ece 551 digital system design & synthesis lecture 11 verilog design for synthesis
TRANSCRIPT

ECE 551Digital System Design &
Synthesis
Lecture 11
Verilog Design for Synthesis

Topics
Optimization from the Design Level Interaction of Description and Synthesis Critical Path Optimization High-Level Architectures for Datapaths
2

Overview In the previous lecture, we looked at ways
the synthesis tool can automatically optimize our logic
In this lecture, we will look at the ways the designer who is writing the HDL code can optimize and manage trade-offs.
3

Overview How you implement something in Verilog can
have a profound effect on what is actually synthesized (and the effort required to do it!) Functionally identical ≠ identical hardware
To be effective, you need to Know what it is that you are trying to describe (i.e.
not viewing Verilog as an abstract language) Know how the desired hardware should be
organized Know how the synthesis tools will be likely to
implement a given description Describe the hardware in a way that causes the
synthesis tools to do what you want4

Knowing what you want to describe
Case Study: Multiplier
5

4-Input Multiplier
6
module mult(output reg [31:0] out, input [31:0] a, b, c, d);
always@(*) begin out = ((a * b) * c) * d; end
endmodule
What does the below code describe?

Multiplier Implementation
7
Area: 47381 Delay: 8.37
How can we improve the delay and/or area?

Multiplier Redux
8
module multtree(output reg [31:0] out, input [31:0] a, b, c, d);
always@(*) begin out = (a * b) * (c * d); end
endmodule
What are we describing? How will it compare in speed and area?

Tree Multiplier
9
Area: 47590 vs. 47381 Delay: 5.75 vs. 8.37

Multiplier – once again...
10
module multtree(output reg [31:0] out, input [31:0] a, b, c, d);
always@(*) begin out = (a * b) * (c * d); end
endmodule
How can we reduce the area?

Shared Multiplier [1]
11
module multshare(output reg [31:0] out, input [31:0] in, input clk, rst); reg [31:0] multval; reg [1:0] cycle; always @(posedge clk) begin if (rst) cycle <= 0; else cycle <= cycle + 1; out <= multval; end always @(*) begin if (cycle == 2'b0) multval = in; else multval = in * out; endendmodule

Shared Multiplier [2]
12
Area: 15990 vs. 47590 Critical Path Delay: 3.14 Latency: 3.14 * 4
= 12.56 vs. 5.75

Shared Multiplier (cont)
13
module multtree(output reg [31:0] out, input [31:0] a, b, c, d);
always@(*) begin out = (a * b) * (c * d); end
endmodule
Given that only one multiplier will be allowed for the implementation, could we have done better on the latency than the previous example did? At what cost?

Knowing what you want to describe
Lesson: You need to think about what sort of hardware you want to design from the very beginning of the process.
Synthesis tools will only do so much with the descriptions you give them.
14

Knowing what you are describing
Case Study: Mixed Flip-Flops
15

Mixing Flip-Flop Styles (1)
16
module badFFstyle (output reg q2, input d, clk, rst_n); reg q1;
always @(posedge clk) if (!rst_n) q1 <= 1'b0; else begin q1 <= d; q2 <= q1; endendmodule
Say we don’t need to reset q2 What will this synthesize to?
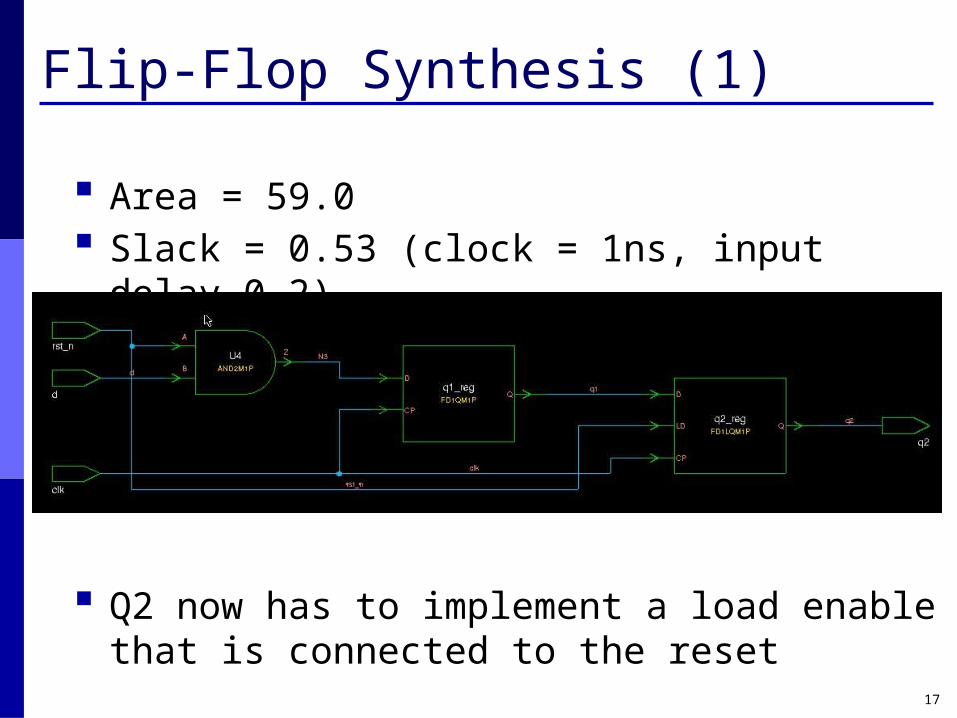
Flip-Flop Synthesis (1)
17
Area = 59.0 Slack = 0.53 (clock = 1ns, input delay 0.2)
Q2 now has to implement a load enable that is connected to the reset

