etapes d'exécution des...
TRANSCRIPT

4. 1
Etapes d'exécution des instructions
Etapes d'exécution des instructions
Exécution
Ecriture résultat
Recherche opérandes
Recherche instruction

4. 2
Etapes d'exécution des instructions
1. Cycle d'exécution des instructions Modèle de Von Neuman
• Le CPU fait une boucle sans fin pour exécuter le programme chargé en mémoire centrale• Chaque étape correspond à une modification d'un composant du chemin de données (la mémoire ou les registres)• Les étapes dépendent de l'instruction à exécuter : opération à effectuer et mode d'adressage• Quelle que soit l'architecture, on retrouve des étapes similaires (même fonction) mais les étapes dépendent du chemin de données

4. 3
Etapes d'exécution des instructions
©W. Stallings « Computer Organization and Architecture »
lecture enmémoire instructionà l'adresse PC
lecture et interprétationdes champs d'instruction
lecture du ou des opérandes
calculs
écriture des résultats
traitement des interruptionsmatérielles (souris, clavier, ...)conditions d'erreur (division par 0,overflow, ...), défaut de page
calcul de la nouvellevaleur de PC(dépend du format de l'instruction)

4. 4
Etapes d'exécution des instructions
● Lecture d’instruction• Charger le 1er mot d'instruction de la mémoire principale vers le registre d'instruction
● Décodage• Lecture éventuelle des autres mots d'instruction (selon le format)• Ces valeurs sont stockées dans l'unité centrale dans des registres internes (registre
d'opérande et de données)● Recherche d’opérandes
• Accès aux registres (si mode registre)• Calcul d’adresse et recherche d’opérandes mémoire (si mode mémoire)
● Exécution• Calcul dans l’ALU pour les instructions arithmétiques ou logiques• Calcul de l’adresse de branchement pour les instructions de contrôle
● Ecriture résultat• Modification de l’opérande destination pour les instructions arithmétiques ou logiques• Modification de PC pour les instructions de contrôle

4. 5
Etapes d'exécution des instructions
Exemple : PROCSI
MEMOIRE
RD1
ROP PC
BUS
DA
TA
_BU
S
RD2
IR
SR REG
AD
DR
ES
S_B
US
AS
R/W
R/Wreg
CSreg3
16
SP
RAD
donnéesinstructions
DScontrôle

4. 6
Etapes d'exécution des instructionsExemple de décomposition en étapes pour PROCSI
lecture instruction
add R2, # 80
rad pc ir mem[rad]pc pc + 1
rad pc rop mem[rad]pc pc + 1
reg[ir(0..2)] rd1
lecture du 2ème mot d’instruction (constante 80)
rd1 reg[ir(0..2)]rd2 rop
rd1 rd1 + rd2
ir(0..2) : bits 0, 1 et 2 de ir qui contiennent le code du registre destinationreg[ir(0..2)] est le registre destination
lecture du code instruction
décodage
recherche opérande
exécution
écriture résultat
R2 <- R2 + 80

