towards an on-demand peer feedback system for a clinical knowledge base: a case study with order...
TRANSCRIPT

Available online at www.sciencedirect.com
www.elsevier.com/locate/yjbin
Journal of Biomedical Informatics 41 (2008) 152–164
Towards an on-demand peer feedback system for a clinicalknowledge base: A case study with order sets
Nathan C. Hulse a,b,*, Guilherme Del Fiol a,b, Richard L. Bradshaw b,Lorrie K. Roemer b, Roberto A. Rocha a,b
a Department of Biomedical Informatics, University of Utah, Salt Lake City, UT, USAb Knowledge Management Team, Intermountain Healthcare, Salt Lake City, UT, USA
Received 13 November 2006Available online 18 May 2007
Abstract
Objective. We have developed an automated knowledge base peer feedback system as part of an effort to facilitate the creation andrefinement of sound clinical knowledge content within an enterprise-wide knowledge base. The program collects clinical data stored inour Clinical Data Repository during usage of a physician order entry program. It analyzes usage patterns of order sets relative to theirtemplates and creates a report detailing the usage patterns of the order set template. This report includes a set of suggested modificationsto the template.
Design. A quantitative analysis was performed to assess the validity of the program’s suggested order set template modifications.Measurements. We collected and deidentified 2951 instances of POE-based orders. Our program then identified and generated feed-
back reports for thirty different order set templates from this data set. These reports contained 500 suggested modifications. Five orderset authors were then asked to ‘accept’ or ‘reject’ each suggestion contained in his/her respective order set templates. They were alsoasked to categorize their rationale for doing so (‘clinical relevance’ or ‘user convenience’).
Results. In total, 62% (309/500) suggestions were accepted by clinical content authors. Of these, authors accepted 32% (36/114) of thesuggested additions, 74% (123/167) of the suggested pre-selections, 76% (16/25) of the suggested de-selections, and 68% (131/194) of thesuggested changes in combo box order.
Conclusion. Overall, the feedback system generated suggestions that were deemed highly acceptable among order set authors. Futurerefinements and enhancements to the software will add to its utility.� 2007 Elsevier Inc. All rights reserved.
Keywords: Knowledge acquisition; Knowledge bases; Software; Clinical information systems; XML; Decision support; Knowledge management;Knowledge representation
1. Introduction
Sound knowledge bases are vital to advanced comput-erized healthcare applications [1,2]. Clinical knowledgebases must be comprehensive, up-to-date, and easy-to-use in order to adequately address the needs of healthcareproviders [3]. Advanced computerized healthcare applica-tions require a wide variety of knowledge assets, including
1532-0464/$ - see front matter � 2007 Elsevier Inc. All rights reserved.
doi:10.1016/j.jbi.2007.05.006
* Corresponding author. Present address: 1908 Jackson Street, Kays-ville, UT 84037, USA.
E-mail address: [email protected] (N.C. Hulse).
order sets, drug–drug interaction rules, practice guide-lines, and clinical protocols. These knowledge assets areused to support the daily workflow of clinicians, whilepromoting the adoption of best practices and evidence-based strategies. Advanced clinical systems with embed-ded decision support capabilities offer the potential toreduce the incidence of serious medical errors andimprove the quality of health care delivery processes whilelowering their overall costs [4–7]. The success of the con-temporary clinical decision support system is largely afunction of the quality of the medical knowledge uponwhich it is built [8].

N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164 153
1.1. Change in medical knowledge
The explosion of clinical knowledge in recent years hasmajor implications for both medical practitioners and clin-ical information system developers. Roughly two millionarticles focused on a wide variety of biomedical topicsare published each year [9]. Despite this knowledge growth,researchers have shown that processes that drive wide-spread acceptance of newfound knowledge into clinicalpractice are often very slow [10]. Clinicians are forced tocope with ‘information overload’ and often find the processof locating clinical information and evaluating its relevanceand credibility to be difficult [11]. Traditional educationalchannels are unlikely to narrow the existing time gapbetween the discovery of new knowledge and its integrationinto clinical practice.
An obvious consequence of the fast-paced growth ofmedical knowledge is the need for constant updates andexpansions of knowledge bases that drive clinical applica-tions [12]. As eloquently stated by Matheson [13], ‘‘Theoverarching informatics grand challenge facing society isthe creation of knowledge management systems that canacquire, conserve, organize, retrieve, display, and distributewhat is known today in a manner that informs and edu-cates, facilitates the discovery and creation of new knowl-edge, and contributes to the health and welfare of theplanet’’. Given the fast pace of medical knowledge discov-ery, constantly changing medical knowledge bases are inev-itable. Change may be necessary for many differentreasons, including changes in the evidence concerning thebenefit or harm associated with treatments, new researchindicating that previously unimportant outcomes are nowconsidered important, changes in the availability of inter-ventions, and even shifts in societal values placed on med-ical outcomes [14]. Although experts agree that change isnecessary, no definitive guidelines exist concerning the issueof when clinical knowledge content should be revised[1,14]. The realities of maintaining and incorporating newknowledge into knowledge bases show that it is a labor-intensive process, commonly requiring substantial timecommitments from both domain experts and knowledgeengineers [1,15,16].
1.2. Processes for knowledge refinement
Several channels exist for bringing about these changes,including formal, structured processes involving systematicliterature review and scheduled meetings between domainexperts and knowledge engineers [14,17,18]. Other less-for-mal processes such as e-mail, hallway conversations, andgeneral interactions between clinicians can also initiatechange. The multidisciplinary nature of clinical care alsoprovides ample opportunities for knowledge exchange,i.e., the different medical professionals involved in thetreatment process represent a ‘knowledge community’ inwhich different individuals can exchange information andcreate new knowledge [19,20].
As a common thread to all of these processes, the impor-tance of feedback in promoting the maintenance and devel-opment of knowledge bases is paramount [19,21,22]. Insystematic audits, clinical experts gather and review mea-sures of clinical performance over a given time period[23]. As necessary, they note successes and failures, makerecommendations for adjustments to treatment routines,and publicize their findings with their colleagues. System-atic audit and feedback has been found to be an effectivemethod of bringing about clinical change [23].
Informaticists and practicing clinicians are bothinvolved in efforts to improve the quality of health careprocesses. Unlike the processes described above, whichare typically used by clinicians, informaticists’ efforts torefine clinical applications often involve usability testing[24–26] or data mining [27,28]. Usability sessions typicallyrequire participants to perform a series of highly scriptedtasks in a closed environment while developers and manag-ers observe the users’ behavior in attempts to better under-stand how the software is used. Data mining includesmultiple approaches to identify process patterns using largedatabases [29]. These patterns (and the sequences in whichthey occur) are then subjected to human interpretation inorder to create meaningful information regarding howapplications and health care processes can be improved[30]. These efforts, however, typically focus strictly on thefunctionality and usability of clinical applications and noton the knowledge content used by these applications.
