elasticsearch : petit déjeuner du 13 mars 2014
DESCRIPTION
Elasticsearch est un moteur de recherche Open Source très puissant basé sur Apache Lucene. Il permet l'indexation de millions de données, leur recherche et leur analyse en temps réel. Les outils Elascticsearch sont déjà utilisés par des acteurs de référence tels que FourSquare, GitHub, OpenDataSoft ou encore Dailymotion. Alter Way et Elasticsearch vous convient à venir découvrir la suite Elasticsearch enfin disponible en version 1.0 et prête pour la production !TRANSCRIPT


Agenda & Intervenants

Introduction

Alter Way in 2 slides

Alter Way in 2 slides

Elasticsearch in 1 slide
• More than 6 million downloads
• 450,000 New Downloads per Month
• 1000s of Mission Critical Implementations
• Top Investors: Benchmark Capital, Index
Ventures
• Seasoned Executive Team
– Founded by Creator of Elasticsearch
– Seasoned Executives from SpringSource

Les enjeux de la recherche à
l’ère du BigData

Big Data in Todayʼ’s Business and Technology
Environment : some significant figures
• 2.7 Zetabytes of data exist in the digital universe today. (=1 billion Terabytes)
• 235 Terabytes of data has been collected by the U.S. Library of Congress in April
2011.
• Facebook stores, accesses, and analyzes 30+ Petabytes of user generated data.
• Akamai analyzes 75 million events per day to better target advertisements.
• Walmart handles more than 1 million customer transactions every hour, which is
imported into databases estimated to contain more than 2.5 petabytes of data.
• The largest AT&T database boasts titles including the largest volume of data in one
unique database (312 terabytes) and the second largest number of rows in a unique
database (1.9 trillion), which comprises AT&Tʼ’s extensive calling records.
• Hadoop :
– 94% of Hadoop users perform analytics on large volumes of data not possible
before
– 88% analyze data in greater detail;
– while 82% can now retain more of their data.

The Rapid Growth of Unstructured Data
• YouTube users upload 48 hours of new video every minute of the
day.
• 500+ new websites are created every minute of the day.
• Brands and organizations on Facebook receive 34,722 Likes every
minute of the day.
• 100 terabytes of data uploaded daily to Facebook.
• According to Twitterʼ’s own research in early 2012, it sees roughly
175 million tweets every day, and has more than 465 million
accounts.
• 30 Billion pieces of content shared on Facebook every month.
Data production will be 44 times greater in 2020 than it was in 2009. .

Big Data & Real Business Issues
• 25+ % of decision‐makers surveyed predict that data volumes in their
companies will rise by more than 60% by the end of 2014, with the
average of all respondents anticipating a growth of no less than 42 %.
• 40% projected growth in global data generated per year vs. 5% growth in
global IT spending.
• According to estimates, the volume of business data worldwide, across all
companies, doubles every 1.2 years.
– Poor data can cost businesses 20%–35% of their operating revenue.
– Bad data or poor data quality costs US businesses $600 billion annually.
• 75+ % of decision-makers surveyed anticipate significant impacts in the
domain of storage systems as a result of the “Big Data” phenomenon.
• We anticipate a new challenge : to be able to Search and Analyse all
those datas … in real time !

Présentation des
fonctionnalités
d’Elasticsearch, Logstash,
Kibana et Marvel

StartUp
search = like % ?SELECT doc.*, pays.* FROM doc, pays WHERE doc.pays_code = pays.code AND doc.date_doc > to_date('2011-12', 'yyyy-mm') AND doc.date_doc < to_date('2012-01', 'yyyy-mm') AND lower(pays.libelle) = 'france' AND lower(doc.commentaire) LIKE ‘%produit%' AND lower(doc.commentaire) LIKE ‘%david%';

StartUp
Moteur de recherche ?

elasticsearch ?
plug & play
REST/JSON
scalable
Apache 2 license
Lucene
elasticsearch

Start…
$ wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.0.0.tar.gz!$ tar -xf elasticsearch-1.0.0.tar.gz!$ ./elasticsearch-1.0.0/bin/elasticsearch![INFO ][node ][Ghost Maker] {1.0.0}[5645]: initializing

