trabajo nº 1 completo iniguez y otros seleccion variables estadistico zamzar
TRANSCRIPT

REVISIÓN DE TÉCNICAS BASADAS EN HERRAMIENTAS E INDICADORES ESTADÍSTICOS EN LA SELECCIÓN DE
VARIABLES EN EL ESTUDIO DE EFICIENCIA DE LOS CAPS DE LA CIUDAD DE RÍO CUARTO
PATRICIA A. IÑIGUEZ – MARIANA ARBURUA – JUAN M. GALLARDO – ERNESTO L. FERREYRA – FERNANDO J. NEGRO – ADRIANA L. IÑIGUEZ
Facultad de Ciencias Económicas - Universidad Nacional de Río Cuarto
[email protected], [email protected], [email protected],
[email protected], [email protected], [email protected].
RESUMEN
Las exigencias de DEA respecto a la especificación del problema empírico afectan a dos cuestiones que tienen como objetivo construir el modelo que mejor ajuste a la realidad. Ellas son la selección de las variables y el modelo matemático. La primera cuestión es relevante si se pretende que la medición de eficiencia sea fiable. El número de variables se vincula fuertemente al tamaño de la muestra, cuanto mayor sea ésta, mayor será el número de variables inputs y outputs que se pueden considerar en el modelo.
En el caso particular bajo estudio la muestra es de diecisiete centros lo que limita el número de variables a considerar. Se ha realizado una preselección obteniéndose un conjunto de quince variables, cinco inputs y diez outputs. En el presente se realiza una selección aplicando técnicas basadas en herramientas e indicadores estadísticos. Para el método ECM se realiza un proceso por agregación de variables y se consideran cinco pares iniciales para el método RB. Finalmente se seleccionan los escenarios siguiendo la propuesta de Aragão de Castro Senra, Nanci, Soares de Mello y Angulo Meza (2007). Así, se obtiene un conjunto de variables que maximiza la eficiencia media y minimiza el número de unidades eficientes. Palabras Clave: Eficiencia, DEA, Selección de Variables, Técnicas Estadísticas.
ABSTRACT DEA requirements about the specification of the empirical problem
affecting two issues that aim to build the model that best fits the reality. They are the selection of variables and the mathematical model. The first question is relevant if it is to measure efficiency is reliable. The number of variables is strongly linked to the sample size, the larger the sample, the greater the number of inputs and outputs variables that can be considered in the model.
In the particular case under study sample is seventeen centers which limits the number of variables to consider. It has made a shortlist obtaining a set of fifteen variables -five inputs and ten outputs. In this a selection of variables based on applying tools and techniques statistical indicators is performed. In the case of ECM method is carried out by a process variables aggregation and initial five pairs for RB method are considered. Finally, the scenarios are selected following the proposal of Aragão de Castro Senra, Nanci, Soares de Mello and Angulo Meza (2007). Thus, a set of variables that maximizes the average efficiency and minimizes the number of efficient units is obtained. Key Words: Efficiency, DEA, Variable Selection, Statistical Techniques.

1. INTRODUCCIÓN
El Análisis Envolvente de Datos (DEA) como herramienta de análisis
cuantitativo en las Ciencias de la Administración y la Investigación Operativa muestra un importante desarrollo (Cooper, Seiford, y Zhu, 2004), siendo numerosas las aplicaciones en la evaluación de desempeño de unidades económicas, DMUs (Decision Making Units) en diversos campos. Las múltiples ventajas de este tipo de modelos no paramétricos de medición de eficiencia, permiten su aplicación a la investigación del sistema de salud pública y son ampliamente utilizados en los análisis de eficiencia dentro del sector. Al respecto, mediante un análisis de eficiencia técnica, es posible identificar las unidades que utilizan de manera efectiva los recursos puestos a su disposición y, por el contrario, las unidades ineficientes, ya sea porque no son capaces de obtener la máxima producción con los recursos disponibles, o bien tienen capacidad instalada ociosa. En este marco, en la estimación de la eficiencia técnica con la cual operan las unidades puede identificarse tanto la eficiencia de escala (asociada a su tamaño o capacidad instalada de producción), como la eficiencia técnica pura, la que responde a factores intrínsecos a la gestión de la unidad. Es decir, que no es explicada por factores de escala, sino por el esfuerzo productivo derivado de los procesos de gestión aplicados. Así, el interés se centra en la eficiencia técnica ya que mediante la comparación de esfuerzos productivos entre unidades, es posible establecer procesos de gestión de benchmarking (sistema de comparación entre pares).
Ahora bien, para que las bondades del DEA, tanto desde el punto de vista operativo como de la interpretación de los resultados puedan ser de utilidad práctica, es necesario que la aplicación a una realidad productiva concreta, en este caso los CAPS del Municipio de la Ciudad de Río Cuarto, se ajuste a una serie de requisitos que respalden el alcance y validez de los resultados obtenidos.
La medida de eficiencia propuesta que se determina a través de DEA es relativa y depende de la muestra bajo estudio. Esto exige que las DMUs objeto de estudio sean comparables entre sí. Este requisito de obligado cumplimiento fue destacado por Charnes et al. (1978) cuando, al desarrollar el modelo de la envolvente señalaron la necesidad de que las unidades evaluadas sean homogéneas tanto en los recursos utilizados, como en la producción obtenida y en el entorno en el que operan.
Esto último merece una pequeña consideración especial. Los criterios desde los que se puede valorar la homogeneidad del entorno en el que los centros de salud desarrollan su actividad son diversos. En una primera instancia, considerando que se trata de establecimientos de salud públicos que dependen de una misma unidad administrativa y que sus insumos son financiados por el presupuesto municipal, se puede afirmar que operan en un entorno semejante. Sin embargo, desde otra perspectiva puede considerarse que los resultados de los CAPS1 pueden verse afectados por el entorno no controlable económico-educativo del radio de influencia el que en Ferreyra et al (2013) se ha demostrado no homogéneo. Este hecho implica una particular
1 CAPS: Centro de Atención Primaria de la Salud

atención a la hora de seleccionar el o los modelos con los que se evalúa la eficiencia.
Las exigencias de DEA en cuanto a la especificación del problema empírico afectan a dos cuestiones fundamentales que tienen como objetivo construir el modelo que mejor ajuste a la realidad. Esas decisiones se refieren a la identificación y selección de las variables y al tipo de modelo matemático.
En Iñiguez et al (2014) se concluye una primera etapa de identificación y selección de variables a partir de la cual se obtiene un conjunto de quince2 variables, cinco inputs y diez outputs, las que se muestran en la Tabla 1. Este número no resulta adecuado dado que cuanto mayor es el número de variables incluidas en un modelo DEA, mayor es la dimensionalidad del espacio de producción y, por tanto, el análisis será menos exigente. Más precisamente, un aumento en el número de variables incluidas en el modelo DEA tiende a desplazar las unidades hacia la frontera eficiente, provocando una disminución de su capacidad de discriminación. Por tal motivo, Cooper, Seiford y Tone
(2006), aconsejan que 𝑁 ≥ 𝑚𝑎𝑥 {𝐼𝑥𝑂, 3(𝐼 + 𝑂) }3. En estos términos, se deberían analizar al menos 50 DMUs. Pero ello no es factible; los CAPS a evaluar son diecisiete, por tanto deben aplicarse algunos métodos de selección de variables que consideren, además de las relaciones entre ellas, la contribución a la medida de eficiencia de modo de reducir el número de variables a uno adecuado.
Tabla 1: Variables y Valores en cada CAPS
Fuente: Elaboración propia a partir del relevamiento de datos en la Subsecretaria de Salud de la
Municipalidad de Río Cuarto
Así las cosas, en Iñiguez et al (2015) se realiza un primer proceso de selección aplicando técnicas estadísticas, pero al ser significativo el número de variables algunas técnicas no dieron resultados razonables, caso del método propuesto por Pastor et al (2002). Esta técnica, inicia el proceso de selección con un modelo con las quince variables el que no discrimina y al eliminarse sólo una variable en cada iteración no puede mostrar el efecto marginal que cada una de ellas podría tener sobre el nivel eficiencia de cada DMU. Por otra parte, en el caso de la técnica de regresión propuesta por Ruggiero (2005) se probaron sólo dos pares iniciales.
