which attention is needed for implicit sequence learning?
TRANSCRIPT

Journal of Experimental Psychology:Learning, Memory, and Cognition1999, Vol. 25. No. 1, 236-259
Copyright 1999 by the American Psychological Association, Inc.0278-7393/99/S3.00
?Which Attention Is Needed for Implicit Sequence Learning?
Luis Jimenez and Castor MendezUniversidad de Santiago
-The role of attention in implicit sequence learning was investigated in 3 experiments in whichparticipants were presented with a serial reaction time (SRT) task under single- or dual-taskconditions. Unlike previous studies using this paradigm, these experiments included onlyprobabilistic sequences of locations and arranged a counting task performed on the samestimulus on which the SRT task was being carried out. Another sequential contingency wasalso arranged between the dimension to be counted and the location of the next stimulus.Results indicate that the division of attention barely affected learning but that selectiveattention to the predictive dimensions was necessary to learn about the relation between thesedimensions and the predicted one. These results are consistent with a theory of implicitsequence learning that considers this learning as the result of an automatic associative processrunning independently of attentional load, but that would associate only those events that areheld simultaneously in working memory.
This article concerns the question of which attention isnecessary for implicit sequence learning to take place.Starting from Johnston and Dark's (1986) distinction be-tween two different meanings of attention, referred to asmental effort and selective processing, we simultaneouslyinvestigated the role of attention in implicit sequencelearning under each of these two meanings. The results ofthree experiments conducted to analyze these issues revealthat attending to (i.e., selectively processing) the to-be-associated elements is necessary to produce implicit learningof complex sequences embedded in the material of a serialreaction time (SRT) task. On the contrary, decreasingparticipants' attentional resources (i.e., increasing the re-quired mental effort by adding a simultaneous task) pro-duces little or no effects on this form of implicit sequencelearning.
Implicit Learning, Attention, and Automaticity
Implicit learning has typically been defined as the acquisi-tion of knowledge that takes place independent of consciousattempts to learn and largely in the absence of explicitknowledge of what has been acquired (Reber, 1993). Fromthis definition, it has often been suggested that this learningshould be accomplished through automatic learning mecha-nisms (Cleeremans & Jimenez, 1998; Frensch, 1998; Per-
Luis Jimenez and Castor Mendez, Facultad de Psicologfa,Universidad de Santiago, Santiago, Spain.
This work was supported by Grant XUGA21102B93 from theConselleria de Education e Ordenacion Universitaria da Xunta deGalicia (Spain). We thank Axel Buchner for his advice on the use ofthe G • Power program and Maria-Jose Sampedro for assistance indata collection.
Correspondence concerning this article should be addressed toLuis Jimenez, Facultad de Psicologfa, Universidad de Santiago,Santiago, 15706 Spain. Electronic mail may be sent [email protected].
ruchet & Gallego, 1997). However, the issues of automatic-ity have been too problematic in themselves to allow for animmediate appraisal (e.g., J. D. Cohen, Dunbar, & McClel-land, 1990; Logan, 1988), and thus many studies of implicitlearning have taken the somewhat indirect route of assessingthe automatic nature of these processes by analyzing theeffects that several attentional manipulations may produceon these learning results.
The relation between automaticity and attentional issuescan be traced back to the most classic definitions ofautomatic processes. Posner and Snyder (1975), for in-stance, made this relation explicit by simply opposingattentional and automatic processes, hence assuming thatautomaticity should be defined by its opposition to "con-scious attention." Other authors, such as Schneider andShiffrin (1977; see also Schneider, Dumais, & Shiffrin,1984), even though proposing a longer list of characteristicsthat could help in distinguishing between what they calledcontrolled and automatic processing, still suggested a coredefinition of automaticity that precisely fits with the twomeanings of attention distinguished by Johnston and Dark(1986). In their definition, Schneider and his colleaguesclaimed that a process would be automatic (a) if it does notuse general processing resources (i.e., lack of mental effort)or (b) if it runs independent of attentional control, inresponse to external stimulus inputs (i.e., lack of selectiveprocessing).
Empirically, each of these two different meanings ofattention has received an independent methodological treat-ment. On one hand, the view of attention as mental effortderives from the assumption that attentional processing,unlike automatic processing, is limited by some centralresources that should be shared among all concurrent tasks(Cowan, 1988; Schneider etal., 1984). Accordingly, divided-attention and dual-task paradigms assess this attentionaldependence by presenting participants with several simulta-neous stimuli and with simultaneous tasks, and by compar-ing the performance obtained under these conditions with
236

ATTENTION AND IMPLICIT SEQUENCE LEARNING 237
that obtained under comparable conditions in which partici-pants are presented with only a single stimulus and with asingle task.
On the other hand, the notion of attention as a selectiveprocess has to do with the idea that nonautomatic processesneed to be selectively initiated and monitored, whereasautomatic processes run independent of any deliberatedattempt and are just prompted by the external stimulus input.This idea has fostered a number of methodological varia-tions on selective-attention paradigms, in which participantsare typically told to pay attention to only some part of thestimulus display and in which the aim is to find out whetherthe "to-be-ignored" part of the stimulus still affects perfor-mance (e.g., Eriksen & Eriksen, 1974; Stroop, 1935).
Divided Attention and Implicit Learning
The role of attention in implicit learning has usually beenaddressed by relying on divided-attention procedures. Forinstance, the inclusion of a secondary task that requiresparticipants to generate random numbers during the learningphase has been shown to interfere with learning in bothartificial-grammar learning (e.g., Dienes, Altman, Kwan, &Goode, 1995; Dienes, Broadbent, & Berry, 1991) andsystem-control tasks (Hayes & Broadbent, 1988). Likewise,the inclusion of a secondary stimulus (e.g., a tone) and of asecondary task that requires participants to keep a runningcount of the number of target tones presented during an SRTtask has also been found to interfere with learning in atypical sequence learning paradigm (Nissen & Bullemer,1987). Therefore, it would seem that attention as mentaleffort would be necessary even for implicit learning, and thatthe underlying processes could not be considered as auto-matic, judged from this criterion of automaticity.
However, there are at least two alternative interpretationsof these results that would not imply the conclusion thatimplicit learning is affected by the scarcity of attentionalresources. First, it is possible that only explicit learningcould be affected by this lack of resources, but that theinterference effects observed through the measures of perfor-mance would derive from the fact that these measures arenot pure measures of implicit learning, thus being sensitiveto some explicit learning as well (Curran & Keele, 1993;Jimenez, Mendez, & Cleeremans, 1996a, 1996b). Second, itmay also be the case that implicit learning would indeed beaffected by these manipulations, but not because of theirpurported effects on the availability of attentional resourcesbut because of some other effect produced by training underconditions of dual task (Stadler, 1995).
The analysis of these two possibilities has been speciallypursued in the context of sequence learning. In this para-digm, participants are presented with a speeded task duringwhich they have to respond to the location of a targetstimulus appearing on each trial at one of several possiblelocations on a computer screen. The series of locationsfollows a regularity that is not revealed to participants.Although in most studies this series of locations is structuredto follow a fixed and repeating sequence (e.g., Nissen &Bullemer, 1987), some authors have used sequential mate-
rial generated on the basis of a complex set of rules fromwhich one can produce several alternative deterministicsequences (e.g., Lewicki, Hill, & Bizot, 1988; Stadler, 1989)or have based the sequence on the output of probabilistic andnoisy, finite-state grammars (Cleeremans & McClelland,1991; Jimenez et al., 1996a). In general, the results obtainedin each version of this paradigm have uniformly shown thatparticipants' performance with the SRT task expressessensitivity to the sequential constraints regardless of thenature of the generation rules, and that this sensitivity is notnecessarily accompanied by conscious awareness of therelevant sequential constraints when assessed by a compa-rable direct measure. This latter issue, however, remains oneof the most contentious ones in the relevant literature (seeJimenez et al., 1996a; Perruchet & Amorim, 1992; Reed &Johnson, 1994; Shanks & Johnstone, 1998).
The sensitivity of this sequence learning to the availabilityof attentional resources has been frequently addressed in thisparadigm. As described earlier, the secondary task usuallyconsists of asking participants to monitor auditory stimulipresented during the interval between two visual reaction-time (RT) trials. For instance, one can ask participants tokeep a running count of the number of high-pitched tonespresented so far and to report the total number at the end of ablock. The first study to use this methodology was reportedby Nissen and Bullemer (1987), who observed that thepresence of this tone-counting task completely eliminatedthe effect of sequence learning. Thus, they concluded thatattention was necessary for sequence learning to occur.However, subsequent research has led to a significantreappraisal of this conclusion.
A. Cohen, Ivry, and Keele (1990), for instance, observedthat sequence learning could remain unaffected by distrac-tion when the sequence was simple enough; that is, when itcontained at least one simple association between twoconsecutive items. By the same token, Reed and Johnson(1994; see also Shanks & Johnstone, 1998) confirmed thatsequence learning could still be produced under dual-taskconditions, even when more complex sequences containingexclusively "ambiguous" dependencies were presented (i.e.,dependencies such that two previous sequence elements arealways necessary to predict the location of the next one).Other authors (e.g., Frensch, Buchner, & Lin, 1994), how-ever, showed that while learning can indeed take place underboth single-task and dual-task conditions, and for bothsimple and ambiguous sequences, the learning effect wasnevertheless significantly reduced under distraction. There-fore, these results would still be compatible with theconclusion that implicit sequence learning is modulated byhow participants allocate attentional resources.
Other results, finally, have led different authors to rejectthis idea. For instance, Stadler (1995) provided convincingevidence that the effects of the tone-counting secondarytasks were more similar to the effects of disrupting thetemporal organization of the sequence by allowing variabil-ity in the response-stimulus interval (RSI; for similaranalyses of these effects, see also Frensch et al., 1994;Frensch & Miner, 1994) than to the effects of increasing thememory load. Accordingly, Stadler also observed that limit-

238 JIMENEZ AND MENDEZ
ing attentional resources by means of an attentional manipu-lation that did not require continuous monitoring of incom-ing stimuli (i.e., by asking participants to memorize unrelatedmaterial for the duration of the task) produced less interfer-ence effects and that this interference was more specific tothe direct measures. On the basis of these results, heconcluded that implicit sequence learning can be cast as anautomatic process that associates the representations of allevents simultaneously activated in short-term memory, andthat the interference produced by the tone-counting second-ary task may arise from (a) a disruption of the temporalorganization of the sequence and (b) a disruption in theacquisition of explicit knowledge. Willingham, Greenberg,and Thomas (1997) recently observed that, contrary toStadler's proposals, the inconsistency of the RSI could affectonly the expression but not the acquisition of sequencelearning. Frensch, Lin, and Buchner (1998), on the otherhand, similarly observed that the interference produced bydual-task conditions could be restricted to the expression oflearning rather than to the production of an acquisitiondeficit. In any case, these results are all subject to a potentialconfusion between explicit and implicit learning effects,because they use exclusively deterministic sequences.Willingham et al., for instance, considered participants ashaving explicit knowledge only if they correctly producedfive or more consecutive trials from their deterministicsequence. However, many authors have claimed that explicitsequence knowledge can take the form of shorter sequencefragments (i.e., Perruchet & Gallego, 1997), so that it isperfectly possible that participants have explicitly learnedabout some of these fragments, and that the differencesobserved between different RSIs or attentional conditionswould amount to the effects produced by these manipula-tions on either the acquisition or the expression of thisexplicit knowledge.
To confirm the conclusion that neither implicit sequencelearning nor its expression is affected by the inclusion of adual-task procedure, one must therefore find out whether theobserved interference could be reduced or even eliminatedby presenting participants with a sequence that would be lessaccessible to explicit knowledge, and by using less disrup-tive stimuli for the secondary task. To alleviate the disrup-tion without affecting the memory load required by thissecondary task, we propose to perform a counting task onthe same visual stimuli on which the SRT task is beingcarried out, instead of interposing a set of auditory stimuli inthe intertrial intervals. To avoid a conscious apprehension ofthe sequence, on the other hand, we propose to use aprobabilistic sequence generated by a noisy, finite-stategrammar, instead of a fixed, deterministic sequence. Underthese circumstances, if implicit sequence learning could betaken to be an automatic effect of the simultaneous activa-tion of the to-be-associated stimuli, and if explicit learningcould be successfully precluded by the use of probabilisticcontingencies, then one could expect the differences inlearning between single- and dual-task conditions todisappear.
Selective Attention and Sequence Learning
The claim that sequence learning is produced by means ofan automatic associative process does not imply, however,that this process should necessarily associate all the externalinputs in a nonselective fashion, and regardless of partici-pants' attempts to either process or ignore them. On thecontrary, it is reasonable to assume that learning couldassociate only those representations that are simultaneouslyactive and, therefore, that selective attention may be neces-sary to associate the temporally separated events that takepart of a typical sequence learning paradigm. This hypoth-esis, however, has received little empirical interest in theliterature of sequence learning, and there are only somepreliminary results relevant to this point, obtained mostly inthe course of studies that aimed at different issues.
In one of these studies, Willingham, Nissen, and Bullemer(1989) wanted to separate motor from perceptual compo-nents of sequence learning by means of an experiment inwhich they included a perceptual sequence (i.e., a sequenceof locations) in the context of a task that required partici-pants to attend and to respond to another stimulus dimension(i.e., the color of the stimuli). Willingham et al. supposedthat, if sequence learning involved perceptual learning of thesequence of locations, then knowing where the next stimuluswas going to appear would help participants to improveresponse times to the color-discrimination task. The fact thatthere was no evidence of such improvement during thatcolor-discrimination task led Willingham et al. to concludethat sequence learning could not be reduced to this form ofspatial learning. However, one may offer an alternativeaccount to explain these results, by arguing that attending tothe to-be-associated dimensions could be necessary forsequence learning to take place and that participants in thecolor-discrimination task would simply have ignored thespatial dimension.
In a related study, Mayr (1996) argued that this lack ofeffects might also have been due to the facts that (a) stimuluslocations were too near from each other and (b) colordiscriminations were too easy to perform, so that even ifspatial learning had occurred, it would have produced littleeffect on the color-discrimination performance. Accord-ingly, Mayr conducted some experiments in which thelocations were further separated and in which a more
• difficult discrimination combining shapes and colors wasused, requiring participants to produce different orientingresponses to each successive location. Under these circum-stances, Mayr reported that participants could expressspatial learning even in the context of an object-discrimina-tion task.
The difference observed between Mayr's (1996) resultsand those reported by Willingham et al. (1989) can also beaccounted for in terms of the effects of selective attention.Thus, participants in the Willingham et al.'s conditions mayhave failed to learn about the spatial sequence because thespatial dimension was irrelevant for them, but ignoring thisspatial dimension would have been made more difficultunder the conditions established by Mayr, precisely because