4. 7
Etapes d'exécution des instructions
MEMOIRE
RD1
ROP PC
BUS
DA
TA
_BU
S
RD2
IR
SRREG
AD
DR
ES
S_B
US
AS
R/W
R/Wreg
CSreg3
16
SP
RAD
donnéesinstructions
DS
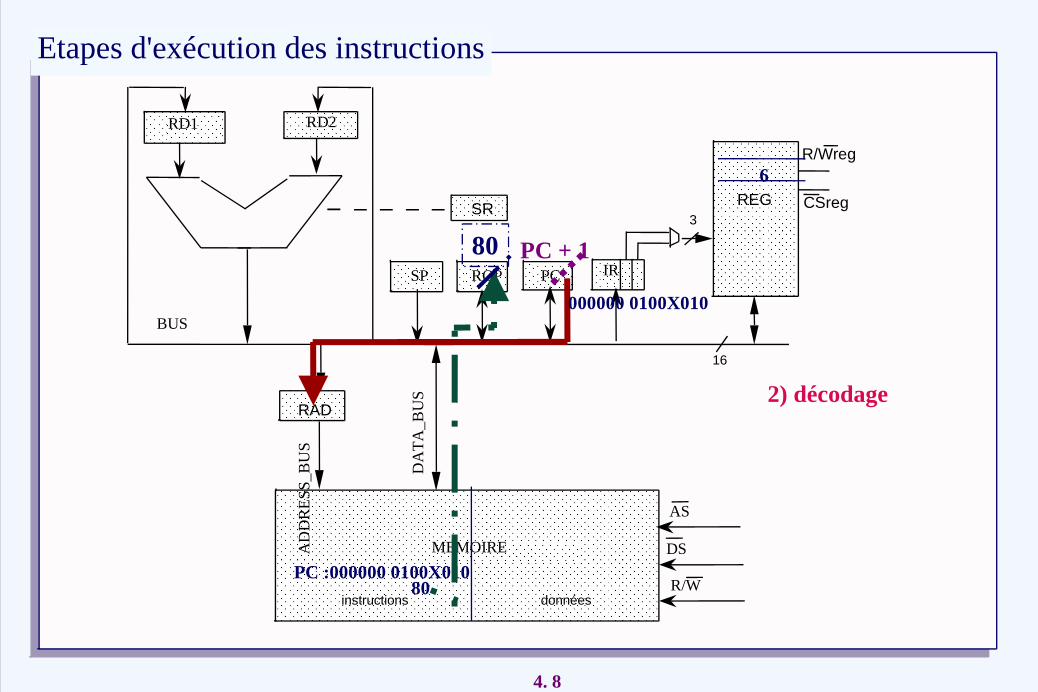
1) Lecture instruction
PC + 1
ADD R2, #80
PC:000000 0100X010 80
6
Légende :
en 1eren 2èmeen 3ème
000000 0100X010
4. 8
Etapes d'exécution des instructions
MEMOIRE
RD1
ROP PC
BUS
DA
TA
_BU
S
RD2
IR
SRREG
AD
DR
ES
S_B
US
AS
R/W
R/Wreg
CSreg3
16
SP
RAD
donnéesinstructions
DS
2) décodage
PC + 1
PC :000000 0100X010 80
80
6
000000 0100X010

4. 9
Etapes d'exécution des instructions
3) recherche opérande
80
010
17
MEMOIRE
RD1
ROP PC
BUS
DA
TA
_BU
S
RD2
IR
SRREG
AD
DR
ES
S_B
US
AS
R/W
R/Wreg
CSreg3
16
SP
RAD
donnéesinstructions
DS
806
6
000000 0100X010
000000 0100X010

4. 10
Etapes d'exécution des instructions
4) Exécution
80
17
MEMOIRE
RD1
ROP PC
BUS
DA
TA
_BU
S
RD2
IR
SRREG
AD
DR
ES
S_B
US
AS
R/W
R/Wreg
CSreg3
16
SP
RAD
donnéesinstructions
DS
6
6 80
+
86
000000 0100X010

4. 11
Etapes d'exécution des instructions
5) Ecriture résultat
80
010
17
MEMOIRE
RD1
ROP PC
BUS
DA
TA
_BU
S
RD2
IR
SRREG
AD
DR
ES
S_B
US
AS
R/W
R/Wreg
CSreg3
16
SP
RAD
donnéesinstructions
DS
86 6
86
000000 0100X010

4. 12
Etapes d'exécution des instructionsExemple de décomposition en étapes pour PROCSI
mem[rad] rd1
add [80], R3
rad pc ir mem[rad]pc pc + 1
rad pc rop mem[rad]pc pc + 1
rd1 reg[ir(3..5)]rad roprd2 mem[rad]
rd1 rd1 + rd2
ir(3..5) : bits 3, 4 et 5 de ir qui contiennent le numéro du registre sourcereg[ir(3..5)] est le registre source (R3 ici)rd2 contient MEM[80]
rop contient 80
lecture instruction
décodage
recherche opérande
exécution
écriture résultat
MEM[80] <- MEM[80] + R3