Por lo anterior, el objetivo del presente es aplicar sobre el conjunto de las quince variables tres técnicas de selección basadas en herramientas e
2 Se informa que inicialmente se preseleccionaron 18 variables, 7 inputs y 11 outputs, pero 3 de ellas asumían valor 0
en muchas DMU y, por ello, fueron eliminadas. 3 I:Input, O:Output
Variables Sigla CAPS 1 CAPS 2 CAPS 3 CAPS 4 CAPS 5 CAPS 6 CAPS 7 CAPS 8 CAPS 9 CAPS 10 CAPS 11 CAPS 12 CAPS 13 CAPS 14 CAPS 15 CAPS 16 CAPS 17
Pediatría (hs. semanales) (I) HP 25,00 25,00 30,00 30,00 30,00 30,00 22,50 27,50 20,00 18,00 25,00 20,00 22,50 30,00 19,00 30,00 46,00
Ginecología (hs. semanales) (I) HG 9,00 12,00 12,00 0,00 20,00 10,00 5,00 8,00 10,50 3,50 10,50 12,00 4,00 5,50 9,50 8,00 8,00
Odontología (hs. semanales) (I) HO 20,00 20,00 19,25 4,00 25,00 0,00 26,25 14,00 24,00 0,00 11,50 16,00 20,00 20,00 0,00 8,00 80,00
Enfermería (I) HE 60,00 90,00 60,00 60,00 90,00 60,00 60,00 60,00 60,00 30,00 90,00 60,00 60,00 60,00 60,00 60,00 600,00
Insumos Enfermería (I) IE 4,44 5,31 3,21 0,48 3,76 3,39 4,05 4,82 4,30 2,69 2,94 4,04 2,25 2,83 1,38 3,17 14,94
C Pediatría (O) CP 4467,00 4176,00 4033,00 1832,00 4586,00 4624,00 2086,00 4089,00 4656,00 2979,00 3909,00 4401,00 3900,00 3931,00 2279,00 1637,00 3794,00
Consulta Clínica Médica (O) CCM 3188,00 3482,00 4458,00 1971,00 4316,00 2917,00 1917,00 4651,00 5066,00 2692,00 3136,00 2717,00 3782,00 3683,00 1139,00 4436,00 6827,00
Consulta Odontología (O) CO 2769,00 2879,00 2755,00 1795,00 3793,00 0,00 3397,00 2522,00 3656,00 0,00 3554,00 2561,00 5327,00 3680,00 0,00 3568,00 10299,00
Inmunizaciones (O) Inmu 13880,00 13314,00 13539,00 5747,00 14465,00 11126,00 9139,00 14217,00 15785,00 6900,00 13262,00 11901,00 15050,00 15085,00 4832,00 12436,00 36939,00
Inyectables (O) Inyec 1072,00 1105,00 1418,00 369,00 1095,00 1087,00 676,00 1407,00 684,00 860,00 609,00 1611,00 911,00 720,00 800,00 1533,00 1484,00
Signos Vitales (O) SV 1142,00 2061,00 475,00 655,00 1179,00 594,00 892,00 989,00 294,00 837,00 763,00 568,00 1123,00 1097,00 732,00 718,00 5069,00
Atención de la Madre y del
Niño(O) AMyN 2043,00 797,00 1211,00 616,00 1323,00 1387,00 867,00 1285,00 2599,00 963,00 1173,00 1524,00 1102,00 1691,00 1045,00 924,00 6524,00
Entrega de Leche (O) ELeche 6655,00 4680,00 3505,00 1449,00 5999,00 3602,00 2642,00 5314,00 8485,00 2691,00 4617,00 5503,00 2741,00 5040,00 2707,00 2876,00 2623,00
Radiografías (O) Radio 181,00 174,00 196,00 93,00 132,00 81,00 97,00 204,00 197,00 98,00 211,00 140,00 206,00 164,00 70,00 398,00 586,00
Medicamentos (O) CMedic 29574,00 19220,00 9570,00 17549,00 32460,00 29180,00 21191,00 41405,00 28023,00 27921,00 36528,00 33677,00 33431,00 39435,00 24867,00 35052,00 287973,00

indicadores estadísticos para separar un número adecuado de variables inputs y outputs, introduciendo cambios en los procesos. Para el caso de la técnica Regression-Based se prueban cinco pares en el paso inicial y para el caso de Efficiency Contribution Measure se realiza el proceso inverso –agregación de una variable- partiendo de un par inicial seleccionado de los cinco antes indicados. El método basado en la Covarianza Parcial se presenta sin cambios. Finalizado este proceso se obtienen distintos conjuntos de variables. La selección del conjunto más adecuado se realiza aplicando el método propuesto por Aragão de Castro Senra, Nanci, Soares de Mello y Angulo Meza (2007).
A fin de alcanzar tal objetivo el trabajo se estructura del siguiente modo: seguidamente se hace una breve referencia de los métodos para la selección de variables basados en herramientas e indicadores estadísticos, luego se aplican al conjunto de variables preseleccionado y, finalmente, se reflejan las principales conclusiones.
Es necesario aclarar que, por razones de espacio, en el presente no se muestran todos los resultados, sólo se presentan los indispensables a los efectos de las conclusiones.
2. PROPUESTAS PARA LA SELECCIÓN DE VARIABLES QUE
UTILIZAN HERRAMIENTAS O INDICADORES ESTADÍSTICOS
En este caso se presentan y aplican tres métodos 1) Técnica Basada en una Regresión (Regression-Based - RB) (Ruggiero, 2005), 2) Método de la Medida de la Contribución a la Eficiencia (Efficiency Contribution Measure –ECM) por agregación de variables (Pastor, Ruiz y Sirvent, 2002), 3) Método de Reducción de Variables basado en la Covarianza Parcial (Partial Covariance - PC) (Jenkins y Anderson, 2003).
2.1. Método Basado en una Regresión (RB)
Ruggiero (2005) afirma que si un input potencial se omite en el modelo
DEA cuando el input está correlacionado positivamente con la medida de eficiencia, entonces, dicho modelo debe ejecutarse nuevamente con esa variable incluida. Una regla similar se define para los outputs. Para la puesta en práctica de esta regla el autor propone resolver el siguiente modelo de regresión:
ET= α+β1z1+β
2z2+…+β
kzk+ ε
donde ET es la medida de eficiencia técnica obtenida de un modelo DEA incluyendo un conjunto de variables de los S outputs y M inputs dados4
; z1 hasta zk son variables candidatas. Si el coeficiente de i en la regresión es estadísticamente significativo a un nivel de significancia dado y tiene el signo
adecuado según sea la medida de eficiencia insumo o producto orientada (i >0
o i <0, respectivamente), la variable zi se considera relevante para el proceso de producción y se añade al modelo DEA. De este modo, se determina un nuevo índice ET y nuevamente se prueba el conjunto de variables candidatas. Este proceso se repite hasta que todas las variables candidatas se consideren
4El proceso puede iniciarse con un único input y un sólo output

irrelevantes, se hallen incluidas en el modelo o se alcance un número adecuado de variables. 2.2. Método de la Medida de la Contribución a la Eficiencia (ECM)
Pastor et al. (2002) desarrollan un método para el análisis de la
relevancia de una variable en función de su contribución a la eficiencia. La variable cuya relevancia se prueba se denomina “candidata”. Así se comparan los resultados de dos modelos DEA, uno con la variable candidata y otro sin ella. Luego, por un test estadístico binomial se determina si el efecto de esta variable en la medida de eficiencia indica que la variable “candidata” es importante para el proceso de producción. Este proceso de selección puede realizase de dos modos: hacia adelante (agregación de variables) o hacia atrás (eliminación de variables). Sea K el conjunto integrado por al menos un input y un output de los M inputs y los S outputs dados, respectivamente. Y sea Z el conjunto de los inputs y outputs candidatos. Los autores cuantifican el impacto marginal de una variable sobre una DMU como el cambio en el índice de eficiencia cuando una determinada variable se incluye en el modelo en comparación con el índice de eficiencia con la variable excluida. Si la diferencia para una DMU es mayor que un umbral predeterminado, se dice que la DMU es afectada por la presencia de la variable. Una variable no tiene influencia significativa si sólo unas pocas DMUs se ven afectadas, es decir, la proporción de DMUs afectadas es menor que un umbral predeterminado.