ATTENTION AND IMPLICIT SEQUENCE LEARNING 239
the procedural changes were meant to force participants tomake orienting responses and eye movements obligatory.Thus, these procedural changes could have produced theeffect of turning this "irrelevant" spatial dimension into arelevant one, thus forcing participants to pay attention to itand, as a consequence, to produce spatial learning effects.
A simple test that selective attention may be necessary forsequence learning to take jplace was conducted in ourlaboratory, by presenting participants with a typical SRTtask, including either a relatively complex sequence oflocations or a very simple predictive relation establishedbetween another dimension of each stimulus and the loca-tion of the next one (Jimenez, Mendez, & Lorda, 1993). Inthis study, participants saw one colored square, out of fourpossible ones, appearing oh each trial at one of four possiblelocations on the screen. The task was simply to respond onthe key corresponding to the current location of the stimulus,regardless of its color. Unknown to participants, theselocations either followed a 10-trial sequence of locations orwere predictable according to a simple relation establishedbetween the color of each stimulus and the location of thenext one (e.g., green squares were always followed by astimulus in the leftmost location, magenta squares alwayspredicted the next one to appear at the rightmost location,and so on). After 400 trials, participants did not learn aboutthe simple contingencies established between colors andlocations, but they learned about the much more complexsequence of locations.
These results may be taken to indicate that the lack ofattention to the predictive dimension completely preventssequence learning to occur. However, some alternativeexplanations of these results are still possible. For instance,the dimensional switch (i.e., the fact that the next location ispredicted by the previous color, instead of by the previouslocation) might have hindered the associative process ormay at least have slowed it down, as compared with thesimpler case in which previous locations predict the follow-ing ones. According to this reasoning, it would be interestingto separate the effects of dimensional switch from those ofselective attention, by guaranteeing that participants payattention to the predictive dimension, even when it isdifferent from the predicted one. The following experimentswere designed to fulfill this goal by including a secondarytask on this predictive dimension.
Overview of the Experiments
In the present experiments, participants were presentedwith a four-choice RT task. The experiments consisted of 10sessions. Each session consisted of 20 blocks of 155 trialseach, for a total of 31,000 trials over the entire experiment.On each trial, a stimulus consisting of one of four possibleshapes (x, *, ?, !) appeared at one of four locations arrangedhorizontally on a computer screen. Participants were to pressas quickly and as accurately as possible the key correspond-ing to the current location of the stimulus. As in previousexperiments by Cleeremans and McClelland (1991) and byJim6nez et al. (1996a), the sequential structure of thematerial was manipulated by generating the sequence on the
basis of a noisy, finite-state grammar. In addition to theprobabilistic sequence of locations, the shape of the stimulusthat appeared on each trial also bore probabilistic informa-tion about where the next stimulus was going to appear.
In all three experiments, participants were assigned toeither a single-task or a dual-task condition. Participantsassigned to the single-task condition were simply told torespond to the SRT task. By contrast, participants in thedual-task condition were required to respond to the SRT taskwhile they kept a running count of the number of trials inwhich any of two shapes, labeled as target shapes, haveappeared so far, and to report the total number at the end ofeach block. After training with the SRT task, all participantswere exposed to 465 trials of a generation task in which,instead of reacting to the current location of the stimulus,participants were asked to predict the location at which thenext stimulus would appear.
With this basic design, the experiments were aimed atfulfilling two simultaneous goals concerning, first, theanalysis of the effects of dividing attention on the learning ofa complex, probabilistic sequence of locations and, second,the analysis of the effects of selective attention on thelearning of a simpler sequential relationship between shapesand locations. Regarding the first goal, we expected that (a)if implicit sequence learning is not affected by the divisionof attention; (b) if using probabilistic sequential constraintsminimizes the acquisition of explicit knowledge; and (c) ifusing a secondary task performed over the same stimuli thatare used for the SRT task minimizes the disruption producedby interposing new stimuli, then all these circumstanceswould collaborate to decrease and eventually eliminate theeffect of divided-attention conditions on sequence learn-ing (see Cleeremans & Jimenez, 1998; for a convergingattempt).
As for the second goal, the comparison between condi-tions of single and dual tasks enabled us to assess the effectof attending to the relevant predictive dimension (i.e., theshapes) on learning about the sequential contingenciesestablished between shapes and locations. The context of thesecondary task provided a cover story that, presumably,enabled us to guarantee that participants were attending tothe predictive dimension, even though they were not lookingfor prospective sequential contingencies. Besides, the factthat the predictive dimension belonged to the same stimuluson which the SRT task was based might ensure that therelevant perceptual input was produced even under single-task conditions, in which the predictor was not task relevant.Thus, if some implicit sequence learning could proceedautomatically from this perceptual input, it should take placeeven under these conditions and should produce someeffects after extended periods of training.
Finally, there was a third, emergent feature of this designthat might also be of interest from the point of view ofanalyzing the role of attention in sequence learning. Asdescribed in the earlier paragraphs, this general designincluded two different but simultaneous predictors of thesame outcome. That is, for each trial, both a sequencecomposed of some previous locations of the stimuli and theshape of the immediate previous one contained information

240 JIMENEZ AND MENDEZ
that may have helped participants to predict where the nextstimulus was going to appear. This preparation resembledsome simpler cue-competition designs that have been exten-sively used in the conditioning literature since Kamin's(1969) discovery of the blocking effect, and that have oftenbeen accounted for in terms of attentional constraints (e.g.,Baker & Mercier, 1989; Kamin, 1969; Mackintosh, 1975).In this context, it would be interesting to find out whethersimilar cue-competition effects can also be observed underthis implicit learning paradigm.
As far as we know, there is only one study that includedsuch a dual-cue preparation within a sequence learningparadigm (Cleeremans, 1997). In this study, participantswere to respond to the location of a dot that followed asequence generated according to a noisy, finite-state gram-mar. These locations could also be predicted by relying onthe current position of another stimulus (a cross) thatappeared on each trial at the location where the next dot wasgoing to appear. Under these circumstances, Cleeremansfound that the presence of such explicit cue completelyprevented the expression of grammar learning, but he alsoshowed that learning was not affected by this manipulation,because it could be observed during a transfer task in whichthe explicit cue had been removed.
Contrary to this case, however, our experiments did notrequire participants to rely on an explicit cue while learningabout an implicit one, but rather to engage in two simulta-neous processes of learning, both of which entailed theacquisition of predictive relationships concerning the sameoutcome. If these two learning processes did not competewith each other for general resources, and if having theoutcome predicted by one cue did not affect learning aboutthe other, then we would be in a good position to claim thatsequence learning was produced by means of automaticmechanisms.
Experiment 1
In this first experiment, we used the basic design de-scribed earlier to assess the effects that asking participants toperform a counting task on the target shapes would have on(a) learning about the sequential constraints imposed by thefinite-state grammar and (b) learning about the sequentialcontingencies established between shapes and locations. Forshort, we refer to the first type of learning as grammarlearning and to the second as shape learning.
We also wanted to make sure that both sources of learningwere implicit as considered from Reber's (1993) secondcriterion, that is, that they resulted in knowledge that waslargely unconscious. To assess this point, we compared thesensitivity of the indirect measures obtained through theSRT task with a similar, but direct measure of the samesequence learning obtained at the end of training (seeJimenez et al., 1996a, for a thorough discussion of thisstrategy). However, as this matter may seem relativelycollateral to our main goal, we will not report here on thisanalysis.
Method
Participants
Eight students of introductory courses in psychology at theUniversity of Santiago in Spain participated in the experiment.Four were randomly assigned to either the single-task condition(henceforth, Condition S) or the dual-task condition (henceforth,Condition D). Participants were paid about $20 for participating inthe study and could earn an additional $30 to $70 depending onperformance (see below).
Apparatus and Display
The experiment was run on IBM-compatible computers. Thedisplay consisted of four dots arranged in a horizontal line on thecomputer screen and separated by intervals of 3 cm. At a viewingdistance of 57 cm, the distance between any two dots subtended avisual angle of 3°. Each screen position corresponded to a key onthe computer keyboard. The spatial configuration of the keys wasentirely compatible with the screen positions (i.e., the key farthestto the left corresponded to the screen position farthest to the left,etc.). The stimulus was a small white shape 0.35 cm high thatappeared on a black screen and was centered 1 cm above one of thefour dots. The shape could be one of the following four signs: x, *,?, or !. The timer was started at the onset of the stimulus and wasstopped by the participant's response. The participant's responsealso produced the removal of the stimulus. The RSI was 240 ms.
Tasks
The experiment consisted of an SRT task followed by ageneration task. However, as we are not including the discussionabout the generation results here, we restrict the description to thefirst, SRT task. This task was carried out during 10 trainingsessions, each composed of 20 blocks of 155 trials. During thistask, participants were required to respond as fast and as accuratelyas possible on each trial, by pressing the key corresponding to thecurrent location of the stimulus. In addition to this task, participantsin Condition D were also told to perform another task, whichrequired them to keep a running count of the number of "targetshapes" that had appeared so far and to report on that number aftereach block of trials.
Procedure
Each participant performed the task at a rate of two sessions perday. Participants were randomly assigned to one of the twoexperimental conditions. They were told that the goal of the
• experiment was to analyze the effects of extended practice onperformance in relatively simple tasks. They were also informedabout the structure of the experiment and about how to place theirfingers on the keyboard. Both accuracy and speed were emphasizedas means of increasing earnings. Participants assigned to ConditionD were instructed to simultaneously keep a count of the number oftrials of the present block in which either "x" or "*" has occurred.The experimenter emphasized that it was not necessary to separatethe occurrences of "x" from those of "*" but only to keep a countof how many times any one of them had been presented so far in agiven block. Participants were urged to be accurate in performingthis counting task to maintain acceptable earnings. No explicitpriority was established between these two simultaneous tasks, butthe goal of achieving good performance in both of them was highlyemphasized. The identity of the two target shapes [x, *] was

