georg lindgren programforklaring i - maths.lth.se · 3.1 3.2 ml−skattning = ... 1 13 25 37 49 61...
TRANSCRIPT

Statistik for modellval och prediktionatt beskriva, forklara och forutsaga
Georg Lindgren
Matematisk statistik, Lunds universitet
Statistik for modellval och prediktion – p.1/42
PROGRAMFORKLARING I
Statistik for modellval och prediktion – p.2/42
Beskriva, forklara, forutsaga
Statistikens uppgift: att skilja systematiskasamband fran slumpmassig variation
Tre nivaer:
• att beskriva observerad variation och samband• histogram, fordelningsanpassning, skattningar
• att forklara variation och samband genom genomtolkbara modellval• skattningar, osakerhet, test
• att forutsaga variation – normal och extrem• modellvalidering
Statistik for modellval och prediktion – p.3/42
Ett exempel: vagriktning och vaghojd
0 100 200 300 4000
50
100
150Våghöjd
0 100 200 3000
50
100
150
200Riktning
0 50 100 150 200 250 300 3500
100
200
300
400Samvariation riktning − våghöjd
Statistik for modellval och prediktion – p.4/42

Riktningsfordelning
Statistik for modellval och prediktion – p.5/42
Ex: Uppdelning i normalfordelningar
0 50 100 150 200 250 300 3500
0.002
0.004
0.006
0.008
0.01
0 50 100 150 200 250 300 3500
0.2
0.4
0.6
0.8
115
Uppdelning av våghöjd i två normalfördelningar
Sannolikhet för tillhörighet
Riktnings- och hojdfordelning kan var for sig delas upp i tvanormalfordelningar – stods inte av tvadimensionell plott.
Statistik for modellval och prediktion – p.6/42
REPETITION
Statistik for modellval och prediktion – p.7/42
Lite repetition
Data = observationer x1, . . . , xn av en stokastisk(slump-)variabel X
Fordelningsfunktion CDF:
FX(x) = Prob(slumpvariaben ≤ x)
Empirisk fordelningfunktion EDF:
Femp(x) =antalet observationer ≤ x
n
Kvantil qα ar sadan att FX(qα) = 1 − α
Alternativt “the return period”FX(q1/α) = 1 − α
Statistik for modellval och prediktion – p.8/42