4. 13
Etapes d'exécution des instructions
2. Cycle d'exécution pipeline
Pour manger : - il faut passer par tous les stands,- 4 personnes sont servies en même temps.
Une personne met 12mn pour être servie.Toutes les 3mn une personne sort de la chaîne.
Durée : 3 mn
Eve
Julie
Anne
Aladin
Sens du parcours

4. 14
Etapes d'exécution des instructions
i
8 ns24 ns24 ns i:
i+1:
i+2:
2 2 2 2
2 2 2 2
2 2 2 2 12 ns12 ns
8 ns 2 2 2 2
i+1
8 ns 2 2 2 2
i+2
8 ns 2 2 2 2
SANS PIPELINE AVEC PIPELINE
• Une instruction est divisée en k étapes indépendantes
• Les étapes de plusieurs instructions s'exécutent en parallèle
• Si une étape dure t unités de temps alors pour n instructions :– sans pipeline : t * k * n unités de temps
– avec pipeline : t * k + t * (n-1) unités de temps
2.1. Les principes

4. 15
Etapes d'exécution des instructions
Contraintes pour que le pipeline soit efficace :
– chaque étape a la même durée : pas d'embouteillage !
– chaque instruction passe par les mêmes étapes : contrôle simplifié, pas de trou dans le pipeline !
Architecture RISC (commercialisé ~ 1986) : ● Jeu d'instructions et modes d’adressage simples,● Accès mémoire par instructions spécialisées (LOAD/STORE),● Débit d'une instruction par cycle : chaque étape dure un cycle donc une instruction sort du pipeline sur chaque cycle
i:
i+1:
i+2:
1 1 1 1
1 1 1 1
1 1 1 1

4. 16
Etapes d'exécution des instructions
Jeu d'instruction RISC
• plus de registres
AMD 64 bits : registres AX, BX, CX, DX, DI, ... étendus à 32 bits (EAX, EBX, ...) et à 64 bits (RAX, ...) + 8 registres R8, ..., R15
• moins de modes d'adressage : instructions de calcul en mode registre + instructions LOAD /STORE
• instructions à 3 opérandes
ARM : add R1, R4, R5
• instructions conditionnelles
AMD 64 bits : cmp eax, ebxbnez suitemov ecx, edx
cmp eax, ebxcmovz ecx, edx

4. 17
Etapes d'exécution des instructions
2.2. Etages de base
• LI lecture d'instruction dans le cache d'instruction
• DE décodage
• CA calcul dans l'ALU (ou calcul d'adresse mémoire ou de branchement)
• MEM accès à la mémoire dans le cache des données (pour les instructions LOAD/STORE)
• ER écriture résultat (modification des registres ou de PC ou du cache de données)

4. 18
Etapes d'exécution des instructions
Numéro d’instruction
Top d’horloge
Etages d’exécution
Sur le top d’horloge 4, il y a exécution en parallèle de l’écriture résultat (ER) de l’instruction i, du calcul (CA) de l’instruction i + 1, du décodage (DE) de l’instruction i+2 et de la lecture (LI) de l’instruction i+3
i:
i+1:
i+2:
i+3:
LI DE CA ER
LI DE CA ER
LI DE CA ER
LI DE CA ER
i:
i+1:
i+2:
i+3:
LI DE CA ER
LI DE CA ER
LI DE CA ER
LI DE CA ER
1 2 3 4 5 6 7
i:
i+1:
i+2:
i+3:
LI DE CA ER
LI DE CA ER
LI DE CA ER
LI DE CA ER
1 2 3 4 5 6 7
Schéma d'exécution temps / étage

4. 19
Etapes d'exécution des instructions
Exemples de pipeline
• Pentium 4 : 20 étages
• AMD 64
– 12 étages pipeline entier et 17 étages pipeline flottant,
– 8 premiers étages = "Fetch/Decode" + "Pack/Decode" et "Dispatch", communs aux entiers et aux flottants
• ARM
– ARM 7, 3 niveaux (lecture d'instruction, décodage, exécution)5
– StrongARM (ARM 8, 9 et SA-1) 5 niveaux (lecture d'instruction, lecture des registres et test de branchement, exécution, écriture cache, écriture registre)