… and play!$ curl -XPUT localhost:9200/sessions/session/1 -d '{! "title" : "Elasticsearch",! "subtitle" : "Make sense of your (BIG) data !",! "date" : "2014-02-13T16:30:00",! "tags" : [ "elasticsearch", "elosi", "cloud" ],! "speaker" : [{! "first_name" : "David", ! "last_name" : "Pilato" ! }]!}'
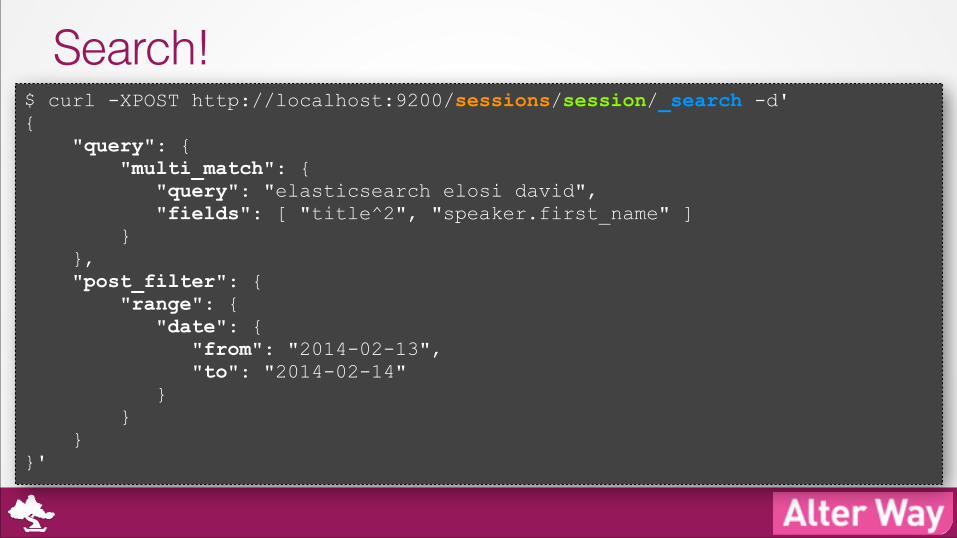
Search!$ curl -XPOST http://localhost:9200/sessions/session/_search -d' { "query": { "multi_match": { "query": "elasticsearch elosi david", "fields": [ "title^2", "speaker.first_name" ] } }, "post_filter": { "range": { "date": { "from": "2014-02-13", "to": "2014-02-14" } } } }'

StartUp
Compute?

$ curl -XPOST http://localhost:9200/sessions/session/_search -d' { "query": { ... }, "aggs": { "by_date": { "date_histogram": { "field": "date", "interval": "day", "format" : "dd/MM/yyyy" } } } }'
"by_date": [ { "key_as_string": "11/02/2014", "doc_count": 1 }, { "key_as_string": "12/02/2014", "doc_count": 2 }, { "key_as_string": "13/02/2014", "doc_count": 3 } ]
Compute!

Let’s make sense of …• logs
• github
• marketing data
• ...
• your data
• your big data

{ "name":"Pilato David", "dateOfBirth":"1971-12-26", "gender":"male", "marketing":{ "fashion":334, "music":3363, "hifi":2351 }, "address":{ "country":"France", "countrycode":"FR", "city":"Paris" } }
Let’s make sense of …• logs
• github
• marketing data
• ...
• your data
• your big data

démo#mstechdays #elasticsearch StartUp
MAKE SENSE OF YOUR (BIG) DATA!
let’s inject some marketing documents…

ELASTICSEARCH
Elastique ? Distribué ?