Mer repetition
Sannolikhetstathet PDF, for stokastisk variabel X:
fX(x) : fX(x) dx = P(x ≤ X ≤ x + dx)
Histogram motsvarar EDF
Vantevarde = (medelvarde) = tyngdpunkt i fordelningen:
E(X) =
∫x fX(x) dx = mX
Varians = (standardavvikelse)2
V(X) = σ2 = E((X − mX)2)
D(X) =√
V(X) = σ
Statistik for modellval och prediktion – p.9/42
Oberoende, beroende, betingning
• Oberoende handelser: P(A och B) = P(A) · P(B)
• Oberoende matningar:
P(x ≤ X ≤ x + dx och y ≤ Y ≤ y + dy)
= fX(x)fY (y) dx dy
• Betingad sannolikhet for handelse A om B:
P(A | B) =P (A och B)
P(B)
Statistik for modellval och prediktion – p.10/42
Summor och medelvarden
• Vantevarden adderas alltid
E(X1 + . . . + Xn) = E(X1) . . . + E(Xn)
• Varianser av oberoende variabler adderas
V(X1 + . . . + Xn) = V(X1) . . . + V(Xn)
• For medelvardet X = (X1 + . . . + Xn)/n av oberoende
observationer med vantevarde m och varians σ2 betyderdetta att
E(X) = m
V(X) = σ2/n, D(X) = σ/√
n
Statistik for modellval och prediktion – p.11/42
Rep: normalfordelning
Normalfordelning N(m,σ) har vantevarde m och varians σ2:
fX(x;m,σ) =1
σ√
2πe−(x−m)2/2σ2
−5 0 5 10 150
0.02
0.04
0.06
0.08
0.1
0.12
0.14
67% inomm ± σ
95% inom m ± 2σ
PDF förN(5,3)
Statistik for modellval och prediktion – p.12/42
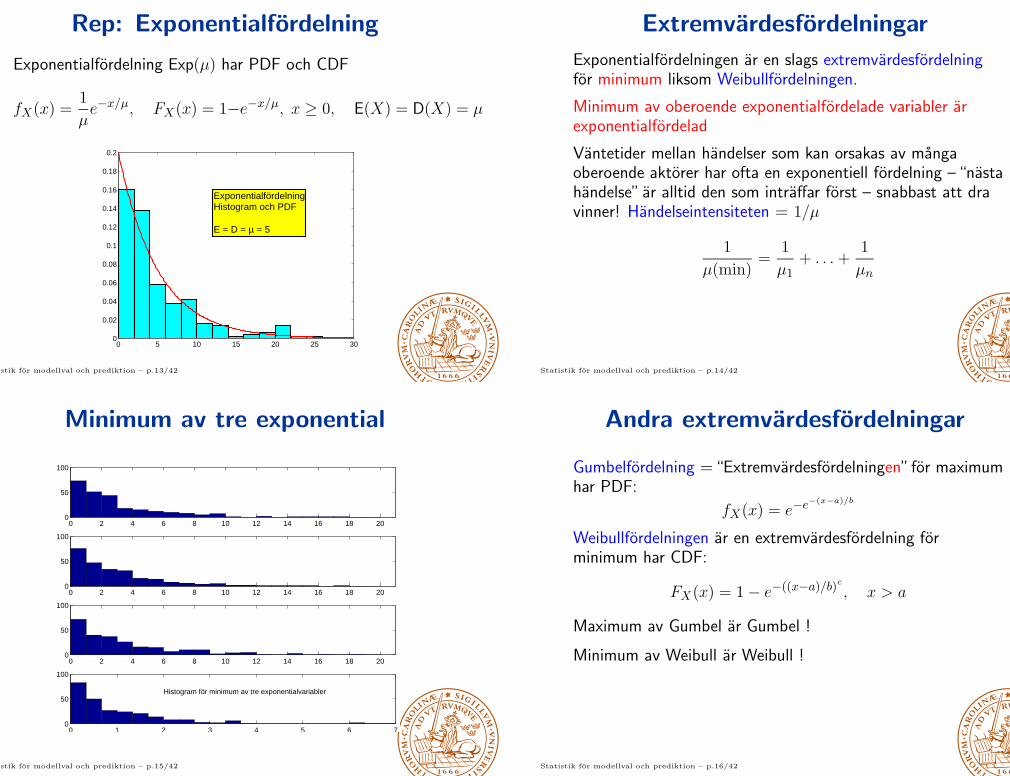
Rep: Exponentialfordelning
Exponentialfordelning Exp(µ) har PDF och CDF
fX(x) =1
µe−x/µ, FX(x) = 1−e−x/µ, x ≥ 0, E(X) = D(X) = µ
0 5 10 15 20 25 300
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
ExponentialfördelningHistogram och PDF
E = D = µ = 5
Statistik for modellval och prediktion – p.13/42
Extremvardesfordelningar
Exponentialfordelningen ar en slags extremvardesfordelningfor minimum liksom Weibullfordelningen.
Minimum av oberoende exponentialfordelade variabler arexponentialfordelad
Vantetider mellan handelser som kan orsakas av mangaoberoende aktorer har ofta en exponentiell fordelning –“nastahandelse” ar alltid den som intraffar forst – snabbast att dravinner! Handelseintensiteten = 1/µ
1
µ(min)=
1
µ1+ . . . +
1
µn
Statistik for modellval och prediktion – p.14/42
Minimum av tre exponential
0 2 4 6 8 10 12 14 16 18 200
50
100
0 2 4 6 8 10 12 14 16 18 200
50
100
0 2 4 6 8 10 12 14 16 18 200
50
100
0 1 2 3 4 5 6 70
50
100
Histogram för minimum av tre exponentialvariabler
Statistik for modellval och prediktion – p.15/42
Andra extremvardesfordelningar
Gumbelfordelning =“Extremvardesfordelningen”for maximumhar PDF:
fX(x) = e−e−(x−a)/b
Weibullfordelningen ar en extremvardesfordelning forminimum har CDF:
FX(x) = 1 − e−((x−a)/b)c
, x > a
Maximum av Gumbel ar Gumbel !
Minimum av Weibull ar Weibull !
Statistik for modellval och prediktion – p.16/42