Para formalizar estos conceptos, se denota con φn(K) al índice de
eficiencia técnica de la n-ésima DMU, evaluada sobre la base de las K variables. Sea z una variable candidata. El impacto marginal de z en la
eficiencia de la n-ésima, DMU se mide como: ρn𝑧=
𝜑𝑛(𝐾)
𝜑𝑛(𝐾+𝑧), donde 𝜑𝑛(𝐾+𝑧) es el
índice de eficiencia de un modelo aumentado, con z; ρn𝑧 es el cambio
proporcional en la eficiencia debido a la presencia de z y se refiere al impacto
marginal de z en la n-ésima DMU. Es claro que 𝜑𝑛(K) ≥ 𝜑𝑛(𝐾+𝑧). ρn𝑧=1(𝜑𝑛(𝐾) =
𝜑𝑛(𝐾+𝑧)) indica que el impacto marginal z en n es nulo; un mayor valor de ρn𝑧
sugiere que z tiene un impacto marginal más significativo en n. Si la variable z no es relevante, la eficiencia no debería afectarse considerablemente por la presencia de z en el modelo. Pastor et al. (2002) proponen un enfoque estadístico para analizar el impacto. Supóngase que ρ
n𝑧 son valores observados
de una muestra aleatoria n, n∈ N, extraída de una población (, F), es aleatoria y sigue una distribución F[1,∞). El impacto marginal significativo
superior al umbral de impacto individual ρ̅ es un evento con probabilidad
p=P{>ρ̅}. Si la probabilidad p es alta, es muy probable que z sea importante
en el modelo DEA dado ρ̅. En efecto, la probabilidad p también puede
interpretarse como la proporción de las DMUs afectadas. Se denota con Tnz a
una variable aleatoria que se define de la siguiente manera:
Tnz= {
1 si Γn>ρ̅
0 para toda otra alternativa, n ∈ N; z Z
Así, Tnz es un indicador de si z afecta a n, y sigue una distribución de
Bernoulli con parámetro p. Dada Tnz, n∈ N distribuido Bernoulli (p), T
z= ∑ Tn
zn∈N

es el número total de DMUs afectadas por la presencia de z, y sigue una binomial (N, p). De este modo, puede plantearse la siguiente prueba de hipótesis de la relevancia de z: H0: p ≤ p
0; HA: p > p
0. Rechazar H0 sugiere que
z es significativa en la evaluación de eficiencia en más de p0 ×100% de las DMUs, porque sus índices de eficiencia tienen una variación superior a ρ̅×100% si z no está en el modelo. Por lo tanto, z debe ser considerado como una variable relevante. La prueba de hipótesis es un test de proporción estándar, y una sencilla prueba basada en una binomial (N, p) puede utilizarse una vez obtenidos los p-valores. 2.3. Método de Reducción de Variables Basado en la Covarianza Parcial
(PC)
Sus autores consideran que una alta correlación entre las variables
inputs y/u outputs puede ser motivo suficiente para la omisión de algunas de ellas. Proponen el uso de herramientas de estadística multivariada para identificar las variables que pueden ser omitidas con la menor pérdida de información. La medida que utilizan es la varianza de un input u output en torno a su media, ya que si su valor es constante (varianza constante) no influye en la distinción de una DMU respecto de otras.
En este método, se normalizan las variables para tener una media igual a 0 y una varianza igual a 1. La normalización de la varianza implica que, en ausencia de cualquier otra información, cada variable input y output seleccionada es igualmente importante para DEA. La varianza condicional de
una variable, denotada por σii.i´´ es la varianza residual en la variable 𝑖 cuando se quita el efecto de i''. Si la variable i está perfectamente correlacionada con 𝑖′′,
entonces el condicionamiento i en i'', σii.i´´, será igual a 0. Por lo tanto, si en un
conjunto ordenado de forma arbitraria de variables x1,…, xM5, condicionado en
xM-1 y xM tiene varianza parcial de x1 a xM-2 igual a cero, entonces, la
información contenida en todas las variables x1,…, xM está en xM-1 y xM.
Si todas las M variables se normalizaron para tener varianza unitaria,
entonces su varianza total combinada es simplemente M. Así si i=p+1,…,M son las variables retenidas que representan la mayor parte de la información de las
M variables y las i=1,…,p se omiten, idealmente la varianza explicada por las variables p+1,…,M será M, y la varianza parcial de variables 1,…,p será cero. Si bien la correlación perfecta es poco probable en datos reales, una varianza parcial residual que sea pequeña, en lugar de 0, es un objetivo aceptable. Con la varianza de cada variable inicialmente normalizada a 1, la varianza residual de las variables condicionadas se controla fácilmente. Por lo tanto, es simple decidir, utilizando la varianza residual, la cantidad de las variables p+1,…,M que representan razonablemente la información de las 𝑀 variables.
El procedimiento resumido se presenta a continuación. a) Normalizar los datos con el fin de obtener una media igual a cero y
una varianza igual a la unidad asegurando que todas las variables son igualmente tratadas.
5Considerando sólo los inputs

b) Dividir las M variables (si se consideran sólo los inputs), etiquetando
como resulte conveniente, en dos conjuntos: i=1,…,p, en
representación de las variables a ser omitidas, y i=p+1,…,M las variables a conservar, ya que contienen la mayor parte de la
información de las M variables. c) Calcular la varianza-covarianza parcial de la matriz
V11.2=V11-V12.(V22)-1.V21, donde V11 representa la matriz de
varianza-covarianza de las variables i=1,…,p; V22 representa la matriz de varianza-covarianza de las variables i=p+1,…,M; V12 (V21)