StartUp
Distributed indices node 1
orders
products
1 2
3 4
1 2
$ curl -XPUT localhost:9200/orders -d '{! "settings.index.number_of_shards" : 4,! "settings.index.number_of_replicas" : 1!}'
$ curl -XPUT localhost:9200/products -d '{! "settings.index.number_of_shards" : 2,! "settings.index.number_of_replicas" : 0!}'

StartUp
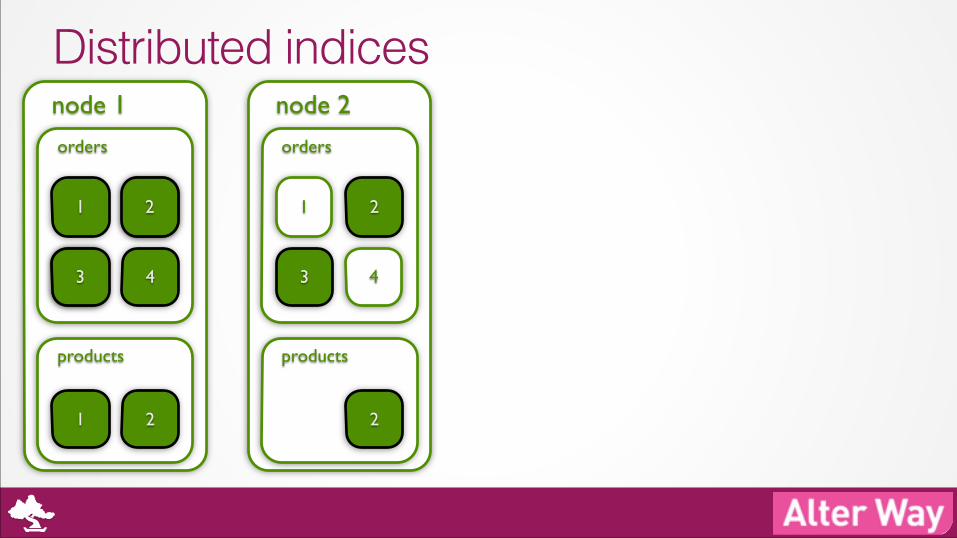
Distributed indices node 1
orders
products
1 2
3 4
1 2
node 2
$ ./elasticsearch-1.0.0/bin/elasticsearch![INFO ][node ][Armageddon] {1.0.0}[5645]: initializing [INFO ][cluster.service][Armageddon] detected_master [Ghost Maker]
StartUp
Distributed indices node 1
orders
products
1
4
1
node 2
orders
products
2
3
2
2
3
1
4
2
3
2

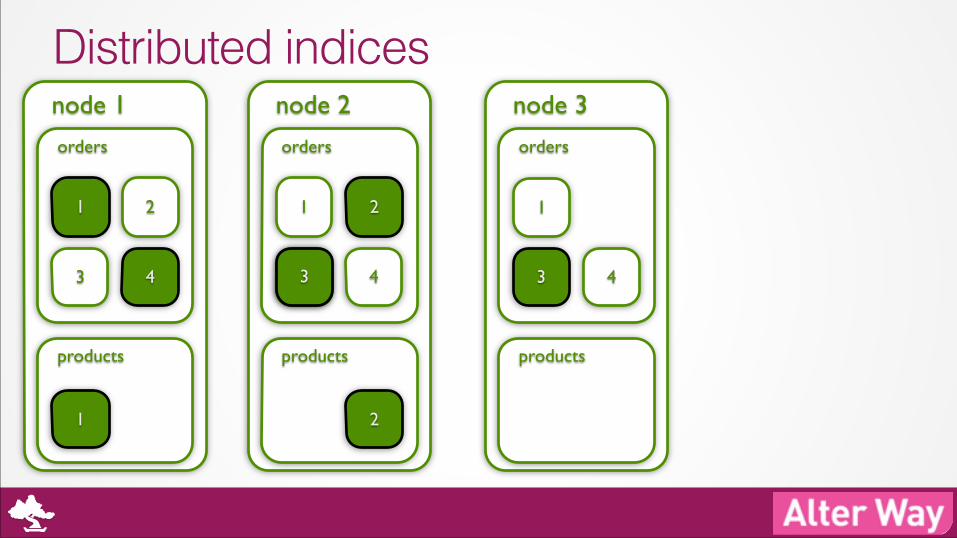
StartUp
node 3
Distributed indices node 1
orders
products
1
4
1
node 2
orders
products
2
3
2
2
3
1
4
$ ./elasticsearch-1.0.0/bin/elasticsearch![INFO ][node ][Karnak] {1.0.0}[5645]: initializing [INFO ][cluster.service][Karnak] detected_master [Ghost Maker]
StartUp
node 3
products
orders
Distributed indices node 1
orders
products
1
4
1
node 2
orders
products
2
33
2
2
3
1
4 3
1
4

elasticsearch.elasticsearch
kibana
logstash
Marvel

Elasticsearch 1.0 : une
solution prête pour la
production !
Revolutionizing Data Search
and Analytics