Ett hjalpmedel: fordelningspapper
Anpassa skalor sa att CDF blir en rat linje:
0 5 10 15 20 25−4
−2
0
2
4Normal Probability Plot
Qua
ntile
s of
sta
ndar
d no
rmal
0.01%0.1%0.5%1%2%5%10%30%50%70%90%95%98%99%99.5%99.9%99.99%
5 10 15 20−4
−2
0
2
4Normal Probability Plot
Qua
ntile
s of
sta
ndar
d no
rmal
0.01%0.1%0.5%1%2%5%10%30%50%70%90%95%98%99%99.5%99.9%99.99%
0 5 10 15 20 25−4
−2
0
2
4Normal Probability Plot
Qua
ntile
s of
sta
ndar
d no
rmal
0.01%0.1%0.5%1%2%5%10%30%50%70%90%95%98%99%99.5%99.9%99.99%
0 5 10 15−4
−2
0
2
4Normal Probability Plot
Qua
ntile
s of
sta
ndar
d no
rmal
0.01%0.1%0.5%1%2%5%10%30%50%70%90%95%98%99%99.5%99.9%99.99%
Statistik for modellval och prediktion – p.17/42
PROGRAMFORKLARING II
Statistik for modellval och prediktion – p.18/42
Modellval – anpassning – validering
Mal pa tre nivaer: att sa bra som mojligt
B: beskriva – valj fordelningstyp och“skatta”parametrar, sam-manfattar det man har sett
F: forklara – valj fordelningstyp och modell for samband(logiskt, fysikaliskt, tolkbart) och skatta parametrar – provahypotes – uppskatta osakerhet
P: forutsaga – valj modell, validera, extrapolera utanfor detredan sedda – vad kan handa
Statistik for modellval och prediktion – p.19/42
Beskriva
Statistik for modellval och prediktion – p.20/42

B: Data eller modellantaganden?
Ju mer data man har desto farre modellantaganden behovs!
B, beskriva: Modell + lite data eller mycket data
Likelihood-principen: Valj den modell och de parametrar somgor att data och modell stammer bast overens i statistiskmening
Likelihood-funktionen i modellen med PDF fX(x; θ) ar propor-tionell mot sannolikheten att fa de data x1, . . . , xn man fatt:
L(x1, . . . , xn; θ) =∏
j
fX(xj ; θ)
OBS: P(X ∈ [xj , xj + dx]) = fX(xj) dx
Statistik for modellval och prediktion – p.21/42
Exempel pa ML-skattning
−5 0 5 10 150
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
Blå: sann pdfm=5σ=3
Röd: "bästa" pdfm=4.3 σ=2.9
ML−skattningmed 100 observationer
Statistik for modellval och prediktion – p.22/42
Normalobservationer och likelihood
−4 −2 0 2 4 6 8 10 12−1
−0.5
0
0.5
1
−4 −2 0 2 4 6 8 10 120
0.5
1
1.5
2
2.5x 10
−32
Likelihood−funktion Rätt m och σ
Fel m och σFel m rätt σ
Statistik for modellval och prediktion – p.23/42
ML-skattning vid normalfordelning
Observationer x1, x2, . . . , xn fran en fordelning med pdffX(x; θ), t ex N(m,σ):
fX(x) =1
σ√
2πe−(x−m)2/2σ2
.
ML-skattningen ar de varden pa m och σ man skall anvanda imodellen N(m,σ) for att det skall bli maximalt troligt att manskall fa det man verkligen fick!
m∗ = x =1
n
∑
i
xi
σ∗ = s =
√1
n
∑
i
(xi − x)2
Statistik for modellval och prediktion – p.24/42

Likelihood-funktion for normalfordelning
Likelihood-funktionen ar proportionell mot“sannolikheten attfa just de varden som man fatt”, som funktion av de okandaparametrarna:
L(m,σ;x1, . . . , xn) =∏
i
fX(xi;m,σ)
for normalfordelningen:
`n(m,σ) = log Ln = −n log σ − n
2log(2π) − 1
2σ2
∑
i
(xi − m)2
Statistik for modellval och prediktion – p.25/42
ML-skattning i exponentialfordelning
• Skatta vantevardet µ med hjalp av x1, . . . , xn
• PDF: fX(x) = (1/µ) e−x/µ, x > 0
• Likelihoodfunktion
L(µ;x1, . . . , xn) =1
µne−
P
j xJ/µ
`(µ) = −n log µ − (1/µ)∑
xj
• Derivera och satt derivatan = 0
− n
µ+
1
µ2
∑xj = 0
• Ger maximum for µ =∑
xj/n = x
Statistik for modellval och prediktion – p.26/42
Likelihood-ytan har maximum i ML-skattningen
4.2 4.25 4.3 4.35 4.4 4.45 4.52.6
2.7
2.8
2.9
3
3.1
3.2
ML−skattning = maximipunkten i Likelihoodytan
m* = 4.3422σ * = 2.8647
m
σ
Statistik for modellval och prediktion – p.27/42
Skattningar i andra fordelningar
Exempel: I exponentialfordelningen Exp(µ), dvs PDF
fX(x) = (1/µ) e−x/µ ar ML-skattningen
µ∗ = x
precis som for normalfordelningen.
ML-skattningen ar ofta enkel att berakna – se Blom – antin-gen exakt med formel, som for normal- och exponentialfordel-ningarna, eller med ett numeriskt optimeringsprogram som forWeibull eller Extremvardesfordelningarna – aven blandningsex-emplet med vaghojd och riktning.
Man kan ocksa jamfora olika fordelningstyper med hjalp avLikelihoodfunktionen – den med hogst likelihood passar bast!
Statistik for modellval och prediktion – p.28/42