representa la matriz de covarianza de las variables i=1,…,p y
i=p+1,…,M (y viceversa). d) Calcular la traza de V11.2 que representa el tamaño de la varianza
residual de las variables i=1,…,p, después del condicionamiento de
las variables retenidas i=p+1,…,M. e) Repetir el procedimiento de etiquetado de las variables i=1,…,M bajo
diferentes particiones con el fin de lograr la mínima varianza en las primeras p variables. Es decir, el número de variables omitidas depende del nivel de la varianza residual de las variables.
3. SELECCIÓN DE VARIABLES EN EL ESTUDIO DE EFICIENCIA DE
LOS CAPS DE LA CIUDAD DE RÍO CUARTO
La aplicación de los distintos métodos se muestra en el orden en que han sido presentados en la sección 2.
3.1. Aplicación de Regression-Based (RB)
Para el caso del método RB se requiere una medida de eficiencia como
punto de partida, lo que implica escoger, al menos, un input y un output. En este proceso se han seleccionado cinco pares input-output conformados por los cinco inputs y el output con mayor correlación lineal respectivamente (ver Tabla 2).
Tabla 2: Matriz de Correlaciones
Fuente: Elaboración Propia con Excel
Primer Par: Se escoge el input HP y el output Inmu. Así, el índice de
(I) HP (I) HG (I) HO (I) HE (I) IE (O) CP (O) CCM (O) CO (O) Inmu (O) Inyec (O) SV (O) AMyN (O) ELeche (O) Radio (O) CMedic
(I) HP 1,0000
(I) HG 0,0584 1,0000
(I) HO 0,6786 0,1382 1,0000
(I) HE 0,7762 0,0304 0,8891 1,0000
(I) IE 0,6849 0,1668 0,9120 0,9257 1,0000
(O) CP 0,0571 0,5797 0,2413 0,0802 0,2689 1,0000
(O) CCM 0,6531 0,2759 0,7252 0,6327 0,7256 0,4223 1,0000
(O) CO 0,6700 0,0500 0,9271 0,8088 0,7851 0,1579 0,7576 1,0000
(O) Inmu 0,7542 0,1782 0,9295 0,8918 0,9223 0,3820 0,8631 0,9070 1,0000
(O) Inyec 0,3426 0,4292 0,3162 0,3179 0,4823 0,2644 0,5148 0,2763 0,4375 1,0000
(O) SV 0,7268 0,0095 0,8653 0,9452 0,9098 0,0955 0,5821 0,7820 0,8525 0,3104 1,0000
(O) AMyN 0,6698 0,0721 0,8836 0,9264 0,9146 0,2724 0,7074 0,7769 0,9166 0,3157 0,8336 1,0000
(O) ELeche -0,2289 0,5675 0,0716 -0,1872 0,0548 0,7224 0,2988 0,0194 0,1328 0,0905 -0,1966 0,0962 1,0000
(O) Radio 0,7180 0,0217 0,7587 0,8046 0,7937 -0,0047 0,8091 0,8386 0,8587 0,5157 0,7496 0,7674 -0,0802 1,0000
(O) CMedic 0,7499 -0,0312 0,8653 0,9860 0,9199 0,0763 0,6432 0,7974 0,8935 0,3380 0,9269 0,9407 -0,1745 0,8181 1,0000
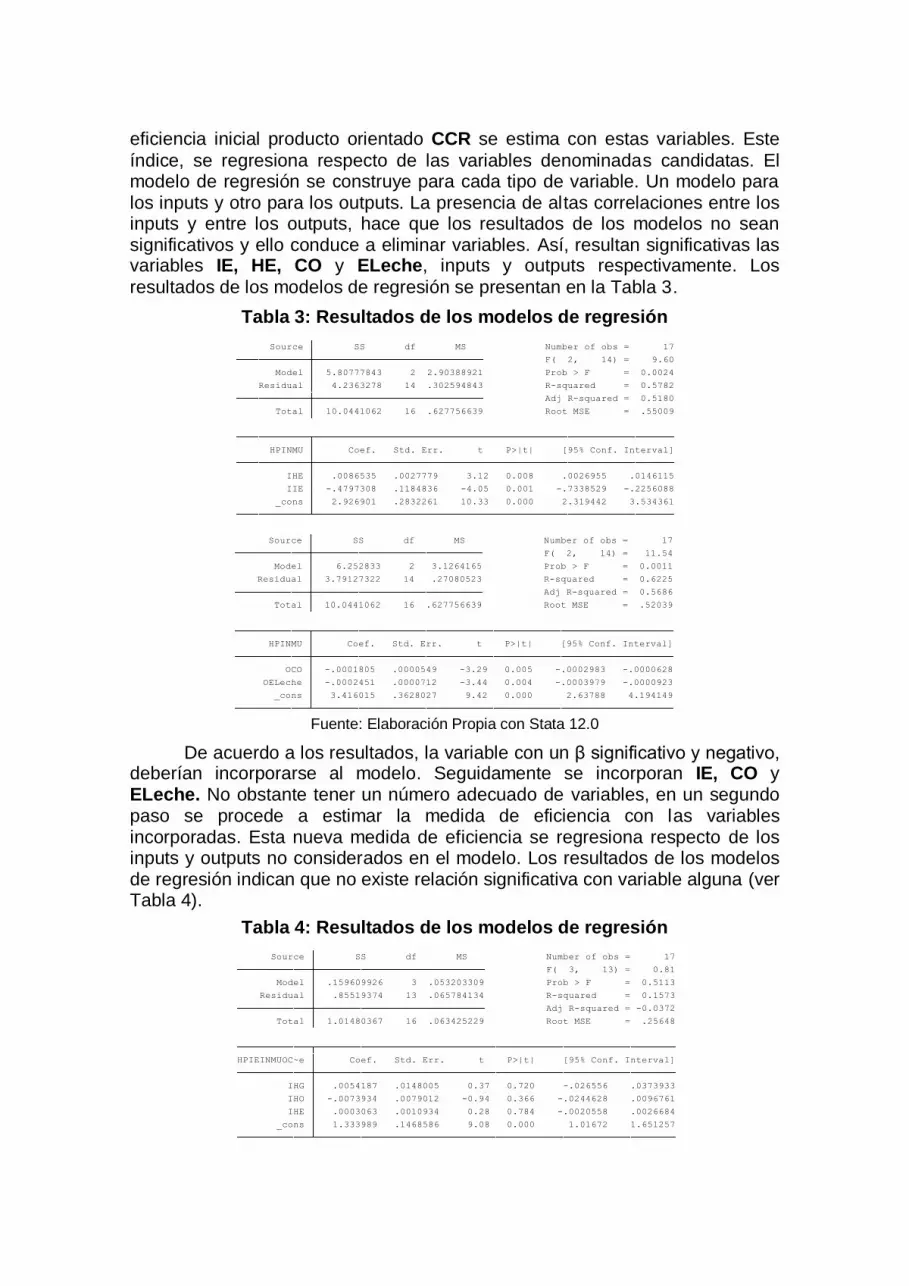
eficiencia inicial producto orientado CCR se estima con estas variables. Este
índice, se regresiona respecto de las variables denominadas candidatas. El modelo de regresión se construye para cada tipo de variable. Un modelo para los inputs y otro para los outputs. La presencia de altas correlaciones entre los inputs y entre los outputs, hace que los resultados de los modelos no sean significativos y ello conduce a eliminar variables. Así, resultan significativas las variables IE, HE, CO y ELeche, inputs y outputs respectivamente. Los
resultados de los modelos de regresión se presentan en la Tabla 3.
Tabla 3: Resultados de los modelos de regresión
Fuente: Elaboración Propia con Stata 12.0
De acuerdo a los resultados, la variable con un β significativo y negativo, deberían incorporarse al modelo. Seguidamente se incorporan IE, CO y ELeche. No obstante tener un número adecuado de variables, en un segundo paso se procede a estimar la medida de eficiencia con las variables incorporadas. Esta nueva medida de eficiencia se regresiona respecto de los inputs y outputs no considerados en el modelo. Los resultados de los modelos de regresión indican que no existe relación significativa con variable alguna (ver Tabla 4).
Tabla 4: Resultados de los modelos de regresión
_cons 2.926901 .2832261 10.33 0.000 2.319442 3.534361
IIE -.4797308 .1184836 -4.05 0.001 -.7338529 -.2256088
IHE .0086535 .0027779 3.12 0.008 .0026955 .0146115
HPINMU Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 10.0441062 16 .627756639 Root MSE = .55009
Adj R-squared = 0.5180
Residual 4.2363278 14 .302594843 R-squared = 0.5782
Model 5.80777843 2 2.90388921 Prob > F = 0.0024
F( 2, 14) = 9.60
Source SS df MS Number of obs = 17
_cons 3.416015 .3628027 9.42 0.000 2.63788 4.194149
OELeche -.0002451 .0000712 -3.44 0.004 -.0003979 -.0000923
OCO -.0001805 .0000549 -3.29 0.005 -.0002983 -.0000628
HPINMU Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 10.0441062 16 .627756639 Root MSE = .52039
Adj R-squared = 0.5686
Residual 3.79127322 14 .27080523 R-squared = 0.6225
Model 6.252833 2 3.1264165 Prob > F = 0.0011
F( 2, 14) = 11.54
Source SS df MS Number of obs = 17
_cons 1.333989 .1468586 9.08 0.000 1.01672 1.651257
IHE .0003063 .0010934 0.28 0.784 -.0020558 .0026684
IHO -.0073934 .0079012 -0.94 0.366 -.0244628 .0096761
IHG .0054187 .0148005 0.37 0.720 -.026556 .0373933
HPIEINMUOC~e Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 1.01480367 16 .063425229 Root MSE = .25648
Adj R-squared = -0.0372
Residual .85519374 13 .065784134 R-squared = 0.1573
Model .159609926 3 .053203309 Prob > F = 0.5113
F( 3, 13) = 0.81
Source SS df MS Number of obs = 17
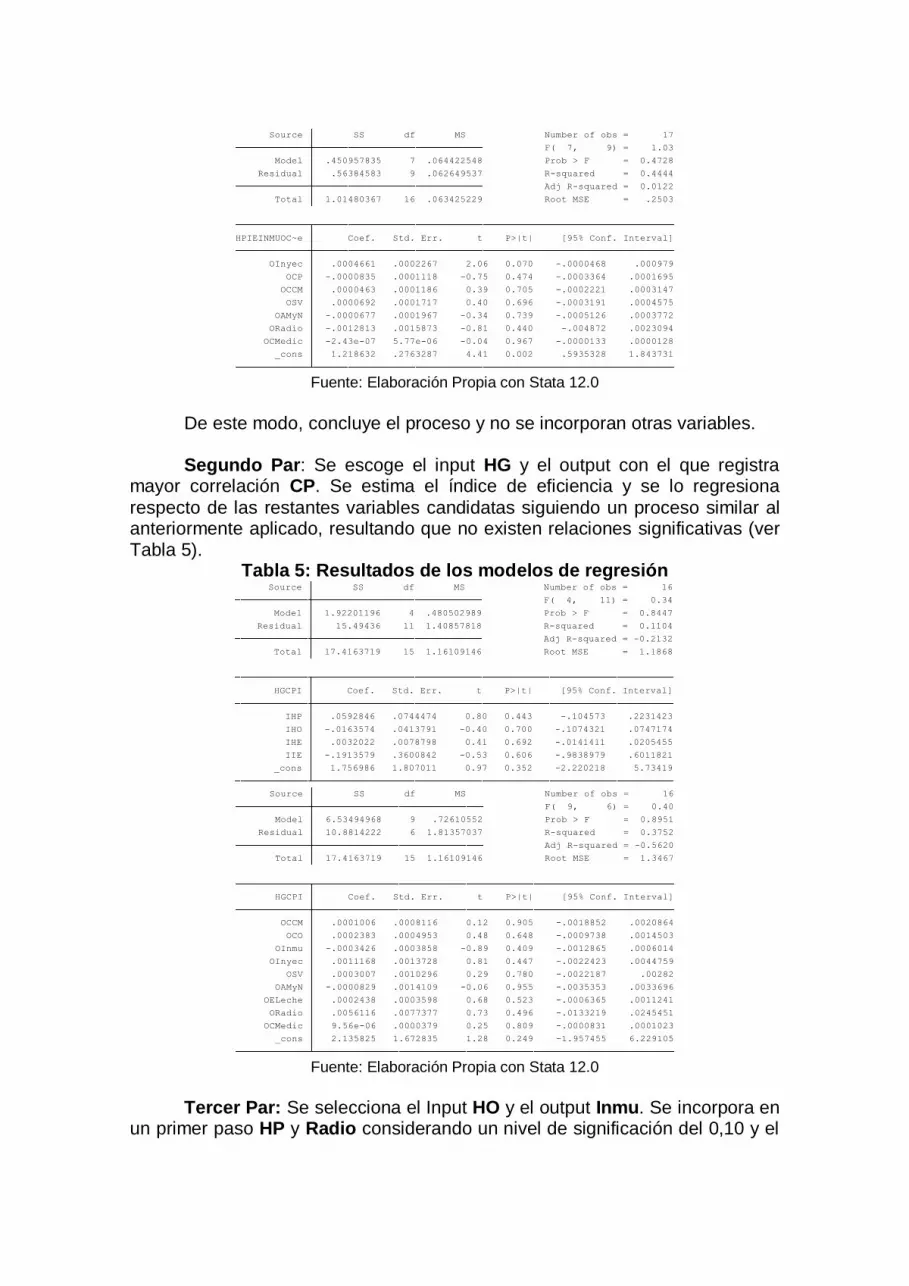
Fuente: Elaboración Propia con Stata 12.0
De este modo, concluye el proceso y no se incorporan otras variables.