Purpose of Elasticsearch
• Organize data and make it easily accessible
– Through powerful search and analytics
– Easily consumable (even for non-data scientists)
– Elegantly handles extremely large data volumes
– Delivers results in real time
• Technology stack agnostic
• Used across all market verticals

Features of Elasticsearch
• Structured & unstructured search
• Advanced analytics capabilities
• Unmatched performance
• Real-time results
• Highly scalable
• User friendly installation and maintenance

User: GitHub
Searches 20TB of data, 1.3 billion files and 130
lines of code using Elasticsearch
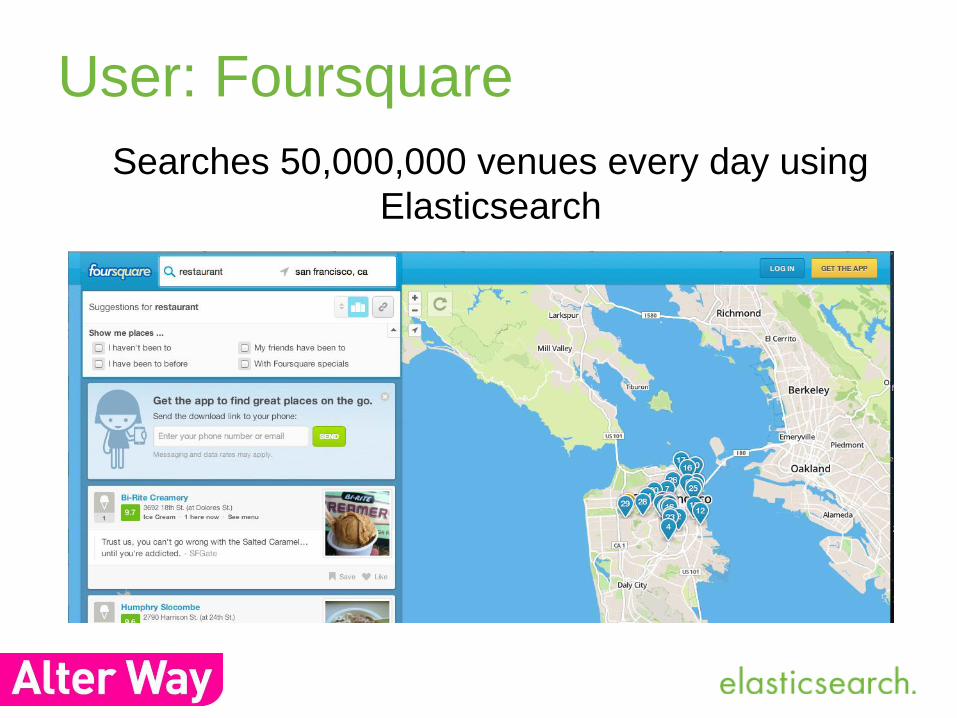
User: Foursquare
Searches 50,000,000 venues every day using
Elasticsearch

User: Fog Creek Software
Searches 40,000,000,000 (40 billion) lines of code
in real-time using Elasticsearch

