hand-written character recognition
DESCRIPTION
Hand-written character recognition. Failure rate for test samples. MNIST: a data set of hand-written digits 60,000 training samples 10,000 test samples Each sample consists of 28 x 28 = 784 pixels Various techniques have been tried Linear classifier:12.0% - PowerPoint PPT PresentationTRANSCRIPT

Hand-written character recognition
• MNIST: a data set of hand-written digits− 60,000 training samples− 10,000 test samples− Each sample consists of 28 x 28 = 784 pixels
• Various techniques have been tried − Linear classifier: 12.0%− 2-layer BP net (300 hidden nodes) 4.7%− 3-layer BP net (300+200 hidden nodes) 3.05%− Support vector machine (SVM) 1.4%− Convolutional net 0.4%− 6 layer BP net (7500 hidden nodes): 0.35%
Failure rate for test samples

Hand-written character recognition
• Our own experiment:− BP learning with 784-300-10 architecture− Total # of weights: 784*300+300*10 = 238,200− Total # of Δw computed for each epoch: 1.4*10^10− Ran 1 month before it stopped− Test error rate: 5.0%


Risk-Averting Error Function
• Mean Squared Error (MSE)
• Risk-Averting Error (RAE)
2
1 12
1 1ˆ( ) ( , )
ˆwhere ( ) ( , ) and
( , ) : training data pairs, 1, ,
K K
k k kk k
k k k
k k
Q y f x gK K
g y f x
x y k K
w w w
w w
K
( )
2
1 1
1 1ˆ( ) exp ( , ) = expK K
k k kk k
J y f x gK K
w w w( )
: Risk-Sensitivity Index (RSI)
1. James Ting-Ho Lo. Convexification for data fitting. Journal of Global Optimization, 46(2):307–315, February 2010.

Normalized Risk-Averting Error
• Normalized Risk-Averting Error (NRAE)
It can be simplified as
( ) : argmax ( ),M kk
g gw w
1
( ) : exp ( )
( ) : ( ) ( )
K
kk
k k M
h v
v g g
w w
w w w

The Broyden-Fletcher-Goldfarb-Shanno (BFGS) Method
• A quasi-Newton method for solving the nonlinear optimization problems
• Using first-order gradient information to generate an approximation to the Hessian (second-order gradient) matrix
• Avoiding the calculation of the exact Hessian matrix can significantly save the computational cost during the optimization

The BFGS Algorithm:
1. Generate an initial guess and an initial approximate inverse Hessian Matrix .
2. Obtain a search direction at step k by solving:
where is the gradient of the objective function evaluated at .
3. Perform a line search to find an acceptable stepsize in the direction , then update
The Broyden-Fletcher-Goldfarb-Shanno (BFGS) Method

4. Set and .
5. Update the approximate Hessian matrix by
6. Repeat step 2-5 until converges to the solution. Convergence can be checked by observing the norm of the gradient, .
The Broyden-Fletcher-Goldfarb-Shanno (BFGS) Method

Limited-memory BFGS Method:• A variation of the BFGS method• Only using a few vectors to represent the
approximation of the Hessian matrix implicitly• Less memory requirement• Well suited for optimization problems with a
large number of variables
The Broyden-Fletcher-Goldfarb-Shanno (BFGS) Method

References
1. J. T. Lo and D. Bassu. An adaptive method of training multilayer perceptrons. In Proceedings of the 2001 International Joint Conference on Neural Networks, volume 3, pages 2013–2018, July 2001.
2. James Ting-Ho Lo. Convexification for data fitting. Journal of Global Optimization, 46(2):307–315, February 2010.
3. BFGS: http://en.wikipedia.org/wiki/BFGS

A Notch Function
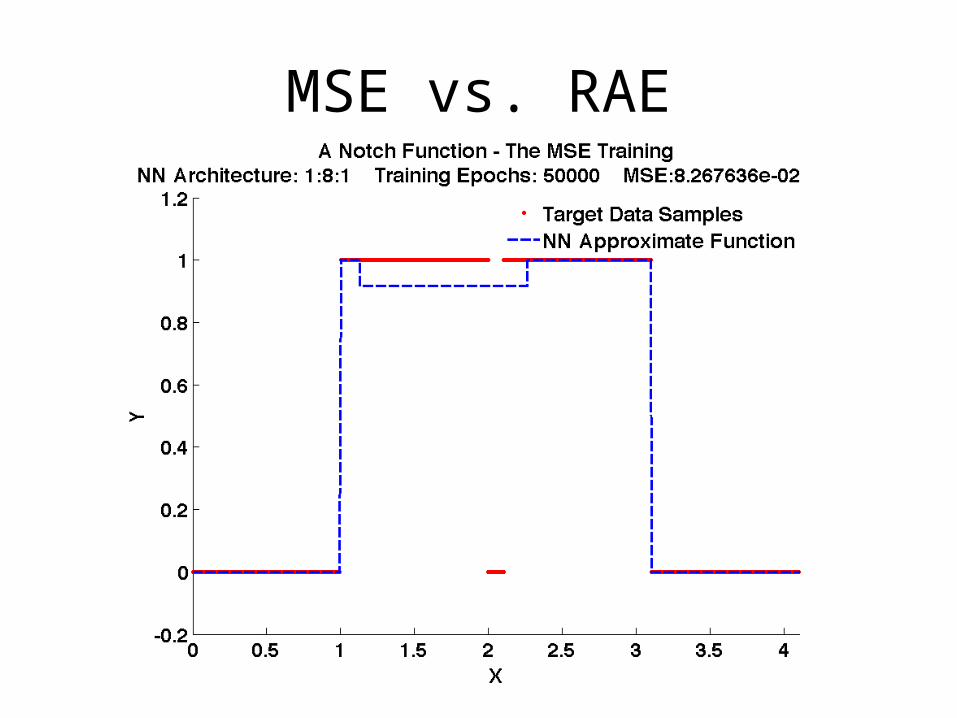
MSE vs. RAE

MSE vs. RAE