Segundo Par: Se escoge el input HG y el output con el que registra
mayor correlación CP. Se estima el índice de eficiencia y se lo regresiona
respecto de las restantes variables candidatas siguiendo un proceso similar al anteriormente aplicado, resultando que no existen relaciones significativas (ver Tabla 5).
Tabla 5: Resultados de los modelos de regresión
Fuente: Elaboración Propia con Stata 12.0
Tercer Par: Se selecciona el Input HO y el output Inmu. Se incorpora en
un primer paso HP y Radio considerando un nivel de significación del 0,10 y el
_cons 1.218632 .2763287 4.41 0.002 .5935328 1.843731
OCMedic -2.43e-07 5.77e-06 -0.04 0.967 -.0000133 .0000128
ORadio -.0012813 .0015873 -0.81 0.440 -.004872 .0023094
OAMyN -.0000677 .0001967 -0.34 0.739 -.0005126 .0003772
OSV .0000692 .0001717 0.40 0.696 -.0003191 .0004575
OCCM .0000463 .0001186 0.39 0.705 -.0002221 .0003147
OCP -.0000835 .0001118 -0.75 0.474 -.0003364 .0001695
OInyec .0004661 .0002267 2.06 0.070 -.0000468 .000979
HPIEINMUOC~e Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 1.01480367 16 .063425229 Root MSE = .2503
Adj R-squared = 0.0122
Residual .56384583 9 .062649537 R-squared = 0.4444
Model .450957835 7 .064422548 Prob > F = 0.4728
F( 7, 9) = 1.03
Source SS df MS Number of obs = 17
_cons 1.756986 1.807011 0.97 0.352 -2.220218 5.73419
IIE -.1913579 .3600842 -0.53 0.606 -.9838979 .6011821
IHE .0032022 .0078798 0.41 0.692 -.0141411 .0205455
IHO -.0163574 .0413791 -0.40 0.700 -.1074321 .0747174
IHP .0592846 .0744474 0.80 0.443 -.104573 .2231423
HGCPI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 17.4163719 15 1.16109146 Root MSE = 1.1868
Adj R-squared = -0.2132
Residual 15.49436 11 1.40857818 R-squared = 0.1104
Model 1.92201196 4 .480502989 Prob > F = 0.8447
F( 4, 11) = 0.34
Source SS df MS Number of obs = 16
_cons 2.135825 1.672835 1.28 0.249 -1.957455 6.229105
OCMedic 9.56e-06 .0000379 0.25 0.809 -.0000831 .0001023
ORadio .0056116 .0077377 0.73 0.496 -.0133219 .0245451
OELeche .0002438 .0003598 0.68 0.523 -.0006365 .0011241
OAMyN -.0000829 .0014109 -0.06 0.955 -.0035353 .0033696
OSV .0003007 .0010296 0.29 0.780 -.0022187 .00282
OInyec .0011168 .0013728 0.81 0.447 -.0022423 .0044759
OInmu -.0003426 .0003858 -0.89 0.409 -.0012865 .0006014
OCO .0002383 .0004953 0.48 0.648 -.0009738 .0014503
OCCM .0001006 .0008116 0.12 0.905 -.0018852 .0020864
HGCPI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 17.4163719 15 1.16109146 Root MSE = 1.3467
Adj R-squared = -0.5620
Residual 10.8814222 6 1.81357037 R-squared = 0.3752
Model 6.53494968 9 .72610552 Prob > F = 0.8951
F( 9, 6) = 0.40
Source SS df MS Number of obs = 16
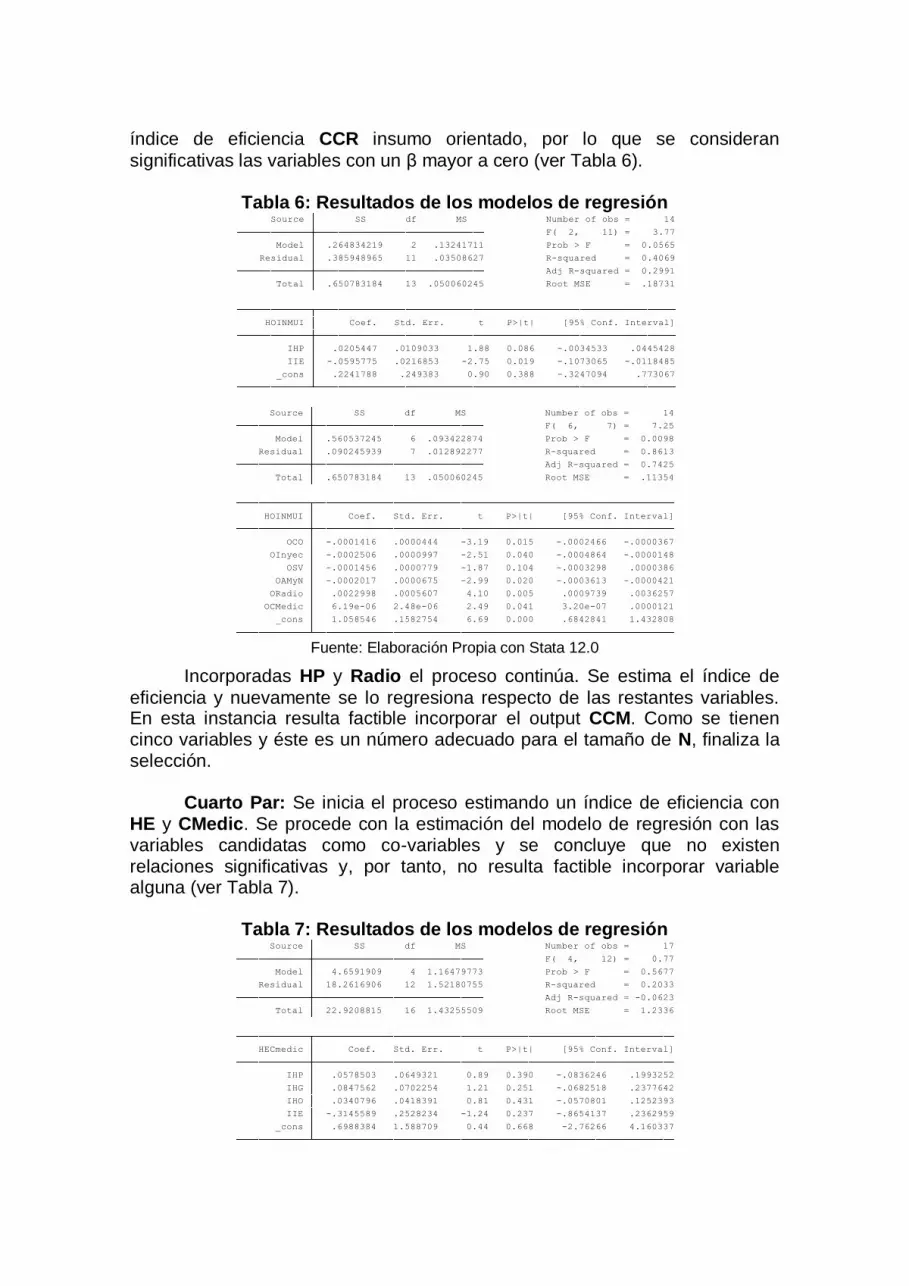
índice de eficiencia CCR insumo orientado, por lo que se consideran
significativas las variables con un β mayor a cero (ver Tabla 6).
