heiko schwarz, detlev marpe, member, ieee, and thomas wiegand, member, ieee overview of the scalable...
Post on 19-Dec-2015
218 views
TRANSCRIPT

Heiko Schwarz, Detlev Marpe, Member, IEEE, and Thomas Wiegand, Member, IEEE
Overview of the Scalable Video
Coding Extension of the
H.264/AVC Standard
presentation by: Fred Scottadapted from: Kianoosh Mokhtarian

Motivation
High heterogeneity among receivers
Connection quality
Display resolution
Processing power
Simulcasting
Transcoding
Scalability

OverviewBackground
Temporal scalability
Spatial scalability
Quality scalability
Conclusion

BackgroundScalability
Temporal
Spatial
Quality (fidelity or SNR)
Object-based and region-of-interest
Hybrid
Applications Encode once, decode with differing quality
Unequal importance + unequal error protection
Player sensitive

Background
Requirements for a scalable video coding technique
Similar coding efficiency to single-layer coding
Little increase in decoding complexity
Support of temporal, spatial, quality scalability
Backward compatibility of the base layer
Support of simple bitstream adaptations after encoding

OverviewBackground
Temporal scalability
Spatial scalability
Quality scalability
Conclusion

Temporal Scalability
Enabled by restricting motion-compensated prediction
Already provided by H.264/AVC
Hierarchical prediction structure
Pictures of temporal enhancement layers: typically B-pictures
Group of Pictures (GoP)

Temporal Scalability: Hierarchical Pred’ Struct’
Dyadic temporal enhancement layers

Temporal Scalability: Hierarchical Pred’ Struct’
Non-dyadic case

Temporal Scalability: Hierarchical Pred’ Struct’
Other flexibilities
Multiple reference picture concept of H.264/AVC
Reference picture can be in the same layer as the target frame
Hierarchical prediction structure can be modified over time

Temporal Scalability: Hierarchical Pred’ Struct’
Adjusting the structural delay

Temporal Scalability: Coding
EfficiencyHighly dependent on quantization parameters
Intuitively, higher fidelity for the temporal base layer pictures
How to choose QPs
Expensive rate-distortion analysis
QPT = QP0 + 3 + T
High PSNR fluctuations inside a GoP
Subjectively shown to be temporally smooth

Temporal Scalability: Coding
EfficiencyDyadic hierarchical B-pictures, no delay constraint

Temporal Scalability: Coding
EfficiencyHigh-delay test set, CIF 30Hz, 34dB, compared to IPPP

Temporal Scalability: Coding
EfficiencyLow-delay test set, 365x288, 25-30Hz, 38dB, delay is constrained to be zero compared to IPPP

Temporal Scalability: Conclusion
Typically no negative impact on coding efficiency
But also significant improvement, especially when higher delays are tolerable
Minor losses in coding efficiency are possible when low delay is required

OverviewBackground
Temporal scalability
Spatial scalability
Quality scalability
Conclusion

Spatial Scalability
Motion-compensated prediction and intra-prediction in each spatial layer, as for single-layer coding
Inter-layer prediction
Same coding order for all layers

Spatial ScalabilityMotion-compensated prediction and intra-prediction
in each spatial layer, as for single-layer coding
Inter-layer prediction
Same coding order for all layers
Access units

Spatial Scalability: Inter-Layer PredictionPrevious standards
Inter-layer prediction by upsampling the reconstructed samples of the lower layer signal
Prediction signal formed by:
Upsampled lower layer signal
Temporal prediction inside the enhancement layer
Averaging both
Lower layer samples not necessarily the most suitable data for inter-layer prediction
Prediction of macroblock modes and associated motion parameters
Prediction of the residual signal

Spatial Scalability: Inter-Layer PredictionA new macroblock type signalled by base
mode flag Only a residual signal is transmitted
No intra-prediction mode or motion parameter
If the corresponding block in the reference layer is:
Intra-coded inter-layer intra prediction
The reconstructed intra-signal of the reference layer is upsampled as a predictor
Inter-coded inter-layer motion prediction
Partitioning data are upsampled, reference indexes are copied, and motion vectors are scaled up

