flat identifiers jennifer rexford advanced computer networks tuesdays/thursdays 1:30pm-2:50pm
TRANSCRIPT

Flat IdentifiersFlat Identifiers
Jennifer RexfordJennifer Rexford
Advanced Computer NetworksAdvanced Computer Networkshttp://www.cs.princeton.edu/courses/archive/fall08/http://www.cs.princeton.edu/courses/archive/fall08/
cos561/cos561/Tuesdays/Thursdays 1:30pm-2:50pmTuesdays/Thursdays 1:30pm-2:50pm

Outline
• Distributed Hash Tables (DHTs)– Mapping key to value
• Flat names– Semantic Free Referencing– DHT as replacement for DNS
• Flat addresses– Routing On Flat Labels– DHT as an aid in routing

Distributed Hash Tables
http://pdos.csail.mit.edu/chord/

Hash Table
• Name-value pairs (or key-value pairs)– E.g,. “Jen” and [email protected]– E.g., “www.cnn.com/foo.html” and the Web
page– E.g., “BritneyHitMe.mp3” and “12.78.183.2”
• Hash table– Data structure that associates keys with
values
lookup(key) valuekey value

Distributed Hash Table
• Hash table spread over many nodes– Distributed over a wide area
• Main design goals– Decentralization: no central coordinator– Scalability: efficient even with large # of
nodes– Fault tolerance: tolerate nodes
joining/leaving
• Two key design decisions– How do we map names on to nodes?– How do we route a request to that node?

Hash Functions
• Hashing– Transform the key into a number– And use the number to index an array
• Example hash function– Hash(x) = x mod 101, mapping to 0, 1, …,
100
• Challenges– What if there are more than 101 nodes?
Fewer?– Which nodes correspond to each hash value?– What if nodes come and go over time?
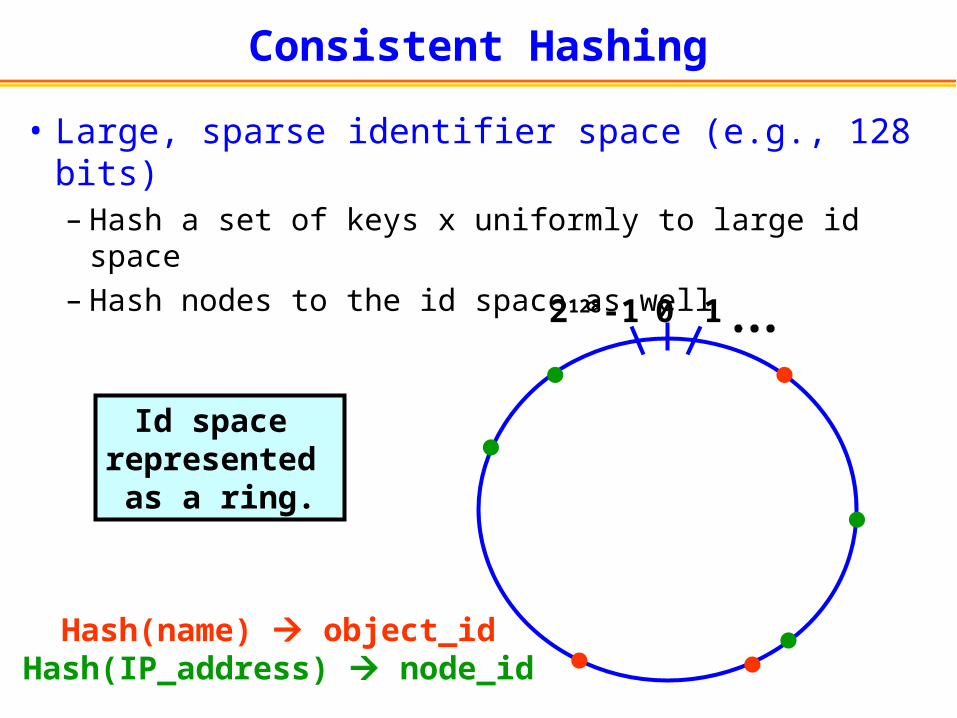
Consistent Hashing
• Large, sparse identifier space (e.g., 128 bits)– Hash a set of keys x uniformly to large id space– Hash nodes to the id space as well
0 1
Hash(name) object_idHash(IP_address) node_id
Id space represented
as a ring.
2128-1