Tabla 6: Resultados de los modelos de regresión
Fuente: Elaboración Propia con Stata 12.0
Incorporadas HP y Radio el proceso continúa. Se estima el índice de
eficiencia y nuevamente se lo regresiona respecto de las restantes variables. En esta instancia resulta factible incorporar el output CCM. Como se tienen cinco variables y éste es un número adecuado para el tamaño de N, finaliza la selección.
Cuarto Par: Se inicia el proceso estimando un índice de eficiencia con HE y CMedic. Se procede con la estimación del modelo de regresión con las variables candidatas como co-variables y se concluye que no existen relaciones significativas y, por tanto, no resulta factible incorporar variable alguna (ver Tabla 7).
Tabla 7: Resultados de los modelos de regresión
_cons .2241788 .249383 0.90 0.388 -.3247094 .773067
IIE -.0595775 .0216853 -2.75 0.019 -.1073065 -.0118485
IHP .0205447 .0109033 1.88 0.086 -.0034533 .0445428
HOINMUI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total .650783184 13 .050060245 Root MSE = .18731
Adj R-squared = 0.2991
Residual .385948965 11 .03508627 R-squared = 0.4069
Model .264834219 2 .13241711 Prob > F = 0.0565
F( 2, 11) = 3.77
Source SS df MS Number of obs = 14
_cons 1.058546 .1582754 6.69 0.000 .6842841 1.432808
OCMedic 6.19e-06 2.48e-06 2.49 0.041 3.20e-07 .0000121
ORadio .0022998 .0005607 4.10 0.005 .0009739 .0036257
OAMyN -.0002017 .0000675 -2.99 0.020 -.0003613 -.0000421
OSV -.0001456 .0000779 -1.87 0.104 -.0003298 .0000386
OInyec -.0002506 .0000997 -2.51 0.040 -.0004864 -.0000148
OCO -.0001416 .0000444 -3.19 0.015 -.0002466 -.0000367
HOINMUI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total .650783184 13 .050060245 Root MSE = .11354
Adj R-squared = 0.7425
Residual .090245939 7 .012892277 R-squared = 0.8613
Model .560537245 6 .093422874 Prob > F = 0.0098
F( 6, 7) = 7.25
Source SS df MS Number of obs = 14
_cons .6988384 1.588709 0.44 0.668 -2.76266 4.160337
IIE -.3145589 .2528234 -1.24 0.237 -.8654137 .2362959
IHO .0340796 .0418391 0.81 0.431 -.0570801 .1252393
IHG .0847562 .0702254 1.21 0.251 -.0682518 .2377642
IHP .0578503 .0649321 0.89 0.390 -.0836246 .1993252
HECmedic Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 22.9208815 16 1.43255509 Root MSE = 1.2336
Adj R-squared = -0.0623
Residual 18.2616906 12 1.52180755 R-squared = 0.2033
Model 4.6591909 4 1.16479773 Prob > F = 0.5677
F( 4, 12) = 0.77
Source SS df MS Number of obs = 17

Fuente: Elaboración Propia con Stata 12.0
Quinto Par: Finalmente se selecciona el par input-output IE-Inmu. Se
procede de igual modo que en el caso del tercer par y en una primera instancia se adiciona el input HP (ver Tabla 8).
Tabla 8: Resultados de los modelos de regresión
Fuente: Elaboración Propia con Stata 12.0
En una segunda iteración se estima el índice con tres variables (IE-HP-
Inmu) y se procede a estimar un modelo de regresión con las restantes variables candidatas como co-variables. De este proceso resulta conveniente incorporar HO y CO (ver Tabla 9). Como se tienen cinco variables, se da por finalizado el proceso.
Probados los cinco pares posibles para iniciar el proceso de selección por el método RB, se obtienen los cinco conjuntos de variables que respetan la pauta dada por Cooper, Seiford y Tone (2006). Los mismos se detallan en la Tabla 10.
_cons 1.679336 2.213718 0.76 0.473 -3.555276 6.913948
ORadio -.0035844 .0137293 -0.26 0.802 -.0360491 .0288803
OELeche -.0002347 .0004509 -0.52 0.619 -.0013008 .0008315
OAMyN -.000166 .00137 -0.12 0.907 -.0034055 .0030735
OSV .000429 .001159 0.37 0.722 -.0023117 .0031696
OInyec .0003518 .0016418 0.21 0.836 -.0035305 .0042341
OInmu -.0001856 .0008073 -0.23 0.825 -.0020946 .0017233
OCO .0002836 .0007923 0.36 0.731 -.0015898 .002157
OCCM .0005524 .0009827 0.56 0.592 -.0017713 .002876
OCP .000381 .0015364 0.25 0.811 -.003252 .004014
HECmedic Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total 22.9208815 16 1.43255509 Root MSE = 1.6488
Adj R-squared = -0.8977
Residual 19.0299306 7 2.71856151 R-squared = 0.1698
Model 3.89095093 9 .432327881 Prob > F = 0.9932
F( 9, 7) = 0.16
Source SS df MS Number of obs = 17
_cons .1367561 .2362936 0.58 0.573 -.3737252 .6472375
IHE -.0009724 .0004944 -1.97 0.071 -.0020404 .0000956
IHG -.0219485 .0091442 -2.40 0.032 -.0417033 -.0021936
IHP .0184572 .0097483 1.89 0.081 -.0026027 .0395171
IEINMUI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total .601545692 16 .037596606 Root MSE = .16312
Adj R-squared = 0.2923
Residual .345887773 13 .026606752 R-squared = 0.4250
Model .255657919 3 .085219306 Prob > F = 0.0589
F( 3, 13) = 3.20
Source SS df MS Number of obs = 17
_cons .6201531 .1272694 4.87 0.000 .3488849 .8914214
OInyec -.0002704 .0001172 -2.31 0.036 -.0005202 -.0000206
IEINMUI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total .601545692 16 .037596606 Root MSE = .17205
Adj R-squared = 0.2127
Residual .444007146 15 .029600476 R-squared = 0.2619
Model .157538546 1 .157538546 Prob > F = 0.0357
F( 1, 15) = 5.32
Source SS df MS Number of obs = 17

Tabla 9: Resultados de los modelos de regresión
Fuente: Elaboración Propia con Stata 12.0
Tabla 10: Conjunto de Variables Seleccionadas por RB
3.2. Aplicación de Efficiency Contribution Measure (ECM)
Para el caso del método ECM por agregación de variables se inicia el proceso de selección con el par input-output HP-Inmu, constituyendo éstas el
conjunto de K variables. Así,φn(K), para n=1, 2, …, 17, se estima con dichas
variables y el conjunto Z de variables candidatas se integra con las 13
restantes. Se estiman, a continuación, 𝜑𝑛(𝐾+𝑧)para n=1, 2, …, 17 y z=1, 2, …, 13, ello permite determinar ρ
nz, para z=1, 2, ..., 13 y n=1, 2, …, 17. Los valores
correspondientes se presentan en la Tabla 11. Se fija un nivel de tolerancia igual aρ̅ y se definen las variables
binomiales y con un p0=0,30 se realizan las pruebas de hipótesis binomial. En las Tablas 12, 13, 14, 15 se presentan las pruebas del test de probabilidad binomial para las cuatro variables que resultan significativas en la evaluación de la eficiencia y que pueden adicionarse al par inicial. Ello debido a que sus
índices ρnz son superiores a ρ̅ en una proporción superior a 0,30.
De lo anterior se obtiene un conjunto de seis variables conformado por HP-HO-HE-IE-Inmu-Inyec.
