genetic report · genetic report documento de estudio unidad 4: “la revoluciÓn genÉtica”...
TRANSCRIPT

GENETIC REPORT
DOCUMENTO DE ESTUDIO UNIDAD 4: “LA REVOLUCIÓN GENÉTICA”
CIENCIAS DEL MUNDO CONTEMPORÁNEO. 1º BACHILLERATO.
I.E.S. PEDRO JIMÉNEZ MONTOYA. BAZA (GRANADA)
CURSO 2013 / 2014

TABLE OF CONTENTS
1.- Genetics:
A) Draw the structure of the DNA and detail its components
B) How is a protein sintetize from a fragment of DNA? Explain all the steps
C) What type of mutations can we find according to where they are produced
(gene or chromosome)1
D) What are the implications of the work done by Gregor Mendel?
2.- Human Genome Project: Time, money and countries involved
3.- Genetic engineering: recombinant DNA technology and PCR
4.- Create a list of the product created from biotechnology techniques:
� Bacteria � Animal and plants � Human beings � Ecosystems
5.- Research: Tell the teacher which subject you are willing to work about.2
1 y 2 Sólo para alumnos del bachillerato biológico / Only needed for biology students

1.1.1.1. A) Draw the structure of the DNA and detail its componentsA) Draw the structure of the DNA and detail its componentsA) Draw the structure of the DNA and detail its componentsA) Draw the structure of the DNA and detail its components
El ADN (ácido desoxirribonucleico) es la
molécula que porta la información genética de
los seres vivos. Pertenece a un grupo de
biomoléculas llamadas ácidos nucleicos. Su
estructura consiste en dos cadenas de ADN en
forma de doble hélice.
DNA (Deoxyribonucleic acid) is the molecule that
carries the genetic information in living beings.
It belongs to a group of biomolecules called
nucleic acids. Its structure consists in two
chains of DNA nucleotides in double helix form.
Los ácidos nucleicos permiten almacenar,
reproducir y expresar la información genética
que se manifiesta en forma de características
biológicas del ser vivo.
Nucleic acids allow to store, reproduce and express genetic information which is
expressed in the form of traits or characteristics of the living being.
Los ácidos nucleicos son polímeros formados por unidades llamadas monómeros que,
en este caso, son los nucleótidos. Nucleic acids are polymers made up by different
units called monomers; in this case they are the nucleotides.
Cada nucleótido tiene 3 componentes químicos distintos: Each nucleotide has 3
different chemical components:
1.- Un grupo fosfato
2.- Un azúcar (hidrato de carbono, concretamente, una pentosa de 5 carbonos)
- En el ARRRRN esa pentosa se llama rrrribosa. Sus bases nitrogenadas son A, G, C y U.
- En el ADDDDN esa pentosa se llama ddddesoxirribosa. Sus bases son A, G, C y T.
Púricas (Adenina: A y Guanina: G)
3.- Una base nitrogenada
Pirimidínicas (Citosina: C y Timina: T) / Uracilo: U (ARN)

Each nucleotide is made up of a
phosphate groupphosphate groupphosphate groupphosphate group, a sugarsugarsugarsugar
(deoxyribose) and a nitrogenous nitrogenous nitrogenous nitrogenous
basebasebasebase (Adenine, Thymine, Cytosine
and Guanine).
Adenine and Guanine are Puric
bases, while Thymine, Citosyne
and Uracile (only in ARN) are
Pirimidinic bases.
La estructura de la hélice está compuesta sólo por el azúcar (ribosa) y por el grupo
fosfato, quedando fuera la base nitrogenada. Estas bases se unen así: A – T y G - C
Las bases nitrogenadas son las que habilitan la unión entre las dos cadenas, ya que
establecen su unión mediante puentes de hidrógeno (3 en el caso de la unión T-A y
dos en el caso de G-C), lo que hace que ambas cadenas queden pegadas.
Each DNA molecule is formed by two strings, which binds each other thanks to the
hydrogen bonds established between their nitrogenous bases and thus create the
double helix shape. The string itself is just made up of the phosphate group and the
sugar. The union of those bases is: thymine with adenine and cytosine with guanine.