Mixing Flip-Flop Styles (2)
18
module goodFFstyle (output reg q2, input d, clk, rst_n); reg q1; always @(posedge clk) if (!rst_n) q1 <= 1'b0; else q1 <= d;
always @(posedge clk) q2 <= q1;
endmodule

Flip-Flop Synthesis (2)
19
Area = 50.2 (85% of original area!) Slack = 0.53 (unchanged)
Without the load enable function, flip flop Q2 is smaller.
Use reset and enable only when you need them!

Mixing Flip-Flop Styles
20
module badFFstyle2 (output reg q2, input d, clk, rst_n); reg q1;
always @(posedge clk, negedge rst_n) if (!rst_n) q1 <= 1'b0; else begin q1 <= d; q2 <= q1; endendmodule
Would an asynchronous reset have fixed it?

Flip-Flop Synthesis (3)
21
Using asynchronous reset instead Bad: Area = 58.0, slack = 0.57 Good: Area = 49.1, slack = 0.57

Knowing what you are describing
Lesson: If you don’t know the rules of the language, it’s easy to describe something different than what you intended.
Following coding style guidelines makes this easier.
22

Knowing the interpretation
Case Study: Conditional Multiplier
23

Conditional Multiplier [1]
24
module multcond1(output reg [31:0] out, input [31:0] a, b, c, d, input sel);
always @(*) begin if (sel) out = a * b; else out = c * d;end
endmodule
What would you expect this to generate?

Conditional Multiplier [2]
25
Area: 15565 Delay: 3.14
Two 32-bit muxes and one multiplier!
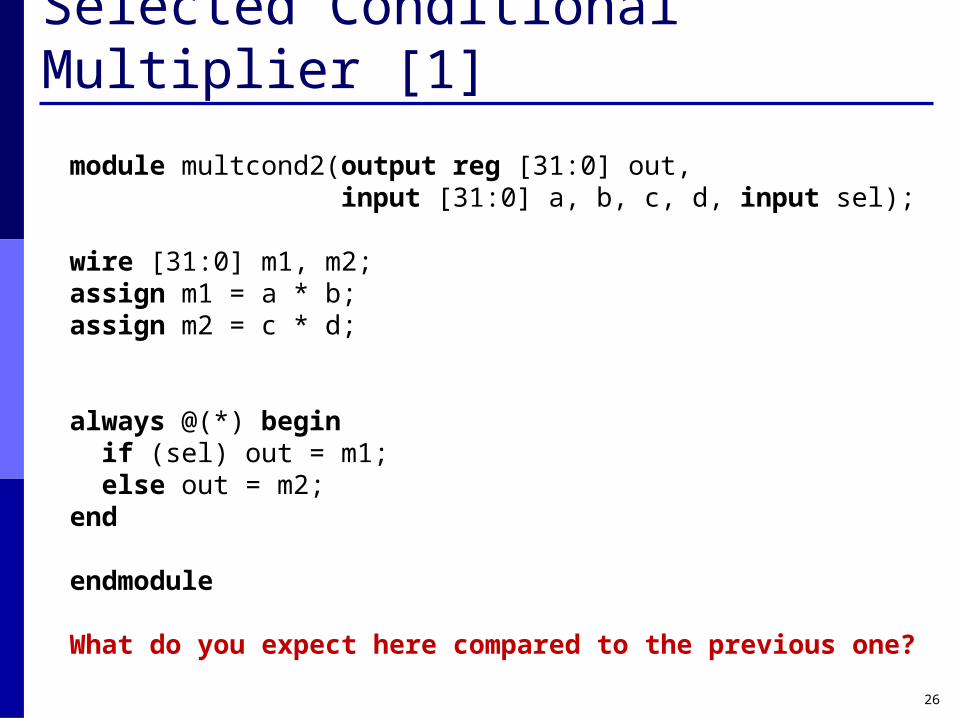
Selected Conditional Multiplier [1]
26
module multcond2(output reg [31:0] out, input [31:0] a, b, c, d, input sel);
wire [31:0] m1, m2;assign m1 = a * b;assign m2 = c * d;
always @(*) begin if (sel) out = m1; else out = m2;end
endmodule
What do you expect here compared to the previous one?