4. 20
Etapes d'exécution des instructions
2.3. Comment ça marche ?
• Chaque étage est “autonome” : il contient les composants nécessaires pour réaliser l'étape d'exécution
– LI: accès à la file d'instructions
– DE : accès aux registres
– CA : unité de calcul
– ER : accès registre et mémoire de données
• Accès en parallèle aux ressources
– Registres : deux accès en lecture et un en écriture simultanément
– Mémoire centrale : cache d'instructions et cache de données
• Deux étages successifs partagent les données
– registres de stockages intermédiaires
– l'étage i écrit le résultat, l'étage i+1 lit le résultat

4. 21
Etapes d'exécution des instructions
PC
Mémoire
Exemple : Exécution de «add R2,R1,R2» suivi de «add R3,R4,R5»
Registres
LI DE CA ER
ALU
Inst Données
R2 <-R1 + R2 R3 < - R4 + R5»
R1=10R2=8R3=0R4=6R5=3

4. 22
Etapes d'exécution des instructions
PC
Mémoire
Registres
LI DE CA ER
ALU
Inst Données
R1=10R2=8R3=0R4=6R5=3
TOP 1
add R2,R1,R2A
dd R
2 R
1 R
2
Exécution de «add R2,R1,R2» suivi de «add R3,R4,R5»
Inst Données

4. 23
Etapes d'exécution des instructions
PC
Mémoire
Registres
LI DE CA ER
ALU
Inst Données
add R3,R4,R5
TOP 2
Add
R3
R4
R5
Add
R2
10
8
accès à R1 et R2
R1=10R2=8R3=0R4=6R5=3
Exécution de «add R2,R1,R2» suivi de «add R3,R4,R5»
Inst Données

4. 24
Etapes d'exécution des instructions
PC
Mémoire
Registres
LI DE CA ER
ALU
Inst Données
R1=10R2=8R3=0R4=6R5=3
TOP 3
Add
R3
6
3
accès à R4 et R5
10 + 8
Add
R2
18
Exécution de «add R2,R1,R2» suivi de «add R3,R4,R5»
Inst Données

4. 25
Etapes d'exécution des instructions
PC
Mémoire
Registres
LI DE CA ER
ALU
Inst Données
R1=10R2=8R3=0R4=6R5=3
TOP 4
accès à R2
18
6 + 3
Add
R3
9
Exécution de «add R2,R1,R2» suivi de «add R3,R4,R5»
Inst Données

4. 26
Etapes d'exécution des instructions
PC
Mémoire
Registres
LI DE CA ER
ALU
Inst Données
R1=10R2=18R3=0R4=6R5=3
TOP 5
accès à R3
9
Exécution de «add R2,R1,R2» suivi de «add R3,R4,R5»
Inst Données

4. 27
Etapes d'exécution des instructions
L'exécution en parallèle rend le contrôle de l'exécution plus complexe :
● Gestion de l'accès simultané aux ressources partagées
Aléas de données : un étage peut lire une donnée avant qu'elle ait été mise à jour
• Gestion des instructions de branchement : les instructions dans le pipeline ne sont pas forcément exécutées
Aléas de contrôle
• Accès à des données d'autres unités fonctionnelles (cas superscalaire)
Aléas structurel
3. Aléas du pipeline

4. 28
Etapes d'exécution des instructions
• lecture avant écriture d’un résultat, • écriture du résultat avant lecture de la donnée (exécution dans le désordre)
Exemple: ADD R1, R2, R3 SUB R4, R1, R5
instructionADD LI DE CA ERSUB LI DE CA ER
Ecriture de R1Ecriture de R1
Aléa de type « lecture avant écriture »
lecture de R1lecture de R1
3.1. Aléas de données

4. 29
Etapes d'exécution des instructions
Solution 1 : suspension d'exécution
ADD R1, R2, R3SUB R4, R1, R5
ADD LI DE CA ERSUB LI DE CA ER
ADD LI DE CA ERSUB LI susp susp DE CA ER
Ecriture de R1Ecriture de R1
lecture de R1lecture de R1
Ecriture de R1Ecriture de R1
lecture de R1lecture de R1