ATTENTION AND IMPLICIT SEQUENCE LEARNING 241
selected arbitrarily and was maintained throughout the experiment.However, as will become apparent when we describe Experi-ment 3, this decision does not seem to have had a substantial effecton the results.
After receiving the instructions appropriate to their condition, allof the participants were given three practice blocks of 15 randomtrials each during which they were given a last chance to askquestions and to interact with the experimenter about the tasksetting. The first experimental session was then initiated. Toeliminate early variability in performance, we began each blockwith a set of 5 random and unrecorded trials. Participants were thenexposed to 150 structured trials. Successive blocks were separatedby a rest break, during which participants in Condition D wereprompted to report on the number of target shapes presented duringthe last block, by entering the number through the keyboard. Thecomputer then displayed the correct number, together with repeatedinstructions about the necessity of being as accurate as possible inresponding to this counting task. After completion of an entiresession, participants were presented with feedback about theirperformance. For participants in Condition S, the computer dis-played information about accuracy and mean RT. For participantsin Condition D, the information about their mean countingaccuracy was also displayed. Likewise, at the end of a session,participants were also shown how much bonus money had beenearned so far in the experiment, according to a formula that, inCondition S, considered accuracy and mean RT. In Condition D,the earnings were also weighted by a term that depended on theaverage counting error.1
Stimulus Generation
Stimuli were generated on the basis of a noisy, finite-stategrammar similar to the one used by Cleeremans and McClelland(1991) and by Jimenez et al. (1996a), with a small proportion ofrandom stimuli (20%) interspersed with structured ones. As shownin Figure 1, the grammar was designed to contain each label in twodifferent arcs, pointing to different successors in each case, so thatconsidering one previous element only indicated that any otherposition (i.e., any other label) was equally likely after the currentone (see Table 1). Repetitions were only allowed in a small numberof trials because of random substitution.
Considering two consecutive elements, however, allowed partici-pants to discriminate on the state of the system, and thus toanticipate the legal successors of each sequence. For instance, thecontext of Locations AC points to Node 3 and thus predicts the nextstimulus to appear at Location D, whereas a similar context such asDC points to Node 0, and correspondingly predicts the appearanceof the next stimulus either at Location A or B (see Figure 1). Giventhat it is always necessary to consider two previous events todiscriminate on the state of the system (i.e., on its current node),
this grammar can be taken, by borrowing A. Cohen et al.'s (1990)terminology, as a probabilistic version of an "ambiguous" se-quence. However, given that (a) knowing the identity of the currentnode did not always completely determine the next location and (b)a proportion of random substitutions were allowed, we could thinkof this structure as more difficult to explicitly break through thanany ambiguous, deterministic sequence.
Stimulus generation proceeded in three phases. First, a sequenceof 30,000 grammatical labels was generated on the basis of thegrammar, by selecting an arc coming out of the current node andrecording the corresponding label on each trial. The current nodewas set to be Node 0 on the first trial of each block and was updatedon each trial to be the node pointed to by the selected arc. Second,there was a 20% chance of substituting a randomly selected label tothe recorded one (identity substitutions were not allowed). Third,the label was used to determine the screen position at which thestimulus would appear by following a 4 X 4 Latin square design, sothat each label corresponded to each screen position for exactly 1 ofthe 4 participants in each condition. Finally, a set of 5 completelyrandom and unrecorded trials were added at the beginning of eachblock of 150 trials to control for initial response variability.
As for the generation of the shapes, it simply proceeded from thetotal sequence of 30,000 labels, with the constraint that each shapeat trial t should predict a specific label (i.e., location) at trial t + 1 in80% of the trials. The mapping between shapes and labels wasselected arbitrarily, and it was as follows: * predicted A; x predictedB; ? predicted C; and ! predicted D. This set of arbitrarycontingencies did not necessarily mean that the two target elements[*, x], which were mapped respectively to Labels A and B, wouldnecessarily predict two consecutive locations. Indeed, as themapping between labels and locations was randomly determined,and it was counterbalanced among participants, these target shapespredicted different screen positions for each participant. Thesepredictive constraints, however, indirectly determined the numberof target shapes that appeared at each block. This number stillvaried from 64 to 94 target shapes per block (roughly from 40% to60% of the trials), with a mean of 77 and a standard deviationof 5.5.
Results
In this section, we analyze grammar and shape learning inturn, by comparing participants' responses to trials that wereeither accurately predicted or nonpredicted by each of thesetwo types of cues. As a preliminary observation, however, itis interesting to point out that participants in Condition Dperformed the counting task with great accuracy. Eventhough there were obvious differences through blocks,sessions, and participants, the worst level of performanceproduced by a single participant throughout a sessionresulted in a mean counting error of only 2.7 per block,which amounts to a pretty good level of performance, andcan be taken as an indication that participants assigned
Figure 1. Finite-state grammar used to generate the stimulusmaterial.
1 The formula used to determine earnings for each session was:E = (ACC - 84) X (880 - RT) X .078 for Condition S, and E =(ACC - 84) x (880 - RT) X .078 X ((15 - Error)/10) forCondition D, where E represents earnings, ACC represents percent-age of hits for the SRT task within that session, RT stands for theaverage reaction time, and Error represents the counting error perblock averaged over the 20 blocks of that session.
242 JIMENEZ AND MENDEZ
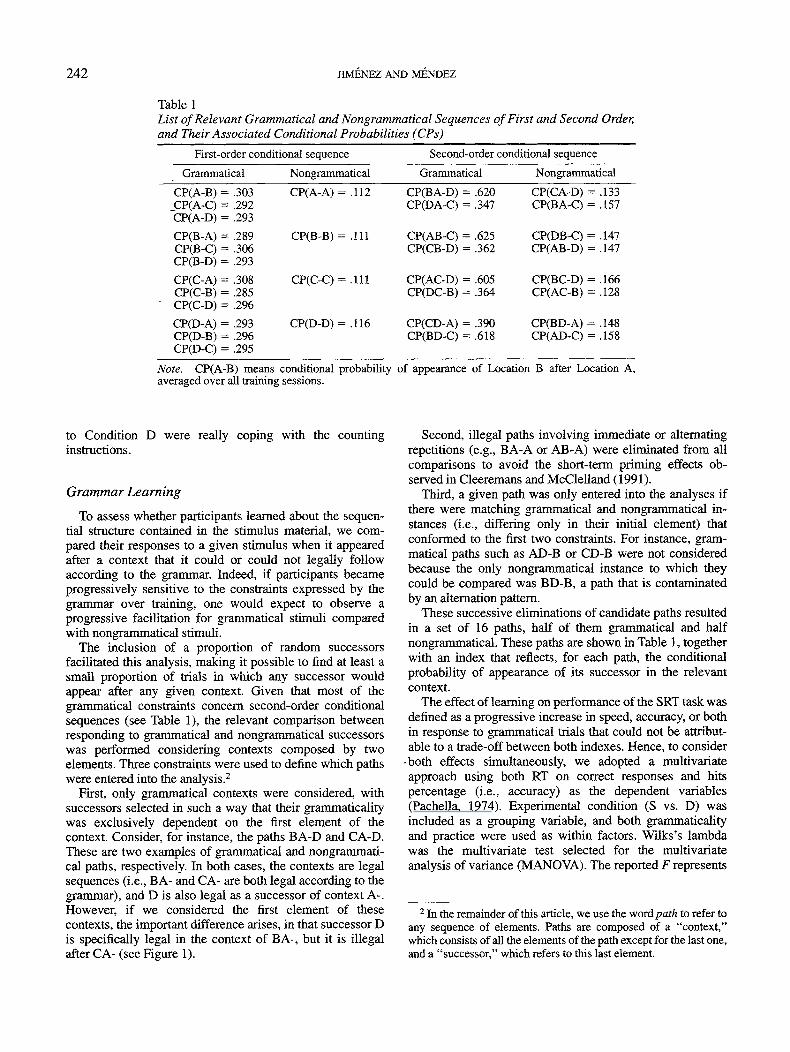
Table 1List of Relevant Grammatical and Nongrammatical Sequences of First and Second Order,and Their Associated Conditional Probabilities (CPs)
First-order conditional sequence Second-order conditional sequence
Grammatical Nongrammatical Grammatical Nongrammatical
CP(A-B) = .303CP(A-C) = .292CP(A-D) = .293
CP(B-A) = .289CP(B-C) = .306CP(B-D) = .293
CP(C-A) = .308CP(C-B) = .285CP(C-D) = .296
CP(D-A) = .293CP(D-B) = .296CP(D-C) = .295
CP(A-A) = .112
CP(B-B) = .111
CP(C-C) = .111
CP(D-D) = .116
CP(BA-D) = .620CP(DA-C) = .347
CP(AB-C) = .625CP(CB-D) = .362
CP(AC-D) = .605CP(DC-B) = .364
CP(CD-A) = .390CP(BD-C) = .618
CP(CA-D) = .133CP(BA-C) = .157
CP(DB-C) = .147CP(AB-D) = .147
CP(BC-D) = .166CP(AC-B) = .128
CP(BD-A) = .148CP(AD-C) = .158
Note. CP(A-B) means conditional probabilityaveraged over all training sessions.
of appearance of Location B after Location A,
to Condition D were really coping with the countinginstructions.
Grammar Learning
To assess whether participants learned about the sequen-tial structure contained in the stimulus material, we com-pared their responses to a given stimulus when it appearedafter a context that it could or could not legally followaccording to the grammar. Indeed, if participants becameprogressively sensitive to the constraints expressed by thegrammar over training, one would expect to observe aprogressive facilitation for grammatical stimuli comparedwith nongrammatical stimuli.
The inclusion of a proportion of random successorsfacilitated this analysis, making it possible to find at least asmall proportion of trials in which any successor wouldappear after any given context. Given that most of thegrammatical constraints concern second-order conditionalsequences (see Table 1), the relevant comparison betweenresponding to grammatical and nongrammatical successorswas performed considering contexts composed by twoelements. Three constraints were used to define which pathswere entered into the analysis.2
First, only grammatical contexts were considered, withsuccessors selected in such a way that their grammaticalitywas exclusively dependent on the first element of thecontext. Consider, for instance, the paths BA-D and CA-D.These are two examples of grammatical and nongrammati-cal paths, respectively. In both cases, the contexts are legalsequences (i.e., BA- and CA- are both legal according to thegrammar), and D is also legal as a successor of context A-.However, if we considered the first element of thesecontexts, the important difference arises, in that successor Dis specifically legal in the context of BA-, but it is illegalafter CA- (see Figure 1).
Second, illegal paths involving immediate or alternatingrepetitions (e.g., BA-A or AB-A) were eliminated from allcomparisons to avoid the short-term priming effects ob-served in Cleeremans and McClelland (1991).
Third, a given path was only entered into the analyses ifthere were matching grammatical and nongrammatical in-stances (i.e., differing only in their initial element) thatconformed to the first two constraints. For instance, gram-matical paths such as AD-B or CD-B were not consideredbecause the only nongrammatical instance to which theycould be compared was BD-B, a path that is contaminatedby an alternation pattern.
These successive eliminations of candidate paths resultedin a set of 16 paths, half of them grammatical and halfnongrammatical. These paths are shown in Table 1, togetherwith an index that reflects, for each path, the conditionalprobability of appearance of its successor in the relevantcontext.
The effect of learning on performance of the SRT task wasdefined as a progressive increase in speed, accuracy, or bothin response to grammatical trials that could not be attribut-able to a trade-off between both indexes. Hence, to consider
•both effects simultaneously, we adopted a multivariateapproach using both RT on correct responses and hitspercentage (i.e., accuracy) as the dependent variables(Pachella, 1974). Experimental condition (S vs. D) wasincluded as a grouping variable, and both grammaticalityand practice were used as within factors. Wilks's lambdawas the multivariate test selected for the multivariateanalysis of variance (MANOVA). The reported F represents
2 In the remainder of this article, we use the word path to refer toany sequence of elements. Paths are composed of a "context,"which consists of all the elements of the path except for the last one,and a "successor," which refers to this last element.
ATTENTION AND IMPLICIT SEQUENCE LEARNING 243
Reaction Time
350 -
Percentage of Hits
4 5 6 7
Trials (x 3100)
Accuracy
10
3 4 5 6 7Trials (x3100)
10
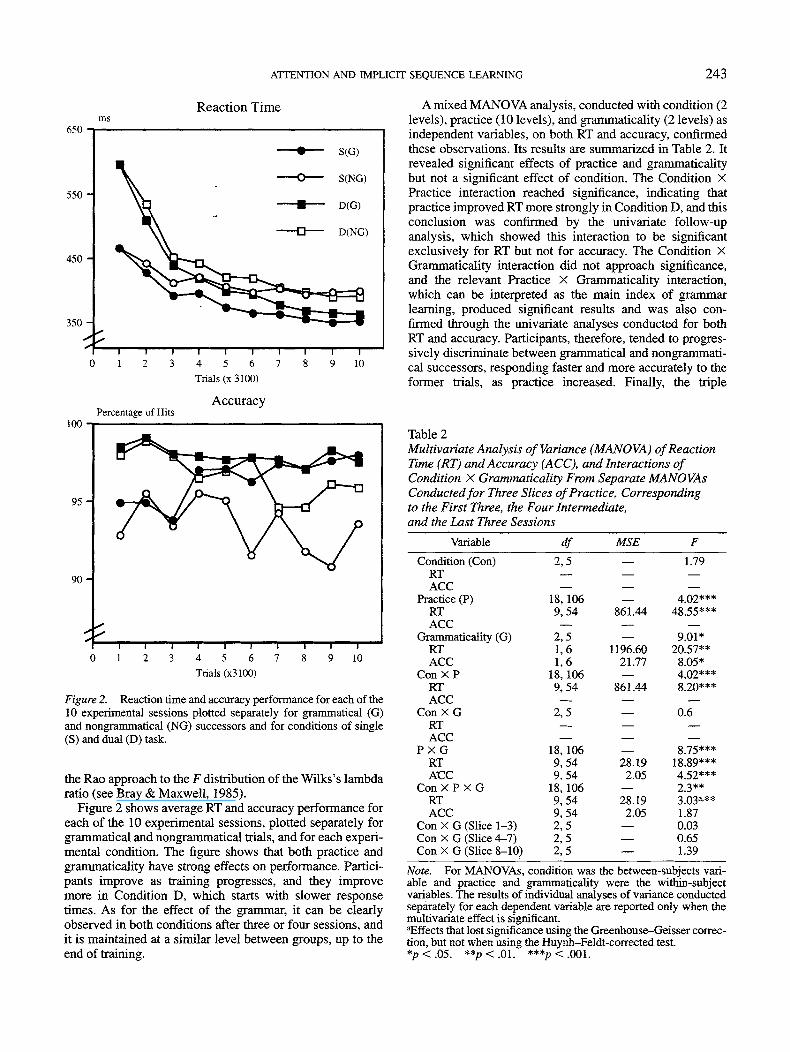
Figure 2. Reaction time and accuracy performance for each of the10 experimental sessions plotted separately for grammatical (G)and nongrammatical (NG) successors and for conditions of single(S) and dual (D) task.
the Rao approach to the F distribution of the Wilks's lambdaratio (see Bray & Maxwell, 1985).
Figure 2 shows average RT and accuracy performance foreach of the 10 experimental sessions, plotted separately forgrammatical and nongrammatical trials, and for each experi-mental condition. The figure shows that both practice andgrammaticarity have strong effects on performance. Partici-pants improve as training progresses, and they improvemore in Condition D, which starts with slower responsetimes. As for the effect of the grammar, it can be clearlyobserved in both conditions after three or four sessions, andit is maintained at a similar level between groups, up to theend of training.
A mixed MANOVA analysis, conducted with condition (2levels), practice (10 levels), and grammaticality (2 levels) asindependent variables, on both RT and accuracy, confirmedthese observations. Its results are summarized in Table 2. Itrevealed significant effects of practice and grammaticalitybut not a significant effect of condition. The Condition XPractice interaction reached significance, indicating thatpractice improved RT more strongly in Condition D, and thisconclusion was confirmed by the univariate follow-upanalysis, which showed this interaction to be significantexclusively for RT but not for accuracy. The Condition XGrammaticality interaction did not approach significance,and the relevant Practice X Grammaticality interaction,which can be interpreted as the main index of grammarlearning, produced significant results and was also con-firmed through the univariate analyses conducted for bothRT and accuracy. Participants, therefore, tended to progres-sively discriminate between grammatical and nongrammati-cal successors, responding faster and more accurately to theformer trials, as practice increased. Finally, the triple
Table 2Multivariate Analysis of Variance (MANOVA) of ReactionTime (RT) and Accuracy (ACC), and Interactions ofCondition X Grammaticality From Separate MANOVAsConducted for Three Slices of Practice, Correspondingto the First Three, the Four Intermediate,and the Last Three Sessions
Variable
Condition (Con)RTACC
Practice (P)RTACC
Grammaticality (G)RTACC
Con X PRTACC
Con X GRTACC
P X GRTACC
Con X P X GRTACC
Con X G (Slice 1-3)Con X G (Slice 4-7)Con X G (Slice 8-10)
df2,5
—18,1069,54—
2,51,61,6
18,1069,54—
2,5——
18,1069,549,54
18,1069,549,542,52,52,5
MSE
——
861.44——
1196.6021.77—
861.44————
28.192.05
—28.192.05
———
F
1.79
—4.02***
48.55***
9.01*20.57**
8.05*4.02***8.20***
—0.6
——
8.75***18.89***4.52***2.3**303a,**1.870.030.651.39
Note. For MANOVAs, condition was the between-subjects vari-able and practice and grammaticality were the within-subjectvariables. The results of individual analyses of variance conductedseparately for each dependent variable are reported only when themultivariate effect is significant.aEffects that lost significance using the Greenhouse-Geisser correc-tion, but not when using the Huynh-Feldt-corrected test.uon, out not wnen using tne Huynn-rej*p < .05. **p < .01. ***p < .001.