Where to Store (Key, Value) Pair?
• Mapping keys in a load-balanced way– Store the key at one or more nodes– Nodes with identifiers “close” to the key – Where distance is measured in the id
space
• Advantages– Even distribution– Few changes as
nodes come and go…Hash(name) object_id
Hash(IP_address) node_id

Nodes Coming and Going
• Small changes when nodes come and go– Only affects mapping of keys mapped
to the node that comes or goes
Hash(name) object_idHash(IP_address) node_id
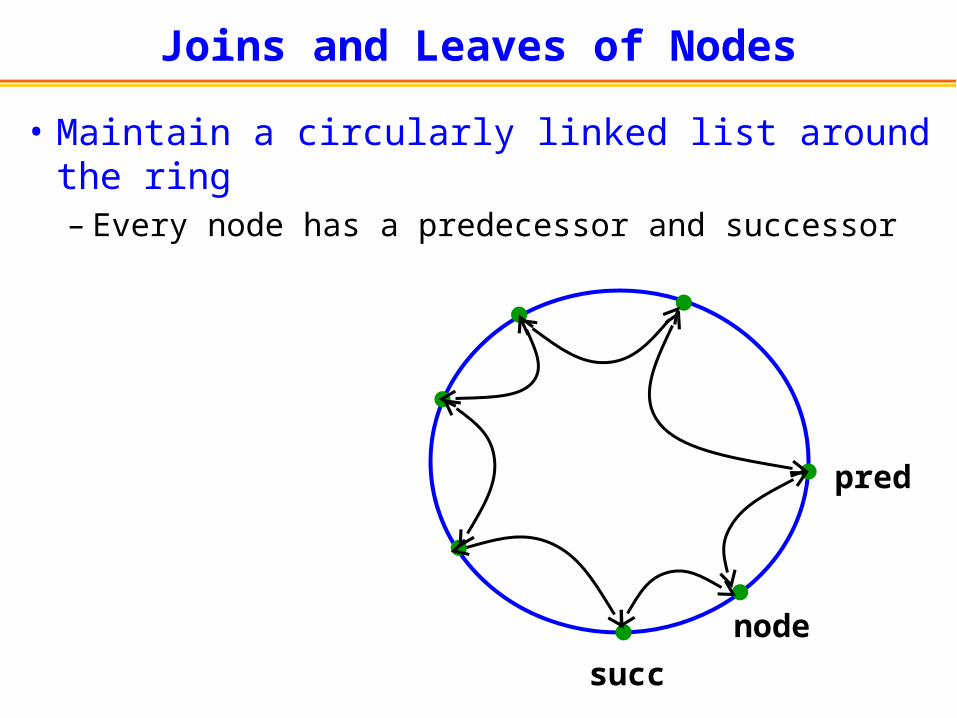
Joins and Leaves of Nodes
• Maintain a circularly linked list around the ring– Every node has a predecessor and successor
node
pred
succ

Joins and Leaves of Nodes
• When an existing node leaves– Node copies its <key, value> pairs to its
predecessor– Predecessor points to node’s successor in the
ring
• When a node joins– Node does a lookup on its own id– And learns the node responsible for that id– This node becomes the new node’s successor– And the node can learn that node’s
predecessor (which will become the new node’s predecessor)

How to Find the Nearest Node?
• Need to find the closest node– To determine who should store (key, value)
pair– To direct a future lookup(key) query to the
node
• Strawman solution: walk through linked list– Circular linked list of nodes in the ring– O(n) lookup time when n nodes in the ring
• Alternative solution: – Jump further around ring– “Finger” table of additional overlay links

Links in the Overlay Topology
• Trade-off # of hops vs. # of neighbors– E.g., log(n) for both, where n is number of
nodes– E.g., overlay links 1/2, 1/4 1/8, … around the
ring– Each hop traverses at least half of the
remaining distance1/2
1/4
1/8

Semantic-Free Referencing(DHT as a DNS Replacement)
http://nms.lcs.mit.edu/projects/sfr/