4. 30
Etapes d'exécution des instructions
Solution 2 : bypass
• la sortie de l’ALU est utilisée directementPour l’exemple «add R1,R2,R3» suivi de «add R6,R1,R5», lors du décodage de «add R6,R1,R5», on utilise la valeur de bypass (i.e sortie de l'ALU après calcul de R2 + R3) au lieu d’aller lire la valeur de R1 dans la RAM.
PC
LI DE CA ER
ALUAdd
R6
8
3
accès à R1 et R5
8+0
R1
8
8

4. 31
Etapes d'exécution des instructions
Exemple de bypass avec l'ARM SA-110
Programme
LDR r1,[r0 + 4]
MOV r2,r1

4. 32
Etapes d'exécution des instructions
3.2. Aléas de contrôle Les instructions qui suivent une instruction de branchement (jmp) ne doivent pas être exécutées.Pourtant, elles sont dans le pipeline suspension du pipeline
LI DEi : jmp 360
i + 1
i + 2
i + 3
LI
A la fin du décodage du « jmp » on sait qu’il s’agit d’un saut- il ne faut pas exécuter les instructions suivantes- il faut suspendre l’exécution jusqu’à ce que l’adresse de branchement soit connue → étage ER

4. 33
Etapes d'exécution des instructions
LI DE CA ER i : jmp 360
i + 1
i + 2
i + 3
inst 360
LI susp susp
H 1 2 3 4
susp susp
susp
5
LI DE CA ER
Pénalité de 3 tops d’horloge !!!Pénalité de 3 tops d’horloge !!!
A la fin de l’étage ER du jmp, on connaît l’adresse de branchement (PC a été modifié)→ l’exécution peut reprendre à l'adresse de branchement
Problème : - on a exécuté l'étape LI de i+1 inutilement- l'étape LI est un accès mémoire donc coûteux

4. 34
Etapes d'exécution des instructions
Solution : branchement avec délai
LI DE CA ER jmp 360
i + 1
i + 2
i + 3
LI DE CA ER
susp
susp LI DE CA ER
Toujours exécutéeToujours exécutée
susp
• Si i est une instruction de saut, on exécute toujours l'intruction i+1•Après décodage du jmp, on sait qu’il faut suspendre l’instruction i+2 → pas d’étape LI inutile• Le compilateur se charge de choisir l'instruction qu'il faut placer dans le délai
inst 360

4. 35
Etapes d'exécution des instructions
Branchement avec délai : Optimisation de code
Objectif : remplir au mieux le pipeline tout en gardant la sémantique du programme→ le compilateur « choisit » l’instruction à mettre derrière le branchement → réorganisation du code ou insertion de NOP (instruction "no operation")
ADD R1,R2,R3jmp boucle
délai
NOP
Insertion de NOP
ADD R1,R2,R3 jmp boucle
délai
Instruction avant
jmp boucleADD R1,R2,R3
ADD R1,R2,R3jmp boucle
Généré par compilateur

4. 36
Etapes d'exécution des instructions
on sait dans l’étage DE du bcc si le branchement doit être pris ou non→ avec le délai, on n'a aucune suspension dans le cas où le branchement est pris
LI DE CA ER Bcc 360
i + 1
bcc PRIS
bcc NON PRIS
LI DE CA ER
susp LI DE CA ER
LI DE CA ER
susp
Branchement avec délai: cas des branchements conditionnels (bcc)
inst 360
Inst i + 2
Toujours exécutéeToujours exécutée

4. 37
Etapes d'exécution des instructions
• Dans le cas des branchements conditionnels, pour savoir quelle instruction mettre dans le délai, il faut “décider” si le branchement sera pris ou non : c'est la prédiction de branchement
• Une première prédiction est faite de façon statique (on choisit d'office que le branchement est pris par exemple); le compilateur tient compte de ce choix pour réorganiser le code• Ensuite on corrige les prédictions de façon dynamique : la partie contrôle change la prédiction si elle était mauvaise