1.1.1.1.B) How is a protein syB) How is a protein syB) How is a protein syB) How is a protein syntntntntheshesheshesizeizeizeizedddd from a fragment of DNA? from a fragment of DNA? from a fragment of DNA? from a fragment of DNA? ExExExExplain all the stepsplain all the stepsplain all the stepsplain all the steps
Este proceso se conoce como el dogma central de la biología molecular. That process
is known as the Central Dogma of molecular biology
¿Pri¿Pri¿Pri¿Primero, qué es una proteína? mero, qué es una proteína? mero, qué es una proteína? mero, qué es una proteína? / First of all, what is a protein?/ First of all, what is a protein?/ First of all, what is a protein?/ First of all, what is a protein?
Las proteínas son biomoléculas de gran tamaño formadas por la unión de moléculas
más sencillas llamadas aminoácidos. Estas proteínas son las responsables de las
funciones celulares y de los rasgos propios de cada individuo (fenotipo). Existen veinte
tipos de aminoácidos diferentes que se unen formando cadenas, con diferentes
números de aminoácidos, y que dan lugar a diferentes tipos de proteínas. Este proceso
ocurre en los ribosomas. Una vez que la secuencia linear de aminoácidos está formada,
se pliega sobre sí misma y la proteína obtiene su configuración tridimensional
característica. Cada proteína tiene su propia función y se diferencian por el orden en el
que se disponen los aminoácidos en su cadena. La siguiente figura muestra como
ejemplo el aminoácido Prolina.
Proteins are big sized molecules made up of amino acids. These proteins are
responsible of the cell’s function and give the unique feature to each living being
(phenotype). There are twenty different amino acids that are joined together creating a
linear sequence of amino acids. That process occurs in the ribosome. Once the protein
has all his amino acids, it gets folds and bends until it gets its 3D configuration. Each
protein has its own function and they are different due to the amino acid’s order.

¿Cuál es el punto de partida? / ¿Cuál es el punto de partida? / ¿Cuál es el punto de partida? / ¿Cuál es el punto de partida? / WhatWhatWhatWhat is is is is
the startthe startthe startthe starting point?ing point?ing point?ing point?
Todo empieza en el ADN, que tiene la
información necesaria para producir la
proteína. Este ADN se localiza en el
núcleo de la célula, organizado dentro de
los cromosomas (los humanos tenemos
23 pares de cromosomas). Cada célula
contiene la misma información genética
que el resto y el ADN se duplica antes de
que cada célula se divida (proceso
llamado replicaciónreplicaciónreplicaciónreplicación)
It all starts with the DNA because it has
the information needed to build the
protein. DNA molecule is located in the
cell’s nucleus, organized into chromosomes (humans have 23 pairs of chromosomes).
Every cell must contain the same genetic information and the DNA is duplicated before
each cell divides (this process is called “replication”).
Cuando se necesita sintetizar proteínas, el gen correspondiente es transcrito a formato
ARN (proceso conocido como transcripcióntranscripcióntranscripcióntranscripción). En primer lugar, el ARN es procesado de
forma que se eliminan las partes no codificantes o intrones y luego es transportado
fuera del núcleo. Una vez en el citoplasma, las proteínas son construidas según la
secuencia del ARN (traduccióntraduccióntraduccióntraducción).
When proteins are needed, the corresponding genes are transcribed into RNA
(transcription). The RNA is first processed so that non-coding parts (introns) are
removed (processing) and is then transported out of the nucleus (transport). Outside
the nucleus, the proteins are built based upon the code in the RNA (translation).