Selected Cond. Mult. [2]
27
Area: 30764 vs. 15565 Delay: 3.02 vs. 3.14 Why is the area larger and
delay lower? 2 multipliers and a 64-bit
mux! So why did that happen?

Resource Sharing Rules
28
Can happen automatically if variable is assigned by multiple expressions (if/else) with the same operation and bit widths NO combinational feedback can be caused Inputs may be reordered to reduce mux area
The Verilog HDL Compiler operates according to the following rules for automatic sharing No sharing in conditional operators
x = s ? (a+b) : (a+c); //will use two adders If/else will permit sharing
Manual control is also available – see reading.

Conditional Multipler – One More Time
29
If you know ahead of time that you want two muxes and one multiplier, describe that directly!
Don’t rely on the synthesis tool to improve inefficient HDL; describe what you want first.
Caveat: You have to know what you want.
module multcond2(output reg [31:0] out, input [31:0] a, b, c, d, input sel);
wire [31:0] op1, op2;assign op1 = sel ? a : c;assign op2 = sel ? b : d;
always @(*) beginout = op1 * op2;
endmodule

Knowing the interpretation
Lesson: Different ways of describing the same behavior in Verilog may lead to different results.
Understanding how the synthesis tool interprets different Verilog constructs is a valuable skill to becoming an expert designer.
30

Knowing the Synthesis Tool
Case Study: Decoder Synthesis
31

Decoder Synthesis
32
Parameterized decoders are commonly written in one of two ways in Behavioral Verilog Use the select input as an index to assert only
the desired output after negating all outputs Test the select input in a loop for all decoder
outputs, and only asserted the matching output
Will this choice affect Circuit delay? Circuit area? Compiler time?
Surprisingly, the answer is: Yes, quite a lot, even though we are trying to describe the exact same hardware!

Decoder Using Indexing
33

Decoder Using Loop
34

Decoder Verilog: Timing Comparison
35

Decoder Verilog: Area Comparison
36

Decoder Verilog: Compile Time Comparison
37

Knowing the Synthesis Tool
Lesson: Never forget that in the end, you are at the mercy of the synthesis tool.
Even when something is part of the Verilog Standard, you can’t always be sure it will be supported (or supported well) by every tool.
This knowledge comes with time. 38

Putting it all Together
If weKnow what hardware we wantKnow how to describe what we wantCan interpret the results we get from
the synthesis tool
Now we can begin making low-level optimizations
39

Late-Arriving Signals After synthesis, we can identify the critical
path(s) that are controlling the overall circuit speed, and which signals are responsible for those path(s).
Assume that one signal to a block of logic is known to arrive after the others. To deal with this:
Circuit reorganization Rewrite the code to restructure the circuit in a
way that minimizes the delay with respect to the late arriving signal
Logic duplication This is the classic speed-area trade-off. By
duplicating logic, we can move signal dependencies ahead in the logic chain.
40

Original Code
41

Original Synthesis
42
What can we do if A is the late-arriving signal?

Reorganized: Operator In if
43
Changed the operation from (A + B) < 24 to A < (24 – B)

Reorganized: New Hardware
44
What’s going on here?