244 JIMENEZ AND MENDEZ
interaction of Condition X Practice X Grammaticality alsoreached significance, suggesting that the pattern of learningwas not the same between conditions. This interaction wassignificant only in the univariate analysis of RT but not inthat conducted with accuracy as the dependent variable.
This final interaction must be interpreted with caution,because it manifests a difference in the relative rhythm withwhich the grammar effects are accrued with training, ratherthan as a difference between conditions with respect to theglobal amount of grammar effects (and indeed, the relevantF for the Condition X Grammaticality interaction was lessthan 1, as shown in Table 2). One may think of at least threealternatives that could account for this complex interactionpattern. First, and perhaps less interesting, it is possible thatthis result will not prove to be replicable, hence beingcompletely attributable to a statistical artifact. Second, itmay also have arisen as a result of a limit in the maximumamount of facilitation available under dual-task conditions, alimit that would produce a deficit specific to participantsassigned to that dual-task condition and restricted to theirlast training sessions, when such a ceiling effect could bereached. Finally, the effect of interaction may preciselydepend on a difference in learning between conditions at thebeginning of training: For instance, participants under thedual-task condition might not learn about the grammarduring these first sessions, when they are occupied inperforming a demanding counting task, but they might beginto learn at a normal rate after some training sessions, whentheir counting performance could arguably have becomeautomatized. To explore these two latter alternatives, wedivided the training period into three consecutive slices,corresponding to the first three, the four intermediate, andthe last three sessions, respectively, and we conductedadditional MANOVAs to each of these slices. Again, therelevant interactions of Condition X Grammaticality did notapproach significance in any of these analyses (see Table 2),so that we should conclude that the triple interaction effectcannot be attributed either to an automatization of thecounting task produced at the beginning of training or to theexistence of a ceiling effect specific to the condition of dualtask.
In summary, therefore, these results showed that partici-pants in both Conditions D and S were able to learn therelatively complex, ambiguous, and probabilistic constraintsimposed by the grammar, as they responded more efficientlyto those successors that were predictable according to theirprevious experience with the SRT task rather than to thosetrials that were illegal according to the grammatical con-straints. The results also indicated that the difference ob-tained between the grammar learning produced under Condi-tions D and S was too small or too inconsistent to result in asignificant Condition X Grammaticality interaction, eitherthrough the overall training period or through the partialanalyses conducted on different slices of this whole period.However, we may not place too much emphasis on this lackof significance, because the design was intended more todiscriminate between learning and nonlearning conditionsthan to discriminate on relatively slight differences withinlearning conditions.3 In any case, given that a triple interac-
tion has been found among condition, grammaticality, andpractice, and that the power of a single experiment may betoo low to justify strong conclusions on the global equiva-lence between conditions, we only conclude from theseresults that participants under either single-task or dual-taskconditions were able to acquire complex, ambiguous, andprobabilistic sequences of locations, and that they mani-fested this sequence learning effect even though they wereengaged in a demanding, secondary task.
Shape Learning
To analyze learning about the predictive sequential contin-gencies established between shapes and locations, we con-ducted a similar analysis by averaging RTs and percentagesof hits for each session and condition, in terms of whetherthese responses were given to trials that were either accu-rately predicted or nonpredicted by the previous shape (i.e.,signaled vs. nonsignaled trials). As indicated earlier, 80% ofthe trials were accurately "signaled" in this way, so that *usually predicted A, x predicted B, ? predicted C, and !predicted D. Furthermore, the signaled versus nonsignalednature of a trial was completely independent of its grammati-cal status, so that a signaled trial can be defined, regardlessof its grammatical status, as any trial for which the previousshape accurately predicts the current location. A nonsignaledtrial was defined in a complementary way, as any trial forwhich the above rule was not satisfied.
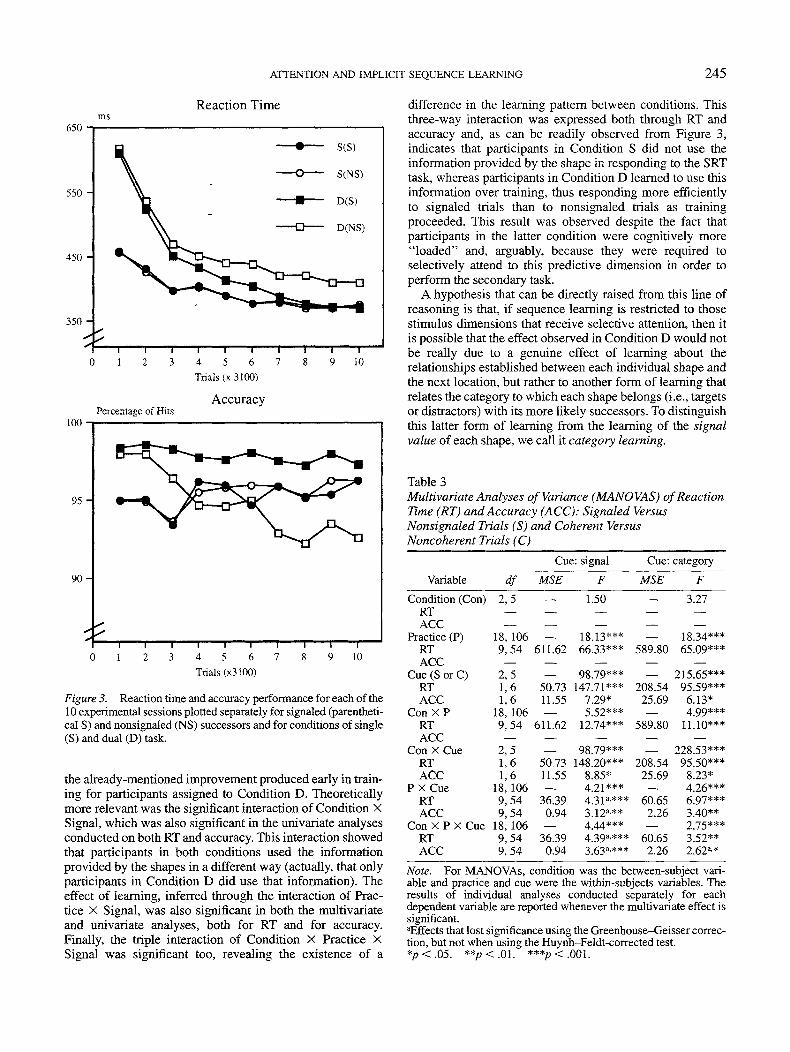
Figure 3 represents these data. As can be readily observed,only in Condition D did participants learn to respond moreefficiently to signaled trials, whereas participants in Condi-tion S, who were not told to attend to the identity of theshapes, did not show any learning about their predictivevalue, even after 31,000 training trials.
The corresponding MANOVA conducted with condition(2 levels), practice (10 levels), and signal value (2 levels) onboth RT and accuracy confirmed the conclusions suggestedby a visual inspection of Figure 3 (see also Table 3). Itrevealed significant effects of practice and of signal valuebut not a significant effect of condition. There was also asignificant Condition X Practice interaction, which reflected
3 The power of this design to detect a Condition X Grammatical-ity interaction in the MANOVA analysis depends on the followingparameters: alpha level (.05), degrees of freedom (2 and 5,.respectively, for numerator and denominator); N (16; total samplesize X number of dependent variables), m (2; number of levels ofthe repeated measures factor),/2 (effect size, defined according to J.Cohen, 1988, conventions), and rho (.89; population correlationbetween the individual levels of the repeated measures effect; seeBuchner, Erdfelder, & Faul, 1997). We estimated this correlationfrom the whole set of data obtained through the three reportedexperiments, by first computing independent correlations for RTand accuracy, and then averaging these indexes by means of a Ztransformation. All these parameters were fed to the G • Powercomputer program (Buchner, Faul, & Erdfelder, 1992). The resultsshowed that the design was powerful enough to detect largeinteractions of Grammaticality X Condition (1 — (3 = .99 for/ = .40), but that it may have problems to detect medium effects(1 - P = . 79 for/ =.25).
ATTENTION AND IMPLICIT SEQUENCE LEARNING 245
Reaction Time
450 -
350 -
Percentage of Hits
4 5 6 7
Trials (x 3100)
Accuracy
10
9 0 -
4 5 6
Trials (x3100)
10
Figure 3. Reaction time and accuracy performance for each of the10 experimental sessions plotted separately for signaled (parentheti-cal S) and nonsignaled (NS) successors and for conditions of single(S) and dual (D) task.
the already-mentioned improvement produced early in train-ing for participants assigned to Condition D. Theoreticallymore relevant was the significant interaction of Condition XSignal, which was also significant in the univariate analysesconducted on both RT and accuracy. This interaction showedthat participants in both conditions used the informationprovided by the shapes in a different way (actually, that onlyparticipants in Condition D did use that information). Theeffect of learning, inferred through the interaction of Prac-tice X Signal, was also significant in both the multivariateand univariate analyses, both for RT and for accuracy.Finally, the triple interaction of Condition X Practice XSignal was significant too, revealing the existence of a
difference in the learning pattern between conditions. Thisthree-way interaction was expressed both through RT andaccuracy and, as can be readily observed from Figure 3,indicates that participants in Condition S did not use theinformation provided by the shape in responding to the SRTtask, whereas participants in Condition D learned to use thisinformation over training, thus responding more efficientlyto signaled trials than to nonsignaled trials as trainingproceeded. This result was observed despite the fact thatparticipants in the latter condition were cognitively more"loaded" and, arguably, because they were required toselectively attend to this predictive dimension in order toperform the secondary task.
A hypothesis that can be directly raised from this line ofreasoning is that, if sequence learning is restricted to thosestimulus dimensions that receive selective attention, then itis possible that the effect observed in Condition D would notbe really due to a genuine effect of learning about therelationships established between each individual shape andthe next location, but rather to another form of learning thatrelates the category to which each shape belongs (i.e., targetsor distractors) with its more likely successors. To distinguishthis latter form of learning from the learning of the signalvalue of each shape, we call it category learning.
Table 3Multivariate Analyses of Variance (MANOVAS) of ReactionTime (RT) and Accuracy (ACC): Signaled VersusNonsignaled Trials (S) and Coherent VersusNoncoherent Trials (C)
Variable
Condition (Con)RTACC
Practice (P)RTACC
Cue (S or C)RTACC
Con X PRTACC
Con X CueRTACC
P X CueRTACC
Con X P X CueRTACC
df2,5
18, 1069,54
2,51,61,6
18, 1069,54—
2,51,61,6
18,1069,549,54
18,1069,549,54
Cue
MSE
——
611.62
—50.7311.55—
611.62——
50.7311.55—
36.390.94—
36.390.94
: signal
F
1.50
18.13***66.33***
98.79***147.71***
7.29*5.52***
12 74***—
98.79***148.20***
8.85*4.21***4 3Ja,**#3.12a-**4 44***4 39a,***3.63a-***
Cue:
MSE
——
589.80
—208.54
25.69—
589.80——
208.5425.69—
60.652.26—
60.652.26
category
F
3.27
18.34***65.09***
215.65***95.59***
6.13*4.99***
11.10***—
228.53***95.50***
8.23*4.26***6 9 7 * * *3.40**2.75***3.52**2.62**
Note. For MANOVAs, condition was the between-subject vari-able and practice and cue were the within-subjects variables. Theresults of individual analyses conducted separately for eachdependent variable are reported whenever the multivariate effect issignificant.aEffects that lost significance using the Greenhouse-Geisser correc-tion, but not when using the Huynh-Feldt-corrected test.*p<.05. **/><.01. ***p<.001.
246 JIMENEZ AND MENDEZ
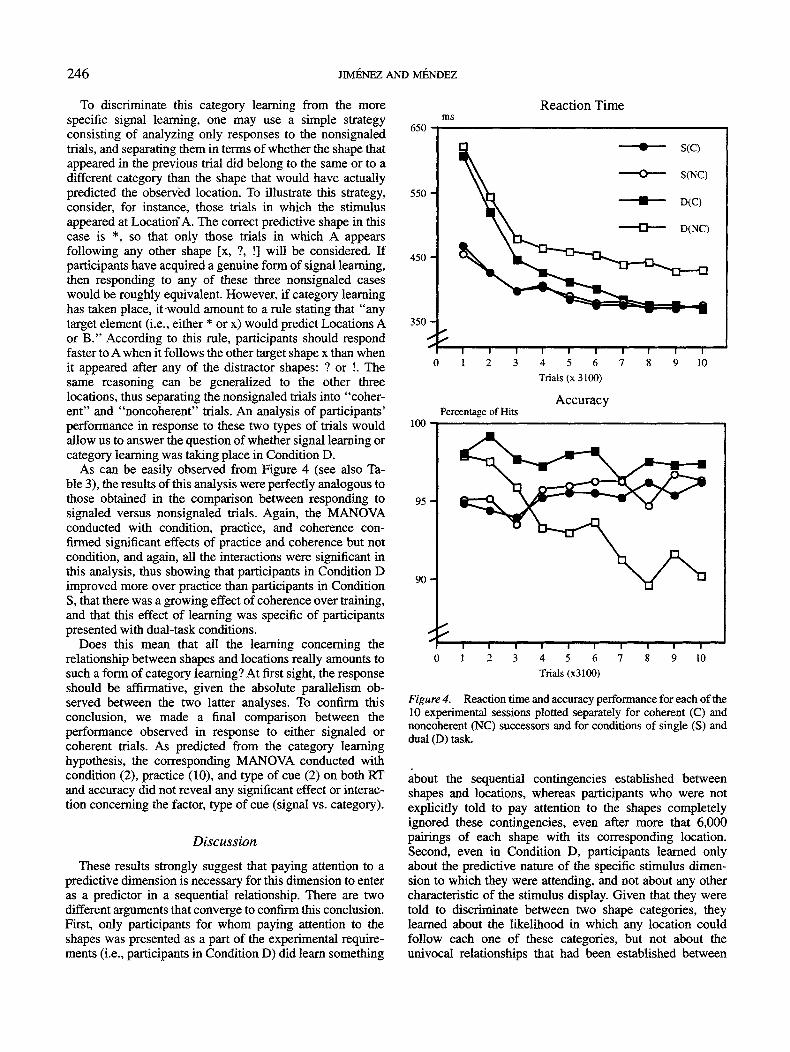
To discriminate this category learning from the morespecific signal learning, one may use a simple strategyconsisting of analyzing only responses to the nonsignaledtrials, and separating them in terms of whether the shape thatappeared in the previous trial did belong to the same or to adifferent category than the shape that would have actuallypredicted the observed location. To illustrate this strategy,consider, for instance, those trials in which the stimulusappeared at Location A. The correct predictive shape in thiscase is *, so that only those trials in which A appearsfollowing any other shape [x, ?, !] will be considered. Ifparticipants have acquired a genuine form of signal learning,then responding to any of these three nonsignaled caseswould be roughly equivalent. However, if category learninghas taken place, it would amount to a rule stating that "anytarget element (i.e., either * or x) would predict Locations Aor B." According to this rule, participants should respondfaster to A when it follows the other target shape x than whenit appeared after any of the distractor shapes: ? or !. Thesame reasoning can be generalized to the other threelocations, thus separating the nonsignaled trials into "coher-ent" and "noncoherent" trials. An analysis of participants'performance in response to these two types of trials wouldallow us to answer the question of whether signal learning orcategory learning was taking place in Condition D.
As can be easily observed from Figure 4 (see also Ta-ble 3), the results of this analysis were perfectly analogous tothose obtained in the comparison between responding tosignaled versus nonsignaled trials. Again, the MANOVAconducted with condition, practice, and coherence con-firmed significant effects of practice and coherence but notcondition, and again, all the interactions were significant inthis analysis, thus showing that participants in Condition Dimproved more over practice than participants in ConditionS, that there was a growing effect of coherence over training,and that this effect of learning was specific of participantspresented with dual-task conditions.
Does this mean that all the learning concerning therelationship between shapes and locations really amounts tosuch a form of category learning? At first sight, the responseshould be affirmative, given the absolute parallelism ob-served between the two latter analyses. To confirm thisconclusion, we made a final comparison between theperformance observed in response to either signaled orcoherent trials. As predicted from the category learninghypothesis, the corresponding MANOVA conducted withcondition (2), practice (10), and type of cue (2) on both RTand accuracy did not reveal any significant effect or interac-tion concerning the factor, type of cue (signal vs. category).
Discussion
These results strongly suggest that paying attention to apredictive dimension is necessary for this dimension to enteras a predictor in a sequential relationship. There are twodifferent arguments that converge to confirm this conclusion.First, only participants for whom paying attention to theshapes was presented as a part of the experimental require-ments (i.e., participants in Condition D) did learn something
Reaction Time
650
5 5 0 -
450-
3 5 0 -
0 1 2 3 4 5 6 7 9 10
Percentage of HitsAccuracy
2 3 4 5 6 7
Trials (x3100)
10
Figure 4. Reaction time and accuracy performance for each of the10 experimental sessions plotted separately for coherent (C) andnoncoherent (NC) successors and for conditions of single (S) anddual (D) task.
about the sequential contingencies established betweenshapes and locations, whereas participants who were notexplicitly told to pay attention to the shapes completelyignored these contingencies, even after more that 6,000pairings of each shape with its corresponding location.Second, even in Condition D, participants learned onlyabout the predictive nature of the specific stimulus dimen-sion to which they were attending, and not about any othercharacteristic of the stimulus display. Given that they weretold to discriminate between two shape categories, theylearned about the likelihood in which any location couldfollow each one of these categories, but not about theunivocal relationships that had been established between