User: StumbleUpon
Delivers millions of recommendations every day
using Elasticsearch
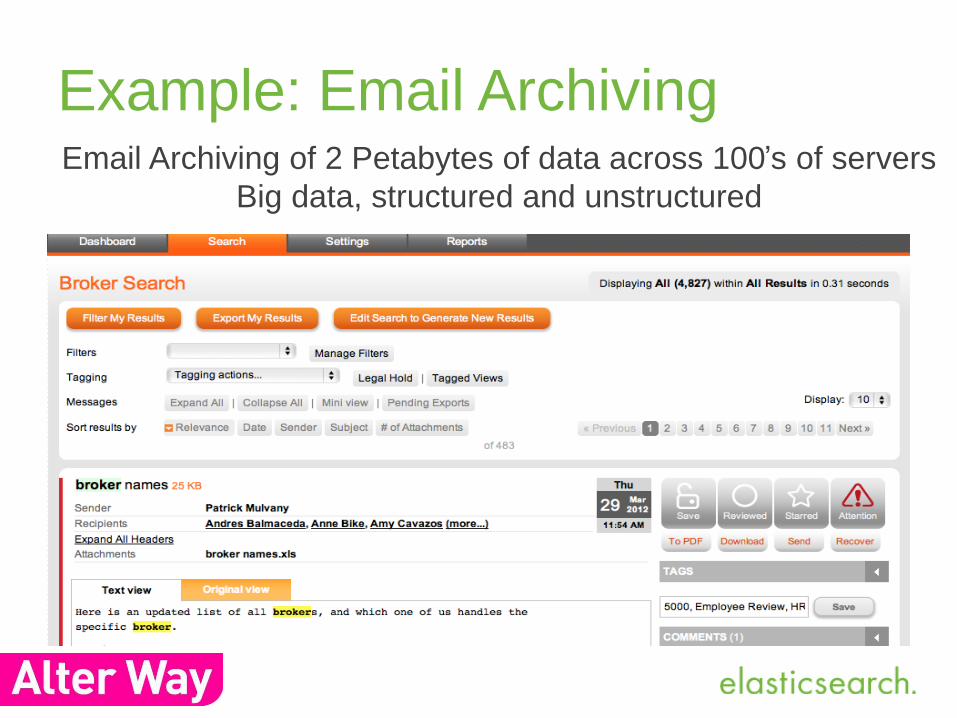
Example: Email ArchivingEmail Archiving of 2 Petabytes of data across 100’s of servers
Big data, structured and unstructured
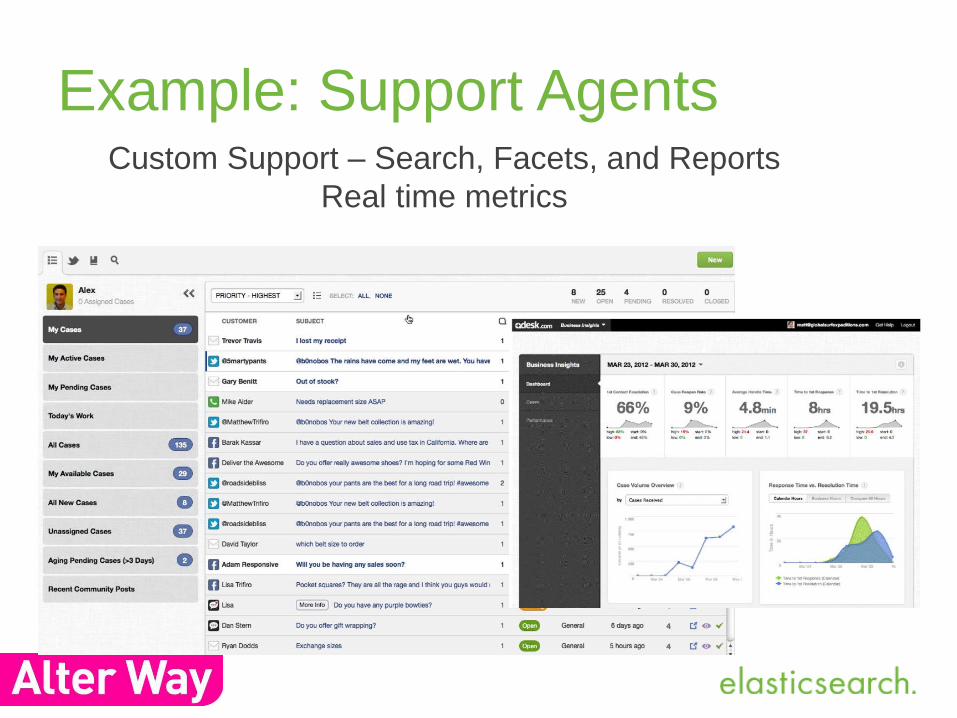
Example: Support AgentsCustom Support – Search, Facets, and Reports
Real time metrics