Motivation for Flat Identifiers
• Stable references– Shouldn’t have to change when object moves
• Object replication– Store object at many different locations
• Avoid fighting over names– Avoid cyber squatting, typo squatting, …
<A HREF=http://isp.com/dog.jpg>my friend’s dog</A>
<A HREF=http://isp.com/dog.jpg>my friend’s dog</A>
<A HREF=http://f0120123112/ >my friend’s dog</A>
<A HREF=http://f0120123112/ >my friend’s dog</A>
Current Proposed

Separate References and User-level Handles
• Let people fight over handles– Do not fight over references– Allow multiple handle-to-reference services
• Flat identifiers– Do not embed object or location semantics– Are intentionally human-unfriendly
Object Location
Human-unfriendly References
User Handles(AOL Keywords,
New Services, etc.)

<A HREF=http://f012c1d/ >Spot</A>
<A HREF=http://f012c1d/ >Spot</A>
Managed DHT-based
Infrastructure
GET(0xf012c1d)
(10.1.2.3, 80, /pics/dog.gif)
o-record
HTTP GET: /pics/dog.gif 10.1.2.3
Web Server
/pics/dog.gif
orec
API• orec = get(tag);• put(tag, orec);Anyone can put() or get()
Semantic-Free Referencing

Resilient Linking
• Tag: abstracts object reachability information
• Object granularity: files, directories, hosts, …
SFR
<A HREF=http://f012012/pub.pdf>here is a paper</A>
<A HREF=http://f012012/pub.pdf>here is a paper</A>
HTTP GET:
/docs/pub.pdf
10.1.2.3
/docs/
20.2.4.6
HTTP GET:
/~user/pubs/pub.pdf(10.1.2.3,80,/docs/)(20.2.4.6,80,
/~user/pubs/)/~user/pubs/

(Doesn’t address massive replication)
Flexible Object Replication
(IP1, port1, path1),(IP2, port2, path2),(IP3, port3, path3),. . .
0xf012012SFR
o-record
• Grass-roots replication– People replicate each other’s content– Does not require control over Web servers

Reference Management
• Requirements– No collisions, even under network partition– References must be human-unfriendly– Only authorized updates to o-records
• Approach: randomness and self-certification– tag = hash(pubkey, salt)– o-record has pubkey, salt, signature– Anyone can check if tag and o-record match

Reducing Latency
• Look-ups must be fast
• Solution: extensive caching– Clients and DHT nodes cache o-records– DHT nodes cache each other’s locations

Routing On Flat Labels(DHT to Help in Routing)

How Flat Can You Get?
• Flat names– DHT as a replacement for DNS
• Stable references, simple replication, avoid fighting
– Still route based on hierarchical addresses• For scalability of the global routing system
• Flat addresses– Avoid translating name to an address– Route directly on flat labels– Questions
• Is it useful?• Can it scale?

Topology-Based Addressing
• Disadvantages: complicates– Access control– Topology changes– Multi-homing– Mobility
• Advantage– Scalability– Scalability– Scalability– …
Area 1
Area 2
Area 4
Area 3
B
J
S
K
Q
F
V
X
A
1.11.2
2.12.2
4.2
4.1
3.33.2
3.1
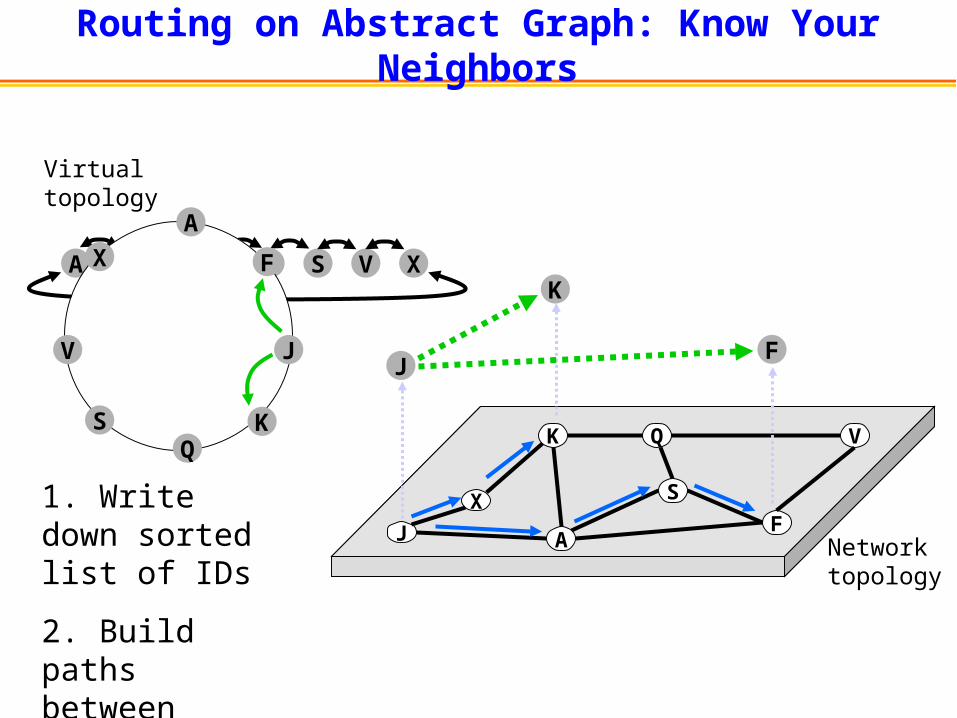
J
K Q
F
V
A
S
Network topology
X
Routing on Abstract Graph: Know Your Neighbors
A F J K Q S V X
J
K
F
1. Write down sorted list of IDs
2. Build paths between neighbors in list
Virtual topology
F
A
J
KQ
V
S
X