Duplication Example: Original Design
45
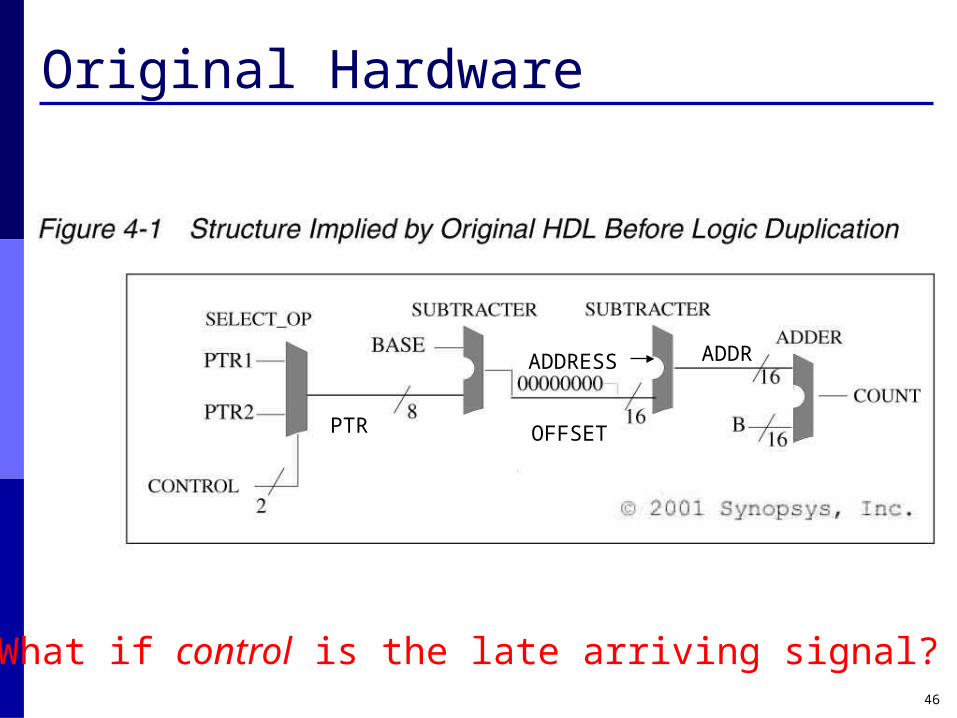
Original Hardware
46
ADDRESS
PTR OFFSET
ADDR
What if control is the late arriving signal?

Data Duplication : New HDL Code
47

Duplication: New Hardware
48
OFFSET1
OFFSET2
ADDR1
ADDR2COUNT2
COUNT1
COUNT1

Exercise
49
Assume we are implementing the below code, and cin is the late arriving signal. How can we optimize the resulting hardware for speed? At what cost?
reg [30:0] a, b;reg [31:0] y;reg cin;
always@(*)y = a + b + cin;

Exercise
50
Rewrite the code below to 1. Minimize area 2. Best performance if sel is late-arriving
reg [3:0] x [3:0];reg [1:0] sel;reg [3:0] y, sum;
always@(*)y = sum + x[sel];

Exercise
51
Revise to maximize performance wrt latereg [3:0] state;reg late, y, x1, x2, x3;always@(*)
case(state)SOME_STATE: if (late) y = x1; else y = x2;default: if (late) y = x1; else y = x3;endcase

52
First, consider how it will synthesize

Optimized Example
53
If you have a small number of case items, the case select signal will be shorter path, but may be a long path with a lot of case items.
For non-parallel case statements, the body of first case item may have a much shorter path than that of the default case.
If it is a parallel case statement, the case select signal will be a short path.
Strategy: If possible, move the late signal to the case select or limit it to the first case item.

Dealing with late signals in Case
54
reg [3:0] state;reg late, y, x1, x2, x3;
always@(*)case(late)
1’b0:if(state == SOME_STATE)y = x2;
elsey = x3;
1’b1: y = x1;endcase

High-Level Datapath Strategies Low-level optimizations can be very valuable,
but from a design perspective, the most important decisions are made at a high level.
Next we will look at three different ways of architecting a datapath and evaluate their trade-offs Single-cycle Multi-cycle Pipelined
55

Single-cycle Multiplier Complete a single computation in one cycle.
56

Multi-cycle Multiplier Spread one operation over multiple cycles. One active computation. Share parts of the datapath to reduce area
57

Pipelined Multiplier Spread one operation over multiple cycles. Multiple active computations. Need extra pipeline registers.
58

Evaluating Tradeoffs Why might we choose one of these over the
other?
Area – self-explanatory Throughput – What is the rate of results?
Product of Frequency and Results/cycle
Latency – How long does it take to produce one result? Product of Frequency and Cycles/computation
59

Single-cycle Multiplier Assume the following delays:
32-bit Mult: 6 ns, 64-bit mult 10 ns, Reg Setup: 2 nsCompute the Throughput and Latency
60

Multi-cycle Multiplier Assume Control Logic not on critical path 128-bit mux: 3 ns, hybrid multiplier: 7 ns
61

Pipelined Multiplier
62

Summary High-Level Strategies for tradeoffs between
Area, Latency, and Throughput Single cycle
Good: latency – (one long cycle) Mixed: throughput - (one output per cycle, but
low freq) Bad: area
Multi-cycle Good: area – (share hardware) Bad: throughput, latency – (<1 output per cycle)
Pipelined Good: throughput – (one output per cycle, high
freq) Bad: latency, area – (multiple cycles, extra
registers)
63

Conclusions The designer is responsible for some
optimizations that cannot be achieved by the synthesis tool.
It takes a lot of knowledge to be an expert designer Hardware Design HDL Synthesis Tool
One of the largest roles of the designer is to understand tradeoffs and make appropriate decisions 64