1.3. Knowledge communities
Researchers have likened the clinical setting to a ‘knowl-edge community’ in which nurses, physicians, and techni-cians are all active participants [31]. In such a model, theclinicians assume the roles of data gatherer, informationuser, knowledge user, and knowledge builder as they treatpatients, interact with others, and use existing informationsystems. As they work with information systems, theyinteract with various forms of knowledge base contentincluding electronic clinical reference material, order sets,protocols, and discharge instructions. In many cases, userschange or modify this content, by changing default valuesin order sets, entering data, or noting reasons for overrid-ing a computerized suggestion. As the records of theseinteractions are stored, so to are the decisions, actions,and preferences of the users. The logs of these interactionscan act as a refining force to the knowledge base by provid-ing a real-world perspective of what works well and whatdoes not.
Similar to what has been proposed by East et al. [32], webelieve that automated retrospective data analyses can beconducted as tools to harvest new knowledge. By analyzingrecorded interactions between users and ‘customizable’knowledge base content, we envision an environment inwhich feedback is an automatic and natural result of usinga clinical application and its knowledge content. This is dif-ferent than the current paradigm, in which nurses or phy-

154 N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164
sicians must actively initiate processes in order to give feed-back and induce change. As user interactions with the‘‘knowledge base content’’ are captured and stored, analyt-ical programs can then process these customizations, iden-tify the relevant patterns, and offer suggestions for change.We anticipate that this approach to knowledge contentrefinement will leverage the actions and decisions of end-users as a driving force for changes in knowledge basecontent.
Ultimately, these individuals are responsible for the carethat patients receive and their clinical proficiency, asreflected through recorded decisions, actions, and prefer-ences, can provide valuable insights for changing theknowledge base. Although it is known that errors in med-icine are prevalent and clinicians are human and prone tomake mistakes [33], we believe that the clinical experienceand synergy derived from team efforts involved in acuteclinical care provide an ideal setting for knowledge basediscovery and refinement. Researchers have noted thatwell-integrated clinical units are ideal settings for clinicalknowledge discovery [20,34].
2. Background
2.1. Knowledge base development
At Intermountain Healthcare (Intermountain), we havebeen developing applications to support the acquisitionand maintenance of clinical knowledge for an enterprise-wide knowledge base. Intermountain is a non-profitintegrated delivery network with 21 hospitals, several out-patient clinics, more than 450 employed physicians, and acomprehensive insurance plan [35]. The clinical knowledgeis stored in an enterprise ‘‘Knowledge Repository’’ (KR), acentral database with service layers designed to supportinteractions with various clinical applications and knowl-edge management tools. The KR is closely tied to a locallydeveloped XML authoring environment, the ‘‘KnowledgeAuthoring Tool’’ (KAT) [36]. Several clinical applicationsrely on the KR for clinical knowledge content, includingan online interdisciplinary clinical reference program[37,38], an ‘‘E-resources manager’’ patterned after the con-cept of an ‘‘infobutton manager’’ [39], a Physician OrderEntry (POE) system, a patient education discharge instruc-tions application, and the ‘‘ForeSight’’ decision supportapplication [40].
Our effort to create and maintain an enterprise-wideknowledge base has been focused largely upon leveragingmotivated clinical domain experts as content authors. Wefavor this approach primarily because these individualsare not only experts in their field, but they are directlyinvolved in using the applications that depend upon theclinical knowledge content they create. These clinicianshave both the clinical experience to authoritatively com-pose the content and the personal investment in makingthe content usable within clinical systems. Also includedin this effort are authors from several ‘‘Clinical Programs’’,
whose directives are to help clinicians deliver the best clin-ical care in a consistent and integrated fashion [41]. EachClinical Program is responsible for defining care manage-ment systems, as well as guiding other ‘best-practice’ initia-tives, and integrating them into routine practicethroughout the Intermountain system. Dedicated develop-ment teams within each Clinical Program are ultimatelyresponsible for the creation and maintenance of the knowl-edge content. Each development team is composed byexperts from a variety of clinical specialties associated witha given medical domain.
2.2. Clinical use of knowledge content
As a case-in-point of how knowledge content created byIntermountain’s clinical teams is used in clinical applica-tions, we highlight the POE system and its direct integra-tion with the KR. The POE system, although still in itsearly stage, is currently being used at four different hospi-tals within Intermountain. The POE application presents‘order sets’ to end-users, defined as groups of orders thatreflect the best practices for a given procedure or diagnosis.POE is embedded as a module of the ‘‘HELP2 ClinicalDesktop.’’ The HELP2 Clinical Desktop is a suite of soft-ware applications designed to support direct patient careand coupled with a longitudinal electronic medical record[42].
Users interact with knowledge base content in POE bychecking or unchecking orders, entering values in textfields, selecting combo box values, and also adding neworders to the form. Under each section heading withinthe order set in POE, users can click an ‘add button’ whichinserts a row to the orders table and allows the user to typeadditional free text orders. Once all orders have been final-ized, the POE application generates PDF-based orderforms and stores the set of issued orders (‘order setrecords’) into the HELP2 longitudinal electronic medicalrecord. Stored orders can be retrieved, changed, and re-printed by the POE user.
Once an authorized user has logged in and selected apatient, he or she can start using POE. This authentica-tion process allows the user to search the KR only fororder sets that are approved for use given the patientlocation (hospital and unit) and other patient characteris-tics (gender, age, health status, etc). Once a selection hasbeen made, the POE system retrieves the appropriateorder set from the KR via a service layer, and rendersit into an HTML form, filled with scripted events andfunctions that implement different POE features. Ordersappear within the order sets as rows within a table andare categorized under group headings. Orders can beeither initially checked (‘pre-selected’) or unchecked (‘des-elected’). Orders can contain fixed text, input fields (withor without default text), combo boxes, and even calcu-lated fields (typically for medication orders). A headersection across the top of the order set contains the orderset title, general inputs specific to the patient (such as

Fig. 1. An illustration of how order sets are rendered within our POE environment. Users can check or uncheck orders (1), enter values in text fields (2),and select combo box values (3). Users can add new orders to the form by clicking an ‘add button’ (4) which inserts a row to the orders table and allows theuser to type additional free text orders.