What’s new in ES 1.0
• Snapshot & Restore
• Distributed Percolation
• Aggregations
• Much more….
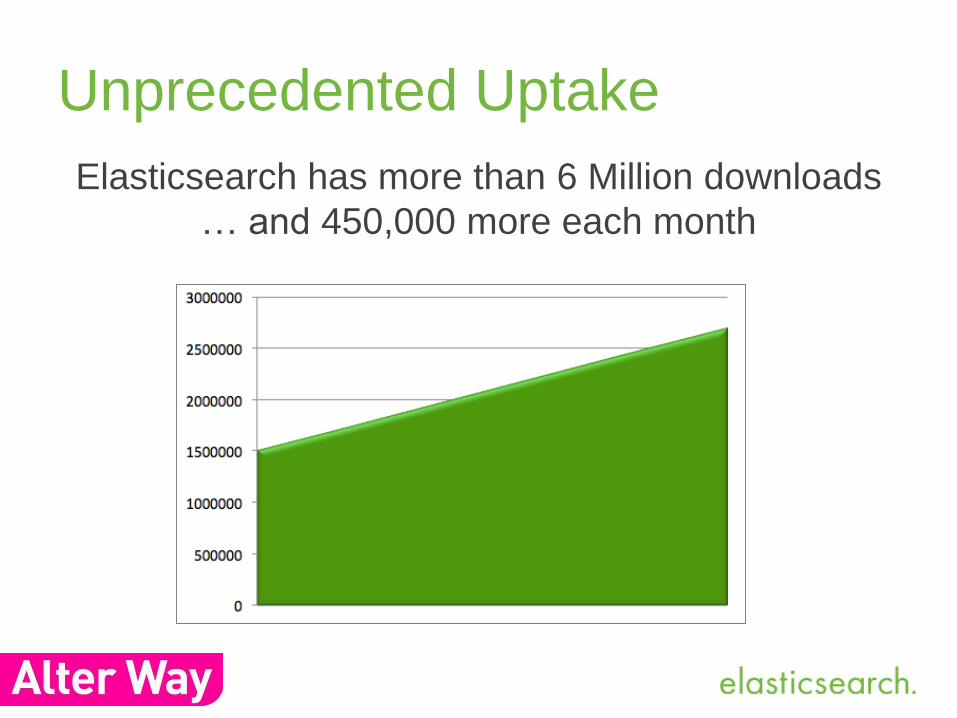
Unprecedented Uptake
Elasticsearch has more than 6 Million downloads
… and 450,000 more each month
Cumulative

Users

User Raves
Chris Cowan @uhduh
I’m in love with @elasticsearch! I want to use it for everything right now!
Alain Richardt @alaincxs
Moving ffrom #solr to # Elasticsearch is like upgrading from a Reliant Robin to a McLaren
F1
Pete Connolly @peteconnolly
Two really useful and productive days of training from @kimchy and @uboness all
about #elasticsearch. Best training course in years
Cyril Lacôte @clacote
#ElasticSearch is the s*&t. Amazingly simple and powerful. Open source is awesome.
That's made my day.
Logan Lowell @fractaloop
Tweaking @elasticsearch for huge indexes can be fun. I'm very glad the IRC channel is
so helpful too.

Product Offerings:Support Throughout Your Project
1. Core Elasticsearch Training
2. Development and Production Support

1: Training
Core Elasticsearch Training
• Two day classroom training
• Delivered by Elasticsearch developers
1. Worldwide Public Courses
2. Onsite Training Course

2: Support

Resources
• www.elasticsearch.com
• www.elasticsearch.org
• User Groups:
http://www.elasticsearch.org/community/forum/
• Contact:
Richard Maurer
Territory Manager

Comment insérer
Elasticsearch dans votre
système d’information et en
tirer le meilleur parti !

Elasticsearch to do What ?

STORE

SEARCH

ANALYZE

Are you ready to use
ElasticSearch in your IT?