Spatial Scalability: Inter-Layer PredictionInter-layer motion prediction (for a 16x16,
16x8, 8x16, or 8x8 macroblock partition)
Reference indexes are copied
Scaled motion vectors are used as motion vector predictors
Inter-layer residual prediction
Can be used for any inter-coded macroblock, regardless of its base mode flag or inter-layer motion prediction
The residual signal of the reference layer is upsampled as a predictor

Spatial Scalability: Inter-Layer PredictionFor a 16x16 macroblock in an enhancement layer:
1
basemodeflag
0
Inter-layer intra prediction (samples values are predicted)
Inter-layer motion prediction (partitioning data, ref. indexes, and motion vectors are derived)
Inter-layer motion prediction (ref. indexes are derived, motion vectors are predicted)
No inter-layer motion prediction
Inter-layer residual prediction
No inter-layer residual prediction

Spatial Scalability: Generalizing
Not only dyadic
Enhancement layer may represent only a selected rectangular area of its reference layer picture
Enhancement layer may contain additional parts beyond the borders of its reference layer picture
Tools for spatial scalable coding of interlaced sources

Spatial Scalability: Complexity Constraints
Inter-layer intra-prediction is restricted
Although coding efficiency is improved by generally allowing this prediction mode
Each layer can be decoded by a single motion compensation loop, unlike previous coding standards
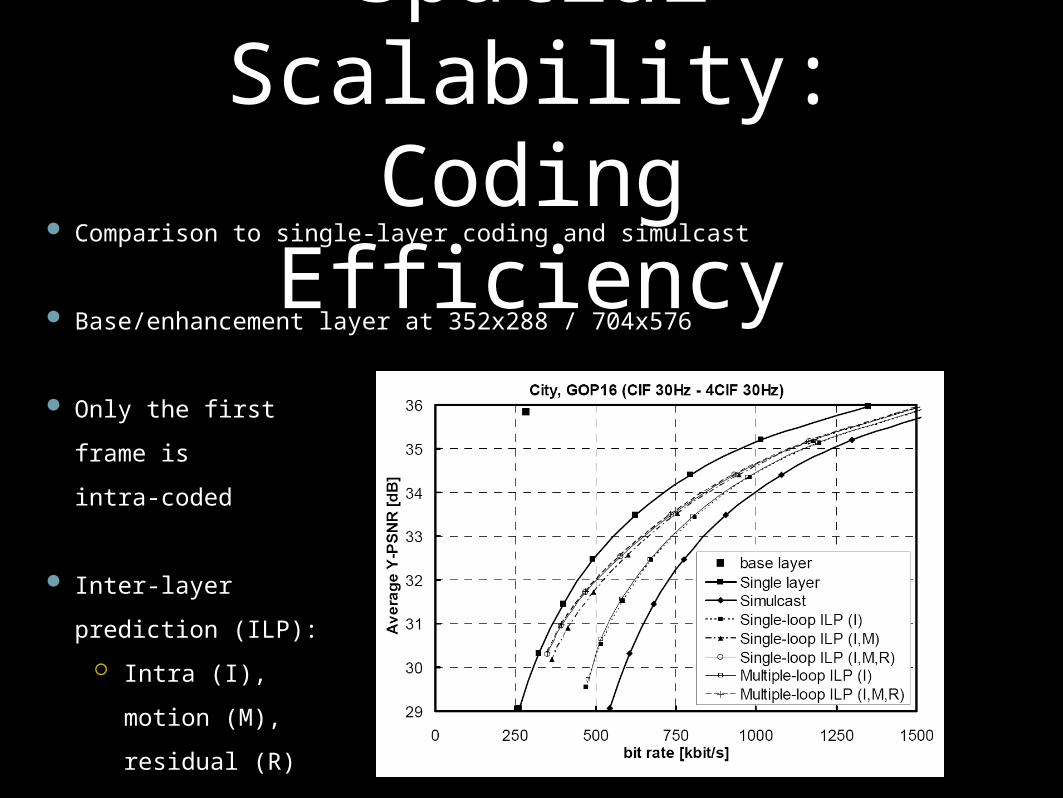
Spatial Scalability: Coding Efficiency
Comparison to single-layer coding and simulcast
Base/enhancement layer at 352x288 / 704x576
Only the first
frame is
intra-coded
Inter-layer
prediction (ILP):
Intra (I),
motion (M),
residual (R)