N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164 155
height and weight), and a navigation section that allowsend-users to quickly move to selected sections within theorder set. Fig. 1 illustrates how order sets are renderedwithin Intermountain’s POE.
2.3. Authoring and review
Using KAT, members of the different Clinical Pro-grams’ development teams, or other Intermountain clini-cians with a recognized expertise, can act as knowledgebase authors and create order sets for the POE system.Order sets can be composed of inline orders in combinationwith references to external modular order groups known asnested order sets. These nested order sets exist separatelyfrom the order sets that reference them, but their contentsare compiled into the body of the referencing order set atruntime by the POE application. As such, any changesmade in the nested order sets are immediately propagatedto all order sets that reference them. To date, 13 clinicianauthors have authored 114 active order sets. 48 order setsare actively being used within 9 units at 4 tertiary careIntermountain facilities. To date, over 3000 unique order-ing encounters have been logged by the POE application.
Of the 48 order sets that are actively being used in POE,nearly all have been changed multiple times since their ini-tial release for clinical use. One particular surgery order sethas been revised 44 times during its lifecycle. Within ourknowledge management framework, several channels existthat facilitate the communication between order set usersand authors. In POE, users can conveniently record theirsuggestions and comments using an electronic message
form. Order set authors are notified every time a new mes-sage is created. In addition, more formal review processesare supported through an application known as the‘‘Knowledge Repository Online’’ (KRO) [43]. UsingKRO, reviewers can submit structured reviews for the var-ious types of clinical knowledge content stored in the KR,including order sets. Other channels also facilitate open dis-cussion and review of order sets, including staff meetings,clinical rounds, e-mail, and general interactions betweenclinical knowledge content authors and POE end-users.Despite our efforts to capture the suggestions and com-ments being offered by users, a preliminary analysis indi-cated that most changes made to order sets resulted fromfeedback pathways outside the existing knowledge manage-ment framework [43]. This analysis also indicated thatdirect feedback from peers was one of the most importantfactors leading to the refinement of order sets.
3. Methods
In an effort to improve the order set refinement andupdate process, we decided to implement a computerizedorder set peer feedback system. The peer feedback systemis designed to gather and analyze users’ interactions withorder sets as recorded by the POE application. The analysisprovided is specific to the types of interactions possiblewithin the POE system; namely changes in web elementssuch as checkboxes, input fields, and combo boxes. Thecurrent implementation of the peer feedback systemfocuses solely on POE clinical knowledge content (order

156 N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164
sets) and creates recommendations directed for knowledgecontent authors.
Our primary goals in developing this application were tomake the order sets easier to use and more aligned withclinical practice. Studies have shown that engineering pro-cesses that make best practice ‘‘easier to do’’ are far moreeffective than identifying and attempting to ‘correct’ non-compliant individuals [44]. Our motives to collect the datawere to identify clinical knowledge or wisdom from POEusers, and not to reveal ‘good’ or ‘bad’ practices by specificclinicians.
3.1. Hypotheses
In testing our feedback application, we wanted to deter-mine if a computer-generated report could present accept-able suggestions for authors to change knowledge basecontent, in this case, POE order sets. The suggestions inthe order set feedback reports are divided into four catego-ries. These categories were created to address the followinghypotheses:
1. The order set peer feedback system will successfullyidentify orders to be added to order sets.
2. The order set peer feedback system will successfullyidentify currently ‘pre-selected’ orders that should be‘de-selected’.
3. The order set peer feedback system will successfullyidentify currently ‘de-selected’ orders that should be‘pre-selected’.
4. The order set peer feedback system will successfullyidentify combo box items whose sequence order shouldbe changed.
While the feedback reports may identify clinicallyimportant additions and changes to order sets, we antic-ipate that the majority of the suggested changes willreflect simple modifications that can make order sets
Table 1Needs, features, and requirements for implementing automated order set peer
Needs Features
• Provide view of how order sets are actually beingused within POE
o Ability to drillment level
o High-level viewo Present data us
template
• Computerized generation of reports o Patient/provideo Reports gener
intervention
• Generate suggested changes to order set o Suggest additioo Suggest changeo Propose change
more efficient to use within POE. The computerizedorder set peer feedback system does not search the liter-ature for new evidence, nor does it attempt to assess theclinical validity of the suggestions being made. It simplyprovides order set authors with a summary of how theirorder sets are being tailored and refined by cliniciansthat are using POE to provide care to patients. This isreflected in our final hypothesis:
5. We hypothesize that the order set peer feedback systemwill be more effective in identifying changes suggestedfor reasons of user convenience than clinical relevance.
3.2. Design
As an initial step in the development process, we iden-tified a series of needs, features, and requirements for theorder set peer feedback system. A summary of theserequirements can be found in Table 1. The principalobjectives included de-identification of data, fully auto-mated processes, and generation of meaningfulsuggestions.
The data utilized by the system was deidentified, i.e.,patient and provider identifiers were removed. De-identifi-cation of provider information was important, since therationale for implementing the peer feedback system wasto provide a reflection of actual clinical practice withinthe ‘knowledge community’, rather than focusing on thebehavior of individual physicians. This also preserved ano-nymity, bolstering the concept of true ‘peer review’ inwhich the order set author could not be influenced by theposition or role of POE users.
The order set peer review application was fully comput-erized, that is, able to complete all of its tasks without theintervention of a knowledge engineer. For instance, batchprocesses and services to gather, de-identify, organize, andanalyze the data sets were implemented. This was an impor-
review system
Requirements
down to individual ele-
of order set usageed which is not part of
X Information presented in familiar formatXUsage data for each element in templateX Summary statisticsXRuntime additions
r data removedated without human
XData retrieval serviceXDeidentification serviceXAggregation serviceXReport generation service
ns to templates in initial selection states in combo box order
XEstablish meaningful thresholdsXCreate matching algorithm for accurate
comparisonsXAnalyze elements within report
quantitativelyX Present suggestions in coherent format

Fig. 2. Our proposed knowledge refinement cycle. In the first step,knowledge base content authors create and refine order sets. These arestored in the enterprise knowledge repository. Physicians use these ordersets within POE, and their usage logs are stored by HELP2. Ade-identification service queries HELP2 on a regular basis, extracts andde-identifies all order set records, and stores it in a separate database(feedback database). Other processes access and aggregate these data intoXML datasets specific to each order set template. XSLT routinestransform this XML dataset into a feedback report, which is presentedto the knowledge content authors.
N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164 157
tant point, since manual chart review processes and the likealready exist and are highly labor-intensive. Full computer-ization also maximizes the time and resources of the knowl-edge engineering team, while facilitating a transition to an‘on-demand’ reporting environment in the near future.