ML-skattning med kovariater
10 ars manadsvarden fran en exponentialfordelning – arvantevardet manadsberoende?
1 13 25 37 49 61 73 85 97 1090
5
10
15
20
25
3010 års månadsdata
Statistik for modellval och prediktion – p.29/42
ML-skattning med kovariater
10 ars manadsvarden fran en exponentialfordelning – arvantevardet manadsberoende?
1 13 25 37 49 61 73 85 97 1090
5
10
15
20
25
3010 års månadsdata
Statistik for modellval och prediktion – p.30/42
ML-skattning med kovariater
10 ars manadsvarden fran en exponentialfordelning – arvantevardet manadsberoende?
1 13 25 37 49 61 73 85 97 1090
5
10
15
20
25
3010 års månadsdata
Statistik for modellval och prediktion – p.31/42
Modell och skattning
• Maximering av likelihood-funktionen med
µ(t) = a + b sin 2πt/12
L(a, b) =∏
t
(1/µ(t) e−xt/µ(t)
ger ML-skattningar a∗ = 3.88, b∗ = 2.52
• Om manadseffekt saknas ar b = 0.
• Skatta aven c i den utokade modellen
µ(t) = a + b sin(2πt/12 + c)
Statistik for modellval och prediktion – p.32/42

Ar b = 0 ?
Likelihood-funktionen b ⇒ L(a∗, b) visar om b kan vara 0!
−1 −0.5 0 0.5 1 1.5 2 2.5 3−300
−295
−290
−285
−280
−275
−270
−265Profil−likelihood, a=3.88
log L(b)
b* = 2.52
Statistik for modellval och prediktion – p.33/42
Forklara
Statistik for modellval och prediktion – p.34/42
F: Forklara – osakerhet, konfidens, test
Hur saker ar man pa sin anpassade modell? Hur osaker ar skat-tningen θ∗ av en parameter, t ex θ = medeltemperaturhojnin-gen per ar ?
Kan det tankas att parametern θ ar 0 ?
Konfidensomrade for en skattad parameter ar ett omradeberaknat fran observerade data, som med viss given sanno-likhet, konfidens, innehaller det efterfragade parametervardet.
Om data avviker fran nagon uppsatt hypotes sa kan man fragasig om avvikelsen ar ett tecken pa att hypotesen ar fel.Signifikans ar sannolikheten att fa sa “avvikande” varden somman faktiskt fatt, om hypotesen skulle vara sann.
Statistik for modellval och prediktion – p.35/42
Konfidensomrade
Likelihood-ytans krokning ger en uppskattning av osakerheten:
Liten krokning, t ex i m-led, ⇒manga m-varden passar ungefar lika bra till data ⇒stor osakerhet i skattningen av m.
Osakerheten i skattningarna anges med ett konfidensomradesom med given sannolikhet, konfidens, innehaller det sokta“ratta”parametervardet.
Statistik for modellval och prediktion – p.36/42

