generowanie i wizualizacja zbioru mandelbrota na cuda
TRANSCRIPT

Paweł Nowak
Generowanie i wizualizacja zbioru
Mandelbrota na CUDA

Zbiór Mandelbrota (żuk Mandelbrota) -podzbiór płaszczyzny zespolonej, którego brzeg jest jednym ze sławniejszych fraktali. Nazwa tego obiektu została wprowadzona dla uhonorowania jego odkrywcy, francuskiego matematyka Benoit Mandelbrota.
Co to jest zbiór Mandelbrota?

By zdefiniować zbiór Mandelbrota, zdefinujemy najpierw dla danego punktu p na płaszczyźnie zespolonej nieskończony ciąg liczb zespolonych z0, z1, z2, ... o wartościach zdefiniowanych następująco:z0 = 0zn+1 = zn2 + p
Zbiór Mandelbrota (ang. Mandelbrot Set) definiujemy jako zbiór liczb zespolonych p takich, że zdefiniowany powyżej ciąg nie dąży do nieskończoności.
Zbiór Mandelbrota z matematycznego punktu widzenia

Otóż fraktalem jest brzeg tego zbioru. W praktyce by narysować fraktale oblicza się kolejne przybliżenia zbioru, które oznacza się różnymi kolorami. I tak kolejne przybliżenia zdefiniujemy jako zbiór liczb zespolonych p takich, że:
• 1 przybliżenie: wszystkie punkty• 2 przybliżenie: |z1| < 2• 3 przybliżenie: |z1| < 2 oraz |z2| < 2• 4 przybliżenie: |z1| < 2 oraz |z2| < 2 oraz |z3| < 2• ... • n-te przybliżenie: |z1| < 2 oraz |z2| < 2, ... |zn-1|
< 2
Gdzie w tym wszystkim fraktal?

Jak ten fraktal wygląda?

• CUDA (ang. Compute Unified Device Architecture) to opracowana przez firmę Nvidia uniwersalna architektura procesorów wielordzeniowych (głównie kart graficznych) umożliwiająca wykorzystanie ich mocy obliczeniowej do rozwiązywania ogólnych problemów numerycznych w sposób wydajniejszy niż w tradycyjnych, sekwencyjnych procesorach ogólnego zastosowania.
CUDA?

Integralną częścią architektury CUDA jest oparte na języku programowania C środowisko programistyczne wysokiego poziomu, w którego skład wchodzą m.in. specjalny kompilator (nvcc), debugger (cuda-gdb, który jest rozszerzoną wersją debuggera gdb umożliwiającą śledzenie zarówno kodu wykonywanego na CPU, jak i na karcie graficznej), profiler oraz interfejs programowania aplikacji. Dostępne są również biblioteki, które można wykorzystać w językach Python, Fortran, Java, C# oraz Matlab. Pierwsze wydanie środowiska wspierało systemy operacyjne Windows oraz Linux. Od wersji 2.0 wspierany jest również Mac OS X.
Jak programować na CUDA?

• CUDA C rozszerza C pozwalając programiście na definiowanie funkcji C nazywanych kernelami (kernels), które są wykonywane N razy równolegle przez N wątków CUDA
• Kernele są definiowane poprzez dodanie specyfikatora __global__ przy deklaracji. Wywołanie kernelu odbywa się poprzez specjalną konstrukcję wywołania funkcji z modyfikatorem <<…>> w, którym jest podana ilość bloków i wątków, które wywołują kernel
Każdy wątek otrzymuje swoje specyficzne ID, które jest dostępne poprzez strukturę threadIdx
CUDA – Kernele

// Kernel definition __global__ void VecAdd(float* A, float* B, float*C) {
int i = threadIdx.x; C[i] = A[i] + B[i];
}
int main() { ... // Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C); }
CUDA – Kernele - Przykład