We also decided that efforts had to be made in order toensure that the generated feedback reports containedmeaningful suggestions. As part of this requirement, weestablished a required minimum threshold of use before agiven order set template would be analyzed by the system.This threshold was deliberately set at a low level to beginwith, but will undoubtedly increase as the pilot implemen-tation of the POE system expands. We also determined thatthe analysis algorithms used to generate suggestions wouldrely on exact matches and percentage-based analysis, andnot on ‘best-estimate’ algorithms.
3.3. System description
As part of the order set peer feedback application devel-opment, we created a set of services to support the require-ments previously established. We did not want to tie ourapplication directly to the production HELP2 longitudinalelectronic medical record, so we created a batch processthat extracts and de-identifies all ‘order set records’ fromthe clinical database during ‘non-peak’ hours. Using a ser-ies of Java-based SQL and XSLT routines, this processstrips the data of patient and provider identifiers andmoves it into a non-production environment. We alsocoded a Java servlet that allows for HTTP access to theseXML data stored in the database tables. This service pro-vides quick, programmatic access to the de-identified dataand is used extensively by the other services.
Another service analyzes the de-identified records andcreates XML data aggregates for those records derivedfrom templates that met the minimum usage threshold.The actual generation of the order set feedback reports isperformed as an XSLT routine against this aggregatedXML data set. The result is an HTML-based order setfeedback report containing several different sections. Thetables in the report are generated using a combination ofXSLT and embedded inline JavaScript routines that inter-act heavily with the Document Object Model of the HTMLreport. Scripted routines analyze the page as it is being ren-dered within the browser, and copy and recreate HTMLelements as necessary. The routine analyzes the originalorder set line by line, using context derived from the orderset XML schema, and searches for matches in the issuedorders using a series of algorithms that combine elementsof string matching and context matching. Since our currentknowledge content contains structured text yet few codedelements, we were forced to implement the matching algo-rithms using a ‘best-match’ algorithm involving character-based comparisons and spatial context within the XMLelements. An overview of the flow of information in ourproposed knowledge refinement cycle is illustrated inFig. 2.
3.4. Feedback report description
The order set feedback report generated by the feedbacksystem is divided into four sections. The first section,labeled ‘‘Orders’’, is patterned directly after the appearanceof the order set within the POE application (see Fig. 3). Tothe left of each order there is a numeric fraction, indicatingthe number of times the order was selected as the numera-tor, and the total number of instances the order set was usedas the denominator. The fraction provides a general per-spective of how often each order is being used within a givenorder set. Similar statistics are included for each elementfound within every combo box associated with an order.For example, Fig. 3 illustrates that the first order underthe ‘Diet/Nutrition’ header was used 12 times out of the29 times that the order set was used. Within those 12instances, physicians specified a ‘regular’ diet eight times,a ‘clear liquid’ diet once, a ‘full liquid’ diet twice, etc. Alsoin this report section, colored combo boxes replace theblank text fields that are available within an order set.The elements within these combo boxes represent the entriesthat were typed by users at runtime, as well as a numberindicating how many times each entry was used. This is alsoshown in Fig. 3, where physicians have typed ‘QID’ 12 timesfor the text field of the ‘Ambulate times’ order.
The second section of the report is labeled ‘‘Statistics’’and it provides a set of summary statistics regarding theoverall usage of the order set (Fig. 4). Whereas the first sec-tion of the report focuses on individual orders, the secondsection provides summaries regarding usage patterns of allthe pre-selected, de-selected, and added orders in the order

Fig. 3. The first section of the order set feedback report. This section details how each element in the order set is used across all instances of use withinPOE. Each order is portrayed as it is in the POE application, with the inclusion of numeric indicators that describe how often each order is used (1).Similar statistics are included for each text field and combo box element in the order set (2).
Fig. 4. The second section of the order set report. This section provides a general, high-level summary of how the order set is being used by clinicianswithin POE. The first table contains numbers detailing the types of orders present in the order set (pre-selected and de-selected). The second table givesusage statistics regarding the pre-selected orders in the order set, and the third gives similar statistics for de-selected orders. The final table details thenumber of times in which users added new orders to the order set by using the ‘add button’.
158 N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164
set. It details the composition of the order set, specificallythe number of initially checked and unchecked orders. Thissecond report also includes a set of statistics indicating theprevalence of ‘user-initiated’ orders that were added byend-users via the POE ‘add button’. In some ways, thesenumbers can be used as an overall metric of compliancewith any given order set.
The third section of the report is entitled ‘‘Additions’’and it details the orders in the data set that were addedby end-users via the POE ‘add button’ (see Fig. 5). Theseadditions normally represent orders that were never partof the original order set. However, added orders may alsorepresent duplicates, indicating that the user was not ableto find or easily use the same order in the original order

Fig. 5. The third section of the order set feedback report. This section provides a summary of all ‘user-initiated’ orders that were entered by physicians inPOE, categorized by the headers under which they were added. Orders can appear multiple times if users manually entered the same order in differentordering sessions. It is hoped that this portion of the report will provide valuable information to content authors as to possible deficiencies in the order settemplate that could be remedied by including other orders.
N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164 159
set. This third section consists of a series of tables whereeach of the added orders is categorized by their respectiveorder set group heading. Identical entries were mergedand counted. No attempt was made to perform any anal-ysis of the entries to try to find identical orders that werejust typed differently. This reflects the limitations imposedby the string matching process that was used, and also thefact that the order sets did not contain coded orders,
Fig. 6. The fourth section of the order set feedback report. This section combito the order set, changes in initial selection state of given orders, and even po
which would resolve the current order matchinglimitations.
The fourth section of the report entitled ‘‘Critique’’ con-tains a set of suggested changes based on the data pre-sented in the previous three sections of the report(Fig. 6). The suggestions are divided into four tables, onecontaining potential additions to the order set, anothercontaining candidate orders for ‘pre-selection’, yet another
nes all the suggestions to the order set author, including possible additionstential changes in combo box order.