ATTENTION AND IMPLICIT SEQUENCE LEARNING 247
each individual shape and the next location. To put itdifferently, even though the target shape * predicted Loca-tion A for the next trial with a likelihood of .80, whereas theother target shape x usually predicted B, and it only precededA with a probability of .07, participants reacted to bothshapes in almost the same way, as if they had encoded a rulestating that "after any target shape, Location A or B are to beexpected." This conclusion^ was confirmed by the absoluteequivalence observed between responses to signaled and tocoherent trials.
If selective attention seems to play an important role inthis form of sequence learning, it is also important to pointout that, whatever would be the actual mechanism underly-ing this learning, it seems to be compatible with a number ofother simultaneous processes. First, it is compatible with thedivision of attention produced by the simultaneous perfor-mance of an SRT task and of a counting task. Second, it isalso compatible with a simultaneous learning process involv-ing the acquisition of information concerning another predic-tive dimension (i.e., the immediate sequence of locations)that predicts the same outcome (i.e., the location of thestimulus for the next trial).
Focusing on this other source of sequential information,the results of this experiment have shown that participantscan learn about an ambiguous sequential structure evenunder conditions of divided attention and that, in the specificcircumstances imposed by this experiment, learning isbarely affected by both the inclusion of a dual-task manipu-lation and by the acquisition of a simultaneous source ofsequence learning involving a prediction of the sameoutcome. What is not clear yet, from these results, is whetherthe triple interaction obtained in the analysis of grammarlearning does really indicate a systematic difference betweenthe learning pattern produced under Conditions D and S orwhether, on the contrary, it should simply be discarded as astatistical artifact. Experiment 2 is aimed at addressing thisquestion more systematically.
Experiment 2
The main goal of Experiment 2 is to replicate Experiment1, providing a more definitive response to the question ofwhether the division of attention does produce any effect onthe learning of these grammatical constraints. Indeed, evenif the triple interaction found in Experiment 1 prove to bereplicable, it can be attributed not only to a learning problembut also to an expression deficit (e.g., Cleeremans, 1997;Frensch et al., 1998). It is possible, for instance, that trainingunder both focused and divided attention would give placeto the same grammar learning but that the behavioralexpression of this learning would be hindered by thesecondary task. To address this possibility, we propose toremove the secondary task at some point near the end of thetraining period and to analyze whether any possible differ-ence arising early in training would disappear with theremoval of this task.
This removal can be done by following two strategies.The most immediate one is just to instruct participants todiscontinue the counting task. By doing that, we will
eliminate the cognitive load imposed by the secondary task.However, if the same shapes continue to be presented, wewill not control for the possibility that participants who havelearned about the predictive relationships established be-tween shapes and locations could still pay attention to theshapes or could manifest some other cue-competition effectthat may affect their performance (Cleeremans, 1997).Therefore, completely removing the shapes and replacingthem with a new, neutral one can be taken as an alternativestrategy to control for these interference effects.
The first strategy of eliminating only the task whilemaintaining the shapes may still be useful, however, toexplore the use that participants can make of whateverknowledge they may have acquired about the relationshipsestablished between shapes and locations. If Experiment 1showed that only sequential contingencies involving at-tended dimensions could be learned, a related question thatwe would like to address in this experiment is whether, onceacquired, the expression of this learning also requiresattentional processing of the relevant dimension. If that werethe case, then eliminating the secondary task should alsoeliminate the effect of the shapes, even though the relevantinformation would still be available.
Method
The method was equivalent to that reported for Experiment 1except that, after Session 8, participants in Condition D wereinstructed to discontinue the counting task. For Sessions 9 and 10, aneutral shape, 0, substituted the previous shapes for participantsassigned to Condition S and also for a half of those assigned toCondition D (thus labeled as D-S, for Condition D-without-shapes). For the other half, the same shapes were maintainedthrough Sessions 9 and 10, although they were also instructed todiscontinue the counting task after Session 8. This condition waslabeled D-T, for Condition D-without-task.
Participants
Twelve students of introductory courses in psychology at theUniversity of Santiago in Spain participated in the experiment.Four were randomly assigned to each different conditions, S, D-S,and D-T. Participants were also paid about $20 for participating inthe study and could earn additional bonus money depending onperformance.
Procedure
The- apparatus, stimulus display, and tasks were the same as inExperiment 1, except for the change of all the previous shapes bythe neutral shape, 0, which was introduced for some conditions atthe beginning of Session 9. In Condition S, participants justobserved the change without any further comment. For thoseassigned to Condition D-S, this change coincided with the instruc-tion to discontinue the counting task. Finally, this change did notoccur for participants in Condition D-T, for whom the same shapescontinued to be presented during Sessions 9 and 10, even thoughthey were explicitly instructed to abandon the counting task.
Results
Performance of the counting task was also very accuratein this experiment, with a mean deviation from the exact

248 JIMENEZ AND MENDEZ
number of targets of 1.11 and 1.35 units per block, respec-tively, for Conditions D-S and D-T.
To analyze grammar and shape learning, we separate theresults obtained up until Session 8 from the transfer effectsproduced in each condition after removing the shapes (S),the secondary task (D-T), or both of them (D-S). For thislatter analysis, we compare the trend observed in eachcondition between the responses to the two sessions previ-ous to the transfer (Sessions 7/8) and the responses to thetwo sessions that immediately follow this change (Sessions9/10).
Grammar Learning
RT and accuracy-measures were obtained for grammaticaland nongrammatical successors and were averaged for eachsession and condition in exactly the same way as inExperiment 1. A MANOVA was conducted over the firsteight sessions, with condition (3), practice (8), and grammati-cality (2) as independent variables and with RT and accuracyas dependent variables (see Table 4). The results replicatedthe most important effects observed in Experiment 1.However, in this case, condition also produced a significanteffect, restricted to the measure of RT, as confirmed by thefollow-up analyses. Specifically, participants in Condition Sproduced the fastest average responding (375 ms), whereastheir responses in Conditions D-S and D-T averaged 409 and444 ms, respectively. The effect of practice was also
Table 4Multivariate Analysis of Variance of Reaction Time (RT)and Accuracy (ACC), With Condition as aBetween-Subjects Variable and Practice andGrammaticality as Within-Subject Variables
Variable
Condition (Con)RTACC
Practice (P)RTACC
Grammaticality (G)RTACC
Con X PRTACC
Con X GRTACC
P X GRTACC
Con X P X GRTACC
df4,162,9—
14,1247,63
2,81,91,9
28,12414,63
—4,16
14, 1247,637,63
28,124——
MSE
10,509.98——
2,813.45
—555.96
9.79
2,813.45—
——39.41
1.70———
F
3.91*7.18*
—16.92***62.18***
—22.19***49.92***23.60***
1.83*327a,***
—0.31
——
6.96***13.56***6.46***0.57
——
significant, with mean RTs decreasing over the first eightsessions from 592 to 344 ms. Grammaticality was signifi-cant, too, producing an average advantage for grammaticalsuccessors of about 27 ms in RT and of 2.4 points in themeasure of accuracy. The interaction of Condition XPractice also reached significance, confirming the trend alsofound in Experiment 1, and according to which participantsassigned to dual-task conditions produced greater improve-ments in RTs than those assigned to single-task conditions(the average differences from the first to the eighth sessionwas of 146 ms for participants in Condition S, and of 252and 344 ms, respectively, for participants assigned toConditions D-T and D-S). The effect of sequence learning,operationalized as the interaction of Practice X Grammatical-ity, was also significant, both for RT and for accuracymeasures, and it showed that, with practice, participantslearned to perform according to the constraints imposed bythe grammar, reaching a final advantage in favor of grammati-cal trials of about 34 ms and 3.9 points in the measure ofaccuracy. The interactions of Condition X Grammaticalityand of Condition X Practice X Grammaticality did not evenapproach significance (see Table 4), and none of them wassignificant either in a set of analyses conducted separately tocompare Condition S with each one of the dual-taskconditions. Therefore, these results indicated that partici-pants in all of these conditions did learn about the grammarin almost the same way.4
Given that there was no difference in the expression ofgrammar learning between dual- and single-task conditions,there seemed to be no grounds to predict a differential effectof the manipulation introduced after Session 8, in whicheither the shapes (S), the secondary task (D-T), or both ofthem (D-S) were removed. A MANOVA was conducted totest for this effect, averaging the performance obtainedbefore and after transfer (Sessions 7 and 8 vs. Sessions 9 and10), and considering condition and grammaticality as theother two independent variables. This analysis showed aneffect of grammaticality, F(2, 8) = 67.75, p < .001, as wellas an interaction of Transfer X Grammaticality, F(2, 8) =5.19, p < .05, which should be interpreted as the usualpattern of improvement in learning as training progresses.Crucially, this effect did not differ among conditions, asinferred from the lack of significance of the three-wayinteraction of Condition X Transfer X Grammaticality,F(4, 16) = 0.06, thus showing that removing the countingtask after Session 8 did not produce any positive effect in theexpression of grammar learning, as compared with the effectproduced by removing the shapes in Condition S. Therefore,we conclude that performing the counting task did not seemto interfere with either the acquisition or the expression ofgrammar learning.
Note. The results of individual analyses conducted separately foreach dependent variable are reported whenever the multivariateeffect is significant."Effects that lost significance for any epsilon-corrected test.*p < .05. ***p < .001.
4 The addition of a group made this design more powerful todetect a hypothetical Condition X Grammaticality interaction, ascompared with that used in Experiment 1. The power, computedthrough G • Power for the same parameters entered in Experi-ment 1, except that N was 24 and degrees of freedom were 4 and 16,was now 1 — p = .97 for a medium effect ( / = .25). Power,however, still remained too low to detect a small effect.
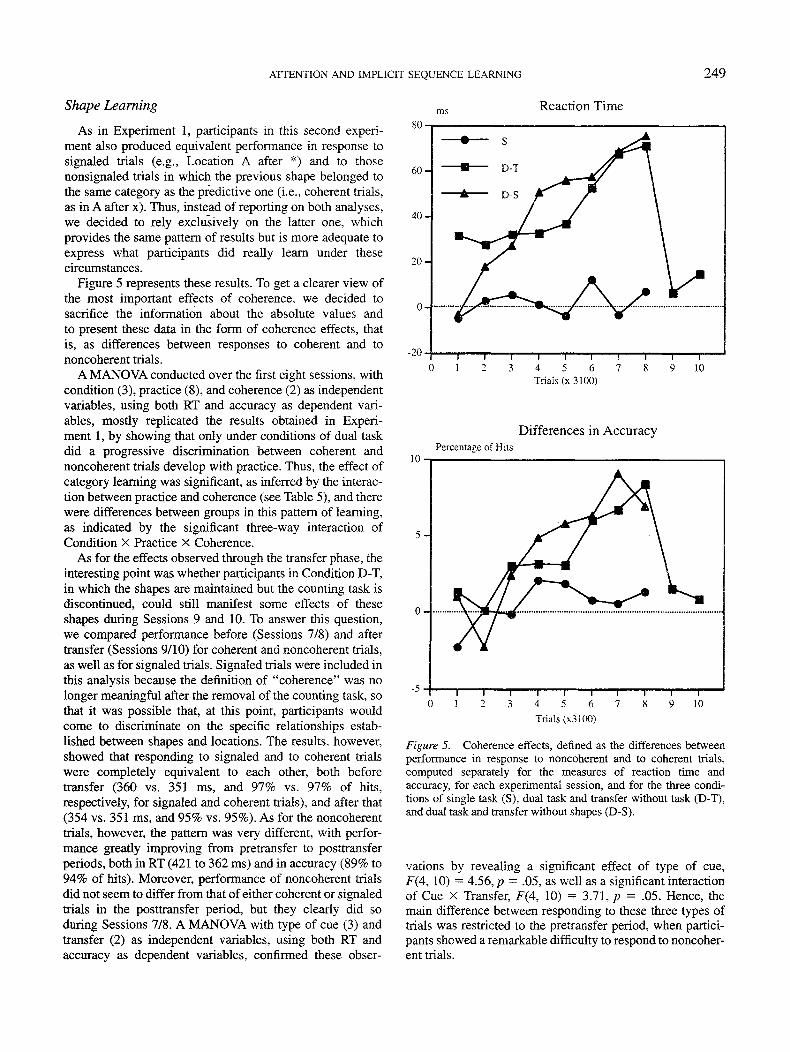
ATTENTION AND IMPLICIT SEQUENCE LEARNING 249
Shape Learning
As in Experiment 1, participants in this second experi-ment also produced equivalent performance in response tosignaled trials (e.g., Location A after *) and to thosenonsignaled trials in which the previous shape belonged tothe same category as the predictive one (i.e., coherent trials,as in A after x). Thus, instead of reporting on both analyses,we decided to rely exclusively on the latter one, whichprovides the same pattern of results but is more adequate toexpress what participants did really learn under thesecircumstances.
Figure 5 represents these results. To get a clearer view ofthe most important effects of coherence, we decided tosacrifice the information about the absolute values andto present these data in the form of coherence effects, thatis, as differences between responses to coherent and tononcoherent trials.
A MANOVA conducted over the first eight sessions, withcondition (3), practice (8), and coherence (2) as independentvariables, using both RT and accuracy as dependent vari-ables, mostly replicated the results obtained in Experi-ment 1, by showing that only under conditions of dual taskdid a progressive discrimination between coherent andnoncoherent trials develop with practice. Thus, the effect ofcategory learning was significant, as inferred by the interac-tion between practice and coherence (see Table 5), and therewere differences between groups in this pattern of learning,as indicated by the significant three-way interaction ofCondition X Practice X Coherence.
As for the effects observed through the transfer phase, theinteresting point was whether participants in Condition D-T,in which the shapes are maintained but the counting task isdiscontinued, could still manifest some effects of theseshapes during Sessions 9 and 10. To answer this question,we compared performance before (Sessions 7/8) and aftertransfer (Sessions 9/10) for coherent and noncoherent trials,as well as for signaled trials. Signaled trials were included inthis analysis because the definition of "coherence" was nolonger meaningful after the removal of the counting task, sothat it was possible that, at this point, participants wouldcome to discriminate on the specific relationships estab-lished between shapes and locations. The results, however,showed that responding to signaled and to coherent trialswere completely equivalent to each other, both beforetransfer (360 vs. 351 ms, and 97% vs. 97% of hits,respectively, for signaled and coherent trials), and after that(354 vs. 351 ms, and 95% vs. 95%). As for the noncoherenttrials, however, the pattern was very different, with perfor-mance greatly improving from pretransfer to posttransferperiods, both in RT (421 to 362 ms) and in accuracy (89% to94% of hits). Moreover, performance of noncoherent trialsdid not seem to differ from that of either coherent or signaledtrials in the posttransfer period, but they clearly did soduring Sessions 7/8. A MANOVA with type of cue (3) andtransfer (2) as independent variables, using both RT andaccuracy as dependent variables, confirmed these obser-
Reaction Time
o I 2 3 4 5 6 7Trials (x 3100)
10
Differences in AccuracyPercentage of Hits
4 5 6
Trials (x3J 00)
10
Figure 5. Coherence effects, defined as the differences betweenperformance in response to noncoherent and to coherent trials,computed separately for the measures of reaction time andaccuracy, for each experimental session, and for the three condi-tions of single task (S), dual task and transfer without task (D-T),and dual task and transfer without shapes (D-S).
vations by revealing a significant effect of type of cue,F(4, 10) = 4.56, p = .05, as well as a significant interactionof Cue X Transfer, F(4, 10) = 3.71, p = .05. Hence, themain difference between responding to these three types oftrials was restricted to the pretransfer period, when partici-pants showed a remarkable difficulty to respond to noncoher-ent trials.