4. 38
Etapes d'exécution des instructions
Branchement conditionnel avec délai: Optimisation de codePrédiction STATIQUE
si R2 =0 alorsADD R1,R2,R3
Instruction avant
ADD R1,R2,R3si R1 =0 alors
délai
Instruction cible
MOV R0,R1SUB R5,R6,R7
ADD R1,R2,R3si R1 =0 alorsSUB R5,R6,R7
Instruction après
ADD R1,R2,R3si R1 =0 alors
SUB R5,R6,R7
ADD R1,R2,R3si R2 =0 alors
délaiMOV R0,R1SUB R5,R6,R7
ADD R1,R2,R3si R1 =0 alors
délaiMOV R0,R1SUB R5,R6,R7
MOV R0,R1SUB R5,R6,R7
MOV R0,R1SUB R5,R6,R7
MOV R0,R1
pas de dépendance entre inst. avant et condition de test
dépendance entre inst. avant et condition de test.spéculation branch pris
dépendance entre inst. avant et condition de test.spéculation branch non pris

4. 39
Etapes d'exécution des instructions
Prédiction de branchement DYNAMIQUE : (bas niveau, par la partie contrôle)
Pendant que le processeur travaille, l’unité de pré-extraction des instructions travailleet lit les instructions qu’il faudra exécuter bientôt
→ prédiction spéculative du fait que le branchement courant sera pris ou pas.
Algorithme de Smith (prédiction à 2 bits):
P FP FNP NP
pris
pris prispris
non pris
non pris
non pris non pris
P: PrisFP: Faiblement Pris
FNP: Faiblement Non Pris NP: Non Pris

4. 40
Etapes d'exécution des instructions
Pourquoi tant de mal?
• Instructions de branchement : 20% des instructions d’un programme
• Branchement conditionnel pris dans 60% des cas
• Branchement pris
- des instructions ont été chargées dans le pipeline inutilement (il faut stopper leur exécution)
- l’instruction peut ne pas être dans la file des instructions (ni dans le cache d’instruction, ni dans la mémoire centrale) -> accès disque -> coûteux !
•Branchements avec délais + optimisation de code : dans les DSP (ex : téléphones portables)•Dans les CPU actuels, la prédiction des branchements permet d'anticiper l'exécution dans le désordre

4. 41
Etapes d'exécution des instructions
4. Une version pipeline de PROCSI: PIPSI
• Pipeline de 4 étages: LI (instruction fetch), DE (decode), EX (execute), EC (écriture)
• Opérations arithmétiques/logiques : seulement modes registre/registre et immédiat / registre
• Accès mémoire par instruction load/store en mode direct et indirect
• Toutes les instructions sont codées sur 2 mots de 16 bits
• Cache de données (1 cycle processeur)
• Cache d’instruction (1 cycle processeur)
• Le banc de registres internes (REG) permet 2 accès lecture et un accès écriture simultanément (i.e sur un même top)

4. 42
Etapes d'exécution des instructions
Pcde Pcex
ROP ROPde ROPex
PC
IR Irde Irex
Cache instruction
Cache données
REG
+2
Ad-read1
Ad-read2
RD1
RD2
out1
out2
FEtch DEcode EXecute
resex
ECriture
Dat
a-in
Dat
a-ou
t
in
Ad-write
Add
ress
Dat
a_hi
gh
Dat
a_lo
w
Adr
e ss
33 3

4. 43
Etapes d'exécution des instructions
add R7, #1 FEir <- mem
i[pc]
rop <- memi[pc+1]
pc <- pc + 2
DErd1 <- roprd2 <- reg[ir[0..2]]pc
de <- pc
irde
<- ir
ropde
<- rop
EXres
ex <- rd1 + rd2
pcex
<- pcde
irex
<- irde
ropex
<- ropde
ECreg[ir
ex[0..2]] <- res
ex
store [80], R0 FEir <- mem
i[pc]
rop <- memi[pc+1]
pc <- pc + 2
DErd1 <- reg[ir[3..5]]pc
de <- pc
irde
<- ir
ropde
<- rop
EXres
ex <- rd1
pcex
<- pcde
irex
<- irde
ropex
<- ropde
ECmem
d[rop
ex] <- res
ex
FEaccès mémoire inst.1er mot dans ir2ème mot dans rop
DErecherche d'opérandes
EXcalculslecture mém. data
ECécriture regécriture mém. data