Table 2Order sets included in the experiment, along with the number of times theywere used in POE (‘order set records’)
Order set title Records # ofversions
Asthma 188 4Sedated ABR EEG 130 1IVIG Infusion 114 2Cellulitis 86 3Febrile infant 75 1Seizure 75 4ICU Admit—UVRMC 73 22Generic STRICU Admission 70 14Croup 67 4GYN Short Stay Postop—AFH 56 11Drug/Toxic Substance Overdose ICU Admission 53 2Closed head injury 50 3Hyperbilirubinemia 46 1Hysterectomy/Gyn Post-Operative and Admit
Orders—AFH42 23
Abdominal pain 32 3Generic MICU Admission Orders 31 1GI Bleeding Admission Orders 30 21General Surgical/Post-Operative Orders 29 36General order form 24 6Respiratory Failure (Hypoxic) ICU Admission
Orders19 10
Stroke ICU Admission Orders 19 9Sepsis (Severe) ICU Admission Orders 18 17Bronchiolitis 18 5Respiratory ICU Admission Orders 14 1Trauma ICU Admission Orders 13 10Diabetic Ketoacidosis ICU Admission Orders 11 30General Surgery Post-Op ICU Admission Orders 11 28Liver Transplant ICU Admission Orders 11 19MedSurg Admission Orders—USR 10 20Pneumonia (Severe) ICU Admission Orders 10 14
160 N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164
containing candidate orders for ‘de-selection’, and the lasttable containing suggested changes in the sequence ofcombo box items. Orders are included in the ‘suggestedadditions’ section if users at runtime add them exactlythe same way at least twice on different occasions. A per-centage-based algorithm was used to identify candidateorders for ‘pre-selection’ and ‘de-selection’. If a‘de-selected’ order in the order set template was used 50%of the time or more, it is included in the ‘suggested pre-selections’ table. Inverse logic follows for the ‘suggestedde-selections’ table. Finally, any instances in the order setin which a combo box’s default value (first item) was notthe most commonly used option was included in the‘suggested change in combo box sequence’ table.
3.5. Validation
We designed a validation experiment to determine if theorder set peer feedback system was capable of producingreports containing pertinent suggestions to authors. Wedetermined that any given version of an order set thatwas used at least ten times in the POE system would be eli-gible for inclusion in the experiment. It is important to notethat within our knowledge management framework, ordersets can be very easily changed, versioned, and republished.Furthermore, our POE system allows for only one activeversion of any given order set to be used at a time. As such,at any given point of time, all POE users are using the sameversion of an order set. We decided not to compare datawhose order set versions were different, since changesacross versions of an order set can be either very minoror quite dramatic. This threshold was determined after aquick audit of actual POE usage patterns (Table 2). Thethreshold is initially low in part due to the fact that thePOE application is still only used in specific pilot sites.We anticipate that this threshold will increase as the usageof POE expands.
In order to validate the feedback system, we presentedthe generated reports to each of the original order setauthors. We felt that these clinicians would be the bestjudges of the suggestions in the order set feedback reports,since they are recognized domain experts. These authorsactively use the order sets in POE and work closely withother colleagues. Both the authors and their associatesare members of the ‘knowledge communities’ under study.Each author was asked to accept or reject each recommen-dation provided in the order set feedback report. In addi-tion, the authors were asked to indicate the reason foraccepting or rejecting a change suggestion, focusing oneither ‘clinical relevance’ or ‘user convenience’. Withregards to the aforementioned hypotheses in this experi-ment, we decided that the suggestions for each categorywould be deemed ‘acceptable’ if they were accepted greaterthan 50% of the time.
Prior to meeting with the order set authors we drafted adetailed agenda. We planned to start each meeting by pre-senting the rationale for the project and outlining the basics
of the order set feedback reports. Next, we planned todescribe the data that we wanted regarding the suggestionspresented in the feedback reports. During each meeting wealso answered questions regarding the order set feedbackreports. We ended each meeting by discussing the timeframe in which authors would be able to judge the recom-mendations in the feedback reports.
Authors were provided with a feedback report for eachof the order sets they had authored that met the thresholdmentioned before. They also received MS Word data entryforms; one form for each order set. The data entry formincluded all suggested changes specific to a given orderset (see Appendix A for an example). We also asked theauthors to respond to a small set of questions regardingthe appropriateness of the thresholds used in defining theelements of the reports, as well as soliciting any suggestionsfor improving them (see Appendix B). We instructed eachauthor to return vie e-mail the survey results and analysesregarding the order set feedback suggestions.
The responses received from the authors were aggre-gated into a spreadsheet. The results were then organizedby author, the respective order sets, as well as the catego-ries of suggested changes.
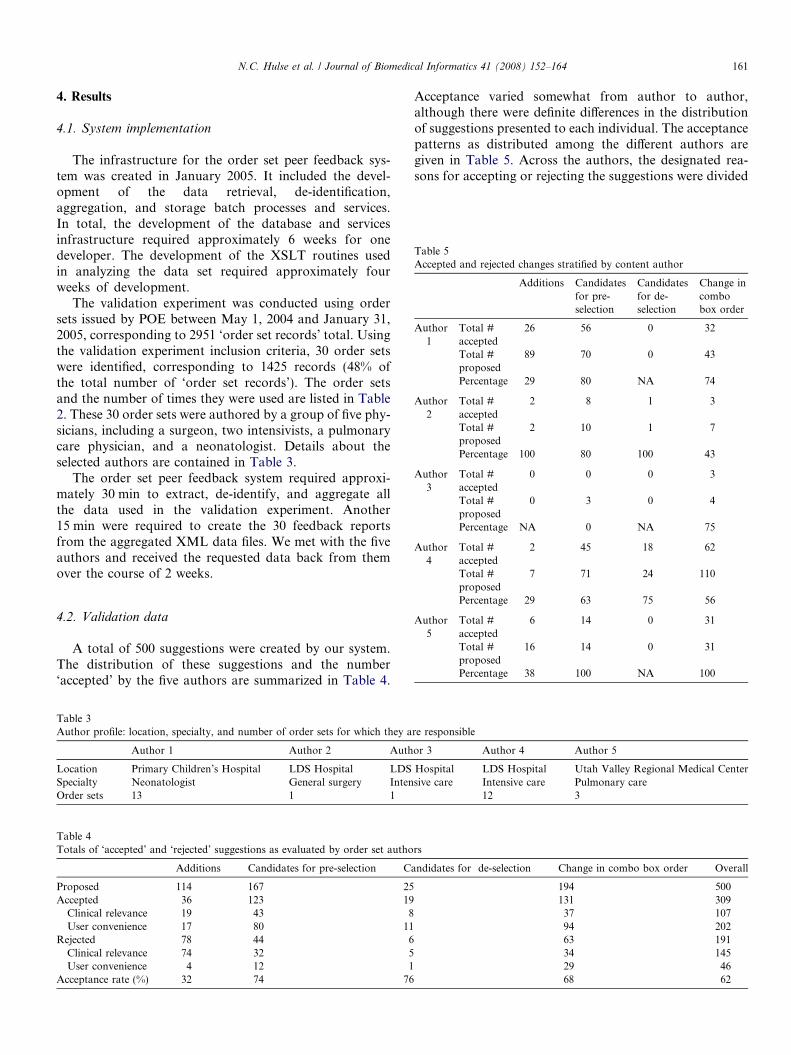
Table 5Accepted and rejected changes stratified by content author
Additions Candidatesfor pre-selection
Candidatesfor de-selection
Change incombobox order
Author1
Total #accepted
26 56 0 32
Total #proposed
89 70 0 43
Percentage 29 80 NA 74
Author2
Total #accepted
2 8 1 3
Total #proposed
2 10 1 7
Percentage 100 80 100 43
Author3
Total #accepted
0 0 0 3
Total #proposed
0 3 0 4
Percentage NA 0 NA 75
Author4
Total #accepted
2 45 18 62
Total # 7 71 24 110
N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164 161
4. Results
4.1. System implementation
The infrastructure for the order set peer feedback sys-tem was created in January 2005. It included the devel-opment of the data retrieval, de-identification,aggregation, and storage batch processes and services.In total, the development of the database and servicesinfrastructure required approximately 6 weeks for onedeveloper. The development of the XSLT routines usedin analyzing the data set required approximately fourweeks of development.