Spatial Scalability: Coding Efficiency
Comparison to single-layer coding and simulcast
Base/enhancement layer at 352x288 / 704x576
Only the first
frame is
intra-coded
Inter-layer
prediction (ILP):
Intra (I),
motion (M),
residual (R)

Spatial Scalability: Coding Efficiency
Comparison to single-layer coding and simulcast
Base/enhancement layer at 352x288 / 704x576
Only the first
frame is
intra-coded
Inter-layer
prediction (ILP):
Intra (I),
motion (M),
residual (R)

Spatial Scalability: Coding EfficiencyComparison of fully
featured
SVC “single-loop ILP (I, M, R)”
to scalable profiles of previous
standards “multi-loop ILP (I)”

Spatial Scalability: Encoder Control
JSVM software encoder control
Base layer coding parameters are optimized for that layer only
performance equal to single-layer H.264/AVC

Spatial Scalability: Encoder Control
JSVM software encoder control
Base layer coding parameters are optimized for that layer only
performance equal to single-layer H.264/AVC
Not necessarily suitable for an efficient enhancement layer coding
Improved multi-layer encoder control
Optimized for both layers

Spatial Scalability: Encoder Control
QPenhancement layer = QPbase layer + 4
Hierarchical B-pictures, GoP size = 16
Bit-rate increase relative to single-layer for the same quality is always less than or equal to 10% for both layers

OverviewBackground
Temporal scalability
Spatial scalability
Quality scalability
Conclusion

Quality ScalabilitySpecial case of spatial scalability with identical picture
sizes
No upsampling for inter-layer predictions
Inter-layer intra- and residual-prediction are directly performed in transform domain
Different qualities achieved by decreasing quantization step along the layers
Coarse-Grained Scalability (CGS) A few selected bitrates are supported in the scalable bitstream
Quality scalability becomes less efficient when bitrate difference between CGS layers gets smaller

Quality Scalability: MGS
Medium-Grained Scalability (MGS) improves:
Flexibility of the stream
Packet-level quality scalability
Error robustness
Controlling drift propagation
Coding efficiency
Use of more information for temporal prediction

Quality Scalability: MGS
MGS: error robustness vs. coding efficiency
A
C
B
D

Quality Scalability: MGSMGS: error robustness vs. coding efficiency
Pictures of the coarsest temporal layer are transmitted as key pictures
Only for them the base layer picture needs to be present in decoding buffer
Re-synchronization points for controlling drift propagation
All other pictures use the highest available quality picture of the reference frames for motion compensation
High coding efficiency

Quality Scalability: Encoding, Extracting
Encoder does not known what quality will be available in the decoder
Better to use highest quality references
Should not be mistaken with open-loop coding
Bitstream extraction
based on priority identifier of NAL units assigned by encoder

Quality Scalability: Coding Efficiency
BL-/EL-only control: motion compensation loop is closed at the base/enhancement layer
2-loop control: one motion compensation loop in each layer
adapt. BL/EL control: use of key pictures

Quality Scalability: Coding Efficiency
MGS vs. CGS

SVC encoder structure example

OverviewBackground
Temporal scalability
Spatial scalability
Quality scalability
Conclusion

Conclusion
SVC outperforms previous scalable video coding standards
Hierarchical Structures
✦Temporal and Spatial
Inter-layer and Intra-layer prediction
Medium Grain Scalability (MGS)

ReferencesH. Schwarz, D. Marpe, and T. Wiegand, “Overview of the
scalable video coding extension of the H.264/AVC standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 17, no. 9, pp. 1103–1120, September 2007.
T.Wiegand, G. Sullivan, J. Reichel, H. Schwarz, and M.Wien, "Joint Draft ITU-T Rec. H.264 | ISO/IEC 14496-10 / Amd.3 Scalable video coding," Joint Video Team, Doc. JVT-X201, July 2007.
H. Kirchhoffer, H. Schwarz, and T. Wiegand, "CE1: Simplified FGS," Joint Video Team, Doc. JVT-W090, April 2007.