but..
– Pairwise Boosting

Audio Fingerprint● Binary classifier but..
– Pairwise Boosting– fm = value from haar filter, t = the threshold
x1 = x2
h(x1, x2)x1 ≠ x2
h(x)

Audio Fingerprint● Binary classifier but..
– Pairwise Boosting– fm = value from haar filter, t = the threshold
● Error is computed as usual

Audio Fingerprint● Binary classifier but..
– Pairwise Boosting– fm = value from haar filter, t = the threshold
● Error is computed as usual
Track A Track A' 1
Track A Track B 0

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Each feature (hm) has a threshold and a
location+size

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Each feature (hm) has a threshold and a
location+size

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Each feature (hm) has a threshold and a
location+size

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Each feature (hm) has a threshold and a
location+size● Each threshold defines a bit (above or below
threshold)

Audio Fingerprint● Vision-inspired algorithm
(Ke, Hoiem, Sukthankar, 2005)● Each feature (hm) has a threshold and a
location+size● Each threshold defines a bit (above or below
threshold)● 32 features = 32 bits
300ms = 1 0 1 1 1 1 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 0 1 1 0 1 1 0 0 0 0 0 = 3158426464
Key

Audio Fingerprint● DB Creation
― Process all the frames of a track (get all the keys)— Store them sequentially with the track ID

Audio Fingerprint● Retrieval
―Process n sequential frames of a track (i.e. 15 secs)
―Create additional 32x keys with one bitflip―Query the DB with the keys and keep only the
tracks with 70% of the matched keys―Align the candidates (i.e. with dynamic
programming) with the query―Compute the hamming distance―Keep the winner!

APIInvite to play

Last.fm API & Openness
• Read & write access to Last.fm data– tags for tracks, album, artists– bio/descriptions for artists, albums, tracks, tags..– similar artist, tracks, tags, users– events – user history, top tags, charts, age, gender..
• Large developer community• Non commercial license!

Having fun with tags …
http://playground.last.fm

Having fun with tags …
http://playground.last.fm

Having fun with tags …
http://playground.last.fm

Self organizing map of last.fm similar artists
..and not just with tags

Open Issues Combining similarity spaces
― CF: users/tags― Content based (LSH/euclidean space?)― Other sources (users/labels/wiki/..)
Who to trust?― Understand the users (classification?)― Content based (LSH/euclidean space?)― Other sources (users/labels/wiki/..)
Do more tag with tags― Smaller set, more refined algorithms!
Taking advantage of users feedback Scale, scale, scale, scale...

The End
Questions?

Computational Infrastructure
• Hadoop– Open source Apache project– Map/reduce– Easy to scale certain algorithms to
large amounts of data
• Hadoop UK user grouphttp://tech.groups.yahoo.com/group/huguk/

Playlist Generation
• People want– Repetition, especially on well targeted radio
• People don’t want– Similar tracks connected– Totally obscure stuff, even if they say so
(obscure = something they did not know about)

Music Recommendations in 5 Years?
• Music content– 200 million tracks– Subcultures and genres will evolve faster
• Data– More quantity
• 2.5 million tags per month• 800 million listened tracks per month
– More types (listening data, tags, …)
Better recommendationsMore responsive to new trendsBetter internationalization & localization

Music Recommendations in 5 Years?
• Better understanding of listeners• Data portability & openness• Embraced even more by artists & labels• Everything mobile• Human-to-human recommendations