_cons .6507154 .0541418 12.02 0.000 .5353149 .7661158
IHO .0047427 .0021357 2.22 0.042 .0001905 .0092949
IEHPINMUI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total .485904051 16 .030369003 Root MSE = .15614
Adj R-squared = 0.1972
Residual .365684862 15 .024378991 R-squared = 0.2474
Model .120219189 1 .120219189 Prob > F = 0.0422
F( 1, 15) = 4.93
Source SS df MS Number of obs = 17
_cons .7418081 .0969156 7.65 0.000 .5339449 .9496713
OInyec -.000168 .0000913 -1.84 0.087 -.0003637 .0000278
OCO .0000541 .0000141 3.83 0.002 .0000238 .0000844
IEHPINMUI Coef. Std. Err. t P>|t| [95% Conf. Interval]
Total .485904051 16 .030369003 Root MSE = .12878
Adj R-squared = 0.4539
Residual .232177629 14 .016584116 R-squared = 0.5222
Model .253726422 2 .126863211 Prob > F = 0.0057
F( 2, 14) = 7.65
Source SS df MS Number of obs = 17
Var1 Var2 Var3 Var4 Var5
1º HP IE Inmu CO ELeche
2º HG CP - - -
3º HO HP Inmu Radio CCM
4º HE CMedic - - -
5º IE HP HO Inmu CO

Tabla 11: Estimación de ρnz (ECM por Agregación de Variables)
Fuente: Elaboración Propia con DEA Solver Pro 7.0
Tabla 12: Prueba de Hipótesis Binomial para HO
Fuente: Elaboración Propia con Stata 12.0
Tabla 13: Prueba de Hipótesis Binomial para HE
Fuente: Elaboración Propia con Stata 12.0
Tabla 14: Prueba de Hipótesis Binomial para IE
Fuente: Elaboración Propia con Stata 12.0
DMU (I) HG (I) HO (I) HE (I) IE (O) CP (O) CCM (O) CO (O) Inyec (O) SV(O)
AMyN
(O)
ELeche
(O)
Radio
(O)
CMedic
CAPS 1 1,0000 1,2280 1,2718 1,0705 1,1101 1,0058 1,0000 1,1361 1,0000 1,0000 1,0153 1,0000 1,0000
CAPS 2 1,0000 1,2280 1,0164 1,0210 1,0819 1,0098 1,0000 1,1572 1,1281 1,0000 1,0105 1,0000 1,0000
CAPS 3 1,0000 1,3375 1,5262 1,1875 1,0275 1,0439 1,0000 1,2370 1,0000 1,0000 1,0070 1,0000 1,0000
CAPS 4 4,1919 1,8743 1,5262 4,1919 1,0996 1,0873 1,0895 1,0882 1,0000 1,0000 1,0068 1,0185 1,0000
CAPS 5 1,0000 1,2072 1,0174 1,1548 1,0936 1,0146 1,0000 1,1304 1,0000 1,0000 1,0129 1,0000 1,0000
CAPS 6 1,0000 2,0948 1,5262 1,1766 1,4336 1,0099 1,0000 1,2112 1,0000 1,0000 1,0095 1,0000 1,0000
CAPS 7 1,0000 1,0322 1,1446 1,0670 1,0114 1,0032 1,2607 1,1241 1,0000 1,0000 1,0082 1,0000 1,0000
CAPS 8 1,0000 1,4455 1,3990 1,0740 1,0168 1,0371 1,0000 1,2159 1,0000 1,0000 1,0113 1,0000 1,0000
CAPS 9 1,0000 1,0174 1,0174 1,0174 1,0174 1,0174 1,0000 1,0116 1,0000 1,0000 1,0174 1,0000 1,0000
CAPS 10 1,0000 2,0948 1,8314 1,1143 1,4892 1,2369 1,0000 1,3101 1,0000 1,0000 1,0119 1,0000 1,0000
CAPS 11 1,0000 1,4900 1,0164 1,1684 1,0174 1,0066 1,0000 1,0211 1,0000 1,0000 1,0104 1,0027 1,0000
CAPS 12 1,0000 1,2280 1,0174 1,0353 1,2756 1,0056 1,0000 1,3495 1,0000 1,0000 1,0146 1,0000 1,0000
CAPS 13 1,0000 1,1740 1,1446 1,2005 1,0142 1,0085 1,2005 1,0747 1,0000 1,0000 1,0042 1,0000 1,0000
CAPS 14 1,0000 1,3189 1,5262 1,2612 1,0143 1,0076 1,0000 1,0277 1,0000 1,0000 1,0098 1,0000 1,0000
CAPS 15 1,0000 2,0948 1,0172 1,5642 1,6269 1,0065 1,0000 1,6505 1,1039 1,2245 1,0604 1,0000 1,0000
CAPS 16 1,0000 1,6958 1,5262 1,1900 1,0026 1,1308 1,0216 1,3051 1,0000 1,0000 1,0060 1,9372 1,0000
CAPS 17 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
Rho medio1,1421
Pr(k >= 14) = 0.000012 (two-sided test)
Pr(k <= 14) = 0.999999 (one-sided test)
Pr(k >= 14) = 0.000012 (one-sided test)
IHO 17 14 5.1 0.30000 0.82353
Variable N Observed k Expected k Assumed p Observed p
Pr(k <= 0 or k >= 10) = 0.015019 (two-sided test)
Pr(k <= 10) = 0.996765 (one-sided test)
Pr(k >= 10) = 0.012693 (one-sided test)
IHE 17 10 5.1 0.30000 0.58824
Variable N Observed k Expected k Assumed p Observed p
Pr(k <= 1 or k >= 9) = 0.059552 (two-sided test)
Pr(k <= 9) = 0.987307 (one-sided test)
Pr(k >= 9) = 0.040277 (one-sided test)
IIE 17 9 5.1 0.30000 0.52941
Variable N Observed k Expected k Assumed p Observed p

Tabla 15: Prueba de Hipótesis Binomial para Inyec
Fuente: Elaboración Propia con Stata 12.0
3.3. Aplicación de Partial Covariance (PC)
En el caso del método PC, el análisis se realizó hasta una partición de
seis variables retenidas y nueve omitidas. Ya que al retener un número superior, si bien puede aumentar la proporción de varianza en dicho conjunto, el número de variables no resulta acorde al tamaño de la muestra. A medida que se incrementa la cantidad de variables retenidas mayor es la proporción de varianza retenida, aunque el incremento marginal es cada vez menor. En la Tabla 16 se presentan las mejores combinaciones, en términos de varianza retenida, entre inputs y outputs, desde dos variables a seis variables.
Tabla 16: Particiones y Combinaciones con
Mayor Proporción de Varianza Retenida
Fuente: Elaboración Propia con Lenguaje R
Tomando en consideración la recomendación del Cooper, Seiford y Tone
(2006) la cantidad máxima de variables a considerar son cinco. En función a los resultados plasmados en la Tabla 16, debería seleccionarse la combinación que retiene el 86,4 % de la varianza total. Esto es, los inputs HG y HE y los outputs CCM, Inyec y ELeche. No obstante, las otras tres combinaciones son tan próximas, en valor de varianza retenida que sería conveniente evaluar los resultados de esos modelos.
Pr(k <= 2 or k >= 8) = 0.182025 (two-sided test)
Pr(k <= 8) = 0.959723 (one-sided test)
Pr(k >= 8) = 0.104640 (one-sided test)
OInyec 17 8 5.1 0.30000 0.47059
Variable N Observed k Expected k Assumed p Observed p
PVR
I.HE O.ELeche 0,665
I.HG O.Inmu 0,662
I.HE O.Inmu 0,660
I.HE O.Inyec O.ELeche 0,779
I.HE O.CP O.Inyec 0,767
I.HG O.Inmu O.Inyec O.ELeche 0,827
I.HG I.HE O.Inmu O.Inyec 0,827
I.HE O.CP O.Inmu O.Inyec 0,824
I.HG I.HE O.Inyec O.ELeche 0,824
I.HG I.HE O.CCM O.ELeche O.Inyec 0,864
I.HG I.HE O.Inmu O.CP O.Inyec 0,863
I.HG I.HE O.Inmu O.ELeche O.Inyec 0,862
I.HG O.CMedic O.Inmu O.ELeche O.Inyec 0,860
I.HG I.HE I.HP O.CCM O.Inyec O.ELeche 0,897
I.HG I.HE I.HP O.CP O.Inmu O.Inyec 0,894
I.HG I.HE O.CP O.Inmu O.Inyec O.ELeche 0,892
I.HG I.HE I.HP O.Inyec O.ELeche O.Radio 0,892
I.HG I.HE I.HP O.Inmu O.Inyec O.ELeche 0,892
Mejores Participiones Desde 2 a 6 Variables Retenidas

3.4. Selección del Mejor Escenario.
Como puede observarse los conjuntos de inputs y outputs seleccionados
difieren de un método a otro, por tanto, cabe la pregunta ¿cuál es el mejor de los escenarios? Para dar respuesta se recurre a la última etapa del método propuesto por Aragão de Castro Senra et al (2007) denominado Método Multicriterio Combinatorio por Escenarios el que se basa en la construcción de un indicador para cada escenario que se construye siguiendo la propuesta de Soares de Mello et al (2004).
En este caso, cada conjunto de variables determinado por los tres métodos aplicados constituye una alternativa o escenario. Para cada uno de
ellos se determina un indicador S=∝SEF+(1-∝) SDIS con ∝=0,50. SEF es el valor normalizado de la eficiencia media y mide el ajuste a la frontera. Éste alcanza el valor 1 en la eficiencia máxima y 0 en la eficiencia mínima. Por otra parte, el indicador SDIS es el valor normalizado del número de DMUs eficientes que se desea minimizar. Este indicador alcanza el valor 1 para el menor número de DMUs en la frontera y 0 para el mayor.