Github projects
• Many
project
s
• Great
activity
• Many
langua
ges

Clients

Scripting Plugins Language

Why it ‘s easy

• One to
many
• Zero
conf
• Cloud
oriente
d
• Scalab
ility
Start Small Grow Big

Where / How can you use
ElasticSearch?

VIA
Centralized Log Storage (eg.)

…
CMS Search Engine

• Faceting
• Fuzzy Search
• Speed
• Auto Completion
• Geo Search
• Log Analysis
Ecommerce Enhanced Search
Engine

• REST based
• Memory and I/O efficient
• Adaptive I/O
• Map/Reduce API support
• Pig support
• Hive support
• = elasticsearch-hadoop
Combining Hadoop & ElasticSearch

It’s up to you to decide what to build with ES

Analysis / Dasboards
Some Examples

Kibana examples : IRC Activity
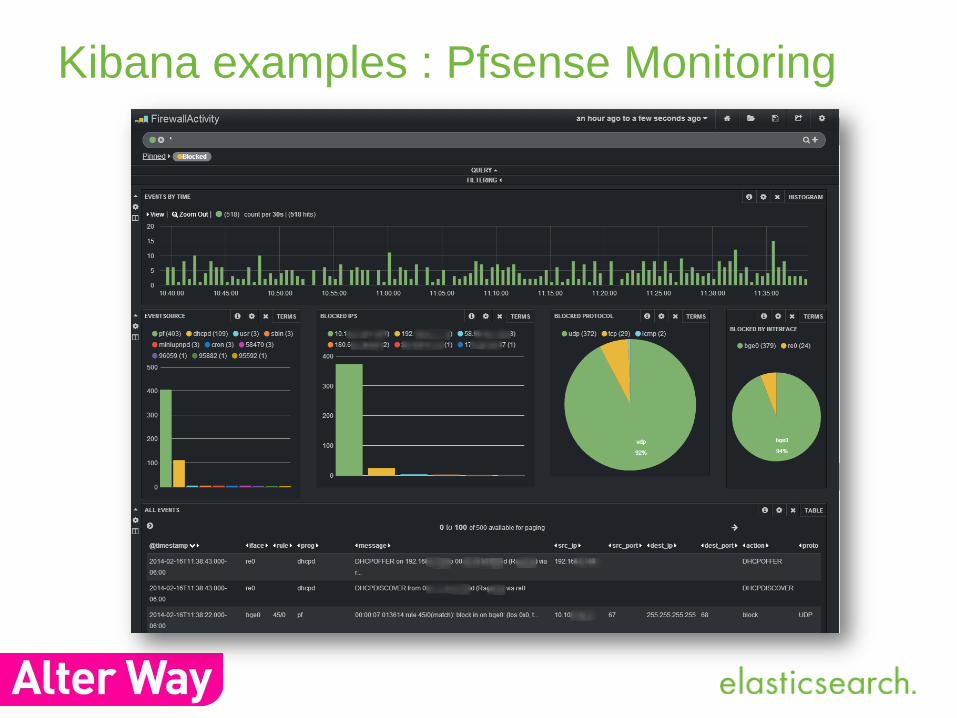
Kibana examples : Pfsense Monitoring
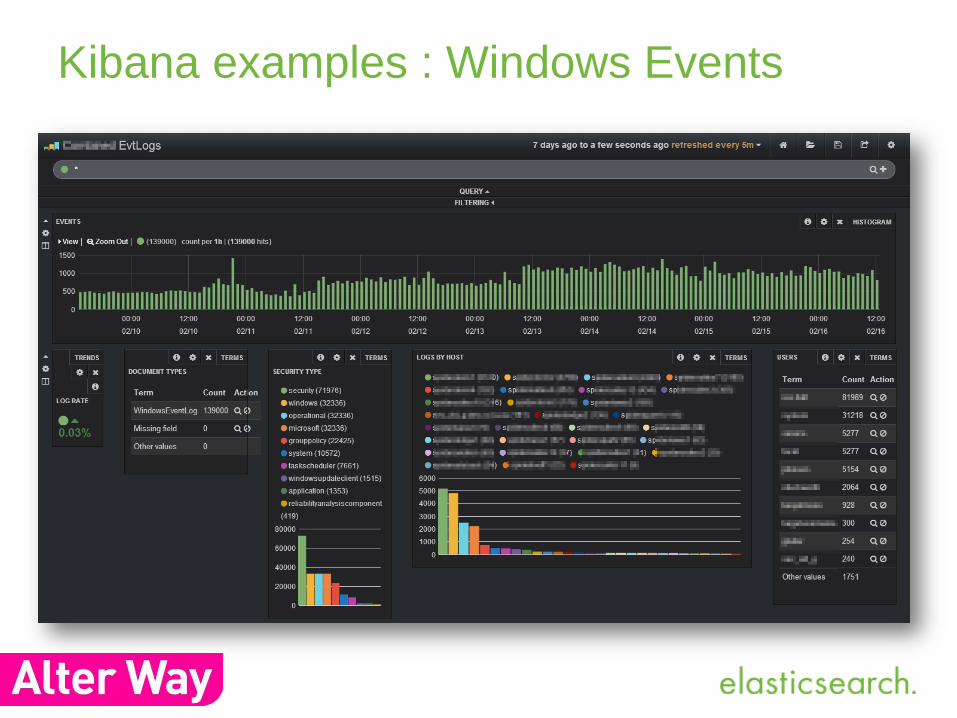
Kibana examples : Windows Events