Konfidensintervall vid normalfordelning
Skattningarna av m och σ baserade pa n > 100 observationeri en normalfordelning N(m,σ) har konfidensintervall med 95%konfidens:
Im : x ± 2 s/√
n = 4.34 ± 0.57
Iσ : s ·(
1 ±√
2
n
)= 2.86 · (1 ± 0.14)
T ex n = 200 for ett fel inom ± 10% i skattning av standard-avvikelsen σ.
Statistik for modellval och prediktion – p.37/42
Forklaring
• Skatta m med enda observation x av en normalvariabelX ∈ N(m,σ)
• Skattningen m∗ = x har osakerheten σ:
P(m − 2σ < X < m + 2σ) = 0.95 = P(X − 2σ < m < X + 2σ)
dvs sannolikheten att hamna inom ±2σ = tvastandardavvikelser fran vantevardet ar 95%.
• Med fler matningar tar man medelvardet X. Det harocksa vantevardet m men variansen σ2/n ochstandardavvikelsen σ/
√n.
• Alltsa: X och m har 95% chans att hamna hogst σ/√
nfran varandra.
• Ersatt σ med skattningen s.
Statistik for modellval och prediktion – p.38/42
Komplikation vid sma stickprov
Eftersom skattningen σ∗ = s i sig ar osaker maste man modi-fiera x± 2s/
√n vid sma stickprov nar man skall skatta m i en
normalfordelning.
Koefficienten 2 maste bytas mot en “t-kvantil” t0.025(n), somberor av n. For konfidensen 95% galler:
n 10 20 30 40 50
t(n) 2.23 2.09 2.04 2.02 2.01
Statistik for modellval och prediktion – p.39/42
Allman princip for konfidensomraden
Antag att vi har r okanda parametrar som skall skattas ochforses med osakerhet; t ex θ = σ (r = 1) eller θ = (m,σ)(r = 2) i normalfordelning med kant medelvarde eller medbade medelvarde och standardavvikelse okanda.
Om n = antalet observationer ar“stort”kan man anvanda engenerell, approximativ, metod for att gora ettkonfidensomrade for θ baserad pa log-likelihooden,
`n(θ) = log Ln(θ;x1, . . . , xn).
ML-skattningen θ ar det θ-varde som gor likelihooden sa storsom mojligt. Konfidensomradet skall innehalla de θ-varden somgor likelihooden“nastan lika stor”.
Statistik for modellval och prediktion – p.40/42
Allman princip vid stora stickprov
Ett 95% konfidensomrade for en r-dimensionell parameter θ
med ML-skattningen θ, dvs `n(θ) = maxθ `n(θ), ar de vardenpa θ som gor
`n(θ) >
`n(θ) − 1.9 om r = 1
`n(θ) − 3.0 om r = 2
`n(θ) − 3.9 om r = 3
Statistik for modellval och prediktion – p.41/42
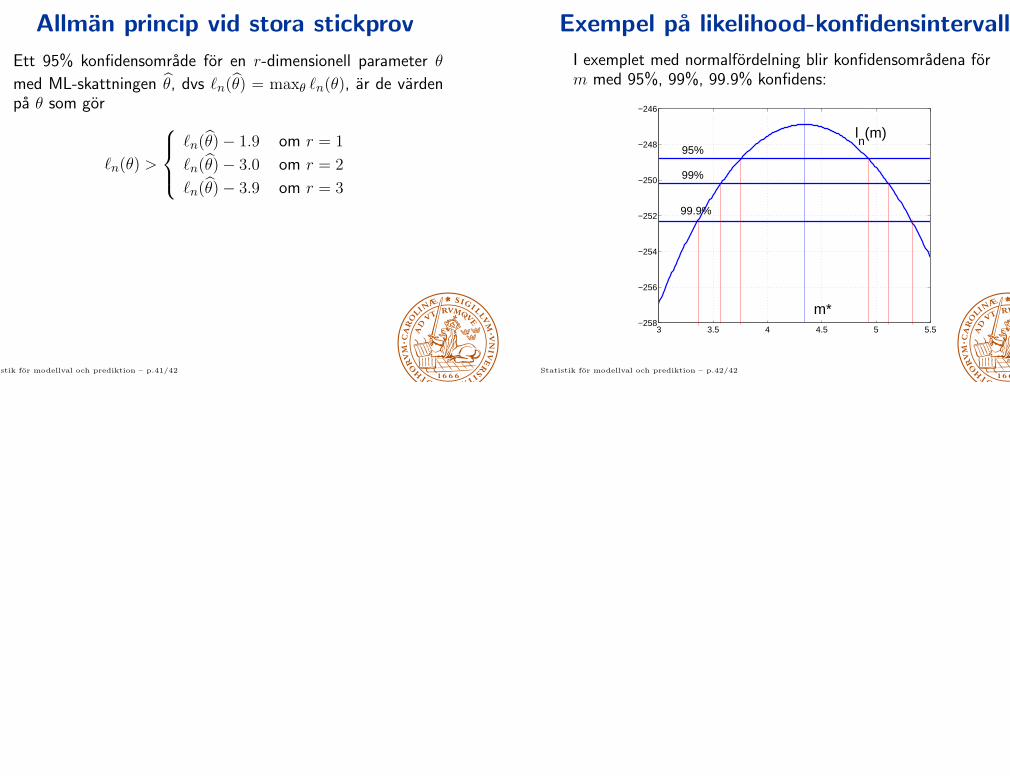
Exempel pa likelihood-konfidensintervall
I exemplet med normalfordelning blir konfidensomradena form med 95%, 99%, 99.9% konfidens:
3 3.5 4 4.5 5 5.5−258
−256
−254
−252
−250
−248
−246
95%
99%
99.9%
m*
ln(m)
Statistik for modellval och prediktion – p.42/42