The validation experiment was conducted using ordersets issued by POE between May 1, 2004 and January 31,2005, corresponding to 2951 ‘order set records’ total. Usingthe validation experiment inclusion criteria, 30 order setswere identified, corresponding to 1425 records (48% ofthe total number of ‘order set records’). The order setsand the number of times they were used are listed in Table2. These 30 order sets were authored by a group of five phy-sicians, including a surgeon, two intensivists, a pulmonarycare physician, and a neonatologist. Details about theselected authors are contained in Table 3.
The order set peer feedback system required approxi-mately 30 min to extract, de-identify, and aggregate allthe data used in the validation experiment. Another15 min were required to create the 30 feedback reportsfrom the aggregated XML data files. We met with the fiveauthors and received the requested data back from themover the course of 2 weeks.
proposedPercentage 29 63 75 56
Author5
Total #accepted
6 14 0 31
Total #proposed
16 14 0 31
Percentage 38 100 NA 100
4.2. Validation data
A total of 500 suggestions were created by our system.The distribution of these suggestions and the number‘accepted’ by the five authors are summarized in Table 4.
Table 3Author profile: location, specialty, and number of order sets for which they a
Author 1 Author 2 Auth
Location Primary Children’s Hospital LDS Hospital LDSSpecialty Neonatologist General surgery IntenOrder sets 13 1 1
Table 4Totals of ‘accepted’ and ‘rejected’ suggestions as evaluated by order set autho
Additions Candidates for pre-selection C
Proposed 114 167 25Accepted 36 123 19
Clinical relevance 19 43 8User convenience 17 80 11
Rejected 78 44 6Clinical relevance 74 32 5User convenience 4 12 1
Acceptance rate (%) 32 74 76
Acceptance varied somewhat from author to author,although there were definite differences in the distributionof suggestions presented to each individual. The acceptancepatterns as distributed among the different authors aregiven in Table 5. Across the authors, the designated rea-sons for accepting or rejecting the suggestions were divided
re responsible
or 3 Author 4 Author 5
Hospital LDS Hospital Utah Valley Regional Medical Centersive care Intensive care Pulmonary care
12 3
rs
andidates for de-selection Change in combo box order Overall
194 500131 30937 10794 20263 19134 14529 4668 62

162 N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164
almost evenly; with 252 of the responses indicating ‘clinicalrelevance’ while 248 cited ‘user convenience’.
Responses from the surveys also indicated that allauthors felt that the current thresholds were appropriateand adequate. However, nearly all indicated that thesethresholds would likely need to be adjusted over time bothto accommodate a larger POE audience, as well as to cap-ture all pertinent knowledge while tuning out ‘noise’. Allthe authors indicated that they would like access to orderset peer feedback reports on a regular basis, no more thanmonthly and no less than quarterly. Four of the fiveauthors indicated that they would like an extra sectionadded to the order set feedback reports, specifically, a sec-tion recommending orders to be removed from thetemplate.
5. Discussion
Considering the four types of suggestions made by theorder set peer feedback system, three provided input thatwas accepted by our clinical panel greater than 50% ofthe time, including some whose acceptance rate was as highas 76%. Only the suggested additions of orders to the orderset did not reach the predefined threshold, as they wereaccepted approximately 32% of the time. These data sug-gests that we should reject Hypothesis 1 and acceptHypotheses 2–4.
It is likely that the lower acceptance rate for suggestedadditions to the order set is attributable to the string-matching algorithm we used to identify candidates foraddition to the order set. If a more sophisticated match-ing algorithm were used, perhaps grouping orders despitespelling and word order differences, the ability to identifymeaningful additions would improve. Another possiblereason for the higher rejection rate was the adoption ofa ‘count-based’ inclusion threshold, as opposed to a per-centage-based. We opted to use an algorithm that recom-mended addition to the order set if any order had beenmanually added via the ‘add button’ at least twice. Weopted to use this count-based threshold rather than a per-centage-based threshold due to our inability to groupidentical orders, again due to the string matching limita-tions. Further review of the suggestions for additionrevealed that the majority of the orders rejected were rec-ommended for inclusion in a general admission order set.Upon discussing the issue with the clinical author respon-sible for the order set, he confirmed being hesitant toinclude many of the suggested orders in an order setdesigned to be generic.
The differences present in the distribution of suggestedchanges across knowledge content authors make it difficultto compare authors’ responses, and consequently to deter-mine if there are systematic differences in how the authorsrate the suggestions. This is largely due to the unequalnumbers of order sets for which each author is responsible,as well as how frequently the order sets were used. Inter-rater agreement was not assessed, since each author was
asked only to rate the suggestions pertaining to his ownorder sets. Further research involving clinical panels foreach specific order set will be necessary to determine ifagreement levels tend to be specific to individuals, special-ties, regions, or patient populations.
5.1. Clinical pertinence vs. user convenience
Of the accepted suggestions, roughly 65% were classifiedas accepted for reasons of ‘user convenience’. Alternately,of the rejected suggestions, 76% cited ‘clinical relevance’as the reason. These data suggest that the feedback systemidentifies elements in the order set that can be changed toimprove user convenience more successfully than it findsclinically relevant ones. This supports our final hypothesis.We anticipated this largely because the system bases itsanalysis from recorded interactions with an existing orderset, and not by identifying new clinical evidence throughmore elaborate methods. It is notable, however, that morethan a fifth of all the suggestions analyzed were acceptedfor reasons of ‘clinical relevance’. Although much of theknowledge abstracted from the ‘knowledge community’assessed in the study deals with creating convenient, easy-to-use knowledge content, a noteworthy portion of the sug-gestions can be considered harvested knowledge that isclinically applicable.