Tomemos esta secuencia de ADN como ejemplo:
GCAUGCUGCGAAACUUUGGCUGA
Podemos separar la secuencia en codones (tripleta de
aminoácidos que codifica para un aminoácido) de tres
formas diferentes:
1. GCA UGC UGC GAA ACU UUG GCU GA
2. G CAU GCU GCG AAA CUU UGG CUG A
3. GC AAAAUGUGUGUG CUG CGA AAC UUU GGC UGA
¿Cómo podemos saber qué pauta de lectura es la correcta de las tres?
Todas las regiones que codifican para proteínas empiezan con la misma secuencia:
AUG, codón que codifica para el aminoácido Metionina (Met). Por lo tanto, la pauta de
lectura correcta deberá contener el codón AUG. (en el ejemplo, la buena es la tercera)
Del mismo modo que hay una señal para el inicio, hay otra para la finalización de la
lectura, y esta se produce con los codones: UAA, UAG y UGA. Estos se conocen como
codones STOP y determinan la finalización de la síntesis de la proteína.
We understand the protein-coding sequence of a gene as a sentence made up
entirely of 3-letter words. In the sequence, each 3-letter word is a codon,
specifying a single amino acid in a protein. Have a look at this sentence:
Thesunwashotbuttheoldmandidnotgethishat.Thesunwashotbuttheoldmandidnotgethishat.Thesunwashotbuttheoldmandidnotgethishat.Thesunwashotbuttheoldmandidnotgethishat.
If you were to split this sentence into individual 3-letter words, you would
probably read it like this:
The sun was hot but the old man did not get his hat. The sun was hot but the old man did not get his hat. The sun was hot but the old man did not get his hat. The sun was hot but the old man did not get his hat.
This sentence represents a gene. Each letter corresponds to a nucleotide
base, and each word represents a codon. What if you shifted the "reading
frame?" You would end up with:
T hes unw ash otb utt heo ldm and idn otg eth ish at. T hes unw ash otb utt heo ldm and idn otg eth ish at. T hes unw ash otb utt heo ldm and idn otg eth ish at. T hes unw ash otb utt heo ldm and idn otg eth ish at. Or
Th esu nwa sho tbu tth eol dma ndi dno tge thi sha t.Th esu nwa sho tbu tth eol dma ndi dno tge thi sha t.Th esu nwa sho tbu tth eol dma ndi dno tge thi sha t.Th esu nwa sho tbu tth eol dma ndi dno tge thi sha t.
As you can see, only one of these reading frames translates into an
understandable sentence. In the same way, only one reading frame within a
gene codes for the correct protein.
Think about it…

Take this DNA sequence as an example:
GCAUGCUGCGAAACUUUGGCUGA
You can separate the sequence into 3-letter codons (each codon corresponds to a
specific amino acid), in 3 different ways:
4. GCA UGC UGC GAA ACU UUG GCU GA
5. G CAU GCU GCG AAA CUU UGG CUG A
6. GC AUGAUGAUGAUG CUG CGA AAC UUU GGC UGA
How can you tell which reading frames is the correct one?
All protein-coding regions begin with the sequence "AUG," which encodes the amino
acid methionine (Met). Therefore, the correct reading frame will contain the codon
"AUG."
The same way we can also predict the end of a protein by finding one of these three
codons: UAA, UAG and UGA they are known as STOP codons because they are the end
of the amino acid chain.
How How How How can can can can we we we we predict the amino acid sequence of predict the amino acid sequence of predict the amino acid sequence of predict the amino acid sequence of aaaa protein protein protein protein????
Simple question, use the Universal Genetic Code. It is the instruction manual that all
cells use to read the DNA sequence of a gene and build a corresponding protein.
Proteins are made of amino acids that are fixed together in a chain. Each 3-letter DNA
sequence, or codon, encodes a specific
amino acid.
The code has several key features:
� All protein-coding regions begin
with the "start" codon, AUG.
� There are three "stop" codons that
mark the end of the protein-
coding region.
� Multiple codons can code for the
same amino acid.