Dla wygody, threadIdx jest 3-elementowym wektorem, dlatego wątek może być identyfikowany poprzez 1-wymiarowy, 2-wymiarowy lub 3-wymiarowy indeks wątku, zawarty w 1-wymiarowym, 2-wymiarowym indeksie bloku.Bloki są organizowane w jedno- lub dwuwymiarowym gridzie (sieci)
CUDA – Hierarchia Wątków
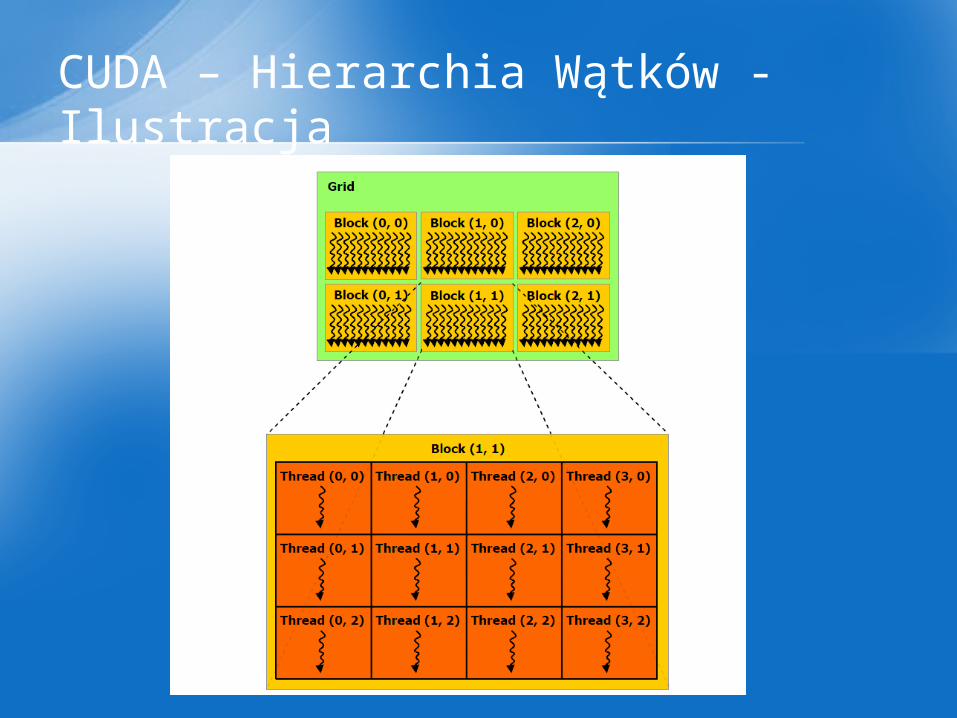
CUDA – Hierarchia Wątków - Ilustracja
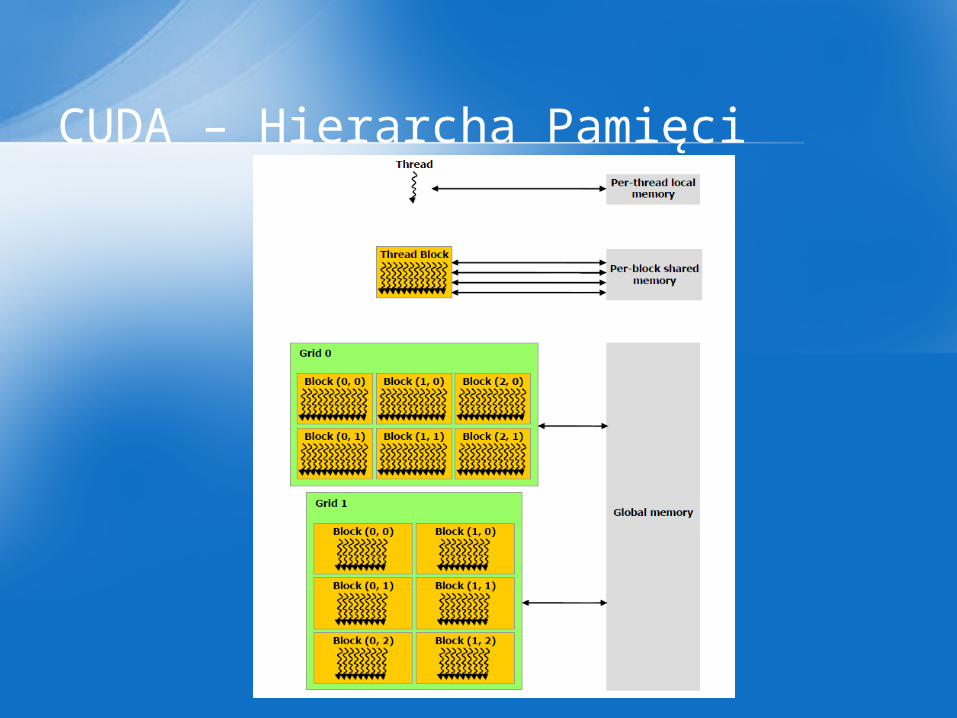
CUDA – Hierarcha Pamięci