250 JIMENEZ AND MENDEZ
Table 5Multivariate Analysis of Variance of Reaction Time (RT)and Accuracy (ACC), With Condition as aBetween-Subjects Variable and Practice and Coherenceas Within-Subject Variables
Variable
Condition (Con)RTACC
Practice (P)RTACC
Coherence (C)RTACC
Con X PRTACC
Con X CRTACC
P X CRTACC
Con X P X CRTACC
- df
4,16- 2,9
14, 1247,63
2,81,91,9
28, 12414,63
—4,16——
14, 1247,637,63
28, 124
—
MSE
13,525.48——
2,802.61
—1,824.77
24.99—
2,802.61——
1,824.77——100.72
4.67—100.72—
F
3.40*10.35**
—15.88***59.53***
16.54***23.67**16.45**2.18**3.203-**
—2.465.04*
—6.96***
12.79***7.12**2.34***4.16***
—
Note. The results of individual analyses conducted separately foreach dependent variable are reported whenever the multivariateeffect is significant.aEffects that lost significance for any epsilon-corrected test.* 0 5 * * 0 1 *** 001*p<.05.
y p***/><• 001.
Discussion
As a whole, the results of Experiment 2 are compatiblewith those obtained in Experiment 1, including someadditional, evidence that reinforces our conclusions on anumber of issues. First, all participants learned about thesequential constraints imposed by an ambiguous and proba-bilistic grammar, and they learned about this grammar in asimilar way regardless of whether they were assigned to acondition of dual or single task. Thus, the interaction ofCondition X Grammaticality was not significant in any ofthese experiments, and the three-way interaction that hadbeen observed in Experiment 1, and that was about the onlyresult that suggested the existence of an effect of dividingattention on sequence learning, was no longer replicatedthrough Experiment 2. Moreover, for Conditions D-S andD-T of this second experiment, the removal of the secondarytask late in training did not release any facilitation effect thatcould have remained latent during dual-task training, so thatit could be assumed that the counting task did not interfereeither with the acquisition or with the expression of gram-mar learning.
As for the shape learning, the results of both experimentsconfirmed that participants who were not required to per-form any task concerning the shapes did not show any effectof learning about the predictive nature of these shapes, andthat those who had been told to arbitrarily ascribe each shapeto one of two complementary categories did precisely learn
about the sequential contingencies that related these catego-ries with their most likely successors, but not about thespecific relationships arranged between each individualshape and its successor.
Moreover, this relationship between what participantsattend to and what they learn about seemed to be alsoextensible to the expression of learning, judging from theremoval of the effects manifested in Condition D-T whenparticipants were told to discontinue the counting task.However, this loss of sensitivity associated to the removal ofthe counting task can be taken as arguing in favor of acompeting interpretation of the results obtained under single-task conditions.5 Indeed, if participants who have learnedabout the shape-location contingencies failed to expresstheir knowledge once they were told to discontinue thecounting task, then it might be argued that the sameexpression problem could have affected participants pre-sented from the beginning with conditions of a single task.The weak point of this reasoning is that it should be based onthe somewhat unsatisfactory claim that attention to the cuewould not be necessary to produce learning, but that itshould be necessary to express these learning results.Although this kind of hypothesis could still be construed as apossibility, a more likely account for these effects mayassume that what participants learn under dual-task condi-tions has to do with the responses required during thecounting task, rather than with any pattern of the stimuli.Thus, if participants have learned about the possible succes-sors of their counting responses, then it would come as nosurprise that removing the counting task would eliminate theeffects of the cue, as well as that participants presented withsingle-task conditions did not show any learning about thesecontingencies. In Experiment 3, we address this questionmore specifically.
Experiment 3
For Experiment 3, we propose a manipulation that fulfillsthree simultaneous goals. First, we want to find out whetherusing different shapes as targets would produce the samepattern of results that have been consistently found inExperiments 1 and 2 by using [*, x] as the target set.
Second, we want to ascertain whether using a moredifficult secondary task could bring about some differencesbetween Conditions D and S. Even though it is unlikely thatthe counting task could be learned up to a point in which itcan become completely automatic, it might be argued thatsome of its components, namely, those involved in theassignment of each shape to a response category, may wellbecome automatic with practice, thus freeing resources to beallocated to sequence learning. The automatization of thispart of the secondary task could be produced if there is aconsistent mapping throughout training between shapes andresponses (see Schneider & Shiffrin, 1977). Thus, to preventthis possibility, and to simultaneously increase the atten-
5 We are grateful to David Shanks for having suggested thispossibility to us.

ATTENTION AND IMPLICIT SEQUENCE LEARNING 251
tional demands of the counting task, we decided to vary thismapping for each session.
Third, we also want to address the question raised at thediscussion of Experiment 2, about whether the shapelearning observed through the previous experiments shouldbe considered as a form of either stimulus-based or response-based learning. For this latter question, the use of variedmapping between shapes and responses will make it possibleto dissociate the predictions advanced from each of thesealternatives. Hence, if the predictive relationships betweenshapes and successors are maintained throughout training,but the required response to each shape is continuouslyvaried, then any effect obtained in these conditions couldsafely be attributed to a form of stimulus-based learning. Onthe contrary, if we include a condition in which the targetshapes are varied, but in which the appropriate relationshipsbetween counting responses and successors are maintained,we could assess the hypothesis of whether the categorylearning is indeed best described as a form of response-based learning.
Method
For this final experiment, three more conditions were consid-ered, including a condition of single task (Condition S) and twodifferent conditions of dual task. Participants assigned to either ofthese latter conditions were now told to keep a count of a differentpair of target shapes for each training session. In one of theseconditions (DS, for divided attention with shapes as cues), thecontingencies between shapes and locations were maintained as inprevious experiments. For the other condition (DR, for dividedattention with responses as cues), the shapes were manipulated insuch a way that, even though the same shapes would no longerpredict the same locations, still performing a counting responseuniformly predicted the same pair of successors, whereas encoun-tering a noncounting trial was consistently associated with the twocomplementary locations.
Participants
Twelve students of introductory courses in psychology at theUniversity of Santiago in Spain participated in the experiment.Four were randomly assigned to each one of the three differentconditions: S, DS, and DR. Participants were also paid about $20for participating in the study and could earn additional incentivesdepending on performance.
Procedure
The apparatus and stimulus display were the same as inExperiment 1. The tasks were also the same as in Experiment 1except that, in the conditions of dual task, a different pair of shapeswas presented at the beginning of each session as the target set.During the first session, participants had to count up the sameshapes that had served as targets for the previous experiments[*, x]. From here on, this pair was systematically changed for eachsuccessive session, so that (a) all possible combinations of targetswould be used at least once and (b) the similarity betweenconsecutive target sets was minimized. Thus, during the secondsession, the target set was complementary to the first one [?,!], thenit was changed to be a combination of the two previous sets [*, ?],then to the set complementary to the previous one [x, !], then again
to a combination of elements from the two previous sets [*, !], andthen, finally, to the set that was complementary to the previous one[x, ?]. After the sixth session, all the possible pairs of shapes hadalready been used, and the target sets were repeated, beginningwith the first one.
Stimulus Generation
The series of locations was exactly the same one used forExperiments 1 and 2. The series of shapes also remained un-changed for Conditions S and DS but was modified for ConditionDR. To generate a new series of shapes that would fulfill therequired criterion (i.e., that a counting response would be associ-ated with the same pair of successors consistently throughouttraining, despite the fact that the mapping between shapes andresponses was varied for each session), we started with the originalseries used for the other conditions, and randomly substituted foreach appearance of the original target shapes [* or x] a shape thatwould belong to the target set for that specific session. Likewise, ashape that would belong to the abstractor set for that sessionrandomly substituted for each appearance of the original distractors[? or !], so that the relationship between counting responses andlocations was maintained exactly as it was during Experiments 1and 2.
Results
Despite its increased difficulty, the secondary task wasagain performed with great accuracy by those participantsassigned to dual-task conditions, yielding mean deviationsfrom the correct number of targets of 0.89 and 0.57 perblock, respectively, for Conditions DS and DR.
Grammar Learning
Table 6 summarizes the results of the MANOVA con-ducted with condition (3), practice (10), and grammaticality(2) as independent variables, using RT and accuracy asdependent variables. Participants' performance over all threeconditions, 10 sessions, and two types of trials averaged 432ms and 95% of hits. The effect of condition did not reachsignificance, but the other two main variables did. Practiceproduced a significant decrease in RT that amounted to 209ms from the first to the last session, but that was traded off bya simultaneous decrease in accuracy of about 3.4 points.Grammaticality also produced an effect of increased speedof an average of 32 ms, accompanied in this case by asimultaneous increase of 3.0 points in accuracy. The effect ofpractice was modulated by that of condition, so that in bothdual-task conditions (DS and DR) higher increases in speed,of 266 and 231 ms, respectively, were traded off bysimultaneously decreases of 5.0 and 4.9 points in percent-ages of hits, whereas in Condition S the improvement in RTwas less important (128 ms), but it was not accompanied bya comparable decrease in accuracy (which is only of 0.4points). The interaction of Condition X Grammaticality wasnot significant, but the learning effect, operationalized as theinteraction of Practice X Grammaticality, was highly signifi-cant, producing differences in RT between grammatical andnot grammatical trials that passed from 3 ms at the beginningof training to 45 ms at the end, and from 0.1 to 5.3 points in

252 JIMENEZ AND MENDEZ
Table 6Multivariate Analysis of Variance of Reaction Time (RT)and Accuracy (ACC), With Condition as aBetween-Subjects Variable and Practice andGrammaticality as Within-Subject Variables
Variable
Condition (Con)RTACC
Practice (P)RTACC
Grammaticality (G)RTACC
C o n X PRTACC
Con X GRTACC
P X GRTACC
Con X P x GRTACC
df4,16——
18,1609,819,812,81,91,9
36,16018,8118,814,16——
18,1609,819,81
36,160
—
MSE
———
682.054.74—
265.3913.34—
682.054.74————
58.492.05—
—
F
2.11——
34.23***166.23***
7.62***118.62***234.17***41.65***
3.56***8.19***2.35**1.76——
10.26***18.98***12.16***
1.04
—
Note. The results of individual analyses conducted separately foreach dependent variable are reported whenever the multivariateeffect is significant.**p<.01. ***/?<.001.
accuracy. The three-way interaction of Condition X Prac-tice X Grammaticality did not reach significance hencesuggesting again that all three groups contributed in asimilar way to this learning effect.
Shape and Response Learning
As for the learning related with the other cue, weconducted two separate analyses, considering first the predic-tive relationships established between shapes and locationsfor both Conditions S and DS, and then looking at thepredictive relationships established between responses andlocations for Condition DR.
As illustrated through Figure 6, responding to signaledand to nonsignaled trials seemed to be roughly equivalentfor both Conditions S and DS. Crucially, there seemed to beno effect of the signal developing with practice. Thecorresponding MANOVA with condition (2), practice (10),and signal value (2) confirmed this impression, as neither theinteraction of Practice X Signal nor the triple interaction ofCondition X Practice X Signal approached significance.Unexpectedly, however, there were significant effects ofsignal, F(2, 5) = 18.24, p < .01, and of the Signal XCondition interaction, F(2, 5) = 13.29, p = .01, whichshowed a general trend to respond more efficiently tosignaled trials, specifically in Condition DS. At this point,we do not have a satisfactory account for these effects,which appear to be small but consistent. However, and
despite their meaning, what is important to realize is thatthey do not qualify as effects of shape learning, because theyare not developed with training.
As for the relationship established in Condition DRbetween counting responses and locations, Figure 6 is mostclear at illustrating that participants learned about this set ofcontingencies. Thus, they became progressively more ca-pable of discriminating between predictable and nonpredict-able locations in terms of whether the previous response hadbeen a counting or a noncounting response, and despite thefact that these counting responses were associated for eachsession to a different target set. The MANOVA conductedwith practice (10) and predictive value (2) showed asignificant effect of practice, F(18,52) = 20.46, MSE = p<.001, but not an effect of the predictive value. Importantly,however, the interaction of Practice X Predictive Value wassignificant, too, F(18,52) = 3.27, p < .001, as it was for RT,F(9, 27) = 4.80, MSE = 94.38, p < .001, and accuracy,F(9, 27) = 5.23, MSE = 4.32, p < .001. The effect foraccuracy just lost significance when the most conservativeepsilon correction of Greenhouse-Geisser was applied(e = .159), but it remained significant after applying theHuynh-Feldt corrected test (e = .263).
Discussion
For grammar learning, the results of this experiment againsuggest that complex sequence learning can be achieved inconditions of dual task, at about the same rate at which theyare accrued under a single task, and regardless of whetherparticipants also learn about another cue that predicts thesame outcome. The three-way interaction of Condition XPractice X Grammaticality had a power of 1 — 3 = .94 for asmall size effect, and it did not approach significance in themultivariate analysis (see Table 6). Therefore, we can befairly confident that, under these conditions, grammar learn-ing does not depend on the simultaneous performance of acounting task.6
Moreover, given that only participants in Condition DRdid learn about the simultaneous cue, specific pairwisecomparisons can be arranged between groups to separate theeffects attributable to distraction and to cue-competitioneffects. On the one hand, given that participants in Condi-tions DS and S did precisely differ in task load, but none ofthem had learned about the concurrent cue, a comparisonbetween them could be taken as a contrast for the distractioneffect in the absence of any effect of that concurrent cue. Onthe other hand, given that participants in Conditions DR andDS were all facing the task under comparable attentionaldemands, but they differed in the extent to which theylearned about the concurrent cue, a comparison between
6 The power for this three-way interaction, considering smallsize effects, is 1 - (3 = .948, using a = .05; N = 24 (12 X 2dependent variables); m = 20 [2 (grammaticality) X 10 (practice)];p = .89; df = (36, 160); and/2 = .10. For the interaction ofCondition X Grammaticality, on the other hand, the power of thisdesign was exactly the same as that computed for the sameinteraction of Experiment 2.
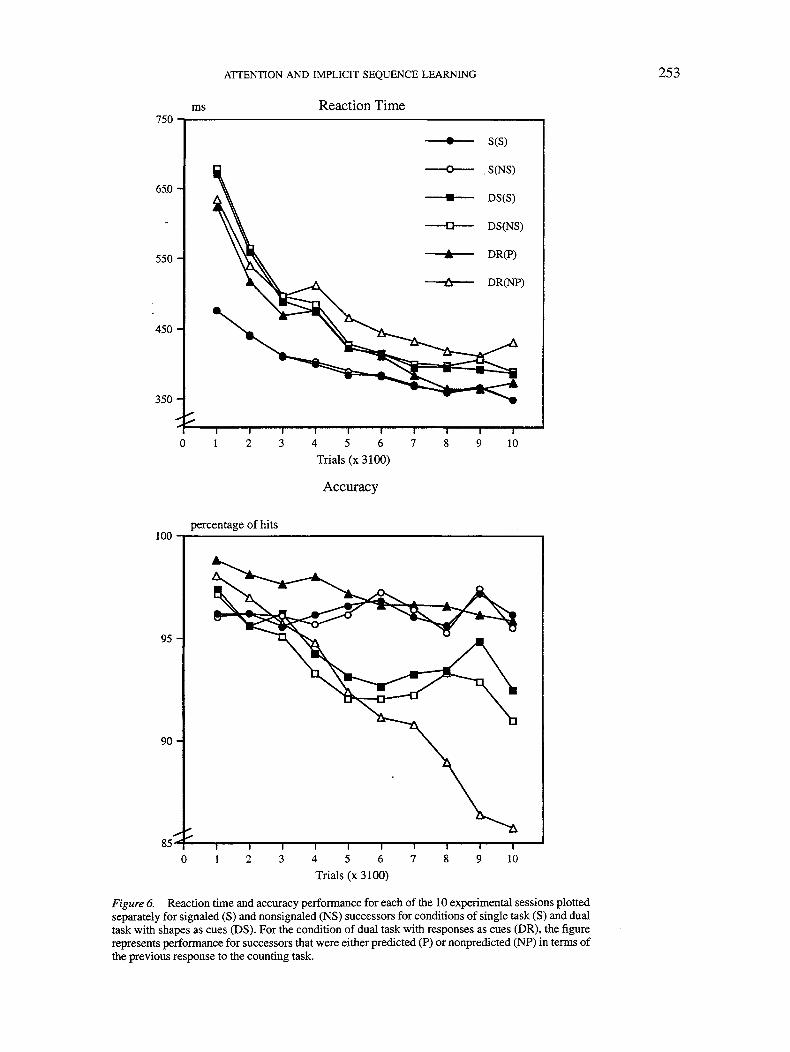
ATTENTION AND IMPLICIT SEQUENCE LEARNING 253
65.0-
-
5 5 0 -
4 5 0 -
3 5 0 -
ms
1
Reaction Time
0
•
*
- S(S)
- .S(NS)
- DS(S)
- DS(NS)
- DR(P)
- DR(NP)
4 5 6 7
Trials (x 3100)
Accuracy
9 10
percentage of hits
8 5 -
4 5 6Trials (x 3100)
10
Figure 6. Reaction time and accuracy performance for each of the 10 experimental sessions plottedseparately for signaled (S) and nonsignaled (NS) successors for conditions of single task (S) and dualtask with shapes as cues (DS). For the condition of dual task with responses as cues (DR), the figurerepresents performance for successors that were either predicted (P) or nonpredicted (NP) in terms ofthe previous response to the counting task.