J
K Q
F
V
A
S
Network topology
X
Routing on Abstract Graph: Forwarding Packets
Virtual topology
F
A
J
KQ
V
S
X
Send(K,F)
Q
J
K
F

J
K Q
F
V
A
S
Network topology
X
Routing on Abstract Graph: Stretch Problem
Virtual topology
F
A
J
KQ
V
S
X
Send(J,V)
J FA
X
V
Resulting path length: 10 hops
Shortest path length: 3 hops

J
K Q
F
V
A
S
Network topology
X
Routing on Abstract Graph: Short-cutting
Virtual topology
F
A
J
KQ
V
S
X
Send(J,V)
Resulting path length: 4 hops
Shortest path length: 3 hops
J FX
V
A
X

Identifiers
• Identity tied to public/private key pair– Everyone can know the public key– Only authorized parties know the private key
• Self-certifying identifier: hash of public key• Host associates with a hosting router
– Proves it knows private key, to prevent spoofing
– Router joins the ring on the host’s behalf
• Anycast– Multiple nodes have the same identifier

Basic Mechanisms behind ROFL
• Goal #1: Scale to Internet topologies– Mechanism: DHT-style routing, maintain
source-routes to successors (fingers)– Provides: Scalable network routing without
aggregation
• Goal #2: Support for BGP policies– Mechanism: Intelligently choose successors
(fingers) to conform to ISP relationships– Provides: Support for policies, operational
model of BGP

How ROFL Works
ISPISP
0xFA2910x3B57E(joining host)
0x3F6C0
0x3BAC80x3B57E
0x3F6C0
Successor list: 0x3F6C0
Pointer list: 0x3F6C0 0x3BAC8
Pointer cache: 0x3B57E
2. hosting routers participate in ROFL on behalf of hosts
3. hosting routers maintain pointers with source-routes to attached hosts’ successors/fingers
4. intermediate routers may cache pointers
5. external pointers provide reachability across domains
1. hosts are assigned topology-independent “flat” identifiers
0x3BAC8

• Economic relationships: peer, provider/customer
• Isolation: routing contained within hierarchy
hierarchy #1 hierarchy #2 hierarchy #3
customer link
peer link
Internet Policies Today
• Economic relationships: peer, provider/customer
• Isolation: routing contained within hierarchy
prefer customer over peer routes
provider routes must not be exported to peers
Source Destination

Isolation in ROFL
Traffic between two hosts traverses no higher than their lowest common provider in the AS hierarchy
Joininghost
InternalSuccessor
ExternalSuccessor
ExternalSuccessor
Source Destination

Discussion
• How flat should the world be?– Flat names vs. flat addresses?
• What should be given a name?– Objects?– Hosts?– Networks?
• What separation to have?– Human-readable names– Machine-readable references– Network location