• Model programowania CUDA zakłada, że wątki CUDA, są wykonywane fizycznie na innym urządzeniu, które działa jako koprocesor dla hosta. Dlatego kernele wykonują się na GPU, gdy pozostała część kodu wykonuje się na CPU
• Model programowania CUDA zakłada, również, że host i device (GPU) posiadają oddzieloną od siebie własną pamięć RAM. Dlatego nie można dostać się do pamięci GPU z CPU tak po prostu. Należy wykonać funkcję odpowiedzialną za kopiowanie zawartości pamięci
CUDA – Heterogeniczne Programowanie
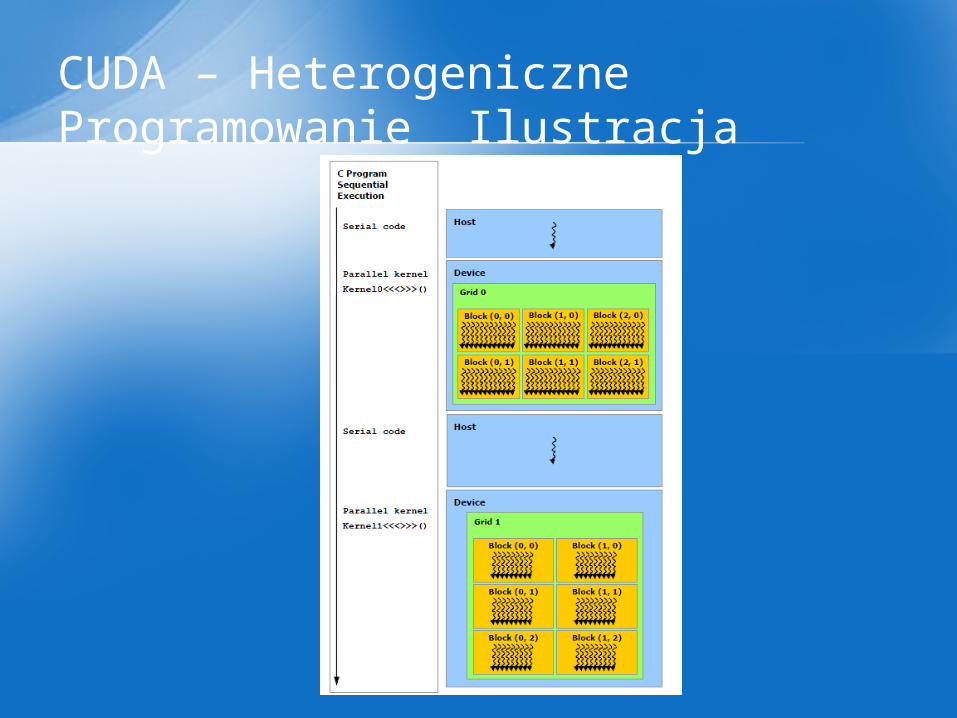
CUDA – Heterogeniczne Programowanie Ilustracja

Architektura CUDA jest zbudowana wokół skalowalnej tablicy wielowątkowych Strumieni Multiprocesorowych. Kiedy grid kernelu jest wywoływany bloki gridu są wyliczane i przekazywane do multiprocesora. Wątki w bloku są wykonywane równocześnie na jednym multiprocesorze, i wiele bloków może być wykonywanych równocześnie na jednym multiprocesorze
CUDA - Architektura

Zamierzam zrównoleglić wyliczanie zbioru Mandelbrota na architekturze CUDA poprzez podzielenie obliczania całej płaszczyzny liczb zespolonych na fragmenty.Byłyby one wyliczane na przez poszczególne bloki wątków.
Zrównoleglenie wyliczania zbioru Mandelbrota
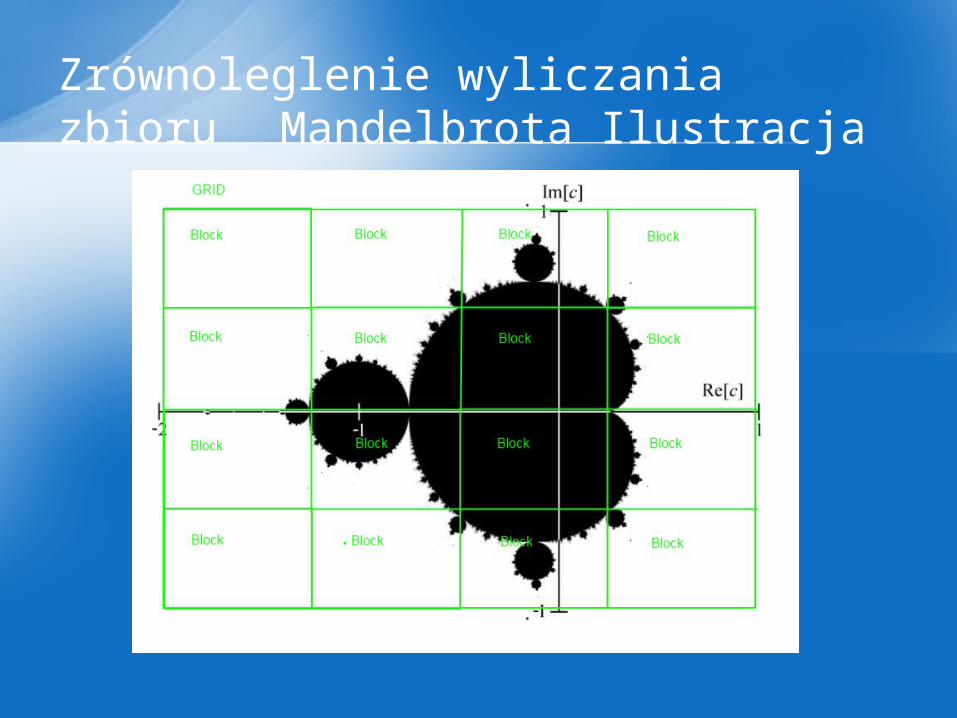
Zrównoleglenie wyliczania zbioru Mandelbrota Ilustracja

Zbiór Mandelbrota:http://en.wikipedia.org/wiki/Mandelbrot_setCUDA:http://www.nvidia.pl/object/cuda_home_new_pl.html
Linki:

Dziękuję za uwagę!
Prezentacja dostępna pod adresem:http://www.slideshare.net/nowy20/generowanie-i-wizualizacja-zbioru-mandelbrota-na-cuda