1.C) What type of mutations can we find according to where they are produced (gene 1.C) What type of mutations can we find according to where they are produced (gene 1.C) What type of mutations can we find according to where they are produced (gene 1.C) What type of mutations can we find according to where they are produced (gene
or chromosome)or chromosome)or chromosome)or chromosome)
Una mutación es un proceso que produce un cambio permanente en la secuencia de
ADN. Cambiando la secuencia de ADN también se puede cambiar la secuencia de
aminoácidos de la proteína que se codifica. Distinguimos entre mutaciones génicas
(afectan a un solo gen) o cromosómicas (afectan al cromosoma)
Mutation is a process that makes a permanent change in a DNA sequence. Changing a
gene's DNA sequence can change the amino acid sequence of the protein it codes for.
We distinguish between genic mutations and chromosomal mutations.
1.c.11.c.11.c.11.c.1---- Tipos de mutaciones GénicasTipos de mutaciones GénicasTipos de mutaciones GénicasTipos de mutaciones Génicas
Encontramos las sustituciones, las inserciones y las delecciones.
SustitucionesSustitucionesSustitucionesSustituciones: Consiste en el cambio de base de una secuencia nucleotídica.
Diferenciamos entre:
Neutra o silenciosa: puede ser porque el cambio de base no implica cambio en el
aminoácido (hay aminoácidos que están codificados por codones diferentes) o
simplemente el cambio de aminoácido que provoca la mutación no implica un cambio
estructural en la proteína, por lo que no le afecta a su funcionamiento normal.
De sentido erróneo: Son las sustituciones que generan el cambio de un aminoácido y
que en general alteran la funcionalidad de la proteína codificada originalmente.
Sin sentido: crean un codón de stop o codón sin sentido (UAA, UAG y UGA),
ocasionando una proteína más corta de lo normal
Point MutationsPoint MutationsPoint MutationsPoint Mutations: They are single base changes in a
gene's DNA sequence. They can be further categorized:
Silent mutations do not cause amino acid changes.
Missense mutations cause a single amino acid change within the protein.
Nonsense mutations create a premature "stop" codon, causing the protein to be
shortened.

Inserciones y deleccionesInserciones y deleccionesInserciones y deleccionesInserciones y delecciones
Consisten en añadir (inserción) o eliminar (delección) de una o más bases nucleotídicas
en el fragmento de AND. A menos que la mutación afecte a
tres bases seguidas, estas conllevan el cambio de la pauta
de lectura de un gen, cambiando consecuentemente el
agrupamiento de las bases dentro del codón. Estas
mutaciones suelen afectar de forma importante a la
secuencia de aminoácidos de la proteína sintetizada.
Insertion and Deletion MutationsInsertion and Deletion MutationsInsertion and Deletion MutationsInsertion and Deletion Mutations
Insertion mutations and deletion mutations add or remove
one or more DNA bases. Insertions and deletions (unless
they happen in multiples of 3) can shift the reading frame
of a gene, changing the grouping of bases into codons.
Also called frameshift mutations, these changes can greatly affect a protein's amino
acid sequence.
1.c.21.c.21.c.21.c.2---- Mutaciones cromosómicasMutaciones cromosómicasMutaciones cromosómicasMutaciones cromosómicas
Una mutación cromosómica es un cambio impredecible en un cromosoma. Su causa
puede ser de origen natural (resultado de un problema ocurrido durante la meiosis) o
bien provocado por un agente mutagénico (sustancias químicas, radiación, etc.).
A chromosome mutation is an unpredictable change in a chromosome. They are the
result of any problems that occur during meiosis (cell division process of gametes) or
by mutagens (chemicals, radiation, etc.).
Encontramos dos tipos de mutaciones cromosómicas. There are two types of
chromosomal mutations:
Mutaciones cromosómicasMutaciones cromosómicasMutaciones cromosómicasMutaciones cromosómicas numéricas: numéricas: numéricas: numéricas:
Aneuploidía: el individuo tiene un número anormal de cromosomas, debido a
problemas durante la meiosis. Por ejemplo, trisomía en el 21 (S. Down)