254 JIMENEZ AND MENDEZ
them may serve as a contrast for a potential effect of cuecompetition in grammar learning. These pairwise compari-sons were conducted separately and confirmed (a) that therewas no difference in grammar learning between ConditionsDS and S, despite the facts that participants in Condition DSwere trained under dual-task conditions and that they did notlearn about the other cue, Condition X Practice X Grammati-cality interaction F(18, 106) = 0.85; and (b) that there wasalso no difference between the grammar learning manifestedunder Conditions DR and DS, although only participantspresented with DR conditions did learn about the predictivevalue of the concurrent cue, Condition X Practice XGrammaticality interaction, F(18,106) = 0.76.
As for the learning about the concurrent cue, finally, theabsence of shape learning observed in both Conditions S andDS, together with the clear response-based learning ob-served in Condition DR, provide us clear evidence about thespecific conditions that are required for a predictor to enteras a part of a predictive relationship. We discuss theimplications of these results with respect to the role ofattention in sequence learning in the General Discussion.
General Discussion
The present series of experiments analyzed the role ofattention in implicit sequence learning by including twotypes of attentional manipulations. It obtained results thatare coherent with a view of this learning as a result of aprocess that would proceed regardless of whether partici-pants are simultaneously engaged in a secondary task, andindependent of whether they are simultaneously acquiringknowledge about any other predictor of the same outcome.The fact that this sequence learning appears to be at worstonly barely affected by these manipulations does not neces-sarily mean that this process would run in a completelynonselective way, or that it would associate any perceptualinput impinging on the system. Rather, the results of thesestudies consistently indicate that what participants learnunder these circumstances is intimately bound to the tasksthat they are told to perform.
As for the implicit nature of this sequence learning, thepresent series of experiments also included a test of whetherthese results can be considered to be "largely unconscious,"as required by the most widely accepted definitions ofimplicit learning (e.g., Reber, 1993; see also Jimenez, 1997;Jimenez et al., 1996a). A comparison between otherwisesimilar direct and indirect measures of the knowledgeacquired under these circumstances showed that an impor-tant part of the relevant knowledge was exclusively ex-pressed through the indirect measures, not only for theknowledge about the sequence of locations, but also for theknowledge related with the other cue (i.e., the shapes).However, given that the questions at issue in this study arenot directly related with those about the conscious versusnonconscious status of these learning results, we would liketo sidestep this issue and to focus at greater length on theimplications that these results would bear on the discussionabout the role of attention in sequence learning. We addressthe effects of divided attention, cue competition, and selec-
tive attention separately, and we end by discussing thetheoretical issue of whether it is still possible, in the face ofthese results, to consider this implicit sequence learning asan automatic result of the processing of the relevant stimuli.
Divided Attention and Implicit Sequence Learning
The results of these experiments provide support to theclaim that, at least when the conditions resemble those usedin this study (i.e., probabilistic sequences presented duringlong training periods and counting tasks conducted on thesame stimulus on which the SRT task is being performed), adual-task manipulation does barely affect die outcome ofsequence learning. Through these three experiments, weconsistently found that participants presented with eithersingle- or dual-task conditions learn to discriminate betweengrammatical and nongrammatical successors of previoustrials, and that there are no significant differences betweenthem with regard to the size of this grammar learning effect.
We must handle these null effects with care, as they havebeen obtained from samples of participants that are consider-ably smaller that those usually used in studies that includeonly deterministic sequential material. However, we see atleast three reasons that may justify our reliance on thisconclusion. First, these null effects have been systematicallyreplicated and extended across three successive experi-ments, with the interactions of Condition X Grammaticalityconsistently producing low scores. Second, comparablepositive effects have been obtained for analogous interac-tions whenever a substantial difference between conditionswas immediately apparent from the figures (as it happened,for instance, in the analyses corresponding to the shapelearning effects), thus suggesting that the design was capableof detecting learning differences between conditions when-ever they reached a certain minimum size. Third, eventhough me number of participants in each condition wassmall, the facts that (a) two dependent variables weresimultaneously analyzed through the MANOVA analyses;(b) multiple measures were taken from each participant andeach dependent variable, thus contributing to keep errorvariances low; and (c) the values of the individual levels ofthe repeated measures factors were highly correlated, thusincreasing the value of the noncentrality parameter A (seeBuchner, Erdfelder, & Faul, 1997), all combined to producea design that was powerful enough to detect both large.(f = .40) and medium (f = .25) size effects for the Condi-tion X Grammaticality interactions (see discussion of Experi-ment 2) and even small effects (f = .10) for the three-wayinteraction of Condition X Practice X Grammaticality inExperiment 3 (see Footnote 6). There is no previous studythat might serve as a reference to estimate the effect size thatwe should expect to obtain through this kind of experiment,but comparable studies conducted with deterministic se-quences have reported interactions between task load (singlevs. dual task) and type of trial (structured vs. random) thattypically ranged from medium (e.g., Stadler, 1995, Experi-ment 1, F[l, 95] = 4.88; R2 = 0.05; f = .23) to large effects(e.g., Frensch et al., 1994; Experiment 1, F[l, 105] = 18.04,R2 = .15, f = .42). Therefore, from the analyses reported in

ATTENTION AND IMPLICIT SEQUENCE LEARNING 255
this study, we may at least conclude that the effects ofincluding a secondary task in these particular conditions aresmaller than those reported in previous studies that useddeterministic sequential structures and included tone count-ing as the secondary task.
The difference between-our results and those reported inthese previous studies can be attributed to a combination oftwo factors that we manipulated deliberately to avoidalternative interpretations of dual-task effects, and to a thirdfactor that came up as a side effect of our previous choices.First, we wanted to avoid the possibility that the inclusion ofoutside stimuli (e.g., tones) within a visual sequence mightproduce a disruption in this sequence that could pass for aneffect of task load, which is why we included a secondarytask conducted on the very same stimuli on which partici-pants performed the SRT task. Second, we also wanted torule out the possibility that a difference in performancebetween single- and dual-task conditions might arise from adifference in explicit acquisition, rather than from a differ-ence in implicit learning, and we addressed this question byarranging a situation in which more complex, only probabi-listic sequential material was used. In this situation, bothstimuli that conform and that do not conform to thegeneration rules were presented simultaneously with certainprobability, and hence any consciously noted contingencymay eventually be disconfirmed by further trials. Cleer-emans and Jimenez (1998) recently found that the transferfrom single- to dual-task conditions is specifically harmfulfor deterministic sequences, and they attributed this differ-ence in the effect of distraction to the different role thatexplicit learning processes could play in the acquisition ofeither probabilistic or deterministic sequences. Hence, iflearning of deterministic sequences is more open to explicitacquisition than learning of probabilistic structures, then it iseasy to infer that task load should specifically affect learningof the first type of sequences, not because implicit learningdepends on the amount of attentional resources available butbecause explicit learning is admittedly affected by theseresources.
Unfortunately, the use of probabilistic contingencies,although having the advantage of increasing the control overexplicit learning, comes also with the side effect of requiringmore training than any comparable deterministic paradigm.Moreover, when a dual-task condition is used over extendedperiods of training, this may open the possibility that thesecondary task would become automatic, hence allowingresources to be allocated to the process of learning, evenunder conditions of dual task.7 This claim is consistent withthe trend observed throughout the three experiments towardreducing the differences in RTs between dual- and single-task conditions with practice, but, in turn, the hypothesis ofthe automatization of the counting task is hard to reconcilewith the fact that this task requires participants to perform adifferent response for each trial (i.e., to update a counterwhenever the current shape belongs to a given target set). Asargued earlier, it is possible that some components of thistask have actually become automatic, such as the ascriptionof each shape to its corresponding category, but this is not
consistent with the result observed in Experiment 3, whichshows that continuously changing the mapping betweenshapes and responses does not produce a change in theobserved pattern of grammar learning. Therefore, we favorthe conclusion that the counting task constituted a demand-ing task throughout the training period, but that participantsmay have learned over training about how to best interleavethe different requirements of their tasks to perform themoptimally. In addition, it is also interesting to point out thatthe increase in speed produced over practice in dual-taskconditions should not be entirely considered as an effect oflearning, for it also reflects the effect of a trade-off betweenspeed and accuracy that was specific to these conditions. InExperiment 3, for instance, participants in Conditions DSand DR produced improvements over practice of 266 and231 ms, respectively, but these improvements were offset byaverage decreases in accuracy of 5.0 and 4.9 points for eachof these two groups. This trade-off was not present inCondition S, however, which produced an improvement ofonly 128 ms, but with a smaller decrease in accuracy, of only0.4 points. Analogous, but less significant, results were alsoobtained for the other experiments, thus suggesting that theimprovement produced in RTs for dual-task conditions werenot so much attributable to the automatization of thesecondary task as to the progressive development of a trendtoward responding faster but less accurately as trainingproceeded.
Attention and Concurrent Cues
The results of the present experiments showed thatparticipants can learn to predict the location of the nextstimulus, not only on the basis of a set of previous locations,but also on the basis of a concurrent cue related with theshape of the previous stimulus. They showed that this latterform of learning is only manifested when participants needto pay attention and to respond to these shapes, and thatlearning about these concurrent cues does not eliminate theeffects of grammar learning. Indeed, given that only partici-pants in conditions of dual task did acquire this shapelearning, the general equivalence of the grammar learningobserved between single- and dual-task conditions can betaken as evidence not only in favor of the resilience of theseimplicit learning effects to task load, but also to thecompetition between concurrent cues.
In Experiments 1 and 2, indeed, these two factors of usingconcurrent cues and of performing under dual-task condi-tions were completely conflated with each other, so that wecould only conclude that the combination of both effectsproduced the same pattern of results than that produced bytheir simultaneous absence. This may raise the point that,instead of an effect of competition between cues, perhaps acompensatory effect might also have taken place, so that apotential interference in grammar learning produced by thedual task could have been offset by a comparable advantagegained in this condition from the consideration of the
7 We thank Tim Curran for suggesting this possibility.

256 JIMENEZ AND MENDEZ
shapes.8 On a closer analysis, however, we think that thisinterpretation can be discarded on the bases of both proce-dural and empirical arguments. First, on procedural grounds,we should point out that both types of sequential relation-ships were probabilistic in nature and that both probabilitieswere independent, so that the probability of a trial to beaccurately predicted by the previous shape was exactly thesame for either grammatical or nongrammatical trials. Thatmeans that the effect of shape learning could not unduly passfor an effect of grammar learning in the absence of a genuinegrammar-learning effect. Besides, the fact that there was nointeraction between those effects could be empiricallyconfirmed through Experiment 3, in which both of theseeffects could be separated. This experiment included acondition of dual task in which participants did not learnanything about the concurrent cue (DS), and a comparisonbetween the grammar learning produced in this conditionand that manifested in condition DR confirmed that therewere no significant "compensatory" effect derived from theconsideration of the other cues. Moreover, a pairwisecomparison between the grammar learning observed inConditions S and DS, which differed specifically in taskload, also confirmed that the effect of including a secondarytask was not significant even when the concurrent cues werenot considered.
The conclusion that the processes of implicit learning arenot affected by other ongoing processes of learning iscoherent with some further results obtained in the samecontext of the SRT task (e.g., Cleeremans, 1997; Mayr,1996). Mayr, for instance, included two different andcompletely independent contingencies, related respectivelywith the sequence of objects that were to be identified andwith the sequence of locations in which they would appear,and he observed that each sequence could be acquiredindependently, without any competition for a limited amountof resources. Cleeremans (1997), on the other hand, showedthat participants can implicitly learn about a probabilisticsequential structure even though the next location wasalready predicted by a salient cue that was absolutelyreliable. In that experiment, however, Cleeremans found thatthe presence of such a salient cue interfered with theexpression, but not with the acquisition, of implicit grammarlearning. In contrast, our series of experiments have showedthat no effect of competition between cues is obtained whenthe cues are less obvious than that used by Cleeremans.Therefore, an interesting hypothesis that may provide a toolto distinguish between implicit and explicit learning pro-cesses could state that implicit learning processes should notinterfere with either the acquisition or the expression of anysimultaneous source of implicit learning, whereas explicitlearning could affect at least the expression, if not theacquisition, of simultaneous learning.
Selective Attention: When an EventBecomes a Predictor
Throughout this article, we presented evidence aboutcertain conditions in which participants learn about complexsequences of stimuli and about other conditions in which
comparatively simpler contingencies are not learned. Inclosing this discussion, therefore, we need to consider thespecific constraints that determine whether or not an eventcan become a predictor and whether, in the face of theseresults, the learning processes exemplified through thisexperimental paradigm can still be considered as automatic.
The results that are relevant to this final discussion can besummarized as follows. First, participants engaged exclu-sively in a task that requires them to respond to successivelocations (i.e., Conditions S) learn only about the complexsequential structure underlying these locations, but not aboutcomparatively simpler relationships established betweenshapes and locations. Second, learning about the relation-ships between shapes and locations is acquired whenparticipants are told to perform a secondary task thatrequires them to consider these shapes and to respond tothem (Conditions D). Third, the effect of shape learningdisappears in Condition D when, after a period of training,participants are told to discontinue the secondary task.Fourth, learning about the relationships established betweenshapes and locations depends on the specific task thatparticipants are told to perform with these shapes and seemsto be related with the responses required by the shapes ratherthan with their identities. Thus, as participants are told tocategorize the shapes and to count them only if they belongto the target set, they did not learn to associate eachindividual shape with the following location, but only theircategorization or counting response with the more likelysuccessors of these responses.
All of these four results are compatible with a version ofthe attention hypothesis that have been put forward byLogan and his colleagues (Logan & Etherton, 1994; Logan,Taylor, & Etherton, 1996) in the context of Logan's "in-stance theory of automaticity." The attention hypothesisessentially claim that "people learn what they attend to andexpress what they learned in transfer if they attend to thesame things in the same way" (Logan et al., 1996, p. 620).This theory assumes that encoding is an obligatory result ofattention, so that attention would be not just a necessarycondition, but also a sufficient condition for learning. In thecase of the present experiments, such a hypothesis wouldpredict that only participants who attend to the shapes wouldlearn to associate them with the next attended event, and thatonly the attended dimension of these shapes (i.e., theirascription to a given category) could become associated withthe next event.
In a sense, however, our interpretation of this hypothesisis more stringent than that proposed by Logan and Etherton(1994). Indeed, these authors claimed that attending to thecategory ascription of two simultaneous stimuli wouldproduce an association between the identities of thesestimuli as a whole and not merely between their respectivecategory labels. For instance, in their Experiment 6, Loganand Etherton presented two simultaneous words and askedparticipants to perform a different categorization task oneach of them (e.g., metals vs. countries, for one word, and
8 We thank Peter F. Dominey and Michael Stadler, who simulta-neously pointed out this possibility.