Kibana examples : Inventory
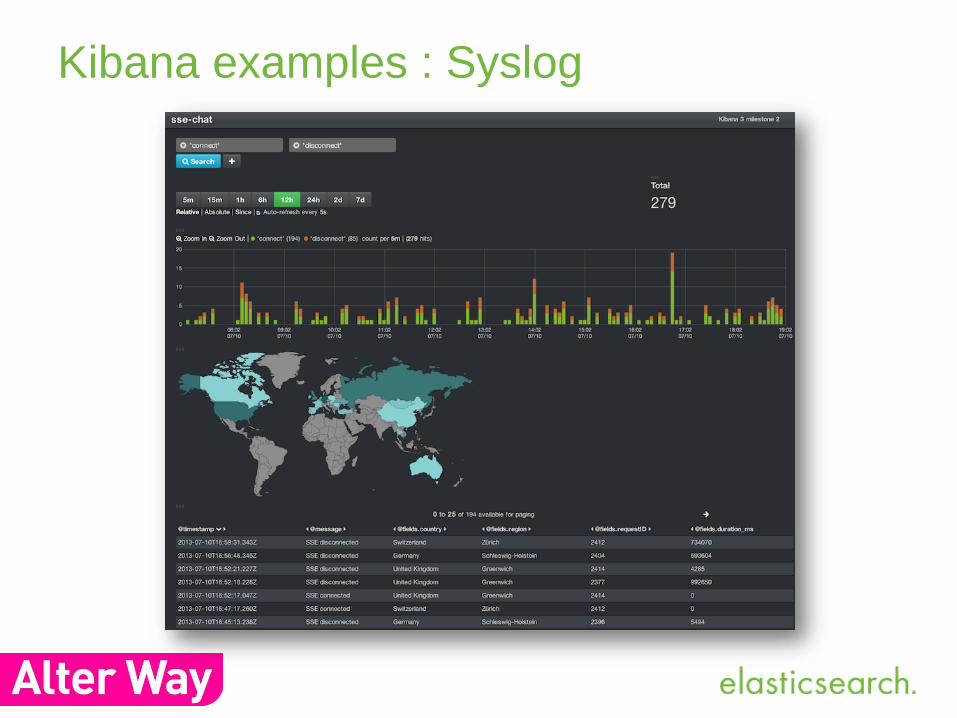
Kibana examples : Syslog

ES = No Limits

Conclusion

Conclusion
• Il est temps de révolutionner la façon dont vous valorisez
vos données : offrez Elasticsearch à vos applicatifs !
• La stack ELK (Elasticsearch, Logstash, Kibana) en
version 1.0 est prête pour la production !
• Faites vous accompagner pour bénéficier des bonnes
pratiques et du support à tous les stades de votre projet :
conception, développement, production

Questions / Réponses