Poliploidía: Resulta en un cambio en el número de pares cromosómicos, pudiendo ser
haploidía (se pierde uno: 2n - 1), triploidía (2n + 1), tetraploidía (2n +2)
Mutaciones cromosómicas estructuralesMutaciones cromosómicas estructuralesMutaciones cromosómicas estructuralesMutaciones cromosómicas estructurales
Son alteraciones en la estructura del cromosoma, por lo que afecta a la producción de
las proteínas, ya que los genes cambian o pierden su lugar normal en el cromosoma.
� Duplicación: Se duplica un fragmento de un cromosoma � Delección: Se produce la pérdida de un fragmento de un
cromosoma � Inversión: Se produce un cambio en la secuencia lineal de
los genes de un cromosoma � Translocación: Hay un intercambio o transferencia de
fragmentos cromosómicos entre cromosomas no
homólogos (es decir, que no son del mismo par de
cromosomas).
1.D) What are the implications of the work done by Gregor Mendel?1.D) What are the implications of the work done by Gregor Mendel?1.D) What are the implications of the work done by Gregor Mendel?1.D) What are the implications of the work done by Gregor Mendel?
Gregor Mendel fue un monje cuyo trabajo fue la base para todos los descubrimientos
en el mecanismo de la herencia de caracteres. Experimentó con la planta del guisante,
cruzándola, cruzando diferentes semillas y anotando las características de la siguiente
generación de plantas. Una vez hubo cruzado también a los individuos de la
descendencia (Generación F2), realizó algunas conclusiones y enunció sus tres leyes:
1- Uniformidad de la primera generación
2- Principio de segregación de alelos
3- Ley de la transmisión independiente de caracteres
Gregor Mendel was a monk whose work was the basis of all the discoveries on the
mechanisms of trait inheritance. He experimented with the pea plant, by crossing
different pea plant seeds and recording what characteristics the next generation had.
After crossing the offspring too, he made some conclusions and enunciated his three
laws:
1- Act of Uniformity of hybrids of the first generation
2- Law of segregation of alleles
3- Law of the independence of non-antagonistic characters".
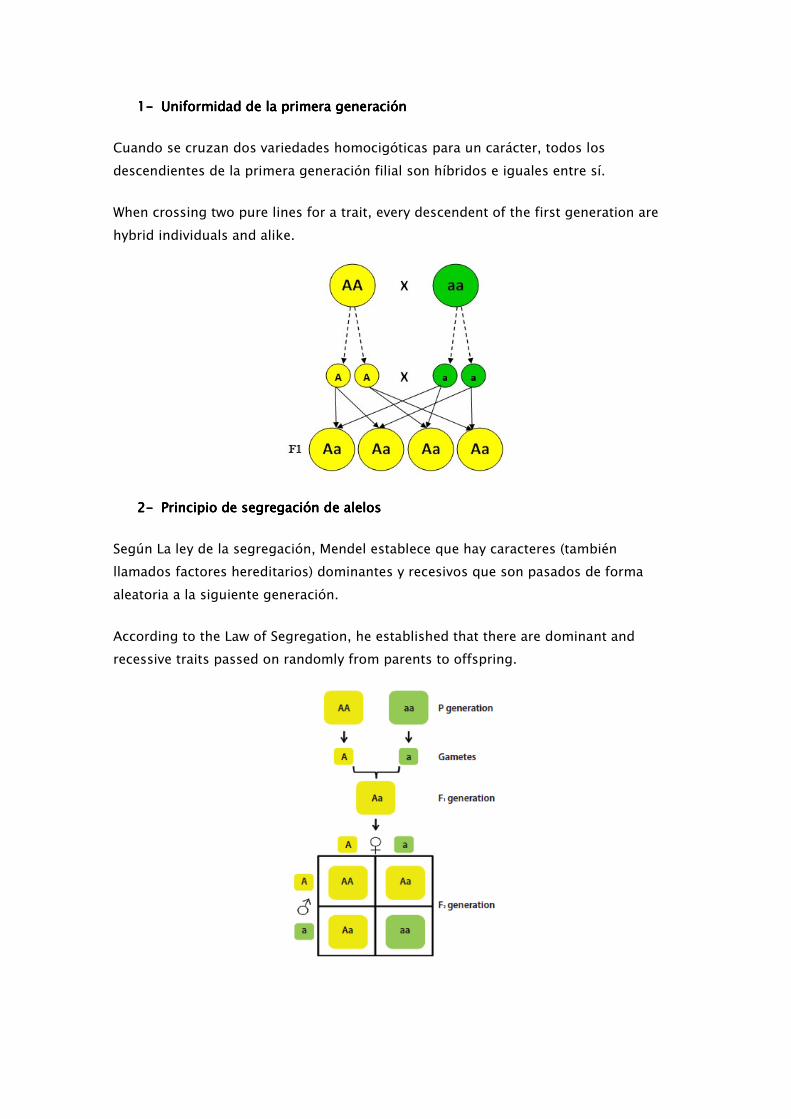
1111---- Uniformidad de la primera generaciónUniformidad de la primera generaciónUniformidad de la primera generaciónUniformidad de la primera generación
Cuando se cruzan dos variedades homocigóticas para un carácter, todos los
descendientes de la primera generación filial son híbridos e iguales entre sí.
When crossing two pure lines for a trait, every descendent of the first generation are
hybrid individuals and alike.
2222---- Principio de segregación de alelosPrincipio de segregación de alelosPrincipio de segregación de alelosPrincipio de segregación de alelos
Según La ley de la segregación, Mendel establece que hay caracteres (también
llamados factores hereditarios) dominantes y recesivos que son pasados de forma
aleatoria a la siguiente generación.
According to the Law of Segregation, he established that there are dominant and
recessive traits passed on randomly from parents to offspring.