ATTENTION AND IMPLICIT SEQUENCE LEARNING 257
vegetables vs. objects of furniture, for the other). Theycontrolled the experiment so that, in general, the categoriza-tion response provided to one task did not predict responseto the other task. Still, they found that participants learned torespond faster to pairs of words that had been repeated overtraining than to those that were presented for the first time.This effect was not observed when participants had torespond to only one of the members of the pair, and thusLogan and Etherton argued that the facilitation observedshould be due to an association between the words whichwas only produced when both words were attended.
Why has a similar result not been produced in our seriesof experiments, in which participants categorized shapeswhile responding to locations, but in which they did notlearn to associate the identity of each shape with thefollowing location? A straightforward, but still provisionalanswer to this question may point to the differences betweenthese two designs concerning the temporal arrangement ofthe associations. Thus, whereas in the experiment of Loganand Etherton (1994) the identity of each word shouldbecome associated with the identity of a simultaneous word,in the present experiments the identity of each shape shouldnot become associated with the location at which it appearsfor that precise trial, but rather with the location at which thenext stimulus is going to appear for the next trial. This nexttrial would appear after about 700 ms, depending onparticipants' response latencies, and after making severaldecisions and responses on the previous item, includingpressing the key corresponding to its current location,deciding about whether or not the current shape correspondsto the target set, and updating the counter when necessary.Under these circumstances, it is not unlikely that the delayexisting between shapes and locations could hinder theassociation between them, and that the categorization deci-sion on the shapes could inhibit any preliminary representa-tion of their identities, thus preventing them from becomingassociated with forthcoming locations.
This time-interval account can also be compatible withthe production of associations between successive locations,precisely because the processing of each location, althoughseparated by comparable intervals, is maintained in virtue ofthe response requirements of the task. On the contrary, theresponse requirements concerning the counting task wouldmotivate participants to ignore the identity of the shapes andto concentrate only on their ascription to a given category, sothat it comes as no surprise that they would learn preciselyon that dimension.
At this point, an account of the present results in terms ofthe attention hypothesis, plus a reference to the effects of thetime interval and to the role of the tasks that participants aretold to perform in the course of training, may seem a bitspeculative. However, this perspective is coherent with thatadopted by several other authors who have pointed out theimportance of the interstimulus interval as a factor inimplicit sequence learning (Frensch et al., 1994; Frensch &Miner, 1994; Stadler, 1995), and who tended to characterizethis learning as an automatic associative process that wouldassociate all the representations that are simultaneouslyactive in short-term memory at a given point (Frensch &
Miner, 1994; Stadler, 1995). Most of the results observed inthe present experiments are compatible with such a generalaccount, which takes implicit learning to be an automaticprocess, but that need not assume that it should associateevery perceptual input impinging on the system in acompletely nonselective way. Rather, this perspective wouldclaim that attending to a predictor, and even requiring aresponse to it, could be necessary to maintain its representa-tion activated long enough to enable it to become associatedwith the next event.
The role of coactivation is fundamental to account forautomatic learning in several general theories of learningand memory (e.g., Cowan, 1988, 1995; Logan, 1988; Logan& Etherton, 1994), but it is not the only way in which effectssuch as those obtained in this study have been interpreted.Schmidtke and Heuer (1997) reported on results that aresimilar to the ones presented in this article, but they tried toexplain them in terms of what they called a task integrationhypothesis. In their study, they used deterministic sequencesand several groups of participants who differed in terms ofwhether they were or were not told to perform a secondarytask. The secondary task consisted of pressing a foot pedaleach time that a given target tone was presented. They foundthat learning about the relationships between tones andlocations was only obtained in conditions in which partici-pants responded to the tones. Despite the similarity existingbetween their results and those reported in the present study,Schmidtke and Heuer suggested an alternative interpreta-tion: that participants in dual-task conditions integrated thesequences of tones and locations into a single sequencecomposed by a series of tones and locations and based theirresponses on this complex and integrated sequence. In ourcase, however, this account is not adequate, because it wouldpredict that removing the secondary task should have adeleterious effect on grammar learning, which would amountto the whole disintegration of the sequence. As observed inour Experiment 2, however, neither eliminating the second-ary task nor removing the shapes produced such an interfer-ence, so that we conclude that our participants were able tolearn and manage both types of contingencies separately.
References
Baker, A. G., & Mercier, P. (1989). Attention, retrospectiveprocessing and cognitive representations. In S. Klein & R. R.Mowrer (Eds.), Contemporary learning theories: Pavlovianconditioning and the status of traditional learning theory(pp. 85-116). Hillsdale, NJ: Erlbaum.
Bray, J. H., & Maxwell, S. E. (1985). Multivariate analysis ofvariance. Beverly Hills, CA: Sage.
Buchner, A., Erdfelder, E., & Faul, F. (1997). How to use G • Power[On-line]. Retrieved December, 1, 1997, from http://www.psychologie.uni-trier.de:8000/projects/gpower/how_to_usegpower, html.
Buchner, A., Faul, F., & Erdfelder, E. (1992). GPOWER: A priori-,post-hoc and compromise power analyses for the Macintosh[Computer program]. Bonn, Germany: Bonn University.
Cleeremans, A. (1997). Sequence learning in a dual-stimulussetting. Psychological Research, 60, 72-86.
Cleeremans, A., & Jime'nez, L. (1998). Implicit sequence learning:The truth is in the details. In M. A. Stadler & P. A. Frensch

258 JIMENEZ AND MENDEZ
(Eds.), Handbook of implicit learning (pp. 323-364). ThousandOaks, CA: Sage.
Cleeremans, A., & McClelland, J. L. (1991). Learning the structureof event sequences. Journal of Experimental Psychology: Gen-eral, 120, 235-253.
Cohen, A., Ivry, R. I., & Keele, S. W. (1990). Attention andstructure in sequence learning. Journal of Experimental Psychol-ogy: Learning, Memory, and Cognition, 16, 17-30.
Cohen, J. (1988). Statistical power analysis for the behavioralsciences. Hillsdale, NJ: Erlbaum.
Cohen, J. D., Dunbar, K., & McClelland, J. L. (1990). On thecontrol of automatic processes: A parallel distributed account ofthe Stroop effect. Psychological Review, 97, 332-361.
Cowan, N. (1988). Evolving conceptions of memory storage,selective attention, and their mutual constraints within thehuman information-processing system. Psychological Bulletin,104, 163-191.
Cowan, N. (1995). Attention and memory. New York: OxfordUniversity Press.
Curran, T., & Keele, S. W. (1993). Attentional and nonattentionalforms of sequence learning. Journal of Experimental Psychol-ogy: Learning, Memory, and Cognition, 19, 189-202.
Dienes, Z., Airman, G. T. M., Kwan, L., & Goode, A. (1995).Unconscious knowledge of artificial grammars is applied strate-gically. Journal of Experimental Psychology: Learning, Memory,and Cognition, 21, 1322-1338.
Dienes, Z., Broadbent, D., & Berry, D. (1991). Implicit and explicitknowledge bases in artificial grammar learning. Journal ofExperimental Psychology: Learning, Memory, and Cognition,17, 875-887.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise lettersupon the identification of a target letter in a nonsearch task.Perception & Psychophysics, 16, 143-149.
Frensch, P. A. (1998). Same concept, multiple meanings: On howto define the concept of implicit learning. In M. Stadler & P. A.Frensch (Eds.), Handbook of implicit learning (pp. 47-104).Thousand Oaks, CA: Sage.
Frensch, P. A., Buchner, A., & Lin, J. (1994). Implicit learning ofunique and ambiguous serial transitions in the presence andabsence of a distractor task. Journal of Experimental Psychol-ogy: Learning, Memory, and Cognition, 20, 567-584.
Frensch, P. A., Lin, J., & Buchner, A. (1998). Learning versusbehavioral expression of the learned: The effects of a secondarytone-counting task on implicit learning in the serial reaction timetask. Psychological Research, 61, 83-98.
Frensch, P. A., & Miner, C. S. (1994). Individual differences inshort-term memory capacity on an indirect measure of seriallearning. Memory & Cognition, 22, 95-110.
Hayes, N. A., & Broadbent, D. E. (1988). Two modes of learningfor interactive tasks. Cognition, 28, 249-276.
Jimenez, L. (1997). Implicit learning: Conceptual and methodologi-cal issues. Psychologica Belgica, 37, 9-28.
Jim6nez, L., Mendez, C , & Cleeremans, A. (1996a). Comparingdirect and indirect measures of sequence learning. Journal ofExperimental Psychology: Learning, Memory, and Cognition,22, 948-969.
Jimenez, L., Mendez, C , & Cleeremans, A. (1996b). Measures ofawareness and of sequence knowledge. In Psyche: An interdisci-plinary journal of research on consciousness [On-line]. Re-trieved July 16, 1997, from http://psyche.cs.monash.edu.au/v2/psyche-2-33-jimenez.html.
Jim6nez, L., Mendez, C , & Lorda, M. J. (1993). Aprendizajeimplfcito, atencion y conciencia en una tarea de tiempo dereacci6n serial [Implicit learning, attention and awareness in a
serial, reaction-time task]. Revista de Psicologia General yAplicada, 46, 245-255.
Johnston, W. A., & Dark, V. J. (1986). Selective attention. AnnualReview of Psychology, 37, 43—75.
Kamin, J. L. (1969). Predictability, surprise, attention, and condi-tioning. In B. A. Campbell & R. M. Church (Eds.), Punishmentand aversive behavior (pp. 279-296). New York: Appleton-Century-Crofts.
Lewicki, P., Hill, T., & Bizot, E. (1988). Acquisition of proceduralknowledge about a pattern of stimuli that cannot be articulated.Cognitive Psychology, 20, 24-37.
Logan, G. D. (1988). Toward an instance theory of automatization.Psychological Review, 95, 492-527.
Logan, G. D., & Etherton, J. L. (1994). What is learned duringautomatization? The role of attention in constructing an instance.Journal of Experimental Psychology: Learning, Memory, andCognition, 20, 1022-1050.
Logan, G. D., Taylor, S. E., & Etherton, J. L. (1996). Attention inthe acquisition and expression of automaticity. Journal ofExperimental Psychology: Learning, Memory, and Cognition,22, 620-638.
Mackintosh, N. J. (1975). A theory of attention: Variations in theassociability of stimuli with reinforcement. Psychological Re-view, 82, 276-298.
Mayr, U. (1996). Spatial attention and implicit sequence learning:Evidence for independent learning of spatial and nonspatialsequences. Journal of Experimental Psychology: Learning,Memory, and Cognition, 22, 350-364.
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements oflearning: Evidence from performance measures. Cognitive Psy-chology, 19, 1-32.
Pachella, R. G. (1974). The interpretation of reaction time ininformation processing research. In B. Kantowitz (Ed.), Humaninformation processing (pp. 41-84). Potomac, MD: Erlbaum.
Perruchet, P., & Amorim, P. A. (1992). Conscious knowledge andchanges in performance in sequence learning: Evidence againstdissociation. Journal of Experimental Psychology: Learning,Memory, and Cognition, 18, 785-800.
Perruchet, P., & Gallego, J. (1997). A subjective unit formationaccount of implicit learning. In D. Berry (Ed.), How implicit isimplicit learning? (pp. 124-161). Oxford, United Kingdom:Oxford University Press.
Posner, M. I., & Snyder, C. R. R. (1975). Attention and cognitivecontrol. In R. L. Solso (Ed.), Information processing andcognition: The Loyola symposium (pp. 55-85). Hillsdale, NJ:Erlbaum.
Reber, A. S. (1993). Implicit learning and tacit knowledge.London: Oxford University Press.
Reed, J., & Johnson, P. (1994). Assessing implicit learning with• indirect tests: Determining what is learnt about sequence struc-
ture. Journal of Experimental Psychology: Learning, Memory,and Cognition, 20, 585-594.
Schmidtke, V., & Heuer, H. (1997). Task integration as a factor insecondary-task effects on sequence learning. PsychologicalResearch, 60, 53-71.
Schneider, W., Dumais, S. T., & Shiffrin, R. M. (1984). Automaticand controlled processing and attention. In R. Parasuraman &D. R. Davis (Eds.), Varieties of attention (pp. 1-27). Orlando,FL: Academic Press.
Schneider, W., & Shiffrin, R. M. (1977). Controlled and automatichuman information processing: I. Detection, search, and atten-tion. Psychological Review, 84, 1-66.
Shanks, D. R., & Johnstone, T. (1998). Implicit knowledge insequential learning tasks. In M. A. Stadler & P. A. Frensch

ATTENTION AND IMPLICIT SEQUENCE LEARNING 259
(Eds.), Handbook of implicit learning (pp. 533-572). ThousandOaks, CA: Sage.
Stadler, M. A. (1989). On learning complex procedural knowledge.Journal of Experimental Psychology: Learning, Memory, andCognition, 15, 1061-1069.
Stadler, M. A. (1995). Role of attention in implicit learning.Journal of Experimental Psychology: Learning, Memory, andCognition, 21, 819-827.
Stroop, J. R. (1935). Studies of interference in serial verbalreactions. Journal of Experimental Psychology, 18, 643-662.
Willingham, D. B., Greenberg, A. R., & Thomas, R. C. (1997).Response-to-stimulus interval does not affect implicit motor
sequence learning, but does affect performance. Memory &Cognition, 25, 534-542.
Willingham, D. B., Nissen, M. J., & Bullemer, P. (1989). On thedevelopment of procedural knowledge. Journal of ExperimentalPsychology: Learning, Memory, and Cognition, 15, 1047-1060.
Received M y 24, 1997Revision received March 16, 1998
Accepted April 8, 1998
Statement of Ownership, Management, and Circulation(Ftoaumdtv & useless)
14 EH
7S0 First Street, NE • Washington, DC 20002-4242
American Psychological Assoc7S0 First Street. NEWashington, PC 20002-4242
Susan Knspp, American Psychological Associatio:7S0 First Street, NE - Washington, DC 20002-4
American Psychological Association O First Street, NE
Icwtruetkm* to PubUatwrs