The validation experiment was valuable in assessingthe thresholds that we defined for the order set peer feed-back reports. In general, the percentage-based thresholdsperformed better than the count-based ones. The 50%cutoff for suggesting candidate orders for pre-selectionand de-selection seemed to perform relatively well. It isinteresting to note that moving the threshold for suggest-ing pre-selected orders up to 60% and de-selected ordersdown to 40% does not improve the overall acceptancerate of the generated suggestions. In fact, the acceptancepercentage rate stays nearly the same, while the numberof identified acceptable changes decreases. All the clinicalauthors indicated that the thresholds were acceptable intheir present state and that any adjustments wouldlikely result from further experience with the feedbackreports.
The order set templates under scrutiny in these studieswere not user-specific. The institutions adopting the POEpilot system wanted to restrict the amount of personaliza-tion that would be allowed for crafting order sets. Thisdecision was made largely to back recent initiatives forcompliance with enterprise ‘best-practice’ guidelines. In asense, this enforced the usage of more general order settemplates, with very few exceptions crafted to meet theneeds of specific units and/or user groups. Since our entireuser base was using these condition-specific order set tem-plates, their additions/changes/subtractions provided aricher base for the feedback experiment. If personalizedorder sets were used, it is anticipated that fewer changeswould be suggested, especially those classified for ‘userconvenience’.

N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164 163
5.2. Limitations
There are inadequacies with our approach, in large mea-sure due to the adoption of string-matching algorithms.These limitations are particularly manifested when multipleorders in the original order set are identical (as in the caseof multiple generic medication orders). These orders arerelatively indistinguishable with simple string matching.In an environment containing coded elements, this wouldbe greatly simplified and much more complete and accu-rate. Our study is also quite limited by the small numberof clinical authors exposed to the order set feedback sug-gestions during the validation experiment. Panels of expertclinicians for each order set would be able to provide amore accurate view of which suggestions are ‘acceptable’.Finally, a greater number of POE end-users would providea larger ‘knowledge community’ from which to abstractmore representative change suggestions.
5.3. Future research
A natural extension of our peer feedback system wouldbe to suggest candidate orders for removal from the orderset. Nearly all of the clinicians in our panel indicated thatthey would like to see this functionality added to the feed-back system. The general consensus among the authors wasthat removing orders would help streamline the order setsand facilitate navigation through the content using POE.There was some discrepancy among the authors as to whatthresholds would be most appropriate for use, with somesuggesting a percentage-based algorithm, others support-ing a count-based approach. We plan to include this func-tionality in the next release of the system. Another naturalextension would be to cluster the data sets according topatient diagnoses in the analyses, especially for more gen-eric order sets. We could then potentially identify neworder sets for commonly seen conditions, as opposed tousing a generic one that is continuously being customizedfor the same reasons.
We also envision extending the peer feedback systemsuch that it supports knowledge content beyond just ordersets. Since the system operates on a basis of comparinginstance data with original knowledge base content, anystored information that is in XML (or can easily be encap-sulated in XML) could be analyzed by the system. Thiswould require the creation of additional analysis routines,but the general approach is likely to remain the same.We plan to implement similar routines for other types ofinteractive knowledge base content, including bedside doc-umentation templates, patient discharge instructions, andalso alerts, reminders, and more sophisticated computer-ized clinical protocols.
As the order set peer feedback system matures, we planto analyze several aspects of the suggestions that it pro-poses. First, we plan to assess the types of suggestedchanges and compare them with those identified throughexisting feedback channels (formal review, interaction with
colleagues, etc.) to determine if they are the same types ofchanges, or if they are substantially different in nature. Fur-thermore, we intend to assess the impact of the order setsuggestions to determine if they really improve the orderset, like, for instance, by decreasing the number of pre-selected orders that have to be deselected. We intend todetermine if the number of suggestions decreases over time,or if the same suggestions recur from one report to thenext, when not initially accepted by the author. We alsoplan to study the suggestions over time to determine if theyremain consistent or if they contradict themselves in differ-ent reports (e.g., a given order is suggested for pre-selectionin one report, and de-selection in a future one). Further-more, we intend to attune the report generation algorithmto only include salient order sets used at a higher threshold(for example 50 or more, as opposed to the 10 required forour experiment) to avoid fatiguing our clinical contentauthors and to determine if our experimental resultsremain the same. We will also explore the possibility of cre-ating an analysis algorithm to compare and draw conclu-sions from different versions of the same order set. Thiswill be greatly facilitated by our plans to use coded ordersand medications throughout the order sets. At present, ourmatching algorithms depend entirely on string matchingand context-based position analysis, without any abilityto anticipate content changes across versions. With codedorders throughout the order sets in the knowledge base,the algorithms could be altered to effectively report againstmultiple versions of any given order set.
6. Conclusion
We have developed an automated order set peer feedbacksystem that successfully identifies areas for improvement inorder sets. The system draws its suggestions from an analysisof actual clinical usage patterns of the order sets within aPOE environment. The system analyzes the decisions andactions of ‘knowledge workers’ in the clinical environmentas they customize order sets. The majority of the acceptablesuggestions pertain to changing the order set for reasons ofuser convenience. We anticipate that similar approachescan be used to refine most types of interactive knowledgebase content. It is hoped that implementing automated pro-cesses to facilitate knowledge content analysis and refine-ment will ease some of the burdens associated withmaintaining large clinical knowledge bases. By analyzingthe interaction of clinicians as participants in ‘knowledgecommunities’ we hope to abstract meaningful new informa-tion to refine our clinical knowledge engineering effort.
Acknowledgments
We thank the clinical authors who participated in ourvalidation experiment. We are also appreciative for the col-laboration of the POE development team at Intermoun-tain. Nathan Hulse is supported by a grant from theNational Library of Medicine (No. 2 T15 LM07124).

164 N.C. Hulse et al. / Journal of Biomedical Informatics 41 (2008) 152–164
Appendix A. Supplementary data
Supplementary data associated with this article can befound, in the online version, at doi:10.1016/j.jbi.2007.05.006.
References
[1] Giuse DA, Giuse NB, Miller RA. Evaluation of long-term mainte-nance of a large medical knowledge base. J Am Med Inform Assoc1995;2(5):297–306.