3333---- Ley de la transmisión independiente de caracteresLey de la transmisión independiente de caracteresLey de la transmisión independiente de caracteresLey de la transmisión independiente de caracteres
Con la ley de la transmisión independiente concluyó que dos caracteres pueden ser
pasados de forma independiente unos de otros a la descendencia. With the Law of
Independent Assortment, Mendel established that two traits were passed on
independently of other traits from parent to offspring.
Ejemplo: Cruzó dos líneas puras para dos caracteres, plantas con semillas amarillas y
lisas (caracteres dominantes) con plantas con semillas verdes y rugosas (caracteres
recesivos). En la primera generación obtuvo descendientes con los caracteres
dominantes: solo consiguió individuos amarillos y lisos. Pero al cruzar entre sí estos
descendientes pudo comprobar que los caracteres recesivos de la otra línea pura
aparecían en la segunda generación filial o F2 en la proporción 9:3:3:1.
El trabajo de Mendel implicó (no en su día, sino años más tarde) una nueva dimensión
en la teoría de la herencia de caracteres. El supuso, según las conclusiones de su
estudio, que los caracteres de la madre o del padre no surgen espontáneamente en la
descendencia, sino que son pasados de padres a hijos aunque los padres no los
presenten. Esto le llevó a la conclusión de que estos caracteres podían ser expresados
o no, pero que ya estaban “dentro” de cada individuo. Hoy día, sabemos que esto es
así ya que cada gen tiene dos “versiones” de sí mismo (los alelos, uno del padre y otro
de la madre) y que estos pueden ser dominantes o recesivos. La herencia de estos
caracteres dominantes o recesivos obedece simples leyes estadísticas.
Mendel´s work had a relevant impact some years later about the inheritance theory of
traits. After examining the results of his crossing experiment, he deduced that many
maternal and paternal traits do not "merge" in the offspring, but are instead passed
intact; that some of these characteristics are dominant while other characteristics are
recessive; and that the inheritance of such traits obeys simple statistical laws

2.2.2.2.---- Human Genome Project: Human Genome Project: Human Genome Project: Human Genome Project:
The goal of the Human Genome Project is to create maps showing where genes are
located on human genes.
a. Period of time: 3 stages (13 years)
� 1990 - 95 � 1993 - 98 � 1998 - 2003
b. Budget: HGP ended up with a final cost of $2.7 billion, $300 million under the initial
budget $3 billion)
c. How many countries were involved?: there were 18 countries working in the HGP.
USA was the coordinator. The rest of the countries who took place were: Australia,
Brazil, Canada, China, Denmark, France, Germany, Israel, Italy, Japan, Korea, Mexico,
The Netherlands, Russia, Sweden and United Kingdom.
3.3.3.3.---- Genetic engineering: recombinant DNA technology and PCR Genetic engineering: recombinant DNA technology and PCR Genetic engineering: recombinant DNA technology and PCR Genetic engineering: recombinant DNA technology and PCR
Recombinant DNA technology:
It’s a technique that allows to isolate a gene from an organism, and to manipulate it,
and to put it in a different organism. The target of this process is that the new
organism is able of producing the searched protein.
1. Firstof all, the desired gene must be located in its DNA molecule.
2. Then the genetic material of both cells is isolated.
3. DNA of the human cell is cut with restriction enzymes (also known as molecular
scissors). They are capable of finding the right place where the wanted gene is held.
4. This fragment is then joined to a vector that carries that gene to the other organism.
It’s joined by ligase enzymes (molecular glue) allowing the gene to be inserted inside
the new host cell.
5. The division of host cells is induced, and that way the cloning of this gene is
produced.