En la tabla 17 se muestra el valor del S para escenario.
Tabla 17: Índices de Eficiencia y Número de Unidades Eficientes
Fuente: Elaboración Propia Con DEA Solver Pro 7.0
De acuerdo al indicador S que se muestran en la Tabla 17, el escenario
más favorable corresponde al conjunto de variables determinado por el método PC que retiene el 86,3 % de la varianza. Ese conjunto está integrado por las variables HG, HE, Inmu, CP, Inyec. El segundo conjunto a poca distancia del primero es el determinado por el método RB y está integrado por las variables HO, HP, Inmu, Radio, CCM. El menos apropiado es el que resulta de la
DMU RB1 RB2 RB3 RB4 RB5 Pastor PC1 PC2 PC3 PC4
CAPS 1 0,7810 0,5091 0,850 0,5296 0,8520 0,9390 0,9366 0,9321 0,9366 0,8229
CAPS 2 0,6771 0,3569 0,816 0,2295 0,8172 0,8395 0,5057 0,6030 0,6030 0,4702
CAPS 3 0,7258 0,3447 0,760 0,1714 0,7680 1,0000 0,8280 0,9509 0,9509 0,4877
CAPS 4 1,0000 - 0,455 0,3143 1,0000 1,0000 1,0000 1,0000 1,0000 -
CAPS 5 0,8466 0,2352 0,725 0,3875 0,7366 0,7504 0,5872 0,6459 0,6459 0,3414
CAPS 6 0,6282 0,4743 0,967 0,5225 1,0000 1,0000 0,6510 0,7943 0,7726 0,4693
CAPS 7 0,6651 0,4279 0,522 0,3795 0,6377 0,6270 0,5999 0,6181 0,6496 0,6664
CAPS 8 0,6915 0,5242 0,938 0,7415 0,9347 1,0000 0,9045 0,9893 0,9893 0,8208
CAPS 9 1,0000 0,4548 1,000 0,5018 1,0000 1,0000 1,0000 1,0000 1,0000 0,8818
CAPS 10 0,5614 0,8730 1,000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
CAPS 11 0,8995 0,3818 1,000 0,4361 1,0000 1,0000 0,5117 0,5824 0,5745 0,4806
CAPS 12 0,7672 0,3762 0,910 0,6031 0,9130 1,0000 0,9805 0,9366 0,9805 0,5819
CAPS 13 1,0000 1,0000 0,984 0,5987 1,0000 1,0000 0,9645 1,0000 1,0000 1,0000
CAPS 14 1,0000 0,7331 0,826 0,7062 0,8770 0,9954 1,0000 0,9912 1,0000 1,0000
CAPS 15 0,9175 0,2460 0,677 0,4453 1,0000 1,0000 0,4845 0,4651 0,4845 0,3625
CAPS 16 0,6444 0,2099 1,000 0,6277 1,0000 1,0000 0,8913 0,8993 0,8993 0,7805
CAPS 17 1,0000 0,4864 1,000 0,5157 1,0000 1,0000 0,2892 0,4856 0,4856 1,0000
Eficiencia Media 0,8121 0,4771 0,849 0,5124 0,9139 0,9501 0,7726 0,8173 0,8219 0,6979
Nº Unidades
Eficientes5 1 5 1 9 12 4 4 5 4
Eficiencia Media
Norm.0,7082 0,0000 0,786 0,0746 0,9235 1,0000 0,6248 0,7192 0,7290 0,4668
Nº Unidades
Eficientes Norm0,6364 1,0000 0,6364 1,0000 0,2727 0,0000 0,7273 0,7273 0,6364 0,7273
Indicador S 0,6723 0,5000 0,7111 0,5373 0,5981 0,5000 0,6760 0,7233 0,6827 0,5970

aplicación del método ECM. Este hecho también fue observado, aunque en un
proceso inverso (eliminación de variables), en Iñiguez et al. (2015).
4. CONCLUSIÓN Los resultados alcanzados, así como los procesos de selección de cada
uno de los métodos, revelan que existe un fuerte vínculo intra-inputs e intra-outputs, este hecho es muy evidente si se aplica la técnica RB. Evidentemente, el proceso productivo de los CAPS se pone en marcha desde cualquiera de los servicios básicos, pediatría, clínica médica, enfermería, ginecología y odontología y ello hace que todas las variables tengan similar comportamiento, haciendo que más de una combinación de inputs y outputs pueda resultar representativa de todo el proceso productivo. Es claro que el servicio de inmunizaciones (vacunación obligatoria) es un output importante. En casi todos los escenarios participa y si se revé la matriz de correlaciones lineales se observa que se vincula fuertemente con la mayoría de los inputs y outputs.
Los métodos basados en herramientas e indicadores estadísticos han facilitado la selección de un número adecuado de variables. No obstante, es necesario reconocer que para el caso del método RB, los conjuntos que
resultan, están condicionados al par inicial de inputs y outputs que se considere. Para realizar un análisis completo deberían evaluarse los cincuenta pares posibles. Además, resulta necesario destacar que el método ECM no ha brindado una solución razonable. También pueden probarse los cincuenta pares inicial posibles. No obstante, podría decirse que opera mejor cuando el número de DMUs es mayor o el número de variables es menor. El proceso de selección se ha probado de ambos modos por eliminación y por agregación y en ambos casos se arriba a un conjunto de variables que no discrimina razonablemente, por tanto para este caso no resulta de aplicación.
5. REFERENCIAS ARAGÃO DE CASTRO SENRA, L.F., NANCI, L.C., SOARES DE MELLO, J.C.C.B. y ANGULO MEZA L.A. (2007). “Estudo Sobre Métodos de Seleção de Variáveis em DEA”. Pesquisa Operacional, v.27, n.2, p.191-207.
COOPER W. W, SEIFORD L. y TONE K. (2006). Introduction to Data Envelopment Analysis and Its Uses with DEA-Solver Software and References, Springer.
COOPER, W.W., SEIFORD, L. M., y ZHU, J. (2004). Handbook on Data Envelopment Analysis. Norwell, MA. Kluwer Academic Publishers.
CHARNES, A., COOPER, W. W. y RHODES, E. (1978). “Measuring the Efficiency of Decision Making Units”. European Journal of Operational Research, 2(6), 429-444.
FERREYRA, E., IÑIGUEZ, P., ARBURUA, M. y CERUTTI DEPETRIS F. (2013). “Análisis de Eficiencia de los Centros de Atención Primaria de la Salud de la Ciudad de Río Cuarto: Estudio del Entorno Socio-Económico”. Anales de las XX Jornadas de Intercambio de Conocimientos Científicos y Técnicos.

Facultad de Ciencias Económicas. Universidad Nacional de Río Cuarto.
IÑIGUEZ, P., ARBURUA, M., GALLARDO, J. M. y NEGRO, F. J. (2014). “Estudio de la Eficiencia de los Centros de Atención Primaria de la Salud. Identificación de las Variables que Constituyen Inputs y Outputs”. Anales de las XXI Jornadas de Intercambio de Conocimientos Científicos y Técnicos. Facultad de Ciencias Económicas. Universidad Nacional de Río Cuarto.
IÑIGUEZ, P., ARBURUA, M., GALLARDO, J. M. y FERREYRA, E. L. (2015). “Selección de Variables en el Estudio de Eficiencia de los CAPS de la Ciudad de Río Cuarto. Aplicación de Métodos Basados en Herramientas e Indicadores Estadísticos”. Anales de las XXX Jornadas Nacionales de Docentes de Matemática de Facultades de Ciencias Económicas y Afines. Facultad de Ciencias de la Administración - Universidad Nacional de Entre Ríos.
JENKINSON, L. y ANDERSON, M. A. (2003). “Multivariate Statistical Approach to Reducing the Number of Variables in Data Envelopment Analysis”. European Journal of Operational Research, 147:51 – 61.
PASTOR, J. T., RUIZ, J. L. y SIRVENT I. (2002). “A Statistical Test for Nested Radial DEA Models”. Operations Research 50(4): 728-735.
RUGGIERO, J. (2005). “Impact Assessment of Input Omission on DEA”. International Journal of Information Technology & Decision Making 04(03): 359-
368.
SOARES DE MELLO, J. C. C. B., GOMES, E., MEZA, L.A., y LINS, M.P.E. (2004). “Selección de variables para el incremento del poder de discriminación de los modelos DEA”. Revista Escuela de Perfeccionamiento en Investigación Operativa, 24, 40-52.