[2] Geissbuhler A, Miller RA. Distributing knowledge maintenance forclinical decision-support systems: the ‘‘knowledge library’’ model. In:Proceedings of the AMIA symposium, 1999. p. 770–4.
[3] Wyatt JC. Management of explicit and tacit knowledge. J R Soc Med2001;94(1):6–9.
[4] Kaushal R, Shojania KG, Bates DW. Effects of computerizedphysician order entry and clinical decision support systems onmedication safety: a systematic review. Arch Intern Med2003;163(12):1409–16.
[5] Bates DW et al. Reducing the frequency of errors in medicine usinginformation technology. J Am Med Inform Assoc 2001;8(4):299–308.
[6] Bates DW et al. The impact of computerized physician order entryon medication error prevention. J Am Med Inform Assoc1999;6(4):313–21.
[7] Bates DW et al. Effect of computerized physician order entry and ateam intervention on prevention of serious medication errors. JAMA1998;280(15):1311–6.
[8] Clancey WJ, Shortliffe EH. Readings in medical artificial intelligence:the first decade. Reading(MA): Addison-Wesley PublishingCo; 1984.
[9] Mulrow CD. Rationale for systematic reviews. BMJ1994;309(6954):597–9.
[10] Balas EA, Boran SA. Managing clinical knowledge for healthcareimprovement in Yearbook of Medical Informatics. Bethesda(MD): NLM; 2000. p. 65–70.
[11] Candy PC. Preventing ‘‘information overdose’’: developing informa-tion-literate practitioners. J Contin Educ Health Prof2000;20(4):228–37.
[12] Staab S et al. Knowledge processes and ontologies. IEEE Intell Syst2001;16(1):26–34.
[13] Matheson N. Things to come: postmodern digital knowledgemanagement and medical informatics. J Am Med Inform Assoc1995;2(2):73–8.
[14] Shekelle P et al. When should clinical guidelines be updated? BMJ2001;323(7305):155–7.
[15] Kuperman GJ, Fiskio JM, Karson A. A process to maintain thequality of a computerized knowledge base. In: Proceedings of theAMIA symposium, 1999. p. 87–91.
[16] Greenes RA. Decision support at the point of care: challenges inknowledge representation, management, and patient-specific access.Adv Dent Res 2003;17:69–73.
[17] Wilkinson SG, Rocha RA, Rhodes J. Analyzing knowledge basecontent development and review: recommendations for a robustknowledge management infrastructure. In: Proceedings of the AMIAsymposium, 2002. p. 1199.
[18] Wyatt JC. Practice guidelines and other support for clinical innova-tion. J R Soc Med 2000;93(6):299–304.
[19] Fischer G, Ostwald J. Knowledge management: problems, promises,realities and challenges. IEEE Intell Syst 2001;16(1):60–72.
[20] Clemmer TP, Spuhler VJ. Developing and gaining acceptance forpatient care protocols. New Horiz 1998;6(1):12–9.
[21] Hooff Bvd et al. Knowledge sharing in knowledge communities. In:Huysman M, editor. Communities and technologies. Nether-lands: Kluwer Academic Publishers; 2003. p. 119–41.
[22] Young T et al. Using industrial processes to improve patient care.BMJ 2004;328(7432):162–4.
[23] Jamtvedt G et al. Audit and feedback: effects on professional practiceand health care outcomes. Cochrane Database Syst Rev2003:CD000259.
[24] Patel VL et al. Bridging theory and practice: cognitive science andmedical informatics. Medinfo 1995;8(Pt 2):1278–82.
[25] Kushniruk AW et al. ‘Televaluation’ of clinical information systems:an integrative approach to assessing Web-based systems. Int J MedInform 2001;61(1):45–70.
[26] Kushniruk AW, Patel VL, Cimino JJ, Usability testing in medicalinformatics: cognitive approaches to evaluation of informationsystems and user interfaces. In: Proceedings of the AMIA annualfall symposium, 1997. p. 218–22.
[27] Hobbs GR. Data mining and healthcare informatics. Am J HealthBehav 2001;25(3):285–9.
[28] Doddi S et al. Discovery of association rules in medical data. MedInform Internet Med 2001;26(1):25–33.
[29] Haug PJ, Rocha BH, Evans RS. Decision support in medicine: lessonsfrom the HELP system. Int J Med Inform 2003;69(2-3):273–84.
[30] Cimino JJ, et al. Use of online resources while using a clinicalinformation system. In: AMIA annual symposium proceedings, 2003.p. 175–9.
[31] Snyder-Halpern R, Corcoran-Perry S, Narayan S. Developingclinical practice environments supporting the knowledge work ofnurses. Comput Nurs 2001;19(1):17–23. quiz 24–6.
[32] East TD et al. Knowledge engineering using retrospective review ofdata: a useful technique or merely data dredging? Int J Clin MonitComput 1991;8(4):259–62.
[33] Kohn LT, Corrigan JM, Donaldson MS, editors. To err is human:building a safer health system. Washinton (DC): Institute of Med-icine, National Acad Press; 2000.
[34] Berwick DM. Disseminating innovations in health care. JAMA2003;289(15):1969–75.
[35] Intermountain Health Care Available: <http://www.ihc.com>.[36] Hulse NC et al. KAT: a flexible XML-based knowledge authoring
environment. J Am Med Inform Assoc 2005;12:418–30.[37] Hougaard J. Developing evidence-based interdisciplinary care stan-
dards and implications for improving patient safety. Int J MedInform 2004;73(7-8):615–24.
[38] Xu X, Del Fiol G, Rocha RA. Towards a flexible web-basedframework to navigate clinical reference documents. Medinfo2004;2004(CD):1915.
[39] Cimino JJ, Li J. Sharing infobuttons to resolve clinicians’information needs. In: AMIA annual symposium proceedings,2003. p. 815.
[40] Steiner DJ et al. Medical data abstractionism: fitting an EMR toradically evolving medical information systems. Medinfo2004;2004:550–4.
[41] Intermountain Health Care Clinical Programs. Available at: <http://www.ihc.com/xp/ihc/physician/clinicalprograms>. Accessed Sep 7,2004.
[42] Clayton PD et al. Building a comprehensive clinical informationsystem from components. The approach at Intermountain HealthCare. Methods Inf Med 2003;42(1):1–7.
[43] Wilkinson SG. Knowledge repository online: an electronic knowledgedevelopment and maintenance process. In: Department of medicalinformatics. Salt Lake City: University of Utah; 2003. p. 156.
[44] James B. Making it easy to do it right. N Engl J Med2001;345(13):991–3.