(En español está en el blog)
PCR Polymerase Chain Reaction:
Esta técnica sirve para amplificar un fragmento de ADN. Consta de tres pasos:
� Desnaturalización: calentamiento de la mezcla para separar la doble cadena del
ADN. � Hibridación: Se reduce la temperatura para que se unan las bases de ambos
recipientes en el sitio donde se encuentra una secuencia. � Elongación: Aumenta la temperatura y se replica las hebras de ADN esto hace que
el ADN se extienda.
Es una técnica de biología molecular desarrollada en 1986 por Kary Mullis, cuyo
objetivo es obtener un gran número de copias de un fragmento de ADN particular,
partiendo de un mínimo; en teoría basta partir de una única copia de ese fragmento
original, o molde. Esta tecnología es muy importante necesario para muchas técnicas
de identificación de ADN (criminalística, huella genética, test de paternidad,
enfermedades genéticas, clonación de genes, etc.)
It is a biological molecular technique developed by Kary Mullis in 1986, which objective
is to obtain a huge number of copies of a particular DNA. This technique is used to
amplify a piece of DNA and make easier to identify viruses or bacterium, which is very
important in DNA identification techniques (criminology, genetic footprint, fatherhood
tests, genetic diseases, genes clonation, etc.)
4.- Create a list of the product created from biotechnology techniques:
� Bacteria � Animal and plants � Human beings � Ecosystems
4.1.- Bacteria
Biotechnology industry uses bacterial cells for the production of biological substances
that are useful to human existence, including biofuels, foods, medicines, vaccines,
antibiotics, hormones, enzymes, proteins, and nucleic acids. Other applications have
been industrial, pharmaceutical and food microbiology.

Biotechnology has produced human hormones such as insulin, enzymes such as
streptokinase, and human proteins such as interferon.
4.2.- Animals and plants
PlantPlantPlantPlant products of biotechnology approved for food use have been modified to contain
traits such as:
• Genetically modified crops
• Insect resistance
• Disease resistance
• Herbicide tolerance
• Altered nutritional profile
• Enhanced storage life
Some of the plants used in biotechnology are maize, papaya, cotton, rice, alfalfa,
tomatoes and potatoes.
Genes can be introduced into plants by a bacterium Agrobacterium tumefaciens.
Using A. tumefaciens, plants have been genetically engineered so that they are
resistant to certain pests, herbicides, and diseases.
Some other applications of biotechnology in plants are developments in fields like
agriculture, horticulture, food and food-processing, paper, pulp and timber,
pharmaceuticals, medical, phytoremediation, marine applications, non-food uses of
plants and industrial crops.
AnimalAnimalAnimalAnimal biotechnology is the use of science and engineering to modify living
organisms. The goal is to make products, to improve animals and to develop
microorganisms for specific agricultural uses.
Examples of animal biotechnology include creating transgenic animals (animals with
one or more genes introduced by human intervention).
Some specific genes can be inserted into some animals to produce different
substances of interest, like insulin, grow hormones, enzymes or antibodies.
Another major application of animal biotechnology is the use of animal organs in
humans. Pigs currently are used to supply heart valves for insertion into humans.

4.3.- Human beings
Escherichia coli bacteria, given a copy of the gene for human insulin, can make insulin.
Gene therapy – altering DNA within cells in an organism to treat or cure a disease – is
one of the most promising areas of biotechnology research. New genetic therapies are
being developed to treat diseases such as cystic fibrosis, AIDS and cancer.
DNA testing is also used on human fossils to determine how closely related fossil
samples are from different geographic locations and geologic areas
4.4.- Environment
Bioremediation, Waste treatment and Pollution prevention are widely used as
biotechnology tools.
Environmental engineers use bioremediation in two basic ways. They introduce
nutrients to stimulate the activity of bacteria already present in the soil at a waste site,
or add new bacteria to the soil. The bacteria digest the waste at the site and turn it into
harmless products. After the bacteria consume the waste materials, they die, and the
toxic substance is released from the environment.
Another example is a genetically modified bacteria that degrade petroleum products,
using them in cleanup of oil spills or polluted soils.
5.- Research: Not applicable